Mechanizm buforowania
Zapewnia jednolity dostęp do urządzeń blokowych dla systemów plików.
Zapobiega wielokrotnemu czytaniu z dysku tych samych danych, zbędnego ich zapisywania na dysk.
Umożliwia wcześniejsze przeczytanie danych (w wolnym momencie), które będą najprawdopodobniej później potrzebne.
Pozwala nie zatrzymywać procesu, który chce coś zapisać na dysk lub odczytać z dysku.
Pozwala rozłożyć zapisy w czasie.
Zapewnia synchronizację.
W Linuksie istnieje pięć pamięci podręcznych związanych z systemami plików. Są to:
- pamięć podręczna buforów (buffer cache)
- pamięć podręczna stron (page cache)
- pamięć podręczna katalogów (dcache)
- pamięć podręczna i-węzłów (i-node cache)
- pamięć podręczna punktów montowań (mount cache)
Główną pamięcią podręczną jest obecnie pamięć stron.
Przechowuje się w niej strony plików (niekoniecznie kolejne bloki pliku z dysku).
Główne struktury danych to: tablica hashująca i listy stron plików przy każdym i-węźle.
Na stronach są zazwyczaj bufory (ich dane) - jeśli czytamy stronę pliku to tworzymy kilka buforów na tej stronie, i wczytujemy do nich dane (chociaż tak nie musi być).
Bufory nie są już tak istotną częścią linux'a jak w jądrach przed 2.4; spadek ich ważności uwidacznia się w przydzielanej im pamięci (e. g. tablica hashująca 4 razy mniejsza niż tablica hashująca page cache'a).
Buforowanie jest prawie całkowicie uwątkowione, tzn. blokadę jądra (kernel_lock) zamyka się rzadko, a większość pracy wykonywana jest asynchronicznie.
Jest ono też przystosowane do działania na systemach wieloprocesorowych.
czytanie bloków
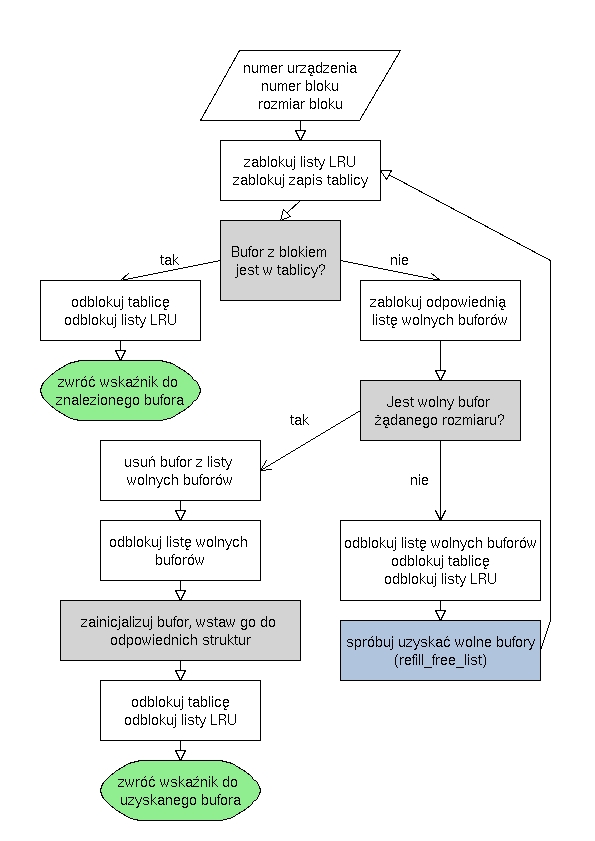
getblk
Dane: numer urządzenia, numer bloku, rozmiar bloku
Zwraca bufor z żądanym blokiem, jeśli już taki jest, lub pusty zaalokowany bufor.
Tablica buforów to tablica hashująca z liniowym rozwiązywaniem kolizji.
Gdy szuka się bufora, oblicza się dla niego funkcję hashującą, i przegląda listę w tablicy, na pozycji odpowiadającej wartości funkcji.
Aby bufor został uznany za właściwy zgodzić się musi wszystko - urządzenie, numer i rozmiar.
Po pierwsze w breadzie, ale poza tym w niektórych systemach plików (nfs, jfs, fat...) i w procedurach obsługi urządzeń blokowych.
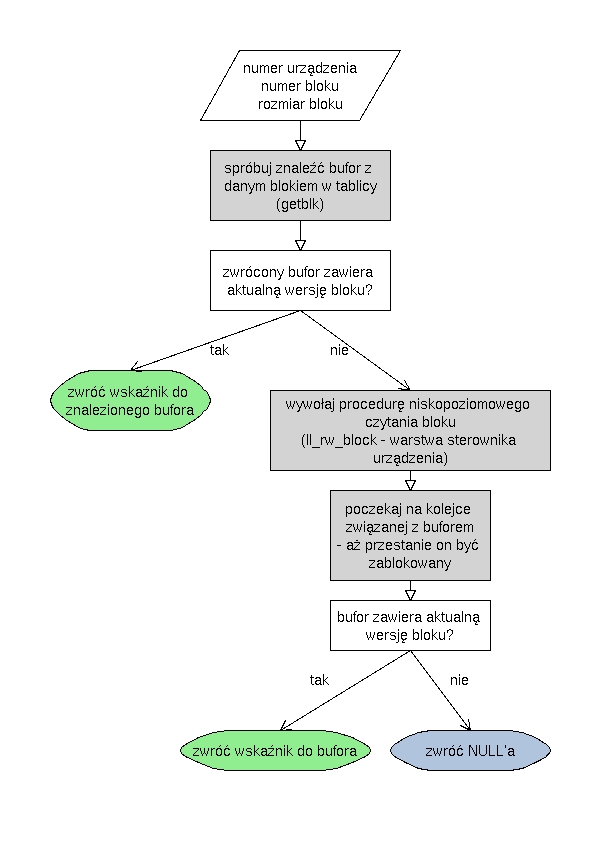
bread
Dane: numer urządzenia, numer bloku, rozmiar bloku
Zwraca bufor zawierający dany blok.
Jeśli bufor nie jest zablokowany, to go blokuje, jeśli jest, to nie robi nic.
Jeśli bufor jest aktualny to nie robi nic.
Dodaje żądanie do kolejki odpowiedniego urządzenia (dokładniej wywołuje make_request_fn - zdefiniowaną dla każdego urządzenia).
Ustawia funkcję wywoływaną po zakończeniu transmisji (funkcja ta powinna przynajmniej odblokować i oznaczyć bufor jako aktualny).
Zwiększa licznik użytkowników bufora.
Dodaje się do kolejki czekających na bufor.
Dopóki bufor jest zablokowany:
- wykonuje zadania z kolejki zadań dyskowych (run_task_queue (&tq_disk)),
- oddaje procesor.
Usuwa się z kolejki czekających na bufor.
Zmniejsza licznik użytkowników bufora.
Głównie przy czytaniu bloków przez system plików (ext2, ext3, minix, nfs, reiserfs...).
Jest tak gdyż tylko system plików wie, dokładnie którego bloku potrzebuje.
Wykorzystanie jest często pośrednie - system plików tworzy swoją procedurę czytania bloku (..._get_block - z użyciem bread'a),
którą używa przy definiowaniu procedury wczytywania strony (i-node->adress_space_operations->readpage() - zazwyczaj wczytanie strony pełnej buforów).
Ta ostatnia procedura jest z kolei używana przy czytaniu plików. (Tak jest na przykład dla ext2.)
Jest również wykorzystywany, w niektórych sterownikach urządzeń.
zwalnianie buforów
brelse
Powiadamia system, że już nie używamy bufora.
Atomowo zmniejsza ilość użytkowników bufora (b_count).
Licznik ten służy jako pewnego rodzaju blokada, dopóki jest większy od zera system nie pozbędzie się bufora. Większość operacji na buforach jest otoczona parą: zwiększ licznik, zmniejsz licznik.
Brelse dodatkowo dodaje wpis do historii bufora.
Jest to funkcja "do pary" do bread'a, który zwiększa ten licznik.
bforget
To samo co brelse, poza tym, że próbuje wstawić bufor na listę wolnych buforów.
Algorytm:
- Zablokuj listy LRU.
- Zablokuj tablicę hashującą.
- Atomowo sprawdź i zminiejsz liczbę użytkowników bufora.
- Jeśli bufor nie ma użytkowników, nie jest zablokowany, nie jest chroniony to usuń go ze wszystkich struktur.
- Odblokuj tablicę i listy.
- Jeśli bufor spełnił warunki p. 4 (był nieużywany) to dodaj go do odpowiedniej listy wolnych buforów.
odzyskiwanie wolnych buforów
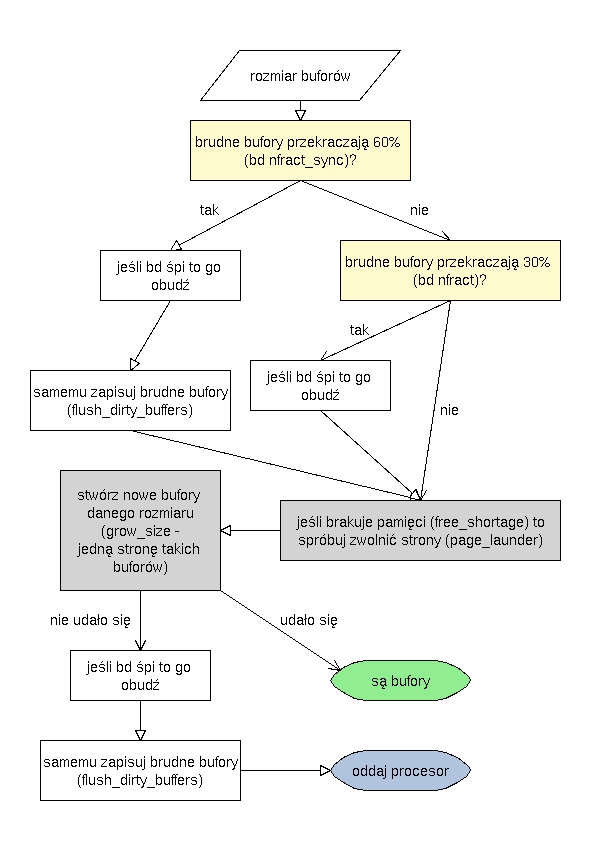
refill_freelist
Dane: rozmiar buforów
Uzupełnia jedną z list wolnych buforów.
Sprawdza czy jest odpowiednia ilość nieaktywnych czystych stron - takich jakie są potrzebne do utworzenia buforów.
Przenosi strony na listę nieaktywnych czystych; flaga GFP_NOFS zapobiega próbom zapisania stron na dysk (poprzez adress_space_operations->writepage() -
co mogłoby prowadzić do zapętlenia).
Nie żądamy też zapewnienia uzyskania stron (poprzez ich synchroniczne zwalnianie).
Alokuje jedną stronę (page_alloc (GFP_NOFS)).
Blokuje tę stronę.
Tworzy na niej bufory (create_buffers).
Blokuje odpowiednią listę wolnych buforów.
Dodaje wszystkie bufory na listę.
Odblokowuje listę.
Dodaje tę stronę do cache'a stron (lru_cache_add).
Odblokowuje stronę.
Pobiera nagłówki buforów, z listy nieużywanych lub nowe (tworzone alokatorem płytowym - SLAB_NOFS), i przydziela im obszary danych na otrzymanej stronie.
W getblk, gdy brakuje bloków.
Utrzymywana jest rezerwa nieużywanych nagłówków buforów dla asynchronicznych operacji
wejścia/wyjścia - żeby uniknąć blokady; na przykład przy braku pamięci i konieczności
wyrzucania stron na dysk.
demony dyskowe
Zmienione bufory od czasu do czasu przydałoby się zapisać na dysk.
Robią to dwa demony - kupdate i bdflush.
Pierwszy budzi się co pewien czas (co 5 sS) i zapisuje wszystkie metadane i brudne bufory.
Drugi jest budzony zazwyczaj gdy brudnych buforów zaczyna być zbyt dużo, czy też brakuje miejsca na nowe bufory.
Obydwa wykorzystują procedurę (asynchronicznego) zapisywania buforów na dysk: flush_dirty_buffers (jest to w ogóle jedyna taka procedura).
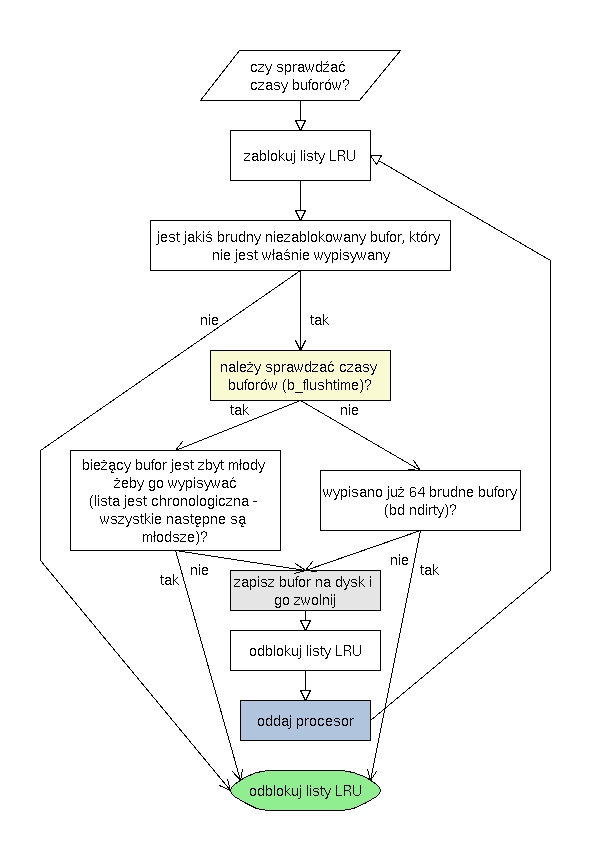
flush_dirty_buffers
Dane: tryb działania
Zapisuje i zwalnia brudne bufory.
Demon bdflush w kółko wykonuje następujące czynności:
- Wypisuj brudne bufory (flush_dirty_buffers), bez sprawdzania czasów.
- Jeśli nic nie udało się wypisać lub jest mniej niż 30% (nfract) brudnych buforów to
wykonaj zadania dyskowe (tq_disk) i uśnij.
Demona można budzić - wakeup_bdflush - dzieje się to czasem podczas uzyskiwania wolnych buforów.
Kupdate - drugi demon, budzi się co pewien czas i wypisuje niezablokowane węzły indeksowe,
super bloki, i stare bufory; wykonuje, również synchronicznie, kolejkę zadań dyskowych (run_task_queue(&tq_disk)).
Działanie bdflush'a jest sparametryzowane, można je zmieniać nawet podczas działania
systemu (sys_bdflush).
Parametry demona to:
| parametr | opis | wartość
ustalona | wartość
minimalna | wartość
maksymalna |
| nfract | procent brudnych buforów, przy którym zwalnia się je asynchronicznie | 30% | 0% | 100% |
| nfract_sync | procent brudnych buforów, przy którym zwalnia się je synchronicznie (blokująco) | 60% | 0% | 100% |
| ndirty | maksymalna liczba buforów wypisanych przy jednym obudzeniu | 64 | 10 | 50000 |
| age_buffer | przez jaki czas bufor będzie zbyt młody żeby go wypisać | 30s | 1s | 6000s |
| interval | czas pomiędzy uruchumieniami kupdate'a | 5s | 0s | 600s |
| nrefill | liczba buforów, jaką próbuje się uzyskać przy jednym wywołaniu refill_freelist (nieużywane) | 64 | 5 | 20000 |
Czytanie z wyprzedzeniem