Table of Contents
- Wymagania stawiane systemom plików
- 1. Wstęp
- 2. Ograniczenia
- 3. Struktura fizyczna
- 4. Metadane
- 5. Atrybuty rezydentne i nierezydentne
- 6. LCN i VCN
- 7. Optymalizacja dostępu do zawartości katalogu
- 8. Metody kompresji plików
- 9. Dowiązania (linki)
- 10. Walka z fragmentacją
- 11. Zarządzanie uprawnieniami
- 12. Quota (kontyngenty dyskowe)
- 13. Kroniki
- 1. Sposoby zapisu danych na dysk
- 2. Przyczyny powstawania błędów
- 3. Rodzaje błędów logicznych
- 4. Atomowość operacji
- 5. Kronika
- 6. Rodzaje kronikowania
- 7. Tryby kronikowania
- 8. Czas odtwarzania dzienników przez systemy plików
- 9. Położenie dzienników
- 10. ext3
- 11. Co jeśli dziennik zawiedzie
- 12. Problemy związane z kroniką
- 13. Kronika na przykładzie NTFS
- 14. Inne sposoby na zabezpieczanie danych
- 14. Sposoby dostępu do innych systemów plików
- 15. Szyfrowanie
- 16. WinFS, czyli Windows Future Storage
- Bibliography
Bezpieczeństwo danych
Szybkość działania
Możliwość rozszerzania o dodatkowe funkcje
To są 3 główne cechy, których wymagamy od współczesnych systemów plików, z czego najważniejszą cechą jest oczywiście bezpieczeństwo. Nikt chyba nie chciałby aby jego dane po zapisaniu na dysku mogły ulec uszkodzeniu.
Systemy typu WORN (Write-Once-Read-Never) nigdy nie zdobyły zbyt dużej popularności.
Nie bez znaczenia dla użytkownika jest również szybkość działania systemu plików, gdyż ma ona ogromny wpływ na działanie całego systemu, jako że jak wiadomo na przykład operacje wejścia/wyjścia potrafią stanowić wąskie gardło w pracy systemu.
Coraz częściej jednak przydają się również możliwości rozszerzania systemów plików o funkcje pośrednio tylko związane z przechowywaniem danych, ale udostępniające dodatkowe możliwości czy to kontroli dostępu, wzbogacania danych o kolejne atrybuty, wskazywania związku między plikami, czy też kolejne ułatwienia dla użytkowników. W związku z tym systemy plików stają się coraz bardziej rozbudowane, a część z nich ukierunkowuje się na jedną z wyżej wymienionych cech, lub na określone konkretne zastosowania. Co też na koniec wyraźniej wskażemy, można zauważyć ogólną tendencję ewolucji systemów plików w kierunku systemów baz danych.
W dalszej części postaramy się omówić w jaki sposób dzisiejsze systemy plików realizują stawiane przed nimi zadania.
Na początek omówmy krótko historię podstawowych systemów plików, którymi będziemy się zajmować w trakcie tej prezentacji, a mianowicie Ext3FS i NTFS.
Systemy plików z rodziny ext wywodzą się od systemu plików z systemu operacyjnego Minix, który został zaprojektowany w celach dydaktycznych przez prof. Andrew Tanenbauma. Ze względu na swoje przeznaczenie ten system plików był wolny od większych usterek i porządnie napisany; niestety posiadał dwa podstawowe ograniczenia, które powodowały, że musiał on zostać zmieniony przed wcieleniem go do systemu Linux: maksymalna wielkość woluminu wynosiła 64 MB, a maksymalna długość nazwy pliku: 14 znaków. Zaprojektowano więc najpierw warstwę VFS (Virtual File System), dzięki której łatwo jest podpinać do Linuksa różne systemy plików (wirtualny system plików operuje takimi pojęciami, jak i-węzeł, superblok, plik czy obiekt typu dentry, ale abstrahuje od ich implementacji dyskowej, którą wystarczy wykonać, aby dołączyć nowy system plików do Linuksa). Następnie w kwietniu 1992 udostępniono system plików ext, który usuwał najpoważniejsze ograniczenia Miniksa: maksymalny rozmiar woluminu wynosił 2 GB, a maksymalna długość nazwy pliku - 255 znaków.
System ten także miał pewne mankamenty: nie obsługiwał odrębnych znaczników czasowych dostępu, modyfikacji i-węzła i modyfikacji danych. Ponadto do śledzenia wolnych bloków oraz i-węzłów w systemie plików używał powiązanych list, ale w miarę korzystania z systemu plików listy stawały się nieposortowane, a system plików ulegał fragmentacji, co zmniejszało jego ogólną wydajność.
Te powody doprowadziły do opracowania dwóch nowych systemów plików: XiaFS (który był generalnie oparty na systemie plików Miniksa i oferował tylko kilka ulepszeń - tzn. długie nazwy plików, większe partycje i odrębne czasy modyfikacji, utworzenia i dostępu) oraz Ext2FS (oparty na ExtFS, z wieloma ulepszeniami i możliwościami rozszerzeń). XiaFS był stabilniejszy od Ext2FS (ze względu na minimalistyczną architekturę), ale z czasem w tym drugim wyeliminowano usterki, dodano wiele nowych funkcjonalności i to on stał się podstawowym systemem plików Linuksa na wiele lat. Ext2FS oferuje wiele potężnych narzędzi, które czynią go łatwo zarządzalnym:
mke2fs - inicjuje partycję z pustym systemem plików ext2
tune2fs - zmienia parametry bieżącego systemu plików ext2 (jak reakcję na błąd, maksymalną liczbę montowań czy liczbę bloków zarezerwowanych dla superużytkownika)
e2fsck - tester systemu plików (służy do usuwania niespójności) - bardzo dobre i skuteczne narzędzie
debugfs - pozwala badać wewnętrzne struktury systemu plików
e2defrag - narzędzie do defragmentacji danych
i inne.
Następcą Ext2FS jest Ext3FS (listopad 2001), który oferuje kilka nowych funkcjonalności (dziennik, możliwość powiększania wielkości partycji bez konieczności odmontowywania jej i używanie H-drzew - Hash trees - do przechowywania plików w katalogach). ext2 i ext3 bardzo łatwo konwertować pomiędzy sobą, co wobec kilku wad Ext3FS (brak narzędzi defragmentacyjnych - e2defrag wymaga przekonwertowania ext3 do ext2, zerowanie wskaźników do bloków w i-węzłach usuniętych plików - utrudnia odzyskiwanie danych, brak wsparcia dla przezroczystej kompresji - dostępnej w nieoficjalnej łacie na ext2) powoduje, że ext3 jest obecnie częściej stosowanym systemem plików Linuksa niż np. konkurencyjny ReiserFS (generalnie szybszy, ale mniej stabilny i działający o wiele wolniej w pewnych, złośliwych scenariuszach)
Został przedstawiony w 1995 roku i jest następcą używanych w systemie MS-DOS i we wczesnych wersjach Windowsa systemów FAT (File Allocation Table). Aktualnie wspierane jeszcze w Windowsie systemy FAT to FAT 12 (domyślny format dla 5- i 3.5-calowych dyskietek), FAT 16 (Windows przed 95 OSR2) i FAT 32 (Windows 95 OSR2, 98 i Millenium Edition). System FAT, jak sama nazwa wskazuje, opiera się na tablicy alokacji plików, która jest jego główną i jedyną obok wskazania na boot sector (2 kopie w FAT 32) i katalog superużytkownika (tego drugiego nie ma w FAT 32) metadaną systemu plików. Dla każdego pliku pamiętany jest w niej jego pierwszy klaster (odpowiednik bloku w ext-ach), który wskazuje z kolei na kolejny klaster plików itd., co daje tak zwany łańcuch alokacji pliku. Klastry nienależące do żadnego pliku są oznaczane zerem, a ostatnie klastry pliku -specjalną wartością, równą 0xFFFF w FAT 16 i 0xFFF w FAT 32. Rozmiar tablicy alokacji plików jest rozpoznawany po liczbie w zapisie FAT X (X=12, 16 lub 32) i równy 2X (X to liczba bitów, w jakiej są pamiętane numery klastrów). Rozmiar klastra jest zmienny; w FAT 12 rozmiar klastra to od 512 B do 8 kB, tabela domyślnych rozmiarów dla FAT 16 to:
| Rozmiar woluminu (w MB) | Rozmiar klastra |
|---|---|
| 0-32 (jeżeli mniej niż 16 MB, to Windows używa przy formatowaniu FAT 12 zamiast FAT 16) | 512 B |
| 33-64 | 1 KB |
| 65-128 | 2 KB |
| 129-256 | 4 KB |
| 257-511 | 8 KB |
| 512-1023 | 16 KB |
| 1024-2047 | 32 KB |
| 2048-4095 | 64 KB |
a dla FAT 32 to:
| Rozmiar partycji | Rozmiar klastra |
|---|---|
| 32 MB - 8 GB | 4 KB |
| 8 GB - 16 GB | 8 KB |
| 16 GB - 32 GB | 16 KB |
| 32 GB | 32 KB |
Na podstawie powyższych informacji łatwo liczymy, że maksymalny rozmiar woluminu w FAT 12 to 32 MB, w FAT 16 to 4 GB, a w FAT 32 to 8 TB (ten ostatni teoretycznie, bo obsługuje takie wielkości, ale sam potrafi stworzyć do 32 GB). Wpis katalogowy zajmuje w FAT-ach 32 B (pamięta nazwę w formacie MS-DOS 8.3 - krótką, wielkość, początkowy klaster i czasu ostatniego dostępu i modyfikacji), więc długie nazwy są obsługiwane tandetnie poprzez dodawanie sztucznych wpisów katalogowych, które pamiętają tylko ciąg dalszy nazwy. Kolejnym ograniczeniem jest maksymalna wielkość pliku do 4 GB. Ogólnie systemy FAT są dość stabilne, ale tandetnie napisane i pozbawione wielu istotnych funkcjonalności. Obowiązywały do Windowsa ME.
NTFS jest następcą FAT-a od Windowsów 2000, XP i 2003 Server. Elementem wspólnym jest idea trzymania listy wszystkich plików i folderów w jednym miejscu (NTFS utrzymuje MFT=Master File Table, która jest znacznie lepszą i bardziej wszechstronną wersją File Allocation Table). Przełamuje on wiele ograniczeń wielkościowych systemów FAT (o tym w dalszej części) i oferuje istotnie więcej funkcjonalności, jak: obsługa quoty, zaawansowana kompresja plików (przezroczysta dla użytkownika), szyfrowanie, dziennik (umożliwia odzyskiwanie danych, którego zupełnie brakowało w FAT-ach - tam dla bezpieczeństwa danych przechowywano drugą kopię tablicy alokacji, gdyż utrata tej tablicy jest równoważna z małą szansą na odzyskanie danych) i system dowiązań twardych i symbolicznych.
Aby rozpocząć porównanie NTFS i Ext3FS, przedstawiamy porównanie ograniczeń tych systemów plików:
| System plików | NTFS | ext3 |
|---|---|---|
| Max długość nazwy pliku | 255 znaków | 255 znaków |
| Znaki w nazwie pliku | Unicode (obsługa plików o różnych wielkościach liter w nazwie, ale sam nie tworzy - wsteczna kompatybilność) | Unicode (pełna obsługa plików o różnych wielkościach liter) |
| Wielkość pliku | 16 EB (patrz następne) | 16 GB do 2 TB (zależy od wielkości bloku) |
| Wielkość woluminu (partycji) | 16 EB, ale sterowniki pozwalają na max 256 TB (Windows NT) | 2 TB do 32 TB (jak wyżej) |
| Max liczba plików | 232-1 | Zależy od maksymalnej liczby i-węzłów (podawanej przy instalacji woluminu) |
| Liczba poziomów zagnieżdżenia na ścieżce | Nieograniczona | Nieograniczona |
| Rozmiar bloku/klastra | 512 B-64 KB (w praktyce najczęściej 512 B - 4 KB) | 1 KB-4 KB |
Przypomnienie: 1GB=1024MB, 1TB=1024GB, 1PB=1024TB (petabajt), 1EB=1024PB (exabajt)
Oto tabela domyślnych wielkości klastrów w NTFS (podlegają one modyfikacji przy formatowaniu partycji, w przeciwieństwie do tych z FAT-ów):
| Rozmiar woluminu | Rozmiar klastra |
|---|---|
| 512 MB lub mniej | 512 B |
| 513 MB - 1024 MB | 1 KB |
| 1025 MB - 2048 MB | 2 KB |
| Więcej niż 2048 MB (2 GB) | 4 KB |
Na początek warto wspomnieć, że ext3 został zaprojektowany jako nakładka na ext2 w taki sposób, żeby pozostawić dane zapisywane na dysku niezmienione - co oznacza, że struktura fizyczna tych dwóch systemów plików jest taka sama.
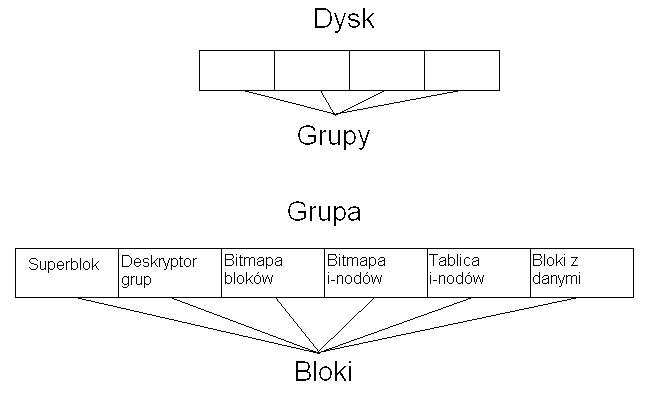
Dysk ext2 jest podzielony na grupy, które składają się z bloków. Bloki mają wielkość od 1KB do 4KB, liczba bloków w grupie zależy od wielkości bloku - bitmapa zajętości bloków w jednej grupie musi zajmować jeden blok - czyli waha sie od 8192 do 16384. W każdej grupie pierwsze kilka bloków (co najmniej 5) jest zajętych przez metadane (dane o danych). W kolejności są to:
Superblok - zawiera informacje fizyczne i o formacie danych - jego kopia znajduje się w pierwszym bloku każdej grupy.
Deskryptor Grup - wawiera informacje o położeniu początków innych części grup, liczbie wolnych i-węzłów i bloków w grupach. Jego kopia także znajduje się w każdej grupie.
Bitmapa zajętości bloków
Bitmapa zajętości i-węzłów
Tablica i-węzłów danej grupy
Bloki danych
Jak widać na metadane przeznaczony jest zawsze taki sam obszar w stosunku do objętości całego dysku, a redundancja danych jest stosunkowo duża - kopia najważniejszych danych znajduje się w każdym bloku - a bloków może być dowolnie dużo.
Dysk NTFS jest zorganizowany zupełnie inaczej - na początek nie istnieje coś takiego, jak jakieś dane w dziwnych miejscach na dysku - wszystko trzymane jest w plikach. Z powodu swoich korzeni - a konkretnie wywodzenia się z systemu plików FAT - wszystkie informacje o plikach są trzymane w tablicy. Wcześniej nazywała się ona File Allocation Table, teraz nazywa się Master File Table (MFT). Co więcej Microsoft chwali się, że MFT już nie jest tablicą, a relacyjną bazą danych - ile w tym prawdy nie da się niestety sprawdzić.
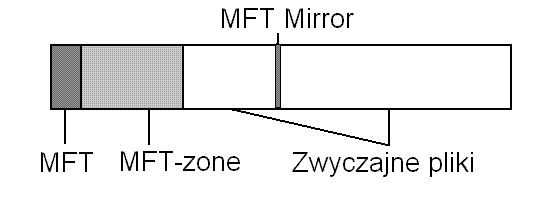
Warto uświadomić sobie jeden fakt - wszystko jest plikiem, co znaczy, że MFT też. Informacje o wszystkich plikach znajdują się w MFT - czyli MFT trzyma też informacje o MFT. MFT znajduje się na początku dysku. Żeby zapobiegać fragmentacji, system plików rezerwuje pewną część dysku - domyślnie 12,5%, ale możliwe jest zwiększenie tego obszaru nawet do 50%. Nie jest tak, że ten obszar jest stracony dla danych - po prostu system będzie go zajmował w ostatniej kolejności. Efekt jest taki, że co prawda nie zapobiega to zupełnie fragmentacji, ale zdecydowanie odwleka ją w czasie.
Kopia zapasowa najważniejszych wpisów w MFT znajduje się w logicznym środku woluminu. Cała reszta dysku jest przeznaczona na pliki - wszystkie inne metadane też są trzymane w plikach, ale już nie mają ustalonego miejsca na dysku. Wszystkie metapliki poza MFT zajmują ok. 16KB, a pojedynczy wpis w MFT zajmuje stałą liczbę klastrów - ustalaną przy formatowaniu dysku (zazwyczaj 1).
MFT - jest pierwszym i najważniejszym metaplikiem. W niej znajdują się informacje o niej samej, oraz o położeniu wszystkich metaplików. Tych metaplików jest 12 i zajmują one pierwsze 12 rekordów MFT, kolejne 4 są zarezerwowane na przyszłość. Rozmiar MFT zależy od liczby plików na woluminie.
MFT Mirror - kopia pierwszych czterech wpisów w MFT, znajdująca się w logicznym środku woluminu.
LogFile - dziennik służący utrzymywaniu spójności danych w razie awarii.
Volume - plik zawierający fizyczne informacje o woluminie oraz różne flagi do określania jego stanu - np. Dirty Flag ustawiany przy montowaniu dysku i czyszczony przy odmontowywaniu - dzięki temu można stwierdzić, czy dysk został odłączony z powodu awarii czy normalnie odmontowany.
Attribute definitions - wszystkie informacje o pliku są zawarte w atrybutach (które nie są niczym innym jak strumieniami danych, czyli ciągami bajtów), a wszystkie informacje o atrybutach są zawarte w tym pliku. Każdy rodzaj atrybutu musi mieć swój wpis tutaj. We wpisie, poza nazwą, trzymane są takie informacje jak np. ograniczenie na wielkość.
Root folder - katalog główny woluminiu.
Bitmap - bitmapa określająca zajętość klastrów na woluminie.
Boot - plik zawierający dane o fizycznych właściwościach woluminu oraz, w wypadku dysków systemowych, kod startujący system operacyjny.
BadClus - plik obsługujący uszkodzone klastry na dysku. Jest to rzadki plik zawierający cały obszar dysku. Uszkodzone klastry są oznaczane jedynkami, a dobre zerami - co jako że plik jest rzadki oznacza, że praktycznie zawiera tylko uszkodzone klastry (o rzadkich plikach więcej informacji można znaleźć w części prezentacji poświęconej kompresji danych). Ponieważ są one zajęte przez ten plik, to żadnemu innemu nie zostaną przydzielone. Pliki systemowe są dostępne tylko dla systemu, więc nikt nie będzie po nim pisał/czytał.
Secure - zawiera tablicę deskryptorów bezpieczeństwa dla wszystkich plików na dysku. Kiedyś każdy plik sam trzymał swój deskryptor, ale było to nieefektywne (więcej o tym pliku w dziale o zarządzaniu uprawnieniami).
Upcase - jako że NTFS tworzy pliki z wyłącznie wielkimi literami w nazwie, powstała szybka metoda konwersji małych znaków na wielkie. Ten plik zawiera tablicę konwersji - tablicę w której na miejscu o konkretnym numerze znajduje się wielka litera, odpowiadająca znakowi o tym numerze.
Extend - Katalog zawierający pliki
$Quota,$ObjId,$Reparsei$UsnJrnl.$Quota- plik z informacjami o quotach wszystkich użytkowników$ObjId- tablica wszystkich Object_ID wszystkich plików na dysku (odpowiednik bitmapy i tablicy i-nodów)$Reparse- informacje o podmontowanych dyskach$UsnJrnl- odczytywalna dla użytkownika wersja dziennika
kolejne 4 numery są nieużywane, ale zarezerowane na przyszłość - do rozwoju systemu.
Metainformacje o plikach w NTFS nazywamy/trzymamy w atrybutach. Ciekawe jest to, że zawartość pliku w NTFS-ie także jest jego atrybutem. Poza zmianą koncepcyjną i trochę prostszą abstrakcją ma to też pewne istotne konsekwencje - konkretnie plik może mieć kilka zawartości. Dokładniej omówimy to później. Wspominamliśmy, że informacje o plikach są trzymane w MFT. Tak istotnie jest, ale z powodu ograniczonego rozmiaru rekordu MFT nie wszystko się tam mieści. Część atrybutów mieszcząca się w MFT nazywana jest rezydentymi, a pozostałe nierezydentnymi. W szczególności, kiedy plik jest mały, jego zawartość będąca przecież atrybutem może się mieścić w MFT. Mamy więc szybki dostęp do małych (800B - 1KB) plików. Niektóre informacje - takie jak np. nazwa pliku, czy prawa dostępu - muszą być rezydentne, inne (jak wspomniana zawartość) nie.
Poniżej znajduje się lista opisów typów atrybutów plików i katalogów w NTFS. Większość z nich została bardziej szczegółowo omówiona w dalszej części prezentacji:
Standard_Information - zawiera takie informacje jak stemple czasowe, czy prawa dostępu - tutaj rozumiane jako rodzaj pliku - archwialny, ukryty itp. Ciekawe jest to, że stemple czasowe są aktualizowane na dysku w odstępach godzinnych, lub przy zamknięciu ostatniej instancji pliku. Służy to zmniejszeniu liczby operacji dyskowych. Ten atrybut jest zawsze rezydentny.
Attribute_List - czasami zdarza się tak, że jeden rekord MFT jest zbyt mały, żeby zmieścić wszystkie atrybuty, które muszą znajdować się w MFT, a także nagłówki atrybutów nierezydentnych. Taka sytuacja może chociażby nastąpić, jeśli do jakiegoś pliku jest bardzo dużo twardych dowiązań - dużo różnych nazw. W takim przypadku plikowi przydzielany jest kolejny rekord w MFT, gdzie są trzymane te nadmiarowe atrybuty, a w Attribute_List są trzymane wskaźniki do tychże atrybutów. Ten atrybut pojawia się rzadko, ale jak już jest, to zawsze znajduje się w MFT (z oczywistych przyczyn).
File_Name - zawiera te informacje, które nazwalibyśmy standardowymi, a nie znajdują się w atrybucie Standard_Information. Te dane to chociażby nazwa pliku - NTFS trzyma dwie różne nazwy - długą do 255 znaków Unicode'a (sam nie tworzy nazw z małymi literami, ale je rozróżnia) i krótką DOSową - do 8 znaków. Poza tym tutaj znajduje się informacja o wielkości pliku i wskaźnik do katalogu macierzystego. Tworząc twarde dowiązanie tak naprawdę tworzymy kolejny atrybut File_Name. Plik zostanie ostatecznie usunięty tylko w wypadku kiedy nie ma już żadnej "nazwy". Dodatkowo przechowuje się w tym atrybucie także flagi, informujące o rodzaju pliku (to samo co w
Standard_Information). Te flagi aktualizujemy tylko w wypadku zmiany nazwy pliku - aktualna kopia zawsze znajduje się w Standard_Information. Ten atrybut także zawsze jest rezydentny.Object_ID - GUID (Globally Unique Identifier) - unikalny identyfikator pliku. To jest odpowiednik numeru i-węzła z Ext2. Poza samym numerem pliku (który teoretycznie może się zmienić w trakcie jego życia) mogą znajdować się tutaj także pierwotny numer pliku (ten przydzielony przy tworzeniu), identyfikator woluminu na którym powstał plik oraz identyfikator domeny/serwera powstania pliku - wszyskto po to, żeby można było jednoznacznie zidentyfikować oraz w razie potrzeby odszukać plik. Stosuje się to np. przy tworzeniu dowiązań - pamiętamy wtedy numer pliku, więc nawet w przypadku zmiany nazwy, czy przeniesienia pliku w inne miejsce możemy go znaleźć.
Security_Descriptor - od NTFS 3.0 wszystkie dane (prawa dostępu do pliku, informacje o właścicielu) zostały przeniesione do pliku
$Securew celu poprawienia wydajności. Wcześniej znajdowały się w tym atrybucie.Volume_Name i Volume_Information - te atrybuty ma tylko plik
$Volume- w nim właśnie są przechowywane wszystkie informacje o woluminie - nazwa, flagi stanu woluminu i numery wersji.Data - zazwyczaj największy atrybut - zawartość pliku. Ciekawe jest to, że plik może mieć kilka atrybutów
Data, a co za tym idzie kilka zawartości. Na pierwszy rzut oka może się to wydawać bez sensu, ale pomyślmy chociażby o plikach graficznych, które w dodatkowym atrybucie trzymają miniaturkę. Główna zawartość pliku jest przechowywana w nienazwanym atrybucieData, a wszystkie inne muszą być jakoś ponazywane. Przy kilku zawartościach pojawia się pytanie o to, co nazywamy wielkością pliku. Projektanci zdecydowali, że rozmiarem pliku będzie wielkość nienazwanego atrybutu. Takie rozwiązanie może spowodować, że mamy na dysku plik, którego główna zawartość (a zatem także oficjalna wielkość) ma rozmiar 1KB, a któraś z nazwanych 1GB. Jeśli wszystkie zawartości pliku są małe (do ok. 1KB), to zawarty jest on w MFT.Index_Root, Index_Allocation, Bitmap - te atrybuty służą do implementacji katalogów. Dopóki katalog jest mały i cały mieści się w rekordzie MFT, to wszystkie informacje o podkatalogach i zawartych w nim plikach znajdują się w
Index_Root, a pozostałe dwa atrybuty nie istnieją. Jeśli jednak katalog jest większy, to istnieją wszystkie trzy i za ich pomocą są zaimplementowane B+-drzewa, na których opiera się struktura katalogów w MFT.Reparse_Point - jest to wyjątkowy atrybut, służący do implementacji dowiązań symbolicznych oraz montowania innych nośników danych. Pomysł polega na tym, że właściwie dowiązania symboliczne jak i punkty montowania są tym samym - odsyłają program w inne miejsce - więc nie widać powodu dla którego należałoby stosować do tego różne rozwiązania. Tak więc
Reparse_Pointjest właśnie dowiązaniem symbolicznym i punktem montowania w jednym. Tworząc taki plik wpisujemy do niego adres tego obiektu, do którego ten plik ma się odwoływać. Teraz wszystkie odwołania do tego pliku są "reparsowane" (przeadresowywane) w taki sposób, żeby odwoływać się pod wpisany adres.EA_Information i EA (Extended Attributes) - FAT trzymał tylko absolutne minimum informacji o pliku - nazwę, prawa dostępu i stemple czasowe. Bardzo szybko okazało się, że to jest za mało - wtedy powstał HPFS (High Performance File System), który rozszerzał FAT-owskie atrybuty właśnie o EA, w którym mogło być trzymane absolutnie cokolwiek, byle miało ograniczoną wielkość (do 64KB). Mogły to być np. informacje o autorze, czy długa nazwa pliku. HPFS był stosowany np. w OS2. Teraz te atrybuty służą zachowaniu kompatybilności z tym systemem.
Logged_Utility_Stream - kolejne 64KB dla programisty, które ten może wykorzystać jak chce. Cechą tego atrybutu jest to, że wszystkie informacje o wszystkich operacjach na nim są zapisywane do dziennika.
Standardowy plik w NTFS posiada atrybuty: Standard_Information, File_Name, Security_Descriptor (co prawda zapisane gdzieś indziej, ale odnoszące się do pliku), Object_ID i Data. Czyli w skrócie przechowuje:
unikalny numer
rodzaj, prawa dostępu i informacje o właścicielu
zawartość
wielkość
stemple czasowe
Dla przypomnienia - i-węzeł zwyczajnego pliku w ext2 przede wszystkim:
I-no - numer i-węzła
Owner Info - identyfikatory własciciela i jego grupy
Mode - rodzaj pliku i uprawnienia dostępu
Direct i Undirect Blocks - wskaźniki na zawartość pliku
Size
Jak widać te informacje są właściwie takie same. Nic dziwnego - jeśli chodzi o metadane trzymane przez systemy plików, to pewnie już dużo zrobić nie można. Wszystkie systemy trzymają właściwie takie same podstawowe informacje, oraz kilka specyficznych dla siebie - zazwyczaj służących do implementacji różnych rozwiązań, specyficznych dla danego systemu - takich jak np. Reparse_Point w NTFS. Informacje te pojawiają się zazwyczaj w stosunkowo niewielu plikach. Zwyczajny plik prawdopodobnie przez dłuższy czas jeszcze będzie wyglądał tak jak dzisiaj, chyba, że nastąpi jakaś rewolucja, na co na razie się nie zanosi. Nawet WinFS prawdopodobnie będzie przechowywał te wszystkie bazowe informacje.
Table 4.1. Porównanie NTFS i ext3
| NTFS | ext3 |
|---|---|
| Około 16 KB (+rozmiar MFT) zarezerowane na metapliki | Stała część dysku zarezerwowana na metapliki (około 2%) |
| Bardzo mała redundacja danych - tylko kopia 4 pierwszych wpisów z MFT | Duża redundancja danych - kopia superbloku i deskryptora grup w każdej grupie |
| MFT zmiennej wielkości | Tablica i-węzłów stałej wielkości - twarde ogranczenie na liczbę plików |
| Klastry wielkości od 512 B do 4 KB (można zmienić do 64 KB) | Bloki od 1 do 4 KB |
| Wielkość metadanych zależy od wykorzystania dysku | Stała wielkość metadanych |
| Rozbudowany i duży kod źródłowy | Prosty i stosunkowo krótki kod źródłowy |
| Skomplikowane i trudne w implementacji struktury danych | Proste i łatwe w implementacji struktury danych |
| Kronikowanie | Kronikowanie |
| Dużo różnych informacji o pliku - wpis w MFT ok. 1 KB | Mało informacji o plikach - i-węzeł zazwyczaj 128 B |
Jak widać tutaj różnice między NTFS-em a ext3 są znaczne. Stanowią one dwa bieguny świata systemów plików. Zdecydowana większość innych systemów plików leży gdzieś po środku - kopiuje pewne rozwiązania z ext, a inne z NTFS. Np. XFS utrzymuje podział na grupy i bloki, ale już tablica i-węzłów jest rozszerzana według potrzeb. Trudno przewidzieć w jakim kierunku będą się rozwijały Linuksowe systemy plików chociażby dlatego, że obecnie nie ma zdecydowanego faworyta - część dystrybucji używa ext3, część ReiserFS. Microsoft idzie w kierunku bardziej bazodanowych systemów - o czym w dalszej częsci referatu (WinFS).
Zazwyczaj uprawnienia dostępu do pliku możemy ustawiać dla trzech rodzajów użytkowników - właściciela, grupy właściciela i reszty świata. ACL umożliwa rozszerzenie tej listy o właściwie cokolwiek - możemy dodawać czy modyfikowć uprawnienia pojedynczych użytkowników, czy dowolnych grup. Cel takich zmian jest jasny - możliwość lepszego zarządzania plikami. Właściwie w każdym nowoczesnym systemie plików można włączyć obsługę ACL-a, więc nie wiem czy można to ciągle nazywać rozszerzaniem.
Można sobie postawić pytanie - dobrze, dziennik zapewnia spójność metadanych - jak jednak sprawdzić, czy same dane na dysku nie zostały uszkodzone w trakcie awarii? Pomysł sam się narzuca - trzymajmy sumę kontrolną każdego pliku. Dzięki temu przy każdym dostępie jesteśmy w stanie sprawdzić, czy plik nie jest uszkodzony, albo w trakcie sprawdzania dysku system sam może znajdować takie pliki. Trzymanie sum kontrolnych może mieć także inne zastosowanie - jeśli użyjemy jakiejś kryptograficznej metody liczenia takiej sumy dla pliku z dołączonym np. hasłem użytkownika, to jesteśmy w stanie sprawdzić, czy do danego pliku nie było nieuprawnionego dostępu. Takie rozszerzenie ma wyraźnie widoczne zalety, więc dlaczego nie jest wszędzie stosowane? Powód jest prosty - sumy kontrolne trzeba przechowywać i sprawdzać. Przechowywanie nie jest problemem: można trzymać w jakimś pliku, który nie będzie za duży. Konieczność sprawdzania sum kontrolnych spowalnia znacznie operacje dyskowe, bo trzeba je liczyć przy każdym dostępie do pliku.
We fragmencie prezentacji tyczącym się MFT zostało wspomniane, że istnieją atrybuty rezydentne i nierezydentne plików. Atrybuty rezydentne są zapamiętywane w domyślnie jednokilobajtowym wpisie w MFT, dzięki czemu dostęp do nich wymaga tylko jednego odczytu dyskowego (jest to bardzo istotną optymalizacją!). Pewne atrybuty muszą być rezydentne (na przykład Standard Information, Filename czy pewna część Index Root dla katalogów). Istnieją jednak pliki, których zawartość nie mieści się w jednym wpisie w MFT, a także katalogi, które zawierają w sobie bardzo dużo plików i podkatalogów - w takich przypadkach potrzebne okazują się atrybuty nierezydentne, czyli niemieszczące się w MFT. W nagłówku każdego atrybutu jest zapisane, czy jest to atrybut rezydentny, czy nie (w przypadku tych pierwszych jest tam także informacja, jaki jest offset między nagłówkiem a wartością atrybutu i jaka jest długość tego atrybutu):
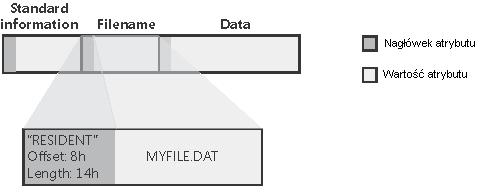
Wartości atrybutów nierezydentnych są przechowywane na dysku, a w MFT znajduje się informacja, gdzie na tym dysku są położone. Kiedy wartość atrybutu staje się większa pod względem rozmiaru, system operacyjny doalokowuje stosowne miejsce na dysku w tak zwanych rzutach (ang. runs) czy jak kto woli ekstentach (ang. extents) - czyli partiach kolejnych klasterów dyskowych (system operacyjny robi to w sposób niewidoczny dla użytkownika). Atrybutami nierezydentnymi mogą być tylko atrybuty o zmiennej wielkości; najczęstsze przykłady to atrybut pliku Data:
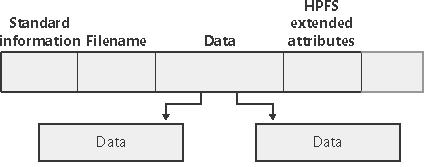
czy atrybuty katalogu Index root+Index allocation+Bitmap (ekstenty w tym drugim przypadku nazywamy buforami indeksowymi):
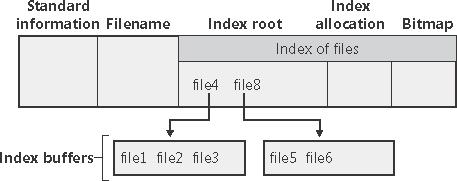
Wreszcie jeżeli w jednym wpisie w MFT nie mieszczą się wszystkie atrybuty danego pliku, to wykorzystywany jest atrybut Attribute list, a niemieszczące się atrybuty są pamiętane w kolejnych wpisach w MFT - Attribute list pamięta trójki: (nazwa atrybutu, kod typu atrybutu, adres rekordu MFT, gdzie się ten atrybut znajduje).
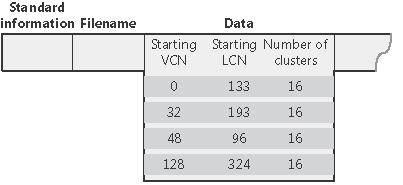
LCN-y (logical cluster numbers) to numery fizycznych klastrów dyskowych. Ich konwersja na adresy fizyczne na dysku jest zatem bardzo prosta (offset dyskowy to iloczyn numeru klastra i wielkości fizycznej klastra).
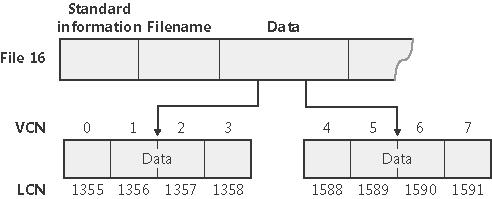
VCN-y (virtual cluster numbers) to z kolei numery przyporządkowywane kolejnym klastrom dyskowym, które są przypisane danemu plikowi - są to numery kolejnych klastrów, w których znajdują się nierezydentne atrybuty danego pliku czy folderu. Oczywiście kolejne numery VCN nie muszą odpowiadać fizycznie kolejnym klastrom (tym niemniej jest tak na pewno w przypadku tego samego ekstentu) - jest to zobrazowane na poniższym rysunku na przykładzie atrybutu Data:
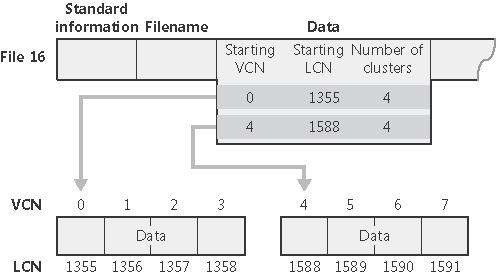
Wreszcie, w ramach nagłówka danego atrybutu nierezydentnego są pamiętane kolejne ekstenty, a dla każdego: numer wirtualny i logiczny pierwszego klastera i liczba klastrów w ekstencie:
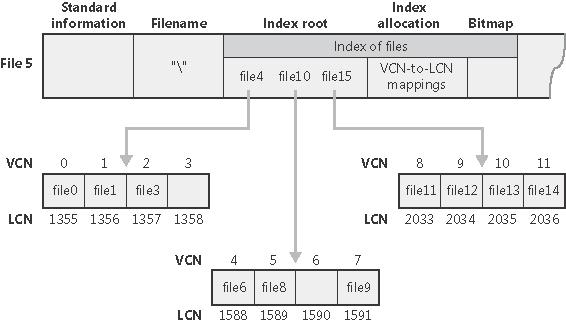
Jak już było wspomniane, atrybuty Index root, Index allocation i Bitmap dla danego katalogu pamiętają pliki i podkatalogi w nim zawarte. Opiszemy je pokrótce (są one istotną optymalizacją):
Index root - Jeżeli jest ich na tyle mało, żeby atrybut ten mógł być rezydentny, to jest pamiętana po prostu ich lista posortowana leksykograficznie po nazwach (pliki pamiętane są za pomocą nazwy, wielkości, stempla czasowego i położenia w tablicy MFT; redundancja stempla czasowego ma cele optymalizacyjne - wyświetlenie stempli czasowych wszystkich plików w katalogu nie wymaga odczytu wszystkich plików z dysku!). Jeżeli atrybut jest nierezydentny, to pliki i podkatalogi są utrzymywane w czterokilobajtowych buforach indeksowych (jak już wspomniane, jest to inna nazwa ekstentów dla tego przypadku). Bufory indeksowe implementują strukturę zwaną B+-drzewem, która stosunkowo minimalizuje liczbę dostępów do dysku, koniecznych do dostępu do danego pliku.
Index allocation - mapowanie między numerami VCN buforów indeksowych a ich numerami LCN.
Bitmap - pamięta, które VCN-y odpowiadają zajętym, a które wolnym buforom indeksowym.
Wykorzystanie B+-drzew, które jak wiadomo z algorytmiki rosną bardziej na szerokość niż na głębokość, pozwala bardzo silnie zoptymalizować wyszukiwanie plików spełniających dane kryteria i wyszukiwanie pliku w katalogu przy posiadaniu jego nazwy nawet w przypadku katalogów z bardzo dużą zawartością. Dlatego też tego typu struktury są używane w NTFS-ie także w innych celach (patrz np. sekcja o pliku
$Secure file), ale także szeroko w innych popularnych Linuksowych systemach plików, takich jak: ReiserFS, XFS czy JFS.
W systemach plików ext bardzo długo do utrzymywania zawartości katalogu wykorzystywano tylko prostych list łączonych. Listy takie bardzo dobrze spisywały się wobec tego, że VFS (Wirtualny system plików) za pomocą struktur dcache (wpisy dentry) bardzo dobrze optymalizuje dostępy do zawartości katalogu. Tym niemniej w przypadku pewnych aplikacji, takich jak cache przeglądarek czy systemy pocztowe korzystające z formatu Maildir, liniowa organizacja listowa powodowała istotne pogorszenie szybkości działania.
Z takich powodów rozważano dołączenie do ext2 struktur danych pokroju B-drzew do reprezentacji zawartości katalogu. Nie zdecydowano się jednak na to, gdyż byłoby to sprzeczne z ideą prostoty kodu przyświecającą temu systemowi plików (implementacja B-drzew w systemie plików XFS jest dłuższa niż cały kod źródłowy ext2 czy ext3!). Poza tym użytkownicy innych systemów plików informowali, że użycie B-drzew powoduje zwiększone szanse na utraty dużych ilości danych, kiedy jeden z wysoko położonych w B-drzewie węzłów ulegnie zniszczeniu.
Dlatego też do systemów plików ext (ext2 w wersjach rozwojowych, a oficjalnie włączone do ext3) wykorzystano inną strukturę danych o nazwie H-drzewa (Hash Trees), która jest specyficznie zoptymalizowana właśnie w kierunku przechowywania katalogów (jest to podejście inne niż w ReiserFS, JFS, XFS czy HFS, gdzie B-drzewa są używane na większą skalę). H-drzewa używają 32-bitowych haszy jako kluczy, a każdy klucz odpowiada przedziałowi nazw przechowywanych w bloku-liściu. Każdy wewnętrzny węzeł takiego drzewa zajmuje tylko 8 bajtów, co powoduje bardzo małe utraty przestrzeni dyskowej (ponad 500 bloków może zostać opisanych przy użyciu czterokilobajtowego bloku indeksowego). H-drzewa mają stałą głębokość (równą jeden lub dwa), w związku z tym nie wymagają używania operacji równoważących i ich implementacja jest o wiele prostsza.
Zadbano także o bardzo dobrą wsteczną kompatybilność struktury danych. Dlatego też bloki-liście są identyczne pod względem struktury z blokami starego typu, a bloki indeksowe są poprzedzone 8-bajtową strukturą, dzięki której stare wersje jądra Linuksa rozpoznają je jako usunięte wpisy katalogowe. Dzięki takiej organizacji łatwo jest także odzyskiwać dane o zawartości katalogu nawet przy zniszczeniu zawartości któregoś węzła wewnętrznego drzewa.
H-drzewa bardzo dobrze spisują się w praktyce, wiele operacji dyskowych na dużych katalogach jest dzięki nim wykonywanych nawet 50-100 razy szybciej.
W Ext2FS występuje teoretyczna możliwość kompresji plików - istnieje kilka wartości, które mogą być przypisane znacznikowi i_flags i-węzła z Ext2 - struktura ext2_inode i które świadczą o jego obsłudze w formie skompresowanej (EXT2_COMPR_FL - kompresowanie pliku, EXT2_COMPRBLK_FL - jeden lub więcej kompresowanych klasterów, EXT2_NOCOMP_FL - nie kompresować, EXT2_ECOMPR_FL - błąd kompresji). Chodzi tu oczywiście o kompresję przezroczystą (niewidoczną) dla użytkownika. W standardowej implementacji Ext2FS nie oferuje jednak możliwości kompresji plików - jest ona dostępna w łatach zawartych w pakiecie e2compr, które są dostępne od 1997 roku. Niestety Ext3FS w ogóle nie oferuje wsparcia dla przezroczystej kompresji plików, więc nawet nie można wykorzystać wyżej wymienionej łatki.
Z kolei - w przeciwieństwie do swoich Windowsowych poprzedników, czyli FAT-ów - NTFS oferuje możliwość kompresji plików za pomocą kilku mechanizmów. Można ustawić żądanie kompresji:
całej zawartości danego woluminu - ustawia się za pomocą funkcji GetVolumeInformation,
danego pliku lub katalogu - ustawia się za pomocą funkcji DeviceIoControl.
UWAGA: Zmiana parametru kompresji danego pliku powoduje natychmiastową zmianę jego stanu, a w przypadku folderów czy woluminów zmiana taka zmienia tylko parametr, jaki będzie przypisywany wszystkim nowym plikom i podkatalogom.
Istnieją dwie główne metody, jakie NTFS stosuje do kompresji plików:
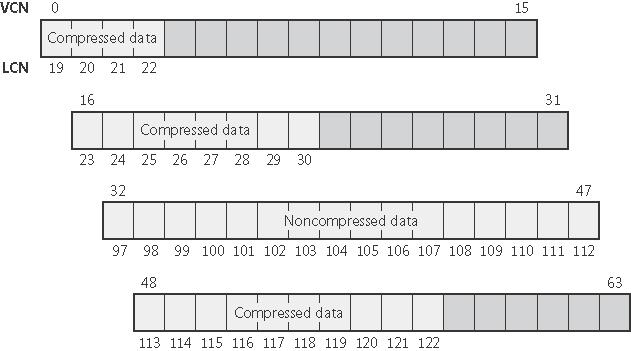
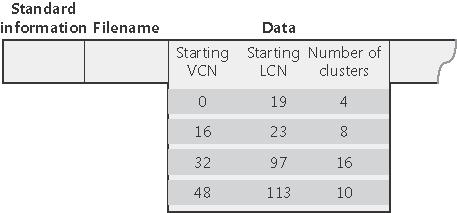
Kompresja rzadkich danych: Rzadkie dane to dane, których znaczną część stanowią zera (dobrym przykładem są rzadkie macierze, które zawierają niewiele niezerowych pól). Kiedy cały dany ekstent wypełniają zera, to NTFS w ogóle nie pamięta zawartości tego ekstentu - patrz rysunek (proszę zwrócić uwagę na brak ekstentów dla VCN-ów 16-31 i 64-127):
W tym przypadku, w MFT nieistniejące ekstenty nie są w ogóle zapisane (o ich istnieniu świadczy tylko nieciągłość w numerach VCN istniejących ekstentów):
Kiedy program próbuje odczytać dane z pliku i w MFT nie ma ekstentu z polami o żądanych numerach, to NTFS zwraca użytkownikowi zera bez jakiegokolwiek odwołania się do dysku, co jest dużym zyskiem czasowym.
Kompresja gęstych danych: Oczywiście istnieją także metody kompresji, które zmniejszają wielkość gęstych danych (z niewielką liczbą zer). Kompresja takich danych polega na tym, że plik kompresowany jest dzielony na jednostki kompresyjne wielkości 16 klastrów. Dla każdej jednostki system sprawdza, czy jej kompresja zmniejszyłaby jej rozmiar o co najmniej jeden klaster; jeżeli tak, to NTFS alokuje odpowiednio mniejszą liczbę klastrów i zapisuje na dysk dane skompresowane, a jeżeli nie, to dane zostają zapisane na dysku w postaci nieskompresowanej. Przykład tak skompresowanego pliku obrazuje rysunek (pierwszy, drugi i czwarty ekstent zostały skompresowane, trzeci nie - niezaciemnione pola obrazują używane klastry):
Dzięki przyjętej zasadzie kompresji tylko przy pewnym zysku, NTFS wie, które fragmenty pliku zostały skompresowane, a które nie - patrzy na liczbę klastrów danego ekstentu i sprawdza, czy jest równa czy mniejsza niż 16:
Na takim pliku wszystkie operacje odczytu i zapisu są wykonywane tylko na całych jednostkach kompresyjnych. W szczególności przy zapisie danych przez użytkownika dane zostają tylko zapisane w pamięci operacyjnej, kompresja i zapis na dysk odbywają się asynchronicznie (leniwie), co pozwala przyspieszyć działanie. Z kolei w celu przyspieszenia odczytu, NTFS stara się alokować kolejne ekstenty w bezpośrednim fizycznym sąsiedztwie, dzięki czemu mechanizm czytania z dysku z wyprzedzeniem (czyli czytania danych tuż za odczytanymi danymi) w połączeniu z asynchroniczną dekompresją może znacznie ten odczyt usprawnić.
Liczba 16 została wybrana jako "trade-off", czyli jako wartość, która jak najlepiej równoważy zysk przynoszony z kompresji danych (czym większa liczba, tym więcej możemy potencjalnie zyskać) i stratę przynoszoną przez konieczność czytania całych jednostek kompresyjnych danych przy każdym błędzie cache miss (czym mniejsza liczba, tym mniej zbędnych danych trzeba wczytać).

Dodatkowo, NTFS udostępnia także specjalny typ rzadkiego pliku. Tego typu pliki są traktowane jak pliku skompresowane metodą kompresji rzadkich danych, ale nie są dokładnie tym samym. Mianowicie dany proces może wskazać pewne fragmenty pliku, które uznaje za puste i wtedy te fragmenty nie są pamiętane, a próba odczytu daje ciąg zer (jak powyżej). Tego typu pliki przydają się w aplikacjach typu klient-serwer, w których istnieje pewien bufor, do którego serwer pisze, a klient z niego czyta. Kiedy klient przeczyta pewien fragment pliku, to nie będzie on już informacji w nim zawartej potrzebował i może ustawić ten fragment jako pusty. Ten mechanizm pozwala uniknąć nieskończonego wzrostu wielkości plików. Inny przykład rzadkiego pliku stanowi bitmapa błędnych klastrów dyskowych, przechowywana jako omówiony już plik metadanych.
Hierarchiczna struktura systemu plików jest bardzo prosta i przejrzysta, ale niekiedy chcielibyśmy posiadać ten sam plik w dwóch różnych miejscach. Zawsze możemy zrobić jego kopię i umieścić ją w docelowym katalogu, ale to zajmowałoby jakże cenne miejsce na dysku.
Dlatego pojawiły się dowiązania. Rozróżniamy dwa rodzaje dowiązań:
Twarde (hard links):
Twarde dowiązania zwiększają liczbę odwołań do pliku, przez co plik zostaje usunięty dopiero po usunięciu ostatniego twardego dowiązania.
Miękkie (soft links)
Miękkie dowiązania nie zwiększają liczby odwołań do pliku, przez co gdy plik zostanie usunięty, dowiązanie staje się błędne.
Dowiązania w Linuksie są bardzo popularne i bardzo często używane. Tworzy się je poleceniem ln, przy czym uruchomienie z opcją -s tworzy link miękki.
Systemy plików ext zawierają informacje o plikach w i-węzłach. Wiele nazw plików może wskazywać na jeden i-węzeł. Każdy i-węzeł zawiera licznik odwołań, czyli liczbę nazw plików, które na niego wskazują. Tak więc stworzenie dowiązania polega po prostu na wpisaniu w pliku w polu i_node wskaźnika do odpowiedniego i-węzła oraz zwiększeniu jego licznika odwołań. Kiedy dowiązanie jest usuwane, licznik odwołań zostaje zmniejszony przez jądro i jeżeli osiągnie on wartość 0, to i-węzeł jest zwalniany. Na tej właśnie zasadzie działają w Linuksie dowiązania twarde.
Twarde dowiązania muszą być używane w ramach jednego systemu plików. Co więcej nie można tworzyć twardych dowiązań do katalogów, aby zapobiec tworzeniu się cykli w drzewie katalogów.
Jeżeli chodzi o dowiązania miękkie, to zawierają one tylko ścieżkę do pliku właściwego. Kiedy jądro napotyka miękkie dowiązanie podczas pobierania i-węzła, to po prostu przechodzi do ścieżki przez niego wskazywanej. Ponieważ miękkie dowiązanie nie wskazuje bezpośrednio na i-węzeł, to jest możliwe tworzenie takich dowiązań do innych (nawet nieistniejących) dysków. Są one bardzo użyteczne, jako że nie mają tylu ograniczeń jak dowiązania twarde, jednak dostęp do nich jest trochę wolniejszy, jako że jądro musi "od początku" odczytać plik wskazywany przez dowiązanie, a także takie dowiązanie jest plikiem, wiec zajmuje i-węzeł na dysku. Jednak i tak są one bardzo popularne i często używane (za ich pomocą można już tworzyć dowiązania do katalogów).
Twarde dowiązania w systemie operacyjnym Windows nie są obsługiwane na katalogach. Aby stworzyć twarde dowiązanie, należy użyć funkcji CreateHardLink lub ln.
Dodatkowo występują także dowiązanie miękkie, czyli tak zwane junctions. "Tłumaczą" one ścieżki w taki sposób, że jeżeli przykładowo katalog c:\temp jest dowiązaniem wskazującym na c:\windows\temp, to program czytający plik c:\temp\a.in naprawdę przeczyta plik c:\windows\temp\a.in. Jest to bardzo użyteczne nie tylko do lepszego układania danych, ale także do stworzenia prostych ścieżek do katalogów, które znajdują się głęboko w hierarchii.
Dowiązania miękkie bazują na mechanizmie reparse points (nie istnieje znane nam dobre polskie tłumaczenie tego terminu, więc pozostaniemy przy oryginale anglojęzycznym). Reparse point to plik lub katalog który posiada atrybut reparse data, w którym jest informacja o lokalizacji oryginalnego pliku. Dodatkowo każdy plik reparse posiada unikalny reparse tag, dzięki czemu jeżeli następuje po raz któryś odwołanie do tego samego pliku reparse, to system nie musi odczytywać informacji z reparse data.
Kiedy NTFS napotyka plik typu reparse to zwraca reparse status code, który informuje system plików, aby ten przegjrzał reparse data. Program odpowiedzialny za dostarczanie danych (czyli system plików lub wejścia/wyjścia) wybiera wówczas jedną z dwóch możliwości:
Podmienienie ścieżki w wywoływanej funkcji
Jest to metoda używana np. przez dowiązania miękkie.
Usunięcie informacji o reparse point i przesłanie pliku pod wskazywany adres.
Jest to używane np. przez HSM (Hierarchical store management), który nieużywane pliki przesuwa na "tańsze" nośniki zamieniając ich oryginalne pozycje na pliki reparse. Jeżeli jakaś aplikacja chce czytać z takiego pliku, to HSM ściąga plik i wstawia go z powrotem na swoje "stare" miejsce.
W systemach Windows bardzo popularne stały się skróty do plików. Jest to bardzo wygodne narzędzie i często stosowane, ale we wcześniejszych wersjach systemu Windows problem pojawiał się, gdy plik, na który skrót wskazywał zostawał przeniesiony. Wtedy Windows starał się go odnaleźć używając rożnego rodzaju heurystyk, które niekoniecznie szybko i skutecznie prowadziły do jego odnalezienia. Podobne problemy pojawiały się przy wykorzystywaniu ideologicznie podobnego mechanizmu OLE (object linking and embedding), który pozwala m.in. na wygodne przenoszenie dokumentów między różnymi aplikacjami pakietu Microsoft Office (Power Point, Word czy Excel).
NTFS zawiera wsparcie do usługi zwanej "distributed link tracking" czyli do usługi śledzenia dowiązań. Usługa ta sprawia, że dowiązania dalej wskazują na poprawne pliki, nawet jeżeli te pliki zostały przesunięte, pod warunkiem jednak, że pozostają w tej samej domenie.
Śledzenie jest w głównej mierze oparte na atrybucie pliku o nazwie Object ID. Dzięki temu system ma możliwość śledzenia zmian umiejscowienia pliku, tak aby dowiązania pozostawały poprawne.
Systemy plików NTFS i ext3 mają różne strategie walki z fragmentacją plików na dysku (czyli zajmowaniem przez pliki wielu wzajemnie niesąsiednich grup bloków czy klasterów). Działanie Ext3FS można porównać do zapobiegania, a NTFS - skutecznego leczenia.
ext3 wykorzystuje dokładnie te same metody, co ext2. System ten stosuje metodę prealokacji bloków, która polega na tym, że na prośbę o powiększenie wielkości pliku stara się mu przydzielić większą liczbę kolejnych bloków (konkretniej 8), niż potrzebuje. Prealokowane bloki są tylko zarezerwowane w bitmapie przydzielonych bloków i przy kolejnej prośbie o powiększenie wielkości pliku mogą zostać wykorzystane - zmniejsza to istotnie fragmentację danych.
Drugą strategią wykorzystywaną przez ext3 jest przydzielanie nowych bloków pliku w pobliżu już istniejących, a przynajmniej w tej samej grupie bloków. Najpierw próbuje więc przydzielać następujący po ostatnim przydzielonym blok danych, w drugiej kolejności szuka wolnego bloku danych w niedużej odległości 64 od najbardziej pożądanego, wreszcie stara się wyszukać w tej samej grupie bloków, a w ostateczności w innej. Nowe bloki są przydzielane, w miarę możności, w tej samej grupie, co odpowiadający im i-węzeł.
Ze względu na bardzo dobrze spisujące się strategie przeciwko fragmentacji danych, kwestię użyteczności defragmentatora w systemach plików ext od dawna uważano za mało istotną. W ext2 istnieje narzędzie defragmentacyjne e2defrag, ale niestety nie daje się go użyć bezpośrednio pod ext3, bez chwilowej konwersji na ext2.
NTFS z kolei nie stosuje tak skutecznych strategii antyfragmentacyjnych. Jedyną używaną w nim strategią jest rezerwowanie specjalnego obszaru na dysku dla MFT (tak zwana MFT zone - strefa MFT), z którego klastry są przydzielane zwykłym plikom tylko wtedy, kiedy nie ma już miejsca w pozostałej części woluminu (zapobiega to fragmentacji newralgicznej struktury danych NTFS).
Ze względu na to, w NTFS istnieją dobre narzędzia defragmentujące. Z jednej strony system plików udostępnia API dla obcych programów defragmentujących:
FSCTL_GET_VOLUME_BITMAP- zwraca mapę wolnych i używanych klastrówFSCTL_GET_RETRIEVAL_POINTERS- zwraca mapę klastrów używanych przez poszczególne plikiFSCTL_MOVE_ FILE- odpowiada za przenoszenie plików.
NTFS dostarcza także własnego narzędzia do defragmentacji (\Windows\System32\Defrag.exe). W Windows 2000 mogło być używane tylko w trybie okienkowym, a w Windowsach XP i 2003 Server może być uruchamiane także w trybie tekstowym, a także o wybranych przez użytkownika porach. Program nie umożliwia takich funkcjonalności, jak wyłączanie z defragmentacji pewnych plików i katalogów czy podawanie na koniec działania szczegółowego raportu - takie możliwości oferuje wiele komercyjnych defragmentatorów.
W Windowsie 2000 defragmentator posiada wiele niedociągnięć: niemożność defragmentacji metadanych NTFS, takich jak MFT czy przenoszenia części plik, które przekraczają 256-kilobajtową granicę w ramach pliku (ze względu na wykorzystanie menedżera cache'u). W Windowsie XP i 2003 Server te ograniczenia zostały przezwyciężone, a jedynym pozostającym jest niemożność defragmentacji plików związanych ze stronicowaniem i plików z logami NTFS-a.
W początkowej wersji NTFS-a, każdy plik i katalog przechowywał swój deskryptor bezpieczeństwa (informację o tym, kto ma do niego jakie prawa) w specjalnym atrybucie. Powodowało to oczywiście bardzo dużą redundancję informacji (często ten sam deskryptor obowiązuje dla danego katalogu wraz ze wszystkimi plikami i katalogami), co w systemach wieloużytkownikowych (np. Windows 2000 Server Terminal Services) powodowało szybkie wyczerpywanie miejsca na dysku.
Dlatego też NTFS od systemu Windows 2000 zawiera specjalny plik metadanych odpowiadających bezpieczeństwu, jakim jest $Secure file. Plik ten zawiera wszystkie deskryptory bezpieczeństwa w systemie (a w związku z tym każdy taki deskryptor jest przechowywany dokładnie raz), poindeksowane na dwa sposoby:
$SDH - hasze z deskryptorów bezpieczeństwa, zorganizowane w B+-drzewo,
$SII - unikalne w systemie numery deskryptorów bezpieczeństwa (przydzielane deskryptorom przy ich tworzeniu).
W osobnym atrybucie tego pliku o nazwie $SDS są zawarte same deskryptory bezpieczeństwa:
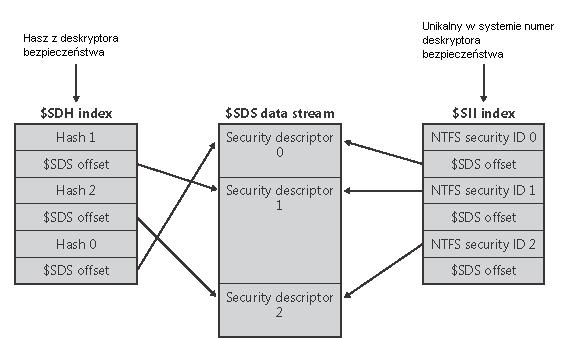
Kiedy nadajemy plikowi czy katalogowi deskryptor bezpieczeństwa, to NTFS sprawdza, czy ten deskryptor już w systemie istnieje, za pomocą mapowania haszy deskryptorów ($SHD) - przejrzenie to następuje po wszystkich polach o tej samej wartości hasza. Jeżeli taki deskryptor istnieje, to znajdzie się on gdzieś na liście, więc będzie można uzyskać jego unikalny numer i zapisać go w szyfrowanym pkiku czy katalogu. Jeżeli ten deskryptor nie istnieje, to zostanie on dodany do pliku $Secure file, a także zostanie mu przydzielony unikalny w systemie numer.
Kiedy z kolei aplikacja próbuje uzyskać dostęp do pliku czy katalogu, to z atrybutu $STANDARD_INFORMATION z MFT jest pobierany unikalny numer jego deskryptora bezpieczeństwa, a następnie w pliku $Secure file za pomocą mapowania numerów deskryptorów w same deskryptory ($SII) uzyskiwany jest ten deskryptor i jest sprawdzane, czy użytkownik ma prawo do wykonania żądanej akcji na tym pliku czy katalogu. Ostatnie 32 użyte deskryptory (a dokładniej ich unikalne numery) są cache'owane przez NTFS, aby nie trzeba było za każdym razem czytać pliku $Secure file.
Inną ciekawą własnością tego pliku jest to, że NTFS nie usuwa z niego nigdy wpisów, nawet jeżeli już żaden plik ani katalog nie odnosi się do nich. Najczęściej nie powoduje to powiększania się pliku $Secure file zbyt mocno, gdyż przeciętnie istnieje stosunkowo niewiele różnych deskryptorów bezpieczeństwa nawet w systemach wieloużytkownikowych.
W ext3 tego typu kwestie nie są brane pod uwagę. Tam prawa dostępu do pliku przechowuje i-węzeł dyskowy w polu i_mode.
Quota jest wygodną funkcjonalnością systemów plików, umożliwiającą limitowanie miejsca dyskowego, z którego użytkownik może korzystać. Jest to szczególnie ważne na wielkich serwerach z tysiącami użytkowników, aby użytkownicy nie mogli całkowicie zapchać dysków.
Ogólnie istnieją dwa rodzaje limitów, które są przyznawane:
Twarde: Twardy limit po ustawieniu nie może nigdy zostać przekroczony. W wypadku, gdy użytkownik lub program przez niego uruchomiony chce zająć więcej miejsca niż limit, system plików na to nie pozwala.
Miękkie: Miękki limit jest często przyznawany z "limitem czasu" (tzw. grace period). Miękki limit może zostać przekroczony przez użytkownika dowolnie wiele razy, ale jeżeli jest przekroczony przez okres czasu dłuższy niż grace period, to część plików zostaje "obcięta" to wielkości limitu miękkiego. Dzięki temu użytkownik ma możliwość tymczasowego przechowywania większych ilości danych.
Na większości serwerów są ustawione limity quoty nie tylko na ilość miejsca zajętego, ale także na np. maksymalną liczbę plików danego użytkownika plików. W większości przypadków oba rodzaje limitów kontyngentów, czyli twarde i miękkie, występują równolegle (czyli każdy użytkownik ma ustawiony jakiś miękki limit i odpowiednio wyższy od niego limit twardy).
W Linuksie quota jest bardzo popularna i prosta w użyciu. Została włączona do jadra Linuksa już od wersji 1.3.8, ale zadomowiła się na dobre w wersji 2.0.
Informacje o limitach dla użytkowników i grup znajdują się jako plik na dysku, na którym owa quota ma być wymuszana. Z reguły jest to plik quota.user lub quota.group w głównym katalogu.
W pliku znajduje się tablica struktur indeksowana po uid lub gid, jedna struktura na dla każdego id użytkownika, niezależnie czy użytkownik ma ustawioną quotę czy nie.
System jest informowany o obecności pliku z limitami przez wywołanie funkcji quotactl. Wtedy wczytuje on limity, najpierw dla użytkowników i grup aktualnie zalogowanych, a później dla pozostałych. Od tej pory każde otwarcie pliku w systemie będzie wiązało się ze sprawdzeniem limitów.
W większości przypadków informacje o limitach danego użytkownika będą przechowywane w pamięci, gdyż często użytkownicy otwierają wiele plików jeden po drugim.
W pamięci informacja o limitach jest trzymana jako hash z uid. jeżeli jeden użytkownik dokonuje wielu operacji dyskowych jedna po drugiej, quota będzie więc sprawdzana bardzo szybko.
Teraz, za każdym razem gdy następuje dostęp do bloku, albo jakiś i-węzeł jest tworzony lub zwalniany, program zarządzający quotą jest o tym informowany i może przerwać operacje. Badania wykazały, że koszt sprawdzania quoty stanowi bardzo mały procent czasu zapisywania nowego bloku na dysk.
W systemie Windows długo nie było wsparcia dla quoty, pojawiło się dopiero wraz NTFS-em.
Quota w systemie NTFS pozwala na ustawienie limitu dla każdego użytkownika z osobna, można również ustawić opcję logowania każdego zdarzenia które przekracza limit. Jeżeli program użytkownika przekracza limit dyskowy, to próba alokacji nowego kawałka dysku kończ y się błędem "disk full".
Ustawienie limitów w Windowsie jest bardzo proste, co pokazuje poniższy obrazek:
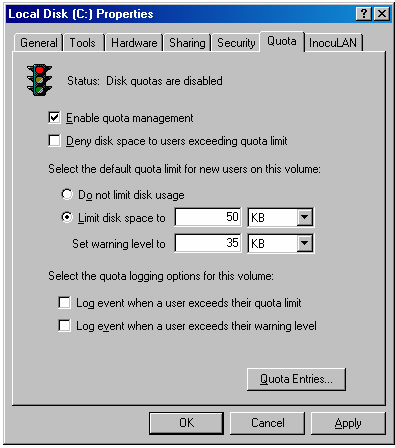
Jak widać można ustawić "warning level", co odpowiada limitowi miękkiemu, oraz "limit disk space", co odpowiada limitowi twardemu. Dodatkowo po kliknięciu w Quota Entries możemy ustawić inne limity aktualnym użytkownikom.
NTFS przechowuje informacje o limitach w pliku \$Extend\$Quota, który zawiera tabele $O i $Q. NFTS przydziela każdemu użytkownikowi unikalny numer UserID. Kiedy administrator ustawia limit dla użytkownika, NTFS przypisuje jego Security ID (SID) numer użytkownika User ID oraz w tabeli $Q zamieszcza informacje o limitach dla danego użytkownika. Informacja w tabeli $Q zawiera nie tylko wartość limitu, ale także ilość aktualnie zajętego miejsca.
Przy liczeniu sumarycznego miejsca zajmowanego przez użytkownika, rozmiar pliku jest liczony na podstawie jego nominalnej wielkości a niekoniecznie ilości faktycznego miejsca zajętego na dysku. Chodzi tu zwłaszcza o rzadkie pliki czy sytuacje, gdy jest włączona kompresja dysku. Wtedy nawet jeżeli plik o rozmiarze 50 KB po skompresowaniu zajmuje na dysku tylko 10 KB, to cała jego wielkość (czyli 50 KB) zostanie uznana jako używana przez użytkownika.
Poniżej znajduje się obrazek ilustrujący wygląd tabel $O i $Q:
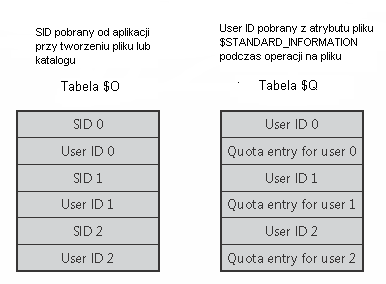
Kiedy aplikacja tworzy plik, NTFS bierze Security ID danej aplikacji i wyszukuje odpowiadający jej numer User ID w tabeli $O. Później sprawdza w tablicy $Q czy stworzenie danego pliku nie przekroczy limitów. Jeżeli przekracza, to NTFS odmawia stworzenia pliku i rejestruje ten fakt w logach systemowych. W przeciwnym przypadku NTFS uaktualnia dane o ilości zajętego przez danego użytkownika miejsca.
W tym rozdziale chcemy przybliżyć wszelkie aspekty związane z kronikami, funkcjami jakie sprawują, oraz ich wpływem na nowoczesne systemy plików.
System plików, otrzymując żądania wykonania operacji, może szeregować poszczególne ich elementy w różny sposób:
ostrożnie
leniwie
Pierwszy z nich - ostrożny - polega na tym, że system w każdym momencie dba by dane znajdowały się w możliwie spójnej formie. To znaczy nie próbuje bronić się przed występowaniem niespójności, natomiast stara się tak uszeregować żądania zapisu, aby nawet w najgorszym wypadku niespójności te były możliwie przewidywalne, oraz by nie były krytyczne, tak aby system mógł je naprawić w dogodnym momencie, a nie było konieczne dogłębne sprawdzanie systemu podczas uruchomienia. Na przykład podczas alokacji miejsca dla plików najpierw ustawiane są odpowiednie bity w bitmapie, a potem przydzielane jest miejsce na plik. W ten sposób jeśli awaria nastąpi po pierwszej operacji, to system najwyżej straci dostęp do pewnych bloków, ale istniejące już dane nie będą uszkodzone. Implikuje to także, że wszystkie operacje są wykonywane kolejno, gdyż przeplatanie operacji może prowadzić do powstawania niespójności.
Ostrożne zapisywanie poświęca szybkość operacji dla względnego bezpieczeństwa, a drugie podejście jest zupełnie inne. Zapisywanie leniwe zapisuje w cache'u operacje, a następnie wykonuje je w zoptymalizowanej kolejności. Daje to wzrost wydajności z dwóch powodów: po pierwsze może zoptymalizować kolejność żądań, tak aby zminimalizować niepotrzebne ruchy głowicy dysku, po drugie może zaoszczędzić wiele operacji, gdyż dane zapisane w buforach mogą się zmienić wielokrotnie zanim zostaną odesłane na dysk. Czas obsługi aplikacji jest też generalnie krótszy, gdyż możemy zwrócić sterowanie do programu, zanim jeszcze operacja zostanie zakończona. Jednak ma on bardzo poważną wadę, gdyż jeśli nastąpi awaria systemu zanim wszystkie operacje zostaną zakończone, to system może znajdować się w niespójnym stanie. Z tego powodu większość administratorów korzystających np. z systemu plików ext2, z namaszczeniem kilkakrotnie wpisywało komendę sync przed przeładowaniem systemu, traktując ją jak zaklęcie mające ustrzec ich przed błędami powstającymi na dysku.
Głównym zadaniem systemów plików jest przechowywanie danych, jak więc się dzieje, że niekiedy dane te znikają, lub nie są dokładnie takie, jak je zapisywaliśmy? Po co w ogóle rozpatrujemy bezpieczeństwo systemu plików? Odpowiedź na to pytanie jest prosta - ponieważ większość danych zapisujemy na dyskach, które mają pewne ograniczenia, gdyby natomiast istniała tania, szybka, trwała (nieulotna), niezawodna i bardzo pojemna pamięć operacyjna, to dyski twarde nie byłyby już wówczas potrzebne. Nie zapewniłoby to pełnego bezpieczeństwa systemu plików, ale mogłoby usunąć jedną z najczęstszych przyczyn powstawania błędów. Przyczyny powstawania błędów można podzielić na dwie zasadnicze grupy:
fizyczne
wynikające z konstrukcji dysku, bad blocks
wynikające z działania czynników zewnętrznych
Powody tych błędów mogą być różne, poczynając od fizycznych awarii napędów, polegających czy to na wadliwym działaniu samego dysku twardego (wad materiałów, z których został wykonany, zużycia powłoki odpowiedzialnej za przechowywanie danych), czy też zniszczeń fizycznych spowodowanych przez czynniki zewnętrzne (woda, ogień, walec drogowy,...). Jednak na tego typu awarie systemy plików nie są w stanie wiele poradzić; mogą one wspierać różne metody robienia kopii bezpieczeństwa, jednak jako że przyczyna powstania problemów jest fizyczna, fizyczne rozwiązania sprawdzają się najlepiej. I mamy tutaj wszelkiego rodzaju macierze dysków twardych RAID (poza typem 0 - który wręcz obniża bezpieczeństwo) oraz replikowanie plików na zewnętrznych nośnikach.
logiczne
wynikające z błędnego działania systemu
wynikające z błędów w implementacji systemu plików
wynikające z przerwania operacji w systemie plików
Logiczne przyczyny prowadzą też głównie do błędów logicznych, które postaramy się scharakteryzować w następnej sekcji. Choć dwie pierwsze przyczyny są rzadkie, to mogą prowadzić do różnych nieprzewidywalnych błędów, natomiast dzisiejsze systemy plików starają się głównie bronić przed ostatnią z tych przyczyn, która występuje najczęściej i z tego powodu jest najbardziej dokuczliwa i nierzadko przyczynia się do utraty danych. Przerwania operacji na systemie plików są w gruncie rzeczy z reguły przejawem pewnych czynników fizycznych, jakimi są awarie zasilania. Błędy mogą wówczas nastąpić czy to z powodu nie zapisania ostatnio wprowadzonych zmian, czy też dlatego, że zapisanie tych zmian nie odbyło się jeszcze do końca na dysku.
Wśród logicznych błędów na dysku, czy też mówiąc inaczej - niespójności metadanych systemu plików z właściwą zawartością dysku, możemy wyróżnić kilka najpopularniejszych:
skrzyżowane pliki - sytuacja ta występuje wówczas, gdy dwie (lub więcej) struktury opisujące pliki twierdzą, że dany klaster (blok) należą do danego pliku
zagubione klastry (bloki) - mamy z nimi do czynienia wówczas, gdy pomimo, że w odpowiednich bitmapach dane miejsce jest uznane za zajęte, to żadna struktura opisująca plik nie odwołuje się do tego miejsca.
nieprawidłowe wartości liczników odwołań - występujące gdy wartość licznika jest różna od rzeczywistej liczby odwołań do danego pliku; wartość ta może być zarówno zbyt duża, jak i zbyt mała, co może powodować później dalsze błędy logiczne
pliki do których nie ma dostępu - występują gdy na dysku znajdują się w pełni poprawne struktury opisujące pliki, jednak ponieważ w żadnym katalogu nie znajdują się wpisy odnoszące się do tych plików, to nie mamy do nich dostępu
błędne rozmiary plików - sytuacja ma miejsce, gdy rozmiar pliku przechowywany w strukturach jest niezgodny z wielkością danych należących do pliku. Może to skutkować w "obcięciu" zawartości plików lub pozostawieniu bezsensownych bajtów na końcu pliku, co w przypadku wielu formatów może utrudnić lub wręcz uniemożliwić ich odczyt
wszelkie inne niespójności metadanych - są to wszelkie inne błędy, z których część może zależeć od konkretnego systemu plików i reprezentacji metadanych przez niego przyjętych - mogą to być wszelkiego rodzaju błędne atrybuty, błędne czasy dostępu, etc.
Wydawać by się mogło z punktu widzenia użytkownika, że wszystkie operacje na dysku pokroju usunięcia pliku powinny być atomowe, jednak w rzeczywistości tak nie jest, jesteśmy w stanie co najwyżej zapewnić atomowość operacji zapisu pojedynczego bloku na dysk. Zatem wiele operacji, które są podstawowymi operacjami dla użytkownika, najczęściej składa się z wielu operacji na systemie plików i jego strukturach.
Można się zastanawiać dlaczego atomowość operacji ma znaczenie. Przyjrzyjmy się dla przykładu operacji usuwania pliku w systemie UNIX - składa się ona co najmniej z dwóch kroków: najpierw następuje usunięcie wpisu w katalogu, następnie i-węzeł pliku ustawiany jest jako wolny. Wydaje się to całkiem naturalnie, jednak co się stanie, jeśli pierwszy krok zdąży się wykonać przed awarią systemu, a drugi już nie zdąży - będziemy mieli do czynienia z osieroconym i-węzłem, a w związku z tym wyciek pamięci, który może wykryć żmudne i czasochłonne przeglądanie całego dysku. Z drugiej strony ,jeśli druga operacja zdąży się wykonać, a pierwsza nie, wówczas może się zdarzyć, że ten i-węzeł zostanie przydzielony do innego pliku, a wpis w katalogu zostanie.
Jak widać z powyższego przykładu ważne jest aby połączenie obu tych operacji było atomowe - wykonały się albo obie pomyślnie, albo też żadna z nich nie odniosła skutku, gdyż w ten sposób system plików z pewnością będzie w stanie spójnym.
Aby zapewnić atomowość operacji, część systemów plików zapożyczyło metodę utrzymywania atomowości operacji (które od tego momentu będziemy nazywać transakcjami) z systemów baz danych. Wykorzystują one do tego celu dziennik zwany też częściej w przypadku systemów plików kroniką. Kronika jest miejscem, gdzie system plików zapisuje przyszłe zmiany w stosunku do systemu plików, rejestrując je zanim jeszcze operacje powodujące te zmiany zostaną faktycznie wykonane. Kronika przydatna jest szczególnie podczas awarii komputera, gdyż poprzez analizę operacji zapisanych w kronice system operacyjny może starać się przywrócić właściwy stan poprzez odtworzenie lub wycofanie przerwanych operacji. Pomaga to w spełnieniu jednego z podstawowych obowiązków systemu operacyjnego, jakim jest zapewnienie, że system plików znajduje się w spójnym stanie, przed udostępnieniem go użytkownikowi.
Głównym celem kroniki jest zachowanie abstrakcji atomowości operacji na systemie plików, co pozwala zachować jego spójność.
Kronika ma niezaprzeczalne zalety, jakimi są:
większe bezpieczeństwo - jest to główna zaleta systemów z kroniką, która jest - przypomnijmy - jednocześnie najważniejszym z wymagań stawianych systemom plików.
krótszy czas przeładowania systemu - jeśli system nie został zamknięty poprawnie, wówczas czas potrzebny na sprawdzenie poprawności dysku może być znaczący szczególnie przy rozmiarach dysków spotykanych w dzisiejszych czasach. Na największych serwerach proces ten mógłby dosłownie zająć kilkanaście godzin, co mogłoby być przyczyną dalszego przestoju systemu po awarii. Istnienie kroniki pozwala zaś na szybkie odtworzenie wszystkich operacji, które nie zdążyły się odbyć do końca przed momentem awarii.
często zaawansowane algorytmy i struktury danych używane do obsługi plików - nie jest to co prawda bezpośrednia zaleta stosowania kroniki, jednak nowoczesne systemy plików używające kroniki korzystają najczęściej z dorobku naukowego algorytmiki w celu przyspieszenia wielu operacji.
Jednak kroniki mają też pewne wady, do których możemy zaliczyć m.in.:
wydłużony czas wykonywania niektórych operacji - dalej będziemy opisywać różne sposoby zmniejszenia nakładu potrzebnego na prowadzenie kroniki, jednak ogólnie rzecz ujmując wiąże się to z tym, że część danych musimy zapisać podwójnie - raz w dzienniku, a drugi raz utrwalając je w systemie plików. Nie zawsze jest to jednak prawdą i przy pewnych konfiguracjach oraz zastosowaniach systemy plików z kroniką mogą okazać się wydajniejsze.
większe skomplikowanie systemu plików - co może być powodem błędów w implementacji, jednak w przypadku dobrze przetestowanych systemów plików z kroniką ryzyko z tym związane jest zaniedbywalnie małe i praktycznie takie samo, jak w wypadku systemów plików bez kroniki.
niezgodność z dotychczasowymi systemami plików - jak się później okaże, nie jest to zawsze prawdą, jednak w większości przypadków zmiana systemu plików na system plików z kroniką oznacza pracochłonne archiwizowanie wszystkich danych zawartych w danym systemie plików, zmianę systemu, a następnie ich odtworzenie, co w złośliwych przypadkach może prowadzić do uszkodzenia lub utraty części danych.
Jak już to zostało wspomniane, dzisiejsze systemy plików stosują technikę rejestrowania zapożyczoną z systemów baz danych. Istnieją dwie podstawowe metody rejestrowania transakcyjnego:
rejestrowanie odtwarzające (redo logging) - polega na rejestrowaniu zmian danych w dzienniku przed ich faktycznym utrwaleniem na dysku. W przypadku awarii systemu, po zatwierdzeniu transakcji w dzienniku, ale przed utrwaleniem związanych z nią zmian w systemie plików, zmiany utrwala się przez ich odtworzenie (ponowne wykonanie) po przywróceniu systemu na podstawie zawartości dziennika transakcji. Żadna z transakcji, które nie zostały zatwierdzone, nie może spowodować trwałych zmian w systemie plików.
rejestrowanie odwołujące (undo logging) - polega na równoległym zapisywaniu transakcji w dzienniku i utrwalaniu związanych z nim zmian w systemie plików. Jeżeli system ulegnie awarii przed zatwierdzeniem transakcji, dziennik musi zawierać informacje niezbędne do wycofania już utrwalonych zmian, związanych z niezatwierdzonymi transakcjami. Tak więc w przypadku korzystania z rejestrowania odwołującego wpisy dziennika muszą zawierać zarówno zapis stanu danych czy metadanych przed wprowadzeniem zmian, jak również zapis samych zmian.
Większość systemów plików z kroniką korzysta z rejestrowania odtwarzającego, jak to ma miejsce m.in. w przypadku systemu ext3, natomiast NTFS częściowo łączy w sobie obie techniki.
Poprzedni podział dotyczył trybów kronikowania, możemy też wyróżnić podział ze względu rodzaj danych podlegających kronikowaniu:
kronikowanie metadanych (write-back)
kronikowanie wszelkich operacji (także danych) (journalling)
zapisywanie do dziennika pełnych bloków (klastrów)
zapisywanie tylko zmian w danych
tryb "uporządkowany" (ordered)
Możemy wymagać od systemu plików, by w dzienniku zapisywał zmiany dokonywane tylko w odniesieniu do metadanych, jak również wszelkie zmiany dotyczące zarówno danych i metadanych. Rejestrowanie wszystkich zmian jest w sposób oczywisty bezpieczniejsze, ale za to dużo wolniejsze niż rejestrowanie wyłącznie zmian metadanych systemu plików. Powolność ta jest rezultatem konieczności wykonywania dla każdej zatwierdzonej transakcji dwóch zbiorów operacji zapisu - pierwszy zbiór zapisywany jest do dziennika, drugi faktycznie utrwala zatwierdzone zmiany w systemie plików. Trzeci tryb rejestrowania daje możliwość pełnego wykorzystania bezpieczeństwa systemu plików z kroniką rejestrującego pełen zestaw danych, nie obarczony spadkiem wydajności operacji. Osiągnięto to dzięki wymuszeniu zapisu na dysk wszelkich danych związanych z transakcją jeszcze przed aktualizacją odpowiednich metadanych systemu plików. Sposób ten gwarantuje uaktualnianie danych przed zapisem na dysk rejestru zmian metadanych, dotyczących zatwierdzonej transakcji, dzięki czemu dane przechowywane w plikach są po ich odtworzeniu na podstawie dziennika zawsze spójne z metadanymi systemu plików.
Aby w pełni zobaczyć różnicę między zapisywaniem tylko operacji dotyczących metadanych a zapisywaniem wszystkich zmian, rozważmy przykład dopisywania danych na końcu pliku. W systemie Linux mogłoby to wyglądać w sposób następujący:
zwiększ rozmiar i-węzła,
zaalokuj miejsce na dodatkowe dane,
zapisz dodatkowe dane do pliku.
Jeśli zapisywaliśmy tylko metadane, nigdy nie będziemy mieli pewności po awarii, czy przed awarią został wykonany krok 3, gdyż informacja na jego temat nie znajdzie się w dzienniku, w związku z tym plik ten może zyskać niepoprawne dane na końcu.
| metadane | dane i metadane | tryb "ordered" | |
|---|---|---|---|
| NTFS | x | ||
| ext3 | x | x | x |
| ReserFS | x | x | x |
| Reiser4 | x | ||
| JFS | x | ||
| XFS | x | ||
| WinFS | x |
Jak widać różne systemy plików obsługują różne tryby kronikowania. Część z nich udostępnia też dodatkowe właściwe dla siebie mechanizmy, pozwalające usprawnić lub lepiej zabezpieczyć operacje na kronice. I tak np. Reiser4 wykorzystuję wędrujące logi (wandering logs), aby zapewnić atomowość operacji, nie będąc zmuszonym do dwukrotnego zapisu tych samych danych stosuje się zmianę położenia danych i dziennika (edrujące logi są opisane dokładniej w dalszej części prezentacji).
Może się zdarzyć, że systemy plików znajdują się w stanie niespójnym, gdyż kroniki nie chronią nas explicite przed powstawaniem niespójności, lecz pozwalają je naprawić. W tym celu przydatne może okazać się odtwarzanie dzienników. Można się zatem zastanawiać kiedy systemy plików wykonują analizę zapisu kroniki, w przypadku nieprawidłowego zamknięcia systemu plików (nie jest ustawiony bit poprawnego odmontowania). Systemy plików odtwarzają dane zapisane w dzienniku:
podczas montowania systemu plików
podczas sprawdzania spójności systemu plików (wg [Hagen])
Większość systemów (w tym NTFS, ext3, XFS, ReiserFS, Reiser4) wykonuje tę operacje automatycznie podczas montowania, tak aby nie udostępniać użytkownikom potencjalnie niespójnego systemu plików, jednak w przypadku systemu plików JFS, zawartość kroniki odtwarzana jest dopiero podczas sprawdzania programem fsck.xfs (fsck = file system consistency check).
Kolejnym aspektem związanym z dziennikami jest ich położenie na dysku. Systemy plików z kroniką mogą się w sposób znaczący różnić umiejscowieniem pliku z kroniką w systemie. Można wyróżnić co najmniej trzy metody przechowywania ich na dysku:
jako jeden z plików w systemie (np. ext3) - jest to najprostsze rozwiązanie, gdyż nie wymaga ono implementacji żadnych specjalnych operacji i zachowuje zgodność z systemami bez kroniki. Rozwiązanie to ma jednak również wady, gdyż operacje na kronice nie są specjalnie optymalizowane, jednocześnie podobnie jak wszystkie pozostałe pliki na dysku kronika jest wówczas podatna na awarie systemu plików, które mogą spowodować niemożność jej odczytu.
w specjalnym wydzielonym obszarze (np. XFS) - kolejną metodą jest umieszczenie kroniki w specjalnie do tego celu wydzielonym obszarze partycji. Rozwiązanie to pozwala zoptymalizować dostęp do kroniki, jak również pozwala zapewnić jej większe bezpieczeństwo poprzez odseparowanie jej od systemu plików.
Obie te metody w przypadku niektórych systemów plików pozwalają umieścić dziennik na innym urządzeniu, co może mieć pozytywny wpływ na wydajność operacji, które mogą być wykonywane jednocześnie, jednak może też narazić system na awarię jeśli awarii ulegnie dysk, na którym przechowywana jest kronika.
Z kolei system JFS - choć nie jest to jeszcze zaimplementowane w Linuksie - pozwala na współdzielenie jednej kroniki przez kilka systemów plików.
w dowolnym miejscu systemu plików (np. Reiser4) - w systemie Reiser4 została zastosowana technika wynaleziona przez Dave Hitz'a - WAFL (Write Anywhere File Layout filesystem). System ten nie nadpisuje bloków na dysku, zamiast tego zapisuje dane w innym miejscu, następnie wskaźniki do tych bloków (zawarte w pewnych blokach pośrednich) znów są zmieniane w ten sam sposób, a operacja jest kontynuowana aż pojedyńczy zapis bloku na dysk kończy z sukcesem transakcję. Takie podejście zapewnia całkowitą atomowość wszystkich operacji na systemie nie powodując jednocześnie narzutu związanego z zapisywaniem wszystkich zmian dwa razy - najpierw w dzienniki, a później utrwalania zmian w systemie plików.
Za dość istotne uznaliśmy również opisanie systemu ext3 i sposobu, w jaki rozszerza on istniejący system ext2, a także konsekwencji z tym związanych. W skrócie zależność między tymi systemami można przedstawić w postaci równania:
Wspomniane już zostały też pozostałe różnice, jakimi są np. H-drzewa, jednak sposób ich zaimplementowania zapewniał wsteczną zgodność z systemem ext2. Najważniejszą jednak różnicą, która spowodowała powstanie nowego systemu plików jest wzbogacenie systemu ext2 o funkcje dziennika. Autorzy systemu ext3 przed jego powstaniem stanęli przed dylematem, czy tworzyć od początku nowy system plików, czy oprzeć się już na jakimś istniejącym, dobrze przetestowanym systemie, jakim bez wątpienia jest system ext2. Pierwszym co zrobiono przy tworzeniu systemu ext3, było skopiowanie kodu źródłowego ext2 i zmiana wszystkich wystąpień ext2 na ext3. Następnie zostało zaprojektowane urządzenie kronikujące (journaling blok device), które odpowiada za prowadzenie dziennika i może być również wykorzystane przez inne komponenty systemu operacyjnego, które chciałyby udostępniać funkcję kroniki. Aby zachować zgodność, kronika jest po prostu jednym z plików w systemie. Ten sposób implementacji sprawia, że system ten jest praktycznie w 100% zgodny z ext2. Ma to daleko idące konsekwencję - gdyż m.in. możemy używać do niego narzędzi zaprojektowanych dla systemu ext2, jak dump i restore, a sam program fsck.ext3 jest również dowiązaniem symbolicznym do e2fsck. Proces konwersji między systemami jest również całkowicie odwracalny, gdyż z jednej strony poprawnie odmontowany system ext3 może być bez najmniejszych problemów zamontowany jako system ext2, jednocześnie konwersja z systemu ext2 do ext3 sprowadza się do wykonania jednego polecenia tune2fs, tworzącego dziennik. Ma to bardzo ważne konsekwencje, gdyż na świecie znajduje się jeszcze wiele serwerów czy komputerów domowych korzystających z systemu ext2 - możemy zatem bardzo łatwo wzbogacić te systemy o funkcję kroniki, a co za tym idzie zwiększyć poziom bezpieczeństwa zapisanych na nich danych, bez potrzeby długotrwałej i dodatkowo narażającej na błędy operacji migracji do całkowicie innego systemu plików. Możliwość łatwej konwersji pozwala także na wykorzystanie w systemie plików ext3 pewnych narzędzi, których w przeciwieństwie do ext2 nie posiada - jak na przykład narzędzia do defragmentacji e2defrag.
Zdarzyć się oczywiście mogą przypadki, kiedy dziennik zawiedzie i czy to poprzez niespójności dziennika, czy niemożności przeprowadzenia zapisanych w nim operacji system znajduje się w stanie niespójnym. Niektóre przykłady kiedy do takiej sytuacji może dojść można znaleźć w pracy [FailureAnalysis], gdzie autorzy skupiają się na niedociągnięciach implementacji kronikowania w różnych Linuksowych systemach plików (w tym wypadku ext3, ReiserFS orax JFS). Jako przykład można przytoczyć sytuację odnoszącą się do systemu ext3, który w wypadku niepowodzenia zapisu fragmentu transakcji, kontynuuje jej zapis i może ją zatwierdzić, zanim błędy w zapisie zostaną skorygowane, co może prowadzić do rozspójnienia systemu. Akcje jakie mogą być podjęte przeż użytkownika (administratora) systemu, aby przywrócić system do spójnego stanu wobec awarii dziennika to:
kontrola spójności systemu - na taką okoliczność większość systemów plików z kroniką udostępnia programy służące do kontroli poprawności metadanych, które w żmudny sposób sprawdzają poprawność metadanych zapisanych na dysku,
nic - wiarę w systemy plików z kroniką powala zachować przeświadczenie programistów systemu XFS, którzy są święcie przekonani, że taka sytuacja zajść nie może, a zarazem podziw dla ich poczucia humoru, gdyż mimo wszystko dla zgodności z semantyką programu fsck dostarczyli odpowiednią wersje tego programu dla ich systemu plików:
fsck.xfs. Poniżej znajduje się strona podręcznika użytkownika, odnosząca się do tego programu:
fsck.xfs(8) fsck.xfs(8)
NAME
fsck.xfs - do nothing, successfully
SYNOPSIS
fsck.xfs [ ...]
DESCRIPTION
fsck.xfs is called by the generic Linux fsck(8) program at startup to check and repair an XFS filesystem.
XFS is a journaling filesystem and performs recovery at mount(8) time if necessary, so fsck.xfs simply
exits with a zero exit status.
If you wish to check check the consistency of an XFS filesystem, or repair a damaged or corrupt XFS
filesystem, see xfs_check(8) and xfs_repair(8).
FILES
/etc/fstab.
SEE ALSO
fsck(8), fstab(5), xfs(5), xfs_check(8), xfs_repair(8).
fsck.xfs(8)
(END)Zauważmy, że wprowadzenie kronikowania do systemu plików, poza problemami natury wydajnościowej niesie ze sobą dodatkowe problemy koncepcyjne, związane z semantyką operacji wykonywanych na plikach.
Istnieją teraz pewne operacje, które należy wykonywać ze szczególną dozą ostrożności tak, aby nie doprowadziły one do rozspójnienia systemu. Rozważmy następujące przykłady:
usuwanie pliku otwartego przez pewien proces - gdy licznik dowiązań do danego pliku spadnie do zera jest on usuwany, jednak jeśli jest on nadal otwarty przez jakiś proces, samo usunięcie jest odkładane do czasu, kiedy zostanie on zamknięty. W przypadku systemu plików z kroniką sytuacja ta jest bardziej skomplikowana, gdyż muszą one gwarantować, że przywrócenie spójności będzie wymagać co najwyżej odtworzenia dziennika. Aby poradzić sobie z tą sytuacją system plików musi już na początku zapisać do dziennika rekord informący o operacji usuwania tego pliku, lecz samą operację może wykonać dopiero (tak jak zwykły system) po zamknięciu tego pliku i dopiero wtedy będzie mógł zatwierdzić tę transakcję.
przeplot operacji usuwania pliku i tworzenia nowego - przykład znów dotyczy usuwania pliku, jednak innego jej aspektu, jak już wcześniej uzasadnialiśmy operacja usuwania pliku składa się z kilku podoperacji, z czego jedną z nich może być (w przypadku systemu Linux) ustawienie w odpowiedniej bitmapie, że dany i-węzeł jest wolny. W przypadku systemów plików z kroniką, które operują transakcjami, muszą one dodatkowo zadbać, żeby żadne inne operacje na tym i-węźle nie mogły zostać zatwierdzone, zanim nie zostanie zatwierdzona transakcja usuwania. Łatwo sobie wyobrazić, co się może stać, gdy zostanie rozpoczęta transakcja usuwania, oraz w cache'u zostanie zmodyfikowana bitmapa i-węzłów, następnie dochodzi do rozpoczęcia i zatwierdzenia transakcji tworzącej nowy plik (pechowo korzystająca z tego samego i-węzła), po czym następuje awaria systemu przed zatwierdzeniem pierwszej transakcji. Podczas przywracania dziennika przy starcie systemu nowoutworzony plik zostanie usunięty poprzez ponowienie niezatwierdzonej transakcji.
Drugi z tych przykładów tak na prawdę symbolizuje szersze wymagania odnośnie poleceń ponawiania i wycofania, zapisanych w dzienniku systemu plików. Mianowicie muszą one mieć taką postać, aby gwarantowały, że ponowienie wykonanych (ale nie zatwierdzonych) operacji lub wycofanie niewykonanych operacji nie prowadziło do powstawania niespójności.
W rozdziale tym postaram się dokładnie opisać sposób realizacji mechanizmu kronikowania w systemie plików NTFS (został on zaczerpnięty wraz z obrazkami z książki [Internals]).
W przypadku NTFS, mamy do czynienia z sytuacją podobną jak w ext3, funkcje kroniki realizowane są przez odrębny moduł, powiązania między modułami wyglądają w sposób następujący:
Ja widać system plików odwołuje się do modułu odpowiadającego za kronikowanie, zapewniającego abstrakcję kroniki i udostępniającego systemowi plików proste operacje na transakcjach. Sam menedżer kronikowania korzysta z menedżera cache'u w celu dostępu do pliku, gdzie zachowuje właściwe dane związane z kroniką.
Plik z kroniką w systemie NTFS składa się z dwóch części:
obszar startowy - są przechowywane dwie kopie danych startowych na wypadek, gdyby jedna z nich stała się niedostępna lub nieczytelna. Zawierają one m.in. takie informacje jak początek obszaru w pliku, od którego powinny być przeglądane rekordy w trakcie odzyskiwania systemu
cykliczny zapis rekordów - zawiera on rekordy dotyczące transakcji wykonywanych przez system plików. Menedżer logu sprawia, że obszar ten wydaje się nieskończony poprzez cykliczny zapis w tym obszarze, używa też logicznych numerów sekwencyjnych (LSN) do identyfikacji numerów rekordów w pliku (NTFS używa 64 bitowych liczb do reprezentacji tych numerów)
System wykonuje operację jednocześnie gwarantując, że system plików może być zawsze odzyskany do stanu spójnego w następujący sposób:
NTFS prosi menedżera kronikowania, aby zapisał w logu (również cache'owanym przez menedżera cache'u) transakcje, które będą modyfikowały strukturę woluminu.
System plików modyfikuje właściwe dane (również w cache'u)
Menedżer cache'u wysyła żądanie do menedżera kronikowania, aby zapisał dane dotyczące transakcji na dysk.
Po zapisie na dysk danych związanych z transakcją menedżer cache'u utrwala zmiany w systemie plików na dysku.
Przy pierwszym dostępie do systemu plików sprawdzane jest, czy w dzienniku nie ma transakcji, które nie zostały utrwalone na dysku.
Menedżer kronikowania może zapisywać wszelkie typy rekordów w pliku. Jednak system plików NTFS stosuje dwa rodzaje rekordów:
rekordy uaktualnień - są najpopularniejszym typem rekordów zapisywanym w dzienniku. Każdy rekord składa się z dwóch rodzajów informacji:
dane ponawiania - informują jakie akcje muszą być podjęte, aby odtworzyć podoperację w pełni zapisanej w dzienniku transakcji (zatwierdzonej)
dane wycofywania - służą do wycofywania zmian wprowadzonych przez częściowo zapisaną transakcję (niezatwierdzoną)
Po zapisaniu tych rekordów do dziennika system plików przystępuje do utrwalania zmian w cache'u, a kiedy skończy modyfikować cache umieszcza w dzienniku kolejny rekord - zatwierdzając transakcję. Jeśli transakcja jest zatwierdzona, to NTFS gwarantuje, że operacja ta zostanie wykonana na systemie plików nawet jeśli nastąpi awaria.
Podczas odzyskiwania kroniki, system ponawia wszystkie zatwierdzone transakcje (chociaż zostały one zatwierdzone, nie wiadomo czy menedżer cache'u zdołał je odesłać na dysk - ma tu duże znaczenie, to co było wcześniej wspomniane, że informacje ponawiające powinny być tak zapisane, że ponowne wykonanie utrwalonej już operacji nie powinno niczego popsuć). Następnie system znajduje wszystkie niezatwierdzone transakcje i odwołuje zmiany podążając za wstecznymi wskaźnikami.
NTFS umieszcza w dzienniku informacje przy wykonywaniu następujących operacji: tworzeniu pliku, usuwaniu pliku, powiększaniu pliku, zmniejszaniu pliku, ustawianiu informacji o pliku, zmianie nazwy pliku, zmianie uprawnień pliku.
punkty kontrolne - jako dodatek do rekordów uaktualnień NFTS co jakiś czas zapisuje punkty kontrolne do pliku, jak ilustruje to poniższy rysunek:
Rekordy kontrolne pozwalają systemowi plików ustalić jakie akcje należy podjąć, aby przywrócić system do spójnego stanu. Dzięki nim wiadomo m. in. od których rekordów należy rozpocząć przetwarzanie. Po zapisie punktu kontrolnego system zapisuje w obszarze startowym jego numer sekwencyjny, tak aby mógł szybko ustalić najnowszy punkt kontrolny.
Pomimo, że dla systemu dziennik sprawia wrażenie nieskończonego, w rzeczywistości oczywiście taki nie jest. Dlatego menedżer cache'u przechowuje liczbę wolnego miejsca w logu, miejsce potrzebne do zapisania wszystkich nadchodzących rekordów i miejsce potrzebne do odwołania wszystkich aktywnych transakcji. Jeśli wolne miejsce nie jest w stanie pomieścić wszystkich zmian, to zwracany jest wyjątek przepełnienia dziennika. Wówczas blokowane są wszelkie operacje na transakcjach dopóki menedżer cache'u nie odeśle na dysk wszystkich niezapisanych danych, włącznie z danymi dotyczącymi dziennika. Po pozytywnym zakończeniu operacji dziennik jest resetowany i wszystko wraca do normy.
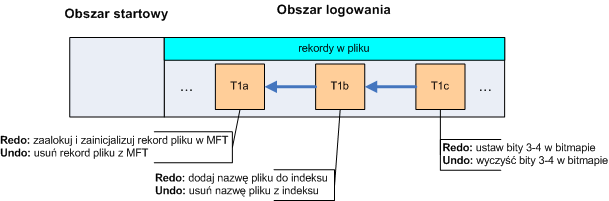
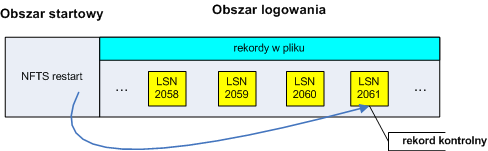
Jak to już zostało wcześniej wspomniane, system NFTS przystępuje do operacji odzyskiwania dziennika przy pierwszym dostępie do systemu plików. Proces ten zależy od dwóch tablic:
tablicy transakcji - przechowuje informacje o transakcjach, które zostały rozpoczęte, ale nie zostały zatwierdzone; wszystkie podoperacje tych aktywnych transakcji muszą zostać wycofane podczas przywracania spójności,
tablica brudnych stron - przechowuje informacje o tym, które strony w cache'u zawierają modyfikacje systemu plików, które nie zostały zapisane na dysk. Te dane muszą być utrwalone na dysku.
NTFS co 5 sekund zapisuje rekord z punktem kontrolnym do dziennika, tuż przed tym zachowywana w kronice jest także aktualna kopia wyżej wymienionych tablic, następnie w rekordzie kontrolnym zapisuje numery rekordów zawierających te tablice. Podczas procesu odzyskiwania danych odszukiwane są najświeższe kopie tych tablic i wczytywane są do pamięci.
Kronika zwykle zawiera jeszcze rekordy uaktualnień znajdujące się za ostatnim punktem kontrolnym. Reprezentują one zmiany, które zaszły później, więc system musi uwzględnić te zmiany w tablicach transakcji i brudnych stron. Po uaktualnieniu tablic zmiany są utrwalane na dysku twardym.
NTFS skanuje dziennik trzy razy, jednak przy pierwszym przebiegu zapisuje go sobie w pamięci, aby zminimalizować liczbę odczytów z dysku. Każdy z tych przebiegów ma określony cel:
faza analizy kroniki,
faza ponawiania operacji,
faza wycofywania operacji.
Analiza kroniki.
Podczas analizy kroniki jest ona przeglądana od początku ostatniego punktu kontrolnego, aby znaleźć rekordy uaktualnień i wykorzystać je do wprowadzenia zmian do tablicy transakcji i brudnych stron. Jak widać na obrazku punkt kontrolny tak naprawdę składa się z trzech rekordów, przez co rekordy uaktualnień mogą być z nimi przemieszane, dlatego system musi zacząć skanowanie od początku ostatniego punktu kontrolnego.
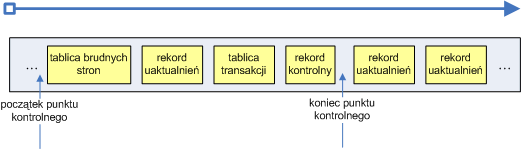
Większość rekordów uaktualnień zapisanych po punkcie kontrolnym reprezentuje modyfikacje albo tablicy transakcji albo tablicy brudnych stron. Jeśli rekord jest np. rekordem zatwierdzającym transakcję, wówczas odpowiedni rekord odpowiadający tej transakcji musi zostać usunięty z tablicy transakcji. Następnie system wyznacza numer najstarszej operacji, która nie została utrwalona na dysku. Tablica transakcji zawiera na koniec numery niezatwierdzonych operacji, natomiast tablica brudnych stron zawiera numery rekordów cache'u, które nie zostały utrwalone na dysku. Numer tej transakcji wyznacza moment, od którego rozpocznie się faza odtwarzania.
Ponawianie operacji.
Podczas fazy ponawiania dziennik jest również przeglądany do przodu rozpoczynając od numeru rekordu wyznaczonego w czasie analizy. System szuka rekordów z uaktualnieniami stron, które następnie są ponawiane.
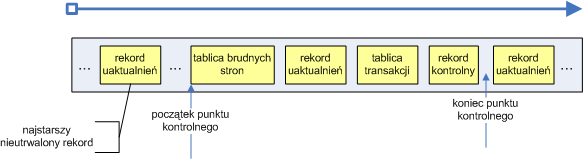
Ja tylko system dojdzie do końca logu, w cache'u znajdują się uaktualnione informacje, które następnie menedżer cache'u leniwie zapisze na dysk.
Wycofywanie operacji.
Po ukończeniu operacji ponawiania system przegląda dziennik od tyłu, wycofując wszelkie niezatwierdzone transakcje. Na rysunku widzimy dwie transakcje, z których pierwsza została zatwierdzona przed awarią systemu, natomiast druga nie. Zatem NTFS musi wycofać drugą transakcję.
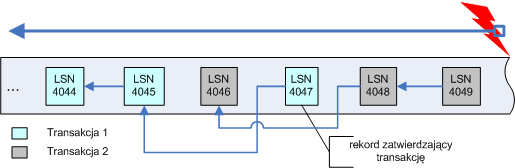
Po ukończeniu fazy wycofywania operacji wolumin znajduje się w stanie spójnym. W tym miejscu następuje wymuszenie zapisu wszystkich danych na dysk i zapisywany jest pusty rekord w rekordzie startowym dziennika oznaczający, że system jest spójny. Na tym cały proces przywracania spójności się kończy.
Pomimo ewolucji dzisiejszych systemów plików nie są one jednak w stanie ochronić nas przed wszelkimi możliwymi awariami, dlatego jeśli naprawdę zależy nam na naszych danych (a w dzisiejszym świecie, często to one, a nie sprzęt stanowią największą wartość) powinniśmy rozważyć przedsięwzięcie dodatkowych środków, mogących zabezpieczyć nas przed ewentualną katastrofą. Pokrótce opiszemy kilka sposobów, dzięki którym będziemy mogli spać spokojniej, wierząc, że nasze dane są bezpieczniejsze:
Zasilacze awaryjne - ich stosowanie może nas uchronić przed awariami systemu z powodu braku zasilania - jakkolwiek dobry by nasz system plików nie był, zawsze w wyniku utraty zasilania możemy bezpowrotnie stracić część danych (szczególnie w przypadków systemów plików bez kroniki). Poza tym awaria taka powoduje przestój w pracy systemu, co w większości wypadków jest dalece nieporządane, a czasami wręcz niedopuszczalne.
Kopie bezpieczeństwa - możemy tutaj tak naprawdę wyodrębnić kilka sposobów sporządzania kopii naszych danych, różniących się pewnymi właściwościami. W przypadku każdej z tych metod musimy jednocześnie pamiętać, że dane te będą tak bezpieczne, jak bezpieczne będą nośniki, na których będą przechowywane - na nic się zdadzą kopie bezpieczeństwa, które zostaną zniszczone wraz z oryinalnymi danymi (np. w wypadku kataklizmów, jeśli znajdowały się w tym samym miejscu).
kopie danych - charakteryzują się one tym, że przechowują tylko i wyłącznie dane, dzięki czemu łatwe jest ich przeniesienie do innego systemu plików, jednak przez to, że nie zawierają również metadanych mogą pomijać pewne ważne aspekty metadanych, których nie obsługują (coś takiego może wystąpić np. w wypadku wspominanych wcześniej list ACL).
zrzuty (obrazy) partycji - kopie te zawierają jednocześnie dane jak i metadane, w związku z czym oczywiście zawierają pełniejsze informacje o systemie plików. Przez to jednak odtworzenie danych w innych lub inaczej skonfigurowanych systemach może być utrudnione i wymagać specjalnego oprogramowania.
migawki (snapshots) - są one zazwyczaj rozwiązaniem krótkotrwałym, pozwalającym jednak zachować pełne dane z konkretnego momentu. Są one z wielu powodów wygodne - na przykład nie wymagają tworzenia od razu pełnych kopii danych - co może być procesem długotrwałym przy dużych systemach, jednocześnie, często wymagającym zamknięcia wszelkich otwartych plików (co wiąże się z przerwą w działaniu systemu na czas "czynności serwisowych"). Idea migawek polega na tym, że po wykonaniu migawki system nie zmienia już zapisanych na dysku danych, lecz wszelkie zmiany zapisuje w nowym miejscu - w ten sposób stare dane pozostają niezmienione (z czymś podobnym mamy do czynienia w przypadku funkcyjnych struktur danych, gdzie w niektórych przypadkach możemy w każdym momencie mieć dostęp do całej "historii" obiektu). Rozwiązanie to jest szybkie i wygodne, gdyż możemy odtworzyć dowolny plik w nienaruszonym stanie z danego czasu, jednak ceną jaką za to płacimy jest większe zużycie przestrzeni dyskowej. Wielu producentów urządzeń do przechowywania danych wyposaża je w mechanizmy migawek, również Microsoft wyposażył swój system w ten mechanizm, nazywający się w tym wypadku "Volume Shadow Copy Service".
Macierze dysków twardych - rozwiązanie to może nie tylko zwiększyć bezpieczeństwo danych, ale również przy odpowiednich wariantach może prowadzić do wzrostu wydajności operacji dyskowych. Chroni nas ono głównie przed fizyczną awarią jednego lub więcej dysków twardych przechowujących nasze dane. Różne warianty RAID różnią się zarówno sposobem zabezpieczania danych (czy jest to rzeczywista kopia, czy odpowienie sumy kontrolne), liczbą dysków przed awarią których nas bronią, dodatkowym nakładem na przechowywane dane oraz szybkością dostępu do danych. Jako, że nie jest to główny temat prezentacji, zainteresowanych odsyłam do artykułu: Wiki
Przyjrzyjmy się sposobom, na jakie możemy odczytywać pliki z innych (nierdzennych dla naszego systemu operacyjnego) systemów plików.
Na początku należy powiedzieć o warstwach, w których może być implementowany dostęp do tych systemów. Możemy wyodrębnić następujący podział:
zawarte w jądrze systemu - wówczas mamy dostęp do wszelkich struktur jądra, jednak jeśli jądro nie obsługuje modułów, to musi zostać przekompilowane z kodem obsługującym dany system plików. Poza tym dla systemów o zamkniętym jądrze napisanie kodu obsługującego dany system plików w tej warstwie jest niemożliwe.
napisane jako sterownik - wówczas jądro udostępnia metody, jednak kod obsługujący system plików znajduje się całkowicie poza jądrem systemu (nawet nie jako moduł) - z tą systuacją mamy głównie do czynienia w WindowsNT.
jako programy użytkowe - nie korzystają one ze struktur jądra oraz do dostępu do dysku, a jedynie używają wysokopoziomowych funkcji systemu - jest to najczęściej spotykane w obsłudze różnego rodzajów obrazów.
Generalnie nie stanowi to większego problemu, gdyż dla większości systemów plików o otwartej specyfikacji istnieją odpowiednie moduły do jądra, obsługujące dany system plików. Jedyny problem stanowią systemy o zamkniętej specyfikacji - jak to ma miejsce np. w przypadku NTFS. Co prawda istnieją standardowe moduły jądra, obsługujące podstawowe operacje na tym systemie plików, lecz w zasadzie ograniczają się one wyłącznie do odczytu - możliwa jest co prawda modyfikacja, jednak nie może ona zmieniać rozmiaru pliku. Istenieją też komercyjne produkty dla Linuksa, umożliwiające pełen dostęp do systemu NTFS - jednym z takich programów jest Paragon NTFS for Linux .
Tu sprawa wygląda również obiecująco, gdyż dla większości linuksowych systemów plików istnieją OpenSource'owe narzędzia, służące do dostępu do danych zapisanych na tych partycjach. Jest wiele programów umożliwiających dostęp do systemu ext2, np. programy takie jak: FSDext2, explore2fs. Istnieją również wtyczki (pluginy) do popularnego menedżera plików (TotalCommander) umożliwiające odczyt z systemów ext2, ext3 oraz ReiserFS.
Po bardziej szczegółowe informacje odnośnie dostępu do linuksowych systemów spod Windows oraz windowsowych spod Linuksa odsyłamy do pliku HOW-TO oraz do artykułu.
W systemie plików ext3 nie istnieje wbudowane narzędzie do szyfrowania danych (zwłaszcza w formie przezroczystej dla użytkownika). Istnieje za to wiele łatek (jak choćby: CFS, TCSF, CryptFS, BestCrypt i inne), które pozwalają na wiele możliwości w zakresie szyfrowania danych. Ponieważ jednak nie są one wbudowane w sam system plików ext3, to nie będziemy ich w tym miejscu omawiać.
Z kolei NTFS udostępnia bardzo szerokie wbudowane możliwości, jeżeli chodzi o szyfrowanie plików. Szyfrowanie jest przezroczyste (niewidoczne) dla użytkownika i odbywa się z wykorzystaniem EFS (Encrypting File System). W Windowsie 2000 EFS jest zaimplementowane jako sterownik urządzenia działający w trybie jądra i ściśle związany ze sterownikiem NTFS, a w Windowsie XP i 2003 Server jest on po prostu połączony ze sterownikiem NTFS-a.
z poziomu aplikacji - mamy do dyspozycji funkcje EncryptFile i DecryptFile z WinAPI, a także FileEncryptionStatus do uzyskania atrybutów zaszyfrowania pliku czy katalogu
za pomocą Eksploratora Windows - wybierając menu zaawansowane właściwości pliku czy katalogu
szyfrować możemy także z linii komend za pomocą polecenia cipher.
Kiedy użytkownik po raz pierwszy coś szyfruje, jest dla niego tworzona para kluczy, publiczny i prywatny. Będą mu one służyły dalej do szyfrowania i deszyfrowania plików. Kiedy szyfrujemy dany plik, to jest dla niego tworzony w EFS tak zwany FEK, czyli File Encryption Key (będący pewną losową wartością przypisaną temu plikowi). Za pomocą FEK zawartość pliku jest szyfrowana tudzież deszyfrowana przy użyciu symetrycznego algorytmu szyfrowania, jakim jest w Windowsie 2000 i Windowsie XP algorytm DESX (silniejszy wariant DES-a), zaś w Windowsie XP z Service Pack 1 i Windowsie 2003 Server - AES (Advanced Encryption Standard). Jest także możliwość włączenia jeszcze silniejszego algorytmu szyfrowania, mianowicie 3DES. Symetria algorytmu polega na tym, że tym samym kluczem plik można szyfrować i deszyfrować.
Po co nam w takim razie klucz publiczny i prywatny użytkownika? Otóż kluczem publicznym użytkownika jest szyfrowany FEK (gdyż jego postać niezaszyfrowana, jak już zostało wspomniane, pozwalałaby na natychmiastowe odszyfrowanie pliku) i taka zaszyfrowana kopia jest trzymana dla danego pliku dla każdego użytkownika, który ma mieć możliwość ten plik szyfrować i deszyfrować. Taka właśnie metoda została wybrana, gdyż szyfrowanie symetryczne jest o wiele szybsze od niesymetrycznego, a więc do dużych partii danych (zawartość pliku) używany DESX-a lub AES-a, zaś do samego tylko FEK-a używamy RSA (klucz publiczny i prywatny).
W szyfrowaniu najważniejszym (i wymagającym największego bezpieczeństwa) punktem jest więc klucz prywatny. Klucz ten jest przechowywany w katalogu profilu użytkownika (\Documents and Settings) w podkatalogu Application Data\Microsoft\Crypto\RSA (w polskojęzycznej wersji Windowsa często katalog Application Data ma nazwę Dane aplikacji). Dla jego ochrony, wszystkie pliki katalogu RSA są szyfrowane za pomocą losowego 64-bajtowego klucza symetrycznego, tzw. master key, który jest specyficzny dla użytkownika. Ten z kolei jest przechowywany w katalogu Application Data\Microsoft\Protect i jest zaszyfrowany za pomocą algorytmu 3DES z użyciem klucza, którego część jest oparta na haśle danego użytkownika. Tak więc zmiana hasła użytkownika powoduje odszyfrowanie jego master key i ponowne zaszyfrowanie z użyciem nowego hasła.
Sterownik EFS działa w trybie jądra (podobnie zresztą jak sterownik NTFS, a w nowszych wersjach jest w niego wbudowany). Kiedy tylko NTFS napotyka zaszyfrowany plik, wywołuje stosowne funkcje EFS, które zajmują się szyfrowaniem i deszyfrowaniem danych na żądanie dostępu wykonane przez aplikację użytkownika. Aby jednak odszyfrować FEK-a danego pliku, EFS musi wykorzystać klucz prywatny użytkownika z pomocą funkcji kryptograficznych, działających w trybie użytkownika. Za pomocą sterownika KSecDD zostaje wywołana odpowiednia funkcja, która znajduje się w LSASS (Local Security Authority Subsystem, który odpowiada za zarządzanie sesjami, ale także kluczami EFS) - komponentem LSASS-a wysłuchującym takie żądania jest Lsarv (Local Security Authority Server). On to zleca CSP (cryptographic service provider) poprzez Microsoft CryptoAPI (CAPI) żądanie odszyfrowania FEK-a, które ten wykonuje, po czym Lsarv zwraca EFS-owi odszyfrowany klucz.
Jak wiadomo systemy plików były kwestią, którą zajmowano się prawie od samego początku istnienia komputerów. Jednakże jeszcze kilkanaście lat temu, projektujący nie skupiali się na optymalizowaniu wyszukiwania plików, gdyż w tamtych czasach pojemności dysków nie przekraczały kilku megabajtów. Jednakże w dzisiejszym świecie, przy dzisiejszych olbrzymich dyskach i wielkich ilościach plików kwestia szybkiego wyszukiwania staje się coraz ważniejsza.
Aktualne systemy plików działają dość szybko, oraz dobrze zarządzają miejscem na dysku. Dodatkowo metadane również zajmują niewielką ilość miejsca. Jednakże wszystkie aktualne systemy plików mają strukturę hierarchiczną. To oznacza, że dla każdego pliku wiemy, w jakim katalogu się znajduje i dla każdego katalogu wiemy, jakie zawiera pliki. Każdy plik posiada w tym momencie unikalną ścieżkę, dzięki której możemy go znaleźć. Jest to bardzo prosta, ale też bardzo szybka struktura, do której wszyscy zdążyli się już przyzwyczaić.
Jednak największą jej wadą jest brak możliwości tworzenia dodatkowych połączeń miedzy plikami. Próbą rozwiązania tego problemu jest tworzenie linków, dzięki czemu odnosi się wrażenie, że plik jest w kilku miejscach naraz. Dodatkowo wprowadza się dodatkowe atrybuty do pliku, co umożliwia dodanie dodatkowych informacji i późniejsze wyszukiwanie po nich.
Jednak ciągle wyszukiwanie jest bardzo kosztowne. Aktualnie próby radzenia sobie z tym problemem polegają na indeksowaniu i cache'owaniu zapytań, wiec przy założeniu, że użytkownik zadaje pytania o podobne pliki, ten algorytm działa, jednak przy złośliwych przypadkach użytkownik może bardzo długo czekać na interesujące go pliki.
Ideą "nowego podejścia" jest powiedzenie, że wszystko jest relacją. WinFS będzie wykorzystywał bazę danych do przechowywania plików. Pod tą wartwą będzie system plików NTFS, będzie również dostępny "stary" API, dzięki czemu będzie zachowana wsteczna kompatybilność.
Głównymi zaletami takiego podejścia są bardzo wydajne możliwości wyszukiwania w takim systemie. Jak wiadomo bazy danych są pisane pod kątem optymalizacji wyszukiwań, więc wyszukiwanie plików zarówno po ich nazwach jak i atrybutach będzie bardzo szybkie. Dodatkowo wielką zaletą będzie możliwość dodawania "połączeń" między plikami, ich grupowania po pewnych cechach itp.
Z punktu widzenia użytkownika nie będzie struktury hierarchicznej. Znaczy się, jeżeli ktoś będzie chciał to będzie mógł tworzyć zagnieżdżone katalogi itp. itd., ale one nie będą w ten sposób przechowywane na dysku.
Głównymi wadami WinFS-a są oprócz tego, że metadane zabiorą o wiele więcej miejsca, to koszt wielu operacji się powiększy. Dodatkowo każdy kto używał bazy danych, wie że w dużym stopniu wykorzystuje ona pamięć operacyjną i czas procesora. Tak więc wymagania sprzętowe WinFS-a będą istotną kwestią.
Dodatkowo bardzo poważną wadą może okazać się brak dostępu spod innych systemów operacyjnych. Już w NTFSie pojawiają się problemy z zapisem plików spod Linuksa, więc nie wiadomo, jak będzie wyglądała sytuacja w stosunku do WinFS. Czas pokaże. Jedną z najważniejszych wad WinFS jest także to, że nie pojawi się wcześniej niż w roku 2007.
Na poniższym obrazku znajduje się struktura WinFS-a. Jak widać bazuje on na systemie plików NTFS oraz na nowym "engine" SQL-a Yukonie, który też jeszcze nie został wypuszczony.
[FailureAnalysis] Model-Based Failure Analysis of Journaling File Systems (pdf).