Rysunki są dziełem studentów III roku informatyki MIM.
W Linuksie rolę metryczki procesu pełni struktura task_struct. Zawiera ona wszystkie informacje o danym procesie (często w postaci wskaźników do innych struktur). Uwaga: niektóre nazwy pól na rysunkach są już nieaktualne w jądrze 2.6.
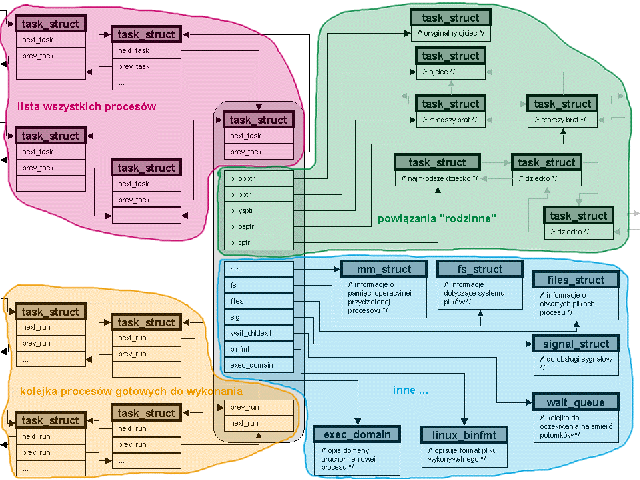
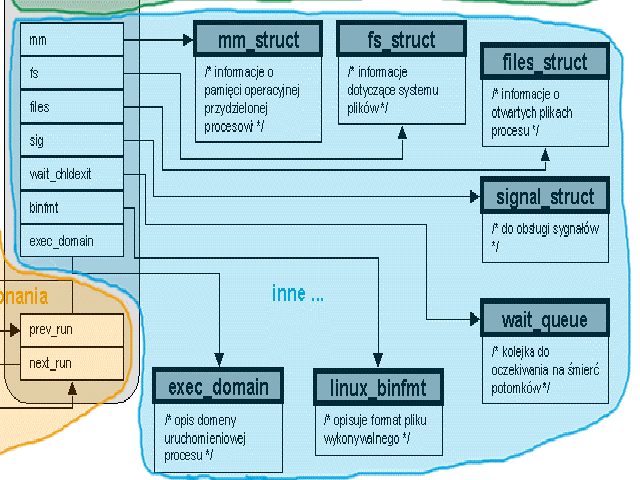
Jest to struktura związana z każdym istniejącym w systemie procesem. Struktura struct task_struct jest zdefiniowana w pliku /include/linux/sched.h. Jej rozmiar to około 1.7 KB.
Oto kilka podstawowych pól tej struktury:
volatile long state - określa stan procesu.
Możliwe stany są zdefiniowane jako stałe w pliku /include/linux/sched.h:
/* in tsk->state */
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define TASK_STOPPED 4
#define TASK_TRACED 8
/* in tsk->exit_state */
#define EXIT_ZOMBIE 16
#define EXIT_DEAD 32
/* in tsk->state again */
#define TASK_NONINTERACTIVE 64
TASK_RUNNING - proces się wykonuje bądź jest gotowy do wykonania.
TASK_INTERRUPTIBLE - proces jest lub może zostać uśpiony w stanie przerywalnym, czyli że zostanie wznowiony po nadejściu sygnału lub po upływie czasu budzenia. Ostatnie oznacza, że proces może zostać uśpiony na pewien zadany czas (możliwość często używana przez programy obsługi urządzeń).
TASK_UNINTERRUPTIBLE - proces jest lub zostanie uśpiony w stanie nieprzerywalnym (np. w oczekiwaniu na i-węzeł). Proces taki może zostać wznowiony jedynie na skutek wywołania funkcji wake_up() - ściślej jego stan zostanie zmieniony na TASK_RUNNING.
TASK_STOPPED - proces został wstrzymany, ani się nie wykonuje, ani nie jest gotowy do wykonania. Proces przejdzie w ten stan np. na skutek otrzymania sygnału SIGSTOP. Może zostać wznowiony jedynie na skutek otrzymania sygnału SIGCONT.
EXIT_ZOMBIE - proces wykonał funkcję exit(), ale jego proces macierzysty nie wykonał jeszcze dla niego funkcji wait() (w celu pobrania kodu wykonania). Metryczka procesu pozostanie w systemie aż do chwili wykonania wait() przez proces macierzysty.
struct thread_info *thread_info - dowiązanie do struktury thread_info zawierającej niskopoziomowe informacje o procesie
pid_t pid - unikatowy identyfikator procesu.
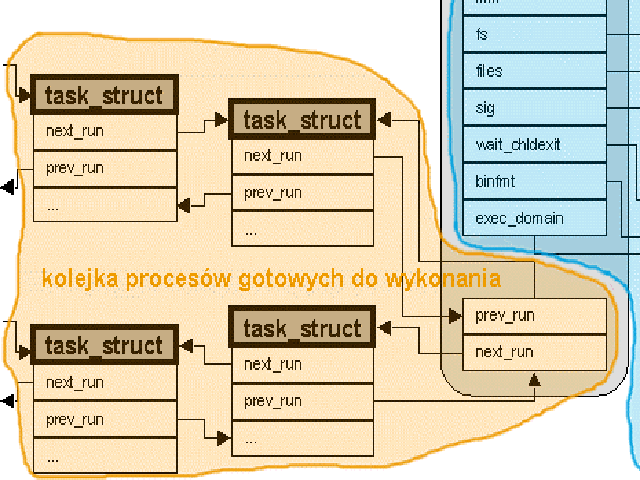
struct list_head run_list - dowiązania do następnego i poprzedniego procesu w kolejce procesów gotowych.
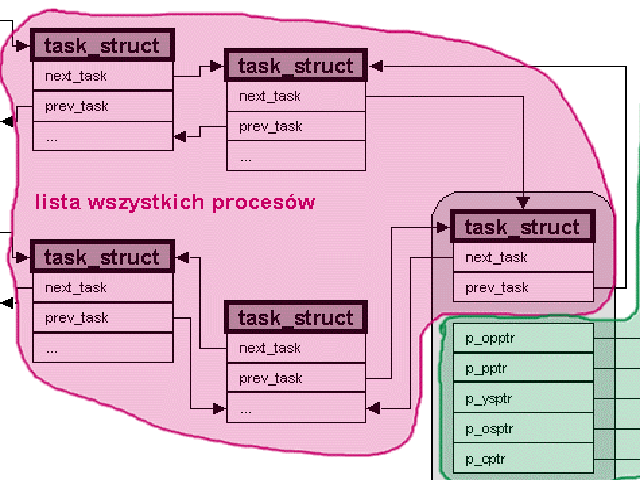
struct list_head tasks - dowiązania do następnego i poprzedniego procesu na liście wszystkich procesów.
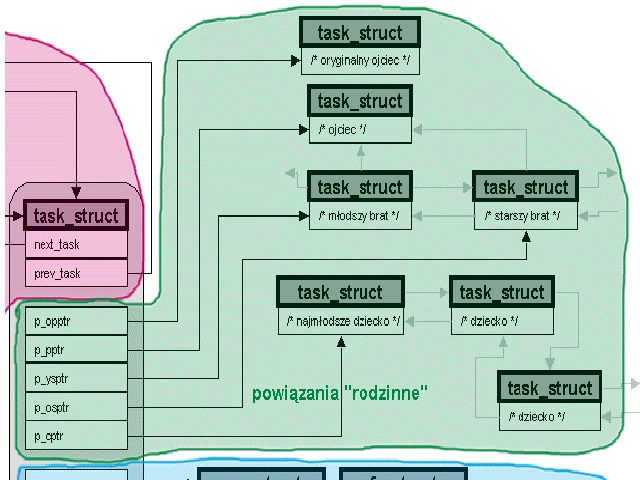
struct task_struct *real_parent, parent - powiązania rodzinne procesu: oryginalny ojciec (podczas odpluskwiania), ojciec
struct list_head children, sibling - powiązania rodzinne procesu: dzieci, rodzeństwo
Dla każdego procesu wskaźnik do jego task_struct jest dostępny w strukturze thread_info przechowywanej wraz z jego stosem trybu jądra. Obie struktury są trzymane w pojedynczym, dynamicznie alokowanym obszarze pamięci o wielkości 8 KB.
Struktura thread_info zaczyna się na początku tego obszaru pamięci, a stos na końcu i rośnie "w dół" (uwaga: rysunek tylko w przybliżeniu obrazuje tę strukturę i zawiera odwołanie do nieistniejącej nazwy task_union).
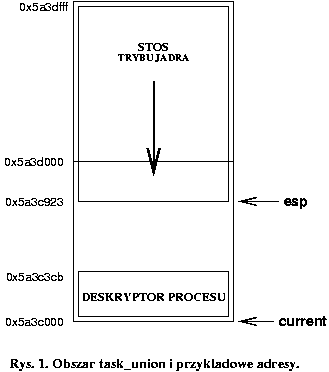
Zawartość tego obszaru pamięci jest zdefiniowana przez unię thread_union (z pliku /include/linux/sched.h) i strukturę thread_info (z pliku /include/asm-i386/thread_info.h).
#define THREAD_SIZE (8192)
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
struct thread_info {
struct task_struct *task; /* main task structure */
struct exec_domain *exec_domain; /* execution domain */
unsigned long flags; /* low level flags */
unsigned long status; /* thread-synchronous flags */
__u32 cpu; /* current CPU */
int preempt_count; /* 0 => preemptable, <0 => BUG */
mm_segment_t addr_limit; /* thread address space:
0-0xBFFFFFFF for user-thread
0-0xFFFFFFFF for kernel-thread
*/
struct restart_block restart_block;
unsigned long previous_esp; /* ESP of the previous stack in case
of nested (IRQ) stacks
*/
__u8 supervisor_stack[0];
};
Jądro najczęściej odwołuje się do procesów poprzez wskaźnik do ich metryczki. Korzysta w tym celu ze specjalnego makra (zależnego od architektury), gdyż te odwołania muszą być bardzo szybkie. W niektórych architekturach wskaźnik do bieżącego procesu przechowuje się w rejestrze, tam gdzie rejestrów nie jest za wiele wykorzystuje się wskaźnik stosu.
Wskaźnik stosu, określający położenie wierzchołka stosu, jest trzymany w rejestrze esp. W szczególności, kiedy pewien proces wykonuje się w trybie jądra, rejestr esp wskazuje na wierzchołek stosu trybu jądra tego właśnie procesu. Skoro struktura thread_info procesu i jego stos trybu jądra są trzymane w 8 KB ( = 213 bitowym) obszarze pamięci, a thread_info zaczyna się na początku tego obszaru, więc wystarczy zamaskować 13 najmniej znaczących bitów w rejestrze esp, by dostać się do wskaźnika na strukturę aktualnie wykonywanego procesu (o ile proces znajduje się w trybie jądra).
Realizuje to makro current_thread_info, zawierające kilka tylko instrukcji asemblera (znajduje się w pliku /include/asm-i386/thread_info.h, reszta deklaracji w /include/asm-i386/current.h).
static inline struct thread_info *current_thread_info(void)
{
struct thread_info *ti;
__asm__("andl %%esp,%0; ":"=r" (ti) : "0" (~(THREAD_SIZE - 1)));
return ti;
}
static __always_inline struct task_struct * get_current(void)
{
return current_thread_info()->task;
}
#define current get_current()
Makro current i current_thread_info zazwyczaj pojawia się w kodzie jądra jako przedrostek pól task_struct procesu.
Wyznaczanie wskaźnika na task_struct aktualnie wykonywanego procesu dzięki temu jest bardzo szybkie. Nie trzeba przechowywać globalnej zmiennej current czy (w systemach wieloprocesorowych) całej tablicy current.
Czasem jądro musi pobrać wskaźnik na task_struct procesu mając tylko jego PID. (Jest to potrzebne np. w funkcji systemowej kill()). Przeszukiwanie listy wszystkich procesów i sprawdzanie pól pid w strukturach task_struct procesów byłoby nieefektywne.
Wprowadzono tablicę haszującą pid_hash. Każda pozycja tablicy jest dwukierunkową listą struktur task_struct procesów, dla których funkcja haszująca przekazuje tę samą wartość. Listy są zrealizowane za pomocą pól pid_link w task_struct procesu.
struct pid_link
{
struct hlist_node node;
struct pid *pid;
};
struct task struct {
...
struct pid_link pids[PIDTYPE_MAX];
...
}
Identyfikator procesu jest zaimplementowany jako struktura. Jednym z celów takiego rozwiązania jest uniknięcie problemów z ponownym użyciem numeru czy metryczki procesu przez nowy proces (po zakończeniu działania poprzedniego procesu, który korzystał z tego samego numeru czy metryczki). Jednym z pól tej struktury jest ten właściwy numer procesu.
static inline struct pid *get_pid(struct pid *pid)
if (pid)
atomic_inc(&pid->count);
return pid;
}
Funkcja haszująca (w praktyce makro) pid_hashfn() tłumaczy podany PID na pozycję w tablicy pid_hash:
Przy wywołaniu funkcji schedule() (w wyniku obsługi przerwania, bądź obsługi wywołania systemowego) może pojawić się potrzeba przełączenia kontekstu (zmiany aktualnie wykonywanego procesu).
Kontekstem sprzętowym nazywamy zestaw danych ładowanych do rejestrów procesora przed wznowieniem wykonania procesu. Zmiana kontekstu jest to więc zmiana wartości rejestrów procesora polegająca na zapamiętaniu poprzednich wartości w celu przywrócenia ich w chwili przyznania procesowi procesora i odtworzeniu wartości związanych z procesem, któremu przekazuje się procesor.
Kontekst sprzętowy jest przechowywany w strukturze thread_struct (p->thread) procesu (plik /include/asm-i386/processor.h).
Do przechowywanych w tej strukturze rejestrów należą między innymi:
Przełączenie kontekstu następuje na skutek wywołania makra switch_to() (plik /include/asm-i386/system.h) przez funkcję schedule().
Proces szeregujący (ang. scheduler) to część jądra zajmująca się przydzielaniem procesom procesora, zgodnie z pewną polityką, za pomocą pewnych mechanizmów.
Polityka obejmuje:Mechanizmy to środki umożliwiające realizację polityki:
Procesy można zakwalifikować jako zorientowane obliczeniowo i zorientowane na wejście-wyjście. Metoda szeregowania powinna umieć sobie radzić z dwoma przeciwstawnymi celami: minimalizacją czasu reakcji i maksymalizacją przepustowości. Faworyzowanie procesów zorientowanych na wejście-wyjście zwykle poprawia pierwszy z tych mierników, gdyż taki charakter mają procesy interakcyjne. Linux faworyzuje takie procesy, ale nie zapominając o zadaniach zorientowanych obliczeniowo.
Stosowane strategie szeregowania często wykorzystują priorytety. Procesy o wyższym priorytecie dostają procesor przed procesami o niższym priorytecie i na dłuższy odcinek czasu. Priorytety mogą zmieniać się dynamicznie. Proces rozpoczyna działanie z pewnym priorytetem bazowym, ale w trakcie działania ten priorytet może się zmniejszyć lub zwiększyć.
Linux rozróżnia następujące klasy, w kolejności malejących priorytetów:
proces idle
Jest to proces o numerze 0, tworzony bez udziału fork, inicjowany makrodefinicją INIT_TASK. Cały czas znajduje się w stanie TASK_RUNNING i w przypadku, gdy nie ma nikogo chętnego do pracy on otrzymuje procesor. Gdy tylko pojawi się jakikolwiek inny proces gotowy do wykonania, idle jest wywłaszczany.
Dygresja: proces o numerze 0, zwany swapper, jest tworzony podczas fazy inicjacji jądra i jako jedyny ma statycznie alokowane struktury danych (makrodefinicja INIT_TASK). Funkcja start_kernel() inicjuje wszystkie struktury danych jądra, włącza przerwania i tworzy kolejny proces, o numerze 1, tzw. init. Proces init po wybraniu do wykonania wykonuje funkcję init(). Proces 0 po utworzeniu procesu 1 wykonuje funkcję cpu_idle().
Procesy te mają bezwzględne pierwszeństwo przed zwykłymi procesami, tzn.:
W klasie RT procesy mogą być szeregowane na dwa sposoby:
Przerywa swoje działanie gdy:
Przerywa swoje działanie gdy:
Do wykonania zostaje wybrany ten z procesów gotowych, który ma największą wartość priorytetu dynamicznego.
Przerywa swoje działanie gdy:
Pola w strukturze task_struct i thread_info:
unsigned long policy - określa tryb szeregowania dla procesu. Dostępne tryby to: SCHED_NORMAL, SCHED_FIFO, SCHED_RR, SCHED_BATCH.
int static_prio - priorytet statyczny, użytkownik może go zmienić wywołując funkcję nice(). Priorytet statyczny przyjmuje wartości od 0 do 139, wartość nice dla procesu przyjmuje wartości od -20 do 19 (domyślnie 0). Makro TASK_NICE wylicza wartość nice dla ustalonego static_prio, a makro NICE_TO_PRIO wylicza wartość static_prio dla ustalonego nice.
p->static_prio = NICE_TO_PRIO(nice);
int prio - priorytet dynamiczny, wyliczany przez system w trakcie działania systemu, mi.in. na podstawie priorytetu statycznego.
unsigned long sleep_avg - reprezentuje stosunek czasu wykonywania do oczekiwania procesu.
enum sleep_type sleep_type - przyjmuje jedną z wartości: SLEEP_NORMAL, SLEEP_NONINTERACTIVE, SLEEP_INTERACTIVE, SLEEP_INTERRUPTED
unsigned long long timestamp - data zdarzenia (kiedy proces zaczął się wykonywać lub kiedy został dodany do kolejki), używany do aktualizowania sleep_avg.
TIF_NEED_RESCHED - bit wskazujący, że system powinien dokonać przeszeregowania procesów najwcześniej gdy tylko będzie to możliwe. Jego wartość dostarcza funkcja need_resched:
static inline int need_resched(void)
{
return test_thread_flag(TIF_NEED_RESCHED);
}
Zmienna jiffies
Licznik czasu systemowego.

Priorytet dynamiczny procesu jest przechowywany w polu task_struct->prio. Jest oparty na priorytecie statycznym. Priorytet dynamiczny jest sumą priorytetu statycznego i pewnego bonusu, który zwiększa priorytet dynamiczny procesom interaktywnym, a zmniejsza procesom zorientowanym na obliczenia.
Kwant czasu to okres na jaki proces dostanie procesor. Przykładowe liczby: minimalny kwant wynosi 5 msec, domyślny 100 msec, a maksymalny 800 msec.
Podstawową strukturą danych, wchodzącą w skład każdej kolejki procesów gotowych, jest kolejka priorytetowa. Taka kolejka jest zadeklarowana jako struktura z następującymi polami:

/*
* These are the runqueue data structures:
*/
#define MAX_RT_PRIO 100
#define MAX_PRIO (MAX_RT_PRIO + 40)
#define BITMAP_SIZE ((((MAX_PRIO+1+7)/8)+sizeof(long)-1)/sizeof(long))
struct prio_array {
unsigned int nr_active;
unsigned long bitmap[BITMAP_SIZE];
struct list_head queue[MAX_PRIO];
};
Z każdym procesorem jest związana jedna struktura runqueue. W runqueue znajdują się procesy gotowe do wykonania. Podstawowymi składowymi struktury runqueue są dwie tablice typu struct prio_array:

struct runqueue {
spinlock_t lock; /* spinlock do ochrony kolejki */
unsigned long nr_running; /* liczba procesów gotowych do wykonania */
unsigned long nr_switches; /* liczba przełączeń kontekstu */
unsigned long expired_timestamp; /* czas ostatniego przełączenia kolejek */
int best_expired_prio;
unsigned long nr_uninterruptible; /* liczba procesów śpiących z zablokowanymi przerwaniami */
struct task_struct *curr; /* proces wykonywany tego procesora */
struct task_struct *idle; /* proces idle tego procesora */
struct prio_array *active; /* wskaźnik do kolejki active */
struct prio_array *expired; /* wskaźnik do kolejki expired */
atomic_t nr_iowait; /* liczba procesów czekających na I/O */
struct task_struct *migration_thread; /* */
struct list_head migration_queue; /* */
...
};
Główne procedury procesu szeregującego to schedule() i scheduler_tick(). Głównym zadaniem procedury schedule() jest wybór następnego procesu do wykonania i przekazanie mu procesora. Procedurę wywołuje jądro, gdy chce zasnąć lub gdy należy wywłaszczyć proces. Procedura scheduler_tick() przelicza priorytety i kwanty czasu.
Wybór procesu o najwyższym priorytecie jest prostym zadaniem. Najpierw trzeba ustalić, w której kolejce znajduje się ten proces. Linux utrzymuje dwie kolejki procesów gotowych dla każdego procesora. W kolejce active są przechowywane te procesy, którym pozostał niezerowy kwant czasu, a w kolejce expired te, które już zużyły swój kwant. Kiedy proces zużyje swój kwant jest przenoszony z kolejki active do kolejki expired. Od razu wylicza się dla niego nowy kwant. Gdy kolejka active staje się pusta, wystarczy zamienić active z expired, co odbywa się w czasie stałym. W procedurze schedule znajduje się kod:
struct prio_array array = rq->active;
if (!array->nr_active) {
/*
* Switch the active and expired arrays.
*/
schedstat_inc(rq, sched_switch);
rq->active = rq->expired;
rq->expired = array;
array = rq->active;
rq->expired_timestamp = 0;
rq->best_expired_prio = MAX_PRIO;
}
Mamy już pewność, że kolejka active zawiera proces o najwyższym priorytecie. Znajdujemy ten proces.
struct task_struct *prev, *next;
struct list_head *queue;
struct runqueue *rq;
prio_array_t *array;
int idx;
prev = current;
rq = this_rq(); /* kolejka runqueue TEGO procesora */
array = rq->active;
idx = sched_find_first_bit(array->bitmap); /* pierwszy zapalony bit */
queue = array->queue + idx;
next = list_entry(queue->next, struct task_struct, run_list);
Jeśli nowo wybrany proces (next) jest różny od poprzednio wykonywanego (prev), to nastąpi przełączenie kontekstu.
if (prev != next) {
next->timestamp = now;
rq->nr_switches++;
rq->curr = next;
++*switch_count;
prepare_task_switch(rq, next);
prev = context_switch(rq, prev, next);
Jak widać ten kod nie zależy od liczby procesów w systemie, jest prosty i szybki, wykonuje się w czasie stałym.
Procedura scheduler_tick() jest wywoływana przy każdym przerwaniu pochodzącym od zegara.
Najpierw obsługiwane są procesy czasu rzeczywistego. Procesy szeregowane zgodnie z zasadą kolejki prostej (FIFO) nie wymagają żadnej akcji, gdyż nie korzystają z kwantu czasu. Procesy szeregowane zgodnie ze strategią karuzelową (RR) po upłynięciu kwantu czasu idą na koniec kolejki procesów gotowych (o tym samym priorytecie) - od razu dostają nowy kwant (wywołanie funkcji task_timeslice()).
if (rt_task(p)) {
if ((p->policy == SCHED_RR) && !--p->time_slice) {
p->time_slice = task_timeslice(p);
p->first_time_slice = 0;
set_tsk_need_resched(p);
/* put it at the end of the queue: */
requeue_task(p, rq->active);
}
goto out_unlock;
}
Jeśli proces zużyje swój kwant czasu, to przelicza się mu na nowo priorytet (funkcja effective_prio()) i wylicza nowy kwant czasu (funkcja task_time_slice()). Proces zasadniczo powinien powędrować teraz do kolejki expired, ale jeśli proces szeregujący stwierdzi, że ma do czynienia z procesem interakcyjnym (makro TASK_INTERACTIVE), to wstawi go z powrotem do kolejki active, upewniwszy się przedtem jednak, że nie spowoduje to zagłodzenia procesów czekających w kolejce expired, czyli nie ma tam procesów, które czekają już bardzo długo, bo dawno nie przełączano kolejek (makro EXPIRED_STARVING).
if (!--p->time_slice) {
dequeue_task(p, rq->active);
set_tsk_need_resched(p);
p->prio = effective_prio(p);
p->time_slice = task_timeslice(p);
p->first_time_slice = 0;
if (!rq->expired_timestamp)
rq->expired_timestamp = jiffies;
if (!TASK_INTERACTIVE(p) || EXPIRED_STARVING(rq)) {
enqueue_task(p, rq->expired);
if (p->static_prio < rq->best_expired_prio)
rq->best_expired_prio = p->static_prio;
} else
enqueue_task(p, rq->active);
} else {
...
}
Jeśli kwant czasu procesu jeszcze się nie skończył, to lepiej się upewnić, że kwant nie jest nadmiernie duży i że proces nie próbuje zmonopolizować procesora. W takim przypadku "dzieli się kwant na mniejsze kawałki" - czyli po prostu przenosi proces na koniec kolejki procesów o tym samym priorytecie.
} else {
* This only applies to tasks in the interactive
* delta range with at least TIMESLICE_GRANULARITY to requeue.
*/
if (TASK_INTERACTIVE(p) && !((task_timeslice(p) -
p->time_slice) % TIMESLICE_GRANULARITY(p)) &&
(p->time_slice >= TIMESLICE_GRANULARITY(p)) &&
(p->array == rq->active)) {
requeue_task(p, rq->active);
set_tsk_need_resched(p);
}
}
Działanie procesu szeregującego ilustruje następujący diagram.

W funkcji activate_task wywoływana jest procedura recalc_task_prio, która korzysta z funkcji effective_prio. Funkcja effective_prio modyfikuje statyczny priorytet procesu o bonus zależny od interaktywności procesu. Bonus, który proces może otrzymać to wartość z przedziału [-5,5]. Procesy interaktywne mogą dostać bonus równy 5, wtedy wartość ich priorytetu zmaleje o 5 (będą ważniejsze).
Przy ustalaniu "interaktywności" jądro stosuje pewną heurystykę w celu określenia, czy proces jest zorientowany obliczeniowo, czy na wejście-wyjście. Najlepszym miernikiem jest czas spania procesu: im więcej czasu proces spędza śpiąc, tym jest bardziej interaktywny. Jeśli proces dłużej się wykonuje niż śpi, to nie jest interaktywny.
Do implementacji tej heurystyki Linux wykorzystuje pole sleep_avg w metryczce procesu przyjmuje wartości od 0 do MAX_SLEEP_AVG. Wartość sleep_avg:

Ta metoda jest dość dokładna, bo bierze pod uwagę nie tylko jak długo proces śpi, lecz także jak krótko się wykonuje.
Wyliczenie kwantu czasu jest już proste, bo wystarczy wziąć pod uwagę dynamiczny priorytet procesu. Gdy proces tworzy potomka, musi się z nim podzielić pozostałym mu kwantem czasu (dzięki temu użytkownikowi nie uda się zagarnięcie procesora przez tworzenie dużej liczby procesów potomnych). Gdy kwant zostanie zużyty, nowy jest wyliczany w funkcji task_timeslice(). Nowa wartość zależy od priorytetu dynamicznego i priorytetu statycznego procesu. Wartością domyślną (dla nice = 0 i zerowego bonusu) jest 100 msec.
Przeliczanie priorytetów odbywa się jedynie dla procesów użytkowych, nie dla procesów czasu rzeczywistego.
W jądrze 2.4 była jedna wspólna kolejka wszystkich procesów:

Na kolejnych diagramach pokazano różnice w zachowaniu algorytmu szeregowania w jądrze 2.4 i 2.6.




| ©Janina Mincer-Daszkiewicz |