Implementacja Pamięci Wirtualnej w systemach Linux oraz FreeBSD
Jan Iwaszkiewicz
J.Iwaszkiewicz@zodiac.mimuw.edu.pl
Dokument ten został przygotowany jako pomoc do ćwiczeń z Systemów Operacyjnych
na Wydziale Matematyki, Informatyki i Mechaniki Uniwersytetu Warszawskiego.
Różnica między pamięcią wirtualną a tradycyjnym zarządzaniem pamięcią polega na tym, że w pamięci wirtualnej możemy odwzorować dużo więcej procesów niż mieści się pamięci głównej i przestrzeń adresowa każdego z nich może przekraczać rozmiar pamięci głównej. Uzyskujemy ten efekt trzymając tylko najpotrzebniejsze części danych i kodu w pamięci głównej a resztę przechowując na dysku.
Pamięć Wirtualna ma za zadanie dawać iluzje dużej jednorodnej szybkiej pamięci operacyjnej.
Systemy z rodziny unix do implementacji pamięci wirtualnej używają segmentacji ze stronicowaniem. Oprócz dyskowego systemu plików i fizycznej pamięci operacyjnej systemy te używają też pamięci podręcznej stron i pamięci podręcznej pliku wymiany.
Implementacja pamięci wirtualnej w Linuksie jest oparta na abstrakcyjnym modelu PAMIĘCI WIRTUALNEJ, który jest niezależny od architektury komputera. Dzięki temu, lwia część implementacji jest wspólna dla wszystkich architektur. Ten model jest dostosowywany do konkretnego sprzętu. Na przykład na 32-bitowym procesorze Intel redukuje się jeden poziom stronicowania. Jednak dla zachowania zgodności z modelem niezależnym od architektury, jest to robione w ten sposób, że pośredni katalog stron (patrz w algorytm tłumaczenia adresu) ma rozmiar 1. Linux używa tego abstrakcyjnego modelu nawet na architekturach, które wcale nie wspomagają stronicowania.
W Linuksie model pamięci niezależny od architektury przewiduje Segmentację z potrójnym stronicowaniem. Oznacza to, że logiczna przestrzeń adresowa jest podzielona na segmenty. Przestrzeń adresowa segmentu podzielona jest na strony, w ten sposób, że adres określa się poprzez pozycje w. Do stron dostajemy się poprzez pozycję w katalogach stron. , że niemożliwe jest liniowe adresowanie.
Mechanizm segmentacji odgrywa tylko pomocniczą rolę, ponieważ wszystkim procesom użytkownika używają wspólnych segmentów. Pamięć jest podzielona na 4 segmenty. Odpowiednio po jednym na dane i na kod dla jądra i dla reszty procesów.
Do zarządzania wolnymi stronami użyty jest Algorytm Bliźniaków
Stronicowanie jest głównym mechanizmem w Pamięci Wirtualnej Linuxa. Algorytm używany do obsługi stronicowania przybliża strategię LFU (Least Frequently Used - usuwania najrzadziej używanych stron). Do oceny zasadności trzymania stron w pamięci głównej Linux używa mechanizmu postarzania.
Stronicowanie wymusza przeznaczenie części pamięci na katalogi i tablice stron. Katalog lub tablica stron zajmuje jedna stronę (co dla i386 daje 1000 pozycji). Strony te nie są nigdy przenoszone na dysk.
Przestrzeń adresowa segmentu (4 GB dla procesora Intel) podzielona jest na równe części nazywane stronami (4kB dla procesora Intel). Pamięć fizyczna jest podzielona na części (tej samej wielkości, co strony) nazywane ramkami. Ta przestrzeń podzielona na dwie części:
0 - 3GB przestrzen uzytkownika
3GB - 4GB przestrzen zarezerwowana dla jadra.
Postarzanie jest realizowane przez demona kswapd() i działa następująco: Każda strona ma przypisany wiek (page->age) - liczbę całkowitą większą bądź równa 0. Większy wiek oznacza wyższy priorytet. Demon kswapd() podwyższa wiek strony o 3 przy każdym jej użyciu, pod warunkiem że jest już na liście active_list. Co pewien czas, zależny od zapotrzebowania na pamięć, redukuje on o połowę wiek wszystkich stron, które nie są używane. Czyli eksponencjalnie szybko zapominamy, o tym że strona była używana.
Algorytm Tłumaczenia adresu pamięciowego wiąże się ściśle z abstrakcyjnym modelem PAMIĘCI WIRTUALNEJ, wykorzystywanym przez Linuksa.
Tłumaczenie odbywa się w sprzętowej jednosce zarządzania pamięcią - Memory
Management Unit (MMU), pod nadzorem jądra systemu.
Algorytm dzieli się na dwie fazy:
Adres wirtualny(logiczny) --> Adres liniowy (Segmentacja)
Adres liniowy --> Adres fizyczny (Stronicowanie)
1. Adres wirtualny(logiczny) --> Adres liniowy
Adres wirtualny ma 48 bitów. Oto jego format:
|
47-32 |
31-0 |
|
selektor segmentu |
offset w segmencie |
Segment pamięci jest określony przez selektor w adresie wirtualnym. Selektor
określa pozycje w tablicy z deskryptorami segmentów oraz prawa, z jakimi proces
korzysta z pamięci. Oto format deskryptora:
|
15-3 |
2 |
1-0 |
|
indeks |
TI |
RPL |
TI - Table Indicator - określa, do której tablicy deskryptorów się odwołujemy
0 - globalna tablica deskryptorów
1 - lokalna tablica deskryptorów
Linux używa tylko Globalnej tablicy deskryptorów (TI == 0).
RPL - określa prawa procesu. Linux wyróżnia tylko dwa:
0 - poziom jądra
1 - poziom użytkownika
Każdy segment w systemie opisany jest przez ośmiobajtowy deskryptor segmentu,
który zawiera niezbędne informacje (adres fizyczny, wielkość, typ oraz prawa).
Po znalezieniu deskryptora odczytujemy adres fizyczny danego segmentu i dodajemy
go do przesunięcia w segmencie. Wynikiem jest adres liniowy (długość:
32 bity).
Adres liniowy składa się z adresu strony i przesunięcia wewnątrz niej. Ta faza translacji adresu polega na przetłumaczeniu adresu wirtualnej strony na adres ramki i dodaniu doń przesunięcia wewnątrz strony.
Położenie strony w pamięci fizycznej jest określone przez indeksy w katalogach/tablicach stron. W abstrakcyjnym modelu pamięci wirtualnej są to: Katalog Stron - Page Global Directory (pgd), pośredni katalog stron - Page Middle Directory (pmd) i tablica stron - Page Table (pt)??. Dla procesorów x86 pośredni katalog stron jest pomijany (pozycja w głównym katalogu jest traktowana jako pośredni katalog stron).
Format adresu liniowego na procesorze 32-bitowym Intel
jest następujący:
|
31-22 |
21-12 |
11-0 |
|
katalog |
tablica |
offset |
Sam Algorytm tłumaczenia adresu liniowego działa następująco:
- Z głównego katalogu stron odczytujemy adres pośredniego katalogu stron
- Stąd odczytujemy adres tablicy stron (na procesorze Intel pomijane)
- Z tablicy stron odczytujemy adres fizyczny szukanej strony i po dodaniu offsetu (ostatnie 12 bitów) mamy już gotowy adres fizyczny.
Ponieważ pamięć główna jest podzielona na ramki o stałym rozmiarze, to do określenia pozycji strony/katalogu nie potrzebujemy offsetu w adresie. W związku z tym w tej części adresu przechowujemy informacje o tablicy stron/stronie.
Oto format takiej informacji na procesorze Intel:
|
31-12 |
11-9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
ADRES |
OS |
O |
O |
D |
A |
O |
O |
U/S |
R/W |
P |
D - czy strona jest zmodyfikowana (dirty page)
R/W - czy użytkownik ma prawo modyfikacji, czy tylko odczytu
U/S - 1 oznacza stronę użytkownika (nie systemową)
P - czy jest w pamięci (1-tak, 0-nie i reszta bitów to położenie w pliku wymiany - swap file)
A - czy strona była użyta (accessed)
OS - do wykorzystania przez system (LRU, etc.)
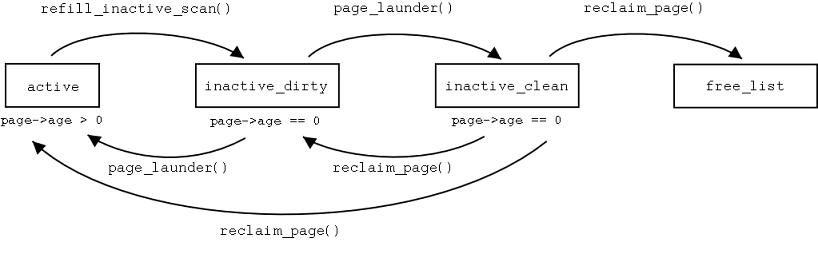
Cykl życia strony użytkownika w pamięci wirtualnej
Aby zrozumieć istotę działania linuksowej implementacji pamięci wirtualnej,
prześledźmy żywot strony, wczytanej do pamięci głównej.
Zacznę od diagramu kolejek, w których znajdują się odnośniki do stron pamięci wirtualnej.
Diagram 1. Możliwe przejścia między kolejkami w pamięci wirtualnej
Prezentujemy cykl życia strony P, która jest częścią zmapowanego
(funkcją mmap()) pliku z danymi
(dla stron plików z kodem cykl jest prostszy, ponieważ strony nie są modyfikowane
ani zapisywane na dysk.
1. Strona P jest wczytana z dysku i dodana do pamięci podręcznej
stron,
co może zajść na kilka rożnych sposobów:
- Proces użytkownika próbuje odczytać te stronę. To powoduje
błąd braku
strony. Strona jest wczytana do pamięci podręcznej stron i dodana do tablic
stron. Teraz strona zaczyna swoje życie w pamięci podręcznej i-węzła i na
liście procesów aktywnych (active_list).
- Strona jest wczytana z pliku wymiany jako leżąca w sąsiedztwie
ciągu wczytywanych stron (readahead).
Te strony są wczytywane, ponieważ koszt wczytania ich i usunięcia w razie
gdyby nie były potrzebne jest bardzo niski.
-Strona P jest wczytana, podczas wczytywania z wyprzedzeniem (readahead) klastra (grona) dyskowego, zawierającego inną stronę, która wywołała błąd braku strony (page fault). Strony takie jak P zaczynają swoje życie w podręcznej pamięci stron, związanej ze zmapowanym plikiem i na liście active_list.
2. P jest zapisana
przez proces (ustawia się bit DIRTY).
P cały czas jest na liście active_list.
3. P nie jest używane przez pewien czas. Wiek (page->age)
jest redukowany przez
demona kswapd(). Aktywność demona kswapd() zależy od zapotrzebowania na
pamięć.
4. Brak wolnej pamięci, kswapd() woła swap_out(). Jeśli wiek
strony został już
zredukowany do 0 i nie było do niej odwołań, to strona jest usuwana z wirtualnej
przestrzeni adresowej procesu. Swap_out() nie usuwa stron z pamięci. Usuwa
jedynie odnośnik procesu. Jest sprawa podręcznej pamięci stron i mechanizmu
wymiany, aby zapisać
tę stronę, jeśli była zmieniona. Jeśli pojawiło się kolejne zadanie do PTE
w
czasie, gdy swap_out() sprawdza ta stronę to strona jest odmładzana zamiast
być
wyrzucona.
5. Dalszy upływ czasu.
6. refill_inactive_scan() poszukuje stron, które można przesunąć
na listę
inactive_dirty. P właśnie się do tego nadaje, ponieważ jej wiek jest znów
równy 0 i
nie ma jej w przestrzeni adresowej żadnego procesu.
7. Proces użytkownika próbuje odczytać stronę P, ale nie jest
ona obecna w
Pamięci Witalnej procesu, ponieważ funkcja swap_out() usunęła odpowiednią
pozycje w tablicy stron. Procedura obsługi błędów woła funkcje
__find_page_nolock(), aby ta zlokalizowała
stronę P w Pamięci Podręcznej Stron.
8. Czas mija... swap_out() postępuje jak w punkcie 4. refill_inactive_scan() deaktywuje stronę P, przenosząc ja na listę inactive_dirty().
9. Strona nie jest używana przez dłuższą chwilę czasu. Brakuje
pamięci.
10. Funkcja page_launder() jest wołana, aby zapisać mało używane, zmodyfikowane
strony (ang. clean some dirty pages). Znajduje ona
P na liście inactive_dirty_list. Zauważa, ze P jest rzeczywiście
zmodyfikowana i próbuje zapisać ją na dysk. Po zapisaniu
strona może być przeniesiona na listę inactive_clean_list. Jeśli
page_launder() decyduje się zapisać stronę na dysku to ma
miejsce następująca sekwencja zdarzeń:
- Strona jest blokowana.
- Wołamy metodę writepage mapowania strony P. To wywołanie powoduje
asynchroniczne zapisanie strony w odpowiednim systemie plików. To kończy
działanie page_launder()'a dla strony P, która pozostaje na liście inactive_dirty_list
i jest odblokowywana, gdy zapis jest zakończony.
- Następnym razem, gdy page_launder() jest wołany, znajduje on stronę P-
czystą (nie zmodyfikowaną) i przenosi ją na
listę inactive_clean_list, o ile żaden proces nie zaczął jej używać w
międzyczasie.
11. page_launder() jest ponownie uruchamiany, znajduje stronę
P - nie używaną
i czystą oraz przenosi ją na listę
inactive_clean_list strefy strony P??.
12. Ktoś chce zaalokować wolna stronę w strefie strony P. Zadanie
to może
być spełnione po odesłaniu z pamięci
pewnej strony o stanie inactive_clean. P zostaje wybrane do odesłania.
Funkcja reclaim_page() usuwa P z Pamięci Podręcznej
Stron (zapewniając, ze żaden inny proces nie będzie w stanie ustawić
odnośnika do tej strony).
lub:
Demon kreclaimd() stara się zwolnić pamięć. Odsyła stronę P na
dysk i
zwalnia ją.
Podobnie jak Linux, FreeBSD używa mechanizmu postarzania.
- Obsługa Pamięci Fizycznej
Oto możliwe stany strony w pamięci wirtualnej.
Od strony implementacji wygląda to
tak, że strony są reprezentowane przez struktury
vm_page. Zmapowane do pamięci pliki są reprezentowane przez struktury vm_object. Wiele objektów (vm_object) może reprezentować
jeden fizyczny plik, otwarty przez różne procesy. System FreeBSD używa
funkcji copy_on_write() do zapisu stron, modyfikowanych przez procesy. Oznacza
to, że kilka obiektów vm_object może zawierać wskaźniki do tej samej
strony. Faktyczne kopiowanie następuje dopiero przy zapisie do niej.
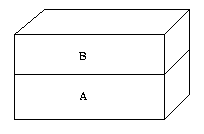
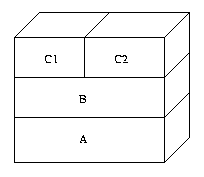
Model warstwowy
Warstwa jest zbiorem objektów reprezentujących ten sam fragment
pamięci. Każdy objekt odpowiada innemu procesowi, pracującemu na tym fragmencie
danych. Zbiorowi danych odpowiada pierwsza wartswa. Następną warstwą jest
warstwą copy_on_write, w której trzymane są te strony, które musiały być
skopiowane. ` Gdy proces wykonuje funkcję fork(), do warstwy dodaje się
dodatkowy obiekt dla nowego procesu.
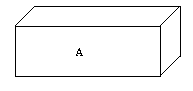
Przykład:
Rozpatrzmy proces, który rozpoczyna działanie i wywołuje funkcję fork().
Niech A będzie warstwą reprezentującą plik otwarty przez nasz proces.
Źródła: