![]()

Niskopoziomowy język programowania pozwalający na:
Bardziej niskopoziomowego języka już się nie używa. (Najniższym jest ręczne-kodowanie w kodach binarnych instrukcji).
Asembler jest mocno-niskopoziomowym językiem:
Asembler jest mocno-niskopoziomowym językiem, to znaczy:
Standardową metodą uzyskania kodu asemblera
jest wywołanie twojego kompilatora z flagą -s.
działa to dla większości unix-owych kompilatorów,
włączając w to gnu c compiler (gcc).
Dla gcc, bardziej zrozumiały kod asemblera będzie wyprodukowany
po użyciu opcji -fverbose-asm.
Oczywiście, jeśli chcesz dostać dobry kod asemblera,
nie zapomnij użyć opcji optymalizacji.
Zasady uzyskania efektywnego kodu:
Języki takie jak
objectivecaml, sml, commonlisp, scheme, ada, pascal, c, c++,
wśród innych,
wszystkie mają wolne zoptymalizowane kompilatory,
które zoptymalizują masę twoich programów.
Zwykle będą lepsze niż ręczny kod asemblera.
Wniosek: pisz (o ile potrzebujesz) małe sekcje kodu w
asemblerze
W celu przyspieszenia aplikacji powinieneś robić zrobić to tylko dla fragmentów kodu będących wąskim gardłem programu.
Stąd, jeśli określisz fragmenty kodu jako zbyt wolne, powinieneś
Dobrze znany kompilator gnu c/c++ (gcc), zoptymalizowany 32-bitowy kompilator będący sercem projektu gnu, wspiera całkiem dobrze architekturę x86, włączając w to zdolność wstawiania kodu asemblera w programach w c, w sposób gdzie zarządzanie rejestrami może być wyspecyfikowane lub pozostawione gcc. Kompilator gcc działa na większości dostępnych platform, godnych uwagi: linux-a, *bsd, vst, os/2, *dos-a, win*, itd.
windows:
linux:
ftp://prep.ai.mit.edu/pub/gnu/ razem ze wszystkimi wersjami aplikacji z projektu gnu. dokumentacja:
http://www.leo.org/pub/comp/os/os2/gnu/emx+gcc/
kompilacja:
gcc -02 -fomit-frame-pointer -w -wallpp
-02 jest dobrym poziomem optymalizacji w większości
przypadków.
Linux próbuje utrzymać rozgraniczenie między częścią kodu žródłowego
zależną od sprzętu i niezależną.
Katalogi arch i include zawierają
podkatalogi odpowiadające dostępnym platformom sprzętowym.
standardowe nazwy platform są następujące:
Składnia asemblera AT&T różni się znacząco od składni Intela, znanej z dokumentacji procesorów tej firmy. W Linuksie używana jest właśnie składnia AT&T. Poniżej znajdują się najważniejsze różnice między tymi dwoma składniami.
W składni Intela przed nazwami rejestrów i przed wartościami podawanymi bezpośrednio nie stosuje się prefiksów, które pojawiają sie w składni AT&T. Rejestry poprzedzone są znakiem '%', natomiast wartości bezpośrednie poprzedzone są znakiem '$'. W składni Intelowej liczby szesnastkowe miały sufiks 'h' natomiast w składni AT&T stosowana jest notacja z prefiksem '0x'. Przykłady:
AT&T
movl $1, %ebx
|
Intel
mov ebx, 1
|
Drugą istotną różnicą jest kolejność zapisywania argumentów instrukcji. W składni AT&T argumenty są w odwrotnej kolejności niż w składni Intela, pierwszy parametr to źródło a drugi to cel. Oba sposoby zapisu mają swoje uzasadnienie, składnia Intelowa przypomina przypisanie z języków wysokiego poziomu, gdzie na zmienną po lewej stronie zapisuje się wartość z prawej strony (najpierw cel a potem źródło), natomiast w AT&T odpowiada to naturalnej kolejności np. czytania i pisania od lewej do prawej, czyli najpierw pobierana jest wartość z lewej strony i z tą wartością następuje przejście na prawa strone gdzie jest ona zapisana (najpierw źródło a potem cel). Przykłady:
AT&T
movl (%ebx), %eax
|
Intel
mov eax, [ebx]
|
W składni Intela chcąc dostać się do zawartości komórki w pamięci, np. zawartej w rejestrze eax, trzeba było zastosować nawiasy '[' i ']', natomiast w składni AT&T stosowane są nawiasy '(' i ')'.
AT&T
movl (%ebx), %eax
|
Intel
mov eax, [ebx]
|
Znany z Intela zapis złożonych operacji na pamięci (segreg:[base + index * scale + disp]) w AT&T prezentuje się w mniej zrozumiały sposób (%segreg: disp(base, index, scale)). Poza bazą operacji, pozostałe argumenty są opcjonalne, skala domyślnie ustawiana jest na 1. W przeciwieństwie do składni AT&T w Intelowej od razu widać o jakie przesunięcie chodzi. Przykłady:
AT&T
movl (%ebx), %eax
|
Intel
mov eax, [ebx]
|
Operacje na pamięci w składni AT&T mają dodany sufiks, mówiący o rozmiarze argumentu. Sufiks 'l' (long) oznacza rozmiar 4 bajtów, 'w' (word) 2 bajtów, a 'b' (byte) oznacza 1 bajt. W składni Intela rozmiar rozpoznawany jest po typie argumentów lub w przypadku komórki pamięci używana jest specjalna składnia np. 'dword ptr [eax]'. Przykłady:
AT&T
movb %bl, %al
|
Intel
mov al, bl
|
Dalekie skoki wywołania procedur znane z Intela
(call/jmp far section:offset) w asemblerze AT&T mają
postać lcall/ljmp $section, $offset.
Oprócz pisania kodu w czystym asemblerze, przydatne okazuje się
wstawianie fragmentów programu, zapisanych w asemblerze, do źródła
programu, pisanego w języku wysokiego poziomu, np. C. GCC umożliwia
kompilowanie plików źródłowych języka C ze wstawkami w asemblerze
(ze składnią AT&T). Ogólna forma wstawek asemblerowych jest
wspólna dla różnych platform, ale więzy argumentów maja różne znaczenie
dla różnych platform sprzętowych. Tutaj omawiany będzie wariant w
architekturze x86 Intela.
Wstawki asemblerowe można pisać w sposób zupełnie bezpośredni, po prostu
pisząc kod jaki chcemy wykonać:
__asm__ ("
|
movl $1, %eax
|
Jeżeli użycie asemblera sprowadza się do takiego wywołania jak
wyżej to taka forma może wystarczać. Ale asembler w GCC pozwala
zapisać skrótowo pewne operacje, które zostaną automatycznie rozwinięte
do odpowiednich instrukcji asemblerowych.
Jest możliwe określenie danych,
które zostaną użyte jako wejście i wyjście instrukcji asemblerowych oraz
rejestry, które zostaną zmodyfikowane. Każdy argument może być opisany
przez typ (więzy) oraz wyrażenie ze świata języka C w nawiasach. Wyrażenia w części
output muszą być "l-wartościami" (kompilator może to sprawdzać), bo
na te wartości będzie dokonywany zapis.
Manual do GCC twierdzi, że instrukcje asemblerowe wewnątrz
szablonu nie są w żaden sposób parsowane i sprawdzane przez kompilator
zatem nie będzie sprawdzone czy instrukcja jest poprawną instrukcją
dla asemblera danego procesora, czy ma poprawną liczbę argumentów itd.
Natomiast praktyka wykazuje coś zupełnie przeciwnego, czyli nie dość, że
instrukcje są sprawdzane to również sprawdzana jest poprawność argumentów.
Najczęstszym sposobem dostawania się do zdefiniowanych w szablonie
argumentów jest używanie ich numeracji w kolejności, tj. %0 dla pierwszego
argumentu, %1 dla drugiego itd.
Przykład:
int a;
int b = 10;
int c = 20;
__asm__ ("
|
mov %2, %0"
|
Powyższy przykład wymaga kilku wyjaśnień. Jak zostało wspomniane wyżej,
po instrukcji występuje opis wyjścia, wejścia i modyfikowanych rejestrów.
Części te oddzielane są dwukropkami, zatem instrukcja jest postaci:
__asm__ ("instrukcje" : output : input : modify);. Jeżeli chcemy
pominąć sekcję output, to należy pozostawić puste miejsce po pierwszym
dwukropku (dobrze jest zaznaczyć komentarzem, że celowo nic tam nie zostało
umieszczone). Modify również jest opcjonalne. Argumenty do zapisu muszą być
poprzedzone znakiem "=".
Typy (więzy) argumentów, o których wspomniane jest wyżej są określane literami
w cudzysłowie. Tutaj dochodzimy do części związanej ze sprzętem. Część typów
jest wspólna dla wszystkich platform, natomiast wiele z nich jest specyficznych
dla konkretnych architektur, a wynika to chociażby z tego, że na różnych
architekturach nazewnictwo i liczba rejestrów jest zupełnie inne. Do wspólnych
więzów należą:
| m | dostęp do pamięci |
| 0, 1, ... | oznaczenie argumentu, który już występuje na liście argumentów |
| i | bezpośrednia wartość |
| r | jakiś rejestr ogólny |
Podstawowe więzy specyficzne dla architektury Intela:
| a, b, c, d, D, S | odpowiednio rejestry eax, ebx, ecx, edx, edi, esi |
| q | jeden z rejestrów eax, ebx, ecx, edx |
Wszystkich więzów jest znacznie więcej i do ciekawszych zastosowań
warto zapoznać się z pełną listą zawartą w manualu do GCC.
Zamiast numerów wejść/wyjść można podawać bezpośrednio nazwę rejestru,
którego chce się używać, ale wtedy należy go poprzedzić dwoma znakami "%",
na przykład: __asm__ ("xorl %%ebx, %%ebx", : : "b" (b));
Warto obejrzeć do czego rzeczywiście rozwijane są nasze przykładowe szablony.
Znany już program:
int a;
int b = 10;
int c = 20;
__asm__ ("
|
mov %2, %0"
|
Kompiluje się do czegoś zbliżonego:
1. movl -8(%ebp),%eax
2. movl -12(%ebp),%ecx
3. movl %ecx, %eax
4. movl %eax,%edx
5. movl %edx,-4(%ebp)
1., 2. - wartości zmiennych zdeklarowanych wyżej są wrzucane do
rejestrów eax i ecx, co wynika z wiersza : "0" (b), "c" (c),
który żąda zapisania do rejestru ecx ("c") wartości zmiennej c, natomiast
zapis "0" (b) żąda zapisania wartości zmiennej b do rejestru wskazywanego
przez typ podany jako pierwszy czyli rejestr eax ("=a").
3. - instrukcja mov %2, %0 z podstawionymi odpowiednimi
parametrami, zatem na pierwszy parametr podstawiony jest typ podany jako
trzeci ("c") czyli %eax, a na drugi - typ podany jako pierwszy ("=a") czyli
eax.
W wierszu : "=a" (a) zażądaliśmy zapisania, po wykonaniu kodu,
zawartości rejestru eax do zmienej a, co realizują instrukcje 4.-5.
Warto również wiedzieć, że kompilator sprawdza rozmiar typu podanego
w nawiasach i na podstawie tej informacji generuje odpowiedni rejestr, czyli
gdyby zamiast int w programie zapisać zmienne typu
char i zamiast instrukcji movl zapisać instrukcję
movb to kompilator zapisałby program jako:
movb -2(%ebp),%al
movb -3(%ebp),%cl
movb %cl, %al
movb %al,%dl
movb %dl,-1(%ebp)
Widać, że zostały użyte rejestry rozmiaru jednego bajtu.
Na koniec jeszcze krótki przykład użycia typu "m" czyli odnoszącego
się do pamięci.
Jasne jest, że instrukcja:
__asm__ ("movl %0, %1" : : "a"(b), "b"(c));
rozwinie się do:
movl -8(%ebp),%eax
movl -12(%ebp),%ebx
movl %eax, %ebx
Czyli wartości zmiennych zostaną zapisane do rejestrów eax i ebx, na których
następnie zostanie wykonana operacja mov.
Do czego natomiast rozwinie się kod jeżeli zażądamy korzystania
bezpośrednio ze zmiennej w pamięci? Następujący kod:
__asm__ ("movl %0, %1" : : "a"(b), "m"(c));
rozwinie się do:
movl -8(%ebp),%eax
movl %eax, -12(%ebp)
Czyli zostanie wykonana bezpośrednia operacja na pamięci. Pozornie drugi
zapis wygląda na lepszy, bo zapis jest krótszy, ale często nie da się wykonać
operacji bezpośrednio na komórkach pamięci (chociażby w powyższy przykład
nie skompiluje się, jeżeli również w pierwszym typie podalibyśmy "m"), a także ze
względów wydajnościowych takie rozwiazanie może okazać się gorsze (nieraz instrukcje
działają na komórkach pamięci znacznie wolniej niż na rejestrach).
Omawiany kod źródłowy znajduje się w kodzie źródłowym jądra w
include/asm-i386/atomic.h
Pisząc kod w C nigdy nie ma gwarancji, że wykonywana operacja (np. a=a+1)
wykona się w sposób niepodzielny (a++ też nie;).
Łatwo może dojść do sytuacji, w której
jeden proces odczyta wartość a aby dodać do niej 1, ale zanim doda, to
drugi proces również odczyta a i doda do niej 1, następnie jeden zapisze
swoją wartość i drugi zapisze. Efektem będzie to, że skutek odniesie
tylko jedna z operacji a oba procesy będa przekonane, ze ich operacja
wykonała się prawidłowo. Wydaje się, że w trybie jądra nie jest to problem,
bo proces nie może zostać wywłaszczony. Ale okazuje się, że problem robi się
poważny w architekturze wieloprocesorowej, gdzie wiele procesów może jednocześnie
znajdować się w trybie jądra oraz oczywiście w trybie użytkownika, gdzie procesy
wywłaszczane są bardzo często.
Pożądanym byłoby posiadanie operacji realizujących, podobne do powyższej,
instrukcje w sposób atomowy. O pewnych instrukcjach asemblera z góry
wiemy, że są atomowe. Instrukcje asemblera dla procesorów 80x86 są
niepodzielne gdy:
dec, inc) i żaden inny procesor
nie przejął szyny danych między wczytaniem i zapisem, w systemie
jednoprocesorowym są zawsze niepodzielne
lock, wtedy
są niepodzielne również w systemie wieloprocesorowym, szyna danych
jest wówczas blokowana na czas wykonania całej instrukcji
Instrukcje zaczynające się od rep nie są niepodzielne, procesor
przed każdym powtórzeniem instrukcji po rep sprawdza czy nie
czekają przerwania do obsłużenia.
Jądro Linuksa dostarcza zestawu operacji pozwalających wykonać operacje
niepodzielne na atomowym typie danych:
typedef struct { volatile int counter; } atomic_t;
Operacje inicjalizacji, odczytu i zapisu wartości są operacjami
pobierającymi coś z pamięci 0 lub 1 razy zatem będą atomowe bez
dodatkowej pomocy.
W przypadku operacji dodawania do licznika mamy do czynienia z operacją
sięgającą do pamięci po starą wartość i następnie zapisującą nową, wiec
istnieje tutaj problem opisany wyżej na przykładzie a=a+1. Operacja jest
realizowana poprzez następujący kod:
static __inline__ void atomic_add(int i, atomic_t *v)
{
__asm__ __volatile__(
LOCK "addl %1,%0"
:"=m" (v->counter)
:"ir" (i), "m" (v->counter));
}
Procedura wykonuje zwykłe asemblerowe dodawanie i dla systemu jednoprocesorowego
działa to dobrze. Działa to również dobrze dla systemu wieloprocesorowego
dzięki makru LOCK, jakie poprzedza instrukcję addl, a które
zdefiniowane jest na początku pliku:
#ifdef CONFIG_SMP
#define LOCK "lock ; "
#else
#define LOCK ""
#endif
Jeżeli jądro zostało skompilowane dla systemu wieloprocesorowego (Symmetrical
multiprocessing), to makro LOCK definiowane jest jako lock ; i
dodawane jest do instrukcji addl. Instrukcja lock
jak zostało opisane wyżej, blokuje szynę danych, dzięki czemu addl
wykonuje się niepodzielnie również na systemach wieloprocesorowych.
Analogiczne operacje są dostarczone do inkrementacji (incl)
i zmniejszania wartości (decl) oraz odejmowania
(subl) od licznika.
Dostarczone są również operacje pozwalające zmienić wartość i dokonać
sprawdzenia czy osiągnięto zero po tej operacji:
static __inline__ int atomic_dec_and_test(atomic_t *v)
{
unsigned char c;
__asm__ __volatile__(
LOCK "decl %0; sete %1"
:"=m" (v->counter), "=qm" (c)
:"m" (v->counter) : "memory");
return c != 0;
}
Jedyną różnicą w stosunku do poprzedniego kodu jest instrukcja sete
która sprawdza stan flagi ZF po wykonaniu instrukcji decl. Jeżeli
osiągnięto zero po odjęciu, to sete zapisuje 1 do c, w przeciwnym
wypadku w c ląduje 0. Istotne jest to, że nie następuje w drugiej
instrukcji pobranie wartości tylko sprawdzenie flagi (której inny proces
nie może zmienić), która została ustawiona w atomowej operacji.
Pozostałe operacje atomowej zmiany wartości i sprawdzenia nowej wartości
wyglądają analogicznie.
Powyższe operacje zostały zapisane w asemblerze, aby mieć pewność (wynikającą z możliwości
architektury), że dzięki wykorzystaniu dobrze określonych instrukcji asemblerowych, otrzymamy
operacje niepodzielne. W samym języku C nie dałoby się tego wyrazić, bo nie mam żadnej wiedzy
na temat tego czy dodawanie jest realizowane właśnie jako pojedyncze add oraz,
że w przypadku wieloprocesorowym zostanie użyta instrukcja lock.
Na procesorach Intela, dzięki wsparciu sprzętowemu (instrukcja
lock) kod atomowego dodawania i wszystkich innych
atomowych operacji jest bardzo prosty i przejrzysty. Ale nie wszędzie
sytuacja wygląda tak dobrze. Dla przykładu na maszynach SPARC nie ma
wsparcia w postaci instrukcji analogicznej do Intelowego lock.
Również sam asembler ma inną składnię, inne rejestry i oczywiście inny zestaw
instrukcji niż wersja dla procesorów Intela. W związku z brakiem mechanizmu
blokowania szyny danych, problem trzeba rozwiązać w inny sposób. Kod instrukcji atomic_add w
include/asm-sparc/atomic.h wygląda następująco:
static __inline__ int __atomic_add(int i, atomic_t *v)
{
register volatile int *ptr asm("g1");
register int increment asm("g2");
ptr = &v->counter;
increment = i;
__asm__ __volatile__(
"mov %%o7, %%g4\n\t"
"call ___atomic_add\n\t"
" add %%o7, 8, %%o7\n"
: "=&r" (increment)
: "0" (increment), "r" (ptr)
: "g3", "g4", "g7", "memory", "cc");
return increment;
}
To już wygląda mniej ciekawie niż wersja Intelowa, wymaga większej liczby
rejestrów globalnych ogólnego przeznaczenia (g3, g4, g7) i co gorsza, woła
jeszcze jakąś zewnętrzną funkcję ___atomic_add, którą można
odnaleźć w
arch/sparc/lib/atomic.S. Jako, że nie mamy do dyspozycji Intelowego
locka, zatem wyłączane są przerwania i dodawanie do wartości atomowej
obłożone jest spinlockiem.
Fragment programu (dotyczący systemu wieloprocesorowego), realizujący
procedurę ___atomic_add (w całości pisana w asemblerze) wygląda
dość koszmarnie, jeżeli nie jest się przyzwyczajonym do składni tego asemblera:
or %g3, PSR_PIL, %g7 ! wyłączenie przerwań
[...]
#ifdef CONFIG_SMP
1: ldstub [%g1 + 3], %g7 ! załadowanie slowa z blokadą
! (test-and-set)
orcc %g7, 0x0, %g0 ! czy udało się przejąć blokadę
bne 1b ! jeżeli nie to skok do 1:
ld [%g1], %g7 ! załadowanie słowa atomowego
add %g7, %g2, %g2 ! dodanie wartości do słowa
st %g7, [%g1] ! zapisanie bajtu - zwolnienie blokady
[...]
Patrząc na kod Intelowy i SPARC-owy raczej ciężko dojść do wniosku, że
realizują tę samą teoretycznie prostą czynność. Podobne warianty procedur
atomowych są stworzone dla wszystkich innych architektur, które wspiera
Linux.
Dla wszystkich architektur jest również dostępny podobny zestaw operacji atomowych
działający na bitach wartości atomowej, szczegóły w pliku bitops.h.
Omawiany kod źródłowy znajduje się w kodzie źródłowym jądra w
include/asm-i386/spinlock.h
Realizacja ochrony sekcji krytycznej w systemie wieloprocesorowym, gdzie
nie wystarcza już zwykłe wyłączenie przerwań, może być w Linuksie
realizowana poprzez mechanizm spinlock'ów. Zasadniczo dostępne są dwa
rodzaje spinlock'ów - zwykłe, blokujące sekcję krytyczną dla jednego
procesu i read-write, umożliwiające odczyt wielu procesom i zapis tylko
dla jednego (jest jeszcze trzeci rodzaj, ale jego użycie jest bardzo
ograniczone). W dalszej części opisana zostanie realizacja podstawowych
spinlock'ów.
Jeżeli może wystąpić sytuacja wyścigu z procedurami obsługi przerwań, wtedy
należy używać spinlock'a, wzbogaconego o wyłączanie przerwań na czas
oczekiwania na blokadzie.
W pliku
include/linux/spinlock.h zdefiniowane są operacje na spinlock'u, które
w miarę potrzeb są zmieniane w plikach specyficznych dla danej architektury.
W tym pliku można znaleźć definicję makra spin_lock_irqsave:
#define spin_lock_irqsave(lock, flags) do { local_irq_save(flags); spin_lock(lock); } while (0)
Definicję makra local_irq_save odnaleźć można w pliku
include/asm-i386/system.h:
#define local_irq_save(x) __save_and_cli(x)
które z kolei jest zdefiniowane następująco:
#define __save_and_cli(x) do { __save_flags(x); __cli(); } while(0);
a te makra w końcu rozwijane są do konkretnego kodu:
#define __save_flags(x) __asm__ __volatile__("pushfl ; popl %0":"=g" (x): /* no input */)
#define __cli() __asm__ __volatile__("cli": : :"memory")
Instrukcja pushfl wysyła 32-bitowe słowo, zawierające flagi
na stos, a następnie słowo to jest pobierane ze stosu i zapisywane
na zmienną. Instrukcja cli powoduje wyłączenie obsługi przerwań.
Po zapisaniu flag i wyłączeniu przerwań można przejść do zasadniczej części,
czyli do blokady spinlock:
static inline void spin_lock(spinlock_t *lock)
{
[...]
__asm__ __volatile__(
spin_lock_string
:"=m" (lock->lock) : : "memory");
}
spinlock_t to struktura zawierająca licznik:
typedef struct {
volatile unsigned int lock;
[...]
} spinlock_t;
I ostatecznie rozwijane jest makro spin_lock_string czyli
zasadnicza część spinlock'a:
1. #define spin_lock_string \
2. "\n1:\t" \
3. "lock ; decb %0\n\t" \
4. "js 2f\n" \
5. LOCK_SECTION_START("") \
6. "2:\t" \
7. "cmpb $0,%0\n\t" \
8. "rep;nop\n\t" \
9. "jle 2b\n\t" \
10. "jmp 1b\n" \
11. LOCK_SECTION_END
Makra LOCK_SECTION_START i LOCK_SECTION_END
tworzą oznaczenia i nazwy sekcji.
W linii 3. w sposób atomowy zmniejszana jest wartość licznika w strukturze
spinlock_t. Jeżeli znak jest ujemny (4.) to wykonywany jest skok do przodu
(2f - forward) do etykiety 2: (6.).
Jeżeli jesteśmy w 6. to znaczy, że nie udało się przejąć blokady.
W instrukcji 7. porównywana jest aktualna wartość licznika
spinlock'a z zerem. Jeżeli wartość nie jest dodatnia to następuje
skok w tył do etykiety 2:. Jeżeli natomiast wartość licznika jest dodatnia
(a dokładnie równa 1), to znaczy, że pojawiła się szansa na przejęcie
blokady i następuje skok w tył do etykiety 1:, gdzie nasz proces
ponownie stoczy bitwę o spinlock'a.
Oddanie spinlock'a jest znacznie prostsze. Jeżeli zapamiętane zostały flagi
i wyłączone przerwania, to teraz należy to odkręcić:
#define spin_unlock_irqrestore(lock, flags) do { spin_unlock(lock); local_irq_restore(flags); } while (0)
Wywołanie spin_unlock jak poprzednio zawiera asemblerowe makro:
static inline void spin_unlock(spinlock_t *lock)
{
[...]
__asm__ __volatile__(
spin_unlock_string
);
}
#define spin_unlock_string \
"movb $1,%0" \
:"=m" (lock->lock) : : "memory"
Jedyną czynnością jest zapisanie 1 do wartości licznika spinlock'a, dzięki
czemu inny proces może przejąć blokadę.
local_irq_restore(flags) rozwijane jest do funkcji
__global_restore_flags(flags), która w zależności od stanu flag podanych
w parametrze wykonuje cli lub sti, w zależności od tego jak
flaga IF była ustawiona przed naszymi operacjami na spinlock'u.
Ponownie asembler musiał być użyty w implementacji spinlock'a głównie z powodu
braku możliwości wyrażenia specyficznych operacji sprzętowych w C, takich jak
atomowy zapis i odczyt spinlock'a (w przeciwnym przypadku do sekcji krytycznej
mogłoby wejść wiele procesorów).
Start systemu rozpoczyna się od BIOS'u. BIOS wybiera urządzenie, z którego
uruchomiony zostanie system oraz ładuje pierwszy sektor z urządzenia
(bootsector rozmiaru 512b) do pamięci (pod adres 0x7c00). Dalej kontrolę
przejmuje program z bootsectora, który ładuje kolejne części programu
uruchamiającego (setup), procedury do dekompresji oraz skompresowany
obraz jądra Linuksa, który jest dekompresowany już w trybie chronionym.
Początek całego procesu jest realizowany przez kod asemblerowy, dalsze
części inicjalizacji są zapisane w C.
Zaprezentowane niżej początkowe fragmenty inicjalizacji pochodzą z:
arch/i386/boot/bootsect.S
Bootsector ładowany przez BIOS może być bootsector'em Linuxa (np. ładowanie z
dyskietki), LILO, można też ładować system przez loadlin. Przyjrzymy się
trochę bliżej pierwszemu wariantowi (z ładowaniem z dyskietki dla
uproszczenia).
Ważne rzeczy dzieją się już na samym początku kodu załadowanego do pamięci
przez BIOS:
movw $BOOTSEG, %ax
movw %ax, %ds
movw $INITSEG, %ax
movw %ax, %es
movw $256, %cx
subw %si, %si
subw %di, %di
cld
rep
movsw
ljmp $INITSEG, $go
$BOOTSEG to oryginalny adres, pod którym załadowany jest program z
bootsectora (0x7c00). Pierwszą rzeczą, którą program chce wykonać, to
przeniesienie siebie w inne miejsce w pamięci
(do $INITSEG = 0x90000) aby móc zapisać swój kod, kod dalszej części
uruchamiania systemu (setup) oraz programów pomocniczych w spójnym fragmencie
pamięci. W tym celu rejestr ds,
będący źródłem dla instrukcji movs jest ustawiany na początek
programu startowego w pamięci, a rejestr es jako cel kopiowania
ustawiany jest na początek obszaru, do którego chcemy program załadować.
Kopiowanie przenosi za jednym razem 2 bajty, a łącznie trzeba przekopiować
512 bajtów (rozmiar bootsectora), zatem trzeba skopiować 256 dwubajtowych
słów, co ostatecznie wykonuje rep movsw po czym następuje
daleki skok do offsetu $go w segmencie $INITSEG,
czyli kolejne instrukcje pobierane są już z obszaru, do którego skopiowany
został program z bootsectora od etykiety go:.
Działamy w trybie rzeczywistym, zatem do poprawnego działania potrzebny
jest stos trybu rzeczywistego, który trzeba ręcznie ustawić.
go: movw $0x4000-12, %di
movw %ax, %ds
movw %ax, %ss
movw %di, %sp
Wartość 0x4000-12 jest dobrana tak, żeby to wszystko grało, tj. żeby była
większa od sumy długości bootsectora, dalszego programu uruchamiającego
(setup) i żeby zostało trochę miejsca na stos.
Warto zwrócić uwagę, że różnego rodzaju przypisania są optymalizowane
aż do bólu, czyli kosztem wysokiej nieczytelności kodu są wycinane
zbędne przypisania, np. w kodzie powyżej w ax jest wartość
$INITSEG, wstawiona tam w poprzedniej części kodu.
W dalszej części kodu program próbuje za pomocą funkcji BIOS'u 0x13
odczytać pierwszy sektor i ustalić liczbę sektorów:
movw $disksizes, %si
probe_loop:
lodsb
cbtw
movw %ax, sectors
cmpw $disksizes+4, %si
jae got_sectors
xchgw %cx, %ax
xorw %dx, %dx # dysk i głowica równe 0
movw $0x0200, %bx # 512 bajtów
movw $0x0201, %ax # 1 sektor, funkcja 2 przerwania 0x13
int $0x13
jc probe_loop
Po załadowaniu pierwszego sektora wypada poinformować użytkownika, że coś się już wydarzyło i będzie się działo dalej, zatem wypisywany jest komunikat "Loading" używając przerwania $0x10.
got_sectors:
movb $0x03, %ah
xorb %bh, %bh
int $0x10
movw $9, %cx
movb $0x07, %bl
movw $msg1, %bp
movw $0x1301, %ax
int $0x10
[...]
msg1: .byte 13, 10 # zdefiniowane na końcu pliku
.ascii "Loading"
Dalszym etapem jest załadowanie dalszej części programu uruchamiającego
system (czyli setup) od razu za programem z bootsectora. Program z bootsectora
umiesczony był pod adresem 0x90000 i mial 512 bajtów, zatem dalszą część
programu należy umieścić w pamięci, rozpoczynając od adresu 0x90200 oraz
ładowany jest skompresowany obraz jądra do odpowiedniego miejsca w pamięci
(zależnie od rozmiaru może być umieszczony pod jednym z dwóch adresów).
Kod realizujący tę część zawiera sporo zawiłości technicznych, np. żeby
uwzględnić liczbę sektorów, jaką ustaliliśmy przed chwilą i sporo innych i
nie będziemy go tutaj dokładniej omawiać.
W zależności od liczby sektorów na dyskietce ustalane jest główne urządzenie
z obrazem jądra:
movw root_dev, %ax
orw %ax, %ax
jne root_defined
movw sectors, %bx
movw $0x0208, %ax # /dev/ps0 - 1.2Mb
cmpw $15, %bx
je root_defined
movb $0x1c, %al # /dev/PS0 - 1.44Mb
cmpw $18, %bx
je root_defined
movb $0x20, %al # /dev/fd0H2880 - 2.88Mb
cmpw $36, %bx
je root_defined
movb $0, %al # /dev/fd0 - autodetect
root_defined:
movw %ax, root_dev
Ustalony typ urządzenia zapisywany jest w root_dev.
W tym momencie mamy w pamięci załadowany kod dalszego programu
uruchamiającego system (setup), skompresowany obraz jądra w ustalonym
miejscu i znane jest urządzenie główne. Zatem można przejść do wykonywania
kodu setup:
ljmp $SETUPSEG, $0
Dalszy kod startujący system można znaleźć w pliku
arch/i386/boot/setup.S.
W części setup system próbuje odczytać (z BIOS'u i stosując przeróżne
sztuczki) dane o systemie - pamięć, informacje o dyskach, ustawia
opóźnienie klawiatury, inicjuje kartę graficzną, szuka myszy, sprawdza
czy BIOS obsługuje APM itd. Na końcu następuje przejście do trybu
chronionego.
W dalszej części wywoływana jest funkcja startup_32() z pliku
arch/i386/boot/compressed/head.S,
której zadaniem jest m.in. ustawienie stosu oraz zdekompresowanie obrazu
jądra.
Żeby sprawa wyglądała jeszcze bardziej przejrzyście, to w pliku o tej
samej nazwie ale w innym katalogu
arch/i386/kernel/head.S
istnieje kolejna funkcja startup_32(), która z kolei przygotowuje środowisko
dla pierwszego procesu Linuksa.
W ostatniej fazie wywoływana jest funkcja start_kernel(), która już jest
pisana w języku C, a która rozpoczyna się wypisaniem komunikatu
"Linux version 2.4.22..." i wykonywana jest dalsza inicjalizacja systemu.
Startowanie systemu jest klasycznym przykładem kodu systemu operacyjnego, którego
nie da się zapisać w języku wysokiego poziomu i korzystanie z asemblera jest
koniecznością, żeby móc wykonać takie rzeczy jak przeniesienie się do innego
miejsca w pamieci, skoki sterowania programu do konkretnych miejsc w pamięci czy
w końcu przełączenie z trybu rzeczywistego w tryb chroniony, który zupełnie
zmienia sposób dostępu do pamięci.
Jednym z możliwych pól zastosowania asemblera, jest korzystanie ze
specyficznych właściwości sprzętu, np. kart graficznych lub procesorów.
W Linuksie można również znaleźć przykłady takiego zastosowania asemblera,
aczkolwiek nie są to bardzo często spotykane fragmenty.
Kilka pomocniczych funkcji zostało zapisanych z użyciem specyficznych dla
pewnych procesorów instrukcji 3DNow,
przykładem może być funkcja zastępująca w pewnych przypadkach
standardowe memcpy. W
include/asm-i386/page.h odnaleźć można następujące definicje:
#ifdef CONFIG_X86_USE_3DNOW
#define copy_page(to,from) mmx_copy_page(to,from)
#else
#define copy_page(to,from) memcpy((void *)(to), (void *)(from),
PAGE_SIZE)
#endif
#define copy_user_page(to, from, vaddr) copy_page(to, from)
Makro copy_user_page jest ostatecznie rozwijane albo
do standardowego memcpy albo do mmx_code_page
jeżeli pozwala na to konfiguracja systemu.
Właściwą funkcję mmx_copy_page (a właściwie jedną z dwóch - znów w
zależności od typu procesora są dwie funkcje do wyboru) można oszukać w
arch/i386/lib/mmx.c:
void mmx_copy_page(void *to, void *from)
{
if(in_interrupt())
slow_copy_page(to, from);
else
fast_copy_page(to, from);
}
Funkcja slow_copy_page jest mało interesująca bo nie zawiera
instrukcji specyficznych dla maszyn z 3DNow. Natomiast w
fast_copy_page już można zobaczyć zupełnie nowe instrukcje:
static void fast_copy_page(void *to, void *from)
{
int i;
kernel_fpu_begin();
__asm__ __volatile__ (
"1: prefetch (%0)\n"
" prefetch 64(%0)\n"
" prefetch 128(%0)\n"
" prefetch 192(%0)\n"
" prefetch 256(%0)\n"
"2: \n"
".section .fixup, \"ax\"\n"
"3: movw $0x1AEB, 1b\n" /* jmp on 26 bytes */
" jmp 2b\n"
".previous\n"
".section __ex_table,\"a\"\n"
" .align 4\n"
" .long 1b, 3b\n"
".previous"
: : "r" (from) );
for(i=0; i<4096/64; i++)
{
__asm__ __volatile__ (
"1: prefetch 320(%0)\n"
"2: movq (%0), %%mm0\n"
" movq 8(%0), %%mm1\n"
" movq 16(%0), %%mm2\n"
" movq 24(%0), %%mm3\n"
" movq %%mm0, (%1)\n"
" movq %%mm1, 8(%1)\n"
" movq %%mm2, 16(%1)\n"
" movq %%mm3, 24(%1)\n"
" movq 32(%0), %%mm0\n"
" movq 40(%0), %%mm1\n"
" movq 48(%0), %%mm2\n"
" movq 56(%0), %%mm3\n"
" movq %%mm0, 32(%1)\n"
" movq %%mm1, 40(%1)\n"
" movq %%mm2, 48(%1)\n"
" movq %%mm3, 56(%1)\n"
".section .fixup, \"ax\"\n"
"3: movw $0x05EB, 1b\n" /* jmp on 5 bytes */
" jmp 2b\n"
".previous\n"
".section __ex_table,\"a\"\n"
" .align 4\n"
" .long 1b, 3b\n"
".previous"
: : "r" (from), "r" (to) : "memory");
from+=64;
to+=64;
}
kernel_fpu_end();
}
Bez zbytniego zagłębiania się w kod można zauważyć pojawienie się
instrukcji prefetch, która ściąga z wyprzedzeniem obszary
pamięci do cache'a, żeby przyspieszyć proces kopiowania pamięci.
Dalej w pętli procedura wykonuje szereg instrukcji movq, które za
jeden z argumentów przyjmują 64-bitowe rejestry mmx, tzw.
quadword. W jednym obrocie pętli kopiowane są od razu 64 bajty, co
znacznie przyspiesza standardowe kopiowanie obszarów pamięci.
Zatem w Linuksie nie dość, że jest konieczność zapisywania pewnych fragmentów
kodu w asemblerze, aby kod mógł się wykonać na konkretnych architekturach, to
również zdarzają się przypadki wykorzystywania właściwości konkretnych procesorów
z danej architektury.
Architektura intel 80x86 zawiera specjalny segment tss (task state segment).
Przechowuje on kontekst obecnie działającego procesu. Każdy proces ma swój własny segment
tss o minimalnej wielkości 104 bajtów. Dodatkowe bajty są potrzebne systemowi operacyjnemu
do przechowywania rejestrów, nie zachowanych automatycznie przez sprzęt i do przechowywania
dodatkowych informacji(mapy bitowej uprawnień i/o).
Segment tss ma postać:
| tss | ||
|---|---|---|
| offset | górne słowo | dolne słowo |
| 00h | zarezerwowane | link |
| 04h | esp0 | |
| 08h | zarezerwowane | ss0 |
| 0ch | esp1 | |
| 10h | zarezerwowane | ss1 |
| 14h | esp2 | |
| 18h | zarezerwowane | ss2 |
| 1ch | cr3 | |
| 20h | eip | |
| 24h | eflags | |
| 28h | eax | |
| 2ch | ecx | |
| 30h | edx | |
| 34h | ebx | |
| 38h | esp | |
| 3ch | ebp | |
| 40h | esi | |
| 44h | edi | |
| 48h | zarezerwowane | es |
| 4ch | zarezerwowane | cs |
| 50h | zarezerwowane | ss |
| 54h | zarezerwowane | ds |
| 58h | zarezerwowane | fs |
| 5ch | zarezerwowane | gs |
| 60h | zarezerwowane | ldtr |
| 64h | offset mapy i/o (iobp) | zarezerwowane |
| 68h | opcjonalne dane systemu | |
| iopb-20h | opcjonalna mapa przekierowania przerwań | |
| iopb | opcjonalna mapa dostępnych portów i/o | |
Specjalny rejestr procesora tr (task register) przechowuje selektor do aktywnego segmentu tss. Na jego podstawie procesor dokonuje uaktualnienia danych w tss.
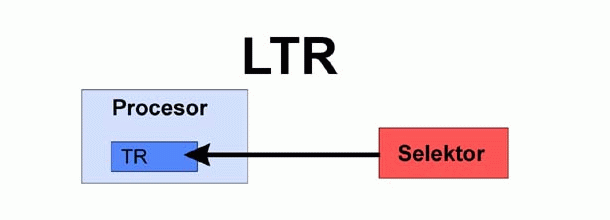
Do załadowania nowego selektora do rejestru tr służy instrukcja ltr. Jej parametrem może być rejestr albo komórka pamięci.
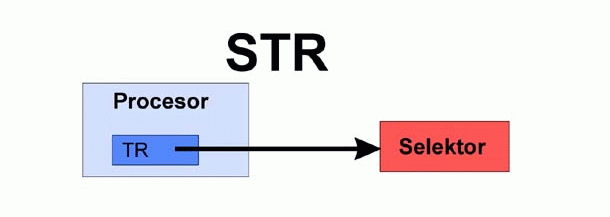
Dla symetrii oprócz instrukcji ltr istnieje instrukcja str. Umożliwia ona odczytanie selektora z rejestru tr.
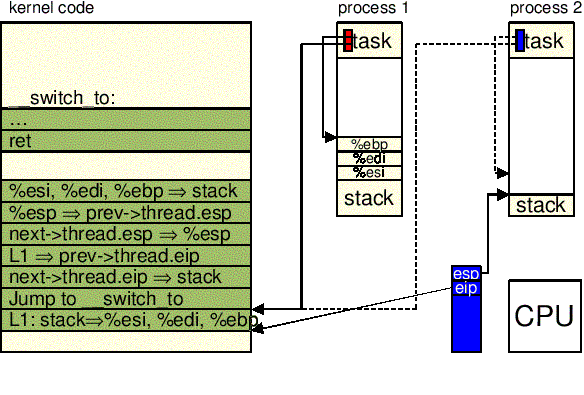
Makro switch_to wykonuje przełączanie procesów. Przede wszystkim
używa dwóch parametrów oznaczanych jako prev i
next: pierwszy z nich jest wskažnikiem do deskryptorów procesu,
który ma być uśpiony, a drugi jest wskažnikiem
do deskryptora procesu, który ma być wykonywany przez procesor. Makro to
jest wywoływane przez funkcję schedule().
Makro switch_to() jest jedną z najbardziej zależnych od
procesora procedur jądra. oto opis czynności wykonywanych
w przypadku procesorów intel.
Funkcja __switch_to operuje na parametrach prev i next,
które oznaczają poprzedni i nowy proces. Funkcja __switch_to jest zdefiniowana w
pliku nagłowkowym
include/asm-i386/system.h. Funkcja ta dopełnia działanie rozpoczęte przez makro
switch_to(). Zawiera włączony do kodu c
kod asemblera, który może być nieczytelny.
switch_to()W pliku include/linux/sched.h znajduje się pole odpowiadające strukturze, która to zawiera informacje przechowywane w tss
struct task_struct {
...
/* CPU-specific state of this task */
struct thread_struct thread;
}
W pliku include/asm-i386/processor.h znajduje się definicja struct thread_struct
struct thread_struct {
unsigned long esp0;
unsigned long eip;
unsigned long esp;
unsigned long fs;
unsigned long gs;
/* Hardware debugging registers */
unsigned long debugreg[8]; /* %%db0-7 debug registers */
...
/* floating point info */
union i387_union i387;
/* virtual 86 mode info */
struct vm86_struct * vm86_info;
unsigned long screen_bitmap;
unsigned long v86flags, v86mask, v86mode, saved_esp0;
/* IO permissions */
int ioperm;
unsigned long io_bitmap[IO_BITMAP_SIZE+1];
};
switch_to():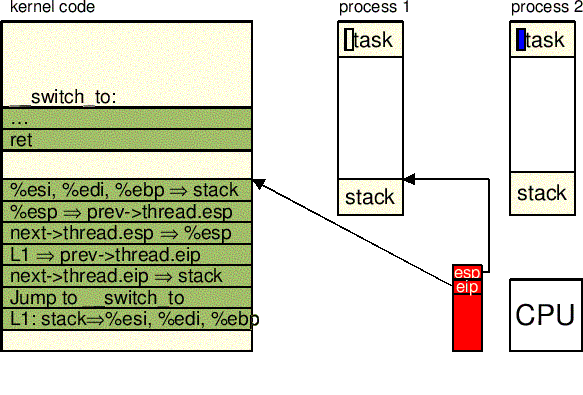
prev i next odpowiednio w
rejestrach eax i edx.
: "a" (prev), "d" (next)
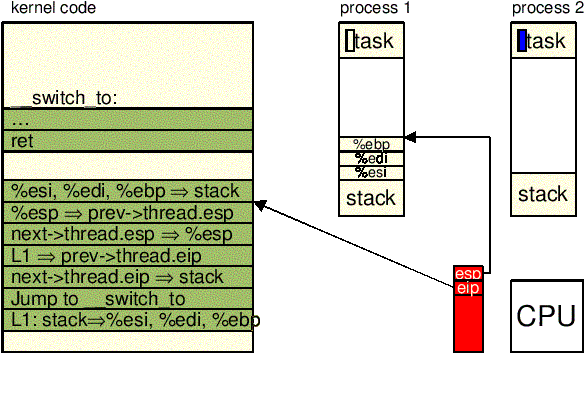
esi, edi i
ebp w stosie trybu jądra prev.
"pushl %%esi\n\t" \
"pushl %%edi\n\t" \
"pushl %%ebp\n\t" \

esp w prev->thread.esp tak, by
pole to wskazywało na wierzchołek stosu trybu jądra.
prev :
"movl %%esp,%0\n\t" /* save prev->thread.ESP */ \
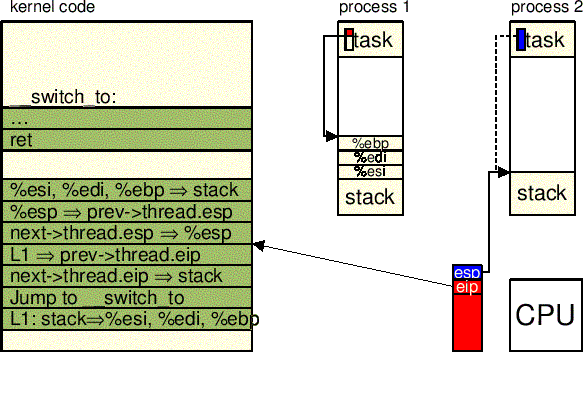
next->thread.esp do esp. od tej chwili jądro
zaczyna operować na stosie jądra next,
więc to właśnie ta instrukcja wykonuje właściwe przełączenie kontekstu z
prev do next. Zmienianie
stosu jądra zmienia również aktualny proces, ponieważ adres deskryptora
procesu jest ściśle powiązany z adresem stosu trybu jądra (patrz: macro current).
"movl %3,%%esp\n\t" /* restore next->thread.ESP */ \
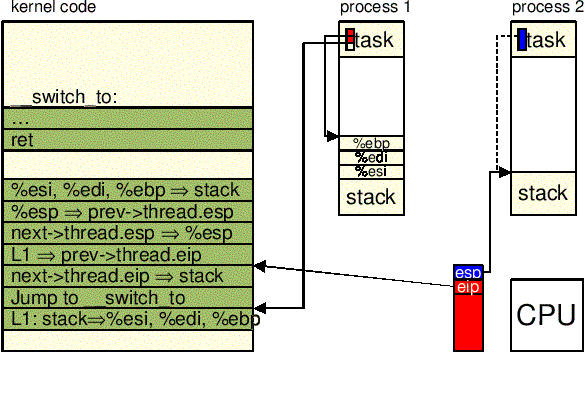
1 w prev->thread.eip.
gdy proces usypiany wznowi wykonanie, wykona
instrukcję oznaczoną 1:
"movl $1f,%1\n\t" /* save prev->thread.EIP */ \
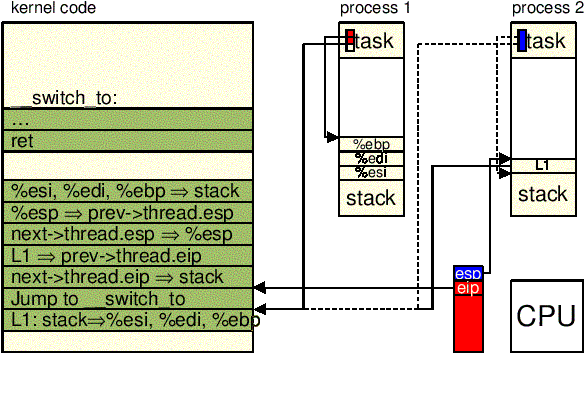
next wartość
next->thread.eip.
"pushl %4\n\t" /* restore next->thread.EIP */ \
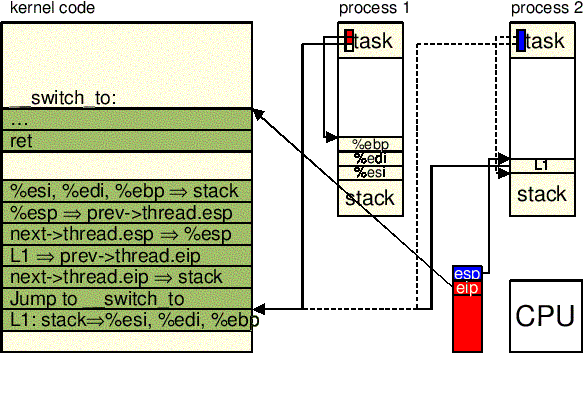
__switch_to():
"jmp __switch_to\n" \
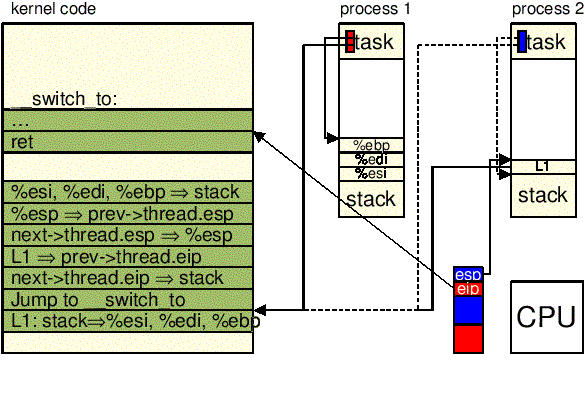
unlazy_fpu(), które opcjonalnie zachowuje
zawartość rejestrów koprocesora matematycznego.
tr. Wykorzystuje się m. in.
makro /include/arch/asm-i386/desc.h:
(#define load_TR(n) __asm__ __volatile__("ltr %%ax"::"a" (__TSS(n)<<3)) )
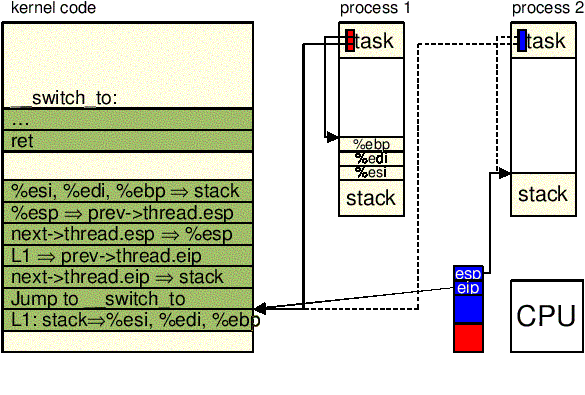
"1:\t" \
"popl %%ebp\n\t" \
"popl %%edi\n\t" \
"popl %%esi\n\t" \