Zarządzanie procesami
Plan prezentacji
- Struktury danych do opisu procesu
- Tablica procesów
- Struktura task_struct
- Lista wszystkich procesów
- Kolejka procesów gotowych
- Powiązania rodzinne procesu
- Stany procesu, diagram przejść międzystanowych
- Szeregowanie procesów
- Wprowadzenie
- Pola w task_struct związane z szeregowaniem
- Klasy priorytetowe procesów
- Szeregowanie procesów rzeczywistych
- Szeregowanie procesów zwykłych
- Synchronizacja procesów na poziomie jądra
- Usypianie i budzenie procesów
- Implementacja semaforów systemowych
- Obsługa sygnałów
- Funkcje systemowe do obsługi procesów
- Funkcja fork()
- Funkcja exec()
- Funkcja exit()
- Funkcja wait()
- Wątki w Linuksie
1.1. Tablica procesów
Linux do przechowywania danych o wszystkich uruchomionych
procesach używa tablicy task. Jej deklaracja znajduje się w pliku
include/linux/sched.h:
struct task_struct *task[NR_TASKS]
Jak widać liczba procesów jest ograniczona przez stałą NR_TASKS,
wynoszącą standardowo 512. Związane są z nią dwie inne wartości:
MAX_TASKS_PER_USER - ograniczenie liczby procesów, jaką
może uruchomić zwykły użytkownik, stanowi połowę NR_TASKS
MIN_TASKS_LEFT_FOR_ROOT - minimalna liczba wolnych miejsc na
procesy, którą może wykorzystać tylko root, standardowo wynosi 4
Stałe te są zdefiniowane w pliku include/linux/tasks.h.
Pierwsze pole tablicy wskazuje na zmienną init_task.
Jej wartość jest na stałe zaszyta w pliku sched.h, są to dane pierwszego
procesu tworzonego przy starcie systemu, zwanego idle. Jest to w
zasadzie pseudoproces, nie odpowiada mu żaden plik wykonywalny. Jako jedyny
powstaje on bez pomocy funkcji fork(). Zadaniem tego procesu jest
inicjalizacja niektórych struktur systemowych i stworzenie procesu init
przy
pomocy funkcji clone(), później wykonuje nieskończoną pętlę. Ponieważ
jego priorytet jest najniższy w systemie, jest wykonywany tylko wtedy,
gdy nie ma żadnych procesów gotowych. Nigdy nie ginie i jest zawsze gotowy
do działania - wartością jego pola state jest TASK_RUNNING,
jednak nie jest ono nigdy sprawdzane. Jego PID jest równy 0. Proces
init
ma PID równy 1 i wykonuje kod z pliku /sbin/init.
Nowo powstałemu procesowi przydzielane jest pierwsze wolne
miejsce w tablicy, które zatrzymuje do końca istnienia. Kończenie się starszych
procesów może powodować powstawanie dziur, dlatego procesy powiązane są
w dwukierunkową listę cykliczną (pola next_task i
prev_task
w task_struct)o początku i końcu w init_task. Dzięki temu przy przeglądaniu
procesów nie trzeba przechodzić całej tablicy.
Plan prezentacji
1.2 Struktura task_struct
Procesy
Pamięć
Pliki
Sygnały
Czas
Identyfikator procesu
Różne
Uwaga: struktury task_struct nie można łatwo zmieniać przez dopisywanie,
zamienianie kolejności czy usuwanie gdyż niektóre funkcje asamblerowe odwołują
się do części ze składników przez adresy względne.
struct task_struct {
volatile long state;
Zmienna state zawiera kod obecnego stanu procesu. Zmienna ta może przyjmować
następujące wartości:
TASK_RUNNING 0
TASK_INTERRUPTIBLE 1
TASK_UNINTERRUPTIBLE 2
TASK_ZOMBIE 4
TASK_STOPPED 8
TASK_SWAPPING 16
long counter;
long priority;
cycles_t avg_slice;
Zmienna counter przechowuje czas mierzony w tyknięciach przez jaki może
jeszcze działać. Natomiast zmienna priority jest podstawą do wyznaczenia
początkowej wartości counter przez funkcję szeregującą schedule. Zmienna
avg_slice pozwala w architekturach wieloprocesorowych oceniać czas
wykorzystania procesora przez proces.
unsigned long flags;
Zmienna flags zawiera połączenie flag stanu systemu: PF_PTRACED,
PF_TRACESYS, PF_STATRTING i PF_EXITING. PF_TRACED i PF_TRACESYS
oznaczają, iż proces jest monitorowany przez inny proces za pomocą wywołania
systemowego ptrace. PF_STARTING i PF_EXITING oznacza,
że proces jest akurat rozpoczynany lub zakańczany. Dostępne są też inne
flagi:
PF_ALIGNWARN
PF_FORKNOEXEC
PF_SUPERPRIV
PF_DUMPCORE
PF_SIGNALED
PF_MEMALLOC
struct exec_domain *exec_domain;
W systemie Linux mogą być uruchamiane programy z innych systemów dla
procesorów i386 zgodnych ze standardem iBCS2. Procesy zgodne ze standardem
iBCS2 różnią się nieznacznie, a zmienna exec_domain przechowuje opis mówiący,
który typ systemu UNIX ma być emulowany.
procesy
struct task_struct *next_task, *prev_task;
struct task_struct *next_run, *prev_run;
Zmienne next_task i prev_task pozwalają powiązać wszystkie dostępne
w systemie procesy w dwukierunkową listę cykliczna. Zmienne next_run i
prev_run są używane przy "wiązaniu" procesów w kolejki zadań oczekujących.
struct task_struct *p_opptr, *p_pptr, *p_cptr, *p_ysptr,
*p_osptr;
*p_opptr oryginalny ojciec
*p_pptr ojciec
*p_cptr najmłodszy syn
*p_ysptr młodszy brat
*p_osptr starszy brat
struct task_struct **tarray_ptr;
Wskaźnik do tablicy task[]. Więcej na
temat tej struktury napisane jest w rozdziale 1.1.
struct task_struct *pidhash_next;
struct task_struct **pidhash_pprev;
Wskaźniki te wykorzystywane są przez tablicę z hashowaniem, w której
funkcja hashujaca korzysta z pidów procesów.
pamięć
struct mm_struct *mm;
Elementy struktury mm_struct opisują początek i koniec segmentów wchodzących w skład
przestrzeni adresowej obecnie wykonywanego programu.
pliki
struct fs_struct *fs;
W strukturze fs_struct znajdują się dane związane z systemem plików.
Składa się ona z czterech pól: count, umask, root, pwd.
struct files_struct *files;
najważniejsze pola tej struktury to:
atomic_t count;
fd_set close_on_exec_init;
fd_set open_fds_init;
struct file * fd_array[NR_OPEN_DEFAULT];
struct file ** fd;
sygnały
int pdeath_signal;
Numer sygnału, który będzie wysłany do siebie gdy zakończy się proces
ojca.
struct signal_struct *sig;
Wskaźnik do tablicy przechowującej informacje na temat sposobu obsługi
sygnału. Dokładniej jest ona opisana w rozdziale 5
omawiającym sygnały.
sigset_t signal, blocked;
Zmienne signal i blocked zawierają maski bitowe sygnałów odpowiednio otrzymywanych
przez proces oraz tych, które zamierza obsłużyć później, a które są obecnie
zablokowane.
czas
unsigned long start_time;
Moment, w którym proces został wygenerowany.
long per_cpu_utime[NR_CPUS], per_cpu_stime[NR_CPUS];
Tablice te przechowują informacje ile czasu proces spędził odpowiednio
w trybie użytkownika i w trybie systemowym na poszczególnych procesorach
identyfikator procesu
pid_t pid; Numer indentyfikacyjny procesu
pid_t pgrp; Numer indentyfikacyjny grupy procesów
pid_t session; Identyfikator sesji.
int leader; Proces będący liderem sesji.
int ngroups; Ilość grup do których należy
proces.
gid_t groups[NGROUPS]; Tablica w której
kolejnymi elementami są struktury opisujace grupy do których proces należy.
różne
unsigned long personality;
int dumpable:1;
int did_exec:1;
Flaga dumpable wskazuje, czy obecny proces ma dokonać zrzucenia obszaru pamięci
jeśli pojawią się określone sygnały.
Niezbyt jasna składnia obowiązująca
w standardzie POSIX wymaga aby podczas wywołania setpgid dokonano rozróżnienia
czy proces wykonuje ciągle oryginalny program czy też załadował nowy program
przy pomocy wywołania systemowego execve. Informacje te można monitorować
przy pomocy flagi did_exec.
struct linux_binfmt *binfmt;
Ta zmienna umożliwia uruchamianie pod Linuksem prawie każdego programu
przez napisanie jego nazwy. By to osiągnąć należy podać jaki interpreter
będzie użyty. Struktura linux_binfmt zawiera wskaźniki do funkcji używanych
do ładowania programu i bibliotek dzielonych oraz "zrzucania" obszaru pamięci.
int exit_code, exit_signal;
Kod zakończenia procesu i sygnał wyjścia.
struct wait_queue *wait_chldexit;
struct semaphore *vfork_sem;
Atrybuty te wykorzystywane są przy wywołaniach systemowych odpowiednio
wait4 i vfork jako kolejki procesów uśpionych do których proces wstawia
sam siebie.
struct sem_undo *semundo;
Gdy proces zostanie przerwany powinien pozwalniać zajmowane przez siebie
semafory potrzebne do tego informacje przechowywane są w zmiennej semundo.
struct sem_queue *semsleeping;
Atrybut ten wykorzystywany jest w momencie gdy proces jest "zatrzymywany"
przy przechodzeniu przez semafor jako kolejka procesów uśpionych, do których
proces wstawia sam siebie.
long need_resched;
int processor;
int last_processor;
unsigned long policy, rt_priority;
Zmienne te zostały opisane w rozdziale 3.1 .
Uwagi do poprzednich wersji jądra:
Dawniej były dostępne zmienne errno i debugreg[8]. Przechowywały one
odpowiednio: kod błędu kopiowany w momencie wychodzenia z wywołania systemowego
na zmienną globalną errno; natomiast debugreg[8] przechowywała rejestry
z informacjami do usuwania błędów. Poprzednio były wykorzystywane tylko
w wywołaniu systemowym ptrace.
Plan prezentacji
1.3 Lista wszystkich procesów
Wszystkie procesy umieszczone są na cyklicznej liście dwukierunkowej przy
pomocy następujących elementów struktury procesu (task_struct).
-
struct task_struct * prev_task - poprzedni element
-
struct task_struct * next_task - następny element
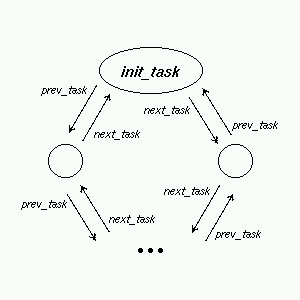
Zmienna globalna INIT_TASK określa pierwszy proces na tej liście.
Z listą wszystkich procesów związana jest zmienna globalna
NR_TASKS, której wartością jest liczba wszystkich procesów w systemie
(nie licząc INIT_TASK).
Istnieje wiele algorytmów, które biorą pod uwagę każde zadanie, dlatego
zdefiniowane zostało makro for_each_task(p) (w pliku
sched.h) przeglądające wszystkie procesy z listy (z wyjątkiem
INIT_TASK).
Plan prezentacji
1.4 Kolejka procesów gotowych
Kolejka procesów gotowych jest listą wszystkich procesów ubiegających się
o procesor. Jest to cykliczna lista dwukierunkowa połączona za pomocą następujących
elementów struktury 'task_struct':
-
struct task_struct * prev_run - poprzedni element
-
struct task_struct * next_run - następny element
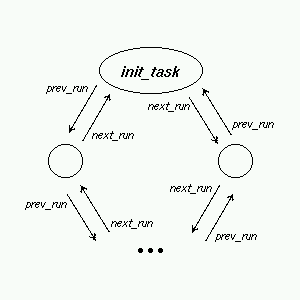
Początkowo znajduje się na niej jedynie proces INIT_TASK.
Program szeregujący wyszukuje proces, któremu zostanie przydzielony procesor
przeglądając tę właśnie listę.
Z kolejką procesów gotowych związana jest
zmienna globalna nr_running, której wartością jest liczba
procesów ubiegających się o przydział procesora (nie licząc procesu INIT_TASK).
Na kolejce procesów gotowych można wykonywać następujące operacje (zdefiniowane
w pliku sched.c):
- void add_to_runqueue (struct task_struct * p)
-
UWAGA: proces jest wstawiany na początek kolejki procesów gotowych
-
void del_from_runqueue (struct task_struct * p)
-
void move_last_runqueue (struct task_struct * p)
-
void move_first_runqueue (struct task_struct * p)
Plan prezentacji
1.5 Powiązania rodzinne procesów
W Linuksie wszystkie procesy należą do jednego drzewa, którego korzeniem
jest proces init (ma on pid równy 1). Osierocone
procesy przejmuje proces
init i w ten sposób każdy proces ma swojego
ojca. Drzewo procesów można wyświetlić (w trybie tekstowym) przy pomocy
polecenia pstree.
Oto wynik jego przykładowego działania:
init-+-atd
|-crond
|-gpm
|-inetd
|-kerneld
|-kflushd
|-klogd
|-kswapd
|-login---bash---pstree
|-lpd
|-5*[mingetty]
|-sendmail
|-syslogd
`-update
Polecenie pstree ma kilka
pouczających opcji, np. -u wyświetla w nawiasie nazwę użytkownika
(uid) procesu, jeżeli nastąpiła jego zmiana. -p wyświetla
także identyfikator (pid) procesu. Polecam przeczytanie man
pstree.
A oto drzewo procesów getty zaraz
po zalogowaniu się jednego użytkownika:
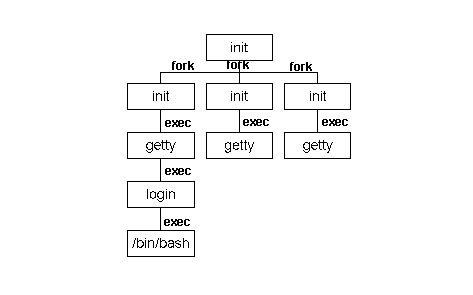
Dowiązania do innych procesów:
Powiązania rodzinne procesu są reprezentowane przez wskaźniki - pola struktur
task_struct:
struct task_struct* p_opptr - wskaźnik do oryginalnego ojca
struct task_struct* p_pptr - wskaźnik do ojca
struct task_struct* p_cptr - wskaźnik do najmłodszego syna
struct task_struct* p_ysptr - wskaźnik do młodszego brata
struct task_struct* p_osptr - wskaźnik do starszego brata
Na poniższym rysunku widać je dla drzewa procesów zawierającego ojca
i dwóch synów. Gdy jakieś pole na nic nie wskazuje, oznacza to, że jego
wartością jest NULL albo wskazuje na obiekt spoza tego drzewa.
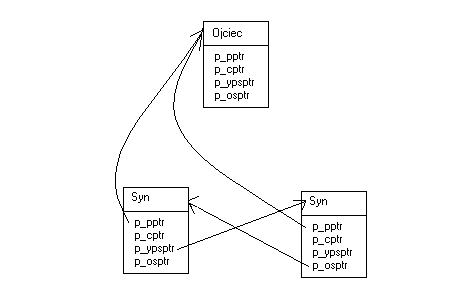
Plan prezentacji
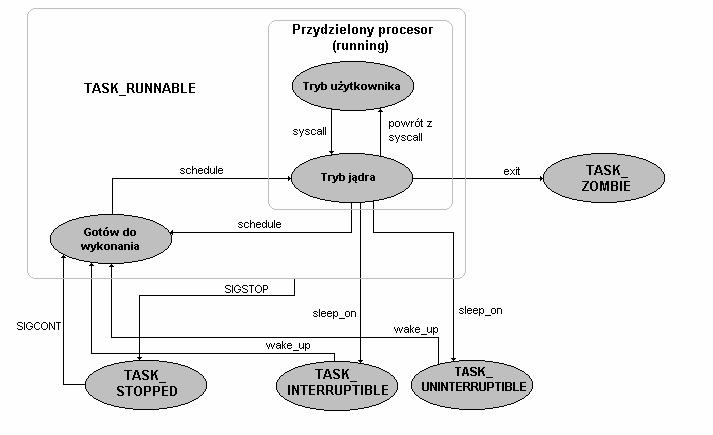
2. Stany procesu, diagram przejść międzystanowych
W strukturze task_struct umieszczone jest pole
volatile long state;
Pole to określa stan, w jakim aktualnie znajduje się dany proces. Proces
może, reagując na pewne zdarzenia i okoliczności, zmieniać swój stan. Pole
to może przyjąć jedną z następujących wartości:
- TASK_RUNNING (0) - proces jest procesem, który aktualnie
wykorzystuje procesor lub czeka na jego przydzielenie (jest na liście
procesów gotowych do wykonywania).
- TASK_INTERRUPTIBLE (1) - proces czeka na określone zdarzenie.
Różnica pomiędzy tym stanem, a TASK_UNINTERRUPTIBLE jest taka, że tutaj
proces obsługuje nadchodzące sygnały. Proces w tym stanie jest po prostu
uśpiony i po nadejściu sygnału lub zajściu zdarzenia, na które czekał,
umieszczany jest w kolejce procesów gotowych do wykonania.
- TASK_UNINTERRUPTIBLE (2) - podobnie jak TASK_INTERRUPTIBLE, ale w
tym stanie proces nie obsługuje nadchodzących sygnałów. Proces znajduje się
w tym stanie zwykle w oczekiwaniu na spełnienie jakiegoś warunku związanego
ze sprzętem.
- TASK_STOPPED (4) - proces został wstrzymany po otrzymaniu
odpowiedniego sygnału (SIGSTOP, SIGSTP, SIGTTIN, SIGTTOU) lub będąc
monitorowanym przez inny proces przy użyciu wywołania systemowego
ptrace przekazał sterowanie do procesu monitorującego.
Opuszczenie tego stanu możliwe jest jedynie po otrzymaniu sygnału
SIGCONT.
- TASK_ZOMBIE (8) - proces został przerwany (skończył swój
komputerowy żywot), ale jego struktura znajduje się jeszcze w tabeli
procesów.
- TASK_SWAPPING (16) - stała ta jeszcze nie jest używana w wersji
systemu 2.2. Żaden proces nie znajduje się nigdy w tym stanie.
O procesie, który znajduje się aktualnie w stanie TASK_RUNNABLE i
jest tym, który ma aktualnie przydzielony procesor, mówimy, że się właśnie
wykonuje. Proces taki może wykonywać się w jednym z dwóch
następujących trybów:
- Tryb użytkownika - tryb podstawowy procesu.
- Tryb jądra - w tym trybie możliwe jest wywoływanie funkcji
systemowych.
Oto diagram możliwych przejść procesu (nad strzałkami podane są funkcje i
zdarzenia, pod wpływem których proces zmienia stan):
Plan prezentacji
3 Szeregowanie procesów - wprowadzenie
Linux jest system wielozadaniowym. Oznacza to iż możliwe jest jednoczesne
działanie wielu procesów. Aby możliwe było uzyskanie wrażenia wielozadaniowości
systemu operacyjnego, w sytuacji gdy liczba zadań, przewyższa liczbę
procesorów w jakie wyposażona jest maszyna na której zadania te są realizowane,
system operacyjny powinien być wyposażony w specjalne oprogramowanie
umożliwiające zrealizowanie wyżej nakreślonego celu. Ważne jest aby zbiór
programów zajmujących się wielozadaniowością, był wrażliwy na takie zjawiska
które w teorii programowania współbieżnego są nazywane blokadą i zagłodzeniem.
Współbieżne wykonywanie kilku zadań jest realizowane poprzez dzielenie czasu
procesora przez wiele procesów. System operacyjny musi więc zawierać algorytmy
umożliwiające szeregowanie algorytmów i wybór procesu który będzie realizowany
w danym przedziale czasowym.
Zbiór funkcji i procedur służących do szeregowania, budzenia, usypiania
procesów jest nazywany w języku angielskim "scheduler". Najważniejszą
zaś funkcją odpowiedzialną za wybór procesu jest funkcja
schedule().
Procesy czasu rzeczywistego i procesy zwykłe
Wyróżniamy dwie grupy procesów. Procesy czasu rzeczywistego oraz procesy
zwykłe. Procesy czasu rzeczywistego to wszelkie procesy, które wymagają
"dostępu" do procesora w z góry określonych przedziałach czasowych. Są to
na przykład procesy odpowiedzialne za obsługę linii produkcyjnych
Ogólny opis szeregowania procesów w starszych wersjach Linuksa
Z punktu widzenia użytkownika są procesy bardziej i mniej znaczące.
Procesy bardziej znaczące otrzymują wyższy priorytet, a jednocześnie większy
przedział czasowy w przypadku dostania procesora. Wybór procesu następuje ze
względu na kwant czasu jakim dysponuje proces. Cóż jednak zrobić gdy
proces w trakcie wykonywania oczekuje na przykład na naciśnięcie klawiatury,
czy dostęp do dysku. W takiej sytuacji jest on wprowadzany do grupy
procesów uśpionych, a procesor jest przydzielany kolejnemu procesowi. Po
wystąpieniu zdarzenia procesor powraca do grupy procesów pracujących. Po
wyczerpaniu kwantu czasu przez wszystkie procesy następowało przydzielenie
kwantów czasu wszelkim istniejącym procesom.
Zmienna jądra odpowiadająca czasowi systemowemu
Tyknięcia zegara systemowego w architekturze i386 są realizowane co 10
milisekund. Obsługa przerwania zegara systemowego powoduje obniżenie
wartości counter, a w przypadku wykorzystania całego kwantu
ustawienie odpowiednich flag.
Plan prezentacji
3.1 Pola w task_struct zwiaząne z szeregowaniem
- volatile long state;
- stan procesu, algorytm szeregowania wybiera jeden z gotowych
procesów (w stanie TASK_RUNNING).
- struct task_struct *next_run, *prev_run;
- wskaźniki na następny i poprzedni proces gotowy.
- unsigned long policy;
- tryb szeregowania procesu (SCHED_FIFO, SCHED_RR,
SCHED_OTHER)
- long priority;
- tzw. priorytet statyczny, który jest podstawą do obliczenia
kwantu czasu na jaki procesowi przyznawany będzie procesor.
- long counter;
- pozostała część bieżącego kwantu czasu (ile tyknięć zegara
pozostało do wywłaszczenia).
- rt_priority;
- numer kolejki koncepcyjnej do jakiej proces należy (0 dla trybu
SCHED_OTHER, 1..99 dla pozostałych trybów szeregowania)
- long need_resched;
- ustawienie tej flagi oznacza, że należy wykonać algorytm
szeregowania (funkcja schedule()). Jest ustawiana, gdy bezpośrednie
wywołanie tego algorytmu mogłoby trwać za długo - np. w procedurze obsługi
przerwania zegarowego.
- int processor;
- procesor na jakim proces się wykonuje lub NO_PROC_ID, jeśli się
nie wykonuje.
- int last_processor;
- procesor na jakim proces się ostatnio wykonywał lub NO_PROC_ID,
jeśli się jeszcze nie wykonywał. Scheduler wykorzystuje tę
informację przy wyborze zadania dla wolnego procesora. Faworyzowany
jest procesor na którym zadanie było ostatnio wykonywane, gdyż w
jego pamięci podręcznej mogą jeszcze znajdować się dane procesu, co
przyspieszy jego wykonywanie.
Plan prezentacji
3.2 Klasy priorytetowe procesów
- procesy czasu rzeczywistego (RT) (najwyższy priorytet) mogą być uruchamiane tylko przez super użytkownika
- procesy zwykłe
- proces idle (najniższy priorytet)
Procesor jest w całości przydzielany klasie o najwyższym priorytecie,
dopiero gdy nie ma gotowych żadnych procesów klasy o wyższym priorytecie,
przydzielany jest klasie o niższym priorytecie. Dodatkowo, w przypadku
pojawienia się gotowego procesu z klasy o wyższym priorytecie podczas wykonywania
procesu z klasy o niższym priorytecie, proces wykonywany zostaje natychmiast
wywłaszczony.
Kolejki koncepcyjne
Klasa RT dodatkowo podzielona jest na 99 kolejek koncepcyjnych.
Numer kolejki oznacza priorytet wykonania. Zasady wywłaszczania w obrębie
kolejek koncepcyjnych są takie same jak pomiędzy procesami RT a zwykłymi.
Plan prezentacji
3.3 Szeregowanie procesów rzeczywistych
Wstęp
W jądrze Linuksa możemy wyróżnić dwa typy procesów: procesy zwykłe
- tworzone poprzez wywołanie funkcji fork() oraz procesy
czasu rzeczywistego. Te drugie różnią się od poprzednich tym, że
muszą mieć dostępny procesor w ściśle określonym przedziale czasowym
. Znajdują one zastosowanie w systemach gdzie czas reakcji na
określone zdarzenia musi być szybki i precyzyjny, na przykład
urządzenia pomiarowe takie jak system chłodzenia reaktora atomowego.
Pierwsze implementacje procesów czasu rzeczywistego zostały
dołączone do jądra Linuksa w wersji 1.3.8. Standartowe dystrybucje
omawianego systemu nie posiadają w pełni profesjonalnej obsługi
procesów czasu rzeczywistego, między innymi dlatego, że czas reakcji
systemu na zdarzenie może wynosić 10 ms co dla procesów wymagających
czasu reakcji 5 ms może okazać się niewystarczające. Dla w pełni
profesjonalnej obsługi procesów czasu rzeczywistego istnieją
specjalne dystrybucje jądra.
Tworzenie i obsługa procesów czasu rzeczywistego
Ze względów bezpieczeństwa procesy czasu rzeczywistego mogą być
tworzone tylko przez administratora systemu. Wynika to z faktu, że
algorytm wybierający proces do wykonania wybierze zawsze proces
czasu rzeczywistego przed procesami zwykłymi. W przypadku
stworzenia procesu pętlącego się lub wymagającego dużo czasu
procesora system może sprawiać wrażenie tak jakby się zawiesił.
Procesy czasu rzeczywistego pogrupowane są w 99 kolejkach
koncepcyjnych o numerach od 1 do 99. Im wyższy numer kolejki
tym proces dostanie szybciej procesor.
Przykład W systemie są dwa procesy czasu rzeczywistego
pierwszy proces w kolejce o numerze 33 i drugi w kolejce 24,
algorytm szeregujący procesy będzie wybierał proces z kolejki o
numerze 33 dopóki ten nie zakończy się, lub zostanie uśpiony.
Dopiero potem zostanie wybrany proces z kolejki o numerze 24.
Wyróżniamy dwa rodzaje trybów szeregowania procesów czasu
rzeczywistego.
- SCHED_RR:
- Jest to metoda bardzo zbliżona do metody SCHED_OTHER, proces
dostaje procesor na kwant czasu zapisany w jego task_struct w polu
counter. Po upłynięciu tego kwantu czasu zostaje wywłaszczony mu
procesor i zostaje uruchomiony algorytm szeregujący
procesy.
- SCHED_FIFO:
- Proces dostaje procesor do chwili gdy sam go nie zwolni lub
pojawi się proces z kolejki koncepcyjnej o wyższym numerze. W chwili
pojawienia się procesu bardziej uprzywilejowanego procesowi zostaje
odebrany procesor i zostaje umieszczony na początku kolejki
procesów, tak by w chwili gdy procesy z kolejek o wyższych numerach
skończą domagać się procesora został wybrany proces, który był
poprzednio wykonywany.
Proces czasu rzeczywistego może oddać procesor w trzech
sytuacjach.
- zostanie wywołana funkcja exit()
- pojawi się proces z wyższej kolejki koncepcyjnej
- proces wywoła funkcję sched_yield().
Funkcja sched_yield() powoduje, że procesowi zostaje
wywłaszczony procesor i zostaje umieszczony na końcu kolejki
procesów gotowych do wykonania.
Przykład W systemie są dwa procesy czasu rzeczywistego A i
B w tych samych kolejkach koncepcyjnych. Procesem wykonywanym jest
proces A i wywołuje funkcję sched_yield(). Wtedy proces A
zostaje odłożony na końcu kolejki procesów gotowych do wykonania i
proces szeregujący wybiera jako następny do wykonania proces B.
Do tworzenia procesów czasu rzeczywistego służy funkcja
sched_setscheduler() z biblioteki <sched.h>. Ma ona
następującą postać:
sched_setscheduler(pid_t pid, int policy, const struct sched_param *param)
sched_setparam(pid_t pid, sched_param *param)
Gdzie pid oznacza pid procesu na którym ma zostać wykonana
operacja w przypadku podania pid==0 oznacza to, że zostanie zmieniony sposób
szeregowania procesu, który wywołał tę funkcję. Zmienna policy
oznacza tryb szeregowania procesu dla procesów czasu rzeczywistego może
ona przyjmować wartości SCHED_RR i SCHED_FIFO.
Struktura sched_param składa się z pola int
sched_priority które oznacza numer kolejki koncepcyjnej do której ma
należeć proces czyli może przyjmować wartości od 0 do 99.
Jeżeli mielibyśmy stworzyć proces czasu rzeczywistego należący do
drugiej kolejki koncepcyjnej i mający tryb szeregowania SCHED_FIFO to
wyglądałoby to mniej więcej tak:
param.sched_priority=2;
sched_setscheduler(0,SCHED_FIFO,*param);
Jeżeli wykonanie funkcji się nie powiedzie się to zwróci ona na
wyniku -1 i zapisze następujące wartości na zmiennej errno:
ESRCH - nie istnieje proces o takim pidzie
EPERM - użytkownik nie ma uprawnień
EINVAL - podane wartości nie mają sensu
Implementacja
Za szeregowanie procesów w systemie Linux odpowiada funkcja
schedule(). Wywołuje ona funkcję goodness() która zwraca
priorytet dynamiczny procesu. Dla procesów czasu rzeczywistego wynosi ona
rt_priority + 1000 gdzie pole rt_priority struktury task_struct
odpowiada numerowi kolejki koncepcyjnej, do której należy proces. Dla
procesów zwykłych wartość funkcji goodness() jest równe polu counter
procesu. Przy czym wartość pola counter nie może być większa niż (2*priority)
procesu. Wartość pola priority nie może przekroczyć stałej 2*DEF_PRIORITY,
która standardowo ma wartość 20 co sprawia, że największe wartości, funkcja
goodness()zwraca dla procesów czasu rzeczywistego. Funkcja schedule()
wybiera następny proces, z procesów gotowych, z największą wartością zwróconą
przez funkcję goodness. Stąd procesy czasu rzeczywistego dostaną procesor
wcześniej niż procesy zwykłe.
Funkcje jądra na podstawie pola policy struktury task_struc
orientują się jakie typy procesów mają rozpatrywać. Dla procesów czasu
rzeczywistego pole to może mieć wartość SCHED_FIFI lub SCHED_RR, a dla
procesów zwykłych tylko SCHED_OTHER. Funkcja schedule() wykorzystuje tę
własność sprawdzając czy proces, któremu skończył się kwant czasu nie jest
szeregowany SCHED_RR jeśli tak to otrzymuje automatycznie następny kwant
czasu. Ponieważ funkcja goodness dla procesów czasu rzeczywistego sprawdza
tylko wartość rt_priority procesu. Zatem istnieje możliwość, że wybrany
proces mógł mieć wartość pola counter równą zeru, mimo że mogły istnieć
procesy zwykłe o niezerowej wartości pola counter.
Funkcja sched_setscheduler() wywołuje funkcję jądra
_sys_sched_setscheduler() która ma postać:
_sys_sched_setscheduler(pid_t pid, int policy,struct sched_param *param)
{
return setscheduler(pid, policy, param);
}
Funkcja setscheduler oprócz sprawdzenia poprawności
przekazanych parametrów ma następującą budowę
- blokuje kolejkę procesów
- znajduje task procesu o szukanym pidzie
- ustawia zadane parametry w strukturze task
- ustawia task na początku kolejki
- ustawia zmienną wykonywanego procesu need_resched na 1
- odblokowuje kolejkę procesów
Plan prezentacji
3.4 Szeregowanie procesów zwykłych
Procesy zwykłe szeregowane są zgodnie ze strategią SCHED_OTHER i wszystkie
znajdują się w kolejce koncepcyjnej nr 0.
Funkcja goodness()
Funkcja goodness ocenia na ile dany proces jest odpowiednim do
przydzielenia mu czasu procesora. Działa ona w następujący sposób:
- dla procesów czasu rzeczywistego zwracana jest wartość 1000 +
rt_priority
- dla procesów zwykłych wartość pola counter +
+ PROC_CHANGE_PENALTY, jeśli proces wykonuje się na tym samym procesorze
+ 1, jeśli jest on bieżącym procesem
Opis działania funkcji schedule()
Funkcja ta wybiera proces, któremu zostanie przydzielony procesor.
-
Gdy proces jest szeregowany w trybie SCHED_RR i skończył mu się
kwant czasu (counter = 0), to przyznaj mu nowy kwant i przesuń na koniec
jego kolejki koncepcyjnej.
-
Jeśli bieżący proces jest w stanie TASK_INTERRUPTABLE i nadszedł
dla niego sygnał, którego nie blokuje to zmień jego stan na TASK_RUNNING,
wpp usuń go z kolejki procesów gotowych
-
Przejdź po kolejce procesów gotowych i wybierz pierwszy z procesów dla
których funkcja goodness zwróciła maksymalną wartość.
Gdy wszystkie procesy gotowe wykorzystały swoje kwanty czasu i nie
ma procesów czasu rzeczywistego wykonaj dynamiczne przeliczanie priorytetów
-
Przełącz kontekst na wybrany proces (switch_to), o ile wybrany
został proces różny od bieżącego.
Dynamiczne przeliczanie priorytetów
Priorytet statyczny
Priorytet statyczny procesu zapisany jest w strukturze task_struct w polu
priority. Jest to liczba z przedziału -20..20 (-20 to najwyższy). Jest on
zmieniany np. przez funkcję nice(). Używa się go do wyliczania
priorytetu dynamicznego procesu (przydzielania kwantu czasu).
Priorytet dynamiczny
Priorytet dynamiczny procesu zapisany jest w strukturze task_struct w polu
counter. Służy on do wybierania procesu do wykonania. Jeśli proces jest
procesem aktualnie wykonywanym, counter jest zmniejszany wraz z
każdym tyknięciem zegara (jeśli jest większy od 0). Jeśli counter =
0 , oznacza to, że proces wyczerpał czas przydzielony mu przez jądro i
, jeśli jeszcze się nie zakończył, jest wstawiany do kolejki procesów
gotowych i wywoływana jest funkcja schedule().
Przeliczanie
Jeśli w systemie nie ma żadnych gotowych procesów czasu rzeczywistego, a
wszystkie procesy zwykłe wykorzystały swoje kwanty czasu tzn . dla każdego
procesu counter = 0, jądro wykonuje przeliczenie dynamicznych
priorytetów wszystkich procesów w systemie. Procesom gotowym zwyczajnie
przydzielany jest następny kwant czasu tzn. counter :=
priority, natomiast procesom śpiącym priorytet ten jest dodatkowo
podwyższany (tzw. postarzanie procesów): counter :=counter / 2
+ priority. Powoduje to, że po obudzeniu procesy te będą
faworyzowane w przydzielaniu im czasu procesora.
Cechy algorytmu szeregującego
Procesy czasu rzeczywistego są obsługiwane wcześniej niż procesy zwykłe,
w związku z czym procesy zwykle nie spowodują zagłodzenia.
Wady algorytmu szeregującego procesy zwykłe:
-
jeśli w systemie działają procesy długie i wyczerpią one swój kwant
czasu to muszą czekać na wyczerpanie się kwantów czasu innych procesów,
co powoduje urywaną pracę procesów (jest to niekorzystne dla niektórych
klas procesów np. dla procesów interakcyjnych)
-
Nie rozróżnia procesów nastawionych na obliczenia lub interakcję. Jeśli
działają 2 procesy: A interakcyjny i B obliczeniowy, to A nie wykorzystuje
całego przydzielonego sobie czasu i usypia, B dostaje procesor i trzyma
go cały swój kwant. Dlatego obciążenie systemu procesami obliczeniowymi
znacznie utrudnia pracę z procesami interakcyjnymi.
Zalety:
-
algorytm jest sprawny, nie powoduje zagłodzenia procesów oraz wyklucza
możliwość blokady, a także jest łatwy do zrealizowania,
-
kosztowne przeliczanie priorytetów nie odbywa się zbyt często,
-
algorytm jest sprawiedliwy i nie faworyzuje żadnego procesu w obrębie grupy
procesów o tym samym priorytecie.
Plan prezentacji
4.1 Usypianie i budzenie procesów
Często zdarza się, że działający proces musi zostać wstrzymany i
może być kontynuowany dopiero po zajściu konkretnego zdarzenia.
Takim zdarzeniem może być zwolnienie się zasobu, podniesienie
semafora, pojawienie się informacji w łączu lub zakończenie pracy
procesu potomnego. W Linuksie procesy oczekujące na konkretne
zdarzenie umieszczane są w osobnych kolejkach. Elementy tych kolejek
mają następującą strukturę, zdefiniowaną w pliku wait.h:
struct wait_queue
{
struct task_struct *task;
struct wait_queue *next;
};
W jądrze Linuksa (pliki: sched.h i sched.c)
zdefiniowane są następujące funkcje:
- void interruptible_sleep_on(struct wait_queue **p)
- long interruptible_sleep_on_timeout(struct wait_queue **p, long timeout)
- void sleep_on(struct wait_queue **p)
- long sleep_on_timeout(struct wait_queue **p, long timeout)
- void wake_up(struct wait_queue **q)
- void wake_up_interruptible(struct wait_queue **q)
Pierwsze cztery funkcje, służące do usypiania procesów, wykonują
następujący algorytm:
(p - wskaźnik do kolejki procesów oczekujących, w której
umieszczony zostanie dany proces)
{
Ustaw stan procesu na uśpiony (TASK_INTERRUPTIBLE względnie TASK_UNINTERRUPTIBLE)
Wstaw proces do kolejki p
Wywołaj szeregowanie (schedule względnie schedule_timeout)
Usuń proces z kolejki p
}
Pozostałe funkcje, implementujące budzenie procesów, działają
według poniższego schematu:
(q - wskaźnik do kolejki
procesów oczekujących na dane zdarzenie)
{
Dla każdego procesu p w kolejce q (względnie tylko dla procesów będących w stanie TASK_INTERRUPTIBLE)
{
Zmien stan procesu p na TASK_RUNNING
Uaktualnij kolejkę procesów gotowych
}
}
Uwagi:
- Funkcja wake_up nie usuwa procesu z kolejki procesów
oczekujących. Dzieje się to w odpowiedniej funkcji sleep_on w
momencie gdy proces ponownie dostaje sterowanie po wykonaniu przez
schedule.
- Funkcja schedule_timeout i inne z nią związane zostały
zaimplementowane w jądrze Linuksa w listopadzie 1998.
Plan prezentacji
4.2 Implementacja semaforów systemowych
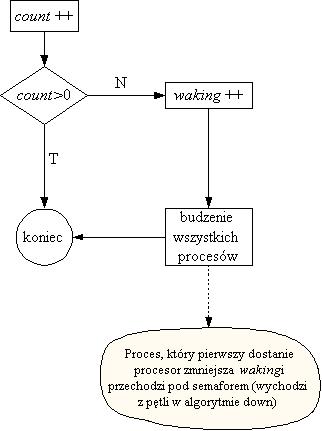
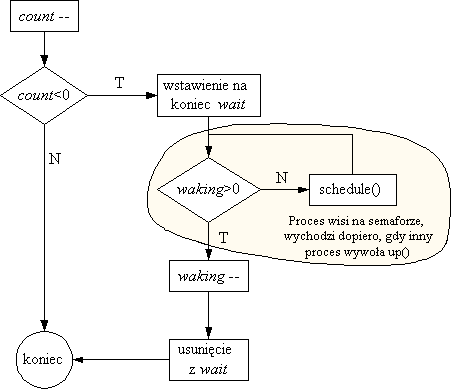
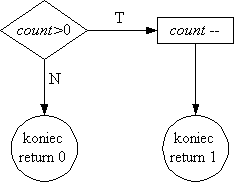
Struktuktura reprezentująca atrybuty semafora systemowego:
struct semaphore {
atomic_t count;
int waking;
struct wait_queue * wait;
};
- count jest to po prostu licznik typu int, na którym wszystkie
niezbędne operacje (dodawanie, odejmowanie, sprawdzanie wartości oraz
ustawianie wartości) są zdefiniowane jako operacje atomowe (patrz plik
atomic.h); jeżeli count jest ujemne, to moduł z count
mówi o ilości procesów wiszących na semaforze, a dodatnia wartość
count jest po prostu wartością semafora.
- waking jest zmienną pomocniczą, która mówi ile procesów w
danej chwili przejdzie pod semaforem; wartość tej zmiennej jest zawsze
dodatnia, i powinna zawsze być inicjowana na 0.
- wait jest kolejką procesów wiszących na semaforze.
Funkcje i makra obsługujące operacje na semaforach:
| Operacja |
semaphore.h |
semaphore.S |
sched.c |
| up |
void up(struct semaphore * sem) |
ENTRY(__up_wakeup) |
void __up(struct semaphore * sem) |
| down |
void down(struct semaphore * sem) |
ENTRY(__down_failed) |
void __down(struct semaphore * sem) |
| down_interruptible |
int down_interruptible(struct semaphore * sem) |
ENTRY(__down_failed_interruptible) |
int __down_interruptible(struct semaphore * sem) |
| down_trylock |
int down_trylock(struct semaphore * sem) |
ENTRY(__down_failed_trylock) |
int __down_trylock(struct semaphore * sem) |
Operacje na semaforze powodują wywołanie wyżej wymienionych funkcji (makr) w
następującej kolejności:

Dokładniejszy opis znajduje się w opisie poszczególnych operacji.
Podniesienie semafora
Opuszczenie semafora
Warunkowe opuszczenie semafora
Autor: Rafał Otto
Plan prezentacji
5. Sygnały
1. Wstęp
Sygnały to jeden ze sposobów komunikacji między procesami. Jego główne cechy to:
- asynchroniczność - wysyłający nie czeka, aż proces odbierze sygnał
- jedynym przekazem jest numer, poza tym sygnał nie niesie żadnej informacji
- nadawca sygnału jest nieznany
- ilość przesłanych sygnałów danego typu jest nieznana, proces wie tylko, czy sygnał się
pojawił
- proces nie musi odbierać sygnału czy reagować na niego (nie dotyczy części sygnałów)
Zatem sygnały mają dużo mniejsze możliwości niż inne mechanizmy IPC (Inter-Process
Commmunication). W wielu sytuacjach są jednak bardzo potrzebne.
Sygnały można podzielić na:
- sygnały wysyłane przez jądro, gdy proces spowoduje błąd działania systemu lub sprzętu:
SIGILL, SIGIOT, SIGBUS, SIGFPE, SIGSEGV, SIGXCPU, SIGXFSZ, SIGPWR
- sygnały nakazujące procesowi zakończenie, wstrzymanie lub wznawianie działania, lub
informujące o tym: SIGINT, SIGQUIT, SIGKILL, SIGTERM, SIGCHLD, SIGCONT, SIGSTOP, SIGTSTP
- sygnały terminala: SIGHUP, SIGTTIN, SIGTTOU, SIGWINCH
- sygnały wejścia/wyjścia: SIGPIPE, SIGURG, SIGIO
- sygnały użytkowe: SIGUSR1, SIGUSR2, SIGALRM, SIGVTALRM
- sygnały pojawiające się, gdy program jest śledzony: SIGTRAP, SIGPROF
Sygnał do procesu może być wysyłany przez:
- jądro
- inny proces (funkcja systemowa
kill(...))
- bezpośrednio przez użytkownika (polecenie systemowe
kill)
2. Główne struktury danych
Najważniejsze pola w strukturze task_struct (rekordzie opisującym proces) używane
w mechanizmie przesyłania sygnałów to:
sigset_t signal - długie słowo, w którym każdy z bitów oznacza, czy dany
sygnał został przesłany do procesu
sigset_t blocked - analogicznie, bit określa, czy sygnał jest zablokowany
struct signal_struct *sig - tablica przechowująca głównie informacje o
zachowaniu procesu po odebraniu danego sygnału.
Głównym polem struktury signal_struct jest struktura sigaction
zawierająca pola:
sa_handler - adres funkcji-handlera dla sygnału, wartość SIG_IGN (ignorowanie
sygnału) lub SIG_DFL (obsługa domyślna)
sa_mask - maska sygnałów, które są blokowane w trakcie działania handlera
sygnału
sa_flags - flagi określające różne sprawy związane z obsługą sygnału
3. Wysyłanie sygnałów
Wysłanie sygnału do procesu polega na ustawieniu odpowiedniego bitu w polu signal. Proces
dowiaduje się o przyjściu sygnału odczytując w pewnym momencie zawartość swego pola signal.
Funkcją odpowiadającą bezpośrednio za wysłanie konkretnego sygnału do danego procesu jest
wewnętrzna funkcja jądra:
int send_sig_info(int sig, struct siginfo *info, struct task_struct *t)
parametry: numer sygnału, informacje o wysyłającym, proces docelowy
wynik: numer błędu lub 0
działanie:
- jeśli błędny numer sygnału, to:
return -EINVAL;
- jeśli wysyłający nie ma uprawnień do wysyłania sygnały, to:
return -EPERM;
- jeśli sygnał = 0 lub proces jest zombie, to:
return 0;
- jeśli sig in (
SIGKILL, SIGCONT), to:
- jeśli proces był zastopowany, to go budzi:
wake_up_process(t);
- zeruj w polu signal bity odpowiadające sygnałom
SIGSTOP,
SIGTSTP, SIGTTOU, SIGTTIN;
- jeśli sig in (
SIGSTOP, SIGTSTP, SIGTTIN,
SIGTTOU), to: wyzeruj bit odpowiadający SIGCONT;
- jeśli sygnał może być dalej zignorowany, to:
- jeśli proces jest w stanie
TASK_INTERRUPTIBLE i sygnał jest "w toku", to:
wake_up_process(t);
return 0;
- ustaw odpowiedni bit w polu signal;
- jeśli sygnał nie jest zablokowany, to ustaw: sygnał "w toku";
- jeśli proces jest w stanie
TASK_INTERRUPTIBLE i sygnał jest "w toku", to:
wake_up_process(t);
return 0;
Sygnał może być przesłany do procesu, gdy:
- wysyłający jest superużytkownikiem, lub
- wysyłany jest SIGCONT oraz proces wysyłający i odbierający są z tej samej sesji, lub
- identyfikator wysyłającego (uid lub euid) jest równy identyfikatorowi użytkownika procesu
odbierającego (uid, euid), lub
- wartość uprzywilejowania w parametrze info funkcji send_sig_info jest niezerowa
Funkcja systemowa kill(...) wywołuje funkcje kill_proc(...),
kill_sl(...) i kill_pg(...), które z kolei korzystają z funkcji
send_sig_info(...). Zdarza się, że sygnał musi być wysłany bezwarunkowo - służy do
tego wewnętrzna funkcja jądra:
int force_sig_info(int sig, struct siginfo *info, struct task_struct *t)
działanie:
- jeśli proces jest zombie, to:
return -ESRCH;
- jeśli obsługa sygnału jest ustawiony na
SIG_IGN (ignorowanie), to: zmień
obsługę na SIG_DFL (domyślną);
- zeruj bit sygnału w polu
blocked;
send_sig_info(...);
4. Odbieranie sygnałów
Ogólny schemat
- Główną część obsługi sygnałów wykonuje funkcja do_signal.
- do_signal wywoływana jest przez funkcję ret_from_sys_call,
która z kolei wywoływana jest przy powrotach z funkcji systemowych oraz procedur obsługi przerwań.
- Z sygnałami obsługiwanymi w sposób domyślny oraz ignorowanymi przez proces do_signal
radzi sobie samodzielnie.Obsługę sygnałów, dla których proces zdefiniował sobie własne procedury obsługi,
zleca funkcji handle_signal.
- Funkcja handle_signal wcale nie wywołuje procedury obsługi
zdefiniowanej przez proces. Zamiast tego dokonuje sprytnych manipulacji na stosie oraz ustawia wskaźnik
instrukcji procesu tak, żeby proces ten po otrzymaniu procesora rozpoczął działanie od wykonania procedury
obsługi, a następnie wywołał funkcję sys_sigreturn.
Jeśli proces otrzymał kilka sygnałów, to tworzonych jest kilka ramek na stosie.
A oto schemat przepływu sterowania:
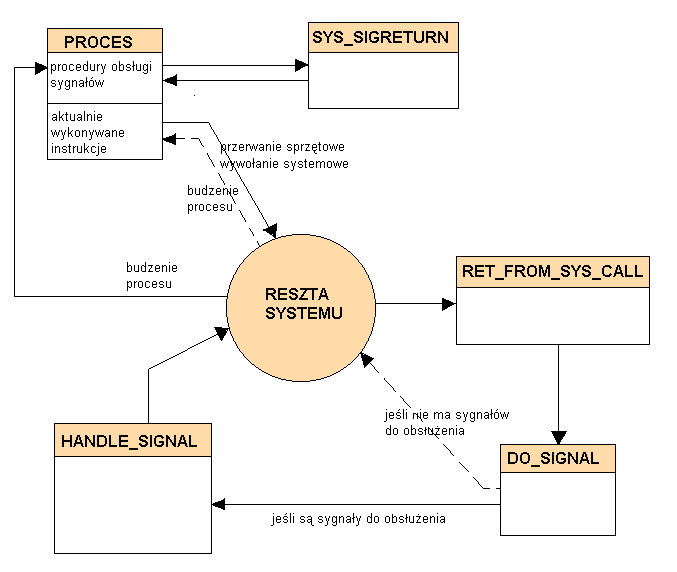
Działanie funkcji do_signal
Funkcja ta obsługuje sama sygnały, dla których proces nie zdefiniował sobie własnej procedury obsługi,
natomiast obsługę pozostałych sygnałów pozostawia funkcji handle_signal.
Algorytm działania do_signal:
 *) czyli na przykład:
*) czyli na przykład:
- SIGCONT,SIGCHLD - ( ignorowane ) przechodzi do obsługi kolejnego sygnału
- SIGSTOP - ( zatrzymanie procesu ) zatrzymuje proces, powiadamia o tym jego rodzica i wywołuje funkcję szeregujacą
- SIGKILL,SIGSEGV - ( zakończenie procesu ) kończy proces, ewentualnie wykonuje zrzut pamięci na dysk ( np. dla SIGSEGV )
Działanie funkcji handle_signal
i sys_sigreturn
Funkcja handle_signal zajmuje się sygnałami, dla których proces zdefiniował
własne procedury obsługi. Stos i wskaźnik instrukcji procesu modyfikowane są tak, żeby proces po
otrzymaniu procesora wykonał najpierw procedurę obsługi dla danego sygnału, a następnie wywołał funkcję
systemową sys_sigreturn.
Co się dzieje ze stosem? handle_signal wkłada tam (licząc od dołu):
- adres powrotu, czyli adres instrukcji, którą proces właśnie miał wykonać
- adres funkcji sys_sigreturn
Wskaźnik instrukcji procesu ustawiany jest na pierwszej instrukcji procedury obsługi.
Poza tym handle_signal wykonuje jeszcze następujące czynności:
- Blokuje obsługiwany właśnie sygnał, chyba że użytkownik zażyczy sobie inaczej - patrz
struktura sigaction pole sa_flags, flaga SA_NODEFER
- Jeśli użytkownik tego zażąda, przywraca standardową obsługę tego sygnału - patrz struktura
sigaction pole sa_flags, flaga SA_ONESHOT
Funkcja sys_sigreturn zajmuje się odblokowaniem sygnału, który
zablokowała handle_signal.
5. Modyfikacja obsługi sygnałów
Blokowanie sygnałów - funkcja sys_sigprocmask
Pozwala na zablokowanie lub odblokowanie sygnału. Operuje na polu blocked
w strukturze procesu.
Własna procedura obsługi sygnału - funkcja sys_sigaction
Pozwala na zdefiniowanie własnej procedury obsługi sygnału.Operuje na polu
sig w strukturze procesu.
Które z blokowanych sygnałów nadeszły - funkcja sys_sigpending
Informuje, które z blokowanych sygnałów nadeszły.
Autorzy:
Sebastian Łopieński - części 1-3
Małgorzata Wrzesińska - części 4-5
Plan prezentacji
6.1 Funkcja fork() - tworzenie nowego procesu
Spis treści
Wprowadzenie
Zadaniem funkcji fork() jest tworzenie nowego procesu, będącego potomkiem
procesu wywołującego. Wszystkie procesy w systemie powstają za jej pomocą,
oprócz procesu o pidzie 0, który jest tworzony wewnętrznie przez jądro przy
ładowaniu systemu do pamięci.
Podstawowy interfejs programisty:
pid_t fork(),
gdzie wartość zwracana jest liczbą określającą tożsamość procesu:
- ojciec otrzymuje pid potomka
- potomek otrzymuje zero
lub informującą o błędzie w przypadku niepowodzenia przy
tworzeniu nowego procesu: -1. Stąd typowy sposób użycia fork:
main(argv,argc)
{
switch(fork())
{
case -1 : /* zgłoszenie błedu */
case 0 : /* bezpośrednio kod potomka lub wywołanie funkcji exec */
default : /* kod ojca */
}
}
Proces potomny dziedziczy po macierzystym cały jego kontekst, z jedynym
wyjątkiem - właśnie wartością zwracaną przez fork(). Powstanie nowego
procesu jest niemożliwe w przypadku braku pamięci lub przy przekroczeniu
limitu na liczbę procesów.
Szkic algorytmu dla funkcji fork()
Jądro wykonuje następujące działania:
- Sprawdza dostępność zasobów:
- czy nie została przekroczona maksymalna dostępna liczba zadań w
systemie, określona przez stałą NR_TASKS (wynoszącą 512, w wersji
jądra 2.2.12),
- czy pozostanie wystarczająca liczba możliwych procesów dla
administratora (roota) ustalona przez MIN_TASKS_LEFT_FOR_ROOT
(wynoszącą 4 w tejże wersji),
- czy dany użytkownik nie przekroczy swojego limitu liczby procesów
okręlonego przez stałą MAX_TASKS_PER_USER (wynoszącą przykładowo
NR_TASKS/2).
- Przydziela nowemu procesowi:
- wolną pozycję w tablicy procesów,
- unikatowy pid.
- Inicjuje wartości struktury task_struct:
- kopiując większość danych ze struktury procesu macierzystego,
- zaznaczając, że nowy proces nie wykonał jeszcze exec i że nie można go
przerwać ani wyrzucić z pamięci.
- Tworzy logiczną kopię kontekstu ojca:
- kopiując informacje o deskryptorach plików, procedury obługi sygnałów
oraz - za pomocą techniki copy-on-write (kopiuj dopiero przy próbie
zapisu) - segmenty pamięci,
- uwzględniając ewentualne żądania współdzielenia pewnych
zasobów przez ojca i syna (wtedy nie kopiuje zasobów, lecz zwiększa odpowiednie
liczniki dostępu).
- Zwiększa plikom, związanym z rozmnożonym procesem, liczniki w tablicy
plików oraz i-węzłów.
- Wstawia nowy proces do kolejki procesów gotowych do wykonania.
- Przekazuje:
- pid potomka - procesowi macierzystemu,
- 0 - potomkowi.
Następny temat
Poprzedni temat
Spis treści
Implementacja
Funkcja fork dostępna dla programisty jest zaimplementowana za pomocą
ukrytej dla niego funkcji do_fork(), której funkcje składowe, znajdujące się
w pliku kernel/fork.c omówione są poniżej:
- Funkcja
find_empty_process()
- Funkcja sprawdza, czy
uruchomienie kolejnego procesu nie spowoduje przekroczenia któregoś z
limitów na liczbę procesów. Następnie przeszukiwana jest globalna tablica
zadań, w celu znalezienia indeksu pozycji, która ma wartość NULL. Jeśli nie
ma wolnej pozycji, to zwracaną wartością jest
-EAGAIN, wpp. znaleziony indeks.
- Funkcja get_pid()
- Funkcja zwraca unikatowy (wyjątek - funkcja clone()) identyfikator procesu. Nowy pid jest równy
zwiększonemu o jeden ostatnio przydzielonemu pidowi, przy czym jeśli tak
obliczony pid przekroczy wartość 32768, to zostaje zredukowany do 1.
Następnie jest sprawdzane, czy nowy pid nie koliduje z żadnym
wykorzystywanym aktualnie pidem lub pgrp-idem (identyfikatorem grupy).
Jeżeli jest kolizja to bierzemy kolejny pid.
- Funkcja dup_mmap()
- Funkcja składowa funkcji copy_mm(). Kopiuje strony pamięci procesu
macierzystego do przestrzeni potomka za pomocą techniki copy-on-write, tzn.
fizyczne kopiowanie strony odbywa się dopiero przy próbie zapisu na niej
przez jeden z tych procesów.
- Funkcja copy_mm()
- Funkcja przydziela miejsce na strukturę opisujacą pamięć i wywołuje
powyższą funkcje - dup_mmap(). Zeruje statystyki dotyczące dostępu do
pamięci. W przypadku żądania współdzielenia pamięci przez ojca i potomka
segmenty nie są kopiowane, lecz są zwiększane odpowiednie liczniki
odwołań.
- Funkcja copy_fs()
- Funkcja inkrementuje liczniki odwołań do i-węzłów katalogu głównego i
aktualnego oraz tworzy strukturę fs_struct
- Funkcja copy_files()
- Funkcja kopiuje prywatną tablicę deskryptorów plików procesu oraz
zwiększa liczniki odwołań do i-węzłów tych plików.
- Funkcja copy_sighand()
- Funkcja kopiuje procedury obsługi sygnałów.
- Zbierzmy wszystko razem: funkcja do_fork()
- Jest to główna funkcja algorytmu fork, wywołująca wszystkie wyżej
wspomniane funkcje. Jej dużą zaletą jest, że w razie niepowodzenia na
jakimkolwiek etapie usuwa ona wszelkie utworzone przez siebie struktury i
wycofuje wprowadzone ustalenia. Kolejne czynności:
- alokacja pamięci na:
- strukturę task_struct, do której wskaźnik zostanie umieszczony
w tablicy procesów.
- stos jądra
- wywołanie funkcji find_empty_process()
- inicjalizacja różnych wartości struktury nowego procesu:
- zaznaczenie, ze proces jest nowy i nie wykonał jeszcze exec, że
procesu nie można wyrzucić z pamięci oraz go przerwać
- przypisanie pidu procesu
- wyzerowanie zegaru
- wstawianie procesu do tablicy procesów
- utworzenie dowiązań sąsiadów i przodków w tablicy procesów.
- kopiowanie informacji o deskryptorach plików: copy_files()
- wywołanie funkcji copy_fs()
- wywołanie funkcji copy_sighad()
- wywołanie funkcji copy_mm()
- wywołanie niskopoziomowej funkcji copy_thread(), która powoduje
'fizyczne rozdzielenie' procesów ojca i potomka. Z punktu widzenia procesu
potomnego sytuacja wygląda tak jakby wywołał on funkcję systemową
fork(), a następnie otzymał kod powrotu 0.
- wywołanie funkcji wake_up_process, która zmienia flagę nowego procesu na
TASK_RUNNING oraz wstawia go do kolejki procesów gotowych do
wykonania.
Pokrewne funkcje systemowe
Interfejs ukrytej procedury do_fork stanowią trzy funkcje:
Opiszemy teraz dwie ostatnie
z nich.
Nadmiarowa funkcja vfork()
Funkcja ta pochodzi z systemu BSD, gdzie powstała aby przyśpieszyć
tworzenie nowego procesu. Było to osiągnięte poprzez to, że potomek operował
w przestrzeni adresowej ojca, więc kopiowanie było zbędne. Jednak wadą
funkcji vfork było założenie, że natychmiast po niej musiała być wywołana
funkcja exec, która sama przydzieli nowemu procesowi pamięć. W Linuksie
rozwiązano to inaczej: za pomocą wspomnianej techniki copy-on-write, czyli
poprzez współdzielenie pamięci, aż do próby zapisu na niej. Podejście to
czyni zbędnym założenie o wywoływaniu exec i zapewnia, że nie będzie
niepotrzebnego kopiowania. Zatem w Linuksie fork i vfork są synonimami.
Funkcja clone() - wsparcie wątków
Funkcja ta umożliwia współdzielenie przez proces macierzysty
i potomny rozmaitych zasobów:
- pamięci,
- tablicy deskryptorów,
- tablicy obsługi sygnałów,
- pidu, co ułatwia implementację wątków.
Funkcja staje się dostępna po skompilowaniu jądra
z ustawionym symbolem CLONE_ACTUALLY_WORKS_OK.
Plan prezentacji
6.2 Funkcja exec() - wywoływanie innego programu
Wprowadzenie
Przeznacznie:
Funkcja exec() zmienia kontekst poziomu użytkownika danego procesu na kopie
programu wykonywalnego umieszczonego w pliku dyskowym. Jeżeli funkcja
zostanie wykonana bezbłędnie, to poprzedni kontekst procesu znika i już
nigdy nie zostanie odtworzony. Warto zwrócić uwagę, że funkcja exec nie
powoduje powstania nowego procesu, lecz jedynie dokonuje wymiany kontekstu
istniejącego procesu (wywołującego tę funkcję), który otrzymuje nowy segment
danych, kodu i stosu.
Interfejs programisty:
Istnieje cała rodzina funkcji exec() różniących się postacią
przyjmowanych argumentów. Wszystkie funkcje z tej grupy mają nagłówki wg.
schematu:
exec<suffix>(nazwa_pliku_wykonywaln,argumenty_wywoł,środowisko),
gdzie <suffix> składa się z liter oznaczających:
- p - plik wykonywalny jest określony za pomocą samej nazwy (ostatniego
członu), bez podawania ścieżki dostępu
- l - argumenty wywołania programu są podane w postaci listy, czyli ciągu
kolejnych argumentów-napisów
- v - argumenty wywołania programu są podana postaci wektora, czyli
tablicy wskaźników do argumentów-napisów
- e - podajemy również środowisko wywołania w postaci napisów:
nazwa=wartość
UWAGA: ciąg argumentów w obydwu postaciach musi być zakończony zerem.
W ten sposób uzyskujemy sześć funkcji:
- execl
- execv
- execlp
- execvp
- execle
- exexve,
z których wszystkie korzystają z funkcji systemowej sys_execve
wywołującej funkcję do_execve, która zawiera algorytm exec().
Przykładowe zastosowanie:
W połączeniu z funkcjami systemowymi fork i wait można
za pomocą funkcji exec zrealizować następujący mechanizm: przekazujemy
sterowanie do uruchamianego programu, a po jego zakończeniu,
kontynuujemy wykonywanie pierwotnego procesu wywołującego bez utraty żadnych
danych.
Szkic algorytmu exec
- Odczytanie i-węzła pliku z programem wykonywalnym i sprawdzenie,
czy:
-
jest to zwykły plik (nie katalog) z jakimkolwiek uprawnieniem
do wykonywania
-
system plików zezwala na wykonanie, tzn. czy nie został zamontowany
z flagą
IS_NO_EXEC
-
użytkownik ma prawo do wykonania danego programu
-
plik nie jest otwarty do zapisu
-
Kopiowanie argumentów wywołania i środowiska do tymczasowego
obszaru pamięci, który stanie się częścią przestrzeni adresowej procesu
-
Odszukanie i wywołanie procedur odpowiedzialnych za dalsze
ładowanie i uruchomianie programu, specyficznych dla danego formatu
pliku wykonywalnego
Formaty plików wykonywalnych
Linux obsługuje automatycznie wiele formatów plików wykonywalnych.
Format jest rozpoznawany po pierwszych 128 bajtach pliku i odszukiwany
w liście załadowanych formatów zawartej w zmiennej globalnej jądra formats.
Następnie odnajdywana jest procedura obsługi danego formatu. Standardowe
formaty rozpoznawane przez Linuksa:
- skrypty shellowe
- programy i applety w Javie
- a.out
- ELF (Executable and Linking Format) - najbardziej uniwersalny
i wygodny
Można też udostępniać obsługę innych formatów poprzez załadowanie
dodatkowych modułów.
Obsługa sygnałów
Jeżeli w procesie została zmieniona standardowa obsługa pewnych
sygnałów, to po wywołaniu exec-a zostanie ona przywrócona w tych przypadkach,
dla których proces ustawił samodzielne procedury obsługi. Sygnały ignorowane
przed wykonaniem exec-a będą nadal ignorowane. Za zmianę sposobu reagowania
na sygnały odpowiada procedura flush_old_signals (plik fs/exec.c).
Plan prezentacji
6.3 Funkcja exit()
Spis treści
Wprowadzenie
W systemie Linux procesy kończą się wykonując funkcję systemową exit.
Proces wywołujący exit przechodzi do stanu ZOMBIE, zwalnia swoje zasoby
i oczyszcza kontekst, z wyjątkiem pozycji w tablicy procesów. Sposób wywołania
funkcji jest następujący: exit (status); przy czym status jest wartością
całkowitą przekazywaną procesowi macierzystemu do zbadania. Przyjmuje się
zasadę, że liczba zero oznacza poprawne zakończenie się procesu, a wartość
statusu różna od zera wskazuje na wystąpienie błędu. Procesy mogą wołać
exit jawnie bądź niejawnie na zakończenie programu; funkcja inicjująca
dołączana do wszystkich programów w C wywołuje exit po powrocie programu
z funkcji main. Z drugiej strony jądro może wywołać funkcję exit na potrzeby
procesu po nadejściu nieprzechwytywanego sygnału. W tym przypadku wartością
status jest numer sygnału.
Krótki opis algorytmu
algorytm exit
wejście : kod zakończenia procesu;
wyjście : brak;
{
Zapisz dane o pracy procesu do pliku rozliczeniowego;
if (używał semaforów) Odwróć efekty wykonania operacji semaforowych;
Zwolnij pamięć przydzieloną procesowi na segmenty danych, kodu, tablice stron;
Zamknij otwarte pliki;
Zwolnij i-węzły bieżącego i głównego katalogu;
Zamknij tablice obsługi sygnałów;
Ustaw stan procesu na ZOMBIE;
Ustaw wartość exit_code;
Powiadom proces macierzysty o swojej śmierci;
for each (potomek) {
Uczyń proces init (1) procesem macierzystym wszystkich
procesów potomnych, jeśli któreś z dzieci było w stanie ZOMBIE, to wyślij
do init sygnał śmierci potomka;
}
if (lider grupy procesów związanej z terminalem sterującym)
Wyślij sygnał zawieszenia do wszystkich procesów związanych
z tym terminalem;
Wywołaj szeregowanie procesów (bez powrotu);
}
Zapisywanie danych do pliku rozliczeniowego
#define ACCT_COMM 16
struct acct {
char ac_comm[ACCT_COMM]; /* Nazwa programu*/
time_t ac_utime; /* Czas w trybie użytkownika */
time_t ac_stime; /* Czas w trybie jądra */
time_t ac_etime; /* Czas pracy w sek. */
time_t ac_btime; /* Czas rozpoczęcia pracy */
uid_t ac_uid; /* User ID */
gid_t ac_gid; /* Group ID */
dev_t ac_tty; /* Identyfikator terminala */
char ac_flag; /* Info o zakończonym procesie */
long ac_minflt; /* Błędy strony*/
long ac_majflt;
long ac_exitcode; /* Kod zakończenia programu */
};
Fragment z pliku linux/acct.h:
#define AFORK 0001 /* proces wykonał fork bez exec'a
#define ASU 0002 /* proces używał przywilejów superużytkownika
#define ACORE 0004 /* został wykonany zrzut pamięci (dumped core)
#define AXSIG 0010 /* proces został zabity przez sygnał
Na ac_minflt, ac_majflt wpisywana jest ilość małych i dużych błędów stron
(w celu rozliczenia zużycia pamięci przez proces). Na ac_exitcode zapisywany
jest kod zakończenia procesu (parametr wywołania z funkcji exit).
Modyfikacja wartości używanych semaforów
Możliwa jest taka sytuacja, że proces wykonujący exit korzystał z semaforów.
Może to doprowadzić do sytuacji niepożądanej z punktu widzenia programisty,
np.: proces wykonujący exit może opuścić semafor, uniemożliwiając w ten
sposób wejście do sekcji krytycznej innym procesom i otrzymać sygnał SIGKILL.
Zapobieganie: Proces wykonujący funkcje systemową semop ustawia opcje
SEM_UNDO
PRZYKLAD
Proces X wykonał 3 razy operację opuszczenia semafora S z flagą
SEM_UNDO. Powoduje to, że wartość dostosowawcza dla semafora S wynosi
3. Teraz proces X wykonuje operację podniesienia semafora S. Wartość
dostosowawcza wynosi 2.
Zwalnianie pamięci przydzielonej procesowi
Zamykanie otwartych plików
Zwalnianie i-węzłów
Zwalnianie tablicy obsługi sygnałów
Ustawianie pól state i exit_code.
Powiadamianie procesów 'spokrewnionych'
o swojej śmierci
- Powiadomienie procesu macierzystego.
- Przebudowa drzewa procesów, adopcja procesów.
- p_pptr (wskaźnik do ojca);
- p_cptr (wskaźnik do listy dzieci);
- p_ysptr (wskaźnik do 'poprzedniego' brata);
- p_osptr (wskaźnik do 'następnego' brata);
- Śmierć lidera grupy związanej z terminalem sterującym
Zakończenie - wywołanie szeregowania
procesów
Plan prezentacji
6.4 wait() - wstrzymanie procesu do momentu zakończenia działania określonego potomka.
pid_t waitpid(pid_t pid, int *addr_stat, int options)
Wejście:
- miejsce w którym ma zostać zwrócony kod wyjściowy zakończonego procesu potomnego
- wartość określająca na zakończenie jakich procesów należy oczekiwać. Można czekać na:
- dowolny proces o zadanym identyfikatorze
- dowolny proces
- dowolny proces potomny należący do grupy procesu wołającego wait
- proces potomny o zadanym identyfikatorze
Wyjście:
Kod błędu, albo dane dotyczące zakończonego procesu (pid, powód śmierci, kod
zakończenia).
Działanie:
Funkcja czeka, aż któryś z procesów spełniający wymagane warunki przejdzie
do stanu TASK_STOPPED lub TASK_ZOMBIE. W tym celu przeglądana
jest tablica procesów.
- Jeżeli nie ma w niej procesu o wyspecyfikowanym identyfikatorze
pid lub gid, zwracany jest błąd.
- W przeciwnym wypadku:
- Jeżeli żaden z pasujących procesów nie zakończył
się, proces wywołujący wait zmienia swój stan
na TASK_INTERRUTIBLE po czym zasypia
dopuszczając przerwania. Po obudzeniu sprawdzany
jest powód obudzenia i jeżeli był nim sygnał o
śmierci potomka - ponownie przeglądane są dzieci, w
przeciwnym wypadku funkcja kończy się błędem.
- Gdy znaleziony został pasujący proces w stanie
TASK_STOPPED, to sprawdzane jest, czy nie był
on już wychwycony wcześniej. Jeżeli był - szuka
innego procesu, jeżeli zaś nie był - funkcja
zaznacza go jako wychwycony, po czym kończy
działanie zwracając dane na temat zakończonego
procesu.
- Gdy znaleziony został pasujący proces w stanie
TASK_ZOMBIE, to zwiększany jest czas
wykorzystania procesora przez proces wykonujący
wait o czas zużyty przez potomka. Jeśli
potomek miał innego oryginalnego ojca to jest mu
wysyłany sygnał o śmierci potomka, w przeciwnym
wypadku zwalniane są zasoby związane z procesem i
funkcja kończy się z odpowiednim wynikiem.
Algorytm sys_wait4
{
sprawdź poprawność argumentów i ewentualnie zwróć błąd
wstaw proces do swojej kolejki wait_chldexit
powtarzaj1:
dla każdego dziecka wykonuj
{
jeśli proces nie należy do interesującego nas zbioru
przejdź do następnego potomka
jeżeli stan == TASK_STOPPED
{
jeżeli proces był już wychwycony to
przejdź do następnego (exit_code == 0)
zapisz dane statystyczne o procesie
wyzeruj exit_code
usuń kolejkę wait_chldexit
zwróć pid zatrzymanego procesu
}
jeżeli stan == TASK_ZOMBIE
{
zwiększ czas wykorzystania procesora przez proces
wywołujący wait o czas zużyty o potomka
zapisz dane statystyczne o procesie
jeśli wskaźniki do p_opptr i p_pptr są różne
to powiadom prawdziwego ojca o śmierci
w przeciwnym wypadku
zwolnij task_struct i miejsce w tablicy procesów
usuń kolejkę wait_chldexit
zwróć pid zakończonego procesu
}
}
// tu dochodzimy jeśli nie ma zatrzymanych ani martwych dzieci
jeśli nie ma dzieci to zwróć błąd
jeśli jest ustawiona opcja WHOANG to zwróć 0
jeśli nadszedł nieoczekiwany sygnał to zwróć błąd
zaśnij dopuszczając przerwania
idź do powtarzaj1
}
Plan prezentacji
7. Wątki w Linuksie
Wątki
- jednocześnie wykonujące się procesy, korzystające z
wspólnego środowiska systemowego(pamięci, tablicy deskryptorów plików).
Ścisła definicja -- sekwencyjny przepływ sterowania
- Komunikacja i przełączanie między wątkami jednego procesu jest dużo
tańsze.
- Procesy uniksowe = "ciężkie" (duże narzuty czasowe na komunikację, przełączanie
procesora między kontekstami)
Rodzaje wątków (różnice w implementacji):
- "poziomu jądra" - korzystają ze wsparcia jądra systemu Linux
(sys_clone()), pozwalają wykorzystać wiele procesorów, we-wy w jednym wątku
nie blokuje drugiego, zajmują miejsca w tablicy procesów, większe narzuty
czasowe
- "poziomu użytkownika" - niewidoczne dla systemu(nie używają
wsparcia ze strony systemu), korzystają z sygnałów (SIGALRM do
przełączania między wątkami), tylko na jednym procesorze, blokująca funkcja
systemowa blokuje wszystkie wątki, mniejsze narzuty czasowe
- "hybrydowe" - łączą zalety powyższych rodzajów wątków tworząc
pule watków-robotników (jest ich N = liczba równoległych operacji wejścia-wyjścia
+ liczba procesorów) poziomu jądra przypisywanych wątkom poziomu użytkownika,
których może być dużo więcej.
Inne nazewnictwo:
- "poziomu jądra" (1-1)
- jeden wątek jądra na każdy wątek użytkownika
- "poziomu użytkownika" (1-n)
- jeden wątek jądra na wiele wątków użytkownika
- "hybrydowe" (m-n)
- wiele wątków jądra na więcej wątków użytkownika
Terminologia:
- Asynchroniczne i blokujące wywołania systemowe
- Granica ochrony
- Punkty anulowania (cancellation points)
Oba rodzaje wątków mogą mieć taki sam interfejs (np. pthreads i
LinuxThreads Xavier'a Leroy'a).
Standard IEEE interfejsu: POSIX 1003.1c(niestety dostępny za odpłatnością
:()
- Tworzenie wątków: pthread_create()
- Czekanie na zakończenie innego wątku: pthread_join()
- Blokowanie dostępu do sekcji krytycznych(semafory):
pthread_mutex_lock(), pthread_mutex_unlock()
- Zawieszanie i oczekiwanie na wznowienie przez inny wątek(zmienne warunkowe):
pthread_cond_wait(), pthread_cond_signal(), pthread_cond_bcast().
- Zwalnianie semafora w razie błędu (mechanizm "cancellation points"
przypominający obsługę wyjątków): pthread_cleanup_push(),
pthread_cleanup_pop().
Wsparcie jądra systemu: funkcja sys_clone()
Czego należy wymagać od kodu, który ma dobrze współpracować z wątkami:
- "reentrant" - wielokrotne "wejście" do kodu(np. funkcji) bez
wychodzenia zeń jest bezpieczne; kod nie może używać zmiennych globalnych,
ani statycznych lub musi to robić bardzo ostrożnie(w sekcji krytycznej lub
operacjami atomowymi)
- "async-safe" - kod może być wykonywany z procedury obsługi
sygnału, powinien być "reentrant"
- "mt-safe" - kod może być używany w programie wielowątkowym,
zapewniając jednocześnie rozsądny poziom współbieżności
Ograniczenia jądra Linuksa:
- dla wątków korzystających ze wsparcia jądra(funkcja clone()):
- stała NR_TASKS w jądrze (sched.h) -- standardowo 512
- ograniczenia architektury x86: NR_TASKS=<4090
- algorytmy w jądrze działają w czasie O(n) względem liczby wątków - należy
unikać większej ilości, niz 100
Ograniczenia LinuxThreads:
- tablica wątków jest wielkości PTHREADS_MAX = 1024(można
zrekompilować)
- każdy wątek rezerwuje 2MB pamięci wirtualnej na stos, a na Intelu tylko
pierwsze 1GB jest na to przeznaczone (można zmienić wielkość rezerwowanego
obszaru używając atrybutu setstackaddr)
Funkcja clone()
__clone(int (*fn) (void *arg), void *child_stack,int flags,void *arg)
- W przypadku dzielenia pamięci, należy zaalokować stos dla
nowego procesu i przekazać początkowy wskaźnik stosu tej funkcji
child_stack.
- Wsparcie dla wątków zapewniają flagi: CLONE_VM, CLONE_FS,
CLONE_SIGHAND, CLONE_FILES
Działanie na poziomie biblioteki LIBC:
- Wywołuje funkcję jądra sys_clone.
- W procesie potomnym wykonywanie nie jest kontynuowane w miejscu
wywołania clone, zamiast tego wywoływana jest podana funkcja fn
której przekazywany jest wskaźnik na jej argumenty arg.
- Po zakończeniu działania tej funkcji proces potomny kończy
działanie zwracając wynik jej działania jako swój kod wyjścia.
- Funkcja może też sama zakończyć działanie wywołując exit().
Działanie na poziomie jądra, funkcja sys_clone
- Pobiera z rejestrów flagi (eax) oraz nowy wskaźnik stosu (ecx).
W przypadku gdy nowy wskaźnik stosu nie zostanie podany, używany jest stos
procesu-ojca, co jest niewskazane przy dzieleniu pamięci (poprawne działanie
takich procesów jest prawie niemożliwe).
- Wywoływany do_fork():
- Kopiuje strukturę task bieżącego procesu.
- Wywołuje funkcje kopiujące pozostałe struktury procesu (pamięć,
parametry lekkiego procesu, pliki, sygnały), które również aktualizują
strukturę task.
Wykorzystanie flag do tworzenia wątków
- CLONE_VM (funkcja copy_mm())
- Zwiększa ilość procesów korzystających z tej struktury
pamięci
- Czyści fault & swap info
- Wywołuje copy_segments()
- Kopiuje adres i rozmiar tablicy stron dla nowego procesu. (W tablicy
adresów tablic stron).
- Aktualizuje strukturę lekkiego procesu (pole tsk->tss.ldt)
Ponieważ procesy korzystają ze wspólnej tablicy
stron, wszystkie zmiany pamięci/alokacja pamięci będzie widoczna w pozostałych.
- CLONE_FS (funkcja copy_fs())
- Zwiększa licznik procesów korzystających z struktury fs
Wszystkie wątki korzystają z tego samego systemu plików. (Nie jest zmieniany
katalog główny, a jeśli jeden proces wykona chroot() to zmiana
dotyczy wszystkich).
- CLONE_FILES (funkcja copy_files())
- Zwiększa licznik procesów korzystających z struktury files
Procesy korzystają ze wspólnych uchwytów do plików.
- CLONE_SIGHAND (funkcja copy_sighand())
- Zwiększa licznik procesów korzystających z struktury sig
Obsługa sygnałów jest wspólna dla wszystkich procesów
Plan prezentacji