Spis treści
Rozdział 1 Wprowadzenie do języka XML
1.1 Poprzednicy XML-a SGML i HTML
1.2 XML historia, teraźniejszość
1.3 Standardy rozszerzające definicję języka XML
1.3.2 Przestrzenie nazw Namespaces in XML
1.4 Interfejsy umożliwiające dostęp do zawartości dokumentów XML-owych
1.4.1 SAX
1.4.2 DOM
Rozdział 2 Edytory dokumentów zapisanych w standardzie XML
2.1 Klasyfikacja edytorów
2.2 Przegląd edytorów
2.2.1 XML Notepad (Microsoft)
2.2.2 XED (University of Edinburgh)
2.2.3 XMLwriter (Wattle Software)
2.2.4 XML Spy
2.2.5 Athens Editor (Swift, Inc)
2.2.6 Emacs
2.3 Zestawienie cech edytorów
3.1 Wstępne założenia projektu edytora
3.2.1 Język programowania i biblioteki
3.2.3 Reprezentacja dokumentu w edytorze
Rozdział 4 Opis konstrukcji programu XPad
A Opis zawartości dyskietek dołączonych do pracy
Wstęp
Zatwierdzony ponad dwa lata temu standard Extensible Markup Language (XML) rozpoczął okres bardzo szybkiego rozwoju tego metajęzyka. Jego twórcy bazując na wcześniejszych doświadczeniach stworzyli język prosty, rozszerzalny, o ścisłej definicji. Co więcej, rosnąca popularność tego języka i powiększający się obszar jego zastosowań sprawiają, że nadal trwają prace mające na celu dostosowanie go do nowych potrzeb. Powstało już kilka standardów bazujących na XML-u oraz znacznie rozszerzających jego możliwości, a wiele nowych jest w przygotowywaniu.
XML jest językiem opisu struktury dokumentu, pozwalającym na wyróżnienie w tekście informacji o znaczeniu poszczególnych jego fragmentów. Pierwowzorem XML-a jest ustalony i używany od wielu już lat metajęzyk Standard Generalized Markup Language (SGML), który pomimo swych dużych możliwości nigdy nie zdobył większej popularności. Skomplikowanie samego języka, do którego próbowano dołączyć wiele potencjalnie użytecznych, ale w praktyce rzadko wykorzystywanych elementów, utrudniało nie tylko tworzenie oprogramowania wspomagającego ten standard, ale i jego zrozumienie. Szybko rozwijająca się sieć Internet potrzebowała nowego medium wymiany informacji, które byłoby w stanie zastąpić lub chociażby wspomóc używany powszechnie format HTML. Potrzebowano rozszerzalności i uniwersalności SGML-a, ale za znacznie niższą cenę.
Konstrukcja XML-a, mimo że oparta o rozwiązania znane z SGML-a, choć dużo prostsza, nadal zachowuje potencjał poprzednika. Często można spotkać się z opinią, że XML dostarcza 80 procent funkcjonalności SGML-a przy jednoczesnym ograniczeniu do 20 procent stopnia komplikacji języka. Co ciekawsze dokumenty XML-owe są poprawnymi dokumentami SGML-owymi. Elegancka konstrukcja standardu znacznie ułatwiła zrozumienie samego języka, a w konsekwencji tworzenie oprogramowania. Powstało wiele systemów, często rozwijanych przez konkurujących ze sobą producentów, które wykorzystują XML w różnorodny sposób, najczęściej jako metodę reprezentacji swoich danych, czy do komunikacji z innymi systemami. Dzięki tego typu działaniom XML zaczął być postrzegany jako uniwersalny łącznik, jednolite medium wymiany danych umożliwiające zapewnienie zgodności pomiędzy tak bardzo różnorodnym oprogramowaniem, z jakim mamy obecnie do czynienia.
Jedną z bardziej zauważalnych i wykorzystywanych cech dokumentów XML-owych jest stosowanie formatu tekstowego. Pozwala to na bardzo łatwe czytanie oraz ręczne modyfikowanie informacji zawartej w takim dokumencie. Warto porównać to do problemów, które występują przy dokumentach zapisanych binarnie. W takich przypadkach często nawet odczytanie ich zawartości, nie mówiąc o modyfikacji, jest bardzo trudne, zwłaszcza, gdy nie posiadamy programu specjalnie przystosowanego do obsługi tego konkretnego formatu binarnego. Fakt możliwości wykorzystania do edycji dokumentów XML-owych niemal dowolnego edytora tekstowego nie oznacza, że nie można stworzyć programów lepiej nadających się do tego celu. Zwłaszcza, że ten najprostszy sposób radzenia sobie z edycją ma wiele wad, które stają się coraz dokuczliwsze wraz ze wzrostem wielkości dokumentu, stopniem skomplikowania jego struktury oraz rozległością koniecznych do przeprowadzenia modyfikacji. Dlatego też powstało wiele programów przeznaczonych do redakcji dowolnych dokumentów zapisanych w standardzie XML. Różnią się wieloma cechami: sposobem prezentacji edytowanego dokumentu, udostępnianymi metodami jego modyfikacji, uwzględnianiem różnych fragmentów standardu jak i standardów dodatkowych, stopniem pomocy udzielanej użytkownikowi, stopniem samodzielności czy możliwością zintegrowania z większym systemem. Cały czas pojawiają się też nowe. Warto zauważyć, że coraz częściej spotyka się w dostępnych edytorach bardziej zaawansowane funkcje, które w większym stopniu wykorzystują specyfikę XML-a.
W większości z dostępnych edytorów XML-owych zwrócono uwagę jedynie na jedną z cech dokumentów XML-owych dobre uformowanie[1]. Edytory te umożliwiały łatwe tworzenie hierarchicznej struktury dokumentu z elementów, atrybutów, tekstów, komentarzy itp. Nie korzystały jednak z informacji definiującej strukturę dokumentu. Co najwyżej zaznaczały błędy znalezione przez zewnętrzny parser. Ostatnio coraz częściej dostępne są edytory korzystające również z informacji zawartej w deklaracji typu dokumentu, bądź w jego odpowiedniku, w taki sposób, by użytkownik był cały czas informowany o wpływie swoich decyzji na strukturalną poprawność dokumentu[2]. Umożliwia to skupienie się nad znaczeniem wprowadzanych modyfikacji, bez potrzeby martwienia się o to, czy tak zmieniony dokument nadal będzie akceptowalny. Dodatkowo informowanie użytkownika przez edytor o konstrukcjach dostępnych w danym miejscu przyspiesza tworzenie poprawnych dokumentów spełniających określone wcześniej warunki znika potrzeba pamiętania nazw wszystkich wykorzystywanych elementów, atrybutów, czy ich wzajemnych zależności.
Celem niniejszej pracy jest przedstawienie projektu edytora, który powstał w celu zaprezentowania metody edycji dokumentów XML-owych wykorzystującej informację zawartą w Document Type Declaration[3] (DTD). Edytor posługuje się tekstowym trybem pracy działając bardzo podobnie do zwykłych edytorów tekstowych. W odróżnieniu od nich potrafi analizować redagowany dokument i wykorzystywać niektóre zawarte w nim informacje tak, aby ułatwić użytkownikowi pracę. Między innymi edytor wyszukuje informacje o użytym DTD, a następnie wczytuje go i używa zdefiniowanych w nim identyfikatorów do prezentacji spisu konstrukcji poprawnych w danym kontekście. Dodatkową cechą edytora jest jego budowa zaprojektowano go w taki sposób, że można wykorzystywać go jako części innych programów, przykładowo w miejscu zwykłego pola edycji tekstu.
W rozdziale 1 chciałbym krótko zaprezentować standard XML, skupiając się przede wszystkim na tych jego cechach, które są pomocne przy projektowaniu edytora. W tym rozdziale znajduje się też opis dwóch innych standardów zbudowanych na podstawie XML-a, rozszerzających jego możliwości i wpływających na konstrukcję edytora.
W rozdziale 2 przedstawię istniejące już i dostępne w Internecie edytory. Na początku wskażę te ich cechy, które z punktu widzenia tworzonego programu są najbardziej interesujące. Później zaprezentuję kilka wybranych edytorów, wraz z ich dłuższymi charakterystykami, oraz końcowe zestawienie ich własności.
W rozdziale 3 znajdą się informacje o projekcie edytora. Najpierw omówię cele, do jakich dążyłem projektując edytor, wskażę cechy edytora, na których najbardziej mi zależało, a następnie przedstawię dokładniej motywy stojące za kilkoma decyzjami projektowymi.
W rozdziale 4 przedstawię opis zrealizowanego w ramach tej pracy programu. Omówię ogólnie jego budowę, wyjaśnię jej wpływ na osiągnięcie wcześniej zakładanej funkcjonalności, jak również zaprezentuję niektóre ciekawsze funkcje programu. W tym rozdziale chciałbym jeszcze wspomnieć o zastosowanych metodach zapewniających możliwe dalsze rozszerzanie funkcjonalności edytora, jak również przedstawić niektóre z potencjalnych rozszerzeń.
Rozdział 5 poświęcę na podsumowanie projektu.
Rozdział
3
Cel projektu
W poprzednim rozdziale zaprezentowałem drobny wycinek oprogramowania służącego do edycji dokumentów korzystających ze standardu XML. Starałem się zwrócić uwagę na różnice w podejściu do reprezentacji dokumentu i metod jego modyfikacji. Jednocześnie wskazywałem te cechy programów, które wydawały mi się najważniejsze. Oczywiście ich wybór jest bardzo subiektywny, zależny od indywidualnych preferencji użytkownika. W moim przypadku największe znaczenie mają te cechy programów, dzięki którym można ułatwić oraz przyspieszyć redagowanie dokumentu, ale bez konieczności zmiany wcześniejszych przyzwyczajeń. Takimi też preferencjami kierowałem się projektując mój edytor.
Pomysł stworzenia tekstowego edytora dokumentów XML-owych powstał przy okazji prac nad kilkoma projektami, w których ważne miejsce zajmował XML. W większości z nich język ten był używany jedynie przez projektantów systemu, ale w niektórych istniała również potrzeba udostępnienia użytkownikom prostego, a zarazem dość uniwersalnego narzędzia do edycji tego typu dokumentów. W tych ostatnich przypadkach użycie jednego z dostępnych edytorów wiązało się z wieloma problemami. Prawie wszystkie edytory ograniczały swoją pomoc do kontroli, czy tworzony dokument jest poprawnie uformowany. Poprawność struktury dokumentu można było sprawdzić w tych edytorach jedynie w określonych momentach, co było dość niewygodne. Dodatkowo edytory te nie zostały skonstruowane z myślą o wykorzystaniu ich w większym systemie. Na koniec można jeszcze wspomnieć o problemie natury finansowej: ceny większości edytorów (a już w szczególności tych, które spełniałyby inne warunki) były dość wysokie, co w zestawieniu z warunkami licencyjnymi skutecznie ograniczało możliwość ich rozpowszechniania.
3.1 Wstępne założenia projektu edytora
Przystępując do projektu myślałem o stworzeniu uniwersalnego edytora XML-owego, jak najbardziej dostosowanego do moich potrzeb. Oto cechy edytora, do których osiągnięcia dążyłem projektując i implementując program Xpad.
ˇ Praca w systemie Microsoft Windows, w możliwie wielu jego wersjach. Funkcje programu, których implementacja wymagałaby wykorzystania bardziej zaawansowanych elementów systemu operacyjnego (zwłaszcza tych, które nie są dostępne w jego popularnych wersjach), w miarę możliwości powinny być opcjonalne. Chciałbym też, aby konstrukcja programu pozwalała na wykorzystanie jego części w innych systemach operacyjnych, po ewentualnych niewielkich modyfikacjach kodu.
ˇ Praca w trybie tekstowym, pozwalającym na dowolne modyfikacje źródła dokumentu, przy równoczesnej ciągłej kontroli jego poprawności. Innymi słowy projektowany edytor powinien zachowywać się jak zwykły edytor tekstowy, oferując funkcjonalność dostępną powszechnie w tego rodzaju programach, a dodatkowo pomagać przy edycji dokumentów XML-owych w taki sposób, by pomoc ta nie była dla użytkownika uciążliwa.
ˇ Pomoc przy edycji dokumentów stworzonych przy użyciu podstawowej wersji standardu XML. Do tego punktu można zaliczyć wyświetlanie podpowiedzi w postaci spisu poprawnych, w danym miejscu dokumentu, nazw elementów, ich atrybutów oraz nazw encji. Pomoc tego typu powinna być dostępna nawet w dokumentach, w których brak jest deklaracji typu. Oczywiście wtedy można ją ograniczyć, wyświetlając listę np. nazw elementów czy atrybutów już użytych w dokumencie.
ˇ Ciągła kontrola poprawności dokumentu wraz z zaznaczaniem tych jego fragmentów, które ją naruszają. Dotyczy to zarówno dobrego uformowania dokumentu, jak i poprawności strukturalnej. Kontrola ta powinna być możliwie pełna, jednak nie jest konieczne by wykrywała ona wszystkie błędy, zwłaszcza w poprawności strukturalnej.
ˇ Modułowa konstrukcja. Edytor powinien składać się z niezależnych części, tak by niektóre z nich można było wykorzystać jako części innych projektów, bądź zastąpić nowymi bez potrzeby modyfikacji istniejących. W szczególności powinno być możliwe przystosowanie programu do pracy z innymi typami dokumentów, jak np. kodem programu.
ˇ Budowa programu pozwalająca wykorzystać właściwą część edycyjną programu w innych systemach (ta cecha częściowo wynika z postulatu o modułowej konstrukcji programu). Oznacza to, że część edycyjna powinna w miarę możliwości obsługiwać standardy komponentów wizualnych ActiveX[10] (a również, jeśli to byłoby możliwe, ActiveDocument[11]).
ˇ Możliwość dołączenia do programu nowych, niezależnych modułów rozszerzających pierwotną funkcjonalność edytora. W przypadku dokumentów XML-owych mogłyby one udostępniać informację, podobną do tej, jaką można uzyskać z DTD, korzystając z innych metod, np. z deklaracji zapisanej w standardzie XML Schema lub z własnych plików konfiguracyjnych. Inne funkcje, które można by zrealizować poprzez tego typu rozszerzenia, to np. pomoc w tworzeniu wyrażeń w języku Xpath, czy prezentowanie zawartości dokumentu w niestandardowy sposób.
ˇ Użycie tylko takich zewnętrznych komponentów lub fragmentów kodu, których licencje nie nakładają ograniczeń na dalsze ich wykorzystanie.
3.2 Decyzje projektowe
W czasie prac nad edytorem napotkałem wiele problemów. Niektóre z nich, te bardziej istotne, dość mocno skorygowały moje pierwotne zamierzenia dotyczące bądź funkcjonalności edytora, bądź sposobów jej osiągnięcia. Poniżej chciałbym opisać część z nich.
3.2.1 Język programowania i biblioteki
Jedna z decyzji, którą musiałem podjąć podczas projektowania programu, dotyczyła wyboru języka programowania. W szerszym sensie determinuje to wybór platformy programowej, czyli jednolitego zbioru bibliotek, zasad ich użycia i sposobów implementacji potrzebnej funkcjonalności programu.
Pod uwagę brałem dwa języki programowania, Javę i C++. Opracowany przez firmę Sun język Java wraz z nieodłącznymi bibliotekami tworzącymi wirtualny system operacyjny, wydawał się być bardzo dobrym rozwiązaniem. Sam język jest elegancki i wolny od różnych niezbyt udanych konstrukcji znanych choćby z języka C++. Do zalet tego rozwiązania można też zaliczyć dostępne razem z językiem Java biblioteki, które w dużym stopniu upraszczają korzystanie z usług systemu operacyjnego. Umożliwia to skoncentrowanie się nad rozwiązaniem zasadniczego problemu, bez konieczności dokładnego poznawania szczegółów działania systemu operacyjnego. Szczególnie ważne jest to w przypadku systemu Windows, w którym z wielu powodów ogromna funkcjonalność często udostępniana jest w sposób nadmiernie skomplikowany. Niestety, niektóre z powyższych zalet środowiska Java, z punktu widzenia projektanta programu o zdefiniowanych wcześniej wymaganiach, są równocześnie wadami tego rozwiązania. Myślę, że język wraz z obowiązkowymi bibliotekami zbyt daleko posunął się w dążeniu do niezależności od systemu. W praktyce uniemożliwia to stworzenie programu działającego zgodnie z regułami obowiązującymi programy pracujące pod kontrolą konkretnego systemu operacyjnego i korzystającymi w pełni z jego możliwości. Uwidacznia się to zwłaszcza wtedy, gdy zaistnieje potrzeba użycia w programie bardziej zaawansowanych usług oferowanych przez system operacyjny. Inną wadą tego rozwiązania jest stosunkowo mała szybkość działania programów pisanych w tym języku[12] (szczególnie, gdy porówna się ją z wymaganiami stawianymi aplikacjom przeznaczonym tylko dla systemu Windows). To wszystko spowodowało, że zdecydowałem się użyć języka C++. Ale nadal pozostawał problem wyboru bibliotek, upraszczających korzystanie z funkcji systemu.
W przypadku programów pisanych w języku C++ i działających w systemie Windows ich wybór jest całkiem duży, ale tylko nieliczne z nich oferują pełną paletę możliwości, przynajmniej w zakresie celów stawianych przed projektowanym edytorem. Jednym z bardziej znanych jest biblioteka klas Microsoft Fundation Classes (MFC) [msftptf00]. Dużej liczbie programów stworzonych przy jej pomocy oraz dobremu opanowaniu jej mechanizmów przez programistów piszących pod Windows można zawdzięczać łatwość zdobycia zarówno przykładów, jak i prawie kompletnych implementacji niemal każdej potrzebnej części programu. Niestety, ma ona też wiele wad. Zaprojektowana dość dawno, była ciągle udoskonalana. Jednak konieczność zapewnienia zgodności z poprzednimi wersjami znacznie ograniczała pole manewru przy próbach unowocześnienia. Również używanym w niej konstrukcjom oraz metodom rozwiązania problemów programistycznych daleko do dzisiejszych standardów. Ponieważ zależało mi na możliwie małym edytorze, bez niepotrzebnego bagażu kodu, postanowiłem użyć rozwiązań znanych z innego systemu ATL.
Active Template Library (ATL) [msftptf00] jest biblioteką zaprojektowaną w celu uproszczenia tworzenia komponentów opartych na standardzie COM[13] przy pomocy języka C++. Jej konstrukcja bazuje na szablonach, wielokrotnym dziedziczeniu i makrodefinicjach. Pozwala ona znacznie uprościć tworzony kod poprzez udostępnienie implementacji wielu elementów standardowej funkcjonalności komponentów. Dzięki zastosowanym w bibliotece ATL rozwiązaniom tworzony przy jej pomocy kod jest przejrzysty, funkcjonalny i zawiera wszystkie wymagane części wewnątrz samego programu, bez konieczności instalowania w systemie dodatkowych bibliotek czy zasobów. Pozwala to na tworzenie bardzo małych, a jednocześnie w pełni wartościowych komponentów COM. Biblioteka ta przystosowana do wspomagania tworzenia komponentów, nie zawiera mechanizmów potrzebnych przy budowaniu całych programów. Pewną próbą mającą wypełnić tą lukę była nieoficjalnie tworzona przez programistów firmy Microsoft biblioteka Windows Template Library (WTL). Jest ona rozszerzeniem biblioteki ATL pomocnym przy budowie całych programów, udostępniając szablony implementujące kod potrzebny m. in. przy obsłudze okien, menu, dialogów oraz innych elementów systemu Windows. W bibliotece tej można znaleźć bardzo ciekawe rozwiązania, w wielu przypadkach znacznie przewyższające poziomem te oferowane przez MFC. Niestety, mimo wielu zalet, szanse na jej rozwój czy zdobycie większej popularności nie wydają się duże. Uznałem ją jednak za wystarczającą na potrzeby tego projektu.
Użycie bibliotek ATL sprawia, że zrealizowanie niektórych z zakładanych celów projektu edytora jest znacznie łatwiejsze. Przede wszystkim prostsze jest wykorzystanie jego części edycyjnej w postaci komponentu ActiveX w innych programach, gdyż biblioteka udostępnia implementację większości metod koniecznych do obsługi obowiązkowych interfejsów komponentu. Również implementacja interfejsów wymaganych przez standard Automation[14] staje się dużo łatwiejsza. Użycie WTL pozwala na dalsze uproszczenie implementacji tych fragmentów kodu programu, które są konieczne w środowisku Windows. Dodatkowo, biblioteka ATL tak bardzo upraszcza korzystanie z technologii COM, że można tą technologię stosować nawet wewnątrz programu, jako metodę separowania kodu i łączenia poszczególnych jego części.
3.2.2 Parser
Początkowo zakładałem wykorzystanie gotowego parsera. Jednak okazało się, że takie rozwiązanie utrudnia, a czasami uniemożliwia, osiągnięcie zakładanej funkcjonalności programu. Pierwszym problemem był brak dobrego sposobu uzyskania informacji zawartej w deklaracji typu dokumentu. W standardzie XML-a określone są minimalne wymagania stawiane parserom. Wśród nich wymienione jest obowiązkowe przekazywanie aplikacji danych o zdefiniowanych w DTD encjach parsowalnych oraz notacjach[15]. Wszystkie inne informacje zawarte w DTD parser może lub (w przypadku parserów sprawdzających zgodność struktury dokumentu z informacjami z DTD) musi rozpoznawać i przetwarzać na własne potrzeby, ale nie jest zobowiązany do ich udostępnienia aplikacji. Ponieważ podstawowa funkcjonalność edytora opiera się na informacjach dostarczanych przez DTD dokumentu, konieczne jest użycie parsera przekazującego te dane.
Innym problemem, jaki napotkałem, było skorelowanie pozycji znaku w tekście z jego rolą w strukturze dokumentu XML-owego. Rozwiązanie tego problemu ma duże znaczenie, gdyż zasadnicza część edytora bazuje na informacji określającej znaczenie każdego znaku w dokumencie, rozróżniającej znaki składające się np. na nazwy elementów, atrybutów, bądź ich wartości. Standardowy interfejs DOM nie udostępnia tego typu informacji. Posługując się zaś parserem implementującym inny popularny standard SAX (również w jego najnowszej wersji) jesteśmy w stanie bezpośrednio określić znaczenie jedynie niektórych fragmentów tekstu dokumentu. Przykładowo, parser przekazuje poprzez interfejs SAX informację o rozpoznanym znaczniku początku elementu, wraz z danymi o jego pozycji w tekście źródłowym, ale wszystkie atrybuty tego elementu udostępnia w postaci zbioru, bez możliwości określenia ich pozycji. W takich przypadkach należy użyć własnego parsera, dzięki któremu można określić położenie konkretnego atrybutu, ale stosując takie rozwiązanie negujemy korzyści wypływające z ograniczenia się tylko do użycia parsera SAX.
Kolejnym problemem wiążącym się z użyciem standardowego parsera jest jego reakcja na napotkane w dokumencie błędy. Wiele parserów, postępując zgodnie z wymaganiami zapisanymi w standardzie XML[16], po zgłoszeniu pierwszego błędu krytycznego (dotyczącego np. poprawnego uformowania dokumentu) przerywa dalszą pracę nie pozwalając na analizę reszty dokumentu. Taka reakcja parsera jest w pełni uzasadniona w normalnych aplikacjach, ale jest sprzeczna z wymaganiami projektowanego edytora, gdyż specyfika jego działania sprawia, iż redagowany dokument bardzo często jest niepoprawny. Innymi słowy, w projektowanym edytorze potrzebny byłby taki parser, który umożliwiałby analizę całych dokumentów, nawet tych z poważnymi błędami w budowie. Znajdując błąd w dokumencie parser powinien możliwie poprawnie przeanalizować resztę dokumentu, podobnie jak ma to miejsce w przypadku parserów HTML-owych.
Dostępne powszechnie parsery są przystosowane do wczytywania całych dokumentów. Użycie takiego typu parsera stanowi istotny problem, gdyż edytor wymaga szybkiego, wielokrotnego analizowania tego samego dokumentu po modyfikacjach nawet niewielkich fragmentów tekstu. Warto zauważyć, że większość zmian dokonywanych podczas redagowania dokumentu ogranicza się do pojedynczych znaków, wpływając na niewielki fragment struktury dokumentu. Należy dążyć do skrócenia czasu analizy dokumentu, gdyż następuje ona po każdej modyfikacji jego treści. Bardzo nieprzyjemną, lecz nadal spotykaną cechą edytorów jest zbyt długi czas upływający pomiędzy wciśnięciem klawisza, a pojawieniem się odpowiadającego mu symbolu na ekranie. Często jest to wynik trwających zbyt długo operacji wykonywanych bezpośrednio po naciśnięciu klawisza. Efekt ten można wyeliminować na dwa sposoby: projektując program wielowątkowy dokonujący części analizy w wątku pomocniczym lub odkładając wykonanie bardziej czasochłonnych operacji na czas przerwy w pisaniu. Pierwsze z rozwiązań jest trudniejsze w implementacji, zaś drugie jest niezbyt wygodne w przypadku szybciej piszących osób.
Przedstawione powyżej powody sprawiły, że zdecydowałem się na rozwiązanie zakładające użycie dwóch parserów. Jeden z nich to normalny, pełny parser języka XML. Używany byłby do odczytywania informacji zawartych w deklaracji typu dokumentu oraz, na życzenie użytkownika, w celu dokładnego sprawdzenia poprawności redagowanego dokumentu. Warto zauważyć, że istniałaby możliwość zastosowania dowolnego parsera, jeśli tylko udostępniałby wszystkie istotne informacje z DTD.
Drugi z używanych w edytorze parserów, parser inkrementalny, miałby specyficzną konstrukcję dostosowaną do nietypowych zadań. Należy do nich szybkie parsowanie modyfikowanego dokumentu, w taki sposób, aby jak najlepiej odtworzyć jego strukturę, nawet w przypadku napotkania poważnych błędów w jego budowie. Warto jeszcze raz podkreślić niezgodność pracy tego parsera z wymogami standardu. Aby skrócić czas pracy, parser powinien również uwzględniać informacje o lokalizacji dokonanych zmian. Przekazywane przez niego dane o strukturze dokumentu muszą być tak skonstruowane, by umożliwiać szybkie określenie tekstu odpowiadającego danemu fragmentowi struktury oraz to samo w drugą stronę części struktury odpowiadającej wskazanemu znakowi tekstu. Dzięki temu byłoby możliwe użycie tych danych do realizacji kilku najważniejszych funkcji programu, na przykład do obsługi kontekstowego formatowania dokumentu. Dane można też wykorzystać do zaprezentowania użytkownikowi dodatkowych informacji o określonym fragmencie dokumentu, jak również przy różnego rodzaju podpowiedziach. Dodatkowe informacje wyświetlane po wskazaniu kursorem miejsca w tekście dokumentu to między innymi definicje wskazanych encji, elementów, atrybutów oraz informacje pomocnicze przypisane do struktury dokumentu.
Dane przekazywane przez parser inkrementalny do edytora, w swej podstawowej postaci zawierałyby tylko informacje wynikające bezpośrednio z tekstu dokumentu. Dzięki temu nie musiałby on analizować i wykorzystywać deklaracji typu dokumentu, co znacząco uprościłoby jego konstrukcję. W kolejnym etapie do danych dołączana byłaby również informacja wynikająca z DTD bądź XML Schema. Zaletami tego rozwiązania jest zarówno uproszczenie budowy danych służących reprezentacji struktury dokumentu, zachowanie zdolności szybkiej ich modyfikacji (zwłaszcza przy niewielkich zmianach w treści), jak i umożliwienie wyboru dowolnej metody kontroli poprawności strukturalnej.
3.2.3 Reprezentacja dokumentu w edytorze
Kolejny problem stanowił wybór sposobu odwzorowania redagowanego dokumentu XML-owego w strukturach programu. Potrzebowałem zarówno czysto tekstowej postaci tego dokumentu, jak i dostępu do jego struktury logicznej. Początkowo zastanawiałem się nad możliwością przechowywania redagowanego dokumentu wyłącznie w postaci obiektów określonych w standardzie DOM, choć o nieco rozszerzonej definicji i funkcjonalności. Pozwalałoby to przechować w nich dodatkową informację, nieistotną z punktu widzenia języka XML i semantyki zapisanych przy jego pomocy danych. Informacja ta umożliwiałyby zachowanie oryginalnej tekstowej postaci dokumentu. W jej skład wchodzą między innymi dane o położeniu i rodzaju znaków równoważnych (w standardzie XML) pojedynczej spacji. Gdyby zaistniała potrzeba odwzorowania przy ich pomocy treści dokumentów z błędami uformowania, modyfikacje definicji obiektów byłyby jeszcze większe. Równocześnie niektóre operacje modyfikujące dokument stałyby się znacznie trudniejsze do implementacji. Jednym ze sposobów uproszczenia kodu edytora, jest ograniczenie się w trybie tekstowym do akceptowania tylko tych zmian, które nie naruszają dobrego uformowania dokumentu. Inne zmiany mogłyby być przeprowadzone za pomocą metod pośrednich (dodatkowe dialogi). Takie rozwiązanie, zastosowane w edytorze XED (rozdział 2.2.2) sprawia, że niektóre proste modyfikacje dokumentu stają się trudne do przeprowadzenia. Jeszcze jednym problemem, który trzeba rozwiązać decydując się na reprezentację tekstu dokumentu w postaci obiektów DOM, jest opracowanie sposobu umożliwiającego szybkie pobieranie danych z tej struktury w celu ich wyświetlenia (tzn. w postaci poszczególnych wierszy dokumentu). Podsumowując, rozwiązanie takie nie spełnia celów projektu, zwłaszcza uwzględniając skomplikowanie implementacji.
Za znacznie prostsze rozwiązanie uznałem stworzenie zwykłego edytora tekstowego, a następnie dodanie do niego specjalnej funkcjonalności edytora XML-owego. W ten sposób mogłem rozdzielić dwie podstawowe funkcje programu. Część implementująca zwykły edytor tekstowy odpowiadałaby za przechowywanie tekstu dokumentu, jego modyfikowanie i informowanie o tych zmianach. Dodatkowo część ta mogłaby zapewniać również inne usługi np. obsługę funkcji cofania i przywracania zmian (ang. Undo/Redo), czy wyszukiwania tekstu. A co ważniejsze, nie byłaby ona w żaden sposób przystosowana do edycji dokumentów XML-owych i mogłaby znaleźć zastosowanie w dowolnym typie edytora tekstowego. Druga część edytora odpowiadałaby za interpretację dokumentu w kategoriach języka XML i dopiero ona udostępniałaby funkcjonalność właściwą dla edytora XML-owego. Wykorzystywane byłyby w nim wyniki działania uproszczonego parsera opisanego w rozdziale 3.2.2, czyli stworzony obraz struktury dokumentu. Ta część edytora uzupełniałaby dane zawierające wskazane fragmenty dokumentu (a przekazywane przez pierwszą część edytora), o informacje określające ich znaczenie i sposób prezentacji.
W niektórych edytorach nie przechowuje się pełnej informacji o formatowaniu znaków, gdyż jej ustalenie, w razie potrzeby, jest bardzo proste. Dla przykładu, w programie EditPad każdemu wierszowi tekstu odpowiada informacja o przynależności jego pierwszego znaku do elementu struktury dokumentu (np. komentarza). Sposób formatowania kolejnych znaków wiersza ustala wywoływany w razie konieczności parser. Takie stosunkowo proste rozwiązanie często jest zupełnie wystarczające zwłaszcza, gdy rozmiar danych przechowywanych w każdym wierszu nie jest duży, a ponowna analiza tekstu dokumentu jest dostatecznie szybka i nie wpływa negatywnie na działanie programu.
W części edytorów (np. SciTE [scin00]) do każdego znaku dołącza się informację o sposobie jego prezentacji. Takie rozwiązanie pozwala na podział programu na część odpowiadającą za wyświetlenie dokumentu na ekranie i część, która określa formatowanie poszczególnych jego fragmentów. Ma to szczególne znaczenie w sytuacjach, gdy proces analizowania i formatowania dokumentu jest dość wolny i częste jego wykonywanie (np. gdy zachodzi potrzeba wyświetlenia fragmentu dokumentu), oznaczałoby znaczne spowolnienie działania programu. Korzystając z tego rozwiązania, formatowanie wykonujemy tylko w następstwie modyfikacji treści dokumentu, częściej zaś wystarczy użyć wcześniej zapamiętanych danych. Dodatkowo proces formatowania można podzielić na dwa etapy. W pierwszym dokonuje się wstępnego sformatowania znaków. Operacja ta przebiega na tyle szybko, że można wykonać ją bezpośrednio po zmodyfikowaniu treści dokumentu, a przed jego wyświetleniem. Drugi etap formatowania dokumentu polega na doprecyzowaniu niektórych elementów formatowania, np. poprzez dodanie kolorowych linii podkreślających te fragmenty dokumentu, które naruszają jego strukturalną poprawność. Operacja ta może być asynchroniczna, trwać dłużej i modyfikować wcześniej ustalone formatowanie dokumentu.
W projektowanym edytorze zastosowałem rozwiązanie zapożyczające po trochu z obu powyżej zaprezentowanych metod ustalania sposobu formatowania dokumentu. Edytor posługując się strukturą używaną przez parser inkrementalny ustala sposób formatowania dokumentu. Ponieważ jest to bardzo szybki proces, nie ma potrzeby dublowania informacji poprzez przechowywanie danych o znaku łącznie z informacjami o sposobie jego wyświetlenia. Dodatkowo w procesie ustalania sposobu formatowania tekstu można wykorzystać dane parsera, na podstawie których można wyróżnić elementy naruszające dobre uformowanie dokumentu lub jego strukturalną poprawność.
Kończąc omawianie metod reprezentacji tekstu i struktury dokumentu w programie warto jeszcze wspomnieć o rozwiązaniu zaprezentowanym w pracy [andrew86]. Przedstawiono tam sposób przechowywania tekstu dokumentu i informacji o sposobie formatowania jego fragmentów. Tekst reprezentowany jest logicznie jako tablica znaków, zaś informacje o sposobie jego wyświetlania trzymane są w kolekcji, której elementami są struktury zawierające numer pierwszego znaku i długość obszaru, którego dotyczy dany element. Z każdym elementem kolekcji związana jest informacja o sposobie wyświetlania danego fragmentu dokumentu. Modyfikując tekst dokumentu należy w zależności od położenia zmian uaktualnić informacje w elementach powyższej kolekcji. To rozwiązanie wydaje się być bardzo wygodne w przypadku edytorów, w których sposób formatowania poszczególnych znaków jest określany przez użytkownika. Jednakże w przypadku projektowanego edytora XML-owego, sposób formatowania dokumentu nie jest stały, gdyż każda modyfikacja jego treści może spowodować konieczność ponownego ustalania sposobu formatowania każdego znaku. Dodatkowo niekorzystną cechą tego rozwiązania są wymagania pamięciowe związane z przechowywaniem informacji.
Rozdział
4
Opis konstrukcji programu XPad
W rozdziale 3.2 opisałem niektóre z decyzji, które podjąłem w czasie projektowania programu XPad (Rysunek 9) i podczas jego implementacji. Poniżej chciałbym nieco bliżej zaprezentować jego budowę, przedstawić metody osiągnięcia niektórych celów oraz dokładniej omówić działanie edytora.
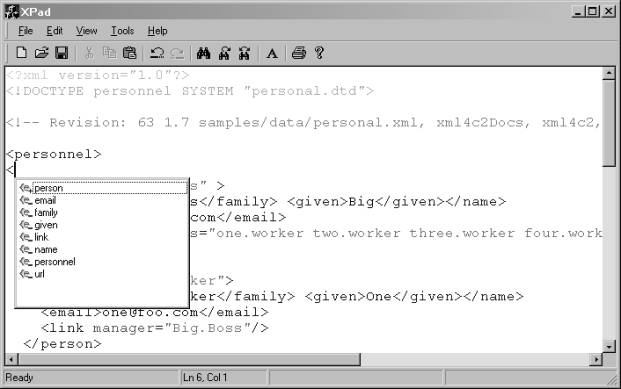
Rysunek 9. Edytor XPad
4.1 Ogólna koncepcja
Jednym z ważniejszych celów projektu było stworzenie programu, którego części można byłoby wykorzystać i modyfikować niezależnie od siebie, bez konieczności dokonywania zmian w ich kodzie źródłowym. Dlatego zdecydowałem się zastosować komponenty. Komponentami są niezależne moduły programu, które komunikują się poprzez abstrakcyjne interfejsy. Każdy z komponentów może implementować kilka interfejsów, zarówno mających różne przeznaczenie, jak i będących kolejnymi wersjami pojedynczego interfejsu. Implementacja interfejsu przez komponent to zobowiązanie do zapewnienia obsługi wszystkich zadeklarowanych w interfejsie metod. Ponieważ komponenty mogą komunikować się jedynie poprzez interfejsy, to szczegóły ich budowy i działania nie są znane, co pozwala na zastąpienie poszczególnych komponentów bez potrzeby modyfikacji (oraz nawet ponownego kompilowania) reszty. Oczywiście powyższa koncepcja znana jest od dawna, a w niektórych językach programowania (np. w Javie) jest bardzo istotnym elementem ich konstrukcji. W swoim programie zastosowałem rozwiązania bazujące na technologii COM (dokładniejszy opis znajduje się w rozdziale 3.2.1), dzięki czemu, zastosowanie powyżej przedstawionej koncepcji stało się łatwiejsze w programie napisanym w języku C++. Wykorzystanie tej technologii nie tylko upraszcza wewnętrzną strukturę programu, ale umożliwia też łatwiejsze zintegrowanie go z innymi narzędziami dostępnymi w środowisku Windows.
4.2 Budowa programu
Komponenty tworzące program można podzielić na dwie grupy. Pierwsza z nich zapewnia środowisko, druga zaś implementuje właściwą część edycyjną. Tego rodzaju rozdzielenie funkcjonalności pozwala nie tylko wykorzystywać część edycyjną w postaci komponentu w innych programach, ale również użyć części kontrolującej środowisko tam, gdzie byłaby przydatna jej funkcjonalność.
Jak już wspomniałem, koncepcja implementacji programu opiera się na idei komponentów. Warto dokładniej przyjrzeć się jej wpływowi na współdziałanie powyżej zdefiniowanych części edytora. Przyjmijmy, że część implementująca środowisko nie potrafi obsługiwać pasków narzędzi lub paska stanu. W takim przypadku właściwa część edycyjna, czyli komponent implementujący widok dokumentu, może uzyskać o tym informację przez sprawdzenie, czy komponent środowiska obsługuje określony interfejs. Jeśli sprawdzenie wypadnie negatywnie, to komponent implementujący widok dokumentu może ograniczyć swoją funkcjonalność albo stosować jakieś własne metody symulacji brakujących części interfejsu użytkownika. Po zainstalowaniu ulepszonej wersji komponentu środowiska, nowa funkcjonalność stanie się automatycznie dostępna dla wszystkich komponentów (dokładniej dla tych, które tej funkcjonalności oczekiwały i potrafią ją wykorzystać). Jednocześnie komponenty nie wymagające tej funkcjonalności nadal będą pracowały poprawnie, tak długo, jak długo będą dostępne wykorzystywane przez nie interfejsy (być może takie, które zapewniają słabszą wersję jakiejś usługi). Możliwe jest też np. stworzenie nowego rodzaju komponentów działających w warstwie pomiędzy komponentami środowiska a komponentami części edycyjnej programu pozwalających na łączenie wielu różnych dokumentów w projekty. Komponenty obu wcześniejszych warstw nie musiałyby być modyfikowane, gdyż nadal jedne obsługiwałyby pojedynczy dokument, zaś drugie działałyby tak jakby były jedynymi komponentami edycyjnymi obsługiwanymi przez program.
4.2.1 Środowisko
Komponenty środowiska zapewniają miejsce, w którym można umieścić komponenty implementujące dokument i jego widoki. Zarządzają one tymi częściami aplikacji oraz jej interfejsu graficznego, które są współdzielone przez poszczególne dokumenty i widoki. Przykładem takich elementów jest główne okno aplikacji, paski narzędzi, pasek stanu oraz niektóre standardowe dialogi. Ta część programu XPad odpowiada również za stworzenie szablonu dokumentu, na bazie którego mogą powstawać nowe dokumenty określonego typu. Odpowiada również za powołanie nowych komponentów implementujących ich widoki.
Komponenty implementujące tą część edytora oferują wiele usług. Oto najważniejsze z nich.
ˇ Tworzenie i zarządzanie głównym oknem aplikacji, wraz z konieczną komunikacją z systemem operacyjnym.
ˇ Tworzenie i zarządzanie wszystkimi innymi oknami używanymi przez aplikację, zwłaszcza utworzonymi na żądanie komponentów obsługujących dokumenty. Do tej kategorii zaliczyć można zarówno główne okna widoków dokumentu, jak i okna pomocnicze (np. wyświetlające strukturę dokumentu), ale tylko takie, które mają być kontrolowane przez środowisko. Położeniem i wyglądem ramek (a co za tym idzie częścią ich funkcjonalności np. możliwością dokowania, czyli przyczepiania do ramki okna aplikacji) wszystkich tego typu okien zarządza środowisko. Natomiast zawartością tych okien sterują komponenty odpowiadające za widoki dokumentu.
ˇ Udostępnianie współdzielonych części interfejsu użytkownika. Części interfejsu, takie jak główne menu aplikacji, pasek stanu, niektóre paski narzędziowe, są dostępne zawsze, ale ich funkcje zależą od obiektu aktywnego w danym czasie. Informacje wyświetlane w pasku stanu mogą być inne w przypadku, gdy użytkownik pracuje w oknie tekstowym dokumentu, a inne, gdy używa graficznej, drzewiastej reprezentacji jego struktury. Jeszcze wyraźniej można zauważyć tego rodzaju współdzielenie zasobów uruchamiając w systemie Windows programy korzystające z technologii OLE.
ˇ Udostępnienie pewnych ogólnych usług dla działających w tym środowisku komponentów. Do tej grupy można zaliczyć możliwość przechowywania ustawień preferencji użytkownika dla poszczególnych komponentów w jednym miejscu, bądź zapamiętywanie stanu poszczególnych elementów interfejsu graficznego przy końcu pracy.
Należy podkreślić, że powyższa lista nie jest zamknięta. Komponentowa budowa programu pozwala na niezależne rozszerzanie poszczególnych jego części, co ułatwia dodanie nowych usług do części obsługującej środowiska (np. podobnych do oferowanych w pakiecie Microsoft Visual Studio).
4.2.2 Edytor
Część zasadnicza edytora XML-owego obejmuje komponenty implementujące funkcjonalność dokumentów i funkcjonalność ich widoków. Komponenty te odpowiadają m. in. za stworzenie nowego dokumentu, wczytanie już istniejącego bądź zapisanie redagowanego. Odpowiadają również za jego modyfikowanie, analizę poprawności z punktu widzenia standardu XML oraz udostępnianie danych potrzebnych do implementacji funkcji kontekstowego sugerowania nazw elementów i atrybutów.
Część tę tworzy kilka komponentów, z których każdy jest odpowiedzialny za implementację pewnej części funkcjonalności edytora. Komponenty można zaklasyfikować do jednej z dwóch grupy. W pierwszej realizowane są funkcje dokumentu XML-owego, tzn. przechowuje się jego zawartość, umożliwia modyfikowanie jego treści, udostępnia informacje na temat jego struktury. Do drugiej zaliczane są komponenty odpowiadające za graficzną prezentację dokumentu widoki.
Poniższa lista zawiera opis najważniejszych komponentów z pierwszą grupy, czyli tych, które zarządzają dokumentem.
ˇ Komponent zarządzający reprezentacją dokumentu tekstowego. Przechowuje on tekst dokumentu i umożliwia wykonanie na nim prostych operacji. Między innymi, pozwala zastąpić określony fragment dokumentu nową treścią. Umożliwia również pobranie zawartości dowolnego wiersza bądź fragmentu dokumentu. Dodatkowo udostępnia metody ułatwiające obsługę znaków tabulacji. To wszystko należy do jego podstawowej funkcjonalności, ale może też implementować dodatkowo inne pomocne interfejsy np. wyszukiwania tekstu. Komponent ten po każdej modyfikacji tekstu powiadamia inne zarejestrowane w nim komponenty o tym fakcie.
ˇ Komponent umożliwiający zaimplementowanie możliwości cofania ostatniej operacji dokonanej na tekście dokumentu oraz jej ponownego wykonywania (funkcja Undo/Redo). Komponent ten może też oferować rozszerzoną usługę, np. pozwalać na zapamiętanie sekwencji operacji zmian tekstu, oraz określenia typu każdej z nich (np. w celu wyświetlenia listy zawierającej informację, pozwalającą stwierdzić, czy wycofywana bądź przywracana operacja polegała na wpisaniu tekstu, czy na przeformatowaniu jego części).
ˇ Komponent, którego zadaniem jest wczytanie dokumentu ze wskazanego pliku bądź zapis do tego pliku z uwzględnieniem kodowania dokumentu. Program do przechowywania dokumentu w pamięci korzysta ze standardu Unicode, stąd wynika potrzeba jego konwersji. Od komponentu jest wymagana obsługa standardu kodowania znaków UTF-8 oraz obu wersji Unicodu (Little i Big Endian), ale oczywiście im więcej innych rodzajów kodowania będzie rozpoznawanych, tym lepiej. W praktyce komponent ten będzie zapewne korzystał z usług oferowanych przez bibliotekę MLang będącą częścią pakietu Microsoft Internet Explorer, bądź np. z biblioteki firmy IBM o nazwie ICU, która również pozwala na obsługę różnych standardów kodowania tekstu.
ˇ Komponent ułatwiający użycie pełnego parsera języka XML. Wykorzystywany jest głównie w dwóch celach. Po pierwsze w przypadku konieczności sprawdzenia na żądanie użytkownika poprawności całego dokumentu. Po drugie w celu odczytania informacji z deklaracji typu dokumentu. Komponent ten nie musi sam zawierać implementacji parsera. Może wykorzystać także parsery zewnętrzne, jednakże pod warunkiem, że nie pociągnie to za sobą zmniejszenia jego wymaganej funkcjonalności.
Program wykorzystuje trzy komponenty, które zapewniają funkcjonalność widoku dokumentu.
ˇ Komponent prezentujący dokument w formacie tekstowym. Do jego zadań należy wyświetlenie formatowanego tekstu (jeśli komponent realizujący funkcje dokumentu udostępnia interfejs pozwalający uzyskać informacje o sformatowaniu wskazanego fragmentu dokumentu), komunikacja z komponentami środowiska zarządzającymi oknami.
ˇ Komponent wyświetlający strukturę redagowanego dokumentu. Komponent ten korzysta ze standardowego obiektu graficznego systemu Windows w celu wyświetlenia drzewa, z pomocą którego można np. zaznaczyć i znaleźć w widoku tekstowym określony fragment struktury.
ˇ Komponent obsługujący okienko używane w czasie dopełniania nazw. Jest to bardzo prosty komponent, do którego zadań zalicza się tylko obsługę okna z listą nazw i zaznaczanie nazwy, która jest najbardziej podobna do wpisanej części.
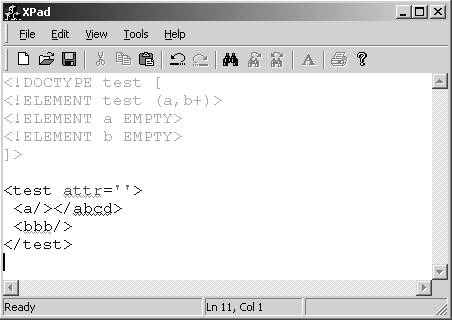
Rysunek 10. Wyróżnianie błędów w dokumencie
4.3 Funkcje edytora
Edytor XPad jest edytorem tekstowym, w którym zastosowano mechanizmy pomocne przy redagowaniu dokumentów XML-owych. Poniżej znajdują się opisy niektórych usług oferowanych przez edytor.
ˇ Edycja dokumentu tekstowego. Dostępne są wszystkie funkcje, które można spotkać w normalnych edytorach tekstowych: wyszukiwanie i zastępowanie tekstu, możliwość wielokrotnego wycofywania operacji i przywracania wycofanych.
ˇ Możliwość zaznaczania fragmentów dokumentu wyznaczanych elementami jego struktury, przenoszenia kursora na początek lub koniec wskazanego elementu.
ˇ Dopełnianie nazw elementów, atrybutów, encji, uwzględniające informacje zawarte w deklaracji typu dokumentu. Program pokazuje również wszystkie identyfikatory użyte w dokumencie, a nie zadeklarowane w DTD, dzięki czemu możliwa jest praca także z dokumentami nie posiadającymi DTD. Jednak w tym ostatnim przypadku wyświetlane są zawsze wszystkie użyte nazwy bez jakiegokolwiek ich podziału, gdyż edytor nie jest w stanie określić, które z nich mogą być użyte w danym miejscu.
ˇ Formatowanie tekstu dokumentu XML-owego z uwzględnieniem składni języka. Edytor wyróżnia kolorami nazwy elementów, atrybutów, komentarze ułatwiając rozróżnienie tych konstrukcji.
ˇ Ciągła analiza tekstu dokumentu w celu rozpoznania jego XML-owej struktury. Program podczas modyfikowania dokumentu rozpoznaje jego strukturę oraz potrafi wykryć niektóre błędy, takie jak podwójne użycie tego samego atrybutu, brak znacznika kończącego element bądź użycie elementu, który nie został zadeklarowany w DTD dokumentu. W celu wyróżnienia błędów w redagowanym dokumencie program posługuje się kilkoma metodami. Używa czerwonej czcionki do wskazania tych konstrukcji, które nie mogą być poprawnie sparsowane, jak na przykład rozpoczęcie nazwy atrybutu od cyfry. Jeśli natomiast można poprawnie rozpoznać dany fragment dokumentu, ale narusza on dobre uformowanie dokumentu, to ten fragment zostanie podkreślony czerwoną falującą linią (Rysunek 10). Jako przykład można podać znacznik otwierający element bez odpowiadającego mu znacznika kończącego. W przypadku naruszenia poprawności strukturalnej np. poprzez użycie niezadeklarowanego atrybutu błędny element podkreślony zostanie na zielono. Trzeba jednak pamiętać, że nie wszystkie błędy znajdujące się w dokumencie są zaznaczane. Aby mieć pewność, że redagowany dokument jest poprawny, można nakazać edytorowi przeprowadzenie pełnej kontroli dokumentu.
ˇ Wykonywanie sprawdzania dobrego uformowania dokumentu oraz jego zgodności z DTD (jeśli dokument zawiera deklarację typu). Użytkownik ma możliwość ręcznego wywołania tej funkcji, głównie w celu dokładnego sprawdzenia poprawności redagowanego dokumentu.
ˇ Możliwość wczytywania i zapisu dowolnych dokumentów tekstowych zakodowanych w standardach Unicode lub UTF-8. Dokumenty, w których kodowanie znaków jest określone inaczej, muszą rozpoczynać się poprawną deklaracja dokumentu XML-owego. W takich przypadkach edytor korzysta z komponentu, w którym z kolei wykorzystana jest biblioteka MLang, będąca integralną częścią programu Microsoft Internet Explorer (biblioteka ta nie może być rozpowszechniana samodzielnie).
ˇ Program czytając lub zapisując dokument traktuje go jako zwykły dokument tekstowy (jeśli się pominie kwestię związaną z rozpoznawaniem deklaracji dokumentu XML-owego używaną do określenia standardu kodowania znaków). Umożliwia więc wczytanie nawet dokumentów niepoprawnie uformowanych oraz nie wymaga poprawienia wszystkich znalezionych błędów przed rozpoczęciem właściwej pracy.
4.4 Rozbudowa programu
Edytor XPad może być wykorzystywany przy redagowaniu dokumentów XML-owych, ale nie jest on w stanie konkurować z edytorami komercyjnymi. Nie było to też celem jego tworzenia. Starałem się raczej tak go zaprojektować, by móc testować za jego pomocą różne pomysły i rozwiązania. Chciałem by jego konstrukcja była możliwie otwarta, by dawała się łatwo zmodyfikować lub rozszerzyć o kod implementujący nową funkcjonalność. Edytor w swej podstawowej wersji nie udostępnia wielu często spotykanych funkcji. Wiele z jego części wymaga ulepszenia, bądź całkowitej przebudowy. Co ciekawe, komponentowa budowa programu pozwala na sukcesywne ulepszanie poszczególnych jego fragmentów nawet przez niezależnie pracujące osoby.
Spis możliwych ulepszeń programu mógłby być bardzo długi, gdyż można znaleźć wiele funkcji przydatnych w tego typu aplikacji. Poniższe zestawienie obejmuje jedynie niektóre z możliwych udoskonaleń, szczególnie te, których brak najbardziej odczuwa się przy pracy z edytorem.
ˇ Wspomagania standardu przestrzeni nazw. Jest to jedno z najbardziej istotnych rozszerzeń funkcjonalności edytora. Nie tylko ułatwia ono redagowanie dokumentów wykorzystujących ten standard (wśród nich są popularne arkusze stylów XSL), ale też pozwala na dodanie do edytora funkcjonalności zależnej od tego standardu.
ˇ Możliwość używania standardu XML Schema (zachowując współdziałanie z DTD). Wobec rosnącego znaczenia nowego standardu definiowania struktury dokumentu jego implementacja w edytorze jest na pewno bardzo potrzebna. Podobnie jak w przypadku przestrzeni nazw, funkcjonalność edytora mogłaby być znacznie powiększona, gdyby udało się dodać rozpoznawanie tego typu opisu struktury dokumentu.
ˇ Większa pomoc przy edycji dokumentów, w których zastosowano niektóre z bardziej popularnych standardów, jak XSL lub XLink. Pomoc ta powinna jak najbardziej upraszczać proces edycji tego typu plików nawet bardziej, niż by można to było uczynić wykorzystując jedynie informację dostępną poprzez analizę schematu struktury pliku.
ˇ Rozbudowanie dostępnych widoków i stworzenie nowych. Dostępne w edytorze widoki edytowanego dokumentu w postaci tekstowej i drzewiastej są jednymi z wielu użytecznych. Przykład edytora XML Spy pokazuje, że nawet sposób pokazywania drzewiastej struktury dokumentu można bardzo udoskonalić. Również tryb tekstowy można rozbudować o nowe możliwości jak np. ukrywanie niektórych fragmentów tekstu.
ˇ Zapis plików w różnych standardach (np. automatyczna zamiana niektórych znaków w tekście dokumentu na encje znakowe).
ˇ Możliwość obserwowania bezpośrednio w edytorze wyników przekształceń wykorzystujących redagowany arkusz stylów XSL. Taka funkcjonalność, często udostępniana przez programy komercyjne, jest stosunkowo łatwa do zaimplementowania, a równocześnie bardzo pomaga w pracy z takimi rodzajami plików.
ˇ Ulepszenie trybu wyszukiwania tekstu w dokumencie (np. poprzez możliwość ograniczenia obszaru szukania do wartości atrybutów) oraz wskazywania i zaznaczania jego fragmentów (np. przy pomocy wyrażeń XPath).
ˇ Poprawienie funkcjonalności interfejsu aplikacji, a w szczególności umożliwienie modyfikowania pasków narzędzi oraz skrótów klawiaturowych. Zmiany może nie są konieczne, ale na pewno mile widziane.
ˇ Drukowanie tekstu dokument XML-owego. Tę funkcjonalność można zaimplementować stosunkowo łatwo, pod warunkiem, że edytor miałby opcję łamania wierszy (ang. word wrap).
ˇ Zarządzanie projektami w przypadku dokumentów XML-owych, z których każdy jest zapisywany w osobnym pliku, możliwość łączenia wielu plików w ramy jednego projektu jest dość istotna.
Rozdział
5
Zakończenie
Podsumowując swój projekt chciałbym jeszcze raz odnieść się do podjętych w czasie jego trwania decyzji oraz celów, jakie postawiłem sobie na początku pracy, jak również do otrzymanych wyników.
Przede wszystkich chciałbym zaznaczyć, że nie dążyłem do stworzenia programu, dorównującego łatwością obsługi czy funkcjonalnością programom komercyjnym. Zamierzałem jedynie zaprojektować taki edytor, który można by było w przyszłości rozbudowywać oraz używać jako wygodnej podstawy do dalszych eksperymentów. Zależało mi również na doświadczeniu, jakie mógłbym zdobyć w czasie realizacji tego projektu, a następnie wykorzystać przy konstruowaniu edytorów dostosowanych specjalnie do pracy z tekstami programów tworzonych w niektórych językach programowania. Tego typu edytory powinny nie tylko udostępniać wyróżnianie składni (obecnie jest to bardzo często spotykana funkcja edytorów), ale też automatycznie analizować tekst. Wyniki tej analizy można by wykorzystać np. przy prezentacji pewnych części dokumentu w innej formie (np. wyświetlającej jedynie nagłówki funkcji), jak również do stworzenia systemu inteligentnej pomocy. Pozwalałby on na podpowiadanie możliwych do użycia w danym miejscu nazwy zmiennych, klas i metod, na wyświetlenie dodatkowej informacji na ich temat, oraz na szybkie informowanie o zauważonych błędach (np. użycie niezadeklarowanej zmiennej). Z dotychczasowych doświadczeń wynika, że konstrukcja edytora XML-owego oraz wyżej wspomnianych jest podobna, a co za tym idzie zarówno zdobyte w trakcie tworzenia projektu doświadczenie jak i stworzone fragmenty kodu programu, można będzie wykorzystać w kolejnych pracach.
Równocześnie chciałbym wyjaśnić, że dostępna wersja programu jest jedną z wielu powstałych w czasie realizacji projektu. Na pewno trudno uznać ją za ostateczną, za produkt łączący wszystkie doświadczenia i stanowiący ich ukoronowanie, dlatego choćby, że nie zawiera wszystkiego nad czym pracowałem i co udało mi się osiągnąć. Jest raczej wskazaniem kierunku, w którym chciałbym dalej pójść. Powodem takiego stanu rzeczy jest fakt, że znalazła się w niej tylko część pomysłów dotyczących funkcjonalności edytora oraz sposobów jej osiągnięcia. Niektóre okazały się dostatecznie dobre, by je pozostawić, z niektórych zaś zrezygnowałem po stwierdzeniu, że dalsza praca nad nimi jest bezcelowa. Natomiast jeszcze inne, pomimo poprawnego działania, zastąpiłem okresowo ich prostszymi wersjami, często w celu ułatwienia sobie prac nad innymi częściami edytora. Ponieważ traktowałem edytor głównie jako sposób przetestowania różnych idei związanych realizacją redagowania dokumentów, nigdy nie starałem się, by edytor osiągnął jakąś z góry ustaloną formę. To ostatnie byłoby trudne, zważywszy, że w czasie projektu często zmuszony byłem ponownie zastanawiać się nad wcześniej wybranymi celami, gdy okazywały się albo mniej przydatne, niż zakładałem na początku, albo zbyt trudne do implementacji.
Z perspektywy czasu wiele decyzji podjętych w czasie projektowania oraz implementacji edytora trudno uznać za w pełni uzasadnione. Co prawda, znacznie łatwiej to zauważyć mając większe doświadczenie zdobyte właśnie dzięki pracy nad nim, podczas prób wyboru optymalnych rozwiązań oraz implementacji różnorodnych sposobów osiągnięcia zakładanej funkcjonalności. Mimo to, przeglądając wszystkie nietrafione pomysły, można mieć wrażenie, że choćby część z nich można było przewidzieć i wcześniej z nich zrezygnować, bądź zastosować inne metody ich realizacji.
Jako część projektu zbudowałem pełny parser sprawdzający poprawność struktury. Poświęciłem na to stosunkowo dużo czasu, zwłaszcza przy tworzeniu tych jego części, które są odpowiedzialne za parsowanie DTD. Standard XML jest w tym miejscu dość zawiły (przynajmniej dla mnie) i w wielu przypadkach dopiero porównanie tekstu standardu z wynikami działania parsera, na zestawie testowych dokumentów XML-owych, pozwalało ustalić zgodny ze standardem sposób działania parsera. Do zalet własnoręcznego napisania parsera zaliczyłbym nie tylko możliwość dostosowania go do specyficznych potrzeb edytora bądź innego programu (znacznie ułatwione z uwagi na dobrą znajomość sposobu jego działania), możliwość dokładnego zapoznania się zarówno z tekstem standardu definiującego język XML, ale też posiadanie nieograniczonych praw do tej implementacji. Natomiast wśród wad takiego rozwiązania wymienić można zarówno większe trudności przy rozbudowie i uaktualnianiu kodu, jak i dużą ilość czasu, jaką musiałem poświęcić na jego stworzenie. Jak napisałem w rozdziale 3.2.2, początkowo planowałem znacznie większe wykorzystanie tego parsera w programie, jednak wraz z zastosowaniem parsera inkrementalnego, jego rola znacznie zmalała. Obecnie wykorzystuję go tylko do sprawdzania poprawności strukturalnej całego dokumentu względem deklaracji typu dokumentu oraz do odczytywania informacji z DTD. Obie te rzeczy stosunkowo łatwo wykonać przy użyciu np. parsera MSXML 3.0. Dlatego pytanie o zasadność konstrukcji własnego parsera i związanymi z tym nakładami pracy nadal pozostawiam otwarte.
Innym problemem, często napotykanym podczas implementacji edytora, było zrozumienie działania niektórych funkcji systemu operacyjnego Windows. Pomimo posiadania dokładnej dokumentacji wraz z wieloma przykładami, niekiedy trudno było mi odgadnąć prawidłowy sposób ich użycia, bądź zastosować preferowany sposób rozwiązania konkretnego problemu. To wszystko znacznie wydłużało czas realizacji projektu. Sądzę, że użycie innego środowiska do testowania różnych implementacji niektórych z funkcji edytora byłoby znacznie lepszym rozwiązaniem, nawet przy założeniu konieczności późniejszego przepisania ich w języku C++.
W sumie uważam, że projekt edytora XML-owego spełnił swoje zadanie. Pracując nad nim wiele dowiedziałem się o pisaniu tego typu programów. Miałem też możliwość zmierzenia się z wieloma problemami pojawiającymi się zarówno w czasie projektowania jak i implementacji. Wiele z tych doświadczeń już udało mi się wykorzystać w innych projektach, dzięki czemu mogłem uniknąć popełnienia ponownie tych samych błędów, które wpłynęły niekorzystnie na realizację tego projektu.
Literatura
[amaya00] Amaya, http://www.w3.org/Amaya, 2000.
[andrew86] Wilfred J. Hansen, Data Structures in the Andrew Text Editor, http://www.cs.cmu.edu/~wjh/papers/byte.html, 1986.
[badstyle96] Tony Sanders, HTML Bad Style Page, http://www.earth.com/bad-style/, 1996.
[bernerslee00] Tim Berners-Lee, http://www.w3.org/People/Berners-Lee/Overview.html, 2000.
[bosakcv99] Curriculum Vitae: Jon Bosac, http://www.ibiblio.org/bosak/cv.htm, 1999.
[htmlhist] Tim Berners-Lee, A short history of web development, http://www.w3.org/People/Berners-Lee/ShortHistory.html
[htmlhp00] HyperText Markup Language Home Page, http://www.w3.org/MarkUp/, 2000.
[mathhp00] W3Cs Math Home Page, http://www.w3.org/Math/, 2000.
[msftptf00] Microsoft Corp, Platform SDK, 2000.
[sax00] David Megginson, SAX 2.0/Java final release,http://www.megginson.com/SAX/, 2000.
[scin00] Neil Hodgson, Scintilla and SciTE, http://www.scintilla.org, 2000.
[sgml86] Information processing Text and office systems Standard Generalized Markup Language (SGML), ISO8879:1986.
[sgmlhist93] Charles Goldfarb, SGML History, http://www.oasis-open.org/cover/sgmlhist0.html, 1993.
[sgmlxml97] James Clark, Comparision of SGML and XML, http://www.w3.org/TR/NOTE-sgml-xml-971215, 1997.
[valid95] Tony Sanders, Why Validate Your HTML, http://www.earth.com/bad-style/why-validate.html, 1995.
[xhtml00] XHTML 1.0: The Extensible HyperText Markup Language, http://www.w3.org/TR/xhtml1, 2000.
[xmladn98]Tim Bray, The Annotated XML 1.0 Specification, http://www.xml.com/axml/testaxml.htm, 1998.
[xmlgd99] Ian S. Graham, Liam Quin, The XML Specification Guide, John Wiley & Sons Inc., 1999.
[xmlptr00] XML Pointer, XML Base, XML Linking, http://www.w3.org/XML/Linking.html, 2000.
[xmlspec98]Tim Bray, Jean Paoli, C.M. Sperberg-McQueen, Extensible Markup Language (XML) 1.0,http://www.w3.org/TR/1998/REC-xml, 1998.
[xmlten00] Bert Bos, XML in 10 points, http://www.w3.org/XML/1999/XML-in-10-points, 2000.
[xnames99] Tim Bray, Dave Hollander, Andrew Layman, Namespaces in XML, http://www.w3.org/TR/REC-xml-names/, 1999.
[xschem00] XML Schema, http://www.w3.org/XML/Schema.html, 2000.
[xslhp00] Extensible Stylesheet Language, http://www.w3.org/Style/XSL/, 2000.