| 1. | Rzut oka na najważniejsze cechy AFS. | |
| 2. | AFS - szczegóły | |
| 3. | W ramach podsumowania - porównanie AFS z NFS | |
| 4. | AFS dziś. Od AFS do DFS - czyli o historii |
Każdy komputer może być albo klientem, albo serwerem, ale nigdy nie pełni obu funkcji jednocześnie. Oprogramowanie systemu AFS składa się z dwóch części: oprogramowania serwera i oprogramowania klienckiego. Każda z tych części działa jako proces poziomu użytkownika systemu UNIX. Proces-serwer nosi nazwę Vice. Proces-klient to Venus.
Wszystkie komputery pogrupowane są w klastry (ang. cell ). Na każdy klaster składa się kilka serwerów (musi być co najmniej jeden w klastrze) i ileś stacji roboczych (klientów AFS). Komputer może w danym momencie należeć tylko do jednego klastra. Klient może sięgać do plików umieszczonych na dowolnym serwerze, ale podział na klastry umożliwia szybszy dostęp do plików na serwerach zlokalizowanych w tym samym klastrze, co stacja robocza klienta. Dlatego z reguły konfiguruje się system tak, by pliki, których dany użytkownik potrzebuje najczęściej (np. jego katalog domowy), znalazły się na serwerze w tej samej części systemu, gdzie ów użytkownik przeważnie korzysta ze stacji roboczych. Można to robić podczas działania systemu (por. przezroczystość wędrówki).
Pierwotnie wszystkie serwery i stacje robocze działały pod nadzorem systemów operacyjnych UNIX 4.3 BSD lub Mach.
Procesy Vice i Venus zrealizowane były jako pakiet
niewywłaszczalnych wątków. Jądro systemu operacyjnego UNIX nieznacznie
zmodyfikowano: W początkowych implementacjach systemu AFS po prosu tak,
by wykrywać odwołania do plików współdzielonych i przekazywać je do
Venus (dzięki temu uzyskuje się
przezroczystość dostępu).
Późniejsze wersje AFS mogą
działć pod nadzorem również innych systemów operacyjnych. Od AFS v3.0
jądro klienta zawiera zarządcę pamięci podręcznej
(ang. Cache Manager), który
posługuje się interfejsem identyfikatorów plików
(w AFS zwanych też v-węzłami) - dzięki temu Vice nie musi
zajmować się stanem klienta, co byłoby konieczne przy używaniu
tradycyjnych deskryptorów plików. Zarządca pamięci podręcznej zastąpił
proces Venus i zrealizowany jest już nie jako proces użytkownika, ale
moduł jądra systemu operacyjnego. Oprogramowanie serwera zostało
podzielone na kilka procesów, m.in.
- serwer plików (File Serwer)
- najbardziej podstawowy z serwerów,
- monitor systemu (Basic OverSeer
Serwer) - nadzorujący pracę pozostałych procesów-serwerów,
- serwer autentykacji,
- serwer ochrony dostępu (Protection Server) - zarządzający Listami Kontroli Dostępu (ACL).
- serwer woluminów (Volume Serwer)
- wspiera administratorów w zarządzaniu
woluminami.
- serwer lokalizacji woluminów (Volume
Location Server), zarządzający bazą danych położenia
woluminów.
- serwer kopii zapasowych (Backup Server).
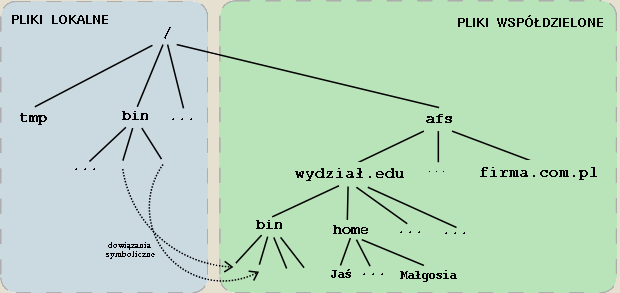
Procesy użytkowe, działające na stacji roboczej (komputerze-kliencie systemu AFS) mogą korzystać z plików lokalnych oraz współdzielonych. Wszystkie pliki współdzielone widziane są po stronie klienta jako znajdujące się w jednym poddrzewie lokalnej hierarchii plików. Katalogiem, w którym stacja robocza montuje hierarchię plików współdzielonych jest zazwyczaj /afs . Z lokalnych katalogów mogą prowadzić dowiązania symboliczne do plików z pamięci dzielonej. (Tak implementowane są niektóre standardowe pliki systemu UNIX, np. znajdujące się w katalogach /bin, /lib itp.) Pliki lokalne to przeważnie tylko pliki systemowe niezbędne do działania stacji roboczej oraz te pliki, które użytkownik chce z jakichś względów przechowywać lokalnie.
Rys.
Przestrzeń nazw plików widziana przez użytkownika.
Użytkownikom udostępniona jest jednolita przestrzeń nazw plików współdzielonych - na każdej stacji roboczej wygląda ona tak samo, a użytkownik potrzebuje znać tylko nazwę ściekową pliku, a nie jego lokalizację. AFS zapewnia zatem przezroczystość położenia plików współdzielonych. (Co prawda podział przestrzeni nazw na komputerze-kliencie na pliki lokalne i współdzielone powoduje pewną utratę przezroczystości położenia, ale tylko w zakresie podziału na pliki lokalne i współdzielone.)
Według przyjętej konwencji nazwa ścieżkowa pliku zaczyna się od
/afs/<nazwa_klastra>/... . (Nazwa klastra jest z reguły
podobna do nazwy domeny internetowej.)
Pliki współdzielone są pogrupowane w woluminy (ang. volumens). Ułatwia to ich lokalizację (o czym za chwilę) i przemieszczanie (którego dokonuje się np. w celu równoważenia obciążenia). Wolumin zawiera poddrzewo plików i katalogów z hierarchii plików współdzielonych. Np. katalog domowy jednego użytkownika jest zazwyczaj przechowywany w osobnym woluminie. Rozmiar każdego woluminu jest ograniczony (quota) przez administratora systemu.
Nazwa ścieżkowa pliku jest analizowana po stronie klienta - zapobiega to przeciążeniu serwera, co jest ważne, jeśli system ma być skalowalny. Procesy Venus tłumaczą nazwy ścieżek podane przez procesy użytkownika na identyfikatory fid , które służą do identyfikowania plików w komunikacji między procesami Vice i Venus. Identyfikatory fid mają budowę podobną do uchwytów plików w NFS: 32-bitowy identyfikator woluminu, 32-bitowy numer v-węzła, 32-bitowy numer pokolenia v-wezła. (Numer v-węzła jest po prostu numerem i-węzła na liście i-węzłów woluminu).
Jak Venus tłumaczy ścieżkę pliku na jego fid : Baza danych położenia woluminów
odwzorowuje identyfikatory woluminów na ich fizyczne położenie (by
dostęp do tej bazy nie stał się wąskim gardłem, jest ona powielana na
każdym serwerze.) Klient w swojej pamięci podręcznej przechowuje
dowiązania symboliczne, katalogi i pozycje z bazy danych położenia
woluminów. Nazwa ścieżkowa jest analizowana po jednej składowej.
Venus w pierwszej kolejności korzysta z danych zapisanych w swojej
pamięci podręcznej. Dopiero jeśli tam nie ma potrzebnego katalogu, to
ściąga go (w całości) z serwera (i zapamiętuje na przyszłość w pamięci
podręcznej).
Z odnajdowaniem woluminów jest podobnie. Z tym, że o ile informacje o
katalogach są aktualizowane jak wszystkie dane w pamięci podręcznej
(poprzez mechanizm powiadomień), więc powinny być aktualne, o tyle
pozycje z bazy danych woluminów zapisane w swojej pamięci podręcznej,
klient traktuje tylko jako podpowiedzi. Jeśli położenie wolumenu
zmieniło się, to serwer odrzuci zlecenie. Wtedy klient pyta bazę danych
na serwerze o aktualne położenie.
Niestety taki sposób tłumaczenia ścieżki pliku powoduje, że klient
musi znać format zapisu katalogu na serwerze.
Dzięki bazom danych położenia woluminów, powyższy mechanizm zapewnia nie tylko - wspomnianą już - przezroczystość położenia, ale i niezależność położenia (przy zmianie fizycznego położenia wolumenu, jego nazwa nie zmienia się) oraz przezroczystość wędrówki (można przenosić woluminy podczas działania systemu). Mianowicie, jeśli wolumin został przeniesiony, a najbliższy serwer jeszcze nie ma w swojej bazie aktualnionej informacji na ten temat, to klient sięga do starej lokalizacji woluminu. Jednak tamten serwer ma już informacje o nowej lokalizacji i wie, gdzie przekazać zlecenie. Przenoszenie woluminów wymaga zatem zmian tylko w bazach danych po stronie serwerów (nie wymaga żadnego konfigurowania po stronie klientów!).
By umożliwić dobrą skalowalność
systemu AFS, zadbano o zmniejszenie generowanego przez niego ruchu w
sieci i obciążenia serwerów. W tym celu zastosowano protokół stanowy i
duże pamięci podręcznie po stronie klienta.
Mechanizm współdzielenia plików zaprojektowano biorąc pod uwagę cechy typowych zleceń dostępu do plików:
- typowe pliki są małe,
- dostęp do pliku jest z reguły sekwencyjny,
- operacje czytania plików są znacznie częstsze niż operacje pisania,
- większość plików jest zapisywanych tylko przez jednego użytkownika,
- odwołania do plików są skumulowane, tzn. jeśli odwołanie do pliku
nastąpiło niedawno, to z dużym prawdopodobieństwem w najbliższym czasie
znów nastąpi odwołanie do tego pliku.
Komputer klienta przechowuje na swoim dysku kopie plików, z których korzysta klient. Proces Venus zarządza tą pamięcią podręczną - gdy potrzebne jest zwolnienie miejsce na kolejny plik ściągany z serwera, Venus usuwa z dysku pliki nie używane od najdłuższego czasu (czyli zgodnie z zasadą LRU). Kiedy w pamięci znajdą się wszystkie pliki aktualnie używane przez klienta, staje się ona w dużym stopniu niezależna od serwerów, a ruch sieciowy i obciążenie serwera bardzo się zmniejszają.
W celu zoptymalizowania korzystania z sieci, w AFS transmisje plików są masowe : W pierwotnej implementacji systemu pliki były przesyłane miedzy serwerami i klientami (oraz zapisywane na dysku klienta) w całości. W przypadku bardzo dużych plików było to jednak niepraktyczne, więc w wersji 3.0 pliki są przesyłane i zapisywane w pamięci podręcznej w 64-kilobajtowych porcjach.
WAŻNE : Spójność pamięci podręcznych utrzymywane jest poprzez mechanizm zawiadomień (callback):Do pliku wysyłanego do klienta, serwer (proces Vice) załącza znacznik zwany obietnicą zawiadomienia (ang. callback). Venus zapisuje ten znacznik na dysku klienta, podobnie jak sam plik. Znacznik ten oznacza, że gdy główna kopia pliku, znajdująca się na serwerze, zmieni się, to serwer zawiadomi tego klienta o tym fakcie. Nazywa się to złamaniem obietnicy. Zawiadomienie polega na wywołaniu przez Vice zdalnej procedury w procesie Venus.
Znacznik obietnicy powiadomienia może mieć jedną z dwóch wartości:
ważny albo nieważny. W momencie otrzymywania pliku od serwera jest
ważny. Gdy klient otrzymuje od serwera zawiadomienie, to ustawia
znacznik na nieważny. Jednak w tym momencie nie ściąga aktualnej kopii z
serwera - zrobi to później i tylko pod warunkiem, że zajdzie taka
potrzeba, tzn. jakiś proces użytkownika będzie potrzebował tego pliku.
Poniższa tabela opisuje korzystanie ze znacznika ważności kopii
lokalnej u klienta, podczas realizacji odwołań do plików w systemie AFS.
| Proces użytkownika |
Jądro
systemu operacyjnago |
Klient (proces Venus ) |
Sieć |
Serwer
(proces Vice) |
||
|
|
||||||
| open() |
Jeśli nazwa
otwieranego pliku odnosi się do pliku współdzielonego, to przekazuje
zlecenie do procesu Venus. |
|
|
|
||
| Jeśli pliku nie ma w pamięci podręcznej lub jego znacznik jest nieważny, to zamawia plik u tego serwara Vice, który jest opiekunem woluminu zawierającego ten plik. | -> | |||||
| Przesyła do klienta plik wraz z obietnicą powiadomienia. Rejestruje u siebie tę obietnicę powiadomienia. | ||||||
| Zapisuje kopię pliku w pamięci podręcznej na lokalnym dysku i umieszcza ją w lokalnym systemie plików. Znacznik pliku jest ważny. | <- | |||||
| Otwiera plik lokalny i zwraca jego deskryptor do programu użytkowego. | ||||||
|
|
||||||
| read() |
Wykonuje zwykłą
uniksową operację czytania z kopii lokalnej. |
|||||
|
|
||||||
| write() |
Wykonuje zwykłą
uniksową operację pisania do kopii lokalnej. |
|||||
|
|
||||||
| close() |
Zamyka kopię
lokalną i powiadamia Venus o zamknięciu pliku. |
|
|
|
||
| Jeśli kopia lokalna została zmieniona, to wysyła kopię do tego serwera Vice, który jest opiekunem woluminu tego pliku. | -> | |||||
| Zastępuje plik przesłanymi danymi. Wysyła zawiadomienia do wszystkich innych klientów, mających obietnicę zawiadomienia o tym pliku. | ||||||
| Procesy Venus, które otrzymały powiadomienia (czyli to już inni klienci, niż ten, który wykonywał close() ) ustawiają znaczniki kopii tego pliku w swoich pamięciach podręcznych na nieważny. | <- | |||||
|
|
||||||
Z powyższego schematu widać, że semantyka aktualizacji w AFS (w
wersji 2.0) jest semantyką sesji (open-to-close): Operacje
zapewniające spójność pamięci podręcznych wykonywane są tylko w momencie
otwierania i zamykania pliku (plik współdzielony z ziarnistością funkcji
systemowych open() i close(), a nie read() i write(), jak w systemie Unix).
Posługiwanie się semantyką sesji należy zaliczyć do wad systemu AFS,
ponieważ programy użytkownika operują na plikach współdzielonych tak,
jak na lokalnych; czyli przeważnie tak, jakby była zapewniona semantyka
uniksowa. Tymczasem semantyka sesji
mocno różni się od semantyki uniksowej. Np. w AFS klient może nie
móc uaktualnić pliku z powodu awarii serwera, sieci lub rzeczywistych
błędów, takich jak zapelnienie dysku. Przez to na plikach
współdzielonych funkcja close()
kończy się błędem częściej niż na plikach lokalnych (program użytkownika
z regóły nie sprawdza jej wyniku i nie podejmuje działań korygujących),
a funkcja write() kończy
się powodzeniem nieraz również wtedy, gdy nie powinna.
Zdażają się sytuacje, gdy zawiadomienie o zmianie pliku z
jakichś powodów nie dotarło. Venus musi starać się wykrywać takie
sytuacje:
Ze względu na możliwość pominięcia zawiadomienia (np. w wyniku
awarii sieci) w momencie otwierania pliku klient dysponuje aktualną
wersja pliku lub przestarzałą co najwyżej o czas T.
By realizować mechanizm zawiadomień, serwer musi przechowywać pewne
dane na temat klientów i plików znajdujacych się w ich pamięciach
podręcznych, co do których wysłał obietnice zawiadomienia. Tym samym AFS
jest protokołem
stanowym.
Każdej grupie lub użytkownikowi można nadawać prawa normalne i negatywne. Dany użytkownik ma określone prawo (powiedzmy r) do danego katalogu, jeśli: ma przyznane pozytywne prawo r jako pojedynczy użytkownik lub należy do przynajmniej jednej z grup posiadających pozytywne prawo r, a ponadto użytkownik ten nie ma nadanego negatywnego prawa r ani nie należy do żadnej z grup posiadających negatywna prawo r do tegoż katalogu.
Ponadto
pozostawiono także standardowe bity praw uniksowych. Jednak spośród
nich tylko prawa właściciela mają jakiekolwiek znaczenie: by dany plik
mógł być w ogóle przez kogokolwiek czytany, zapisywany lub wykonywany
muszą być ustawione uniksowe prawa dla właściciela odpowiednio r,w
lub x. Użytkownik musi pomyślnie przejść przez oba testy
(prawa ACL i prawa uniksowe).
W AFS sprawdzanie, że użytkownik jest rzeczywiście tym, za kogo się
podaje, jest realizowane przez mechanizmy znane pod nazwa Kerberos. (Jest to system stworzony przez MIT,
ale Transarc zaimplementował własną wersję, opartą o MIT Kerberos V4,
który wówczas nie był jeszcze publicznie dostępny.) W rzeczywistości
Kerberos zapewnia zabezpieczenia takie jak przesyłane przez sieć
zaszyfrowane hasło, ale bez potrzeby wpisywania hasła co chwila.
Ogólnie mówiąc działa to tak: Stosowana jest dwustronna autentykacja (ang. mutual authentication - i
klient, i serwer potwierdzają swoją tożsamość) za pomocą metody
współdzielonego sekretu. W tym celu (tuż po zalogowaniu się użytkownika
do systemu AFS za pomocą swojego hasła lub później, na prośbę
użytkownika) serwer autentykacji
(trzecia zaufana strona) wydaje klientowi token, zawierający m.in.
zaszyfrowany bilet serwera
plików (ticket) i klucz
sesyjny. Dane te służą następnie klientowi i serwerowi do wzajemnego
potwierdzenia tożsamości, poprzez protokół przesyłania odpowiednich
szyfrowanych informacji.
| AFS
v3 |
NFS
v3 |
|
| Architektura |
Architektura
klient-serwer. Komputery tworzą logiczną jednostkę - klaster. |
Architektura klient-serwer.
Każdy komputer jest niezależny od pozostałych. |
| Zarządzanie
zbiorem plików - woluminem. |
Zarządzanie każdym z plików
osobno. |
|
| Jednolita przestrzeń nazw widoczna tak samo
dla wszystkich komputerów. |
Przestrzeń nazw może być
widoczna inaczej dla różnych komputerów. |
|
| Analiza
nazwy ścieżkowej po stronie klienta(bardziej przerzucona na klienta niż
w NFS). Klient musi znać format zapisu katalogu na serwerze. |
Analiza nazwy ścieżkowej po stronie klienta. Klient nie musi znać formatu zapisu katalogu na serwerze. | |
| Automatyczna
lokalizacja położenia plików przez procesy systemowe. Uaktualnianie baz danych położenia woluminów
- znajdujacych się serwerach. |
Lokalizacja położenia plików
zależna od punktu zamontowania ustalanego przez administratora
komputera. |
|
| Serwery stanowe. |
Serwery bezstanowe. |
|
| Utrzymywanie
spójności pamięci podręcznych oparte o mechanizm zawiadomień. |
Utrzymywanie spójności pamięci podręcznych oparte o mechanizm znaczników czasowych. | |
| Wydajność |
Odporny na błędy system dyskowej pamięci podręcznej zmniejsza obciążenie serwerów i sieci. | Mała pamięć podręczna utrzymywana w pamięci. |
| Mechanizm zawiadomień gwarantuje spójność pamięci podręcznej. Semantyka open-to-close. Atrybuty plików są przechowywane w pamięci podręcznej przez kilka godzin. | Pamięć podręczna jest aktywnie
odświeżana co jakiś czas - możliwe jest powstanie niespójności w
zawartości plików. Atrybuty plików są przechowywane w pamięci podręcznej przeważnie do 60 sekund. |
|
| Ruch sieciowy
jest zmniejszony poprzez wykorzystanie mechanizmu zawiadomień
i wysyłanie dużych porcji danych. |
Dosyć duży ruch sieciowy
spowodowany małą wielkością pamięci podręcznych i ich aktualizacją. |
|
| Replikowanie plików (tworzenie kopii "tylko do odczytu") pomiędzy kilka serwerów w celu zrównoważenia obciążenia serwerów. Ale: administrator musi ręcznie wydawać polecenie uaktualnienia kopii, gdy główna kopia się zmieni! (Dlatego w ten sposób warto replikować tylko pliki rzeczywiście często używane i rzadko zmieniane.) | Brak replikowania plików w celu
obniżenia obciążenia serwerów. |
|
| Skalowalność - utrzymuje dobrą wydajność w instalacjach dowolnych rozmiarów, w sieciach lokalnych i rozległych. Choć dostęp do plików współdzielonych jest wolniejszy niż do lokalnych. | Najlepsza w małych i średnich instalacjach. Bardzo niewydajny w przypadkach sieci rozległych, choć wydajniejszy od AFS w małych instalacjach przy niewielkim obciążeniu. | |
| Odporność na awarie |
Replikacja
plików w obrębie wolumenu w trybie "tylko do odczytu". Automatyczne
przełączenie na dostępną replikę pliku w przypadku niedostępności
bieżącej kopii. |
Brak replikacji plików. |
| Pliki pozostają dostępne dla użytkowników w czasie rekonfiguracji (przezroczystość wędrówki). Zmiana położenia plików nie zmienia ich nazw i nie trzeba przy tym nic konfigurować po stronie klienta (niezależność położenia). | Użytkownicy tracą dostęp do plików w czasie rekonfiguracji. Zmiana położenia pliku wymaga zmiany punktu zamontowania po stronie klienta. | |
| W
protokole stanowym trudniej jest usuwać skutki awarii. |
Protokół bezstanowy, więc
usuwanie skutków awarii łatwiejsze. |
|
| Administracja | Zarządzanie
systemem z dowolnego komputera. |
Zarządzanie serwerem wymaga zalogowania się na niego. |
| Kwota zasobów dyskowych ustalana jest dla woluminów. | Kwota zasobów dyskowych ustalana jest dla użytkowników. | |
| Wykonanie kopii zapasowej systemu nie
wymaga zablokowania dostępu do plików. Wykorzystywany jest
specjalizowany AFS Backup System. |
Kopia zapasowa wykonywana jest przy użyciu standardowych narzędzi UNIXa i wymaga zablokowania dostępu do archiwowanych plików. | |
| Odtworzenie
plików z kopii zapasowej jest łatwo dostępne dla użytkowników. |
Tylko administrator może
odtworzyć pliki z kopii zapasowej. |
|
| Bezpieczeństwo |
Autentykacja
oparta jest na systemie Kerberos. |
Autentykacja oparta jest na
identyfikatorze użytkownika i adresie IP jego komputera. Można dodać
obsługę systemu Kerberos. |
| Prawa dostępu do katalogów kontrolowane są przez rozbudowane listy kontroli dostępu. Pozostawiono uniksowe prawa dostępu, ale mają one nieco inne znaczenie. | Prawa dostępu do plików i
katalogów kontrolowane są przez standardowe uniksowe bitowe prawa
dostępu. |
|
| Użytkownicy
mogą definiować własne grupy i nadawać im prawa dostępu. |
Grupy z określonymi prawami
dostępu są definiowane przez administratora. |
|
| Dwustronna
autentykacja serwerów i klientów. Secure
RPC jest zawsze używane do przesyłania przez sieć. |
Secure RPC może być użyte do
przesyłania przez sieć. |
|
| Koszt |
Wyższy niż w
przypadku NFS. Potrzebny jest administrator, dużo pamięci. |
Koszt stosunkowo niski. |
| Złożoność |
Bardziej
złożony. |
Prosty. Łatwy do zrozumienia.
Łatwiejszy do zaimplementowania. |
Andrew File System był rozwijany w Carnegie Mellon University (CMU) od 1984 roku. Celem było udostępnienie uniwersyteckiemu kampusowi rozproszonego systemu plików, w którym byłyby przechowywane katalogi domowe i który działałby efektywnie nawet przy niskiej przepustowości sieci komputerowej kampusu. (Andrew File System był rozproszonym systemem plików dla systemu Andrew - rozproszonego serwisu komputerowego kampusu Carnegie Mellon. Andrew to imię fundatora tego uniwersytetu.) Na wersji 2.0 Andrew File System bazuje rozproszony system plików CODA, który również powstał na CMU.
W 1989 roku (po wypuszczeniu wersji 3.0) z zespołu rozwijającego
Andrew File System powstaje Transarc Corporation ,
by przekształcić ten system w produkt komercyjny. Firma ta zmieniła
nazwę systemu na AFS. Firma Transarc stała
się w roku 1999 częścią IBM, a rozwijaniem AFS zajęły się IBM Pittsburgh
Labs.
Wersje AFS rozwijane przez IBM
(jak AFS v3.6, czy jego następca OpenAFS, który jest oferowany jako
"open source") działają pod nadzorem odpowiednich wersji różnorodnych
systemów operacyjnych - m.in. AIX, Solaris, HP-UX, Digital Unix, Linux,
MS Windows, MacOs X.
Open Software Foundation (OSF) w 1990 roku wybrała AFS firmy Transarc jako rozproszony system plików (Distributed File System - DFS) dla swojego rozproszonego środowiska obliczeń (Distributed Computing Environment - DCE). (Obecnie używany w kampusie Carnegie Mellon rozproszony serwis komputerowy Andrew II jest oparty właśnie na OSF DCE/DFS, zamiast na Andrew File System)
IBM DCE (rozproszone środowisko
obliczeń firmy IBM) oparte jest o technologie wybrane przez OSF. Zatem
IBM DCE/DFS bazuje na AFS v3, choć dodaje sporo własnej funkcjonalności
(przede wszystkim lepsze gwarancje spójności pamięci podręcznych i
semantykę współdzielenia plików bardziej podobną do uniksowej). IBM DCE
zostało przyjęte jako przemysłowy standard usług rozproszonych.