Informacje ogólne
JFS - Journaled File System
JFS jest systemem plików tworzonym na licencji GNU General Public License. Główni twórcy kodu źródłowego - jest ich czterech - są pracownikami firmy IBM. W chwili pisania niniejszego tekstu, najnowszą wersją JFS jest 1.1.4 . Strona domowa projektu znajduje sie pod adresem http://www-124.ibm.com/developerworks/oss/jfs/
JFS po raz pierwszy ujrzał światło dzienne w 1999 roku w systemie OS/2 Warp Server. Pod koniec tego samego roku zaczęły się też prace nad przeportowanie systemu plików dla Linuxa.
Po raz pierwszy został dodany do "oficjalnego" jądra Linux'a w wersji 2.5.6 kernela. W wersji 2.4.x JFS po raz pierwszy znalazł się w jądrze 2.4.20 - zmodyfikowanej przez Marcelo Tosatti.
Charakterystyka systemu plików, czyli kilka faktów na dzień dobry.
- Rozmiary bloku: 512, 1024, 2048, lub 4096 KB
- Minimalny rozmiar partycji: 16 MB
- Maksymalny rozmiar partycji: 32 PB
- Maksymalny rozmiar pliku: 4 PB
- Journaling
- Dynamiczna allokacja i-węzłów
- 64-bitowy system plików
- Używanie zaawansowanych struktur danych (B+drzew) w celu zwiększenia wydajności.
- Możliwość zmiany wielkości już założonej partycji (dokładniej: agregatu).
- Jest jeszcze lepszy od wszystkich innych pod każdym możliwym względem.
Ekstent (ang. extent)
Ekstent (ang. extent - po polsku "zakres") jest to spójny fragment przestrzeni adresowej.
Agregat
Cały spójny fragment twardego dysku zajmowany przez system plików JFS, tworzy jeden "agregat" (ang. aggregate). W ramach agregatu, jest zachowany stały "rozmiar bloku agregatu" - równy 512, 1024, 2048, lub 4096 KB, lecz nie mniejszy niż rozmiar bloku dla danej partycji. Rozmiar "bloku agregatu" jest najmniejszą porcją danych na jakiej będzie operował system plików.Agregat zawiera:
- Główny Superblok Agregatu oraz Zapasowy Superblok Agregatu (ang. Primary/Secondary Aggregate Superblock). Znajdują się w nich elementarne dane o agregacie takie jak rozmiar całego agregatu, rozmiar bloku agregatu itp. Zapasowy superblok jest dokładną kopią głównego. Superbloki mają stałą lokalizację, dzięki temu łatwo je znaleźć w razie awarii.
- Tablica i-węzłów agregatu (ang. Aggregate Inode Table). Zawiera i-węzły opisujące struktury kontrolne agregatu.
- Zapasowa tablica i-węzłów agregatu (ang. Secondary Aggregate Inode Table). I-węzły agregatu są kluczowe dla działania systemu pliku, stąd konieczność przechowywania ich kopii. Duplikowane są jedynie wskaźniki dla bloków, same dane nie są duplikowane.
- Mapa allokacji bloków (ang. Block Allocation Map). Mapa zawierająca stan allokacji wszystkich bloków w agregacie.
- Przestrzeń robocza dla
fsck. Podczas działania programufsckniezbędna jest pewna ilość pamięci. Ponieważ nie można mieć pewność że będzie dostępna ona w postaci RAM, pewną ilość obszaru dysku trzeba przeznaczyć na przestrzeń roboczą która zawsze będzie wolna. - Log (ang. In-line Log). Miejsce używane do logowania zmian w metadanych. Znajduje się on zaraz za przestrzenią roboczą dla
fsck
Grupy allokacji
Grupy allokacji wyznaczają podział agregatu na logiczne części. Grupy allokacji mają na celu przechowywanie blisko siebie, powiązanych ze sobą danych (np. plików w ramach jednego katalogu). Jednocześnie niepowiązane ze sobą dane będziemy starali się umieścić w innych grupach allokacji, aby móc później umieścić powiązane z nimi dane w tej samej grupie. Takie grupowanie danych przyspiesza dostęp sekwencyjny oraz odczyty bloków o których wiemy że zazwyczaj beda odczytywane razem (np. pliki w ramach jednego katalogu). Strategia ta powinna byc już znana z systemu plików ext2.
Fileset
Fileset (nie tlumacze tego slowa aby nie utrudniac ewentualnej dalszej lektury w jez. angielskim) jest to zbiór plików i katalogów tworzących drzewiastą strukturę. Funkcjonalność fileset'u jest zbliżona do funkcjonalności partycji. Jeden agregat może zawierać wiele fileset'ów. każdy fileset może być niezależnie mountowany - tak jak partycje. Należy zwrócić uwagę że filesety z jednego agregatu dzielą miejsce na twardym dysku. Jest to zatem funkcjonalność której nie daje zwykły podział na partycje.
Każdy fileset posiada:
- Tablicę i-węzłów Filesetu (ang. Fileset Inode Table) - tablica i-węzłów dla całego filesetu.
- Mapę Allokacji i-węzłów Filesetu. Zawiera informacje o stanie allokacji i-węzłów filesetu oraz ich położeniu na dysku. Nowo zainicjalizowany fileset posiada zallokowany tylko jeden ekstent i-węzłów. W ramach potrzeby tworzone są kolejne.
- I-węzeł filesetu nr 0 - zarezerwowany.
- I-węzeł filesetu nr 1 - zawiera dodatkowe winformacje które się nie zmieściły w Mapie Allokaji i-węzłów Filesetu.
- I-węzeł filesetu nr 2 - i-węzeł głównego (root) katalogu filesetu. Jest to zgodne z konwencją stosowaną w Unix'ach.
- I-węzeł filesetu nr 3 - plik ACL (Access Control List).
I-węzły o numerach większych równych 4 są używane przez zwykłe pliki, katalogi, linki, itp.
I-węzły
I-węzły są allokowane dynamicznie. Jeśli zabraknie i-węzłów, przydzielany jest nowy ekstent z trzydziestoma dwoma i-węzłami. Dzięki temu nie trzeba podczas zakładania systemu plików przewidywać ile plików będziemy chcieli przechowywać na dysku. Jest to tym ważniejsze iż w JFS i-węzeł ma znaczne rozmiary - zajmuje 512 bajtów. Ma to jednak wadę: aby zarządzać dynamicznie przydzielanymi i-węzłami, potrzeba dodatkowych struktur co do których trzeba zapewnic że zachowają spójność przy ewentualnym przerwaniu dostaw prądu.
Pliki
Pliki są opisywane przez i-węzły. Każdy plik jest przechowywany na nośniku danych w formie zbioru spójnych kawałków danych (ekstentów). Aby sprawnie zarządzać zbiorem opisów ekstentów i operowac na nim, użyto B+drzew. Dzięki B+drzewom możemy bardzo szybko odnaleźć parametry ekstentu zawierającego dany fragment pliku.
B+drzewa
B+drzewa przyspieszają operacje zapisu i odczytu ekstentów - najczęściej wykonywanych operacji. Dzięki nim, łatwo jest odnaleźć określony ekstent, wstawic ekstent w środku pliku lub skasowac go.
Kluczami węzłów B+drzewa są logiczne offsety początków ekstentów.
Podobnie jak w ext2, pliki mogą być "dziurawe" tzn. części pliku które nie były nigdy zapisywane, nie zajmują fizycznie miejsca na nośniku danych.
Zarządzanie miejscem na dysku
Do utrzymywania informacji o tym które bloki agregatu są wolne, a które zawierają już jakieś dane, służy Mapa Allokacji Bloków (Block Allocation Map). Ponieważ wszystkie filesety dzielą bloki w agregacie więc wystarczy jedna Mapa Allokacji Bloków dla całego agregatu.
Mapa Allokacji Bloku jest zwykłym plikiem, opisywanym przez i-węzeł agregatu o numerze 2. Mapa ta jest inicjalizowana przy tworzeniu systemu plików (agregatu).
Ponieważ ilość bloków na twardym dysku może być bardzo duża, zaangażowano różne struktury danych do zarządzania informacjami o stanie allokacji bloków.
Podstawową strukturą opisującą bloki jest struktura (
dmap). Jednym z jej pól jest mapa bitowa . Bit ustawiony na 1 oznacza blok zajęty, 0 - blok wolny. Każda taka mapa zajmuje 1024 bajtów, zatem na jednej mapie mieści się informacja o stanie allokacji 8192 bloków. Map jest tyle aby opisac całą przestrzeń twardego dysku.

Z racji na ilość map bitowych, jest nad nimi nadbudowane drzewo zrównoważone o stopniu wierzchołków równym
Maksymalnie drzewo to może mieć trzy poziomy, co determinuje maksymalny rozmiar partycji. Dla bloku o rozmiarze 4KB mamy:
Drzewo to pozwala szybko odnaleźć odpowiednią mapę bitową.
Dodatkowo, aby usprawnic wyszukiwanie wolnych bloków, w ramach każdej struktury
dmap, na mapie bitowej, dla kolejnych słów (32 bitów) budowane jest drzewo bliźniaków.

Obliczana jest w nim długość najdłuższego (w sensie algorytmu bliźniaków) spójnego odcinka bloków w ramach danej bitmapy.
Na rysunku -1 oznacza blok zajęty, liczba X większa od zera oznacza że w poddrzewie jest wolny blok długości 2^X.
Na podstawie takiego drzewa, tworzona jest tablica w której dla każdego bitu jest obliczana największa ilość wolnych bloków począwszy od danego miejsca, biorąc jedynie pod uwagę brata bliźniaka. Obliczenie to ilustruje rysunek:
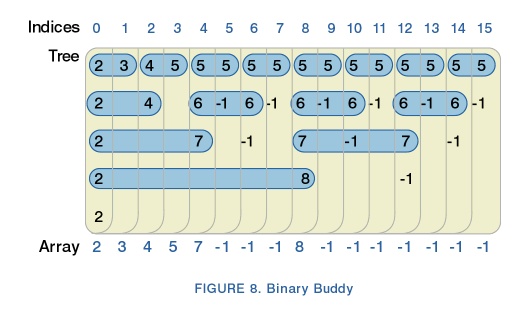
Nad takimim tablicami (tworzonymi dla każdych 32 bitów) budowane jest drzewo wyglądające następująco:
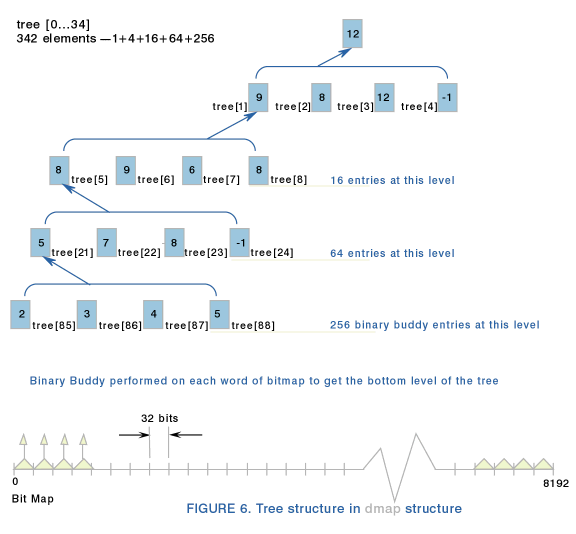
Drzewo to śledzi maksymalną ilość ciągłych bloków. W liściach znajduje się tablica powstała w wyniku działania algorytmu bliźniaków.
Allokacja i-węzłów
Jak już wspominaliśmy, w JFS i-węzły są allokowane w sposób dynamiczny. Przydział odbywa się w porcjach 32 i-węzłowych.
Przy pracy z i-węzłami potrzebne są następujące funkcjonalności:
- Mając dany numer i-węzła, znaleźć odpowiadającą mu strukturę na dysku.
- Dla danej grupy allokacji, znajdź fizycznie najbliższy wolny i-węzeł (tworzenie pliku w katalogu).
- Allokowanie nowej grupy i-węzłów. Wymaga znalezienia 32 numerów i-węzłów które nigdzie nie są używane.
Mapa Allokacji i-węzłów
Mapa Allokacji i-węzłów rozwiązuje problem szukania i-węzła o danym numerze.
W JFS jest rozróżnienie pomiędzy i-węzłami agregatu i i-węzłami fileset'u. Dlatego istnieje oddzielna mapa allokacji i-węzłów agregatu i mapa allokacji i-węzłów fileset'u.
Mapa Allokacji i-węzłów składa się ze zbioru Grup Allokacji i-węzłów (ang. Inode Allocation Groups(IAG)). Każdy IAG opisuje 128 grup i-węzłów. Każda grupa i-węzłów zawiera 32 i-węzły, zatem IAG opisuje w sumie 4096 i-węzły.
Informacja który i-węzeł jest wolny a który zajęty jest przechowywana w mapach bitowych. Mapa allokacji jest mapą bitową. Każdy i-węzeł jest opisany przez jeden bit. Jedna grupa i-węzłów zawiera 32 kolejne numery i-węzłów. Jeden IAG opisuje kolejne 4096 i-węzły.
Oprócz mapy bitowej, IAG przechowuje dla każdej grupy i-węzłów (jest ich 128 w IAG), opis ekstentu w którym się ona znajduje.
Opis mapy allokacji i-węzłów dla filesetu jest przechowywany w i-węźle filesetu, zatem bloki (ekstenty) w których znajdują sie dane IAG są przechowywane przez to samo B+drzewo które przechowuje ekstenty plików. Kluczem w B+drzewie jest offset IAG.
Dla każdego filesetu, w i-węźle nr 1 znajduje się blok kontrolny Mapy Allokacji i-węzłów danego filesetu w którym znajduje się tablica pozycji kolejnych IAG. Jest to ostatnim brakującym klockiem naszej układanki. Teraz bowiem procedura znajdywania danego węzła wygląda następująco:
- Zajrzyj do danych opisywanych przez i-węzeł 1 filestu.
- Odczytaj gdzie się znajduje IAG dla danego i-węzła. Np dla i-węzeła nr 9157 potrzebujemy odszukać trzeci IAG (bo jeden IAG opisuje 4096 kolejnych i-węzłów).
- Mając offset pod którym jest szukany IAG, znajdujemy w B+drzewie filesetu odpowiedni IAG.
- Z tego IAG wyciągamy ekstent pod którym znajduje się grupa i-węzłów dla 9157.
- Wyciągamy z ekstentu fragment odpowiadający szukanemu i-węzłowi.

Katalogi
Katalogi są zbiorami odwzorowań pomiędzy nazwą pliku/podkatalogu/linku/... a odpowiadającym mu i-węzłem. I-węzeł będący katalogiem zawiera zatem B+drzewo w którym znajdują sie obiekty zawarte z katalogu. Elementy B+drzewa są indeksowane względem nazwy.Opis małych katalogów, zawierających nie więcej niż 8 obiektów jest przechowywany bezpośrednio w i-węźle.
Journaling
JFS nie loguje danych jakie są zapisywane w trakcie transakcji, a jedynie metadane. Dlatego też nie mamy takiej funkcjonalności jak w bazach danych że awarie pozostawiają stan informacji w bazie w stanie spójnym, a jedynie mamy zapewnione że metadane nie zostaną uszkodzone.Nie należy używać journalingu na laptopach, chyba że mamy pewność że posiadany twardy dysk nie buforuje zapisów. Często się bowiem zdarza że HDD w laptopach z różnych oszczędnościowych powodów opóźniają zapis. Wówczas system plików nie ma kontroli nad tym co zostało faktycznie zapisane w związku z czym nie jest w stanie zagwarantować spójności metadanych. Zatem zdarzenia takie jak wyczerpanie się baterii mogą stanowić zagrożenie dla partycji.
Jak działa journaling (w telegraficznym skrócie)?
Podczas dokonywania zmian na metadanych, przed ich rozpoczęciem i po zakończeniu jest zapisywane że zaczęła / skończyła się transakcja polegająca na XYZ. Zapisywane są też działania pośrednie. Gdy nastąpi awaria i system jest uruchamiany ponownie, JFS czyta plik z logiem i powtarza wykonywanie transakcji które zdążyły być zacommit'owane ale nie zostały zapisane. Następnie JFS znajduje w logu wszystkie transakcje które nie zostały zacommit'owane w momencie przerwana pracy komputera i cofa ich wykonanie, przywracając metadane do stanu sprzed ich wykonania.
Oto lista operacji które modyfikują metadane w związku z czym muszą być logowane:
- Tworzenie pliku (create)
- Tworzenie linku twardego (link)
- Tworzenie katalogu (mkdir)
- Tworzenie dowiązań do urządzeń (mknod)
- Usuwanie pliku (unlink)
- Zmiana nazwy (rename)
- Usuwanie katalogu (rmdir)
- Tworzenie linku symbolicznego (symlink)
- Zmiana praw dostępu
- Zapis do pliku (write) - w rzadkich przypadkach
- Obcinanie pliku (truncate)
Ponieważ w logu znajdują się informacje o tym które struktury były zmieniane w trakcie awarii, nie ma potrzeby skanowania całego twardego dysku jak to było w ext2. Logowanie jedynie metadanych pozwala na zachowanie wystarczająco wysokiej wydajności systemu.
Czytadła
Informacje dla ciekawskich i tych którzy są gotowi przeczytać wszystko byleby się nie uczyć do sesji:- IBM: JFS layout - główne informacji do niniejszego referatu.
- IBM: JFS overview - trochą ogolniejszych informacji, po czesci marketingowy bełkot.
- JFS Log How the Journaled File System performs logging - jak w tytule.
- Systemy Operacyjne dla III roku na Uniwersytecie Warszawskim - to samo co na tym referacie, ale napisane rok temu. Tlumaczenia artykulu z pierwszego linku.
- Journaled File System Technology for Linux - strona główna projektu JFS dla Linuxa, prowadzona przez IBM.
Copyright (tfelypoC)
Autor: Jacek Kołodziej (jk197877@students.mimuw.edu.pl)Wszystkie obrazki pochodzą ze strony IBM: JFS layout (http://www-106.ibm.com/developerworks/linux/library/l-jfslayout/). Również większość informacji pochodzi ze wspomnianego artykułu i w zaden sposob nie stanowia dorobku intelektualnego wyzej podpisanego autora. Nie mniej jednak bledy merytoryczne, stylistyczne i ortograficzne sa wylaczna zasluga Jacka Ko?odzieja i jest on jedynym podmiotem majacym prawo do jakichkolwiek wpływów z nich wynikających.