Na początek dowiemy się jak działa scheduler w systemach opartych na Windows NT. Windows NT to rodzina systemów Windows typu New Technology firmy Microsoft. Wszystkie wersje systemów z rodziny NT (za wikipedia.org):
Podstawową jednostką szeregowania w Windows NT jest wątek. Wątki to częsci procesów. Kilka wątków może działać w jednej przestrzeni adresowej procesu. Programy mogą być jedno-procesowe, a procesy jedno-wątkowe. Wtedy sytuacja jest oczywista. Jednak równie naturalną sytuacją są programy wielo-procesowe, których procesy są wielo-wątkowe. Wtedy z punktu widzenia systemu operacyjnego i synchronizacji sytuacja jest najtrudniejsza. Natomiast scheduler traktuje wszystkie wątki niezależnie. Nie ma znaczenia, czy działają w ramach jednego procesu czy programu. Scheduler rozpatrzy je oddzielnie.
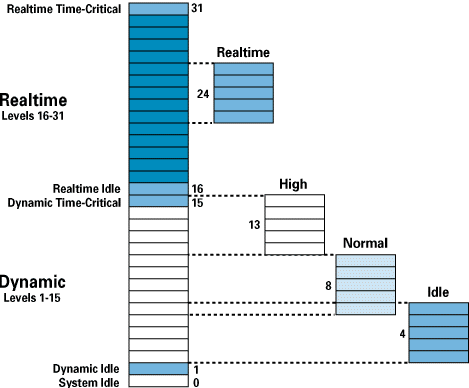
Scheduler Windowsa NT używa priorytetów od 0 do 31. Im większa wartość, tym wyższy priorytet.
Wątek o piorytecie 0 to wątek typu Idle lub Proces Bezczynności.
Wątki o priorytetach od 1 do 15 to wątki typu dynamic.
Wątki o priorytetach od 16 do 31 to wątki typu realtime.
Jeżeli programujemy jakiś wątek i chcemy nadać mu priorytet, nie możemy tego zrobić w sposób bezpośredni - liczbowy.
Interfejs Win32 API udostępnia dwustopniowe, w pewnym sensie opisowe nadawanie priorytetów.
Najpierw ustawiamy tzw. priority class wątku (w nawiasach wartości priorytetu).
Mamy tutaj do wyboru: idle (4), normal (8), high (13) i realtime (24).
Te wartości są modyfikowane przez tzw. relative priority, które są dodawane do priority class (w nawiasach wartości).
Mamy tutaj do wyboru: lowest (-2), below normal (-1), normal (0), above normal (+1) i highest (+2).
Tak wygląda struktura priorytetów:
A tak wyglądają priorytety relatywne:
Interfejs Win32 API dostarcza również 2 modyfikatory specjalne. Są to idle i timecritical.
Timecritical powoduje, że wątek typu dynamic dostaje priorytet 15, a wątek typu realtime dostaje priorytet 31. Są to maksymalne wartości dla tych typów.
Idle powoduje, że wątek typu dynamic dostaje priotytet 1 a wątek typu realtime dostaje priorytet 16. Są to minimalne wartości dla tych typów (0 jest zarezerwowane dla specjalnego wątku który odpowiada za bezczynność).
Scheduler przydziela wątkom kwanty, tak by wątki mogły się wykonywać. Kwanty to czasy jakie przysługują wątkom na pobyt procesorze (o ile się do niego dostaną i nie zostanę wyrzocone przed czasem przez inny proces). Wiadomo, że dlugość kwantu musi być odpowiednio dobrana (przypomnijmy sobie problem udawania wspólbieżności przez system operacyjny oraz problem związany z kosztem zmiany kontekstu przy dużym ruchu wątków w procesorze).
Systemy typu NT Server i NT Workstation mają różne polityki dotyczące długości kwantu.
W NT Server kwanty wszystkich wątków wynoszą 120ms.
W NT Workstation kwanty wątków działających w tle wynoszą 20ms. Natomiast kwanty wątków "aktywnych" wynoszą od 20 do 60ms (patrz rysunek).
Kilka słów na temat tego co będzie robił scheduler w Windowsie NT. Gdy kwant bieżącego wątka zostanie wyczerpany (a wątek się jeszcze nie zakończył), to scheduler wywoła algorytm FindReadyThread na stukturze Dispatcher Ready List (o niej za chwile) i sprawdzi czy nowy wątek ze stuktury ma wyższy priorytet od bieżącego. Jeżeli tak, to podmienia, jeżeli nie, to stary wątek zostaje w procesorze, a nowy wraca spowrotem do kolejki.
Wątki które zawieszają się w oczekiwaniu na zdarzenie, "marnują" kwant, odchodzą do kolejki wątków czekających na I/O i system wywołuje FindReadyThread. Po aktywacji wątka który czekal w kolejce I/O (tzn. po tym jak otrzymał zasoby/akcje) jest on traktowany tak, jakby był nowym wątkiem.
Jeżeli pojawia się nowy wątek, scheduler wywołuje algorytm ReadyThread, który mówi czy wątek ma przejąć do kolejki czy zacząć się wykonywać.
Żeby zobaczyć jak działają algorytmy FindReadyThread i ReadyThread zobaczmy czym jest i jak działa struktura Dispatcher Ready List (rysunek wraz z pokazaniem działania FindReadyThread):
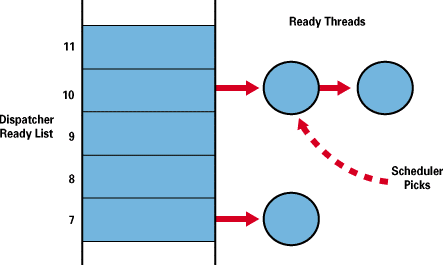
Oto dokładniejszy opis Dispatcher Ready List, FindReadyThread i ReadyThread.
Dispatcher Ready List to struktura o 31 polach odpowiadających
priorytetom wątków. Każde pole jest kolejką GOTOWYCH
wątków o tym priorytecie.
FindReadyThread znajduje pole o najwyższym
priorytecie w Dispatcher Ready List (idzie od góry DRL) w którym jest niepusta kolejka i
wyjmuje z niej pierwszy wątek.
ReadyThread zajmuje się wstawianiem do Dispatcher Ready List.
Algorytm dostaje wątek gotowy do wykonania i sprawdza czy ma on
wyższy priorytet niż bieżący wątek wykonujący się w procesorze. Jeżeli tak, to podmienia
bieżący wątek. Przerwany wątek jest kierowany na DRL. Wpp. bieżący wątek wykonuje się nadal, a
nowy idzie na DRL. ReadyThread umieszcza wątek w kolejce w
odpowiednim polu DRL. Jeżeli wątek wykorzystał już co najmniej
jeden kwant, to idzie na początek kolejki, wpp. na koniec.
Priorytety wątków typu dynamic mogą być modyfikowane przez
system (w przypadku wątków realtime system może używać tylko modyfikatorów typu time-critical i idle opisanych
wcześniej).
Jeżeli następuje zdarzenie na które czekał zablokowany wątek
typu dynamic, to dostaje on bonus do priorytetu.
Jeżeli wątek otrzymał jakikolwiek bonus, to za każdym razem gdy wątek przerobi kwant, jego bonus maleje o 1. Pamiętajmy jednak, że maleje tylko jego bonus (czyli po jakimś czasie bonus będzie wynosił 0). Jego piorytet pierwotny (czyli priority class + relative priority) pozostaje nieruszony.
Bez zewnętrznej kontroli algorytmy FindReadyThread i ReadyThread
mogą zagładzać wątki o niskim priorytecie (ich kolejki nigdy
nie będą nawet dotykane przy FindReadyThread).
NT Balance Set Manager to mechanizm uruchamiany co sekundę.
Uruchamia algorytmScanReadyQueues.
ScanReadyQueues skanuje DRL (od priorytetu 31 w dół). Szuka
wątków które nie miały procesora przez ostatnie 3 sekundy i kiedy
taki znajdzie, daje mu bonus. Jego kwant zostaje
podwojony, a priorytet dostaje nawiększą możliwą wartość dla
wątków typu dynamic (czyli 15, taka jak modyfikator
time-critical). Gdy wątek skonsumuje przedłużony kwant, jego
priorytet i długość kwantu wracają do poprzedniego stanu.
Technologia NT wspiera SMP (symmetric multiprocessing), czyli architekturę opartą na
wielu takich samych procesorach działających rownorzędnie.
Na następnym obrazku widać różnicę między SMP a ASMP (asymmetric
multiprocessing).
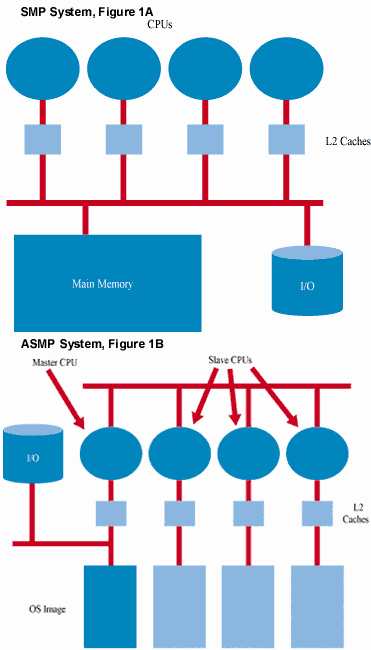
Struktury danych i algorytmy zawarte w systemach operacyjnych z rodziny Windowsów NT mogą obsługiwać nawet 32 procesory. Jednak NT Workstation ogranicza liczbę procesorów do 2, a NT Server do 4 procesorów. Jest to wynik polityki marketingowej - bogatsza wersja wymaga odrębnej licencji OEM (w niektórych opracowaniach znajdują się informację o 8 procesorach).
Kilka podstawowych faktów z działania schedulera:
Strategia realizowana przez scheduler NT dla wielu procesorów nazywa się soft affinity. W tej metodzie wątek pamięta:
FindReadyThread jest uruchamiany na konkretnym procesorze, kiedy jest on przygotowany do przyjęcia wątku. FindReadyThread zakłada blokadę na DRL i skanuje DRL od najwyższego priorytetu w celu znalezienia niepustej kolejki z wątkiem który ma wpis w hard affinity z danym procesorem. Znaleziony wątek jest markowany znacznikiem primary candidate. Jeżeli znaleziony kandydat spełnia jeden z warunków:
Zobaczmy na rysunek:
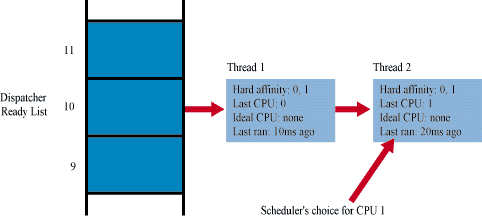
ReadyThread jest uruchamiany z konkretnym wątkiem, kiedy przychodzi jako nowy, lub staje się gotowy. ReadyThread zakłada blokadę na DRL i sprawdza, czy któryś procesor z hard affinity wątka nie jest wolny (tzn czy procesor w tej chwili nie wykonuje jakiegoś innego wątka). Jeżeli taki wolny procesor się znajdzie, to koniec - sprawa jest załatwiona i procesor wykonuje dany wątek. Jeżeli nie ma wolnych procesorów z hard affinity wątka, to scheduler patrzy na ideal processor wątka (lub jeżeli nie ma ideal processor, to patrzy na ostatnio używany procesor). Jeżeli priorytet wątka na tym procesorze jest niższy od naszego wątka, to procesor przestaje wykonywać poprzedni wątek i zaczyna wykonywać nowy (tzn, ten z którym został uruchomiony ReadyThread). Wpp. nasz wątek wędruje do kolejki w odpowiednim miejscu na DRL Na sam koniec ReadyThread zwalnia blokadę na DRL.
Istnieją scenariusze, które pokazują, że strategia nie jest optymalna ze względu na operacje
(np. pokazują, że lepiej jest wymieniać wątek o najniższym priorytecie, nie patrząc gdzie ostatnio wykonywał się proces),
ale w przypadku schedulingu optymalność operacji w pesymistycznych
scenariuszach to tylko jeden z wyznaczników.
Generalnie, strategia soft affinity jest używana z powodu
dobrej współpracy z bazą SQL Server i na tej podstawie bada się
skalowalność (tzn. czy zwiększanie liczby procesorów powoduje
spodziewane zwiększenie wydajności). I tam sprawdza się ona
dobrze.
Ciekawostką jest to, że scheduler powstał najpierw dla wersji wielo-procesorowej, a potem została wyprodukowana wersja obcięta na potrzeby jednego procesora. To może w pewnym stopniu tłumaczyć udziwnienie wersji schedulera również w wersji jedno-procesorowej. Niestety powoduje to wadę, że stacje klienckie, którym wieloprocesorowość i baza SQL Serwer jest daleka, często nie działają tak dobrze, jak byśmy się tego spodziewali.
Informacje n/t schedulera NT wraz z obrazkami pochodzą ze strony: http://www.windowsitpro.com .
Jądro 2.6 wprowadza kilka istotnych zmian do Linuxa. Jedną z nich jest przebudowanie systemu zarządzającego kolejkowaniem - schedulera. Zmiany są duże, a w schedulerze może nawet rewolucyjne, patrząc na politykę jaką scheduler kieruje się w nowej wersji jądra w porównaniu z tą z poprzedniego.
Linux od czasu swego powstania zdominował rynek systemów operacyjnych dla serwerów. Odcisnęło się to na jego architekturze, która jest inna, niż systemy Microsoftu, lub Apple'a. Jednakże ostatnimi czasy, coraz więcej entuzjastów Linuxa twierdzi, że jest to także dobry system dla stacji roboczych (biurowych). Między innymi dlatego powstał scheduler 2.6.x (napisany przez Ingo Molnara) - aby zaspokoić wymogi rynku systemów operacyjnych typu desktop.
Oprócz tego mamy nastepujące założenia projektowe dla schedulera: - ma być wydajny (czas zużyty na jego aktywność jest czasem zmarnowanym z punktu widzenia użytkownika) - ma być interakcyjny - czyli szybko reagować na działania użytkownika - ma być w miare sprawiedliwy i nie dopuszczać do zagłodzeń - ma wspierać technologie SMP (Multiprocesorową - wyjaśnienie w dziale scheduler Windows NT) - ma wspierać procesy soft real-time
Różnie można mierzyć wydajność schedulera - jedni chcieliby, żeby jak najefektywniej zarządzal pracą procesów, inni chcieliby wysokiej interaktywności (która pociąga za sobą dużą liczbę zmian kontekstów) Scheduler 2.6.x pozwala na dostrajanie ręczne (tzw tuning) , czyli można nim zaspokoić rynek HPC (high-performance computing) oraz rynek desktop (aplikacje biurowe - szybki czas reakcji), a także pozostający po środku rynek serwerowy.
Ważny fakt !! Scheduler dziala w czasie O(1) dzieki zastosowaniu nowych struktur danych. Sa to Runqueue oraz Priority Arrays.
Zasada dzialania.
Scheduler posiada dwie tablice priority arrays - active, expired.
Priority arrays służą do trzymania w nich procesów (opriorytetowanych)
i wyciągania z nich procesu o największym priorytecie w czasie O(1)
Idea dzialania schedulera jest taka:
Bierzemy proces o największym priorytecie z tablicy active, dajemy mu procesor,
jak zużyje swój kwant czasu, to obliczamy mu nowy kwant i wrzucamy do tablicy
expired.
Czynność wykonujemy, aż się skonczą procesy z tablicy active - wtedy
zamieniami nazwami tablice expired<->active i zaczynamy od nowa.
Do tego dochodzą triki o których poźniej.
Runqueue jest to struktura danych, ktora dla kazdego procesora trzyma informacje o procesach wykonujacych sie na nim. W szczegolnosci posiada pola:
prio_array_t arrays[2]
prio_array_t *active
prio_array_t *expired
Podmienianie wskaźników działa w czasie O(1). O ile wyciąganie procesu o największym priorytecie działa w czasie O(1) to nasz powyższy algorytm przedstawiający działanie schedulera też działa w czasie O(1).
Priority Arrays
Są to tablice do trzymania i odnajdowania procesu o największym priorytecie.
Zasada działania jest taka:
trzymamy tablicę bitów, gdzie bitów jest tyle ile priorytetów
unsigned long bitmap[BITMAP_SIZE]Teraz potrzebujemy jeszcze tablicy
struct list_head queue[MAX_PRIO]
Prorytety procesów RT są obliczane statycznie - od razu dostają jakiś (stały) priorytet z zakresu 0..99 i z takim priorytetem się wykonują. Przy czym proces RT moze byc szeregowany jedna z dwoch strategii (uzytkownik decyduje) : FIFO - procesy RT o większym priorytecie najpierw (wywłaszczają procesy o mniejszym priorytecie) i dostają procesor aż się wykonają. RR - najpierw bedą się wykonywać procesy z wyższym priorytetem, a jeśli jest kilka o tym samym, to przyznawane im bedą rowne kwanty czasu i bedą cyklicznie dostawać procesor).
Priorytet zwykłych procesów składa się z:
Ad 1) mapuje priorytet procesu od 100-140.
Ad 2) pozwala na maksymalną modyfikację w wysokości 1/4 zasięgu (40) czyli proces może uzyskać albo -5 albo +5 za swoją interakcyjność/nieinterakcyjność.
Oczywiscie procesy te nie mogą wyjechać poza zakres 100..140.
Dynamiczny priorytet jest liczony w momentach kiedy dany proces się budzi, albo na żądanie scheduler_tick(). W każdym razie przelicza się tylko jeśli zmienił się średni czas spania (który to jest głównym elementem heurystyki z pkt. 2) ).
Kwanty czasu
Kwanty czasu liczone są prosto, mapuje się priorytet w wartości z MIN_TIMESLICE..MAX_TIMESLICE
Jeśli dany proces jest uważany za interaktywny (często zasypia czekając na I/O), to o ile nie ma w tablicy expired procesu o większym priorytecie, wstawiamy go spowrotem do tablicy active zamiast do tablicy expired.
Wsparcie SMPScheduler 2.6.x wspiera technologię multiprocessingu, głównie dzięki mechanizmowi load_balancing, który jest niczym innym niż odciążaniem najbardziej zapracowanego procesora przez inne, mniej obciążone procesory. Oczywiście, load_balancing w Linuxie 2.6.x stara się przenosić jak najkorzystniej procesy, czyli żeby miały blisko pamieć z której chcą korzystać i inne zasoby. Odpowiadaja za to tzw. scheduler_domains, o których nie będę pisał, ponieważ są nieciekawe.
TIMESLICE_GRANULARITY
Aby wesprzeć jeszcze bardziej interakcyjność, wprowadzono stałą TIMESLICE_GRANULARITY.
Odpowiada ona za to, że jeśli naraz mamy w tablicy active kilka procesów o tym samym
priorytecie (dynamicznym) to zamiast dać cały kwant do wykorzystania pierwszemu
z listy, potem drugiemu itp, to szeregujemy je algorytmem RR z kwantem równym
TIMESLICE_GRANULARITY (i kładziemy spowrotem do tablicy active).
Na początku pliku kernel/sched.c znajduje się kilka makr (począwszy od MIN_TIMESLICE), które można edytować w celu zmiany działania schedulera Linuxa. Po ich zmianie konieczna jest ponowna kompilacja jądra (nie istnieje przy tym żaden sensowny sposób na ich zmianę w skompilowanym jądrze).
Należy pamiętać, że wprowadzone zmiany mogą mieć bardzo zróżnicowany efekt w zależności od środowiska, w jakim jądro będzie pracować. Najlepiej więc dostrajanie schedulera przeprowadzić metodą prób i błędów, za każdym razem obserwując zachowanie systemu w docelowym środowisku pracy.
MIN_TIMESLICE, MAX_TIMESLICE oraz DEF_TIMESLICE
Makro MIN_TIMESLICE określa najmniejszy kwant czasu, jaki wątek może otrzymać. MAX_TIMESLICE określa maksymalny kwant czasu jaki może przyznać scheduler. Średni kwant czasu jest określony przez uśrednienie wartości MIN_TIMESLICE oraz MAX_TIMESLICE. Zwiększenie wartości dowolnego z tych makr zwiększy średnią długość przedziału czasu przyznawanego procesom.
W najnowszych wersjach jądra nastąpiły zmiany w makrach określających przedziały czasu. Zamiast MAX_TIMESLICE mamy makro DEF_TIMESLICE określające domyślny kwant czasu który wątek może otrzymać. Domyślny maksymalny kwant czasu wzrósł z 200 milisekund do 800 milisekund. Ponieważ wartość HZ może być zmieniana podczas konfiguracji jądra wprowadzono też ograniczenie aby wartość MIN_TIMESLICE była niemniejsza od czasu jednego cyklu zegara.
Większe przedziały czasu oznaczają większą efektywność całego systemu ponieważ przełączanie kontekstu będzie wykonywane rzadzej. Warto jednak zwrócić uwagę na fakt, że procesy intearkcyjne mają wyższy dynamiczny priorytet od procesów wykonujących intensywne obliczenia. Jest więc bardzo prawdopodobne, że wywłaszczą one te drugie i to bez względu na wartość MIN_TIMESLICE i DEF_TIMESLICE. Duże przedziały czasu nie powinny więc znacząco wydłużyć czasu reakcji procesów interakcyjnych. Za to w przypadku dużej ilości procesów te z niskim priorytetem będą musiały czekać dłużej na swoją kolej. Gdyby jednak większość procesów pracowała z tym samym dynamicznym priorytetem czas reakcji byłby jeszcze dłuższy ponieważ żaden proces nie mógłby wywłaszczyć innego.
PRIO_BONUS_RATIO
Makro to określa jaką część (ile procent) możliwych wartości priorytetów proces może zyskać lub stracić przy wyliczaniu priorytetów.
Domyślnie makro to ma wartość 25. Ponieważ mamy 20 dodatnich i ujemnych wartości priorytetów domyślnie proces może dostać bonus (lub karę) maksymalnie o 5 poziomów.
Wartość tego makra określa na ile statyczne wartości nice są brane pod uwagę przy wyliczaniu priorytetów. Zwiększenie tej wartości powoduje, że nawet ustawienie dość dużej wartości nice mogą mieć mniejszy efekt niż podbicie priorytetu przez scheduler dla innego procesu.
Jeśli to makro ma małą wartość wartość nice ma większe znaczenie przy wyliczaniu priorytetów.
MAX_SLEEP_AVG
Im większa wartość tego makra, tym więcej czasu proces musi spełnić zawieszony aby był uznany za proces interakcyjny.
Zwiększenie tej wartości prawdopodobnie spowoduje wydłyżenie czasu reakcji procesów interakcyjnych. Taka sytuacja może być pożądana w systemie z nieinterakcyjnymi procesami ponieważ spowoduje to jednakowe traktowanie wszystkich procesów. Wydajność systemu może przy tym wzrosnąć ponieważ oznacza to rzadsze podbijanie priorytetu a przez to rzadsze wywłaszczanie.
STARVATION_LIMIT
Interakcyjne procesy są wstawiane na początek tablicy uporządkowanej według priorytetów. Może to doprowadzić do zagłodzenia innych procesów. Jeśli pewien proces nie wykonywał się przez czas dłuższy niż STARVATION_LIMIT interakcyjny proces jest wstrzymywany aby ten pierwszy mógł skorzystać z procesora. Zmniejszenie tej wartości powoduje wzrost czasu reakcji procesów interakcyjnych ponieważ częściej muszą one ustępować procesor innym procesom. Jednocześnie podział czasu procesora staje się bardziej sprawiedliwy. Zwiększenie tej wartości skraca czas reakcji procesów interaktywnych kosztem pozostałych procesów.
W porównaniu z jądrem 2.6 algorytm szeregowania zadań jest dość prosty i nie zajmuje wiele miejsca (około trzy razy mniej kodu).
Wady schedulera 2.4
Preferowanie zadań wykonujących głównie operacje wejścia-wyjścia ma szereg wad.
Po pierwsze - nieinterkacyjne wątki wykonujące głównie operacje wejścia-wyjścia mają podwyższony priorytet nawet jeśli nie jest to potrzebne. Przykład: baza danych pobierająca lub zapisująca dużo danych.
Po drugie - wątki które mają charakter interakcyjny i jednocześnie wykonują dużo obliczeń mają długie czasy reakcji. Efekt podbicia priorytetu jest niwelowany przez "karę" nakładaną na procesy intensywanie korzystające z procesora.
Taki charakter ma wiele programów "multimedialnych" i to zachowanie schedulera nie jest dopuszczalne z punktu widzenia współczesnego użytkownika komputera osobistego.
Rozwiązanie powyższych problemów wymaga innego sposobu na określenie interakcyjności wątku. Czas, jaki proces spędza zawieszony nie jest dobrym kryterium.
Jedną z głównych zalet Windows NT (i pochodnych) które mogłem znaleźć był "krótki" czas reakcji na interakcje użytkownika. Niektórzy zaliczają wręcz Windows NT do kategorii hard-realtime. Jak to wygląda w praktyce?
W praktyce opóźnienia są małe jeśli obciążenie systemu jest małe. Wystarczy jednak uruchomić jakiś program wykonujący intensywnie obliczenia (np mathlab lub mencoder) i opóźnienia w reakcji można liczyć w sekundach lub nawet minutach. Z całą pewnością nie można w ten sposób spełnić wymagań systemu czasu rzeczywistego. W takich warunkach jądro Linuxa (nawet baardzo stare:->) pracuje dużo lepiej. Oczywiście takie zachowanie jest spowodowane nie tylko konstrukcją schedulera lecz także (a może przede wszystkim) wadliwą architekturą. Spośród wad schedulera WinNT warto wymienić:
Zbyt mało możliwych wartości priorytetówTeoretycznie mamy możliwe 32 priorytety. Priorytet 0 jest zarezerwowany dla procesu bezczynności. Priorytety 31-16 są zarezerwowane dla procesów czasu rzeczywistego. Priorytety 1-15 są wykorzystywane przez "zwykłe" procesy. W niektórych zastosowaniach to zdecydowanie za mało.
Sposób określania które procesy są interakcyjnePrzyjęty algorytm jest dość podobny to stosowanego w jądrze 2.4. Miarą interaktywności procesu ma być czas przez który proces korzysta z procesora. Takie podejście było wystarczające dawno temu (np. dla edytorów tekstu) ale okazuje się niewystarczające chociażby dla aplikacji multimedialnych - interaktywnych i jednocześnie wykonujących intensywne obliczenia.
Warto też wymienić następujące wady, wynikające nie tylko z zachowania schedulera:
Inwersja priorytetów związana z obsługą GUIInwersja priorytetów to zjawisko występujące kiedy wykonuje się kilka procesów i procesy o różnych priorytetach komunikują się ze sobą. Może się okazać że proces o wysokim priorytecie nie może się wykonywać ponieważ czeka na odpowiedź procesu o niskim priorytecie, który z kolei jest ciągle wywłaszczany przez trzeci (mniej ważny niż pierwszy) proces. W rezultacie będzie się wykonywał głownie trzeci proces, mimo tego że pierwszy ma wyższy priorytet.
Komunikacja aplikacji z interfejsem użytkownika odbywa się za pomocą synchronicznych wywołań systemowych. Powoduje to zawieszenie programu wykonującego wywołanie systemowe do czasu zakończenia wywołania. Nawet jeśli program wykonywany był z wyższym niż domyślny priorytet (być może realtime) i tak będzie musiał czekać na obsłużenie przez interfejs który pracuje z domyślnym priorytetem.
Wadliwy mechanizm obsługi przerwańDuże opóźnienia mogą powstawać na skutek mechanizmu obsługi przerwań. Czas działania procedury obsługi przerwania miał być skrócony do minimum. Miało to zapewnić krótki czas reakcji na przerwania. Handler wykonuje jedynie kolejkowanie DPC (Deferred Procedure Call; wykorzystuje kolejkę prostą!) i kończy działanie. Cała praca związana z obsługą przerwania jest wykonywana właśnie przez te procedury. Wykonanie odbywa się w kontekście jądra przed wszystkimi czekającymi procesami. To podejście ma następujące skutki: