ActiveCode: uniwersalny system prezentacji programów komputerowych w Internecie
Michał Gruszczyński
Praca magisterska (fragmenty)
Uniwersytet Warszawski
1998
Do niedawna większość danych przesyłanych w sieci World Wide Web stanowiły proste dokumenty będące mieszaniną tekstu, rysunków i hiperłączy. Do ich obsługi doskonale nadawał się język HTML oferujący zestaw kilkudziesięciu etykiet do fo
rmatowania tekstu w przeglądarce. W ostatnich latach, wraz z rozwojem sieci WWW, złożoność i różnorodność dokumentów znacznie wzrosła; język HTML jest często zbyt ubogi, aby wyrazić tę złożoność. Rozszerzenie języka HTML poprawiło nieco sytuację (między innymi przez wprowadzenie atrybutów ID i CLASS); mimo to sztywny zestaw etykiet znacznie ogranicza możliwość opisu złożonych danych. Pojawia się potrzeba standardu specyfikacji nowych typów dokumentów do indywidualnych zastosowań użytkowników sieci. Drugą poważną wadą HTML jest brak możliwości rozdzielenia opisu od sposobu ich wyświetlania, co uniemożliwia przedstawianie danych w różnych perspektywach.Język XML wychodzi naprzeciw tym wyzwaniom. Można go postrzegać jako bardziej elastyczną wersję HTML. XML jest tekstowym standardem specyfikacji dokumentów opartym na etykietach (ang. markup tags). Umożliwia on definiowanie przez uży
tkownika nowych etykiet, co pozwala na specyfikowanie nowych typów dokumentów o złożonej strukturze. Standard XML zapewnia, że dokument każdego typu jest zbudowany według tych samych reguł leksykalnych. Dzięki temu można tworzyć narzędzia rozpoznające język XML i używać ich do przetwarzania dokumentów dowolnego typu. Ponadto język XML zapewnia oddzielenie opisu danych od opisu ich prezentacji. Ściślej mówiąc, XML opisuje wyłącznie warstwę treściową dokumentu, natomiast warstwa prezentacyjna musi być zdefiniowana oddzielnie w programie klienta.Opisany w tej pracy system ActiveCode wykorzystuje paradygmat XML do prezenta
cji programów komputerowych w sieci World Wide Web. System został zaprojektowany z myślą o prezentacji kodu C++ w przeglądarce WWW.W systemie ActiveCode opis treści pliku źródłowego C++ jest oddzielony od opisu jego prezentacji. Do opisu treści opracowany został nowy format dokumentu, zwany ActiveC, zdefiniowany za pomocą języka XML. Do opisu prezentacji służy pojęcie perspektywy, czyli zbioru reguł określających formatowanie wizualne oraz intera
ktywność, jakimi będą obdarzone poszczególne struktury kodu C++. Użytkownik systemu może skorzystać z zestawu gotowych perspektyw lub opracować i zrealizować swoją własną perspektywę.Główne zalety systemu ActiveCode to:
Środowiskiem działania systemu ActiveCode jest serwer WWW, na którym są publ
ikowane dokumenty ActiveC, oraz lokalny komputer użytkownika systemu, na którym działa program pobierający i prezentujący dokumenty ActiveC. Implementacja systemu polega na napisaniu procedur generujących i analizujących dokument ActiveC oraz procedur prezentujących dokument ActiveC w wybranej perspektywie. Użycie narzędzi wspierających język XML i funkcji przeglądarki WWW znacznie ułatwia implementację. Opisana w tej pracy przykładowa realizacja ActiveCode dla systemu Win32 wykorzystuje interfejs programowy przeglądarki Internet Explorer do prezentacji kodu oraz systemowy procesor XML do analizy dokumentu ActiveC.Inspiracją dla ActiveCode były inne witryny WWW umożliwiające przeglądanie kodu źródłowego. Jedną z nich jest witryna Linux Source Navigator
[3], zawierająca kod systemu Linux. Oferuje ona udogodnienia prezentacji kodu typowe dla systemów IDE, takie jak wyróżnianie symboli leksykalnych kolorami lub nawigacja za pomocą hiperłączy. Inna witryna, MSDN Library [4], oferuje funkcję przeglądania konspektu ułatwiającą poruszanie się po strukturach kodu i dokumentacji. System ActiveCode dorównuje możliwościami powyższym systemom, jednocześnie próbując przezwyciężyć ich ograniczenia.Wybór języka C++ nie zmniejsza ogólności projektu Act
iveCode. Architektura systemu ActiveCode nadaje się do prezentacji programów napisanych w dowolnym innym języku programowania. W tym celu należałoby zmodyfikować format dokumentu ActiveC oraz opracować i zrealizować nowe perspektywy. Jest to stosunkowo proste zadanie, szczególnie w przypadku języków zbliżonych składniowo do C++, takich jak C, Ada, BASIC lub Pascal.W skład projektu ActiveCode wchodzą:
Niniejsza praca opisuje system ActiveCode oraz format Act
iveC. Rozpoczyna się wprowadzeniem do tematyki aplikacji internetowych. Następne rozdziały zawierają opis architektury systemu, definicję formatu ActiveC, przegląd technik tworzenia perspektyw oraz omówienie implementacji programu ActiveC Viewer. W ostatnich rozdziałach są przedstawione możliwości dalszego rozwoju systemu oraz podsumowanie. Dodatek zawiera formalną definicję formatu ActiveC.Wzrost popularności Internetu w ostatnich latach dał impuls do powstania
pierwszych systemów informacyjnych działających w środowisku sieci WWW (w oparciu o protokół HTTP) lub, ogólniej, w sieci Internet (w oparciu o protokół TCP/IP). Do najczęściej wymienianych zalet takich systemów należą łatwość wdrażania i niezależność od systemu operacyjnego. Specyfika Internetu wymusza jednak zmiany w architekturze systemów informacyjnych. Tradycyjna, dwuwarstwowa architektura klient-serwer jest zastępowana przez architekturę trójwarstwową. Różnica polega na dodaniu warstwy pośredniej między środowiskiem serwera baz danych i środowiskiem interfejsu użytkownika. Warstwa ta zarządza procesami przetwarzania danych, implementując logikę aplikacji. Warstwa pośrednia może być implementowana jako monitor transakcyjny, serwer komunikatów, serwer aplikacji lub broker obiektów. Architektura trójwarstwowa okazuje się efektywniejsza w systemach z dużą, liczoną w tysiącach, liczbą użytkowników; ponadto wydzielenie warstwy pośredniej znacznie zwiększa skalowalność i przenośność systemu informacyjnego w porównaniu z klasycznym modelem klient-serwer [8].W systemie informacyjnym działającym w sieci WWW transport informacji pomiędzy warstwami danych, logiki i interfejsu odbywa się przy użyciu protokołu HTTP. Jaki
ego formatu należy użyć do transportu informacji? HTML, typowy format sieci WWW, nie pozwala na kodowanie złożonych struktur danych. Opracowywanie specjalnego formatu na potrzeby danego systemu informacyjnego, pomijając dodatkowy nakład pracy, uniemożliwia swobodną wymianę danych między dwoma różnymi systemami. To ograniczenie jest szczególnie dotkliwe dla aplikacji internetowych, gdyż zmniejsza otwartość systemu, a więc i jego popularność. W celu dostarczenia elastycznego formatu danych ogólnego przeznaczenia, World Wide Web Consortium opracowało nowy język zapisu danych, zwany Extensible Markup Language (XML) [11]. Język XML różni się od HTML w trzech głównych aspektach:Podstawą specyfikacji XML jest stworzony ponad 30 lat temu Standard Generalized Markup Language. SGML pozwala na zdefiniowanie gramatyki opisującej treść d
okumentu. Taka gramatyka składa się z zestawu etykiet, którymi opatruje się tekst w dokumencie, oraz zestawu reguł opisujących zależności między etykietami. Dzięki temu przy pomocy SGML można reprezentować dane dowolnego rozmiaru i niemal dowolnego stopnia złożoności. Język XML jest podzbiorem SGML zorientowanym na przetwarzanie i przesyłanie w sieci WWW; dzięki temu XML jest językiem znacznie mniejszym i prostszym, często określanym jako zawierający 20% złożoności i 80% funkcjonalności języka SGML [2].Według J. Bosaka, istnieją cztery kategorie systemów, w których jęz
yk XML ma szansę znaleźć zastosowanie [1]. Dwie z nich to:W systemie informacyjnym, w którym serwer WWW komunikuje się z klientem-przeglądarką WWW, logiczna warstwa pośrednia musi być fizycznie zaimplement
owana po stronie serwera lub po stronie klienta. Implementacja po stronie klienta jest preferowana z punktu widzenia efektywności systemu. W takiej implementacji komunikacja w sieci polega wyłącznie na przesyłaniu danych, natomiast ich przetwarzanie i prezentacja odbywają się w programie przeglądarki.Język XML współtworzy warstwę pośrednią systemu informacyjnego. Jego podst
awowym zastosowaniem jest reprezentacja danych. Dokumenty XML są generowane z bazy danych, przesyłane w sieci i interpretowane w programie klienta. Do generacji XML z różnych źródeł danych służą programy zwane konwerterami. Przesyłaniem i rozpoznawaniem dokumentów XML zajmują się parsery i inne narzędzia wspomagające, zarówno po stronie serwera jak i klienta. Do wyświetlania danych XML w przeglądarce służą natomiast perspektywy, określające sposób formatowania tekstu, tworzenia zestawień, tabel, diagramów itp.Istnieją systemy informacyjne działające w sieci WWW używające XML do wymiany danych. Przykłady takich systemów to:
Przegląd systemów prezentacji kodu
Impulsem do
powstania systemów prezentacji kodu w Internecie są projekty programistyczne, których autorzy chcą udostępnić współpracownikom lub klientom kody źródłowe programów na stronach WWW.Jednym z takich systemów jest Linux Source Navigator [3]. Jest to witryna zawieraj
ąca pliki źródłowe systemu operacyjnego Linux w postaci stron WWW. LSN wyświetla kod C zaznaczając jednostki leksykalne różnymi kolorami. Oprócz tego, nazwy struktur danych zawierają odsyłacze do ich definicji (w formie hiperłączy), co ułatwia poruszanie się wśród plików systemu. Strony LSN generowane są z plików C za pomocą skryptu w języku Perl na serwerze WWW. Skrypt śledzi odwołania i deklaracje nazw obiektów w plikach C, tworzy hiperłącza i formatuje kod w języku HTML. Autorzy LSN nie udostępniają technologii generacji stron WWW innym użytkownikom sieci. Teoretycznie jednak system może być stosowany do publikacji dowolnego kodu C, pod warunkiem zainstalowania odpowiedniego oprogramowania na serwerze.Prezentacja kod
u w LSN jest prosta i czytelna; swoboda nawigacji między plikami znacznie ułatwia czytanie kodu. Poważnym ograniczeniem systemu Linux Source Navigator jest natomiast brak możliwości dostosowania prezentacji do indywidualnych potrzeb użytkownika. Każda modyfikacja wyglądu strony wymaga zmiany programu generatora stron na serwerze WWW. Zewnętrzny użytkownik nie może więc dokonać takiej modyfikacji, ponieważ dotyczyłaby wszystkich innych użytkowników systemu. Można temu zaradzić umieszczając na serwerze wiele generatorów stron oferujących różne perspektywy prezentacji. Jednak również wtedy możliwości prezentacji ograniczone są do tych perspektyw, które oferuje właściciel systemu. Powodem tego braku elastyczności jest fakt, że dokument HTML docierający do przeglądarki użytkownika nie zawiera opisu danych, lecz tylko ich wizualne odwzorowanie. Dlatego przeglądarka może wyświetlić ten dokument tylko na jeden sposób. Innymi słowy, warstwa logiki danych jest zaszyta w programie generatora stron. W systemie ActiveCode logika danych jest natomiast zawarta w dokumencie ActiveC przesyłanym do przeglądarki użytkownika. Dzięki temu klient systemu ActiveCode ma pełną swobodę w prezentacji kodu C++. Może on wybrać jedną z perspektyw dostępnych na serwerze, lub skorzystać z własnej perspektywy.Innym popularnym systemem prezentacji kodu jest witryna MSDN Library Online firmy Microsoft [4]
, która zawiera dokumentację technologii systemu Windows. Jej ciekawą funkcją jest applet Java umieszczony w lewej części ekranu który wyświetla tzw. widok konspektu (ang. outline view) Jest to diagram przedstawiający dostępne strony w postaci drzewa zorganizowanego według kategorii tematycznych. Po kliknięciu na nazwę strony, jej treść wyświetlana jest w prawym oknie ekranu. Okno konspektu ułatwia czytanie rozbudowanych dokumentów, informując użytkownika, gdzie w danej chwili się znajduje. Podobne rozwiązanie zostało przyjęte w przykładowej implementacji systemu ActiveCode opisanej w rozdziale 6.Witryna MSDN Library Online jest jednak jeszcze mniej elastyczna niż Linux Source Navigator, ponieważ widok konspektu jest na stałe związany z zestawem stron, które opisuje. Użycie okna konspektu do wyświetlania innego zestawu stron wymaga zmian
w kodzie systemu. Podobna sytuacja ma miejsce w przypadku witryny Projektu LabLinux [5] prezentującej dokumentację systemu Linux. LabLinux zawiera między innymi wizualizację struktur danych w formie diagramów z hiperłączami. Kliknięcie myszą na składową struktury będącą np. wskaźnikiem do innej struktury powoduje wyświetlenie rysunku tej struktury. Takie przedstawienie danych jest bardzo atrakcyjne, nie może być jednakże automatycznie stosowane do kodu C, ponieważ każdy diagram musi być wykonany ręcznie przy użyciu edytora graficznego. Stworzenie automatycznego generatora diagramów stanowi jedno z proponowanych rozszerzeń systemu ActiveCode, które są opisane w rozdziale 7.Oprócz systemów działających w sieci WWW, istnieje wiele narzędzi prezentacji k
odu. Mają one jednak nieco inny zakres zastosowań. Przykłady takich narzędzi to:Powyższe systemy zawierają, oprócz prezentacji, dodatkowe funkcje: edycję kodu, kompilator, kontrolę wersji itp. Dlatego najczęściej są przeznaczone do pracy na p
ojedynczym komputerze lub w sieci lokalnej. Mimo to wiele udogodnień stosowanych w tych systemach stało się inspiracją dla aplikacji działających w sieci WWW (również dla ActiveCode).ARCHITEKTURA SYSTEMU ACTIVECODE
Zadaniem systemu ActiveCode jest przekształcenie surowego kodu C++ na preze
ntację tego kodu na stronie WWW. Dzieje się to w dwóch fazach. Najpierw z pliku źródłowego C++ jest generowany dokument ActiveC, który zawiera opis kodu C++ w języku XML. Następnie dokument ActiveC jest prezentowany wizualnie na komputerze użytkownika, przy użyciu jednej z dostępnych perspektyw.Tworzeniem dokumentu ActiveC zajmuje się moduł zwany konwerterem ActiveC. Konwerter wczytuje kod źródłowy, identyfikuje zawarte w nim stru
ktury C++ i generuje dokument ActiveC zapisując do niego etykietowany kod źródłowy.Drugą część systemu ActiveCode stanowi przeglądarka ActiveC, która prezentuje dokument ActiveC na stronie WWW. Prezentacja polega na zastosowaniu wobec dokumentu perspektywy. Perspektywa jest to zbiór reguł określających, w jaki sposób struktury kodu C++ będą wyświetlane na stronie WWW i w jaki sposób strona WWW będzie reagować na zdarzenia użytkownika.
Oddzielenie zadania generacji dokumentu ActiveC od zadania jego prezen
tacji jest wygodne z kilku powodów. Po pierwsze, te dwa zadania mogą być wykonywane przez niezależne programy. Komunikacja między nimi polega na przesłaniu dokumentu ActiveC przez sieć. Po drugie, uzyskujemy możliwość trwałego zapisania struktury kodu C++ w postaci dokumentu ActiveC, który można przechowywać na dysku oraz przesyłać pocztą elektroniczną lub protokołem FTP.Konwerter ActiveC
Dokument ActiveC składa się z kodu C++ opatrzonego etykietami XML. Etykiety zawierają informacje o strukturach języka C++ występujących w kodzie źródłowym: deklaracjach, komentarzach, dyrektywach preprocesora i jednostkach leksykalnych. Miejsce wystąpienia struktury w kodzie jest sygnalizowane obecnością stosownej et
ykiety: przed wystąpieniem struktury znajduje się etykieta otwierająca, a za tekstem struktury następuje etykieta zamykająca. Właściwości struktury C++, takie jak nazwa deklaracji, wartość stałej itp., są zapisane w formie atrybutów etykiety XML.Etykiety w dokumencie ActiveC są uporządkowane zgodnie z regułami języka XML. Podstawowa reguła brzmi, że pary etykiet muszą być poprawnie zagnieżdżone (tzn. muszą prawidłowo zawierać się w sobie lub być rozłączne). Dzięki tej własności dokument XML można przedstawić w postaci drzewa etykiet, które odpowiada drzewu str
uktury kodu C++. Takie przedstawienie jest często używane w narzędziach przetwarzających dokumenty XML, ponieważ ułatwia ono dostęp programowy do zawartości dokumentu.Konwerter ActiveC wczytuje na wejściu strumień kodu C++ i analizuje go. W czasie analizy konwerter wyodrębnia jednostki leksykalne, dyrektywy i komentarze oraz próbuje rozpoznać i zinterpretować deklaracje obiektów. Przeanalizowany kod jest wyp
isywany na wyjściu razem z odpowiednimi etykietami ActiveC.Analiza kodu C++ podczas konwersji do for
matu ActiveC jest podobna do analizy składniowej wykonywanej podczas kompilacji kodu. Dlatego do implementacji konwertera warto użyć narzędzia wspomagające tworzenie kompilatorów. W przykładowej aplikacji ActiveC Viewer opisanej w rozdziale 6. konwerter ActiveC został utworzony za pomocą generatora analizatorów składniowych Bison w systemie GNU.Przeglądarka ActiveC
Zadaniem przeglądarki ActiveC jest prezentacja dokumentu ActiveC na stronie WWW według wybranej perspektywy. Kod C++ oraz etykiety ActiveC są interpr
etowane przez przeglądarkę i wyświetlane w postaci elementów strony WWW.Pojęcie perspektywy w systemie ActiveCode jest nieformalne. Perspektywę definiuje się opisując słownie wizualizację każdej struktury C++ na stronie WWW oraz sposób reagowania elementów strony WWW na zdarzenia użytkownika. Nie istnieje obecnie standard automatycznego odwzorowywania elementów XML na elementy strony WWW. Próbą stworzenia takiego standardu jest specyfikacja obiektowego modelu dokumentu (
DOM) [10] oraz związanego z nim języka XSL [12]. Na razie jednak te standardy są niekompletne. Dlatego implementacja perspektywy wymaga ręcznego zaprogramowania reguł wyświetlania dokumentu ActiveC i interakcji z użytkownikiem. Rozdział 5 zawiera przegląd technik implementacji perspektyw.Zanim przeglądarka ActiveC będzie mogła zastosować perspektywę, musi ona prz
eczytać dokument ActiveC i udostępnić go procedurom prezentującym. Udostępnienie dokumentu polega na przedstawieniu go w wewnętrznej reprezentacji przeglądarki. Najczęściej reprezentacją tą jest opisane wyżej drzewo etykiet lub, równoważnie, struktura obiektowa. Przekształcenie dokumentu ActiveC na drzewo etykiet jest krokiem automatycznym wykonywanym przez program zwany parserem XML. Parsery XML są dostępne jako komponent przeglądarki WWW lub jako biblioteka danego języka programowania (np. Java).Ten rozdział zawiera kompletny opis formatu dokumentu ActiveC. Reguły gram
atyczne formatu w jednolitej postaci znajdują się w dodatku na końcu pracy.Informacje ogólne
Definicja formatu ActiveC, podobnie jak każdego innego formatu opartego na języku XML, składa się z opisu elementów XML, które mogą się pojawić w dokumencie ActiveC. Na opis każdego elementu składają się:
Oprócz składni jest zdefiniowane znaczenie każdego elementu XML. W dokumencie ActiveC elementy służą do identyfikacji symboli leksykalnych i konstrukcji języka C++. Definicja ActiveC przypisuje każdy element do symbolu lub konstrukcji języka, precyzuje miejsce pojawienia się etykiety elementu w kodzie źródłowym, oraz określa przeznaczenie i sposób użycia atrybutów elementu.
Format ActiveC opisuje następujące struktury ję
zyka C++:Powyższe elementy języka C++ zostały uwzględnione w formacie ActiveC, ponieważ w większości systemów prezentacji kodu właśnie te elementy są przedmiotem wiz
ualizacji. W razie potrzeby uwzględnienia innych struktur C++ w prezentacji kodu, format ActiveC może zostać rozszerzony. Rozszerzenie polega na zdefiniowaniu nowych elementów XML przeznaczonych do opisu danej struktury i umieszczeniu opisu tych elementów w definicji ActiveC. Niektóre z proponowanych rozszerzeń systemu ActiveCode opisanych w rozdziale 7. zakładają dołączenie do formatu ActiveC pozostałych struktur języka C++, np. instrukcji sterujących.Ten rozdział zawiera omówienie technik formułowania i realizacji perspektyw w sy
stemie ActiveCode.Perspektywa jest odwzorowaniem elementó
w dokumentu XML na elementy strony WWW. Nie istnieje obecnie standardowy język specyfikacji tego odwzorowania. W związku z tym perspektywy są definiowane nieformalnie w postaci opisu tekstowego, a następnie implementowane ręcznie w dostępnym interfejsie programisty.Do opisu wyglądu i zachowania strony WWW dobrze nadaje się mechanizm zwany obiektowym modelem dokumentu (ang. Document Object Model)
[10]. Jest to standard opracowany w celu udostępnienia struktury strony WWW interfejsowi programisty (np. językowi JavaScript). DOM udostępnia następujące elementy strony WWW:Specyfikacja DOM przewiduje możliwość dynamicznej zmiany zawartości prawie każdego elementu strony WWW w dowolnej chwili. DOM określa również model zdarzeń (ang. event model), który opisuje zestaw zdarzeń wywołanych na elementach stron WWW przez użytkownika. Model zdarzeń pozwala na programowanie intera
kcji użytkownika ze stroną WWW przez tworzenie procedur obsługi zdarzeń. Standard DOM umożliwia więc przekształcenie strony WWW w interaktywną aplikację działającą w środowisku przeglądarki.Przeglądarki Netscape i Internet Explorer w wersji 4. posiadają ograniczone wsparcie dla modelu DOM w postaci tzw. dynamicznego języka HTML (ang. Dynamic HTML). Dzięki DHTML można programować niektóre elementy strony WWW używając tej samej notacji obiektowej co w DOM. Przyszłe generacje przeglądarek WWW mają zawierać kompletne wsparcie dla DOM. Wówczas będzie można aut
omatyczne stosować reguły perspektywy w przeglądarce WWW. W aplikacji ActiveC Viewer opisanej w następnym rozdziale język DHTML jest używany m. in. do dynamicznej budowy listy deklaracji po załadowaniu dokumentu ActiveC.Do pełnego opisu perspektywy, oprócz wyglądu i zachowania elementów strony WWW, potrzebny jest jeszcze mechanizm przypisywania elementów dokumentu XML odpowiednim elementom strony WWW. Próbą stworzenia takiego mechan
izmu jest język Extensible Stylesheet Language (XSL) [12]. XSL wprowadza pojęcie arkusza stylu, czyli zestawu reguł przekształcania elementów XML na elementy HTML lub DHTML. Na przykład następująca reguła XSL dotyczy etykiety XML o nazwie DECLARATION:<rule>
<target-element type="DECLARATION"/>
<A NAME='=getAttribute("name")'/>
<I>
<children/>
</I>
</rule>
Zastosowanie tej reguły spowoduje umieszczenie hiperłącza na stronie WWW (obiekt HTML o nazwie <A>) o adresie równym wartości atrybutu
name etykiety DECLARATION. Ponadto zawartość etykiety DECLARATION (komenda <children/>) zostanie wyświetlona czcionką pochyłą (obiekt <I>).Standard XSL jest obecnie w fazie projektowania, jednakże jego pierwsza wersja p
osiada kilka zadowalających implementacji. W aplikacji ActiveC Viewer procesor MSXSL jest używany do zaznaczania symboli leksykalnych C++ różnymi kolorami, zgodnie z przygotowanym wcześniej arkuszem stylu.W przyszłości, dzięki połączeniu DOM i XSL będzie możliwe zdefiniowanie pe
rspektywy w postaci jednocześnie czytelnej dla człowieka i gotowej do użycia w przeglądarce WWW. Na razie, aby użyć daną perspektywę w systemie ActiveCode, należy ją, przynajmniej częściowo, zaimplementować ręcznie.Ten rozdział zawiera opis przykładowej implementacji systemu ActiveCode pr
ogramu ActiveC Viewer.ActiveC Vi
ewer został stworzony po to, by zademonstrować działanie systemu ActiveCode w praktyce. Program był rozwijany równolegle z projektem samego systemu. W tym czasie służył on również do sprawdzania poprawności przyjętych rozwiązań oraz do weryfikacji formatu ActiveC. ActiveC Viewer umożliwia konwersję pliku źródłowego C++ na dokument ActiveC oraz jego prezentację w przeglądarce według przykładowej perspektywy.ActiveC Viewer został zaimplementowany dla systemu Win32 (Windows 95/98/NT) i prz
eglądarki Internet Explorer 4.Konwerter
Konwerter ActiveC w programie ActiveC Viewer jest programem typu wejście-wyjście, uruchamianym z linii poleceń. Konwerter czyta kod C++ ze standardowego strumienia wejściowego i wypisuje tekst dokumentu ActiveC na standardowe wyjście.
Utworzony plik ActiveC jest zapisywany w lokalnym systemie plików lub umieszczany na serwerze WWW.Konwerter ActiveC został napisany przy pomocy generatora analizatorów leksyka
lnych Flex oraz generatora analizatorów składniowych Bison działających w systemie GNU. Dane wejściowe dla programu Bison stanowił opis gramatyki C++ oparty na publicznie dostępnej definicji gramatyki C++ autorstwa J. Roskinda [6]. Produkcje gramatyki zostały zredukowane do opisu struktur C++ występujących w formacie ActiveC. W efekcie otrzymano rodzaj translatora C++ który zamiast budowy drzewa programu wypisuje kod C++ opatrzony etykietami XML.Przeglądarka
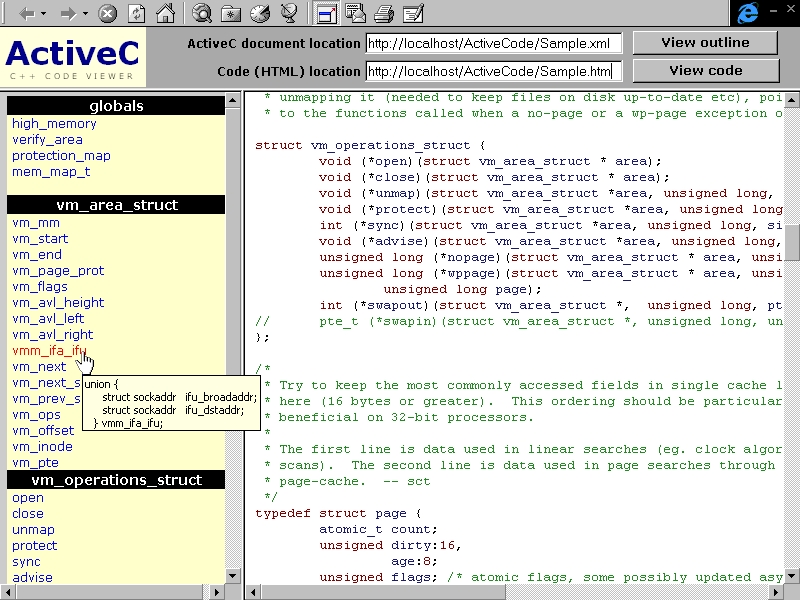
W programie ActiveC Viewer przeglądarka ActiveC jest osadzona wewnątrz przeglądarki WWW. Rysunek 1 przedstawia okno działającej przeglądarki.
Rysunek 1. Okno przeglądarki ActiveC Viewer
Perspektywa, według której zbudowano przeglądarkę, składa się z trzech okien (r
amek). Okno poziome w górnej części przeglądarki służy tylko do wpisania nazwy prezentowanego dokumentu ActiveC i po przeczytaniu dokumentu może być ukryte. Właściwa prezentacja kodu odbywa się w dwóch oknach sąsiadujących pionowo. Prawe okno (okno kodu) zawiera tekst pliku źródłowego C++ w oryginalnej treści i ułożeniu. Aby zwiększyć czytelność kodu, symbole leksykalne języka są zaznaczone różnymi kolorami, np. wszystkie słowa kluczowe są wyświetlane na czerwono, a komentarze na zielono. W lewym oknie przeglądarki (oknie konspektu) znajduje się zestawienie deklaracji występujących w pliku źródłowym. Deklaracje są podzielone na deklaracje obiektów o zasięgu globalnym, i na deklaracje składowych klas. Każdy wiersz konspektu zawiera nazwę deklarowanego obiektu. Pełny tekst deklaracji jest wyświetlany w okienku podpowiedzi (ang. ToolTip) pojawiającym się po umieszczeniu wskaźnika myszy nad nazwą obiektu. Synchronizacja pomiędzy oknami odbywa się po kliknięciu myszą deklaracji w oknie konspektu. Wówczas tekst w oknie kodu zostanie przewinięty, aby wyświetlić treść deklaracji. Oprócz wymienionych funkcji użytkownik może korzystać ze standardowych poleceń przeglądarki IE4, takich jak drukowanie, zaznaczanie tekstu, użycie prawego klawisza myszy, zmiana szerokości i rozmiaru okien oraz komenda cofnij.Do implementacji perspektywy ActiveC Viewer użyto kombinacji języków DHTML, JavaScript oraz XSL. Zawartość okna kodu jest plikiem HTML generowanym na serwerze z pliku ActiveC za pomocą procesora MSXSL. Do generacji służy arkusz stylu XSL, który przypisuje symbolom leksykalnym C++ różne kolory czcionek.
Oprócz tego arkusz stylu dla każdej deklaracji powoduje wstawienie w pliku HTML znacznika A, czyli tzw. kotwicy, umożliwiającej skok do tego miejsca w kodzie po kliknięciu hiperłącza w oknie konspektu programu.Zawartość okna konspektu jest generowana dynamicznie w programie przeglądarki po załadowaniu dokumentu ActiveC. Generację wykonuje procedura w języku Jav
aScript, która odwiedza węzły drzewa dokumentu (utworzonego automatycznie przez parser) identyfikując te węzły, które oznaczają deklaracje. Dla każdej deklaracji procedura generuje wiersz tabeli HTML zawierający nazwę deklarowanego obiektu, okienko podpowiedzi oraz hiperłącze do okna kodu. Opisana procedura jest wykonywana najpierw dla obiektów globalnych, a następnie dla każdej klasy zdefiniowanej na poziomie pliku.Pliki wchodzące w skład progra
mu ActiveC Viewer|
Nazwa pliku |
Przeznaczenie |
|
acc.exe |
Program konwertera ActiveC. |
|
acv.htm |
Główny dokument przeglądarki ActiveC. |
|
acv_nav.htm |
Górne okno przeglądarki. |
|
acv_out.htm |
Lewe okno przeglądarki. Jego zawartość jest modyfikowana po zał adowaniu dokumentu ActiveC. |
|
code.xsl |
Arkusz stylu dla procesora XSL, służący do generacji dokumentu HTML wyświetlanego w prawym oknie przeglądarki. |
Architektura systemu ActiveCode zapewnia możliwość jego rozbudowy i dostosow
ania go do potrzeb użytkownika przy jednoczesnym zachowaniu stałego formatu danych. Do tego celu służy pojęcie perspektywy. Chcąc dodać nową funkcjonalność do prezentacji kodu, wystarczy opracować i zaimplementować nową perspektywę lub rozszerzyć jedną z istniejących perspektyw.Ponieważ jednak możliwości przeglądarek szybko się zwiększają, trudno przewidzieć jaką funkcjonalność, jakie udogodnienia prezentacji i jaki interfejs programowy będą oferować następne wersje. Wtedy może dojść do sytuacji, w której opis kodu zawarty w formacie ActiveC nie wystarczy do zrealizowania perspektywy. Wówczas trzeba będzie rozszerzyć definicję formatu ActiveC, przy zachowaniu zasad obowiązujących dla języka XML. W szczególności, nowe wersje formatu ActiveCode powinny być nadzbiorami wersji p
ierwotnej dzięki temu będzie można stosować stare perspektywy do dokumentów w nowym formacie. Oczywiście, zachowanie zasady nadzbioru nie jest możliwe, jeśli format jest niezależnie rozwijany przez dwie osoby.W przyszłości ActiveCode mógłby rozszerzać swoje zastosowanie poza prezentację kodu. Poniżej omówiono możliwe kierunki rozwoju i specjalizacji systemu.
Graficzna prezentacja C++
Graficzne metody wizualizacji C++ są bardzo popularne, szczególnie w narzędziach CASE. Za pomocą rysunków i diagramów można przedstawiać struktury i zależności występujące między obiektami w kodzie. Na przykład Object Modeling Technique (OMT) J. Rumbaugha
[7], popularna metodologia inżynierii oprogramowania, zawiera następujące formy wizualizacji kodu: diagramy klas, diagramy przepływu danych, scenariusze wywołania funkcji i diagramy implementacji (ang. deployment diagrams). Do implementacji przeglądarki diagramów najlepiej użyć języka Java lub napisać komponent ActiveC. Obie technologie obsługują XML i zawierają biblioteki wspomagające grafikę wektorową.Animator
System ActiveCode został zaprojektowany z myślą o prezentacji struktur danych, czyli aspektu statycznego programu C++. Jednak bardzo pouczająca może też być wizualizacja dynamiki pracy programu. Do tego celu należałoby rozszerzyć format ActiveC o opis instrukcji sterujących i wywołań funkcji. Animator można impl
ementować przy użyciu technik graficznych opisanych w poprzednim akapicie.Zarządzanie projektem i kontrola wersji
System ActiveCode
posiada mechanizm grupowania wielu plików w formie projektu. Przydatnym usprawnieniem byłaby możliwość kompilacji lub konsolidacji projektu. W tym celu można zdefiniować analogiczny do ActiveC format pliku Makefile. Wtedy po wydaniu polecenia kompilacji przeglądarka ActiveC sprawdzałaby zależności między plikami i uruchamiała kompilator. W podobny sposób można np. przeprowadzać grupową archiwizację plików.Mając system zarządzania projektem można dodać do niego kontrolę wersji. Wym
agałoby to rozbudowania struktury elementu VERSION w formacie ActiveC. Przeglądarkę należałoby natomiast rozszerzyć o możliwość zapisu i przenoszenia plików oraz o mechanizmy blokowania, tak aby zawsze udostępniała najnowszą wersję pliku.Edycja kodu
Wprowadzenie możliwości edycji kodu C++ w przeglądarce wymaga znacznego ro
zbudowania perspektywy. Łatwiejszy w implementacji jest edytor, w którym kod C++ wpisuje się bezpośrednio z klawiatury. Wtedy jednak prezentacja kodu byłaby uaktualniana dopiero po powtórnym przeczytaniu kodu przez konwerter ActiveC. Większą wygodę daje natomiast edytor strukturalny, w którym wpisanie konstrukcji języka C++ wymaga wydania konkretnego polecenia wtedy edytor przy każdym poleceniu wstawiałby do dokumentu ActiveC odpowiednie etykiety.Kompilacja
D
ziałanie systemu ActiveCode pod wieloma względami przypomina działanie kompilatora C++. Dokument ActiveC zawiera opis struktur kodu C++ w postaci drzewa, podobnego do drzewa programu. Algorytm aplikowania perspektywy, w którym odwiedza się węzły drzewa dokumentu XML wypisując polecenia, przypomina fazę generacji kodu. Stąd powstaje pomysł rozszerzenia ActiveCode o możliwość kompilacji. W tym celu należałoby znacznie rozbudować format ActiveC, aby uwzględniał on całą składnię C++. Wtedy konwerter ActiveC automatycznie przeprowadzałby analizę składniową programu. Do projektanta należałoby natomiast zaimplementowanie analizy kontekstowej, generacji kodu i optymalizacji.W ramach projektu ActiveCode zaprojektowano format dokumentu ActiveC oraz arch
itekturę systemu prezentacji dokumentów. Zaimplementowano również przykładową aplikację demonstrującą możliwości systemu ActiveCode.W trakcie pracy nad systemem projekt formatu ActiveC był często modyfikowany. Powodem zmian były problemy przy wdrażaniu aplikacji, które ukazywały błędy l
ogiczne i luki w formacie ActiveC. Ich usunięcie wymagało modyfikacji formatu. W kilku przypadkach zrezygnowano z pewnych funkcji systemu z powodu trudności w ich realizacji. Na przykład funkcja nawigacji z miejsca wywołania metody do miejsca jej deklaracji okazała się trudna do zrealizowania dla metod przeciążonych lub dziedziczonych z klas nadrzędnych. W efekcie funkcja ta została usunięta z formatu ActiveC. Nie wyklucza to jednak możliwości jej realizacji w przyszłości, pod warunkiem rozszerzenia definicji formatu ActiveC.Działanie systemu na przykładzie aplikacji ActiveC Viewer jest zadowalające. Aplik
acja została zaimplementowana dla platformy Internet Explorer 4 w systemie Windows, która obecnie zapewnia największe wsparcie dla języka XML. Mimo to w czasie implementacji napotkano na trudności spowodowane brakiem pełnej obsługi XML.Wbrew oczekiwaniom, zastosowanie języka XML do opisu danych nie ułatwiło real
izacji projektu. Zysk wynikający z zastosowania wbudowanego parsera do obróbki dokumentu ActiveC został zrównoważony problemami z realizacją perspektyw. Format kodowania struktur języka C++ można więc było zaprojektować z użyciem własnej składni, innej niż w składnia etykiet XML. Wykorzystanie w projekcie technologii XML było jednak słusznym posunięciem wobec wzrastającej popularności tego języka. Podczas kilku miesięcy pracy nad projektem ActiveCode pojawiło się na rynku dużo narzędzi wspomagających tworzenie i wyświetlanie dokumentów XML; firmy Microsoft i Netscape zapowiadają pełną obsługę języka XML w następnych wersjach przeglądarek. W przyszłości ma on szansę stać się podstawowym językiem opisu dokumentów w sieci World Wide Web. Użycie języka XML powoduje, że implementacje ActiveCode będą działać w coraz większej liczbie systemów operacyjnych.DODATEK FORMALNA DEFINICJA FORMATU ACTIVEC
<!DOCTYPE ACTIVEC [
<!--
Wersja: 1.0.2
Data: 9 listopada 1998
Definicja struktury dokumentu ActiveC (DTD)
-->
<!-- ** Makrodefinicje ** -->
<!-- Symbole leksykalne j
ęzyka C++ --><!ENTITY CPPSYMBOL "ID | KEY | OP | CONSTANT">
<!-- Komentarze i dyrektywy preprocesora -->
<!ENTITY OTHERSYMBOL "DIR | COMMENT | COMMENT2 ">
<!-- Separatory -->
<!ENTITY SEPARATOR "NL | W | T">
<!-- Wszystkie symbole leksykalne -->
<!ENTITY RUNNINGCODE "#PCDATA | %CPPSYMBOL | %OTHERSYMBOL | %SEPARATOR">
<!-- Definicje elementów
1. Ogólna struktura dokumentu ActiveC
2. Deklaracje
3. Symbole leksykalne -->
<!-- ** 1. OGÓLNA STRUKTURA DOKUMENTU ACTIVEC ** -->
<!-- Element początkowy
- projekt C++ --><!ELEMENT ACTIVEC (PROJECTINFO? , (SOURCEFILE | TEXTFILE)*) >
<!ATTLIST ACTIVEC name CDATA #REQUIRED>
<!-- Streszczenie zawartości projektu -->
<!ELEMENT PROJECTINFO (#PCDATA)>
<!-- Plik tekstowy o nieznanej zawartości (bez etykiet X
ML) --><!ELEMENT TEXTFILE (#PCDATA)>
<!ATTLIST TEXTFILE name CDATA #IMPLIED>
<!ATTLIST TEXTFILE type CDATA #IMPLIED>
<!-- Plik źródłowy C++ -->
<!ELEMENT SOURCEFILE (FILEINFO? , CODE)>
<!ATTLIST SOURCEFILE name CDATA #REQUIRED>
<!-- Opis zawartośc
i pliku --><!ELEMENT FILEINFO (AUTHOR? , VERSION? , DATE? , ABSTRACT?)>
<!ELEMENT AUTHOR (#PCDATA)>
<!ELEMENT VERSION (#PCDATA)>
<!ELEMENT DATE (#PCDATA)>
<!ELEMENT SUMMARY (#PCDATA)>
<!-- Zawartość pliku - kod C++ -->
<!ELEMENT CODE (%RUNNINGCODE | DECL)*>
<!-- ** 2. DEKLARACJE ** -->
<!-- Nazwa typu lub obiektu, używana w elementach DECL i DECLARATOR -->
<!ELEMENT NAME EMPTY>
<!ATTLIST NAME value CDATA #REQUIRED>
<!-- Ogólna deklaracja -->
<!ELEMENT DECL (%RUNNINGCODE | NAME | ISCLASS | CLASSBODY | ENUMBODY | DECLARATOR | LINKAGE | TEMPLATE)*>
<!-- Specyfikator typu -->
<!-- Element NAME (zdefiniowany powyżej) -->
<!ELEMENT ISCLASS EMPTY>
<!-- Element obowiązkowy -->
<!-- Informuje, czy deklaracja zawiera definicję klasy -->
<!ATTLIST ISCLASS value ( yes | no ) #REQUIRED>
<!-- ** Deklarator ** -->
<!ELEMENT DECLARATOR (%RUNNINGCODE | NAME | FUNCTIONBODY)*>
<!-- Nazwa (identyfikator) wprowadzana w deklaratorze -->
<!-- Element NAME (zdefiniowany powyżej) -->
<!-- Rodzaj deklaratora -->
<!ATTLIST DECLARATOR type ( data | function ) #IMPLIED>
<!-- Treść funkcji -->
<!ELEMENT FUNCTIONBODY (%RUNNINGCODE | DECL)*>
<!-- ** Definicja klasy ** -->
<!ELEMENT CLASSBODY (%RUNNINGCODE | BASECLASS | ACCESS | DECL)*>
<!ATTLIST CLASSBODY type ( class | struct | union ) #IMPLIED>
<!-- Klasa podstawowa -->
<!ELEMENT BASECLASS EMPTY>
<!ATTLIST BASECLASS name CDATA #REQUIRED>
<!ATTLIST BASECLASS accesstype ( private | protected | public ) #IMPLIED>
<!-- Specyfikator dostępu -->
<!ELEMENT ACCESS EMPTY>
<!ATTLIST ACCESS type ( private | protected | public ) #IMPLIED>
<!-- ** Definicja wyliczenia ** -->
<!-- Lista elementów wyliczenia -->
<!ELEMENT ENUMBODY (%RUNNINGCODE | ENUMCONSTANT)*>
<!-- Element wyliczenia -->
<!ELEMENT ENUMCONSTANT EMPTY>
<!ATTLIST ENUMCONSTANT name CDATA #REQUIRED>
<!ATTLIST ENUMCONSTANT value CDATA #IMPLIED>
<!-- ** Specjalne deklaracje ** -->
<!-- Specyfikacja łączenia -->
<!ELEMENT LINKAGE (%RUNNINGCODE | DECL)*>
<!ATTLIST LINKAGE linkagestring CDATA #REQUIRED>
<!-- Deklaracja wzorca -->
<!ELEMENT TEMPLATE (%RUNNINGCODE | NAME | DECL)*>
<!-- ** 3. SYMBOLE LEKSYKALNE ** -->
<!-- Dyrektywa preprocesora -->
<!ELEMENT DIR (#PCDATA | SEPARATORS)*>
<!ATTLIST DIR type ( define | undef | include | if | ifdef | ifndef | elif | else | endif | line | error | pragma | emptydir ) #IMPLIED>
<!ATTLIST DIR filename CDATA #IMPLIED >
<!-- Komentarz typu "/* ... */" -->
<!ELEMENT COMMENT (#PCDATA | SEPARATORS)*>
<!-- Komentarz typu "// ... " -->
<!ELEMENT COMMENT2 (#PCDATA | SEPARATORS)*>
<!-- Znak końca wiersza -->
<!ELEMENT NL EMPTY>
<!-- Spacja -->
<!ELEMENT W EMPTY>
<!-- Tabulator -->
<!ELEMENT T EMPTY>
<!-- ** Symbole leksykalne języka C++ ** -->
<!-- Identyfikator -->
<!ELEMENT ID EMPTY>
<!ATTLIST ID value CDATA #REQUIRED>
<!--
Słowo kluczowe --><!ELEMENT KEY EMPTY>
<!ATTLIST KEY value ( asm | asmlinkage | auto | break | case | catch | char | class | const | continue | default | delete | do | double | else | enum | extern | float | for | friend | goto | if | inline | int | long | new | operator | overload | private | protected | public | register | return | short | signed | sizeof | static | struct | switch | template | this | throw | try | typedef | union | unsigned | virtual | void | volatile | while ) #REQUIRED>
<!-- Operator -->
<!ELEMENT OP (#PCDATA)>
<!-- Lit
erał --><!ELEMENT CONSTANT EMPTY>
<!ATTLIST CONSTANT type ( integer | octal | hex | floating | character | string ) #IMPLIED>
<!ATTLIST CONSTANT value CDATA #REQUIRED>
]>