Grzegorz Kaczor ( 181264 )
W tym referacie zostanie omówione zastosowanie i implementacja funkcji fork(), vfork() i clone() w Linuksie, a także implementacja samego mechanizmu przełączania kontekstu realizowanego przez jądro Linuksa. Temat dotyczy jądra w wersji 2.4.7
Rozdział pierwszy opisuje zastosowanie wyżej wymienionych funkcji i ogólną problematykę z nimi związaną. W rozdziale drugim postaram się dokładniej przyjrzeć funkcjom fork(), vfork() i clone() ''od środka'', czyli omówię funkcję do_fork(). W rozdziale trzecim mowa będzie o implementacji przełączania kontekstu - o makrze switch_to(). Czwarty rozdział stanowić będą zadania do obu tematów, a piąty rozwiązania i szkice rozwiązań.
W referacie postaram się zamieszczać jak najmniej kodu źródłowego. Postaram się to robić tylko tam, gdzie jest to konieczne lub tam, gdzie rzeczywiście to coś wyjaśnia. Poza tym w przypadku kodu składającego się z dużej ilości asemblera postaram się napisać to w sposób uproszczony, nie niszcząc funkcjonalności, za to poprawiając czytelność.
W miarę możliwości opisy algorytmów i struktur danych będą dokładne, w większości nie będę jednek opisywać struktur danych, z których będę korzystać. Zakładam, że są one Czytelnikowi znane.
W tym podrozdziale przedstawię sposób tworzenia procesów w Linuksie od strony bardziej ogólnie - do szczegółów implementacji przejdę w rozdziale drugim.
Od strony programisty tworzenie nowego procesu przebiega najczęściej w sposób następujący: programista wywołuje funkcję fork() na przykład w taki sposób:
pid = fork();
if ( pid < 0 ) syserr("nie udalo sie fork");
if ( pid ) {
// jestesmy w procesie macierzystym
... kod dla procesu macierzystego ...
}
else {
// jestesmy w procesie potomnym
... kod dla procesu potomnego ...
[ execve(...); ]
}
Z funkcjami vfork() i clone() sprawa wygląda podobnie. Jak widzimy, żeby podany powyżej kod mógł się wykonywać, funkcja fork() musi tworzyć nowy proces i w procesie macierzystym zwracać coś niezerowego, a w procesie potomnym zero. Tak jest w rzeczywistości, funkcja fork() w procesie macierzystym zwraca PID właśnie utworzonego procesu potomnego, a w procesie potomnym 0. Ponadto, żeby programista mógł używać zadeklarowanych wcześniej zmiennych w kodzie potomka, muszą one być potomkowi znane. Wcale nie znaczy to, że potomek od początku wykonuje kod rodzica. Nie - odpowiednio aktualizuje się tylko przestrzeń adresowa potomka i dane dotyczące rejestrów.
Tym właśnie zajmuje się funkcja fork() - oprócz tworzenia nowego procesu dba o spójność informacji związanych z nowym procesem, a także wprowadza proces do struktur jądra i przygotowuje do wykonywania się w środowisku wieloprogramowym.
Różnice
Chociaż działają podobnie - tworzą nowe procesy - to jednak funkcje fork(), vfork() i clone() różnią się od siebie - fork() tworzy nowy proces i kopiuje jego przestrzeń adresową i inne informacje o procesie ( z dokładnością do zastosowania copy-on-write, o tym będzie później ); vfork() wstrzymuje wykonanie procesu macierzystego do momentu wykonania przez potomka _exit() lub execve() - przydaje się to, jeśli tworzymy nowy proces i zaraz wykona on execve(), żeby wykonywać inny kod, wtedy nie ma sensu kopiowanie przestrzeni adresowej rodzica, skoro nie będziemy z niej korzystać; clone() umożliwia zdecydowanie, które fragmentu struktur danych związanych z jądrem procesy będą współdzielić - przestrzeń adresową, procedury obsługi sygnałów, informację o systemie plików, tablicę deskryptorów plików. Clone() służy do tworzenia LWP - tzw. lekkich procesów - współdzielących ze sobą pewne elementy struktur danych związanych z jądrem. Na LWP oparta jest w Linuksie np. implementacja wątków.
Wywołanie
pid_t fork(void);
pid_t vfork(void);
int __clone(int (*fn) (void *arg),
void *child_stack,
int flags,
void *arg);
Argumenty funkcji:
Implementacja funkcji fork(), vfork() i clone() sprowadza się do wykonania z różnymi argumentami funkcji do_fork(), o której będzie mowa w następnym rozdziale.
W każdym systemie wieloprogramowym pojawia się problem przełączania kontekstu. Zwłaszcza w systemach jednoprocesorowych, kiedy chcemy stworzyć płynnie działający system, umożliwiający ''jednoczesne'' wykonywanie różnych programów. W tym rozdziale opiszę ogólnie podstawowe problemy związane ze zmianą kontekstu.
Żeby jądro Linuksa mogło wywłaszczyć proces, musi zachować stan odpowiednich rejestrów procesora z momentu wywłaszczania tak, żeby proces, kiedy znowu przyjdzie czas na jego wykonanie, mógł wykonywać się bez problemów, i żeby programista nie musiał troszczyć się o obsługę sytuacji, kiedy proces jest wywłaszczany.
Kontekstem sprzętowym nazywamy zestaw danych potrzebny do załadowania do rejestrów procesora przed wznowieniem wykonania procesu. Zmiana kontekstu jest to więc zmiana wartości rejestrów procesora powiązana z zapamiętaniem wartości poprzednich w celu przywrócenia ich w chwili przyznania procesowi procesora.
Dane potrzebne procesowi odpowiadające zawartości rejestrów, która ma być zachowana, przechowywane są w strukturze thread_struct (p->thread) procesu. Strukturę tą przedstawiam poniżej:
struct thread_struct {
unsigned long esp0;
unsigned long eip;
unsigned long esp;
unsigned long fs;
unsigned long gs;
/* Hardware debugging registers */
unsigned long debugreg[8]; /* %%db0-7 debug registers */
/* fault info */
unsigned long cr2, trap_no, error_code;
/* floating point info */
union i387_union i387;
/* virtual 86 mode info */
struct vm86_struct * vm86_info;
unsigned long screen_bitmap;
unsigned long v86flags, v86mask, v86mode, saved_esp0;
/* IO permissions */
int ioperm;
unsigned long io_bitmap[IO_BITMAP_SIZE+1];
};
Do przechowywanych w tej strukturze rejestrów należą między innymi rejestry segmentowe fs i gs, wskaźnik instrukcji eip, wskaźnik stosu esp i esp0, a także rejestry zmiennoprzecinkowe, którym odpowiada pole i387. Zapisywana tutaj jest także mapa uprawnień IO, która jest ładowana do segmentu TSS związanego z procesorem, na którym wykonuje się proces. W bliższe szczegóły tej struktury nie będę się na razie zagłębiać.
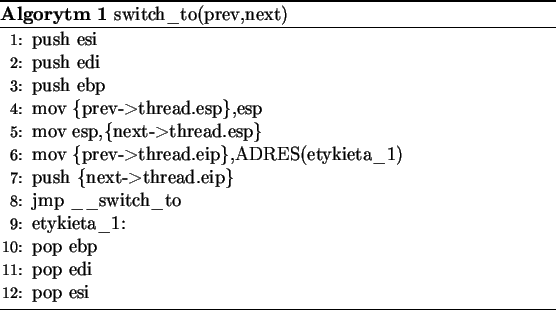
Przełączenie kontekstu następuje na skutek wywołania makra switch_to() przez funkcję schedule(). Zdarzenie takie zachodzi wtedy, kiedy proces aktualnie się wykonujący na danym procesorze skończy się, pojawi się proces o wyższym priorytecie niż działający aktualnie, proces zawiesi się w oczekiwaniu na jakieś zdarzenie, np. operację wejścia/wyjścia, albo skończy się procesowi kwant czasu.
W przypadku wszystkich trzech funkcji fork(), vfork() i clone(), wywoływana jest funkcja do_fork(). Omówieniem tej funkcji zajmiemy się w następnym podrozdziale.
Sygnatura funkcji do_fork() wygląda tak:
int do_fork(unsigned long clone_flags, unsigned long stack_start,
struct pt_regs *regs, unsigned long stack_size)
Argumenty:
Nie wdając się w szczegóły, warto powiedzieć, że wywołanie fork() jest to wywołanie z clone_flags = SIGCHLD, co oznacza niewspółdzielenie zasobów, a vfork() to wywołanie z clone_flags = SIGCHLD | CLONE_VM | CLONE_VFORK. Clone() może być wywoływane z różnymi ustawieniami clone_flags ( zob. opis vfork() w rozdziale 1 ).
Przyjrzyjmy się po kolei etapom tworzenia nowego procesu przez funkcję do_fork().
Tak przygotowany proces może się już zacząć wykonywać, może też mieć p->counter == 0. Wtedy zacznie się wykonywać wraz z rozpoczęciem nowej epoki i odnowieniem kwantów czasu.
W tej sekcji dokumentu omawiam niektóre funkcje, których do_fork() używa
do
inicjalizacji zmiennych deskryptora nowego procesu.
#define alloc_task_struct()
((struct task_struct *) __get_free_pages(GFP_KERNEL,1))
Funkcja ta zwraca wskaźnik do struktury task_struct będącej początkiem
bloku o wielkości 8KB, zawierającego jeszcze dodatkowo miejsce na stos
procesu w trybie jądra. W celu zwiększenia efektywności jest tutaj
zrealizowany cache programowy polegający na tym, że funkcja
alloc_task_struct() rzeczywiście alokuje pamięć tylko wtedy, jeśli jest to
konieczne, a jeśli nie, to przyznaje procesowi jeden z posiadanych przez
siebie bloków. Po zakończeniu pracy, kiedy proces zwalnia strukturę przy
pomocy free_task_struct(), być może nie zostanie ona w rzeczywistości
zwolniona - może zostać przechowana na wypadek, gdyby inny proces
jej potrzebował. Przyspiesza to sytuacje, kiedy jeden proces się kończy, a
zaraz potem tworzy się proces następny - dzięki cache'owi nie ma potrzeby
wywoływania dealokacji i zaraz potem ponownej alokacji pamięci ( na blok
tego samego rozmiaru co ten przed chwilą zwolniony ).
static inline void copy_flags(unsigned long clone_flags,
struct task_struct *p)
Funkcja służy do ustawiania flag procesu - zeruje na początku flagi
PF_SUPERPRIV ( proces nie korzystał jeszcze z uprawnień superużytkownika )
i PF_USEDPFU ( proces nie korzystał jeszcze z rejestrów floating-point ),
następnie ustawia flagę PF_FORKNOEXEC i ewentualnie zeruje zmienną ptrace
procesu, jeśli flaga CLONE_PTRACE nie była ustawiona.
static int get_pid(unsigned long flags)Funkcja zwraca numer PID dla nowo tworzonego procesu. Jeśli jest ustawiona flaga CLONE_PID, to zwraca PID aktualnego procesu. Jeśli nie, i ostatni nadany pid zwiększony o 1 jest mniejszy od PID_MAX, to zwraca ten pid. Jeśli możemy, to nadajemy kolejne PID'y coraz większe, aż przekroczymy PID_MAX i wtedy musimy wybrać z wolnych PIDów o niższych numerach. Robi się to przechodząc po kolei po liście wszystkich procesów w celu wyszukania PID'u o najniższym wolnym numerze większym od ostatnio przyznanego PID'u. Jeśli i to się nie uda, zaczynamy szukanie od numeru 300 ( pomijamy procesy-demony ).
static inline int copy_fs(unsigned long clone_flags,
struct task_struct * tsk)
Funkcja ta służy do kopiowania informacji o systemie plików, które
przechowuje proces, to znaczy m.in. korzenia drzewa katalogów, katalogu aktualnego
i umask. Jeśli była ustawiona flaga CLONE_FS, wtedy tylko zwiększa licznik
referencji do oryginalnej struktury fs_struct. Jeśli nie, woła funkcję
__copy_fs_struct, która kopiuje dane ze starej struktury.
static int copy_files(unsigned long clone_flags,
struct task_struct * tsk)
Funkcja ta służy do przekopiowania tablicy deskryptorów plików - podobnie,
jak funkcja copy_fs(), jeśli jest ustawiona flaga CLONE_FILES, to tylko
zwiększa licznik referencji.
static int copy_mm(unsigned long clone_flags,
struct task_struct * tsk)
Funkcja kopiuje zawartość przestrzeni adresowej procesu current do tsk i
zwiększa odpowiednie liczniki użycia. Wykonuje to tylko wtedy, jeśłi nie była
ustawiona flaga CLONE_VM; jeśli tak, to zwiększa licznik referencji i ustawia
tylko odpowiednie wskaźniki.
Tutaj stosuje się w przypadku forka metodę copy-on-write, która polega na tym, że nie ma rzeczywistego kopiowania stron pamięci od razu, a dopiero wtedy, kiedy któryś proces będzie chciał coś do nich zapisać. Wtedy dana strona fizyczna jest kopiowana, a kopia przyznawana jest procesowi potomnemu. Dzięki temu oszczędza się czas na kopiowanie całej przestrzeni adresowej w sytuacji, kiedy zaraz po forku proces wykonuje execve().
static inline int copy_sighand(unsigned long clone_flags,
struct task_struct * tsk)
Kopiuje struktury odpowiedzialne za obsługę sygnałów, konkretnie strukturę
signal_struct. Jeśli była ustawiona flaga CLONE_SIGHAND, zwiększa tylko
liczniki referencji.
extern int copy_thread(int, unsigned long, unsigned long,
unsigned long, struct task_struct *,
struct pt_regs *)
Funkcja ta służy do zainicjowania stosu trybu jądra procesu potomnego.
Inicjuje się go wartościami z rejestrów procesora podczas wykonywania
clone() ( żeby możliwe było zjawisko `startu od forka' procesu potomnego ).
Wartości te są w tej chwili przechowywane na stosie trybu jądra procesu
macierzystego. Po skopiowaniu zawartości rejestrów pole odpowiadające
rejestrowi eax jest ustawiane na 0 ( wartość zwracana do potomka przez
fork() ), a esp na liczbę będącą argumentem linii poleceń. Teraz te wartości
zostają zapisane do struktury thread procesu potomnego. Podobnie z
wartościami rejestrów fs i gs - także są zapisywane do struktury thread.
Pole eip struktury thread ( instruction pointer ) zostaje ustawione na adres
asemblerowego makra ret_from_fork(), tak aby nowo utworzony proces zaczął
swoje wykonanie od tego makra.
Kolejnym krokiem jest wykonanie makra unlazy_fpu, które zachowuje rejestry
zmiennoprzecinkowe i zeruje flagę PF_USEDFPU, a także w rejestrze cr0
ustawia flagę TS na 1. Związane jest to ze specjalnym mechanizmem
zachowywania rejestrów zmiennoprzecinkowych, o którym będzie mowa w części o
zmianie kontekstu. Na końcu następuje skopiowanie zawartości struktur
do zachowywania rejestrów zmiennoprzecinkowych procesu macierzystego do
struktur procesu potomnego.
Treść może się wydać trochę niezrozumiała, dlatego zapiszę algorytm w ''pseudojęzyku'' i w wersji uproszczonej:
A __switch_to:

Ze względów efektywnościowych w przełączaniu kontekstu rezygnujemy z wykonywania jakichkolwiek zbędnych operacji. Jednym ze sposobów przyspieszenia przełączania kontekstu jest próba zmniejszenia ilości operacji zachowywania i przywracania wartości rejestrów zmiennoprzecinkowych. Technika ta działa w ten sposób:
Proces macierzysty dzieli swój counter na pół i połowę oddaje procesowi potomnemu. Jeśli zostanie mu 0, to ustawia flagę need_resched.
This document was generated using the LaTeX2HTML translator Version 99.2beta8 (1.43)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 referat.tex
The translation was initiated by Janina Mincer-Daszkiewicz on 2001-12-27