|
|
|
Tematem nimniejszego dokumentu są lokalne systemy plików. W dalszej części będziemy po kolei opisywać różne znane systemy plików. Nasze opisy nie dostarczą dość informacji, by napisać własną implementację, a jedynie by zrozumieć główne rozwiązania danego systemu. Pozwoli nam to ocenić różnice danych systemów, ich wady i zalety.
Przed twórcą systemu plików stoi wiele wyzwań:
Dwa pierwsze punkty dotyczą dodatkowych danych jakie będzą obsługiwane w danym systemie plików. Część z nich jest niezbędna samej implementacji, na przykład parametry dysku czy wielkości jednostek alokacji. Większość jednak potrzebna jest użytkownikowi. Słabości tej części są przyczynami wielu komplikacji w przyszłości. Przykładem może być problem z dostarczeniem długich do nazw plików w systemie „Windows 95” , lub brak list praw dostępu w „ext2”
W ewolucji systemów pliów daje się zauważyć zmiane warzności poszczgólnych cech systemu dla projektanta. Początkowo od wygody urzytkownika warzniejsza była prostota implementacji. Systemy optymalizowano by dostarczały jak najwięcej przestrzeni dla danych często kosztem wydajności. Z czasem jak nośniki stawały się tańsze daje się zauwarzyć wzrost nakładów na wydajność. Dopiero ostatnio twórcy są gotowi rezygnować z wydajność na korzyść bezpieczeństwa.
Z przedstawionych powyrzej zwgledów ocena jakości systemu pliku nie może być jednoznaczna. Jak zobaczymy dalej mniej wydajne systemy będą zwykle miały albo mniejszą fragmentacje wewnętrzna albo większe bezpieczeństwo.
Dalej bedziemy posługiwać się następującymi pojęciami:
- blok dyskowy
- Jednostka transmisji z urządzeniem blokowym
- klaster
- Grupa bloków dyskowych używana jako jednostka alkocji
„FAT” był jedynym systemem plików w systemie „DOS” . Podobno początkowo nie posiadał nawet podkatalogów. W miarę współczesny wygląd uzyskał dopiero w „DOS 2.0” .
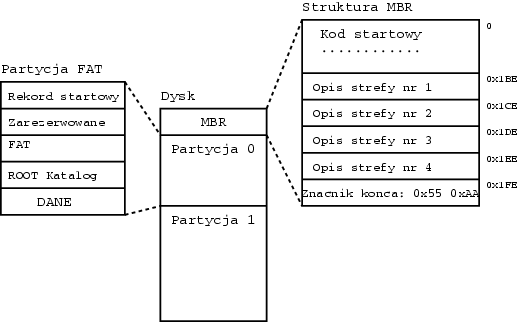
Dysk w systemie „DOS” podzielony jest na partycje. Przykład takiego podzału widać na rysunku 2.1.1. Pierwszy sektor dysku nazywa się „Master Boot Sector” w skrócie „MBR” . Pod koniec tego sektora znajduje się opis podziału dysku na strefy, tak zwana tablica partycji. Budowę tablicy partycji przedstawia tabela 2.1.2
| Wielkość | Bajty | Zawartość | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | Znacznik aktywności strefy. (0x00 = nieaktywna, 0x80 = aktywna) | ||||||||
| 1 | 1 | Początek strefy: numer głowicy | ||||||||
| 2 | 2-3 | Początek strefy: numer cylindra i sektora. Numer sektora koduje pierwsze 5 bitów. | ||||||||
| 1 | 4 | Rodzaj strefy. Kodowany jest tu rodzaj systemy
plików. Dla DOS są to:
|
||||||||
| 1 | 5 | Koniec strefy: numer głowicy. | ||||||||
| 2 | 6-7 | Koniec strefy: numer cylindra i sektora. Numer sektora koduje pierwsze 5 bitów. | ||||||||
| 4 | 8-11 | Początek strefy: adres liniowy liczony w sektorach od początku danego dysku logicznego. | ||||||||
| 4 | 12-15 | Wielkość partycji w sektorach. |
Strefa rozszerzona definiuje dysk logiczny. Strefa taka ma strukturę dokładnie taką samą jak dysk i posiada własną tablicę partycji.
Strefa z systemem plików zamiast tablicy partycji posiada rekord ładujacy, którego zawartość opisuje parametry dysku i strefy. (patrz tabela 2.1.3). Bajty 11-23 definują bloki parametrów BIOS (BPB).
| Wielkość | Bajty | Zawartość |
|---|---|---|
| 3 | 0-2 | Instrukcja skoku do początku programu ładującego |
| 8 | 3-10 | Nazwa systemu (w ASCII) |
| 2 | 11-12 | Wielkość sektorów w bajtach |
| 1 | 13 | Liczba sektorów w jednostce alokacji JAP |
| 2 | 14-15 | Liczba sektorów zarezerwowanych na początku dysku. Jest przesunięciem tablicy FAT w sektorach od początku dysku logicznego (zwykle 1). |
| 1 | 16 | Liczba kopii FAT |
| 2 | 17-18 | Maksymalna liczba plików w katalogu głównym |
| 2 | 19-20 | Całkowita liczba sektorów na dysku |
| 1 | 21 | Bajt identyfikacji nośnika |
| 2 | 22-23 | Liczba sektorów zajętych przez FAT |
| 2 | 24-25 | Liczba sektorów na ścieżce |
| 2 | 26-27 | Liczba głowic dysku |
| 2 | 28-29 | Liczba sektorów ukrytych |
Jednostką alokacji jest klaster, który składa się z całkowitej liczby bloków dyskowych.
„File Allocation Table” jest strukturą opisującą zarówno kolejność klastrów w plikach, jak i wolne klastry. Początkowo była to tablica liczb 12-bitowych, czyli dwa elementy mieściły się w dwóch bajtach. Później wraz ze wzrostem rozmiarów dysków wprowadzono tam liczby 16- i 32-bitowe.
Libczba znajdująca się w tablicy FAT12 miała następujące znaczenie:
| 0x000 | Indeks w tablicy jest numerem wolnego klastra |
| 0xFF7 | Dany klaster jest uszkodzony i nie powinien być alokowany |
| 0xFF8-0xFFF | Oznacza że dany klaster jest ostatnim klastrem pliku do którego należy |
| inny | Jest numerem następnego klastra pliku, do którego należy nasz blok. |
W wersji 16-bitowej 0x000 stało się 0x0000, 0xFF7 stało się 0xFFF7, idt. Analogicznie dla wersji 32-bitowej 0x000 stało się 0x00000000, 0xFF7 stało się 0xFFFFFFF7, 0xFF8 przeszło na 0xFFFFFFF8, itd.
Na rysunku 2.2.1 pokazany jest fragment przykładowego FAT. Zostały tam zaznaczone wpisy pliku zaczynającego się od klastra 0x025, a kończącego się na klastrze 0x023.
Fakty:
Katalog jest zwykłą tablicą rekordów zgodnych z tabelką. 2.3.1
| Wielkość | Bajty | Zawartość |
|---|---|---|
| 8 | 0-7 | Nazwa pliku |
| 3 | 8-10 | Rozszerzenie pliku |
| 1 | 11 | Atrybuty |
| 10 | 12-21 | Zarezerwowane |
| 2 | 22-23 | Czas utworzenia lub aktualizacji pliku |
| 2 | 24-25 | Data utworzenia lub aktualizacji pliku |
| 2 | 26-27 | Numer pierwszego klastra (JAP) |
| 4 | 28-31 | Wielkość |
Bity atrybutów:
- 0
- Plik tylko do odczytu (readonly)
- 1
- Plik ukryty (hidden)
- 2
- Plik systemowy
- 3
- Etykieta dysku
- 4
- Podkatalog
- 5
- Plik archiwizowalny
- 6,7
- Nie wykorzystywane
Pierwszy znak nazwy pliku ma szczególne znaczenie:
- 0x00
- Wpis pusty
- 0xE5
- Wpis skasowanego rekordu może być nadpisany przy tworzeniu nowego pliku
- 0x05
- Jako że 0xE5 jest dopuszczalnym znakiem nazwy pliku, to nie może wystąpić jawnie -- zamiast tego umieszczany jest kod 0x05
- 0x2E
- Jest to znak kropki, jeśli następnym bajtem jest też kropka, to jest to wpis wskaźnika do katalogu rodzica. Dla katologu głównego adres ten jest równy 0.
Wraz z pojawieniem się „Windows 95” , FAT zyskał długie nazwy plików. Odbyło się to przy zachowaniu kompatybilności z systemem DOS. Wykorzystano fakt, że nie wyświetla się wpisów etykiet dysku z wyjątkiem pierwszego takiego wpisu w katalogu głównym.
Własności wpisu długiej nazwy:
| Wielkość | Bajty | Zawartość |
|---|---|---|
| 1 | 0 | ID |
| 10 | 1-10 | 5 pierwszych znaków |
| 1 | 11 | Atrybuty = 0xFF |
| 1 | 12 | Zarezerwowane |
| 1 | 13 | Suma kontrolna krótkiej nazwy, której dotyczy ten opis. Jeśli program nie znający długich nazw dokona zmian, powinno to być wykryte. Nieaktualne wpisy powinny wtedy zostać anulowane. |
| 12 | 14-25 | 6 liter |
| 2 | 26-27 | Numer JAP. Powinno być 0 |
| 4 | 28-31 | 2 litery |
Jak widać w rekordzie może być maksymalnie 13 liter. Nie używane litery ustawia się na 0.
Dodatkowych wyjaśnień wymaga pole „ID” .
Budowa dysku jest bardzo prosta:
Bloki i-węzłów to tablica stałej wielkości rekordów opisujących i-węzeł. Przestrzeń ta ma stałą wielkość, czyli dana jest z góry określona maksymalna liczba plików. Ta zła własność została zachowana i chrakteryzuje również system „ext3” .
Jest bardzo prosta. Korzysta się tu ze zoptymalizowanego przeszukiwania liniowego. Ulepszenie polega na tym, że w superbloku znajduje się tablica numerów wolnych i-węzłów.







Zastosowany algorytm był wystarczająco wydajny. Alokacje i-węzłów są stosunkowo rzadkie w porównaniu z alokacjami bloków dyskowych. Kosztowna operacja uzupełniania listy wykonywana jest rzadko i w praktyce wykonuje się szybciej niż w pesymistycznym przypadku, ponieważ węzły alokowane w tym samym czasie zazwyczaj są również zwalniane w bliskich odcinkach czasu.
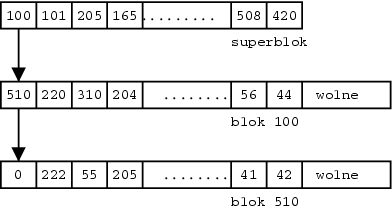
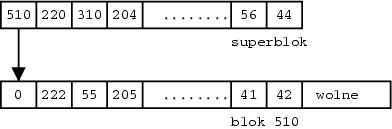
Do zarządzania wolnymi blokami używa się list wolnych bloków. Początek listy znajduje się w superbloku. Każdy węzeł listy zawiera tablice wolnych bloków ze wskaźnikiem na wolny blok zawierający następny węzeł.
Na przedstawionym przykładzie kolejne alokacje będą dawać bloki: 420, 508, ..., 165, 205, 101, 100, ...
Alokacja bloku 100 przebiega w spoób wyjątkowy, ponieważ blok ten jest następnikiem superbloku w liście i nie może być on natychmiastowo użyty. Najpierw jego zawartość zostaje przekopiowana w miejsce pustej tablicy w superbloku (patrz rysunek).
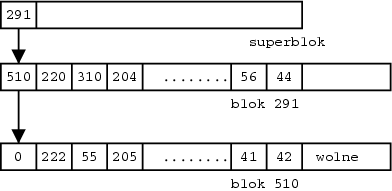
Zwalnianie bloku polega na dopisaniu bloku na koniec tablicy znajdującej się w superbloku. Jeśli tablica jest pełna i nastąpi zwolnienie bloku, powiedzmy numer 291, to zawartość superbloku zostanie skopiowana do bloku 291, a tablica wolnych bloków będzie posiadać teraz tylko jeden wpis 291.
Alokator ten jest stosunkowo szybki, ma jednak bardzo poważną wadę: bloki w liście nie są ułożone w żaden rozsądny sposób, przez co pliki ulegają wysokiej fragmentacji.
Adresowanie bloków w i-węźle przebiega przez strukture teblicową.
Standardowe bloki miały po 1kb.
„Linux” pisany był pod systemem „Minix” i początkowo jako swój system plików używał systemu z Minix-a. System ten jest podobny do SystemV. Podobnie jak on, ma z góry ustaloną liczbę i-węzłów. Dodatkowo nie posiada bloków potrójnie pośrednich, ponieważ bloki numerowane są liczbami 16-bitowymi, dzieki czemu w bloku pośrednim mieści się 512 adesów. Pozwala to zmniejszyć liczbę bloków adresujących.
| Blok ładujący | Superblok | Bitmapa i-węzłow | Bloki i-węzłów | Bitmapa bloków | Bloki danych |
Wprowadzanie map bitowych przyśpiesza alokację, ponieważ mapy są dostatecznie małe, by móc przechowywać je w pamięci. Mapy ułatwiają również walkę z fragmentacją.
Wpisy katalogowe były stałej wiekości, ustalonej z góry i zapisanej w superbloku.
Własności:
Implementacja Minix-a z jądra 1.0 rozpatrywała adresowanie takie, jak przy SystemV (32-bitowe adresowanie z odwołaniem potrójnie pośrednim).
Ograniczenia Minix-a spowodowały, że rozpoczęto prace nad jego modyfikacjami. Jedną z nich, choć nie jedyną, była implementacja systemu „ext2” , który rozwiązuje większość problemów z Minix-a. Posiada zmienną wielkość wpisu w strukturze katalogu, dzięki czemu nie występuje problem z długimi nazwami. Jedynym ograniczeniem jest to, że wpis musi się mieścić w pojedyńczym bloku dyskowym.
W opisie grupy znajdują się informacje o pozycjach dyskowych pozostałych elementów grupy.
Większość informacji o tym systemie plików była podana na wykładzie, dlatego nie będę tu przedstawiać więcej detali. Zamiast tego omówię niektóre rozszerzenia tego systemu.
Standardowa implementacja ext2 używa katalogów w postaci niezindeksowanej. Przez co koszt n wstawień do katalogu wynosi O(n^2)
Rozpoczęto, i zadaje się że nadal trwa, wiele projektów których celem jest dodanie B-drzew do ext2. Z dostępnych rozwiązań interesująca wydaje się implementacja indeksowanych katalogów wykonana przez Daniela Phillipsa.
Operacja wyszukiwania:
W praktyce kolizje zdarzają się wyjątkowo rzadko.
Operacja dodawania nazwy jest stosunkowo prosta. Najpierw znajduje się blok, w którym nazwa mogła by występować, zgodnie z tym co jest napisane powyżej. Jeśli w bloku jest wolne miejsce, to można od razu dodać nowy wpis.
Jeśli brakuje miejsca, trzeba wykonać podział bloku tak, jak ma to miejsce przy zwykłych B-drzewach.
ext2 z journalingiem nazywany jest ext3. W przciwieństwie do innych implementacji systemu plików z tranzakcjami oprócz journalingu metadanych posiada on możliwość logowania zmian bloków.
Szczegóły tego rozszerzenia są omówione w następnym rozdziale.
W rozdziale tym zostanie omówiona architektura systemu plików „ext3” . Zostaną omówione co ciekawsze detale szegóły z implementacji, których celem będzie nauczenie metod stosowania i implementacji „journalingu” we własnych aplikacjach.
Dyskusje zaczniemy od tego czym są transakcje. Sama koncepcja pochodzi z baz danych, w których ważne okazało się zachowanie spójności danych w trakcie złożonych operacji.
Często jako przykład użyteczności transakcji podaje się system bankowy. Na rysunku 4.1.1 podany został bardzo prosty przykład sytuacji gdy brak synchronizacji prowadzi do błędów.
| Wpłata $10 na konto | x1 | Wpłata $5 na konto | x2 |
|---|---|---|---|
| x1 := <zawartość konta $500> | $500 | ||
| x2 := <zawartość konta $500> | $500 | ||
| x1 := x1 + $10 | $510 | ||
| x2 := x2 + $5 | $505 | ||
| <konto> := x2 | $505 | ||
| <konto> := x1 | $510 |
Podstawowe własności transakcji to:
- Atomowość
- Transakcja wykonuje się w całości lub wcale.
- Spójność
- Po wykonaniu stan systemu spełnia więzy spójności. Dane tworzą poprawną całość.
- Izolacja
- Inne wykonywane transakcje nie mają wpływu na siebie.
- Trwałość
- Zatwierdzona transakcja zostanie wykonana na trwałe i jej wynik nie zostanie utracony.
Systemy plików są bardzo szczególnym rodzajem baz danych. Transakcje wykonywane w typowych systemach plików są łatwiejsze w implementacji niż w ogólnym bazodanowym przypadku.
Od systemu z transakcjami oczekujemy że po nagłej awarii i ponownym uruchomieniu system znajdzie się poprawnym z punktu widzenia jego budowy stanie. Oczekujemy że każda rozpoczęta transakcja albo będzie całkowicie zakończona albo całkowicie anulowana.
Na przykład gdy kasujemy plik mogą być wykonywane następujące operacje:
Teraz jeśli awaria nastąpi w punkcie 4 zanim zapiszemy blok ze zmniejszonym licznikiem. Na dysku będą znajdować się zaalokowane bloki do których nie będzie żadnej referencji. By móc stwierdzić że wartość licznika i i-węźle jest fałszywa trzeba przejrzeć wszystkie wpisy katalogowe. Gdyby awaria nastąpiła nastąpiła podczas zwalniania bloków, to by dokończyć tą operacje trzeba przejrzeć wszystkie struktury indeksowe. Tym samym widać że w standardowym systemie plików start systemu po awarii łączy się z pełną rekonstrukcją wszystkich metadanych.
Głównym celem wprowadzenia journalingu jest uzyskanie atomowości tego typu operacji.
Systemy plików charakteryzują następujące własności:
W systemie „ext3” podstawową operacją jest zapis bloku. Pojedyncza transakcje jest tu sekwencją operacji zapisu określonych danych w określonym miejscu. Takie podejście powoduje że:
Ostatni punkt jest bardzo ważną i wydajną optymalizacją.
Obsługa journalingu została wyjęta do oddzielnego modułu Journaling Block Device (JBD).
- Punkt kontrolny
- Tranaskcje są łączone w grupy. Zmknięcie grupy nazywany punktem kontrolnym
- Deskryptor punktu kontrolnego
- Opis, w logu, operacji jakie należy wykonać by system plików osiągnoł punkt kontrolny. By wykonać te operacje trzeba jeszcze mieć zawartość bloków danych.
- journal_t
- Opisuje całkowity stan danego logu. Zarządza rozmieszczeniem deskryptorów transakcji w logu, oraz synchronizacją z dyskiem.
- handle_t
- Znacznik tworzonej transakcji. Operacje wykonywane zostaną wykonane w całości lub wcale. Mogą się one wykonać tylko wtedy gdy operacje starszych znaczników też zostały wykonane.
Funkcje te zakładają log odpowiednio na: spójnym obszarze urządzenia blokowego, w podanym i-węźle
Zapisuje wszystkie dane do logu i na dysk. Używane przy przemontowywaniu w tryb tylko do odczytu.
Blokuje wszystkie przyszłe tranzakcje w chwili rozpoczęcia. Blokuje do chwili aż aktualnie trwające tranzakcje się nie zakończą.
Zdejmuje blokadę na nowe tranzakcje
Tworzy nowy log.
Inicjuje struktury danych dla istniejącego już logu
Zwalnia strukturę. Przeciwieństwo „init”
Wznawia log po awarii. Najpierw znajduje się deskryptor transakcji o najnowszym numerze. Następnie
Rozpoczyna nową tranzakcje. Wartość „nblocks” określa ile maksymalnie bloków będzie modyfikować. Funkcja „journal_start” czeka aż w logu będzie dostatecznie dużo wolnego miejsca
Pozwala w tym samym znaczniku otworzyć nową tranzakcje
Próbuje zwiększyć maksymalną liczbe modyfikowanych bloków. Ponieważ nie ma anulowania transakcji trzeba sobie poradzić nawet wtedy gdyby zwiększenie byłoby niemożliwe
Poinformowanie że będziemy pisać do danego bufora. Zgodnie z tym co było mówione jeśli ta tranzakcje łączona jest z inną nie trzeba nic robić. Natomiast jeśli rozpoczęto zapis lub realizacje transakcji z użyciem danego bufora to trzeba wykonać kopie roboczą.
Poinformowanie o dostępie do nowego bloku. Sprawdza się czy bufor jest używany przez inną tranzakcje (to się nie powinno zdarzyć).
Poinformowanie o zwolnieniu bufora. Dzieki temu nie trzba trzymać jego kopii.
Dodanie do transakcji operacji modyfikacji bloku. Podczas zapisu bufor zostanie umieszczony w logu. „Linux” pozwala na efektywne zpisywanie bufora w innym miejscu niż docelowe. Robi się to tworząć nowy nagłówek bufora z innym adresem ale tym samym wskaźnikiem do danych.
To co wyżej tylko dla metadanych. „ext3” może pracować w różnych trybach. Journaling danych jest opcjonalny, efektywniej jest zapisywać tylko metadane. Jest ich mniej więc tranzakcje na nich lepiej się łączą w gupy.
Zamknięcie tranzakcji. Nie jest ona wykonywana natychmiast (może że jest ustawiony tryb synchroniczny), przez co może być łączona z kolejną.
Celem jest zsynchronizowanie listy operacji z logiem. Funkcja wołana jest z demona synchronizującego „kjournald”
Później funkcja „log_do_checkpoint” może nas doprowadzić do stanu w którym bufory znajdą się we właściwych miejscach. Działanie polega na wykonywani operacji z listy.
By zakończyć transakcje trzeba przejść następujące etapy: