Kernel 2.6
Prezentacja przedstawiająca nowe cechy jądra systemu Linux o numerze 2.6.
Autorzy: Maciej Cielecki, Konrad Durnoga, Adam Fuksa i Jędrzej Fulara.
(zaleca się oglądanie rysunków z ustawioną 24-bitową głębią barw)

Prezentacja przedstawiająca nowe cechy jądra systemu Linux o numerze 2.6.
Autorzy: Maciej Cielecki, Konrad Durnoga, Adam Fuksa i Jędrzej Fulara.
(zaleca się oglądanie rysunków z ustawioną 24-bitową głębią barw)
Linux bardzo się zmienił w wersji 2.6. Poniżej przedstawiamy wybrane przez nas zmiany, które wybraliśmy jako wyjątkowo interesjuące.
Zgodnie z życzeniem pani JMD, stworzyliśmy wiele diagramów przedstawiających różne procesy w nowym jądrze.
AIO pozwala nawet pojedynczemu wątkowi aplikacji na wykonywanie operacji I/O jednocześnie z dowolnym innym przetwarzaniem. Jest to zrealizowane poprzez interfejs pozwalający na wysyłanie jednego lub więcej żądań operacji I/O w jednym wywołaniu systemowym bez potrzeby czekania na zakończenie tych operacji. Takie żądania zawsze powiązane są z jakimś kontekstem.
long sys_io_submit(aio_context_t ctx_id, long nr, struct iocb __user * __user *iocbpp)
Oddzielny interfejs jest odpowiedzialny za zbieranie zakończonych operacji związanych z danym kontekstem.
long sys_io_getevents(aio_context_t ctx_id, long min_nr, long nr, struct io_event __user *events, struct timespec __user *timeout)
Poniższe funkcje służą do tworzenia i kasowania kontekstu
long sys_io_setup(unsigned nr_events, aio_context_t __user *ctxp)
long sys_io_destroy(aio_context_t ctx)
Można także spróbować anulować asynchroniczą operację I/O
long sys_io_cancel(aio_context_t ctx_id, struct iocb __user *iocb, struct io_event __user *result)

AIO znajduje zastosowanie w aplikacjach, które wykonują bardzo dużo operacji I/O, np
AIO w linuxie jest niezgodne z POSIX, ale za to jest wydajniejsze. Obsługa AIO została dołączona do jądra 2.6. Istnieją także patche na jądro 2.4.
Źródła:
W jądrze 2.6 zaimplementowano od nowa mechanizm blokowego I/O. Twórcy postawili przed sobą następujące zadania:
Do tej pory do obsługi żądań używano struktury buffer_head. Nie pozwalała ona na realizację wyżej wymienionych postulatów. Na przykład jedno duże żądanie było zawsze rozbijane na wiele małych. Powodowało to duży narzut pamięci związany z tworzeniem dużej ilości struktur buffer_head (po jednym dla każdego kawałka).

Obecnie przyjęte rozwiązanie o wiele efektywniej gospodaruje pamięcią. Wprowadzono nową strukturę Bio (zdefiniwana w inlude/linux/bio.h).
struct bio {
sector_t bi_sector;
struct bio *bi_next;
struct block_device *bi_bdev;
unsigned long bi_flags;
unsigned long bi_rw;
unsigned short bi_vcnt; /* ilosc bio_vec */
unsigned short bi_idx; /* aktualny indeks w tablicy wektorow */
unsigned short bi_phys_segments;
unsigned short bi_hw_segments;
unsigned int bi_size;
unsigned int bi_hw_front_size;
unsigned int bi_hw_back_size;
unsigned int bi_max_vecs;
struct bio_vec *bi_io_vec; /* tablica bio_vec */
bio_end_io_t *bi_end_io;
atomic_t bi_cnt;
void *bi_private;
bio_destructor_t *bi_destructor;
};
Struktura bio zawiera tablicę struktur bio_vec. Bio_vec to krotka, złożona ze stony, offsetu na stronie, od którego rozpoczyna się bufor i długości tego bufora:
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
};
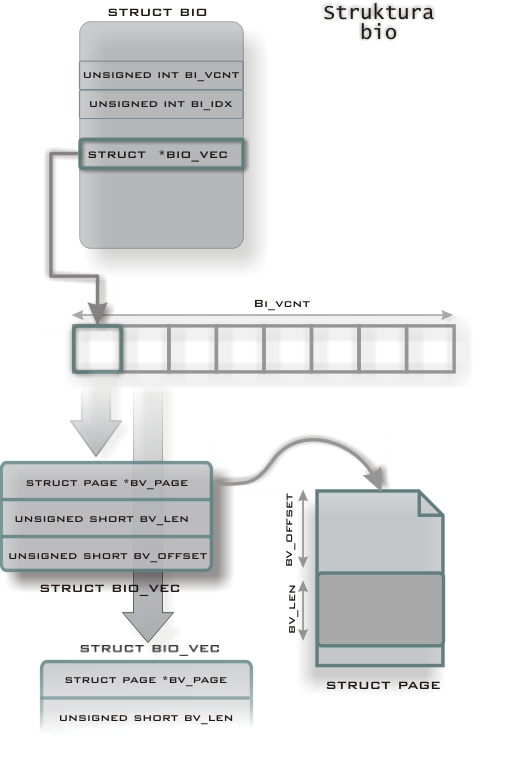
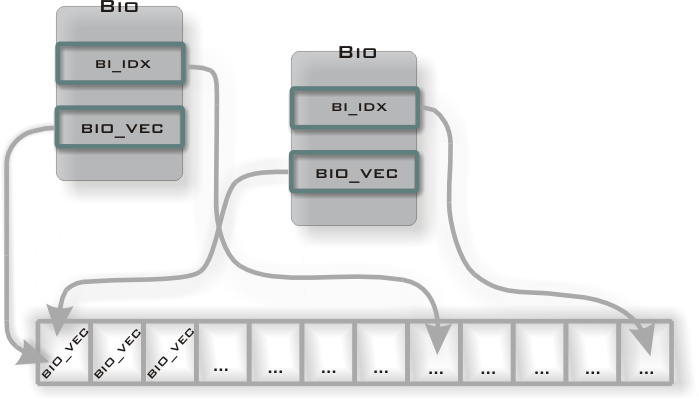
Tablica bi_io_vec może być współdzielona przez różne struktury bio. Umożliwia to zrealizowanie wymagania dotyczącego równoległego odczytu z niezależnych źródeł (np. macierze dyskowe RAID).


W dotychczasowych wersjach Linuksa procesy działające w trybie jądra (w tym również procesy użytkownika, które znalazły się w trybie jądra przy wywołaniu funkcji systemowych) nie mogły zostać wywłaszczone przez inny proces. Mogły one działać dopóty, dopóki same dobrowolnie nie zrzekły się procesora (np. dopóki nie powróciły z wywołania z funkcji systemowej bądź nie zasnęły w oczekiwaniu na jakiś zasób). Czas jaki procesy mogły pozostawać w trybie jądra, a tym samym blokować dostęp do procesora, nie był ograniczony przez żadną arbitralnie ustaloną wartość. Mogło to powodować, że proces przebywał w przestrzeni jądra nawet kilkaset milisekund. Z punktu widzenia niektórych aplikacji (na przykład multimedialnych) wymagających częstego (co kilka / kilkanaście milisekund) dostępu do procesora tak długie oczekiwanie jest nieakceptowalne. Rozwiązaniem tego problemu jest wprowadzony w jądrze 2.6 mechanizm wywłaszczania jądra (preemptible kernel). Obserwujemy obecnie tendencję do przekształcania Linuxa w system w pełni Real-Time'owy, czyli taki, w którym każde przerwanie zostanie obsłużone w z góry narzuconym czasie.
W jądrze 2.6 możliwe jest wywłaszczenie każdego wątku, w tym również działającego w trybie jądra, w (prawie) dowolnym momencie. Takie podejście jest źródłem pewnych trudności: należy zapewnić spójność wszystkich danych w krytycznych momentach.
Na przyład taki kod mógłby mieć niepożądany efekt:
int arr[NR_CPUS]; arr[smp_processor_id()] = i; /* tutaj następuje wywłaszczenie */ j = arr[smp_processor_id()]; /* i oraz j nie muszą być takie same - proces mógł wrócić na inny procesor */
Istnieją więc momenty, w których wywłaszczenie NIE MOŻE nastąpić. Należy więc newralgiczne pukty kodu chronić - używając specjalnych locków (preempt_enable(), preempt_disable()).
#define preempt_disable() \
do { \
inc_preempt_count(); \
barrier(); \
} while (0)
#define preempt_enable() \
do { \
preempt_enable_no_resched(); \
preempt_check_resched(); \
} while (0)
Czasami preempt_enable() i preempt_disable() są wołane implicite. Na przykład w funkcjach obsługujących wirujące blokady.
#define spin_lock_irqsave(lock, flags) \
do { \
local_irq_save(flags); \
preempt_disable(); \
_raw_spin_lock(lock); \
} while (0)
#define spin_unlock_irqrestore(lock, flags) \
do { \
_raw_spin_unlock(lock); \
local_irq_restore(flags); \
preempt_enable(); \
} while (0)
Proces działający w trybie jądra można więc wywłaszczyć, gdy nie ma on założonego żadnego locka.
Aby uczynić jądro wywłaszczalnym, dodano do task_struct licznik preempt_count. Na początku jego wartość wynosi zero. Przy każdym założeniu locka jego wartość jest zwiększana, a przy zdjęciu - zmniejszana o jeden.
Gdy licznik wynosi zero, można proces wywłaszczyć. Przy powrocie z przerwania do przestrzeni jądra, sprawdzane są licznik preemt_count oraz flaga zwracana przez need_resched(). Jeśli licznik jest wyzerowany a flaga ustawiona, to oznacza, że oczekuje jakiś gotowy do wykonania proces o wyższym priorytecie oraz jądro jest w stanie stabilnym. Można przekazać sterowanie. Jeśli jednak licznik jest różny od zera, oznacza to, że nie można wywołać funkcji schedulera. Sterowanie jest przekazywane z powrotem do tego samego procesu.
Wywłaszczenie jądra może również nastąpić explicite: jeśli proces znajdujący się w jądrze zasypia lub wywoła funkcję schedule(). W tym wypadku nie jest sprawdzana wartość licznika preempt_count. Zakłada się, że proces wołający schedule() wie co robi.
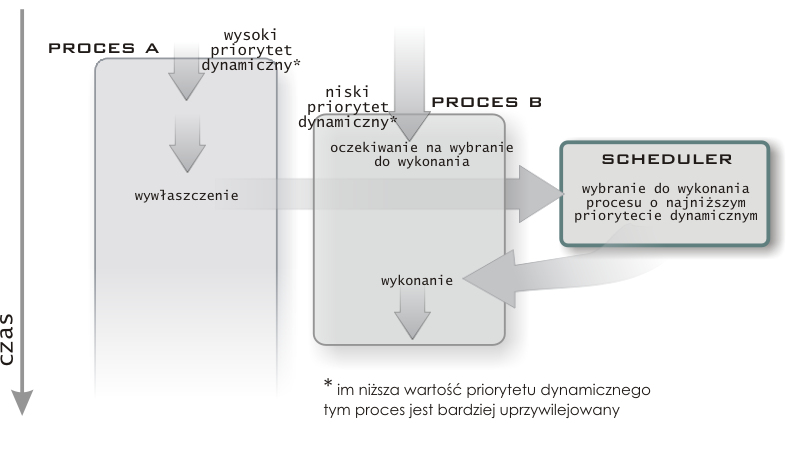
A więc, podsumowując - jądro może być wywłaszczone, gdy:
Jądro umożliwia dynamiczne ("w locie") zmienianie szybkości procesora. Możliwy jest zarówno odczyt jak i zapis do pliku /proc/cpufreq.
Wspierane są między innymi technologie: Intel SpeedStep, Itel Xeon, AMD PowerNow K6, AMD Elan czy VIA Cyrix Longhaul
Powyżej opisana właściwość jest szczególnie istotna w oszczędnym gospodarowaniu energią, co z kolei ma kluczowe znaczenie dla komputerów przenośnych.
Źródło: www.brodo.de/cpufreq
NUMA jest architekturą wieloprocesorową zaprojektowaną w celu pokonania ograniczeń architektury SMP (Symmetric Multi-Processing). W SMP wszystkie dostępy do pamięci odbywały się po tej samej, wspólnej dla wszystkich CPU szynie. Spełniało to swoje zadanie dla relatywnie małej ilości procesorów. Jednak wraz ze wzrostem ich liczby (dziesiątki lub setki), CPU zaczynają współzawodniczyć o dostęp do wspólnej szyny, która staje się wówczas wąskim gardłem całego systemu. NUMA rozwiązuje ten problem poprzez ograniczenie liczby procesorów korzystających z tej samej szyny.
W architekturze NUMA cały system podzielony jest na tak zwane węzły. Jeden węzeł obejmuje bloki pamięci, procesory i urządzenia wejścia - wyjścia, które są fizycznie podpięte do jednej szyny pamięci. Pamięć znajdująca się w tym samym węźle co procesor jest jego pamięcią lokalną (ang. local), zaś ta z innych węzłów - zdalną (ang. remote). Jakkolwiek możliwy jest dostęp zarówno do jednej jak i do drugiej pamięci, to jednak odwołanie do pamięci zdalnej jest dużo mniej efektywne niż do lokalnej.
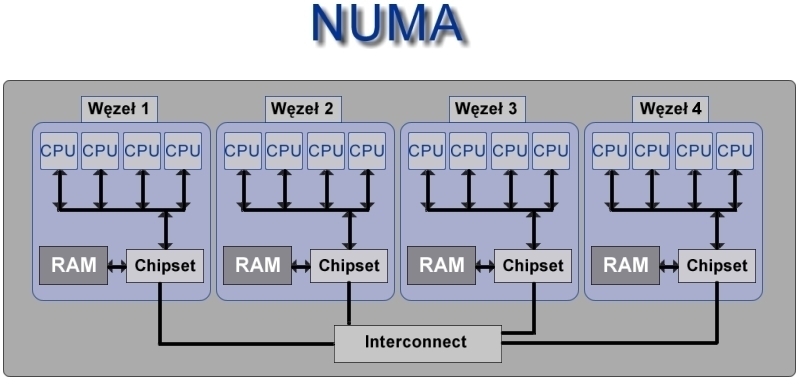
Jądro 2.6 udostępnia programowe wsparcie dla obsługi architektury NUMA. "Planista przydziału procesora" stara się nie przydzielać procesu do wykonania na procesory z różnych węzłów. Co więcej, zarządzanie pamięcią zorganizowane jest tak, by proces nie musiał sięgać do pamięci z innych węzłów.
Dodatkowo jądro stara się równoważyć obciążenie różnych węzłów. Wykorzystywane są do tego następujące funkcje (kernel/sched.c)
static int find_busiest_node(int this_node) static int sched_best_cpu(struct task_struct *p) void sched_balance_exec(void) static void balance_node(runqueue_t *this_rq, int idle, int this_cpu)
W jądrze 2.6.5 równoważenie to było wykonywane co 400 ms.
Przykładowe architektury NUMA:
Firma Intel w linii procesorów P4 wprowadziła technologię Hyper-Threading. Jest to sprzętowe symulowanie na jednym fizycznym procesorze kilku procesorów logicznych. Technologia ta przyspiesza wykonywanie aplikacji wielowątkowych.
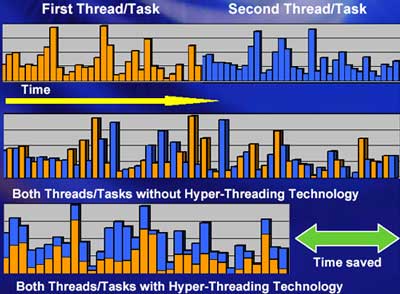
Jądro 2.6 wspiera obsługę procesorów z technologią HT: rozpoznaje zarówno procesory fizyczne jak i logiczne. (Patrz kernel/cpu/intel.c oraz kernel/sched.c)
Obecnie rozwijane są dwa konkurencyjne projekty obsługi wątków zgodne ze standardem POSIX. Są to NGPT (New Generation POSIX Threads) oraz NPTL (Native POSIX Thread Library).
Rozważane są różne modele obsługi wątków.
Do tworzenia procesów wielowątkowych używana jest funkcja clone(). Powoduje ona jednak nieprzenośność kodu.
Realizowana przez IBM oraz Intel biblioteka NGPT jest oparta na hybrydowym modelu M:N. Uznaje się, że model ten jest najlepszą drogą do osiągnięcia optymalnej wydajności. Wymaga on jednak utrzymywania dwóch specjalnych schedulerów: jednego w przestrzeni jądra, drugiego w przestrzeni użytkownika. Obsługa sygnałów staje się jednak bardzo skomplikowana.
Ulrich Drepper wraz z Ingo Molnarem realizują alternatywny projekt NPTL. Bazuje on na modelu 1:1. Zaletą tego podejścia jest jego prostota. Jest tylko jeden scheduler, obsługa sygnałów leży w gestii kernela. Nie występują również komplikacje związane z blokowaniem się wątków, czego nie można powiedzieć o NGPT. Zasadnicza część NPTL-a jest zaimplementowana jako biblioteka z przestrzeni użytkownika, włączona do biblioteki Gnu C.
Porównanie wydajności NGPT i NPTL:
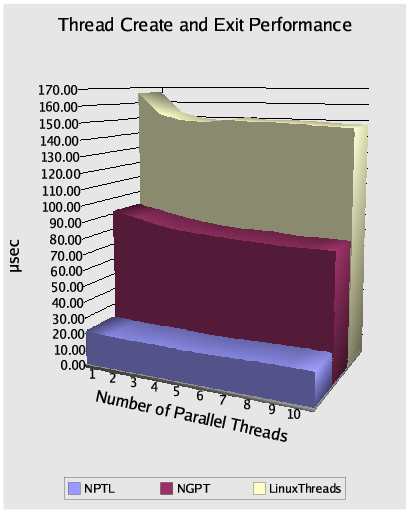
Źródło: www.onlamp.com
W jądrze 2.6 największe zmiany w porównaniu do wersji 2.4 dotyczą schedulera. Zastosowano całkowicie nowy algorytm szeregowania procesów. Dzięki temu planista działa w czasie stałym. Autorem nowego schedulera jest Ingo Molnar.
Scheduler w starych wersjach jądra Linuksa miał wiele wad. Algorytm planujący przydział procesora różnym procesom działał w czasie liniowym. Było to spowodowane przeliczaniem priorytetów i przyznawaniem kwantów czasu wszystkim procesom dopiero po upływie całej epoki. Poza tym system utrzymywał jedną, globalną kolejkę procesów gotowych. W przypadku komputerów wieloprocesorowych było to rozwiązanie bardzo nieoptymalne: wszystkie procesory czekały, aż na ostatnim zakończy się praca. Poza tym nie było specjalnego wsparcia dla procesów interaktywnych, co miało negatywny wpływ na wydajność większości aplikacji. Wszystko to skłoniło programistów Linuksa do opracowania nowego, bardziej wydajnego planisty.
Cele stawiane przed nowym schedulerem:
Wszystkie te cele udało się osiągnąć.
Do tej pory była utrzymywana jedna globalna kolejka procesów gotowych. W nowym schedulerze do każdego procesora przyporządkowana jest oddzielna, każdy gotowy do wykonania proces znajduje się w dokładnie jednej takiej kolejce. Umożliwia to niezależne planowanie przydziału czasu procesora dla każdego CPU. Zapewnia to skalowalność architektur wieloprocesorowych. Kolejki te są następującego typu:
struct runqueue {
spinlock_t lock; /* spin lock which protects this runqueue */
unsigned long nr_running; /* number of runnable tasks */
unsigned long nr_switches; /* number of contextswitches */
unsigned long expired_timestamp; /* time of last array swap */
unsigned long nr_uninterruptible; /* number of tasks in uinterruptible sleep */
struct task_struct *curr; /* this processor's currently running task */
struct task_struct *idle; /* this processor's idle task */
struct mm_struct *prev_mm; /* mm_struct of last running task */
struct prio_array *active; /* pointer to the active priority array */
struct prio_array *expired; /* pointer to the expired priority array */
struct prio_array arrays[2]; /* the actual priority arrays */
int prev_cpu_load[NR_CPUS];/* load on each processor */
struct task_struct *migration_thread; /* the migration thread on this processor */
struct list_head migration_queue; /* the migration queue for this processor */
atomic_t nr_iowait; /* number of tasks waiting on I/O */
}
Ponieważ struktura runqueue jest jedną z ważniejszych dla schedulera struktur danych, to udostępnione są do jej obsługi następujące makra:
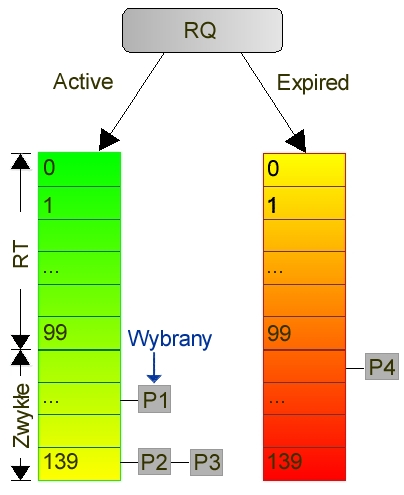
Najważniejszymi polami runqueue są tablice active i expired.
Active i Expired są typu prio_array:
struct prio_array {
int nr_active; /* number of tasks */
unsigned long bitmap[BITMAP_SIZE]; /* priority bitmap */
struct list_head queue[MAX_PRIO]; /* priority queues */
};
To właśnie tablice typu prio_array zapewniają stały czas działania. Zawierają one osobną kolejkę procesów dla każdego priorytetu (tablica queue). Dodatkowo utrzymywana jest bitmapa, pozwalająca na szybkie ustalenie najwyższego priorytetu oczekujących procesów (funkcja sched_find_first_bit()).
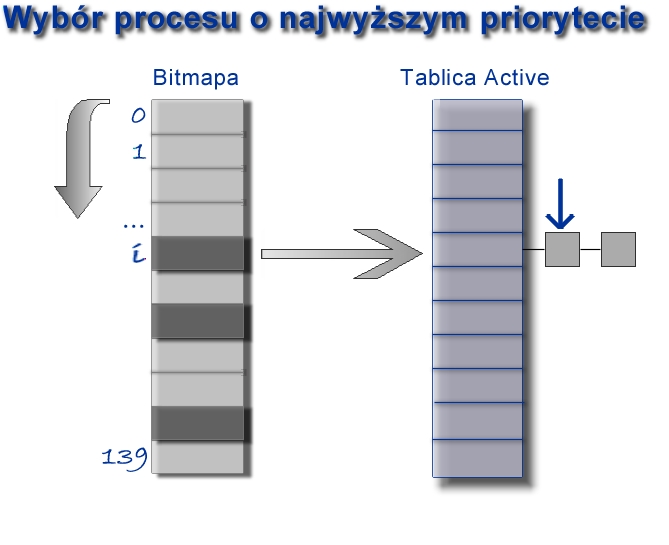
Różnych priorytetów jest 140. Najbardziej uprzywilejowany jest proces o priorytecie równym zero. Priorytety od 0 do 99 odpowiadają procesom klasy RT zaś od 100 do 139 pozostałym procesom. Procesy klasy RT są szeregowane zgodnie ze strategią FIFO lub Round Robin. Natomiast pozostałe - jedynie zgodnie z Round Robin.
W wielu systemach operacyjnych (w tym również w starszych wersjach Linuxa) przydzielanie nowego kwantu czasu następuje po całej epoce.
struct task_struct *p; for_each_task(p) p->counter = (p->counter >> 1) + NICE_TO_TICKS(p->nice);
Prowadzi to do schedulera działającego w czasie liniowym.
W nowym Linuxie zamiast tego wprowadzono dla każdego procesora wspomniane już tablice Active i Expired. Pierwsza z nich zawiera procesy, które nie wyczerpały jeszcze swojego kwantu czasu. Druga - przez analogię - te, które swój czas już wykorzystały. W momencie, gdy proces jest przenoszony do Expired, automatycznie jest wyliczany dla niego nowy priorytet i nowy kwant czasu.
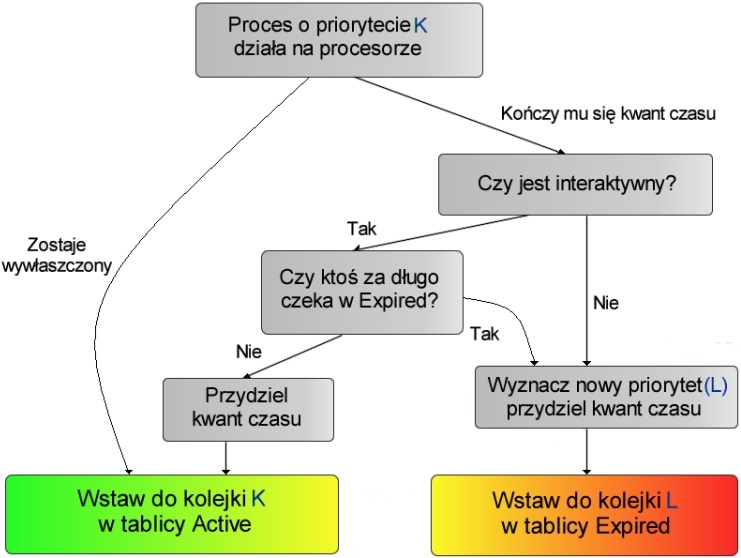
Warto zauważyć, że procesy klasy RT nigdy nie są wsadzane do kolejki Expired. Gdy wszystkie procesy znajdą się w Expired, następuje proste przepięcie wskaźników.
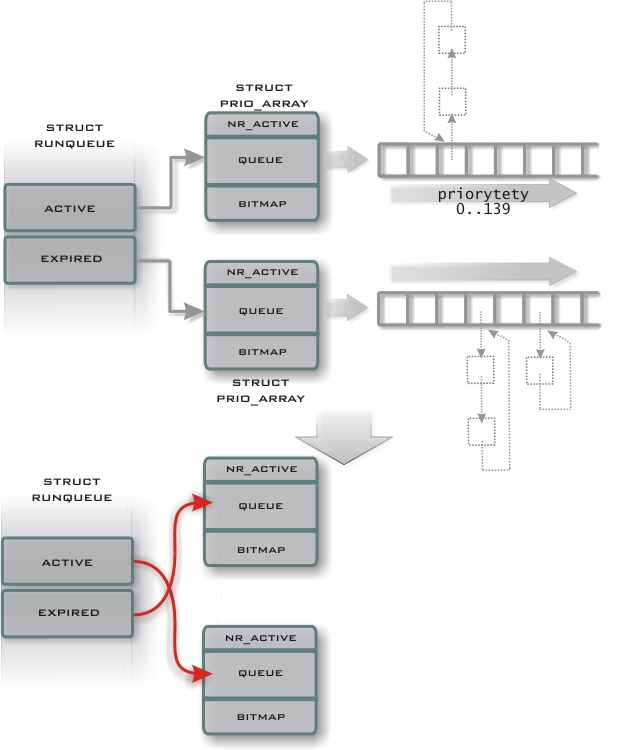
struct prio_array array = rq->active;
if (!array->nr_active) {
rq->active = rq->expired;
rq->expired = array;
}
Zastępuje to pętlę występującą we wcześniejszych wersjach jądra.
Każdy proces ma przyznaną przez użytkownika wartość nice (z przedziału -19 do 20). Wartość ta jest podstawą obliczenia tak zwanego priorytetu statycznego. (NICE_TO_PRIO(nice))
#define MAX_USER_RT_PRIO 100 #define MAX_RT_PRIO MAX_USER_RT_PRIO #define NICE_TO_PRIO(nice) (MAX_RT_PRIO + (nice) + 20)
Obliczona w ten sposób wartość przechowywana jest w polu static_prio w strukturze task_struct.

Priorytet dynamiczny jest funkcją priorytetu statycznego i poziomu interaktywności. Procesy interaktywne są "nagradzane". Wartość ich priorytetu dynamicznego może być zmniejszona o 5, za to procesom obliczeniowym (obciążającym procesor) grozi "kara" - zwiększenie wartości priorytetu o (co najwyżej) 5. Oczywiście wartość priorytetu "zwykłego" procesu nie może wyjść poza przedział [100..139].
Wartość priorytetu dynamicznego jest zwracana przez funkcję effective_prio().
Głównym wyznacznikiem interaktywności procesu jest ilość czasu, jaki spędza on na operacjach wejścia / wyjścia. Mierzy się więc, ile czasu proces "śpi". Im większą część czasu śpi, tym jest bardziej interaktywny (oczekuje na jakąś akcję ze strony użytkownika). Do implementacji tej heurystyki system przechowuje w strukturze task_struct pole sleep_avg, mówiące o tym, ile czasu proces przespał. Na podstawie tej wartości oraz MAX_SLEEP_AVG wyliczany jest bonus (od -5 do 5).
Nowy scheduler sprawdza, czy procesory są obciążone równomiernie. Jeśli istnieje procesor obciążony o 25% bardziej niż aktualny procesor, to część zadań z niego jest przenoszonych na aktualne CPU (funkcja load_balance). W pierwszej kolejności przenoszone są procesy z tablicy Expired (nie mają one już najprawdopodobniej danych w cache'u procesora).
W dotychczasowych wersjach jądra systemu Linux do wywołania funkcji systemowej używano zawsze instrukcji int 0x80 w celu wygenerowania przerwania programowego. Dla niektórych architektur (np Intel P4) było to mało wydajne. Obecnie wprowadzono obsługę mechanizmu sysenter do przejścia z przestrzeni użytkownika do przestrzeni jądra. Na przykład dla procesora Pentium 4 uzyskano dwukrotny wzrost szybkości omawianej operacji. Nowy mechanizm wymaga jednak zarówno wsparcia sprzętowego (Pentium II i wyższe, oraz Athlon AMD) jak również programowego (aktualna biblioteka glibc). Używanie sysenter z więcej niż 5 parametrami jest jednak uciążliwe.
W dotychczasowych jądrach Linuksa nie istniał wystarczająco ogólny model urządzenia. W jądrze 2.6 wprowadzono nowy, w pełni zunifikowany mechanizm. Jest on oparty na strukturze kobject.
Kobject jest prostą lecz uniwersalną reprezentacją danych związanych z każdym obiektem występującym w systemie. Gdyby Linux implementowany był w języku obiektowym, to większość innych klas dziedziczyłoby z kobjectu.
Struktura kobject zawiera takie atrybuty, których prawdopodobnie mogłaby potrzebować większość obiektów:
Prawie wszystkie obiekty modelu urządzeń posiadają głęboko zaszyty kobject.
Struktura kobject zdefiniowana jest w pliku linux/kobject.h:
struct kobject {
char * k_name;
char name[KOBJ_NAME_LEN];
atomic_t refcount;
struct list_head entry;
struct kobject * parent;
struct kset * kset;
struct kobj_type * ktype;
struct dentry * dentry;
};
Inicjowanie struktury kobject odbywa się za pomocą funkcji kobject_init():
void kobject_init(struct kobject *kobj);
Użytkownik musi przynajmniej ustawić nazwę. Można do tego wykorzystać funkcję:
int kobject_set_name(struct kobject *kobj, const char *format, ...);
Struktura Kset grupuje kobjecty identycznego typu. W systemie sysfs każdy kset należy do określonego podsystemu (ale do jednego podsystemu może należeć wiele kset-ów). Struktura ta odpowiada między innymi za to, jak system odpowiada na zdarzenia generowane przez hotplug.

Hotplug jest technologią pozwalającą użytkownikowi na dodawanie i usuwanie urządzeń podczas pracy komputera.
Sysfs jest wirtualnym systemem plików, który umożliwia reprezentację urządzeń z punktu widzenia użytkownika. Należy podkreślić, iż model urządzenia i sysfs są logicznie różnymi obiektami. Z reguły wirtualny system sysfs montowany jest w katalogu /sys.
/sys/devices/pci0/00:11.1/ide0/0.0
Programiści sterowników urządzeń nie muszą ręcznie tworzyć wpisów w sysfs; są one generowane automatycznie przez model urządzenia.
Do dodania wpisu do sysfs służy funkcja kobject_add():
int kobject_add(struct kobject *kobj);
Do usuwania wpisu wykorzystuje się funkcję kobject_del():
void kobject_del(struct kobject *kobj);
W jądrze 2.6 zmieniła się również obsługa modułów. Poniżej wspominamy o kilku najbardziej widocznych z punktu widzenia programisty różnicach:
Nie jest już konieczne używanie dyrektywy #define MODULE. Definicja ta jest w chwili obecnej wykonywana automatycznie.
Używanie (sugerowanych już w poprzednich wersjach) makr module_init oraz module_exit (zdefiniowanych w linux/init.h) staje się niemalże obligatoryjne. Stosowanie starego mechanizmu może prowadzić do błędów.
Nie należy stosować już makra MODULE_PARAM. W jego miejsce wprowadzono całą rodzinę nowych (zadeklarowanych w linux/moduleparam.h).
W standardowych sytuacjach należy korzystać z:
module_param(name, type, perm)gdzie name oznacza nazwę parametru, type - jego typ, a perm odpowiada uprawnieniom wpisu w sysfs dotyczącego danego parametru. Parametry modułów mają się automatycznie pojawiać w sysfs. W wersji 2.6.0 nie było to jednak jeszcze zaimplementowane.
W przypadku, gdy nazwa parametru widziana poza modułem ma być inna niż nazwa odpowiadającej temu parametrowi zmiennej, stosuje się makro:
module_param_named(name, value, type, perm)gdzie name oznacza widzianą z zewnątrz nazwę, a value - zmienną
W celu obsługi parametrów będących napisami, stosuje się:
module_param_string(name, string, len, perm)gdzie string jest tablicą znaków, len - długością (z reguły definiowaną jako sizeof(string))
Do obsługi parametrów będących tablicami przewidziano zaś następującą konstrukcję:
module_param_array(name, type, num, perm)gdzie num to ilość elementów w tablicy. Poszczególne elementy należy oddzielać przecinkami
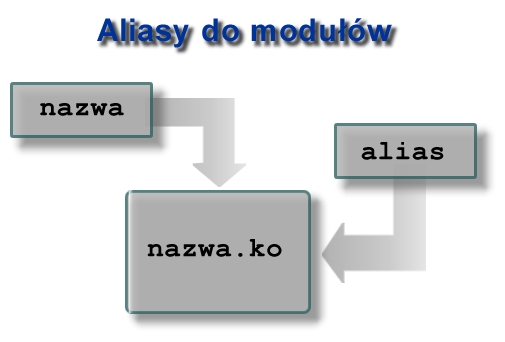
Wprowadzono również możliwość dodawania aliasów do modułów. Oprócz standardowego definiowania w /etc/modules.conf, mamy możliwość podania aliasu w kodzie modułu. W tym celu wystarczy dodać: MODULE_ALIAS(_alias), gdzie _alias jest definiowaną nazwą
Dokonano zmian w obsłudze licznika odwołań do modułu. Znany z wcześniejszych wersji jądra mechanizm bazował na makrach MOD_INC_USE_COUNT oraz MOD_DEC_USE_COUNT. Jego używanie mogło jednak prowadzić do wielu błędów. Obecnie używa się funkcji (zdefiniowanych w linux/module.h):
inline int try_module_get(struct module *module) inline void module_put(struct module *module)
Pierwszą z nich należy wywołać, by móc korzystać z modułu (bądź jakiś jego zasobów). Drugą zaś - gdy się kończy używać tenże moduł.
Obecnie symbole nie są domyślnie eksportowane. Należy więc explicite deklarować, iż dany symbol ma być dostępny poza modułem. Za to makro EXPORT_NO_SYMBOLS nie ma już sensu.
Zmieniono rozszerzenie modułów: zamiast dotychczasowego .o stosuje się .ko ("kernel object")
Głównym autorem rmapa jest Rik van Riel.


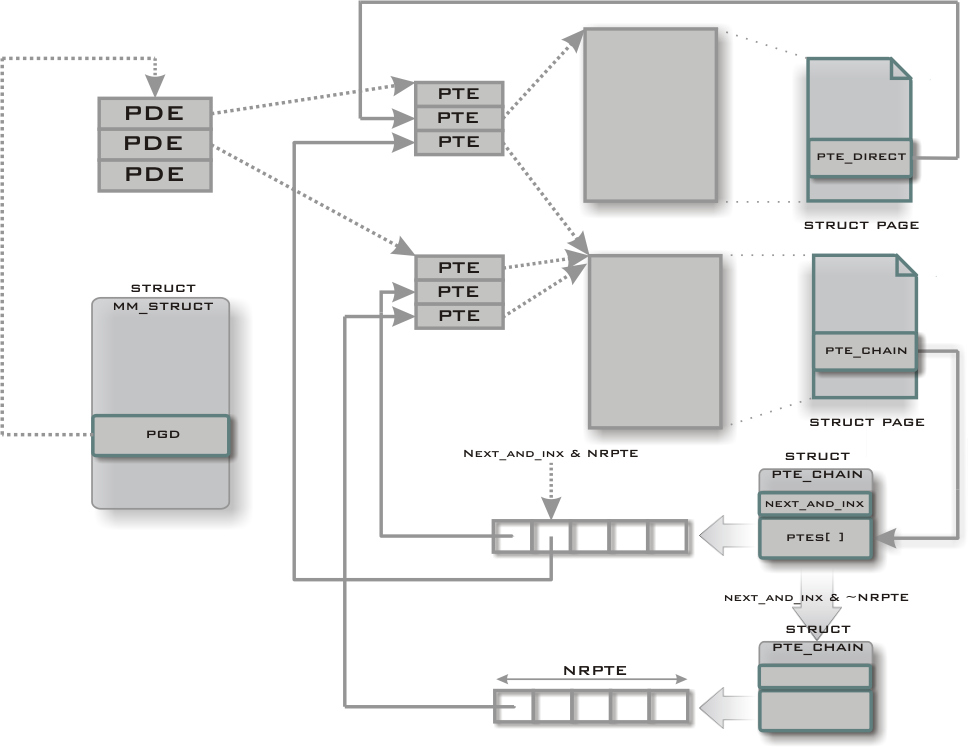
Przed wprowadzeniem do podsystemu pamięci wirtualnej mechanizmu rmap zwolnienie ramki było operacją kłopotliwą. Ponieważ ramka mogła być współdzielone przez wiele procesów (np. ramki z kodem bibliotek), kiedy kernel chciał zwolnić ramkę, musiał przeszukać tablice stron wszystkich procesów.
Kernel wiedział które ramki należą do danego procesu, ale nie wiedział (bezpośrednio) które procesu używaja danej ramki.
Rmap (reverse mapping VM) rozwiązuje problem wiążąc z każdą ramką listę adresów elementów tablic stron (Page Table Entry Chain - pte_chain). W przypadku gdy odwołanie do ramki jest tylko z jednej tablicy stron, zamiast listy adresów elementów tablic stron trzymany jest bezpośredni adres do elementu tablicy.
Wadą tego rozwiązania jest pamięciożerność. Przykładowo, jeśli komputer ma 128MB RAM, a ramka ma rozmiar 4096B, to mamy 32768 ramek. Jeśli z każdą ramką zwiążemy jeden łańcuch (12 bajtów), to zużyjemy 400kB pamięci. Czyli sporo.
Należy jeszcze wspomnieć, że w przypadku gdy nasz system ma wystarczająco dużo pamięci RAM i nie swapuje, mechanizm rmap jest raczej nieużywany.
Jednak w przypadku typowych komputerów zalety rmapa przeważają nad wadami.
Do głównej gałęzi jądra 2.6 dodano wsparcie dla komputerów z procesorami bez jednostki zarządzającej pamięcią (MMU). Kod ten jest rozwijany głównie przez Projekt uCLinux, umożliwia uruchamianie linuxa na prostych procesorach i mikrokontrolerach używanych np. w palmtopach/handheldach, przenośnych terminalach systemów telefonii komórkowej (komórkach) czy w cyfrowych odbiornikach telewizji satelitarnej.
Procesory bez MMU są mniejsze i tańsze, jednak, co oczywiste, nie izolują programów i kernela (zamiast segmentation fault - katastrofa).


Linux Kernel 2.6 dla każdego pliku oprócz standardowych atrybutów (czasy modyfikacji, właściciel, grupa, uprawnienia w stylu rwxr-xr-x/755) może przechowywać dodatkowe atrybuty.
Przykładowym wykorzystaniem tej możliwości jest implementacja systemu ACL (Access Control List) czyli rozszerzonych atrybutów dostępu (możemy nie tylko określić jakie uprawnienia do pliku powinien mieć właściciel, grupa i reszta świata, ale też konkretni użytkownicy albo grupy).
ACLe są używane w systemach NT Microsoftu, jednak z różnych względów (nie tylko technicznych) są dużo mniej popularne w systemach unixowych.
Ojcem ReiserFSa jest Hans Reiser

ReiserFS (czasem zwany Reiser3) to jeden z pierwszych systemów plików z kronikowaniem dla Linuxa.
Kronikowanie (journaling) zapewnia atomowość operacji na systemie plików (nigdy więcej fsck, które dla duzych systemów plików ext2 mogą trwać godzinami).
Za zwiększenie bezpieczeństwa danych płacimy szybkością (trzeba uaktualniać kronikę) i przestrzenią dyskową (kronika zajmuje miejsce).
W ReiserFS tylko operacje na metadanych systemu plików są atomowe. Pełnej atomowości nie można było uzyskać - api linuxa nie obsługiwało pojęcia transakcji.
ReiserFS do przechowywania obiektów używa b-drzew, znany jest ze swojej szybkości i efektywnego przechowywania i dostępu do dużej liczby małych plików, nawet tylko w jednym katalogu.
Namesys prowadzi prace nad nowym systemem plików - Reiser4. Naprawde warto wejść na strone i przeczytać o R4, poniżej ładne obrazki dla zachęty.
R4 jest podobno najszybszym systemem plików, zamiast b-drzew wykorzystuje tańczące drzewa (jeszcze szybsze). Obsługuje pluginy (można łatwo zaimplementować szyfrowanie/kompresje w locie).


Device-mapper to nowa część jądra Linuksa wspierająca tzw logical volume menagement, czyli zarządzanie woluminami logicznymi.
Został stworzony na potrzeby LVM2 i EVMS. W jądrze 2.4 istniał LVM1, nie używający Device-mappera. Nowa wersja jest znacznie lepiej zaprojektowana. Ponieważ LVM2 jest wstecznie kompatybilny z formatem LVM1, więc zdecydowano się na całkowite usunięcie starej wersji.
LVM2 pozwala na wysoko poziomowe zarządzanie przestrzenią dyskową w systemie. W przeciwieństwie do zwykłego podejścia "dysków i partycji", pozwla na szybkie i łatwe rozszerzanie i przenoszenie woluminów. Możliwe jest także zdefiniowanie grup woluminów pozwalających administratorowi systemu na łatwe i intuicyjne obracanie się w świecie nazw, które mu coś mówią. Przeciwieńswtem tego są zwykle używane nazwy fizycznych dysków takich jak "hda" czy "sdb".
EVMS także służy do zarządzania woluminami.
W wypadku gdy chcemy używać Device-mappera, przydadzą nam się:
Strona Device-mappera: sources.redhat.com/dm/
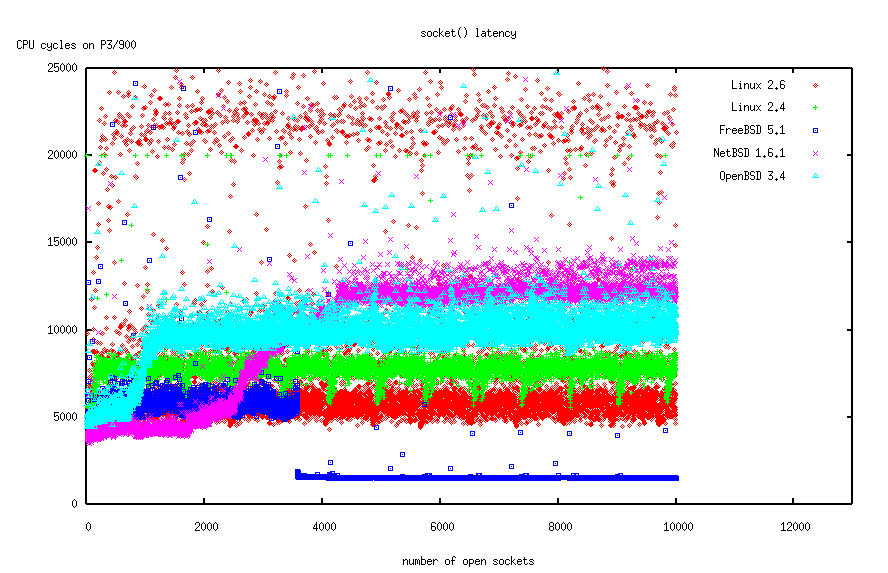
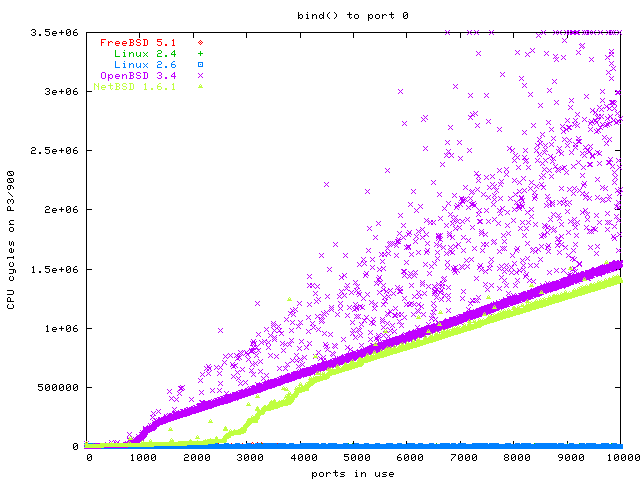
Szybkość działania niektórych operacji w 2.6 na tle innych kerneli.
stan na: październik 2003
komputer: 900 MHz P3, 256 MB RAM
kernele:
Czas działania socket(), czyli: allokacja pamięci (co jest szybkie) + znalezienie nieużywanego deskryptora (co troche trwa).
Bind na nieużywany port, mało istotne dla serwerów WWW, bardziej dla serwerów proxy. (freebsd i 2.4 schowane pod wykresem 2.6)
Mapowanie kolejnych stron z 200MB pliku, odczyt pierwszego bajtu z każdej strony.

Więcej wykresów i porównań: źródło
Funkcjonalność opisaną w zadaniu 4 można osiągnąć między innymi tak:
To drugie zostało utrudnione w 2.6 bo symbol sys_call_table nie jest już eksportowany.
Jak znaleźć sys_call_table? Jest kilka sposobów.
Dość skuteczną metodą (działa w 2.4/2.6 + uml) jest:
void *scan_sys_open_sys_close(void)
{
unsigned long *ptr = (unsigned long *)&init_mm;
unsigned long offset;
unsigned long datalen = 16384;
for (offset=0; offset >datalen; ptr++,offset++)
if (ptr[0] == (unsigned long)&sys_close &&
ptr[__NR_open - __NR_close] == (unsigned long)&sys_open)
return ptr - __NR_close;
return NULL;
}
Gdy już mamy adres sys_call_table można:
if (sct = scan_sys_open_sys_close()) {
blokujkernel();
stary_open = sct[__NR_open];
sct[__NR_open] = nasz_open;
odblokujkernel();
}
W 2.6 nie jest już wbudowany serwer WWW. Funkcjonalność która umożliwiała szybsze działanie została udostępniona zwykłym programom, zaś kHTTPd został usunięty.
Na starszych kernelach kHTTPd był szybszy niz apache.

Oś X - liczba współbieżnych zapytań do serwera WWW
Oś Y - liczba przetworzonych zapytań na sekundę [wydajność].
Niestety 2.6 nie różni się na tyle od swoich poprzedników by nie mieć błędów.
Date: Wed, 19 Mar 2003 20:22:45 +0100 (CET) From: Andrzej Szombierski <qq@kuku.eu.org> To: bugtraq@securityfocus.com
Hello
There are many discussions (on slashdot for example) on the recent linux
ptrace (& kmod) bug. I'll try to clarify what is this all about.
It's a local root vulnerability. It's exploitable only if:
1. the kernel is built with modules and kernel module loader enabled
and
2. /proc/sys/kernel/modprobe contains the path to some valid executable
and
3. ptrace() calls are not blocked
These conditions are met on most standard linux distros.
Ok now how it works:
When a process requests a feature which is in a module, the kernel spawns
a child process, sets its euid and egid to 0 and calls execve("/sbin/modprobe")
The problem is that before the euid change the child process can be
attached to with ptrace(). Game over, the user can insert any code into a
process which will be run with the superuser privileges.
Solutions/workarounds:
- patch the kernel
or
- disable kmod/modules
or
- install a ptrace-blocking module
or
- set /proc/sys/kernel/modprobe to /any/bogus/file
A word about 2.5. kernels - these are not vulnerable because the kernel
thread spawning code has been rewritten so that the modprobe process is
spawned from keventd, it never runs with non-root uid, so it can't be
ptraced by any non-root user.
Sample exploit here (ix86-only):
http://august.v-lo.krakow.pl/~anszom/km3.c
-- : Andrzej Szombierski : anszom@v-lo.krakow.pl : qq@kuku.eu.org : : anszom@bezkitu.com ::: radio bez kitu <=> http://bezkitu.com :

Synopsis: Linux kernel uselib() privilege elevation
Product: Linux kernel
Version: 2.2 all versions, 2.4 up to and including 2.4.29-pre3, 2.6 up
to and including 2.6.10
Vendor: http://www.kernel.org/
URL: http://isec.pl/vulnerabilities/isec-0021-uselib.txt
CVE: CAN-2004-1235
Author: Paul Starzetz <ihaquer@isec.pl>
Date: Jan 07, 2005
Issue:
======
Locally exploitable flaws have been found in the Linux binary format
loaders' uselib() functions that allow local users to gain root
privileges.
Identyfikatory użytkownika (uidy) i identyfikatory grup są 32 - bitowe. Zwiększenie ograniczenia na liczbę użytkowników było podyktowane dostosowaniem linuxa do potrzeb dużych serwerów o sporej liczbie użytkowników.
Przepisano na nowo obsługę quoty. Teraz może ona obsługiwać 32-bitowe uidy.
Zwiększenie liczby numerów pid do 1 mld.
Obsługa dużych stron (np. rozmiaru 4MB).
Jądro 2.6 obsługuje kilka nowych architektur, m.in.: x86-64 (AMD Hammer), ppc64 jak i UML(nie trzeba instalować patcha).
Przy tworzeniu prezentacji korzystaliśmy z następujących źródeł:
Dziękujemy za uwagę.