
Protokol komunikacyjny to zbior zasad i norm, ktorych musza przestrzegac komunikujace sie ze soba obiekty. Poniewaz protokoly moga byc dosc skomplikowane, nadaje im sie strukture warstwowa. Wedlug modelu OSI (polaczenia systemow otwartych, ang. Open Systems Interconnection) wyroznaiamy siedem takich warstw. Na samym spodzie wystepuje warstwa fizyczna, nastepnie idac w gore kolejno warstwy kanalowa, sieciowa, transportowa, sesji, prezentacji i warstwa zastosowan. Niektorzy posluguja sie jednak bardziej uproszczonymi schematami - i tak Stevens wyroznil cztery podstawowe warstwy - od spodu: kanalowa, sieciowa, transportowa i na gorze procesowa. W kazdej z wyzej wymienionych warstw zdefiniowane sa osobne protokoly.
Komunikacja ma charakter sekwencyjny - dane docieraja do odbiorcy w tej samej kolejnosci w jakiej sa nadawane. W protokolach stosuje sie kontrole poprawnosci majaca na celu wyeliminowanie ewentualnych bledow. Mozna wyroznic dwa podstawowe rodzaje bledow - zmodyfikowanie danych podczas transmisji oraz utrate danych. Podstawowa motoda do wykrywania bledow w czasie transmisji jest dolaczanie do danych sumy kontrolnej (ang. check sum). Jezeli odbiorca po otrzymaniu danych stwierdzi, ze zostaly one uszkodzone (nie zgadza sie suma kontrolna), to zada od nadawcy ponownej transmisji uszkodonego segmentu. Oprocz tego czesto stosuje sie tez metode potwierdzenia pozytywnego, czyli wyslania przez odbiorce po prawidlowym odebraniu przez niego porcji danych krotkiej informacji do nadawcy, ze zostaly one odebrane bez bledow. Natomiast gdy dane znikna w sieci i nadawca po ustawionym uprzednio czasie oczekiwania na odpowiedz (ang. timeout) nie otrzyma pozytywnego potwierdzenia, to wysyla dane jeszcze raz. Oprocz tych mechanizmow stosuje sie jeszcz sterowanie przeplywem (ang. flow control) albo powstrzymywanie (ang. packing) majace na celu zabezpieczenie odbiorcy przed nadmiernym przeciazeniem nadchodzacymi danymi. Jezeli nadawca wysyla informacje zbyt czesto, to odbiorca moze sie "zapchac" i czesc z nich utracic. Powszechnie przyjelo sie nazywac dany protokol niezawodnym jesli jest on sekwencyjny, korzysta z kontroli poprawnosci oraz ma sterowanie przeplywem.
Tryb polaczeniowy (ang. connection oriented) polega na ustanowieniu logicznego polaczania pomiedzy dwoma komunikujacymi sie ze soba procesami. Aby nawiazac komunikacje trzeba najpierw nawiazac polaczenie. Z obslugi polaczeniowej korzysta sie wtedy, gdy powstaje potrzeba przesylania wielu komunikatow w dwu kierunkach. Najlepszym przykladem takiego polaczenia jest telnet, a protokol polaczeniowy to TCP.
Tryb bezpolaczeniowy (lub obsluga datagramowa) jest przeciwstawieniem do trybu polaczeniowego. W tym przypadku komunikaty przekazywane sa zupelnie niezaleznie. Typowym przykladem trybu bezpolaczeniowego jest usluga poczty elektronicznej, a protokol bezpolaczniowy to UDP.
Polaczenie ustala sie miedzy dwoma procesami w celu przesylania danych pomiedzy nimi. Przez asocjacje (ang. association) bedziemy rozumiec piecio elementowy zbior okreslajacy oba polaczone procesy: protokol, adres lokalny, proces lokalny, adres zdalny, proces zdalny. Natomiast polasocjacja to opis polowy zdarzenia, czyli: protokol, adres lokalny, proces lokalny albo: protokol, adres zdalny, proces zdalny. Polasocjacje nazywaja sie takze gniazdem (pochodzi z systemu BSD) - gniazdo to jeden z dwoch koncowych punktow komunikacji.
Adresy IP (ang. internet protocol) sa obecnie 32-bitowe i sa wykorzystywane do identyfikowania komputera (a tak na prawde karty sieciowej) oraz sieci, do ktorej komputer jest podlaczony. Strukture adresu IP przedstawia ponizszy rysunek:

Pierwsze (stale) bity adresu okreslaja format danego adresu. Wyroznia sie cztery klasy adresow:
Jezeli mamy ethernetwa siec, w ktorej sie korzysta z TCP/IP, to mamy do czynienia z dwoma rodzajami adresow: 32-bitowy adres internetowy i 48-bitowy adres ethernetu. Mamy wiec do rozwiazania dwa problemy:
Do rozwiazania pierwszego problemu sluzy protokol ARP, ktory pozwala stacji poprzez siec ethernet wyslac do wszystkich stacji specjalny pakiet, w ktorym prosi stacje o okreslonym numerze IP, by wyslala swoj adres ethernetowy. Opis protokolu znajduje sie w RFC0826.
Protokol RARP dotyczy sieci z bezdyskowymi terminalami. Co najmniej jeden system w sieci jest serwerem RARP i zawiera 32-bitowy adres IP i odpowiadajacy mu 48-bitowy adres ethernet. Kazda stacja robocza moze w ten sposob otrzymac swoj adres IP. Opis protokolu jest umieszczony w RFC903.
System rozproszony to zbior niezaleznych, polaczonych w siec komputerow mogacych sie ze soba swobodnie komunikowac. Z punktu widzenia uzytkownika siedzacego przy jednym z takich komputerow istotnym jest, ze ma on dostep do zasobow innych komputerow z danego systemu.
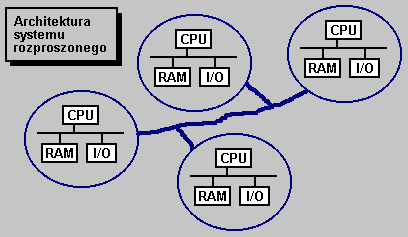
Jest wiele rodzajow systemow rozproszonych. Luzno powiazane sieci rozlegle (WAN). Mocniej powiazane sieci lokalne (LAN). Silne powiazane systemy wieloprocesorowe (SMP). Zalety systemow rozproszonych sa oczywiste (dzieki nim wlasnie mozesz odczytac ten dokument): dzielenie zasobow, przyspieszenie obliczen (obliczenia moga byc prowadzone rownolegle na wielu procesorach), niezawodnosc (w przypadku awarii jednego komputera jego prace moze przejac inny). Podstawowymi wadami systemow rozproszonych sa male bezpieczenstwo (doste do danych przez osobe niepowolana) i dosc skomplikowane oprogramowanie (wymusza to sama architektura systemow rozproszonych)
Systemy satelitarne to silnie skupiona grupa komputerow wokol jednego. Ten jeden nazywa sie komputerem centralnym, zas pozostale podlaczone do niego, to komputery satelitarne. Zaden komputer satelitarny nie ma urzadzen zewnetrznych z wyjatkiem tych koniecznych do komunikacji z procesorem centralnym. Komputery satelitarne korzystaja jedynie z urzadzen I/O komputera centralnego.

Wszystkie wywolania funkcji systemowych procesory satelitarne kieruja do procesora centralnego. Na procesorze centralnym dzialaja specjalne procesy rdzenne (po jednym na kazdy proces na procesorze satelitarnym) obslugujace wywolania funkcji systemowych na tychze procesorach satelitarnych. Wszystkie procesy uzytkownikow przypisane sa do procesorow satelitarnych i nie przemieszczaja sie miedzy tymi procesorami. Same procesory satelitarne posiadaja bardzo uproszczony system operacyjny zarzadzajacy pamiecia, obslugujacy przerwania i odpowadajacy za komunikacje z procesorem centralnym (a dokladnie z procesami rdzennymi - agentemi procesow procesora satelitarnego na procesorze centralnym), czyli jedynym swiatem zewnetrznym jaki widzi procesor satelitarny.
W trakcie inicjacji systemu jadro procesora centralnego samo laduje system do procesorow satelitarnych i przygotowywuje je do pracy, przydziela im procesy. Jadro procesu centralnego samo decyduje na ktorym procesorze bedzie wykonywany nowy proces zainicjowany wywolaniem funkcji fork (niezaleznie od tego, na ktorym procesorze zostala ta funkcja wywolana), oprocz tego dla nowego procesu satelitarnego tworzy takze odpowiedni mu proces rdzenny
System satelitarny dziala jako jednostka. Komputery satelitarne sa mocno zdegenerowane (poprzez brak urzadzen wejscia/wyjscia) i nie maja prawdziwej autonomii. Skazane sa na "laske i nielaske" procesora centralnego.
System typu "Newcastle" to juz niezaleznie od siebie (autonomiczne), ale polaczone ze soba komputery. Obydwa posiadaja niezalezne od siebie jadra, niezaleznie od siebie wywoluja funkcje systemowe.
Za komunikacja miedzy nimi odpowiada specjana biblioteka C. Kiedy proces probuje otworzyc plik ze zdalnego komputera, biblioteka nawiazuje kontakt ze zdalnym komputerem, tworzy na nim proces rdzenny (podobnie jak w systemach satelitarnych staje sie on agentem procesu lokalnego na komputerze zdalnym). Przy kolejnych probach komunikacji ze zdalnym plikiem biblioteka C oraz proces rdzenny przejmuja obowiazki jadra i obsluguja polecenia odczytu i zapisu.
Uzytkowik jest w stanie poznac, ze dany plik znajduje sie na zdalnym komputerze po sciezce. Kazdy taki plik ma przed zwykla sciezka dodany jakis znak specjalny oraz nazwe komputera, z ktorego ten plik pochodzi np.: komp2!/home/plik.txt lub /../komp2/home/plik.txt.
Podstawowa zaleta systemow typu "Newcastle" jest to, ze metode komunikacji miedzy komputerami mozna zaimplementowac bez zmian w jadrze systemu. Jest ona takze dosc wygodna z punktu widzenia uzytkownika. Niestety metoda jest malo elastyczna a napisane wczesniej programy korzystajace z plikow zdalnych trzeba rekompilowac. Metoda jest takze dosc pamieciozerna - kazdy program korzystajacy z dobrodziejstw komunikacji miedzykomputerowej ma biblioteke C w sobie. Kazdy proces komunikujacy sie ze zdalnym komputerem tworzy swojego agenta w postaci procesu rdzennego - przy aktywnej komunikacji miedzy komputerami tworzy sie dosc pokazna liczba procesow.
Systemy przezroczyste dzialaja na podobnej zasadzie do systemow typu "Newcastle". Podstawowa roznica miedzy nimi jest to, ze w systemach przezroczystych za komunikacje ze swiatem zewnetrznym odpowiada juz samo zmodyfikowane jadro, a nie jak w typie "Newcastle" - nakladka w postaci biblioteki C. Druga roznica jest to, ze dostep do plikow z innego komputera jest osiagany poprzez montowanie - fragment drzewa katalogowego zdalnego komputera podczepia sie do komputera lokalnego. Dzieki temu dla uzytkownika moze byc niedostrzegalne to, ze korzysta on z plikow z innego komputera, gdyz sciezka dostepu do plikow lokalnych niczym sie nie rozni od sciezki do plikow z komputera zdalnego.

Zielona strzalka na rysunku pokazuje sposob w jaki zostal zamontowany (podczepiony) katalog usr jednego komputera do drugiego. Ze wzgledu na sposob realizowania polaczen miedzy komputerami dzieli sie systemy przezroczyste na dwie grupy. W systemach przezroczystych z procesami rdzennymi podczas montowania komputer lokalny (klient) nawiazuje polaczenie z komputerem zdalnym (serwerem). Zostaje stworzony proces rdzenny (agent klienta na serwerze) obslugujacy zadania klienta. W specjalnej tablicy montowan jadro utrzymuje informacje o uzyskanych dotychczas polaczeniach. Dostep do plikow serwera jest realizowany w podobny sposob jak do plikow lokalnych - poprzez tablice deskryptorow, tablice plikow do tablicy i-wezlow, z tym ze i-wezly odnosza sie do zdalnych komputerow. Jadro klienta samo rozpoznaje, ze chodzi o plik zdalny i przekazuje procesowi rdzennemu na serwerze indeks i-wezla zadanego pliku. Proces rdzenny na podstawie przekazanego mu w komunikacie indeksu organizuje dostep do zadanego pliku. W wyniku przeprowadzania w duzej ilosci polaczen ze zdalnymi komputerami moze w systemie pojawic sie duzo zupelnie bezczynnych procesow rdzennych. Aby temu zaradzic stworzono systemy przezroczyste bez procesow rdzennych. Roznica miedzy systemami z procesami rdzennymi polega na tym, ze w tablicy i-wezlow na komputerze lokalnym przechowywany jest nie indeks pliku na zdalnym komputerze, ale takze jego i-wezel (wraz z informacja, ze plik znajduje sie na komputerze zdalnym). Jadro w przypadku proby dostepu do takiego pliku komunikuje sie z jadrem komputera zdalnego i bezposrednio od niego dostaje dostep do zadanego pliku.