Wydział
Matematyki, Informatyki i Mechaniki
Marcin
Chałotowski
Nr albumu:
159127
System zarządzania treścią
Praca magisterska
na kierunku INFORMATYKA
Praca wykonana pod
kierunkiem
dr Janiny Mincer-Daszkiewicz
Instytut Informatyki
Grudzień 2002
Pracę przedkładam do oceny
Data Podpis
autora pracy:
Praca jest gotowa do oceny przez recenzenta
Data Podpis
kierującego pracą:
Streszczenie
W niniejszej pracy przedstawiono opis sposobu realizacji systemu efinityXML, który jest narzędziem do budowania portali i serwisów internetowych. Jest to narzędzie z grupy systemów do zarządzania treścią. efinityXML udostępnia szereg funkcji niezbędnych przy tworzeniu i redagowaniu portali, takich jak zarządzanie użytkownikami, obieg dokumentów, czy generowanie dokumentów w różnych formatach.
efinityXML jest programem napisanym przy użyciu technologii Java i XML. Zastosowanie technologii Java 2 Enterprise Edition daje duże możliwości integracji systemu z innymi oraz konfigurację na wielu serwerach (ang. clustering)
Słowa kluczowe:
Java, Java 2 Enterprise Edition, XML, Internet, dokument, przeglądarka, aplikacja internetowa
Klasyfikacja
tematyczna:
H. Information Systems
H.3 Information Storage And Retrieval
H.3.5 Online Information Services
Spis
treści
2. Systemy
zarządzania treścią
2.2. Rozwój systemów zarządzania treścią
2.3.3. Systemy z
grupy wolnego oprogramowania
3. Prezentacja
systemu efinityXML
3.4. Historia dokumentu i wartości domyślne
3.13. Proces wdrożenia systemu
4.2.2. Konfiguracja
wielu serwerów
5.2. Wykorzystane oprogramowanie w języku Java
5.2.2. Przetwarzanie
XML-a – Cocoon
5.2.3. Odwzorowanie
danych relacyjnych na obiektowe
6.2.3. Informacje
o zalogowanym użytkowniku
6.4.1. Informacje
o dokumencie
6.5. Zarządzanie użytkownikami
1. Wprowadzenie
W ostatnich latach rozwój Internetu zupełnie zmienił oblicze informacji. W sieci jest dostępnych coraz więcej serwisów z coraz większą ilością informacji. Nowe serwisy są bardziej czytelne, zapewniają lepszą nawigację i więcej funkcji. Z czasem kolejne portale są coraz doskonalsze.
Obecnie jest coraz więcej narzędzi i programów, które pozwalają na szybkie budowanie funkcjonalnych portali. Narzędzia te umożliwiają realizację coraz bardziej zaawansowanych serwisów, w których zarówno można tworzyć treść, jak i importować ją z zewnętrznych systemów, oglądać i przeszukiwać.
Na rynku istnieje szereg bardzo funkcjonalnych narzędzi służących do zarządzania treścią. Posiadają one wiele funkcji, dobrą dokumentację i wsparcie techniczne. Ich wadą jest jednak cena, zupełnie nieprzystająca do polskich warunków rynkowych. Z drugiej strony dostępne są systemy tańsze, jednak ich jakość i funkcjonalność pozostawia wiele do życzenia.
Celem mojej pracy jest zbudowanie systemu zarządzania treścią, nazwanego efinityXML, który dostarczałby wszystkie funkcje niezbędne przy tworzeniu dużych portali i serwisów. Ważnymi cechami nowego systemu powinny być: wydajność, możliwości rozbudowy o nowe funkcje, łatwość integracji z systemami działającymi w przedsiębiorstwach. Efektem ma być system, który będzie narzędziem do poważnych zastosowań, a jednocześnie jego cena będzie adekwatna do możliwości finansowych firm na polskim rynku.
Realizacji zadania podjąłem się przy założeniu, że będę korzystał z nowoczesnych technologii opartych na języku Java i standardzie XML. Są to technologie, które zapewniają bardzo dużą wydajność oraz duże możliwości integracji z innymi systemami. Ponadto przyszłość tych technologii wygląda bardzo obiecująco, między innymi dlatego, że w ich rozwój są zaangażowane największe na świecie firmy. Wiele obecnie tworzonych systemów jest realizowanych w tych właśnie technologiach lub są one dostosowane do integracji za pomocą języka Java i dokumentów XML.
Dalsza część pracy jest zorganizowana w następujący sposób:
· w rozdziale 2 przedstawiam ogólnie pojęcie systemów zarządzania treścią oraz ich historię,
· w rozdziale 3 znajduje się ogólny opis systemu efinityXML,
· rozdział 4 zawiera opis wybranych rozwiązań zastosowanych w efinityXML, a rozdział 5 opis technologii użytych do budowy systemu zarządzania treścią efinityXML,
· w rozdziale 6 umieściłem szczegółowy opis funkcji administracyjnych efinityXML, a w rozdziale 7 dokonałem podsumowania projektu.
2. Systemy zarządzania treścią
2.1. Definicja
Czym są systemy zarządzania treścią (ang. CMS od Content Management Systems)? Są to systemy służące do zarządzania serwisami internetowymi, ich wyglądem, treścią i funkcjami, przez wielu użytkowników. Przeważnie systemy takie implementowane są do tworzenia i utrzymywania serwisów korporacyjnych, intranetów, ekstranetów oraz aplikacji internetowych, w których mamy do czynienia z dużą ilością dokumentów i funkcji. Istnieje wtedy konieczność odpowiedniej organizacji i administracji takim systemem przez dużą liczbę redaktorów/administratorów, którzy korzystają z systemu z różnych miejsc (rozproszone środowisko administracji).
Zwykle systemy do zarządzania treścią są potrzebne wtedy, gdy mamy do czynienia z następującymi rodzajami funkcjonalności [1]:
· automatyczny obieg dokumentów (ang. workflow),
· wzory dokumentów (ang. templates),
· autoryzacja i autentykacja użytkowników, zaawansowane mechanizmy bezpieczeństwa,
· automatyczna publikacja i archiwizacja dokumentów,
· integracja z innymi systemami,
· skalowalność.
Dzięki zastosowaniu systemu zarządzania treścią można osiągnąć następujące korzyści:
· podział prac i kompetencji podczas tworzenia treści,
o decentralizacja,
o twórcy biorą pełną odpowiedzialność za stworzoną treść,
· aktualność treści, odpowiednia archiwizacja,
· szybkość i niezależność w realizacji celów biznesowych związanych z istnieniem serwisu czy portalu,
· obniżenie kosztów utrzymania,
· kontrola wersji,
· kontrola różnych kanałów przekazu, tj. strony WWW, strony WAP, telefoniczne systemy obsługi klienta i inne.
2.2. Rozwój systemów zarządzania treścią
Wraz z początkiem lat dziewięćdziesiątych nastąpił gwałtowny rozwój Internetu. Coraz więcej stron edytowanych było ręcznie lub przez proste systemy stosowane jedynie przez ich twórców. Efektem tego były wysokie koszty utrzymania i jednocześnie mała liczba dostarczanych funkcji [2].
Sytuacja ta spowodowała konieczność rozwoju systemów CMS, szczególnie w prasie i firmach produkujących dużo treści, takich jak raporty, opracowania i aktualne wiadomości. Celem było oddzielenie treści serwisu od jego strony wizualnej i logiki. Dzięki temu zabiegowi nie potrzeba było webmasterów do zarządzania serwisami – mogły to robić osoby nie będące informatykami, czy też specjalistami od stron WWW i związanych z nimi technologii.
Z jednej strony budowano systemy na potrzeby konkretnych serwisów, z drugiej powstawały gotowe systemy zawierające szereg wspólnych funkcji i narzędzi służących do tworzenia nowych portali i serwisów. Wśród tych drugich były takie, które powstawały od początku (Vignette [21]) oraz takie, które rozwinęły się z systemów do zarządzania dokumentami (Documentum [17], FileNet [20]).
Z czasem na czoło wysunęła się grupa firm (przeważnie amerykańskich), które oferując zaawansowane systemy zarządzania treścią, pozyskiwały najbogatszych klientów. Firmy te dostarczają bardzo złożone systemy, posiadające dużo funkcji, które nie zawsze są wykorzystywane przez użytkowników. Często są one również zintegrowane z systemem operacyjnym np. Windows, czy oprogramowaniem użytkowym, np. Microsoft Office. Integracja ta pozwala na szybką i wygodną pracę osób tworzących treść.
Obecnie wśród systemów zarządzania treścią wykształciły się dwa trendy technologiczne: systemy oparte na J2EE [27] oraz platforma .NET [23]. Wspólną cechą obu technologii jest intensywne wykorzystanie XML jako formy opisu danych. Daje to ogromne możliwości jeśli chodzi o indeksowanie treści oraz prezentowanie ich za pomocą różnych mediów. Drugą cechą wspólną jest duży nacisk na integrację z innymi systemami. Są to zarówno nowe systemy jak i już wdrożone systemy klasy enterprise (tzw. legacy systems).
2.3. Istniejące systemy CMS
W rozdziale tym przedstawione są ogólnie kategorie istniejących produktów do zarządzania treścią ([4], [5], [6], [7], [8], [9]).
2.3.1. Duże systemy
Jest to kategoria największych i najdroższych systemów. Często koszty licencji na produkty do zarządzania treścią to kilkaset tysięcy dolarów. Jednak funkcjonalność tych systemów jest bardzo duża. Zwykle jest to podstawowy serwer do zarządzania treścią oraz szereg specjalistycznych dodatkowych aplikacji służących do integracji z innymi systemami (Vignette Enterprise Connectors, seria Content Services for ... firmy Documentum), personalizacji serwisów (Vignette Dialog, Broadvision Command Center [19]), czy serwowania danych poprzez różne media (BroadVision Multi-Touchpoint Services, Documentum Content Rendition Services).
Podstawowe funkcje takich systemów obejmują obieg dokumentów, autoryzację i autentykację, statystyki i inne.
Wraz z produktem oferowane są szkolenia, dokumentacja i metodologia związana z tworzeniem, utrzymywaniem i administracją portalem.
Do tej kategorii zalicza się produkty firm Broadvision, Vignette, Documentum, Interwoven [18] i FileNet Corp.
2.3.2. Średnie systemy
Systemy w tej grupie to tańsze i uboższe w funkcje aplikacje, pozwalające na budowanie i zarządzanie serwisami. Zwykle wraz ze spadkiem ceny klient otrzymuje uboższe usługi pomocy technicznej. Systemy takie mają dość ograniczone możliwości integracji z innymi systemami, np. z bazami danych. Często też produkty w tej grupie nie są skalowalne zarówno z punktu widzenia mocy obliczeniowej całego systemu, jak i jego przyszłego rozwoju.
Systemy tego typu warto wziąć pod uwagę w następujących sytuacjach:
· interesuje nas prosty serwis o podstawowych funkcjach,
· chcemy stworzyć intranet pełniący funkcję bazy wiedzy, bez integracji z wewnętrznymi systemami w firmie,
· budujemy system, wobec którego nie mamy planów rozwoju,
· nie mamy budżetu, który by pozwalał na zakup systemu z p. 2.3.1.
Do tej grupy zaliczamy produkty firm RedDot [16], NetObjects [26], Microsoft Content Management Server [24].
2.3.3. Systemy z grupy wolnego oprogramowania
Wśród produktów z grupy wolnego oprogramowania (ang. open source) w dziedzinie systemów zarządzania treścią nie ma dużego wyboru. Są to systemy, które dostarczają podstawowe funkcje, mają małe możliwości integracji, nie mówiąc o braku wsparcia dla obiegu dokumentów. Technologie w jakich są one tworzone to Python, PHP, czy Perl ([40], [41], [42]). Wyjątkiem jest tu Cofax stworzony w technologii Java [11].
Najbardziej zaawansowanym technologicznie systemem wydaje się być Zope [10]. Posiada on dobre mechanizmy kontroli dostępu, wersjonowania dokumentów, indeksowania treści oraz administrowania poprzez strony WWW. Za tym systemem przemawia również jego dojrzałość (jest rozwijany od kilka lat) i duża grupa programistów skupionych wokół tego projektu. Wadą Zope jest to, że został on stworzony w Pythonie, co może ograniczać zastosowanie tego rozwiązania w dużych projektach, gdzie ważnymi atutami są możliwości integracji, skalowalność, a przede wszystkim technologia, która pozwala na dobre projektowanie, zarządzanie kodem, utrzymanie systemu oraz posiada odpowiednie narzędzia do tworzenia kodu i projektowania (np. Java, .NET). Ponadto dla Zope stworzono wewnętrzny język skryptowy DTML (ang. Document Template Markup Language), który nie ma zastosowania poza tym systemem.
Przykłady systemów zarządzania treścią w tej kategorii to Zope, OpenCMS [12], Midgard [25], Cofax.
3. Prezentacja systemu efinityXML
3.1. System CMS
System efinityXML jest systemem typu CMS. Jego cechą wyróżniającą jest to, że działa na zasadzie przetwarzania dokumentów XML przy użyciu arkuszy styli – XSL. W dokumentach rozdzielona została treść od wyglądu dzięki czemu można tworzyć różne wzorce dla różnych grup użytkowników, czy też dla różnych mediów przekazu. I tak możliwe jest na bazie jednego repozytorium tworzenie jednocześnie wielu wersji naszego portalu: dla przeglądarek internetowych, w wersji WAP, czy też do druku (np. w formacie PDF).
System efinityXML dostarcza szereg funkcji, które umożliwiają wygodne i efektywne tworzenie treści i zarządzanie systemami informacyjnymi. Cała obsługa systemu odbywa się poprzez przeglądarkę WWW, bez konieczności instalacji dodatkowego oprogramowania. Prostota obsługi, wbudowany edytor wizualny (ang. WYSYWIG od What You See Is What You Get) oraz mechanizmy wzorców pozwalają na redagowanie treści użytkownikom biznesowym, którzy nie mają nic wspólnego z informatyką.
Ogarnięcie procesu powstawania treści w dużych korporacjach bywa trudne, a często niemożliwe bez specjalnych procedur i narzędzi. Dzięki zintegrowanemu obiegowi dokumentów efinityXML jest w stanie sprostać potrzebom dużych grup użytkowników zarządzających serwisami. Daje możliwość dokładnego określenia procesu życia każdego nowego dokumentu, procedur jakie muszą zostać przeprowadzone i trybu jego akceptacji przed opublikowaniem. O zleceniu akceptacji można powiadamiać osoby zainteresowane pocztą elektroniczną lub za pomocą krótkiej wiadomości SMS – dzięki tym mechanizmom czas całego procesu jest skrócony do minimum.
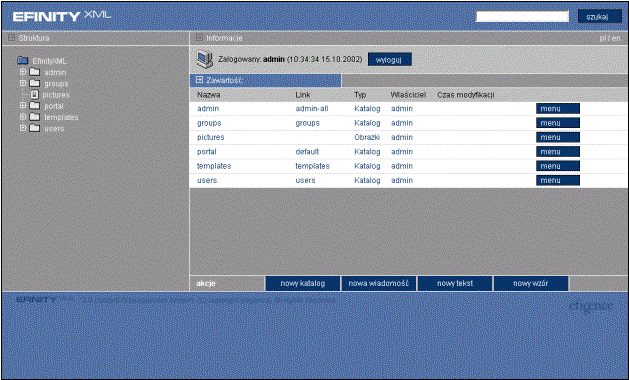
Na etapie wdrożenia efinityXML dostarcza szereg narzędzi ułatwiających i skracających jego czas, a końcowym użytkownikom udostępnia jednolity sposób zarządzania różnymi elementami portalu. efinityXML stanowi zestaw modułów funkcjonalnych (komponentów), które służą do zbudowania serwisu, oraz aplikację, przy użyciu której administratorzy będą zarządzać treścią. Każda aplikacja zbudowana przy użyciu efinityXML posiada architekturę wielowarstwową, dzięki której uporządkowane są funkcje związane z różnymi poziomami dostępu do zasobów systemu, danych i innych systemów (por. Rys. 3‑1).

Rys. 3‑1 Architektura rozwiązania opartego na systemie efinityXML
W dalszych punktach rozdziału opisane są najważniejsze cechy systemu.
3.2. Użytkownicy
System zapewnia możliwość definiowania użytkowników i grup, do których należą. Każdej z grup można przydzielać prawa dostępu do dowolnych zasobów systemu. Może to być na przykład prawo odczytu, czy zmiany dokumentu, ale również prawo oglądania statystyk lub historii dokumentów.
Zdefiniowanie grup biznesowych w portalu umożliwi użytkownikom dostęp do określonych zasobów i funkcji systemu. Przykładem jest portal informacyjny w firmie. Grupa użytkowników „Dział marketingu” może dodawać i edytować materiały z kategorii „Marketing i sprzedaż”, natomiast użytkownicy z grupy „Handlowcy” mają wgląd do tych materiałów.
3.3. Dokumenty
Dokumenty w systemie są przechowywane podobnie jak pliki na dysku – w strukturze drzewiastej. efinityXML posiada szereg wbudowanych rodzajów dokumentów, które można dołączać do serwisów: wiadomość, najczęściej zadawane pytania (ang. FAQ), forum dyskusyjne, plik, tablica ogłoszeń. Każdy z dokumentów posiada szereg pól: z danymi oraz metadanymi (dane informacyjne, np. słowa kluczowe, opis, data publikacji itp.), które można edytować.
|
Rys. 3‑2 Ekran edycji dokumentu typu Wiadomość |
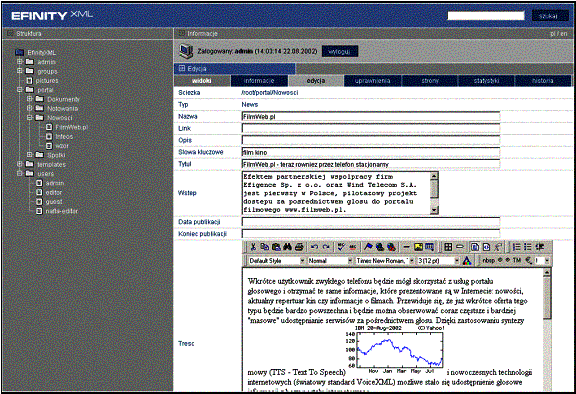 Intuicyjny
edytor wizualny pozwala na edycję dokumentów osobom nie znającym języka HTML.
Ponadto system jest zintegrowany z aplikacjami biurowymi takimi jak Microsoft
Word, dzięki czemu możliwe jest przenoszenie dokumentów wraz z formatowaniem
(por. Rys. 3‑2).
Intuicyjny
edytor wizualny pozwala na edycję dokumentów osobom nie znającym języka HTML.
Ponadto system jest zintegrowany z aplikacjami biurowymi takimi jak Microsoft
Word, dzięki czemu możliwe jest przenoszenie dokumentów wraz z formatowaniem
(por. Rys. 3‑2).
3.4. Historia dokumentu i wartości domyślne
Z każdym dokumentem w systemie związane są dodatkowe funkcje – historia oraz statystyki. Dzięki statystykom można dokładnie śledzić operacje wykonywane na dokumencie (edycja, oglądanie dokumentu, oglądanie jego historii). System umożliwia dowolne filtrowanie i sortowanie wpisów w raportach statystycznych.
Historia każdego dokumentu jest pamiętana w systemie, każdy kto posiada odpowiednie uprawnienia może oglądać poprzednie wersje, a w razie potrzeby może przywrócić wcześniejszą postać dokumentu.
Wzorce to specjalne dokumenty, nadające domyślne wartości nowym obiektom dodawanym do tego samego katalogu, w którym się znajdują. Dzięki wzorcom można w dokładny sposób opisywać lub narzucać użytkownikom sposób inicjowania nowych dokumentów. Definiowanie wzorców w istotny sposób wpływa na szybkość tworzenia treści.
3.5. Grafika
Pliki graficzne przechowywane są w repozytoriach. Są to zbiory, które podlegają takim samym regułom jak inne dokumenty w systemie. Obrazki z repozytoriów dostępne są bezpośrednio do umieszczenia w edytorze wizualnym, dzięki czemu użytkownicy w szybki sposób mogą tworzyć dokumenty zawierające grafikę.
3.6. Wyszukiwarka
Wbudowany system wyszukiwawczy indeksuje każdy dokument w momencie jego zapisywania. Na sposób indeksowania dokumentu oprócz treści wpływają również metainformacje, takie jak słowa kluczowe czy też opis.
3.7. Wersje językowe
efinityXML posiada dwujęzyczny interfejs użytkownika – polski oraz angielski. W prosty sposób można również stworzyć dowolne nowe wersje językowe. Dzięki technologii Java jest możliwe przechowywanie danych w różnych formatach kodowania znaków diakrytycznych.
3.8. Obieg dokumentów
Do organizacji procesu tworzenia treści służy system obiegu dokumentów. Proces taki jest podzielony na etapy. Każdy dokument aby mógł zostać opublikowany musi przejść cały proces akceptacji, w którym odpowiednie grupy użytkowników muszą aprobować jego treść. Każdy z uczestników, którzy biorą udział w tworzeniu dokumentu, może być automatycznie powiadamiany o jego stanie, zarówno pocztą elektroniczną, jak i krótką wiadomością tekstową SMS. Pozwala to na sprawne i zgodne z wewnętrznymi procedurami w przedsiębiorstwie zorganizowanie całego procesu tworzenia nowych dokumentów.
3.9. Technologia
efinityXML jest aplikacją stworzoną w technologii J2EE (Java 2 Enterprise Edition). Wykorzystuje zarówno serwer internetowy (tzw. servlet container), jak i serwer aplikacji Enterprise Java Beans. Zastosowanie tych technologii zapewnia transakcyjność systemu, jego skalowalność i wysoki poziom bezawaryjności. Również istotny jest fakt, że obecnie wiele systemów informatycznych w przedsiębiorstwach (tzw. systemy klasy enterprise) tworzonych jest w tej technologii. Daje to duże możliwości integracji z tymi systemami oraz świadczy o dojrzałości technologii Java.
efinityXML jest systemem stworzonym zgodnie z ogólnie dostępną specyfikacją Java 2 Enterprise Edition przygotowaną przez konsorcjum firm (m.in. SUN, IBM, BEA). Pozwala to na dowolny wybór serwera aplikacji, jak również bazy danych do przechowywania relacyjnych danych. Do tej pory system został przetestowany w dwóch konfiguracjach:
· serwer aplikacji JBoss 3.0 i baza danych PostgreSQL 7.2 ([30], [15]),
· serwer aplikacji BEA Weblogic 7.0 oraz baza danych Oracle 8.0 ([22], [13]).
Możliwe jest oczywiście uruchomienie efinityXML w innych konfiguracjach oprogramowania.
Technologia Java zapewnia również niezależność od platformy systemowej (możliwość uruchomienia w systemie Linux, Solaris, Windows 2000/NT). efinityXML przetestowano dla platformy Linux Red Hat (wersje od 6.0 wzwyż) oraz Windows 2000.
3.10. Wydajność
EfinityXML charakteryzuje się dużą wydajnością jak na systemy przetwarzające dokumenty XML – dzięki wykorzystaniu metody SAX (ang. Simple API for XML). Jako bazowe rozwiązanie do obsługi plików XML wykorzystano system Cocoon 2.0 – uznane na świecie rozwiązanie dostępne na licencji wolnego oprogramowania.
Ponadto gdy system będzie obsługiwał duże liczby użytkowników należy rozważyć konfigurację klastrową. Zapewnia to dużą skalowalność oraz niezawodność rozwiązania (ang. scalability and failover).
3.11. Integracja
Obecne wdrożenia nowoczesnych systemów informatycznych często wymagają integracji z wieloma innymi systemami wewnątrz przedsiębiorstwa. Jest to ważne wymaganie, które dobrze zrealizowane decyduje o funkcjonalności i wymiernych korzyściach z instalacji takiego systemu. efinityXML z racji technologii, w jakiej został stworzony, dostarcza wiele argumentów, które mają znaczenie przy podejmowaniu decyzji o jego zastosowaniu we wdrożeniu. Z jednej strony jest to popularność Javy jako platformy do realizacji systemów dla biznesu, z drugiej jest to szeroka gama specyfikacji i technologii pozwalających na różnego typu integrowanie danych i procesów z innymi systemami. Ponadto istotna jest również dojrzałość i mnogość gotowych rozwiązań firm trzecich pozwalających na szybkie zrealizowanie zamierzonych celów w postaci integracji systemów.
O popularności Javy świadczą na przykład badania, które zostały przeprowadzone wśród australijskich firm. Wynika z nich, że 71% firm albo już wdrożyło, albo jest w trakcie wdrożenia systemów opartych na Javie. Innym znamiennym faktem są decyzje twórców największych systemów informatycznych dla biznesu o migracji lub tworzeniu nowych wersji swojego oprogramowania na platformę Java. Wśród takich firm jest SAP, Oracle, IBM, Sun i inne.
Jest wiele technik integracji efinityXML z istniejącymi systemami. Może to być integracja za pomocą WebServices – ostatnio bardzo głośnej technologii promowanej przez Microsoft, IBM, BEA, Sun i inne korporacje, opartej na wywoływaniu zdalnie metod przy użyciu protokołu HTTP w formacie XML. Inną możliwością jest zastosowanie technologii JCA (Java Connector Architecture [27]) z założenia służącej do integracji danych pomiędzy różnymi systemami. W grę wchodzą również bardziej niskopoziomowe techniki, takie jak JMS (Java Messaging Service) czy JDBC.
Istnieje również szereg gotowych rozwiązań sprzedawanych przez specjalizujących się w tym dostawców. Są to na przykład konektory do systemów Siebel, SAP, Baan, czy też aplikacje pozwalające na dostęp do danych i serwisów takich produktów jak Lotus Domino czy Microsoft Exchange. Systemy te dostarczają dane lub interfejsy do procesów i metod w jednym ze standardów (np. JCA lub jako API w Javie).
3.12. Architektura
System został napisany w technologii J2EE, przy wykorzystaniu specyfikacji Enterprise Java Beans. Wszystkie moduły odpowiedzialne za poszczególne funkcje systemu napisane są jako komponenty sesji (ang. session bean). Są to:
· moduł operacji na drzewie portalu – oferuje wszystkie usługi związane z podstawowymi operacjami na drzewie, np. odczyt potomków węzła, trawersowanie drzewa itp.;
· moduł bezpieczeństwa – implementuje wszystkie funkcje autoryzacji i autentykacji. Moduł ten umożliwia nadawanie i odbieranie uprawnień, pobieranie danych z uwzględnieniem praw dostępu itp.;
· moduł wyszukiwania i indeksowania – odpowiada za odpowiednie indeksowanie węzłów w drzewie oraz oferuje usługi wyszukiwania;
· moduł generowania wyglądu – tutaj zaimplementowane są wszystkie algorytmy wyznaczające odpowiednie strony do pokazania zadanych węzłów oraz budujące stronę z portletów;
· moduł historii – udostępnia usługi pobierania poprzednich wersji zadanego węzła, ich przywracania i zapamiętywania;
· moduł edycji danych – tu zaimplementowane są funkcje związane z tworzeniem, edycją i usuwaniem danych. Funkcje takie jak edytuj, czy usuń realizują kolejno wszystkie niezbędne operacje, które należy wykonać aby edytować dane (np. dla edycji: zablokuj węzeł, sprawdź czy nie nastąpiło naruszenie zasad współużytkowania, zmień węzeł, zapisz zdarzenie w dzienniku zdarzeń itp);
· moduł zdarzeń – udostępnia wszystkie funkcje związane z dziennikami zdarzeń;
· moduł poczty – udostępnia wszystkie funkcje związane z wysyłaniem poczty;
· moduł sesji – zaimplementowane tu są funkcje sesji użytkownika i przechowywania danych trwałych, czyli takich, które można odczytać, gdy użytkownik będzie ponownie korzystał z systemu;
· moduł obiegu dokumentów – udostępnia wszystkie funkcje obiegu dokumentów;
· moduł szybkiego odczytu danych – tutaj zaimplementowano funkcje szybkiego pobierania danych tylko do odczytu (por. p. 4.2.4);
· moduł wzorców – udostępnia usługi związane z nadawaniem predefiniowanych wartości polom węzłów w drzewie portalu.
3.13. Proces wdrożenia systemu
Proces konstrukcji systemu budowanego na bazie efinityXML może składać się z następujacych etapów: analizy i specyfikacji wymagań, projektowania, implementacji, testowania, instalacji i pielęgnacji. W rozdziale tym opiszę etap analizy i specyfikacji wymagań, gdyż jest on ważnym elementem wdrożenia takiego systemu.
Na etapie analizy określa się sposób zastosowania systemu do rozwiązania, na co składają się: wybranie elementów systemu, które zostaną zastosowane w projekcie, zmiany których należy dokonać w istniejących typach dokumentów, oraz funkcje serwisu, które muszą zostać zaimplementowane.
Etap analizy jest podzielony na kilka części:
· określenie grup użytkowników systemu,
· określenie ogólnych wymagań funkcjonalnych systemu w kontekście poszczególnych grup użytkowników,
· określenie architektury informacyjnej systemu,
· zdefiniowanie struktury logicznej rozwiązania,
· zdefiniowanie struktury fizycznej rozwiązania.
Podczas dwóch pierwszych części ustala się zakres funkcjonalny systemu oraz grupy użytkowników wraz z ich reprezentantami. Ważnym etapem jest określenie architektury informacyjnej wdrażanego serwisu, czyli typów dokumentów, struktury serwisu i nawigacji w systemie.
Określenie typów dokumentów polega na wymienieniu wszystkich niezbędnych rodzajów węzłów jakie mogą się znajdować w drzewie portalu, jak np. wiadomość, kategoria portalu, najczęściej zadawane pytania, ankieta itp. Następnie każdy z tych elementów powinien zostać dokładnie opisany: jakie pola będzie zawierał oraz jakie będzie ich znaczenie.
Opracowanie struktury serwisu to opisanie i narysowanie mapy serwisu wraz z dokładnym wskazaniem gdzie będą pojawiały się poszczególne typy dokumentów i które pola będą wyświetlane. W dokumencie z analizą w części dotyczącej architektury informacyjnej powinny również znaleźć się opisy funkcji i reakcji systemu na różne akcje użytkownika, np. sposób oddawania głosów w ankiecie, sposób dodawania nowych wiadomości itp.
Trzecim elementem opracowania architektury informacyjnej jest stworzenie ogólnego planu poszczególnych stron oraz opracowanie nawigacji. Na tym etapie faktycznie wszystkie strony powinny zostać podzielone na portlety (por. p. 4.1.1).
W dalszej części analizy określa się strukturę logiczną rozwiązania, która w każdym wdrożeniu może mieć podobny kształt ze względu na zastosowanie efinityXML oraz technologii J2EE.
Na koniec analizy określa się architekturę fizyczną rozwiązania, czyli liczbę i rodzaj serwerów, serwery i sprzęt zewnętrzny (zewnętrzne źródła danych) oraz sposób instalacji oprogramowania serwerowego.
4. Wybrane rozwiązania
4.1. Generowanie stron
Zwykle strony w portalach są złożone. Na jednej stronie znajduje się szereg informacji, które pochodzą z różnych źródeł, dotyczą różnej tematyki, udostępniają użytkownikowi różne funkcje. Takie różne fragmenty stron często powtarzają się na wielu stronach portalu. Są to na przykład menu główne, różnego rodzaju skróty wiadomości, pole logowania użytkowników itp.
Ponadto w stosunku do portalu należałoby również oczekiwać, że można będzie w prosty sposób zmieniać wygląd elementów strony pełniących te same funkcje. Wymaganie to dotyczy zarówno możliwości zmian wyglądu stron WWW, jak i zmian wyglądu dla stron WAP. Chodzi o to, by można było raz wprowadzoną do systemu treść prezentować zarówno na ekranie monitora przez przeglądarkę WWW, jak i na ekranie telefonu komórkowego wyposażonego w przeglądarkę WAP.
4.1.1. Konstrukcja strony
W efinityXML rozdzielono wygląd od treści, czego efektem jest to, że w systemie mamy pojęcie węzła w drzewie portalu (danych) oraz strony (wyglądu). Węzeł w drzewie portalu to zarówno dowolny dokument, jak i katalog. Aby konkretny węzeł mógł zostać zaprezentowany użytkownikowi, niezbędne jest użycie do tego strony.
W celu zoptymalizowania stron – zarówno procesu ich powstawania, jak i korzystania z nich – wprowadzone zostało pojęcie portletu. Portlet jest to taki wycinek strony, który posiada określoną funkcjonalność, wygląd (lub kilka wyglądów) i może być umieszczany na różnych stronach portalu.
Przykład
Mamy portlet, który nazwijmy „menu”. Jego zadaniem jest wyświetlanie kategorii w menu. Jeśli taki portlet jest wyświetlany na stronie, która obrazuje dokument w jakiejś kategorii, to powinien on rozwinąć bieżącą kategorię, czyli wyświetlić również wszystkie podkategorie.
Pojęcie portletu wprowadzili twórcy projektu JetSpeed [37]. Również oni dostarczyli pierwszą specyfikację portletu. Tę specyfikację zmodyfikowali następnie specjaliści z największych firm zajmujących się językiem Java. W dalszej kolejności zdefiniowano interfejsy portletów – Java Portlet API [38]. W efinityXML portlet nie jest zgodny z Java Portlet API, jednak jego funkcjonalność jest podobna.
Dla lepszego zrozumienia procesu generowania stron opiszmy sposób budowania strony.
System aby wyświetlić dany dokument pobiera odpowiednią stronę. Każda strona składa się z kilku portletów. Jeden z tych portletów powinien wygenerować fragment strony HTML z wiadomością, a inne powinny wygenerować stałe fragmenty strony, które zawsze będą takie same, niezależnie od tego jaką wiadomość będziemy wyświetlać. Mogą to być na przykład:
· portlet menu główne – wyświetla menu główne, z rozwiniętą tą kategorią, w której znajduje się bieżący dokument,
· portlet menu globalne – wyświetla zawsze takie samo menu globalne. W tym menu znajdują się stałe elementy, takie jak kontakt, mapa serwisu, szukaj.
Kolejno każdy z portletów generuje fragmenty strony, które następnie połączone dają w efekcie całą stronę, która prezentuje wiadomość w portalu (por. Rys. 4‑1).
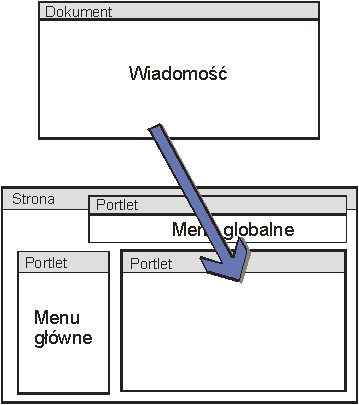
Rys. 4‑1 Budowa strony portalu
Możemy więc do jednej wiadomości przypisać szereg stron, z których każda w inny sposób będzie prezentowała treść: jedna w formie strony HTML, inna w fromacie PDF, a jeszcze inna jako stronę WAP.
Można uzależnić sposób wyboru jednej ze stron od różnych czynników. Na przykład strona HTML będzie wyświetlana domyślnie, jeśli zaś w adresie internetowym pojawi się parametr o nazwie format o wartości pdf, to zostanie wybrana wersja strony generująca odpowiedni dokument dla programu Acrobat Reader.
4.2. Wydajność
efinityXML jest systemem, za pomocą którego można budować duże serwisy, które są odwiedzane przez wielu użytkowników jednocześnie. Z tego powodu przy jego tworzeniu położono nacisk na wydajność i skalowalność.
4.2.1. Przetwarzanie XML-a
Na wydajność systemu istotny wpływ miało zastosowanie interfejsów SAX [43] do przetwarzania dokumentów XML. Ten sposób przetwarzania polega na tym, że podczas parsowania dokumentu wywoływane są zdarzenia odpowiadające typowi elementu, który został rozpoznany. W odróżnieniu od metody DOM, informacje o dokumencie nie są przechowywane w pamięci komputera w postaci specjalnych struktur danych. Powoduje to oszczędność zasobów systemu i pozwala na pracę z dokumentami wielokrotnie większymi niż pamięć potrzebna do przechowania tych dokumentów.
Zastosowanie narzędzia Cocoon 2 umożliwiło takie właśnie procesowanie dokumentów XML.
4.2.2. Konfiguracja wielu serwerów
Często duże serwisy internetowe mają tylu odwiedzających, że nawet bardzo dobry serwer nie jest w stanie obsłużyć wszystkich użytkowników. Wtedy istotnym w wyborze rozwiązania do budowy portalu jest fakt, że zastosowane narzędzie może być konfigurowane i uruchamiane na wielu współpracujących serwerach jednocześnie (ang. clustering).
efinityXML jest programem, który może być uruchomiony w konfiguracji klastrów dzięki zastosowaniu odpowiedniej architektury oraz zastosowaniu do jego budowy technologii J2EE.
Serwery J2EE, takie jak np. JBoss 3, mogą być konfigurowane do pracy w klastrach (por. Rys. 4‑2). Wtedy pomiędzy klientem a serwerem generującym stronę znajduje się pośredni serwer HTTP, który odpowiada za zlecenie zadania jednemu z serwerów aplikacji. Ponadto jeśli serwer aplikacji umożliwia replikację sesji użytkownika, to można tak skonfigurować system, aby osiągnąć dużą niezawodność. Gdyby jeden z serwerów aplikacji nie mógł wygenerować odpowiedzi (z powodu błędu, niedostępności itp.), drugi mógłby przejąć jego zadania.
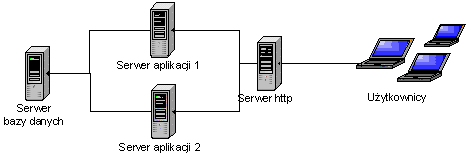
Rys. 4‑2 Konfiguracja serwerów w klastrze
4.2.3. Prawa dostępu
W efinityXML prawa dostępu określane są dla grup użytkowników i są dziedziczone w drzewie portalu. Gdy użytkownik wykonuje jakiekolwiek operacje na elementach drzewa portalu, za każdym razem sprawdzane są uprawnienia. Aby wyznaczyć rzeczywiste uprawnienia, system musi wykonać szereg operacji pobrania pewnych danych z bazy danych, takich jak grupy, do których należy użytkownik, czy uprawnienia nadrzędnych węzłów. Operacje te są niezwykle kosztowne i mogą negatywnie wpływać na wydajność systemu. Dlatego w efinityXML wszystkie rzeczywiste uprawnienia do węzłów wyznaczane są w momencie nadawania praw, a odpowiednio konstruowane zapytania do bazy danych uwzględniają mechanizmy praw dostępu tak, by nigdy pobieranie danych z bazy nie wymagało wykonywania dodatkowych operacji.
4.2.4. Dane tylko do odczytu
efinityXML jest programem napisanym zgodnie ze specyfikacją J2EE. Intensywnie wykorzystuje mechanizmy komponentów danych (ang. entity bean) oraz sesji (ang. session bean). Jednak często komponenty danych uważane są za elementy powodujące duże opóźnienia w systemie. Ich sposób funkcjonowania może powodować, że pobieranie jednocześnie dużych ilości danych w jednym zapytaniu może trwać bardzo długo (nawet kilka, kilkanaście sekund). Taka sytuacja jest niedopuszczalna w przypadku generowania stron internetowych. Aby temu zapobiec, w efinityXML dane tylko do odczytu pobiera się bezpośrednio z bazy danych (oczywiście z uwzględnieniem uprawnień). Nie powoduje to dodatkowych komplikacji przy transakcjach, gdyż dane te nie są modyfikowane, a w istotny sposób wpływa na szybkość działania systemu.
4.2.5. Kolejki komunikatów
W przypadku wielu operacji wykonywanych w systemie ich efekt nie musi być znany od razu. Często można zlecić systemowi pewne zadania i nie oczekiwać na ich realizację. W efinityXML wiele z zadań zlecane jest przy użyciu kolejki komunikatów JMS (ang. Java Messaging System), dzięki temu serwer jest w stanie szybko przekazać użytkownikowi odpowiedź, a pozostałe zadania wykonać później. Dzieje się tak w przypadku rejestrowania zdarzeń w dzienniku zdarzeń, wysyłania wiadomości pocztą elektroniczną, indeksowania węzłów, czy wysyłania powiadomień krótką wiadomością tekstową SMS.
5. Zastosowane technologie
W rozdziale opisano technologie i programy, które zastosowano do realizacji systemu efinityXML. Niektóre programy, jak na przykład serwer aplikacji JBoss, mogą zostać zastąpione produktami innych firm, np. komercyjnym serwerem IBM WebSphere albo BEA Weblogic.
System zarządzania treścią efinityXML został stworzony w technologii Java 2 Enterprise Edition (w skrócie J2EE). Każda aplikacja zgodna z tą specyfikacją powinna posiadać trójwarstwową architekturę. Najwyższy poziom to warstwa interfejsu użytkownika. Może ona obejmować komunikację za pomocą przeglądarki WWW lub też aplikacji napisanej w Javie. W pierwszym przypadku strony internetowe powstają przy użyciu technologii serwletów, JSP lub podobnej. Drugi przypadek wymaga zastosowania bibliotek SWING, AWT lub SWT.
Warstwa pośrednia to poziom, na którym dokonywane są wszystkie biznesowe operacje na danych. Zwykle niezbędna jest wtedy transakcyjność systemu. Tę warstwę realizują moduły Enterprise Java Beans – komponenty, które są instalowane na serwerze aplikacji.
Najniższa warstwa to warstwa danych, czyli całe oprogramowanie związane z przechowywaniem danych (np. relacyjne bazy danych, obiektowe bazy danych czy bazy XML-owe) oraz pobieraniem, zapisywaniem i reprezentacją tych danych w środowisku języka Java.
5.1. Baza danych
Jako repozytorium danych relacyjnych wykorzystano transakcyjną bazę danych PostgreSQL. Baza ta posiada bardzo dużą funkcjonalność, jest bardzo stabilna i wydajna. W większości przypadków zastosowań jest to rozwiązanie najkorzystniejsze ze względu na ekonomię rozwiązania.
Dzięki zastosowaniu narzędzi do generowania klas reprezentujących dane możliwe jest zastosowanie dowolnej innej bazy danych (por. p. 5.2.3), np. IBM DB2, Oracle 8i/9i. System został przetestowany również z bazą danych Oracle 8i.
5.2. Wykorzystane oprogramowanie w języku Java
5.2.1. Serwer aplikacji
Niezbędnym elementem w przypadku wdrożenia aplikacji w technologii J2EE jest serwer aplikacji. Jest to oprogramowanie, które dostarcza szereg funkcji związanych z administracją, utrzymaniem i działaniem aplikacji J2EE. Serwer aplikacji niezależnie od platformy, na jakiej jest instalowany oraz firmy, która tworzyła ten serwer zawsze udostępnia aplikacjom takie samo środowisko – sposób połączeń z innymi systemami, buforowanie zasobów systemowych, wykorzystanie kolejek komunikatów. Dzięki temu możliwe jest stworzenie aplikacji, która może być uruchomiona na serwerach aplikacji różnych producentów.
efinityXML został przetestowany na serwerach aplikacji JBoss 2.4, JBoss 3.0 oraz BEA Weblogic 6.0.
5.2.2. Przetwarzanie XML-a – Cocoon
System efinityXML został zaimplementowany przy użyciu Cocoon 2.0 [29] –oprogramowania do tworzenia aplikacji po stronie serwera opartych na przetwarzaniu plików XML.
Cocoon jest określany jako tzw. szkielet do budowy systemów publikacyjnych, czyli zestaw programów i modułów oraz skojarzona z nimi metodyka i filozofia, które zapewniają programiście możliwość szybkiego tworzenia zaawansowanych aplikacji. W Cocoonie XML jest przetwarzany metodą SAX, co zapewnia bardzo dużą wydajność i elastyczność tworzonych rozwiązań. Ponadto Cocoon posiada scentralizowany system konfiguracji i zarządzania, który pomaga w tworzeniu skomplikowanych aplikacji po stronie serwera.
5.2.3. Odwzorowanie danych relacyjnych na obiektowe
Problem w języku angielskim jest opisywany terminem O/R mapping, co jest skrótem od Object Relational Data Mapping, czyli odwzorowywania danych relacyjnych na obiektowe. Gdy tworzymy aplikacje w technologii J2EE, dane, na których operujemy, są udostępniane jako obiekty, ale przechowywane w bazach danych jako relacyjne dane. Takie podejście z jednej strony zapewnia dużą wydajność rozwiązania ze względu na dojrzałość relacyjnych baz danych, a z drugiej zapewnia odpowiedni formalizm i łatwość operowania na danych w obiektowym języku Java. Problem w tym, że gdy zastosujemy taką architekturę, to potrzebujemy metod, które będą tłumaczyły te dane, czyli będą odpowiedzialne za inicjowanie obiektów reprezentujących dane, zapisywanie zmienionych danych do bazy, tworzenie i usuwanie. Trzeba to zrealizować w taki sposób, aby programista nie zajmował się jednocześnie oprogramowywaniem odwzorowania i metodami biznesowymi aplikacji.
Aby ułatwić tworzenie aplikacji operujących na danych z bazy danych stworzono narzędzia służące do automatyzowania procesów i metod związanych z odwzorowaniem danych z bazy danych na obiekty. Rozwiązania te można podzielić na dwie grupy w zależności od sposobu realizacji.
Pierwsza z nich to rozwiązania oparte na dynamicznym tworzeniu, podczas wykonywania kodu programu, skojarzeń pomiędzy właściwościami obiektu (czyli jego zmiennymi) z kolumnami w tabelach. Klasy, które reprezentują dane, nie mają żadnych metod, które służą do odwzorowania. Wszystkie zapytania i polecenia do bazy danych tworzone są na zewnątrz – przez oprogramowanie narzędziowe, podczas wykonywania kodu. Do tego celu służy zestaw interfejsów z pakietu java.lang.reflect.* [39].
Zastosowanie tych rozwiązań powoduje, że stworzone aplikacje charakteryzują się dużą przejrzystością pisanego kodu – obiekty nie zawierają metod odpowiedzialnych za administrację danymi. Obiekty i metody z pakietu java.lang.reflect.* są niestety wolne, co powoduje, że przetwarzanie dużych ilości danych jest bardzo uciążliwe i obniża wydajność całego rozwiązania. Do tej grupy zaliczamy rozwiązania takie jak Castor, JBoss CMP, Hibernate, CocoBase ([31], [36], [32], [35]).
Druga grupa to rozwiązania oparte na generowaniu kodu. Narzędzia takie na podstawie specyficznych plików konfiguracyjnych lub znaczników w kodzie (komentarze JavaDoc) generują kod, który będzie odpowiedzialny za pobieranie, zapisywanie, usuwanie i dodawanie danych do bazy danych. Te rozwiązania charakteryzują się lepszą wydajnością. Jednak posiadają one również wady – przede wszystkim kod źródłowy jest długi i nieczytelny. Poza tym często też narzędzia do generowania kodu utrudniają zmiany w oprogramowaniu. Raz wygenerowany kod jest później zmieniany przez programistów co uniemożliwia ponowne generowanie kodu, gdy zachodzą zmiany w definicjach danych.
W tej grupie są produkty firm MVCSoft, XDoclet, Cocobase ([33], [34], [35] – produkt ten zarówno ma możliwości generowania kodu, jak i działa jako narzędzie odwzorowujące na bieżąco).
Do odwzorowywania danych w efinityXML użyto narzędzia Persistence Generator. Jest to oprogramowanie, które generuje kod metod zajmujących się pośrednictwem pomiędzy bazą danych a obiektami Javy. Zaletą tego rozwiązania jest jego duża wydajność oraz możliwość ponownego generowania, które zachowa wszystkie zmiany dokonane w kodzie klasy.
Persistence Generator umożliwia:
· generowanie klas, które są odwzorowywane jednocześnie na wiele tabel,
· obsługę tzw. klas zależnych. Zawsze gdy wykonywane są jakieś operacje na obiekcie, te same operacje są również wykonywane na obiektach zależnych,
· obsługę kolekcji,
· odwzorowanie relacji 1 do 1, 1 do wielu.
Zaletą tego rozwiązania jest to, że bazuje ono na przetwarzaniu plików XML. Opis struktury danych (klasy oraz struktury bazy danych) znajduje się w pliku XML, a generowanie kodu źródłowego polega na przetwarzaniu XML-a przez arkusze styli XSL. Definicje arkuszy styli znajdują się w oddzielnym pliku. Jeśli zachodzi potrzeba zmiany bazy danych, a co za tym idzie sposobu operowania na danych z bazy danych (specyficzne instrukcje SQL, np. do generowania automatycznych kluczy głównych), to wystarczy podmienić plik arkusza stylu lub zmodyfikować go, a następnie wygenerować ponownie kod metod służących do odwzorowania.
6. Interfejs użytkownika
6.1. Logowanie
Aby uprawniony użytkownik (również Administrator) mógł administrować systemem, czyli edytować dokumenty, parametry systemu, czy użytkowników, musi posiadać konto w systemie wraz z odpowiednimi uprawnieniami zezwalającymi na edycję określonych dokumentów.
Aplikacja administracyjna jest dostępna na tym samym serwerze, na którym zainstalowano portal. W celu autoryzacji i rozpoczęcia administracji trzeba przejść na stronę logowania o adresie postaci:
http://{adres_serwera}/{kontekst}/admin,
czyli na przykład:
http://www.firmax.pl/efinity/admin (por. Rys. 6‑1)
|
Rys. 6‑1 Ekran logowania |
Należy podać identyfikator użytkownika oraz hasło, a następnie kliknąć na przycisk zaloguj. Pokaże się wówczas główny ekran administracyjny wraz z drzewem dokumentów obejmującym część serwisu, do której prawo edycji ma zalogowany użytkownik.
6.2. Nawigacja
Główny ekran administracyjny (por. Rys. 6‑2) podzielony jest na kilka części – portletów (por. p. 4.1), z których każdy posiada swoje funkcje w procesie administracji.
|
Rys. 6‑2 Główny ekran administracyjny |
Portlet to obiekt, który można skojarzyć z krótkim programem, który w
odpowiedni sposób pobierze z systemu i przetworzy potrzebne nam dane, a
następnie zaprezentuje je na ekranie. Portlet w połączeniu z arkuszem styli jest widoczny dla
użytkownika jako prostokątny obszar na stronie.
6.2.1. Drzewo dokumentów
Po lewej stronie znajduje się struktura informacyjna portalu, jak i danych dodatkowych, np. grup użytkowników, użytkowników itp. (por. Rys. 6‑3). Poszczególne katalogi w drzewie odpowiadają kategoriom w portalu.
Naciśnięcie na znak plus w drzewie dokumentów spowoduje rozwinięcie katalogu, przy którym znajdował się znak oraz przejście do tego katalogu. Wtedy na ekranie edycyjnym pojawi się lista dokumentów i katalogów.
Naciśnięcie na nazwę elementu w drzewie dokumentów (element w drzewie dokumentów nazywamy węzłem) powoduje dwie różne akcje w zależności od rodzaju węzła na jaki kliknięto. Jeśli był to katalog, to na ekranie edycyjnym pokaże się jego zawartość.
|
Rys. 6‑3 Drzewo dokumentów portalu |
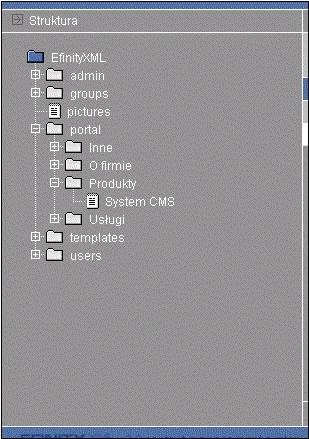
Jeśli natomiast klikniętym elementem był inny dokument, to na ekranie edycyjnym
wyświetlone zostaną informacje o węźle (por. p. 6.3).
6.2.2. Ekran edycyjny
Jest to pole, w którym pojawiają się – w zależności od wybranej funkcji – najważniejsze dane, informacje lub kontrolki do edycji danych. Na przykład jeśli edytujemy dokument typu nowość, to na ekranie edycyjnym pokażą się pola, w których można edytować: tytuł, wstęp, datę publikacji, treść nowości, słowa kluczowe, nazwę dokumentu i inne. Jeśli przeglądamy katalog, to pojawią się tam wszystkie dokumenty umieszczone w bieżącym katalogu wraz z podstawowymi informacjami.
menu kontekstowe – dotyczy ono funkcji, jakie wykonuje się na dokumentach, np. edycja, edycja uprawnień, usuwanie itp. Jeśli jesteśmy w trakcie wykonywania jakiejś operacji na dokumencie, to najważniejsze funkcje są widoczne w pasku pomiędzy informacją o zalogowanym użytkowniku a ekranem edycyjnym (por. rys. 6‑4). Gdy użytkownik jest w trakcie przeglądania zawartości katalogu, to menu kontekstowe dla danego dokumentu znajduje się po prawej stronie (por. Rys. 6‑5).
![]()
rys. 6‑4 Menu kontekstowe podczas operacji na dokumencie

Rys. 6‑5 Menu kontekstowe podczas przeglądania zawartości katalogu
menu narzędziowe – znajdują się tu funkcje dodatkowe, które dotyczą obecnie wyświetlanych na ekranie edycyjnym treści. Dla ekranu z listą dokumentów w bieżącym katalogu (por. Rys. 6‑6) będą to funkcje tworzące nowe dokumenty, a dla edycji dokumentu są to funkcje zapisz i anuluj.
![]()
Rys. 6‑6 Menu narzędziowe
6.2.3. Informacje o zalogowanym użytkowniku
|
Rys. 6‑7 Portlet z informacjami o użytkowniku |

W tym polu znajdują się podstawowe informacje o zalogowanym użytkowniku, czasie
ostatniego logowania oraz funkcja wyloguj (por. Rys. 6‑7). Z funkcji wyloguj
należy skorzystać pod koniec pracy, lecz jeśli użytkownik będzie nieaktywny
przez 30 min (czas ten może być dowolnie konfigurowany), to zostanie
automatycznie wylogowany.
6.2.4. System wyszukiwania
W prawym górnym rogu ekranu zawsze znajduje się pole wyszukiwania (por. Rys. 6‑8) które umożliwia przeszukanie portalu według specjalnych, administracyjnych kryteriów. Dla administratorów dokumenty i katalogi indeksowane są nie tylko standardowo po ich treści, ale również brane pod uwagę są metainformacje, na przykład nazwa dokumentu i opis. Wynik wyszukiwania pokazywany jest jako nazwa dokumentu, jego opis oraz wartość procentowa obrazująca dopasowanie dokumentu do szukanej frazy. Użytkownik po wybraniu spośród wyników wyszukiwania dowolnego dokumentu lub katalogu zostanie przeniesiony na stronę z informacjami o wybranym węźle (por. p. 6.4.1).
|
Rys. 6‑8 Pole wyszukiwania |
6.2.5.

Wersja językowa
Jest to funkcja pozwalająca na zmianę wersji językowej interfejsu użytkownika (por. Rys. 6‑9). Obecnie dostępna jest wersja polska i angielska. Na etapie wdrożenia sytemu możliwe jest stworzenie dowolnych nowych wersji, bowiem wszystkie komunikaty systemu są zdefiniowane w oddzielnych plikach.
|
Rys. 6‑9 Przełącznik wersji językowej |
6.3.

Drzewo dokumentów
Jest to struktura reprezentująca zarówno architekturę informacyjną portalu, jak i inne dodatkowe informacje. Wygląd takiego drzewa zależny jest od tego w jaki sposób zaimplementowane zostaną funkcje portalu oraz jaka będzie jego architektura.
W drzewie takim znajduje się również szereg elementów stałych, występujących w każdym wdrożeniu. Są to: katalog z użytkownikami – users, miejsce gdzie umieszczone są wszystkie konta użytkowników; grupy – groups, tutaj są wszystkie grupy użytkowników; katalog admin – struktura portalu, reprezentująca aplikację administracyjną.
Nie zawsze jednak całe drzewo dokumentów jest widoczne dla użytkowników. To, które katalogi i dokumenty pojawią się w drzewie, zależne jest od aktualnych praw dostępu, jakie posiada zalogowany użytkownik. Zalecane jest, aby udostępniać osobie zarządzającej portalem tylko te elementy, którymi powinna administrować. Dobrym pomysłem jest tworzenie grup użytkowników edytorzy kategorii X, edytorzy kategorii Y, administratorzy użytkowników itp. Dzięki temu unika się przypadkowych ingerencji w dane, którymi użytkownik nie powinien się zajmować.
Przykład:
W serwisie korporacyjnym firmy X, na pierwszej stronie znajdują się następujące elementy:
· lista kategorii – o firmie, produkty, usługi, kontakt,
· nowości – skrót ostatnich 5 wiadomości; subskrypcja nowości i pole wyszukiwania.
Powyższa struktura może zostać odwzorowana na drzewo, które w węźle portal będzie miało katalogi: o firmie, produkty, usługi, kontakt i nowości. Dokumenty znajdujące się w pierwszych czterech katalogach wyświetlane będą po wejściu w odpowiadające im kategorie w portalu, a dokumenty zawarte w katalogu nowości wyświetlane będą w formie skróconej na pierwszej stronie. Wybranie dowolnej z nowości z pierwszej strony spowoduje pokazanie pełnej treści nowości.
6.4. Właściwości dokumentów
Każdy dokument w efinityXML posiada szereg cech, które mogą być oglądane lub edytowane. Są to między innymi informacje o dokumencie, jego treść, uprawnienia, czy opis sposobu wizualizacji. Dane te przedstawia się w grupach, dla każdej z grup istnieje odpowiednia pozycja w menu kontekstowym. W dalszej części tego punktu opisane są wszystkie takie zakładki.
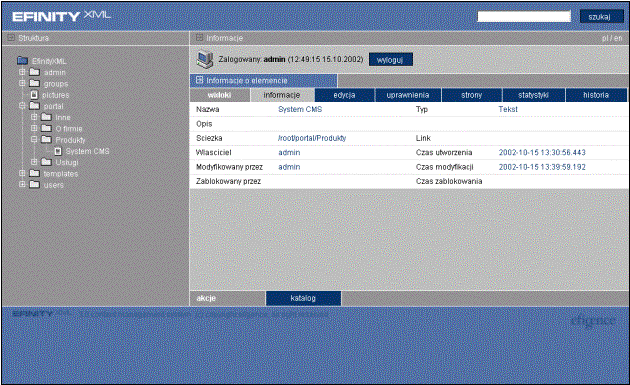
6.4.1. Informacje o dokumencie
Znajdują się tu podstawowe informacje o dokumencie, takie jak nazwa, opis, ścieżka, czas stworzenia oraz nazwa użytkownika, który stworzył dokument, czas modyfikacji oraz nazwa użytkownika, który ostatnio zmodyfikował dokument, informacje o ewentualnej blokadzie dokumentu do edycji (por. Rys. 6‑10).
6.4.2.
Edycja dokumentów
|
Rys. 6‑10 Ekran z informacjami o dokumencie |
Aby móc edytować dokument, trzeba z menu kontekstowego wybrać pozycję edycja.
Uwaga! Niektóre z węzłów w drzewie portalu nie mają możliwości edycji (np. korzeń drzewa, albo dokumenty typu strona, portlet por. p. 6.6) – w takim przypadku w menu kontekstowym nie ma tej opcji.
Blokowanie
efinityXML w trakcie edytowania dowolnego dokumentu blokuje go w taki sposób, że każdy użytkownik inny niż edytujący nie będzie miał możliwości wprowadzania zmian. Konieczność odblokowania dokumentu może zajść wtedy, gdy na przykład jeden z edytorów rozpoczął zmiany dokumentu, ale nie zakończył ich zapisaniem lub anulowaniem. Do usunięcia blokady służy funkcja odblokuj w menu kontekstowym.
Informacje o aktualnym stanie edycji można znaleźć we właściwościach „Informacje o dokumencie” (por. p. 6.4.1). Jest tam informacja o edytującym użytkowniku i czasie zablokowania do edycji. Pozycja Zablokowany przez informuje o tym, który użytkownik zablokował dokument, a pozycja Czas zablokowania informuje o tym, kiedy blokada nastąpiła.
W menu kontekstowym dokumentów, które można edytować (np. wiadomość, tekst, najczęściej zadawane pytania – por. p. 6.6) znajdują się funkcje: zablokuj i odblokuj. Służą one do wykonywania następujących:
zablokuj – powoduje zablokowanie dokumentu do edycji bez przejścia do ekranu edycyjnego.
odblokuj – odblokowuje dokument. Wykonanie tej funkcji powoduje, że ktokolwiek był w trakcie edytowania tego dokumentu nie będzie miał możliwości zapisania wprowadzonych zmian. Dlatego też należy ją stosować z rozwagą.
Edytowanie treści dokumentu
Każdy rodzaj dokumentu w systemie posiada pola, z opisem cech dokumentu oraz pola z treścią (por. Rys. 6‑12).
|
Rys. 6‑11 Menu narzędziowe dokumentu |
![]()
Każdorazowo po zmianie lub dodaniu dokumentu należy do zapisania zmian użyć
przycisku zapisz w menu narzędziowym (por. Rys. 6‑11). Jeśli jednak rezygnujemy z wprowadzonych zmian, to
trzeba użyć przycisku anuluj, który spowoduje, że edytowany
przez nas dokument zostanie odblokowany.
UWAGA! Należy pamiętać o tym, aby odblokować dokument po edycji (czyli użyć zapisz lub też anuluj). Pomoże to uniknąć sytuacji, gdy wiele dokumentów w systemie jest pozornie edytowanych, a użytkownicy mają kłopot z rozróżnieniem, który z zablokowanych dokumentów rzeczywiście jest edytowany.
|
Rys. 6‑12 Edycja dokumentu typu wiadomość |
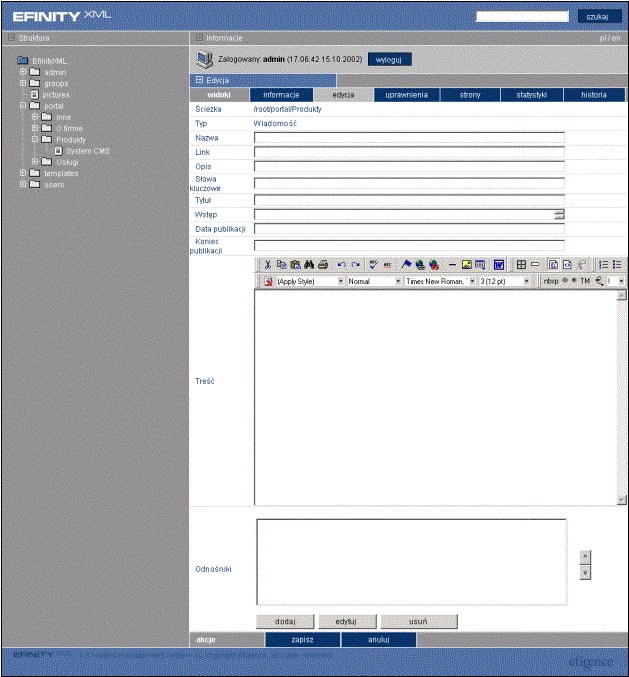
Każdy dokument posiada pola, które są charakterystyczne dla jego typu (część z
pól jest wspólna dla wszystkich dokumentów). Oto przykładowe pola dokumentu
Wiadomość:
nazwa – jest to nazwa dokumentu, która pojawi się w aplikacji administracyjnej (w drzewie dokumentów lub na liście dokumentów w katalogu) oraz jako nazwa dokumentu w wynikach wyszukiwania.
opis – krótki opis zawartości dokumentu.
skrót (ang. link) – pole, którego wartością jest ciąg znaków identyfikujący dokument w systemie. Jeśli użytkownik użyje tego ciągu w adresie internetowym (np. http://www.efinity.com/efinity/{skrot}), to system wyświetli odpowiedni dokument używając domyślnego wyglądu.
słowa kluczowe – jest to pole, w którym powinny znaleźć się oddzielone spacjami słowa charakteryzujące tematykę dokumentu. Podczas wyszukiwania portalu najwyższy priorytet posiadają informacje zawarte w tym polu (por. p. 6.4.8).
data publikacji – określa termin pojawienia się wiadomości w portalu. Pole to pozwala na redagowanie dokumentów przed czasem ich publikacji, np. w tygodniu można wprowadzić nowe wiadomości, które pojawią się w weekend.
tytuł, wstęp, treść – pola, które określają treść wiadomości. W zależności od miejsca pokazywania wiadomości pojawiać się będą wartości różnych pól, np. tytuł i wstęp pojawią się na pierwszej stronie jako zapowiedź, a tytuł i treść znajdą się z całą wiadomością.
dowiązania – lista dowiązań do innych dokumentów w portalu. Do wiadomości można przypisać listę innych dowolnych dokumentów, do których pod treścią wiadomości pojawią się dowiązania.
Edycja pól typu html
Z efinityXML zintegrowano wizualny edytor do edycji kodu w języku HTML – eWebEditPro 3.0. Działa on w oknie przeglądarki. Jest to narzędzie, dzięki któremu możliwe jest tworzenie treści bez znajomości znaczników języka HTML. Użytkownicy mogą umieszczać w tekście, w dowolny sposób, obrazki z repozytoriów danych, tabelki, zmieniać styl czcionki, jej charakter. eWebEditPro pozwala na kopiowanie tekstu z innych programów (np. Microsoft Word, Microsoft Excel) z zachowaniem formatowania przenoszonej treści.
Korzystanie z tego edytora jest bardzo proste, pojawia się on jako jedno z pól do edycji w dokumencie. Wystarczy zmienić treść tekstu, nadać mu odpowiednie formatowanie i ewentualnie dodać obrazki, tabele. Zapamiętanie zmian nastąpi wraz z zapisaniem całego dokumentu.
6.4.3. Uprawnienia
Każdy dokument, katalog, czy też obiekt, który znajduje się w portalu podlega systemowi uprawnień. Dostęp do dowolnego węzła jest określany na podstawie praw przypisanych do węzła i do jego węzłów macierzystych (katalogi, w których znajduje się dokument) oraz na podstawie grup, do których należy bieżący użytkownik.
System uprawnień opiera się na kilku pojęciach, które warto na początku wyjaśnić.
Typ uprawnienia – określa rodzaj czynności jaką można wykonywać na węźle. Przykładem typu uprawnienia może być możliwość czytania dokumentu, zmiany dokumentu, udostępniania uprawnień do dokumentu innym użytkownikom, czy oglądania statystyk.
Tryb nadania uprawnienia – określa czy dany typ uprawnienia nadajemy czy też odbieramy. Wartości trybu to nadaj lub zabroń. Stan pośredni, czyli taki, gdy węzeł nie ma nadanego uprawnienia ani w trybie nadaj, ani zabroń, oznacza, że nie ma uprawnienia do tego węzła.
Uprawnienie – jest to typ uprawnienia do węzła w drzewie (dokumentu lub katalogu) wraz z trybem, czyli określeniem czy dane prawo zostało nadane, czy zabronione.
Przykład:
Jeśli do dokumentu przypiszemy typ uprawnienia odczyt w trybie zabroń dla grupy goście, to będzie to oznaczać, że wskazani użytkownicy nie będą mieli możliwości oglądania tego dokumentu.
efinityXML posiada system uprawnień, które są dziedziczone w drzewie portalu. Oznacza to, że jeśli jakieś uprawnienie jest nadane katalogowi, to również wszystkie elementy, które znajdą się poniżej tego katalogu (w nim albo w katalogach, które znajdują się w bieżącym katalogu) też będą miały nadane to prawo, o ile nie mają inaczej zdefiniowanych praw tego typu.
Dzięki powyższemu mechanizmowi nie trzeba każdemu dokumentowi w portalu
oddzielnie nadawać uprawnień. Nowo dodane węzły będą posiadały takie sama prawa
dostępu jak katalog, w którym zostały stworzone.
Przykład:
|
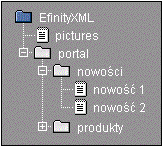
Rys. 6‑13 Przykładowe drzewo portalu |
Jeśli drzewo portalu jest zdefiniowane jak na Rys. 6‑13 i dla katalogu portal jedynym prawem jakie zdefiniowano jest prawo odczytu dla grupy goście, to oznacza to, że każdy użytkownik, który należy do grupy goście będzie miał dostęp do katalogu portal oraz wszystkich dokumentów położonych poniżej.
Jednak jeśli dla katalogu nowości nadamy prawo odczytu w trybie zabroń dla grupy goście, to użytkownicy z grupy goście nie będą mieli możliwości odczytu ani katalogu nowości, ani żadnych dokumentów w tym katalogu.
Uprawnienia w efinityXML nadawane są grupom użytkowników. Aby użytkownik miał jakiekolwiek uprawnienia do węzłów, musi należeć do grupy, która te uprawnienia ma nadane. Użytkownik może należeć do dowolnej liczby grup. Jeśli jednak zdarzy się tak, że użytkownik należy do dwóch grup, z których jedna ma uprawnienie czytania w trybie nadaj, a druga w trybie zabroń, to o faktycznym uprawnieniu zadecyduje ich kolejność na liście ACL węzła.
W efinityXML istnieje dwóch specjalnych użytkowników. Pierwszy to administrator – posiada wszystkie prawa do wszystkich elementów w systemie, niezależnie od praw nadanych węzłom. Drugi to guest (gość) – użytkownik, za którego jest brany każdy kto nie jest zalogowany do systemu. Aby określić dostęp do zasobów portalu dla zwykłych odwiedzających, należy nadać uprawnienia użytkownikowi gość.
Dodatkowo bardzo ważne jest, aby użytkownik miał pełne prawa (administracyjne) do dokumentów, które stworzył. W przypadku właściciela pliku nie mają znaczenia żadne uprawnienia przypisane do dokumentu.
W systemie typy uprawnień są predefiniowane i mogą to być:
READ_NODE – możliwość oglądania zawartości dokumentu,
WRITE_NODE – możliwość zapisywania zmian w dokumencie,
CREATE_NODE – zwykle nadawane węzłom, w których umieszczane są inne węzły (np. katalog). Określa czy można w bieżącym węźle tworzyć węzły-dzieci,
ALLOW_DENY – możliwość nadawania i odbierania uprawnień innym użytkownikom,
VIEW_STATS – możliwość oglądania statystyk węzła,
HISTORY_PREVIEW – możliwość oglądania historii dokumentów,
HISTORY_RESTORE – możliwość przywracania poprzednich wersji dokumentu.
Wyświetlanie bieżących uprawnień
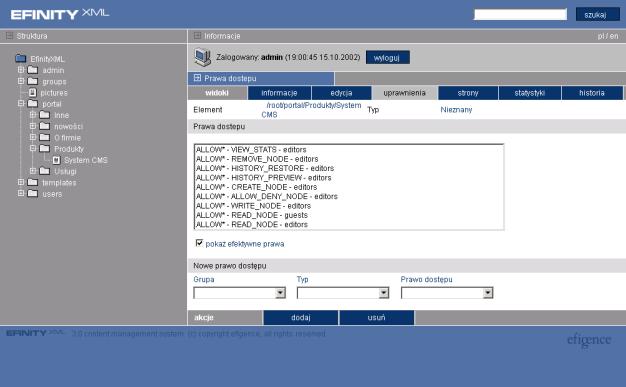
Wybranie funkcji uprawnienia z menu kontekstowego spowoduje wyświetlenie na ekranie listy z wszystkimi prawami dostępu do dokumentu (por. Rys. 6‑14).
Rys. 6‑14 Ekran z uprawnieniami do dokumentu
Na liście „Prawa dostępu” znajdują się informacje o prawach dostępu.
Pojedyncza pozycja ma postać
{tryb_nadania_uprawn.}‑{typ_uprawnienia}‑{nazwa_grupy}.
Przykładowo pozycja ALLOW – VIEW_STATS – editors oznacza, że przypisano w trybie nadaj uprawnienie VIEW_STATS grupie użytkowników editors.
Prawa te wyświetlone są w kolejności ich priorytetów. Oznacza to, że prawo, które znajduje się na liście wyżej posiada wyższy priorytet i w przypadku gdy nadane prawa będą kolidować ze sobą, to ono właśnie zadecyduje o uprawnieniu.
Przykład:
Jeśli bieżący użytkownik należy do grup „goście” i „edytorzy”, a dokumentowi nadano prawa w następującej kolejności:
· prawo odczytu dla grupy „edytorzy” w trybie nadaj,
· prawo odczytu dla grupy „goście” w trybie zabroń,
to będzie on mógł odczytać ten dokument. Dzieje się tak dlatego, że prawo odczytu w trybie nadaj ma większy priorytet niż „zabronienie” tego samego typu prawa.
Dodatkowo pole Efektywne prawa dostępu umożliwia podejrzenie efektywnych praw dostępu do danego węzła. Ustawienie tej flagi spowoduje, że pokazane zostaną prawa jakie będzie miał dokument po uwzględnieniu jego położenia w drzewie portalu oraz praw wszystkich katalogów nadrzędnych, w których się znajduje. Ułatwia to szybkie znajdowanie problemów na jakie mogą natrafić administratorzy podczas zarządzania dokumentami. Uprawnienia, które są dziedziczone, czyli nadane zostały katalogom położonym wyżej w hierarchii drzewa, wyświetlane są z gwiazdką. Przykładowo może to być wpis postaci „ALLOW * - VIEW_STATS – editors”.
|
Rys. 6‑15 Okno dodawania nowego prawa dostępu |

Dodawanie uprawnień
Poniżej okna z bieżącymi prawami dokumentu znajduje się okno Nowe prawo dostępu (por. rys. 6-15). Są tu: lista grup, lista z trybami uprawnień oraz lista typów uprawnień. Aby dodać nowe prawo, należy z każdej z list wybrać odpowiednią pozycję, a następnie kliknąć Dodaj. Nowe uprawnienie zostanie dodane na końcu listy uprawnień.
UWAGA! Dla dowolnego węzła w drzewie niemożliwe jest dodanie tego samego uprawnienia dla tej samej grupy dwa razy, nawet jeśli dodawane uprawnienia są w różnym trybie. Oznacza to, że jeśli na liście już nadanych uprawnień znajduje się pozycja zawierająca taką samą grupę oraz taki sam typ uprawnienia jak nowo dodawany, to operacja dodania uprawnienia będzie niemożliwa.
6.4.4. Strony
Filozofia tworzenia portalu w efinityXML opiera się na oddzieleniu treści od wyglądu. Dlatego też administrator edytując dokumenty zmienia ich treść. Aby taki dokument można było pokazać w portalu, należy przypisać do niego jeden z dostępnych wyglądów. Takie wyglądy w efinityXML nazywają się stronami. Oczywiście do jednego dokumentu można przypisywać różne strony, dzięki czemu ten sam dokument w zależności od różnych warunków, np. format przekazu (PDF, HTML, WAP), może zostać pokazany w inny sposób.
Dokładny opis sposobu generowania stron oraz ich konstrukcji znajduje się w p. 4.1.
Format wyświetlania dokumentu podczas generowania strony zależy od kilku czynników. Po pierwsze ma na to wpływ parametr o nazwie format w adresie internetowym dokumentu. Jeśli dany dokument dostępny jest pod adresem:
http://www.firmax.com/efinity/nowosc1
to po dodaniu parametru format o odpowiedniej wartości:
http://www.firmax.com/efinity/nowosc1?format=pdf
przekazany zostanie dokument po wizualizacji za pomocą strony, która określona
jest dla formatu PDF.
Po drugie podczas wdrożenia efinityXML można tak skonfigurować system, aby niektóre formaty były przekazywane zawsze, gdy zostaną spełnione specjalne warunki, np. strona oglądana będzie przez przeglądarka WAP. Można też tak skonfigurować serwer, aby dane z portalu były serwowane na dwóch portach: 80 – serwowanie formatów HTML, PDF; 8888 – serwowanie jedynie formatu WAP.
W efinityXML liczba formatów jest nieograniczona. W trakcie wdrożenia systemu, na etapie analizy określa się sposoby i formaty prezentowania danych w portalu. Później administratorzy mogą przyporządkowywać te formaty do danych (dokumentów).
Administracja stronami dla dokumentu
|
Rys. 6‑16 Ekran edycji stron dla dokumentu |
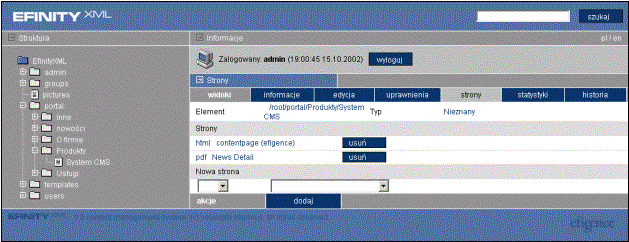
[MC1]Aby obejrzeć strony służące do wizualizacji
bieżącego dokumentu, należy przejść do funkcji Strony w
menu kontekstowym (por. Rys.
6‑16).
Na ekranie edycyjnym pojawią się informacje związane z prezentowaniem dokumentu w portalu. W sekcji Strony znajduje się lista wszystkich stron udostępnionych dla bieżącego dokumentu: najpierw jest podany format (np. „html”, „pdf”), a później nazwa strony. Jeśli na liście znajduje się wiele par, które mają ten sam format, to bieżący dokument będzie wyświetlany zgodnie z którymś z tych opisów, przy czym wybór jest losowy.
Przy każdej parze znajduje się przycisk usuń, który umożliwia usunięcie tej pary.
W sekcji Nowa strona znajdują się listy, które pozwalają na przypisanie nowych stron do bieżącego dokumentu. Po wybraniu odpowiedniego formatu oraz strony, która ma prezentować dokument, należy wybrać przycisk dodaj z menu narzędziowego.
Jeśli nie wybierze się żadnego z formatów, to zostanie dodana strona w formacie html.
6.4.5. Statystyki
efinityXML rejestruje wszystkie zdarzenia jakie zachodzą w systemie. Zachowywane informacje to czas zdarzenia, jego rodzaj oraz dane użytkownika, który je wywołał.
Oto zdarzenia jakie mogą zajść w systemie:
VIEW NODE – wyświetlenie dokumentu,
EDIT NODE – edycja obiektu,
SAVE NODE – zapisanie dokumentu,
LOGIN – zalogowanie użytkownika (zdarzenie zachodzące tylko dla obiektu typu Użytkownik),
LOGIN FAILED – wylogowanie użytkownika (zdarzenie zachodzące tylko dla obiektu typu Użytkownik),
VIEW NODE HISTORY – obejrzenie historii dokumentu,
RESTORE NODE HISTORY – przywrócenie poprzedniej wersji dokumentu,
LOCK NODE – zablokowanie dokumentu do edycji. To zdarzenie jest rejestrowane jedynie wtedy, gdy obiekt został zablokowany za pomocą funkcji Zablokuj dostępnej z menu kontekstowego,
UNLOCK NODE – odblokowanie dokumentu zablokowanego do edycji. To zdarzenie jest rejestrowane jedynie wtedy, gdy obiekt został zablokowany za pomocą funkcji Zablokuj dostępnej z menu kontekstowego,
CREATE NODE – stworzenie dokumentu.
Oglądanie statystyk
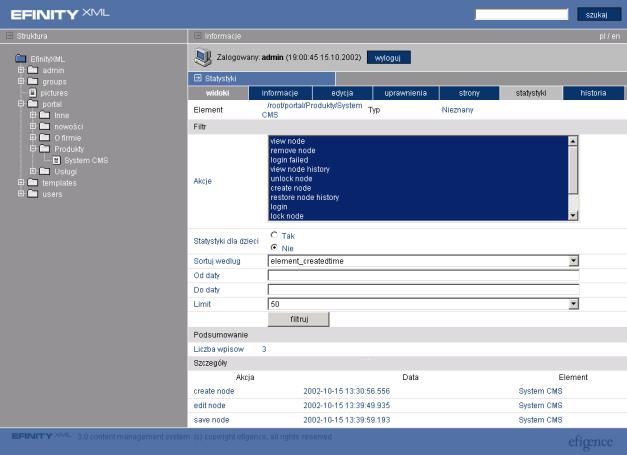
Aby przejść do statystyk dokumentów, należy wybrać z menu kontekstowego pozycję Statystyki (por. Rys. 6‑17).
Rys. 6‑17 Ekran statystyk dokumentu
Ekran edycyjny podzielony jest na dwie części. Górna dotyczy preferencji wyświetlania dokładnych statystyk oraz filtrów, a dolna to lista wpisów w dzienniku systemowym.
Poszczególne pozycje części do filtrowania to:
Akcje – zaznaczając poszczególne zdarzenia z listy możemy udostępniać tylko określone akcje.
Statystyki dla potomków – jeśli zaznaczymy tę pozycję, to będą pokazywane wpisy z dziennika bieżącego węzła oraz wszystkich innych węzłów, które znajdują się poniżej (dla katalogów pokazywane są wszystkie statystyki zawartych w nich dokumentów).
Sortuj według – umożliwia określenie sposobu sortowania poszczególnych pozycji w dzienniku.
Od daty, Do daty – wpisując daty w formacie „hh:mm dd-MM-yyyy” można ograniczyć zakres wyświetlanych statystyk.
Limit – określa liczbę wpisów pokazywanych na jednej stronie.
Aby zmienić filtrowanie wpisów w dzienniku, należy wybrać odpowiednie wartości wymienionych opcji i kliknąć przycisk filtruj. Wtedy lista wpisów w sekcji szczegóły zostanie zmieniona.
|
Rys. 6‑18 Ekran z historią dokumentu |
6.4.6. Historia

Aby usprawnić proces zarządzania życiem dokumentów niezbędne jest pamiętanie
ich poprzednich wersji. efinityXML automatycznie pamięta każdą wersję
dokumentów określonych typów, np. wiadomości, tekstu itp. (historia dla
katalogów nie jest rejestrowana – nie ma to sensu, gdyż zapamiętywane byłyby
jedynie nazwy katalogu). Ponadto nie zawsze pamiętane są również wszystkie pola
dokumentu. W przypadku wiadomości są to jedynie pola tytuł, wstęp, treść, data
publikacji i data końca publikacji.
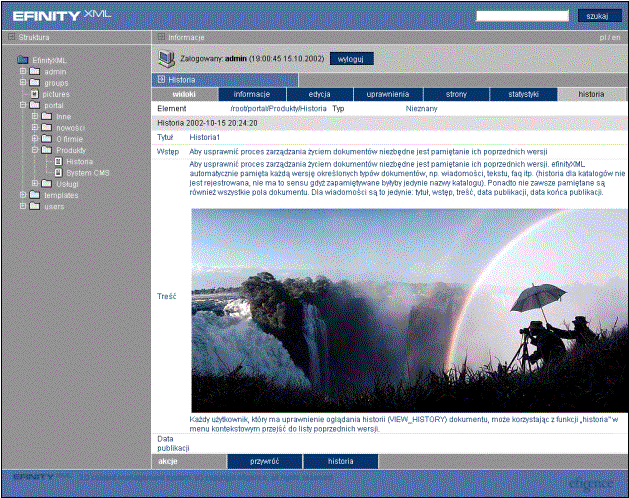
Każdy użytkownik, który ma uprawnienie do oglądania historii (uprawnienie
VIEW_HISTORY) dokumentu, może korzystając z funkcji Historia w
menu kontekstowym przejść do listy poprzednich wersji (por. Rys. 6‑18).
|
Rys. 6‑19 Ekran podglądu poprzedniej wersji dokumentu |
Lista poprzednich wersji (por. Rys. 6‑19) zawiera datę modyfikacji, nazwę użytkownika, który jej dokonał oraz przycisk przywróć. Wybór tego przycisku powoduje przywrócenie odpowiadającej mu wersji dokumentu. Gdy użytkownik wybierze pozycję z listy, pokazany zostanie ekran z podglądem poprzedniej wersji dokumentu.
W menu narzędziowym pozycje oznaczają kolejno: przywróć – przywraca bieżącą wersję dokumentu, historia – powrót do listy wszystkich wersji dokumentu.
6.4.7. Wzorce
Wzorce to specjalne dokumenty, które można umieszczać w dowolnym miejscu w strukturze drzewa portalu. Są to szablony do tworzenia nowych dokumentów.
efinityXML udostępnia różne typy wzorców, które określają wartości różnych właściwości nowych dokumentów. Na przykład dokument typu Wzór stron będzie określał strony, za pomocą których będą pokazywane nowe dokumenty.
Przykład:
Mamy następujące drzewo:
Rys. 6‑20 Przykładowe drzewo portalu
Jeśli w katalogu nowości umieścimy wzór stron, który nazwiemy wzór stron nowości i edytując go ustalimy stronę [html – strona nowości], to dla każdej nowo utworzonej wiadomości w katalogu nowości lub w katalogach, które znajdują się w nim, stroną ją wyświetlającą będzie [html – strona nowości].
Sposób przyporządkowywania wartości do nowo tworzonych dokumentów jest ściśle określony. Najpierw tworzona jest lista wszystkich wzorców, które mają być zaaplikowane do dokumentu. Są to wszystkie wzorce, które znajdują się kolejno w coraz wyższych katalogach od miejsca położenia dokumentu do korzenia drzewa portalu (nazwanego efinityXML). Następnie wzorce z listy są aplikowane do dokumentu w odwrotnej kolejności. W efekcie jeśli dany wzorzec zdefiniowany był bliżej tworzonego dokumentu w hierarchii drzewa portalu, to ma większy priorytet i zasłania ustawienia wzorców umieszczonych powyżej.
6.4.8. Wyszukiwanie
efinityXML ma wbudowany system indeksujący i wyszukiwania. Każdy dokument w portalu w momencie stworzenia lub zapisu nowej wersji jest odpowiednio indeksowany. Istnieją dwa indeksy dokumentów dla każdej instalacji efinityXML – pierwszy to indeks użytkowników, a drugi to indeks administracyjny.
Każdy z tych indeksów bierze pod uwagę różne pola w dokumencie. Indeks dla użytkowników przede wszystkim agreguje dane z pól słowa kluczowe oraz pól z treścią dokumentu. Indeks administracyjny agreguje słowa z tych pól co indeks użytkowników, ale również z pól Nazwa, Opis, Dowiązanie. Dodatkowo ten drugi indeksuje również obiekty takie jak Użytkownicy i Grupy użytkowników, które są pomijane przez indeks użytkowników.
Indeks administracyjny jako pełniejszy (bierze pod uwagę również metainformacje) służy do przeszukiwania zasobów przez użytkowników w aplikacji administracyjnej, drugi zaś służy do wyszukiwania przez zwykłych gości portalu.
6.4.9. Wersje językowe
Interfejs użytkownika aplikacji administracyjnej może mieć różne wersje językowe. Obecnie zaimplementowane są dwie wersje, polska i angielska. Ponieważ mechanizm wersji językowych korzysta z technologii I18N zaimplementowej w Javie (wszystkie komunikaty danych zapisane są w oddzielnym pliku), więc w bardzo prosty i szybki sposób można stworzyć dowolną nową wersję językową.
Jeśli do tego zaimplementowane zostaną nowe typy dokumentów z wersjami językowymi, to cały portal – część dla użytkowników oraz aplikacja administracyjna –, będą wielojęzycznym systemem, który może uwzględniać językowe preferencje użytkownika.
Wersję językową strony do wyświetlenia wybiera się zgodnie z następującymi algorytmami:
· jeśli w adresie (URL) znajdował się parametr locale, to odpowiednia wersja językowa jest ustawiana, ale tylko do wyświetlenia bieżącej strony;
· jeśli użytkownik korzystał już z efinityXML przy użyciu bieżącej przeglądarki (ciasteczko identyfikujące sesję przeglądarki już zostało utworzone), to wybranym językiem będzie ten, który był ostatnio używany w tej przeglądarce;
· jeśli użytkownik właśnie się zalogował, to:
o jeśli jest to pierwsze logowanie i dla użytkownika jest zdefiniowana wersja językowa, to wybierz ją,
o jeśli jest to pierwsze zalogowanie i dla użytkownika nie jest zdefiniowana wersja językowa, to sprawdź kolejno dla wszystkich grup, do których należy użytkownik, czy jest zdefiniowana preferowana wersja językowa. Jeśli tak, to ją wybierz, wpp wybierz standardową wersję językową dla efinityXML,
o jeśli nie jest to pierwsze zalogowanie, to użyj wersji językowej, która była poprzednio używana przez tego użytkownika.
![]()
Zmian wersji językowej można dokonywać za pomocą dowiązań w aplikacji
administracyjnej znajdujących się w prawej części paska tytułowego portletu z
informacją o zalogowanym użytkowniku (por. Rys.
6‑21).
Rys. 6‑21 Przełącznik wersji językowej |
6.4.10. Zarządzanie grafiką
W systemie efinityXML znajdują się repozytoria plików, które mogą służyć zarówno jako magazyny dla plików graficznych używanych później w treści dokumentów, jak i plików do ściągnięcia przez użytkowników. Większość uprawnień dotyczy tak samo repozytoriów plików, jak i innych węzłów, z tym że wszelkie uprawnienia obowiązują jednocześnie dla całej grupy plików. Ponadto odczyt tych plików zawsze jest możliwy przez wszystkich.
Zwykle, jeśli podczas wdrożenia nie wyspecyfikuje się inaczej, pliki są dostępne pod adresem internetowym takim jak nazwa repozytorium. Jeśli repozytorium nazywa się gfx, to wszystkie pliki z tego repozytorium pobiera się w następujący sposób: http://www.firmax.com/efinity/gfx/{nazwa_pliku}
|
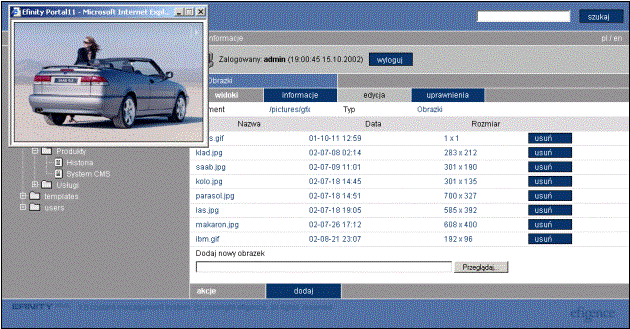
Rys. 6‑22 Ekran do administracji plikami |
Ze względu na wydajność, statystyki dla repozytoriów danych nie są
rejestrowane.
Administracja plikami
Dla węzła w drzewie portalu reprezentującego repozytorium plików są dostępne trzy funkcje z menu kontekstowego (por. Rys. 6‑22). Są to: informacje – podstawowe dane dotyczące węzła, edycja – edytowanie repozytorium, szczegółowy opis funkcji znajduje się dalej w tym punkcie, uprawnienia – możliwość edycji uprawnień dla węzła. Edycja uprawnień ma sens jedynie w ograniczonym zakresie. Nadawanie prawa odczytu nie ma sensu, gdyż każdy może odczytać te pliki. Uprawnienia dotyczące statystyk oraz historii również nie dotyczą tego typu obiektu, gdyż ani jedne, ani drugie funkcje nie obowiązują repozytoriów plików. Istotna jest jedynie możliwość edycji plików w repozytorium, czyli uprawnienie WRITE_NODE.
Po wybraniu funkcji edycja dla repozytorium plików na ekranie pojawi się lista wszystkich plików. Jeśli są to pliki graficzne, to obok widoczny powinien być rozmiar grafiki w pikslach, a gdy użytkownik kliknie na nazwę pliku, to w nowym oknie (ang. pop-up), pokazany zostanie podgląd grafiki.
Przycisk usuń po prawej stronie każdego z plików służy do usunięcia pliku z repozytorium. UWAGA! Należy uważnie usuwać pliki, gdyż może się tak zdarzyć, że usuwany plik jest używany w dokumentach w portalu. efinityXML nie sprawdza takich zależności.
Dodanie nowego pliku następuje poprzez wybranie przycisku przeglądaj... (albo browse... w angielskiej wersji przeglądarki), a następnie wskazaniu w lokalnym systemie pliku, który chcemy dodać. Potem już wystarczy wybrać dodaj i plik znajdzie się w repozytorium. Teraz będzie on dostępny dla użytkowników i dla administratorów w wizualnym edytorze HTML.
6.5. Zarządzanie użytkownikami
System praw dostępu w efinityXML opiera się na przydzielaniu uprawnień dla grup. Do tych grup mogą należeć jedynie użytkownicy. Nie ma jednak ograniczenia co do liczby grup, do jakich należy użytkownik.
Grupy oraz Użytkowników można odnaleźć w drzewie portalu. Znajdują się oni odpowiednio w katalogach groups i users w głównym katalogu systemu (efinityXML). Dzięki temu, że są to takie same obiekty jak inne dokumenty, które mogą się znaleźć w drzewie portalu, można nimi tak samo zarządzać z poziomu przeglądarki. Można edytować istniejące obiekty, dodawać nowe, zmieniać do nich uprawnienia (żeby inni użytkownicy mieli dostęp i możliwość zarządzania kontami i grupami), czy też oglądać statystyki, wśród których znajdują się informacje o tym kto i kiedy się logował lub kto edytował konta.
6.5.1. Użytkownicy
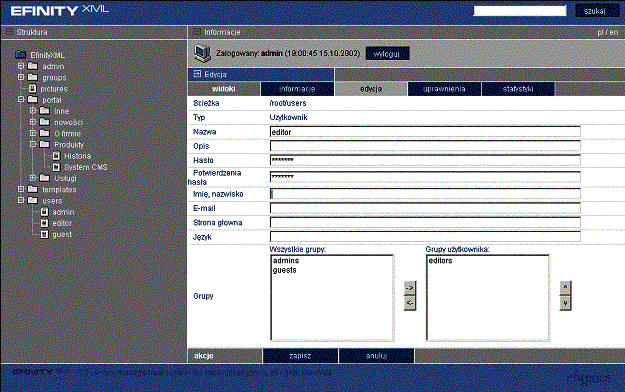
Rys. 6‑23 Ekran do edycji danych o użytkowniku
Aby obejrzeć listę kont w portalu, należy wyświetlić zawartość katalogu users. Przy każdej z pozycji na liście znajduje się menu kontekstowe, w którym dostępne są wszystkie funkcje jakie można wykonywać na obiekcie Użytkownik.
Podczas edycji użytkownika (por. Rys. 6‑23), oprócz podstawowych danych identyfikujących właściciela konta, tj. imię i nazwisko, adres elektroniczny (jest on przydatny na przykład do powiadamiania o dokumentach do zaakceptowania), telefon komórkowy (do powiadamiania za pomocą krótkiej wiadomości SMS), znajdują się również:
· informacja o stronie startowej – po zalogowaniu użytkownik zostanie na nią przekierowany. Jest to namiastka personalizacji (mechanizmy personalizacji nie są funkcjami systemów CMS, do tego służą inne rozwiązania; problem jest omówiony szerzej w p. 3.11),
· informacja o domyślnej wersji językowej użytkownika – gdy użytkownik zaloguje się po raz pierwszy, wymieniona tutaj wersja językowa zostanie użyta do wyświetlania stron.
Można również definiować do jakich grup użytkowników należy edytowany użytkownik.
Algorytm, który wyznacza stronę startową po zalogowaniu użytkownika oraz wersje językową interfejsu użytkownika uwzględnia kolejność w jakiej użytkownik należy do grup użytkowników. Kolejność ta nie ma wpływu na wynik wykonania algorytmu wyznaczania praw dostępu.
6.5.2. Grupy
Grupy, podobnie jak użytkownicy, są elementami drzewa portalu i znaleźć je można w katalogu groups w głównym katalogu systemu. Również menu kontekstowe dla grupy wygląda tak samo jak dla użytkownika.
Pola, które edytuje się dla grupy, to jedynie nazwa oraz opis grupy.
6.6. Typy obiektów w drzewie
Wszystkie obiekty mają swoją unikatową pozycję w drzewie portalu. W zależności od uprawnień nadanych w aplikacji administracyjnej, użytkownik ma dostęp do całości lub też do części węzłów. Na etapie wdrożenia systemu powinna tak zostać skonstruowana architektura drzewa portalu, aby w intuicyjny sposób odwzorowywała rzeczywistą architekturę informacyjną serwisu.
Część z obiektów jakie mogą się znaleźć w drzewie, ma swoje określone miejsce. Na etapie analizy można również określić dodatkowe warunki dotyczące dokumentów.
Przykład
W serwisie na pierwszej stronie znajdują się odnośniki do kategorii, w każdej z kategorii powinny znajdować się dokumenty tekstowe. Jeśli klikniemy na kategorię, to system wyświetli stronę ze wstępem opisującym kategorię oraz listą dokumentów, które się w niej znajdują.
Implementacją takiej architektury serwisu może być następująca struktura efinityXML:
· w katalogu portal znajdują się katalogi odpowiadające poszczególnym kategoriom,
· system będzie wyświetlał na pierwszej stronie nazwy katalogów jako nazwy kategorii,
· dokumenty w katalogach kategorii będą traktowane jako teksty w kategoriach,
· jeśli w katalogu znajduje się dokument o nazwie opis, to należy go traktować jako opis kategorii i wyświetlać w całości na stronie reprezentującej kategorię. Pod nim powinna znaleźć się lista dokumentów w kategorii.
Na różnych typach obiektów opisanych w bieżącym rozdziale mogą być wykonywane różne funkcje (funkcje menu kontekstowego). Ponadto są one indeksowane w systemie w różny sposób (bądź też w ogóle nie są indeksowane).
6.6.1. Katalog
Jest to podstawowy obiekt w drzewie portalu, który zarówno agreguje niektóre dane, jak i może służyć do reprezentacji różnych kategorii, podkategorii itp.
Pola do edycji
Nazwa – nazwa katalogu, używana do reprezentacji obiektu w drzewie portalu oraz na liście obiektów w katalogu. W zależności od semantyki katalogu w kontekście wdrożenia oraz innych czynników zdefiniowanych dla wdrożenia traktowana również jak informacja dla użytkownika systemu (np. pokazywana jako nazwa kategorii, jeśli katalog reprezentuje kategorię),
Opis – krótki opis prezentujący zawartość. Często używany również jako opis dokumentu pojawiający się w liście wyników wyszukiwania,
Skrót – ciąg reprezentujący dokument. Ciąg ten musi być unikatowy w skali całego systemu. Jeśli użytkownik wpisze w przeglądarkę adres postaci: http://www.firmax.com/efinity/{nazwa_skrotu}, to w odpowiedzi system wyświetli dokument, który ma skrót {nazwa_skrótu}. Do wyświetlenia tego dokumentu użyta zostanie domyślna strona (to zachowanie może ulec zmianie, jeśli wdrożony został np. portal również w wersji WAP – wtedy można tak skonfigurować efinityXML, aby po podaniu wymienionego adresu przy użyciu przeglądarki WAP, pokazała się strona w formacie odpowiednim dla bieżącego urządzenia).
Indeksowanie
Indeks administracyjny – indeksowane są pola słowa kluczowe, nazwa, opis.
Indeks portalu – indeksowane są pola słowa kluczowe, nazwa, opis.
6.6.2. Korzeń
Jest to główny element całego systemu. Nie może być usunięty ani zmieniony. Można mu przypisywać uprawnienia. Jest to specjalna wersja Katalogu.
Indeksowanie
Indeks administracyjny – obiekt nie jest indeksowany.
Indeks portalu – obiekt nie jest indeksowany.
6.6.3. Wzorzec stron
Typ wzorca zapewniający nowo dodawanym dokumentom przyporządkowanie stron, które będą służyć do pokazywania dokumentu.
Indeksowanie
Indeks administracyjny – indeksowane są pola nazwa i opis.
Indeks portalu – obiekt nie jest indeksowany.
6.6.4. Użytkownik
Obiekt reprezentujący konto w systemie.
Pola do edycji
Nazwa – nazwa konta (ang. login).
Opis – krótki opis.
Imię i nazwisko – identyfikacja użytkownika.
Hasło.
E-mail – w pole to można wpisać więcej niż jeden adres poczty elektronicznej, każdy z nich powinien być oddzielony spacją. W aplikacji administracyjnej, niektóre funkcje zawierają opcję powiadamiania za pomocą poczty elektronicznej (np. o przejściu dokumentu przez kolejny etap procesu obiegu dokumentów). Wartość tego pola to adres, na który zostanie wysłanie powiadomienie. Jeśli zaimplementowane zostaną dodatkowe funkcje w systemie, powodujące wysłanie listu pocztą elektroniczną, to powinny korzystać z tych danych.
Strona główna – jest to pole, którego wartością jest adres strony, którą system wyświetli po tym, jak użytkownik zaloguje się do systemu. Może to być adres bezwzględny (co jest mało sensowne, aczkolwiek możliwe) lub adres względny, np. wartość pola Skrót jakiegoś dokumentu lub katalogu.
Język – pole określające preferowaną wersję językową interfejsu użytkownika.
Grupy – pola pokazujące przynależność do grup użytkowników. Uwaga! Kolejność przynależności do grup ma znaczenie (por. p. 6.5).
Indeksowanie
Indeks administracyjny – indeksowane są pola nazwa, opis, imię i nazwisko.
Indeks portalu – obiekt nie jest indeksowany.
6.6.5. Grupa
Obiekt reprezentujący grupę użytkowników. Obiekty tego typu znajdują się w katalogu efinityXML/groups.
Pola do edycji
Nazwa, Opis – pola te, jak dla większości obiektów w drzewie portalu oznaczają nazwę obiektu oraz jego opis i używane są np. do wyświetlania podczas prezentacji wyników wyszukiwania.
Strona główna – wartość tego pola brana jest pod uwagę w algorytmie wyznaczania strony, która zostanie pokazana użytkownikowi po zalogowaniu.
Język – pole to, tak jak Strona Główna, służy do określania preferencji wersji językowej dla grup użytkowników.
Indeksowanie
Indeks administracyjny – indeksowane są pola nazwa, opis.
Indeks portalu – obiekt nie jest indeksowany.
6.6.6. Wiadomość
Obiekt reprezentujący wiadomość: tekst w połączeniu z określoną datą oraz odnośnikami do innych dokumentów w portalu. Korzystanie z obiektu Wiadomość w portalu jest dokładnie określane na etapie wdrożenia i w zależności od miejsca oraz strony użytej do wizualizacji, będą wyświetlane różne pola.
Pola do edycji
Nazwa – nazwa dokumentu. Pojawiać się ona powinna w trzech miejscach: w drzewie portalu w aplikacji administracyjnej, na liście dokumentów katalogu w aplikacji administracyjnej oraz jako nazwa dokumentu na liście wyników wyszukiwania w aplikacji administracyjnej. Czwarte miejsce to może być (to jest zależne od decyzji podjętych podczas analizy i wdrożenia) lista wyników wyszukiwania w portalu.
Opis – krótki opis dokumentu.
Skrót – jak w obiekcie Katalog.
Tytuł – tytuł wiadomości pokazywany w portalu.
Wstęp – skrót wiadomości, wyświetlany razem z tytułem.
Treść – treść wiadomości. Pole to jest typu HTML, co oznacza, że podczas edycji w miejscu tego pola pokaże się wizualny edytor HTML ułatwiający pracę z treścią w języku HTML. Edytor ten jest zintegrowany z repozytoriami plików, dzięki czemu można w intuicyjny sposób umieszczać grafikę w treści.
Data publikacji – data wpisywana w formacie „hh:mm dd-MM-yyyy” decydująca o tym od kiedy wiadomość będzie pokazywana.
Data archiwizacji – format jak Data publikacji, pole to określa czas, w jakim dokument powinien zostać zarchiwizowany.
Odnośniki – lista odnośników do innych dokumentów w portalu tematycznie związanych z bieżącym.
Indeksowanie
Indeks administracyjny – indeksowane są pola: słowa kluczowe, nazwa, opis, tytuł, wstęp, treść.
Indeks portalu (użytkownika) – pola: słowa kluczowe, tytuł, wstęp, treść.
Inne funkcje
Podczas wdrożenia określany jest sposób wyświetlania wiadomości w portalu oraz miejsca, w których będzie ona dostępna. Warto tutaj wspomnieć o możliwości takiej implementacji, która pozwoli na stworzenie portalu, w którym dokumenty będą automatycznie kojarzone przez system. Na stronie pokazującej treść dokumentu (np. wiadomości) na dole można wyświetlić wszystkie albo kilka najważniejszych (np. 5) odnośników do innych dowolnych dokumentów w portalu. Lista ta tworzona jest poprzez przeszukiwanie zawartości portalu za pomocą słów kluczowych bieżącego dokumentu. Dzięki temu mechanizmowi administratorzy portalu nie muszą się martwić o kojarzenie odpowiednich dokumentów, wszystkie odnośniki wyświetlane są automatycznie. Jeśli jakiś dokument z portalu zostanie usunięty, to również usunięte zostaną informacje o nim ze wszystkich indeksów, więc nie pojawi się na liście dokumentów skojarzonych.
6.6.7. Tekst
Prostsza wersja obiektu wiadomość. Służy do reprezentowania dokumentów tekstowych w portalu, opisów itp.
Pola do edycji
Nazwa – nazwa dokumentu, analogicznie jak w obiekcie Wiadomość (por. p. 6.6.6).
Opis – krótki opis dokumentu.
Skrót – por. p. 6.6.1.
Tytuł – tytuł wiadomości pokazywany w portalu.
Treść – treść wiadomości. Pole w formacie HTML (por. p. 6.6.6).
Indeksowanie
Indeks administracyjny – indeksowane są pola: słowa kluczowe, nazwa, opis, tytuł, treść.
Indeks portalu (użytkownika) – pola: słowa kluczowe, tytuł, treść.
6.6.8. Repozytorium plików
Jest to specjalny obiekt, który reprezentuje grupę plików. Dokładny opis czym jest repozytorium plików znajduje się w p. 6.4.10.
Indeksowanie
Obiekt ten nie jest indeksowany.
6.6.9. Strona
Obiekt reprezentujący stronę, za pomocą której wyświetlane są dokumenty. Obiekt taki składa się z portletów, z których każdy może mieć dodatkowo przypisany obiekt z drzewa portalu. Ponadto strona ma również przypisany arkusz styli (por. p. 6.6.11).
Więcej na temat stron znajduje się w p. 4.1.
Indeksowanie
Indeks administracyjny – indeksowane są pola nazwa i opis.
Indeks portalu – obiekt nie jest indeksowany.
6.6.10. Portlet
Reprezentacja portletu w drzewie portalu.
Więcej na temat stron i portletów można znaleźć w rozdziale 4.1.
Indeksowanie
Indeks administracyjny – indeksowane są pola nazwa i opis.
Indeks portalu – obiekt nie jest indeksowany.
6.6.11. Arkusz styli
Arkusz styli (ang. stylesheet) to obiekt reprezentujący dokument XSL, w którym zapisane są reguły wizualizacji różnych danych wygenerowanych przez portlety lub strony. Obiekt ten nie jest edytowalny w aplikacji administracyjnej efinityXML.
Indeksowanie
Indeks administracyjny – obiekt nie jest indeksowany.
Indeks portalu – obiekt nie jest indeksowany.
7. Podsumowanie
Efektem niniejszej pracy jest system zarządzania treścią - efinityXML, który jest nowoczesnym narzędziem do tworzenia portali i serwisów internetowych.
System ten posiada wymaganą funkcjonalność, która jest niezbędna w projektach komercyjnych. Wymienić należy:
· przejrzysty interfejs użytkownika,
· system autoryzacji i autentykacji,
· funkcje niezbędne do pracy grupowej,
· możliwość tworzenia treści dostępnej w różnych formatach (PDF, HTML, WAP),
· ogromne możliwości integracji z innymi systemami,
· relatywnie krótki czas realizacji portalu,
· możliwość prostego rozbudowywania o nowe funkcje.
Ponadto efinityXML spełnia również wymagania portali, które służą dużej grupie użytkowników: jest narzędziem wydajnym i skalowalnym.
System jest napisany w technologiach Java i XML, co świadczy o tym, że są to technologie dojrzałe i – wbrew panującym stereotypom – wydajne. Przy okazji tworzenia efinityXML powstało szereg modułów funkcjonalnych (np. moduł bezpieczeństwa, moduł szybkiego odczytu danych, wyszukiwania), które można wykorzystać w innych projektach nie związanych z zarządzaniem treścią.
Zastosowanie efinityXML nie powoduje konieczności zakupu dodatkowych licencji na oprogramowanie. Przedsiębiorstwa mogą zastosować wcześniej zakupione pakiety (serwery aplikacji J2EE, bazy danych) lub oprzeć system na technologiach udostępnianych na licencji wolnego oprogramowania.
System efinityXML został już użyty do realizacji dwóch serwisów internetowych. Korzysta z niego z powodzeniem wielu użytkowników.
Autor zastrzega sobie wszelkie prawa do kodów źródłowych systemu efinityXML.
8.
Bibliografia
[1]
Martin
Burns, Your clients
need a Content Management System, http://www.evolt.org/article/rating/20/5127/
[2]
Ben
Sullivan, Content Management for the
Masses, http://www.ojr.org/ojr/technology/1015018005.php
[3]
The
Forrester Report, Managing Content Hypergrowth, January 2001
[4] Strona domowa projektu CMSWatch, http://www.cmswatch.com/
[5] Strona domowa magazynu „CM Focus magazine”, http://www.cmfocus.com
[6] Strona domowa projektu ContentManger http://www.contentmanager.eu.com/
[7]
Product
Review: Content-Management Solutions, VarBusiness, http://www.varbusiness.com/Components/Search/Article.asp?ArticleID=29295
[8]
Lista
dyskusyjna „Content Management List”, http://www.cms-list.org
[9]
Content
Management Systems Review, http://www.pcmag.com/category2/0,4148,4803,00.asp
[10] Strona domowa projektu Zope, http://www.zope.rog
[11] Strona domowa projektu Cofax, http://www.cofax.org
[12] Strona domowa projektu OpenCMS, http://www.opencms.com
[13] Strona domowa Oracle, http://www.oracle.com
[14] Strona domowa IBM, http://www.ibm.com
[15] Strona domowa PostgreSQL http://www.postgresql.org
[16] Strona domowa RedDot, http://www.reddot.com
[17] Strona domowa Documentum http://www.documentum.com
[18] Strona domowa Interwoven http://www.interwoven.com
[19] Strona domowa Broadvision http://www.broadvision.com
[20] Strona domowa FileNet Corp. http://www.filenet.com
[21] Strona domowa Vignette http://www.vignette.com
[22] Strona domowa BEA http://www.bea.com
[23] Strona domowa Microsoft .NET http://msdn.microsoft.com/netframework/
[24] Strona domowa Microsoft Content
Management Server, http://www.microsoft.com/cmserver
[25] Strona domowa projektu Midgard, http://www.midgard-project.org
[26] Strona domowa NetObjects, http://www.netobjects.com
[27]
Strona
domowa Java Connector Architecture, http://java.sun.com/j2ee/connector
[28]
Dokumentacja
Java 2 Enterprise Edition http://java.sun.com/j2ee/docs.html
[29] Strona domowa Cocoon, http://xml.apache.org/cocoon
[30] Strona domowa JBoss, http://www.jboss.org
[31] Strona domowa Castor, http://castor.exolab.org
[32] Strona domowa Hibernate, http://hibernate.sourceforge.net
[33] Strona domowa MVCSoft, http://www.mvcsoft.com
[34] Strona domowa projektu XDoclet, http://xdoclet.sourceforge.net
[35] Strona firmy Though Inc., http://www.thoughtinc.com
[36] Strona projektu JBoss CMP, http://www.jboss.org/developers/projects/jboss/jaws.jsp
[37] Strona projektu JetSpeed, http://jakarta.apache.org/jetspeed
[38] Strona projektu Java Portlet API, http://www.jcp.org/en/jsr/detail?id=168
[39] Dokumentacja API Java 2 Standard Edition, http://java.sun.com/j2se/1.4.1/docs/api/
[40] Strona domowa języka PHP, http://www.php.net
[41] Strona domowa języka Python, http://www.python.org