Wprowadzenie [Paweł Gora]
Czym są rozproszone systemy plików?
- Rozproszone systemy plików pozwalają na rozproszenie danych po wielu lokalizacjach fizycznych (serwerach) w taki sposób, że zwykły użytkownik nie jest świadom istnienia wielu (często odległych) serwerów, z któych na jego stację kliencką są sprowadzane określone zasoby. Pojedynczy serwer może przechowywać część systemu plików.
Cechy rozproszonych systemów plików
- Przezroczystość położenia: nazwa pliku nie daje żadnej wskazówki na temat fizycznego położenia pliku, zdalny dostęp do danych staje się podobny do lokalnego dostępu
- Niezależność położenia: nazwy plików nie trzeba zmieniać w przypadku, gdy plik zmienia swoje fizyczne położenie; jest ona jednoznaczna dla całego systemu
- Przezroczystość dostępu: programy są nieświadome rozproszenia plików
- Wysoka wydajność komunikacji i przetwarzania zadań
- Spójność danych
- Niezawodność: system pozostaje spójny nawet w sytuacji, gdy jeden z serwerów przestanie działać; zapewnione jest to dzięki redundancji
- Przezroczystość zwielokrotnienia: istnienie wielu kopii danych jest ukryte przed użytkownikiem
- Prosta obsługa: interfejs umożliwiający wygodne zarządzanie systemem, pomimo jego często skomplikowanej struktury
- Wysoka dostępność: dzięki redundancji pobierana jest "najbliższa" kopia danych
- Drobnoziarniste rozpraszanie danych
Dostęp do plików
Model zdalny
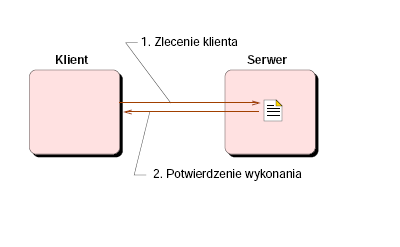 Zalety:
Zalety:
- Nie ma potrzeby sprowadzania plików do klienta
- Efektywna realizacja małych modyfikacji
Wady:
- Opóźnienia związane ze zdalnym wykonywaniem poleceń
- Narzut komunikacyjny
Pamięci podręczne
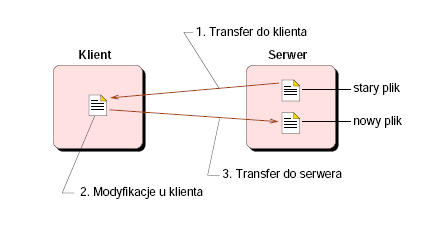 Zalety:
Zalety:
- Prosty interfejs usług plikowych
- Model korzystny podczas wykonywania wielu złożonych operacji
- Niezawodność: dane nie przepadają podczas awarii
Wady:
- Duży narzut komunikacyjny przy wykonywaniu małych modyfikacji
- Wymagana przestrzeń dyskowa lub pamięciowa, aby przechowywać tymczasowo plik
- Problem spójności pamięci podręcznych
Przykłady rozproszonych systemów plików
- Google FS
- Global FS
- Lustre FS
- AFS (Andrew File System)
- Coda
The Global File System [Krzysztof Choromański]
Wstęp
Global File System to nowatorskie podejście do budowy systemów plików rozproszonych:
- Rozproszony system plików oparty na technologii "shared network storage". Podłączone do sieci urządzenia przechowujące dane bezpośrednio obsługują klientów
- Jego klient nie jest świadom istnienia innych klientów w sieci
- Nie ma w nim bezpośredniej komunikacji między węzłami sieci(klastra)
- System szybki, skalowalny, o wysokiej przepustowości
- Umożliwia obsługę większości czołowych platform serwerowych wspieranych przez RedHat
- Szybko odnajduje swoje miejsce w niemal każdej gałęzi przemysłu
- Obsługuje bardzo dużą liczbę aplikacji
- Zapewnia wysoką wydajność i zmniejsza stopień skomplikowania czynności administracyjnych
- Nie posiada słabych punktów, których awaria zakłócałaby działanie systemu: każdy serwer może otrzymać status zbędnego w celu uzyskania niezakłóconej, ciągłej pracy, niezależnie od usterek
- Staje się obecnie kluczowym elementem współczesnej infrastruktury komputerowej w przedsiębiorstwach
Powstanie nowego systemu plików
- GFS był początkowo tworzony jako część projektu informatyków z University of Minnesota w 1997 roku. Pierwotnie napisany na systemy operacyjne SGI's IRIX
- W 1998 roku system został przeniesiony na Linux'a, przede wszystkim z powodu dostępności kodu źródłowego, co znacznie ułatwiło dalszy rozwój systemu
- Wkrótce potem powstaje Sistina Software - organizacja skupiająca się na gromadzeniu nowych rozwiązań związanych z platformą Linuxa. Jednym z jej sztandarowych opensourcowych projektów staje się Global File System
- W 2001 roku Sistina decyduje się uczynić z GFS produkt komercyjny
- Opiekę nad projektem przejmuje firma RedHat, systematycznie finansując dalszy jego rozwój. Powstaje GFS2
- Obecnie GFS stał się częścią takich dystrybucji Linuxa jak Fedora i Centos
Omówienie projektu
Architektura Global File System
Global File System był projektowany jako system dla linuxowych klastrów. Różni się on od standardowych systemów plików rozproszonych. Główne cechy architekrury GFS:
- Wszystkie węzły są równouprawnione - nie ma wyróżnionego serwera centralnego czy kilku serwerów obsługujących pozostałe wierzchołki - klientów
- Urządzenia przechowujące dane łączą się z komputerami - klientami za pośrednictwem sieci SAN(Storage Area Networks). SAN umożliwia urządzeniom używać własnych interfejsów, takich jak SCSI, aby bezpośrednio podłączyć się do sieci. Poniżej zaprezentowano schematycznie model SAN na tle innych rozwiązań:
- GFS grupuje urządzenia z danymi w logiczne grupy, udostępniając klientowi zunifikowaną przestrzeń, którą będzie współdzielił z innymi węzłami. Tę kolekcję urządzeń podłączonych do sieci nazywa się w skrócie NSP (Network Storage Pool). NSPs-y są dzielone na grupy urządzeń podobnych typów
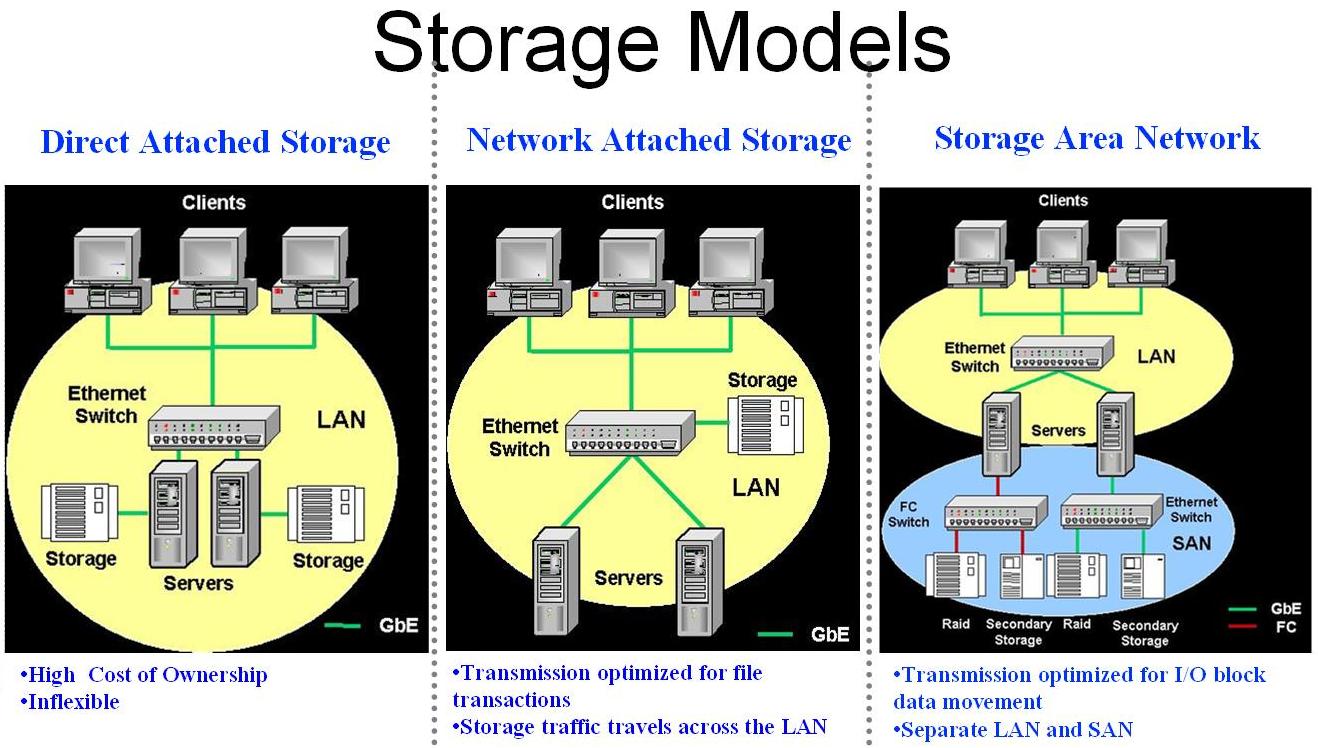
Przewaga architektury GFS nad innymi istniejącymi systemami plików rozproszonych:
- Zaprojektowanie GFS w technologii SMC (Symmetric Multi-Client) umożliwia klastrom systemu zachowywać się jak komputery klasy SMP (Symmetric Multiprocessor Computers). Ponadto awaria któregokolwiek komputera klienckiego nie ma zauważalnego wpływu na inne komputery
- GFS korzysta z architektury NAS-2, zdefiniowanej jako tak zwana Network SCSI. Dane są bezpośrednio przesyłane odbiorcy z urządzeń podłączonych do sieci poprzez sieć SCSI-3. Ścieżka, po której przesyłane są dane jest o wiele prostsza od tej, która występuje chociażby w systemie NFS. Porównanie obu ścieżek kontroli i przepływu danych dla GFS i NFS zaprezentowane zostało poniżej:
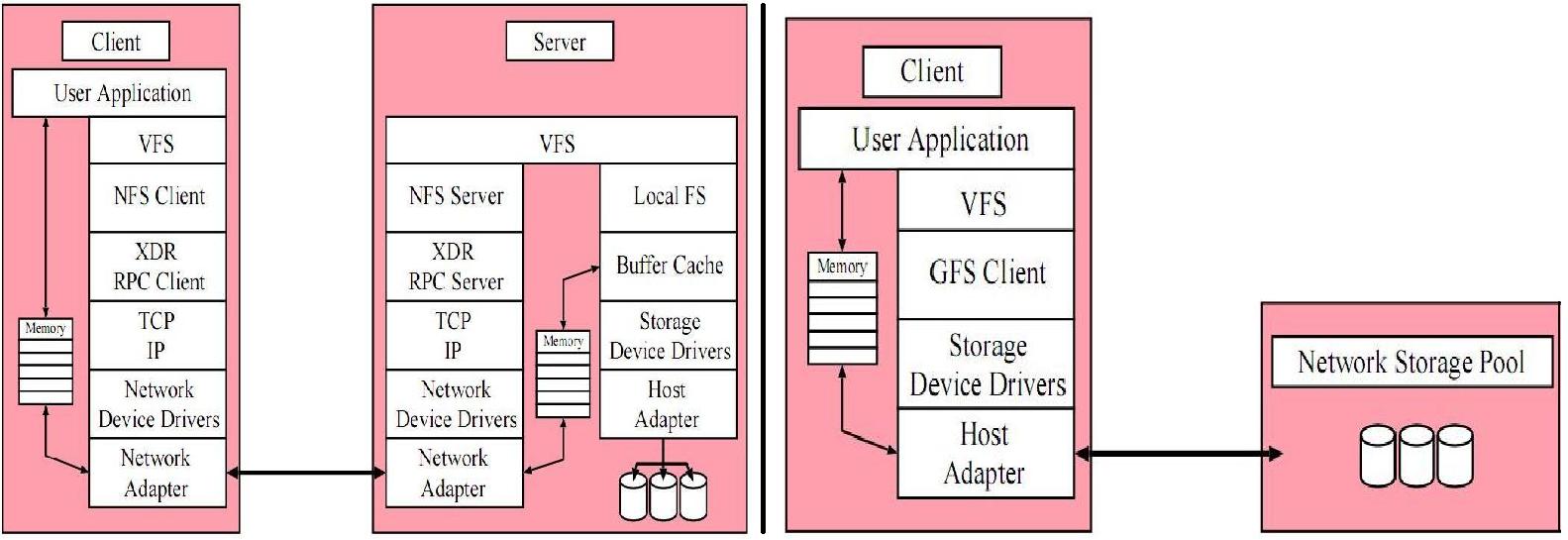
- GFS nie powstawał jako modyfikowany lokalny system plików, lecz efekt zupełnie nowego podejścia do budowy systemów plików rozproszonych. Zamierzeniem autorów systemu było nadanie mu cechy dużej skalowalności, co teraz jest w pełni realizowane. Wydajność systemu może być inkrementalnie skalowalna do setek stacji klienckich
- GFS oferuje architekturę, która grupuje urządzenia we współdzielone przez stacje klienckie grupy (storage pools). Grupy te dzielone są na podgrupy (storage subpools), charakteryzowane właściwościami wchodzących w ich skład urządzeń
- GFS zapewnia idealną spójność danych. Żądania odczytu powodują pobranie najbardziej aktualnych danych. Wykorzystywane są takie narzędzia jak GULM, czy DLM (Distributed Lock Manager)
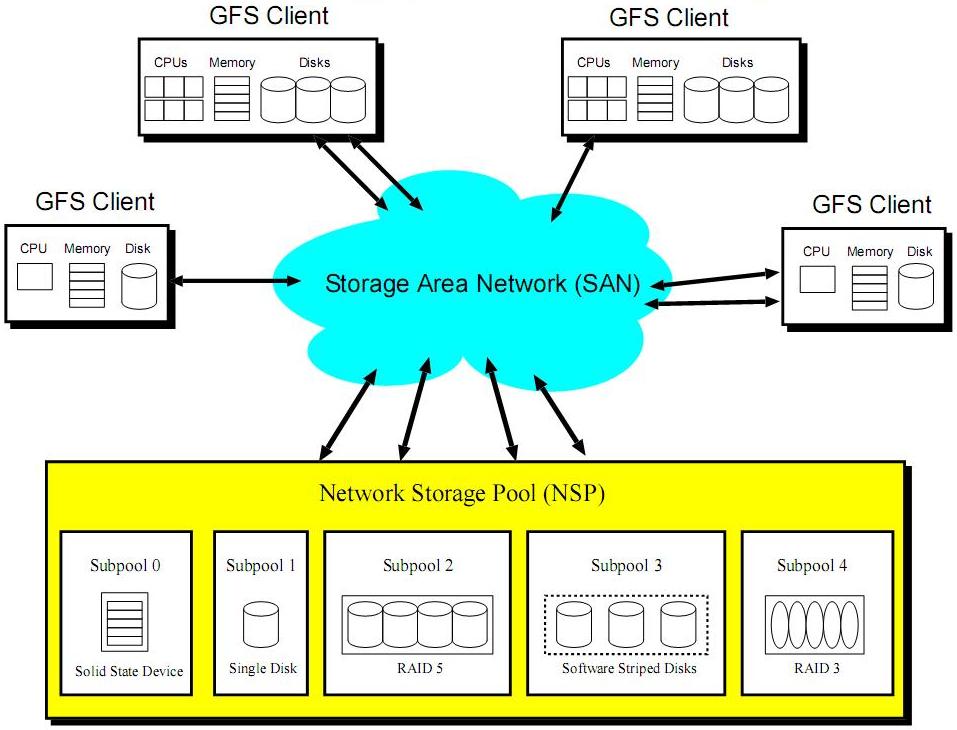
Środowisko
GFS to klastrowy rozproszony system plików. Pierwotnie, w przeciwieństwie do komercyjnych systemów plików, GFS skupiał się głównie na zwiększeniu wydajności działania klastra składającego się z relatywnie małej liczby węzłów. Miał zapewnić lepsze działanie aplikacji przeprowadzających skomplikowane obliczenia naukowe. Obecnie architektura GFS jest w pełni skalowalna i może być użyta w heterogenicznych systemach, których klienci korzystają z różnych systemów operacyjnych
Architektura GFS często używana jest w środowisku, w którym klient GFS może eksportować dane otrzymane za pomocą GFS do komputerów nie podłączonych do SAN. W tej sytuacji klient GFS zachowuje się jak serwer dla klienta korzystającego np: z protokołu HTTP
Tego typu sytuacja przedstawiona została na poniższym rysunku:
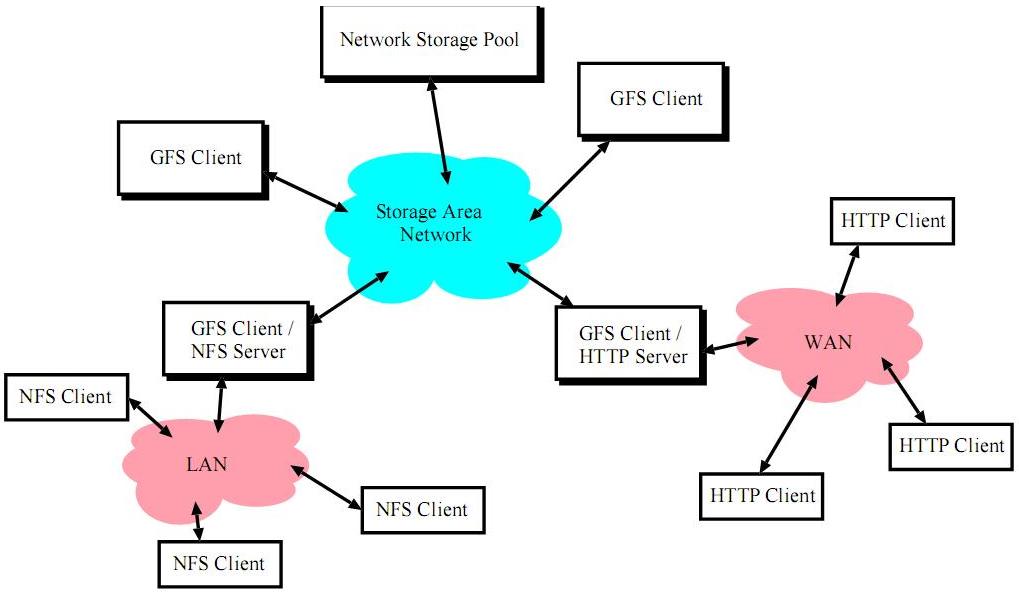
Struktura systemu plików
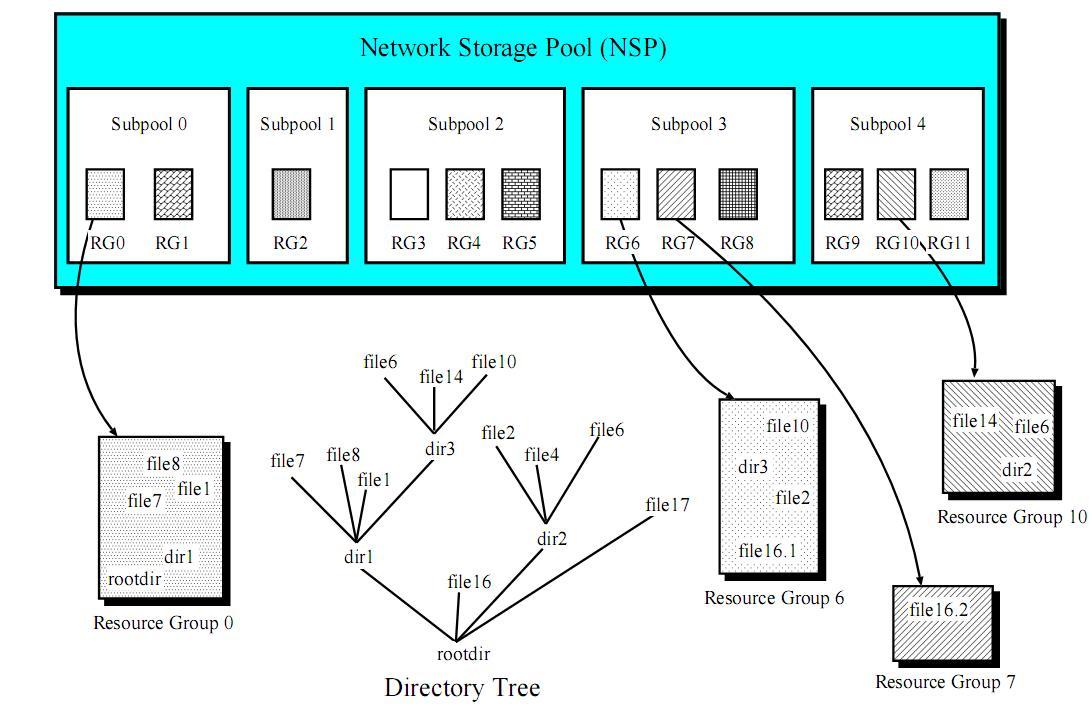
System NSP(Network Storage Pool) zapewnia każdej maszynie zunifikowaną przestrzeń adresową, za pomocą której klient ma dostęp do wszystkich urządzeń z danymi, podłączonych do sieci. Driver NSP dokonuje translacji logicznej przestrzeni adresowej widocznej przez klienta na przestrzeń adresową każdego urządzenia. Komendy
Global File System organizuje systemy plików w wiele tak zwanych "resource groups" (RG). Można je traktować jako małe systemy plików. Każda grupa zawiera informacje podobne do tych w tradycyjnych superblokach. Pojedynczy plik może znajdować się w wielu RG. Możliwe jest też przenoszenie plików do różnych
GFS korzysta ze struktury dinode, zajmującej cały blok w systemie plików. Każdy dinode składa się z sekcji informacji oraz sekcji danych. Jeśli rozmiar pliku jest większy niż rozmiar sekcji danych, dinode zawiera tablicę wskaźników do bloków danych lub bloków pośrednich. Drzewa metadanych Global File System różnią się od tradycyjnych unixowych struktur. Drzewo inodów UFS (Unix File Systems) zawiera liście położone na różnej wysokości w drzewie. GFS natomiast całą sekcję danych traktuje jako składającą się ze wskaźników pośrednich tego samego typu. Oznacza to, że drzewo inodów ma liście położone na tej samej wysokości. Tradycyjne rozwiązanie unixowe oraz to stosowane w Global File System przedstawione zostały na rysunkach poniżej.
Na pierwszym rysunku pokazano klasyczną strukturę UFS:
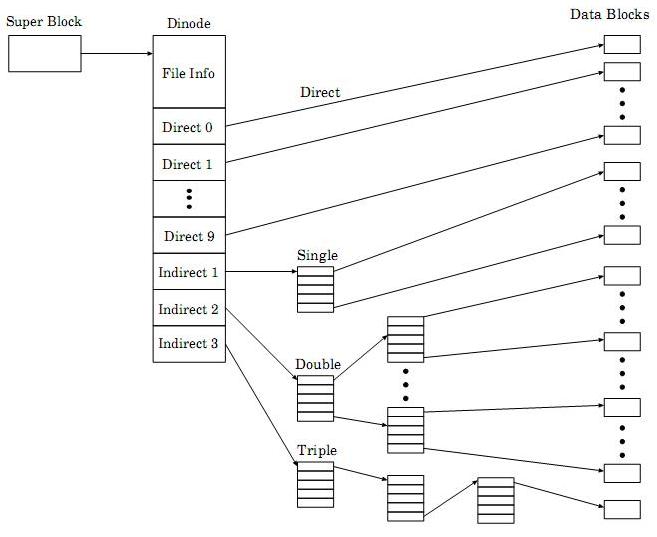
...A teraz drzewo inodów w Global File System:
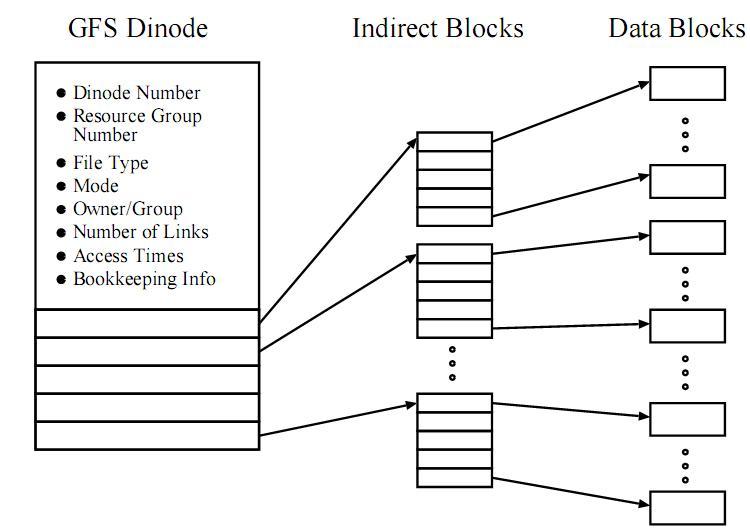
Kierunki rozwoju - Global File System2
Spadkobiercą GFS stał się GFS2 - rozproszony 64-bitowy symetryczny klastrowy system. W pierwszej kolejności jest on przeznaczony dla omówionej wcześniej sieci SAN, w której każdy węzeł ma taki sam dostęp do danych. GFS2 powstał na początku 2005 roku w wyniku prac nad dalszym rozwojem GFS. Jego autorem był Ken Preslan. Po długim czasie modyfikacji i przeglądania kodu, system został zaakceptowany w wersji jądra linuxa 2.6.16. Poniżej zaprezentowano kilka rozwiązań przyjętych w GFS2:
- Tak jak w GFS korzysta się z mechanizmu
RG (resource groups); każda RG składa się z bloku nagłówkowego zawierającego pewne sumaryczne informacje, po którym następują bloki bitmap oraz bloki z danymi. W bitmapie blok jest reprezentowany przez dwa bity, których znaczenie zostało wyjaśnione w tabeli poniżej:
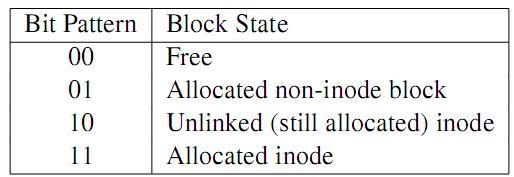
- Po GFS odziedziczone zostały też drzewa metadanych jednakowej wysokości
- GFS2 korzysta z wielu typów klastrowych locków/zamków (nazywanych glockami). Każdy lock ma nazwę składającą się z 64 bitów. Nazwa powstaje w wyniku konkatenacji tupu glock'a oraz numeru glock'a (w obrębie danego typu). Tak stworzona nazwa jest następnie konwertowana na napis ASCII, który jest przekazywany do DLM (Distributed Lock Manager). DLM traktuje locki/zamki jako zasoby. Każdy zasób jest stowarzyszony z tak zwanym lock value block (LVB). Jest to po prostu pamięć będąca w stanie przechować kilka bajtów danym związanych z danym zasobem.
- Podsystem zamków/locków jest zmodularyzowany, zatem łatwy do zastąpienia w przypadku zapotrzebowania na bardziej zaawansowanego menagera w przyszłości
Podsumowanie
Powodów do stosowania systemów opartych na technologii GFS jest wiele. Oto kilka z nich:
- Możliwość współdzielenia wszystkich zasobów systemu przez wiele stacji klienckich, które mają do nich bezpośredni dostęp za pomocą tak zwanego "storage pool"
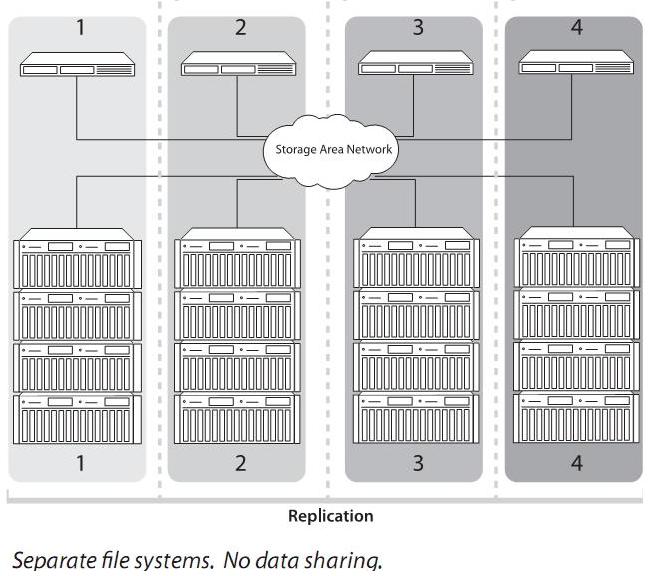
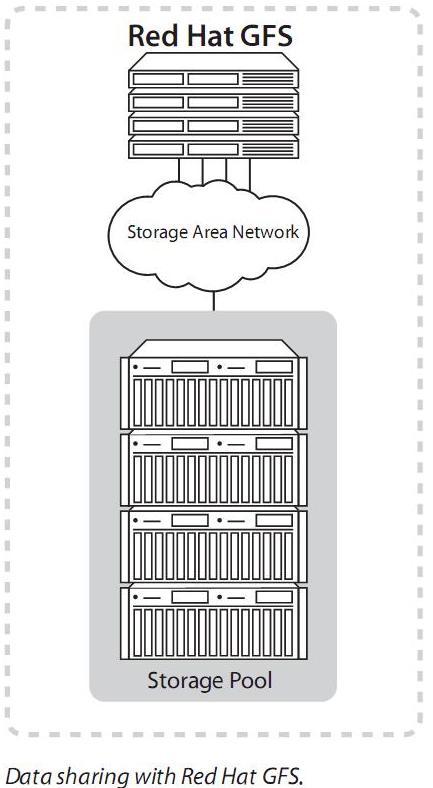
- Łatwość dołączania kolejnych urządzeń do systemu, całkowita niezależność komputera - klienta od pozostałych węzłów sieci
- Ochrona danych poprzez wykonywanie na bieżąco backupów i.t.p.
- Zredukowane (w stosunku do innych rozwiązań) koszty utrzymywania dużej wydajności systemu oraz łatwość zarządzania
- Wspieranie architektur Intel X86, Intel Itanium2, AMD, AMD64, Intel EM64T
- Współpraca z systemami klastrowymi firmy RedHat wykonującymi tak zwane "mission-critical applications"
- Skalowalna alternatywa dla systemu NFS
- Global File System jest idealnym rozwiązaniem dla użytkowników z wymagającymi oczekiwaniami dotyczącymi transportu danych, korzystającymi z aplikacjami obsługującymi skomplikowane naukowe obliczenia. Skalowalność do setek stacji klienckich oraz terabajtów danych daje nieograniczone wręcz możliwości. GFS przekracza bariery wyznaczone przez tradycyjne, oparte na protokole TCP/IP rozwiązania.
- Użycie GFS upraszcza zarządzanie danymi i znacznie redukuje koszty utrzymania systemu
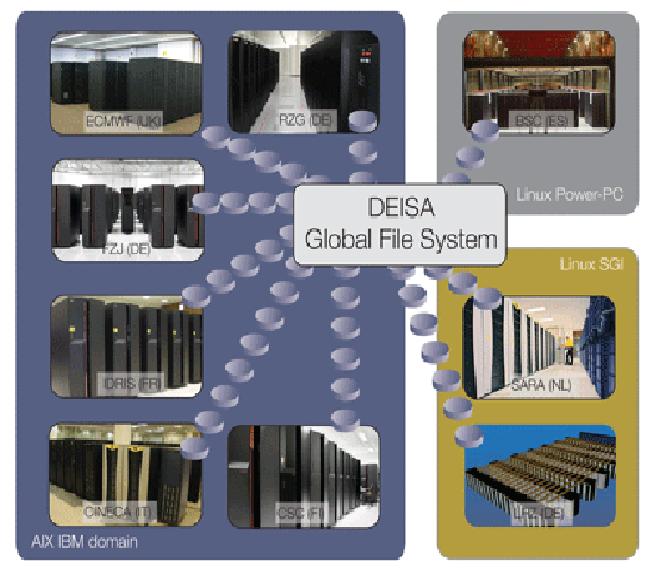
- Global File System jest stosowany w nowatorskim projekcie mającym na celu ścisłe połącznie czołowych ośrodków europejskich dokonujących złożonych obliczeń naukowych
The Google File System [Paweł Brach]
Wstęp
- Google File System (GFS) jest rozproszonym systemem plików używanym jako warstwa przechowywania danych. Wraz z innymi technologiami stanowi fundament, na którym opiera się działanie większości usług oferowanych przez firmę Google. GFS jest przykładem realizacji idei jak za pomocą tysięcy tanich PC-tów, uzyskać wydajność przewyższającą najszybsze superkomputery.
Powstanie nowego systemu plików
- W roku 2003 Google Labs (dział badawczy Google) opublikował w sieci dokument, w którym opisuje projekt i implementację używanego w firmie systemu plików Google File System (GFS), który został następcą systemu BigFiles, napisanego przez Paga i Brina podczas studiów na uniwersytecie Stanford do przetrzymywania olbrzymich plików na dysku.
- Główną ideą stojącą za wynalezieniem własnego systemu plików jest, idąc za wypowiedzią Jeffreya Dean'a - jednego z inżynierów w Google "posiadanie pewnej informacji, nawet jeśli przechowujemy ją na niepewnych maszynach". Priorytetem było zapewnienie, że odczytywane dane są poprawne. Osiągnięto to dzięki redundancji danych, bowiem dla każdego pliku, przynajmniej jego trzy kopie są przechowywane na innych komputerach podłączonych do jednego klastra. W przypadku braku odpowiedzi na próbę odczytu pliku z jednego z komputerów, co najmniej dwa pozostałe komputery będą mogły udostępnić ten plik. Rozproszenie plików jest jednym z najważniejszych założeń, ponieważ oprogramowanie Google'a regularnie doświadcza różnych niespodziewanych błędów, takich jak bugi w systemie operacyjnym, uszkodzenia dysków twardych, pamięci, połączeń sieciowych czy zaniki prądu.
- Google ujawniło, że w obecnej chwili w firmie działa ponad 50 klastrów GFS z kilkoma tysiącami serwerów w każdym klastrze, co pozwala jej magazynować peta-bajty danych.
Omówienie projektu
Założenia
Podczas projektowania systemu plików dla potrzeb Google, musiano brać pod uwagę wiele problemów, z którymi musiał on sobie sprawnie radzić. W systemie przyjęto następujące założenia:
- System jest zbudowany z wielu niedrogich komputerów PC, które teoretycznie mogą ulegać częstym awariom. System na bieżąco monitoruje i wykrywa awarię swoich serwerów i w razie potrzeby odzyskuje utracone dane.
- Typowe pliki trzymane na GFS'ie mają rozmiar od 100 megabajtów do kilkunastu gigabajtów. System zapewniać efektywne zarządzanie takimi plikami. Małe pliki również są wspierane, ale system nie optymalizuje operacji na takich plikach.
- Najczęściej występującymi odczytami z plików są: duże sekwencyjne odczyty oraz małe odczyty w losowych miejscach pliku. W odczytach sekwencyjnych aplikacja kliencka głównie odczytuje tysiące kilobajtów (często 1MB i więcej) ze spójnego obszaru w pliku. Natomiast w odczytach z losowych miejsc pliku, czyta co najwyżej kilka kilobajtów z ustalonego offsetu. Dla zwiększenia efektywności system sortuje małe odczyty względem offsetów.
- System obciążany jest również wieloma dużymi sekwencyjnymi zapisami do pliku, które zwiększają ich rozmiar. Wydajność małych zapisów w losowych pozycjach w pliku nie jest zapewniana.
- W systemie zaimplementowana jest sprawna obsługa wielu klientów, którzy współbieżnie korzystają z tych samych plików. Pliki często są wykorzystywane jako kolejki producentów - konsumentów. Atomowość operacji dodawania danych przez producentów piszących do tego samego pliku oraz zminimalizowana synchronizacja zapewnia dużą wydajność (plik może być później odczytywany jednocześnie przez wielu konsumentów).
- Transmisja danych z dużą szybkością jest priorytetem (kosztem większych opóźnień).
Interfejs
GFS udostępnia powszechny interfejs systemu plików. Pliki przechowywane są hierarchicznie w katalogach i identyfikowane przez swoje ścieżki. System wspiera typowe operacje na plikach jak: create, delete, open, close, read i write.
Ponadto GFS posiada operację snapshot oraz record append. Pierwsza z nich tworzy niskim kosztem kopię pliku lub całego drzewa katalogów. Druga pozwala wielu klientom jednoczesne dodawanie danych do tego samego pliku zapewniając atomowość operacji każdego klienta.
Architektura
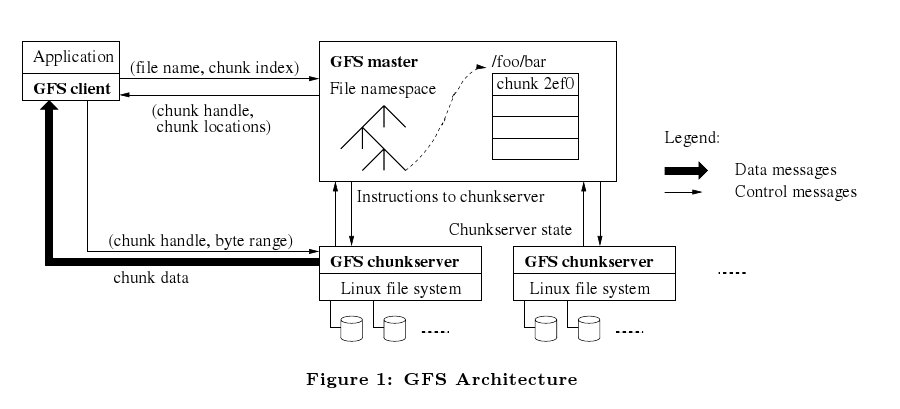
Pojedynczy klaster GFS składa się z jednego serwera głównego, tzw. mastera, i kilkuset, lub kilku tysięcy tzw. chunk-serwerów (lub blok-serwerów), czyli komputerów, które właśnie przechowują pliki. W danej chwili z systemu może korzystać wielu klientów, żądając dostępu do plików.
Typowe pliki trzymane na GFS'ie mają rozmiar od 100 megabajtów do kilkunastu gigabajtów. Aby więc efektywnie zarządzać dostępnym miejscem, GFS trzyma dane w 64-megabajtowych częściach (ang. chunk), co można porównać do bloków na normalnym systemie plików. Dla porównania, typowy rozmiar bloku na Linuxie to 4 kilobajty. Aby przechowywać 128 megabajtowy plik, GFS używa więc dwóch bloków. Jednak z drugiej strony 1 megowy plik zużywa jeden 64 megabajtowy blok co powoduje, że większość jego pozostanie wolna, ale ponieważ tak małe pliki w GFS'ie są bardzo, bardzo rzadkie, inżynierowie Google nie muszą się martwić zmarnowanym miejscem.
Każda część pliku jest identyfikowana przez unikalny 64 bitowy uchwyt pliku (ang. chunk handle), który jest przypisywany przez serwer główny w momencie jej tworzenia. Chunk-serwery przechowują dane na swoich lokalnych dyskach twardych (jako pliki w systemie Linux). Aby zapewnić niezawodność systemu, każdy chunk trzymany jest na wielu chunk-serwerach. Standardowo tworzone są trzy kopie plików, ale możliwe jest zdefiniowanie własnego poziomu replikowania.
Serwer główny przechowuje jedynie metadane zawierające nazwy plików, ich rozmiar i położenie w klastrze. Serwer główny monitoruje również blok serwery, w Google mówią, że sprawdza czy bije im serce (robi to za pomocą specjalnych instrukcji HeartBeat). W przypadku, gdy jeden z komputerów przestanie odpowiadać wówczas jest zgłaszany jako uszkodzony. Jest odpowiedzialny również, za zarządzanie osieroconymi fragmentami plików i migracją danych pomiędzy chunk-serwerami.
W momencie kiedy aplikacja próbuje odczytać dany plik, główny serwer zwraca jej dokładne adresy komputerów go przechowujących. Pomiędzy serwerem a klientami wysyłane są tylko metadane. Następnie aplikacja komunikuje się bezpośrednio z chunk-serwerem.
Chunk-serwery i klienci nie używają dodatkowej pamięci podręcznej cache do przechowywania danych z plików. Po stronie klienta zysk byłby niewielki, ponieważ większość aplikacji korzysta z danych które są zbyt duże żeby mogły zostać zapamiętane w pamięci cache (przechowywane są tylko metadane). Chunk-serwery nie potrzebują dodatkowego cachowania z uwagi na to, że korzystają ze swoich lokalnych dysków twardych, więc zwykłe buforowanie plików w Linuxie utrzymuje odpowiednie dane w pamięci.
Serwer główny (master)
Posiadanie głównego serwera ogromnie upraszcza projekt i umożliwia podejmowanie przez niego wielu decyzji związanych z zarządzaniem plikami przy wykorzystaniu globalnej wiedzy o systemie. Jednocześnie dostarcza problemów z minimalizowaniem jego udziału w operacjach zapisu i odczytu plików, aby serwer główny nie stał się wąskim gardłem całego systemu. Serwer nigdy bezpośrednio nie udostępnia danych. Klienci odpytują serwer, dostając informacje, z którym chunk-serwerem muszą się skomunikować. Metadane, które otrzymują są przez nich cachowane w celu ograniczenia połączeń z serwerem.
Komunikacja z serwerem jest przedstawiona na poprzednim rysunku. Na początku, korzystając z ustalonego rozmiaru chunk'a oraz offsetu, klient oblicza numer części pliku, który jest mu potrzebny (chunk index). Następnie odpytuje serwer główny, podając mu nazwę pliku i chunk index. Master przekazuje uchwyt do pliku (chunk handle) wraz z położeniem jego wszystkich kopii. Klient buforuje tą informację wykorzystując nazwę pliku i chunk index jako klucz. W kolejnym kroku, aplikacja wysyła żądanie jednej kopii fragmentu pliku (domyślnie najbliższej). Żądanie to zawiera uchwyt do pliku i przedział adresów z chunk'a. Późniejsze odczyty z tej części pliku nie wymagają już komunikacji klient - serwer (do momentu, gdy dane w buforze nie wygasną lub plik zostanie otwarty ponownie).
Rozmiar chunk'a
Wybór odpowiedniego rozmiaru chunk'a jest jedną z kluczowych decyzji w systemie. W przypadku GFS'a inżynierowie podjęli decyzję, ustalając jego rozmiar na 64MB, co jest dużo większe niż rozmiar bloku w typowym systemie plików. Opóźniona alokacja przestrzeni dyskowej pozwala unikać wewnętrznej fragmentacji plików.
Duży rozmiar chunk'a ma wiele zalet. Przede wszystkim pozwala zredukować liczbę niezbędnych interakcji z serwerem. Jest wielce prawdopodobne, że aplikacja kliencka będzie wykonywać wiele operacji na tym samym fragmencie pliku. Pozwala to zmniejszyć koszt utrzymywania ciągłego połączenia z chunk-serwerem. Kolejnym powodem jest zmniejszenie metadanych przechowywanych na serwerze (co pozwala na utrzymywanie ich w pamięci i przynosi dodatkowe korzyści).
Z drugiej strony, duży rozmiar bloku może spowodować w przypadku małych plików (np. mniejszych niż rozmiar chunk'a) duże obciążenie chunk-serwerów.
Metadane
Interakcja systemu
Projektując system brano pod uwagę minimalizowanie wpływu serwera głównego na wszystkie operacje w systemie.
Modyfikowanie plików
Podczas działania systemu spotykamy się z operacjami, które modyfikują zawartość lub metadane dotyczące pliku, a właściwie konkretnego chunk'a (np. write, append). Każda taka zmiana musi zostać uwzględniona we wszystkich kopiach chunk'a. W GFS'ie odbywa się to za pomocą szeregowego przesyłania danych pomiędzy chunk-serwerami. Master wyznacza jeden z chunk-serwerów i oznacza go jako primary. Z tym serwerem komunikuje się klient i on jako pierwszy zapisze zmodyfikowaną wersję chunk'a. Pozostałe chunk-serwery otrzymują od serwera wyznaczonego jako primary polecenie zapisu nowej kopii tego chunk'a.
Prześledźmy teraz dokładnie proces komunikacji pomiędzy serwerami:
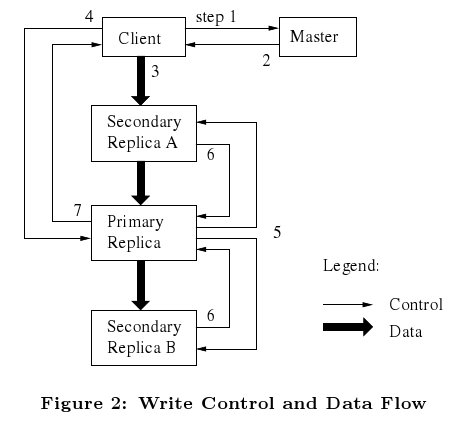
- Aplikacja kliencka wysyła żądanie do mastera o wskazanie chunk-serwera, który został wyznaczony jako primary (jeśli taki nie istnieje to master wyznacza go teraz) i posiada odpowiednią część pliku.
- Master przekazuje informacje o serwerze primary oraz o pozostałych kopiach żądanego chunk'a oznaczonych jako secondary. W przypadku, gdy master nie odpowiada, wszystkie kroki muszą zostać wykonane ponownie.
- Klient wysyła dane w dowolnym porządku do wszystkich chunk-serwerów posiadających kopie chunk'a. Każdy serwer zapamięta je w wewnętrznym buforze LRU.
- Kiedy wszystkie chunk-serwery potwierdzą odbiór danych, klient wysyła do serwera primary polecenie ich zapisu. Serwer ten zastosuje wszystkie modyfikacje do swojej lokalnej kopii tego chunk'a.
- Serwer primary wysyła do pozostałych chunk-serwerów polecenie zapisu. Każdy z tych serwerów zastosuje wszystkie zmiany do swojej kopii (tak samo jak to zrobił krok wcześniej serwer primary).
- Serwery secondary potwierdzają zakończenie operacji zapisu.
- Następnie serwer primary powiadamia klienta o zakończeniu procesu zapisu (we wszystkich kopiach).
Dla przykładu, przesłanie 1MB danych do wszystkich kopii trwa około 80 ms.
Atomowa operacja dopisywania (record append)
GFS udostępnia atomową operację dopisywania do pliku (record append). W tradycyjnym zapisie klient specyfikuje offset, pod ktorym mają zostać zapisane dane. W przypadku dopisywania, klient podaje jedynie dane, które chce zapisać. GFS dopisuje je atomowo jako jeden sekwencyjny zapis danych pod offsetem, który jest wybierany przez system i zwracany klientowi. Operacja ta jest podobna to operacji zapisu do pliku otwartego z opcją O_APPEND w systemie Unix.
Przebieg operacji record append jest podobny do opisanego wcześniej procesu zapisu do pliku. Klient wysyła dane do wszystkich chunk-serwerów posiadających ostatnią część pliku. Następnie wysyła żądanie do serwera primary. Serwer ten sprawdza czy zapis do tego chunk'a może spowodować, że jego rozmiar przekroczy ograniczenie (64MB). W takim przypadku, bieżący chunk jest uzupełniany do maksymalnego rozmiaru i primary wysyła żądanie do pozostałych serwerów, aby postąpili tak samo. Następnie klient jest informowany, że musi ponowić zapis do pliku (do kolejnego chunk'a). Jeśli rekord, który ma zostać zapisany, mieści się w bieżącym chunk'u dane są zapisywane i postępowanie jest identyczne jak w przypadku zwykłego zapisu.
Snapshot
Operacja snapshot tworzy kopię pliku lub całego drzewa katalogów. Użytkownik, może szybko utworzyć nową gałąź będącą kopią ogromnego zbioru danych. Tworzenie ich, umożliwia szybkie przywrócenie wszystkich plików do zapisanego stanu. Kiedy master odbiera żądanie wykonania snapshot'a, wycofuje wszystkie oczekujące operacje korzystające z chunk'ów, które mamy skopiować. To wymusza na klientach, którzy chcą je zmodyfikować ponowną komunikację z masterem i daje mu możliwość wcześniejszego skopiowania danych. Na początku kopiowane są metadane dotyczące tych chunk'ów.
W momencie kiedy klient chce zapisać jakieś dane do pewnego chunk'a po wykonaniu snpashot'a wysyła żądanie do mastera. Serwer główny zauważa, że liczba referencji do tego chunk'a jest większa niż jeden i opóźnia odpowiedź klientowi. W tym czasie, serwer wysyła polecenie utworzenia kopii do wszystkich chunk-serwerów posiadających kopię chunk'a. Dopiero teraz klient otrzymuję odpowiedź.
Operacje mastera
Serwer główny wykonuje wiele operację związanych z zarządzaniem metadanymi, podejmuję decyzję o położeniu chunk'ów, tworzy je oraz koordynuje cały system, dba o spójność danych i wydajność systemu. W tej części bardziej szczegółowo zostaną omówione niektóre z czynności mastera.
Zarządzanie metadanymi i blokady
Wiele operacji serwera zabiera dużo czasu (np. snapshot). Dlatego postanowiono umożliwić mu wykonywanie wielu operacji w tym samym czasie. Wymagało to założenia blokad.
Każda operacja mastera wymaga założenia pewnych blokad na drzewie katalogów. Jeśli chcemy mieć dostęp do danych o pliku /d1/d2/.../dn/leaf, muszą zostać założone blokady czytelników na katalogi /d1, /d1/d2, ..., /d1/d2/.../dn i następnie blokada pisarza lub czytelnika na całą ścieżkę /d1/d2/.../dn/leaf.
Przeanalizujmy przykładowy scenariusz. Chcemy utworzyć plik /home/user/foo podczas wykonywanej operacji snapshot katalogu /home/user do katalogu /save/user. Operacja snapshot wymaga założenia blokad czytelników na katalogi /home i /save oraz blokad pisarzy na /home/user i /save/user. Natomiast operacja tworzenia pliku będzie wymagała założenia blokady czytelników na /home i /home/user i blokady pisarza na /home/user/foo.
Odśmiecanie (garbage collection)
Po usunięciu pliku, GFS nie zwalnia natychmiast zasobów, które on zajmował. Czynność ta zostaje opóźniona i co pewien czas master zajmuje się odśmiecaniem danych, które on przechowuje i chunk-serwerów.
Wykrywanie nieaktualnych replik
Kopie chunk'ów mogą stać się nieaktualne np. w przypadku nieudanego zapisu (nie wszystkie chunk-serwery zakończyły operację sukcesem). Wszystkie zmiany w plikach są wersjonowane, co umożliwia wykrycie nieaktualnego fragmentu pliku i zaktualizowanie go.
Testy wydajności
Przeanalizujmy wyniki kilku testów systemu GFS, żeby zilustrować problemy z jakimi borykają się inżynierowie w Google.
Badania zostały przeprowadzone na klastrze GFS złożonym z jednego mastera, dwóch jego kopii, 16 chunk-serwerów i 16 klientów. Jest to bardzo uproszczony klaster stworzony specjalnie dla testów. W rzeczywistości składa się on z wielu tysięcy chunk-serwerów i klientów.
Każda z maszyn posiada podwójny procesor PIII 1.4 GHz, 2GB pamięci, dwa dyski twarde 80GB 5400 rpm i karty sieciowej 100 Mbps (full-duplex). Sieć została zbudowana za pomocą switchy HP 2524. 19 maszyn serwerowych jest podłączona do jednego switcha, a do drugiego 16 maszyn klienckich. Switche połączone są za pomocą łącza o przepustowości 1Gbps.
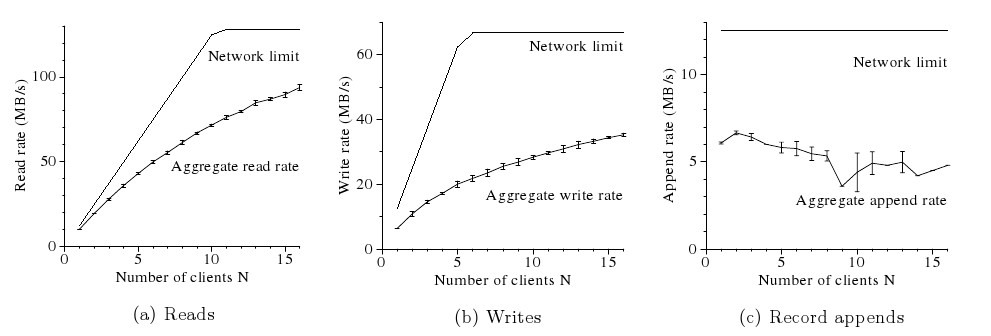
- N klientów odczytuje dane z systemu plików. Każdy z nich odczytuje losowo 4MB z 320GB pliku. Czynność ta jest powtarzana 256 razy, żeby każdy odczytał 1GB danych. Rysynek a) przedstawia sumaryczną prędkość odczytu przez N klientów i teoretyczny limit. Górnym limitem transferu pomiędzy switchami jest 125MB/s (12.5 MB/s przypada na klienta ponieważ ogranicza go karta sieciowa). W przypadku, gdy tylko jeden klient korzysta z systemu plików zaobserwowano transfer rzędu 10MB/s co stanowi 80% możliwości. Dla 16 klientów, wydajność spada do 75% (łączny transfer 94MB/s, 6MB/s na klienta).
- N klientów zapisuje dane do N różnych plików. Każdy z nich zapisuje 1GB danych do nowego pliku w seriach po 1MB. Górny limit wynosi 67MB/s ponieważ każdy bajt musi zostać zapisany do trzech chunk-serwerów. W przypadku 1 klienta średni transfer wyniósł 6.3MB/s (około 50% możliwości). W przypadku 16 klientów spadł on do 2.2MB/s (łączny transfer 35Mb/s).
- N klientów dopisuje dane do jednego pliku. Transfer jest uzależniony od ograniczenia chunk-serwerów posiadających ostatni fragment pliku, który zostaje modyfikowany i wynosi on 6MB/s w przypadku jednego klienta i 4.8MB/s kiedy jest ich 16.
Przykładowe klastry GFS
Poprzednie testy były przeprowadzona na bardzo uproszczonym klastrze GFS'a. W Google działają klastry o następujących parametrach:
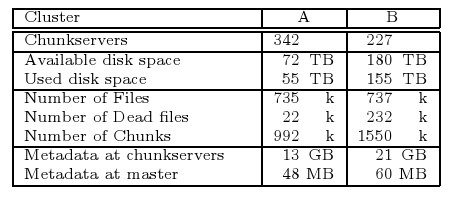
Transfery jakie uzyskano w powyższych konfiguracjach kształtują się następująco:
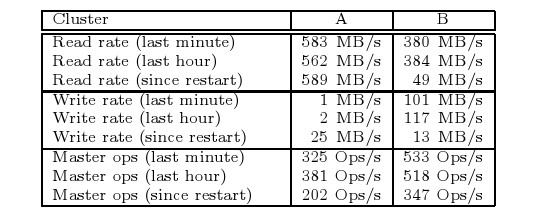
Inżynierowie z Google przeprowadzili eksperyment polegający na odłączeniu jednego chunk-serwera z klastra B, który przechowywał około 15000 chunk'ów (600GB danych). Wszystkie fragmenty zostały odzyskane w ciągu 23 minut.
Podsumowanie
The Google File System demonstruje jak za pomocą zwykłych komputerów PC uzyskać wydajność superkomputera, który potrafi sprawnie obsługiwać ogromne ilości danych. GFS jest cały czas rozwijany i usprawniany. Z wielkim sukcesem znalazł zastosowanie w Google i rozwiązał wszystkie stawiane przed nim problemy.
The Lustre File System [Paweł Gora]
Wstęp
- Lustre FS to klastrowy, skalowalny system plików oparty na sieciach (klastrach) zawierających 10 tysięcy węzłów, udostępniających petabajty danych. Zapewnia brak pojedynczych punktów awarii, szybki start i dużą wydajność. Aktualnie jest on dostępny tylko na platformie Linux.
Nazwa Lustre pochodzi od słów: linux oraz cluster.
Powstanie Lustre FS
- Architektura Lustre FS została zaproponowana w 1999 roku przez Petera Braama, naukowca z Carnegie Mellon University. Założył on firme Cluster File Systems, która wydała Lustre 1.0 w 2003 roku. W październiku 2007 roku firma została nabyta przez Sun Microsystems. W kwietniu 2007 roku została wydana wersja Lustre 1.6.0.
Kluczowe cechy Lustre FS
- Duża pojemność
- Dobre mechanizmy odzyskiwania danych: możliwość odtworzenia stanu w momencie, gdy jeden z węzłów sieci przestanie działać (failover)
- Rozproszony dostęp do plików (możliwość jednoczesnego zapisu i odczytu z różnych fragmentów tego samego pliku dzięki efektywnym mechanizmom zapewniającym współbieżność)
Składniki Lustre FS
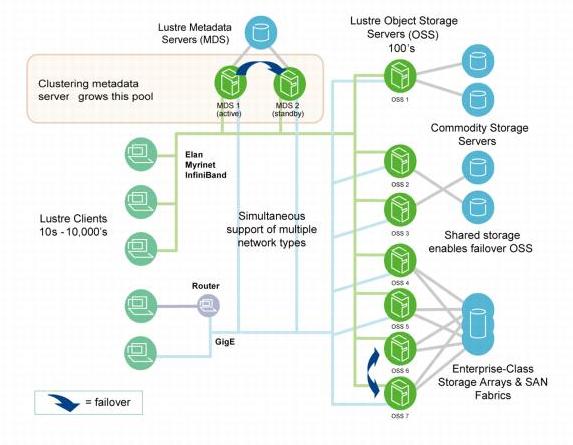
- Serwer zarządzający MGS (Management Server)
- MDT (Meta Data Targets)
- Składnice obiektów OST (Object Storage Targets)
- Programy klienckie Lustre
MGS
MDT
OST
Klienci
- Klienci są "użytkownikami" systemu plików
- Po zamontowaniu systemu plików widzą oni przez cały czas jedną, spójną przestrzeń danych
- Ich oprogramowanie składa się z interfejsów do targetów MDT, OST oraz do serwera zarządzającego. Są to odpowiednio: Metadata Client (MDC), Object Storage Client (OSC) oraz Management Client (MGC).
- Programy klienckie są również wyposażone w mechanizmy montowania systemu plików Lustre FS
- Różni klienci mogą w tej samej chwili zapisywać do różnych fragmentów tego samego pliku; w tym samym czasie inni klienci mogą czytać z tego samego pliku
- Niemal wszystkie czynności systemów Target są wyzwalane przez zapytania płynące od klientów
Komunikacja między komponentami
Kluczowe cechy LNET:
- Możliwość korzystania z transferu RDMA (remote direct memory access)
- Wsparcie dla wielu powszechnych typów sieci (np. IP, InfiniBand)
- Możliwość jednoczesnej obsługi wielu typów sieci
- Dobre mechanizmy odzyskiwania danych
Zasoby dyskowe komunikują się z systemem plików (a dokładniej z MDT oraz OST) przy pomocy tradycyjnej technologii SAN (Storage Area Network).
Źródła
- "Proceeding of the Linux Symposium - The GFS2 Filesystem" - Steven Whitehouse
- "The Global File System - A File System for Shared Disk Storage" - Kenneth W. Preslan, Matthew T. O'Keefe
- "The Google File System" - Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung
- "Lustre File System" - Peter J. Braam
- "Rozproszone systemy plików" - Cezary Sobaniec
- "Lustre 1.6 Operations Manual v1.9" - http://manual.lustre.org/manual/LustreManual16_HTML/TOC.html