Uniwersytet Warszawski
Wydział Matematyki, Informatyki i Mechaniki
Karol Bieńkowski
Nr albumu: 181029
Implementacja standardów XPointer i
XInclude
Praca magisterska
wykonana pod kierunkiem
dr Janiny
Mincer-Daszkiewicz
Instytut Informatyki
Warszawa, czerwiec 2003ale
Pracę przedkładam do oceny
Data Podpis
autora pracy:
Praca jest gotowa do oceny przez recenzenta
Data Podpis
kierującego pracą:
Streszczenie
Treścią
pracy jest opis napisanego przeze mnie programu – implementacji standardów
XPointer i XInclude. Standardy te zostały zdefiniowane przez World Wide Web
Consortium, żeby ułatwić pracę z dokumentami XML. Praca zawiera omówienie
wymagań stawianych programowi, w tym opis wykorzystywanych standardów, projekt
programu oraz przegląd jego zastosowań, spośród których najważniejszym jest
system zarządzania dokumentami.
Słowa kluczowe
Standardy XML, XPointer, XInclude, Java, Saxon
Klasyfikacja tematyczna wg ACM Computing Classification System (1998)
I.7.2. Document and
Text Preparation – Markup Languages, Standards
D.
Software
Spis treści
2.1. Ogólnie o XML i standardach
2.2.1. Dokumenty przetwarzane automatycznie
2.2.2. Dokumenty tworzone przez człowieka
2.3. Opisy standardów uwzględnianych
przy implementacji
2.3.1. Standardy pomocnicze: XML, Namespaces,
Base, InfoSet
2.3.2. XPath – standard bazowy dla XPointer
2.4. Wymaganie związane z językiem
programowania i modelem przetwarzania.
2.4.5. Porównanie XML InfoSet i SAX
2.6. Istniejące implementacje XInclude
oraz XPointer
3.1.2. Resolwery dla schematów URI
3.3. Architektura XPointer -
Saxon
3.3.3. Zakres i punkt jako węzły
3.5. Obsługa wyjątków w XInclude
4.2.2. Klasa implementująca zakres
4.2.6. Porządek węzłów w dokumencie
4.3. Aplikacja testowa, przykłady
XInclude i XPointer
5.1. XInclude przy tworzeniu
dokumentacji w DocBook
5.2. XLink – standard wykorzystujący
XPointer
5.3. e:kms - system zarządzania
dokumentami
1.
Wstęp
W 1998 roku XML (eXtensible Markup Language) [XML] zyskał rekomendację World Wide Web Consortium [W3C], dzięki czemu stał się oficjalnym standardem. Wkrótce standard doczekał się licznych implementacji, w tym darmowych, zatem informatycy dostali narzędzia do pracy z dokumentami XML. Rosnące wymagania stawiane tym narzędziom wymusiły powstanie kolejnych standardów, związanych z XML-em i rozszerzających jego możliwości. Wiele z nich zyskało status rekomendacji W3C. Zaczął się wyścig: W3C ogłaszało nowe standardy, a programiści próbowali nadążyć z ich implementacją. Standardy, które już doczekały się implementacji, to m.in. XML Namespaces [XMLNames] i XPath [XPath]. XML Namespaces, który rozszerza semantykę XML-a o możliwość definiowania przestrzeni nazw oraz XPath, czyli język zapytań służący do adresowania elementów wewnątrz dokumentu są od dawna obsługiwane przez ogólnodostępne narzędzia XML. Jednakże istnieją standardy wciąż czekające na realizację. Należą do nich XPointer [XPtr] i XInclude [XIncl], którym poświęcona jest ta praca.
1.1. Cel pracy
W ramach pracy napisałem program implementujący XPointer i XInclude, który wypełnia lukę w implementacjach standardów. Program powstał na zamówienie firmy, która chciała wzbogacić swój system zarządzania dokumentami o obsługę kolejnych standardów. Obsługa XPointer i XInclude miała stać się jednym z atutów systemu, wyróżniającym go spośród konkurencyjnych rozwiązań. Realizacja standardów to główne wymaganie, jakie zostały postawione programowi przeze mnie i zleceniodawcę. Jednak także wydajność programu miała podlegać ocenie, a niektóre założenia projektowe zostały narzucone z góry, choćby wybór Javy [J2SE] jako języka programowania.
Celem tego dokumentu jest opis programu i procesu jego powstawania. Opis byłby niepełny bez przedstawienia wszystkich standardów, które bezpośrednio wywarły wpływ na implementację, stanowiąc część specyfikacji zadania. W pracy nie podejmę się szczegółowego opisu implementacji, tylko przedstawię ogólną architekturę rozwiązania oraz najciekawsze miejsca w kodzie. Zamieszczone przykłady wykorzystania XInclude i XPointer uzasadnią sens powstania programu.
1.2. Struktura pracy
Pierwsza część pracy, czyli opis wymagań stawianych programowi, to głównie przegląd standardów XML-owych. Standardy znalazły się w części poświęconej wymaganiom, gdyż realizacja standardów to główne zadanie programu. Nie będę streszczał specyfikacji standardów, zamiast tego przedstawię te fragmenty standardów, które mają bezpośrednie znaczenie dla implementacji XPointer i XInclude. W tej części pracy opiszę również standardowe modele przetwarzania XML-a w Javie, gdyż jednym z wymagań względem programu jest obsługa tych modeli. Pierwszą część zakończę opisując dostępne implementacje XPointer i XInclude, wykazując ich ograniczenia i dowodząc potrzeby stworzenia własnej implementacji standardów. Druga część pracy, czyli projekt, dotyczy ogólnej architektury programu oraz decyzji, które musiały zostać podjęte przed rozpoczęciem implementacji. Trzecia część to opis implementacji, a właściwie jej najbardziej interesujących fragmentów. Na zakończenie, w czwartej części pracy, przedstawiam dwa możliwe zastosowania programu: tworzenie dokumentacji w DocBook [DocBook] oraz system zarządzania dokumentami ze wsparciem XML-a.
2. Wymagania
Program – implementację XInclude i XPointer – napisałem na zlecenie firmy empolis Polska [Emp]. Program miał stać się modułem systemu zarządzania dokumentami, który zawiera specjalne wsparcie dla dokumentów XML. Wymagania opisane w tym rozdziale, stanowiące część zlecenia, zostały przygotowane przez firmę empolis. Położono nacisk na to, by program nadawał się do wygodnego użycia w istniejącym już systemie.
Realizacja standardów to
najważniejsza część wymagań stawianych programowi, stąd tyle miejsca tego
rozdziału poświęcam na ich opis. Niektóre ze standardów doczekały się nowych
wersji, już po rozpoczęciu mojej implementacji. Dzięki odnośnikom zawartym w
kolejnych rozdziałach można uzyskać dostęp do wersji, które zostały przeze mnie
wykorzystane.
2.1. Ogólnie o XML i standardach
XML jest językiem definiującym
sposób znakowania dokumentów tekstowych. XML wywodzi się od SGML-a, jest jego
uproszczoną wersją. SGML powstał na potrzeby tworzenia elektronicznych wersji
dokumentacji i innych dokumentów technicznych. W odróżnieniu od innych języków
znakowania SGML umożliwiał wstawianie do tekstów dowolnych znaczników. SGML nie
podaje semantyki znaczników, jedynie definiuje ich składnię. SGML pozostał
nieznany szerokiemu gronu informatyków – jego składnia była zbyt skomplikowana,
a narzędzia do przetwarzania dokumentów SGML-owych są zbyt drogie. Dlatego
powstał XML, który odziedziczył pomysł wstawiania dowolnych znaczników, ale
składniowo jest znacznie prostszy.
Przyjrzyjmy się prostemu przykładowi dokumentu w XML.
<?xml version="1.0"
charset="iso-8859-2"?>
<osoba>
<imię>Karol</imię>
<nazwisko>Bieńkowski</nazwisko>
</osoba>
Treścią dokumentu jest krótki tekst ("Karol Bieńkowski"), ale odpowiednio oznakowany. Cały tekst leży między znacznikiem otwierającym <osoba> a zamykającym </osoba>, a ponadto poszczególne wyrazy są oznaczone jako <imię> i <nazwisko>. Przykład, choć prosty, pokazuje ideę XML-a: pozwolić autorowi dokumentu dowolnie oznaczyć swój tekst przy użyciu wybranych przez autora znaczników. Dzięki znakowaniu zawartość dokumentu otrzymuje semantyczne znaczenie, co ułatwia automatyczne przetwarzanie dokumentów.
XML zyskał szybko dużą popularność dzięki temu, że powstało wiele oprogramowania umożliwiającego jego przetwarzanie. Jednak sam standard XML jest na tyle prosty, że to oprogramowanie nie dawało dużych możliwości twórcom aplikacji, umożliwiało właściwie tylko czytanie i zapisywanie dokumentów oraz ich walidację. Walidacja to sprawdzanie czy dokument jest zgodny z pewną definicją (DTD) określającą, m. in. dozwolone w dokumencie elementy. Szybko powstały kolejne standardy, które umożliwiły bardziej zaawansowane operacje na dokumentach XML-owych: XSLT do opisu reguł transformacji dokumentów XML w inne dokumenty XML, XML Schema do tworzenia definicji dokumentów, XPath do adresowania informacji wewnątrz dokumentów i inne. Te nowe standardy, sygnowane przez W3C, szybko zyskały akceptację użytkowników, więc powstały programy je implementujące. Dziś trudno sobie wyobrazić system do pracy z XML nie wspierający np. XSLT czy XPath. Najbardziej znane narzędzia do przetwarzania XML-a napisane w Javie realizujące wymienione standardy to Xalan [Xalan] i Saxon [Saxon].
Do tej samej rodziny standardów, rozszerzających funkcjonalność XML-a, należą XPointer i XInclude. Stworzono je by ułatwić wykorzystanie XML-a w aplikacjach. XPointer to język pozwalający na zaadresowanie (wybranie) dowolnej części dokumentu XML, np. elementu, fragmentu tekstu, zbioru elementów. XPointer jest w pewnym sensie odpowiednikiem SQL-a, jeżeli potraktujemy plik XML jako bazę danych. XPointer został także zaproponowany jako standardowy sposób na wskazywanie fragmentów dokumentów w adresach URL. Obecnie pewien sposób wskazania fragmentu w dokumencie HTML, np. http://examle.org/doc.html#rozdzial1. Taki adres odpowiada adresowi kotwicy <a name=”rozdzial”> w dokumencie doc.html. Opisany sposób adresowania jest niewystarczający dla XML-a, gdyż niektóre dokumenty nie pozwalają na wstawianie do nich kotwic. XPointer jest o wiele bardziej elastyczny i daje możliwość obejścia tego ograniczenia.
XInclude to prosty standard definiujący sposób scalania dokumentów XML-owych. Model przetwarzania dokumentów wykorzystujących XInclude jest podobny do przetwarzania plików języka C korzystających z dyrektywy #include. XInclude ma znacznie większe możliwości, m. in. włączanie fragmentów dokumentów oraz dwa tryby włączania: jako tekst i jako XML. Do wskazywania fragmentów dokumentów do włączenia wykorzystywane są zapytania XPointer. Zatem standardy są powiązane – XInclude używa XPointer, więc implementacja XInclude musi zawierać moduł realizujący XPointer.
2.2. Zastosowania XML
Wraz z upowszechnianiem standardu XML wyodrębniły się dwa obszary jego zastosowań. Każdy z nich wykorzystuje specyficzną klasę dokumentów.
2.2.1. Dokumenty przetwarzane automatycznie
Do pierwszej klasy należą dokumenty tworzone i przetwarzane automatycznie. Są generowane przez komputery, po to, by zostać przetworzone przez inne maszyny. Można za ich pomocą integrować systemy działające na różnych platformach i napisane w różnych językach programowania. Do tej klasy dokumentów należą komunikaty SOAP. SOAP to odmiana RPC, w której zarówno żądania jak i odpowiedzi są przesyłane jako dokumenty XML. Dokumenty przetwarzane automatycznie cechuje prostota struktury, są one odzwierciedleniem struktur danych, na których operuje oprogramowanie: liczb, napisów, rekordów z relacyjnych baz danych, kolekcji. Nie ma tu miejsca na wykorzystanie XPointer i XInclude.
2.2.2.
Dokumenty tworzone przez człowieka
Standardy XPointer i XInclude są wykorzystywane w drugiej klasie dokumentów – tworzonych przez człowieka. Do tej klasy zaliczają się, m. in. dokumentacje, książki, strony WWW. Wykorzystanie XInclude umożliwia tworzenie pojedynczej książki przez wielu ludzi – każda z osób może tworzyć poszczególne rozdziały, a następnie fragmenty są scalane przez parser XInclude. XPointer może być w pełni wykorzystany dopiero wtedy, gdy dokumenty są przechowywane w wyspecjalizowanym repozytorium wspierającym XML-a. Wtedy możliwe jest tworzenie w dokumentach odnośników do innych dokumentów, a nawet do ich fragmentów. Można sobie wyobrazić następujący scenariusz obsługi takich odnośników: po kliknięciu na odnośnik zobaczymy wskazywany dokument z podświetlonym wskazanym fragmentem.
2.3. Opisy standardów uwzględnianych przy implementacji
2.3.1. Standardy pomocnicze: XML, Namespaces, Base, InfoSet
XML
Specyfikacja XML określa składnię dokumentów XML-owych. Był to pierwszy standard, z którym musiałem się gruntownie zapoznać by rozpocząć pracę. Specyfikacja wprowadza podstawowe pojęcia dotyczące XML-a, zawiera reguły, które muszą spełniać programy przetwarzające dokumenty XML-owe, opisuje sposób przechowywania dokumentów w fizycznych plikach. Jednak najobszerniejsza część specyfikacji to dokładny opis składni dokumentów XML-owych, oczywiście z pełną gramatyką. Niektóre fragmenty specyfikacji nie miały bezpośredniego znaczenia dla mojego programu, gdyż do przetwarzania dokumentów XML używałem gotowych bibliotek. Biblioteki ukrywały wiele niuansów standardu, takich jak obsługa encji wewnętrznych. W kolejnych paragrafach skupię się na tych fragmentach specyfikacji, którymi musiałem zająć się w swoim kodzie.
Specyfikacja definiuje sposób odczytu kodowania plików (w terminologii specyfikacji nazywanych encjami) zawierających dokumenty XML-owe. Każda implementacja XML-a musi obsługiwać standardy UTF-8 oraz UTF-16, mile widziana jest również obsługa kodowań rodziny ISO-8859-n. Za rozpoznawanie kodowania odpowiedzialny jest parser XML, ale XInclude dopuszcza także włączanie plików tekstowym. Przy takim włączaniu nie mogę się posłużyć parserem XML, więc wybór kodowania spośród UTF-8, UTF-16 i ISO spada na parser XInclude. Specyfikacja XInclude zakłada, że wykrywanie kodowania włączanego pliku tekstowego ma odbywać się tak jak zdefiniowano w XML, więc z np. uwzględnieniem BOM (ang. Byte Order Mark) i XML-owej deklaracji kodowania (<?xml version=”1.0” encoding=”iso-8859-2”?>). Musiałem dokładnie poznać ten mechanizm.
Kolejnym ważnym z punktu widzenia XInclude pojęciem w XML-u są nieparsowalne encje zewnętrzne. Encje zewnętrzne to pliki (np. obrazki), do których można odwoływać się z wewnątrz dokumentu XML. Specyfikacja określa, że na początku dokumentu mogą pojawić się deklaracje encji nieparsowalnych. Taka deklaracja to związanie nazwy encji z jej identyfikatorem. Przykładem identyfikatora encji, zwanego systemowym, jest nazwa pliku. Po deklaracji encji w ciele dokumentu używa się już samej nazwy encji, zapominając o identyfikatorze. Deklarowanie encji na początku stwarza problemy parserowi XInclude. Wyobraźmy sobie sytuację, kiedy włączany dokument używa encji. Deklaracja encji powinna znaleźć się w wynikowym dokumencie, co oznaczałoby konieczność wstrzymania generacji sekcji deklaracji aż do przetworzenia wszystkich inkluzji. Po analizie tej specyfikacji postanowiłem w parserze XInclude ignorować encje nieparsowalne.
XML Namespaces
XML Namespaces to rozszerzenie XML, które definiuje przestrzenie nazw elementów. Każda przestrzeń nazw ma unikalne URI określone przez jej twórcę. W jednym dokumencie mogą być elementy z wielu przestrzeni nazw. Żeby określić przynależność dokumentu do przestrzeni nazw, najpierw trzeba zadeklarować przestrzeń nazw. Deklaracja przestrzeni to przypisanie prefiksu do URI przestrzeni. Deklaracja przestrzeni obowiązuje w elemencie ją deklarującym oraz w jego podelementach. Deklaracja ma postać atrybutu o prefiksie xmlns.
<?xml version=”1.0”?>
<a:root xmlns:a=”http://example.org/namespace”>
<a:elt1/>
<elt2/>
</a:root>
W przykładowym dokumencie elementy <root> i <elt1> należą do przestrzeni z URI http://example.org/namespace, identyfikowanej przez prefiks „a”.
To, że deklaracja przestrzeni nie jest globalna, ale ograniczona do elementu ma znaczenie dla XInclude. Kiedy jest włączany fragment dokumentu wykorzystującego przestrzenie nazw, trzeba zadbać o dodanie do wynikowego dokumentu deklaracji przestrzeni z dokumentu włączanego.
Przykład
Jeżeli z tego dokumentu włączamy tylko element <b>
<?xml version=”1.0”?>
<a xmlns:x=”http://example.org/ns”>
<b>
<x:c/>
</b>
</a>
to w wynikowym dokumencie znajdzie się fragment:
<b xmlns:x=”http://example.org/ns”>
<x:c/>
</b>
a więc implementacja musi dodać
dodatkowy atrybut xmlns:x,
deklarujący przestrzeń http://example.org/ns.
XML Base
XML Base [XMLBase] definiuje sposób wyznaczania adresu URI, który jest używany do zamieniania adresów względnych na bezwzględne (ang. base URI). Ma znaczenie podobne do znacznika <base> w HTML-u. Standard określa, że domyślnym bazowym adresem URI do ustalania względnych adresów jest URI dokumentu oraz pozwala na przedefiniowanie adresu bazowego. Przedefiniowanie adresu odbywa się za pomocą atrybutu xml:base, Deklaracja nowego adresu bazowego obowiązuje w elemencie, który użył atrybutu xml:base i jego podelementach. Sposób działania i problemy z implementacją w XInclude są podobne jak z XML Namespaces.
Załączony przykład pokazuje, że adresem bazowym dla elementu <elt> pozostaje file:///home/kb/subdir, niezależnie od tego czy element występuje on w swoim źródłowym dokumencie, czy w dokumencie będącym wynikiem działania parsera XInclude. Z przykładu widać, że parser musi wstawiać dodatkowe atrybuty xml:base - w tym przypadku dla elementu <a> oraz dla elementu <test>.
Oto dokument źródłowy, którego adres URI to „file:///home/kb/test.xml”, reprezentujący ścieżkę w systemie plików:
<?xml version=”1.0”?>
<root>
<xi:include href=”included.xml”/>
<xi:include href=”included.xml#xpointer(//test)”/>
</root>
Tutaj mamy plik o nazwie included.xml, który znajduje się w tym samym katalogu dyskowym, co text.xml:
<?xml version=”1.0”?>
<included>
<a xml:base=”subdir”>
<test/>
</a>
<b xml:base=”http://www.example.org”/>
</included>
A oto plik wynikowy, powstały po przetworzeniu test.xml za pomocą parsera XInclude:
<?xml version=”1.0”?>
<root>
<included xml:base=”file:///home/kb/included.xml”>
<a xml:base=”file:///home/kb/subdir”>
<test/>
</a>
<b xml:base=”http://www.example.com”/>
</included>
<elt xml:base=”file:///home/kb/subdir”/>
</root>
XML InfoSet
XML InfoSet [XMLInfoSet] to pomocnicza specyfikacja, która definiuje terminologię dla innych standardów, w szczególności dla XInclude. Zgodnie z XML InfoSet, z każdym dokumentem XML związany jest zbiór jednostek informacyjnych (ang. information item), które tworzą zbiór informacji (InfoSet). Jednostki podzielone są na jedenaście typów, odpowiadających strukturom zdefiniowanym w składni XML. Te typy to:
- Dokument,
- Element,
- Atrybut,
- Instrukcja przetwarzania,
- Nierozwinięta referencja do encji,
- Znak,
- Komentarz,
- Deklaracja DTD,
- Encja nieparsowalna,
- Notacja,
- Przestrzeń nazw.
Poszczególne jednostki mają własności, których wartościami są inne jednostki, np. jednostka Element ma własność [children], której wartością jest lista podelementów. W XML InfoSet nie ma odpowiedników dla wszystkich konstrukcji języka XML, np. nie ma jednostek informacyjnych odpowiadających deklaracji elementu.
Specyfikacja XInclude określa scalanie dokumentów w terminologii jednostek informacyjnych. Parser XInclude działa na fizycznych obiektach dostarczonych przez biblioteki XML, a nie na abstrakcyjnych jednostkach informacyjnych. Wymusza to konieczność odwzorowania jednostek informacyjnych na struktury używane przy programistycznym przetwarzaniu dokumentów XML-owych. Odwzorowanie w formie tabeli pojawia się w projekcie aplikacji.
Przykład
Jednostce informacyjnej Element odpowiada w modelu SAX [SAX] para zdarzeń startElement() i endElement(), a w modelu DOM [DOM] obiekt klasy Element. Modele SAX i DOM są szczegółowo opisane w następnych rozdziałach. W składni XML element to część tekstu od znacznika otwierającego do zamykającego, oto reprezentacja elementu o nazwie „elem”:
<elem>
<sub1>txt</sub1>
<sub2/>
</elem>
Struktury ze składni XML, które nie mają odpowiedników w
InfoSet są ignorowane przez XInclude.
2.3.2. XPath – standard bazowy dla XPointer
XPath jest bardzo ważnym standardem dla implementacji XPointer, gdyż XPointer jest zdefiniowany jako rozszerzenie XPath. Obydwa standardy korzystają z tych samych pojęć i terminologii. Rysunek 1 pokazuje, w jaki sposób standardy są ze sobą powiązane. XPath to język zapytań, który umożliwia wyszukiwanie składników dokumentów XML-owych. Jego składnia trochę przypomina ścieżki w systemie plików, np. wyrażenie /document/para/title wskazuje na element <title> będący dzieckiem elementu <para> zawartego w <document>. XPath umożliwia również wykonywanie operacji logicznych i arytmetycznych, a także zawiera wbudowane funkcje. To powoduje, że wyrażenia XPath mogą być dość skomplikowane: count(/document/*[title = ‘Introduction’) + string-length(/document[1]) > 100.
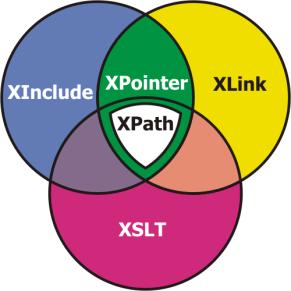
Rysunek 1. Powiązanie standardów XML-owych
XPath operuje na własnym modelu dokumentu XML. Ten model opisuje dokument jako drzewo składające się z węzłów, które są jednego z siedmiu typów: korzeń, element, tekst, atrybut, przestrzeń nazw, instrukcja przetwarzania lub komentarz. Pojęcie węzła w XPath jest niezwykle istotne, węzeł to najmniejsza część dokumentu, która może być zaadresowania przy pomocy wyrażenia. Model dokumentu zdefiniowany w XPath jest podobny zarówno do XML InfoSet, jak i do DOM, ale nie jest izomorficzny z żadnym z nich. Jedną z różnic w stosunku do InfoSet jest liczba typów węzłów (np. w XPath nie ma węzłów encji). Od DOM różni go m. in. inne traktowanie węzłów tekstowych (w XPath węzły tekstowe nie mogą być sąsiednimi braćmi, w DOM mogą) oraz węzłów przestrzeni nazw.
Wartości wyrażeń XPath mają jeden z czterech typów: zbiór węzłów (ang. node-set), wartość logiczna, liczba lub napis. Najciekawsze, zarówno dla użytkownika, jak i dla programisty jądra XPath, są wyrażenia ewaluujące się do zbioru węzłów. Przykłady takich wyrażeń, to / oznaczający korzeń drzewa dokumentu i wyrażenie ścieżkowe /document/section/para. Pierwsze wyrażenie zawsze przekaże zbiór jednoelementowy, podczas gdy drugie przekaże wiele węzłów, gdy dokument zawiera wiele sekcji i paragrafów.
Obliczenie każdego wyrażenia XPath wymaga dostarczenia kontekstu. Kontekst jest zdefiniowany przez bieżący węzeł, bieżącą pozycję, rozmiar, bibliotekę funkcji i przestrzeni nazw. Kontekst wpływa na niektóre funkcje i konstrukcje XPath, np. . oznacza zawsze bieżący węzeł, a funkcja position() przekazuje bieżącą pozycję w kontekście. Kontekst ma znaczenie przy wyliczaniu predykatów, które filtrują węzły.
Wyrażenia ścieżkowe składają się z kroków, a każdy krok to składa się z osi, testu oraz dowolnej liczby predykatów. Rozważmy krok wyrażenie/para[./title = ‘Intro’][1]. Zakładamy, że zostało obliczone poprzednie wyrażenie, które przekazało jakiś zbiór węzłów. Przystępujemy do obliczania kroku, który przekaże nowy zbiór węzłów. Po wyeliminowaniu skróconej notacji XPath wyrażenie przyjmuje postać:
wyrażenie/child::para[self:node()/child::title = ‘Intro’][position() = 1]
Dla każdego węzła w przekazanego przez wyrażenie zrób:
- osią w tym kroku jest child, zawierająca wszystkie dzieci w, więc weź zawartość tej osi dla węzła w;
- niech c będzie jednym dzieci, testem w tym kroku jest para, który sprawdza nazwę węzła, więc sprawdź czy nazwa c to para, jeśli nie to odrzuć c;
- jeżeli c nie zostało odrzucone, to oblicz dla niego pierwszy predykat (self:node()/child::title = ‘Intro’) przyjmując następujący kontekst: c jest węzłem bieżącym, bieżąca pozycja to numer kolejny c na liście dzieci w o nazwie para; jeśli predykat przekaże false, to odrzuć c;
- jeżeli c nie zostało odrzucone, to oblicz drugi predykat (position() = 1), c jest węzłem bieżącym, a bieżącą pozycją jest miejsce c na liście otrzymanej po zastosowaniu pierwszego predykatu; odrzuć c, gdy predykat przekaże false;
- jeżeli c nie zostało odrzucone, to dodaj je do wyniku całego wyrażenia.
XPath definiuje jedenaście osi: child, descendant, parent, ancestor, following-sibling, preceding-sibling, following, preceding, attribute, namespace, self, descendant-or-self, ancestor-or-self. Każda z osi to funkcja, która węzłowi przyporządkowuje uporządkowaną listę węzłów. Test węzła to albo nazwa (* pasuje do wszystkiego), albo typ węzła z nawiasami na końcu, np. text() albo node(). Predykat to dowolne wyrażenie XPath, które jest obliczane i konwertowane na wartość logiczną. Oblicza się go dla każdego węzła pasującego do osi i testu. XPath definiuje konwersję wszystkich typów na wartość logiczną, np. niepusty zbiór węzłów to true, a pusty to false.
Specyfikacja definiuje dla każdego węzła jego wartość tekstową (ang. string-value) oraz nazwę (ang. expanded-name). Wartości te są ważne, gdyż przy ich pomocy definiuje się kiedy węzeł należy do osi oraz kiedy spełnia test i predykat. Ma to znaczenie przy rozszerzaniu XPath do XPointer. Szczegóły zostaną podane w następnym rozdziale.
Żeby używanie XPath było łatwiejsze, specyfikacja przewiduje skróconą składnię wyrażeń ścieżkowych. Kilka przykładów składni skróconej: . to skrót na self::node(), oś child może być pominięta, // oznacza /descendant-or-self::node()/, a @ odpowiada osi attribute.
Przykładowe zapytania XPath pokazują możliwości języka:
- para - zbiór podelementów węzła kontekstowego o nazwie para,
- * - wszystkie dzieci węzła kontekstowego,
- @version - węzeł odpowiadający atrybutowi węzła kontekstowego o nazwie version,
-
//para[@* = 'pl'] - węzeł
para w dowolnym miejscu dokumentu, jeżeli
jeden z jego atrybutów jest równy 'pl',
- text() - wszystkie dzieci węzła kontekstowego, które są typu tekstowego, np. dla <elt>ala</elt> będzie to węzeł ala
- para[last()] - ostatni podparagraf, czyli węzeł, dla którego predykat last() przekaże true,
- /document/*[2]/section[1] - ścieżka bezwzględna, prowadząca do sekcji,
- ../title - podelement title rodzica bieżącego węzła,
- para[@lang="pl"][2][string-length(.) > 10] - drugi podparagraf z tych po polsku, jeśli dłuższy niż 10 znaków,
- /document/para[./title/@lang = /document/@lang] - te paragrafy, które mają tytuł w języku dokumentu
- child::para - to samo co para; tak naprawdę to para jest tylko skrótem do tego wyrażenia zawierającego jawnie podaną oś,
-
following-sibling::*[1]
-
następny brat po węźle kontekstowym.
2.3.3. XPointer
XPointer to rozszerzenie XPath. Jest to język do adresowania fragmentów dokumentów XML. Został przewidziany do stosowania w adresach URL wykorzystujących protokół HTTP, np. http://example.org/doc.xml#xpointer(//para[2]). Specyfikacja XPointer składa się z dwóch mało związanych ze sobą części, pierwsza dotyczy XPointer Parts, druga to uogólnienie XPath.
XPointer Parts
XPointer Parts określa ogólną formę zapytań. Całe wyrażenie XPointer składa się z wielu części, każda część to oddzielne zapytanie należące do jakiegoś schematu.
xmlns(a = http://example.org/ns) xpointer(/document/title[@a:lang=’pl’]) xpointer(/document/title)
Powyższe zapytanie składa się z trzech części: pierwsza ma schemat xmlns, a dwie następne używają schematu xpointer. Specyfikacja definiuje, że części przetwarzane są od lewej do prawej, aż do momentu, kiedy zapytanie w jednej z części przekaże wynik. Zapytania ze schematu xmlns nigdy nie przekazują wyniku, więc po ich przetworzeniu parser zawsze czyta kolejną część. Są one używane do definiowania przestrzeni nazw dla zapytań ze schematu xpointer, które następują po nich. W zapytaniu, które przedstawiłem, mamy dwa zapytania ze schematu xpointer. Dzięki regule przetwarzania części, gdy pierwsze z nich się nie powiedzie, to zostanie wykorzystane drugie.
Specyfikacja XPointer definiuje semantykę dwóch schematów. Znaczenie xmlns przedstawiłem na przykładzie. Zapytania drugiego ze schematów, xpointer, to uogólnione zapytania XPath. Zostaną opisane w następnym punkcie. W dalszej części pracy będę podawał zapytania XPointer pomijając nazwę schematu, np. /document/title zamiast pełnego xpointer(/document/title). XPointer Parts daje także możliwość używania innych schematów, tworzonych na potrzeby konkretnych zastosowań. Każdy parser musi interpretować schematy xmlns i xpointer oraz jest zobowiązany do ignorowania zapytań w schematach, których nie zna.
Oprócz definicji części, specyfikacja podaje jeszcze dwie skrócone formy zapytań XPointer. Pierwsza z nich to nazwy podstawowe (ang. bare-names). Nazwa podstawowa to zapytanie składające się z jednego napisu, np. chapter1. Takie zapytanie jest równoważne zapytaniu xpointer(id(chapter1)), gdzie id() jest funkcją przekazującą element dokumentu o zadanym identyfikatorze. Nazwy podstawowe zostały wprowadzone dla zgodności z adresowaniem przy pomocy kotwic znanym z HTML. Druga skrócona forma zapytań to sekwencja dzieci, np. content/3/12, które tłumaczy się do xpointer(id(content)/*[3]/*[12]).
Uogólnienie XPath
Druga, ważniejsza część standardu XPointer, to opis języka zapytań opartego na XPath. Choć standard XPointer obejmuje zarówno XPointer Parts, jak i uogólnienie XPath, to często używa się nazwy XPointer tylko do drugiej części standardu. Ja także w tym dokumencie często utożsamiam pojęcie „wyrażenia XPointer” z zapytaniem ze schematu xpointer, które jest zaledwie częścią pełnego wyrażenia XPointer.
Specyfikacja XPointer rozszerza model XPath o dwa nowe pojęcia: punkt i zakres (ang. range). Punkt to dowolne miejsce w dokumencie XML-owym. Jest on jednoznacznie zdefiniowany przez parę węzeł-kontener i liczba-indeks. W każdym węźle tekstowym istnieją punkty między poszczególnymi literami oraz punkt na początku (z indeksem 0) i na końcu węzła (z indeksem równym długości tekstu zawartego w węźle). W elementach punkty istnieją między dziećmi oraz na początku i końcu.
Przykład
<elem>tex·t<a/>·<b/>·x</elem>
W podanym przykładzie mamy trzy punkty:
- indeks pierwszego z nich to 3, a kontener to węzeł tekstowy o wartości „text”,
- drugi ma indeks 2, a kontener <elem>,
- trzeci to albo (3, <elem>), albo (0, „x”),
- podkreślenie wskazuje na zakres od pierwszego do drugiego punktu.
Zakres to para dowolnych punktów z dokumentu, zwanych początkowym i końcowym. Wspólna nazwa na punkty, zakresy i węzły to lokacje. Tak więc XPointer uogólnia pojęcie węzła do pojęcia lokacji.
Lokacje występują w wyrażeniach XPointer, wszędzie tam gdzie XPath dopuszcza węzły. Każde wyrażenie XPath jest poprawnym wyrażeniem XPointer, jedyną różnicą jest to, że wyrażenie operuje na zbiorze lokacji (ang. location-set) zamiast na zbiorze węzłów. Przykładowo, test węzła w XPath filtruje zbiory węzłów, a w XPointer elementami filtrowanego zbioru mogą być też punkty i zakresy. Żeby zachować zgodność z wyrażeniami XPath, XPointer dla punktów i zakresów definiuje wartość tekstową, nazwę oraz zawartości wszystkich jedenastu osi. XPointer rozszerza także porządek zupełny na węzłach do porządku na lokacjach.
Oczywiście konstrukcje XPath wykorzystywane w XPointer nie pozwalają na stworzenie punktów ani zakresów. Do tworzenia punktów służą funkcje start-point() oraz end-point(). Funkcja start-point(zbiór-lokacji) przekazuje zbiór punktów początkowych dla każdej lokacji z parametru. Pojęcie punktu początkowego jest zdefiniowane w specyfikacji, np. punktem początkowym dla elementu jest punkt, z tym węzłem jako kontenerem i indeksem 0. Do tworzenia zakresów można użyć funkcji range(), range-inside() i string-range() oraz nowego rodzaju przejścia w wyrażeniach ścieżkowych /range-to().
Dwie ostatnie metody są najbardziej przydatne. Konstrukcja zbiór-lokacji-1/range-to(zbiór-lokacji-2) buduje po jednym zakresie dla każdej pary węzłów v, w, gdzie v Î zbiór-lokacji-1, a w Î zbiór-lokacji-2. Za pomocą funkcji string-range() można wyszukiwać wzorce w tekście dokumentu. Funkcja tworzy zakres dla każdego znalezionego wzorca.
Oto wyrażenie, które tworzy zbiór z różnych typów lokacji i pokazuje, że predykaty z XPath mogą operować na zakresach:
xpointer(//para[title/@urgent | string-range(title, ‘!!!’)])
Tutaj wyrażenie-predykat to suma dwóch zbiorów. Pierwszy to zbiór atrybutów urgent elementu <title>, a drugi to zbiór zakresów obejmujących trzy wykrzykniki w elemencie <title>.
Przykłady
Przegląd możliwości języka XPointer:
- xpointer(/document/chapter[1]/range-to(/document/chapter[3])) - wybierze przedział od początku pierwszego rozdziału do końca trzeciego,
- xpointer(//start-mark/range-to(following-sibling::end-mark[1]) - wybierze z dokumentu wszystkie przedziały zawarte między odpowiednimi parami znaczników <start-mark/> i <end-mark/>; warto; zauważyć, że kontekst wyrażenia po range-to zmienia się podobnie jak kontekst predykatów XPath,
-
xpointer(string-range(/,
"XML")) - tworzy zbiór zawierający przedziały reprezentujące
napis "XML", np. <para>MSXML4 is a new XML processor.</para>,
- xpointer(string-range(//chapter/title, "Big")) - przekazuje przedziały ze słowem Big z tytułów rozdziałów. Funkcja string-range() może mieć dodatkowe parametry, które rozszerzają/zwężają znalezione zakresy, np. string-range(/, "XML", 2, 5)[1] znajdzie pierwsze wystąpienie XML i przekaże "ML???" gdzie znaki ? to kolejne litery po tym wystąpieniu (czyli "ML4 i" z poprzedniego przykładu),
- xpointer(//para[string-range(./title, ‘XML’)]) - przekaże te elementy-paragrafy, których tytuł zawiera tekst „XML”.
2.3.4.
XInclude
XInclude to standard określający jak scalać dokumenty XML-owe. Sposób wykorzystania XInclude jest intuicyjny: w dokumencie, do którego chcemy włączyć zawartość innego dokumentu wstawiamy specjalny element. Ten element to <xi:include>, gdzie xi oznacza prefiks przestrzeni nazw http://www.w3.org/2001/XInclude. W trakcie przetwarzania dokumentu parser XInclude zamienia każdy element <xi:include> na zawartość dokumentu wskazanego przez atrybut href tegoż elementu. Element <xi:include> może mieć jeszcze dwa dodatkowe atrybuty: parse oznaczający czy dokument będzie włączany jako tekst czy jako XML oraz encoding pozwalający na ręczne wyspecyfikowanie zestawu znaków używanego we włączanym pliku. Rysunek 2 ilustruje sposób przetwarzania pojedynczego elementu <xi:include>, uwzględniając sposób wykorzystania klas języka Java.
Tym co odróżnia XInclude od dyrektywy #include w C jest możliwość wstawiania fragmentów dokumentów. Specyfikacja fragmentu odbywa się przy pomocy XPointer. Drugą ciekawą cechą XInclude jest możliwość zdefiniowania reakcji parsera na błąd w przy pobieraniu włączanego dokumentu. Gdy wczytywanie dokumentu się nie uda, to parser przetwarza elementy <xi:fallback>, jeżeli zostały zdefiniowane dla elementu <xi:include>.
Mimo, że standard jest prosty, na programistę implementującego go czeka wiele pułapek.
- Trzeba poprawnie obsłużyć standardy XML Base i XML Namespaces;
- Należy liczyć się z zapętleniem włączanych dokumentów;
- Jeśli element <xi:include> jest korzeniem w swoim dokumencie źródłowym, to włączany fragment dokumentu musi stanowić poprawny dokument XML, żeby dokument wynikowy też był poprawny;
- Obsługa XPointer nie jest łatwa. Przy włączaniu zakresu, który tylko częściowo pokrywa węzły, np. <a>bardzo <b>ważny</b> tekst</a>, należy odpowiednio pootwierać i pozamykać znaczniki. Wynik zapytania XPointer nie zawsze jest poprawnym dokumentem XML, gdyż wynikiem zapytania może być kawałek tekstu lub wiele węzłów. To powoduje dalsze komplikacje dla XInclude.
XInclude opisuje scalanie dokumentów w terminologii wprowadzonej przez XML InfoSet. InfoSet to model całkowicie abstrakcyjny, stąd konieczność odwzorowania jednostek informacyjnych na struktury używane w wybranym modelu przetwarzania dokumentów.
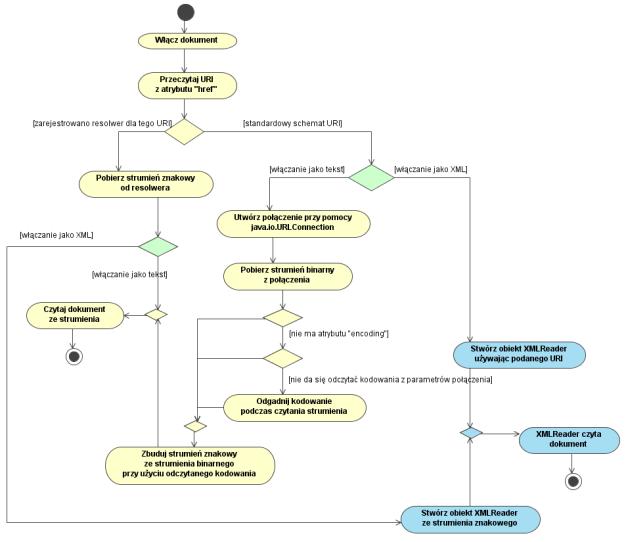
Rysunek 2. Czytanie włączanych dokumentów
Przykład 1. Włączanie jako XML i jako tekst.
Dokument źródłowy:
<?xml version=”1.0”?>
<document xmlns:xi=”http://www.w3.org/2001/XInclude”>
<xi:include src="include1.xml" parse="xml"/>
<after-first-incl/>
<xi:include src="include1.xml" parse="text"/>
after-all
</document>
Plik include1.xml:
<?xml version=”1.0”?>
<include>
<b>inc</b>luded
</include>
Wynik:
<?xml version=”1.0”?>
<document>
<include>
<b>inc</b>luded
</include>
<after-first-incl/>
<include>
<b>inc</b>luded
</include>
after-all
</document>
Przy włączaniu jako tekst znaki mniejszości zostały zastąpione przez <, żeby zostały zinterpretowane jako wartość tekstowa, a nie jako znaczniki.
Przykład 2. Włączanie z wykorzystaniem zapytania XPointer
Dokument źródłowy:
<?xml version=”1.0”?>
<document xmlns:xi=”http://www.w3.org/2001/XInclude”>
<xi:include src="include2.xml#xpointer(//para)" parse="xml"/>
</document>
Plik include2.xml:
<?xml version=”1.0”?>
<include>
<title>a title</title>
<para>paragraph 1</para>
<para>paragraph 2</para>
</include>
Wynik:
<?xml version=”1.0”?>
<document>
<para>paragraph 1</para>
<para>paragraph 2</para>
</document>
2.4. Wymaganie związane z językiem programowania i modelem przetwarzania
Oprócz głównego wymagania, jakim jest implementacja XInclude i XPointer, program musiał spełniać kilka innych wymagań. Te wymagania dotyczyły języka programowania, używanych bibliotek oraz modelu przetwarzania dokumentów XML.
2.4.1. Java
Java staje się coraz popularniejszym językiem programowania. Jest używana w projektach, w których nacisk kładziony jest na jakość kodu, a wydajność nie jest kluczowa. Aplikacje napisane w Javie można wykonywać na każdym systemie operacyjnym wyposażonym w maszynę wirtualną Javy, łatwo jest je odpluskwiać, są bezpiecznie oddzielone od systemu operacyjnego. Składnia języka jest prosta i nie pozwala programistom na stosowanie sztuczek dozwolonych w językach niższego poziomu. Dzięki temu kod aplikacji Javowych jest czytelny nie tylko dla jego twórców. Obiektowość Javy oraz jej rozbudowana biblioteka standardowa wymuszają na programistach korzystanie ze sprawdzonych wzorców pisania kodu. Twórcy Javy dołożyli starań, by korzystanie z zewnętrznych bibliotek było bardzo łatwe. Wszystkie te zalety spowodowały, że Java zyskała popularność zarówno w środowisku akademickim, jak i komercyjnym. Najpopularniejsze zastosowanie Javy to wielowarstwowe systemy serwerowe (J2EE). Mój program ma znaleźć zastosowanie w takich systemach, dlatego miał zostać napisany w Javie.
2.4.2. DOM
Document Object Model został zdefiniowany przez W3C, żeby ujednolicić sposób dostępu do dokumentów XML i HTML. DOM to zestaw interfejsów, dzięki którym programista widzi dokument jako drzewo, po którym może nawigować. DOM zawiera metody zarówno do odczytu, jak i modyfikacji drzewa dokumentu. Istnieje wiele implementacji tych interfejsów, choćby te dostępne z poziomu języka JavaScript w przeglądarkach Internet Explorer 6.0 i w Mozilla 1.0. Specyfikacja DOM podaje interfejsy, które muszą być zaimplementowane przez dostawcę DOM (np. przez przeglądarkę), a które mogą być wykorzystywane przez użytkowników DOM (np. autorów stron WWW).
DOM ma wiele zalet, choćby intuicyjny sposób użycia interfejsów. Zalety powodują, że model ten wykorzystywany jest dość często, więc mój parser musiał współpracować z DOM. Jednak nie we wszystkich zastosowaniach można posługiwać się tym modelem. Ma on kilka wad, a najważniejszą z nich jest duża pamięciożerność, gdyż implementacje DOM muszą wczytać cały dokument, by zbudować w pamięci drzewo. Dlatego powstał konkurencyjny SAX, któremu poświęcam następny rozdział.
Interfejsy DOM należą do
standardowej biblioteki Javy od wersji 1.4, ale w Javie nie ma implementacji
tych interfejsów. Najczęściej używaną implementacją DOM w Javie jest parser
Xerces, jest on często dołączany do narzędzi programistycznych dla Javy.
DOM Traversal and Range
W tej specyfikacji, będącej rozszerzeniem podstawowego DOM, pojawia się pojęcie zakresu, znane także z XPointer. DOM Traversal and Range [DOM_TR] definiuje interfejs Range, reprezentujący zakres. Mój parser XInclude miał udostępniać metodę, która przekazuje obiekty implementujące ten interfejs, żeby użytkownik mógł w standardowy sposób pobierać informacje o zakresie.
2.4.3.
SAX
SAX to konkurencyjny wobec DOM model dostępu do dokumentów XML. Parser SAX nie wczytuje całego dokumentu naraz do pamięci, lecz generuje zdarzenia w trakcie czytania dokumentu. Dla przykładu, gdy parser napotka w trakcie przetwarzania dokumentu na znacznik otwierający, to generuje zdarzenie startElement(). Zdarzenie polega na wywołaniu metody na zarejestrowanym programie obsługi zdarzeń. Żeby skorzystać z parsera należy najpierw zaimplementować własny program obsługi, potem zarejestrować go w parserze i rozpocząć przetwarzanie dokumentu.
SAX jest troszkę trudniejszy do zrozumienia, ale o wiele szybszy niż DOM. Wymaga istotnie mniej pamięci. Zalety SAX spowodowały, że to on miał zostać modelem pracy mojej implementacji XInclude. Poza tym, gdy jakikolwiek program obsługuje SAX, to bardzo łatwo dodać do niego obsługę DOM - istnieją standardowe biblioteki do budowania drzewa DOM ze strumienia zdarzeń SAX i serializowania drzewa DOM do strumienia zdarzeń SAX.
Najważniejsze interfejsy SAX to: XMLReader reprezentujący parser, implementowany przez twórcę biblioteki SAX oraz ContentHandler, który jest dostarczany przez użytkownika biblioteki. Zdarzenia SAX są zdefiniowane w różnych interfejsach-programach obsługi; oprócz ContentHandler jest też LexicalHandler, DTDHandler, DeclHandler i ErrorHandler.
Interfejsy SAX, podobnie jak dla DOM, zawarte są w Javie 1.4.
2.4.4. Filtry SAX
Specyfikacja SAX przewiduje możliwość tworzenia filtrów i zestawiania ich w łańcuch. Filtr to obiekt implementujący zarówno interfejs XMLReader, jak i ContentHandler. Kiedy filtry są połączone w łańcuch, to każdy filtr ma poprzednika (z wyjątkiem pierwszego), dla którego jest programem obsługi zdarzeń, jak i następnika (z wyjątkiem ostatniego), który jest jego programem obsługi. Rysunek 3 pokazuje szczegółowo wywołania metod przy przetwarzaniu dokumentu za pomocą filtrów SAX. Filtry mogą wykonywać różne operacje, choćby transformacje XSLT. Dobrym pomysłem jest też napisanie filtru realizującego XInclude. Moja aplikacja musiała zawierać taki filtr.
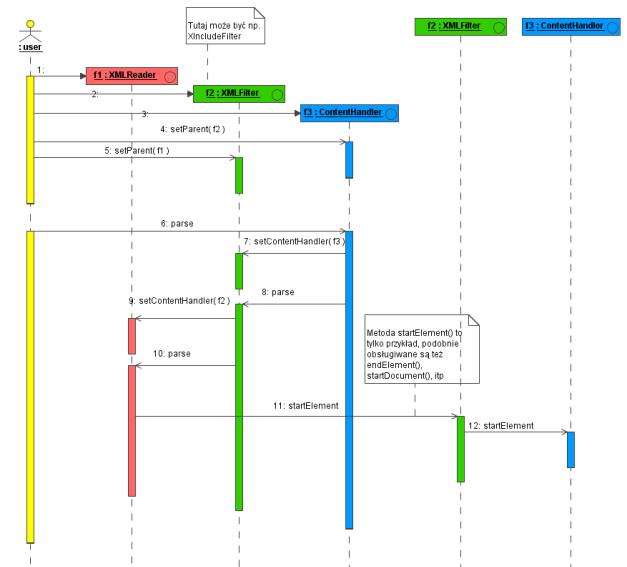
Rysunek 3. Działanie filtrów SAX. Obiekt f2 to filtr SAX
2.4.5. Porównanie XML InfoSet i SAX
Zamieszczona tabelka prezentuje porównanie SAX, który jest modelem pracy parsera XInclude i InfoSet, przy pomocy którego zdefiniowano włączanie dokumentów.
|
Jednostka informacyjna nazwy i numerowanie z XML InfoSet |
Zdarzenie SAXmetody z klas z
interfejsu org.xml.sax |
|
2.1. Document |
ContentHandler.start/endDocument |
|
2.2. Element |
ContentHandler.start/endElement |
|
2.3. Attributes |
ContentHandler.startElement.atts |
|
2.4. ProcInstr |
ContentHandler.processingInstruction |
|
2.5. UnexpEntRef |
ContentHandler.skippedEntity |
|
2.6. Character |
ContentHandler.characters/ignorableWhitespace |
|
2.7. Comment |
ext.LexicalHandler.comment |
|
2.8. DocTypeDecl |
ext.LexicalHandler.start/endDTD |
|
2.9. UnparsedEnt |
DTDHandler.unparsedEntityDecl |
|
2.10. Notation |
DTDHandler.notationDecl |
|
2.11. Namespace |
Można odczytać na podstawie
Element i Attributes |
W XML InfoSet nie ma odpowiedników dla wielu konstrukcji z XML, np. nie ma jednostek informacyjnych odpowiadających wnętrzu DTD. Ta składnia ma nawet odpowiedniki w modelu SAX, zdefiniowane w interfejsie DeclHandler. Ta część modelu SAX nie musi być wykorzystywana w parserze XInclude, gdyż model XInclude jest oparty na XML-InfoSet.
Jednostki UnparsedEnt i Notation powinny znaleźć się w dokumencie powstałym po parsowaniu XInclude, ale z powodów wymienionych w rozdziale poświęconym XML-owi, zdecydowałem się je ignorować.
2.5. Dodatkowe wymagania
2.5.1. Własne schematy URI
Atrybut href elementu <xi:include> zawiera URI dokumentu, który ma zostać włączony do dokumentu źródłowego. To URI może być postaci http://example.net/doc.xml lub file:///home/kab/doc.xml. Te dwa adresy URI używają standardowych schematów http oraz file. Obsługa tych dwóch standardów nie zawsze jest wystarczająca. W systemie przechowywania dokumentów dokumenty mają wewnętrzne identyfikatory. Te identyfikatory mogą używać zupełnie innego schematu, np. content://kb@people/docs/20021221/test1. Żeby parser XInclude był pożyteczny w takich aplikacjach, musiał umożliwić użytkownikowi zarejestrowanie własnego resolwera schematów. Resolwer to obiekt, który dla danego URI przekazuje strumień znakowy, z którego można przeczytać dokument. W tym przypadku użytkownik musi napisać resolwer schematu content. Resolwer jest klasą napisaną w Javie i może np. czytać dane z bazy danych.
2.5.2. Kolorowanie zakresów
Implementacja XPointer powinna być tak napisana, by umożliwić pokolorowanie zakresów wybranych przez wyrażenie XPointer. Taka funkcjonalność jest potrzebna do wizualizowania powiązań między fragmentami dokumentów. Wymaganie było następujące:
- na wejściu parser dostaje dokument XML i wyrażenie XPointer,
-
użytkownik ma zobaczyć w edytorze dokument z
naniesionymi graficznie informacjami o odnośnikach do tego dokumentu
wykorzystujących XPointer.
2.5.3. Aplikacja przykładowa
Ważnym wymaganiem było też przygotowanie prostej w użyciu aplikacji testowej, najlepiej okienkowej. Aplikacja testowa miała pokazywać zarówno możliwości XPointer, jak i XInclude.
2.6.
Istniejące implementacje XInclude oraz XPointer
XInclude i XPointer są znanymi
standardami, więc wydaje się oczywiste, że powinny doczekać się wielu
implementacji, w tym także typu Open Source. Jednak pełne implementacje nie
powstały. Prawdopodobnie są dwie przyczyny tego stanu rzeczy: po pierwsze
standardy jeszcze nie osiągnęły ostatecznej wersji (zwłaszcza XPointer), po
drugie ich implementacja nie jest prosta.
2.6.1.
Implementacje XInclude
Na rynku dostępnych jest kilka
implementacji XInclude w Javie, ale żadna z nich nie realizuje standardu w
całości. Wybór przygotowałem na podstawie raportu [XInclImpl] o
implementacjach XInclude opublikowanego przez W3C 28 lutego 2003.
GNUJAXP XIncludeFilter
Autor: David Brownell,
http://www.gnu.org/software/classpathx/jaxp/apidoc/gnu/xml/pipeline/XIncludeFilter.html
W ogóle
nie obsługuje XPointer, a także brak pełnego wsparcia dla URI zawierających
narodowe symbole spoza tablicy ASCII.
jd.xinclude
Autor: Johannes Döbler,
http://www.aztecrider.com/xinclude/
Implementacja jest płatna, więc
nie mogłem jej przetestować, ale wydaje się, że obsługuje tylko schemat element().
XInclude Transformer
Autor: Apache, http://xml.apache.org/cocoon/userdocs/transformers/xinclude-transformer.html
Implementacja XInclude wykorzystująca XPath, bez wsparcia dla XPointer. Używa XML Base do ustalania adresów włączanych zasobów.
XIncluder 1.0d10
Autor: Elliotte Rusty Harold, http://xincluder.sourceforge.net
Nie obsługuje XPointer ani konstrukcji <xi:fallback>. Składa się zaledwie z kilku klas, na których wzorowałem się implementując XInclude. Oprócz głównych braków funkcjonalności zawiera wiele niedociągnięć, jak brak wsparcia XML Base czy prawidłowego traktowania przestrzeni nazw.
Libxml2 2.5.4
Autor: Daniel Veillard, http://xmlsoft.org
Prawie pełna implementacja XPointer i XInclude.
Niestety nie w Javie, tylko w C. Wchodzi w skład projektu Gnome.
2.6.2. Implementacje XPointer
Przegląd implementacji XPointer przygotowałem na podstawie raportu [XPtrImpl] W3C z 7 listopada 2002 oraz dodatkowo ze stron Uniwersytetu w Bolonii [XPtrBol].
XLip
Autor: Fujitsu,
http://www.labs.fujitsu.com/free/xlip/en/
Pełna implementacja XPointer w
Javie, zawiera wszystkie główne konstrukcje języka. Nie była dostępna kiedy
zaczynałem pracę. Można ją testować za darmo, ale wykorzystanie komercyjne
wymaga specjalnej zgody i pewnie jest płatne. Kod źródłowy nie jest dostępny.
Libxml
Autor: Daniel Veillard, http://xmlsoft.org/
Implementacja w C, opisana w
rozdziale 2.6.1.
Amaya
Autor: W3C, http://www.w3.org/Amaya/
Nie ma pełnego wsparcia XPath ani
XPointer.
4XPointer
Autor: Fourthought, Inc., http://4suite.org
Napisana w języku Python. Nie
implementuje całego standardu.
XLinkProxy
Autor: Federico Folli, Uniwersytet w Bolonii,
http://www.cs.unibo.it/~fabio/XPointer/MyXpointEN.htm
Implementacja ma pewne ograniczenia, takie jak: brak obsługi przestrzeni nazw, niektórych predykatów, osi. Napisana w języku Microsoft JScript 5.5, przy wykorzystaniu parsera MSXML4.0.
XSLT++
Autor: Claudio Tasso pod kierunkiem Fabio Vitali, Uniwersytet w Bolonii,
http://www.cs.unibo.it/~fabio/XPointer/
Niepełna implementacja XPointer, w Javie. Oparta na Xalanie. Przyglądałem się jej kodowi przed przystąpieniem do mojej implementacji. Ja swoją implementację oparłem na Saxonie, więc nie skorzystałem z możliwości wykorzystania źródeł XSLT++.
3. Projekt
Swoją aplikację nazwałem Xinpo. Nazwa powstała z
liter dwu implementowanych standardów XInclude i XPointer.
Xinpo składa się z dwu modułów, każdy z nich jest odpowiedzialny za
realizację jednego ze standardów. W następnych podrozdziałach opiszę oba
moduły.
3.1. Architektura XInclude
Wybranym modelem przetwarzania dokumentów przez parser XInclude jest SAX, stąd najważniejszą klasą tego modułu jest filtr realizujący włączanie plików. Filtr reagując na element <xi:include> powołuje do życia obiekty odpowiedzialne za realizację logiki zdefiniowanej w standardzie. Główne klasy modułu opisane są w kolejnych punktach. Rysunek 4 zawiera te klasy w postaci diagramu.
3.1.1. Klasy
XIncludeFilter
Najważniejsza klasa implementacji XInclude. Zadaniem klasy jest zastępowanie pary zdarzeń odpowiadających elementowi <xi:include> zdarzeniami wygenerowanymi przez włączany dokument lub jego fragment. Oprócz tego klasa obsługuje elementy <xi:fallback> oraz dba o obsługę błędów. Tworzy obiekty TextIncluder lub XMLIncluder i jest programem obsługi zdarzeń przez nie generowanych.
TextIncluder
Jest tworzony, gdy trzeba włączyć dokument tekstowy, tzn. gdy atrybut parse elementu <xi:include> ma wartość „text”. Czyta dokument, uwzględniając jego kodowanie i generuje zdarzenia przekazywane do XIncludeFitler.
XMLIncluder
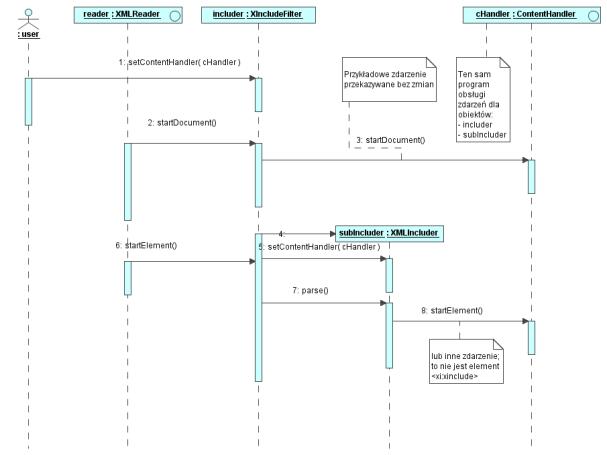
Jest tworzony, gdy trzeba włączyć dokument XML, niezależnie od tego czy dokument będzie włączany w całości, czy tylko jego fragment. Generuje zdarzenia SAX przekazywane do nadrzędnego programu obsługi (tj. innego obiektu XMLIncluder lub do XIncludeFilter). Jest odpowiedzialny za wykrywanie cykli i dodawanie atrybutów xml:base przy włączaniu całych plików. Jeśli włączany jest tylko fragment dokumentu, to powołuje do życia obiekt XPointerToSAX. W przypadku, gdy włączany dokument zawiera <xi:include>, powstaje drugi XMLIncluder i oba obiekty XMLIncluder są łączone jak filtry SAX. Sytuację, gdy powstają dwa obiekty XMLIncluder, ilustruje rysunek 5.
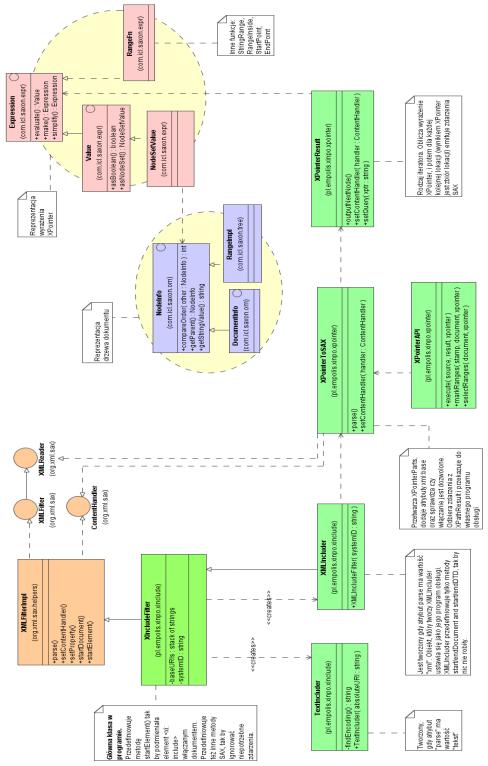
Rysunek 4. Główne klasy implementacji. Na
rysunku są również interfejsy SAX oraz model wyrażenia i dokumentu z Saxona
Rysunek 5. Włączanie wielopoziomowe
XPointerToSAX
Obsługuje XPointer Parts oraz dodaje atrybuty xml:base do włączanych lokacji. Tworzy XPointerResult. Implementuje interfejsy XMLReader, ContentHandler i LexicalHandler.
XPointerResult
To tutaj jest tworzona obiektowa reprezentacja wyrażenia XPointer oraz dokumentu, na którym będzie wykonywane zapytanie. Klasa jest rodzajem iteratora po wyniku zapytania, czyli po zbiorze lokacji. Rysunek 6 pokazuje interakcje obiektu XPointerResult z innymi obiektami używanymi do przetwarzania zapytań XPointer w XInclude.
Jedna z metod tej klasy rozstrzyga czy wynik zapytania XPointer może zostać użyty do włączania. Niektóre sytuacje są niedozwolone, np. nie można włączać lokacji reprezentujących atrybuty. W takim wypadku metoda przekaże błąd.
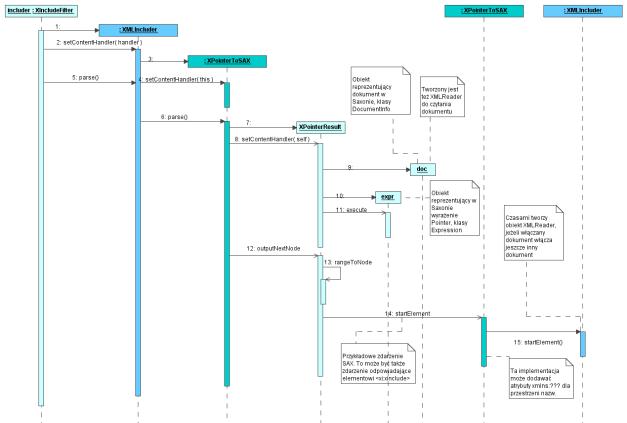
Rysunek 6.
XPointer
dla XInclude
3.1.2.
Resolwery dla schematów URI
Do obsługi własnych resolwerów schematów adresów URI dokumentów do włączania służą: interfejs SchemeResolver oraz klasa PluggableSchemeResolver. SchemeResolver to obiekt, który zamienia URI na strumienie znaków, a PluggableSchemeResolver to jego implementacja umożliwiająca rejestrowanie oddzielnych resolwerów dla różnych schematów URI. Na rysunku 7 pokazałem sposób wywołania metod przy rejestracji resolwera, a na rysunku 8 diagram klas implementujących resolwery.
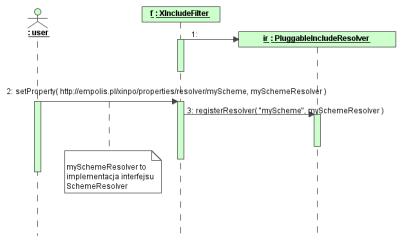
Rysunek 7. Rejestracja resolwera schematu
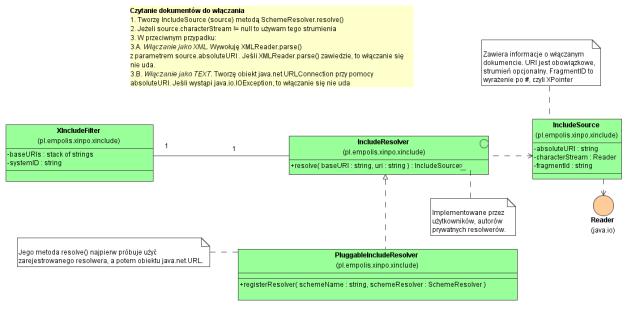
Rysunek 8. Resolwery
schematów URI - klasy
3.2. Wybór parsera XPath
XPointer jest standardem opartym na XPath, stąd pomysł, żeby nie implementować parsera od podstaw, tylko oprzeć implementację na gotowym parserze XPath. Jednakże istnieje kika powodów, które przemawiają za pisaniem własnego parsera: poznanie cudzego kodu może zająć dużo czasu, istniejące parsery XPath mogą nie być w 100% zgodne ze standardem, licencja może nie pozwalać na modyfikacje.
Znalazłem dwa parsery, które potencjalnie nadawały się do
rozszerzenia: Xalan i Saxon. Zarówno Xalan (napisany przez Apache Group), jak i
Saxon (autorstwa Micheala H. Kay’a) są procesorami XSLT. XPath znalazł się w
nich dlatego, że XPath jest on częścią składową XSLT. Oba parsery spełniały
większość wymagań, jakie postawiłem parserowi do rozszerzania: były napisane w
Javie, dostępne na zasadzie Open Source oraz zgodne z XPath. Postanowiłem oprzeć własną
implementację na jednym z nich. Początkowo skłaniałem się ku Xalanowi, ponieważ
jest bardziej znany i nawet miał wydzielone API do XPath. Przekonałem się
jednak, że jego kod jest bardzo zawiły, gdyż zawiera mnóstwo warstw interfejsów
i implementacji. Poza tym Xalan był w trakcie przebudowy, kod był zaśmiecony,
często występowały komentarze mówiące o tym, że niektóre fragmenty kodu są
wciąż w fazie testów. Dla odmiany Saxon był napisany elegancko, schludnie i
konsekwentnie. Widać było, że był dziełem jednej osoby, a nie zlepkiem wielu
idei jak Xalan. Nawet dokumentacja do Saxona, choć krótsza niż dla Xalana,
okazała się być bardziej rzeczowa. Mój wybór padł na Saxona, na stabilną wersję
6.5.2.
3.3. Architektura XPointer - Saxon
Parser XPointer w Xinpo to rozszerzenie parsera XPath zawartego w Saxonie, więc architektura parsera została przejęta z Saxona. Dwie główne struktury w parserze to drzewo wyrażenia oraz drzewo dokumentu. Węzłami pierwszego drzewa są wyrażenia, np.: pojedynczy węzeł (/), funkcja (count(wyrażenie)) albo ścieżka (wyrażenie/wyrażenie). W drugim drzewie są węzły reprezentujące dokument, np. element, atrybut albo komentarz. Drzewo wyrażenia powstaje z tekstowego zapytania XPointer. Wykonanie zapytania to obliczenie wartości wyrażenia. Wartością wyrażenia może być liczba, wartość logiczna, napis lub zbiór węzłów dokumentu. Widać więc wyraźne powiązanie obu drzew - wyrażenie zawsze wykonujemy na jakimś dokumencie i jego wynikiem są węzły z tego dokumentu. Implementacja XPointer wymaga zmian w obu drzewach. Do drzewa wyrażeń trzeba dodać nowe wyrażenia zdefiniowane przez XPointer (nowe funkcje, wyrażenie/range-to(wyrażenie)). Drzewo dokumentu musi być poszerzone o zakresy i punkty, w ten sposób z drzewa węzłów staje się drzewem lokacji.
3.3.1. Wyrażenie
Żeby dostosować drzewo wyrażeń do XPointer należy zmodyfikować lekser, parser oraz zdefiniować klasy reprezentujące nowe wyrażenia XPointer. Lekser, czyli moduł odpowiedzialny za podział zapytania na pojedyncze symbole, musiał być rozszerzony o interpretację wyrażenia /range-to i nowych testów węzłów point() oraz range(). Parser to moduł budujący rekurencyjnie drzewo wyrażenia. XPointer dodaje kilka nowych wyrażeń, dla których utworzyłem klasy RangeToExpression, StringRange, RangeFn, RangeInside, StartPoint i EndPoint. Zmodyfikowany parser buduje drzewo zawierające także obiekty tych klas.
3.3.2. Drzewo dokumentu
Drzewo dokumentu jest generowane ze strumienia zdarzeń SAX.
Zawiera elementy, komentarze i inne obiekty odpowiadające strukturze dokumentu
XML. XPointer uogólnia węzły do lokacji, stąd konieczność stworzenia klas
reprezentujących zakres i punkt, które będą w programie traktowane tak jak
węzły drzewa dokumentu.
3.3.3. Zakres i punkt jako węzły
W Saxonie do reprezentacji zbioru węzłów używa się klasy NodeSetValue, która jest iteratorem obiektów reprezentujących węzły implementujące interfejs NodeInfo. NodeSetValue to wynik wykonania NodeSetExpression. Pojawia się pytanie, jak w tym modelu reprezentować punkty i zakresy. Skoro zbiorczą nazwą na punkty, zakresy i węzły jest lokacja, to klasy powinno się przemianować na LocationSetExpression, LocationSetValue i LocationInfo. Uznałem jednak, że to nie ma sensu i nazwy klas pozostawiłem niezmienione. Dzięki temu modyfikacje Saxona są o wiele mniejsze i w przyszłości łatwiej będzie scalić moje zmiany z kolejną edycją Saxona. Jedyne co traci się na pozostawieniu nazw klas, to semantyczne znaczenie nazw klas – w mojej implementacji punkty i zakresy są tym znaczeniu węzłami. Z przyjętej konwencji wyniknęło m. in. to, że w parserze XPointer klasa implementująca zakres (RangeImpl) jest implementacją interfejsu NodeInfo.
Warto zauważyć, że zakresy i punkty są trochę innymi
rodzajami lokacji niż elementy. Elementy powstają w czasie budowania drzewa
dokumentu i wyrażenia operują na gotowych obiektach je reprezentujących.
Zakresów i punktów w tym drzewie nie ma, ponieważ nie są powiązane relacjami
ojciec-syn z węzłami. Zakresy i punkty są tworzone tylko na żądanie, wtedy
kiedy są wynikiem jakiegoś wyrażenia. Nie jest to wyjątek w Saxonie, węzły
atrybutów także są tworzone leniwie, np. przy ewaluacji wyrażenia /elem[@atr = '1'].
3.4. API
Dobrze zaprojektowany interfejs programistyczny aplikacji
(API) ma decydujące znaczenie dla wygody korzystania z aplikacji. Interfejsy
dla XPointer i XInclude zostały zaprojektowane tak, by sposób ich działania był
oczywisty dla osób znających modele SAX i DOM. Zarówno parametry metod, jak i
przekazywane wartości są instancjami standardowych klas zdefiniowanych w Javie.
Opis API pozwala szybko poznać możliwości programu, dlatego postanowiłem go
umieścić w pracy. Mimo tego, że realizowane standardy są skomplikowane, samo
API jest bardzo proste.
3.4.1.
API
dla XInclude
· org.xml.sax.XMLFilter getXIncludeFilter()
Specjalna metoda, która przekazuje implementację interfejsu XMLFilter realizującą XInclude.
· void execute(org.xml.sax.InputSource source, javax.xml.transform.sax.SAXResult result)
Przetwarzanie wykonuje się w modelu SAX, tzn. na wejściu metoda dostaje ciąg zdarzeń SAX a w wyniku jej działania generowane są zdarzenia przekazywane do obiektu ContentHandler wyspecyfikowanego przez result. W wyniku działania metody każde zdarzenie odpowiadające elementowi <xi:include> jest zastępowane ciągiem zdarzeń odpowiadających włączanemu dokumentowi.
InputSource jest
obiektem, który określa strumień wejściowy, bajtowy lub znakowy, nazwę pliku
lub URL, z którego czytany jest dokument źródłowy. SAXResult
przechowuje obiekt ContentHandler
oraz LexicalHandler.
· void execute(String systemId, javax.xml.transform.sax.SAXResult result)
Jest aliasem do poprzedniej metody, w najczęściej używanym
przypadku, kiedy parametrem jest nazwa pliku lub URL. Jej treść to wywołanie: execute(new InputSource(systemId), result).
3.4.2.
API dla XPointer
·
void
execute(org.xml.sax.InputSource src,
String xptr, javax.xml.transform.sax.SAXResult result)
Na wejściu
dostaje strumień zdarzeń SAX, emituje zdarzenia SAX dla elementów wybranych
przez wyrażenie XPointer. Zdarzenia są przekazywane do obsługi przez program
obsługi zdefiniowany przez element SAXResult.
Wywołujący tę metodę musi być świadomy tego, iż zdarzenia wyemitowane w wyniku
wykonania tej metody niekoniecznie stanowią poprawny dokument XML – wynikiem
może być np. wygenerowanie pojedynczego zdarzenia odpowiadającego atrybutowi.
· void execute(String systemId, String xptr, javax.xml.transform.sax.SAXResult result)
Jest aliasem do poprzedniej metody, w najczęstszym przypadku
kiedy parametrem jest nazwa pliku lub URL.
·
void
markRanges(org.xml.sax.InputSource src, String xptr, String stamp,
javax.xml.transform.sax.SAXResult result)
Metoda przepisuje dokument źródłowy na docelowy, wstawiają
instrukcje przetwarzania w miejsca określone przez wyrażenie XPointer. Dla
każdej lokacji wskazanej przez wyrażenie wstawiane są dwie instrukcje
przetwarzania: jedna zaznacza początek lokacji, a druga koniec. Każda z
instrukcji przetwarzania ma dwa pseudo-atrybuty. Atrybut stamp ma taką wartość, jak parametr stamp metody markRanges().
Powinien być stosowany, gdy na jednym dokumencie wykonamy wiele zapytań - stamp pozwoli je rozróżnić. Dobrym pomysłem
może być użycie samego wyrażenia xptr jako
atrybutu stamp. Atrybut num określa numer kolejny lokacji. Umożliwia
połączenie instrukcji w pary. Metoda ta pozwala zrealizować jedno z wymagań
stawianych programowi: przy jej pomocy można napisać program, który wyświetla
tekst, podświetlając obszary należące do lokacji wybranych przez XPointer.
Oto przykład, ilustrujący dokument z oznaczonym zakresem:
<p>
<?saxon:start-range num="1" stamp="">Ala <b>ma<?saxon:end-range num="1" stamp=""></b> kota
</p>
· void markRanges(String systemId, String xptr, String stamp, javax.xml.transform.sax.SAXResult result)
Jest aliasem do poprzedniej metody, w najczęstszym przypadku
kiedy parametrem jest nazwa pliku lub URL.
· java.util.List execute(org.xml.sax.InputSource src, String xptr)
Wynikiem obliczenia wyrażenia XPointer jest lista lokacji. Lokacje na liście to obiekty standardowych klas zdefiniowanych w DOM: org.w3c.dom.Node lub org.w3c.dom.range.Range. Użytkownik może używać metod zdefiniowanych w DOM do dalszej obróbki wyniku.
· void execute(String systemId, String xptr)
Jeszcze jeden pomocny skrót.
3.4.3.
XIncludeFilter
Implementacja interfejsu XMLFilter, realizująca standard XInclude. Powstanie filtru było ważnym wymaganiem dla programu. XMLFilter to standardowy interfejs, dzięki temu parser XInclude może być wykorzystywany przez wiele aplikacji przetwarzających potokowo dokumenty XML. Taka aplikacja ma zwykle plik konfiguracyjny, który zawiera nazwy klas implementujących używane filtry. Dzięki temu można dodawać nowe filtry do istniejącej aplikacji, jedynym wymaganiem jest to, by klasa filtru implementowała interfejs XMLFitler.
3.5.
Obsługa wyjątków w XInclude
Wszystkie błędy raportowane są za pomocą wyjątków, będących podklasą SAXException. Wyjątki te są zgłaszane z metod filtru XInclude obsługujących zdarzenia generowane przez poprzednik filtru. Większość wyjątków jest zgłaszanych w metodzie startElement()wołanej w celu przetworzenia elementu <xi:include>. Parser generuje kilka rodzajów wyjątków:
- IncludeCycleException - jest zgłaszany, gdy pojawi się cykl we włączeniach, np. A włącza B, B włącza C, C włącza A,
- SyntaxErrorException - błąd składni XInclude: nie ma atrybutu href w elemencie <xi:include> albo wartość atrybutu parse jest inna niż „text” albo „xml”,
- ResourceNotFoundException - nie udało się znaleźć zasobu do włączenia; możliwe powody: zasób nie istnieje, schemat URI jest nieznany, jest błąd składniowy w URI, zasobu nie daje się pobrać, XPointer ma błąd składniowy oraz nie ma podelementu <xi:fallback>,
- InclusionNotAllowedException - w pewnych okolicznościach włączanie jest niedozwolone: korzeń dokumentu nie może być zastąpiony przez kilka węzłów, nie można włączyć węzła reprezentującego atrybut,
- EncodingException – włączany zasób zawiera ciąg znaków niedopuszczalny przez wybraną tablicę znaków,
-
BaseResolvingException
-
gdy nie uda się obliczyć adresu bazowego (base URI), może się to zdarzyć
gdy atrybut xml:base używa schematu URI
nie rozpoznawanego przez klasę java.net.URL
i zarejestrowane resolwery.
4. Implementacja
4.1. XInclude
Implementacja XInclude była raczej nieciekawa. Zajęła też niewiele czasu w porównaniu z czasem poświęconym na poznanie specyfikacji XInclude i innych specyfikacji wpływających na działanie parsera. Trochę wysiłku wymagało poznanie Javowego API do XML-a. Większość zadań, które były niezbędne przy budowie parsera, to zadania nie wymagające wysiłku koncepcyjnego, lecz biegłości w sprawach technicznych. Do takich zadań można zaliczyć: wykrywanie kodowania plików oraz problem obsługi znaków niedozwolonych w URI. W następnych paragrafach opiszę te problemy, których rozwiązanie nie było tak oczywiste.
4.1.1. Obługa XML Base
Standard XML Base musiał być uwzględniony w dwóch miejscach. Po pierwsze URI ustalone za pomocą atrybutu xml:base musi być wykorzystywane do rozwiązywania względnych adresów URI włączanych dokumentów. Po drugie, przy wstawianiu fragmentu innego dokumentu trzeba wstawić do wynikowego dokumentu atrybut xml:base określający bazowe URI zaczerpnięte z dokumentu, z którego pochodził fragment. Żeby zrealizować pierwsze wymaganie przechowuję w XIncludeFilter stos URI podawanych w atrybutach xml:base. Drugie wymaganie jest trochę trudniejsze w realizacji. Pierwszy etap to pobranie adresu bazowego wstawianego elementu z miejsca jego pochodzenia (robię to w XPointerResult, szukając atrybuty xml:base w przodkach węzła), a drugi dodanie do wyniku atrybutu xml:base (robię to w XMLIncluder). Gdy włączamy wiele węzłów lub zakres nie będący poprawnym dokumentem XML, to należy wstawić po jednym atrybucie xml:base na każdy włączany węzeł-korzeń poddokumentu.
4.1.2.
Elementy
<xi:fallback>
XInclude dopuszcza wzajemne zagnieżdżenie elementów <xi:include> i <xi:fallback>. Zgodnie ze specyfikacją cała zawartość elementu <xi:include> jest ignorowana, z wyjątkiem zawartości podelementu <xi:fallback>, ale tylko wtedy, gdy włączanie się nie uda. Element <xi:fallback> nie może wystąpić bez <xi:include> ani jako brat innego <xi:fallback>. Element <xi:fallback> oczywiście może zawierać kolejne elementy <xi:include>. Komplikacje przy implementacji tej funkcjonalności spowodowane były tym, że w parserze SAX nie ma w ogóle dostępu do kontekstu parsowania, w szczególności nie można łatwo dostać ojca przetwarzanego węzła. Jeśli chcemy uzyskać takie informację, to trzeba własnoręcznie tworzyć stos. Zatem stworzyłem w XIncludeFilter stos obiektów zawierających stan parsowania elementów <xi:include> (IncludeElemState), zawierających:
- głębokość elementu; wykorzystywane jest do parowania elementu otwierającego i zamykającego;
- informację o tym czy należy ignorować obecny element <xi:include> - jest on ignorowany, gdy występuje wewnątrz <xi:include>, który się powiódł, lub gdy nie było <xi:fallback>;
- informację o tym czy aktualny element <xi:include> się powiódł;
- informację o błędzie, jeśli włączanie się nie powiodło;
- informację o tym czy znaleziono już element <xi:fallback> w aktualnym elemencie <xi:include>.
4.1.3. Cykle
Do wykrywania cykli używam stosu, w którym przechowywane są
URI wszystkich dokumentów na ścieżce włączania. Cykl występuje wtedy, gdy w
stosie wystąpią dwa takie same URI. Stos URI przechowuję w obiekcie XIncludeFilter, a sprawdzenia duplikatów
dokonuję w klasie XMLIncluder. Stos
musi być przekazywany między obiektami XMLIncluder
odpowiedzialnymi za kolejne włączania.
4.1.4. XPointer dla XInclude
Warstwa pośrednicząca między XInclude a XPointer składa się z kilku klas, dzięki którym zapytania XPointer mogą być używane w XInclude. Te klasy to rodzaj interfejsu do XPointer, skrojonego specjalnie do wykorzystania w XInclude. Główne klasy tego interfejsu to XPointerToSAX oraz XPointerResult. Klasy te są odpowiedzialne m. in. za obsługę XML Base oraz kontrolę, czy lokacje przekazane z XPointer mogą być włączane. Niektóre włączania są zabronione:
- nie można włączać węzłów atrybutów i przestrzeni nazw,
- jeśli <xi:include> jest korzeniem, to włączany dokument musi być parsowany jako XML, a jeśli włączany jest fragment, to musi on reprezentować poprawny dokument XML.
4.2.
XPointer
Większa część implementacji XPointer to modyfikacja klas Saxona i rozszerzanie jego struktur danych. Są jednak fragmenty kodu zupełnie niezależnie od Saxona: parser XPointer Parts oraz interfejs między XPointer a XInclude. Te fragmenty to tylko mała część implementacji, większość wysiłku poświęciłem na modyfikację Saxona. W dalszych podrozdziałach opiszę najciekawsze z tych modyfikacji.
4.2.1. Wyrażenie /range-to
Jedyne całkiem nowe wyrażenie w XPointer to RangeToExpression, które parser tworzy po napotkaniu konstrukcji wyrażenie/range-to(wyrażenie)[predykat]*. Żeby dodać do kodu Saxona nowe wyrażenie musiałem zaimplementować kolejno wszystkie metody zdefiniowane w interfejsie Expression. Wyrażenie /range-to jest podobne do zwykłego wyrażenia ścieżkowego wyrażenie/test[predykat]* (reprezentowanego w Saxonie przez klasę PathExpression) i dzięki temu mogłem oprzeć implementację RangeToExpression na klasie PathExpression.
Wyrażenie /range-to jest dość skomplikowane, ma dwa podwyrażenia: wyrażenie startowe określa zbiór węzłów, z którego są brane punkty początkowe, a wyrażenie kroku definiuje punkty końcowe. Konwersją węzłów na punkty startowe i końcowe zajmują się funkcje zdefiniowane w standardzie XPointer: start-point() oraz end-point(). Wynikiem wyrażenia jest zbiór wszystkich zakresów, które mogą być utworzone z punktów startowych i końcowych. Zbiór wynikowy może być jeszcze filtrowany przez wiele predykatów.
Obliczmy następujące wyrażenie:
xpointer((//d/*/range-to(//e/*)[3])[2])
W tym wyrażeniu zbiór startowy to zbiór wszystkich dzieci elementów d w dokumencie, a zbiór końcowy to dzieci elementów e. Najpierw budujemy zakresy, których punkt startowy jest dzieckiem elementu d, a końcowy trzecim w porządku spośród wszystkich dzieci elementów e. Następnie wybieramy drugi przedział z tych, które powstały.
Metody, które trzeba było zaimplementować w klasie RangeToExpression to między innymi:
- simplify() – Metoda wołana przed obliczeniem wyrażenia, zawiera reguły, dzięki którym można uniknąć obliczania niepotrzebnych podwyrażeń. W przypadku /range-to jest to np. reguła, która mówi, że jeżeli jedno z podwyrażeń (startowe lub kroku) jest pustym zbiorem lokacji, to całe wyrażenie przekazuje pusty zbiór zakresów. Dzięki temu można uniknąć obliczania podwyrażeń.
-
enumerate() – W
przypadku wyrażeń będących podklasą NodeSetExpression,
a do takich należy RangeToExpression,
metoda ta jest używana do obliczenia wartości wyrażenia. Przy pomocy tej
właśnie metody zdefiniowane są metody evaluate(),
evaluateAsBoolean() i podobne. Metoda enumerate() z RangeToExpression
przekazuje iterator, który tworzy kolejne zakresy. Iterator ten korzysta
z iteratorów uzyskanych z wywołania metody enumerate()
na wyrażeniu startowym i wyrażeniu kroku – z tych poditeratorów dostaje punkty
startowe i końcowe. Obliczanie wyrażeń w Saxonie jest leniwe – iterator, który
jest przekazywany tworzy nowe węzły dopiero na żądanie, także obliczanie
podwyrażeń odbywa się wtedy, gdy jest to konieczne.
Poza tymi dwoma najważniejszymi musiałem zaimplementować
kilka innych metod oraz stworzyć pomocnicze iteratory i inne klasy narzędziowe.
4.2.2. Klasa implementująca zakres
Do drzewa dokumentu dodałem klasę RangeImpl odpowiedzialną za implementację zakresów i punktów. Zgodnie z XPointer zakres składa się z dwóch punktów, a każdy punkt to para węzeł-kontener i liczba-indeks. Moja reprezentacja zakresu ma pola: startContainer, startIndex, endContainer, endIndex oraz isPoint określające czy obiekt reprezentuje zakres, czy pojedynczy punkt. Odbiega to troszkę od modelu zdefiniowanego w XPointer, gdyż nie zdecydowałem się na wprowadzenie oddzielnej klasy dla punktów.
Przy implementacji zakresu, podobnie jak przy implementacji wyrażeń, byłem niemalże prowadzony za rękę przez autora Saxona, gdy pisałem kolejne metody wymaganego interfejsu. Tym razem było to interfejs NodeInfo, czyli interfejs przewidziany w Saxonie dla węzłów drzewa dokumentu.
Oto kilka metod, które dają pojęcie o rodzaju funkcjonalności udostępnianej przez obiekty NodeInfo:
- getNodeName() – przekazuje nazwę węzła; oprócz tej, są podobne metody do pobierania typu węzła, jego przestrzeni nazw, odcisku palca używanego do szybkiego indeksowania, itp.,
- isSameNode(NodeInfo other) – sprawdza, czy węzeł jest tożsamy z innym węzłem,
- compareOrder(NodeInfo other) – sprawdza, czy węzeł występuje przed innym węzłem w porządku dokumentu,
- getStringValue() – pobiera wartość tekstową węzła, czyli wszystkie litery zawarte w węźle; w przypadku zakresu metoda przechodzi przez wszystkie węzły tekstowe, które są częściowo lub całkowicie pokryte przez zakres i konkatenuje wartości tych węzłów,
- getEnumeration(byte axisNumber, NodeTest nodeTest) – przekazuje iterator po węzłach dla zadanej osi (axisNumber), iterator zawiera węzły przefiltrowane przez nodeTest. XPointer określa zawartość osi dla zakresów przy pomocy zawartości osi dla węzła zawierającego punkt startowy zakresu, dzięki czemu implementacja tej metody była szybka.
Elementy drzewa dokumentu w Saxonie implementują również interfejs org.w3c.dom.Node, są więc zgodne ze standardem DOM. Jednak Saxon obsługuje tylko metody służące do odczytu, pozostałe to tylko zaślepki. Zatem drzewo DOM w Saxonie nie jest w pełni funkcjonalne, nie można go modyfikować. Aby moje poprawki były również zgodne z DOM, dodałem do mojej klasy RangeImpl metody zawarte w interfejsie org.w3c.dom.ranges.Range – oczywiście tylko te, które służą do odczytu.
Ciekawą cechą Saxona jest to, że zawiera dwie implementacje drzewa dokumentu: standardową i małą (ang. tiny). Drzewo w tej drugiej powstaje o wiele szybciej, ale za to jest wolniejsze w nawigacji. Decyzja o tym, której implementacji użyć należy do użytkownika Saxona. Mój parser XPointer działa ze standardową implementacją, gdyż XPointer wymaga dużej liczby przejść między węzłami i mała implementacja byłaby mniej efektywna.
4.2.3. Ekstrakcja przedziałów
Interfejs NodeInfo definiuje także metodę copy(Outputter out), która służy do generowania zdarzeń SAX odpowiadających węzłowi. Implementacja tej metody w przypadku zakresów jest dość skomplikowana, gdyż trzeba rozważyć wiele przypadków zakresów. Trzeba pamiętać, że zakresy nie zawsze obejmują poprawną część dokumentu, z dobrze pozamykanymi elementami. W takich przypadkach metoda copy() musi pootwierać i pozamykać niektóre znaczniki.
Przykład
<a>
<e>txt</e>
<b>
<k/>
<l>chars</l>
</b>
</a>
Zaznaczony zakres obejmuje w
pliku tekst: xt</e><b><k/><l>ch,
któremu odpowiadają następujące zdarzenia SAX: characters(„xt”),
endElement(„e”), startElement(„b”), startElement(„k”),
endElement(„k”), startElement(„l”), characters(„ch”).
Metoda generująca takie zdarzenia byłaby bezużyteczna, gdyż wygenerowane przez
nią zdarzenia nie tworzą odpowiednio zagnieżdżonych, odpowiadających sobie par.
Zatem copy() musi dodać dodatkowe zdarzenia, tak
by można było sparować każdy startElement(„znacznik”)
z endElement(„znacznik”). Dzięki temu
można użyć wyniku działania metody copy() na
potrzeby XInclude. Dla powyższego
zakresu copy() wyemituje zdarzenia,
które mogą być przedstawione jako następujący fragment XML-a:
<e>xt</e><b><k/><l>ch</li></b>
Zarys implementacji metody:
- jeżeli węzły-kontenery obu punktów zakresu są tożsame, to wszystkie zdarzenia będą od razu sparowane, więc przypadek jest nieciekawy,
- jeżeli nie, to znajdź najbliższego wspólnego przodka węzłów-kontenerów,
- idź skrajnie lewą gałęzią od wspólnego przodka do kontenera startowego wypisując zdarzenia startElement() dla mijanych węzłów,
- przechodź węzły wewnętrzne zakresu w kolejności dokumentu. Da się to zrobić, gdyż drzewo Saxona (wersja standardowa, nie mała) zawiera metody przekazujące kolejne węzły w porządku dokumentu,
- przejdź skrajnie prawą gałęzią od wspólnego przodka do kontenera końcowego wypisując zdarzenia endElement() dla mijanych węzłów,
- jeśli jeden z kontenerów jest przodkiem drugiego, to trzeba wypisać zdarzenia dla wspólnego przodka i wtedy przekazany fragment ma jeden korzeń, w przeciwnym przypadku nie wypisujemy wspólnego przodka i korzeni może być więcej.
Dodatkowa komplikacja algorytmu wynika z konieczności wypisywania dodatkowych atrybutów definiujących przestrzenie nazw i adres bazowy w każdym przekazanym korzeniu.
4.2.4. Zaznaczanie zakresów
Realizacja niektórych wymagań wymagała rozszerzenia interfejsu NodeInfo, a więc także implementacji nowych funkcji we wszystkich istniejących implementacjach NodeInfo. Przykładem jest ElementImpl, klasa reprezentująca element z dokumentu. Jednej z takich metod użyłem do zaznaczania zakresu w dokumencie, czyli do wstawiania instrukcji przetwarzania w miejscu wystąpienia punktów startowych i końcowych zakresów.
Metoda markRanges(Collection ranges, Outputter out, String stamp) powinna być wywoływana dla korzenia drzewa dokumentu, a następnie wywołuje się rekurencyjnie na wszystkich elementach, węzłach tekstowych i innych, zawartych w drzewie dokumentu. W trakcie obchodzenia drzewa metoda kopiuje węzły do programu obsługi zdarzeń out. Jeśli metoda natrafi na węzeł, który jest kontenerem dla zaznaczanego punktu, to emituje dodatkową instrukcję przetwarzania zaznaczającą ten punkt.
Inne metody, które dodałem do klasy NodeInfo to:
- makeRange(int type), gdzie type to START_POINT, END_POINT, COVERING_RANGE lub RANGE_INSIDE - z danego węzła metoda tworzy zakres, tak jak to określono w specyfikacji funkcji XPointer, odpowiednio: start-point(), end-point(), range() i covering-range();
- createStringRanges(String needle) – która jest wykorzystywana przez funkcję string-range() opisaną w następnym paragrafie.
4.2.5.
Funkcja
string-range()
Spośród wszystkich funkcji zdefiniowanych w XPointer najciekawszą jest string-range(). Podstawowa wersja tej funkcji jest dwuparametrowa; pierwszy parametr to zbiór węzłów, w którym jest wyszukiwany wzorzec podany w drugim parametrze. Wynikiem działania funkcji jest zbiór zakresów, np. string-range(/, ‘XML’) przekaże wszystkie zakresy obejmujące tekst „XML” w dokumencie.
Najważniejszą częścią implementacji tej funkcji jest metoda createStringRanges(String needle) zdefiniowana we wszystkich węzłach drzewa dokumentu. Metoda ta obchodzi wszystkie podwęzły danego węzła, w kolejności określonej przez porządek dokumentu. W trakcie wędrówki metoda utrzymuje bufor, w którym konkatenuje wartości napotkanych węzłów tekstowych. Bufor jest używany do wyszukiwania wzorca. Jest on tylko tak długi, jak to jest wymagane, nieużywane części bufora są zwalniane. Przy przechodzeniu do następnego węzła można zwolnić cały bufor, pozostawiając tylko n – 1 znaków, gdzie n to długość wzorca. Dzięki temu unikam pobrania wartości tekstowej całego dokumentu i budowy jednej dużej zmiennej. Oprócz bufora metoda utrzymuje kolekcję punktów dokumentu, gdzie znaleziono wzorzec.
4.2.6. Porządek węzłów w dokumencie
Określony w XPath porządek na węzłach odpowiada kolejności występowania znaczników otwierających w tekstowej reprezentacji dokumentu XML. Obowiązują więc reguły: rodzice przed dziećmi, rodzeństwo w kolejności z pliku. XPointer podaje jak rozszerzyć ten porządek na zakresy i punkty i to w taki sposób, by był on uogólnieniem porządku z XPath. W tym porządku żadne dwa nie tożsame węzły, punkty, lokacje nie są równe. Niestety ten porządek czasami zawodzi.
<?xml version=”1.0”?>
<a><b><c/>©</b>§</a>
Według definicji porządku w tym dokumencie § występuje przed ©, gdyż reguła mówi, że punkt § jest przed © jeżeli węzeł poprzedzający § (tu b) występuje przed węzłem poprzedzającym © (tu c). Definicja porządku jest istotna, gdyż punkt startowy w zakresie musi występować przed punktem końcowym. Zakres (§, ©) jest poprawny zgodnie z XPointer, ale intuicyjnie bezsensowny. W mojej implementacji zachowałem porządek ze specyfikacji, co jednak powoduje, że parser czasami zachowuje się nieobliczalnie.
4.3. Aplikacja testowa, przykłady XInclude i XPointer
Częścią produktu Xinpo jest aplikacja okienkowa, która służy do testowania parserów XInclude oraz XPointer. Można za jej pomocą szybko zobaczyć wynik przetworzenia dokumentu przez parser XInclude oraz zobaczyć zakresy utworzone na podstawie dowolnego wyrażenia XPointer. Są trzy sposoby wizualizacji zakresów: poprzez pokolorowanie, za pomocą instrukcji przetwarzania oraz poprzez wypisanie zawartości zakresu na ekran. Dwie pierwsze metody pokazują zakres na tle dokumentu, na którym zostało wykonane zapytanie, trzecia używa nowego okna. Rysunki 9-14 przedstawiają tę funkcjonalność, a także demonstrują ciekawe zapytania XPointer.
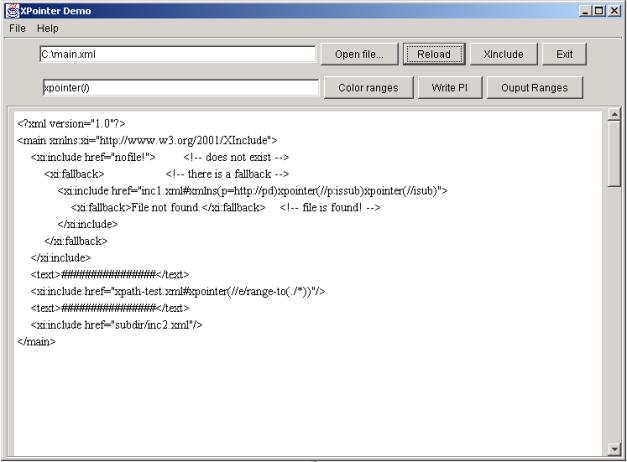
Rysunek 9. Aplikacja
testowa po załadowaniu pliku z elementami <xi:include>
Rysunek 9 pokazuje aplikację testową po załadowaniu przykładowego pliku o nazwie main.xml. Ten i inne pliki wykorzystywane w przykładach znajdują się na załączonej do pracy płycie CD, dzięki czemu testy można łatwo powtórzyć. Plik zawiera przykłady włączania XInclude z wykorzystaniem zapytań XPointer. Dokument wykorzystuje również element <xi:fallback>.
Pierwszy element <xi:include> w pliku zawiera odwołanie do nieistniejącego pliku (nofile!), więc przy przetwarzaniu zgodnie z XInclude zostanie wykorzystany podelement <xi:fallback> zawierający podelement <xi:include>. Ten element włącza fragment pliku inc1.xml adresowany wyrażeniem xmlns(p=http://pd)xpointer(//p:issub)xpointer(//isub). To wyrażenie przekaże wszystkie elementy <issub> z przestrzeni nazw identyfikowanej przez URI http://pd, a jeśli takie elementy nie istnieją w pliku inc1.xml, to przekaże elementy <isub> z domyślnej przestrzeni nazw. Gdyby w pliku inc1.xml nie istniał żaden element <isub>, to do wynikowego pliku zostałby wstawiony tekst „File not found.”.
Kolejny element <xi:include> demonstruje włączanie lokacji wskazanych przez wyrażenie XPointer przekazujące zakresy z pliku xpath-test.xml. Zawartość włączanego pliku to:
<?xml version="1.0"?>
<a xmlns:a="nsa">
<b atr="b">bab<c/><k/><d><l/>xkb<m><p/>end</m></d><n/></b>
aAa
<i xmlns:i="i"/>
<e><f/><g><a:j/></g></e>
<o a:atr="aTTt"/>
</a>
Cechą wyróżniającą ostatni element <xi:include> jest to, że włącza plik znajdujący się w innym katalogu dyskowym niż pozostałe.
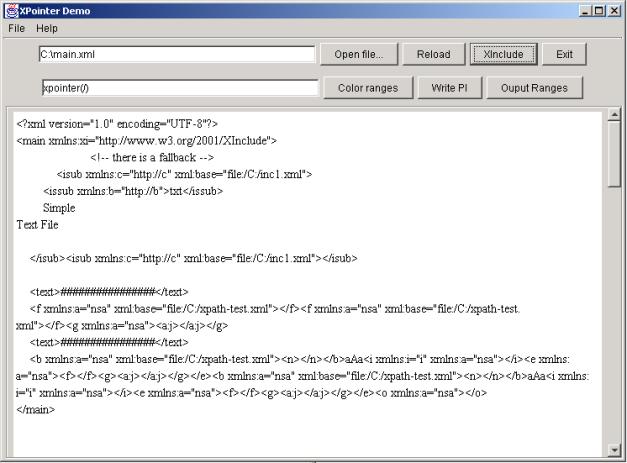
Rysunek 10. Aplikacja
testowa po uruchomieniu parsera XInclude
Aplikacja na rysunku 10 zawiera ten sam dokument, co na rysunku 9, ale po przetworzeniu za pomocą parsera XInclude. Parser został uruchomiony przyciskiem XInclude. Dokument na rysunku 10 nie zawiera już elementów <xi:include>, w ich miejscu pojawiła się zawartość włączanych plików.
Pierwsze włączanie spowodowało
wstawienie zawartość dwóch elementów <isub>
z pliku inc1.xml, gdyż w pliku nie było
elementu <issub> z wymaganej
przestrzeni nazw. Oto cała zawartość włączanego pliku:
<?xml version="1.0"?>
<imain xmlns:c="http://c">
<isub>
<issub xmlns:b="http://b">txt</issub>
<x:include parse="text"
xmlns:x="http://www.w3.org/2001/XInclude" href="inc 3.txt"/>
</isub>
<p:issub xmlns:p="http://p"/>
<isub/>
</imain>
Warto zwrócić uwagę na następujące szczegóły zawarte w pliku wynikowym (z rysunku 10):
- oba elementy <isub> zostały wstawione,
- każdy element <isub> zawiera deklarację przestrzeni nazw http://c, która we włączanym dokumencie nastąpiła u rodzica <isub> (ze względu na zgodność z XML Namespaces),
- każdy element <isub> zawiera atrybut xml:base wskazujący na adres URI włączanego dokumentu (ze względu na zgodność z XML Base),
- dokument zawiera treść pliku tekstowego włączanego z inc1.xml.
Drugie włączanie spowodowało wstawienie zawartości dwóch zakresów: pierwszy zaczyna się od elementu <e> a kończy w <f>, a drugi od <e> do <g>. W tym przypadku również zostały wstawione atrybuty xml:base oraz deklaracje przestrzeni nazw w elementach <f> i <g>.
Ostatnie włączanie odwołuje się do pliku inc2.xml, który znajduje się w podkatalogu subdir. Jego zawartość to:
<?xml version="1.0"?>
<xi:include xmlns:xi="http://www.w3.org/2001/XInclude"
href="../xpath-test.xml#xpointer(//n/range-to(//e | //o))"/>
To włączanie pokazuje dwie ważne cechy działania XInclude:
- adresy pochodzące z włączanego dokumentu są obliczane względem adresu dokumentu je zawierającego, a nie dokumentu głównego, stąd odwołanie do nadkatalogu w pliku inc2.xml (ze względu na zgodność z XML Base);
- wyrażenie XPointer zawarte w pliku inc2.xml przekazuje fragment dokumentu nie posiadający jednego elementu głównego (jest więcej elementów głównych, np. <b>, <i>, widać to na rysunku 10), a mimo to nie występuje błąd przetwarzania; dla kontrastu: gdyby to plik inc2.xml był parsowany przez XInclude wystąpiłby błąd, gdyż wynikiem działania XInclude musi być poprawny dokument XML (z jednym elementem głównym).
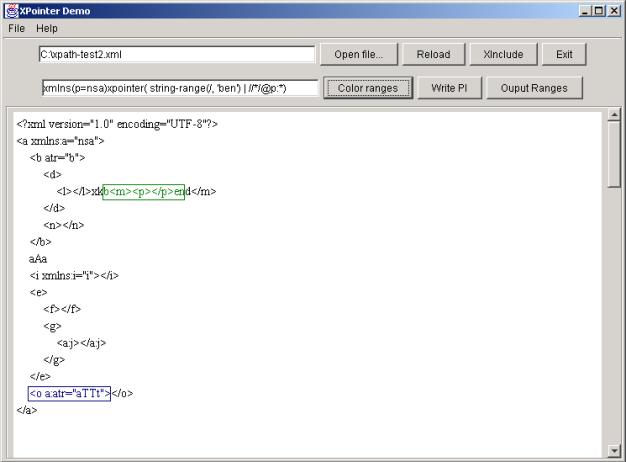
Rysunek 11. Dokument z
pokolorowanymi lokacjami
Aplikacja przedstawiona na rysunku 11 pokazuje zawartość wczytanego pliku xpath-test2.xml z zaznaczonymi zakresami powstałymi w wyniku wykonania zapytania xmlns(p=nsa)xpointer(string-range(/, ‘ben’) | //*/@p:*). Zapytanie zostało wpisane w okienko aplikacji, a następnie, po naciśnięciu przycisku Color ranges aplikacja pokolorowała wybrane zakresy. Podane zapytanie przekazuje sumę dwóch podzapytań, z których pierwsze przekazuje zakres, a drugie atrybut. Suma jest obliczana operatorem |.
Pierwszy zaznaczony na rysunku 11 obiekt (pokolorowany na
zielono, obejmujący tekst „b<m><p></p>en”,
zaznaczony na rysunku ramką) to zakres, który ma oba punkty w węzłach
tekstowych. Drugi zaznaczony obiekt (niebieski, obejmujący tekst „<o a:atr=”aTTt”>”, w ramce) to atrybut
atr elementu <o>
należący do przestrzeni nazw o URI nsa.
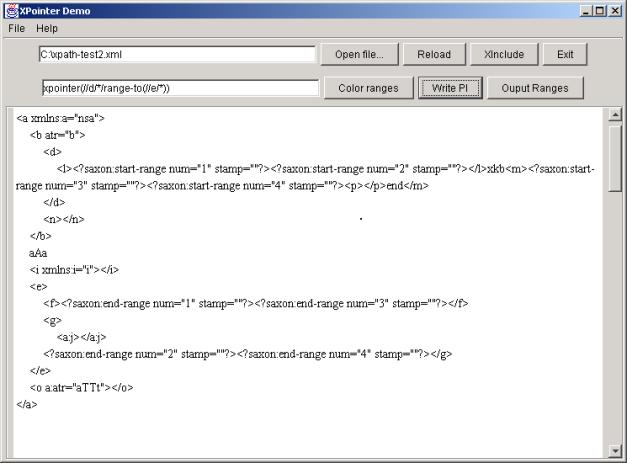 Rysunek
12. Dokument z zakresami oznaczonymi za pomocą
instrukcji przetwarzania.
Rysunek
12. Dokument z zakresami oznaczonymi za pomocą
instrukcji przetwarzania.
Rysunek 12 ilustruje drugą metodę zaznaczania zakresów. Po naciśnięciu przycisku Write PI aplikacja wstawia instrukcje przetwarzania na początku i końcu każdej lokacji otrzymanej w wyniku obliczenia wyrażenia XPointer wpisanego w okienko. Tutaj mamy cztery zakresy, ponumerowane za pomocą pseudo-atrybutu stamp. Początek każdej lokacji jest oznaczony instrukcją przetwarzania <?saxon:start-range num=”n” stamp=””?>, a odpowiadający mu koniec instrukcją <?saxon:end-range num=”n” stamp=””?>.
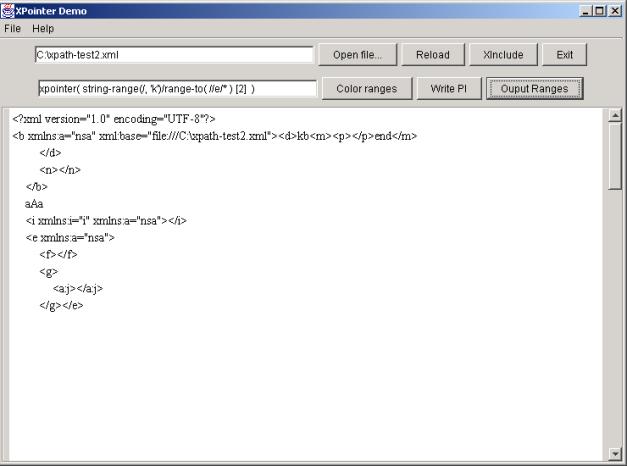
Rysunek 13. Zawartość
zakresu wypisana na ekran
Zapytanie z rysunku 13 (xpointer(string-range(/, ‘k’)/range-to(//e/*)[2])) zostało wykonane na tym samym dokumencie, co zapytania z rysunków 11 i 12. Tym razem został naciśnięty przycisk Output ranges i aplikacja wpisała w okienko zawartość zakresu wybranego przez podane zapytanie. Jak widać wszystkie znaczniki zostały odpowiednio pootwierane i pozamykane. Dla porównania rysunek 14 pokazuje ten sam zakres oznaczony za pomocą instrukcji przetwarzania.
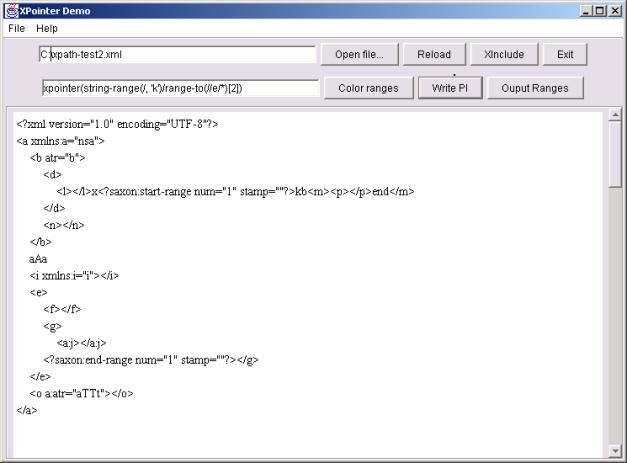
Rysunek 14. Zakres z
rysunku 13 oznaczony za pomocą instrukcji przetwarzania
5. Zastosowania
W tym rozdziale opiszę zastosowania standardów XInclude i XPointer, w których można użyć, bądź już użyto mojego programu. Jedna z firm używa XInclude przy tworzeniu dokumentacji. W podrozdziale 5.1 przedstawię jej doświadczenia szczegółowo opisując proces powstawania dokumenacji. Spróbuję uzasadnić, że mój program mógłby być przydatny w tym i podobnych zastosowaniach. Następny podrozdział to opis kolejnego standardu XML wykorzystującego XPointer – XLink. XLink definiuje sposób wykorzystywania zapytań XPointer do tworzenia odnośników między dokumentami. W ostatnim podrozdziale opiszę system e:kms, przy rozwoju którego biorę aktywny udział. W systemie wykorzystywana jest większość standardów, o których pisałem, w tym XInclude oraz XLink. Wydaje mi się, że system e:kms jest przekonującym dowodem na praktyczną użyteczność standardów XML-owych. System ten warto opisać również z tego względu, że powstały w ramach tej pracy parser XInclude jest jego integralną częścią.
5.1. XInclude przy tworzeniu dokumentacji w DocBook
W tym rozdziale opiszę w jaki sposób można wykorzystać parser XInclude przy tworzeniu dokumentacji. Rozdział powstał na podstawie doświadczeń firmy informatycznej, która tworzy wiele rodzajów dokumentacji do swoich produktów. W tej firmie wszystkie dokumenty powstają w DocBook. DocBook to standard stworzony, by ułatwić tworzenie książek i artykułów, głównie dotyczących komputerów i oprogramowania. Najważniejsza część standardu to definicja typów dokumentów (DTD) zawierająca znaczniki dozwolone w dokumentach DocBook. Istnieją dwie wersje DTD; jedna wykorzystuje SGML, dla nas interesująca jest ta druga, XML-owa. Przykładowe elementy w DTD z DocBook to <Chapter>, <Author> i <Figure>. Poza składnią, DocBook określa także semantykę elementów, czyli definiuje sposób ich wykorzystywania w tworzonych dokumentach.
DocBook jest często wybierany jako standard dokumentacji, gdyż:
- jest instancją XML, więc dokumenty DocBook można tworzyć przy pomocy edytorów XML, dzięki czemu uzyskuje się podpowiadanie składni i walidację poprawności,
- jest popularny, a zatem wspierany przez wiele programów,
- istnieją szablony XSLT konwertujące DocBook do HTML, PDF i innych formatów,
- DTD z DocBook korzysta z encji, dzięki temu może być dostosowywane do potrzeb jego użytkowników.
Te zalety przekonały opisywaną firmę do wykorzystania standardu DocBook. Edytorem wykorzystywanym w firmie do tworzenia dokumentacji jest XML Buddy (wtyczka do IDE eclipse), który zapewnia walidacje i podpowiadanie. Docelowym formatem dokumentacji jest PDF (dokumenty PDF są umieszczane na stronach WWW firmy), Java Help dołączany do programów, bądź HTML w przypadku dokumentacji technicznej.
W firmie powstaje kilka rodzajów dokumentacji:
- dokumentacja użytkownika,
- dokumentacja wdrożenia,
- dokumentacja techniczna,
- dokumenty wewnętrzne.
Szczególnie istotne jest to, że każdy z dokumentów wchodzący w skład danej dokumentacji może być tworzony przez wiele różnych osób. Poza tym istnieją fragmenty dokumentów wspólne dla różnych dokumentacji. Konieczny był zatem sposób na scalanie fragmentów w większe dokumenty. Jedną z rozważanych metod było włączanie przez encje zewnętrzne (zdefiniowane w standardzie XML – jest to zwykłe wklejenie tekstu z zewnętrznego pliku), ale w tej metodzie poddokumenty nie są poprawnymi plikami XML, więc nie mogą być walidowane. Walidowania poddokumentów i podpowiadanie składni w trakcie edycji było na tyle istotne, że zrezygnowano z włączanie poprzez encje i użyto XInclude.
W ostatecznie przyjętym rozwiązaniu, zarówno fragmenty dokumentów, jak i szablony gotowych dokumentów zawierające elementy <xi:include> są przechowywane w repozytorium CVS. Odwołania do włączanych dokumentów zawierają względne ścieżki dyskowe. Proces budowania dokumentacji jest zautomatyzowany za pomocą skryptów programu Ant [Ant].
Do składania dokumentów jest wykorzystywany bardzo prosty parser XInclude, umożliwiający wstawianie tylko całych dokumentów. Gdyby firma zdecydowała się na użycie pełnego parsera XInclude (np. Xinpo), mogłaby skorzystać z włączania fragmentów poddokumentów, co dałoby większą elastyczność w tworzeniu dokumentów.
5.2. XLink – standard wykorzystujący XPointer
XLink [XLink] określa sposób tworzenia odnośników między dokumentami XML. Pojęcie odnośnika zdefiniowane przez XLink jest uogólnieniem pojęcia odnośnika z HTML tworzonego przy pomocy elementu <a href>. XLink jest ciekawy z punktu widzenia tej pracy, gdyż pozwala używać zapytań XPointer przy tworzeniu odnośników do fragmentów dokumentów. Składnia XLink różni się znacząco od odnośników HTML-owych. Do wstawiania odnośników XLink używa atrybutów, a nie dedykowanych elementów, jak HTML. Oto przykład dokumentu używającego odnośników prostych, jednego z dwóch rodzajów XLinków.
<?xml version="1.0"?>
<firma
xmlns:xlink=”http://www.w3.org/1999/xlink”>
<pracownik id=”jkowal”
xlink:type=”simple” xlink:href=”cv/kowal.xml”>
<imię>Jan</imię>
<nazwisko>Kowalski</nazwisko>
</pracownik>
<pracownik id=”jnowak”
xlink:type=”simple” xlink:href=”cv/nowak.xml”>
<imię>Jerzy</imię> <nazwisko>Nowak</nazwisko>
</pracownik>
</firma>
W tym dokumencie zawarte są dwa odnośniki, każdy z nich prowadzi od elementu <pracownik> do zewnętrznego pliku zawierającego życiorys pracownika.
Drugim, o wiele bardziej interesującym rodzajem XLinków są odnośniki rozszerzone (ang. extended). W odróżnieniu od odnośników prostych i tych z HTML, odnośniki rozszerzone mogą wiązać ze sobą więcej niż dwa zasoby. Dodatkowo sam odnośnik może być w innym pliku niż zasoby przez niego łączone. Dla odmiany jeden z zasobów wiązanych odnośnikiem prostym to element będący odnośnikiem (w poprzednim przykładzie jest to element <pracownik>).
Kolejny dokument zawiera jeden rozszerzony Xlink, pokazany również na rysunku 15.
<?xml version="1.0"?>
<projekt
xmlns:xlink=”http://www.w3.org/1999/xlink”
xlink:type= ”extended”>
<nazwa
xlink:type=”title”>Projekt dwuosobowy</nazwa>
<pracownik id=”jkowal”
xlink:type=”locator”
xlink:href=”pracownicy.xml#xpointer(//pracownik[@id=’kowal’])”
xlink:role=”http://example.org/roles/project-manager”
xlink:label=”kowal”>Jan
Kowalski</pracownik>
<pracownik id=”jnowak”
xlink:type=”locator”
xlink:href=”pracownicy.xml#xpointer(//pracownik[@id=’nowak’])”
xlink:role=”http://example.org/roles/project-member”
xlink:label=”nowak”>Jerzy
Nowak</pracownik>
<dokument id=”proj20030515”
xlink:type=”locator”
xlink:href=”projekty/20030515.xml”
xlink:role=”http://example.org/roles/description”
xlink:label=”dok”
/>
<data xlink:type=”resource”
xlink:label=”data”>2003-05-15</data>
<idź xlink:type=”arc”
xlink:from=”nowak”
xlink:to=”kowal”
xlink:title=”Kierownik w projekcie”/>
<idź xlink:type=”arc”
xlink:from=”kowal”
xlink:to=”nowak”
xlink:title=”Podwładny w projekcie”/>
<idź xlink:type=”arc”
xlink:from=”kowal”
xlink:to=”dok”
xlink:title=”Opis projektu”/>
<idź xlink:type=”arc”
xlink:from=”dok”
xlink:to=”data”
xlink:title=”Data rozpoczęcia”/>
</projekt>
Odnośnik z tego dokumentu łączy trzy zasoby zewnętrzne oraz jeden zasób lokalny. Dokument zawiera zwykłe elementy <projekt>, <nazwa>, <pracownik>, <dokument> oraz <data>, które mogą być wykorzystywane do obróbki przez zwykły program, np. działający w modelu DOM bez wsparcia dla XLink. Dla procesora XLink w dokumencie ważne są tylko atrybuty z przestrzeni nazw xlink. Atrybut xlink:type nadaje elementom semantykę wykorzystywaną przez procesor. Element o typie „extended” to element zawierający odnośnik rozszerzony, element „locator” wskazuje na zasób zdalny, a „resource” to zasób lokalny. Element typu „title” to nazwa całego odnośnika. Poza tym procesor może skorzystać z ról do nadawania informacji semantycznej odnośnikom; ta informacja jest zawarta w atrybucie xlink:role. Przykład pokazuje również użycie XPointer do wskazywania na fragment dokumentu. Na końcu odnośnika występują elementy <idź>, które służą do tworzenia łuków, czyli sposobów nawigacji między członami odnośnika. Tutaj łuki prowadzą od członka zespołu do kierownika i odwrotnie oraz od kierownika do dokumentu opisującego projekt i od dokumentu do daty jego rozpoczęcia.
Rysunek 15. Rozszerzony XLink
Odnośnik z przykładu został zaprojektowany do wykorzystania przy wyświetlaniu dokumentu pracownicy.xml. Dokument ten zawiera informacje o wszystkich pracownikach, na te informacje można nałożyć dodatkowo informację odczytaną z odnośnika. I tak przy wyświetlaniu pracownika Jan Kowalski (element //pracownik[@id=’kowal’]) na marginesie pojawi się odnośnik z tytułem „Projekt dwuosobowy”, który da możliwość przejścia do Jerzego Nowaka (z etykietą „Podwładny w projekcie” wziętą z atrybutu elementu <idź>) oraz do dokumentu opisującego projekt (etykieta „Opis projektu”). Po przejściu przez łuk do Jerzego Nowaka będzie można wrócić z powrotem do kierownika, a po przejściu przez łuk do dokumentu zobaczymy datę rozpoczęcia projektu (zatytułowaną „Data rozpoczęcia”). Opisaną funkcjonalność XLinków posiada system e:kms, który przedstawię w następnym rozdziale.
5.3. e:kms - system zarządzania dokumentami
empolis Knowledge Management Suite (e:kms) [ekms] to system firmy empolis służący do zarządzania dokumentami oraz zarządzania wiedzą. Są przynajmniej dwa powody by go tutaj opisać. Po pierwsze mój parser XInclude oraz XPointer powstał na potrzeby tego systemu, co miało wypływ na wiele wymagań stawianych parserowi. Po drugie, e:kms pokazuje możliwości praktycznego wykorzystania oprogramowania XML, w tym realizującego standardy XInclude i XPointer.
Aplikacja została napisana w Javie, do działania wymaga serwera aplikacyjnego J2EE [J2EE] oraz bazy danych SQL.
5.3.1. Ogólnie o systemie
Repozytorium dokumentów
System e:kms składa się z kilku, dość niezależnych od siebie modułów. Jednym z tych modułów jest repozytorium dokumentów. Repozytorium może przechowywać różne rodzaje dokumentów: dokumenty tekstowe, dokumenty XML, pliki programów utworzone przez Microsoft Office, obrazki i inne. Repozytorium traktuje wszystkie dokumenty jak pliki binarne, interpretacją różnych typów dokumentów zajmują się wyższe warstwy systemu, którym repozytorium udostępnia typ MIME. Funkcjonalność, którą zapewnia ten moduł, to oprócz zapisywania i odczytywania dokumentów, także tworzenie kolejnych wersji. Model pracy nad dokumentem w e:kms-ie jest podobny do pracy z CVS-em: najpierw należy pobrać dokument do edycji, następnie użytkownik może dokonywać zmian na utworzonej kopii roboczej, by na końcu zapisać zmieniony dokument. Przy każdym zapisie repozytorium tworzy kolejną wersję dokumentu.
Silnik metadanych, RDF
Drugim ważnym modułem w e:kms-ie jest silnik metadanych. Metadane to dowolne informacje, służące do opisu dokumentu, nie należące do treści dokumentu. Metadanymi są data utworzenia dokumentu, jego autorzy, klasyfikacja dokumentu, streszczenie. Modelem metadanych dla e:kms jest Resource Description Framework [RDF]. W RDF-ie metadaną może być zarówno literał, jak i zasób. Zasób to obiekt, który może mieć kolejne metadane. Każdy dokument jest w e:kms-ie zasobem w sensie RDF, zasobem jest też osoba, która może być wartością metadanej „autor” przypisanej do dokumentu. Osobie możemy przypisywać kolejne metadane: adres poczty elektronicznej, nazwisko, ale także firmę, w której pracuje i dziedziny wiedzy, w których jest ekspertem. Te powiązania tworzą pewien model wiedzy, składający się ze stwierdzeń cecha_x(zasób_y, zasób_z) lub cecha_x(zasób_x, literał_z), np. autor(Praca_magisterska, Karol_Bieńkowski). Wycinek modelu w formie grafu przedstawiono na rysunku 16. Model zdefiniowany w RDF jest podzbiorem modelu zdefiniowanego w Prologu, nie umożliwia wykorzystywania w stwierdzeniach zmiennych ani nie dopuszcza stwierdzeń innych niż dwuargumentowe. Silnik metadanych pozwala odpytywać model (np. podaj wszystkie dokumenty stworzone przez osobę będącą ekspertem w zakresie systemów operacyjnych) oraz umożliwia jego wizualizację w postaci grafu i różnego rodzaju struktur drzewiastych.
Płocka 5a, Warszawa![]()
![]()
![]()
![]()
![]()
![]()
![]()

Rysunek 16. Model RDF
Wyzwalacze i filtry
Do każdej operacji wykonywanej przez repozytorium dokumentów można przypisać wyzwalacz. Kod wyzwalacza ma dostęp do zawartości dokumentu, który jest pobierany lub zapisywany do repozytorium oraz do silnika metadanych. Dzięki temu w wyzwalaczach można wstawiać i usuwać metadane na podstawie zawartości dokumentu. Wyzwalacze są wybierane na podstawie typu dokumentu (XML, PDF, GIF). Mogą być zestawiane w potoki, każdy z wyzwalaczy ma pozwolenie na modyfikację dokumentu, więc można je traktować jak filtry. Dzięki wyzwalaczom można m. in. sprawdzać poprawność dokumentów przed zapisem, formatować dokumenty przed wyświetleniem oraz pobierać z plików Microsoft Office metadane ustawiane przez ich autorów. Każdy program z rodziny Microsoft Office pozwala na ustawienie kilku metadanych dokumentu po wybraniu z menu programu opcji Plik/Właściwości.
5.3.2.
Wsparcie XML
Filtry SAX, XInclude
W przypadku dokumentów XML wyzwalaczami w repozytorium są filtry SAX, zatem kod wyzwalacza ma dostęp do każdego elementu przetwarzanego dokumentu. Ciekawą funkcją e:kms-a jest wybór filtra w oparciu o typ dokumentu XML (deklaracja DOCTYPE). Dzięki temu można skonfigurować filtry tak, by były wywoływane tylko do określonych rodzajów dokumentów.
W standardowo skonfigurowanym systemie są trzy filtry wykorzystujące implementację XInclude dostarczoną przez Xinpo:
- ekstraktor – filtr jest uruchamiany wtedy, gdy dokument jest zapisywany do repozytorium; wyszukuje w zapisywanym dokumencie elementy <xi:include> i dla każdego znalezionego elementu wstawia do metadanych informację o włączaniu,
- kontroler – wywoływany przy usuwaniu pliku z repozytorium, nie pozwala usunąć dokumentu, wtedy, gdy dokument jest włączany z innego dokumentu; informację o tych włączeniach pobiera z metadanych,
- procesor – uruchamiany przy pobieraniu dokumentów do odczytu, zamienia elementy <xi:include> na zawartość włączanego pliku, według standardu XInclude, wykorzystuje prywatny resolwer i dzięki temu włączanym dokumentem może być plik z repozytorium, adresowany za pomocą URI pochodzącego ze schematu zdefiniowanego na potrzeby e:kms-a.
Filtry SAX to miejsce systemu, gdzie Xinpo sprawdza się najlepiej. Dzięki wsparciu XInclude e:kms umożliwia tworzenie dokumentów z fragmentów. Fragmenty są scalane w całość dopiero przy pobieraniu pliku z repozytorium. Dzięki temu odbiorca dokumentu zawsze widzi go w całości, a autorzy mogą pracować nad niezależnie nad jego częściami.
XLink jako standard tworzenie odnośników
System e:kms umożliwia tworzenie odnośników XLink między dokumentami XML. Tworzenie i edycja odbywa się przy pomocy wyspecjalizowanego edytora XML Corel XMetaL. Dzięki przygotowanym przez empolis skryptom w Visual Basic for Applications stworzenie XLinku wymaga:
- otwarcia w XMetaLu, wprost z e:kms dwóch dokumentów XML,
- wybrania w jednym z dokumentach węzła i wskazania, że ma być on odnośnikiem,
- wskazania w drugim dokumencie celu odnośnika.
Dzięki filtrom SAX uruchamianym przy zapisie dokumentów z programu XMetaL odnośniki trafiają do modułu odpowiedzialnego za XLink. Z kolei przy pobieraniu dokumentów z repozytorium jest aplikowana transformacja XSLT (w filtrze SAX), która na podstawie każdego odnośnika zapisanego w module XLink dodaje do dokumentu fragment kodu JavaScript. Kod jest odpowiedzialny za wyświetlenie menu umożliwiającego przejście przez odnośnik wtedy, gdy użytkownik najedzie kursorem myszy nad obszar dokumentu wskazywanym przez XLink.
Implementacja XLink w e:kms-ie na razie nie wykorzystuje Xinpo, więc XLinki nie mogą używać pełnej składni XPointer, a tylko jego podzbiór określony w XPath. Ewentualna zmiana implementacji XLink wymagałaby również przerobienia skryptów dla programu XMetaL, więc nie byłaby prosta.
6. Podsumowanie
W ramach pracy magisterskiej udało mi się stworzyć program o dużych możliwościach i szerokim zakresie zastosowań. Jest on już wykorzystywany w komercyjnym produkcie, co dowodzi jego przydatności. Implementacja programu, zwłaszcza część XPointer, była dość skomplikowana. Wymagała ode mnie wysiłku, zwłaszcza przy poznawaniu kolejnych standardów XML, a potem przy wgłębianiu się w kod Saxona. Jednak dzięki trudnościom, uruchomienie działającej aplikacji dało mi dużą satysfakcję. Projekt był dość specyficzny, gdyż większość wymagań względem mojego programu pochodziło ze specyfikacji przygotowanych przez specjalistów z W3C, a nie od zwykłych użytkowników. Dzięki temu każdy aspekt funkcjonalny programu był ściśle wyspecyfikowany, wystarczyło tylko znaleźć odpowiednie miejsce we właściwej specyfikacji. Jest to oczywiście duża zaleta w porównaniu z większością systemów, gdzie wymagania piszą osoby niewtajemniczone w aspekty tworzenia oprogramowania. Czasami jednak taka ścisła specyfikacja utrudnia programowanie, gdyż nie pozwala na żadną dowolność interpretacji. Niestety okazało się, że specjaliści z W3C również popełniają błędy, np. w specyfikacji porządku węzłów w XPointer.
Najwięcej korzyści z mojej pracy wyciągnie firma empolis Polska, która jest właścicielem kodu powstałego w ramach tej pracy. Firma empolis dostała do ręki narzędzie, dzięki któremu może poszczycić się wsparciem standardów XPointer i XInclude. Jest to mocny atut, gdyż na rynku wciąż nie ma ogólnodostępnych narzędzi realizujących te standardy.
Dużo nauczyłem się już w trakcie pracy nad programem. Przede wszystkim poznałem szczegółowo wiele standardów oraz wiem jak korzystać z XML-a w Javie. Dużo czasu poświęciłem Saxonowi, dzięki temu mogłem dobrze poznać ten parser i nauczyć się od jego autora sztuki eleganckiego programowania. Stałem się ekspertem w zakresie XML-a i związanych z nim standardów, co jest pomocne w mojej obecnej pracy.
Stworzony przeze mnie program realizuje wszystkie wymagania, które zostały mu postawione. Do tej pory nie znaleziono odstępstw od implementowanych standardów. Nie oznacza to jednak, że program nie powinien być rozbudowywany. Pojawiają się kolejne wersje standardów. W3C pracuje nad nową wersją XPath, więc prawdopodobnie kolejna specyfikacja XPointer będzie bazować na XPath 2.0. Nowe wersje Xinpo powinny zawierać funkcjonalność zdefiniowaną w następnych wersjach standardów.
Jestem świadomy jednego ograniczenia programu, które może mieć znaczenie w określonych zastosowaniach. Drzewo dokumentu budowane przez Xinpo może być używane tylko do odczytu, nie można go modyfikować. Zatem każda aplikacja wykorzystująca moduł XPointer z mojego programu musi budować drzewo na nowo po każdej zmianie pliku XML, na którym są wykonywane zapytania. Nie zawsze jest to akceptowalne, np. w przypadku edytora XML chcielibyśmy mieć w pamięci jeden model dokumentu używany zarówno do wyświetlania pliku na ekranie, jak i do obliczania zapytań XPointer. Wszelkie operacje edycji powinny być wykonywane na tym drzewie. Dostosowanie Xinpo do roli w tym systemie wymagałoby rozszerzenia implementacji drzewa dokumentu o operacje służące do modyfikacji. Oczywiście dla użytkowników byłoby najwygodniej, gdyby były to operacje zdefiniowane w DOM. Jest to zadanie dość skomplikowane, m. in. dlatego, że Saxon, z którego pochodzi implementacja drzewa dokumentu, używa wielu indeksów do przyspieszenia wyszukiwania węzłów. Wszystkie te indeksy powinny być synchronizowane ze zmianami w drzewie.
Jestem przekonany, że XPointer i XInclude będą zyskiwać popularność i wkrótce pojawią się ich ogólnodostępne implementacje. Stanie się to wtedy, gdy powstaną stabilne wersje standardów, nad czym wciąż pracuje W3C. Powstawanie nowych wersji standardów i nowych implementacji świadczy o dużym na nie zapotrzebowaniu. Jestem zadowolony z powstałego w ramach pracy programu. W przyszłości będę mógł dostosowywać go do nowych wymagań i dzięki temu w niektórych zastosowaniach będzie miał on przewagę nad konkurencją.
Bibliografia
[Ant] Apache Group, Strona domowa programu Ant, http://ant.apache.org/
[ekms] empolis, Strona
poświęcona systemowi e:kms, http://www.empolis.com/products/prod_emp.asp
[Emp] empolis, Strona domowa firmy empolis Polska, http://www.empolis.pl/
[DocBook] OASIS, O'Reilly, Norman Walsh., Oficjalny podręcznik do DocBook, http://www.docbook.org/
[DOM] W3C,
Specyfikacja Document Object Model Level 2 Core,
http://www.w3.org/TR/DOM-Level-2-Core/, 2000
[DOM_TR] W3C, Specyfikacja Document Object
Model Level 2 Traversal and Range, http://www.w3.org/TR/DOM-Level-2-Traversal-Range/,
2000
[J2SE] Sun, Strona domowa języka Java 2 Standard Edition, http://java.sun.com/j2se/
[RDF] W3C,
Specyfikacja Resource Description Framework,
http://www.w3.org/TR/REC-rdf-syntax/,
1999
[SAX] Strona domowa biblioteki SAX, http://www.saxproject.org/
[Saxon] Michael H. Kay, Strona domowa procesora XSLT Saxon, http://saxon.sourceforge.net/
[W3C] W3C, Strona główna World Wide Web Consortium (W3C), http://www.w3.org/
[Xalan] Apache Group, Strona domowa procesora XSLT i XPath o nazwie Xalan, http://xml.apache.org/xalan-j/
[XIncl] W3C, Specyfikacja (kandydat) XML Inclusions (XInclude) 1.0, http://www.w3.org/TR/2002/CR-xinclude-20020221/
[XML] W3C,
Specyfikacja XML 1.0 Second Edition,
http://www.w3.org/TR/2000/REC-xml-20001006,
2000
[XIncImpl] W3C, Raport o implementacjach XInclude,
http://www.w3.org/XML/2002/09/xinclude-implementation, 28 lutego 2003
[Xlink] W3C, Specyfikacja XML Linking
Language (XLink) 1.0, http://www.w3.org/TR/2000/REC-xlink-20010627/,
2001
[XMLBase] W3C, Specyfikacja XML Base, http://www.w3.org/TR/2001/REC-xmlbase-20010627/, 2001
[XMLInfoSet] W3C, Specyfikacja XML InfoSet,
http://www.w3.org/TR/2001/REC-xml-infoset-20011024, 2001
[XMLNames] W3C, Specyfikacja Namespaces in XML,
http://www.w3.org/TR/1999/REC-xml-names-19990114, 1999
[XPath] W3C, Specyfikacja XML Path Language
(XPath) 1.0,
http://www.w3.org/TR/1999/REC-xpath-19991116, 1999
[XPtr] W3C, Specyfikacja (kandydat) XPointer,
http://www.w3.org/TR/2001/CR-xptr-20010911/, 2001, 2002
[XPtrBol] Strona na Uniwersytecie Bolońskim poświęcona implementacjom XPointer, http://www.cs.unibo.it/~fabio/XPointer/
[XPtrImpl] W3C, Raport o implementacjach XPointer, http://www.w3.org/XML/2002/10/LinkingImplementations.html, 7 listopada 2002
Dodatek A. Zawartość płyty CD
Do pracy załączam płytę CD zawierającą:
- aplikację testową opisaną w punkcie 4 wraz z plikiem plik Readme.txt opisującym sposób jej uruchomienia;
- biblioteki niezbędne do działania aplikacji testowej;
- przykładowe dokumenty XML, które posłużyły do testowania funkcjonalności XInclude i XPointer;
- specyfikacje standardów, które opisałem;
- tę pracę w formacie Microsoft Word 2000 (DOC) oraz w formacie HTML.