Podręczna pamięć buforowa
|
Wiktor Miszuris
II Inf, wm181278
vicor@zodiac.mimuw.edu.pl
rainbow.mimuw.edu.pl/~vicor
Wstęp
Większość urządzeń pamięci masowej są to urządzenia blokowe (dalej będziemy
się odwoływać do nich tylko jako "dyski"). Urządzenia te
pozwalają na dostęp do dowolnej części informacji zapisanej na nich.
Operacja zapisu/odczytu jest niezwykle kosztowna, aby zwiększyć wydajność
operacji zapisu/odczytu na dyski w większości systemów operacyjnych, również
w Linuksie, stosuje się podręczną pamięć buforową. W buforach tych przechowywana
jest dokładna zawartość odpowiadającym im blokom na dysku.
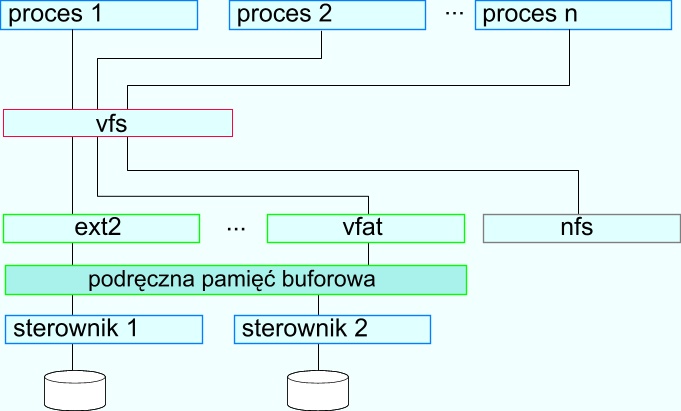
Umiejscowienie podręcznej pamięci buforowej w systemie:
Szczegóły
Pamięć buforów podręcznych spełnia pewne niezmienne założenia:
- Blok na dysku może mieć co najwyżej jednego przedstawiciela wśród buforów
- Bufory zmienione (w blokach, które oni reprezentują, jakiś proces coś zmienił)
powinny kiedyś zostać zapisane na dysk w odpowiednie dla nich miejsce (np.
podczas zamknięcia systemu).
- System Operacyjny wymaga szybkiego zarządzania buforami: kolejki LRU i tablica
haszujaca list buforów.
- System Operacyjny wymaga zarządy buforami: demon bdflush.
Więcej szczegółów
Bufor pamięci podręcznej składa się z dwóch części:
- Nagłówka - zawiera on wszystkie informacje identyfikujące ten bufor.
- Tablicy danych - kopia odpowiedniego bloku na dysku
Opis nagłówka
Pochodzi z include/linux/fs.h:
struct buffer_head {
struct buffer_head *b_next;
/* dowiązanie na następnika w danej liście haszującej */
unsigned long b_blocknr;
/* numer bloku reprezentowanego */
unsigned short b_size;
/* rozmiar bloku */
unsigned short b_list;
/* LRU lista, na której znajduje się ten bufor */
kdev_t b_dev;
/* numer urządzenia */
atomic_t b_count;
/* liczba procesów korzystających z bloku */
kdev_t b_rdev;
/* numer rzeczywistego urządzenie */
unsigned long b_state;
/* mapa bitowa stanu buforu */
unsigned long b_flushtime;
/* czas po jakim zmodyfikowany bufor powinien zostać zapisany */
struct buffer_head *b_next_free;
struct buffer_head *b_prev_free;
/* dowiązania na dwukierunkowych listach
LRU/wolnych buforów */
struct buffer_head *b_this_page;
/* cykliczna lista buforów na jednej stronie */
struct buffer_head *b_reqnext;
/* kolejka żądań */
struct buffer_head **b_pprev;
/* dwukierunkowa lista w tablicy z haszowaniem */
char * b_data;
/* wskaźnik do bloku danych */
struct page *b_page;
/* strona, na którą zmapowany jest ten nagłówek */
void (*b_end_io)(struct buffer_head *bh, int uptodate);
/* zakończenie I/O */
void *b_private;
/* zarezerwowane dla funkcji b_end_io */
unsigned long b_rsector;
/* rzeczywista lokacja buforu na dysku */
wait_queue_head_t b_wait;
/* kolejka oczekujących na dostęp przy blokadzie */
struct inode * b_inode;
/* struktura i-węzła, do której należy blok buforu */
struct list_head b_inode_buffers;
/* dwukierunkowa lista zmodyfikowanych buforów dla danego i-węzła */
};
Haszowanie
Aby przyśpieszyć wyszukiwanie zastosowano tablicę haszującą:static struct
buffer_head **hash_table.
Wyszukiwanie w tablicy następuje przy użyciu funkcji haszującej:
#define _hashfn(dev,block) \
((((dev)<<(bh_hash_shift - 6)) ^ ((dev)<<(bh_hash_shift - 9))) ^ \
(((block)<<(bh_hash_shift - 6)) ^ ((block) >> 13) ^ \
((block) << (bh_hash_shift - 12))))
#define hash(dev,block) hash_table[(_hashfn(HASHDEV(dev),block) & bh_hash_mask)]
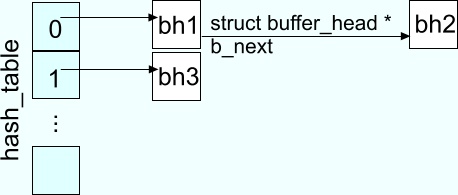
W wyniku działania hash() z parametrami: numer urządzenia i numer bloku otrzymujemy
listę, w której może się już znajdować odpowiedni
bufor. System może teraz przeszukać odpowiednią listę w nadziei, że ten blok
już był czytany i istnieje odpowiedni bufor będący jego odwzorowaniem.
Kolejki buforów wolnych
W Linuksie zaimplementowane są tzw. kolejki buforów wolnych - sama nazwa wskazuje
na przeznaczenie tych struktur. Kolejki trzymane są w tablicy list buforów wolnych.
Tablica ta indeksowana jest rozmiarem bloków, jakie reprezentują bufory znajdujące
się na odpowiednich listach. Dla jądra 2.4.8 tworzone jest siedem kolejek dla
rozmiarów odpowiednio 512B, 1kB, 2kB, 4kB, 8kB, 16kB, 32kB.
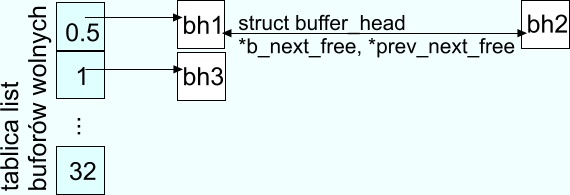
(uwaga: wartości w tablicy na rysunku nie są indeksami - są
to reprezentacje wielkości buforów, jakie znajdują się w odpowiednich kolejkach)
W przypadku, gdy system nie może odnaleźć odpowiedniego buforu w kolejce mieszającej
- pobiera wolny blok odpowiedniego rozmiaru z list buforów wolnych, czyta fizycznie
dane z dysku zapisując informację do nowopobranego bufora i wstawia ten bufor
do kolejki mieszającej.
Kolejki LRU
Jądro zarządza buforami zwalniając je co jakiś czas. Zwolnianie następuje
zgodnie ze strategią LRU (least recently used). W jądrze 2.4.8
zaimplementowanych jest cztery rodzaje kolejek LRU, są to:
- BUF_CLEAN - bufory zawierające aktualne dane
- BUF_LOCKED - bufory zablokowane
- BUF_DIRTY - bufory zmienione
- BUF_PROTECTED - bufory używane przez Ramdisk
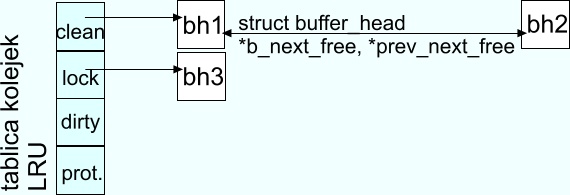
Wracając do nagłówka buforu, możemy teraz już łatwo zlokalizować wszystkie
wymienione tu struktury i zrozumieć powiązania między nimi.
Operacje
bdflush
To jest demon - wątek systemowy, który zajmuje się odśmiecaniem pamięci
podręcznej. Po uruchomieniu przegląda on listy LRU w poszukiwaniu
potencjalnych ofiar na usunięcie z pamięci. Ofiara jest definiowana przez
wiele parametrów, wśród nich są: bit Dirty (czy był
modyfikowany), czas od ostatniej operacji brelse. Jest on budzony przez system
co jakiś czas lub uruchomiany natychmiast po wywołaniu funkcji wakeup_bdflush().
Dokładny opis -> src/linux/fs/buffor.c
Opis taktyki wybierania ofiary:
Blok nie jest zapisywany na dysk aż się trochę nie zestarzeje. Odlicznie zaczyna się
od momentu wykonania operacji brelse() na nim (opisywana dalej) i flaga b_state jest
ustawiona na Dirty. Po zakończeniu odliczania, bufor jest odwzorowany na dysk.
Czas oczekiwania między operacją brelse i zwolnieniem bufora różni
się dla różnych typów danych.
Wszystkie bufory są "postarzane" poprzez funkcje free_more_memory(). W ten sposób
bufory nieużywane całkowicie kiedyś zostaną porzucone i przeniesione do puli
buforów wolnych.
Opis b_flushtime z struct buffer_head
- w jiffies (tyknięciach zegara - 100/s)
- dla nowego bloku ustawiany na 0
Usunięcie ofiary polega na:
- usunięciu nagłówka z kolejki haszującej.
- usunięciu nagłówka z kolejki LRU.
- wstawienie nagłówka do odpowiedniej kolejki buforów wolnych.
refill_freelist(int size)
Parametr wejściowy: rozmiar buforu na blok.
Funkcja próbuje przydzielić stronę na bufory o rozmiarze zadanym przez
parametr. Jeśli ta operacja kończy się pomyślnie - z całej otrzymanej strony
tworzone są bufory odpowiedniej wielkości.
W przypadku braku pamięci uruchomiany jest demon bdflush.
getblk(kdev_t dev, int block, int size)
Jest to podstawowa funkcja całego mechanizmu buforowania.
Funkcja ta służy do uzyskania
buforu dla zadanego bloku. Jest to funkcja niskiego poziomu i nie służy ona do
właściwego obsługiwania informacji znajdującej się w buforach.
Jako parametry przyjmuje ona: numer urządzenia, numer bloku, rozmiar bloku
danych.
(1)Pierwszym krokiem, jaki jest wykonywany jest próba zlokalizowania buforu
w pamięci podręcznej. Poprzez funkcję haszującą otrzymujemy indeks listy, w
której może się znajdować bufor. System przeszukuje tę listę i jeśli znajduje
odpowiedni bufor, to zwraca go.
(2)W przypadku, gdy system nie może znaleźć już istniejącego buforu dla tego
bloku, to musi go utworzyć.
(3)Próbuje w tym celu pobrać jeden bufor z kolejki buforów wolnych o
odpowiednim rozmiarze.
(4)W przypadku pomyślnego pobrania buforu, usuwa go z listy buforów wolnych,
wstawia do odpowiedniej listy LRU i kolejki mieszającej.
(5)W przypadku braku odpowiedniego buforu uruchomiana jest funkcja
refill_freelist(), która próbuje uzupełnić listę wolnych buforów. Powraca do
kroku (3) aż do skutku.
brelse(struct buffer_head * bh)
Funkcja brelse służy do zaznaczenia, że podany przez parametr bufor powinien
być odwzorowany na dysk (jeśli zawiera dane z jakiegoś fizycznego bloku) i
zwolniony (to znaczy przeniesiony do odpowiedniej kolejki LRU i usunięty z
kolejki haszującej).
Właściwymi operacjami zajmuje się demon bdflush, który jest uruchomiany przez
funkcje refill_freelist().
bread(kdev_t dev, int block, int size)
Funkcja ta zwraca bufor z zawartością konkretnego bloku na dysku.
Paramatery wejściowe: numer dysku, numer bloku, rozmiar bloku.
(1)Przydzielenie buforu na blok - getblk().
(2)Jeśli bufor zawiera aktualne dane (funkcja buffer_uptodate()),
to zwróć go.
(3)Inicjacja odczytu bloku do otrzymanego bufora (ll_rw_block()).
(4)Czekaj na koniec odczytu danych.
(5)Jeśli bufor zawiera aktualne dane (funkcja buffer_uptodate()),
to zwróć go.
(6)Błąd, zwolnij otrzymany bufor (funkcja brelse()) - zwróć NULL.
breada - block read-ahead
Zazwyczaj pliki czytane są sekwencyjnie, więc można oczekiwać, że po operacji
odczytu bloku w krótkim czasie nastąpi żądanie odczytu następnego bloku.
System operacyjny Linux miał do tego w wersjach 2.2.20 i wszystkich
wcześniejszych funkcję breada(). Teraz jej już nie ma, bo nie cieszyła się ona
zbyt dużą popularnością - trzeba było ją użyc w swoim programie.
Mechanizm read-ahead jednak pozostał w systemie. Został on przeniesiony w inne
miejsce, dokładnie do warstwy obsługi systemu (konkretnego) plików.
Funkcja generic_file_read(), która jest domyślną funkcją czytania w większości
systemów plików (jest to otoczka dla konkretnej funkcji interpretującej
konkretny system plików inode->i_op->readpage() )
troszczy się o ewentualny odczyt z wyprzedzeniem. Używana jest do tego funkcja
pomocnicza generic_file_readahead(), w której zawarte są zawiłe heurestyki.
Mechanizm odczytu z wyprzedzeniem został więc w ten sposób przerzucony na
moduł obsługi konkretnego systemu plików. Zasadniczo większość systemów plików
korzysta właśnie z funkcji generic_file_read(), aczkolwiek są takie, które
implementują własne funkcje odczytu (np. NFS).
W ten sposób, to system plików decyduje, czy i jakie bloki mają być odczytane
z wyprzedzeniem, ale służy do tego kompletnie inna warstwa niż w
dotychczasowych jądrach Linuksa.
Źródło: linux/mm/filemap.c
Podsumowanie
Zalety
Znaczna poprawa wydajności operacji we/wyjścia poprzez
- zmniejszenie liczby i częstości realnych transmisji z/na dysk
- przyśpieszenie odczytu i zapisu pojedynczych bajtów pliku
Wady
- Możliwość utraty danych w przypadku awarii systemu
- Narzut czasowy podczas odczytu i zapisu bloku
- Zużycie części pamięci na bufory
|
made with love using vi(m)
|