
Historia XFS'a sięga początku lat 90. Wraz z błyskawicznym postępem technologicznym uzyskano możliwość przetwarzania coraz to większej ilości danych. W tamtym okresie inżynierowie z firmy SGI (Silicon Graphics, Inc.) zorientowali się, że obecny system plików EFS (bardzo podobny do Berkeley Fast File System) przestaje wystarczać do nowoczesnych zastosowań. Główną przyczyną były ograniczenia pojemnościowe (system plików do 8GB, rozmiar pliku do 2GB). W poszukiwaniu rozwiązań wzięto pod uwagę:
Obydwa rozwiązanie nie były zadawalające. EFS nigdy nie był zaprojektowany dla wielkich zastosowań, a konkurencyjne systemy plików były równie niedoskonałe i pozostawiały wiele do życzenia.
Dlatego powstały prace w 1993 roku nad nowym systemem plików - XFS. Trwały one do grudnia 1994 roku. XFS był sprzedawany wraz z systemem IRIX 5.3. Na początku 1996 roku firma SGI zdecydowała się na włączenie XFS'a do systemu IRIX 6.2 jako podstawowego systemu plików.
Projektańci nowego systemu plików nie chcieli popełniać tych samych błędów jak w przypadku EFS'a i innych ówczesnych systemów plików. Chcieli stworzyć system, który będzie mógł być wykorzystywany przez jak najdłuższy okres czasu.
Najważniejsze problemy z którymi mieli do czynienia twórcy XFS'a:
System plików XFS zaprojektowany z myślą o przyszłości zawiera wiele odmiennych cech. Mogłoby się wydawać, że niektóre możliwości nigdy nie zostaną wykorzystane i są zbyteczne, lecz są to spostrzeżenia krótkowzroczne. Cechy systemu XFS:
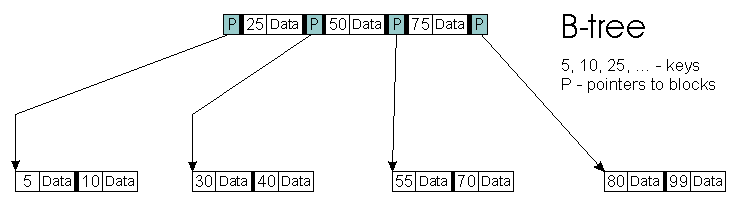
B+-drzewa wywodzą się od zwykłych B-drzew. Najważniejszą różnicą jest trzymanie wszystkich wartości w liściach drzewa, a nie w każdym wierzchołku. Dodatkowo liście powiązane są ze sobą w listę. Na tak zmodyfikowanym drzewie bardzo łatwo można wyszukać wszyskie wartości z pewnego przedziału - wyszukujemy pierwszy i ostatni element i otrzymujemy liste z początkiem i końcem.

XFS obsługuje w pełni 64 bitowy system plików. Wszystkie wskaźniki (bloków, i-węzłów) są 64 bitowe. Aby uniknąć w niektórych przypadkach tłumaczenia wskaźników na 64 bitowe, system plików jest podzielony na grupy alokacji (ang. Allocation Groups - AG). Ich rozmiar jest stały i może wynosić od 16MB do 4GB (w praktyce wykorzystuje się podziały >= 0.5GB). Grupy alokacji ułatwiają wielowątkowe zarządzanie systemem plików.
| superblock | struktura wolnych obszarów | i-węzły | logi | obszar przeznaczony dla plików . . . . . | superblock |
AG są autonomicznymi jednostkami systemu plików XFS'a. Każda AG zawiera osobne struktury wymagane dla zarządzania jej przestrzenią. Odpowiedni rozmiar AG pozwala utrzymać struktury w optymalnym rozmiarze. W skład struktur grupy alokacji wchodzą:
#define XFS_SB_MAGIC 0x58465342 /* 'XFSB' */
#define XFS_SB_VERSION_1 1 /* 5.3, 6.0.1, 6.1 */
#define XFS_SB_VERSION_2 2 /* 6.2 - dodatkowe atrybuty dla plików */
#define XFS_SB_VERSION_3 3 /* 6.2 - nowa wersja i-węzłów */
#define XFS_SB_VERSION_4 4 /* 6.2+ - nowa wersja ciągłości */
typedef __uint64_t xfs_dfsbno_t; /* numer bloku w grupie alokacji */
typedef __uint64_t xfs_drfsbno_t; /* numer bloku w systemie plików */
typedef __uint32_t xfs_agblock_t; /* liczba bloków w grupie alokacji */
typedef __uint32_t xfs_extlen_t; /* rozmiar ciągłości w blokach */
typedef __uint32_t xfs_agnumber_t; /* numer grupy alokacji */
typedef __u64 xfs_ino_t; /* numer i-węzła */
typedef struct xfs_sb
{
__uint32_t sb_magicnum; /* wersja superbloku == XFS_SB_MAGIC */
__uint32_t sb_blocksize; /* rozmiar bloku w bajtach */
xfs_drfsbno_t sb_dblocks; /* liczba bloków danych */
...
uuid_t sb_uuid; /* unikalny numer systemu plików */
xfs_dfsbno_t sb_logstart; /* numer pierwszego bloku logów */
xfs_ino_t sb_rootino; /* numer i-węzła będącego korzeniem
drzewa katalogowego */
...
xfs_agblock_t sb_agblocks; /* rozmiar grupy alokacji w blokach */
xfs_agnumber_t sb_agcount; /* liczba grup alokacji */
...
xfs_extlen_t sb_logblocks; /* rozmiar logu w blokach */
__uint16_t sb_versionnum; /* wersja superbloku XFS == XFS_SB_VERSION */
...
__uint8_t sb_imax_pct; /* maksymalny procentowy udział
i-węzłów w przestrzeni systemu plików */
/* dane statystyczne */
...
__uint64_t sb_icount; /* liczba zajętych i-węzłów */
__uint64_t sb_ifree; /* liczba wolnych i-węzłów */
__uint64_t sb_fdblocks; /* liczba wolnych bloków */
...
xfs_ino_t sb_uquotino; /* numer i-węzła dla kwot użytkowników */
...
} xfs_sb_t;
#define BBSHIFT 9
#define BBSIZE (1<<BBSHIFT)
#define XFS_AGFL_SIZE (BBSIZE / sizeof(xfs_agblock_t))
typedef struct xfs_agfl
{
xfs_agblock_t agfl_bno[XFS_AGFL_SIZE];
} xfs_agfl_t;
#define XFS_AGF_MAGIC 0x58414746 /* 'XAGF' */
#define XFS_AGI_MAGIC 0x58414749 /* 'XAGI' */
#define XFS_AGF_VERSION 1
#define XFS_AGI_VERSION 1
/*
* Drzewo btree numer 0 indeksuje pozycje, a numer 1 - rozmiar.
*/
#define XFS_BTNUM_AGF ((int)XFS_BTNUM_CNTi + 1)
typedef __uint32_t xfs_agino_t; /* numer i-węzła w grupie alokacji */
typedef enum {
XFS_BTNUM_BNOi, XFS_BTNUM_CNTi, XFS_BTNUM_BMAPi,
XFS_BTNUM_INOi, XFS_BTNUM_MAX
} xfs_btnum_t;- w pliku źródłowym fs/xfs/xfs_inum.h:
typedef struct xfs_agf
{
/*
* Nagłówek informacyjny grupy alokacji
*/
__uint32_t agf_magicnum; /* symbol nagłówka == XFS_AGF_MAGIC */
__uint32_t agf_versionnum; /* wersja nagłówka == XFS_AGF_VERSION */
xfs_agnumber_t agf_seqno; /* numer grupy alokacji */
xfs_agblock_t agf_length; /* rozmiar grupy alokacji w blokach */
/*
* Informacje o wolnej przestrzeni
*/
xfs_agblock_t agf_roots[XFS_BTNUM_AGF]; /* bloki, w których znajdują się
korzenie pary drzew wolnych obszarów */
__uint32_t agf_spare0;
__uint32_t agf_levels[XFS_BTNUM_AGF]; /* wartości kluczy określające
poziom drzew wolnych obszarów w odniesieniu
do pozostałych grup alokacji */
__uint32_t agf_spare1;
__uint32_t agf_flfirst; /* indeks pierwszego wolnego obszaru */
__uint32_t agf_fllast; /* indeks ostatniego wolnego obszaru */
__uint32_t agf_flcount; /* liczba bloków wszystkich wolnych ciągłości */
xfs_extlen_t agf_freeblks;/* liczba wszystkich wolnych bloków */
xfs_extlen_t agf_longest; /* rozmiar największego wolnego obszaru */
} xfs_agf_t;
i-węzły oprócz standardowych informacji, posiadają pole opisujące sposób przechowywania danych z pliku. Można to zrobić na trzy sposoby:
Tuż za grupami alokacji znajduje się obszar logów, czyli informacji o ostatnio wykonywanych transakcjach w ramach systemu plików. XFS rejestruje wszystkie zmiany dokonywane na metadanych, tzn. w superblokach, nagłówkach grup alokacji, drzewach wolnych obszarów, drzewach i-węzłów, w samych i-węzłach oraz zawartościach katalogów. Operacje tego typu są opakowywane w transakcje, będące ciągiem zmian w blokach systemu plików. Dzięki temu późniejsza naprawa uszkodzonego systemu plików nie polega na naprawie poszczególnych, złożonych struktur, lecz na dokończeniu ostatnio zaplanowanych zmian w blokach.
XFS umożliwia tworzenie logów na innym urządzeniu niż logowany system plików, co zwłaszcza przy synchronicznym trybie pracy może istotnie zwiększyć wydajność (synchroniczny tryb jest wymuszany np. przez NFS).
#define XLOG_MAX_RECORD_BSIZE (32*1024)
typedef __int64_t xfs_lsn_t; /* numer sekwencyjny logu */
typedef struct xlog_rec_header
{
uint h_magicno; /* symbol logu */
uint h_cycle; /* stan zapisu logu */
int h_version; /* wersja logu */
int h_len; /* rozmiar w bajtach */
xfs_lsn_t h_lsn; /* numer sekwencyjny logu */
xfs_lsn_t h_tail_lsn; /* numer sekwencyjny wcześniejszego,
niezatwierdzonego logu */
uint h_chksum;
int h_prev_block; /* względny numer bloku poprzedniego logu */
int h_num_logops; /* liczba logowanych operacji w ramach tego logu */
uint h_cycle_data[XLOG_MAX_RECORD_BSIZE / BBSIZE];
int h_fmt; /* format logu */
uuid_t h_fs_uuid; /* UUID systemu plików */
} xlog_rec_header_t;
W ramach XFS alokacja obszarów oraz zapis pliku odbywa w dwóch krokach. W pierwszym kroku po otrzymaniu danych do zapisania, umieszczane są one w buforze oraz rezerwana jest odpowiednia ilość miejsca na dysku. W tym momencie XFS nie decyduje jeszcze, dokładnie który obszar na dysku będzie użyty do przechowania danych. XFS odwleka decyzje na możliwie najpóźniejszy moment, tuż przed fizycznym zapisaniem danych na dysk
Opóźniając alokacje obszarów XFS zdobywa wiele możliwości na optymalne zapisywanie danych. Kiedy dochodzi do zapisania danych na dysk XFS może inteligentnie zaalokować wolną przesrzeń - w jednej ciągłej przestrzeni dysku. Niewątpliwą zaletą tego typu buforów plikowych/obszarów jest zmniejszenie fragmentacji zewnętrznej systemu plików, liczby operacji na metadanych oraz szybka obsługa plików tymczasowych (w skrajnym przypadku wcale nie muszą być zapisywane na urządzeniu blokowym).
Listy uprawnień w XFS'ie (Access Control List - ACL) są rozbudowane w stosunku do zwykłych Unix'owych praw dostępu. Oprócz zwykłych praw dla właściciela i grupy pliku można definiować odpowiednie uprawnienia dla każdej konkretnej osoby (grupy osób). Ma to szczególne znaczenie gdy nad danym plikiem ma pracować wiele osób, w żaden sposób nie powiązanych ze sobą.
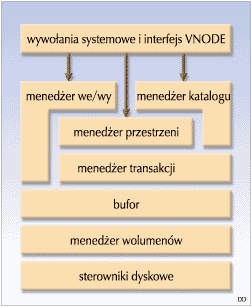
XFS ma architekturę modułową (schemat poniżej). Najważniejszym modułem jest menedżer przestrzeni (Space Manager), którego głównym zadaniem jest obsługa wszystkich obiektów w systemie plików, a zwłaszcza zarządzanie i-węzłami oraz wolnymi obszarami. Modułami pośredniczącymi pomiędzy VFS IRIX-a a menedżerem przestrzeni są menedżer wejścia/wyjścia (I/O Manager) oraz menedżer katalogów (Directory Manager). Pierwszy z nich zajmuje się całościową obsługą plików, a drugi - jak sama nazwa wskazuje - katalogów. Menedżer transakcji zarządza aktualizacją danych. Odpowiada również za operacje księgowania (journaling), które pozwalają na szybką naprawę systemu po awarii.
Ciekawostka: implementacja XFS'a zawiera ponad 50,000 linii kodu w C (styczeń 1996r.).