Uruchamianie systemu i niskopoziomowe mechanizmy obsługi procesów.
Spis treści
- Uruchamianie systemu
- Struktura MBR i tablic partycji dysku systemowego
- Obraz jądra i fazy ładowania obrazu
- Programy ładujące dla Linuksa
- Przebieg budowy struktur jądra i tworzenia pierwszego procesu
- Mechanizm przerwań procesora Intel 386
- Osługa przerwań i wywołań systemowych w Linuksie
- Niskopoziomowa obsługa błędów braku i ochrony strony
- Wsparcie sprzętowe
- Realizacja w Linuksie
- Przełączanie kontekstu
- Wsparcie sprzętowe
- Realizacja w Linuksie
- Mechanizm DMA
- Zegary w Linuksie
- Liczenie czasu
- Przerwania zegarowe i ich obsługa
- Planowanie zdarzeń
- Jak zaimplementować własną funkcję systemową
1. Uruchamianie systemu
1.1 Struktura Master Boot Recordu i tablicy partycji
Po uruchomieniu komputera i wykonaniu wstępnych testów
BIOS ładuje zawartość pierwszego sektora urządzenia do
pamięci operacyjnej pod adres 0x7c00
Struktura Master Boot Recordu:

Struktura tablicy partycji:
struct partition {
unsigned char boot_ind; /* 0x80 - aktywna */
unsigned char head; /* ścieżka początkowa */
unsigned char sector; /* sektor początkowy */
unsigned char cyl; /* cylinder początkowy */
unsigned char sys_ind; /* Typ partycji */
unsigned char end_head; /* ścieżka końcowa */
unsigned char end_sector; /* sektor końcowy */
unsigned char end_cyl; /* cylinder końcowy */
unsigned int start_sect; /* sektor początkowy
partycji */
unsigned int nr_sects; /* liczba sektorów wchodzących
w skład partycji */
}
Przykładowa organizacja dysku twardego:

Podstawowe zasady jakim podlegają partycje na dysku twardym:
- partycje muszą zajmować spójny obszar dysku twardego
- partycje muszą zaczynać się razem z początkiem ścieżki
a kończyć wraz z końcem cylindra
- partycje rozszerzone mogą być zagnieżdżone, ale muszą
zachowywać strukturą listową
- Linux nie reprezentuje zagnieżdżonych partycji rozszerzonych
jako urządzeń
- program fdisk zachowuje odpowiedniość z linuksowymi plikami
urządzeń i nie pokazuje użytkownikowi prawdziwej struktury
dysku twardego
- zdarzają się niespodzianki: wpis w tablicy partycji rozszerzonej
może dotyczyć obszaru, który leży poza nią. Wpis jest traktowany
przez Linuksa jako poprawny i rejestrowane jest odpowiednie
urządzenie
1.2 Obraz jądra
Tworzenie jądra
Katalogi ze źródłami:

Kompilacja:
# make config lub # make menuconfig lub # make xconfig
- konfiguracja
# make depend - zależności dla kompilatora
# make clean - czyszczenie po poprzedniej kompilacji
# make zImage lub # make bzImage - kompilacja jądra
# make modules - kompilacja modułów
# make modules install - instalacja modułów
Instalowanie jądra (czasami robione automatycznie przez make) polega
na przegraniu go z katalogu /arch/i386/boot do podkatalogu /boot
w głównym katalogu, utworzeniu odpowiedniego wpisu w pliku /etc/lilo.conf
i uruchomieniu programu lilo.
Duże jądro (BIG Kernel):

Specyfika ładowania jądra przez program ładujący powoduje, że teoretycznie
nie powinno ono zajmować więcej niż 448 KB, gdyż tyle miejsca jest dla niego
przeznaczone (od adresu 0x90000 będzie zaczynał się setup.
Tymczasem, mimo kompresji, większość współczesnych jąder po kompilacji
zajmuje więcej. W związku z tym możliwe jest skompilowanie jądra jako
dużego (ang. BIG). Tak utworzone jądro różni się od zwykłego
tylko nazwami plików pośrednich i ostatecznego obrazu (mają na początku dodaną
literę 'b'). Informacja o tym, że jądro jest duże jest też przekazywana
do kodu jądra (przez dodanie do opcji kompilatora gcc
deklaracji __BIG_KERNEL__). W ten sposób kod jądra może rozpoznać,
że ma się załadować ,,wyżej'', powyżej granicy 1 MB.
Obraz jądra:
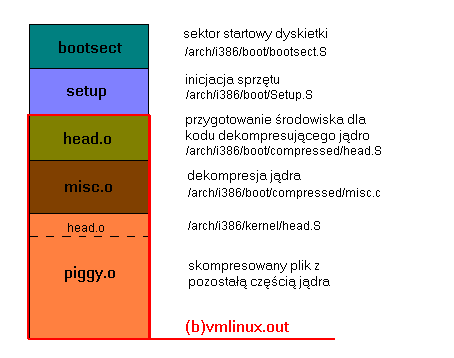
bootsect jest obrazem sektora ładującego system z dyskietki.
Zadaniem umieszczonego tam kodu jest po prostu załadowanie do pamięci
kolejnych ścieżek z dyskietki, zawierających dalszą część jądra. Taka
struktura pliku jądra pozwala na bardzo proste tworzenie dyskietki
ładującej, przez skopiowanie obrazu jądra do fizycznego urządzenia,
np:
# dd if=/boot/vmlinuz of=/dev/fd0
setup powstaje z kompilacji dwóch plików:
arch/i386/boot/setup.S oraz arch/i386/boot/video.S.
Zawiera inicjację sprzętu (w tym karty graficznej), a w szczególności przełącza
procesor w tryb chroniony.
head.o ma za zadanie przygotować środowisko i wywołać pierwszą
części kodu jądra napisaną w C - procedurę dekompresującą jądro umieszczoną w
misc.o.
piggy.o - skompresowana część jądra.
Skompresowana część jądra:
Składowe pliku piggy.o są oddzielnie kompilowane, złączane
za pomocą programu objcopy, kompresowane programem gzip
i łączone linkerem z plikami head.o i misc.o - powstaje
vmlinux.out (lub bvmlinux.out w przypadku dużego jądra).
piggy.o zawiera jeszcze część kodu inicjującego. Jest to min.
head.o (powstały z arch/i386/kernel/head.S, odpowiedzialny
za ostateczne przygotowanie środowiska dla kodu w C, oraz kod utworzony
po kompilacji podkatalogu init, zawierający funkcję wejściową
jądra start_kernel() i tworzenie pierwszego procesu. Dalej zaś
znajduje się już reszta kodu jądra.
Ostatnim etapem tworzenia obrazu jądra jest uruchomienie programu
build (powstałego z kompilacji arch/i386/boot/tools/build.c.
Program ten ustawia jeden za drugim pliki bootsect, setup
i vmlinux.out (bvmlinux.out) i tworzy obraz jądra:
arch/i386/boot/zImage (bzImage).
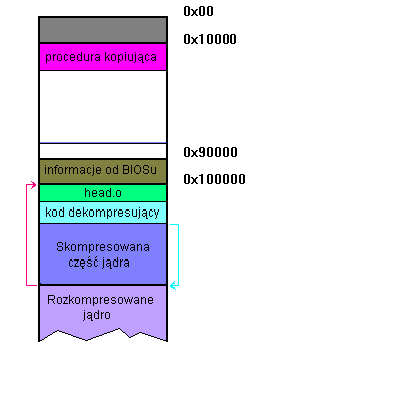
Ładowanie obrazu jądra:
Ładowanie jądra z dyskietki:
-
Ładowanie kolejnych scieżek z dyskietki dopóki nie załaduje się
całego jądra.
-
512-bajtowy kod sektora ładującego dyskietki jest ładowany przez
BIOS pod adres 0x7c00, przesuwa się pod 0x90000,
pod 0x90200 ładuje setup, a pod 0x10000
(0x100000) system - vmlinux.out
-
(bvmlinux.out)
-
Aby przyspieszyć ładowanie, próbuje się odczytywać naraz całe
ścieżki. Ilość sektorów na ścieżce jest ustalana "doświadczalnie",
przez próbę czytania na raz 36, 18, 15 i ostatecznie 9 sektorów
(co odpowiada stacjom 2.88 MB, 1.44 MB, 1.2 MB i 720 KB). Czytanie
jest wykonywane przez wywoływanie przerwania 0x13 BIOS-u.
-
Po załadowaniu setup i ustaleniu rozmiaru ścieżki
wypisywany jest komunikat "Loading".
-
Skok do etykiety START w pliku setup.
Ładowanie jądra z dysku twardego:
-
W przypadku loadlina - korzystamy z funkcji DOS-u
-
W przypadku LILO - korzystamy z pliku mapy,
zawierającego położenie sektorów z obrazami poszczególnych
jąder (/boot/map)
-
Skok do etykiety START w pliku setup.
Konieczność uaktualnienia pliku mapy jest jednym z powodów, dla
których po skompilowaniu jądra trzeba uruchomić lilo.
Inicjalizacja sprzętu (setup):
setup jest odpowiedzialny za uzyskanie od BIOS-u podstawowych
informacji o sprzęcie, które zapisywane są pod adresy 0x90000-0x901FF
- tam, gdzie poprzednio znajdował się bootsect.
- Sprawdzenie wersji loadera, poprawności załadowania i rodzaju jądra
- Rozmiar pamięci (BIOS)
- Rozpoznanie i inicjalizacja karty graficznej
- Ilość i parametry dysków podłączonych do pierwszego kontrolera
- Obecność architektury MCA
- Mysz PS/2
- BIOS APM
Przełączenie w tryb chroniony:
- Wyzerowanie lokalnej tablicy deskryptorów (LDT)
- Ustawienie w globalnej tablicy deskryptorów (GDT) wskaźników
na 4 GB segmenty kodu i danych jądra, zaczynające się od 0
- Wyłączenie przerwań
- Włączenie linii adresowej A20
- Reset koprocesora
- Przesunięcie wektorów przerwań programowych pod 0x20
- Załadowanie słowa stanu procesora z ustawionym bitem trybu chronionego
- Skok do etykiety start_up w pliku head.o
Dekompresja jądra (head.o):
- Ustawienie rejestrów segmentowych
- Wywołanie funkcji dekompresującej z misc.o
- Ewentualne przesunięcie dużego jądra do 0x100000
- Skok do etykiety start_up w pliku head.o
Kod dekompresujący korzysta z kilku funkcji w C, np. tych wykonujących
rzeczywisty algorytm dekompresji PKZIP metody 8, zamieszczonych w
lib/inflate.c. W arch/i386/boot/compressed/misc.c
zaimplementowane są np. własne funkcje malloc(), free()
i puts(), wykorzystywana do wypisania komunikatu
"Uncompressing Linux...", a po skończonej dekompresji
"Ok, booting the kernel."
Dekompresja zwykłego jądra:

Dekompresja dużego jądra:
Przygotowanie środowiska dla kodu w C (head.o):
Stronicowanie pamięci:
- Ustawienie katalogów stron pod adresem 0x101000, zawierającego
wskaźniki na dwie tablice - 0-wą dla użytkownika i 768-ą dla jądra. Pozostałe
wpisy są zerowane.
- Obie pozycje w katalogu wskazują na tą samą tablicę stron pod
0x102000.
- Tablica te realizuje mapowanie identycznościowe - kolejne 1024
strony odpowiadają kolejnym ramkom, począwszy od zerowej - 4 MB pamięci.
- Włączenie bitu mapowania w słowie stanu procesora.
Inne:
- Ustawienie wszystkich wektorów przerwań na funkcję ignore_int(),
wypisującą za pomocą funkcji printk() komunikat
"Unknown interrupt".
- Kopiowanie do strony zerowej (ang. empty_zero_page)
parametrów od lilo i użytkownika.
- Sprawdzenie i zapamiętanie typu procesora
- Uaktualnienie LDT i GDT (nieaktualne po przesunięciu jądra)
- Skok do funkcji start_kernel() z pliku init/main.c.
1.3 Programy ładujące dla Linuksa
Programy ładujące dla Linuksa - LILO
Plan wystąpienia
Pliki wchodzace w skład pakietu LILO
Lilo składa się z dwóch części: programu instalującego plik mapy,
oraz plików odczytywanych podczas startu systemu.
Pliki, po modyfikacji których należy uruchomić
/sbin/lilo
- /boot/map
- /boot/boot.b (nie należy nic w nim zmieniać)
Pliki, których nie należy modyfikować, ale można relokować
- /boot/chain.b
- /boot/os2_d.b (OS/2)
Plik, /etc/lilo.conf
/etc/lilo.conf jest plikiem konfiguracyjnym LILO i można go
dostosowywać do własnych potrzeb
Opcje globalne:
boot=boot_device - urządzenie gdzie zapisany zostanie sektor
ładujący, domyślnie root
default=name - obraz ładowany domyślnie, jeśli nie ma to
pierwszy w pliku
install=boot_sector - instaluje wybrany plik w bootsektorze,
domyślnie /boot/boot.b
map=map_file
message=message_file
time_out=czas - czas po jakim ładowany jest domyślny obraz
verbose=level - poziom szczegółowości raportowania: 0-5
Opcje dla konkretnych obrazów ładowalnych:
label=name
password=password
Opcje tylko dla obrazów jąder Linuksa:
image=file_name
read-only - montuje system plików root tylko do odczytu
read-write
root=root_device - określa urządzenie, które ma być
montowane jako root
Opcje tylko dla innych systemów operacyjnych:
other=device - urządzenie, z którego pobrany zostanie
bootsector
loader=chain_loader - domyślny /boot/chain.b
table=device - określa urządzenie, z którego pobrana
zostanie tablica partycji
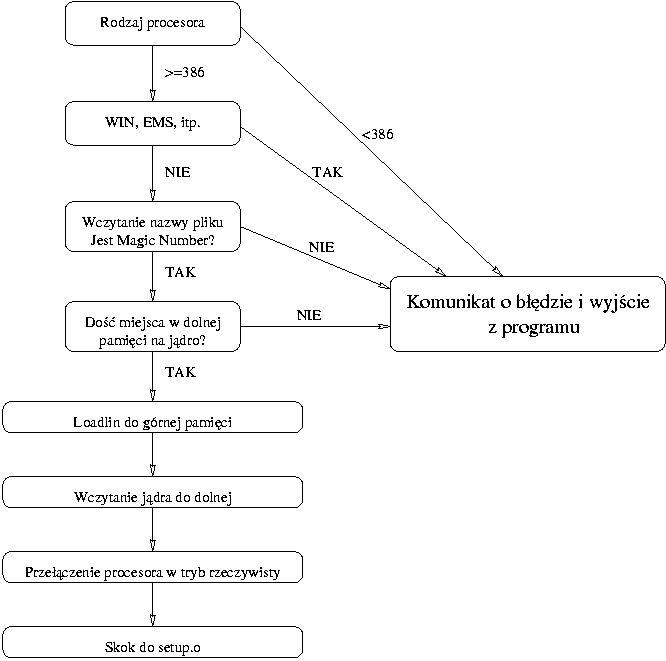
Schemat ładowania systemu
- wczytanie i uruchomienie drugorzędnego programu ładujacego

- przetworzenie linii poleceń
- znalezienie odpowiadającego jej deskryptora obrazu

- wczytanie domyślnej linii parametrów i odpowiedniego obrazu jądra

- przekazanie sterowania do setup.o, fragmentu załadowanego jądra
Programy ładujące dla Linuksa - Loadlin
- Program pod DOS.
- Jądro na partycji dosowej.
- Parametry - nazwa pliku z obrazem jądra, RAM-dysk itp.
1.4 Inicjalizacja struktur jądra i budowa pierwszego procesu.
Pierwszą uczciwą wywoływaną w jądrze funkcją jest start_kernel.
Macza ona palce we wszystkim, dlatego niemożliwe jest streszczenie
jej w kilku słowach. Pozostaje nudne wyliczanie czynności, które
są kolejno wykonywane.
Zajmiemy się następującymi funkcjami z pliku init/main.c
Funkcja start_kernel()
Uwaga o pamięci:
Procedury inicjalizacyjne, przyjmują parametry
memory_start,memory_end rezerwują na własne potrzeby
pamięć z początku i zwracają zmodyfikowany wskaźnik memory_start.
- printk(linux_banner);
- Wypisanie linuksowego tekstu powitalnego.
- setup_arch(&command_line, &memory_start,&memory_end);
-
- pobieranie informacji o sprzęcie (procesor, płyta główna,
BIOS) -- przeważnie odczytywane są informacje ustalone wcześniej
na etapie bootowania (setup).
- ustawiane są pola struktury init_task.mm.
- odczytywanie rozmiaru pamięci
Wykorzystywane są do tego informacje BIOS-u, lecz można je
przeciążyć za pomocą linii poleceń.
- Ustalanie rozmiaru initrd (czyli RAM-dysku, na którym montuje się
korzeń systemu plików).
Sprawdza się, czy obszar przeznaczony na RAM-dysk nie wystaje
poza pamięć.
- Rezerwowanie portów dla standardowych urządzeń (dma, timer, fpu).
Wywoływana jest funkcja request_region.
- ustawianie funkcji odpowiedzialnej za przełączanie konsol
wirtualnyc (zmienna conswitchp).
-
paging_init(memory_start,memory_end);
-
Przygotowuje grunt pod stronicowanie. Katalog stron i tablice
stron są ustawiane tak, że odwzorowują kolejne ramki pamięci
fizycznej. Uwzględnia się to, że pierwsze 4MB zostały już zamapowane
przez head.o. Strona odpowiadające adresowi wirtualnemu 0 jest
odmapowywana, aby wyłapywać odwołania do NULL.
-
trap_init();
- Ustawienie bramek dla przerwań, w tym bramki dla wywołań
systemowych.
-
init_IRQ();
-
Inicjalizacja przerwań. Przypisywane są domyślne hadlery przerwaniom
sprzętowym. Następnie ustawiane są bramki dla przerwań zewnętrznych
(za wyjątkiem obsługującego wywołania systemowe).
-
sched_init();
-
Inicjalizuje tablicę procesów oraz tablicę haszującą dla PID-ów
procesów. Instaluje też procedury obsługi przerwania zegarowego
(ich dolne części) - funkcja init_bh.
-
time_init();
-
Pobiera z CMOS-u czas rzeczywisty i inicjalizuje nim strukturę
xtime.
-
parse_options(command_line);
-
Przetwarza opcje podane w linii poleceń jądra.
-
console_init(memory_start,memory_end);
-
Inicjalizuje osługę konsoli. Ustawia domyślną dyscyplinę linii
(tty_register_ldisc) oraz trukturę opisującą typ terminala.
Następnie inicjalizuje konkretne terminale: wirtualne lub
szeregowe.
-
init_modules();
-
Inicjalizuje obsługę modułów. Pola struktury kernel_module
są przeważnie stałe, inicjalizowane jest jedynie pole nsyms.
-
kmem_cache_init(memory_start, memory_end);
-
Inicjalizuje pamięć podręczną dla jądra.
-
sti();
-
Włączenie przerwań.
-
calibrate_delay();
-
Wyznacza BOGO-Mipsy. Ten test polega na zmierzeniu szybkości
procesora w kręceniu sie w pustej pętli. Wyznaczona wartość przydaje
się niektórym sterownikom urządzeń.
- Sprawdzenie czy nie został zamazany obraz RAM-dysku.
- Mogło tak się stać, gdyż procedury wywoływane powyżej mogły
zabrać ten obszar na swoje potrzeby.
-
mem_init(memory_start,memory_end);
-
Inicjalizuje tablicę mem_map (wywołując clear_bit).
Zaznacza strony zajęte przez jądro
(PG_reserved), strony możliwe do wykorzystania przez mechanizm
DMA (PG_DMA). Następnie wypisuje informację statystyczną
(ilość dostęj pamięci, w tym ilość pamięci zajętej prze jądro, dane,
inicjalizację).
Potem sprawdza się, czy procesor poprawnie interpretuje zabezpieczanie
stron przed zapisem (nie robią tego modele 386 i niektóre dziwne 486).
-
kmem_cache_sizes_init();
-
Dalszy ciąg inicjalizacji pamięci podręcznej jądra.
-
proc_root_init();
-
Rejestrowanie funkcji obsługi dla systemu plików proc;
-
Rezerwacja pamięci podręcznej (przy pomocy kmem_cache_create)
oraz inicjalizacja ewentualnych tablic haszujących dla:
- systemu zarządzania procesami.
uidcache_init();
filescache_init();
- systemu plików
dcache_init();
- systemu zarządzania pamięcią
vma_init();
- buforów systemowych
buffer_init(memory_end-memory_start);
- kolejki sygnałów
signals_init();
- systemu plików
inode_init();
file_table_init();
Uff! Łapiemy oddech i brniemy dalej...
- Wstawianie w tablice struktur IPC wartości IPC_UNUSED
ipc_init();
- Sprawdzenie błędów procesora
check_bugs();
- Linux szczyci się zgodnością ze standardem POSIX.
printk("POSIX conformance testing by UNIFIX\n");
- Uruchamianie wątku jądra, który uruchamia pierwszy proces (funkcja
init().
kernel_thread(init, NULL, CLONE_FS | CLONE_FILES | CLONE_SIGHAND);
- Powiadomienie procedury szeregującej, że już czas zacząć pracę.
current->need_resched = 1;
- Marnowanie czasu procesora.
cpu_idle(NULL);
Funkcja init()
Jest to pierwsza funkcja, która staje się procesem z prawdziwego
zdarzenia. Najważniejszą sprawą jest wywołanie procedury
do_basic_setup(), która wykonuje następujące czynności:
- zawiadamia, że wątek init() będzie adoptował osierocone
procesy:
child_reaper = current;
- rozpoczyna obsługę magistrali systemowych (ISA, PCI itp...) oraz
dołączonych do nich urządzeń.
- inicjalizuje obsługę sieci
sock_init();
- uruchamia demony:
/* Launch bdflush from here, instead of the old syscall way. */
kernel_thread(bdflush, NULL, CLONE_FS | CLONE_FILES | CLONE_SIGHAND);
kernel_thread(kupdate, NULL, CLONE_FS | CLONE_FILES | CLONE_SIGHAND);
/* Start the background pageout daemon. */
kswapd_setup();
kernel_thread(kpiod, NULL, CLONE_FS | CLONE_FILES | CLONE_SIGHAND);
kernel_thread(kswapd, NULL, CLONE_FS | CLONE_FILES | CLONE_SIGHAND);
- wykonuje inne niezbędne czynności:
/* Inicjalizacja urządzeń.. */
device_setup();
/* .. formatów plików wykonywalnych .. */
binfmt_setup();
/* .. systemów plików .. */
filesystem_setup();
/* montowanie korzenia systemu plików.. */
mount_root();
Po powrocie do funkcji init():
- otwiera się konsolę i przekierowuje sę na nią stdout
i stderr:
if (open("/dev/console", O_RDWR, 0) < 0)
printk("Warning: unable to open an initial console.\n");
(void) dup(0);
(void) dup(0);
- wybiera się program, który zajmie się dalszym działaniem systemu.
Jako pierwszy jest brany pod uwagę program wskazany w linii
poleceń.
if (execute_command)
execve(execute_command,argv_init,envp_init);
execve("/sbin/init",argv_init,envp_init);
execve("/etc/init",argv_init,envp_init);
execve("/bin/init",argv_init,envp_init);
execve("/bin/sh",argv_init,envp_init);
panic("No init found. Try passing init= option to kernel.");
Na tym niezwykle pasjonujący ;-) proces uruchamiania systemu się kończy
i rozpoczyna się nudna, codzienna praca.
2. Mechanizm przerwań procesora Intel 386
3. Osługa przerwań i wywołań systemowych w Linuksie
Wprowadzenie
Obsługa przerwań w sposób naturalny mocno uzależniona jest od architektury
komputera . Nas interesuje platforma sprzętowa oparta na jednym procesorze
Intel 80386. Podstawowym źródłem informacji był dla nas kod jądra w wersji
2.2.12.
Rodzaje przerwań:
-
przerwania sprzętowe (hardware interrupts) zgłaszane sa przez
sterownik przerwań na żądanie jakiegoś urządzenia (np. zegara lub klawiatury)
-
wyjątki (exceptions) generowane są przez sam procesor; dzielą
się na:
-
niepowodzenia (faults), zgłaszane przed pełnym wykonaniem instrukcji
i umożliwiające jej powtórzenie; dobrym przykładem jest tu wyjątek #PF
(Page Fault), powstający przy odwołaniu do strony nieobecnej w pamięci
-
potrzaski (traps), sygnalizowane po wykonaniu instrukcji, gdy
spełnione są wyzwalające je warunki; przykładem jest instrukcja int,
której wykonanie zawsze podnosi wyjątek
-
załamania (aborts), powstające w wyniku poważnych i nienaprawialnych
błędów; na przykład wyjątek #DF (Double Fault) podnoszony jest wtedy, gdy
przed zakończeniem obsługi niepowodzenia zgłoszone zostaje następne.
Mechanizm wołania funkcji systemowych
W tablicy funkcji systemowych sys_call_table znajdują się adresy
podprogramów z przestrzeni jądra uruchamianego przez funkcje system_call()
. Nazwa podprogramu to sys_ albo old_ plus
implementowana przez nią funkcja systemowa.
Wywołanie funkcji systemowej wygląda następująco:
-
Funkcja systemowa jest zdefiniowana w bibliotece libc przy pomocy
makra syscallx() (x to liczba argumentów funkcji systemowej).
W przypadku funkcji o zmiennej liczbie argumentów (np. ioctl()),
implementacja jest bardziej skomplikowana, lecz zachowane są opisane poniżej
zasady.
-
Makro syscallx() tworzy fragment kodu, który odkłada na stos przekazane
funkcji argumenty oraz numer funkcji i wykonuje instrukcję int 0x80.
-
Sterowanie przekazywane jest do procedury system_call.
Przed jej wykonaniem procesor zmienia tryb pracy z 3 (poziom użytkownika)
na 0 (poziom jądra), a po powrocie z niej wykonywana jest procedura ret_from_sys_call
po czym procesor wraca do trybu użytkownika.
-
Po powrocie z jądra do przestrzeni użytkownika syscallx() sprawdza
kod powrotu funkcji systemowej. Jeśli jest dodatni, od razu go zwraca.
W przeciwnym razie wstawia do errno wartość -kod_powrotu
i zwraca -1.
Dostęp do danych przechowywanych w przestrzeni adresowej użytkownika (selektor
jego segmentu danych jest w rejestrze FS) zapewniają m.in. makra get_user()
i put_user() zdefiniowane w pliku arch/i386/kernel/segment.h.
Ich wykonanie może spowodować konieczność ściągnięcia do pamięci strony,
do której się odwołują.
Algorytm system_call()
Argument: numer wołanej funkcji systemowej
Wynik: ujemny numer błędu albo nieujemny kod powrotu
{
if(numer_funkcji > NR_syscalls)
return(-ENOSYS);
if(sys_call_table[numer_funkcji]==NULL)
return(-ENOSYS);
return((sys_call_table[numer_funkcji])());
}
Algorytm ret_from_sys_call
{
if(intr_count!=0) // obsługujemy jakieś przerwanie
return; // wróć do przerwanego procesu
while(czekają funkcje "bottom half")
{
++intr_count;
do_bottom_half();
--intr_count;
}
if(przerwanym procesem było jądro)
return;
if(ustawiona jest flaga need_resched)
{
schedule();
goto ret_from_sys_call;
}
if(bieżący proces to task[0]) // do task[0] nie są wysyłane
return; // żadne sygnały
if(czekają jakieś sygnały)
do_signal();
}
Funkcja do_bottom_half() opisana jest niżej
Obsługa wyjatków
Podprogramy obsługi wyjątków składają się z dwóch części: definiowany w
pliku entry.s
fragmentu kodu przechodzi do trybu jądra, woła funkcję o nazwie do_nazwa_wyjatku()
zdefiniowaną zazwyczaj w pliku traps.c
i wraca do przerwanego procesu, wykonując ret_from_sys_call.
Wiekszość podprogramow obsługi generowana jest przez makro DO_ERROR(),
które woła funkcję force_sig()
z odpowiednim numerem sygnału, po czym sprawdza, czy wyjątku nie spowodował
kod jądra (jeśli tak, zatrzymuje system procedura
die_if_kernel()).
| Wyjątek |
Sygnał |
Nazwa podprogramu obsługi |
| 0 |
SIGFPE |
do_divide_error |
| 3 |
SIGTRAP |
do_int3 |
| 4 |
SIGSEGV |
do_overflow |
| 5 |
SIGSEGV |
do_bounds |
| 7 |
SIGSEGV |
do_device_not_available |
| 8 |
SIGSEGV |
do_double_fault |
| 9 |
SIGFPE |
do_coprocessor_segment_overrun |
| 10 |
SIGSEGV |
do_invalid_TSS |
| 11 |
SIGBUS |
do_segment_not_present |
| 12 |
SIGBUS |
do_stack_segment |
| 17 |
SIGSEGV |
do_alignment_check |
Uwaga: wyjątek 9 obsługiwany jest w kontekście procesu, który ostatnio
używał koprocesora (wszystkie pozostałe - w kontekście procesu bieżacęgo).
Poza tym:
-
wyjątek 1 obsługuje funkcja do_debug(), która woła force_sig(SIGTRAP,
current), po czym - jeśli przerwanym procesem był kod jądra - zeruje
rejestr DR7
-
wyjątek 2, będący w rzeczywistości przerwaniem niemaskowalnym (NMI),
obsługuje funkcja do_nmi(), wyświetlająca komunikat o potencjalnych
problemach z pamiecią RAM
-
wyjątek 13 obsługuje funkcja do_general_protection(), w
której po czynnościach związanych z trybem wirtualnym 8086 wołana jest
funkcja force_sig(SIGSEGV, current)
-
wyjątek 16 obsługuje funkcja do_coprocessor_error(), która
po zebraniu argumentow woła (pośrednio) force_sig(SIGFPE) w kontekście
procesu, który ostatni używal koprocesora
-
wyjątki 15 i 18..47 są zarezerwowane. Wykonywana po
ich zgłoszeniu funkcja do_reserved() wyświetla stosowny komunikat.
Obsługa przerwań sprzetowych
Podstawowe informacje dotyczące przerwań sprzętowych:
-
urządzenie (podłączone do sterownika przerwań) dochodzi do wniosku, że
zaszła sytuacja, o której powinień dowiedzieć się procesor (np. naciśnięta
została litera 'A' na klawiaturze) i zgłasza tę potrzebę sterownikowi przerwań
-
sterownik sprawdza, czy nie jest przypadkiem obsługiwane przerwanie o wyższym
lub równym zgłoszonemu priorytecie; jeśli jest, czeka na moment, w którym
wszystkie takie przerwania zostaną obsłużone (najwyższy priorytet ma zegar
systemowy); jeśli obsługiwane jest przerwanie o priorytecie niższym, można
jego obsługę przerwać
-
jeśli w czasie oczekiwania przerwania o numerze n na obsłużenie
nadejdzie drugie przerwanie o tym samym numerze, zostanie ono zignorowane
(przerwania nie są zliczane)
-
gdy sterownik może już zgłosić procesorowi przerwanie, musi poczekać na
ustawienie flagi IF procesora, która odblokowuje przerwania (jest ona automatycznie
kasowana przez procesor przed rozpoczeńciem wykonywania procedury obsługi
przerwania; należy ją ustawić ręcznie lub po zakończeniu procedury odtwarzany
jest jej poprzedni stan)
-
dopóki procedura obsługi przerwania nie wyśle do sterownika sygnału końca
przerwania (EOI, End Of Interrupt), sterownik uważa przerwanie za obsługiwane.
Każde przerwanie opisane jest strukturą irq_desc_t "IRQ descriptor",
która zawiera następujące pola:
typedef struct {
unsigned int status; /* status linii IRQ (włączony, wyłączone itp.) */
struct hw_interrupt_type *handler; /* funkcje obsługi (zależne od typu sterownika)*/
struct irqaction *action; /* dane o zarejestrowanych funkcjach obsługi */
unsigned int depth;
unsigned int unused[4];
} irq_desc_t;
Struktura:
struct hw_interrupt_type {
const char * typename;
void (*startup)(unsigned int irq);
void (*shutdown)(unsigned int irq);
void (*handle)(unsigned int irq, struct pt_regs * regs); /* obsługuje przerwanie */
void (*enable)(unsigned int irq); /* włącza przerwanie nr */
void (*disable)(unsigned int irq); /* wyłącza */
};
zawiera wskaźniki do funkcji obsługi przerwania dla konkretnego typu
sterownika.
W pliku arch/i386/kernel/irq.c makro BUILD_IRQ() tworzy podprogram obsługujący
każde przerwanie, który:
- zapamiętuje rejestry
- odkłada na stos numer przerwania
- wywołuje do_IRQ()
- wykonuje algorytm ret_from_intr, który odnawia rejestry,
w razie potrzeby wywołuje funkcję schedule()
Uwaga: wyjątkiem jest przerwanie zegarowe, które
obsługiwane jest w sposób specjalny.
Funkcja do_IRQ()
- pobiera ze stosu numer przerwania irq
- zwiększa licznik obsłużonych przerwań
- wywołuje irq_desc[irq].handler->handle(irq,®s);
tj. procedurę obsługi przerwania zależna od sterownika. (patrz niżej)
- jeśli jest potrzeba wywołuje do_bottom_half()
W strukturze hw_interrupt_type opisującej sterownik
standartu 8259 PIC (jedyny obsługiwany przez linuksa) w polu
handle znajduje się wskaźnik do funkcji
do_8259A_IRQ()
Funkcja do_8259A_IRQ()
- sprawdza czy przerwanie ma ustawioną flagę IRQ_DISABLED | IRQ_INPROGRESS
jeśli tak kończy pracę
- ustawia flagę IRQ_INPROGRESS
- Dla każdej zarejestrowanej funkcji:
- sprawdza czy funkcja ma ustawioną flagę SA_INTERRUPT
i stosownie ustawia flagę IF procesora
- wywołuje zarejestrowaną funkcję
- jeśli któras z zarejestrowanych funkcji miała ustawioną flagę
SA_SAMPLE_RRANDOM wywołuje funkcję add_interrupt_randomness(irq);
która zwiększa losowość wbudowanego w linuksa generatora liczb losowych
- zeruje flagę IF procesora
- zeruje flagę IRQ_INPROGRESS
- jeśli przerwanie nie ma ustawionej flagi IRQ_DISABLED
odblokowuje je
Rejestrowanie funkcji wołanych przez irq_desc[irq].handler->handle()
Aby irq_desc[irq].handler->handle() miały co robić, trzeba
najpierw zarejestrować wołane przez nie funkcje. Wymienia teraz związane
z tym zadaniem podprogramy:
- request_irq() próbuje zarejestrować funkcje (nie musi się
to udać - może zabraknąć pamięci na struct irqaction lub
wybranym przerwaniem nie można się dzielic); jeśli przerwanie to
nie jest używane, odblokowuje je
- free_irq() wyrzuca funkcje z listy; jeśli lista zostanie
opróżniona, blokuje przerwanie.
Struktura struct irqaction, w której przechowywane są dane
rejestrowanych funkcji, zdefiniowana jest w pliku
include/linux/interrupt.h:
struct irqaction {
void (*handler)(int, // numer obsługiwanego IRQ
void *, // tu będzie irqaction.dev_id
struct pt_regs *); // NULL lub rejestry CPU
unsigned long flags; // flagi SA_*
unsigned long mask;
const char *name; // nazwa funkcji obsługi
void *dev_id; // argument dla handler()
struct irqaction *next; // następna zarejestrowana funkcja
}
W polu flags ustawiane są bity SA_* zdefiniowane w
pliku include/asm-i386/signal.h.
Koncepcja "bottom halves"
Aby zminimalizować czas spędzony w do_IRQ(),
projektanci sterowników urządzeń wymagających czasochłonnej obsługi
powinni podzielić ją na dwie części. Szybka funkcja rejestrowana
przez request_irq() jest wołana w chwili nadejścia przerwania.
Wolniejsza funkcja realizująca drugą część obsługi wstawiana jest
do tablicy bh_base; jej szybka siostra w razie potrzeby zaznacza
(funkcja bh_mark()>), że należy dokończyć (przy włączonych przerwaniach)
obsługę urządzenia.
Pliki zródłowe
- arch/i386/kernel/head.S
- rozpoczyna pracę w trybie wirtualnym (protected mode)
- arch/i386/kernel/entry.S
- niskopoziomowe interfejsy do funkcji systemowych i podprogramów
obsługi wyjątków
- arch/i386/kernel/traps.c
- m.in. ustawia podprogramy obsługi wyjatków
- arch/i386/kernel/irq.c
- obsługa przerwań sprzętowych (kod)
- include/asm-i386/irq.h
- obsługa przerwań sprzętowych (makra)
- linux/kernel/softirq.c
- wykonywanie funkcji "bottom half"
- include/linux/interrupt.h
- wspólne dla wszystkich platform makra
4. Niskopoziomowa obsługa błędów braku i ochrony strony
4.1 Wsparcie sprzętowe
Obsługa błędów braku i ochrony strony wymaga wsparcia sprzętowego. Wsparcie
takie zapewniają procesory rodziny 386. Błąd niepowodzenia stronicowania
może zostać wygenerowany w trakcie translacji adresu liniowego na fizyczny.
Procesor generuje ten błąd jeśli podczas translacji nastąpi odwołanie do
elementu katalogu lub tablicy stron zawierającego wyzerowane pewne bity.
Błędy przy translacji

Znaczenie bitów w elementach katalogu i tablicy stron.

Bity odpowiadające za powstawanie błędów braku i ochrony strony:
- - bit P równy 0 brak strony w pamięci (błąd braku strony)
- - bit W równy 0 brak prawa do zapisu na stronie (błąd ochrony strony)
- - bit U równy 0 wymagany poziom uprzywilejowania CPL < 3 (błąd ochrony
strony jeśli translacja będzie się odbywać na poziomie uprzywilejowania
procesora CPL = 3)
Znaczenie pozostałych bitów:
- - bity PCD, PWT umożliwiają sterowanie pamięcią cache
- - bit A ustawiany przy dostępie do strony
- - bit D ustawiany przy zapisie na stronę
- - bity AVL mogą być wykorzystane do przechowywania własnych informacji
- - bit PSE równy 1 umożliwia korzystanie z 4MB stron na procesorach
Pentium
Bity W i U są ignorowane przez procesor na poziomach uprzywilejowania
CPL < 3. CPL (Current Privilege Level) oznacza aktualny poziom uprzywilejowania
procesora. W trybie jądra CPL = 0, w trybie użytkownika CPL = 3.
Adres liniowy, przy dostępie do którego powstał błąd jest zapisywany do
rejestru CR2. Oprócz tego na stos odkładany jest kod błędu
znaczenie mają tylko trzy najmłodze bity :
- - bit 0 równy 0 oznacza brak strony
- - bit 0 równy 1 oznacza naruszenie ochrony
- - bit 1 równy 0 oznacza próbę odczytu
- - bit 1 równy 1 oznacza próbę zapisu
- - bit 2 równy 0 oznacza poziom uprzywilejowania CPL < 3
- - bit 2 równy 1 oznacza poziom uprzywilejowania CPL = 3
4.2 Realizacja w Linuksie
Zarys algorytmu obsługi "niepowodzenia" stronicowania

page_fault
- Kod page_fault znajduje się w /arch/i386/kernel/entry.S.
Procedura ta jest podkładana po wyjątek 14. Jest ona napisana w asemblerze i jest bardzo prosta.
Kiedy wystąpi błąd braku lub ochrony strony, page_fault wywołuje:
asmlinkage void do_page_fault(struct pt_regs *regs, unsigned long error_code)
.
do_page_fault
- Kod do_page_fault jest już napisany w C. Znajduje się on w /arch/i386/mm/fault.c.
Procedura ta sprawdza, czy mamy do czynienia z błędem braku lub ochrony strony z którym możemy sobie poradzić.
- Jeśli tak to przekazujemy sterowanie do int handle_mm_fault(struct task_struct *tsk, struct vm_area_struct * vma,
unsigned long address, int write_access)
- W przeciwnym wypadku kończymy proces użytkownika lub zatrzymujemy system.
Algorytm do_page_fault

do_page_fault
- Jeśli procedura stwierdzi, że adres dla którego został wygenerowany błąd strony należy do vma_area aktualnego procesu,
wywołuje
int handle_mm_fault(struct task_struct *tsk, struct vm_area_struct * vma,
unsigned long address, int write_access).
Na powyższym rysunku ścieżka sterowania odpowiadająca temu przypadkowi
jest oznaczona grubą linią.
W przeciwnym wypadku do procesu zwykle jest wysyłany odpowiedni sygnał.
5. Przełączanie kontekstu
5.1 Wsparcie sprzętowe
Najważniejszą strukturą danych podczas przełączania kontekstu jest segment TSS (Task State Segment). Przechowuje on kontekst obecnie działającego procesu.
Segment TSS ma postać:
| TSS |
| Offset
| Górne słowo
| Dolne słowo
|
| 00h |
zarezerwowane |
link |
| 04h |
ESP0 |
| 08h |
zarezerwowane |
SS0 |
| 0Ch |
ESP1 |
| 10h |
zarezerwowane |
SS1 |
| 14h |
ESP2 |
| 18h |
zarezerwowane |
SS2 |
| 1Ch |
CR3 |
| 20h |
EIP |
| 24h |
EFLAGS |
| 28h |
EAX |
| 2Ch |
ECX |
| 30h |
EDX |
| 34h |
EBX |
| 38h |
ESP |
| 3Ch |
EBP |
| 40h |
ESI |
| 44h |
EDI |
| 48h |
zarezerwowane |
ES |
| 4Ch |
zarezerwowane |
CS |
| 50h |
zarezerwowane |
SS |
| 54h |
zarezerwowane |
DS |
| 58h |
zarezerwowane |
FS |
| 5Ch |
zarezerwowane |
GS |
| 60h |
zarezerwowane |
LDTR |
| 64h |
offset mapy I/O (IOBP) |
zarezerwowane |
| 68h |
Opcjonalne dane systemu |
| IOPB-20h |
Opcjonalna mapa przekierowania przerwań |
| IOPB |
Opcjonalna mapa dostępnych portów I/O |
Specjalny rejestr procesora TR (Task Register) przechowuje selektor do aktywnego segmentu TSS. Na jego podstawie procesor dokonuje uaktualnienia danych w TSS.

Do załadowania nowego selektora do rejestru TR służy instrukcja LTR. Jej parametrem może być rejestr albo komórka pamięci.

Dla symetrii oprócz instrukcji LTR istnieje instrukcja STR. Umożliwia ona odczytanie selektora z rejestru TR.

Oprócz deskryptorów segmentów TSS w tablicy deskryptorów można tworzyć deskryptory bramy do zadań (Task Gate Descriptor). Każdy taki deskryptor zawiera selektor jednego deskryptora TSS.
W programie można wykonać daleki skok (zwykłe far jmp) pod selektor TSS, albo selektor deskryptora bramy, co spowoduje automatyczne zapamiętanie bieżącego kontekstu, odtworzenie kontekstu z TSS selektora do którego skaczemy oraz uruchomienie zadania które jest powiązane z tym TSS. Jest to odrobinę mylące, gdyż instrukcja jmp nie oznacza skoku pod nowy adres, ale wywołanie sprzętowej procedury przełączania zadań. Daje to gotowy mechanizm przełączania kontekstu. Czas takiego przełączania jest około 300 razy dłuższy od czasu zwykłego skoku.

5.2 Realizacja w Linuksie
W skład kontekstu procesu wchodzą:
- zawartość rejestrów
procesora i przestrzeni adresowej procesu
- struktury jądra
związane z danym procesem.
Jądro zachowuje kontekst gdy system
otrzymuje przerwanie lub proces wywołuje funkcję systemową.
Przełączanie kontekstu polega na zmianie aktualnie wykonywanego
procesu. Przyczyną zmiany kontekstu może być zaśnięcie lub
zakończenie się procesu, bądź wykorzystanie przydzielonego
procesowi kwantu czasu.
W Linuksie wywołanie systemowe jest równoważne wygenerowniu
odpowiedniego przerwania, natomiast przełączenie kontekstu
może nastąpić tylko tuż przed powrotem z procedury obsługi
przerwania. Jednak w trakcie wykonywania procedury obsługi
przerwania może wystąpić przerwanie o wyższym priorytecie i
kontekst procesu, który wykonuje się w trybie jądra musi być
zachowany. Dlatego każdy proces posiada własną przestrzeń na
stosie jądra, w której odkładane są poszczególne warstwy
kontekstu.
Procesory i386 posiadają wsparcie dla przełączania
kontekstu. Z każdym zadaniem związany jest specjalny segment
(task state segment), który zawiera informacje o stanie danego
procesu (rejestry, mapa portów). Wznowienie wykonywania procesu
odbywa się przez skok do jego segmentu TSS. Jednak Linux nie
wykorzystuje w pełni wsparcia sprzętowego. Wprawdzie korzysta z
segmentów stanu zadania, lecz jądro zapamiętuje rejestry
procesora i wykonuje skok do kodu nowego procesu. Umożliwia to
lepszą kontrolę nad segmentami procesu i zapewnia większe
bezpieczeństwo systemu.
Struktury jądra
związane z przełączaniem kontekstu
| 1. |
Pola struktury task_struct [include/linux/sched.h]. |
- struct thread_struct tss
(odpowiada segmentowi TSS danego procesu).
- struct mm_struct mm
(zawiera informacje o pamięci przydzielonej
procesowi oraz o jego segmentach w tablicy LDT).
| 2. |
Struktura thread_struct [include/asm-i386/processor.h]. |
- SS i ESP poziomów: 0, 1, 2
(adresy stosu w odpowiednich trybach uprzywilejowania).
- rejestry segmentowe i ogólnego przeznaczenia.
- adres mapy portów we/wy.
- CR3 (fizyczny adres katalogu stron procesu), LDT (adres
lokalnej tablicy deskryptorów).
- rejestry debugregs
(wykorzystywane przy debugowaniu procesu).
| 3. |
Globalna tablica
deskryptorów segmentów [include/asm-i386/desc.h]. |
- struct desc_struct {unsigned
long a, b} gdt_table[]
(tablica 64-bitowych deskryptorów segmentów).
Etapy przełączania
kontekstu
| 1. |
Wygenerowane zostało
przerwanie lub proces wywołał funkcję systemową. |
- Następuje skok przez odpowiednią bramkę w IDT (tablica
deskryptorów przerwań) do kodu jądra (DPL = 0), który
obsługuje przerwania i wywołania systemowe.
- W tablicy GDT znajdują się deskryptory następujących
segmentów [include/asm-i386/desc.h]:
| |
... |
| 2 |
segment kodu jądra |
| 3 |
segment danych jądra |
| 4 |
segment kodu procesu
użytkownika |
| 5 |
segment danych procesu
użytkownika |
| |
... |
| 12 |
TSS procesu 0 |
| 13 |
LDT procesu 0 |
| 14 |
TSS procesu 1 |
| 15 |
LDT procesu 1 |
| |
... |
| 2. |
Jeśli została wywołana
funkcja schedule()i proces nie jest uprawniony do dalszego
wykonywania się, to należy przełączyć kontekst. |
- Wywołanie makra switch_to(prev,
next, last) [include/asm-i386/system.h].
- Zapamiętanie ESI, EDI, EBP.
- Zapisanie ESP w TSS procesu prev
(wskaźnik na wierzchołek stosu procesu w
segmencie jądra).
- Odtworzenie ESP na podstawie TSS procesu next
(stos nowego procesu).
- Zapisanie adresu powrotu w TSS procesu prev.
- Odłożenie tego samego adresu na stosie
(aktualny stos to stos jądra dla procesu next;
adres powrotu wskazuje na koniec funkcji).
- Wywołanie funkcji __switch_to(prev,
next) [arch/i386/kernel/process.h].
- Zapisanie stanu FPU.
- Wyzerowanie bitu B w tablicy GDT w deskryptorze
segmentu TSS procesu next
(oznacza, że zadanie nie jest aktualnie
wykonywane).
- Załadowanie rejestru TR dla nowego procesu.
- Zapamiętanie rejestrów FS i GS w TSS starego
procesu
(rejestry te nie są używane przez jądro i
wskazują na segmenty procesu).
- Ładowana jest tablica LDT dla nowego procesu.
- Ładowanie rejestru CR3 z TSS procesu next
(CR3 zawiera fizyczny adres katalogu tablic stron
procesu).
- Ustawiane są nowe wartości rejestrów FS i GS.
- Jeśli proces wykonuje się w trybie debug, to
ładowane są rejestry debugregs.
- Powrót do makra switch_to.
- Ponieważ na stosie był adres instrukcji po __switch_to
, to
powrócimy w miejsce po wywołaniu tego makra. W
tym momencie jądro działa już praktycznie w
kontekście nowego procesu.
- Ściągamy EBP, EDI, ESI, które nowy proces
odłożył na swój stos w jądrze gdy
przestawał być aktywnym procesem.
| 3. |
Powrót z funkcji
systemowej lub funkcji obsługi przerwania. |
- Odtworzenie rejestrów (makro RESTORE_ALL).
- Powrót do nowego procesu. Procesor ładuje SS i ESP
(stos procesu w jego segmencie danych), EFLAGS i skacze
pod CS:EIP ze stosu jądra.
[arch/i386/kernel/entry.S]
- Zwykle procesy nie używają swoich tablic LDT. Segmenty
aktualnie wykonywanego procesu określają deskryptory nr
4 i 5 w GDT. Jednak deskryptory te nie zmieniają się
nawet przy przełączaniu kontekstu. Ładowany jest
jedynie rejestr CR3, który zmienia odwzorowanie adresów
liniowych w ramach tego samego segmentu w adresy
fizyczne.
- Przełączanie kontekstu nie jest wykonywane
automatycznie przez procesor, lecz krok po kroku przez
system operacyjny. Dzięki temu można mieć kontrolę
nad tym, czy segmenty procesu do którego skaczemy
znajdują się w pamięci.
6. Mechanizm DMA
Wstęp
DMA służy do kopiowania danych z pamięci operacyjnej do urządzenia
lub w stronę przeciwną bez anagażowania czasu procesora. Obsługa
DMA w jądrze Linuxa jest bardzo silnie zależna od
wykorzystywanej architektury (zwłaszcza magistrali systemowej).
Przydzielanie bufora DMA
Bufor DMA musi znajdować się w ciągłym obszarze pamięci.
Wynika to z tego, że zarówno magistrala ISA jak i PCI operują
na fizycznych (a właściwie magistralowych) adresach pamięci.
Do przeliczanie adresów wirtualnych na adresy jakich używa
magistrala i z powrotem służą funkcje:
- unsigned long virt_to_bus(volatile void * address)
- void * bus_to_virt(unsigned long address)
Istnieją też magistrale w których stosowane są inne rozwiązania
(np. magistrala Sbus pracuje na adresach wirtualnych). Aby
przydzielić bufor DMA musimy się posłużyć funkcją kmalloc
lub get_free_pages. Dla magistrali ISA trzeba przy
alokacji bufora określić priorytet GFP_KERNEL aby
zagwarantować ograniczenia przez nią nakładane.
Obsługa DMA dla magistrali ISA
Oryginalny kontroler DMA dla magistrali ISA mógł obsługiwać
tylko cztery kanały. Aktualnie używany sprzęt zawiera układ równoważny
dwóm takim kontrolerom. Posiada więc on 8 kanałów. Kanał 4
lub inaczej kanal 0 drugiego kontrolera nie jest jednak dostępny
dla urządzeń ISA służy bowiem do połączenia z pierwszym
kontrolerem. Kanały 0--3 są kanałami 8 bitowymi natomiast 5--7
są 16 bitowe. Sterownik DMA posiada kilkanaście rejestrów
sterujących jego działaniem. Dla nas istotne jest, że każdemu
kanałowi DMA przypisane są trzy rejestry: adresowy, liczący
oraz strony. Rejestr adresowy jest 16 bitowy, natomiast stron 8
bitowy. Ponieważ pierwszy sterownik dokonuje transmisji 8
bitowej, a drugi 16 bitowej podczas jednej operacji mogą one
przesłac odpowiednio 64 i 128 kilobajtów danych. Rozmiar
rejestru stron nakłada na magistralę ISA ograniczenie
transmisji do dolnych 16 megabajtów pamięci. Ograniczenie to
jest sprawdzane podczas przydzielania pamięci na bufor DMA jeśli
określimy priorytet GFP_KERNEL.
Struktury danych dla kanałów DMA
struct dma_chan dma_chan_busy[MAX_DMA_CHANNELS]
Pole lock struktury dma_chan
określa czy kanał jest wolny czy przydzielony jakiemuś urządzeniu
(w tym drugim przypadku nazwa tego urządzenia jest wskazywana
przez device_id). Nazwa urządzenia jest
wykorzystywana wyłącznie przez system plików proc.
Tablica dma_chan_busy zawiera informacje o
wszystkich kanałach DMA ( MAX_DMA_CHANNELS jest
dla magistrali ISA zawsze rowne 8).
Przydzielanie i zwalnianie kanałów DMA
Zanim skorzystamy z kanału DMA jądro musi nam go przydzielić.
Ponieważ przy o końcu transmisji DMA informuje nas zazwyczaj
przerwanie je także musimy mieć przydzielone. Ustaliła się
konwencja żeby najpierw żądać przerwania, a dopiero potem
kanału DMA. Następujące funkcje służa do przydzielania i
zwalniania kanałów:
- int get_dma_list(char *buf) - wypisuje
stan kanałów DMA i urządzenia z nich korzystające
- int request_dma(unsigned int dmanr,const char *
device_id) - żadanie przydzielenia kanału DMA
- void free_dma(unsigned int dmanr) -
zwolnienie kanału DMA
Funkcje sterujące kontrolerem DMA
- void disable_dma(unsigned int dmanr) -
wyłacza kanał DMA. Funkcję tę powinno się stosować
przed przed konfigurowaniem sterownika.
- void enable_dma(unsigned int dmanr) - włącza
kanał DMA
- void clear_dma_ff(unsigned int dmanr) -
kasuje przerzutnik bistabilny. Ponieważ sterownik DMA
posiada 8 bitowe porty danych to dostęp do jego wewnętrznych
rejestrów musi być rozbity na części. Przerzutnik
bistabilny decyduje czy wartość jest interpretowana
jako bajt mniej czy bardziej znaczący. Jeśli chcemy
wywołać funkcje ustawiające rejestry sterownika, a nie
jesteśmy pewni czy następna wartość będzie
interpretowana jako mniej znaczący bajt powinniśmy wywołać
wcześniej tą funkcję.
- set_dma_mode(unsigned int dmanr, char mode)
- ustawia tryb pracy kanału DMA. Trybami obsługiwanymi
przez Linux są:
- DMA_MODE_READ - pojedyncza
transmisja z urządzenia do pamięci bez
automatycznej inicjalizacji, adresy są zwiększane
- DMA_MODE_WRITE - pojedyncza
transmisja z pamięci do urządzenia bez
automatycznej inicjalizacji, adresy są zwiększane
- DMA_MODE_CASCADE - połączenie
kaskadowe z innym sterownikiem
- DMA_AUTOINIT - automatyczna
inicjalizacja
- set_dma_page(unsigned int dmanr, char pagenr)
- ustawia stronę pod dla której będzie wykonany
transfer. Funkcja ta jest użyteczna jeśli chcemy
przekroczyć
- set_dma_addr(unsigned int dmanr, unsigned int a) -
ustawia adres bufora DMA, dla drugiego sterownika trzeba
podawać liczbę nieparzystą
- set_dma_count(unsigned int dmanr, unsigned int
count) - liczba bajtów (lub słów w przypadku
kanałów 5--7) do przesłania, dla drugiego sterownika
trzeba podawać liczbę nieparzystą
- get_dma_residue(unsigned int dmanr) -
zwraca 0 jeśli transmisja się zakończyła, w
przeciwnym przypadku wartość jest nieokreślona
Obsługa DMA dla magistrali PCI
Implementacja DMA dla magistrali PCI jest dużo prostsza niż
dla magistrali ISA. Urządzenie które chce czytać lub pisać do
pamięci żada kontroli magistrali, a gdy ją otrzyma samo
kontroluje sygnały elektryczne nią sterujące. Aby przesłać
dane do lub z pamięci wystarczy więc przydzielić bufor DMA
oraz zapisać informacje sterujące transmisją do rejestrów urządzenia.
W przypadku magistrali PCI nie obowiązuje ograniczenie 16
dolnych magabajtów. Bufor DMA może się znajdować w dowolnym
miejscu pamięci głównej.
7. Zegary w Linuksie
7.1 Liczenie czasu
W linuksie czas jest liczony od uruchomienia systemu.
Jednostka czasu jest zdefiniowana za pomocą makrodefinicji HZ.
Dla systemów opartych na procesorze Alpha jest to 256 lub 1024,
dla pozostałych platform 100 czyli 10 milisekund. Oznacza to, że
co 10 milisekund generowane jest przez układ zegara czasu
rzeczywistego tyknięcie, które następnie liczone jest przez
przerwanie zegarowe. Aktualna liczba wygenerowanych tyknięć
znajduje sie w globalnej zmiennej jiffies. Jeśli
zainteresowani jesteśmy czasem rzeczywistym to znajduje się on
w zmiennej xtime, jednak dokładność
zapewniana przez tą zmienna wynosi także tylko 10 milisekund.
Aby odczytać aktualny czas z większą dokładnością musimy
skorzystać z zegara czasu rzeczywistego (robi to np. funkcja void
do_gettimeofday(struct timeval *tv)).
7.2 Przerwania zegarowe i ich obsługa
Ponieważ przerwania zegarowe wykonywane są dość często to
czas ich wykonania powinien być jak najkrótszy. Z tego powodu
procedura ich obsługi podzielona jest na połowę podrzędną i
nadrzędną. Oto jak wygląda część nadrzędna:
void do_timer(struct pt_regs * regs)
{
(*(unsigned long *)&jiffies)++;
lost_ticks++;
mark_bh(TIMER_BH);
if (!user_mode(regs))
lost_ticks_system++;
if (tq_timer)
mark_bh(TQUEUE_BH);
}
Jak widzimy zwiększa ona wartość zmiennej jiffies
oraz zmiennych lost_ticks i lost_ticks_system.
Zmienne te liczą liczbę przerwań jakie upłynęły od czasu
ostatniego wywołania podrzędnej części procedury obsługi
przerwania. Procedura do_timer zaznacza też
jako aktywną swoją podrzędną połowę oraz kolejkę zadań TQUEUE_BH.
Zadania wymagające większej ilości czasu wykonywane są przez
część podrzędną obsługi przerwania zegarowego:
static void timer_bh(void) {
update_times();
run_old_timers();
run_timer_list();
}
Funkcje run_old_timers
oraz run_timer_list zajmują się uruchamianiem
funkcji znajdująceych się na listach starych i nowych liczników
czasu. Funkcja update_timers odpowiada za aktualizację
zegarów w całym systemie oraz do aktualizacji czasów obecnego procesu.
Jeśli upłynął kwant czasu bierzącego procesu to przy najbliższej okazji
uruchamiany jest program szeregujący.
W systemie Linux można ograniczyć "zużycie procesora" przez proces. Robi
się to za pomocą funkcji systemowej setrlimit.
Przekroczenie granicy sprawdzane jest w funkcji update_times, a proces jest
informowany przez sygnał SIGXCPU, albo przerywany przez
SIGKILL.
psecs = (current -> stime + current -> utime) / HZ;
if (psecs > current -> rlim[ RLIMIT_CPU ].rlim_cur) {
/* Wysyłaj SIGXCPU co sekundę */
if (psecs * HZ == current -> stime + current -> utime)
send_sig( SIGXCPU , current ,1);
/* A SIGKILL, gdy zostanie przekroczone maksimum */
if (psecs > current -> rlim [ RLIMIT_CPU ].rlim_max)
send_sig( SIGKILL ,current ,1);
7.3 Planowanie zdarzeń
W Linuksie istnieje możliwość odłożenia wykonania jakiegoś
zadania na pózniej. Najważniejsze mechanizmy wykorzystywane w
tym celu to kolejki zadań i liczniki czasu. O ile kolejki zadań
umożliwiają nam uruchamianie zadań w bliżej nieokreslonej
przyszłości to liczniki czasu pozwalają na określenie dokładnego
czasu wykonania.
Kolejki zadań
Kolejki zadań są mocno związane z mechanizmem części
podrzędnych procedur obsługi przerwań.
struct tq_struct {
struct tq_struct *next;
unsigned long sync;
void (*routine)(void *);
void *data;
};
- void queue_task(struct tq_struct *bh_pointer,
task_queue *bh_list) - umieszczenie zadania w
kolejce
- void run_task_queue(task_queue *list) -
wykonanie kolejki zadań
Predefiniowane kolejki zadań
- tq_timer - kolejka uruchamiana w takcie
przerwania zegarowego (zadania w niej są wykonywane w
trakcie przerwania)
- tq_immediate - kolejka zadań pilnych.
Zadania w niej wykonywane są w momencie powrotu z wywołania
systemowego lub przy uruchamianiu programu szeregującego.
Kolejka jest uruchamiana w trakcie przerwania.
- tq_scheduler - kolejka zadań
wykonywanych podczas działania programu szeregującego (zadania
nie są wykonywane w trakcie przerwania)
- tq_disk - wykorzystywana do wewnętrznego
zarządzania pamięcią
Stare liczniki czasu
Stare liczniki czasu zostały w jądrze linuxa w celu
zachowania kompatybilności. Odradza się ich stosowanie w nowych
programach. Starych liczników czasu jest 32 z czego część ma
już zdefiniowane znaczenie:
#define BLANK_TIMER 0 /* Screen-saver konsoli */
#define BEEP_TIMER 1 /* Głośnik konsoli */
#define RS_TIMER 2 /* Port RS-232 */
#define SWAP_TIMER 3 /* Wymiana stron */
#define BACKGR_TIMER 4 /* Żądanie wejścia/wyjścia */
#define HD_TIMER 5 /* Stary kontroler IDE */
#define FLOPPY_TIMER 6 /* Stacja dysków */
#define QIC02_TAPE_TIMER 7 /* Taśma QIC 02 */
#define MCD_TIMER 8 /* CDROM Mitsumi */
#define GSCD_TIMER 9 /* CDROM Goldstar */
#define COMTROL_TIMER 10 /* Comtrol serial */
#define DIGI_TIMER 11 /* Digi serial */
#define GDTH_TIMER 12 /* Kontroler Gdth scsi */
#define COPRO_TIMER 31 /* 387 błąd sprzętowy (w czasie bootowania) */
Liczniki składają się z funkcji oraz czasu w jakim ma ona
zostać wykonana. Funkcja jest wykonywana tylko raz, jeśli
chcesz ją uruchomić po raz drugi musisz ją ponownie
zarejestrować w liczniku czasu.
struct timer_struct {
unsigned long expires;
void (*fn)(void);
};
extern struct timer_struct timer_table[32];
Nowe liczniki czasu
Nowe liczniki czasu nie nakładają ograniczenia na ilość
zarejestrowanych funkcji są bowiem zaimplementowane jako lista
dwukierunkowa. Dają też możliwość przekazywania argumentów
do uruchamianych funkcji (pole data). Zaleca się
korzystanie z funkcji jądra w celu modyfikowania wartości pól
struktury timer_list po wstawienie jej do listy.
struct timer_list {
struct timer_list *next;
struct timer_list *prev;
unsigned long expires;
unsigned long data;
void (*function)(unsigned long);
};
- void init_timer(struct timer_list * timer)
- inicjowanie struktury liczników czasu
- void add_timer(struct timer_list * timer) -
wstawienie licznika do listy liczników aktywnych. W
wersjach jądra do 1.2 pole timer->expires
traktowano jako wartość bezwzględną, obecnie zaś
jako przesunięcie w czasie względem aktualnej wartości
zmiennej jiffies
- int del_timer(struct timer_list * timer) -
usunięcie licznika z listy liczników aktywnych (jeśli
czas wygaśnięcia upłynął wcześniej to licznik
zostanie usunięty automatycznie)
- int timer_pending(struct timer_list * timer)
- sprawdzenie czy na liście znajduje się jakiś licznik
- void mod_timer(struct timer_list * timer,
unsigned long expires) - modyfikuje czas wygaśnięcia
licznika
8. Jak zaimplementować własną funkcję systemową
Mechanizm wywoływania funkcji systemowych
- podczas wywołania funkcji systemowej następuje przejście z trybu
użytkownika do trybu jądra
- w Linuksie dla procesorów x86 jest to realizowane za pomocą
przerwań (przerwanie 0x80).
Wywołanie funkcji systemowej polega na wypełnieniu odpowiednich rejestrów
i wywołaniu przerwania 0x80. Do tego celu zdefiniowane są specjalne
makra, które zwalniają nas z obowiązku bezpośredniego pisania w
asemblerze.
Kod funkcji systemowej
- z poziomu funkcji systemowej możemy odwoływać się do struktur,
zmiennych i funkcji jądra (należy jedynie pamiętać o dołączeniu odpowiednich
plików nagłówkowych)
- nowe funkcje, zgodnie z konwencją, umieszczamy w katalogu
/usr/src/linux/kernel
- nazwa funkcji powinna mieć postać sys_nazwa_funkcji
Zarejestrowanie nowego wywołania systemowego
- do pliku linux/unistd.h (lub asm/unistd.h) należy dopisać
linijkę:
#define __NR_nazwa_funkcji x
(gdzie x jest najbliższym wolnym numerem)
- plik arch/386/kernel/entry.S zawiera zainicjowaną tablicę wywołań
systemowych (_sys_call_table). Tam też dodajemy naszą funkcję:
.long SYMBOL_NAME(sys_my_getpid)
- należy również zmodyfikować liczbę funkcji:
.rept NR_syscalls-liczba_funkcji
Kompilacja
- modyfikujemy plik Makefile w katalogu kernel tak, aby
uwzględniał naszą nową funkcję systemową
- kompilujemy jądro (make dep, make clean,
make zImage)
- instalujemy nowe jądro w tradycyjny sposób
Jak używać
Przed użyciem funkcji systemowej deklarujemy:
#include <linux/unistd.h>
_syscall0(int,nazwa_funkcji)
Makro _syscall0 (0 oznacza liczbę parametrów) dzięki wpisowi
do linux/unistd.h zna numer naszej funkcji i umieszcza go w
rejestrze wywołując przerwanie 0x80. Procedura obsługi przerwania
szuka w tablicy sys_call_table adresu funkcji pod pozycją
przekazaną w rejestrze. Znajduje ten adres i tam skacze. Funkcje
systemowe działają w trybie jądra i dzięki temu mają
dostęp do wszystkich jego struktur i zmiennych.