Funkcja iget() odpowiada za dostarczenie procesowi i-węzła w pamięci. Pobiera ona jako argumenty: wskaźnik do superbloku dyskowego oraz numer pliku w systemie plików (np. numer i-węzła dyskowego) pozwalające odnaleźć lub umieścić i-węzeł w odpowiednim miejscu tablicy haszującej. Jako wynik jest przekazywany wskaźnik do i-węzła.
Najpierw na podstawie argumentów, znajdujemy listę w tablicy haszującej, na której powinien znajdować się szukany i-węzeł. Następnie przeglądamy tę listę w poszukiwaniu i-węzła, którego superblok i numer są takie, jak argumenty funkcji.
Jeśli znaleziono, to przed przekazaniem go należy wykonać kilka operacji.
Jeśli początkowe poszukiwania nie dały rezultatu, to należy utworzyć nowy i-węzeł wykorzystując w tym celu jeden z nie używanych aktualnie przez żaden proces.
Jeśli takich nie ma, to należy przeznaczyć nową stronę pamięci na
i-węzły, umieścić je na liście dostępnych i pobrać oraz zainicjować
nowy i-węzeł.
Po wykonaniu tej operacji rozpoczynamy poszukiwania
od początku, jeśli jednak nie udało się zaalokować pamięci na nowe
i-węzły, to występuje błąd i przekazuje się wartość NULL.
Funkcja iput() służy do zwalniania i-węzła w pamięci (to miejsce w pamięci może być potrzebne na umieszczenie innego i-węzła). Najpierw zmniejsza się licznik otwarć pliku (i_count) i jeśli jest on nadal większy od zera, to algorytm się kończy. W przeciwnym przypadku
Katalog podobnie jak zwykły plik składa się z ciągu bajtów. Od zwykłego pliku różni go, oprócz pola typu pliku zapisanego w i-węźle, sposób zapisu informacji. W katalogu jest on ściśle określony i stanowi ciąg struktur o następujacej budowie:
struct ext2_dir_entry{
_le32 inode /* numer i-węzła */
_le16 rec_len /* długość pozycji katalogowej */
_le16 name_len /* długość nazwy */
char name[EXT2_NAME_LEN] /* nazwa pliku */
}
Każda pozycja ma rozmiar określony przez długość nazwy zaokrągloną do 4n bajtów i właśnie ta wielkość jest wpisana w polu rec_len. Informacja o faktycznej długości pozycji znajduje się w polu name_len. Nazwa pliku jest ograniczona do 255 znaków (stała EXT2_NAME_LEN). W zależności od ustawienia flagi NO_TRUNCATE, nazwy dłuższe mogą być obcinane lub traktowane jako błędne.
Na początku każdego katalogu znajdują się pozycje o nazwach "." i ".." oznaczające odpowiednio katalog bieżący i macierzysty. W katalogu bedącym korzeniem drzewa systemu plików pozycje te mają numer i-węzła systemu plików.
W katalogu mogą się znajdować pozycje, które mają numer i-węzła równy 0. Taka sytuacja powstaje w momencie usuwania pozycji z katalogu. Dodawanie pliku odbywa się na zasadzie przeszukiwania liniowego do pierwszej struktury, w której numer i-węzła jest równy 0 i jest odpowiednio dużo miejsca. Jeżeli się takiej nie znajdzie, to nowy plik będzie dopisany na końcu.
Procesy użytkowe mogą odczytywać katalog jako plik, jednak zapisywać katalog może tylko jądro, co gwarantuje poprawność danych.
Większość omawianych tutaj algorytmów jest zaimplementowanych w pliku fs/dcache.c, natomiast struktury danych są zdefiniowane w include/linux/dcache.h.
Aby przyśpieszyć dostęp do pozycji katalogowych, część z nich przechowuje się w pamięci, jako obiekty dentry.
Obiekty dentry są tworzone dla każdego składnika ścieżki poszukiwanej przez proces, np. jeśli korzystamy z pliku /etc/passwd, to jądro utworzy trzy obiekty, odpowiednio dla /, etc, passwd. Pozycja katalogu reprezentowana jest przez strukturę dentry.
struct qstr {
const unsigned char * name; /* nazwa */
unsigned int len; /* długość nazwy */
unsigned int hash;
};
struct dentry {
atomic_t d_count; /* liczba korzystających procesów */
struct inode * d_inode; /* i-węzeł */
struct list_head d_hash; /* tablica haszująca */
struct dentry * d_parent; /* obiekt dentry katalogu macierzystego */
struct qstr d_name; /* nazwa */
struct list_head d_lru; /* lista LRU pozycji aktualnie nieużywanych;
/* (dcount = 0) */
struct list_head d_child; /* lista podkatalogów nadkatalogu */
struct list_head d_subdirs; /* lista podkatalogów */
struct list_head d_alias; /* lista aliasów i-węzła */
int d_mounted; /* czy jest to punkt zamontowania */
struct dentry_operations *d_op; /* operacje na strukturze */
struct super_block * d_sb; /*korzeń drzewa dentry */
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* krótka nazwa */
...
};
Obiekty dentry powiązane są w drzewo katalogów za pomocą pól: d_parent, d_child, d_subdirs. Każda pozycja katalogowa jest związana z pewnym i-węzłem (pole d_inode).
Użytkownicy w systemie identyfikują pliki za pomocą nazw, natomiast system identyfikuje pliki za pomocą numerów ich i_węzłów. Rolą tej stuktury jest więc między innymi pośredniczenie między plikiem widzianym przez użytkownika (może on być identyfikowany poprzez wiele ścieżek) a konkretnym plikiem, i-węzłem widzianym przez system.
Obiekt dentry nie ma swojego odpowiednika na dysku, więc w szczególności nie potrzebuje żadnego pola wskazującego, że obiekt był modyfikowany. Każdy obiekt może być w jednym z czterech stanów:
Metody związane z obiektem pozycji katalogu są opisane przez strukturę dentry_operations, której adres jest przechowywany w polu d_op.
struct dentry_operations {
int (*d_revalidate)(struct dentry *, struct nameidata *);
int (*d_hash) (struct dentry *, struct qstr *);
int (*d_compare) (struct dentry *, struct qstr *, struct qstr *);
int (*d_delete)(struct dentry *);
void (*d_release)(struct dentry *);
void (*d_iput)(struct dentry *, struct inode *);
};
Obiekty dentry są umieszczone w tablicy mieszającej dentry_hashtable, której elementami są dwukierunkowe listy cykliczne. Mechanizm ten jest częścią wirtualnego systemu plików, zatem działa dla wszystkich używanych w Linuksie systemów plików.
Pamięć podręczna pozycji katalogów działa także jako kontroler pamięci podręcznej i-węzłów. I-węzły, znajdujące się w pamięci jądra i związane z nieużywanymi pozycjami katalogu, nie są wyrzucane, ponieważ pamięć podręczna pozycji katalogów cały czas ich używa, a więc ich pola i_count mają wartość niezerową. Tak więc obiekty i-węzłów są przechowywane w pamięci RAM i można z nich szybko skorzystać za pomocą odpowiednich pozycji katalogów.
Wszystkie nieużywane pozycje dentry wchodzą w skład dwukierunkowej listy LRU: ostatnio zwolniony obiekt jest umieszczany na początku listy, czyli obiekty najmniej ostatnio używane znajdują się blisko końca. Gdy lista ma zostać skrócona, usuwa się obiekty z końca. Pole d_lru służy do łączenia obiektów na liście LRU.
Każdy obiekt używany jest wstawiany na dwukierunkową listę wskazywaną przez pole i_dentry i-węzła (jest potrzebna lista, bo i-węzeł może być związany z kilkoma twardymi dowiązaniami) - do łączenia w listę służy pole d_alias.
Obiekt używany może się stać ujemny, gdy zostanie usunięte ostatnie twarde dowiązanie do pliku. Obiekt dentry jest wówczas umieszczany na liście LRU nieużywanych obiektów.
Pole d_hash służy do łączenia w listę wszystkich obiektów dentry o tej samej wartości funkcji haszującej.
Oto główne funkcje do obsługi pamięci podręcznej katalogów:
Wewnętrzną reprezentacją plików w Linuksie są i-węzły. Dla użytkownika naturalne jest jednak odwoływanie się do plików za pośrednictwem systemu katalogów i nazw. Aby przekształcić nazwę ścieżkową pliku w numer i-węzła, system musi przejść po wszystkich pośrednich katalogach. Wykonuje to algorytm namei(), parametrem którego jest nazwa ścieżkowa (niektóre funkcje systemowe korzystają z własnych, bardziej rozbudowanych algorytmów). Korzystają z niego między innymi funkcje open(), stat() i mkdir().
Algorytm namei znajduje się w pliku fs/namei.c. Realizuje go funkcja __user_walk().
int __user_walk(const char *name, unsigned flags, struct nameidata *nd)
Parametry wejściowe funkcji to:
Wynikiem działania funkcji jest natomiast:
Idea działania algorytmu wydaje się być prosta. Polega on na przeglądaniu ścieżki i odcinaniu kolejnych jej składowych. Każda składowa jest przekształcana na obiekt dentry. Przekazywany jest obiekt dentry odpowiadający ostatniej składowej. Jednak podczas przeglądania trzeba sprawdzać prawa dostępu oraz w specjalny sposób obsługiwać dowiązania symboliczne i punkty zamontowania innych systemów plików.
Jeśli ścieżka dostępu zaczyna się od nazwy, to poszukiwanie pliku rozpoczyna się od bieżącego katalogu, a jeśli od znaku ukośnika, to od korzenia systemu plików.
Podczas działania algorytmu wielokrotnie przeszukuje się katalog w celu znalezienia pozycji o zadanej nazwie (każdy system plików ma specyficzny dla siebie algorytm przeszukiwania katalogów).
Algorytm posługuje się roboczo strukturą danych typu dentry (pierwsza odpowiada bieżącemu katalogowi current->fs->pwd lub korzeniowi systemu plików właściwemu dla bieżącego procesu current->fs->root) wg następującego schematu:
Szczególnego traktowania wymagają dowiązania symboliczne (pliki zawierające nazwy ścieżkowe innych plików). Aby zapobiec zapętleniu się funkcji, liczy się dowiązania symboliczne podczas przeszukiwania nazw i sygnalizuje błąd wówczas, gdy zostanie przekroczona ich górna granica (5).
Jeśli bieżący i-węzeł jest punktem, w którym został zamontowany jakiś system plików, to zmienia się bieżący i-węzeł na i-węzeł korzenia zamontowanego systemu plików.
Należy zaznaczyć, ze funkcja namei jest odporna na znaki '/'. To znaczy może być ich dowolna liczba na początku, na końcu i pomiędzy nazwami katalogów.
Rejestrowanie systemu plików odbywa się podczas startu systemu lub podczas ładowania modułu jądra, obsługującego dany system plików. Zarejestrowane systemy plików są reprezentowane przez struktury file_system_type, połączone w listę liniową, na początek której wskazuje zmienna file_systems. Struktura file_system_type zawiera następujące pola:
|
Rejestracja systemu plików odbywa się przez wywołanie funkcji register_filesystem(). Funkcja ta jest wywoływana podczas startu systemu bądź podczas ładowania modułu obsługi systemu plików. Istnieje także dualna funkcja unregister_filesystem, która usuwa dany system plików z listy zarejestrowanych systemów.
Do montowania systemu plików w istniejącej strukturze katalogów służy funkcja systemowa sys_mount() (wołająca do_mount), czynność odwrotną wykonuje funkcja sys_umount()(wołająca do_umount) .
asmlinkage
long sys_mount(char * dev_name, char * dir_name, char * type,
unsigned long flags, void * data)
asmlinkage
long sys_umount(char * name, int flags)
Wszystkie zamontowane systemy plików powiązane są w listę liniową, na której początek wskazuje zmienna vfsmount (plik include/linux/mount.h). Elementy tej listy to struktury struct vfsmount.
Superblok jest reprezentowany przez strukturę super_block zdefiniowaną w pliku include/linux/fs.h. Zawiera podstawowe informacje o zamontowanym systemie plików i odpowiada fizycznemu superblokowi dysku.
Każda modyfikacja superbloku powoduje ustawienie flagi s_dirt. Linux okresowo przeszukuje superbloki i uaktualnia informacje na dysku.
struct super_block {
struct list_head s_list;
dev_t s_dev;
unsigned long s_blocksize;
unsigned char s_blocksize_bits;
unsigned char s_dirt;
unsigned long long s_maxbytes; /* Max file size */
struct file_system_type *s_type;
struct super_operations *s_op;
unsigned long s_flags;
struct dentry *s_root;
struct rw_semaphore s_umount;
struct semaphore s_lock;
int s_count;
atomic_t s_active;
struct list_head s_inodes; /* wszystkie i-węzły */
struct list_head s_dirty; /* zmienione iwęzły */
struct list_head s_files;
struct block_device *s_bdev;
void *s_fs_info; /* Filesystem private info */
....
Najważniejsze pola struktury super_block:
Metody obiektu:
struct super_operations {
void (*read_inode) (struct inode *);
void (*write_inode) (struct inode *);
void (*put_inode) (struct inode *);
void (*delete_inode) (struct inode *);
void (*put_super) (struct super_block *);
void (*write_super) (struct super_block *);
int (*statfs) (struct super_block *, struct statfs *, int);
int (*remount_fs) (struct super_block *, int *, char *);
void (*clear_inode) (struct inode *);
....
};
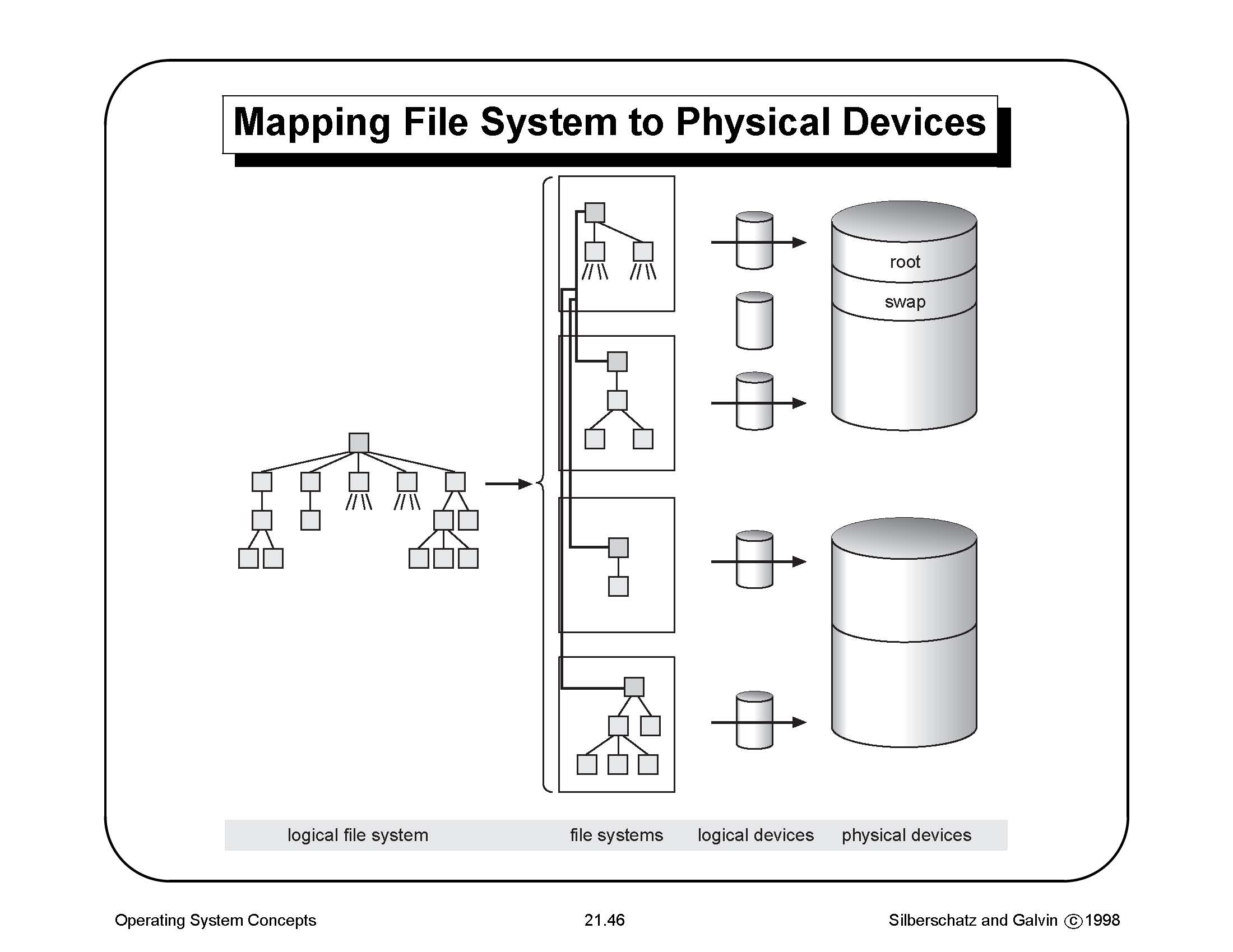
Podstawową fizyczną jednostką danych na dysku jest blok. Wielkość bloku jest stała w ramach całego systemu plików. Oto stałe ograniczające rozmiar bloku dyskowego:
#define EXT2_MIN_BLOCK_SIZE 1024 #define EXT2_MAX_BLOCK_SIZE 4096 /* oczywiście bajtów */
System plików EXT2 na dysku składa się z wielu grup bloków dyskowych. Każda grupa składa się z następujących części:
Podczas inicjowania systemu, do pamięci są wczytywane bloki z deskryptorami grup z pierwszej grupy. Dopóki nie występują sytuacje wyjątkowe, dopóty system nie korzysta z bloków z deskryptorami i z superbloku z pozostałych grup. Deskryptor grupy opisuje struktura ext2_group_desc, która zajmuje 32 bajty, co oznacza, że gdy blok dyskowy ma pojemność 1024 bajty, to jeden blok zawiera 32 deskryptory grup.
struct ext2_group_desc
{
__le32 bg_block_bitmap; /* Blocks bitmap block */
__le32 bg_inode_bitmap; /* Inodes bitmap block */
__le32 bg_inode_table; /* Inodes table block */
__le16 bg_free_blocks_count; /* Free blocks count */
__le16 bg_free_inodes_count; /* Free inodes count */
__le16 bg_used_dirs_count; /* Directories count */
__le16 bg_pad;
__le32 bg_reserved[3];
};
Ponieważ jedna bitmapa zajmuje dokładnie jeden blok, więc jeśli bloki są rozmiaru 1 KB, to pojedynczą mapą możemy opisać 8K bloków, a zatem w grupie mamy 8 MB na bloki z danymi. Jeżeli natomiast bloki dyskowe są rozmiaru 4 KB, to na bloki z danymi mamy wówczas szesnaście razy więcej miejsca, czyli 128MB.
Podzielenie systemu plików na grupy bloków ma na celu zwiększenie bezpieczeństwa oraz optymalizację zapisu danych na dysku. Zwiększenie bezpieczeństwa uzyskuje się poprzez utrzymywanie redundantnych informacji o systemie plików (superblok oraz deskryptory grup) w każdej grupie bloków. Optymalizację zapisu danych zapewniają algorytmy przydziału nowych i-węzłów i bloków dyskowych.
Przydziałem i-węzła tworzonemu plikowi zajmuje się funkcja ext2_new_inode.
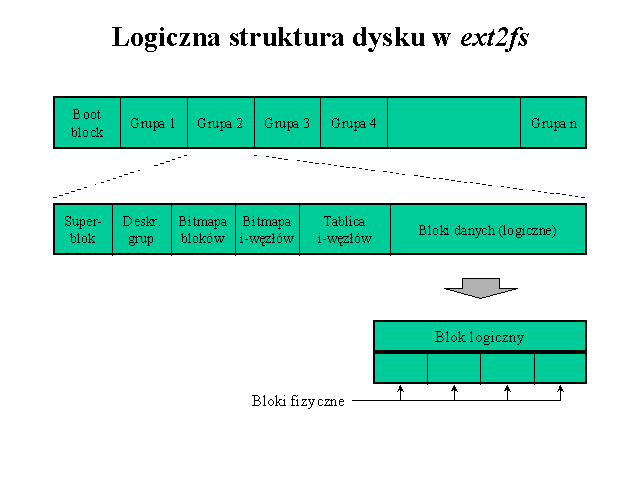
Algorytm przydziału i-węzła zależy od tego czy przydzielamy i-węzeł katalogowi, czy zwykłemu plikowi. Jeśli plik jest katalogiem, to algorytm przeszukuje wszystkie grupy zawierające liczbę wolnych i-węzłów powyżej średniej liczby i-węzłów na całym dysku. Wśród tych grup wybierana jest grupa z największą liczbą wolnych bloków.
Wymaga to przeszukania wszystkich deskryptorów grup, w których znajdują się liczniki wolnych i-węzłów. Nie jest to kosztowne, bowiem tworzenie nowego katalogu nie jest czynnością wykonywaną często, a ponadto wszystkie deskryptory grup są wczytywane do pamięci w momencie ładowania systemu i pozostają tam stale do końca działania systemu (jest ich od kilkudziesięciu do kilkuset).
Jeżeli plik nie jest katalogiem, to szukanie wolnego i-węzła zaczynamy od grupy, w której znajduje się katalog tworzonego pliku. Powoduje to, że z większym prawdopodobieństwem pliki leżące w tym samym katalogu będą znajdować się w tej samej grupie bloków.
Jeżeli w grupie katalogu nie istnieją wolne i-węzły, to przeszukiwanie grup odbywa się przy pomocy algorytmu nazwanego quadratic hash (sprawdza się kolejne grupy oddalone o: 1, 2, 4, ..., 2n < liczba grup (modulo liczba grup).
Gdy nie da to rezultatu, następuje liniowe przeszukiwanie wszystkich grup po kolei począwszy od grupy, w której znajdował się katalog w celu znalezienia grupy z wolnymi i-węzłami.
Po wybraniu grupy bloków, pozostaje wyszukanie wolnego i-węzła w grupie i przydzielenie go utworzonemu plikowi. Informacja, który i-węzeł w grupie bloków jest wolny, a który zajęty jest przechowywana w mapach bitowych. W odróżnieniu od deskryptorów grup, mapy bitowe zajętości i-węzłów nie są wszystkie przechowywane w pamięci. Maksymalną liczbę załadowanych bitmap w pamięci wynosi 8. Zatem widać, że tylko niewielka część bitmap może się znaleźć jednocześnie w pamięci. Gdy liczba grup przewyższa tę stałą (przypadek najczęstszy), wówczas stosuje się algorytm LRU do wymiany bitmap w pamięci. Po znalezieniu i-węzła, bufory zawierające deskryptor grupy i mapę bitową są zaznaczne jako brudne w celu ich późniejszego zapisu na dysk, a wskaźnik do wybranego i-węzła jest przekazywany jako wartość funkcji.
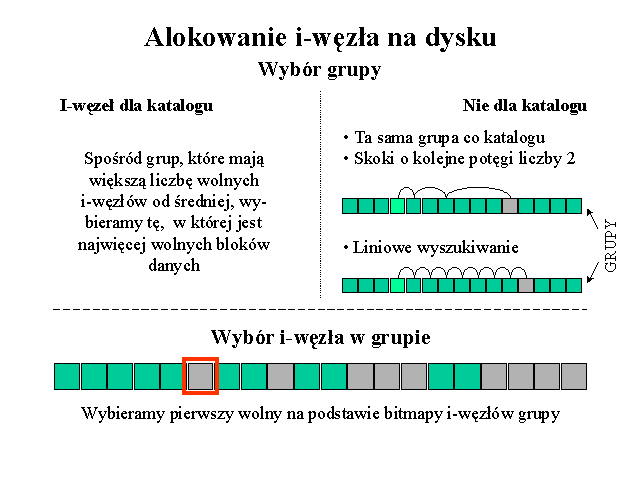
Zwalnianiem i-węzłów na dysku zajmuje się procedura ext2_free_inode. Na początku sprawdza ona, czy można zwolnić i-węzeł. Powody dla których nie można zwolnić to: brak i-węzła, brak urządzenia, licznik procesów używających i-węzła większy od 1, niezerowy licznik dowiązań do i-węzła oraz brak w i-węźle wskaźnika do superbloku.
Po wstępnych sprawdzeniach zakłada się blokadę na superblok, aby zapewnić wyłączność dostępu do niego. Informacje o zwalnianym i-węźle są zapisane w strukturach w pamięci. Po wyliczeniu numeru grupy, do której należy zwalniany i-węzeł wczytuje się jej bitmapę zajętości. Następnie zwalnia się i-węzeł poprzez wyczyszczenie odpowiedniego bitu w bitmapie. Zwiększa się również liczniki wolnych i-węzłów w deskryptorze grupy i superbloku. Ponadto jeśli zwalniano i-węzeł pliku, który był katalogiem, to w deskryptorze grupy zmniejsza się licznik używanych katalogów.
W końcowej fazie zaznacza się, iż był modyfikowany superblok, bitmapa zajętości i-węzłów, deskryptor grupy. Dlatego system operacyjny nie straci informacji o modyfikacji i jeśli będzie chciał sprowadzić nowe i-węzły do pamięci, to ewentualne informacje o zmianach będzie mógł zapisać na dysku. Instrukcją kończącą jest zdjęcie blokady z superbloku.
W systemie Linux operacja przydziału bloków dyskowych jest realizowana przez funkcję ext2_new_block() (wywoływaną z ext2_alloc_block()).
int ext2_new_block (struct inode *inode, unsigned long goal,
u32 *prealloc_count, u32 *prealloc_block, int *err)
Pierwszy parametr funkcji (inode) wskazuje na i-węzeł, dla którego przydzielamy blok, zaś drugi (goal) podaje numer bloku, który chcielibyśmy zaalokować. Jeżeli nie będzie możliwa alokacja bloku o tym numerze, to funkcja spróbuje przydzielić jakikolwiek inny wolny blok.
Funkcja przekazuje numer przydzielonego bloku lub zero jeśli wystąpił błąd. Ponadto zostają uzupełnione parametry:
Z tych właśnie wartości w pierwszej kolejności spróbuje skorzystać funkcja ext2_alloc_block() przy następnym wywołaniu. Oto główne fragmenty:
static int ext2_alloc_block (struct inode *inode,
unsigned long goal, int *err)
{
unsigned long result;
struct ext2_inode_info *ei = EXT2_I(inode);
if (ei->i_prealloc_count &&
(goal == ei->i_prealloc_block || goal + 1 == ei->i_prealloc_block))
{ /* można skorzystać z prealokowanego bloku */
result = ei->i_prealloc_block++;
ei->i_prealloc_count--;
} else {
/* zwolnij prealokowane bloki */
ext2_discard_prealloc (inode);
/* przydziel nowy blok w ext2_new_block */
/* prealokacja - tylko dla zwykłych plików */
if (S_ISREG(inode->i_mode))
result = ext2_new_block (inode, goal,
&ei->i_prealloc_count,
&ei->i_prealloc_block, err);
else
result = ext2_new_block (inode, goal, 0, 0, err);
}
return result;
}
Oto szczegółowy scenariusz działania:
Najpierw procedura pobiera z parametru inode wskaźnik do struktury opisującej superblok bieżącej grupy (tzn. grupy, do której należy podany i-węzeł) i blokuje ten superblok. Gwarantuje to, że żadne dwa procesy nie będą jednocześnie próbowały alokować bloków w tym systemie plików. Jest to konieczne, ponieważ przydzielanie bloków wymaga modyfikacji struktur dyskowych i ich odwzorowania w pamięci (w buforach). W szczególności często modyfikowany jest sam superblok.
W każdym systemie plików pewna liczba wolnych bloków jest zarezerwowana dla administratora systemu. Gdyby nie było tego ograniczenia, łatwo byłoby zablokować system i jedynym ratunkiem byłoby zakończenie wszystkich zadań. Dlatego jeżeli liczba wolnych bloków zapisana w superbloku jest mniejsza niż to minimum, użytkownik wywołujący procedurę nie jest administratorem systemu ani nie ma odpowiednich uprawnień, to wykonanie procedury kończy się z błędem. W przeciwnym przypadku przechodzimy do pierwszej fazy działania, w której próbuje się znaleźć wolny blok.
Bloku zawsze próbujemy szukać najpierw w bieżącej grupie (przy czym zaczynamy poszukiwania od bloku o numerze goal), dopiero potem szukamy w pozostałych. Poza tym, ponieważ sytuacja, w której struktury opisujące stan systemu plików dość rzadko tracą integralność, testowanie, czy jakaś grupa ma wolne bloki, rozpoczyna się zawsze od sprawdzenia licznika wolnych bloków tej grupy. Można założyć, że jego wartość prawie zawsze będzie zgodna z tym, co zawiera bitmapa.
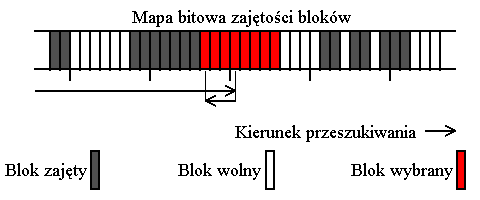
Pobiera się zatem deskryptor bieżącej grupy. Jeżeli licznik wolnych bloków jest większy niż zero, to zostaje załadowana bitmapa zajętości bloków tej grupy i sprawdza się, czy żądany blok jest wolny.
Jeśli jest, to zostaje przydzielony, a jeśli nie, to próbuje się przydzielić jeden z następujących po nim bloków, testując odpowiednie bity w bitmapie zajętości. Szuka się nie dalej niż do końca bieżącej grupy i nie dalej niż do najbliższego bloku o numerze będącym wielokrotnością 64.
if (goal) {
...
k = (goal + 63) & ~63;
goal = ext2_find_next_zero_bit(map, k, goal);
if (goal < k)
goto got_it;
}
Szukanie nowego bloku do przydzielenia w pierwszej kolejności w najbliższym sąsiedztwie podanego bloku ma zasadniczy sens dla prędkości działania systemu plików. Właśnie temu, że podobne przypadki szczególne są uwzględniane w algorytmie przydziału bloków, system plików EXT2 zawdzięcza wyjątkowo niski współczynnik fragmentacji plików. Bloki danego pliku są prawie zawsze położone blisko siebie i wczytywanie pliku jest szybkie.
Jeżeli nie udało się znaleźć wolnego bloku w najbliższym sąsiedztwie, to najpierw przeszukujemy pozostałą, nie sprawdzoną dotąd część bieżącej grupy. Poszukiwania kontynuowane są do końca bieżącej grupy, przy czym najpierw szuka się spójnego ciągu ośmiu wolnych bloków, takich, że pierwszy z nich ma numer będący wielokrotnością ośmiu. Mimo wszystko lepiej, aby blok był w tej samej grupie, nawet, jeżeli do wolnego bloku w innej grupie byłoby bliżej. Dzięki temu zwiększa się prawdopodobieństwo, że wszystkie bloki pliku będą w tej samej grupie lub przynajmniej w maksymalnie kilku, najlepiej sąsiadujących. Powoduje to, że dane plików o i-węzłach z różnych grup są dodatkowo separowane od siebie, co zwiększa stopień uporządkowania na dysku, a właśnie taki cel przyświeca grupom.
p = bitmap + (goal >> 3);
/* szukaj pierwszego zerowego bajtu na prawo od goal */
r = memscan(p, 0, (blocks_per_group - goal + 7) >> 3);
k = (r - bitmap) << 3;
/* k - numer pierwszego bitu na prawo od goal w bajcie złożonym
w całości z zer
*/
Jeśli poszukiwanie całego wolnego bajtu w bitmapie zakończyło się sukcesem, to przeszukuje się bitmapę od początku bajtu wstecz w celu zlokalizowania początku tego wolnego obszaru. Skoro już znaleziono większy wolny obszar, warto upychać dane od początku tego obszaru, żeby go zbyt prędko nie sfragmentować. Znalezione miejsce jest miejscem przydziału nowego bloku.
if (k < blocks_per_group) {
/*
* We have succeeded in finding a free byte in the block
* bitmap. Now search backwards up to 7 bits to find the
* start of this group of free blocks.
*/
for (goal = k; goal && !ext2_test_bit (goal - 1, bitmap); goal--);
Jeżeli nie było takiego spójnego ciągu bloków, to szukamy jakiegokolwiek wolnego bloku od początku do końca grupy.
k = ext2_find_next_zero_bit (bitmap,blocks_per_group,goal);
W przypadku porażki poszukiwanie jest kontynuowane w pozostałych grupach. Najpierw, poczynając od grupy następnej po bieżącej, poszukuje się grupy, która ma jakieś wolne bloki. Testuje się w tym celu licznik wolnych bloków w deskryptorze. Wykorzystuje się tutaj niski współczynnik awaryjności systemu EXT2. Prawdopodobieństwo tego, że gdzieś będą wolne bloki, a licznik będzie zero lub na odwrót, jest na tyle niskie, że można je zlekceważyć.
Po znalezieniu takiej grupy ładuje się jej bitmapę zajętości. Następnie w pierwszej kolejności próbuje się znaleźć w tej grupie ciąg co najmniej ośmiu następujących po sobie wolnych bloków (cały wolny bajt w bitmapie). Czyni się tak po to, aby zwiększyć szansę, że kolejne kilka bloków, które proces będzie chciał alokować, będzie leżało tuż obok właśnie alokowanego. To jeden ze sposobów unikania fragmentacji plików. Opłaca się to czynić, mimo, że czasem konieczne jest powtórne przeszukanie bitmapy, jeśli się nie uda.
Jeżeli nie znajdzie się długiego ciągu wolnych bloków, to próbuje się znaleźć jakikolwiek wolny blok w tej grupie. Jeżeli nie ma, to zgłasza się błąd systemowy integralności informacji w deskryptorze (licznik wolnych bloków). Jeśli zaś wolny blok zostanie znaleziony, to przechodzimy do drugiej fazy działania.
Po ustawieniu bitu zajętości rozpoczyna się następna faza, w której dokonuje się opcjonalnej alokacji z wyprzedzeniem. Chęć dokonania prealokacji deklaruje się za pośrednictwem parametru prealloc_block. Próbuje się alokować dodatkowe bloki spośród następujących bezpośrednio po pierwszym zaalokowanym, ale maksymalnie siedem (czyli 8 łącznie z już zaalokowanym) i tylko do końca bieżącej grupy (tzn. nie więcej niż tyle, ile jest bloków w danej grupie za bieżącym).
Po zakończeniu, w parametrze prealloc_count przekazuje się liczbę prealokowanych w ten sposób bloków. Jest to zwarty obszar, bo prealokacja kończy się po pierwszym niepowodzeniu.
Po fazie prealokacji następuje ostatnia faza działania, w której uaktualnia się struktury na dysku. W pierwszej kolejności oznacza się jako brudny bufor z bitmapą bieżącej grupy i, jeśli jest to konieczne, inicjuje się transmisję synchroniczną i czeka się na jej zakończenie, a jeśli nie, to wyśle się go na dysk synchronicznie.
Zmniejsza się licznik wolnych bloków w grupie. Bufory bloku z deskryptorami grupy i superbloku także oznacza się jako brudne, do zapisania na dysk, ponieważ ich zawartość zmieniła się. Ostatecznie zwalnia się semafor superbloku i kończy wykonanie procedury, przekazując numer zaalokowanego bloku.
Do zwalniania bloków dyskowych służy procedura ext2_free_blocks.
void ext2_free_blocks (struct inode * inode, unsigned long block,
unsigned long count)
Informacja o blokach w grupach jest zapisana w superbloku, deskryptorze i bitmapie zajętości bloków oraz w i-węźle. Zatem zwolnienie bloków polega na aktualizacji tych czterech struktur danych w pamięci i zaznaczeniu, że uległy one modyfikacji.
Procedura zwalnia spójny ciąg bloków dyskowych. Na początku zakładamy blokadę na superblok, aby zapewnić sobie wyłączność dostępu do niego. W fazie wstępnej sprawdzamy poprawność argumentów: czy bloki do zwolnienia leżą w strefie bloków z danymi i czy leżą w obrębie jednej grupy. Następnie wczytujemy bitmapę owej grupy i jej deskryptor. Jeśli struktur tych nie ma w pamięci, to wczytywane są one z dysku.
Po tych wszystkich przygotowaniach przystępujemy do właściwego zwalniania bloków. Odbywa się to przez wyczyszczenie (odpowiadającego zwalnianemu blokowi) bitu w bitmapie zajętości bloków oraz uaktualnienie danych w i-węźle i zwiększenie liczników wolnych bloków w deskryptorze grupy i superbloku.
W końcowej fazie zaznacza się, że modyfikowano bufory zawierające superblok oraz bitmapę zajętości bloków. Instrukcją kończącą procedurę jest zdjęcie blokady z superbloku.
Zadaniem pamięci buforowej jest usprawnienie działania i ujednolicenie interfejsu operacji dyskowych. Dzięki utrzymywaniu puli buforów eliminuje się wielokrotne odwołania do tego samego bloku dyskowego. Opóźniony zapis pozwala na wykonywanie operacji dyskowych w czasie, gdy system jest mniej zajęty. Odczytywanie z wyprzedzeniem przygotowuje blok dyskowy, o który proces prawdopodobnie poprosi w przyszłości.
Począwszy od Linuksa 2.4.10 podręczna pamięć buforowa w praktyce przestała istnieć. Nie przydziela się już buforów indywidualnie, lecz umieszcza je w dedykowanych stronach zwanych 'stronami buforów', które przechowuje się w pamięci podręcznej stron. Strona buforów to strona z danymi, na które wskazują 'nagłówki buforów', których zadaniem jest szybkie odszukanie adresu dyskowego indywidualnego bloku w stronie. W rzeczywistości dane zapisane w stronei nie muszą pochodzić z sąsiadujących ze sobą części na dysku.
Do działania podręcznej pamięci buforowej bloków konieczna jest implementacja pewnej puli buforów umożliwiającej szybkie odszukanie bufora zawierającego dany blok dyskowy. Pula buforów musi zapewniać jednoznaczne odwzorowanie buforów w bloki dyskowe - każdy blok dyskowy znajduje się w pamięci w co najwyżej jednej kopii. Potrzebne są pewne algorytmy kontrolujące przepływ buforów pomiędzy strukturami danych puli buforów i organizację współpracy z pamięcią jądra.
Podstawowe zalety buforowania to zwiększenie wydajności systemu i ujednolicenie interfejsu funkcji dostępu do dysku. Ale ważne jest też np. ukrywanie przed użytkownikiem faktu, że operacje dyskowe są operacjami blokowymi; pozwala to na wykonywanie przez procesy operacji bajtowych. Jądro nie musi znać znaczenia danych dyskowych - mogą to być np. i-węzły.
Niestety mechanim ten ma też wady. Podstawowym problemem związanym z opóźnionym zapisem jest nieznajomość momentu, w którym dane zostają w rzeczywistości zapisywane na dysku. W przypadku awarii systemu dane te zostają utracone. Dodatkowym problemem jest podwójne kopiowanie - z dysku do pamięci jądra i ponownie do pamięci procesu. W Linuksie próbuje się temu zaradzić stosując bufory dzielone.
| ©Janina Mincer-Daszkiewicz |