Projekt Linux 2.4.7
|
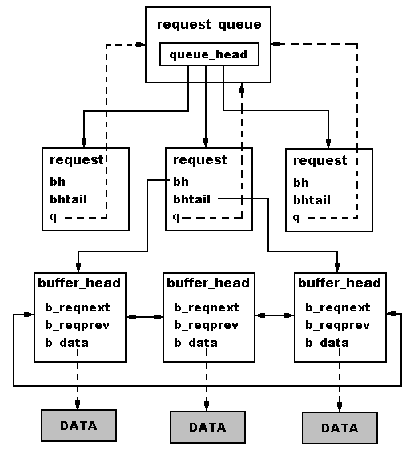 Rys. Struktury danych używane do szeregowania zleceń we-wy. |
1.2. Szeregowanie zadań
Podstawowym mechanizmem służącym do szeregowania żądań dostępu do urządzeń jest funkcjall_rw_block(low level access to block devices)
zdefiniowana w pliku /drivers/block/ll_rw_block.c.
Funkcja ta jest wspólna dla wszystkich urządzeń blokowych. Jest wywoływana
przez funkcję block_read oraz
block_write. Jej głównym zadaniem jest
wysłanie listy buforów do kolejki żądań konkretnego urządzenia ze zleceniem
odpowiedniej operacji (zapisu lub odczytu).
void ll_rw_block(int rw, int nr, struct buffer_head * bhs[])
/* Gdzie rw to rodzaj operacji (READ, WRITE, READA); nr to ilosc buforow
dla operacji odczytu lub zapisu; bhs - tablica wskaźników do tych buforów. */
{
Ustal odpowiednią wielkość bloku dla tego urządzenia;
Sprawdź czy wszystkie bufory mają odpowiednią wielkość;
Jeśli nie to błąd;
Sprawdź czy nie wystąpiła sytuacja,
w której żadany jest zapis na urządzeniu tylko do odczytu;
Jeśli tak to błąd;
Dla każdego wskaźnika z tablicy bhs wywołuj {
Sprawdź czy bufor jest zablokowany.
Jeśli tak pomiń ten bufor,
Jeśli nie ustaw b_state na BH_Lock
Zwiększ ilość odwołań do bufora
i ustaw procedurę kończącą we-wy.
Jeśli żądany jest odczyt
a bufor, do którego odnosi się wskaźnik,
jest już odpowiednio wypełniony pomiń ten bufor.
Jeśli żądany jest zapis
a bufor, do którego odnosi się wskaźnik,
jest czysty pomiń ten bufor.
Wywołaj submit_bh (rw, rozpatrywany bufor)
}
}
Funkcja submit_bh jest bardzo podobna do funkcji
generic_make_reuest i wywołuję tą funkję do wykonania
większej części roboty. Dodatkowymi czynnościami wykonywanymi przez
funkcję są:
sprawdzenie czy b_state równa się BH_Lock jeśli nie to błąd,
ustawienie b_state na BH_Req,
ustalenie b_rdev na podstawie b_dev,
ustalenie b_rsectors na podstawie b_blocknr i b_size.
Głównym zadaniem
generic_make_request, podobnie
jak poprzednio opisanych funkcji, jest przesłanie nagłówka bufora do kolejki
odpowiedniego urządzenia. Definicja znajduje się w pliku
/drivers/block/ll_rw_block.c, oto skrócony opis:
void generic_make_request(int rw, struct buffer_head * bh)
/* Gdzie rw to rodzaj operacji (READ, WRITE, READA); bh - wskaźnik
bufora do przesłania. */
{
Sprawdz czy ustawiona jest procedura
obsłgi końca operacji we-wy. Jeśli nie to błąd.
Sprawdz czy wielkość bloku dla tego urządzenia.
zgadza się z wielkością buforą. Jeśli nie to
wypisz komunikat o błędzie i wywołaj procedurę
końca operacji we-wy. (To się może wydarzyć
np. przy montowaniu urządzenia)
W pętli wykonuj {
q := znajdź kolejkę dla tego urządzenia
Jeśli q równa się NULL to błąd (urządzenie przestało działać)
} do momentu aż powiedzie się wywołanie procedury zlecającej operację
dla tego urządzenia (q->make_request_fn(q, rw, bh))
}
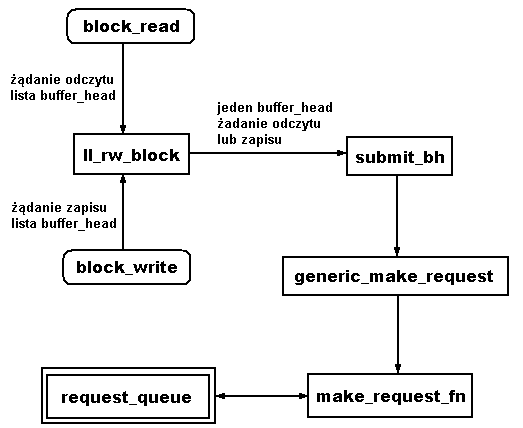 Rys. Schemat wołania funkcji w celu wstawienia żądania. |
1.3. Tworzenie żądań
Wiemy już w jaki sposób odbywa się przesyłanie każdego bufora do kolejki żądań urządzenia. Robią to wyżej opisane funkcję. Oczywiście zaszeregowanie żądania na właściwe miejsce w kolejce i obsługa żądania zależy już od konkretnego urządzenia. W większości przypadków wykorzystywany jest standardowa funkcja szeregująca__make_request, aczkolwiek możliwe jest zdefiniowanie
innej funkcji (trzeba potem jej nazwę umieścić w polu make_request_fn przy
inicjacji kolejki). Funkcja __make_request używa struktury elevator_s.
Struktura ta udostępnia wiele funkcji, za pośrednictwem
których realizowany jest algorytm szeregowania windowego C-LOOK.
Oprócz szeregowania żądań funkcja __make_request zajmuję się synchronizacją.
Może się zdarzyć, że w kolejce brakuje wolnych żądań do pobrania.
Do realizacji czekania służy kolejka wait_for_request. Do samej realizacji
żądania służy funkcja request_fn.
1.4. Algorytm C-LOOK
W algorytmie C-LOOK ramię dysku rozpoczyna od jednej krawędzi dysku i przemieszcza się w kierunku krawędzi przeciwległej, obsługując zamówienia po osiągnięciu każdego kolejnego cylindra, aż dotrze do zamówienia znajdującego się na skraju dysku (zamówienie dotyczące cylindra o najwyższym numerze). Po obsłużeniu ostatniego zamówienia ramię dysku przesuwa się do cylindra z którym związane jest pierwsze zamówienie z kolejki zleceń (zamówienie związane z cylindrem o najmniejszym numerze). C-LOOK należy do klasy algorytmów windy zwanych tak ze względu na analogię w działaniu. Nazwa C-LOOK wzięła się stąd, że przed kontynuowaniem ruchu głowicy ,,patrzy się'' w nich, czy w danym kierunku znajduję się jeszcze jakieś zlecenie.Rozważmy przykład. Zlecenia dotyczące cylindrów przychodzą w następującej kolejności: 98, 183, 37, 122, 14, 124, 65, 67. Głowica znajduje się nad 53 cylindrem.
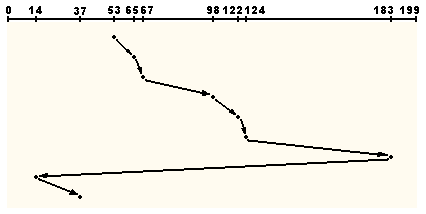 Rys. Planowanie zleceń metodą C-LOOK. |
2. Urządzenie mem
2.1. Wprowadzenie
Pamięć jest widziana w systemie jako urządzenie znakowe o numerze głównym 1. Pewne programy obsługi urządzeń znakowych mogą wykonywać abstrakcyjne funkje nie związane z żadnym fizycznym urządzeniem. Te wirtualne urządzenia, zwane podurządzeniami mem, są identyfikowane numerami podrzędnymi od 1 do 9. Realizują one różne, pożyteczne z punktu widzenia użytkownia, funkcje.2.2. Podurządzenia mem
| Lokalizacja w systemie plików | Numer podrzędny | Realizowana funkcja |
| /dev/mem | 1 | Dostęp do pamięci fizycznej |
| /dev/kmem | 2 | Dostęp do pamięci widzianej przez jądro |
| /dev/null | 3 | Wysyłane dane giną bezpowrotnie |
| /dev/port | 4 | Dostęp do portów we-wy |
| /dev/zero | 5 | Generuje nieskończony ciąg zer |
| /dev/full | 7 | Generuje błąd przepełnienia przy próbie zapisu |
| /dev/random | 8 | Generuje liczby pseudolosowe |
| /dev/urandom | 9 | Generuje liczby pseudolosowe w trybie nieblokującym |
2.3. Funkcje obsługi urządzeń
Funkcje obsługi pierwszych sześciu urządzeń są zaimplementowane w plikudrivers/mem.c. Funkcję obsługi /dev/random
oraz /dev/urandom są zdefiniowane w pliku drivers/random.c.Oto kilka przykładowych funkcji oraz skrócony opis ich działania:
static ssize_t read_mem(struct file * file, char * buf,
size_t count, loff_t *ppos)
/* Fukcja służąca do oczytu z pamięci */
{
jeśli (ppos >= koniec pamięci)
zwróć 0;
jeśli (count > koniec pamieci - ppos)
count = koniec pamieci - ppos;
wywołaj copy_to_user (buf, __va (ppos), count);
/* funkcja pobiera wskaźnik bufora do którego ma skopiować dane, adres
w pamięci od którego ma się zacząc kopiowanie oraz ilość bajtów
do skopiowania. Makro __va dokonuje translacji adresu uwzględniając rozmiar
pamięci zajmowany przez jądro. */
w przypadku powodzenie zwraca count, wpp. BŁĄD;
}
static ssize_t write_kmem(struct file * file, const char * buf,
size_t count, loff_t *ppos)
/* Funkcja służąca do zapisu w pamięci jądra */
{
jeśli (ppos >= koniec pamięci)
zwróć 0;
jeśli (count > koniec pamieci - ppos)
count = koniec pamieci - ppos;
Wywołaj do_write_mem, która po sprawdzeniu czy nie mamy do czynienia
z architekturą sparc lub mc68000 wywołoju funkcję
get_from_user (buf, ppos, count)
w przypadku powodzenie zwraca count, wpp. BŁĄD;
}
2.4. Podurządzenia /dev/random oraz /dev/urandom
W wielu sytuacjach istnieje potrzeba generowania liczb losowych (np. przy przesyłaniu danych protokołem TCP, w kryptografii). ,,Jakość liczb losowych'' (łatwość odgadnięcia algorytmu służącego do ich generowania) jest kluczowa z punktu widzenia bezpieczeństwa wielu aplikacji.Wygodnym interfejsem do generatora ,,dobrych'' liczb losowych są specjalne urządzenia znakowe
/dev/random oraz /dev/urandom.
Podstawą działania generatora dla tych urządzeń
jest pojemnik entropii. Stan pojemnika jest zmieniany na skutek różnych
czynników zależnych od środowiska (ang. enivronmental noise). Czynniki te można podzielić ze względu na ich pochodzenie:
- Pochodzące z klawiatury - czas między kolejnymi naciśnięciami klawiszy i kod ostatnio wprowadzonego znaku,
- Pochodzące od myszy - czas od ostatniego przesunięcia myszy oraz ostatnia pozycja,
- Przerwania - czas między przerwaniami (Nie wszystkie przerwania są dobrym źródłem losowości. Przerwania zegarowe są zbyt regularne. Lepsze w tym przypadku są przerwania od dysku twardego. Ich występowanie jest mniej przewidywalne),
- Urządzenia blokowe - czas od ostatniej pomyślnie zakończonej operacji na urządzeniu blokowym.
Uwaga! Poza interfejsem dostępnym za pośrednictwem urządzeń
/dev/random oraz
/dev/urandom możliwy jest interfejs zaprojektowany do użycia z poza jądra:
void get_random_bytes (void *buf, int nbytes);
Funkcja ta umieszcza żądaną ilość nbytes bajtów w buforze buf.
3. Zadania
Zadanie 1.
Jaka struktura danych jest używana do przechowywania zleceń do urządzenia?Odpowiedź: Kolejka.
Zadanie 2.
Jaka struktura danych jest używana do przechowywania nagłówków buforów (buffer_head) wewnątrz struktury opisującej żądanie?Odpowiedź: Dwukierunkowa lista cykliczna.
Zadanie 3.
Żądania do dysku dotyczące cylindrów przychodzą w następującej kolejności: 35, 1, 77, 19, 120, 189, 15, 165, 55. Głowica dysku znajduje się nad cylindrem 50. W jakiej kolejności zostaną obsłużone te zlecenia zgodnie z algorytmem C-LOOK?Odpowiedź: 55, 77, 120, 165, 189, 1, 15, 35.