Testy
Szymon Toruńczyk
Witold Walkiewicz

Spis treści.
Testy wydajnościowe (Linux-oriented)

Testy wydajnościowe (benchmarks) służą sprawdzaniu i optymalizacji prędkości działania kodu.
Testy syntetyczne (synthetic benchmarks)
- (+) Użyteczne przy badaniu jednego aspektu działania systemu. Można
się spodziewać, że testy np. przepustowości karty sieciowej wyjdą tak
samo niezależnie od procesora.
- (+) Wyglądają fajnie.
- (?) W zasadzie jedyny wybór przy testowaniu sprzętu.
- (---) Zazwyczaj nie za wiele mają wspólnego z rzeczywistym działaniem systemu.
- Dość częstym błędem jest obliczanie wyników różnych tego
rodzaju testów i wyciąganie z nich średniej. To też nie musi odpowiadać
rzeczywistej prędkości działania!
Czym testować
Według niektórych, najlepszym sposobem pomiaru wydajności całego
systemu jest mierzenie czasu rekompilacji jądra. W ten sposób można
powiedzieć, iż np. zwiększenie/zmniejszczenie wartości X o Y%,
zaowocowało zmniejszeniem/zwiększeniem prędkości kompilacji o Z%.
Lepiej nie kompilować jądra z katalogu /usr/src/linux. Szczególnie, jeśli testujemy wpływ zmian w jądrze na wydajność systemu...
Testy na bazie gcc i czasu kompilowania czegokolwiek zakładają, że wyłączone mamy narzędzia w rodzaju distcc czy ccache (skądinąd bardzo przydatne).
Ciekawym rozwiązaniem jest użycie Linux Benchmarking Toolkit. Jest to, zestaw rozmaitych bardziej wyspecjalizowanych narzędzi.
Niebywale przydatny jest LMBenchmark. Oferuje on
m.in. pomiary prędkości operacji na plikach (np. tworzenie i usuwanie
dużej ilości małych plików), operacji sieciowych (TCP i UDP),
przełączanie kontekstów, pomiary prędkości pamięci i wiele innych
Użytecznym narzędziem testowania wydajności systemu jest Byte Linux Benchmarks. http://www.silkroad.com/bass/linux/bm.html
Najprostsze (i często w zupełności wystarczające) narzędzie to time.
Liczy, jak długo wykonywał się dany program. Jednak do konkretnych
zastosowań dobrze jest użyć jednego z kilkudziesięciu ogólnodostępnych
darmowych wyspecjalizowanych narzędzi testujących. Na stronie Linux Benchmark Suite znaleźć można spis (wraz z krótkim opisem) wielu z nich.
Jak testować
- Odpowiedz sobie na pytanie, co chcesz zmierzyć? Jak wiele czasu chcesz spędzić na testowaniu (zadania nr 5 np.)?
- Przygotuj rozmaite zestawy testowe. Użyj wyobraźni i odpowiedzi na pytanie nr 1.
- Używaj sprawdzonych narzędzi. Stabilnej wersji jądra, gcc, libc. No i jakiegoś sprawdzonego programu do liczenia wydajności (np. LMBenchmark).
- Zapisz sobie dokładnie testowaną konfigurację.
- Testuj, modyfikując pojedyncze zmienne, nie kilka naraz. Chcemy wiedzieć dokładnie, co wpływa na wydajność.
- Weryfikuj, weryfikuj, weryfikuj. Uruchom test kilka razy. Jeśli wyniki się różnią, dlaczego?
- Lepiej nie testować na zasadzie umieszczania w kodzie pętli zliczających po n razy to samo. Nigdy nie wiesz, co kompilator z tym zrobi.
- Dla wygody, posłuż się skryptem.
Idealną sytuacją jest, gdy możemy przy okazji przetestować
(funkcjonalną) poprawność działania naszego kodu, jeśli oprócz testów
przygotujemy również pewne założenia, dotyczące rezultatów jego
działania (możemy chociażby sprawdzać, czy program nie zakończył się
błędem). Wtedy też albo wypisujemy czas pracy, albo komunikaty
diagnostyczne.
Narzędzie JMeter
JMeter - krótki opis:
- Służy do testowania różnego rodzaju serwerów, np. FTP, HTTP, baz
danych
- Napisany w Javie, dzięki czemu działa na każdej platformie
- Bardzo łatwo stworzyć pakiet testów, który zbombarduje nasz serwer mnóstwem
rozmaitych zapytań w krótkim czasie, symulując działanie wielu użytkowników
- Możliwość analizy odpowiedzi serwera za pomocą wyrażeń regularnych
- Możliwość graficznej prezentacji wydajnośći systemu oraz poprawności
odpowiedzi
JMeter można znaleźć na tej stronie: jakarta.apache.org
Testy w programie JMeter tworzy się poprzez dodawanie do Planu Testów różnych
elementów, które opisują czynności, które JMeter ma wykonać.
Plan testów może składać się z kilku grup wątków, kontrolerów
logicznych, kontrolerów generujących zapytania do serwera, czasomierzy,
asercji oraz elementów konfiguracyjnych. Plan testów ma strukturę drzewa, a
nowe elementy dodaje się do niego klikając prawym przyciskiem w odpowiednie
jego węzły.
Plan testów, którego działanie polega na cyklicznym wysyłaniu zapytań do
serwera przez grupę wątków miałby taką strukturę:
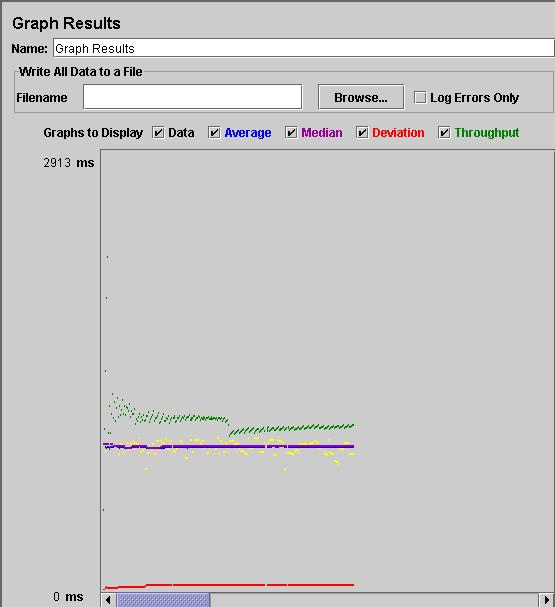
 Po uruchomieniu powyższego planu, moglibyśmy obejrzeć czasy odpowiedzi serwera na wykresie,
dzięki elementowi Graph Results. Otrzymany wynik miałby taką postać:
Po uruchomieniu powyższego planu, moglibyśmy obejrzeć czasy odpowiedzi serwera na wykresie,
dzięki elementowi Graph Results. Otrzymany wynik miałby taką postać:
 W programie JMeter bardzo łatwo jest również
dodać elementy, które np. sprawdzają zwróconą stronę
pod kontem występowania jakiegoś wyrażenia regularnego.
W programie JMeter bardzo łatwo jest również
dodać elementy, które np. sprawdzają zwróconą stronę
pod kontem występowania jakiegoś wyrażenia regularnego.
Analiza poprawności
Jak wiadomo, nasz kod nie zawsze robi to, czego byśmy sobie życzyli.
Metody
- Testowanie na zasadzie scenariuszy testowych - proste i dość skuteczne, ale zawodne (człowiek wszystkiego nie przewidzi).
- Czytanie kodu - popularna, bardzo elastyczna metoda,
polegająca na prześledzeniu działania programu przez człowieka.
Niezawodna tylko wtedy, gdy jest to pracownik Uniwersytetu, a program
pisany jest długopisem na papierze.
- Analiza statyczna kodu - skuteczna, obiecująca metoda, spotykana w wielu kompilatorach.
- Weryfikacja formalna - metoda teoretycznie 100% skuteczna, ale niewygodna i trudna w praktycznej realizacji.
Analiza statyczna

Przegląda wszystkie możliwe ścieżki wykonania, jednocześnie wskazując na tzw. martwy kod. Podaje przyczynę błędu.
Reguły poprawności
Ustalamy reguły, które niekoniecznie muszą
prowadzić do błędu, ale które wskazują na duże prawdopodobieństwo jego
wystąpienia. Niektóre kompilatory wyświetlają je jako ostrzeżenia, inne
nawet jako błędy. Na przykład:
- nie wolno używać pamięci nie zaalokowanej
- nie wolno zwalniać pamięci dwukrotnie
- nie wolno odwoływać się do obszaru pamięci wskazanego przez null
- funkcje systemowe muszą sprawdzać poprawność adresów z przestrzeni użytkownika
Reguły poprawności możemy definiować np. w języku metal, będącym rozszerzeniem języka C.
Opracowywane są metody, które mają na celu automatyczne generowanie
reguł poprawności z kodu źródłowego, na zasadzie propabilistycznej
(większość programistów danej reguły przestrzega, choćby intuicyjnie).
Ponieważ tego rodzaju narzędzia mogą generować masę fałszywych alarmów, konieczne jest odpowiednie ich kolejkowanie.
Z opublikowanego w kwietniu raportu National Cybersecurity
Partnership's Working Group pt. Software Lifecycle, przygotowanego
zgodnie z metodami opracowanymi na Carnegie Mellon University, wynika,
że w komercyjnym oprogramowaniu występuje od jednego do siedmiu błędów
na 1000 linii kodu.
Firma Coverity (założona przez prof. Dawsona Englera, który
rozpoczął prace nad koncepcją metakompilacji) podała natomiast, iż w 5
milionach 700 tysiącach linii kodu, składających się na najnowsze jądro
Linuksa, znaleziono 985 błędów (0,17 błędu na 1000 linii kodu).
Niestety, firma Coverty nie mogła przeprowadzić podobnej analizy na
kodzie źródłowym innego popularnego systemu operacyjnego.
Błędy te znaleziono przy użyciu statycznej analizy kodu źródłowego.
Przykłady (dwa proste)
jądro 2.4.6, plik drivers/char/drm/i810_dma.c
int i810_copybuf(struct inode *inode, struct file *filp, unsigned int cmd,
unsigned long arg)
{
drm_file_t *priv = filp->private_data;
drm_device_t *dev = priv->dev;
drm_i810_copy_t d;
drm_i810_private_t *dev_priv = (drm_i810_private_t *)dev->dev_private;
u32 *hw_status = (u32 *)dev_priv->hw_status_page;
drm_i810_sarea_t *sarea_priv = (drm_i810_sarea_t *)
dev_priv->sarea_priv;
drm_buf_t *buf;
drm_i810_buf_priv_t *buf_priv;
drm_device_dma_t *dma = dev->dma;
if(!_DRM_LOCK_IS_HELD(dev->lock.hw_lock->lock)) {
DRM_ERROR("i810_dma called without lock held\n");
return -EINVAL;
}
if (copy_from_user(&d, (drm_i810_copy_t *)arg, sizeof(d)))
return -EFAULT;
if(d.idx < 0 || d.idx > dma->buf_count) return -EINVAL;
buf = dma->buflist[ d.idx ];
buf_priv = buf->dev_private;
if (buf_priv->currently_mapped != I810_BUF_MAPPED) return -EPERM;
// jaką mamy pewność, że w linii poniżej d.address i d.used
// nie zostały podrzucone przez jakiegoś crackera?
if (copy_from_user(buf_priv->virtual, d.address, d.used))
return -EFAULT;
sarea_priv->last_dispatch = (int) hw_status[5];
return 0;
}
jądro 2.4.4, plik drivers/media/video/videodev.c
static void videodev_proc_create_dev (struct video_device *vfd, char *name)
{
struct videodev_proc_data *d;
struct proc_dir_entry *p;
if (video_dev_proc_entry == NULL)
return;
d = kmalloc (sizeof (struct videodev_proc_data), GFP_KERNEL);
if (!d)
return;
p = create_proc_entry(name, S_IFREG|S_IRUGO|S_IWUSR, video_dev_proc_entry);
// a jeśli p jest null???
p->data = vfd;
p->read_proc = videodev_proc_read;
d->proc_entry = p;
d->vdev = vfd;
strcpy (d->name, name);
/* How can I get capability information ? */
list_add (&d->proc_list, &videodev_proc_list);
}
Pięć przykazań programisty
- Nigdy nie zakładaj, że napisany kod działa poprawnie
- Pisząc kawałek kodu, od razu zastanów się, jak go przetestować
- Nie optymalizuj struktur danych
- Wydajność zależy głównie od algorytmu, a nie od sposobu zakodowania
- Nie ufaj narzędziom testującym
Przykazania programisty dotyczące optymalizacji
Michael Jackson

- Nie rób tego!
- Skoro już musisz to zrobić... zrób to potem!
- Skoro już musisz to zrobić teraz... pisz obszerne komentarze!
- Skoro już musisz to zrobić teraz i bez komentarzy... nie dziw się!
Jeszcze dwa słowa o testowaniu
Nawet jeżeli moduł czy pojedyncza funkcja zostały solidnie
przetestowane, ale w tym czasie zmieniono inny fragment programu,
istnieje ryzyko, że modyfikacja nie pozostanie bez wpływu na działanie
całej aplikacji. Może się bowiem okazać, że po zmianach w pozornie
odrębnej części programu, sprawdzony uprzednio moduł czy funkcja
działają inaczej niż planował autor programu. Stąd zaleca się, by testy
były tak skonstruowane, aby za każdym razem można było uruchamiać
zestaw procedur sprawdzających. Innymi słowy kody funkcjonalny i
testowy muszą być bardzo blisko powiązane. Test powinien być
automatycznie wywoływany wg odpowiedniej kompilacji czy linkowania.
Bodajże najpopularniejszym narzędziem tego typu są moduły xUnit,
związane z Test Driven Development (część extreme programming). Jest to
tzw. framework do tworzenia procedur testowych, opracowany dla
znakomitej większości używanych współcześnie języków programowania. W
wielu przypadkach powstają na bazie xUnit gotowe aplikacje
upraszczające generowanie testów. Przykładowo, w przypadku Delphi czy
C++ Builder można z poziomu środowiska IDE tworzyć szkielety klas
testowych.
Pisanie testów analizujących różne aspekty użycia określonej funkcji
jest kłopotliwe. Obecnie jest opracowywane specjalne narzędzie
przeznaczone dla języka Java, które na podstawie interfejsu opisującego
zachowanie konkretnego elementu języka wygeneruje kod testujący.
Zachowanie funkcji określa się przy użyciu specjalnego języka JML -
Java Modeling Language. Funkcje poprzedzają specjalne sformatowane
komentarze zawierające opisy np. warunków ograniczających zwracaną
wartość, sytuacje gdy dopuszczalne jest zgłoszenie wyjątku. W
niedalekiej przyszłości za pomocą JML będzie można podać konkretny
przypadek użycia danej funkcji. W języku tym są definiowane rozbudowane
asercje, które potem mogą być przekształcone w szkielety modułów
testowych zgodne ze specyfikacją JUnit.
JML ma pozwolić na realizację założeń Design by Contract (podejście
to, zaczerpnięte z języka Eiffel, ma doprowadzić do powstania
bezbłędnego oprogramowania). Można określać warunki, jakie musi
spełniać klient wywołujący daną funkcję, jaki ma być stan metody po
wykonaniu operacji, jakie asercje mają być spełnione w określonych
punktach programu. Test wygenerowany z wykorzystaniem JML wysyła
komunikaty do obiektów Javy i określa, kiedy operacja zakończyła się
niepowodzeniem (czy zdefiniowany przy użyciu JML sposób działania
programu został naruszony). Niestety, dane testowe musi utworzyć
ręcznie programista.
Narzędzie JUnit
Praktycznie jedynym sposobem przetestowania poprawności działania programu, jest przeprowadzenie
testów i sprawdzenie, czy uzyskane wyniki są zgodne ze spodziewanymi.
Jest rzeczą oczywistą, że programista powinien dużo czasu poświęcić na testowaniu wyników
działania programu, a też jego poszczególnych modułów, klas, metod i funkcji już w trakcie powstawania
programu.
Przyspieszyłoby to znacznie usuwania błędów odnalezionych dopiero po napisaniu całego programu,
gdyż nie traci się tyle czasu na lokalizacji źródła błędnego działania.
Niestety, większość firm produkuje programy zawierające duże ilości błędów,
właśnie dlatego, że nie ma czasu na odpowiednie ich testowanie.
Albowiem programista jest opłacany za kod który tworzy, a nie za błedy, które w nim odnajdzie.
Aby programistom chciało się testować pisany kod, potrzebne są narzędzia, które przyspieszają i ułatwiają tę czynność.
Przykładem takiego narzędzia jest JUnit.
Jest to biblioteka, która wspomaga tworzenie testów dla programów pisanych w
Javie.
Scenariusz testowy można bardzo prosto zaimplementować korzystając z klasy TestCase,
która umożliwia również jego automatyczne przeprowadzenie.
Dla przykładu,
utworzymy klasę Complex, która ma służyć do reprezentacji liczb zespolonych.
Odpowiedni kod wygląda mniej więcej tak:
package complex;
public class Complex {
double x, y;
public Complex(double x, double y) {
this.x = x;
this.y = y;
}
public Complex(double x) {
this.x = x;
this.y = 0.0;
}
public double re() {
return x;
}
public double im() {
return y;
}
public String toString() {
StringBuffer buffer = new StringBuffer();
if (im()==0.0)
buffer.append(re());
else if (re()==0.0)
buffer.append(im()+" i");
else
buffer.append("("+re()+" "+im()+" i)");
return buffer.toString();
}
public boolean equals(Object anObject)
{
if (anObject instanceof Complex) {
Complex z= (Complex) anObject;
return (z.re()==x && z.im()==y);
}
return false;
}
public Complex add(Complex z)
{
return new Complex(x+ z.re(), y+ z.im());
}
public Complex multiply(Complex z)
{
return new Complex(z.re()*re() - z.im()*im(), z.re()*im() + z.im()*re());
}
}
Aby przetestować to, co napisaliśmy, tworzymy klasę ComplexTest, pochodną od klasy TestCase.
Odpowiedni kod wygląda tak:
package complex;
import junit.framework.*;
public class ComplexTest extends TestCase {
private Complex i;
private Complex one;
private Complex zero;
public static void main(String args[]) {
junit.textui.TestRunner.run(ComplexTest.class);
}
protected void setUp() {
i= new Complex(0,1);
one= new Complex(1);
zero= new Complex(0, 0);
z1= new Complex(0.2, 0.4);
}
public void testEquals() {
assertFalse(i.equals(null));
assertFalse(i.equals(new Object()));
assertEquals(zero, one); /* TU JEST BŁĄD!!! */
assertEquals(i, new Complex(0,1));
assertEquals(one, new Complex(1, 0));
assertFalse(one.equals(i));
}
public void testAdd() {
Complex expected = new Complex(1, 1);
assertEquals(one.add(i), expected);
assertEquals(one.add(i), expected);
}
public void testMultiply() {
assertEquals(one.multiply(i), i);
assertEquals(i.multiply(one), i);
assertEquals(one.multiply(one), one);
Complex expected = new Complex(-1.0);
assertEquals(i.multiply(i), expected);
}
}
Wywołanie powyżej zaimplementowanej metody Complex.main
powoduje w wyniku pojawienie się na ekranie napisów takiej postaci:
.F..
Time: 0.01
There was 1 failure:
1) testEquals(complex.ComplexTest)junit.framework.AssertionFailedError: expected:<0.0> but was:<1.0>
at complex.ComplexTest.testEquals(ComplexTest.java:29)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at complex.ComplexTest.main(ComplexTest.java:14)
FAILURES!!!
Tests run: 3, Failures: 1, Errors: 0
Wykonywane są wszystkie trzy metody, których nazwa zaczyna się od słowa test.
Przed wywołaniem każdej z nich, wywoływana jest metoda setUp().
Można też manualnie wskazać, które testy mają być wykonywane, przesłaniając metodę
suite klasy TestCase na przykład tak:
public static Test suite() {
TestSuite suite= new TestSuite();
suite.addTest(new ComplexTest("testEquals"));
suite.addTest(new ComplexTest("testMultiply"));
return suite;
}
Jeżeli zamiast textui w metodzie main napisalibyśmy awtui,
to w wyniku otrzymalibyśmy graficzną prezentację przeprowadzonych testów, przykładowo:
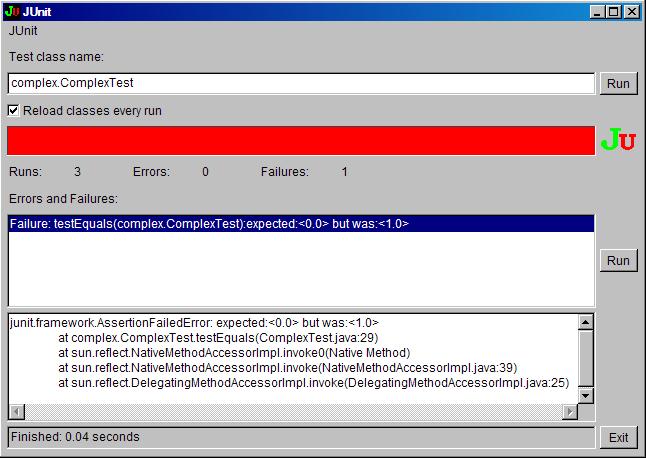
Oprócz JUnit stworzono narzędzia, wspomagające testowanie w innych językach.
Tworzą one rodzinę określaną ogólnie jako
XUnit. W jej skład wchodzą między innymi:
- •JUnit (Java)
- CppUnit (C++)
- Unitpp (C++)
- •PerlUnit (Perl)
- vbUnit (VisualBasic)
- NUnit (C# i .NET)
- pyunit (Python)
- RubyUnit (Ruby)
- SUnit (Smalltalk)
Prędkość

95% czasu wykonania programu wykonywane jest przez 5% kodu. I w zasadzie tylko ten kod należy optymalizować.
Niemal każde komercyjne środowisko IDE jest wyposażone w profiler,
który gromadzi dane o wykonywanym kodzie, wskazuje najwolniej
działające funkcje, analizuje zużycie pamięci.
W przypadku gdy jednak trzeba optymalizować kod "niskopoziomowo", mogą być pomocne narzędzia producentów procesorów.
Intel VTune Performance Analyzer jest narzędziem
przeznaczonym do szczegółowej analizy kodu aplikacji dla procesorów
Intela - obecnie jest dostępna wersja dla Windows i Linuxa. Badane jest
zużycie poszczególnych zasobów procesora, np. czy są optymalnie
wykorzystane mechanizmy równoległego wykonywania instrukcji. Podobny
pakiet opracowała i udostępnia bezpłatnie także AMD. Narzędzie AMD CodeAnalyst
może symulować wykonanie programu z dokładnością do 1 ms. Na bieżąco
można podglądać zawartość poszczególnych potoków przetwarzania, a także
określać, jakie statystyki mają być zliczane.