Zapewne dręczy Cię pytanie jak wyglądają kolejki procesów oczekujących i kolejka procesów gotowych, oraz jak się ma kolejka procesów gotowych do kolejek koncepcyjnych o których wspomniano wyżej.
Kolejki procesów oczekujących
Istnieje wiele kolejek procesów oczekujących, z których każda przyporządkowana jest zdarzeniu innego typu. Kolejki mają postać jednokierunkowych list cyklicznych:Z uwagi na strategiczne znaczenie kolejek i częstość ich używania, wymagają one szczególnej ochrony przed utratą spójności. Istnieją dwie procedury do modyfikacji kolejek, obie na początku blokują przerwania i opuszczają semafor, na końcu podnoszą semafor i odblokowują przerwania.struct wait_queue { struct task_struct * task; struct wait_queue * next; }Z chwilą zajścia zdarzenia budzone są wszystkie procesy na danej kolejce.
void add_wait_queue(struct wait_queue **queue, struct wait_queue *entry)- Wstawia
entryna początek listyqueue.
void remove_wait_queue(struct wait_queue **queue, struct wait_queue *entry)- Usuwa
entryz kolejki.
Kolejka procesów gotowych
Elementami cyklicznej dwukierunkowej kolejki procesów gotowych są strukturytask_structprocesów ze statusemTASK_RUNNING. Kolejki koncepcyjne (na których - przypomnijmy - wiszą procesy czasu rzeczywistego) są logicznie "zanurzone" w kolejce procesów gotowych, co obrazowo przedstawia rysunek.task_struct
struct task_struct *next_run, *prev_run- dowiązania do następnego i poprzedniego procesu gotowego
long rt_priority- Numer kolejki koncepcyjnej procesu (0..99). W kolejce numer
Nczekają procesy czasu rzeczywistego o statycznym priorytecie równymN. Tylko procesy czasu rzeczywistego używają tego pola.
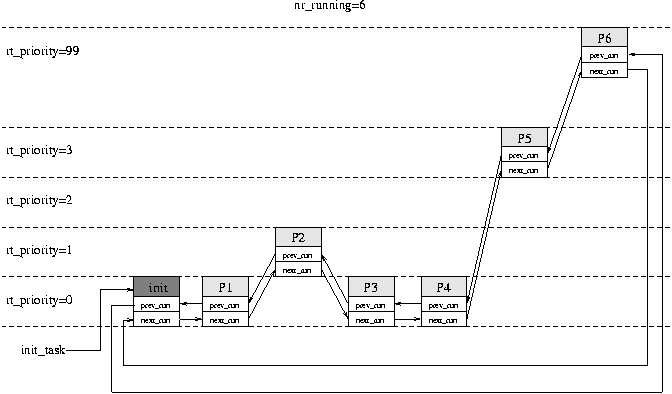 Rys. 1. Kolejki koncepcyjne
Rys. 1. Kolejki koncepcyjnePodobnie jak w przypadku kolejek procesów oczekujących, również w przypadku kolejki procesów gotowych istnieją funkcje do manipulowania elementami kolejki - modyfikują one jedynie wskaźniki
next_runiprev_runoraz zmienną globalnąnr_running.
void add_to_runqueue(struct task_struct * p)- Dodaje proces
pna początek kolejki (tuż za proceseminit).
void del_from_runqueue(struct task_struct * p)- Usuwa proces
pz kolejki.
void move_first_runqueue(struct task_struct * p)- Przesuwa proces
pna początek kolejki procesów gotowych, tj. tuż za proces idle.
void move_last_runqueue(struct task_struct * p)- Przesuwa proces
pna koniec kolejki procesów gotowych, tj. tuż przed proces idle.
Algorytm schedule
task_struct - cd.
policy- Klasa szeregowania procesu (
SCHED_OTHERdla procesów zwykłych,SCHED_FIFOiSCHED_RRdla procesów czasu rzeczywistego)
state- Stan procesu (
TASK_RUNNINGdla procesów gotowych)
counter- Dynamiczny priorytet procesu (liczba pozostałych procesowi jednostek czasu w kwancie), nie wykorzystywany przez procesy czasu rzeczywistego
SCHED_FIFO. Przy rozpoczęciu nowej epoki pole to zawiera długość kwantu procesu. Przerwanie zegarowe zmniejsza wartość tego pola o 1.
priority- Priorytet bazowy procesu. Makro
INIT_TASKustawia wartość bazowego okresu kwantu procesu 0 (swapper) na wartośćDEF_PRIORITY:gdzie#define DEF_PRIORITY (20 * HZ / 100)HZoznacza częstotliwość przerwań zegarowych i w komputerach PC jest ustawiona na 100. Ostatecznie więc w komputerach PCDEF_PRIORITYwynosi 20 taktów, czyli ok. 210 milisekund.
last_processor- Numer procesora na którym ostatnio wykonywał się dany proces
need_resched- flaga ustawiana przez procedurę obsługi przerwania w sytuacji gdy konieczne jest późniejsze wywołanie algorytmu szeregującego zadania.Okoliczności wykonywania algorytmu szeregującego mogą być następujące:
Działanie funkcji
- zaśnięcie procesu w oczekiwaniu na zdarzenie,
- zakończenie procesu,
- przejście z trybu jądra do trybu użytkownika (na koniec wywołania funkcji systemowej lub przerwania)
schedule()w przybliżeniu jest następujące:Wartości zwracane przez
- Wykonuje zaległe zadania zlecone przez ograniczone czasowo procedury przerwań (zwłaszcza przerwanie zegarowe).
- Po kolei dla każdego procesu w kolejce procesów gotowych wywoływana jest funkcja
goodness()i pierwszy proces o najwyższej, nieujemnej wartości zwróconej przez funkcję przejmuje procesor.- Jeżeli nie ma gotowego procesu czasu rzeczywistego i wszystkie procesy zwykłe wyczerpały swój kwant czasu, następuje przeliczenie priorytetów dynamicznych i tym samym przydzielenie nowych kwantów czasu.
goodness():
- -1000 dla procesów wykonujących się na innym procesorze lub nie mogących się wykonywać na danym procesorze,
- 1000 +
rt_prioritydla procesów czasu rzeczywistego,- 0 dla procesu zwykłego który wyczerpał swój kwant czasu,
counter+ 1 dla procesu aktualnie wykonywanego (+1 aby nie wykonywać zbędnego przełączania kontekstu w przypadku gdy priorytet aktualnie wykonywanego procesu tylko nieznacznie różni się od najlepszego kandydata do przejęcia procesora),counter+PROC_CHANGE_PENALTYdla procesu który poprzednio wykonywał się na tym samym procesorze (zaleca się aby dany proces był wykonywany ciągle przez ten sam procesor, aby uniknąć kosztów odświeżania pamięci podręcznej procesora),counterw pozostałych przypadkach.
Funkcje systemowe
Istnieje kilka funkcji systemowych pozwalających użytkownikom kontrolować parametry szeregowania procesów. Większość z tych funkcji - oczywiście - może być wywoływanych tylko przez administratora systemu. Oto najważniejsze z nich.
nice(newprio)- Zmienia priorytet bazowy procesu (pole
task_struct.priority) według wzoru:Następnie otrzymana wartość jest odpowiednio przycinana tak aby spełniała warunek:priority -= newprio/20 * DEF_PRIO + 0.51 <= priority <= 2 * DEF_PRIOgetpriority, setpriority- Odczyt i zmiana priorytetu statycznego grupy procesów.
sched_yield- Dobrowolne zrzeczenie się procesora i przejście na koniec kolejki procesów gotowych.
sched_getscheduler- Odczyt informacji o klasie szeregowania wskazanego procesu.
sched_setscheduler- Umożliwia zmianę klasy szeregowania wskazanego procesu (tylko root).
Wydajność
Algorytm planisty jest stosunkowo prosty, efektywny i łatwy do zaimplementowania. Z uwagi na fakt że jest wykonywany często, słusznie położono nacisk na wydajność aby nie powiększać i tak już sporego narzutu czasowego związanego z przełączaniem kontekstu. Mało wyszukany algorytm posiada również niestety swoje wady, m.in. koszt przeliczania kwantów na początku epoki staje się znaczący gdy liczba procesów staje się duża, preferowanie procesów wykonujących częste operacje I/O niepotrzebnie przyspiesza procesy wsadowe często korzystające z urządzeń zewnętrznych (np. silnik bazy danych), z kolei programy interaktywne które intensywnie korzystają z procesora moga reagować wolno, ponieważ zwiększenie priorytetu dynamicznego dzięki blokującym operacjom I/O może nie zrekompensować zmniejszenia spowodowanego używaniem procesora.
Informacje uzupełniające
Zwykły proces tworząc potomka zrzeka się na jego korzyść połowy swojego kwantu czasu. W ten sposób zapobiega się tendencjom do namnażania potomków celem zawładnięcia czasem procesora kosztem procesów wykonujących inne operacje.
Potrzeba wywłaszczania jądra nie jest jedynym zmartwieniem w przypadku implementacji procesów realizujących politykę sztywnego czasu rzeczywistego (ang. hard real time), np. procesy czasu rzeczywistego często muszą korzystać z zasobów wymaganych także przez zwykłe procesy w wyniku czego może się zdarzyć że proces czasu rzeczywistego będzie musiał poczekać na taki zasób (odwrócenie priorytetów); ponadto proces czasu rzeczywistego może wymagać usługi jądra spełnianej w imieniu innego procesu o niższym priorytecie (ukryte szeregowanie).
Szeregowanie w SVR2 [Bach]Warto wiedzieć, że mechanizm szeregowania procesów w systemie Linux nie jest bynajmniej kanonem wśród systemów operacyjnych, a nawet w świecie Unixa. Aby uzmysłowić sobie różnorodność podejść do tego problemu, proponuję króciutko przyjrzeć się rozwiązaniu zaczerpniętemu z systemu SVR2.
CPU) jest zwiększana podczas przerwania zegarowego. Raz na sekundę przeliczane są priorytety wszystkich procesów przebywających w kolejce procesów gotowych:
Wartość priorytetu_bazowego jest równa wartości poziomu użytkownika 0. Skutkiem takiego przeliczenia jest przemieszczanie się procesów o priorytetach poziomu użytkownika wśród kolejek priorytetowych. Zauważmy że jądro nie modyfikuje priorytetów poziomu jądra, jak również nie pozwala aby w wyniku przeliczenia priorytetów jakiś proces uzyskał wartość z zakresu poziomu jądra. |
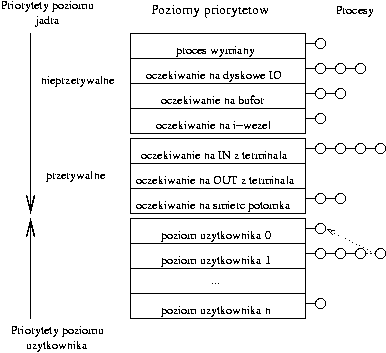 Priorytety procesów dzielą się na dwie klasy: priorytety poziomu użytkownika (dla procesów wywłaszczonych podczas powrotu z trybu jądra do trybu użytkownika) i poziomu jądra (dla procesów wykonujących algorytm sleep). Druga klasa podlega dalszemu podziałowi - procesy o niższym priorytecie są budzone po otrzymaniu sygnału. Liczbowo niska wartość priorytetu oznacza wysoki priorytet szeregowania. Każdej wartości priorytetu przyporządkowana jest kolejka procesów. Zasypiający proces otrzymuje priorytet uzależniony od powodu zaśnięcia (patrz rysunek).
Priorytety procesów dzielą się na dwie klasy: priorytety poziomu użytkownika (dla procesów wywłaszczonych podczas powrotu z trybu jądra do trybu użytkownika) i poziomu jądra (dla procesów wykonujących algorytm sleep). Druga klasa podlega dalszemu podziałowi - procesy o niższym priorytecie są budzone po otrzymaniu sygnału. Liczbowo niska wartość priorytetu oznacza wysoki priorytet szeregowania. Każdej wartości priorytetu przyporządkowana jest kolejka procesów. Zasypiający proces otrzymuje priorytet uzależniony od powodu zaśnięcia (patrz rysunek).Bibliografia
- [Bach] Budowa systemu operacyjnego UNIX, Maurice J. Bach, WNT 1995.
- [Bovet] Linux kernel, Daniel P. Bovet, Marco Cesati, Wydawnictwo RM, Warszawa 2001.
- [Goodheart] Sekrety magicznego ogrodu. UNIX System V Wersja 4 od środka, Berny Goodheart, James Cox, WNT 2001.
Piotr Karpiuk, pk167277@zodiac.mimuw.edu.pl
