
Na rysunku widać strukturę partycji w s5fs.
System plików s5fs (system plików Systemu V) wprowadzono w pierwotnych wersjach systemu UNIX. Ze względu na jego pionierski charakter oraz prostą budowę, zaczniemy naszą analizę właśnie od niego. Przy okazji będzie to dobre wprowadzenie do problematyki związanej z systemami plików.
System plików umieszcza się na pojedynczym dysku logicznym lub partycji. Każdy system plików jest samowystarczalny, zawiera własny katalog główny, podkatalogi, pliki oraz związane z nimi dane i metadane. Drzewo plików widoczne dla użytkownika stanowi połączenie zamontowanych systemów plików.
Na początku partycji znajduje się obszar rozruchowy, może on
zawierać kod niezbędny do rozruchu systemu. Co najmniej jedna partycja
musi zawierać tą informację, ale każda partycja ma obszar rozruchowy,
choć może on być pusty.
Za obszarem rozruchowym znajduje się
superblok, który zawiera atrybuty i metadane dotyczące systemu
plików.
Za superblokiem znajduje się lista i-węzłów,
która jest liniową tablicą i-węzłów (rozmiar tablicy
jest stały co ogranicza liczbę plików). Dla każdego pliku
istnieje jeden i-węzeł, każdy i-węzeł ma unikatowy numer i-węzła,
który jest równy indeksowi i-węzła na liście i-węzłów.
I-węzeł zajmuje 64 bajty, więc w jednym bloku dyskowym może zmieścić
się wiele i-węzłów. Superblok oraz listy i-węzłów
zaczynają się w tym samym miejscu względem początku partycji we
wszystkich partycjach w systemie, dzięki temu numer i-węzła można
łatwo przekształcić na numer bloku itd.
Dalej znajduje się przestrzeń danych - bloki z danymi
plików i katalogów oraz bloki pośrednie.
Partycję można traktować jako liniową tablicę bloków. Rozmiar bloku dyskowego wynosi 512 bajtów pomnożone przez pewną potęgę 2. W zależności od wydania stosowano następujące rozmiary bloków 512, 1024 lub 2048 bajtów. Blok jest najmniejszą jednostką przydziału miejsca na dysku dla pliku oraz jednostką ziarnistości operacji wejścia-wyjścia. Fizyczny numer bloku jest indeksem w tablicy bloków. Podprogram obsługi dysku tłumaczy numer bloku na numer cylindra, ścieżki i sektora, a sposób tego tłumaczenia zależy od fizycznej charakterystyki dysku oraz od położenia partycji na dysku.

Katalog w systemie plików s5fs jest plikiem specjalnym zawierającym listę plików i podkatalogów. Składa się z rekordów o stałym rozmiarze równym 16 bajtów. Pierwsze 2 bajty zawierają numer i-węzła, a następne 14 nazwę pliku. Taka budowa katalogu ogranicza liczbę plików w partycji do 65535 plików ( 0 nie jest poprawnym numerem i-węzła) oraz długości nazw plików do 14 znaków. Ponieważ katalog jest plikiem, ma także i-węzeł, który zawiera pole identyfikujące plik jako katalog. Jeśli numer i-węzła odpowiadający pozycji jest równy 0 to oznacza, że plik już nie istnieje. Katalog główny partycji oraz jego pozycja zawsze mają numer równy i-węzła 2.
I-węzeł zawiera związane z plikiem informacje administracyjne oraz metadane, umieszcza się go na dysku w liście i-węzłów. Tabela zawiera opis pól i-węzła dyskowego.

Pliki w systemie UNIX nie zajmują ciągłego obszaru na dysku, w miarę wzrostu rozmiaru pliku jądro przydziela mu nowe bloki w wygodnym miejscu na dysku, pozwala to łatwo zmniejszać i zwiększać rozmiar pliku nie fragmentując dysku, co byłoby konieczne podczas alokacji ciągłej. Jedynie ostatni blok pliku może zawierać przestrzeń niewykorzystaną. W każdym pliku marnuje się średnio przestrzeń o rozmiarze połowy bloku. System plików musi więc utrzymywać informacje o położeniu bloków każdego pliku. Informacje te przechowuje się w postaci adresów bloków fizycznych. Logiczny numer bloku jest indeksem w tej tablicy. Wielkość tablicy zależy od rozmiaru pliku. Dla dużych plików wymagało by to trzymania tablicy w kilku blokach dyskowych. Większość plików posiada jednak mały rozmiar, więc duże tablice powodowałyby duże straty miejsca. Ponadto przechowywanie tej tablicy w oddzielnych blokach powodowało by konieczność dodatkowych operacji odczytu przy każdym dostępie do pliku, a w konsekwencji malała by wydajność. Dlatego trzyma się małą listę w samym i-węźle, a dodatkowe bloki stosuje się w przypadku dużych plików. Jest to efektywne rozwiązanie do obsługi małych plików i wystarczająco elastyczne do obsługi bardzo dużych plików.
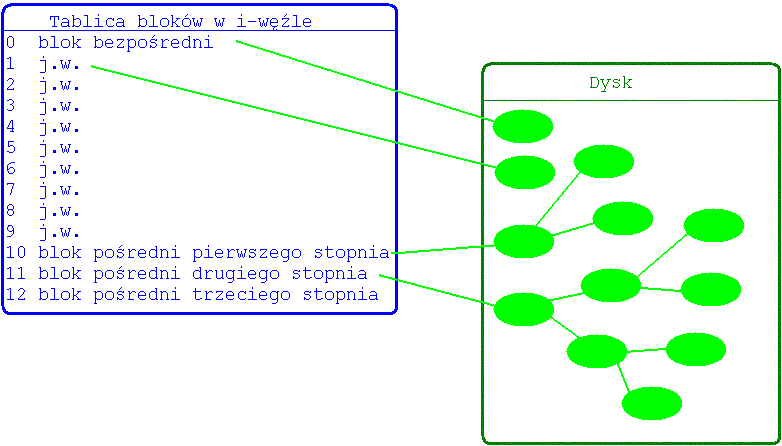
Tą strategię realizuje tablica di_addr - (39 bajtów - 13 elementów, każdy element - 3 bajtowy fizyczny numer bloku). Jeśli rozmiar bloku wynosi 1024 bajty, to taki schemat pozwala na zaadresowanie 10 bloków bezpośrednio, 256 za pośrednictwem bloku pośredniego 65536 (256x256) za pomocą podwójnie pośredniego, 16777216 (256X256X256) za pomocą bloku pośredniego 3 stopnia.
Pliki unix'owe mogą zawierać tzw. dziury. Użytkownik może utworzyć plik, przesunąć go(lseek), ustawić wskaźnik pozycji w pliku na dużą wartość i tam zapisać dane. Przestrzeń bez danych między tą pozycją a początkiem pliku jest dziurą. Jeśli proces spróbuje odczytać tą przestrzeń stwierdzi, że znajdują się tam bajty NULL o wartości 0. Żeby nie marnować miejsca na dziury jądro wpisuje zera w odpowiednie miejsca tablicy di_addr lub bloku pośredniego. Przy próbie odczytu, jądro przekazuje w wyniku blok wypełniony zerami. Przestrzeń dyskowa jest przydzielana jedynie przy zapisie danych do bloku. Ma pewne to ważne konsekwencje. Proces może nagle stwierdzić brak miejsca na dysku podczas zapisywania danych do dziury, a po skopiowaniu pliku z dziurą nowy plik ma zamiast dziury strony wypełnione zerami, ponieważ kopiowanie polega na odczycie zawartości pliku i zapisie jej do nowego pliku. Gdy jądro kopiuje dziurę, tworzy strony wypełnione zerami, nie interpretując ich zawartości. Może to powodować problemy przy korzystaniu z programów do sporządzania kopii zapasowych i archiwizowania takich jak tar lub cpio, które operują na poziomie plików, a nie na poziomie surowego dysku. Administrator systemu może sporządzić kopię systemu plików, a następnie stwierdzić, że ten sam dysk jest za mały do odtworzenia archiwum.
Superblok zawiera metadane dotyczące systemu plików, dla
każdego systemu plików istnieje jeden superblok umieszczony na
początku systemu plików na dysku. Jądro odczytuje superblok
podczas montowania systemu plików i trzyma go w pamięci
operacyjnej aż do chwili zdemontowania systemu plików.
Superblok przechowuje następujące informacje:









Problemy z niezawodnością:
Problemy z wydajnością:
Problemy z funkcjonalnością:
FFS wprowadzony po raz pierwszy do 4.2 BSD ma lepszą wydajność, większą odporność na błędy i bogatszą funkcjonalność niż s5fs. Większość algorytmów wykorzystanych w funkcjach systemowych oraz struktur jądra pozostała w nim niezmieniona. Główne różnice dotyczą warstwy dyskowej, struktur umieszczanych na dysku oraz sposobu przydziału wolnych bloków.
Aby zrozumieć czynniki, które wpływają na wydajność operacji dyskowych, trzeba znać sposób składowania danych na dysku.
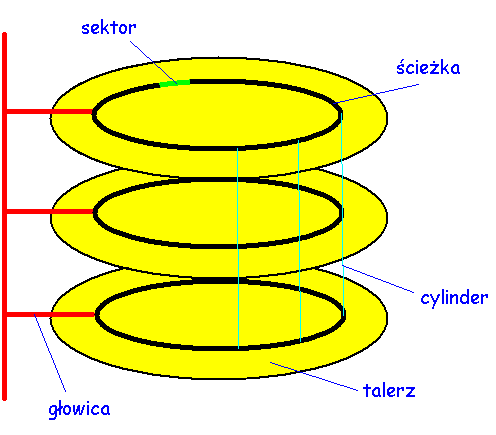
Rozmiar sektora wyznacza ziarnistość dyskowych operacji
wejścia-wyjścia. UNIX traktuje dysk jako liniową tablicę bloków.
Liczba sektorów w bloku jest małą potęgą 2. Dla wygody, możemy
założyć, że jest dokładnie jeden sektor w bloku.
Po obliczeniu
położenia żądanego bloku, podprogram obsługi dysku musi przesunąć
głowicę do odpowiedniego cylindra. Ten czas przemieszczania głowicy
jest główną składową czasu trwania dyskowej operacji
wejścia-wyjścia.
Gdy głowica jest już na właściwej pozycji, trzeba
poczekać aż w wyniku ruchu obrotowego dysku pod głowicą znajdzie się
właściwy sektor. To opóźnienie nazywa się opóźnieniem
obrotowym. Gdy właściwy sektor znajduje się już pod głowicą można
rozpocząć przesyłanie.
Optymalizacja polega więc na zredukowania tych
opóźnień, za pomocą sensownego rozmieszczenia bloków na
dysku.
W ffs partycja dzieli się na jedną lub kilka grup cylindrów,
z których każda jest małym zbiorem kolejnych cylindrów.
Umożliwia to przechowywanie związanych ze sobą danych w tej samej
grupie cylindrów, co ogranicza ruch głowic.
Superblok zawiera
informacje o całym systemie plików, liczbę, rozmiar i
położenie grup cylindrów, rozmiar bloku, łączną liczbę bloków
oraz i-węzłów itd. Dane w superbloku nie zmieniają się chyba, że buduje
się system plików od nowa.
Każda grupa cylindrów ma
strukturę danych zawierającą informacje o tej grupie, listę wolnych
i-węzłów oraz listę wolnych bloków.
Superblok znajduje się na
początku partycji, za obszarem rozruchowym, ale ponieważ jego dane są niezbędne do poprawnego
funkcjonowania systemu plików, należy je chronić przed błędami
dyskowymi. Każda grupa cylindrów zawiera zatem kopię
superbloku. System ffs utrzymuje te kopie pod różnymi
przesunięciami w każdej grupie cylindrów w ten sposób,
że żaden pojedynczy cylinder, ścieżka ani płyta nie zawiera
wszystkich kopii superbloku. Przestrzeń między początkiem grupy
cylindrów a początkiem superbloku jest wykorzystywana do
przechowywania bloków z danymi. Wyjątkiem jest tylko pierwsza
grupa cylindrów.
Zwiększenie rozmiaru bloku poprawia wydajność, gdyż można wtedy
przesyłać większą ilość danych w pojedynczych operacjach we-wy, powoduje to jednak większe straty miejsca. W ffs wykorzystano
zalety
obu rozwiązań i podzielono bloki na fragmenty.
Bloki jednej partycji muszą mieć ten sam rozmiar.
Rozmiar bloku jest potęgą 2 i jest nie mniejszy niż 4096 bajtów,
większość implementacji nakłada na rozmiar bloku górne
ograniczenie równe 8192 bajty - to znacznie więcej niż 512
lub 1024 bajty w s5fs. Oprócz zwiększonej przepustowości
umożliwia to adresowanie plików do 2 do 32 bajtów
długości (4GB) za pomocą jedynie 2 poziomów pośrednich. W ffs
nie ma bloku pośredniego 3 poziomu, chociaż niektóre
warianty używają go do wspierania plików dłuższych niż 4GB.
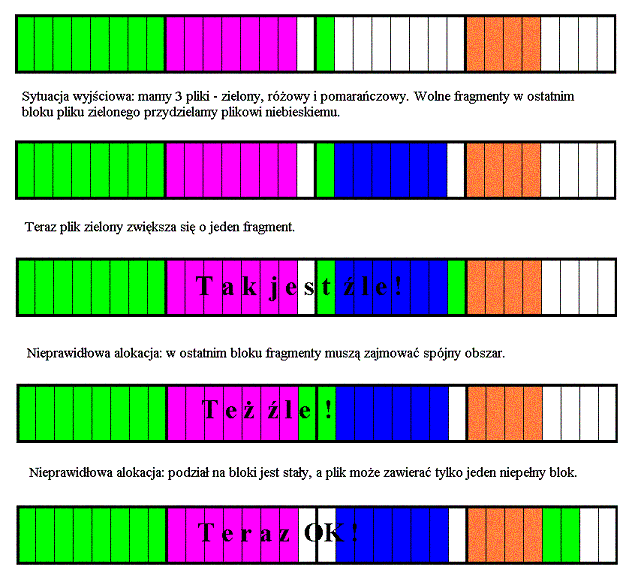
Problem strat miejsca w małych (typowych dla Unix'a) plikach rozwiązano dzieląc każdego blok na kilka fragmentów. Rozmiar fragmentu ustala się podczas tworzenia systemu plików, a liczba fragmentów w bloku może być równa 1, 2, 4 , 8 z dolnym ograniczeniem równym 512 bajtów (jak typowy rozmiar ówczesnego sektora dysku). Ponieważ każdy fragment podlega przydzielaniu i adresowaniu, zamiast listy wolnych bloków - mapa bitowa z informacjami o stanie każdego fragmentu.
Plik w ffs składa się z całkowicie wypełnionych bloków dyskowych z wyjątkiem ostatniego bloku. Blok plikowy musi mieścić się całkowicie w jednym bloku dyskowym, nawet jeśli sąsiadujące bloki dyskowe zawierają wystarczająco dużo następujących bezpośrednio po sobie wolnych fragmentów do przechowania bloku plikowego, to jednak nie można ich łączyć. Co więcej jeśli ostatni blok pliku zawiera więcej niż jeden fragment, to fragmenty te muszą zajmować ciągły obszar w tym samym bloku. Przedstawiony schemat zmniejsza straty przestrzeni dyskowej, ale od czasu do czasu wymaga kopiowania danych plikowych. Rozważmy plik, którego ostatni blok zawiera pojedynczy fragment. Pozostałe fragmenty w tym bloku można przydzielić innym plikom. Jeśli ten plik zwiększy się o jeszcze jeden fragment , to trzeba znaleźć inny blok, w którym byłyby wolne dwa kolejne fragmenty. Pierwszy fragment należy skopiować z pierwotnej pozycji, a drugi wypełnić nowymi danymi.
Implementacja dąży do kompromisu pomiędzy rozmieszczaniem danych w dogodnych miejscach oraz potrzebą ich równomiernego rozproszenia po całym dysku. Zbyt duża lokalność rozmieszczania powodowałaby upychanie danych w jednej grupie cylindrów, w tym przypadku można było by otrzymać jedną dużą grupę cylindrów, tak jak w systemie s5fs. Powyższe reguły przeciwdziałają takiemu scenariuszowi.
Ta implementacja jest bardzo wygodna, gdy na dysku jest dużo wolnego miejsca. Jej wydajność gwałtownie spada przy ok. 90 % zapełnienia dysku. Gdy wolnych bloków jest bardzo mało, to ich znalezienie w optymalnych miejscach staje się trudne. Z tego powodu system plików utrzymuje parametr określający rozmiar zarezerwowanego miejsca, zazwyczaj ustawiany na 10% pojemności dysku. Tylko nadzorca może otrzymywać miejsce z tej rezerwy.
Organizacja danych na dysku jest inna niż w s5fs, dlatego zmiana systemu plików z s5fs na ffs wymaga zrzutu zawartości wszystkich dysków, a następnie ich odtworzenia w nowym systemie plików. Ponieważ te systemy są i tak niezgodne, twórcy ffs wprowadzili także inne zmiany funkcjonalne niezgodne z systemem s5fs.
Niektóre z tych ulepszeń wprowadzono potem do s5fs.
Można powiedzieć, że Linux wyrósł na gruncie systemu Minix stworzonego przez Tanenbauma. Łatwiejszym wyjściem było współdzielenie dysków przez dwa systemy niż implementowanie nowego sytemu plików, stąd Torvalds zdecydował się na zaimplementowanie wsparcia dla systemu plików Minix'a.

Jak widać system plików Minix'a posiadał wiele niedogodności, więc zaczęto myśleć nad wprowadzeniem nowych systemów plików, w czym bardzo pomocne było wprowadzenie powłoki VFS.
Wkrótce po jej zintegrowaniu został dodany system plików Extended File System, który usuwał dwa duże ograniczenia Minix'a: jego maksymalny rozmiar wynosił 2GB, a pliki mogły mieć długość do 255 znaków. To była duża zmiana w stosunku do Minix'a, ale pewne kwestie pozostały nierozwiązane. Nie było wsparcia dla znaczników czasowych, system plików wykorzystywał listy bloków i i-węzłów, co powodowało słabą wydajność, w czasie używania listy stawały się nieposortowane, a system plików ulegał fragmentacji.
Odpowiedzią na te bolączki było wydanie dwóch nowych systemów plików: Xia i Ext2 (Second Extended File System). Xia w znacznej mierze bazowała na Minix'ie i dodała jedynie kilka nowych funkcjonalności. Uogólniając były to: wsparcie dla długich nazw plików, dla większych partycji i dla 3 znaczników czasowych. Ext2 natomiast bazował na kodzie systemu Ext, wprowadzając wiele reorganizacji i ulepszeń. Został stworzony pod kątem rozwoju i stwarzał do tego szerokie możliwości.
W momencie wprowadzenia dwóch nowych systemów plików oferowały one podobną jakość. Ze względu na swój minimalizm Xia okazała się jednak bardziej stabilna. Jednak po pewnym czasie losy się odwróciły i wraz z użytkowaniem systemu Ext2 jego błędy zostały poprawione, a stosowane w nim rozwiązania znacznie poszerzone i ulepszone. To doprowadziło do sytuacji, w której Ext2 stał się standardowym systemem plików Linux'a.
Poniższa tabela prezentuje porównanie kilku podstawowych cech wspomnianych systemów plików:

Na budowę ext2 duży wpływ wywarł system ffs, stąd bardzo liczne podobieństwa. Warto wspomnieć, że podział na grupy cylindrów analogiczny do tego z systemu plików z BSD nie jest już sztywno związany z fizyczną strukturą dysku, gdyż jak wspomniałem nowoczesne dyski wykazują tendencję do zoptymalizowanego dostępu sekwencyjnego i nie ujawniają swojej fizycznej geometrii systemom operacyjnym.
Ze względu na wspomniane podobieństwo oraz fakt, że system ten został dokładnie omówiony na wykładzie i ćwiczeniach nie będę go tu szczegółowiej prezentował.