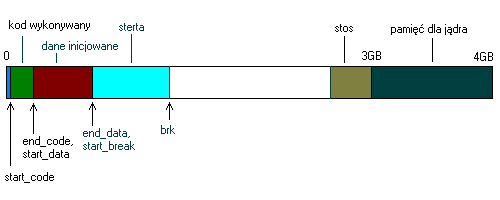
Uproszczony schemat przestrzeni adresowej procesu
W systemie linux każdy proces widzi swoją pamięć jako jednolity
obszar, nie mając dostępu do pamięci innych procesów. Takie rozwiązanie
jest możliwe dzięki mechanizmowi adresowania pośredniego i zastosowaniu
specjalnych struktur danych.
Przestrzeń adresowa każdego procesu wygląda mniej więcej tak:
Schemat ten nie zawiera takich rzeczy jak nazwa, parametry wywołania programu, zmienne środowiskowe i segmety pamięci dzielonej. Jak widać, potencjalnie proces może używać nawet 3GB pamięci operacyjnej (ostatni GB jest dla niego niedostępny). W rzeczywistości powstrzyma go od tego limit pamięci dla użytkownika.
Wszystkie informacje o danym procesie znajdują się w strukturze task_struct, którą nie będziemy się tutaj zajmować. Interesuje nas jedynie pole mm tej struktury, wskazujące na strukturę mm_struct, zawierającą wszystkie informacje o pamięci danego procesu. Wewnątrz tej struktury przyjrzymy się jak został zaimplementowany podział przestrzeni na obszary.
Ważne struktury danych:
Są one powiązane w następujący sposob:
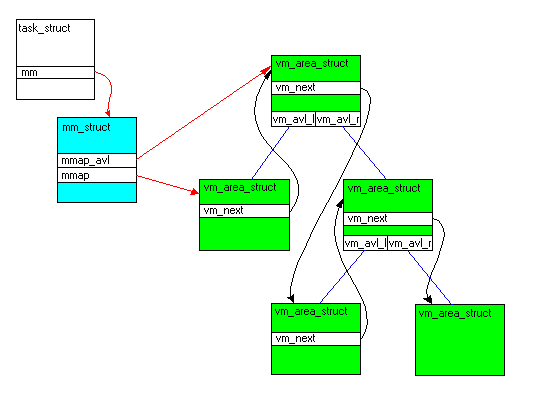
Warto obejrzeć również flagi obszarów, i
pamiętać o istnieniu stałych (include/linux/sched.h):
MAX_MAP_COUNT - Maksymalna liczba obszarów pamięci dla procesu (=65536)
AVL_MIN_MAP_COUNT - Liczba obszarów, przy ktorej jest uruchamiane drzewo
AVL (=32)