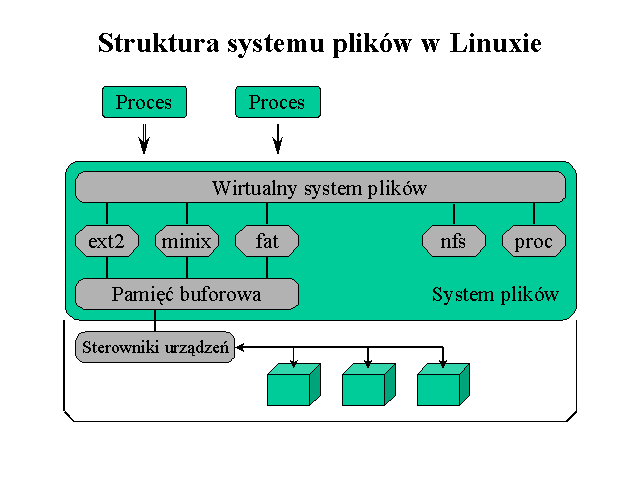
Linux potrafi obsługiwać wiele różnych systemów plików (ściślej: formatów systemów plików). Wirtualny system plików przy dostępie do danych w różnych formatach używa zunifikowanego interfejsu, dzięki czemu z poziomu użytkownika dodanie obsługi nowego formatu danych jest stosunkowo proste.
Taka koncepcja umożliwia implementowanie obsługi zarówno takich formatów danych, które są zapisane na fizycznym nośniku (jak etx2), takich, które są dostępne za pośrednictwem sieci (jak nfs), jak i takich, które są tworzone dynamicznie, na żądanie użytkownika (jak proc).
W systemie operacyjnym Linux procesy odwołują się do plików za pomocą dobrze zdefiniowanego zbioru funkcji systemowych. Zawiera on zarówno funkcje obsługujące istniejące pliki, a wśród nich open(), read(), write(), lseek() i close(), jak i funkcje służące do tworzenia nowych plików, jak creat(). Obejmuje on również funkcje wykorzystywane przy implementacji potoków: pipe() i dup().
Pierwszym krokiem, jaki musi wykonać proces, by uzyskać dostęp do danych istniejącego pliku, jest wywołanie funkcji open(). Jeśli wykona się ona pomyślnie, to przekazuje procesowi deskryptor pliku, za pomocą którego może on wykonywać na pliku inne operacje, takie jak czytanie (read()) i pisanie (write()). Z kolei jeśli dany plik nie istnieje, to proces może go utworzyć za pomocą funkcji creat(), która, tak jak open(), przekazuje w przypadku sukcesu deskryptor pliku. Funkcje read() i write() zapewniają sekwencyjny dostęp do danych. W przypadku, gdy zachodzi konieczność dostępu bezpośredniego (niesekwencyjnego), proces może skorzystać z funkcji lseek(), która umożliwia zmianę bieżącej pozycji w pliku.
Procesy spokrewnione (jak np. przodek i potomek) mogą komunikować się ze sobą za pomocą łączy komunikacyjnych (ang. pipe). Do ich tworzenia służy funkcja pipe(), która przekazuje dwa deskryptory pliku: do czytania i do pisania. Proces potomny (stworzony za pomocą funkcji fork()) dziedziczy powyższe deskryptory od procesu macierzystego, dzięki czemu możliwy jest przepływ danych od jednego z procesów do drugiego. Funkcja pipe() w połączeniu z funkcją dup(), która kopiuje dany deskryptor do pierwszej wolnej pozycji w tablicy deskryptorów, umożliwia zrealizowanie potoków, takich jak w interpretatorze poleceń, które łączą standardowe wyjście jednego procesu ze standardowym wejściem innego.
Gdy proces przestaje korzystać z pliku lub łącza, to może je zamknąć wywołując funkcję close() z odpowiednim deskryptorem. Zwalnia tym samym pozycję w tablicy deskryptorów odpowiadającą zamykanemu plikowi.
Opisane funkcje systemowe mają swoje odpowiedniki w bibliotece standardowych funkcji wejścia-wyjścia. Funkcje standardowe tworzą interfejs wysokiego poziomu między procesem a jądrem, umożliwiający korzystanie z takich udogodnień jak buforowanie, czy sformatowane wyjście. Jednakże przy pisaniu programów użytkowych często zachodzi potrzeba bezpośredniego odwoływania się do funkcji systemowych.
Funkcja creat() służy do tworzenia pliku o podanej nazwie. Jest utrzymana jedynie w celu zachowania zgodności z poprzednimi wersjami Linuksa. Jej działanie sprowadza się do wywołania funkcji systemowej open() z odpowiednimi parametrami:
asmlinkage long sys_creat(const char *pathname, int mode)
return sys_open(pathname, O_CREAT | O_WRONLY | O_TRUNC, mode);
Funkcja systemowa open()służy do otwierania pliku. Jej wywołanie jest pierwszą czynnością, jaką musi wykonać proces chcący uzyskać dostęp do informacji znajdujących się w pliku. Wynikiem działania funkcji open() jest liczba naturalna zwana deskryptorem pliku. W ramach jednego procesu jest ona wykorzystywana jako identyfikator pliku; dwa otwarte przez proces pliki mają różne deskryptory. Jeden plik może zostać przez proces otwarty dwa razy i ma wtedy dwa różne deskryptory.
asmlinkage long sys_open(const char * filename, int flags, int mode)
Deskryptor pliku jest indeksem w tablicy deskryptorów plików (nazywanej także tablicą deskryptorów otwartych plików).
Pierwszą czynnością jest wczytanie nazwy ścieżkowej pliku z przestrzeni adresowej procesu do przestrzeni jądra.
Następnie znajduje się wolne miejsce w tablicy deskryptorów plików. Wybierany jest deskryptor o najmniejszym wolnym numerze, zostanie on zwolniony, jeśli operacja otwarcia pliku się nie powiedzie.
Przegląda się krok po kroku nazwę ścieżkową w celu dotarcia do odpowiadającego plikowi i-węzła, który należy otworzyć (i-węzeł pełni rolę metryczki pliku). Podczas znajdowania i-węzła korzysta się z informacji o atrybutach otwarcia.
Wykonanie funkcji może potoczyć się wielorako, w zależności od tego, jaki jest cel otwarcia pliku, czyli jakie były parametry otwarcia.
Jeśli plik ma zostać stworzony, to jądro sprawdza, czy taki plik już istnieje i w razie czego przekazuje błąd. Błąd pojawia się także wtedy, gdy proces wywołujący nie posiada praw dostępu.
Jeśli prawa są właściwe, to jest pobierany nowy, wolny i-węzeł. Podczas znajdowania nowego i-węzła zakłada się blokadę na i-węzeł katalogu macierzystego, by można było dołączyć do niego nowy i-węzeł. W sytuacji, gdy nastąpiła próba otwarcia do czytania katalogu lub pliku z systemu plików przeznaczonego tylko do odczytu, jest generowany błąd.
Jeśli plik jest otwierany z zamiarem obcięcia, to jest wywoływana funkcja zwalniająca jego bloki.
Jeśli plik ma zostać otwarty do pisania, to podejmuje się próbę uzyskania prawa do pisania w pliku. W przypadku niepowodzenia i-węzeł jest zwalniany, a funkcja przekazuje błąd.
Tworzy się i wypełnia pozycję w tablicy plików (zwanej też tablicą otwartych plików) związanej z danym systemem plików. Będzie z niej można dotrzeć do i-węzła pliku. Ustawia się w niej także bieżącą pozycję w pliku.
Teraz wywołuje się tę część funkcji otwierania pliku, która zależy od konkretnego systemu plików. W systemie plików EXT2 ta część jest pusta. Wreszcie tablica deskryptorów, w miejscu uprzednio wybranym, jest wypełniana wskaźnikiem do wybranej pozycji w tablicy plików, a indeks miejsca, w którym jest wypełniana zostaje przekazany jako wynik działania funkcji.
Funkcja systemowa read() służy do czytania danych z otwartego pliku. Ma ona postać:
asmlinkage ssize_t sys_read(unsigned int fd, char * buf, size_t count)
gdzie fd jest deskryptorem otwartego pliku, buf jest adresem struktury danych w procesie użytkownika, do której wczytujemy dane, natomiast count określa liczbę bajtów, jaką chce wczytać użytkownik. Jeżeli funkcja wykona się pomyślnie, to jako wynik przekaże rzeczywistą liczbę wczytanych bajtów lub 0 w przypadku napotkania końca pliku.
Funkcja rozpoczyna czytanie od bieżącej pozycji w pliku, a po jego zakończeniu zwiększa bieżącą pozycję w pliku o liczbę przeczytanych bajtów. W przypadku stwierdzenia odczytu sekwencyjnego wykorzystuje czytanie z wyprzedzeniem, co znacznie zwiększa wydajność systemu.
Funkcja read(), podobnie jak funkcja write(), jest niezależna od zainstalowanego rodzaju systemu plików. Zrealizowana jest ona na dwóch poziomach: najpierw wykonuje się część wspólną dla wszystkich systemów plików (sprawdzenie praw dostępu oraz poprawności argumentów funkcji), potem następuje wywołanie funkcji właściwej dla danego systemu plików. Ta przynależna konkretnemu systemowi funkcja realizuje odczyt danych z pliku.
Informacja o funkcjach, które realizują operacje na plikach dla danego systemu plików znajdują się w strukturze file_operations. Do struktury tej prowadzi wskaźnik z każdego pliku w tablicy plików. Dla systemu EXT2 funkcją służącą do czytania danych z pliku jest generic_file_read():
ssize_t generic_file_read(struct file * filp, char * buf,
size_t count, loff_t *ppos)
gdzie filp jest pozycją w tablicy plików odpowiadającą danemu plikowi, buf jest adresem struktury danych w procesie użytkownika, do której wczytujemy dane, natomiast count określa liczbę bajtów, jaką chce wczytać użytkownik.
Z kolei generic_file_read() wywołuje do_generic_file_read(), która wykonuje większość pracy.
Jeśli jądro stwierdzi, że pozycja, od której proces chce rozpocząć czytanie danego pliku znajduje się wewnątrz obszaru, który poprzednio był wczytywany z wyprzedzeniem, przyjmuje, że plik jest czytany sekwencyjnie, czyli że powinno być zainicjowane czytanie z wyprzedzeniem danego pliku. W przeciwnym razie jądro zaznacza, że czytanie z wyprzedzeniem nie odbędzie się.
Jądro sprawdza, ile danych może być wczytanych z wyprzedzeniem. Rozmiar danych może się okazać zbyt mały, by warto było inicjować czytanie z wyprzedzeniem. Rozmiar danych do wczytania musi należeć do ustalonego przedziału.
Następnie jądro w pętli wykonuje opisane dalej czynności, aż do zakończenia czytania.
Jądro szuka w pamięci podręcznej stron strony, która zawiera dane z pliku. Może się zdarzyć, że jądro nie znajdzie w pamięci operacyjnej takiej strony - nawet jeśli plik był czytany z wyprzedzeniem, odpowiednia strona mogła zostać usunięta z pamięci. Jądro rezerwuje wówczas wolną ramkę w pamięci i zleca wypełnienie ramki danymi z odpowiadającego jej bloku na dysku.
Jeśli ramka jest wypełniona aktualnymi danymi, bądź jej zawartość jest właśnie aktualizowana, to jądro inicjuje wczytanie odpowiedniej liczby stron z wyprzedzeniem. Następnie czeka, aż na danej ramce zostaną zakończone wszystkie zainicjowane wcześniej operacje wejścia-wyjścia i zostanie ona zablokowana. Jeśli okaże się, że odblokowana ramka zawiera nieaktualne dane, to jądro synchronicznie wypełnia ją danymi z odpowiadającego jej bloku na dysku. Teraz pozostaje jeszcze skopiować dane z odpowiedniego fragmentu ramki do przestrzeni adresowej procesu.
Funkcja systemowa write() służy do pisania danych do otwartego pliku. Ma ona postać:
asmlinkage ssize_t sys_write(unsigned int fd, const char * buf, size_t count)
Funkcja write składa się z dwóch części: niezależnej i zależnej od systemu plików. Część niezależna sprawdza, czy proces ma prawo do pisania w pliku, czy proces ma prawo dostępu do obszaru pamięci, do którego adres przekazał jako parametr wywołania.
Teraz już wywołuje się funkcję właściwą dla konkretnego systemu plików; w przypadku ext2 jest do generic_file_write().
Opuszcza się semafor na i-węźle w celu wykluczenia jednoczesnych zapisów do pliku.
Jądro sprawdza, czy system plików nie jest przeznaczony tylko do odczytu; jeśli tak, to przekazuje błąd.
Jeśli plik został otwarty do dopisywania, to znacznik bieżącej pozycji w pliku jest ustawiany na koniec pliku, w przeciwnym wypadku zapis będzie dokonany od pozycji określonej przez znacznik zapisany w tablicy plików.
Następnie jest obliczany numer bloku, który będzie zapisywany, a który odpowiada wcześniej ustawionemu znacznikowi bieżącej pozycji w pliku, oraz miejsce w tym bloku, od którego rozpocznie się pisanie.
Pisanie do pliku, tak jak czytanie, odbywa się poprzez podręczną pamięć buforową stron. W przypadku pisania pełnych stron sprawa jest prostsza. Jeśli jednak wypisuje się jedynie fragment strony, to najpierw trzeba całą stronę wczytać do pamięci podręcznej, zmodyfikować i dopiero wówczas przeznaczyć do zapisu.
Na końcu jest modyfikowany czas ostatniej modyfikacji pliku i czas ostatniej modyfikacji i-węzła (ustawiane są na czas bieżący). Modyfikowana jest także długość pliku zapisana w i-węźle. Jeśli bieżąca pozycja w pliku jest większa niż zapisana w i-węźle wartość, to zapis trzeba zaktualizować tzn. ustawić długość pliku na równą bieżącej pozycji w pliku. Po zaznaczeniu i-węzła jako brudnego i zwolnienia blokady nałożonej na i-węzeł, funkcja kończy działanie.
W systemie Linux do zamknięcia otwartego pliku służy funkcja systemowa close(). Ma ona postać:
asmlinkage long sys_close(unsigned int fd)
gdzie argument fd określa deskryptor otwartego pliku. Funkcja close() zwalnia deskryptor, dzięki czemu może on być powtórnie przydzielony. Jeśli licznik odwołań do pozycji w tablicy plików związanej z tym deskryptorem jest większy niż 1, to zmniejsza się licznik i operacja się kończy. Jeśli licznik odwołań jest równy 1, to jest zwalniana pozycja w tablicy plików oraz wywoływany algorytm iput() dla odpowiadającego jej i-węzła z tablicy i-węzłów. W przypadku gdy inne procesy odwołują się do tego i-węzła, to jest zmniejszany licznik odwołań do niego. W przeciwnym razie algorytm iput() zwalnia i-węzeł z pamięci i, jeśli to konieczne, uaktualnia jego zawartość na dysku.
VFS reprezentuje podejście obiektowe do systemu plików. Podstawowe obiekty, zapewniające jednolity interfejs do systemów plików o różnych formatach, to:
Przechowuje lokalne dla procesu informacje o deskryptorach otwartych plików i sposobie obsługi plików. Ten obiekt istnieje jedynie w pamięci operacyjnej.
Przechowuje informacje o związku procesu z otwartym plikiem. Ten obiekt istnieje jedynie w pamięci operacyjnej.
Przechowuje informacje o związku między pozycją w katalogu a plikiem. Każdy dyskowy system plików przechowuje tę informację na dysku we właściwy sobie sposób.
Metryczka pliku zawierająca wszystkie podstawowe informacje o pliku. Dla dyskowych systemów plików obiekt ten ma swój odpowiednik w postaci bloku kontrolnego pliku, przechowywanego na dysku. Z każdym i-węzłem jest związany numer i-węzła, który jednoznacznie identyfikuje plik w systemie plików.
Główna struktura danych podręcznej pamięci buforowej stron (ang. page cache). Odwzorowuje wszystkie strony jednego pliku (czyli obraz przestrzeni adresowej tego pliku w pamięci operacyjnej) w bloki dyskowe (czyli obraz przestrzeni adresowej tego pliku na dysku).
Przechowuje informacje o zamontowanym systemie plików. Dla dyskowych systemów plików obiekt ten ma swój odpowiednik w postaci bloku kontrolnego systemu plików, przechowywanego na dysku.
Rysunek ilustruje sytuację, w której trzy różne procesy otworzyły ten sam plik, dwa z nich przy użyciu tego samego twardego dowiązania (ang. hard link). Każdy z procesów sięga za pomocą prywatnego deskryptora pliku do własnej struktury file. Wystarczają dwie struktury dentry, po jednej dla każdego twardego dowiązania. Obie struktury dentry wskazują na ten sam i-węzeł, który identyfikuje ten sam superblok i za jego pomocą ten sam fizyczny plik na dysku.
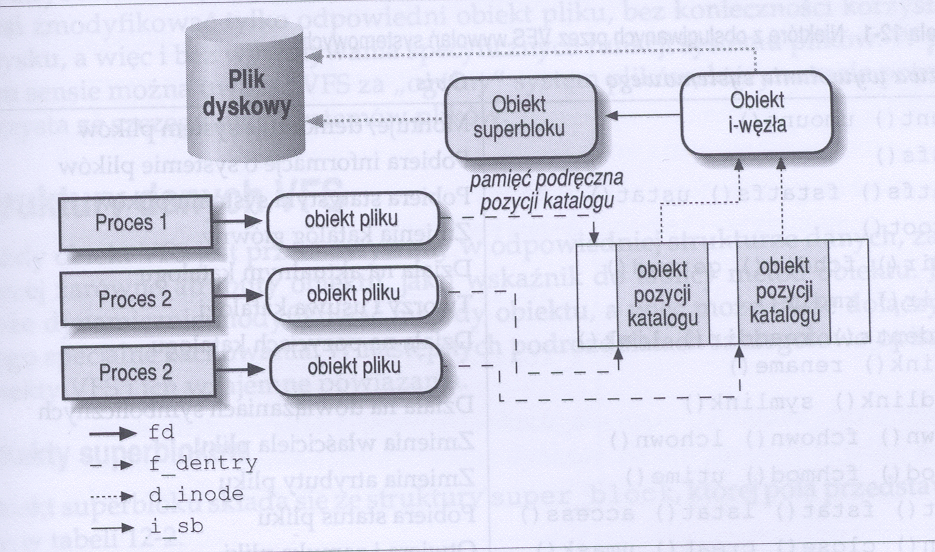
Rysunek: Obiekty VFS (źródło: Bovet, Ceasti, Linux Kernel)
Ze względów efektywnościowych część struktur przechowywanych na dysku jest czasowo utrzymywana w pamięciach podręcznych w pamięci operacyjnej. Linux utrzymuje:
W dalszej części tego oraz podczas dwóch kolejnych wykładów będziemy przyglądać się wykorzystaniu tych struktur w jądrze Linuksa.
Oto pola w metryczce procesu (task_struct) opisujące związek procesu z plikami:
struct fs_struct *fs; /* inf. o systemie plików */
struct files_struct *files; /* inf. o otwartych plikach */
Główne pola struktury fs_struct to dowiązanie do opisu bieżącego katalogu procesu (pwd) oraz korzenia systemu plików (root) . Dzięki tym polom proces zna swój kontekst w systemie plików.
struct fs_struct {
atomic_t count;
int umask;
struct dentry * root, * pwd;
.....
};
Pole count określa liczbę procesów współdzielących tę samą strukturę fs_struct (liczba ta wzrasta podczas wywołania funkcji do_fork() z ustawioną flagą CLONE_FS). Obsługę tego pola ilustruje funkcja copy_fs() wywoływana wewnątrz do_fork().
static inline int copy_fs(unsigned long clone_flags, struct task_struct * tsk)
{
if (clone_flags & CLONE_FS) {
atomic_inc(¤t->fs->count);
return 0;
}
tsk->fs = __copy_fs_struct(current->fs);
if (!tsk->fs)
return -ENOMEM;
return 0;
}
Struktura files_struct zawiera tablicę indeksowaną liczbami naturalnymi, które odpowiadają deskryptorom otwartych plików. Wartością pozycji w tej tablicy jest dowiązanie do globalnej (w ramach systemu plików) tablicy otwartych plików.
#define BITS_PER_LONG 32
#define NR_OPEN_DEFAULT BITS_PER_LONG
struct embedded_fd_set {
unsigned long fds_bits[1];
};
struct fdtable {
unsigned int max_fds;
int max_fdset;
struct file ** fd; /* current fd array */
fd_set *close_on_exec;
fd_set *open_fds;
struct fdtable *next;
};
struct files_struct {
atomic_t count;
struct fdtable *fdt;
struct fdtable fdtab;
spinlock file_lock;
int next_fd;
struct embedded_fd_set close_on_exec_init;
struct embedded_fd_set open_fds_init;
struct file * fd_array[NR_OPEN_DEFAULT];
};
Pole count określa liczbę procesów współdzielących tę samą strukturę files_struct (liczba ta wzrasta podczas wywołania funkcji do_fork() z ustawioną flagą CLONE_FILES).
Podczas tworzenia procesu alokuje się dla niego wstępnie fd_array[NR_OPEN_DEFAULT] na pierwsze 32 otwierane pliki (w razie potrzeby ta tablica jest rozszerzana o kolejne pozycje - na bieżącą tablicę deskryptorów wskazuje pole fd). Pole open_fds jest maską bitową, w której ustawia się bit podczas przydzielania nowego deskryptora oraz zeruje go podczas zwalniania deskryptora. Pole next_fd podpowiada gdzie warto zacząć szukać kolejnego wolnego deskryptora. Ponieważ struktura danych fd_set zawiera 1024 bity, więc tyle maksymalnie otwartych plików może na raz posiadać proces.
Dzięki wywołaniom systemowym dup() i fork() różne deskryptory mogą się odnosić do tego samego otwartego pliku, czyli różne elementy tablicy mogą wskazywać na tę samą pozycję w tablicy otwartych plików.
Struktura file opisuje jedną pozycję w tablicy otwartych plików. Każde wywołanie funkcji open() powoduje przydzielenie dla otwieranego pliku nowej pozycji w tej tablicy. Pozycje mogą być współdzielone (pole f_count większe od jeden) - dochodzi do tego w wyniku użycia funkcji dup() lub fork().
struct file {
struct list_head fu_list;
struct dentry *f_dentry;
const struct file_operations *f_op;
atomic_t f_count;
unsigned int f_flags;
mode_t f_mode;
loff_t f_pos;
....
Pole fu_list pozwala na dowiązanie struktury do jednej (i tylko jednej) z list: listy wszystkich otwartych plików w danym systemie plików (identyfikowanym poprzez swój superblok) lub listy nieużywanych struktur.
Pole f_dentry zawiera dowiązanie do struktury dentry tego pliku, która jest tworzona podczas odwzorowywania nazwy ścieżkowej pliku w numer i-węzła.
Pole f_mode przechowuje informacje o trybie, w jakim otwarto plik.
Pole f_pos zawiera wskaźnik bieżącej pozycji w pliku. W obecnej wersji dla i386 ma długość 64 bity (skorelowane z maksymalnym dopuszczalnym rozmiarem pliku).
Pole f_op zawiera dowiązanie do tablicy wskaźników do metod, jakie mogą być wykonywane na tym pliku. Pole to uzyskuje wartość od inode->i_fop (por. wykład o tablicach rozdzielczych urządzeń).
struct file_operations {
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char *, size_t, loff_t *);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*lock) (struct file *, int, struct file_lock *);
....
};
I-węzeł, czyli metryczka pliku, jest ściągany do pamięci operacyjnej podczas otwierania pliku i rozszerzany o dodatkowe pola (np. wskaźniki i numer i-węzła).
| Typ | Nazwa | Opis |
| unsigned long | i_ino | numer i-węzła w dyskowej tablicy i-węzłów |
| umode_t | i_mode | typ pliku: zwykły(IS_REG), katalog(IS_DIR), łącze nazwane(IS_FIFO),
specjalny, znakowy, 0 gdy wolny;
także prawa dostępu do pliku dla wszystkich, grupy użytkownika oraz jego samego |
| nlink_t | i_nlink | liczba (twardych) dowiązań do pliku |
| uid_t | i_uid | identyfikator właściciela pliku |
| gid_t | i_gid | identyfikator grupy właściciela pliku |
| loff_t | i_size | rozmiar pliku w bajtach (64 bity, czyli 2^64) |
| time_t | i_ctime | czas utworzenia pliku |
| time_t | i_atime | czas ostatniego dostępu do pliku |
| time_t | i_mtime | czas ostatniej modyfikacji pliku |
| unsigned long | i_blocks | liczba bloków dyskowych zajmowanych przez plik |
| unsigned short | i_bytes | liczba bajtów w ostatnim bloku pliku |
| unsigned long | i_blksize | rozmiar bloków do przesyłania danych dyskowych (inicjowane na PAGE_SIZE) |
| dev_t | i_rdev | wskazuje na rzeczywiste urządzenie - tak jak jest zapisany na dysku |
| struct super_block | *i_sb | wskaźnik na superblok urządzenia, do którego należy i-węzeł |
| unsigned int | i_flags | tutaj trzymane są flagi określające sposób korzystania z i-węzła, jak również pliku, który wyznacza (m.in. S_WRITE - do zapisu...) |
| atomic_t | i_count | liczba wykonanych open() na pliku; wartość zero oznacza, że struktura i-węzła jest wolna i może w razie potrzeby być wykorzystywana przez inne procesy |
| struct mutex | i_mutex | semafor binarny do zakładania blokady |
| struct file_lock | *i_flock | struktura przechowująca informacje o blokadach w pliku |
| struct list_head | i_list | wskaźniki utrzymujące listę i-węzłów w różnych stanach |
| struct list_head | i_sb_list | wskaźniki utrzymujące listę i-węzłów jednego superbloku |
| struct list_head | i_hash | wskaźniki łączące i-węzeł w listę z innymi znajdującymi się w tablicy haszującej pod tym samym numerem |
| struct list_head | i_dentry | Lista wszystkich struktur dentry odnoszących się do tego i-węzła |
| struct pipe_inode_info | i_pipe | używane gdy i-węzeł opisuje łącze komunikacyjne |
| struct block_device | *i_bdev | wskaźnik do podprogramu obsługi urządzenia blokowego |
| struct cdev | *i_cdev | wskaźnik do podprogramu obsługi urządzenia znakowego |
| struct inode_operations | *i_op | zestaw operacji na i-węzłach (takich, jak tworzenie nowego), ściśle związanych z wykorzystywanym systemem plików - np. EXT2 |
| const struct file_operations | *i_fop | zestaw operacji na plikach |
| struct address_space | *i_mapping | Wskaźnik do związanego z tym plikiem obiektu address_space |
| struct address_space | *i_data | obiekt address_space tego pliku |
Każdy i-węzeł znajduje się na jednej z trzech listy podwójnie wiązanych (wykorzystuje się w tym celu pole i_list):
globalna dwukierunkowa lista inode_in_use, zawierająca wszystkie używane i-węzły (i_count>0 i i_nlink>0). Nowo przydzielone i-węzły są dodawane do tej listy:
list_add(&inode->i_list, &inode_in_use);
globalna dwukierunkowa lista inode_unused, która zawiera i-węzły z i_count=0;
list_add(&inode->i_list, &inode_unused);
dla każdego superbloku dwukierunkowa lista sb->s_dirty, która zawiera poprawne i-węzły z i_count>0, n_link>0 i i_state & I_DIRTY. Ta lista umożliwa sprawne uaktualnianie kopii i-węzłów na dysku;
list_add(&inode->i_list, &sb->s_dirty);
Ponadto każdy i-węzeł znajduje się na dwukierunkowej liście wszystkich i-węzłów swojego superbloku (pochodzących z tego samego systemu plików). Na listę wskazuje pole s_inodes superbloku, a do tworzenia dowiązań służy pole i_sb_list i-węzła.
Wreszcie każdy i-węzeł znajduje się w tablicy haszującej list dwukierunkowych inode_hashtable. Każdy i-węzeł jest identyfikowany poprzez swój numer oraz numer urządzenia, na którym się znajduje. Tablica haszująca umożliwia szybki dostęp do i-węzła w pamięci: oblicza się dla niego wartość funkcji haszującej i wyszukuje go na odpowiedniej liście w tablicy.
Każdy i-węzeł może się na raz znajdować tylko w tablicy haszującej, tylko w jednym systemie plików oraz na jednej i tylko jednej spośród list inode_inuse, inode_unused i sb->s_dirty.
W pamięci może się znaleźć co najwyżej jedna kopia danego i-węzła dyskowego.
Użytkownik widzi plik jako ciągły strumień bajtów o określonej długości. Gdyby plik na dysku miał również strukturę ciągłą, tzn. zajmował następujące po sobie bloki, to dostęp do wszystkich bajtów pliku byłby bardzo prosty: w i-węźle wystarczyłoby pamiętać adres początku pliku i jego długość. Jednak system operacyjny musi uwzględnić możliwość dynamicznych zmian rozmiaru pliku. Opisana strategia nie pozwala na taką elastyczność systemu plików i powoduje dużą fragmentację wolnego miejsca na dysku. Jądro pozwala na rozproszenie bloków pliku na dysku. Ten sposób przydziału miejsca komplikuje zadanie lokalizacji danych. Utrzymywanie liniowej listy bloków składających się na plik byłoby złym rozwiązaniem - trzeba by narzucić duże ograniczenie na rozmiar pliku bądź dopuszczać i-węzły o zmiennej wielkości. Również obsługa liniowej listy bloków byłaby bardzo nieefektywna.
W Linuksie przyjęto następujące rozwiązanie. W i-węźle przechowuje się niewielkę tablicę numerów bloków składających się na plik. Istotą pomysłu jest wyróżnienie czterech typów adresów przechowywanych w tej tablicy:
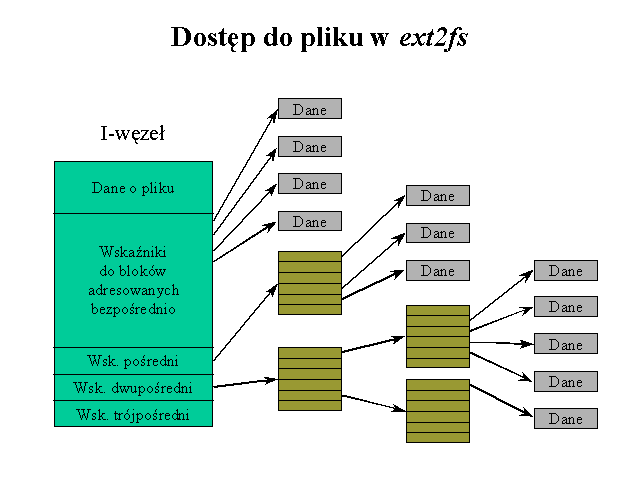
Niektóre numery bloków mogą być równe zero. Oznacza to, że na pewnej przestrzeni pliku nie zostało nic zapisane (sytuacja taka jest możliwa dzięki funkcji lseek()).
W systemie plików EXT2 tablica z adresami w i-węźle ma nazwę:
w przypadku struktury i-węzła w pamięci (jest to pole struktury ext2_inode_info)
w przypadku struktury i-węzła na dysku
Tablica ta ma (w systemie EXT2) rozmiar równy 15. Jest w niej 12 pozycji z adresami bloków bezpośrednich i po jednej pozycji dla bloku pojedynczego, podwójnego i potrójnego pośredniego.
Zadaniem algorytmu bmap jest przekształcanie logicznego numeru bloku w pliku na fizyczny numer bloku na dysku. W systemie plików EXT2 implementacja algorytmu bmap znajduje się w funkcji ext2_bmap().
static int ext2_bmap(struct address_space *mapping, sector_t block)
Pierwszy argument funkcji pozwala dotrzeć do i-węzła pliku. Drugim argumentem jest logiczny numer bloku.
Uproszczona implementacja algorytmu bmap będzie treścią ćwiczeń nr 7.
Załóżmy, że w bloku mieszczą się 4 adresy: addr_per_block = 4, zatem addr_per_block_bits = 2. Przypuśćmy, ze układ bloków pewnego pliku jest taki, jak na rysunku poniżej.
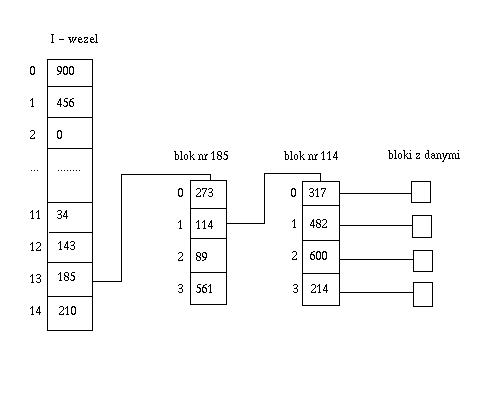
Powiedzmy, że chcemy odczytać blok o numerze (logicznym) 22.
block = 22Ponieważ 22 >= 12, więc blok nie leży wśród bloków bezpośrednich.
block = 22 - 12 = 10Sprawdzamy, że 10 >= addr_per_block, czyli musimy rozpatrywać blok podwójny pośredni.
block = 10 - addr_per_block = 10 - 4 = 6Sprawdzamy, że 6 < 16 (addr_per_block do kwadratu), czyli szukany blok jest w strefie podwójnej pośredniości.
Pobieramy adres bloku podwójnie pośredniego w i-węźle: 185. Wczytujemy blok 185. Mamy 6 > > 2 = 1, czyli szukany blok leży w drugim bloku pojedynczym pośrednim (z zapisanych w bloku o numerze 185). Pobieramy numer tego bloku; jest to 114.
Wczytujemy blok 114. Numer interesującego nas bloku jest na pozycji 6 & (addr_per_block - 1) = 6 & 3 = 2. Zatem numer fizyczny bloku o numerze logicznym 22 to 600.
| Janina Mincer-Daszkiewicz |