20.I.2003

|

|
Przepełnianie buforów
Często mówi się, że żaden system operacyjny nie jest w 100% bezpieczny, a zdolni hakerzy pewnie znajdą w nim jakąś dziurę. Ale czym właściwie są dziury? Zastanówmy się na czym polega włamanie do systemu? Jeżeli komputer nie oferuje żadnych usług (tzn. na jego portach TCP/UDP nie nasłuchują żadne programy to sprawa jest naprawdę ciężka. Gdy jednak maszyna udostępnia poprzez sieć różne usługi, to wystarczy, że połączymy się z jednym z takich programów-serwerów i w jakiś sposób namówimy go, aby umożliwił nam pracę na tym komputerze. Jedyny problem leży w tym, jak nakłonić go by był tak miły, jeżeli nie znamy hasła dostępu.
Opowiem teraz o czymś, co określamy mianem ataku ,,Buffer Overflow'' - czyli przepełnienie bufora.

Aby zrozumieć czym on jest posłużmy się przykładem. Zacznijmy od ataku lokalnego. Załóżmy, że posiadamy już konto w systemie, jednak jest to zwykłe konto, a naszym celem jest uzyskanie praw administratora. (Zazwyczaj o to samo chodzi w atakach zdalnych.)
Na rysunku przedstawiam program, który po podaniu właściwego hasła uruchamia powłokę. Jeżeli dodatkowo jego właścicielem uczynimy użytkownika root oraz ustawimy mu bit SUID, to dostaniemy coś w rodzaju prymitywnego programu su.
Kiedy teraz jako zwykły użytkownik, uruchomimy nasz program i podamy właściwe hasło,
to dostaniemy powłokę z przywilejami administratora.
A co jeśli nie znamy hasła?
W akcie desperacji wpisaliśmy bardzo długi ciąg znaków...
... w wyniku czego spowodowaliśmy zabicie programu-serwera sygnałem SIGSEGV.
Dlaczego tak się stało?
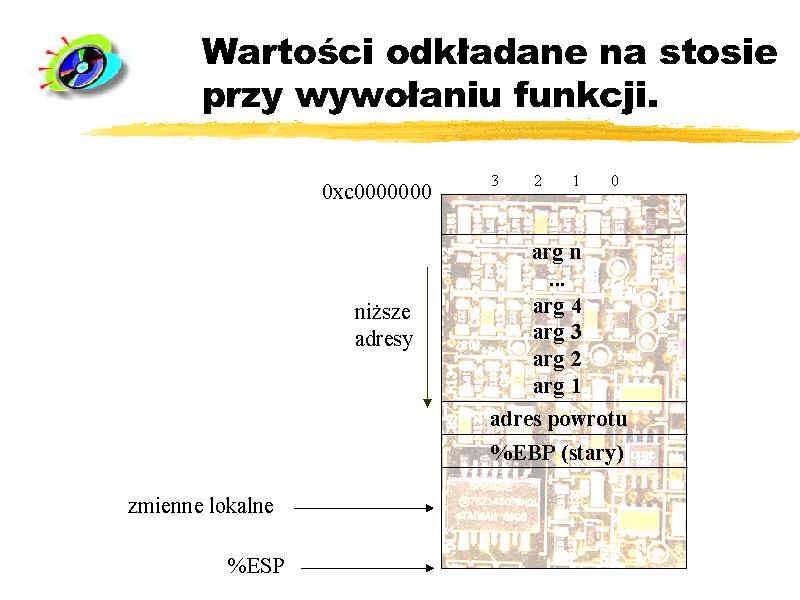
Każde wywołanie funkcji powoduje odłożenie na stos kilku wartości:
- argumentów wywołania,
- adres powrotu,
- wartości rejestru wskaźnika ramki stosu (EBP na i386),
- oraz przedzielane jest miejsce na zmienne lokalne danej funkcji.
W większości implementacji stos ,,rośnie w dół'' adresów pamięci, co oznacza tylko tyle, że wrzucenie kolejnego elementu na stos spowoduje zmniejszenie wskaźnika stosu (ESP) o 4 (w przypadku procesora 32-bitowego). Warto również zauważyć, że jeśli zdefiniujemy w funkcji tablicę, to odwołując się do jej kolejnych elementów (array[0], array[1], ...) idziemy w ,,stronę przeciwną'', niż kierunek wzrostu stosu.
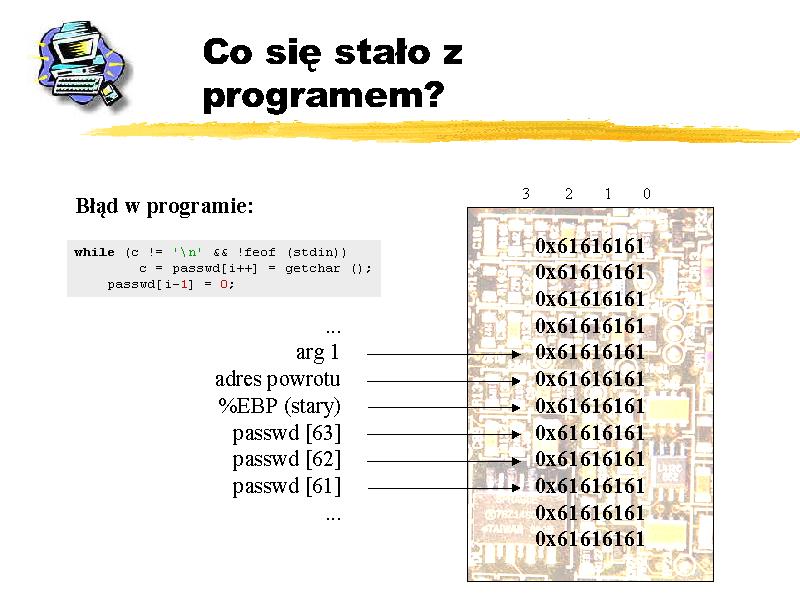
W przedstawionym przykładzie wystąpił błąd segmentacji, ponieważ pętla while, nie sprawdzając rozmiaru tablicy passwd wpisała do niej wszystkie znaki, zamazując adres powrotu z funkcji main. Program wykonywał się dalej normalnie, o czym świadczy pojawienie się komunikatu Nieautoryzowany dostęp!. Następnie instrukcja return -1 spowodowała pobranie ze stosu adresu powrotu z funkcji main, który został nadpisany. W naszym przypadku został więc wykonany skok pod adres 0x61616161 ('a' = ASCII 0x61). Oczywiście pod tym ,,losowym'' adresem pamięć najprawdopodobniej będzie niedostępna i stąd błąd segmentacji.
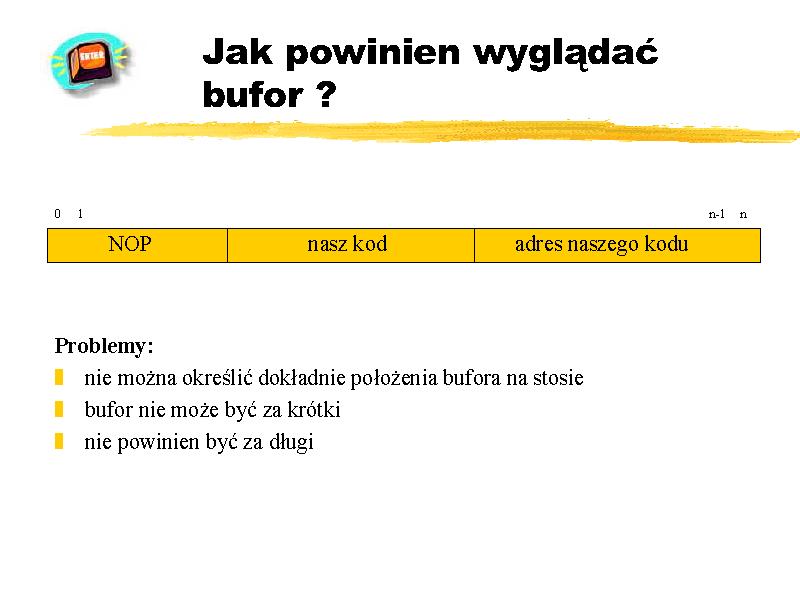
Nadpisując adres powrotu możemy spowodować by program wykonał instrukcje spod podanego przez nas adresu. Ciekawym pomysłem (jeżeli chodzi o kod, który mógłby wykonać atakowany program) jest uruchomienie powłoki z przywilejami administratora. W większości systemów obszar stosu ma atrybut wykonywalności, więc nic nie stoi na przeszkodzie, aby własnie na stosie umieścić takie instrukcje. Musimy w tym celu podać obraz binarny takich instrukcji.
Niestety nie potrafimy określić adresu, pod który wpisujemy nasz bufor. Jeśli nawet rozpatrujemy konkretny system operacyjny na przykład Linux, możemy założyć, że stos rozpoczyna się od znanego nam adresu (0xbfffffff) i rośnie w dół, to z całą pewnością nie możemy nic powiedzieć o tym, jak daleko od wierzchołka stosu zostanie umieszczony nasz bufor. Pamiętajmy, że zanim zostanie wywołana funkcja main() w programie, na stos odkładane są chociażby zmienne środowiskowe. Nie możemy powiedzieć jaka będzie długość zmiennych środowiskowych w atakowanym systemie. Dlatego możemy jedynie w przybliżeniu oszacować potrzebny adres. Ale w tym miejscu napotykamy na problem, ponieważ musimy dokładnie wiedzieć dokąd skoczyć. Z problemem tym można uporać się w ten sposób, że na początku bufora wstawiamy trochę instrukcji pustych (np. NOP na i386) i już prawdopodobieństwo trafienia zwiększy się znacząco.
Pozostał jeszcze problem z doborem odpowiedniej długości łańcucha. Oczywiście, jeśli będzie za krótki , to adres powrotu z funkcji nie zostanie nadpisany. Jeśli natomiast będzie za długi, to adres powrotu zostanie nadpisany nie podanym przez nas adresem, ale wcześniejszymi bajtami, które tworzą obraz binarny naszego kodu. I znowu: jeśli na końcu bufora umieścimy tylko jeden adres powrotu, to musimy go podać z dokładnością do jednego bajtu. Nie jest to sytuacja beznadziejna, o ile tylko dysponujemy kopią atakowanego programu na swoim komputerze. Dzięki temu korzystając z debuggera i zmieniając kolejno długość bufora możemy sprawdzić spod jakiego adresu została wykonana ostatnia instrukcja powodująca wystąpienie sytuacji wyjątkowej. Jeśli spod podanego przez nas adresu - oznacza to, że właśnie dobraliśmy odpowiednią długość łańcucha znaków!
W przypadku, kiedy nie dysponujemy własną kopią programu, powyższa procedura nie zadziała, gdyż system operacyjny nie będzie dostarczał zwykłemu użytkownikowi informacji o tym, gdzie wystapił błąd w programie uprzywilejowanym (nie pojawi się core dump.) W takim przypadku można np. powielać ilość adresów na końcu bufora, dzięki czemu wzrośnie szansa udanego trafienia. Problem polega jednak na tym, że wówczas musimy jednocześnie dobierać zarówno adres skoku, jak i długość bufora.
W ciągu ostatnich kilku lat liczba programów, w których odkryto błędy umożliwiające zastosowanie ataku typu buffer overflow sięgnęła wielu tysięcy! Exploity nadpisujące bufor stały się postrachem administratorów wszystkich systemów operacyjnych. I są nimi do dzisiaj. Próbujemy się zabezpieczyć przed tego typu atakami w różny sposób. Najlepszą metodą obrony jest po prostu unikanie błędów podczas pisania programów. Mylić się jest jednak rzeczą ludzką, dlatego dalej omówię takie sposoby ochrony, które nie wymagają jakiejkolwiek ingerencji w kod źródłowy zabezpieczanego programu.
Jedna z pierwszych metod została zaproponowana przez Solar Designera. Przeznaczona jest dla systemu Linux. Pomysł jest prosty: skoro większość exploitów przekazuje sterowanie do dostarczonego przez siebie kodu, który jest zazwyczaj umieszczany na stosie, to na danie segmentowi stosu atrybutu " niewykonywalności" skutecznie uniemożliwi tego typu ataki. Standardowo w Linuksie stos nie jest ustawiany z takim atrybutem. Powodem tego są używane przez GCC tzw. "trampolinowe" wywołania funkcji oraz obsługa sygnałów. Oba wspomniane mechanizmy wymagają, niestety, możliwości wykonywania instrukcji na stosie. Problem ten został dość sprytnie rozwiązany przez Solar Designera i nie stanowi już większego kłopotu.
Zauważmy jednak, że rozwiązanie to ma istotną wadę. Próbuje zwalczyć skutek, a nie przyczynę. Załóżmy bowiem, że w systemie zainstalowaliśmy omawianą łatę, wówczas opisany sposób wykorzystania ("wyeksploitowania") przykładowego programu nie powiedzie się. Przyglądając się kodowi źródłowemu naszej ofiary dojdziemy do wniosku, że przecież wcale nie musimy dostarczać własnego kodu do wykonania. Akurat w przypadku rozważanego programu taki kod jest częścią programu (setuid() i execl("/bin/sh")). Co więcej, nie dość, że obejdziemy w ten sposób zabezpieczenie, to jeszcze nie musimy się męczyć ze znalezieniem lub napisaniem własnego kodu.
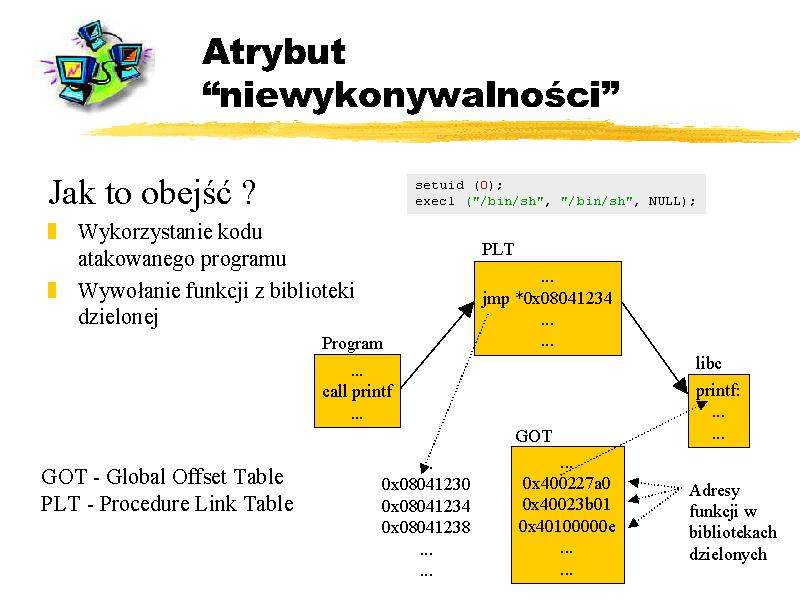
Czasami jednak nie uda się znaleść w atakowanym programie instrukcji, których wykonanie nas by satysfakcjonowało. O ile liczymy jednak na to, że z zainstalowaną łatą Designera będziemy mogli wywołać bezpośrednio jakąś funkcję z libc, są one bowiem mapowane pod adresy, których najbardziej znaczący bajt jest równy 0x00. Jakkolwiek będziemy mogli tam wskoczyć, nie będziemy potrafili przekazać żądanego argumentu do funkcji, ponieważ znak 0x00 oznacza koniec łańcucha ASCII, a my musimy argument umieścić na stosie za (w sensie adresów) adresem funkcji. Jednak i to zabezpieczenie nie jest zbyt skuteczne, gdyż jak pokazał Nergal możemy próbować wywołać funkcje z bibliotek dzielonych nie skacząc bezpośrednio do nich, lecz poprzez tzw. tablicę PLT (ang. Procedure Link Table), która jest o tyle lepsza, że nie znajduje się (zazwyczaj) pod adresem zawierającym zerowe bajt(y). Notabene, kiedy w programie wywołujemy funkcję z biblioteki dzielonej, to jest ona wywoływana właśnie poprzez mechanizm PLT. Skok następuje pod pewien adres w PLT, który to zawiera następnie instrukcję jmp *addr_of_func_addr, pod prawdziwy adres funkcji w bibliotece dzielonej. Przedstawione to jest na rysunku. Przestrzeń, gdzie zapisane są adresy funkcji w bibliotece dzielonej nazywa się Global Offset Table.

Wymienionych wyżej wad nie posiada inny pakiet przeciwdziałający atakom buffer overflow - StackGuard.
Twórcy StackGuarda przyjęli zupełnie inną taktykę.
Ich pakiet jest tak naprawdę łatą na kompilator gcc.
Zastosowanie tej techniki wymaga więc przekompilowania zabezpieczenia programu,
oczywiście bez ingerencji w źródła.
Na czym polega pomysł?
Otóż StackGuard dba o to, aby adres powrotu funkcji był przy wychodzeniu z danej funkcji taki sam,
jak przy wchodzeniu do niej.
Innymi słowy, wykrywa zmianę adresu powrotu dokonaną w ciele funkcji.
(Oczywiście nie muszę wspominać, że takie zmiany dokonują właśnie exploity, z którymi chcemy walczyć.)
Jest to realizowane w następujący sposób.
Podmieniane są dwie funkcje gcc: function_prolog i function_epilogue.
Funkcje te generują instrukcję,
które mają być wykonane w programie użytkownika odpowiednio:
zaraz po przekazaniu sterowania do funkcji oraz tuż przed jej opuszczeniem.
Zmodyfikowanie wspomnianych funkcji powoduje,
że gcc tworzy kod w taki sposób,
aby skompilowane funkcje same sprawdzały czy adres powrotu został przez nie zmodyfikowany!
Tzn. na samym początku funkcja odkłada na stos pewną tajemniczą 32-bitową wartość, zwaną canary ,
a następnie "na końcu" funkcji zdejmuje ową wartość i porównuje ją z oryginałem.
Jeśli wartości są różne, to znaczy, że ktoś "pisał" po stosie
i można podjąć odpowiednie kroki - np. zabić proces i zanotować w dzienniku próbę włamania.
Pamiętajmy, że adres powrotu leży głębiej, niż canary,
więc aby nadpisać adres powrotu (używając przepełnienia bufora) trzeba nadpisać również canary.
Orginalna wartość może być generowana w następujących rozwiązaniach:
- Random Canary. Przy uruchamianiu programu generowana jest tablica losowych liczb 32-bitowych. Do każdej funkcji przypisana jest w czasie kompilacji pewna liczba (jest ona jawna), która później jest używana jako indeks w tablicy. Dzięki temu funkcja może porównać przy wyjściu, czy wartość canary zdjęta ze stosu pokrywa się z tą z tablicy. Ze względu na konieczność istnienia globalnej tablicy, zawierającej wygenerowanie liczby losowe, metoda ta nie nadaje się do zabezpieczenia dynamicznie ładowanych bibliotek współdzielonych, których kod nie może zawierać adresów bezwzględnych (ang. Position Independent Code).
- XOR Random Canary
- Terminator Canary Trzecia metoda jako canary stosuje liczbę będącą złożeniem czterech różnych terminatorów: NULL (0x0), LF (0xa), EOF (-1), CR (0xd)
static const int CANARY_TERMINATOR = 0x00aff0d; Nadpisywanie bufora odbywa się prawie zawsze poprzez funkcję, która kończy kopiowanie właśnie na jednym z tych znaków, więc atakujący w swoim buforze nie może zawrzeć kopii canary.

Panowie Bulba i Kil3r pokazali jak zmienić adres powrotu nie dotykając przy tym "kanarka".
Pomysł (przedstawiony na rysunku) polega na tym,
aby znaleźć taki bufor,
którego przepełnienie spowoduje nadpisanie zmiennej wskaźnikowej w programie,
która następnie jest używana (przez program-ofiarę) jako argument przeznaczenia dla jakieś funkcji typu
strcpy () czy sprintf ().
Przepełniając bufor przypisujemy wskaźnikowi arbitralną wartość.
Następnie trzymamy kciuki za to, aby program wywołał instrukcję kopiującą wartość,
na która my mamy wpływ, pod adres wskazywany przez nasz podmieniony wskaźnik.
Nie da się ukryć, że prawdopodobieństwo zajścia tylu okoliczności naraz jest dość nikłe...
Jeśli jednak mamy szczęście, to naprawdę dostajemy potężne narzędzie.
Oto możemy pisać pod dowolny adres. Oczywiście, teraz możemy podmienić wartość powrotu z funkcji,
nie dotykając "kanarka".
Częściowym rozwiązaniem tego problemu jest wprowadzenie tzw. XOR Random Canary,
które tym różni się od omówionego wcześniej Random Canary,
że na stos odkładana jest nie bezpośrednia wartość pobrana w wygenerowanej losowo tablicy "kanarków",
a jedynie efekt wykonania operacji: canary XOR ret_addres.
Później, na końcu funkcji, wartość zdjętego ze stosu "bezpiecznika" jest "XORowana" z adresem powrotu i otrzymana
liczba porównywana z oryginalną wartością z tablicy.
Oczywiście zakłada się, że włamywacz nie pozna oryginalnej wartości canary.
Dlaczego jest to tylko częściowe rozwiązanie?
Ano dlatego, że skoro ktoś będzie miał możliwość pisania pod wybrany adres w przestrzeni adresowej procesu,
to wcale nie musi zmieniać adresu powrotu z funkcji,
aby zmodyfikować kolejność wykonywania programu.
Możemy zmienić np. adres w tablicy GOT (patrz poprzedni rysunek ) jakieś popularnej funkcji tak,
aby wskazywał na nasz kod, który oczywiście gdzieś umieściliśmy np. na stosie, albo na stercie...
Oczywiście StackGuard niczego nie wykryje, gdyż adres powrotu z funkcji będzie nietknięty (jak i sam "kanarek").
A tu program wywołując jakąś niewinną funkcję (printf() ?) elegancko odda nam sterowanie.
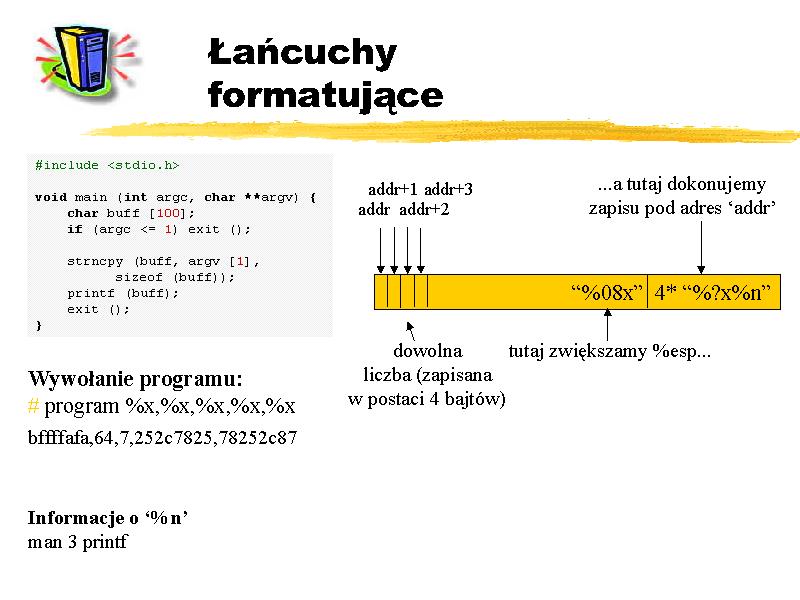
Przypa trzmy się programowi na rysunku.
Widzimy, że żadnego bufora nie da się tu nadpisać,
gdyż używana jest bezpieczna funkcja strncpy ().
Zwróćmy uwagę jednak na funkcję printf ().
Funkcje rodziny printf są dość specyficzne,
mogą bowiem przyjmować zmienną liczbę argumentów.
I nformacja o tym jest przechowywana w pierwszym argumencie (język C, a nie C++).
Każdy dodatkowy argument jest identyfikowany przez pojawienie się symbolu % w pierwszym argumencie,
który jest zawsze łańcuchem znaków. Dzięki temu następujące wywołanie:
./program %x,%x,%x,%x,%x
wyświetli nam zawartość pierwszych 20 bajtów stosu, licząc od adresu argumentu dla funkcji printf (). Jesteśmy więc w stanie podejrzeć zawartość stosu.
Możemy też modyfikować pamięć procesu wykorzystując operator %n. Podanie takiego łańcucha w łańcuchu formatującym, powoduje zdjęcie ze stosu kolejnego słowa i potraktowaniu go jako a dresu zmiennej typu int, pod którą należy zapisać liczbę dotychczas wypisanych znaków (patrz printf(3)). Mamy kontrolę nad liczbą zapisywanych znaków, więc wystarczy, że za pomocą sekwencji %x, przesuniemy wskanik stosu (ESP), w takie miejsce, aby wartość zapisana pod następnym słowem była równa adresowi, pod który chcemy pisać. Wartość ta może być częścią dostarczonego łańcucha, o ile jest niedaleko na stosie. A często jest! Wówczas możemy pisać pod ten adres używając %n.
Maskowanie obecności hakera w systemie
Każdy haker wie, że sztuką nie jest włamanie do systemu, ale pozostanie jak najdłużej nie zauważonym przez zarządcę. Ogólny tok postępowania intruza po włamaniu do systemu jest taki sam dla różnych systemów operacyjnych, dlatego o piszę jak się to robi w Linuxie.

Z reguły pierwszą czynnością wykonywaną zaraz po włamaniu, jest próba zatarcia wszystkich śladów świadczących o przeprowadzonym ataku. Ślady działalności intruza znajdują się w niektórych z logów systemowych, określanych również mianem rejestru lub dziennika zdarzeń . W naszym przypadku większość informacji będzie zawarta w katalogu /var/log. Czynności, które przeprowadzają przedstawione na rysunku polecenia wykonują odpowiednie narzędzia określane mianem log-wipers . Wiele z nich wykrywa położenie kartoteki z dziennikiem zdarzeń i automatycznie przeprowadza proces wymazywania obciążających nas informacji. Tego typu narzędzia są szczególnie przydatne w przypadku binarnych plików logowania, kiedy to edytor potokowy nie zawsze nam pomoże.

Po uzyskaniu dostępu do systemu możemy zainstalować backdoora. Pozwala to na późniejsze wejście do systemu, nawet po załataniu dziury, przez którą pierwotnie uzyskaliśmy do niego dostęp. Jest to dobry pomysł, chociażby z tego względu, że uchronimy się przed przejęciem systemu przez innego włamywacza. Każdy szanujący się haker poprawia nie tylko konkretną dziurę, ale całą politykę bezpieczeństwa. (Trzeba tylko uważać, aby wykonywać czynności w odpowiedniej kolejności)
Jeżeli system oferuje konta z interaktywnymi powłokami (telnet lub jego bezpieczniejsze alternatywy)
możemy pokusić się o próbę złamania haseł.
Najpopularniejszym przeznaczonym do tego celu programem jest John The Ripper,
napisany przez Solar Designera. Program dostępny jest na wielu platformach, m.in.: DOS, Windows i Unix.
Użytkownicy systemu Windows NT mogą również posłużyć się programem IOphtcrack.
Niestety czas potrzebny na złamanie wielu haseł może być bardzo długi
i czasami nie opłaca się podejmować takich działań. Ale zawsze warto spróbować.
Możemy również zainstalować tzw. keyloggera, który notuje wszystkie zdarzenia związane z klawiaturą. Dzięki temu możemy poznać nie tylko hasła użytkowników, ale również poufne informacje. Dla systemów unixowych, do tego celu powstał program o nazwie unix-keylogger.
Możemy również dodać konto użytkownika z uprawnieniami administratora, lub konto zwykłego użytkownika po uprzednim zainstalowaniu jakieś tylnej furtki, np. pliku binarnego z ustawionym bitem s (np. plik wykonywalny powłoki shellowej).
W systemach unix tylną furtkę możemy uzyskać dokonując odpowiedniego wpisu do pliku konfiguracyjnego demona kontrolującego większość połączeń sieciowych (np. inetd, xinetd).
Niestety tego typu drzwi są trywialne i łatwe do wykrycia dla przeciętnego administratora.
Inną możliwością jest użycie koni trojańskich znanych poleceń systemowych, np. ps, login, netstat, które nie tylko ukrywają naszą obecność, ale również udostępniają kilka furtek.
Aby ułatwić życie włamywaczom, są specjalne zestawy, określane mianem rootkit, które zawierają podmienione wersje różnych programów. Przykładem może być Irk , zawierający zestaw kilkudziesięciu koni trojańskich.
W przypadku braku dostępu do powłoki shellowej możemy posłużyć się zmodyfikowanymi wersjami znanych demonów oferujących usługi sieciowe, np. SSH, telnet, FTP, SMTP, itp., a także specjalnymi skryptami CGI czy PHP.
Najciekawszą grupę narzędzi typu backdoor stanowią dedykowane aplikacje sieciowe, które oferują dostęp do systemu po spełnieniu ściśle określonych i wcześniej zdefiniowanych warunków. Przykładem może być udp-backdoor napisany przez MANIAC. Aby backdoor aktywował się, musimy wysłać na określony port docelowy pakiet UDP z określonego portu źródłowego. Wówczas na wcześniej zdefiniowanym porcie przyłączeniowym udostępniona zostanie powłoka shellowa z uprawnieniami roota.

Za pomocą modułów możemy osiągnąć rzeczy wymienione na rysunku .
Ukrywanie odpowiednich ciągów znaków w plikach tekstowych jest przydatne, gdy chcemy w niezauważalny sposób zmodyfikować zawartość plików startowych. Niestety administrator może nas namierzyć, ponieważ zdradzi nas polecenie lsmod, lub plik /proc/modules. Na szczęście większość modułów oferuje funkcje ukrywające również tego typu infor macje.
Zastosowania modułów omówię na podstawie przykładu. W przykładzie posłużę się zestawem knark . Po skompilowaniu odpowiednich modułów (knark.o, modhide.o) i narzędzi (hidef, unhidef, ered, nethide, rootme, taskhack, rexec) możemy przystąpić do maskowania naszej obecności:
- Najpierw ładujemy moduł knark.o
- Jeżeli wgramy dostarczony moduł modhide.o, wówczas z listy modułów zostanie usunięta informacja na temat ostatniego załadowanego modułu. W ten sposób ukryjemy moduł knark.o.
- Zakładając, że plik wykonywalny z backdoorem znajduje się w /usr/sbin/kflushed wpisujemy następne polecenie. W ten sposób ukryjemy plik w systemie.
- Warto ukryć katalog ze źródłami i binariami kanrk.
- Aby ukryć proces odpowiadający za działanie backdoora, wysyłąmy do niego sygnał o numerze 31.
- Jeżeli chcemy ukryć połączenia sieciowe, posłużmy się narzędziem nethide. Aby używać tego programu należy rozumieć format plików /proc/net/[tcp|udp]. (Po wykonaniu polecenia netstat otrzymamy listę połączeń TCP/UDP, które mogą nas zdemaskować. Na przykładzie ukrywamy połączenie związane z gniazdem 192.168.0.2:1981
- Jeszcze lepiej, jeśli ukryjemy wszystkie połączenia inicjowane z maszyny włamywacza (punkt 7).
- Ciekawym narzędziem knark jest narzędzie ered , które służy do konfiguracji tzw. exec-redirection. W dużym uproszczeniu polega to na przekierowaniu oryginalnej ścieżki wykonawczej do określonej ścieżki przez włamywacza. Załóżmy, że plik /usr/libexec/sshd jest koniem trojańskim oryginalnej aplikacji, która wywoływana jest przez plik /usr/sbin/ s shd. Aby nie podmieniać wersji pliku możemy ustawić exec-redirection. Jeżeli system będzie próbował wykonać oryginalny plik, wówczas w sposób niezauważalny wykonany zostanie koń trojański.

W systemie mogą być zainstalowane narzędzia sprawdzające integralność systemu plików (np. te wymienione na rysunku ). Są jednak sposoby na ominięcie tego typu zabezpieczeń. Jeśli administrator przechowuje binaria Tripwire na lokalnym dysku, co bardzo często się zdarza, wówczas możemy się posłużyć od powiednimi koniami trojańskimi. Podmienione wersje programów będą uzupełnione o funkcje, które pomogą w ukryciu naszej obecności w systemie.
Czasami zdarza się, że administrator przechowuje sygnatury plików na lokalnym dysku. Wówczas mamy jeszcze bardziej ułatwione zadanie. Wystarczy ponownie wygenerować sygnatury dla wszystkich plików systemie. Najczęściej sygnatury i binaria Tripwire przechowywane są na bezpiecznym nośniku tylko do odczytu. Wówczas z pomocą przychodzą nam specjalne moduły jądra, jak np. twhack, czy twkiller. Wspomniane moduły wykorzystują przekierowanie plików wykonywalnych. Próba wykonania np. /usr/sbin/sshd zakończy się wykonaniem konia trojańskiego /usr/libexec/sshd, ale wszystkie wywołania systemowe typu open (np. w celu wygenerowania sygnatury) czy stat zostaną przeprowadzone na oryginalnym pliku.
Bezpieczne programowanie
Czym jest bezpieczne programowanie? W prostym rozumieniu bezpieczeństwo to zdolność sprawowania nadzoru nad wykorzystaniem przez innych naszych zasobów komputerowych, czyli zdolność do powiedzenia ,,nie'' (lub ,,tak'') i umiejętności obsłużenia tego odpowiednim działaniem.
Cechy bezpieczeństwa są często kodowane, tak aby były niewidoczne dla użytkownika. Są one często trudne do zobaczenia nawet dla samego programisty. Wiele spośród znalezionych nieoczywistych błędów w zabezpieczeniach pojawia się w postaci efektu ubocznego normalnego algorytmu wykonania, w wyniku którego następuje przeciek ważnej informacji. Inne błędy wiążą się z zaniedbaniem dyscypliny, która nie wpływa na działanie programu, ale mogłaby zapobiec naruszeniu bezpieczeństwa. Oznacza to, że program może przejść bezpiecznie każdy test oraz wykazać pełną funkcjonalność, ale całkowicie nie posiadać zabe z pieczeń.

Na przykład hasło (passphrase) po wprowadzeniu przez użytkownika może zostać zakodowane nieodwracalnym algorytmem (hashed) w celu utworzenia klucza szyfrowania sesji (session encryption key). Jednak kod usuwający z pamięci niezakodowane hasło może zawierać błąd, który powoduje pozostanie hasła w pamięci. Program kontynuuje poprawnie swoje działanie, ponieważ niepotrzebuje już hasła. We wszystkich operacjach jest wykorzystywany zakodowany klucz sesji. Taki program może przejść wszystkie testy funkcjonalności. Jednak agresor po zauważeniu tego przeoczenia może całkowicie obejść zabezpieczenia programu.
Intruz powodując krach programu, po wprowadzeniu hasła może utworzyć plik z obrazem pamięci programu (core dump file), z którego wyizoluje to hasło.
Nie wszystkie błędy w zabezpieczeniach muszą być tak subtelne. Przykładowo, wiele spośród ostatnich błędów w przeglądarce Internet Explorer firmy Microsoft zostało spowodowanych przez translator URL. Konkretny adres URL, który powodował złamanie zabezpieczeń może być zablokowany za pomocą jednego uaktualnienia programu. Ponieważ jednak kontrola niebezpiecznych adresów działa na danym URL zanim nastąpi zdekodowanie symboli sterujących ze znakiem \% agresorzy zdołali wykorzystać te same błędy w oprogramowaniu, kod ując część swojego adresu URL (na przykład kodując wszystkie znaki A za pomocą \%41). By umknąć uwadze programów antywirusowych, wirusy latami używały podobnych metod z różnym skutkiem.

W swoim wystąpieniu z okazji otrzymania nagrody Turinga w 1984 roku, Ken Thompson - jeden z twórców Unix-a - opisał sposób w jaki spowodował niewykrywalną, nawet z dostępnym kodem źródłowym, słabość w zabezpieczeniu w programie narzędziowym.
Thompson opisał, jak zdołał zmodyfikować kompilator języka C we wczesnych wersjach Unix-a tak, aby wykrywał fakt kompilowania programu login(1) i wstawiał kod, który akceptowałby zawsze pewne hasło. Umożliwiało to zarejestrowanie się jako dowolny użytkownik komuś, kto znał to hasło. Następnie zmodyfikował kod źródłowy kompilatora C, aby wykrywał kiedy ten kompilował samego siebie. (wówczas, tak jak i teraz kompilator języka C był sam napisany w C) i wstawiał ów kod (do wykrywania kompilacji programu login i wprowadzania konia trojańskiego) do kompilatora języka C. Potem usunął zmiany, których dokonał w źródle.
Od tego momentu kompilator C w Unix-ie zawsze dołączał jego konia trojańskiego, ilekroć kompilował program login(1). Żadna inspekcja kodu źródłoweg, dokonana dla login lub dla kompilatora C, nie pozoliłaby na wykrycie jekiegokolwiek problemu.
Przykłady takie jak ten pomagają zilustrować, jak dalece współczesny programista ufa dzisiejszemu środowisku komputerowemu. Pokłada się zaufanie w wielu składnikach systemu: kompilatorze, programie ładującym, dynamicznym konsolidatorze, a nawet w dekoderze mikrokodu w CPU - w nadziei, że robią dokładnie to, o co się je prosi.
Każdy z tych składników - zwłaszcza używanych w trakcie wykonywania, taki jak program ładujący, czy dynamiczny konsolidator - może być ze swej strony źródłem słabości w zabezpieczeniach.
Dodatkowe informacje związane z tym tematem można uzyskać pisząc na adres lm181277@zodiac.mimuw.edu.pl