W tym dokumencie będę opisywał budowę i działanie RaiserFS'a w wersji trzeciej. Gotowa jest już specyfikacja wersji czwartej, która to wersja ma się ukazać na początku stycznia 2003. Wersja czwarta różni się znacznie od trzeciej, wszystkie dane przechowywane są na jednym poziomie w B+ drzewie, rozszerzono listy uprawnień, wprowadzono modularność dzięki wtyczkom (plugins).
Rozróżniamy dwa rodzaje objektów: pliki i katalogi. Każdy obiekt w momęcie tworzenia ma nadawany unikalny identyfikator (object id), na podstawie którego jest później rozpoznawany w strukturze systemu plików.
Dane bezpośrednie przechowują:
Dane pośrednie przechowują listę wskaźników do bloków na dysku.
Dane katalogu przechowują klucze pozycji w katalogu oraz ich nazwy.
Dane informacyjne przechowują:
Każdemu item nadawany jest w bardzo przemyślny sposób klucz, który będzie służył do szeregowania wpisów o pliku w B+ drzewie. O kluczu tym można myśleć jak o numerze inoda w ext2. Nadawanie klucza jest tak wymyślone by
Klucz jest nadawany item w następujący sposób:
| Nazwa | Rozmiar (bytes) |
Opis |
| k_dir_id | 4 | Identyfikator katalogu nadrzędnego |
| k_object_id | 4 | Identyfikator objektu |
| k_offset | 4 | Offset w bajtach od początku pliku do miejsca w rozpoczynają się dane zapamiętane przez item |
| k_uniqueness | 4 | Typ item (StatData = 0, Direct = -1, InDirect = -2, Directory = 500) |
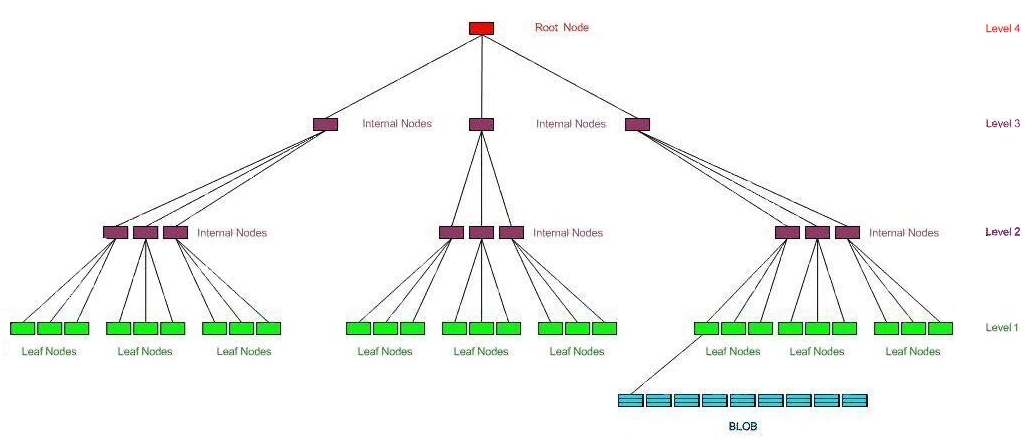
W drzewie tym wyróżniamy następujące rodzaje wierzchołków:
| Nagłówek węzła | Klucz 0 | Klucz 1 | --- | Klucz N | Wsk. 0 | Wsk. 1 | --- | Wsk. N | Wsk. N+1 | Wolne miejsce |
Węzły wewnętrzne zawierają listę par kluczy i wskaźników do poddrzew, gdzie klucz jest równy pierwszemu kluczowi w pierwszym węźle sformatowanym poddrzewa, na które wskazuje wskaźnik.
| Nagłówek węzła | Nagłówek wpisu 0 | Nagłówek wpisu 1 | --- | Nagłówek wpisu N | Wolne miejsce | Item N | --- | Item 1 | Item 0 |
Węzły sformatowane składają się z listy item. Zawierają dane (gdy item informacyjny, bezpośredni lub katalog) lub listę wskaźników do węzłów niesformatowanych (gdy item pośredni).
Węzły niesformatowane przechowują dane, ciąg bajtów.