Systemy
plików z kroniką
Autor: Błażej Piechna
Spis treści:
Bibliografia i gdzie szukać więcej informacji:
Journaling
Journaling(kronikowanie) jest to funkcja systemów plików polegająca na prowadzeniu dziennika (journal), w którym zapisywane są operacje zlecone systemowi plików ale jeszcze nie zakończone (transakcje). Czyli jest to mechanizm podobny do stosowanego w bazach danych.
Operacje zapisu, tworzenia lub usuwania plików lub katalogów nie są atomowe. System plików musi przechowywać oprócz danych zapisywanych w plikach, także dane o samej strukturze plików i strukturze systemu plików (tzw. metadane). Stąd biorą się problemy ze spójnością podczas awarii systemu, gdy nastąpi ona między operacjami na metadanych i operacjami na danych (w trakcie jednej operacji np. zapisu).
Transakcje zapewniają zapis takiej jednej operacji dyskowej (zapisu, tworzenia lub usuwania pliku (katalogu)) do dziennika jako operacji atomowej. Jest ona zapisywana w całości i tylko jeśli wszystkie jej kroki przejdą pomyślnie może zostać uznana za wykonaną.
W momencie uruchomienia systemu po awarii wszystkie operacje w całości zapamiętane w dzienniku są wykonywane, a te które nie są zapisane w całości są wymazywane z dziennika i ignorowane (na pewno nie zostały nawet rozpoczęte na dysku).
W przypadku systemów plików bez dziennika aby przywrócić porządek po nagłej awarii, trzeba uruchamiać specjalny program poprawiający błędne wpisy. W systemie ext2 jest to automatycznie uruchamiany program fsck, który przy dużej powierzchni dysków może działać długo, ale bez niego w przypadku pozostawienia błędów w strukturze plików będą się one propagować aż cała partycja może nie nadawać się do użytku.
Przykładowe błędy to:
- wycieki wolnego miejsca (po przerwanej alokacji nowych bloków lub przy usuwaniu pliku został on już skasowany ale jego bloki nie są jeszcze zaznaczone jako usunięte)
- złe dane o wolnym miejscu w grupie (np. w Ext3 źle działał będzie algorytm przydzielania wolnego miejsca)
- plik1 ma wpisy pośrednie mogące pokazywać na bloki, których system już nie zdążył zająć przed awarią, następnie plik2 je zajmuje, a my teraz zwalniamy plik1 i plik2 traci dane!
System plików z kroniką po restarcie zwykle przywraca spójność dysku w czasie rzędu kilku, kilkunastu sekund.
Restart systemu po awarii w systemach z kronikowaniem nie zależy od wielkości partycji, co jest szczególnie istotne w przypadku wielkich dysków.
Rozróżniamy dwa podstawowe typy kronikowania:
- tylko metadanych (zapewnia spójność metadanych, ale może nie pamiętać ostatnio wpisanych danych tuż przed awarią)
- metadanych i danych (odtworzy wszystko co zostało w całości wprowadzone do dziennika)
Nowoczesne systemy plików z kronikowaniem, o których będzie mowa to:
-
Ext3
-
ReiserFS
-
JFS
-
XFS
Ext3
System plików Ext3 jest to Ext2 z dodanym kronikowaniem. Zgodność jest bardzo duża i umożliwia wymienne montowanie partycji Ext2 pod Ext3 i odwrotnie. Ext3 udostępnia plik dziennika w głównym katalogu partycji. W nowszych wersjach Ext3 jest możliwe aby plik ten był przechowywany na innym dysku komputera.
Journaling jest dostępny przez Journaling Block Device (JBD), jest to moduł napisany w taki sposób aby umożliwić kronikowanie nie tylko dla systemu Ext3.
Do dziennika zapisuje się całe zmienione bloki, w przeciwieństwie do innych systemów plików z kronikowaniem, gdzie najczęściej zapisuje się tylko różnice pomiędzy zapisywanym a istniejącym na dysku blokiem.
Ext3 umożliwia wybór jednego z trzech sposobów journalingu:
· samych metadanych (writeback)
·
metadanych i danych (journal)
· samych metadanych ale z uprzednim zapisywaniem danych (zwany ordered, jest to sposób domyślny)
Tryb writeback:
Zapisywanie w dzienniku tylko metadanych jest czasem niewystarczające aby utrzymać spójność w systemie plików.
Podstawowym problemem w tym przypadku jest to, że przy awarii systemu tracone są dane, a potrafimy odtworzyć jedynie zmiany jakie należało nanieść na bitmapie bloków oraz i-węźle.
Tryb journal (dane i metadane):
Jest to najłatwiejsze rozwiązanie i zarazem najbezpieczniejsze, ale niestety również bardzo kosztowne. Z każdą operacją zapisu wiążą się tu dwie operacje zapisu najpierw do dziennika a potem w docelowe miejsce na dysku.
Tryb ordered:
W trybie pracy ordered przed dokonaniem wpisu zmian metadanych do dziennika, system plików (moduł obsługujący journaling JBD) czeka aż urządzenie potwierdzi zapisanie zmiany danych na dysku. Dopiero wtedy rejestruje w dzienniku operacje na metadanych.
Ext3 w trybie ordered działa zdecydowanie szybciej niż w trybie pełnego kronikowania. Aby jednak nie dochodziło do błedów musi stosować następujące techniki:
- Revoke Records – są to specjalne rekordy zapisywane do dziennika, umożliwiające pominięcie odtwarzania wskazywanych bloków z wcześniejszych transakcji. Używa się ich po skasowaniu metadanych (np. katalogu), żeby modyfikacje już skasowanych struktur nie zamazywały nowych bloków jakiegoś pliku (zostały mu przydzielone po usunięciu z nich danych katalogu)
- nie przydziela na dane tych bloków, które zostały zwolnione, ale operacja ta nie została jeszcze zatwierdzona w dzienniku. Uniemożliwia to zamazanie bloków jednego pliku przez drugi, w przypadku gdy jeszcze możliwe jest powrócenie do danych starego pliku.
- Prowadzenie listy „osieroconych” plików - specjalna lista plików usuniętych z katalogu ale otwartych przez procesy
Indeksowanie katalogów:
Ciekawą funkcją Ext3 jest możliwość włączenia indeksowania katalogów.
W standardowym Ext2 wpisy katalogu są przechowywane w zwykłej liście. Po włączeniu opcji hashed trees katalogi mają postać drzewa, zawierającego bloki z wpisami.
Operacja wyszukiwania pozycji w katalogu opiera się na obliczeniu funkcji haszującej i zejściu w dół po wskaźnikach w drzewie aż do bloku zawierającego wpis pozycji.
Przy dodawaniu nowej pozycji (przepełnienie bloku z wpisami) stosuje się sortowanie wpisów i podział na dwa bloki. Następnie poprawiane są wpisy w indeksach.
Funkcja ta przydaje się w przypadku gdy w katalogach jest bardzo dużo (ponad kilka tysięcy) wpisów (directory entry). Zapewnia to bardzo szybki dostęp do pozycji w katalogu (wyszukiwanie, dodawanie pliku do katalogu). W Ext3 zaimplementowane jest indeksowanie jednopoziomowe co pozwala na utrzymanie około 90000 wpisów.
ReiserFS
Jest to system plików tworzony na zasadzie open source. Stworzony został przez Hansa Reisera.
Podstawowe cechy tego systemu plików to:
- zastosowanie B+ drzew do przechowywania plików i ich i-węzłów. Jedno drzewo obejmuje wszystkie bloki partycji. Jest to więc w pełni oryginalne rozwiązanie.
- zapamiętywanie wielu małych plików lub końcówek dużych plików w węźle drzewa (w metadanych, nie w liściu gdzie przechowywane są fragmenty dużych plików)
- nie posiada i-węzłów (wszystkie informacje są w B+ drzewie)
- kronikowanie metadanych
B+ drzewo:
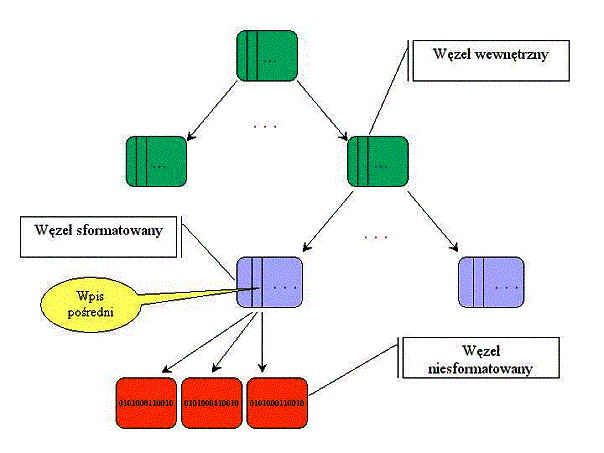
Rysunek 1. Struktura B+drzewa
Wyróżniamy trzy rodzaje węzłów (bloków):
o węzły wewnętrzne (internal nodes) – zestawy kluczy i wskaźników do kolejnych węzłów
o węzły sformatowane (formatted nodes) – są to liście drzewa, które składają się z wpisów (items). Każdy wpis ma swój unikatowy klucz wyszukiwania i może być jedną z postaci:
§ bezpośredni (direct item) – zawiera końcówki (ogony) plików (lub małe całe pliki)
§ pośredni (indirect item) – zawiera wskaźnik do węzła niesformatowanego, który zawiera kolejne bajty pliku, bez końcówki (ogona)
§ katalog (directory item) – zawiera klucz pierwszego wpisu do katalogu i nazwy wpisów (directory entries) i liczbę wpisów tego katalogu
§ stat data – przechowuje dodatkowe dane pliku lub katalogu
- węzły niesformatowane (unformatted nodes) – przechowują fragmenty dużych plików, są w pełni zajęte przez dane
Klucz wyszukiwania w drzewie zawiera:
- identyfikator katalogu nadrzędnego (dir_id 4 bajty)
- identyfikator obiektu (object_id 4 bajty)
- przesunięcie od początku obiektu do bieżącego bajtu (offset 4 bajty)
- typ obiektu {bezpośredni, pośredni, katalog, stat data} (uniqueness 4 bajty)
Plik składa się ze zbioru wpisów pośrednich, które wskazują na bloki niesformatowane (z danymi) oraz do dwóch węzłów bezpośrednich zawierających ogon pliku.
Ogon pliku może wystąpić w dwu węzłach ze względu na mechanizm „upychania ogonów”. Jest to mechanizm, który pozwala na przechowywanie w jednym bloku dyskowym ogonów wielu plików co zmniejsza ilość miejsca potrzebną na ich przechowywanie w porównaniu np. z ext2. Jednak powoduje to problem w momencie dopisywania na koniec pliku. Wtedy może zajść potrzeba przeniesienia ogona pliku do innego węzła bezpośredniego lub rozbicia go na dwa wpisy. Stąd ogon może występować w dwu węzłach.
Dzięki takim składowym klucza wyszukiwania obiekty z tego samego katalogu są położone koło siebie oraz fragmenty składowe danego obiektu (pliku lub katalogu) są również w sąsiednich węzłach w drzewie.
Upychanie ogonów można wyłączyć opcją notail.
Do głównych zalet tego systemu plików należą:
- szybkość porównywalna a nawet lepsza od ext2 mimo zastosowania kosztownej algorytmicznie struktury danych
- oszczędność miejsca w przypadku przechowywania małych plików
To da się jeszcze polepszyć:
- nie najbardziej efektywna obsługa dużych plików (długa droga w drzewie). W wersji 4 systemu ReiserFS jest to poprawione i droga od korzenia do liścia jest taka sama jak droga do węzła niesformatowanego.
JFS
Journaled File System powstał w roku 1990 w firmie IBM.
W roku 1995 dodano wsparcie dla maszyn wieloprocesorowych.
Pierwsza wersja kodu źródłowego powstała w 2000 roku.
Obsługuje mechanizm transakcji, gdyż był projektowany dla zastosowań serwerowych, ale równie dobrze sprawuje się w zastosowaniach klienckich, komputerach domowych.
EKSTENTY I
TECHNIKA GRUP ALOKACJI
Zapisywanie plików poprzez ekstenty – czyli przedziały położonych koło siebie bloków (tu od 1 do 2^24 –1 bloków), traktowane są przez system plików jako jedna jednostka alokacji, określane są przez:
- file offset - przesunięcie logiczne (w pliku lub katalogu)
- length - długość ekstentu (tu 24-bitową, co daje maksymalną długość 64GB przy blokach wielkości 4kB)
- starting blok number - adres fizyczny
Stosowanie ekstentów zapewnia znacznie mniejszy narzut na metadane. System plików stara się jak najlepiej grupować fragmenty jednego obiektu, aby formować jak największe ekstenty. Stosuje technikę grup alokacji, czyli:
- fragmenty tych samych plików i i-węzłów alokuje blisko siebie wychodząc z założenia, że są one potem zwykle wspólnie odczytywane
- rozrzuca takie spójne grupy po całym agregacie, aby w łatwy sposób można je było powiększać
Taka technika powoduje przyspieszenie operacji zapisu i odczytu z dysku.
STRUKTURA SYSTEMU
Agregat – jest to fizyczny nośnik danych
Partycja – logiczny zestaw plików, można ją zamontować
i-węzły, pliki, katalogi
Każdy obiekt w systemie plików jest reprezentowany przez i-węzeł.
i-węzeł jest alokowany dynamicznie co ma szereg zalet:
- nie ma ograniczeń na liczbę plików,
- liczba pamięci na i-węzły jest proporcjonalna do liczby plików a nie duża i stała
-
po usunięciu pliku zwalnia się też pamięć i-węzła
-
i-węzły nie mają zdeterminowanych lokacji na dysku
i-węzeł
ma 4 podstawowe składowe:
-
prawa, czasy, właściciel, grupa, numer partycji,
wielkość i liczba zaalokowanych bloków, deskryptor ekstentu,
-
informacje specyficzne dla systemu operacyjnego (vfsa)
oraz nagłówek B+drzewa
-
albo deskryptory B+drzew z ekstentami albo deskryptory
ekstentów albo ciąg danych
-
albo rozszerzone atrybuty albo kolejne deskryptory
ekstentów albo dalszy ciąg danych,
Plik jest reprezentowany przez i-węzeł, w którym zaczepiony jest korzeń B+drzewa opisującego ekstenty zawierające fragmenty tego pliku.Kluczami B+drzewa są przesunięcia logiczne ekstentów.
JFS umożliwia wybór jednego z dwóch rodzajów zapisu pliku (ogólnie dla całego systemu):
- zwykły zapis
- zapis z kompresją zer, co oznacza nie zapisywanie przedziałów zawierających same zera
Katalog jest reprezentowany przez i-węzeł i jeśli liczba wpisów w katalogu jest niewielka to są one umieszczone bezpośrednio w i-węźle, wpp również zawiera korzeń B+drzewa zawierającego wpisy – nazwy wpisów tego katalogu jako klucze wyszukiwania a wartościami są i-węzły dla tych nazw (standardowe zadanie katalogu).
Zmiany w katalogach są zapamiętywane w dzienniku.
Cechy charakterystyczne JFS:
- od początku zawierał kronikowanie metadanych
- w pełni 64 bitowy
- nie pozwala używać dyskietek jako bazowego urządzenia systemu plików
- współdzielenie dziennika przez wiele zestawów plików na jednym agregacie
- dynamiczne alokowanie i-węzłów
- kompresja zer w plikach
XFS
XFS jest opracowywany przez firmę Silicon Graphics od 1993 roku kiedy to okazało się, że ich stary system plików EFS jest zbyt słaby. W roku 2000 w planach było już przeniesienie XFSa na platformę Linuxa (wcześniej IRIX). Stworzono takie wirtualne warstwy(nakładki) procedur, które zakrywają IRIXowe procedury i dostosowują XFS do współpracy z Linuxem oraz buforem blokowym.
Podstawowymi zastosowaniami tego systemu plików mają być serwery plików, duże komputery przetwarzające dane (dobra skalowalność).
System plików XFS zapewnia wsparcie dla wieloprocesorowych maszyn. Jest systemem 64 bitowym.
Rozmiar bloku w systemie plików jest określany od 512B do 64kB.
STRUKTURA
Struktura, i-węzły, pliki i katalogi są zrealizowane z zastosowaniem podobnych rozwiązań co JFS.
Cechy:
- Journaling tylko metadanych.
- 64 bitowy
- Dynamiczna alokacja i-węzłów
- Wykorzystanie B+drzew do reprezentacji plików i katalogów
- Grupy alokacji i ekstenty
- Opóźnione alokowanie
- Access Control List (lista uprawnień pliku, bogatsza niż poziom Owner/group/all)
- Rozbudowane atrybuty plików
PORÓWNANIE
Wielkości:
|
|
Ext3 |
ReiserFS |
JFS |
XFS |
|
Wielkość systemu plików* |
do 4TB |
do 16TB |
minimalnie od 16MB do maksymalnie 32PB (w zależności od wielkości bloku) |
18000 PB |
|
Wielkość pliku |
do 2GB |
do 16TB (wersja 3.6) |
do 4PB (dla bloku 4kB) |
9000 PB |
|
Wielkości bloków |
1024, 2048, 4096 B |
4kB |
512, 1024, 2048, 4096 B |
512B – 64kB |
|
Licencja |
GPL |
GPL |
GPL |
GPL |
|
Dynamiczna alokacja i-węzłów |
Nie |
Tak. Cała system w jednym B+drzewie |
Tak |
Tak |
|
Kronikowanie Danych |
Możliwe |
Nie |
Nie |
Nie |
|
Możliwość umieszczenia kroniki na innej partycji |
Tak |
Tak |
Tak |
Tak |
|
Ekstenty |
Nie |
Nie (w wersji 4 Tak) |
Tak |
Tak |
*Jądro
w wersji 2.4 bez odpowiednich łatek ogranicza wielkość urządzenia blokowego do
2048GB.
Co przemawia na korzyść nowych systemów plików:
- Szybsza alokacja wolnych bloków. Zastosowanie ekstentów i B+drzew do znajdowania i alokowania porządanej ilości bloków dyskowych.
- Większa liczba pozycji w katalogach. Znacznie lepiej niż lista sprawdzają się tu B+drzewa.
- Kronikowanie zapewnia szybki restart po awarii.
TESTY
Oto
testy przeprowadzone przez firmę Guru Labs:
|
Pliki od 1kB do 9kB, mały ruch (w sumie 150MB) |
Pliki do 300kB, duży ruch (w sumie ponad 19GB) |
|
|
|

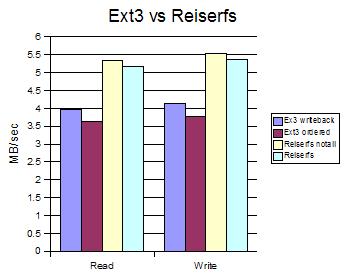
Spostrzeżenia:
- Ext3 jest szybkie przy małym natężeniu ruchu (operacji I/O) szczególnie wersja writeback, ale również ordered jest szybka
- Dla małych plików i obciążeń widać dużą różnicę między poszczególnymi odmianami ReiserFS (włączony/wyłączony notail) oraz Ext3
- Przy dużych plikach i obciążeniach ReiserFS jest wyraźnie wydajniejszy od obu wersji Ext3
- Inne
cechy charakterystyczne dla poszczególnych systemów plików (np. Access Control Lists)
Testy przeprowadzone przez FER.hr
Duży
plik 645MB:
Zapis:
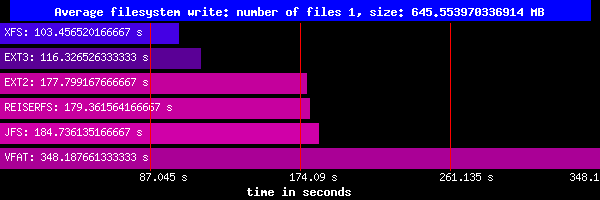
Jak widać zapis dużego pliku najszybciej odbywa się w systemie XFS, potem w Ext3. Pozostałe unixowe systemy plików prezentują podobne wartości.
Odczyt:
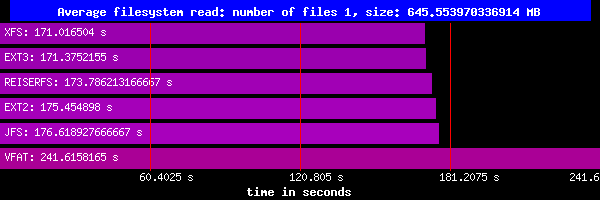
Tu szybkości wszystkich systemów są do siebie zbliżone (vfat trochę odstaje).
Kasowanie:
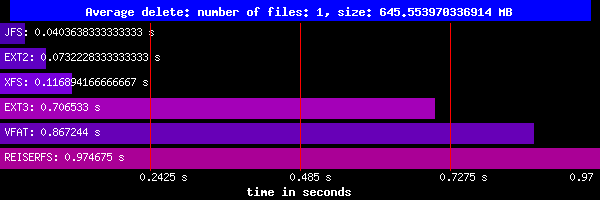
Kasowanie dużego pliku pokazuje jak duże są różnice w algorytmach obsługi systemu plików. JFS, Ext2, i XFS są naprawdę szybkie, pozostałe kasują relatywnie wolno.
Duża
liczba małych plików (10730 plików – 553MB):
Zapis:
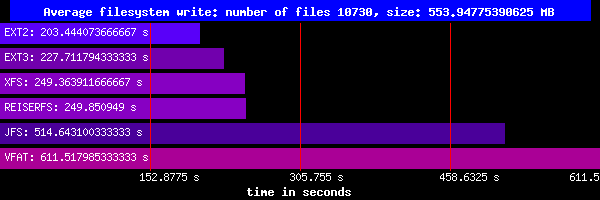
Tu rodzina Ext2 i Ext3 jest najlepsza, dotrzymują jej kroku XFS i ReiserFS a JFS jest wyraźnie słabszy.
Odczyt:
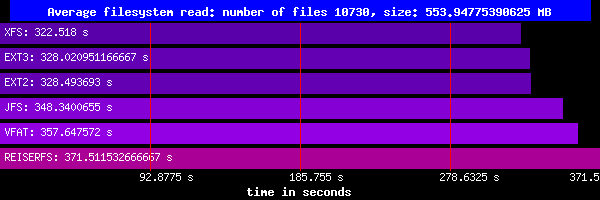
Odczyt małych plików pokazuje, że w odczycie tak naprawdę nie obserwujemy większych różnic.
Kasowanie:
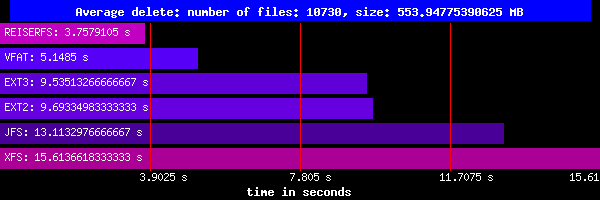
Tu ReiserFS pokazuje się od najlepszej strony, jest około trzech razy lepszy od pozostałych systemów unixowych.
Podsumowanie tych testów:
Ext3 jawi się jako system, który osiąga zwykle jeden z lepszych wyników w każdym teście. Jest do tego wyposażony w mechanizm dziennikowania a więc jest o wiele bezpieczniejszy od Ext2. XFS również osiąga dobre wyniki, jedynie kasowanie wielu małych plików zajęło mu trochę więcej czasu niż pozostałym konkurentom. ReiserFS można uznać za dobry system, ale naprawdę szybki w kasowaniu wielu małych plików w przeciwieństwie do jednego dużego. JFS trochę zawiódł, jest raczej wolny w porównaniu z pozostałymi. VFAT jako windowsowy system plików okazał się najgorszy praktycznie we wszystkich konkurencjach.
TESTY przeprowadzone przez producenta ReiserFS:
W tym teście 80% plików ma wielkość 0-8k, 16% wielkości 0-80k, 0.8 x 4% z przedziału 0-800k, itd. Większość plików to pliki małe, ale większość bajtów jest w dużych plikach.
Legenda:
- A
reiser4
- B
reiser4, extents only
- C
reiserfs v3
- D ext3
in data=writeback mode
- E ext3
in data=journal mode
- F ext3
in data=ordered mode
- G ext3
with htree (hashed directories)
Tabela prezentuje bezwzględne wyniki testów (czas rzeczywisty, użycie procesora) dla ReiserFS 4, oraz stosunki w porównaniu z innymi ww. systemami plików. Czerwone liczby oznaczają stosunek większy od 1.0 co oznacza ile razy ReiserFS4 jest lepszy. Zielone liczby oznaczają, że ReiserFS jest słabszy.
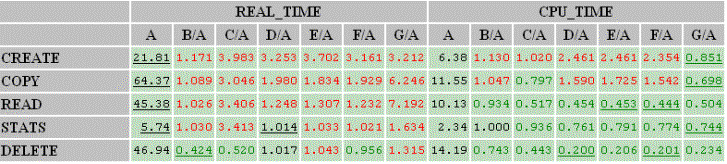
Można zauważyć, że najnowszy ReiserFS 4 przy tak dobranym zestawie danych testowych jest niemal bezkonkurencyjny jeśli spojrzymy na rzeczywisty czas oczekiwania na wykonanie operacji. Producenci podkreślają również, że jest to system w pełni transakcyjny, gdzie wszystkie transakcje wykonują się atomowo.
Interesujące jest również powolne działanie Ext3 z włączoną funkcją indeksowanych katalogów – znacznie spowalnia ona kopiowanie i odczyt.
TEST wykonany przez Constantina
Loizidesa z Uniwersytetu we Frankfurcie:
Przez powyższy link można obejrzeć wszystkie testy jakie wykonał autor. Ja chciałbym zwrócić uwagę na tabelę pokazującą fragmentację wewnętrzną w przypadku 4GB partycji, na której uruchomiono specjalny program jego autorstwa do testowania „starzenia” się systemu plików:
|
System plików |
# plików |
# bajtów |
Wew.
fragmentacja |
|
Reiser |
252738 |
4192538 KB |
6 % |
|
Reiser notail |
227190 |
3791069 KB |
14 % |
|
XFS |
225394 |
3757207 KB |
15 % |
|
JFS |
219376 |
3667703 KB |
17 % |
|
Ext3 |
208314 |
3482720 KB |
21 % |
Widzimy, że opcja notail w systemie ReiserFS wyłącza upychanie plików, co powoduje wzrost szybkości co wiemy z wcześniejszych testów ale również wzrost stopnia fragmentacji wewnętrznej, który nawet w tym przypadku jest niższy niż w pozostałych systemach plików.
Bibliografia
i gdzie szukać więcej informacji:
·
Ext3: http://www.zipworld.com.au/~akpm/linux/ext3
·
Ext3: http://olstrans.sourceforge.net/release/OLS2000-ext3/OLS2000-ext3.html
· Strona projektu JFS: http://oss.software.ibm.com/jfs
· Strona projektu ReiserFS: http://www.namesys.com/
· Strona firmy SGI na temat projektu XFS: http://oss.sgi.com/projects/xfs
· Strona Constantina Loizidesa z testami starzenia systemu plików: http://www.informatik.uni-frankfurt.de/~loizides/reiserfs/agesystem.html
· Strona z testami FER.hr: http://aurora.zemris.fer.hr/filesystems/big.html
· Strona z testami GuruLabs: http://www.gurulabs.com/ext3-reiserfs-5.html
· Strona Linux Magazine z artykułem October 2002 Journaling File Systems:http://www.linux-mag.com/
· Strona z artykułem Journaling File Systems Billa von Hagena:http://www.informit.com/
· Prezentacje SO z roku 2002/2003: http://rainbow.mimuw.edu.pl/Projekt02-03/