Streszczenie
Praca została poświęcona aplikacji WASS będącej środowiskiem umożliwiającym prowadzenie badań w dziedzinie nauk społecznych przy pomocy komputera w środowisku rozproszonym. W pracy opisano wymagania stawiane takiemu środowisku, projekt systemu, sposób wykonania oraz przykładową realizację rzeczywistego badania w zakresie psychologii. Ponieważ WASS jest przykładem aplikacji internetowej, w pracy dokonano przeglądu najpopularniejszych technologii wykorzystywanych przy tworzeniu takich aplikacji.
1. Wstęp
1.1. Cel pracy
1.2. Struktura pracy
2. Tworzenie aplikacji internetowych
2.1. Specyfika aplikacji internetowych
2.2. Wymagania stawiane środowiskom tworzenia i działania aplikacji
2.3. PHP
2.4. ASP
2.5. J2EE
2.6. ASP.NET
2.7. Turbina
3. Projekt
3.1. Analiza wymagań
3.2. Przypadki użycia
3.3. Podział na moduły
3.4. Model danych
3.5. System bezpieczeństwa
4. Architektura Turbiny
4.1. Metodologia MVC
4.2. Model logiczny
4.3. Obsługa żądania
4.4. Serwisy
4.5. Dostęp do danych
4.6. Velocity
4.7. Podsumowanie
5. Implementacja
5.1. Zastosowane technologie
5.2. Architektura aplikacji
5.3. Moduł Security
5.4. Moduł Storage
5.5. Moduł User
5.6. Moduł Admin Test
5.7. Moduł Admin Research
5.8. Moduł Admin Process
5.9. Moduł Object Model
5.10. Dokumentacja techniczna
6. Przykładowe realizacje
6.1. Badanie 1
6.2. Badanie 2
7. Ocena przydatności Turbiny
7.1. Zalety Turbiny
7.2. Wady Turbiny
7.3. Przyszłość Turbiny
Wraz z popularyzacją komputerów osobistych klasy PC i pojawieniem się graficznego interfejsu użytkownika wprowadzonego przez firmę Microsoft znacznie wzrosła liczba osób wykorzystujących komputer zarówno do pracy, jak i do rozrywki. Do grona użytkowników komputerów dołączyły osoby zajmujące się kierunkami uważanymi za humanistyczne, takimi jak psychologia i socjologia. Przedstawiciele nauk społecznych w swej pracy najczęściej wykorzystują edytory tekstu oraz pakiety statystyczne. Zwłaszcza pojawienie się tych drugich, takich jak Statistica i SPSS, ułatwiło analizę wyników badań, nie tylko poprzez obliczanie statystyk opisowych (średnia, mediana, odchylenia standardowe itp.), ale i używanie bardziej zaawansowanych metod, takich jak krokowa analiza regresji wielokrotnej, czy analiza czynnikowa.
Niestety ciągle konieczne jest żmudne wprowadzanie do programów statystycznych odpowiedzi osób badanych, które są zapisane w papierowych kwestionariuszach. Oczywiście najwygodniej byłoby gdyby zarówno badanie, jak i zbieranie odpowiedzi mogło odbywać się elektronicznie. Dlatego tak ważne wydaje się stworzenie środowiska pozwalającego na przeprowadzanie różnorakich badań psychologicznych i socjologicznych przy użyciu komputera. Poza skróceniem czasu obróbki danych, technologie informatyczne oferują takie możliwości jak dokładne sterowanie czasem ekspozycji obrazu, prezentację treści multimedialnych, czy interakcje między badanymi, które przy wykorzystaniu innych technik są kosztowne i kłopotliwe w realizacji podczas badań.
Celem mojej pracy było stworzenie środowiska, pozwalającego na przeprowadzanie badań psychologicznych i socjologicznych przy użyciu komputera. Kluczowym elementem pracy było zaprojektowanie i zaimplementowanie systemu umożliwiającego realizację najpopu-larniejszych typów kwestionariuszy używanych w naukach społecznych. Stworzony system musiał być na tyle otwarty, by można go było łatwo rozwijać, poprzez dodawanie nowych, niedostępnych w "papierowych" badaniach elementów, wzbogacających warsztat badawczy naukowców. Narzędzie to musiało pozwalać na ochronę efektów pracy twórczej naukowców, jakimi są zaprojektowane badania oraz wyniki przeprowadzonych eksperymentów. W tym celu konieczne było zapewnienie odpowiedniego poziomu bezpieczeństwa systemu poprzez określenie sposobu autoryzacji i dostępu do elementów środowiska.
Zdecydowałem się na stworzenie wspomnianego środowiska w postaci aplikacji internetowej, którą nazwałem WASS (Web Application for Social Sciences), nawiązując w ten sposób do nazwy programu SPSS. Jako jedna z osób biorących udział w rozwoju narzędzia wspomagającego proces tworzenia aplikacji internetowych jakim jest Turbina [1], postanowiłem zrealizować tę pracę przy jego pomocy. Na podstawie zdobytych w czasie realizacji tego projektu doświadczeń, chciałem ocenić rzeczywistą przydatność Turbiny.
W rozdziale 2 pracy opisałem sposób tworzenia aplikacji internetowych. Dokonałem analizy specyfiki takich aplikacji, a także zdefiniowałem wymagania stawiane środowiskom tworzenia tego typu programów. Następnie opisałem najpopularniejsze technologie wykorzystywane przy konstruowaniu aplikacji internetowych, z punktu widzenia zdefiniowanych przeze mnie kryteriów.
W rozdziale 3 opisałem wymagania jakie musi spełniać środowisko wspomagające prowadzenie badań w naukach społecznych oraz przedstawiłem projekt takiego narzędzia. W projekcie znalazły się przypadki użycia, podział systemu na moduły oraz model danych.
W kolejnym rozdziale opisałem Turbinę, narzędzie przy pomocy którego powstał mój program. Omówiłem te elementy tego środowiska, które są istotne do zrozumienia sposobu w jakim zrealizowałem system WASS. Opis implementacji poszczególnych modułów umieściłem w rozdziale 5.
W rozdziale 6 przedstawiłem dwa przykładowe badania i sposób ich realizacji przy pomocy stworzonego przeze mnie systemu. Na podstawie doświadczeń zdobytych podczas powstawania systemu WASS, mogłem dokonać oceny przydatności Turbiny jako środowiska tworzenia aplikacji internetowych. Takiej ocenie poświęciłem rozdział 7 pracy. W rozdziale 8 zawarłem ostateczne podsumowanie całego projektu.
W pracy umieściłem ponadto dwa dodatki. W dodatku A opisałem wykorzystywane przez system tabele bazy danych. Dodatek B został zaś poświęcony zawartości dołączonej do pracy płyty CD-ROM.
Trudno jest podać dokładną definicję aplikacji internetowej. Pierwszą próbą sformułowania takiej definicji mogłoby być stwierdzenie, iż jest to program, do którego dostęp odbywa się poprzez strony WWW [2]. Z jednej strony taki opis oddaje najbardziej charakterystyczną cechę aplikacji internetowych, z drugiej jest zbyt ogólny. Uważam bowiem, że nie należy traktować jako aplikacji internetowej strony pozwalającej na włączanie i wyłączanie światła w ogródku, gdyż w tym przypadku ta strona stanowi w istocie tylko interfejs do rzeczywistego urządzenia.
Można też twierdzić, że aplikacją internetową jest program generujący zawartość stron w odpowiedzi na akcje ze strony użytkownika. Ta definicja znakomicie pasuje do opisu różnego rodzaju portali i wortali. Niestety nie oddaje ona jednego ważnego aspektu takich aplikacji, a mianowicie, że poza generowaniem stron, mogą również następować zmiany w samym systemie. Aplikacje internetowe są to więc programy, do których pasują obie podane przeze mnie definicje. Opiszę teraz cechy charakterystyczne takich aplikacji.
Przede wszystkim komunikacja użytkownika z programem odbywa się poprzez strony prezentowane przez przeglądarkę internetową. Dostępne dla korzystającego z programu funkcjonalności powinny więc dać się opisać i zrealizować przy pomocy środków dostępnych w języku HTML [3] i JavaScript [4].
Prezentacja informacji może odbywać się przy pomocy odpowiednio sformatowanego tekstu, grafiki a nawet elementów multimedialnych. Powoduje to, że strona prezentacji może być dużo atrakcyjniejsza i ciekawsza niż jest to możliwe w tradycyjnych aplikacjach (oczywiście przy odpowiednio dużym nakładzie pracy programista C++ może uzyskać podobne efekty i w zwykłej aplikacji).
Sterowanie aplikacją musi odbywać się z użyciem rozwijanych list wyboru, przełączników i pól edycyjnych. Pojawia się tutaj jednak znacząca różnica w porównaniu z tradycyjnymi programami: jest nią praca sekwencyjna. Użytkownik wprowadza zmiany w atrybutach, a następnie musi zatwierdzić te zmiany przesyłając formularz do serwera i oczekiwać na reakcje systemu. W ogólnym przypadku dostępna jest dużo mniejsza "interakcyjność" systemu. Jednocześnie mamy jednak wyraźnie zdefiniowane fazy działania programu: prezentacja, modyfikacja atrybutów, zatwierdzenie, wykonanie, ponowna prezentacja.
Kolejną cechą aplikacji internetowych jest to, że rzeczywiste zmiany w systemie zachodzą na innym komputerze - maszynie będącej serwerem dla danej aplikacji. Następuje więc naturalne oddzielenie interfejsu od implementacji. Aplikacje internetowe są z definicji sieciowe i umożliwiają równoczesny dostęp wielu użytkownikom. Pojawiają się więc problemy zapewnienia bezpieczeństwa oraz programowania współbieżnego.
Ponieważ protokół HTTP [5] używany w komunikacji pomiędzy klientem, jakim jest przeglądarka WWW, a serwerem jest protokołem bezstanowym, więc aby kolejne strony były właściwą odpowiedzią na żądania klienta, z reguły konieczne jest przechowywanie przez system informacji o stanie klienta. Prawie każda aplikacja internetowa musi więc zapewnić przechowywanie tych informacji po stronie serwera, tak by móc identyfikować klientów i poprawnie reagować na ich akcje. Z użytkownikiem związana zostaje sesja opisująca historie jego działań w systemie, tymczasowe wyniki obliczeń itp.
Większość aplikacji internetowych wykorzystuje w czasie swojego działania bazy danych. Służą one najczęściej do przechowywania informacji o użytkownikach, dokumentach i zasobach, jakie obsługuje dana aplikacja. Trzeba tu wspomnieć, że takie środowiska bazodanowe jak Oracle czy SQLServer posiadają wbudowane narzędzia do generowania aplikacji internetowych operujących na danych zgromadzonych w bazach danych.
Specyfika aplikacji internetowych powoduje, że wykazują one duże podobieństwo. Analizując sposób działania większości aplikacji internetowych można odnaleźć następujące wspólne elementy:
...Naturalną konsekwencją występowania wymienionych podobieństw było pojawienie się narzędzi wspomagających proces tworzenia aplikacji, tak by wyeliminować konieczność wielokrotnego pisania kodu o analogicznej funkcjonalności. ... Chciałbym przedstawić zagadnienia jakie należy rozważyć przy porównywaniu różnych środowisk lub przed podjęciem decyzji o wyborze jednej z dostępnych technologii.
Wydajność.
Bezpieczeństwo.
Zarządzanie sesją.
Parsowanie parametrów.
Dostępność bibliotek.
Odpluskwianie.
Podział na warstwy.
Automatyczna walidacja formularzy.
Dostęp do bazy danych.
Budowa aplikacji.
W dalszej części pracy chciałbym omówić wybrane, najpopularniejsze środowiska tworzenia aplikacji internetowych z uwzględnieniem opisanych przeze mnie kryteriów.
PHP jest językiem programowania stworzonym specjalnie po to, by umożliwić dynamiczne generowanie stron WWW [8]. Elementy języka PHP zanurza się w kodzie HTML przy pomocy odpowiednich znaczników. W przypadku żądania prezentacji strony stworzonej w PHP, napotkane znaczniki HTML są przekazywane bez zmian, zaś kod należący do języka PHP zostaje przetworzony przez interpreter. PHP posiada typowe cechy języka skryptowego: jest interpretowany a nie kompilowany, nie posiada mechanizmów typowania, dopuszcza brak deklaracji zmiennych.
...Technologię ASP (Active Server Pages) [11] wprowadziła na rynek firma Microsoft jako część projektu Active Platform. Projekt ten miał na celu stworzenie platformy rozwiązań biznesowych umożliwiającej w spójny sposób oprogramowanie zarówno strony klienta, jak i serwera. Najbardziej znane rozwiązanie wywodzące się z tego projektu to formatki ActiveX [12] oraz właśnie ASP. Strona w ASP składa się, podobnie jak to ma miejsce w przypadku PHP, z elementów języka HTML oraz kodu ujętego w odpowiednie znaczniki. W przypadku ASP można używać dwóch języków programowania: VBScript [13] i JScript [14], będących modyfikacjami VisualBasica i Javy. Podczas obsługi żądania klienta kod zawarty na stronie jest interpretowany. Znów mamy więc do czynienia z technologią opartą na interpretowanym języku skryptowym. Opiszę teraz analizowane przeze mnie cechy tego środowiska.
...Rozszerzenie Javy [17] o nazwie J2EE (Java 2 Extended Edition) [18] zostało opracowane przez firmę Sun Microsystem właśnie z myślą o tworzeniu oprogramowania na potrzeby Internetu. J2EE zawiera w sobie specyfikację takich rozwiązań jak serwlety, JSP i EJB, opisane przeze mnie w kolejnych podrozdziałach. Niektóre właściwości tych technologii są konsekwencją używania Javy jako języka programowania, dlatego cześć z nich opiszę już w tym miejscu.
...Serwlety
Serwlety [19] są obiektami, które realizują żądania klientów poprzez wykonanie akcji po stronie serwera (stąd pochodzi ich nazwa) i przekazanie strony w HTML jako odpowiedzi. Serwlety są obiektami tworzonymi i zarządzanymi przez kontener serwletów [20]. Zadania kontenera serwletów to przede wszystkim:
...JSP
O ile technologia serwletów należy do niskopoziomowych rozwiązań, o tyle JSP (Java Server Pages) [22] jest ekwiwalentem takich technologii jak PHP czy ASP. Strona JSP składa się z kodu HMTL, w którym w specjalnych znacznikach umieszczono kod Javy. Taka strona jest następnie automatycznie kompilowana przez serwer aplikacji do odpowiadającego jej funkcjo-nalnie serwletu, który następnie obsługuje żądania klientów. Dzięki temu istnieje możliwość wykrywania błędów już na etapie kompilacji, a ponadto strony JSP są w istocie wykonywane, a nie interpretowane, co wyraźnie wpływa na wzrost wydajności. A oto szczegółowy opis cech tego środowiska.
...EJB
EJB (Enterprise Java Beans) [25] stanowi rozwinięcie koncepcji obiektów biznesowych opisanej przeze mnie w poprzednim podrozdziale. EJB ma pełnić rolę komponentu, który udostępnia klientowi pewne akcje. Specyfikacja EJB pozwala przed wszystkim na odseparowanie logiki aplikacji od systemu bezpieczeństwa, tworzenie i udostępnianie obiektów klientom i zarządzanie źródłami danych. Siła EJB polega głównie na tym, że wiele zadań jest wykonywanych przez narzędzia obsługujące środowisko działania EJB, a nie przez programistę. Trudno jest mi w zwięzły sposób oddać specyfikę korzystania z technologii EJB, ograniczę się więc tylko do opisu rozważanych przeze mnie kryteriów porównywania.
...Platforma .NET [27] firmy Microsoft, której częścią jest ASP.NET [28], została moim zdaniem stworzona jako odpowiedź na rosnącą popularność środowiska J2EE, o czym mogą świadczyć liczne podobieństwa pomiędzy obiema technologiami. Podstawową zmianą wprowadzoną w ASP.NET w stosunku do ASP było pojawienie się nowego języka programowania C# (choć nadal możliwe jest używanie VisualBasica). C# jest językiem obiektowym bardzo podobnym w swoich założeniach i wyglądzie do Javy. Strony stworzone w nowym ASP nie są już interpretowane, ale kompilowane do MSIL (Microsoft Intermediate Language), który w trakcie działania aplikacji jest zamieniany przez JIT (Just in Time Compiler) na kod wynikowy właściwy dla danej maszyny, co ma znaczący wpływ na poprawę wydajności. A oto podsumowanie możliwości tej platformy.
...Celem projektu Tubine [1,29] było stworzenie jądra - silnika (ang. engine) aplikacji internetowych. Turbina jest więc czymś więcej niż opisane wcześniej technologie, gdyż ma pełnić rolę szkieletu, na podstawie którego są tworzone aplikacje. W projekcie tym określono: sposób realizacji żądań klienta, podział programu na warstwy, dostęp do baz danych, sposób implementacji globalnych usług. Turbina została stworzona w Javie jako serwlet, posiada więc wszystkie opisane wcześniej zalety tej technologii. Ponieważ dokładnemu opisowi Turbiny poświęcę jeden z następnych rozdziałów, ograniczę się teraz do opisu analizowanych przeze mnie kryteriów.
...Z prezentowanego przeze mnie opisu dostępnych środowisk tworzenia aplikacji internetowych wynika, że w przypadku małych i średnich aplikacji możliwości środowisk są porównywalne. Wybór konkretnej technologii może być podyktowany jej wcześniejszą znajomością przez programistę, czy też jego osobistymi upodobaniami. Ja jestem gorącym zwolennikiem technologii opartych na Javie (JSP, Turbina, Cocoon [32]) i namawiałbym każdego do pracy z użyciem jednego z nich. Jednak w przypadku naprawdę małych aplikacji (licznik, formularz rejestracji itp.) najszybciej pożądany efekt można uzyskać przy pomocy PHP.
ASP.NET i EJB zawierają w sobie rozwiązania, w których zakłada się, że aplikacje internetowe będą tworzone w oparciu o komponenty dostarczane przez różnych producentów, a nawet działające na różnych maszynach (np. w niepowiązanych ze sobą firmach). Nie jestem jednak przekonany, czy to podejście oddaje rzeczywistą potrzebę rynku, czy raczej pozostaje niepotrzebnie obciążającym te technologie wodotryskiem.
We wstępie napisałem, że jednym z celów tej pracy było stwierdzenie przydatności Turbiny w tworzeniu rzeczywistych aplikacji internetowych. Mam nadzieję, że to krótkie porównanie najpopularniejszych technologii pokazało, że Turbina w istocie zawiera wiele cech wymaganych od dobrego środowiska programistycznego i wybór przeze mnie tej technologii był w pełni uzasadniony.
WASS (Web Application for Social Sciences) ma być środowiskiem pozwalającym na przeprowadzanie badań psychologicznych i socjologicznych przy użyciu komputera. Metodologia prowadzenia badań w naukach społecznych ma kluczowe znaczenie przy definiowaniu wymagań stawianych temu systemowi, dlatego opiszę w jakim sposób są one realizowane. Typowy eksperyment psychologiczny składa się z następujących części:
Instrukcja wstępna. Badanemu zostaje przedstawiony cel badania, przebieg eksperymentu, zadania stawiane przed badanym, czas trwania eksperymentu.
Właściwy eksperyment. Ten element najtrudniej jest opisać, ponieważ to właśnie on odróżnia od siebie badania. Najczęściej badany proszony jest o wykonanie pewnych zadań (np. zapamiętanie listy słów, opisanie obrazów, rozwiązanie zagadek).
Seria testów. Badany proszony jest o wypełnienie kwestionariuszy, które pozwalają określić jego temperament, osobowość, inteligencje, kontekst kulturowy. Używane są w tym celu standardowe, uznane kwestionariusze dostępne dla osób zajmujących się zawodowo psychologią. Dzięki tej części badania jest możliwe określenie wpływu analizowanych cech na wynik właściwego eksperymentu.
Instrukcja końcowa. Ma ona za zadanie podsumować przeprowadzone badanie, przedstawić prawdziwy cel badania, ujawnić ewentualne manipulacje, jakim poddano badanego.
Eksperyment w naukach społecznych ma więc modularną budowę. Podstawowym komponentem badania jest kwestionariusz - test (czyli ciąg pytań) wraz z towarzyszącą mu instrukcją. Testy różnią się między sobą sposobem, w jaki formułowane są w nich pytania (zwykły tekst, grafika, seria obrazków) oraz sposobem, w jaki udzielana jest na nie odpowiedź (testy wielokrotnego wyboru, zaznaczanie na skali, odpowiedzi opisowe).
Opisany przeze mnie uproszczony przebieg badania w naukach społecznych wskazuje, że najważniejszą cechą wymaganą od środowiska wspomagającego jego prowadzenie jest możliwość stworzenia biblioteki najczęściej używanych kwestionariuszy. Ponadto badacz powinien móc tworzyć swoje własne nowe kwestionariusze. Oba wymagania sprowadzają się do zaimplementowania sposobu, w jaki będzie można zrealizować najpopularniejsze typy testów (typ testu definiuje właśnie sposób zadawania pytań czy udzielania na nie odpowiedzi). Korzystając ze stworzonej bazy testów, badacz powinien móc konstruować badania, poprzez wybór pożądanych testów.
Niestety nie da się przewidzieć wszystkich zadań, jakie badacz będzie chciał przygotować dla badanego, ponieważ zależą one tylko od kreatywności i pomysłowości naukowca. Rozwiązaniem tego problemu mogłoby być stworzenie metajęzyka lub środowiska graficznego (np. w postaci pasków narzędzi) pozwalającego na oprogramowanie dowolnej interakcji z badanym. Uznałem jednak takie podejście za bezcelowe, gdyż użytkownicy tego systemu (czyli psychologowie czy socjologowie) nie będą zainteresowani opanowaniem takiego pseudo języka programowania. Rozszerzaniem systemu o nowe funkcjonalności powinni się zajmować programiści, którzy wykorzystując dostępne w środowisku podstawowe komponenty i mechanizmy będą mogli zrealizować dowolne pomysły naukowców. System powinien dostarczać programiście gotowe rozwiązania umożliwiające na przykład przechowywanie pytań, odpowiedzi badanych, automatyczne ocenianie, dostęp do plików multimedialnych, czy rejestracji badanych.
Dostęp do kwestionariuszy psychologicznych powinien być możliwy wyłącznie dla osób zawodowo zajmujących się psychologią (tak jak ma to miejsce w przypadku ich papierowych odpowiedników). Obecne zaś w systemie testy stworzone przez naukowców będące efektem ich pracy twórczej nie powinny być widoczne dla innych badaczy. Środowisko musi więc zapewniać ograniczanie dostępu do testów, badań oraz ich wyników.
Wymagania techniczne względem tworzonego środowiska są dużo łatwiejsze do określenia. Ponieważ WASS będzie korzystał z Turbiny, więc możliwe będzie jego uruchomienie na dowolnej platformie, dla której dostępna będzie Java i baza danych. Aplikacja powinna dać się uruchomić na istniejących przy wydziałach nauk społecznych serwerach WWW. Korzystający z systemu naukowcy i potencjalni badani to przede wszystkim użytkownicy Windows, nie ma więc specjalnej potrzeby optymalizacji interfejsu aplikacji dla różnych przeglądarek internetowych, choć oczywiście byłoby to dodatkowym atutem systemu.
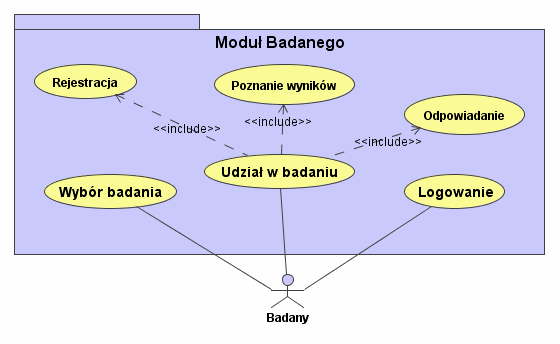
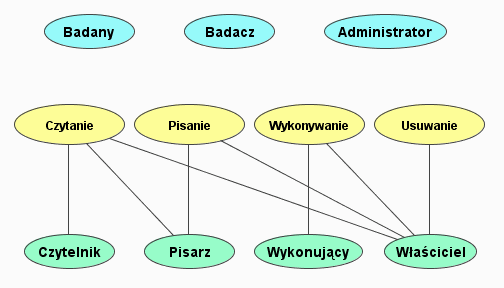
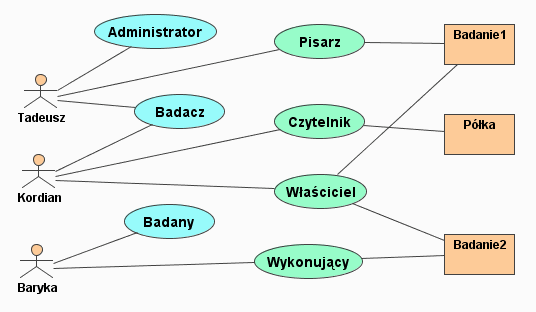
W środowisku można wyróżnić czterech podstawowych aktorów, których opisałem wraz z typowymi dla nich zadaniami.
Badany. Jest użytkownikiem, którego rola ogranicza się głównie do udzielania odpowiedzi na stawiane mu pytania (rysunek 1). Podejmowane przez niego akcje to:
Logowanie. Niektóre z badań mogą mieć wyznaczoną grupę osób, do których są skierowane, dlatego konieczne może być potwierdzenie tożsamości.
Wybór badania.
Udział w badaniu. Przed przystąpieniem do badania użytkownik najczęściej musi się zarejestrować wypełniając odpowiednią ankietę (podać swój wiek, płeć, wykształcenie itp.). Potem wykonuje kolejne zadania, które z reguły wymagają poznania instrukcji testu i odpowiedzi na jego kolejne pytania. Po skończeniu postawionych przed nim zadań prezentowane są mu instrukcje końcowe i ewentualnie wyniki testu.
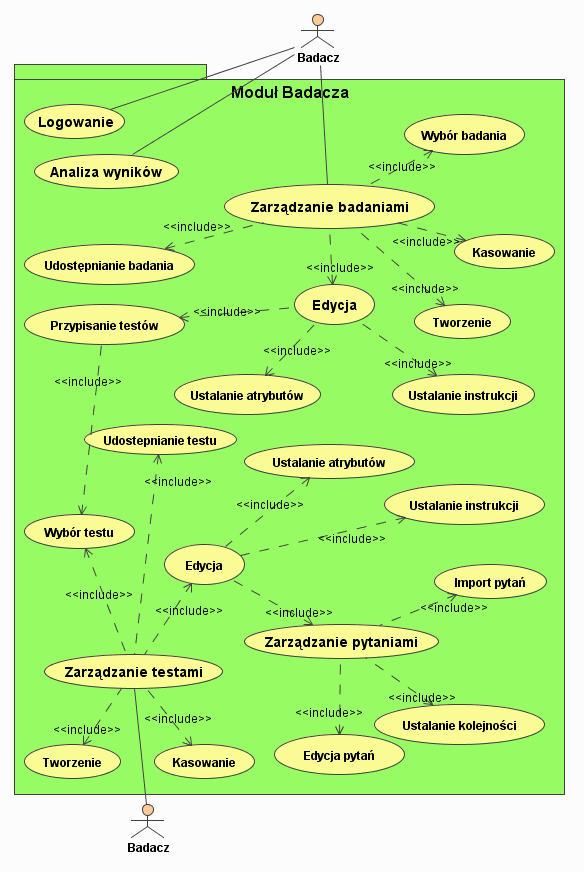
Badacz. To kluczowy aktor w systemie, który tworzy nowe kwestionariusze i badania oraz analizuje ich wyniki (rysunek 2). Do zadań badacza należą:
Logowanie. Konieczne jest ze względu na ograniczanie dostępu do kwestionariuszy, jak i samych badań.
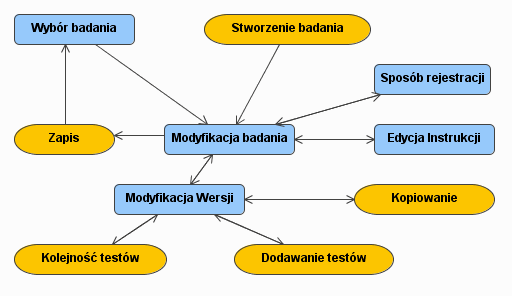
Zarządzanie badaniami. Składa się z takich akcji jak tworzenie, kasowanie, czy edycja badania. Projektowanie badania sprowadza się do definiowania instrukcji, sposobu rejestracji badanych i wreszcie wyborze właściwych kwestionariuszy. Badacz może również udostępniać swoje badania innym naukowcom.
Analiza wyników badań.
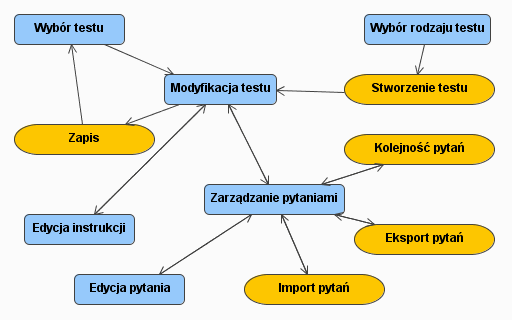
Zarządzanie testami. Badacz może tworzyć, kasować i edytować kwestionariusze. W czasie edycji testu konieczne jest określanie jego zawartości, które odbywa się poprzez zarządzanie pytaniami. Badacz powinien móc dodawać, usuwać i importować pytania, decydować o ich kolejności. Stworzone kwestionariusze mogą być udostępniane innym naukowcom tak by mogły stać się częścią projektowanych przez nich badań.
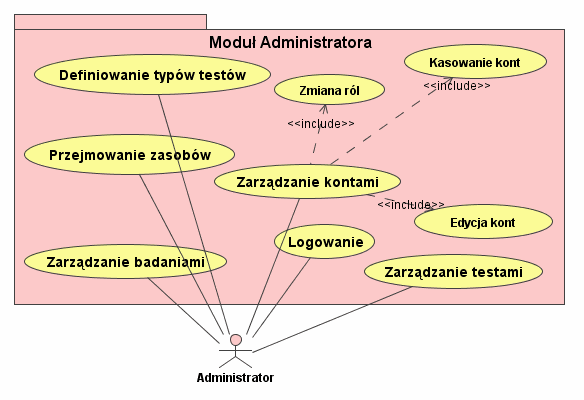
Administrator. Należy do zaawansowanych użytkowników; poza konserwacją systemu, zarządza użytkownikami środowiska i ich uprawnieniami (rysunek 3). Wykonywane przez niego akcje to:
Logowanie.
Przejmowanie zasobów. Administrator może przejmować na własność badania czy testy tak by móc nimi zarządzać i udostępniać je innym użytkownikom.
Zarządzanie badaniami.
Zarządzanie testami.
Definiowanie rodzajów testów. Administrator może tworzyć, edytować i kasować rodzaje testów, które opisują sposób w jaki są obsługiwane przez system kwestionariusze (podczas badania i w czasie zarządzania nimi). Administrator może tworzyć typy testów wykorzystując tylko już istniejące komponenty.
Zarządzanie kontami. Administrator może tworzyć, kasować i modyfikować konta użytkowników oraz określać jakie role pełnią w systemie.
Projektant. Realizuje pomysły badaczy implementując nowe rodzaje testów. Wiąże się to z tworzeniem i modyfikacją elementów odpowiedzialnych za prezentację danego typu testów badanemu oraz za sposób w jaki się nimi zarządza.
Analiza opisanych przeze mnie przypadków użycia i wymagań stawianych przed systemem pozwala na wyodrębnienie w aplikacji następujących modułów (rysunek 4).
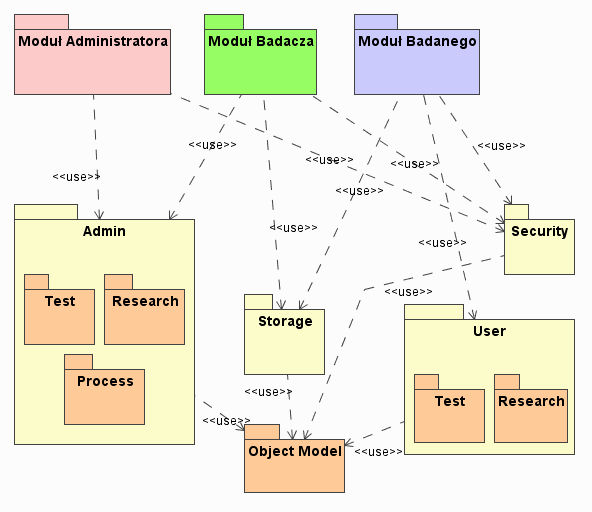
Security. Moduł ten ma zawierać elementy odpowiedzialne za system bezpieczeństwa w aplikacji. Do podstawowych zadań tego modułu należeć będzie autoryzowanie użytkowników oraz kontrola dostępu do aplikacji. Ochrona powinna obejmować zarówno części składowe aplikacji (część administratora, badacza i inne), jak również przechowywane w systemie badania i kwestionariusze. Moduł musi zawierać interfejs pozwalający na zarzą-dzanie kontami użytkowników i ich uprawnieniami. Elementy tego modułu będą używane przez pozostałe części aplikacji.
Storage. Celem tego modułu jest umożliwienie wykorzystywania treści multimedialnych w badaniach. Powinien on pozwalać na przechowywanie w systemie plików graficznych czy dźwiękowych oraz zarządzanie nimi. Musi umożliwiać dołączanie takich właśnie elementów do badań, testów czy pytań.
User. Ta część aplikacji jest odpowiedzialna za właściwe przeprowadzanie badania. Do jej zadań należeć będzie prezentowanie stron zawierających zadania wyznaczone badanemu, przechowywanie jego odpowiedzi, umożliwianie właściwej nawigacji pomiędzy elementami badania i wreszcie dostarczanie użytkownikowi informacji potrzebnych do ukończenia badania, w postaci instrukcji i podpowiedzi.
Admin. Ten moduł grupuje elementy mające wpływ na cały system. Składa się z trzech części: Test, Research i Process. Moduł Test powinien udostępniać funkcjonalności odpowiedzialne za tworzenie i modyfikowanie testów oraz należących do nich pytań. Moduł Research ma być tym fragmentem aplikacji, który pozwala na komponowanie badań z dostępnych w systemie testów. Moduł Process będzie zaś wykorzystywany podczas prezentacji wyników przeprowadzonych już eksperymentów.
Object Model. Ten moduł będzie wykorzystywany przez wszystkie pozostałe części aplikacji, a do jego zadań będzie należało stworzenie warstwy pośredniczącej pomiędzy bazą danych a resztą programu.
W tworzonym środowisku kwestionariusze, badania i ich wyniki będą przechowywane w bazie danych. Ponieważ system ma umożliwiać przeprowadzanie różnorakich eksperymentów, konieczne było zaprojektowanie dość złożonej struktury bazy danych (rysunek 5).
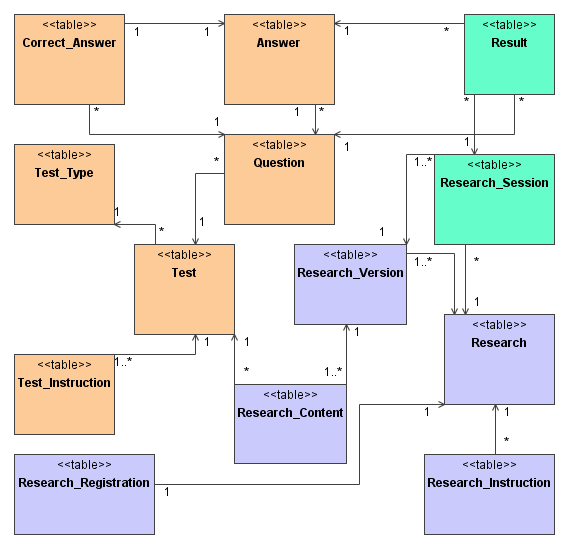
Opis testu pozwalający na jego identyfikacje znajdzie się w tabeli Test, zaś instrukcje wstępne w tabeli Test_Instruction. Z testem powiązane są pytania (elementy tabeli Question), zaś z nimi zbiór dopuszczalnych odpowiedzi przechowywany w tabeli Answer. W niektórych przypadkach znane są poprawne odpowiedzi na zadawane pytania i informacja o tym będzie odnotowana w tabeli Correct_Answer. Opisane tabele powinny pozwolić na przechowywanie w bazie danych dowolnego kwestionariusza począwszy od testu wielokrotnego wyboru, na teście z otwartymi pytaniami kończąc. Niektóre kwestionariusze są do siebie podobne (na przykład testy, w których odpowiada się poprzez wybranie jeden z dwóch odpowiedzi: TAK lub NIE), te podobieństwa zostaną opisane w tabeli Test_Type. Przechowywane w tej tabeli informacje o rodzajach testów posłużą do określenia sposobu, w jaki mają być prezentowane pytania czy też zbierane odpowiedzi.
Całe badanie będzie identyfikowane dzięki atrybutom zawartym w tabeli Research. Zostaną dla niego zdefiniowane instrukcje wstępne (elementy tabeli Research_Instruction) oraz sposób w jaki ma się odbywać rejestracja (Research_Registration). W jednym badaniu będzie można wyróżnić kilka jego wersji, różniących się między sobą na przykład kolejnością testów. Opis wersji badania znajdzie się w tabeli Research_Version, zaś informacja o przy-porządkowaniu do nich właściwych testów zostanie zapisana w tabeli Research_Content.
Przy rozpoczynaniu przez badanego nowego badania zostanie z nim związana sesja (Research_Session), w której znajdą się między innymi dostarczone w czasie rejestracji informacje o użytkowniku. Ponadto sesja pozwoli na identyfikację udzielanych przez badanego odpowiedzi, zapisywanych w tabeli Result.
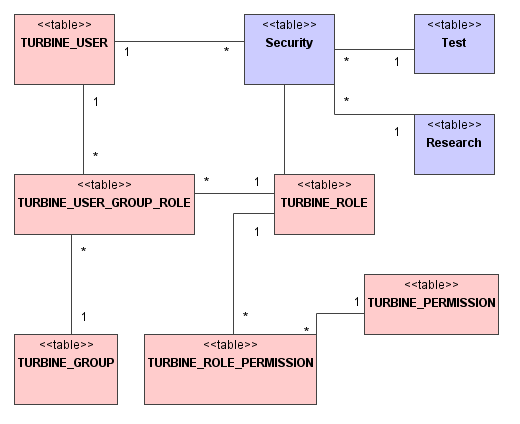
Dostępny w Turbinie model systemu bezpieczeństwa jest niewystarczający dla celów WASS i konieczne będzie jego rozszerzenie. Projektanci Turbiny stworzyli rozwiązanie oparte na pojęciach użytkownika, roli i prawa. W dystrybucji Turbiny nie są zdefiniowane jawnie żadne prawa - osoby wykorzystujące to narzędzie mogą je dowolnie tworzyć (prawa identyfikowane są poprzez swoją nazwę). Rola jest w Turbinie po prostu nazwanym zbiorem praw. Zostało jeszcze wprowadzone pojęcie grupy, przy czym wyboru nazwy twórcy Turbiny dokonali w niefortunny sposób. Grupa w Turbinie nie oznacza bowiem zbioru użytkowników, lecz pozwala na określenie jakie role są przypisane danemu użytkownikowi. W Turbinie użytkownik pełni jakąś rolę w pewnej grupie, zamiast grupa powinno więc być stosowane określenie domena.
Dostarczona w Turbinie implementacja systemu bezpieczeństwa pozwala na stwierdzenie w wygodny sposób, czy dany użytkownik posiada wymagane prawo w jakiejś grupie. Wspierany model systemu bezpieczeństwa jest wystarczający w aplikacji, w której kontroli podlegają konkretne działania klientów (na przykład ogranicza się dostęp do ekranu z listą użytkowników, czy akcji dodającej nowego użytkownika). Nie można go jednak zastosować w sytuacji, gdy konieczne jest ograniczenie dostępu do konkretnych zasobów, a taka potrzeba istnieje w przypadku aplikacji WASS (na przykład tylko właściciel powinien móc modyfikować swoje badanie).
W Turbinie przewidziano możliwość zaimplementowania własnej wersji serwisu odpowiadającego za system bezpieczeństwa, niestety wprowadzenie do niego nowej funkcjonalności (niedostępnej w standardowym API) nie jest wygodne, ponieważ wiąże się z koniecznością ciągłego rzutowania.
Dlatego postanowiłem wprowadzić rozwiązanie hybrydowe i tam gdzie to możliwe korzystać z dostępnego systemu bezpieczeństwa. Wystarcza on na przykład w zupełności do zapewnienia, by z modułu do zarządzania kontami badaczy mógł korzystać tylko administrator. W przypadku potrzeby ograniczenia dostępności jakiegoś zasobu wykorzystywane będą informacje powiązane z danym zasobem (np. testem czy badaniem) poprzez tabelę Security. Tabela ta będzie wiązać role użytkowników z zasobami systemu. Rysunek 6 prezentuje model danych odpowiadający opisanemu przeze mnie rozwiązaniu.
Stworzona przeze mnie aplikacja powstała przy użyciu Turbiny, dlatego zanim przedstawię sposób implementacji WASS, chciałem lepiej opisać to narzędzie.
Ponieważ Turbina jest serwletem Javy, więc aby mógł powstać funkcjonalny system, potrzebne są dodatkowe komponenty, takie jak maszyna wirtualna Javy, kontener serwletów, czy baza danych. Miejsce w systemie Turbiny i aplikacji stworzonej przy jej pomocy schematycznie przedstawiłem na rysunku 7, gdzie nakładanie się elementów oznacza ich interakcje.
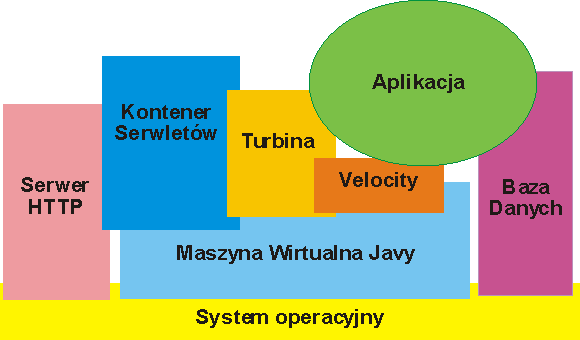
Oto opis znaczenia i roli przedstawionych elementów:
System operacyjny. Odpowiada przede wszystkim za stabilność całego środowiska, bezpieczeństwo (dostęp do plików i innych zasobów) oraz wydajność (na przykład poprzez obsługę maszyn wieloprocesorowych). Z perspektywy Turbiny może być używany dowolny system operacyjny.
Serwer HTTP. To z nim bezpośrednio komunikują się przeglądarki. Jest odpowiedzialny za prezentowanie statycznych treści (stron HTML, obrazków) i za ewentualne dalsze przesłanie żądań (np. do kontenera serwletów). Wybór konkretnego serwera HTTP wpływa na bezpieczeństwo i wydajność systemu.
Maszyna wirtualna Javy. Środowisko uruchomieniowe Javy pozwala na działanie całego systemu, który jest stworzony właśnie w Javie (Turbina, narzędzia do przetwarzania szablonów oraz kod samej aplikacji).
Kontener serwletów. Jego podstawowym zadaniem jest uruchomienie serwletów (jednym z nich jest Turbina), zarządzanie sesjami użytkowników i kierowanie żądań do właściwych obiektów.
Turbina. Podejmuje kolejne działania związane z obsługą żądania, przede wszystkim uruchamiając odpowiednią akcję i ekran.
Webmacro, Velocity. Te narzędzia są odpowiedzialne za wygenerowanie strony HTML na podstawie zadanego szablonu i dynamicznych danych dostarczonych przez aplikację.
Aplikacja. Składa się przede wszystkim z akcji i ekranów, które implementują logikę aplikacji, oraz z szablonów, które na podstawie informacji dostarczonych przez ekrany pozwalają na generowanie wynikowych stron HTML.
Korzystanie ze stron WWW jako interfejsu graficznego aplikacji powoduje, że w interakcji użytkownik - program pojawiają się dobrze zdefiniowane fazy:
Zapisz),
W Turbinie tym fazom działania aplikacji zostały przyporządkowane różne elementy. Wprowadzone zostało pojęcie akcji (ang. action), obiektu dziedziczącego po klasie Action, która ma odpowiadać za realizację żądanych przez użytkownika zmian w systemie. Ekran (ang. screen), obiekt dziedziczący po klasie Screen, ma zaś prezentować stan systemu poprzez wygenerowanie odpowiedzi dla klienta - czyli najczęściej fragmentu kodu HTML. Dzięki istnieniu tych dwóch elementów, aplikacje tworzone w Turbinie są bardziej przejrzyste niż odpowiadające im strony JSP. W przypadku JSP programista najczęściej umieszcza na stronie formularz z ukrytym polem wskazującym, że ma zostać wykonana jakaś akcja. W kodzie odpowiedzialnym za wygenerowanie żądanej strony, umieszcza się ciąg instrukcji if-else, które sprawdzają przesłaną wartość tego ukrytego pola i przekazują sterowanie do miejsca realizującego wskazaną akcję, a dopiero potem następuje przetwarzanie kodu odpowiedzialnego za prezentację stanu systemu.
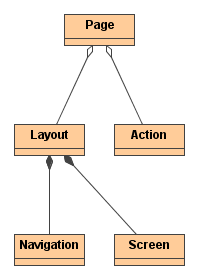
Akcje kontrolują stan systemu, a ekrany odpowiadają za prezentację. Zostały więc zdefiniowane dwa elementy modelu MVC (Model View Controller): kontroler i widok. Trzecim elementem - modelem - w przypadku aplikacji internetowej są dane opisujące stan systemu, a więc przede wszystkim te zgromadzone w bazie danych i w sesjach użytkowników. W przypadku Turbiny modelowi odpowiadają równoważniki (ang. peer), czyli obiektowe reprezentacje tabel oraz ich elementów. Na rysunku 8 przedstawiłem schematycznie realizację modelu MVC w przypadku Turbiny.
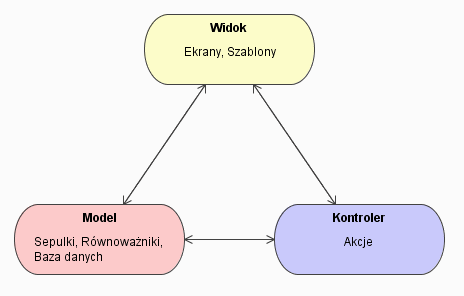
Wydaje się, że zgodność architektury Turbiny z metodologią MVC jest raczej konsekwencją wyróżnienia akcji i ekranów, niż wynikiem świadomej decyzji projektantów. Opiszę teraz dokładniej komponenty składające się na model MVC.
Modelem są te elementy aplikacji, które mają wpływ na stan systemu. Niewątpliwie podstawowy wpływ na działanie aplikacji ma konfiguracja środowiska. Niestety w Turbinie jest ona tylko statyczna i odbywa się poprzez edycję pliku konfiguracyjnego. Dostęp do wartości atrybutów w czasie działania aplikacji umożliwia klasa TurbineResources.
Kolejnym miejscem przechowywania informacji o stanie systemu jest sesja użytkownika. Z użytkownikiem można związać nie tylko ulotne dane (tzn. dostępne do czasu wygaśnięcia sesji), ale również i takie, które będą automatycznie przechowywane przez Turbinę w bazie danych. Dostęp do obu rodzajów danych odbywa się na zasadzie słownika.
Najważniejszym elementem modelu są dane zgromadzone w bazach danych. W Turbinie dostęp do nich odbywa się poprzez ich obiektową reprezentację. Zdefiniowane zostały trzy podstawowe klasy obiektów: Peer, Critieria, BaseObject. Równoważnik (ang. peer) ma być widokiem tabeli z bazy danych, zawiera więc informacje o kolumnach i ich typie oraz pozwala na wykonywanie operacji na tabeli, takich jak wstawianie, usuwanie i wyszukiwanie danych. Przy wykonywaniu tych operacji można korzystać z języka SQL, ale zalecaną metodą jest używanie obiektowej reprezentacji zapytania SQL, jaką jest Criteria. Wynikiem zapytania dotyczącego danej tabeli jest lista sepulek - obiektów dziedziczących po klasie BaseObject i mających atrybuty odpowiadające kolumnom tabeli. Bardziej szczegółowemu opisowi dostępu do baz danych poświęcę jeden z następnych podrozdziałów.
Podstawowym elementem widoku są ekrany. W uproszczeniu, zadaniem programisty jest stworzenie klasy dziedziczącej po klasie Screen oraz metody generującej napis odpowiadający pożądanemu kodowi w HTML. Tworzenie aplikacji w ten sposób, choć zgodne z metodologią MVC nie pozwalałoby na rozdzielenie kodu logiki aplikacji od kodu w HTML-u.
Zalecane rozwiązanie polega na tworzeniu ekranów składających się z dwóch części: z obiektu Javy pobierającego informacje o stanie systemu i szablonu opisującego sposób ich prezentacji. Używa się bowiem w Turbinie jeszcze jednego elementu pośredniczącego - narzędzia renderującego (ang. template engine); może nim być Velocity, Webmacro, czy nawet JSP. Zadaniem tego elementu jest jak najlepsze odseparowanie kodu Javy od kodu części wizualnej strony. Do zadań obiektu implementującego ekran dziedziczący po klasie właściwej dla danego narzędzia (np. VelocityScreen) należą:
Następnie środowisko Turbiny uruchomi narzędzie renderujące, które na podstawie treści szablonu (głównie kod HTML) oraz obiektów przechowywanych w kontekście wygeneruje właściwy fragment strony WWW.
Narzędzia renderujące dopuszczają w szablonie - poza kodem HTML - właściwie tylko wywołania metod obiektów pobranych z kontekstów i rzutowanie ich wyników na napisy. Ograniczenie dostępnych w szablonie konstrukcji powoduje, że jego edycją mogą zajmować się webmasterzy, a nie programiści. Dzięki temu praca osób odpowiedzialnych za wygląd aplikacji może odbywać się niezależnie od pracy programistów. Velocity zostanie opisane dokładniej w jednym z następnych rozdziałów.
Zadaniem kontrolera jest reagowanie na życzenia użytkownika poprzez wykonywanie zmian w systemu. W Turbinie odbywa się to poprzez wywołanie właściwej akcji, czyli klasy dziedziczącej po Action i przeciążającą metodę doPerform zgodnie z logiką aplikacji. Aby zwiększyć podobieństwo do klasycznych aplikacji w modelu MVC, wprowadzono pewien odpowiednik sterowania poprzez zdarzenia (ang. action event).
Jeśli uzna się formularz na stronie WWW za komponent, to naciśnięcia przycisków go zatwierdzających mogą być traktowane jako zdarzenia. Możliwe jest związanie z formularzem tylko jednej akcji, posiadającej zestaw metod odpowiadających tym zdarzeniom (rozpoznawanym po nazwach przycisków). Podstawową korzyścią z takiego podejścia, jest zebranie metod obsługujących daną stronę czy formularz w jednym miejscu, przez co kod i budowa aplikacji stają się bardziej przejrzyste.
Choć akcje powinny zmieniać stan samego systemu, możliwa jest interakcja pomiędzy akcją a następującym po niej ekranem. Akcja może bowiem umieszczać obiekty w kontekście (a więc będą one dostępne w czasie renderowania strony WWW) oraz zmieniać ekran, jaki ma się pojawiać. Należy jednak bardzo ostrożnie korzystać z tych rozwiązań, ponieważ ich obecność zmniejsza czytelność kodu aplikacji.
Podstawowym elementem zarządzającym przepływem sterowania i generowaniem odpowiedzi jest strona (ang. page). Klasa implementująca stronę jest jedna dla całej aplikacji. W większości zastosowań wystarcza użycie dostarczonej wraz z dystrybucją, domyślnej implementacji (DefaultPage). Ewentualne rozszerzenia tego obiektu pozwalają na realizację akcji związanych z obsługą każdego żądania - jako przykład może posłużyć dodanie rejestracji statystyk odwiedzin poszczególnych ekranów.
Kolejnym pojęciem wprowadzonym przez projektantów Turbiny jest układ (ang. layout). W dobrze zaprojektowanym portalu, wygląd kolejnych stron dotyczących tej samej usługi czy tematu jest bardzo podobny. Na kolejnych stronach użytkownik może odnaleźć w tym samym miejscu pasek tytułu, menu, reklamy, czy formularz wyszukiwania, dzięki czemu nie musi za każdym razem na nowo analizować budowy strony. Na tym właśnie polega rola układu, organizuje on kolejne komponenty na stronie, zapewniając grupie stron podobny wygląd.
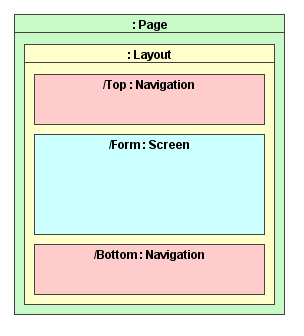
Ta część stron, która ulega zmianom i która jest odpowiedzialna za zapewnienie specyficznej logiki biznesowej aplikacji, to opisany już ekran. Elementy pojawiające się na wielu stronach to nawigacje (ang. navigations). Układ zależy od klasy go implementującej (nie ma właściwie potrzeby tworzenia własnych) oraz od szablonu opisującego położenie komponentów na stronie. W szablonie zostaje wskazane miejsca, gdzie mają zostać wyświetlone zawartości nawigacji oraz ekranu.
Nawigacja i ekran są do siebie bardzo podobne i zostały wyróżnione tylko ze względu na rolę jaką pełnią na stronach, ponieważ jak już wspominałem te same nawigacje mogą pojawiać się na wielu stronach, zaś ekran powinien odpowiadać jednej stronie o określonej funkcjonalności. Oba elementy są realizowane poprzez klas, których zadanie sprowadza się do uzupełnienia kontekstu właściwymi obiektami oraz z szablonów opisujących ich wygląd. Jedyne różnice pomiędzy ekranem a nawigacją są takie, że na stronie może znajdować się tylko jeden ekran, ale wiele nawigacji oraz, że dla nawigacji nie ma wsparcia ze strony systemu bezpieczeństwa. Wzajemne relacje opisanych elementów przedstawia rysunek 9.
Nie będę opisywał dalszych pojęć wprowadzonych przez twórców Turbiny, takich jak na przykład Factories czy Loaders, ani sposobu wiązania szablonów układu z właściwą stroną, ponieważ nie są one istotne dla zrozumienia budowy mojej aplikacji.
Poprawne działanie aplikacji wymaga identyfikacji akcji, która ma być wykonana i ekranu, który ma zostać wyświetlony w odpowiedzi na żądanie klienta. Żądanie przesłane Turbinie składa się z informacji pochodzących z dwóch źródeł: adresu URL i wartości pól formularza.
Na przykładzie adresu :
http://msc.pl/bad/template/admin,Edit.vm/action/admin.Clear/id/1/cmd/a
opiszę sposób, w jaki adresy URL są interpretowane przez Turbinę.
Początek adresu wskazuje na serwer HTTP i ewentualnie aplikację (http://msc.pl/bad) i jest istotny z punktu widzenia wspomnianego serwera HTTP i ewentualnie kontenera serwletów.
Następny fragment: template/admin,Edit.vm, wskazuje na ekran, jaki ma zostać wyświetlony przez Turbinę - w tym przypadku jest to ekran Edit.vm z podkatalogu admin. Jeśli parametr template wskazuje na ekran, który jest szablonem, to Turbina spróbuje odnaleźć dla niego klasę implementującą (admin.Edit w naszym przykładzie), a w przypadku jej braku zastosuje domyślną klasę dla danego typu szablonów (np. VelocityScreen).
Kolejna część adresu, action/admin.Clear, identyfikuje akcję jaką należy wykonać przed przystąpieniem do generowania odpowiedzi. W naszym przykładzie tą akcją jest obiekt klasy Clear z pakietu admin. W URL poza wskazaniem akcji i ekranu może wystąpić jeszcze ciąg parametrów, zakodowanych jako KLUCZ/WARTOŚĆ. W przykładowym adresie przekazane zostały dwa parametry: id o wartości 1 i cmd o wartości a. Turbina w taki sam sposób traktuje parametry przekazane jako części adresu URL i te pochodzące z formularza. Wartości parametrów odczytuje się poprzez obiekt RunData przy użyciu jego metod getString(NAZWA), getInt(NAZWA) itp.
Opiszę teraz jak system reaguje na przesłane przykładowe żądanie o adresie:
http://msc.pl/bad/template/admin,Edit.vm/action/admin.Clear/id/1/cmd/a.
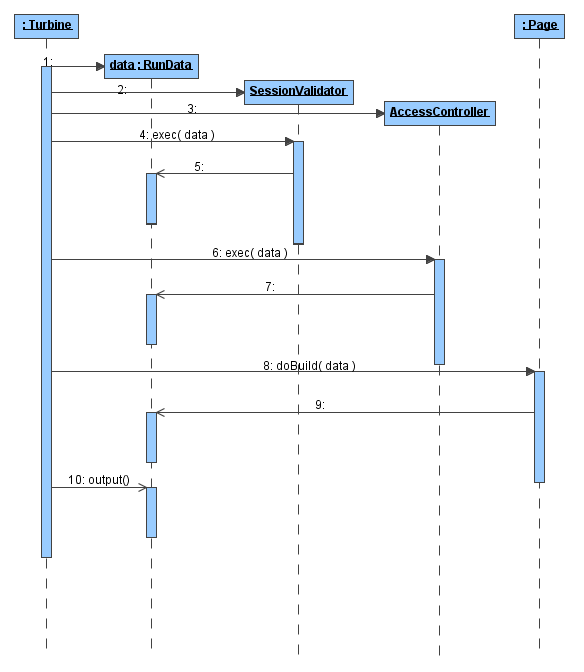
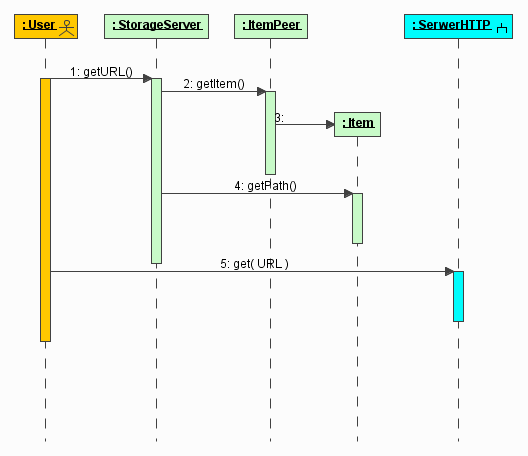
Kontener serwletów sprawdza, że kontekst bad odpowiada aplikacji z jakiegoś katalogu (np. właśnie bad) i że dotyczy serwletu Turbiny. Wywołana zostaje metoda doGet Turbiny z parametrem opisującym to żądanie (HttpServletRequest).
W metodzie doGet tworzony jest obiekt klasy RunData, który poza dostępem do parametrów przechowuje między innymi informacje o generowanej stronie, połączeniu z bazą danych, sesji i użytkowniku. Następnie sprawdza się czy akcja, którą należy wykonać, nie została zdefiniowana jako akcja logująca (poprzez odpowiedni wpis w pliku konfiguracyjnym). Jeśli tak, to uruchamia się ją, by podczas dalszej pracy były dostępne atrybuty użytkownika (w naszym przypadku akcja admin.Clear jest zwykłą akcją). Następnie Turbina sprawdza poprawność sesji użytkownika (SessionValidator) i tworzy opis uprawnień użytkownika - ACL (Access Control List). Jeśli oba działania zakończą się sukcesem, to odnajduje się klasę implementującą stronę i przekazuje do niej sterowanie poprzez wywołanie metody doBuild. Przedstawia to rysunek 10.
Opiszę sposób działania strony na podstawie klasy DefaultPage. W metodzie doBuild tej klasy zostaje stworzony obiekt odpowiadający akcji, którą należy wykonać (w naszym przykładzie będzie to klasa admin.Clear), a następnie wywołuje się jego metodę doBuild. Akcja realizuje cel wyznaczony jej przez programistę i sterowanie wraca do strony. Strona pobiera obiekt klasy odpowiedzialnej za wygenerowanie ekranu (admin.Edit) i uzyskuje od niego nazwę układu, jaki ma być użyty. Strona przekazuje sterowanie do właściwego układu.
W obiekcie układu następuje analiza szablonu definiującego rodzaj i położenie elementów na stronie. Po napotkaniu elementu odpowiadającego nawigacji, zostaje odnaleziona właściwa dla niej klasa i wołana jest jej metoda doBuild. Podobnie dzieje się w miejscu wystąpienia ekranu. Zobrazowałem to na rysunku 11. Nawigacje i ekran w czasie swojego działania dopisują do przekazanego im obiektu RunData wygenerowane fragmenty kodu HTML.
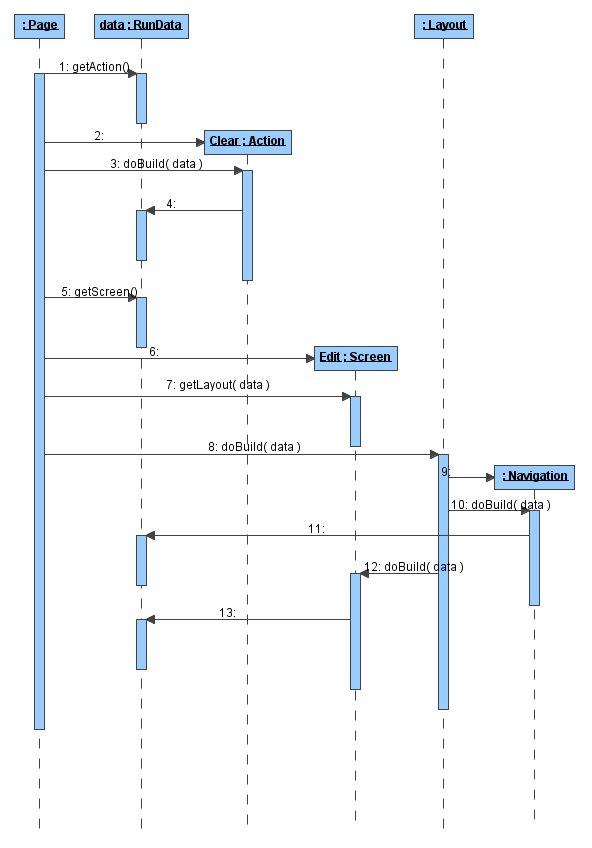
Sterowanie wraca wreszcie do strony, a następnie do Turbiny, która przepisuje wygenerowaną odpowiedź z obiektu RunData na obiekt HttpServletResponse. W tym krótkim opisie pominąłem lub uprościłem sposób odnajdowania, ładowania i przetwarzania klas implementujących akcje, ekrany i nawigacje, by pokazać tylko kluczowe etapy prowadzące do powstania wynikowej strony HTML.
Do poprawnego i wydajnego działania aplikacji często trzeba stworzyć globalnie dostępne elementy. Najbardziej charakterystycznymi przykładami takich elementów są pula połączeń (ang. connection pool) czy globalne bufory (ang. global cache). Wydaje się, że optymalną implementacją tych funkcjonalności jest pojedyncza instancja, inicjowana podczas startu Turbiny. Używany w wielu miejscach aplikacji "narzędziowy" kod warto umieścić w takim ciągle aktywnym obiekcie, by nie obciążać niepotrzebnie procesora powtarzającym się ładowaniem i inicjowaniem instancji jakiejś klasy.
Turbina oferują jednolite rozwiązanie tego zagadnienia w postaci serwisów (ang. services). Serwisy inicjowane są dopiero w chwili ich pierwszego użycia, wykrywane są przy tym wzajemne, cykliczne odwołania pomiędzy serwisami. Turbina informuje serwisy o kończeniu pracy, dzięki czemu mogą one zwolnić lub serializować używane zasoby. W Turbinie większość dostępnych usług zaimplementowano właśnie jako serwisy. A oto niektóre z nich:
Cache Service - globalny bufor.
Intake Service - umożliwia walidację parametrów formularzy.
JSP Service - umożliwia używanie stron JSP jako ekranów i nawigacji.
Logging Service - umożliwia zapisywanie komunikatów o stanie systemu (w tym błędów) z użyciem wielorakich mediów (konsoli, plików, zdalnych serwerów, poczty).
Pull Service - pozwala na umieszczanie obiektów w kontekście wszystkich stron.
Resources Service - pozwala na dostęp do parametrów konfiguracyjnych systemu.
Scheduler Service - uruchamia zadania w określonym czasie lub z określoną częstotliwością.
Velocity Servicy - odpowiada za renderowanie stron z pomocą szablonów Velocity.
XML-RPC - pozwala wołać procedury ze zdalnych serwerów.
XSLT Service - umożliwia transformacje XML z użyciem szablonów XSLT.
W dobrze zaprojektowanej aplikacji pomiędzy bazą danych a elementami z niej korzystającymi znajduje się dodatkowa warstwa pośrednicząca. Celem tej warstwy jest zebranie w jednym miejscu zapytań wyrażonych w SQL, tak by w razie modyfikacji struktury bazy danych możliwa była łatwa zmiana zależnego od niej kodu. Poza tą podstawową rolą często w tej warstwie implementuje się dodatkowe funkcjonalności zwiększające wydajność systemu, jak na przykład bufory do przekazywanych wyników zapytań.
W Turbinie znajduje się narzędzie służące do generacji takiej warstwy pośredniczącej; jest nim Torque. Torque na podstawie XMLowego opisu struktury bazy danych generuje kod SQL tworzący daną bazę (z uwzględnieniem specyfiki produktu) oraz wspomniane wcześniej obiektowe reprezentacje tabel i ich elementów (równoważniki i sepulki).
Opis przykładowej tabeli może wyglądać następująco:
<table name="Test_Instruction" idMethod="autoincrement">
<column name="id" required="true" autoIncrement="true" primaryKey="true" type="INTEGER"/>
<column name="test_id" required="true" type="INTEGER"/>
<column name="text" required="false" type="LONGVARCHAR"/>
<foreign-key foreignTable="Test">
<reference local="test_id" foreign="id"/>
</foreign-key>
<index name="index1">
<index-column name="test_id"/>
</index>
</table>
Ten fragment kodu XML definiuje tabelę o nazwie Test_Instruction o następujących kolumnach: id, test_id i text. Na jego podstawie zostaje wygenerowany następujący kod SQL (dla bazy MySQL):
CREATE TABLE Test_Instruction(
id INTEGER NOT NULL AUTO_INCREMENT,
test_id INTEGER NOT NULL,
text MEDIUMTEXT,
PRIMARY KEY(id),
FOREIGN KEY (test_id) REFERENCES Test (id),
INDEX index1 (test_id));
Torque tworzy również klasę TestInstructionPeer (dziedziczącą po klasie BasePeer), która pozwala na wykonywanie operacji na tej tabeli, dzięki udostępnieniu takich metod jak doSelect, doDelete, doInsert, doUpdate. Wynikiem instrukcji doSelect jest lista obiektów wygenerowanej klasy TestInstruction (dziedziczącej po klasie BaseObject) o metodach:
getId - przekazuje identyfikator instrukcji,
getText - przekazuje tekst instrukcji,
getTestId - przekazuje identyfikator testu ,
getTest - przekazuje obiekt klasy Test wskazywany przez atrybut test_id będący kluczem obcym,
setText - ustala tekst instrukcji,
setTest - ustala test, do którego należy instrukcja,
save - zapisuje obiekt w bazie danych (jeśli jest nowy, to wykonuje się instrukcję insert, w przeciwnym wypadku instrukcję update).
Na podstawie tego prostego przykładu można już zaobserwować podstawowe korzyści wynikające z użycia tego narzędzia:
Mamy możliwość przekazywania obiektu i niezależnego ustalania jego atrybutów po to, by na koniec zapisać jego stan w bazie danych.
Można odczytywać atrybuty obiektu posiadające już właściwy typ bez potrzeby ciągłego rzutowania.
W łatwy sposób można odwołać się do obiektów, z którymi element jest w związku wynikającym z relacji zapisanych w bazie danych.
Po dokonaniu ewentualnych zmian w strukturze bazy, można wygenerować nowe klasy odzwierciedlające zmodyfikowany schemat danych i to kompilator wykryje ewentualne konflikty w klasach korzystających z zawartości bazy danych.
Potrzebna jest również implementacja obiektowej reprezentacji samego zapytania, w przeciwnym bowiem przypadku, przy każdym wywołaniu metody doSelect konieczne byłoby wprowadzanie treści instrukcji select, co podważałoby sens istnienia całej warstwy. Tą obiektową reprezentacją instrukcji select są obiekty klasy Criteria. Można przy ich pomocy definiować kolejne warunki jakie mają być spełnione przez wyniki zapytania. Definiowanie warunków odbywa się z użyciem takich metod jak:
add(NAZWA_KOLUMNY,WART) - równoważną w SQL klauzuli WHERE postaci NAZWA_KOLUMNY=WART,
addIn(KOLUMNA,LISTA_WARTOSCI) - równoważną klauzuli WHERE postaci IN (WAR1, WAR2 ...)
Nazwy kolumn powinny być odczytywane ze stałych zdefiniowanych w równoważniku danej tabeli. W naszym przykładzie kod, który wybiera instrukcje należące do testu pierwszego, może mieć postać:
Criteria cr = new Criteria();
cr.add(TestInstructionPeer.TEST_ID,1);
cr.addAscendingOrderByColumn(TestInstructionPeer.SEQUENCE);
List result=TestInstructionPeer.doSelect(cr);
Nie wszystko da się wyrazić przy pomocy obiektów klasy Criteria (lub nie zawsze jest to wygodne) - w takich sytuacjach można jako parametr metody doSelect przekazać napis będący instrukcją SQL. Czasem pojawia się potrzeba dodania dodatkowych metod do obiektów wygenerowanych przez Torque. Dlatego Torque generuje zawsze dwie klasy - w naszym przypadku byłyby to klasy: BaseTestInstruction i TestInstruction. Programista może dodawać metody do tej drugiej (która oryginalnie tylko dziedziczy po klasie BaseTestInstruction) i nie zostaną one utracone przy ponownym generowaniu klas (bo wygenerowana zostanie tylko klasa BaseTestInstruction).
Podstawową korzyścią wynikającą z używania Torque jest szybkość, z jaką może powstać prototyp aplikacji. Najważniejsze obiekty biznesowe (te przechowywane w bazie danych) są dostępne już w początkowej fazie tworzenia aplikacji, a przy ich pomocy można wygenerować szkielet aplikacji, który następnie uzupełnia się o coraz to nowe funkcjonalności.
Velocity jest narzędziem służącym do generowania stron w HTML na podstawie dostarczonego szablonu. Projekt Velocity jest niezależny od Turbiny. Wykorzystywanie go w aplikacjach opartych na Turbinie jest tylko jednym z zastosowań tego narzędzia.
Szablon w Velocity składa się głównie z kodu w HTML. Zbiór dostępnych instrukcji jest bardzo ograniczony - ma on pozwalać na wygodne renderowanie stron WWW, a nie wykonywanie złożonych operacji. Oto lista podstawowych elementów języka:
Odwołanie do obiektu. Odbywa się poprzez instrukcję $NAZWA_OBIEKTU np.:
<p> Strony od: $begin do: $end. </p>
Szukany obiekt musi znajdować się w kontekście (umieszczony tam np. przez implementację ekranu) lub być zmienną szablonu.
Wywołanie metod obiektu. Po odwołaniu się do obiektu można korzystać z jego metod:
<td>$instruction.getText().subString(0,100) ...</td>
Deklarowanie zmiennej i jej wartości:
#set ($tmp = "cos")
#set ($end = $list.size())
Instrukcja warunkowa:
#if (! $list.isEmpty())
$list.get(0)
#elseif ($com.length() > 0 )
$com
#else
Błąd
#end
Instrukcja pętli. Pętle można zrealizować tylko poprzez listę lub tablicę, np.:
#foreach ($user in $users)
<tr><td>$user.getFirstName()</td>
<td>$user.getLastName()</td></tr>
#end
Operacje arytmetyczne.
Te elementy szablonów Velocity wystarczają w zupełności do stworzenia dowolnego ekranu korzystającego z informacji umieszczonych w kontekście. W przypadku wystąpienia błędów w szablonie informacje o nich zostają umieszczone w dzienniku zdarzeń tak, że możliwe jest określenie miejsc i przyczyn ich wystąpienia.
Mam nadzieję, że ten pobieżny opis Turbiny wystarcza do zrozumienia sposobu w jaki zaimplementowałem moją aplikację oraz pozwala na samodzielne tworzenie aplikacji z wykorzystaniem Turbiny.
Podstawowym narzędziem koniecznym do powstania WASS była oczywiście Turbina. W momencie powstawania tej pracy oficjalną dystrybucją Turbiny była jej wersja 2.0. Oprócz niej w sieci dostępna była również dopiero rozwijana wersja 3.0 Turbiny. Jako podstawę mojej aplikacji wybrałem wersję 2.0 z następujących powodów:
Używaną przeze mnie maszyną wirtualną Javy była wersja JDK 1.3.0. Jako kontener serwletów posłużył darmowy i dostępny wraz z dystrybucją Turbiny Tomcat. Pełnił on również funkcję serwera HTTP, choć nie ma żadnych przeciwwskazań, by wykorzystać w tym celu serwer Apache [33].
Jako narzędzie do renderowania stron zostało użyte Velocity, które oferuje możliwości wystarczające na potrzeby tej aplikacji. Wygląd generowanych stron oparty jest na stylach kaskadowych (CSS) [34], powinny więc być one poprawnie prezentowane przez większość przeglądarek.
Rolę serwera baz danych powierzyłem MySQL [35], którego dystrybucje są dostępne są na platformę Windows i Linux. Ta darmowa baza danych jest najprostsza, a dzięki temu bardzo wydajna, zaś analizując projekt mojej aplikacji nie widziałem potrzeby stosowania bardziej rozbudowanych silników bazodanowych (głównym ograniczeniem MySQL jest brak zagnieżdżonych zapytań SQL oraz więzów integralności). Ponadto śledząc listę dyskusyjną Turbiny nie spotkałem się z żadnymi doniesieniami na temat problemów w czasie integracji Turbiny z tym serwerem bazodanowym.
Aplikacje internetowe tworzone z wykorzystaniem Turbiny można podzielić na dwie grupy:
aplikacje, których jądrem jest właśnie Turbina i które ograniczają się do wykorzystywania wprowadzonego w niej modelu ekran + akcja,
aplikacje posiadające własną implementację jądra (choć oczywiście korzystającą z Turbiny) i definiujące własny model obsługi żądań. Przykładem takiej aplikacji mógłby być portal, w którym żądania zawierają identyfikatory dokumentów, a stworzone jądro generuje odpowiadające im strony.
Analizując wymagania stawiane systemowi WASS nie widziałem potrzeby tworzenia własnego jądra (silnika) aplikacji. Wymagane funkcjonalności doskonale pasują do architektury opartej na ekranach prezentujących dane i akcjach dokonujących zmian w systemie.
Dlatego WASS składa się głównie z klas implementujących ekrany i akcje w sposób pozwalający na realizację stawianych przed systemem celów. Konsekwencją takiego podejścia jest jednak pewne "rozproszenie" aplikacji, bowiem zarówno ekrany, jak i akcje są między sobą słabo powiązane. Ponadto wyróżnione w projekcie moduły nie przekładają się na niezależne fragmenty kodu. I tak na przykład elementy modułu odpowiedzialne za system bezpieczeństwa znajdować się muszą w każdej klasie implementującej ekran czy akcję.
W kolejnych rozdziałach opiszę sposób w jaki zostały zrealizowane funkcje poszczególnych modułów aplikacji.
Zdefiniowałem następujące prawa: czytanie, pisanie, usuwanie i wykonywanie, oraz stworzyłem na ich podstawie role: właściciel, pisarz, czytelnik i wykonujący. Te role przypisuje się użytkownikowi w kontekście konkretnych badań, testów czy półek. Ponadto zostały zdefiniowane globalne role administratora, badacza i badanego (rysunki 12 i 13). Służą one do kontroli dostępu na poziomie operacji.
Model danych dla modułu Security jest zgodny z opisanym w projekcie aplikacji. Ponieważ identyfikatory dla testu i badania mogą przyjmować te same wartości (są to klucze pochodzące z różnych tabel), stworzyłem dodatkową tabelę security_obj, która umożliwia jednoznaczne wiązanie tych elementów z opisem uprawnień przechowywanym w tabeli security.
W sepulce odpowiadającej tabeli security_obj, zaimplementowałem metody umożliwiające pobranie informacji o posiadanych przez użytkownika rolach i prawach. Dzięki temu, nie musiałem powtarzać tego samego kodu w klasach odpowiadających badaniu i testowi, lecz mogłem odwoływać się do metod powiązanych z nimi obiektów klasy SecurityObj. Kontrola dostępu na poziomie operacji odbywa się z wykorzystaniem obiektu ACL dostarczonego przez twórców Turbiny.
W klasach bazowych dla akcji i ekranów (są to MScAction i MScScreen) zaimplementowałem następujący schemat przebiegu autoryzacji:
pobierz z sesji obiekt użytkownika;
jeśli brak obiektu użytkownika, to przejdź do ekranu logowania;
pobierz obiekt ACL dla użytkownika;
jeśli brak obiektu ACL, to przejdź do ekranu logowania;
pobierz wymagane prawo; /* metoda getPermission */
pobierz zasób; /* metoda getSecurityObject */
jeśli użytkownik posiada prawo w obiekcie ACL, to wykonaj akcje, wyświetl ekran;
jeśli zasób jest różny od NULL, to
{
jeśli użytkownik posiada prawo do danego zasobu, to wykonaj akcje, wyświetl ekran;
}
przejdź do ekranu błędu dostępu;
W podklasach MScAction czy MScScreen wystarczy przeciążyć metodę getPermission (powinna ona przekazywać nazwę prawa wymaganego w danej akcji lub ekranie) oraz metodę getSecurityObject (przekazującą zasób, którego ma dotyczyć operacja).
Moduł ten ma umożliwiać umieszczanie plików multimedialnych w badaniach. Zdecydowałem się na przechowywanie plików na dysku, a nie w bazie danych. Rozwiązanie z plikami jest dużo prostsze i wydajniejsze niż to wykorzystujące bazę danych. Plik zostaje tylko opisany w bazie danych i skopiowany do odpowiedniego katalogu w poddrzewie aplikacji, a w przypadku odwołania do niego na podstawie informacji zapisanych w bazie danych zostaje odtworzona ścieżka do pliku i przedstawiona jako adres URL.
Operacje związane z modułem Storage (dodawanie i usuwanie plików, pobieranie odpowiadającym im adresów URL) odbywają się poprzez serwis MScStorage. Pliki są opisane w tabeli Item. Badacze mogą korzystać z niezależnych zbiorów plików w systemie, dzięki tabeli Shelf, która umożliwia tworzenie wirtualnych katalogów z zasobami (półek). Administracja plikami odbywa się z wykorzystaniem ekranów i akcji z pakietu admin.storage. Sposób udostępniania plików został zaprezentowany na rysunku 14.
Z przedstawionym rozwiązaniem wiąże się jednak ryzyko, że osoba nieupoważniona pozna treść zgromadzonych plików multimedialnych. Dostęp do plików odbywa się poprzez serwer HTTP, można więc wyobrazić sobie sytuacje, w której ktoś generuje kolejne nazwy zasobów, by w ten sposób odczytać wszystkie zgromadzone pliki. Nie stanowi to jednak naruszenia zasad bezpieczeństwa systemu, gdyż nie można w ten sposób, ani usunąć ani zmodyfikować przechowywanych zasobów.
Gdyby w przyszłości, zaistniała potrzeba ochrony treści plików mutlimedialnych (np. z powodu wagi zawartych w nich informacji lub ochrony praw autorskich), możliwe będzie stworzenie serwletu, który będzie obsługiwał żądania do zasobów. Jako serwlet będzie miał dostęp do tej samej sesji użytkownika co instancja Turbiny i dzięki zapisanym w niej informacjom będzie przekazywać tylko te pliki, do których użytkownik ma dostęp.
Moduł ten zawiera w sobie elementy odpowiedzialne za przeprowadzenie badania. Oparty jest głównie na ekranach i akcjach z pakietu user (pakiet ten zawiera dwa podpakiety test i admin, grupujące klasy zależne odpowiednio od testów i badań). Po wybraniu badania, w którym użytkownik chce wziąć udział i ewentualnej rejestracji, z klientem zostaje związany obiekt ResearchSession, który przechowuje między innymi opis badanego i stan samego badania (częściowe wyniki, bieżący test itp.). Stworzona sesja jest wykorzystywana przez wszystkie ekrany i akcje aż do zakończenia badania.
To jakie szablony i klasy zostaną użyte przy prezentacji zadań czy zbieraniu odpowiedzi, zależy od atrybutów rodzaju testu powiązanego z danym testem. Rysunek 15 prezentuje sposób nawigacji badanego w systemie. Nie będę wymieniał wszystkich zaimplementowanych ekranów i akcji należących do tego modułu, przynależą one do pakietów msc.modules.actions.user oraz msc.modules.screens.user i są dobrze opisane w załączonej na płycie dokumentacji wygenerowanej z użyciem Javadoc.
W module tym zostały zebrane akcje i ekrany pozwalające na definiowanie treści zadań Zostały one przypisane do pakietów msc.modules.actions.admin.test i msc.modul-es.screens.admin.test. Kluczowymi ekranami dla tego modułu są EditTestQuestions i EditQuestion. Pierwszy ekran pozwala na definiowanie przynależnych do testu pytań i ich kolejności, drugi zaś umożliwia modyfikację pytania i przypisanych do niego odpowiedzi. W opisie rodzaju testu można zdefiniować dla obu ekranów szablony inne niż domyślne (takie, które pozwalają na wprowadzenie danych w sposób charakterystyczny dla danego zadania), można również podać inne klasy implementujące wspomniane ekrany. W większości przypadków różnice pomiędzy rodzajami testów sprowadzać się będą do zmian sposobu ich prezentacji, dlatego wystarczy stworzyć nowe szablony edycyjne dla testu i jego pytań, a następnie opisać je w definicji typu testu. Opis wszystkich klas z przynależnych do modułu pakietów znajduje się w załączonej dokumentacji technicznej. Rysunek 16 przedstawia schemat nawigacji po tej części aplikacji.
Klasy implementujące zarządzanie badaniami umieściłem w pakietach msc.modu-les.actions.admin.research i msc.modules.screens.admin.research. Nie przewiduję potrzeby modyfikowania tej części aplikacji. Wszystkie badania powinny być komponowane w ten sam sposób, a różnice pomiędzy nimi muszą dać się wyrazić poprzez dobór odpowiednich testów. Sposób nawigacji po tej części aplikacji schematycznie prezentuje rysunek 17.
Klasy z pakietów msc.modules.actions.admin.process i msc.modules.scre-ens.admin.process odpowiadają za przetwarzanie zgromadzonych odpowiedzi badanych i ich prezentacje w pożądanej przez badacza postaci. Badacz oczekuje wyników w formie tabeli, w której kolumny odpowiadają wynikom jednego pytania, zaś wiersze są rezultatami kolejnych badanych osób.
W przypadku implementacji poprzednio opisanych zadań, struktura bazy danych w trzeciej postaci normalnej nie wywoływała wzrostu nakładów pracy podczas programowania. W tym jednak module, sposób przechowywania w bazie danych informacji o odpowiedziach nie daje się łatwo przełożyć na formę wymaganą przez badacza. W bazie danych znajdują się bowiem rekordy opisywane sesją, pytaniem i kontenerem testu (ponieważ test może wystąpić kilka razy w tym samym badaniu). Transformacji wyników do wymaganej postaci tabeli nie da się dokonać w oparciu o proste zapytania SQL, dlatego konieczne było zaimplementowanie jej w postaci kodu Javy. W klasie BaseProcessResult zaimplementowałem następujący algorytm przetwarzający wyniki:
pobierz wersje badania;
dla każdej wersji;
{
pobierz sesje, które do niej należą (i są np. poprawnie zakończone);
stwórz słownik, w którym kluczami są sesje a wartościami listy wyników;
pobierz testy należące do wersji i ustaw je według ich kolejności w badaniu;
dla każdego testu;
{
pobierz pytania testu i ustaw je według ich kolejności w teście;
dla każdego pytania;
{
pobierz odpowiedzi na to pytanie należące do wybranych sesji i posortuj je według sesji;
przeglądaj odpowiedzi dodając wyniki do listy ze słownika dla danej sesji (brakujące wyniki uzupełniaj pustymi);
}
}
}
W wyniku działania tego algorytmu dla każdej wersji badania powstaje słownik z listami wyników poszczególnych osób (ewentualnie uzupełnionymi pustymi wpisami, dzięki czemu kolejne elementy list odpowiadają tym samym pytaniom dla wszystkich osób). Na podstawie takiej reprezentacji odpowiedzi badanych w łatwy sposób można wygenerować żądaną tabelę. Wydaje mi się, że ten algorytm jest optymalny zarówno ze względu na przetwarzane wyniki (każdy z nich oglądany jest tylko raz), jak i ze względu na wykonywane zapytania (wykonywane są jednorazowo tylko zbiorcze zapytania: wszystkie testy, wszystkie pytania, wszystkie odpowiedzi).
Podczas transformacji wyników może być użyta funkcja oceniająca (kodująca) odpowiedzi badanych. Za jej dostarczenie odpowiada implementacja klasy o interfejsie Checker. Istnieje możliwość powiązania funkcji oceniającej z rodzajem testu, dzięki czemu podczas prezentacji wyników są one zakodowane w sposób interesujący badacza.
Moduł umożliwia oczywiście wygenerowanie tabeli z przetworzonymi wynikami do pliku tekstowego, który następnie może być analizowany z użyciem programów statystycznych.
Warstwa pośrednicząca pomiędzy bazą danych a innymi elementami aplikacji została stworzona za pomocą Torque w sposób opisany przeze mnie w rozdziale 4.5. Wszystkie wykorzystywane w systemie tabele bazy danych, oraz funkcjonalności dodane do wygenerowanych przez Torque klas zostały opisane w Dodatku A.
Zrealizowana przeze mnie aplikacja składa się z ponad dwustu klas, dlatego nie będę opisywał ich wszystkich. Dokumentacja techniczna dla napisanych klas powstała przy pomocy programu Javadoc i znajduje się na dołączonej do pracy płycie w katalogu API. W przypadku ekranów opis klasy wzbogacony został o informacje dotyczące powiązanych z nimi szablonów (np. umieszczane w kontekście obiekty), dzięki czemu wygenerowana dokumentacja stanowi kompletne źródło informacji o napisanej aplikacji.
Pierwszy przykład nie jest tak naprawdę badaniem naukowym, ale pokazuje uniwersalność stworzonego przeze mnie systemu oraz łatwość realizacji typowego zadania.
6.1.1 Opis problemu
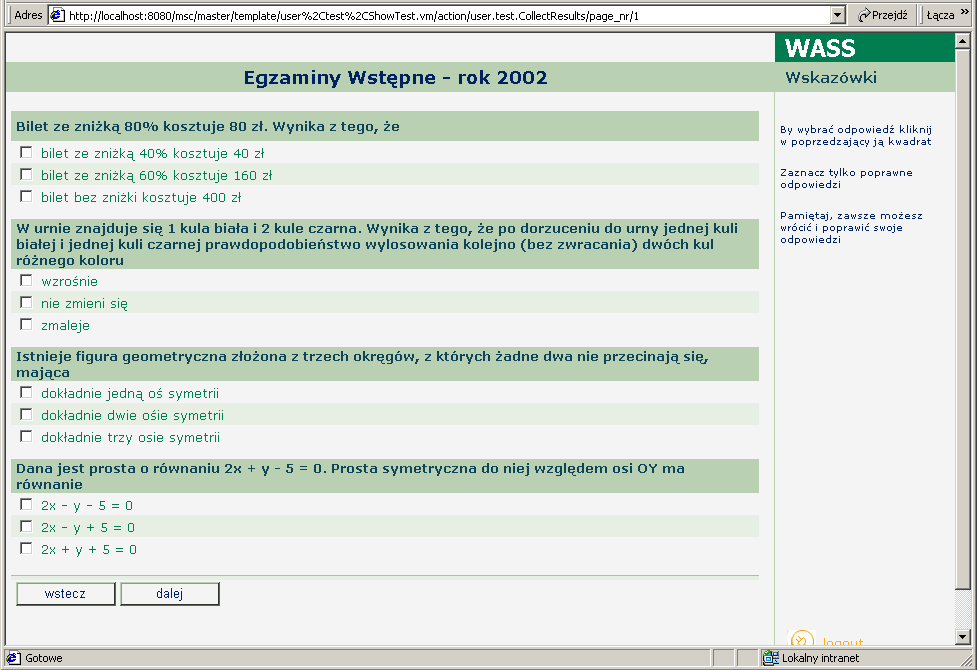
Zostałem poproszony o udostępnienie w Internecie testów z egzaminów wstępnych na Wydział Matematyki, Informatyki i Mechaniki Uniwersytetu Warszawskiego. Kandydaci na studia powinni mieć możliwość wybrania zestawu zadań z interesującego ich rocznika. Po wybraniu takiego zestawu, kandydat może poznać treść kolejnych zadań i udzielać na nie odpowiedzi wykorzystując w tym celu strony WWW. Po rozwiązaniu przez kandydata całego testu, powinno nastąpić automatyczne ocenianie udzielonych przez niego odpowiedzi. Uzyskany przez kandydata wynik będzie zaprezentowany na kolejnej stronie. Zadania egzaminacyjne składają się z krótkiego pytania oraz trzech wariantów odpowiedzi. Od osoby rozwiązującej zadanie oczekuje się, że wskaże które z nich są prawdziwe, a które fałszywe.
6.1.2. Analiza problemu
Z przedstawionego opisu, wynika, że problem sprowadza się do zrealizowania testu z pytaniami wielokrotnego wyboru oraz automatycznej oceny takiego testu. Powstałe testy powinny być dostępne dla dowolnych użytkowników sieci Internet.
6.1.3. Realizacja
Test wielokrotnego wyboru znajduje się w napisanej przeze mnie bibliotece podstawowych typów kwestionariuszy. Dzięki temu postawione zadanie można rozwiązać przy pomocy panelu administracyjnego dostępnego dla badaczy. Zdecydowałem, że pytania egzaminacyjne z kolejnych lat, będą przechowywane jako różne wersje tego samego badania.
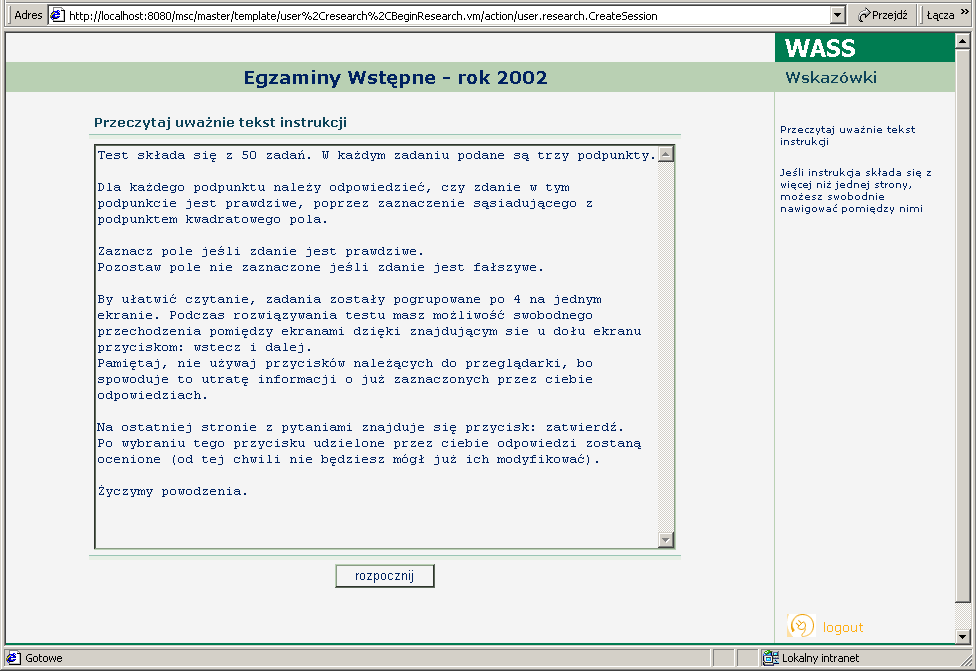
Utworzyłem nowe badanie o nazwie "Egzaminy Wstępne". Ponieważ egzaminy miały być ogólnodostępne, w sposobie rejestracji do badania ustawiłem opcję pozwalającą na nieautoryzowane korzystanie z badania. Wybór wersji został określony jako dowolny, tak by kandydat mógł samemu wybrać, który z egzaminów chce rozwiązać (każda wersja to egzamin z innego roku). Wprowadziłem również tekst instrukcji wstępnej, w którym umieściłem informacje o tym w jaki sposób należy udzielać odpowiedzi na prezentowane zadania.
Dla każdego egzaminu wstępnego z lat ubiegłych utworzyłem nowy test o typie "Test Wielokrotnego Wyboru - Pełny", który opisuje kwestionariusze z właściwą konstrukcją pytań. Następnie ustaliłem funkcję oceniającą na "Duże i Małe punkty", która odpowiada sposobowi w jaki punktowane są rozwiązania zadań w czasie egzaminu. Dla testów nie definiowałem instrukcji wstępnej, gdyż wspólny tekst instrukcji został powiązany z samym badaniem. Testy oznaczyłem jako "wewnętrzne", a więc widoczne tylko z poziomu tego badania, gdyż nie przewiduję ich użycia w innych badaniach. Rysunki 18 i 19 prezentują wygląd ekranów dla tego badania.
W ten prostu sposób został osiągnięty zamierzony cel. Ewentualna analiza wyników uzyskiwanych przez kandydatów może pozwolić na znalezienie pytań sprawiających największą trudność (choć myślę, że lepiej w tym celu wykorzystać archiwalne wyniki rzeczywistych egzaminów).
Badanie to zostało zaprojektowane przez profesora Janusza Grzelaka i jego współ-pracowników z Wydziału Psychologii Uniwersytetu Warszawskiego.
6.2.1. Opis problemu
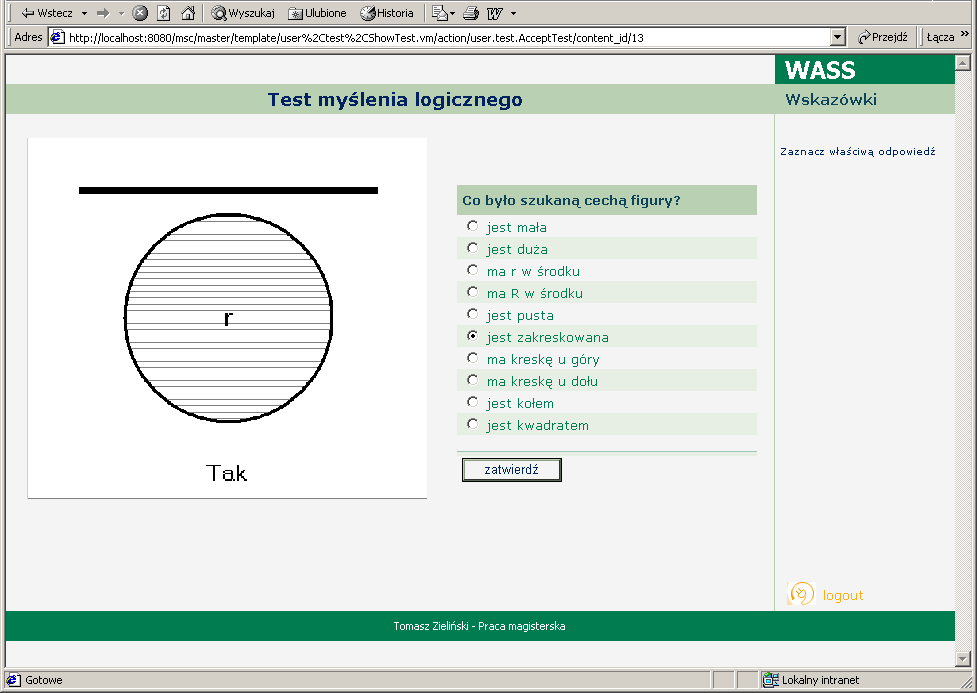
Zaprojektowane badanie składa się z kilku zadań. W zadaniu pierwszym badanemu są prezentowane przez krótki czas kolejne ilustracje opatrzone napisami TAK i NIE. Na ilustracjach przedstawione są różne figury geometryczne. Występują na nich małe i duże koła, zakreślone i puste figury, małe i duże litery. Wszystkie ilustracje opatrzone napisem TAK posiadają jakąś wspólną cechę (np. figury były zakreskowane), zaś na tych oznaczonych tekstem NIE cecha ta nie występuje. Zadaniem badanego po obejrzeniu ilustracji jest wskazanie wspólnej dla nich cechy. W pierwszej części badania, uczestnik proszony jest o rozwiązanie kilku takich zadań.
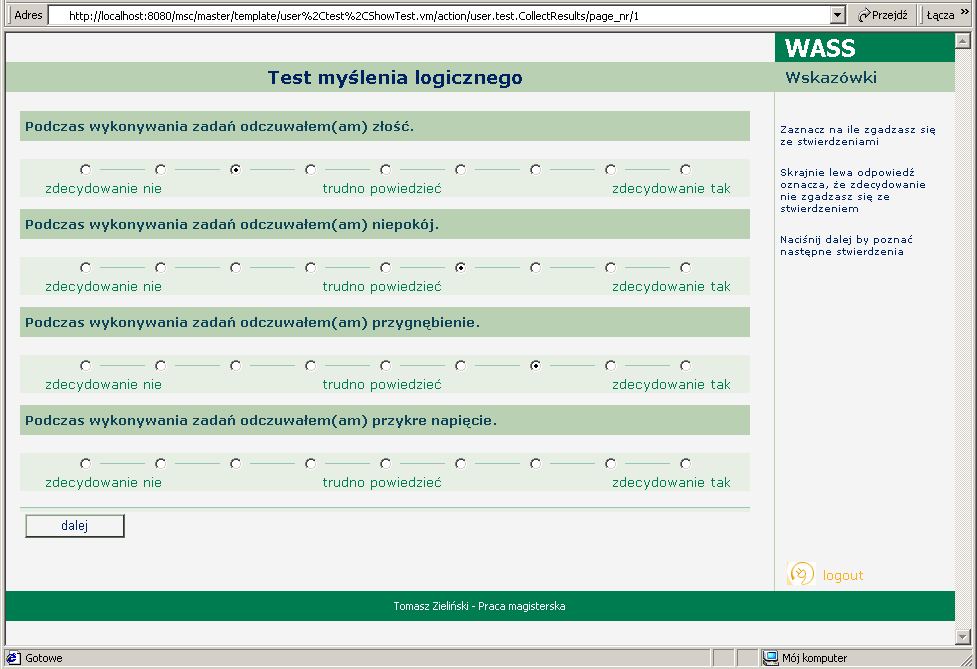
W kolejnej części badania sprawdzany zostaje nastrój badanego. Prezentowane są mu różne stwierdzenia (np. "Podczas wykonywania zadań odczuwałem(am) złość") do których musi się on ustosunkować, zaznaczając na ile się z nimi zgadza (korzystając z liniowej skali).
Kolejnym elementem badania są pytania sprawdzające inteligencję badanego. Uczestnik musi na przykład wybrać z dostępnych odpowiedzi przeciwieństwa podanego słowa, zaznaczyć wniosek będący logiczną konsekwencją zaprezentowanego tekstu itp.
Na zakończenie badany znowu proszony jest o ustosunkowanie się do podanych stwierdzeń poprzez zaznaczenie swojej odpowiedzi na liniowej skali.
Całe badanie występuje w dwóch wersjach. Mają one taki sam przebieg, ale w jednej z nich prezentowane badanemu ilustracje nie mają żadnej wspólnej cechy, przez co uczestnik nie jest w stanie podać poprawnej odpowiedzi. W czasie analizowania wyników tego eksperymentu, porównywane są odpowiedzi osób, które miały szansę na rozwiązanie pierwszego zadania z tymi które były jej pozbawione.
6.2.2. Analiza problemu
Opis badania pozwala na jednoznaczne wyróżnienie testów jakie się na niego składają. Są to: test prezentujący ilustracje, test z liniową skalą badający nastrój, testy wyboru badające inteligencję, test z liniową skalą kończący badanie. Równie naturalne jest wydzielenie z badania dwóch jego wersji, które będą się różniły pomiędzy sobą tylko pierwszym z prezentowanych testów. Głównym problemem może być zrealizowanie zadania z ilustracjami, gdyż przy pomocy języka HTML nie można zapewnić ekspozycji obrazków przez ściśle określony czas.
6.2.3. Realizacja
W przygotowanej przez mnie bibliotece podstawowych typów testów znajdują się oczywiście i takie, które pozwalają na udzielanie odpowiedzi przy pomocy liniowej skali czy poprzez wybór z listy dopuszczalnych możliwości. Główne wyzwanie polega na stworzeniu nowego rodzaju testu, odpowiadającego pierwszej części badania - prezentującej ilustracje badanemu.
Zdecydowałem, że ilustracje będą przechowywane w systemie z użyciem modułu Storage, zaś prezentowane poprzez umieszczony na stronie aplet, który pozwoli na ścisłą kontrolę czasu prezentacji każdego z obrazków.
Stworzyłem klasę SlideQuestion dziedziczącą po ExtendedQuestion, która jest implementacją pytania zawierającego kilka plików graficznych. W klasie tej umieściłem metody pozwalające na ustalanie identyfikatorów obrazków przynależnych do pytania oraz na pobieranie obiektów klasy Item im odpowiadającym. Identyfikatory zasobów związanych z pytaniem zapisywałem na serializowanej liście w tabeli Question_Extenstion.
Następnym etapem pracy było stworzenie nowego szablonu edycji pytania, który pozwoliłby na wybór grafiki dołączanej do pytania. Nie musiałem tworzyć nowej akcji aktualizującej pytanie, gdyż istniejąca już w systemie akcja UpdateQuestion potrafiła zrealizować to zadanie (dzięki metodom ustalającym identyfikatory obrazków dodanym do klasy SlideQuestion).
Poza stworzeniem apletu, który będzie prezentował zawartość pytania w czasie badania, konieczne było jeszcze utworzenie szablonu prezentacji dla tego rodzaju testów, w którym umieściłem odwołanie do właściwego apletu. Był to ostatni etap pracy projektanta nad realizacją tego badania.
Korzystając ze stworzonych klas i szablonów mogłem zdefiniować nowy typ testów: "Pokaz slajdów". W atrybutach tego typu zapisałem informacje o klasie implementującej pytania, szablonie wykorzystywanym w czasie edycji pytania i szablonie prezentującym test badanemu. Od tej chwili w systemie były dostępne wszystkie wymagane przez to badanie rodzaje testów, mogłem więc przystąpić do stworzenia nowych testów, odpowiadających opisanym wcześniej częściom tego badania (pokaz ilustracji, badanie nastrojów, testy na inteligencję). Jako testy o charakterze ogólnym, zostały one udostępnione wszystkim badaczom, dzięki czemu będzie możliwe konstruowanie przy ich pomocy innych eksperymentów naukowych.
Utworzyłem nowe badanie o nazwie "Nastroje" i do jego podstawowej wersji przypisałem właściwe testy oraz ustaliłem kolejność w jakiej mają być prezentowane podczas eksperymentu. Korzystając z funkcji kopiowania wersji, mogłem przygotować kopię podstawowej wersji badania, w której to dokonałem zmiany pierwszego testu. Przy pomocy ekranu pozwalającego na edycję sposobu rejestracji do badania, zdefiniowałem wymagane atrybuty badanych (płeć, wykształcenie, wiek) oraz określiłem wybór wersji na losowy (tak by podobna liczba osób mogła brać udział w obu wersjach badania). W ten sposób uzyskałem badanie realizujące postawiony przez psychologów cel. Rysunki 20, 21 i 22 prezentują ekrany pochodzące z tego badania.
Doświadczenie, które zdobyłem podczas pisania tej pracy pozwala mi na stwierdzenie, że Turbina jest znakomitym środowiskiem tworzenia aplikacji internetowych. Postaram się opisać zarówno największe zalety, jak i niedogodności tego narzędzia.
Znakomitym pomysłem twórców Turbiny był zaproponowany przez nich model logiczny oparty na akcjach i ekranach. Ten podział doskonale pasuje do specyfiki aplikacji internetowych i powoduje, że tworzone aplikacje mają przejrzystą budowę. Takie rozwiązanie uważam za dużo lepsze niż standardowe podejście stosowane na przykład na stronach JSP, gdzie początkowy kod strony odpowiedzialny jest za rozpoznanie żądania klienta, jego realizację i ewentualne prze-kierowanie do kolejnych stron. Metodologia tworzenia aplikacji internetowych korzystających z ekranów i akcji pozwala na wyraźne rozdzielenie elementów odpowiadających za zmianę stanu systemu od części wizualizujących ten stan.
To rozwiązanie ma oczywiście i swoje wady. Sposób pakietowania klas wprowadzony w Turbinie, w którym akcje muszą się znajdować w podpakietach modules.actions, a ekrany w modules.screens, powoduje, że klasy odpowiedzialne za implementację jednej funkcjonalności nie znajdują się w tym samym pakiecie (należy jednak pamiętać, że mają one wyznaczone inne role w aplikacji). Ponieważ najczęściej ekran prezentuje cechy jakiegoś obiektu, zaś akcja je modyfikuje, to by zwiększyć wydajność systemu, obiekt ten umieszcza się najczęściej w sesji użytkownika. Powoduje to powstanie niejawnej komunikacji pomiędzy ekranem a akcją, co może czasem zmniejszać czytelność kodu.
Podział warstwy prezentacji na klasy implementujące ekrany i szablony generujące kod w HTML to kolejna niewątpliwa zaleta Turbiny. Tę aplikację tworzyłem samodzielnie, przez co nie mogłem docenić podstawowej korzyści z takiego rozwiązania, jaką jest niezależna praca nad częścią wizualną i funkcjonalną programu. Wiem jednak o komercyjnych zastosowaniach Turbiny, w których za warstwę prezentacji tworzonych projektów byli odpowiedzialni webmasterzy pracujący równolegle z programistami implementującymi logikę aplikacji.
Kolejnym atutem Turbiny jest Torque pozwalający na generowanie obiektowej reprezentacji bazy danych. Nie będę powtarzał opisanych w poświęconym Torquowi rozdziale 4.5 zalet takiego sposobu dostępu do danych. Podkreślę jednak jeszcze raz łatwość z jaką można stworzyć szkielet (prototyp) aplikacji. Mając wygenerowane obiekty odpowiadające tabelom w bazie danych, wystarczy umieścić je w kontekście ekranów i na ich podstawie wygenerować właściwe formularze. Następnie w treści akcji można dokonać zmian w systemie, wołając metodę setProperties(obiekt) z RunData, a potem metodę save tego obiektu. Taka podstawowa wersja aplikacji pozwala na sprawdzenie funkcjonalności zaprojektowanych rozwiązań i umożliwia stworzenie pełnego systemu przez krokowe uzupełnianie istniejącego szkieletu (przede wszystkim o walidację danych, czy optymalizowanie dostępu do danych).
W przypadku aplikacji tworzonych z pomocą Turbiny faza projektowania może ograniczyć się tylko do zdefiniowania struktury danych oraz wymaganych funkcjonalności. Opis struktury danych pozwoli bowiem na wygenerowanie obiektów biznesowych, zaś specyfikacja funkcjonalna doskonale przekłada się na ekrany i akcje.
Również inne elementy Turbiny, takie jak Cache Service, Scheduler Service, Logging Service oraz zaimplementowany system bezpieczeństwa, skracają czas tworzenia szkieletu aplikacji i ułatwiają jego późniejszą modyfikację.
Nie są to w istocie wady, ale raczej niedociągnięcia wywołane brakiem pewnych funkcjonalności lub niewygodą istniejących rozwiązań.
Elementem Turbiny, który może budzić największe zastrzeżenia, jest system bezpieczeństwa. Nieintuicyjne pojęcie grupy wprowadzone w systemie bezpieczeństwa Turbiny uważam za naprawdę zły pomysł. Nie widzę żadnej przewagi takiego rozwiązania nad klasycznym podejściem, w którym modeluje się użytkownika, grupę użytkowników oraz ich role i prawa. Ponadto brakuje jakiegokolwiek wsparcia w zakresie ograniczania dostępu do samych zasobów, które moim zdaniem jest konieczne w prawie każdej aplikacji
Choć w Turbinie można implementować własne rozwiązania odpowiedzialne za system bezpieczeństwa, to zbyt mało ogólne interfejsy elementów tego systemu uniemożliwiają wykonanie tego w sposób wygodny dla programisty. Bo cóż z tego, że można stworzyć własne klasy implementujące użytkownika, jego ACL czy Security Service, jeśli nie można korzystać z nich w aplikacji w sposób przezroczysty i konieczne jest ciągłe rzutowanie.
Zawarty w Turbinie Intake Service mający umożliwiać automatyczną walidację formularzy, jest narzędziem zupełnie nieużytecznym. Ilość pracy konieczna do zdefiniowania elementów, które miałyby być poddane walidacji, oraz do umieszczenia kodu odpowiadającego za ten proces, jest porównywalna do wysiłku jaki trzeba włożyć przy ręcznej implementacji takiej funkcjonalności. Wydaje mi się, że to Torque powinien być rozszerzony o tą cechę. Mógłby on generować na przykład takie implementacje obiektów biznesowych, które sprawdzają odpowiednie warunki w metodach ustawiających wartości ich atrybutów (oraz tworzyć polecenia SQL z właściwymi dla danej bazy danych więzami integralności). Ponadto brakuje wsparcia dla automatycznego przeładowywania ekranów z błędnie wypełnionymi formularzami.
Choć Turbina ma swoją oficjalną dystrybucję w wersji 2.1, to wydaje się, że jest ona ciągle narzędziem przeznaczonym głównie dla grona osób je rozwijających. W czasie pisania aplikacji wielokrotnie musiałem bowiem czytać źródła Turbiny, naprawiać znalezione w nich drobne błędy, konieczna była również modyfikacja szablonów Torque. Myślę, że rozwiązanie napotykanych problemów było możliwe głównie dlatego, że byłem zaangażowany w rozwój tego narzędzia i dobrze znałem jego budowę.
Pomimo tych niedogodności szczerze polecam Turbinę jako środowisko tworzenia aplikacji internetowych, zwłaszcza w sytuacji gdy planowana jest realizacja kilku projektów. W takim bowiem przypadku wkład pracy włożony w poznanie tego środowiska, procentuje przy kolejnych wdrożeniach. Ponadto możliwe jest wielokrotne wykorzystanie przygotowanych wcześniej rozwiązań, narzędzi i rozszerzeń Turbiny.
Aktualnie trwają prace nad wersja 3.0 Turbiny. W wersji tej wprowadzono inny model logiczny aplikacji oparty na potokach (ang. pipeling), podobnie jak ma to miejsce w Cocoonie. Nie jestem zwolennikiem takiego rozwiązania. Utracono bowiem w ten sposób, największą moim zdaniem zaletę Turbiny - wyróżnienie akcji i ekranu. Ponadto aplikacje stworzone w Turbinie wersji 2 nie będą mogły działać z Turbiną wersji 3, choć twórcy zapewniają, że powstaną narzędzia ułatwiające migracje aplikacji do nowszej wersji.
W ramach projektu magisterskiego udało mi się stworzyć środowisko umożliwiające projektowanie i prowadzenie badań w naukach społecznych z użyciem komputera i sieci Internet. Napisana przeze mnie aplikacja nie posiada żadnych odpowiedników ani w postaci komercyjnych rozwiązań, ani ogólnie dostępnych projektów. Wymienię najważniejsze osiągnięcia mojej pracy.
Przygotowałem bibliotekę najpopularniejszych typów testów, która pozwala na stworzenie elektronicznych odpowiedników podstawowych kwestionariuszy używanych w psychologii czy socjologii.
Zaprojektowałem i zaimplementowałem łatwy w użyciu system bezpieczeństwa, który pozwala na ochronę pracy twórczej naukowców.
Przygotowałem narzędzia wstępnie przetwarzające odpowiedzi badanych, dzięki czemu możliwa jest automatyczna ocena testów oraz prezentacja wyników badań w dogodnej dla badacza formie.
Realizując przykładowe badania, pokazałem uniwersalność i elastyczność zaprojektowanego przeze mnie środowiska oraz łatwość, z jaką można przy jego pomocy tworzyć nowe narzędzia badawcze.
Użyłem Turbiny do realizacji dużego projektu, dzięki czemu mogłem ocenić rzeczywistą przydatność tego narzędzia.
Ponadto do budowy środowiska wykorzystałem jedynie darmowe narzędzia i technologie.
Implementując aplikację WASS zrealizowałem wszystkie założone cele. Mam nadzieję, że stworzony przeze mnie system podniesie komfort pracy korzystającym z niego naukowcom.
Poniżej znajduje się opis wykorzystywanych przez system tabel baz danych, oraz funkcjonalności dodanych do odpowiadającym im równoważnikom i sepulkom.
Tabela Answer
Przechowuje powiązane z pytaniem zbiory dozwolonych odpowiedzi. Umożliwia realizację na przykład testów wyboru lub przechowywanie poprawnych odpowiedzi na pytania otwarte.
|
Kolumna |
Typ |
Opis |
|
id |
Identyfikator |
Identyfikator odpowiedzi. Obecny po to, by ułatwić aktualizacje. |
|
question_id |
Klucz obcy |
Identyfikator pytania, do którego należy odpowiedź (w tabeli Question). |
|
sequence |
Integer |
Kolejność na liście odpowiedzi. |
|
text |
Text |
Treść odpowiedzi. |
Dodane funkcjonalności:
Tabela Correct_Answer
Pozwala na ustalenie, które z powiązanych z pytaniem odpowiedzi należą do zbioru poprawnych. Tabela jest potrzebna do realizacji automatycznego oceniania testów.
|
Kolumna |
Typ |
Opis |
|
question_id |
Klucz zewn. |
Identyfikator pytania, którego poprawna odpowiedź jest opisywana (tabele Question). Ta kolumna jest redundantna; pojawia się by uprościć operacje na bazie danych. |
|
answer_id |
Klucz zewn. |
Identyfikator poprawnej odpowiedzi (tabela Answer). |
Brak dodanych funkcjonalności.
Tabela Item
W tabeli tej są przechowywane informacje o zasobach plikowych zgromadzonych w systemie.
|
Kolumna |
Typ |
Opis |
|
id |
Identyfikator |
Identyfikuje zasób. |
|
shelf_id |
Klucz obcy |
Identyfikator półki, na której znajduje się zasób (tabela Shelf). |
|
name |
Text |
Nazwa zasobu. |
|
file_name |
Text |
Nazwa pliku jaki odpowiada zasobowi na dysku. |
Dodane funkcjonalności:
Tabela Question
Przechowuje informacje potrzebne do odtworzenia pytania. Jest to podstawowa tabela służąca do wypełniania testów treścią.
|
Kolumna |
Typ |
Opis |
|
id |
Identyfikator |
Identyfikuje pytanie. |
|
test_id |
Klucz obcy |
Identyfikator testu, do którego należy pytanie (tabela Test). |
|
sequence |
Integer |
Kolejność pytania w teście. |
|
type |
Integer |
Służy do rozróżniania klas implementujących dany rodzaj pytania. |
|
text |
Text |
Treść pytania. |
Dodane funkcjonalności:
Tabela Question_Extension
Tabela umożliwia przechowywanie danych powiązanych z pytaniem, które zależą od konkretnej implementacji pytania. Dzięki obecności tej tabeli w systemie, będzie możliwe tworzenie pytań zawierających dowolne elementy poza zwykłym tekstem pytania.
|
Kolumna |
Typ |
Opis |
|
question_id |
Klucz zewn. |
Identyfikator pytania, z którym powiązane są dane. |
|
item_id |
Klucz obcy |
Identyfikator zasobu (tabela Item). Pytania najczęściej zależeć będą właśnie od jakiegoś zasobu, dlatego została wprowadzona ta kolumna. |
|
data |
Binaria |
W tej kolumnie będą mogły być serializowane atrybuty pytań wykraczające poza możliwości oferowane przez tabelę Question. |
Dodane funkcjonalności:
Tabela Research
Umożliwia identyfikację badań i przechowuje ich podstawowe atrybuty.
|
Kolumna |
Typ |
Opis |
|
id |
Identyfikator |
Identyfikator badania. |
|
security_id |
Klucz obcy |
Identyfikator obiektu opisującego bezpieczeństwo dla tego badania (tabela SecurityObj). |
|
name |
Text |
Nazwa badania. |
|
purpose |
Text |
Cel w jakim stworzono badanie. |
|
description |
Text |
Opis badania. |
|
modified |
Date |
Data ostatniej modyfikacji. |
|
modified_by |
Klucz obcy |
Użytkownik dokonujący ostatniej modyfikacji. |
|
created |
Date |
Data utworzenia. |
|
created_by |
Klucz obcy |
Użytkownik, który przygotował badanie. |
Dodane funkcjonalności:
Tabela Research_Content
Tabela ta umożliwia przechowywanie informacji o testach przypisanych do danej wersji badania. Jej stworzenie było konieczne, ponieważ w każdej wersji badania ten sam test może wystąpić więcej niż raz.
|
Kolumna |
Typ |
Opis |
|
id |
Identyfikator |
Wykorzystywany przy przechowywaniu wyników. |
|
research_id |
Klucz obcy |
Identyfikator badania (tabela Research). |
|
version_id |
Klucz obcy |
Identyfikator wersji badania (tabela Research_Version). |
|
sequence |
Integer |
Kolejność testu w badaniu. |
|
test_id |
Klucz obcy |
Identyfikator testu (tabela Test). |
Dodane funkcjonalności:
Tabela Research_Instruction
Tabela wiąże z badaniem jego instrukcje wstępne.
|
Kolumna |
Typ |
Opis |
|
id |
Identyfikator |
Identyfikator instrukcji (wprowadzony by ułatwić operacje na bazie danych). |
|
research_id |
Klucz obcy |
Identyfikator badania (tabela Research). |
|
sequence |
Integer |
Kolejność instrukcji. |
|
text |
Text |
Treść instrukcji. |
Brak dodanych funkcjonalności.
Tabela Research_Registration
W tej tabeli przechowywane są informacje o sposobie rejestracji do badania - czyli jakie informacje musi podać użytkownik i w jaki sposób będzie wybierana wersja badania.
|
Kolumna |
Typ |
Opis |
|
id |
Identyfikator |
Wprowadzony by ułatwić operacje na bazie. |
|
research_id |
Klucz obcy |
Identyfikator badania, którego opis rejestracji jest przechowywany (tabela Research). |
|
mask |
Integer |
Maska bitowa kodująca jakie informacje są wymagane od badanego (wiek, płeć). |
|
version_method |
Integer |
Maska bitowa kodująca sposób wyboru wersji. |
Dodane funkcjonalności:
Tabela Research_Session
Ta tabela umożliwia identyfikowanie rozpoczętych badań. Wiąże z prowadzonym badaniem informacje o użytkowniku oraz umożliwia identyfikację udzielanych odpowiedzi. Jej stworzenie było konieczne, ponieważ większość badań będzie prowadzona z anonimowymi badanymi, a ponadto ten sam użytkownik może wielokrotnie brać udział w badaniu, a każda taka próba musi być opisywana niezależnie.
|
Kolumna |
Typ |
Opis |
|
id |
Identyfikator |
Konieczny przy opisie odpowiedzi badanego. |
|
research_id |
Klucz obcy |
Identyfikator rozpoczętego badania (tabela Research). Jest redundantny ponieważ wystar-czyłby identyfikator wersji, ale jego obecność ułatwia operacje na bazie danych. |
|
version_id |
Klucz obcy |
Identyfikator wersji, która została przypisana do tego badania (tabela Research_Version). |
|
date |
Date |
Data badania. |
|
age |
Integer |
Wiek badanego. Najczęściej używane atrybuty są zapisywane w kolejnych kolumnach. |
|
sex |
Text |
Płeć badanego. |
|
Institution |
Text |
Miejsce zatrudnienia. |
|
Education |
Text |
Wykształcenie badanego. |
|
Occupation |
Text |
Zawód badanego. |
Brak dodanych funkcjonalności.
Tabela Resarch_Version
Tabela pozwala na zdefiniowanie badań, które zawierają w sobie kilka wersji (np. różniących się od siebie jednym testem).
|
Kolumna |
Typ |
Opis |
|
id |
Identyfikator |
Wykorzystywany przy przypisywaniu testów. |
|
research_id |
Klucz obcy |
Identyfikator badania, do którego należy wersja (tabela Research). |
|
name |
Text |
Nazwa wersji. |
|
descrption |
Text |
Opis wersji. |
Dodane funkcjonalności:
Tabela Result
W tej tabeli umieszczane są odpowiedzi badanego. Można w niej przechowywać odpowiedzi zarówno dla testów wyboru, jak i dla pytań otwartych.
|
Kolumna |
Typ |
Opis |
|
id |
Identyfikator |
Identyfikator odpowiedzi. |
|
session_id |
Klucz obcy |
Informacja o tym do jakiej instancji badania należy odpowiedź (tabela Research_Session). |
|
content_id |
Klucz obcy |
Pozwala na rozróżnienie odpowiedzi na to samo pytania w różnych instancjach tego samego testu (tabela Research_Content). |
|
question_id |
Klucz obcy |
Identyfikator pytania (tabela Question). |
|
answer_id |
Klucz obcy |
Identyfikator odpowiedzi, jeśli był to test wyboru (tabela Answer). |
|
value |
Text |
Odpowiedź na pytanie otwarte. |
Brak dodanych funkcjonalności.
Tabela Security
Tabela pozwala na przypisywanie użytkownikowi ról w kontekście danego obiektu. Wykorzystywana jest przez moduł Security.
|
Kolumna |
Typ |
Opis |
|
id |
Identyfikator |
Ułatwia operacje na bazie danych. |
|
security_id |
Klucz obcy |
Identyfikuje obiekt, dla którego została zdefiniowana rola (tabela Security_Obj). |
|
user |
Klucz obcy |
Identyfikuje użytkownika, któremu w kontekście danego obiektu została przyznana rola (tabela Turbine_User). |
|
role |
Klucz obcy |
Nazwa przyznanej roli (tabela Turbine_Role). |
Brak dodanych funkcjonalności.
Tabela Security_Obj
Dzięki tej tabeli możliwe było jednakowe traktowanie wszystkich obiektów, do których dostęp limitowany jest na poziomie zasobu. Z każdym takim obiektem wiązany jest odpowiadający mu obiekt przechowywany właśnie w tej tabeli, dzięki temu w systemie bezpieczeństwa nie ma potrzeby niezależnego analizowania badań czy testów.
|
Kolumna |
Typ |
Opis |
|
id |
Identyfikator |
Identyfikuje obiekt opisujący bezpieczeństwo. Jest kluczem obcym dla tabeli Security wiążącej z nim role przyznane użytkownikom oraz dla tabel Test czy Research. |
|
type |
Integer |
Pozwala na stwierdzenie czy obiekt odnosi się do badania, testu, czy półki. |
Dodane funkcjonalności są odpowiedzialne za implementacje dostępu na poziomie zasobu. Są to między innymi:
Tabela Shelf
Umożliwia grupowanie zasobów dyskowych w zbiory oraz niezależne administrowanie takimi zbiorami.
|
Kolumna |
Typ |
Opis |
|
id |
Itentyfikator |
Identyfikator półki. |
|
security_id |
Klucz obcy |
Identyfikator obiektu opisującego dostęp do półki (tabela SecurityObj). |
|
name |
Text |
Nazwa półki. |
|
description |
Text |
Opis przeznaczenia półki. |
Dodane funkcjonalności:
Tabela Test
Tabela przechowuje atrybuty testów umożliwiając ich identyfikację.
|
Kolumna |
Typ |
Opis |
|
id |
Identyfikator |
Identyfikator testu. |
|
type_id |
Klucz obcy |
Rodzaj testu (tabela Test_Type). |
|
security_id |
Klucz obcy |
Identyfikator obiektu opisującego dostęp do testu (tabela Security_Obj). |
|
mask |
Integer |
Maska bitowa z atrybutami testu. |
|
modified |
Date |
Data ostatniej modyfikacji. |
|
modified_by |
Klucz obcy |
Użytkownik dokonujący ostatniej modyfikacji. |
|
created |
Date |
Data utworzenia. |
|
created_by |
Klucz obcy |
Użytkownik, który stworzył test. |
|
style |
Text |
Styl testu. |
|
name |
Text |
Nazwa testu. |
|
check_function |
Text |
Funkcja oceniająca. |
|
description |
Text |
Opis testu. |
Dodane funkcjonalności:
Tabela Test_Instruction
W tabeli znajdują się instrukcje wstępne testów.
|
Kolumna |
Typ |
Opis |
|
id |
Identyfikator |
Identyfikator instrukcji. |
|
test_id |
Klucz obcy |
Identyfikator testu, do którego należy instrukcja (tabela Test). |
|
sequence |
Integer |
Kolejność instrukcji. |
|
text |
Text |
Treść instrukcji. |
Brak dodanych funkcjonalności.
Tabela Test_Type
Dzięki tej tabeli możliwe jest tworzenie rodzajów testów opisujących sposób tworzenia i prezentacji testu.
|
Kolumna |
Typ |
Opis |
|
id |
Identyfikator |
Identyfikator typu testu. |
|
name |
Text |
Nazwa typu. |
|
description |
Text |
Opis przeznaczenia i charakterystyki typu. |
|
modified |
Date |
Data ostatniej modyfikacji. |
|
modified_by |
Klucz obcy |
Użytkownik dokonujący ostatniej modyfikacji. |
|
created |
Date |
Data utworzenia. |
|
created_by |
Klucz obcy |
Użytkownik który stworzył typ. |
|
mask |
Integer |
Maska bitowa z atrybutami typu. |
|
questions_number |
Integer |
Liczba pytań na stronie. |
|
test_edit_tmpl |
Text |
Szablon edycji testu. |
|
test_show_tmpl |
Text |
Szablon prezentacji testu. |
|
test_class |
Text |
Klasa implementująca test. |
|
test_show_class |
Text |
Klasa implementująca ekran do prezentacji testu. |
Brak dodanych funkcjonalności.
Tabele Turbiny
W aplikacji wykorzystywane są również tabele charakterystyczne dla Turbiny. Ponieważ nie były one przeze mnie modyfikowane, więc ograniczę się do ich wymienienia:
- turbine_group
- turbine_permission
- turbine_role
- turbine_role_permission
- turbine_scheduler_job
- turbine_user
- turbine_user_group_role
Do pracy dołączyłem płytę CD-ROM, na której poza aplikacją WASS i jej kodem źródłowym umieściłem wszystkie narzędzia konieczne do poprawnej instalacji systemu na platformach Linux i Windows. Szczegółowy opis procesu instalacji znajduje się w pliku Readme.txt. Poniżej przedstawiam zawartość płyty:
API - w tym katalogu znajdują się wygenerowane przez program Javadoc: dokumentacja techniczna aplikacji WASS oraz opisy klas należących do Turbiny i Javy,
Java - w tym katalogu znajduje się używane przeze mnie JDK,
MySQL - w tym katalogu znajdują się pakiety instalacyjne używanej przez system bazy danych,
Turbine - katalog ze zintegrowaną z Turbiną aplikacją WASS, dokładny opis jego zawartości znajduje się poniżej,
Readme.txt - plik z opisem procesu instalacji aplikacji WASS.
Struktura katalogów aplikacji WASS
W poddrzewie webapps, katalogu Turbine znajduje się katalog msc zawierający wszystkie elementy składowe aplikacji WASS. Katalog ma następującą strukturę:
images - katalog z plikami graficznymi używanymi przez interfejs aplikacji,
logs - katalog z dziennikami zdarzeń,
storage - katalog, z zasobami modułu Storage,
styl - katalog z używanymi stylami kaskadowymi,
templates - katalog z szablonami ekranów, nawigacji i układów,
WEB-INF/build - katalog ze skryptami inicjującymi aplikację,
WEB-INF/conf - katalog z plikami konfiguracyjnymi aplikacji,
WEB-INF/classess - katalog ze skompilowanymi klasami aplikacji,
WEB-INF/lib - katalog z bibliotekami używanymi przez aplikację,
WEB-INF/src - katalog ze źródłami aplikacji WASS.
[1] Strona domowa projektu Turbine,
http://jakarta.apache.org/turbine/
[2] Strona domowa World Wide Web Consortium,
http://www.w3.org/
[3] Strona domowa języka HTML,
http://www.w3.org/MarkUp/
Specyfikacja języka HTML 4.01,
http://www.w3.org/TR/html4/
[4] Opis języka Javascript,
http://wp.netscape.com/eng/mozilla/3.0/handbook/javascript/
[5] Specyfikacja Hypertext Transfer Protocol -- HTTP/1.1,
http://www.ietf.org/rfc/rfc2068.txt
[6] Specyfikacja standardu SSL 3.0,
http://home.netscape.com/eng/ssl3/
[7] Opis modelu MVC,
http://java.sun.com/blueprints/patterns/MVC-detailed.html
[8] Strona domowa języka PHP,
http://www.php.net/;
L. Atkinson, PHP 3, 2000, Helion
[9] Strona domowa produktu PHP Accelerator Cache,
http://www.php-accelerator.co.uk/
[10] Zend Accelerator, galeria kodu, tutoriale itp.,
http://www.zend.com
[11] Przewodnik po ASP,
http://msdn.microsoft.com/library/default.asp?URL=/library/psdk/iisref/aspguide.htm
[12] Strona domowa kontrolek ActiveX,
http://www.microsoft.com/com/tech/ActiveX.asp
[13] Strona domowa języka VBScript,
http://msdn.microsoft.com/scripting/vbscript/default.asp
[14] Porównanie języka JavaScript i JScript,
http://www.javacats.com/US/articles/Jsart.html
[15] Strona domowa firmy Microsoft,
www.microsoft.com
[16] D. J. Reilly, Designing Microsoft ASP.NET Applications, 2001, Microsoft Press.
[17] Strona domowa technologii Java,
http://java.sun.com/
[18] Strona domowa Java 2 Platform, Enterprise Edition,
http://java.sun.com/j2ee/
[19] Opis serwletów,
http://java.sun.com/products/servlet/index.html
[20] Strona domowa serwera Tomcat,
http://jakarta.apache.org/tomcat/
[21] Strona domowa standardu CGI,
http://www.w3.org/CGI/
[22] Strona domowa JSP,
http://java.sun.com/products/jsp/
[23] Opis Modelu 2 dla aplikacji JSP,
http://www.javaworld.com/javaworld/jw-12-1999/jw-12-ssj-jspmvc.html
[24] Strona domowa programu JBuilder,
http://www.borland.com/jbuilder
[25] Strona domowa EJB,
http://java.sun.com/products/ejb/
[26] Strona domowa serwerów aplikacji firmy IBM,
http://www.ibm.com/software/webservers/
[27] Strona domowa technologii .NET,
http://www.microsoft.com/net/
[28] Opis technologii APS.NET,
http://msdn.microsoft.com/library/default.asp?url=/nhp/Default.asp?contentid=28000440
[29] Strona domowa grupy Jakarta,
http://jakarta.apache.org/
[30] Strona domowa narzędzia Webmacro,
http://www.webmacro.org/
[31] Strona domowa narzędzia Velocity,
http://jakarta.apache.org/velocity/
[32] Strona domowa narzędzia Cocoon,
http://xml.apache.org/cocoon/
[33] Strona domowa serwera Apache,
http://httpd.apache.org/
[34] Strona domowa standardu Cascading Style Sheets,
http://www.w3.org/Style/CSS/
[35] Strona domowa serwera MySQL,
http://www.mysql.com/