We wczesnych latach 90. firma Microsoft postawiła sobie za cel stworzenie wysokiej jakości, niezawodnego, bezpiecznego systemu operacyjnego. Miało to na celu wejście na rynek dużych przedsiębiorstw i korporacji. Wcześniejsze produkty Microsoft (MS-DOS, Windows 3.x) opierały się na systemie FAT, który nie dawał odpowiedniej funkcjonalności dla profesjonalnych zastosowań. Wobec tego należało stworzyć nowe rozwiązanie oparte na innej technologii - w ten sposób powstał NTFS.
NTFS jest systemem diametralnie różnym od rodziny FAT. Nie znaczy to jednak, że wszystkie jego rozwiązania są całkowicie nowe i nie znane wcześniej. Na początku lat 90. firma Microsoft we współpracy z IBM utworzyła HPFS (High Performance File System) na potrzeby systemu operacyjnego OS/2. Później drogi obu firm rozeszły się i Microsoft zaczął pracę nad swoim nowym produktem Windows NT opartym na NTFS, który niektóre rozwiązania zaczerpnął właśnie z HPFS.
Główne założenia NTFS:
Najbardziej rozpowszechniona wersja, oficjalnie oznaczona numerem 1.1, nazywana również 4.0 ze względu na jej użycie w popularnym systemie operacyjnym Windows NT 4.0. Wersja ta jest również używana w Windows NT 3.51 oraz wielu innych systemach operacyjnych głównie do celów zgodności, zazwyczaj w trybie "read only".
NTFS 5.0 jest nowszą wersją stosowaną w Windows 2000 posiadającą własności:
- Reparse points - pliki i katalogi mogą mieć powiązane z nimi akcje, które zostają wykonane w momencie wywołania obiektu w jakiś szczególny sposób. Reparse points wykorzystuje się przy tworzeniu symbolicznych dowiązań plików i katalogów (Symbolic links, Junction points), montowania dysków (Volume Mount Points), zdalnych serwerów archiwizacyjnych (Remote Storage Server).
- Udoskonalone bezpieczeństwo i system praw - m. in. przydział praw do zasobów, podział na grupy użytkowników.
- Dzienniki zmian (Change Journals) - wszystkie zmiany w systemie są notowane. W przypadku awarii niedokończone akcje zostają wycofane, dzięki czemu system zawsze pozostaje w stabilnym stanie.
- Kodowanie - ze względu na możliwość ominięcia zabezpieczeń NTFS poprzez niskopoziomowy dostęp w wersji 5.0 dodano możliwość kodowania danych z wykorzystaniem klucza prywatnego i publicznego.
- Disk Quotas - kontrola i limitowanie przestrzeni dyskowej użytkowników.
- Sparse File Support - mechanizm oszczędzający miejsce na dysku w przypadku przechowywania dużych plików złożonych z jednolitych części np. samych zer.
- Disk Defragmenter - defragmentator dysku pozwalający redukować straty przestrzeni dyskowej spowodowane fragmentacją.
Generalnie nie jest zalecane posiadanie na jednym stanowisku wielu wersji NTFS, gdyż może to być źródłem wielu konfliktów między systemami operacyjnymi. W szczególności niepolecane jest instalowanie na jednym komputerze np. Windows2000 i Windows NT.
Pomimo tego istnieje kilka usprawnień jakie wprowadzono celem wyeliminowania lub przynajmniej zmniejszenia ilości problematycznych sytuacji z tym związanych. Są to:
- Automatyczna konwersja w Windows2000 - Windows2000 automatycznie zamienia do NTFS 5.0 każdą napotkaną partycję NTFS 1.1 podczas bootowania. Może to powodować problemy na komputerach z zainstalowanymi Windowsami NT i 2000.
- Automatyczna konwersja przenośnych dysków - sytuacja opisana powyżej ma również miejsce w przypadku dysków wymiennych sformatowanych pod NTFS 1.1.
- .Kompatybilność Windows NT z NTFS 5.0 - w service pack 4 dla NT jest sterownik umożliwiający czytanie danych z partycji NTFS 5.0, jednakże nawet zainstalowanie SP4 nie daje gwarancji, że wszystkie aplikacje będą działać
- Zgodność z innymi systemami operacyjnymi - niektóre z systemów (spoza rodziny produktów Microsoft) mogą korzystać z partycji NTFS, ale tylko w trybie "read only"
NTFS został zaprojektowany w sposób ułatwiający realizację wymagań stawianych temu systemowi, dlatego posiada on wiele niestosowanych wcześniej przez Microsoft rozwiązań. W systemie NTFS podstawową jednostką jest plik. W plikach są trzymane nie tylko dane, ale także wszystkie inne obiekty i informacje systemowe. Struktury służące do zarządzania partycją i tworzenia statystyk są przechowywane w specjalnych plikach tworzonych przy tworzeniu partycji zwanych metaplikami (metadata files albo metafiles). Jedynym wyjątkiem od reguły, że "wszystko jest plikiem" jest partition boot sector, który poprzedza metapliki na partycji NTFS i kontroluje większość podstawowych operacji na partycji NTFS, takich jak ładowanie systemu operacyjnego.
Podobnie jak w innych systemach w NTFS całe użyteczne
miejsce jest dzielone na klastry. NTFS dostarcza prawie wszystkich
rozmiarów klastrów od 512 Bajtów do 64kBajtów. 4kB klaster jest uważany za
standard. NTFS nie posiada anomaliów w zakresie struktury klastrów.
Podczas tworzenia partycji NTFS pierwszym blokiem informacji na partycji jest volume boot sector (nazywany czasami partition boot sector albo volume boot record)
Volume boot sector może w rzeczywistości zajmować do 16 sektorów na dysku i zaczyna się zawsze na pierwszym sektorze partycji i składa się podobnie jak w systemach FAT z dwóch struktur:
- BIOS Parameter Block - blok danych zawierający podstawowe informacje o partycji tj. jej etykieta, rozmiar oraz fakt, że jest to partycja NTFS.
- Volume Boot Code - blok z programem startowym zawierającym instrukcje ładowania systemu operacyjnego. Ten fragment kodu jest obecny na partycji także jako jeden z metaplików.
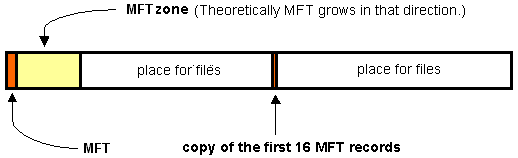
Pierwsze 16 plików NTFS zwanych metaplikami (Metafiles)
jest plikami systemowymi. Każdy z nich jest odpowiedzialny za pewien aspekt
operacji systemowych. Dzięki takiej modularyzacji jest zadziwiająca
elastyczność, np. w przypadku FAT'u fizyczne uszkodzenie w FAT area ma
konsekwencje dla każdej operacji dyskowej, zaś w przypadku NTFS'u można
przenieść, czy nawet podzielić obszary systemowe nie ponosząc żadnej straty z
wyjątkiem pierwszych 16 elementów MFT.
Metapliki są w katalogu głównym dysku NTFS. Ich nazwy zaczynają się od znaku
"$". W poniższej tabelce znajdują się nazwy metaplików i ich funkcje.
|
Plik systemowy |
Nazwa pliku | Rekord MFT | Opis pliku |
|---|---|---|---|
|
Master file table |
$Mft |
0 |
Zawiera jeden podstawowy rekord dla każdego pliku i katalogu na partycji NTFS. Jeżeli informacja jest za duża i nie mieści się w pojedynczym rekordzie alokowane są dalsze rekordy. |
|
Master file table 2 |
$MftMirr |
1 |
Duplikat pierwszych 16 rekordów MFT. Ten plik gwarantuje dostęp do MFT w przypadku uszkodzenia pojedynczego sektora. |
|
Log file |
$LogFile |
2 |
Zawiera listę transakcji używaną przy przywracaniu spójności partycji w sytuacji wystąpienia błędu podczas wykonywania operacji zmieniającej stan. Wielkość dziennika zależy od rozmiarów partycji, może on osiągnąć do 4 MB. |
|
Volume |
$Volume |
3 |
Zawiera informacje o partycji takie jak etykieta, wersja NTFS, data utworzenia. |
|
Attribute definitions |
$AttrDef |
4 |
Tabela nazw atrybutów, numerów i opisów. |
|
Root file name index |
$ |
5 |
Wskaźnik do katalogu głównego (root folder). |
|
Cluster bitmap |
$Bitmap |
6 |
Reprezentacja partycji pokazująca, które klastry są w użytku. |
|
Boot sector |
$Boot |
7 |
Zawiera kod pozwalający zamontować partycję oraz zainicjować ładowanie systemu. |
|
Bad cluster file |
$BadClus |
8 |
Zawiera złe klastry na dysku. |
|
Security file |
$Secure |
9 |
Zawiera unikatowe deskryptory ochronne dla wszystkich plików na dysku. |
|
Upcase table |
$Upcase |
10 |
Konwertuje małe litery na odpowiednie wielkie w kodowaniu Unicode. |
|
NTFS extension file |
$Extend |
11 |
Używany do wielu rozszerzeń takich jak: quota, reparse points. |
| 12–15 |
Zarezerwowane na przyszłość. |
Najważniejszy plik to MFT - Master File Table - tablica
plików.
MFT jest umieszczony w MFT-area. MFT jest jest podzielony na rekordy o ustalonym
rozmiarze (zwykle 1kB), każdy rekord odpowiada jakiemuś plikowi. Ciekawostką
jest, że pierwsze 16 rekordów posiada swoją kopię i jest ona dokładnie w środku
lub na końcu dysku.
Obowiązkowym elementem dla każdego pliku zapisanego na
dysku jest zapis informacji o nim (rekord) w MFT. Dotyczy to wszystkich
informacji o pliku (tj. nazwa, rozmiar i in.) oprócz danych. Wyjątkiem jest
sytuacja, gdy danych jest istotnie mało, tzn. nie więcej niż pozostałego miejsca
w rekordzie dla tego pliku po zapisaniu w nim wszystkich jego informacji. Wtedy
treść pliku jest przechowywana bezpośrednio w MFT. Jeśli jeden rekord nie
wystarcza do zapisania tych informacji, to używa się większej ich liczby. Przy
czym nie muszą to być sąsiednie rekordy.
Schemat struktury rekordu jest następujący:

Partycje NTFS znacząco różnią się od partycji FAT strukturą i funkcjonowaniem, jednak od zewnątrz wyglądają tak samo, jak inne partycje i stosują się do nich te same reguły. Jest to potrzebne i pożądane, żeby przy bootowaniu partycje NTFS mogły być traktowane tak samo jak FAT. Podobnie, jak w przypadku FAT partycje NTFS mogą być zarówno primary partition jak i logicznymi partycjami.
NTFS od początku był projektowany jako system przeznaczony do profesjonalnych zastosowań, gdzie bardzo często potrzebne są duże partycje. Zasadniczo w NTFS partycje mogą być dowolnie duże (ograniczeniem jest 2^64 B, co jest równe 16-cyfrowej liczbie exabajtów). Jednakże istnieją pewne inne ograniczenia:
- rozmiar dysku - obecnie i w najbliższej przyszłości nie będą dostępne tak duże dyski
- systemowe - przy instalacji Windows NT najpierw jest tworzona partycja FAT16, która potem jest konwertowana na NTFS, zatem maksymalny rozmiar partycji bootującej wynosi 4 GB. Nawet partycję systemową stworzy się samemu używając w tym celu innych narzędzi Windows NT nie jest w stanie się bootować z partycji większej niż 7.88GB - jest to związane z nieobsługiwaniem przez NT eozszerzeń przerwania 13h do obsługi dużych dysków. Problemy te wyeliminowano w późniejszych wersjach Windows.
Podobnie jak w systemach rodziny FAT w NTFS zastosowano grupowanie sektorów w klastry celem zmniejszenia fragmentacji na dysku. Rozmiar klastra zależy od rozmiaru partycji:
|
Rozmiar partycji w GB |
Domyślna ilość sektorów na klaster |
Domyślny rozmiar klastra w kB |
|
<= 0.5 |
1 |
0.5 |
|
> 0.5 do 1.0 |
2 |
1 |
|
> 1.0 do 2.0 |
4 |
2 |
|
> 2.0 do 4.0 |
8 |
4 |
|
> 4.0 do 8.0 |
16 |
8 |
|
> 8.0 do 16.0 |
32 |
16 |
|
> 16.0 do 32.0 |
64 |
32 |
|
> 32.0 |
128 |
64 |
W tabelce użyto dwóch kolorów dla odróżnienia dwóch systemów wyznaczania rozmiaru klastra w zależności od wersji systemu. Windows NT 3.5 i wcześniejsze używa danych jak w tabeli. Windows NT 3.51 i późniejsze - tylko biała część tabeli, dla partycji powyżej 4 GB zawsze stosuje klastry wielkości 4kB. Różnica ta jest spowodowana wbudowaną opcją kompresji plików w późniejszych wersjach Windows. Oczywiście można sformatować dysk z parametrem A i podać inny rozmiar klastra, jednakże należy przy tym być ostrożnym, gdyż ryzykujemy niemożność korzystania z wbudowanej kompresji plików oraz potencjalnie większą utratę przestrzeni spowodowaną większą fragmentacją. W obecnych warunkach najczęściej spotykanym rozwiązaniem kompromisowym jest klaster wielkości 4kB.
W NTFS'ie katalog jest specyficznym plikiem
przechowującym referencje do innych plików i katalogów, ustanawiającym
hierarchiczną strukturę danych zapisanych na dysku. Plik katalogu jest
podzielony na bloki; każdy z nich zawiera nazwę pliku, podstawowe atrybuty i
referencję do elementu w MFT, który dopiero daje kompletną informację o
elemencie katalogu. Wewnętrzna struktura katalogu jest drzewem binarnym.
Przyspiesza to wyszukiwanie pliku w katalogu. Zamiast wyszukiwania liniowego tak
jak w FAT wyszukujemy plik metodą bisekcji tzn. najpierw wybieramy plik ze
środka katalogu i uzyskujemy informację, czy szukany plik znajduje się
wcześniej, czy później w katalogu. Następnie z odpowiedniego fragmentu wybieramy
środkowy plik i powtarzamy. W ten sposób zmniejszamy obszar poszukiwań za każdą
iteracją dwukrotnie.
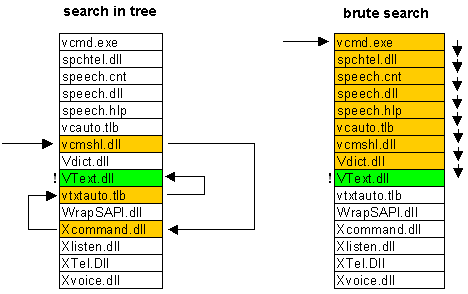
Dla porównania: w katalogu zawierającym 1000 pozycji np.
FAT wykona średnio 500 porównań, zaś system oparty na binarnym wyszukiwaniu
tylko 10. Należy dodać, że utrzymanie struktury drzewiastej jest dosyć
kosztowne, z kolei nowsze systemy oparte na FAT (Windows98, Windows2000) stosują
optymalizacje polepszające wyszukiwanie. Tak więc różnica ta nie jest aż tak
drastyczna.
Jaka informacja może być uzyskana tylko po przeczytaniu pliku katalogu? Taka,
jak po wydaniu komendy dir. Żeby uzyskać efekt elementarnej nawigacji po dysku
wcale nie potrzeba wchodzić w MFT dla każdego pliku. Wystarczy jedynie
przeczytać najpopularniejsze informacje z pliku katalogu w którym dany plik się
znajduje. Główny katalog na dysku - root - nie różni się od zwykłych katalogów
niczym poza referencją do niego z metapliku MFT.
W NTFS wszystkie pliki są przechowywane w ten sam sposób: jako zbiór atrybutów, dotyczy to także danych pliku które są traktowano jako jeden z jego atrybutów "data attribute". Sposób przechowywania danych zależy od rozmiaru pliku. Struktura każdego pliku opiera się na informacjach i atrybutach przechowywanych dla każdego pliku:
- Nagłówek (Header - H) - zestaw danych niskiego poziomu używanych przez NTFS do zarządzania katalogiem, zawiera m.in. wskaźniki do innych atrybutów pliku oraz wolnych miejsc w rekordzie, jest częścią informacji o pliku zapisaną w MFT, ale nie jest atrybutem pliku.
- Informacja standardowa (Standard Information attribute - SI) - dane o pliku takie jak stemple czasowe z datą stworzenia, ostatniej modyfikacji i dostępu do pliku, parametry np. "read only", "hidden".
- Nazwa pliku (File Name Attribute - FN) - ten atrybut przechowuje nazwę związaną z plikiem. Należy zauważyć, że plik może występować pod wieloma nazwami (może być podlinkowany w różnych miejscach) wobec tego może mieć wiele atrybutów FN.
- Dane (Data Attribute) - właściwa zawartość pliku.
- Deskryptor bezpieczeństwa (Security Descriptor Attribute - SD) - informacje związane z bezpieczeństwem i kontrolą dostępu do pliku.
Jeżeli plik wraz z informacją o nim jest wystarczająco mały aby go pomieścić w rekordzie MFT cała powyższa iformacja jest tam zapisywana, jeżeli nie jest to możliwe, niektóre atrybuty umieszcza się poza MFT czyniąc je nierezydentnymi. Postępowanie jest następujące:
Wskaźniki do danych są przechowywane w postaci pary: adres początku i długość, dzięki temu nie trzeba czytać całego pliku, żeby znaleźć jego koniec tak, jak w systemach FAT. Rozwiązanie to pozwala na zmniejszenie fragmentacji.
W NTFS nie ma ograniczeń na rozmiar pliku. Plik może teoretycznie zająć całą powierzchnię partycji minus miejsce na MFT i niezbędne struktury oraz informacje.
Nazwa pliku może się składać z dowolnych znaków (również ze znaków diakrytycznych dowolnego języka). Jest ona zapisywana przy użyciu 16-bitowej reprezentacji Unicode, co daje 65535 różnych znaków. Maksymalna długość nazwy to 255 znaków. Zastrzeżonymi znakami są: ? " / \ < > * | : . Dozwolone są wielkie litery, przy czym przy odwoływaniu się do plików nie są one rozróżniane.
Wszystkie atrybuty w NTFS zależnie od swojego rozmiaru i charakterystyki są przechowywane na jeden z dwóch sposobów: rezydentne - stosunkowo małe, przechowywane bezpośrednio w MFT, nierezydentne - nie mieszczące się w MFT (w ich miejscu jest trzymany wskaźnik do nich).
NTFS posiada pewne predefiniowane typy atrybutów. Najczęściej spotykane to:
- Attribute list - metaatrybut opisujący inne atrybuty, umieszczany w MFT jest listą wskaźników do nierezydentnych atrybutów
- Bitmap - mapa zajętości klastra
- Data - dane
- Extended Attribute (EA) - specjalne atrybuty wprowadzone na potrzeby zgodności z systemem OS/2
- File Name (FN) - nazwa pliku, jeden plik może mieć wiele atrybutów FN
- Index Root Attribute - aktualny zbiór plików wewnątrz katalogu. Jeżeli katalog jest mały informacja ta jest w MFT, jeżeli jest za duży - częściowo jest w tym atrybucie, częściowo na zewnątrz.
- Security Descriptor (SD) - informacje o autorze, właścicielu, prawach dostępu, i kontroli dostępu
- Standard Information (SI) - podstawowe informacje o pliku tj. stemple czasowe i in.
- Volume Name, Volume Information, Volume Version - nazwa partycji, wersja systemu itp.
Ponadto w NTFS istnieje możliwość definiowania swoich typów atrybutów przez niektóre aplikacje.
Jedną z nowych możliwości dodanych do wersji 5 NTFS (Windows2000) jest możliwość tworzenia specjalnych funkcji systemowych i wiązania ich z plikami, bądź katalogami. Właściwość ta została zaimplementowana przy życiu obiektów zwanych reparse points.
Systemy oparte na NTFS posiadają pewne zabezpieczenia i system praw, które mają zastosowanie głównie w systemach wieloużytkownikowych. Jednakże zakres bezpieczeństwa nie jest związany bezpośrednio z systemem plików NTFS, lecz z wersją systemu operacyjnego.
- indywidualne konta użytkowników zabezpieczone hasłem,
- konto gościa,
- grupy użytkowników współdzielące dostęp do zasobów limitowany prawami,
- prawa dostępu nadawane przez administratora
W atrybucie SD (Security Descriptor) każdego pliku są zapisane dwie listy z informacjami o użytkownikach uprawnionych do tego pliku, oraz o sposobie w jaki mogą korzystać z tego pliku poszczególni użytkownicy.
- System Access Control List (SACL) - lista kontroli dostępu używana przez system do kontroli i nadzoru prób dostępu do obiektu przez użytkowników.
- Discretionary Access Control List (DACL) - tu są zapisane prawa poszczególnych użytkowników i grup do korzystania z pliku
Każdy zapis (Access Control Entry - ACE) w liście ACL zawiera kod ID użytkownika lub grupy i informację o prawach które mają być stosowane odnośnie tego użytkownika. W liście można umieszczać kombinacje zapisów które razem określają zbiór praw (bądź restrykcji) dostępu. Ponadto istnieją nazwy grup o specjalnym znaczeniu np. Everyone. Oczywiście przy bardzo złożonej strukturze grup może zaistnieć sytuacja w której prawa się wykluczają (np. indywidualne i grupowe) wtedy zastosowanie mają reguły określające priorytety jednych praw nad drugimi. Istnieje ponadto mechanizm dziedziczenia list kontroli dostępu dla obiektów. Dziedziczy się po nadkatalogu. Zależnie od wersji dziedziczenie może być statyczne lub dynamiczne (zmiany praw katalogu pociągają automatyczne zmiany praw obiektów wewnątrz).
Podstawowe prawa w NTFS:
|
Prawo |
Litera skrótu |
Prawo przydzielone dla pliku |
Prawo przydzielone dla katalogu |
|
Read |
R |
Odczyt pliku |
Przeglądanie zawartości katalogu |
|
Write |
W |
Zapis pliku |
Zmiana zawartości katalogu (tworzenie podkatalogów i plików) |
|
Execute |
X |
Wykonywanie pliku |
Przechodzenie do podkatalogu i przeglądanie jego struktury |
|
Delete |
D |
Kasowanie pliku |
Kasowanie katalogu |
|
Change Permissions |
P |
Zmiana praw pliku |
Zmiana ustawień praw katalogu |
|
Take Ownership |
O |
Zmiana właściciela pliku |
Zmiana właściciela katalogu |
W późniejszych wersjach systemów operacyjnych stosowane są kombinacje praw. Zależności między prawami w Windows2000 a Windows NT pokazuje tabela:
|
Prawa złożone (Windows 2000 i Windows NT 4.0 SCM) |
Windows NT |
|||||
|
(R) |
(W) |
(X) |
(D) |
(P) |
(O) |
|
|
Przechodzenie katalogu / |
|
|||||
|
Przeglądanie katalogu / |
|
|||||
|
Czytanie atrybutów |
|
|
||||
|
Czytanie atrybutów poza MFT |
|
|||||
|
Tworzenie plików / |
|
|||||
|
Tworzenie katalogu / |
|
|||||
|
Zapisywanie atrybutów |
|
|||||
|
Zapisywanie atrybutów poza MFT |
|
|||||
|
Rekurencyjne kasowanie |
||||||
|
Kasowanie |
|
|||||
|
Czytanie praw |
|
|
|
|||
|
Zmiana praw |
|
|||||
|
Zmiana właściciela |
|
|||||
UWAGA: Prawo rekurencyjnego kasowania jest osobnym prawem i nie składa się ono z żadnych praw podstawowych.
Aby uniknąć konieczności nadawania praw na niskim poziomie każdemu elementowi osobno istnieją w NTFS tzw. prawa grupowe, tzn. jest możliwość nadawania całych zestawów praw grupom obiektów.
Przy rozwiązywaniu problemów związanych ze sprzecznymi prawami stosuje się następujący algorytm:
NTFS jest systemem odpornym na błędy, który potrafi
samoistnie poprawić niemal każdą zaistniałą usterkę. Każdy nowoczesny system
plików opiera się na idei transakcyjności - akcje są wykonywane całkowicie i
poprawnie albo wcale.
Przykład : Jesteśmy w trakcie nagrywania danych na dysk. Nagle okazuje
się, że nie można nagrać informacji w miejsce w które zaplanowaliśmy z powodu
uszkodzenia dysku. Zachowanie NTFS'u w tej sytuacji będzie następujące:
transakcja nagrywania zostanie wycofana w całości, system zorientuje się, że
nagranie nie powiodło się, miejsce jest oznaczane jako uszkodzone, dane są
nagrywane w innym miejscu - zostaje stworzona nowa transakcja.
odzyskiwanie transakcji (Transaction Recovery) - za każdym razem, gdy partycja NTFS jest montowana do systemu oraz przy każdym ładowaniu systemu wykonywany jest proces odzyskiwania transakcji. Co 8 sekund pracy do dziennika jest zapisywany tzw. checkpoint, dla oznaczenia, że do tego momentu "nie stało się nic złego" i nie trzeba oglądać dalej dziennika. Odzyskiwanie transakcji polega na przejrzeniu dziennika aktywności systemu od czasu ostatniego checkpoint. Przejrzenie odbywa się w 3 krokach:
Krok analizy: system analizuje zawartość dziennika, żeby określić, które części partycji muszą być sprawdzone i ewentualnie poprawione.
Krok ponawiający: system wykonuje transakcje zapisane w dzienniku i jeszcze nie wykonane.
Krok wycofujący: system wycofuje niekompletne transakcje, aby pozostać w stabilnym stanie.
NTFS zapisuje wszystkie wykonywane zmiany danych na dysku w tzw. Dzienniku Zmian (Change Journal). Dla każdej partycji istnieje jeden dziennik, który jest początkowo pustym plikiem, potem za każdym razem, gdy na dysku jest wykonana jakaś zmiana, do dziennika jest zapisywany stosowny rekord. Każdy rekord jest identyfikowany unikatowym 64-bitowym numerem USN (Update Sequence Number). Każdy rekord składa się z numeru USN, nazwy zmienianego pliku oraz zmiany (właściwie wskaźnika do zmienianego miejsca). Dzienniki są wykorzystywane w procesie odzyskiwania transakcji.
NTFS dostarcza kilku właściwości pozwalających zwiększyć jego tolerancję na błędy i stosunkowo łatwo je poprawiać. Należą do nich:
- Transakcyjność operacji - opisana powyżej
- Sofware RAID Support - NTFS może wykorzystywać macierze RAID, co pozwala na duplikowanie danych szczególnie istotnych, wymagających ochrony
- Dynamiczne przemapowanie złych klastrów -Gdy podczas operacji czytania, bądź pisania wykryty zostanie uszkodzony klaster to zostaje on natychmiast oznakowany, aby w przyszłości był omijany, a dane zostają przeniesione w inne miejsce.
Te właściwości czynią NTFS systemem w miarę niezawodnym i stosunkowo bezpiecznym. Nieoznacza to jednak, że sytuacje awaryjne nie mogą się pojawić w ogóle.
Wbrew panującej opinii dyski NTFS ulegają fragmentacji i należy je defragmentować. Fragmentacja w przypadku NTFS wygląda nieco inaczej niż w przypadku innych filesystemów. Tutaj głównym problemem jest rozproszenie danych plików które "urosły" po całym dysku. Również kłopotliwe jest rezerwowanie miejsca na MFT które w przypadku braku miejsca na zwykłe pliki jest dynamicznie zmniejszane o płowę. Przy dużym zapełnieniu dysku operacja ta jest powtarzana wielokrotnie powiększając każdorazowo fragmentację. Co więcej ciężkie jest defragmentowanie w takiej sytuacji, gdyż mało jest wówczas wolnego miejsca na wykonywane operacje.
NTFS posiada wbudowane wspomaganie kompresji dysku. W
tym celu są używane Stacker i DoubleSpace. Dowolny plik lub katalog na dysku
może być przechowywany w postaci skompresowanej bez jakichkolwiek konsekwencji
dla aplikacji. Kompresja plików jest szybka, jednakże posiada jedną dużą wadę -
olbrzymią fragmentację skompresowanych plików.
Kompresja jest prowadzona blokami po 16 klastrów i używa tzw. wirtualnych
klastrów. To pozwala na uzyskanie ciekawych efektów, takich jak skompresowanie
połowy pliku.
Przykład:
typowy zapis dla pliku niezkompresowanego:
Klastry 1-43 są przechowywane na dysku w klastrach od 400
Klastry 44-52 są przechowywane na dysku w klastrach od 8530
typowy zapis dla pliku skompresowanego:
Klastry 1-9 są przechowywane na dysku w klastrach od 400
Klastry 10-16 nie są przechowywane nigdzie
Klastry 17-18 są przechowywane na dysku w klastrach od 409
Klastry 19-36 nie są przechowywane nigdzie
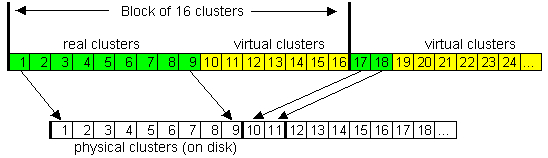
Widać, że skompresowany plik posiada "wirtualne" klastry,
które nie posiadają
prawdziwych informacji. Gdy system widzi taki klaster, orientuje się, że dane z
poprzednich klastrów są skompresowane i należy je rozpakować tak, żeby po
dekompresi wypełniły wirtualne klastry do 16 włącznie.
Ponieważ NTFS ma być systemem z założenia bezpiecznym, więc musi oferować zabezpieczenia również przed próbą niskopoziomowego obejścia zabezpieczeń i praw dostępu. W tym celu jest stosowane kodowanie plików. Począwszy od wersji 5 dostępne jest kodowanie plików i katalogów na życzenie użytkownika. Kodowanie opiera się o algorytmy wykorzystujące klucz publiczny i klucz prywatny.