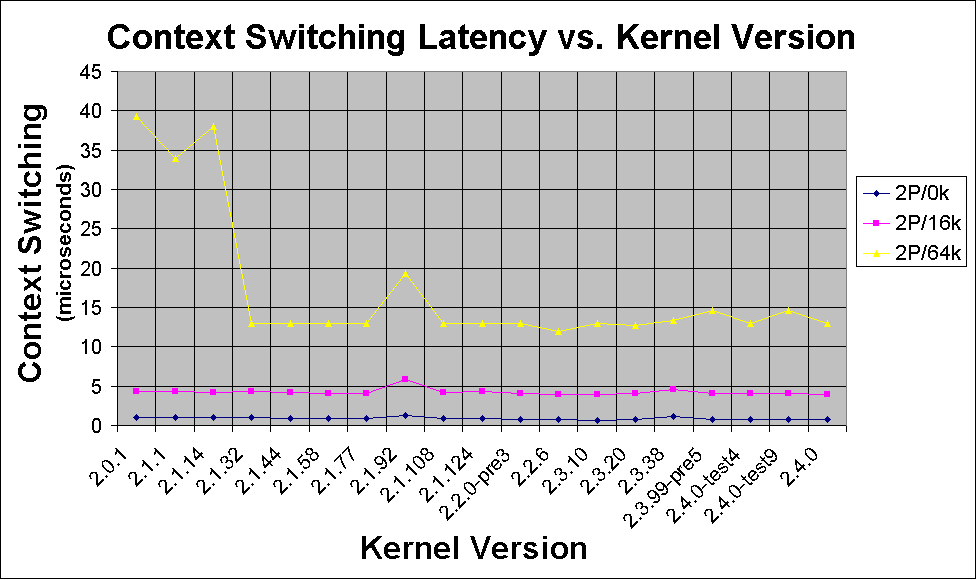
Przełączanie kontekstu
Jednym z najważniejszych zadań jądra systemu operacyjnego jest zarządzanie procesami i wątkami. Przełączanie kontekstu zdarza się gdy prosesy są przełączane na CPU i jest dużym wydatkiem bo w tym czasie system nie pracuje.LMBench mierzy czas przełączania kontekstu tworząc 2, 4, 8 lub 16 procesów połączonych w pierścień. Każdy proces wysyła dane do następnego przy użyciu łacza pipe. Wielkości komunikatów są 0k, 16k lub 64k.
Wyniki uzyskane przez LMBench dla 2 procesów i komunikatów wielkości 0k i 16k.
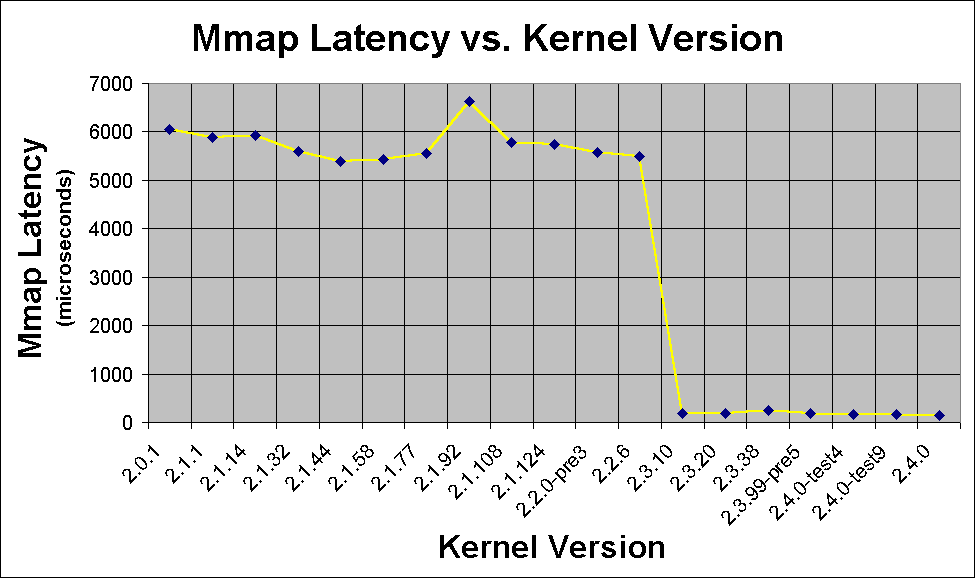
Mmap Latency
Mmap (memory map) latency mierzy jak długo procesor allokuje nowy segment pamięci RAM i prenosi do niego zawartość pliku. Zakładamy, że plik jest już w cachu. To jest test podsystemu zarządzania pamęcią, a nie podsystemu plików.Z wykresu możemy wywnioskować, że między jądrem 2.2.6 i 2.3.10 nastąpiła zmiana, pozwalająca na szybszą allokacje pamięci.
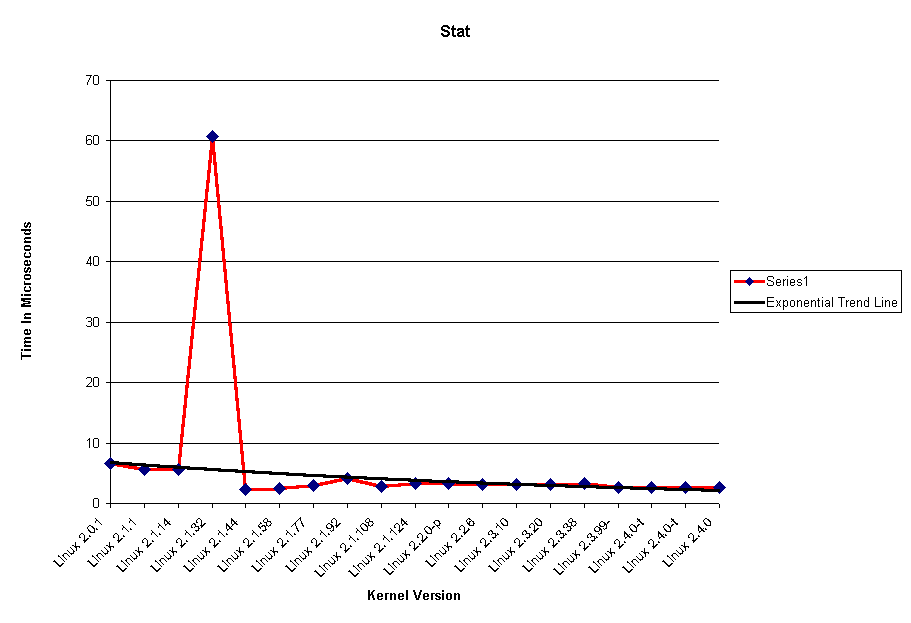
Stat
stat() zwraca informacje o pliku takie jak prawa dostępu, ostatnia modyfikacja, ostatni dostęp, nazwa pliku.
Prędkość stat() zależy od prędkości CPU, efektywności kernela, a także od dysku.
Testy zostały przeprowadzone na tym samym komputerze, przy tych samych warunkach, aby testy zależały jedynie od kodu.
Stat
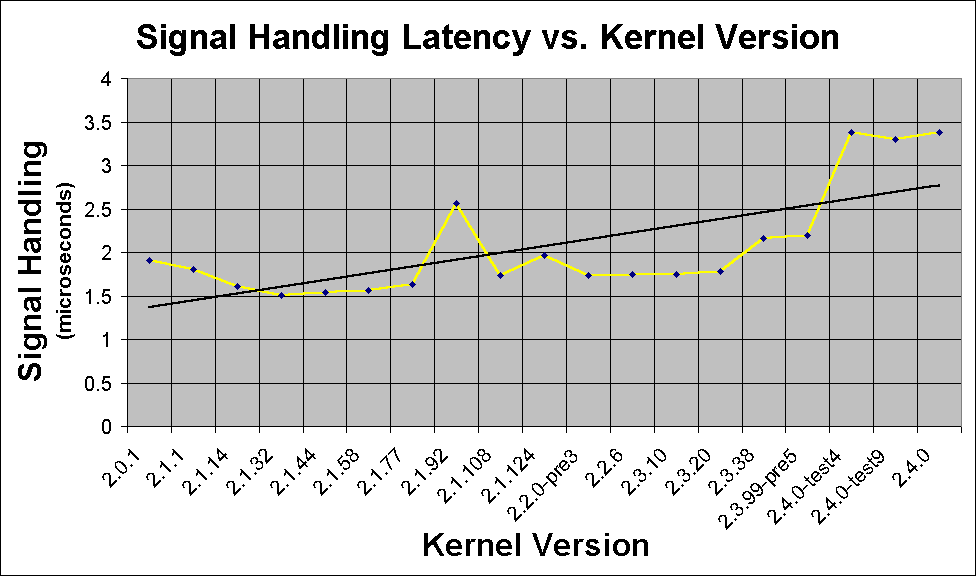
Specjalne zdarzenia powodują wysyłanie do systemu specjalnych sygnałów. Sygnały mozna podzielić na trzy kategorie: błędy (dzielenie przez 0, odwoływanie się do niedozwolonych obszarów w pzmięci), zdarzenia zewnętrzne i prośby.
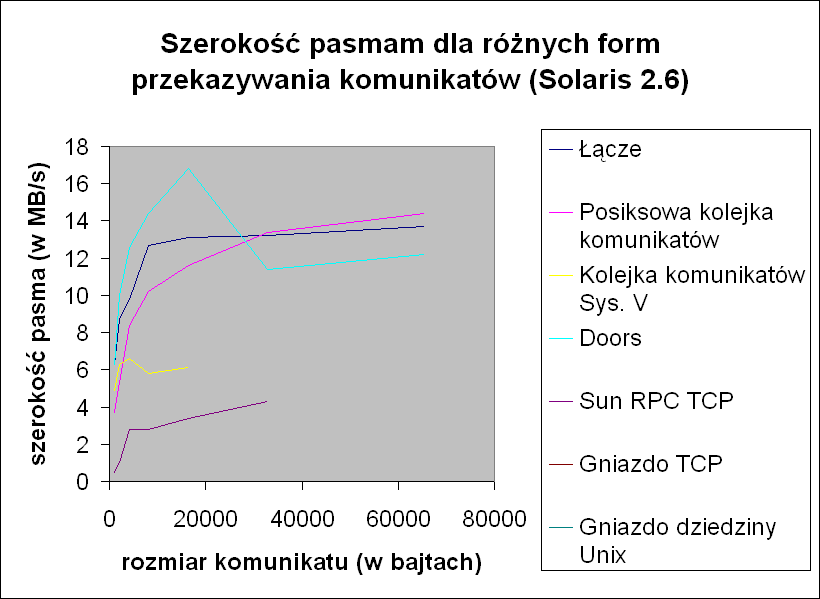
Możemy używać prostych programów do pomiaru wydajności kanałów komunikacji międzyprocesorowej, tak abyśmy mogli podjąć dobrze przemyślaną decyzję, których form komunikacji używać dla konkretnych zadań.
Gdy porównujemy różne postaci przekazywania komunikatów interesują nas dwie miary.
- Szerokość pasma (bandwidth), czyli szybkość z jaką możemy przesłać dane kanałem komunikacji. Aby ją określić wysyłamy z jednego procesu do drugiego dużą ilość informacji (miliony bajtów).
- Czas oczekwania (latency) czyli jak długo transmitowany jest krótki komunikat z jednego procesu do drugiego i z powrotem. Mierzymy tu czas przesłania komunikatu jednobajtowego i potwierdzenia jego przyjścia (round-trip time).
W rzeczywistości, szerokość pasma mówi nam o tym, jak długo trwa przesłanie dużej ilości danych przez kanał komunikacji międzyprocesorowej; ale kanały tego typu są również używane do przekazywania krótkich komunikatów sterujących, więc za pomocą czasu ocekiwania określamy czas potrzebny systemowi na przesłanie małych ilości danych. Obie wartości są więc istotne.
Wyniki
Do pomiarów użyto dwóch środowisk: SpacrStation 4/110 z systemem Solaris 2.6 oraz Digital Alpha (DEC 3000 model 300, Pelican) z systemem Digital Unix 4.0B.
Wyniki pomiaru czasu oczekiwania przy przesyłaniu komunikatów
latencyWyniki pomiaru szerokości pasma przy przesyłaniu komunikatów
Szerokość pasma dla różnych form przekazywania komunikatu (Solaris 2.6)Szerokość pasma dla różnych form przekazywania komunikatu (Digital Unix 4.0B)

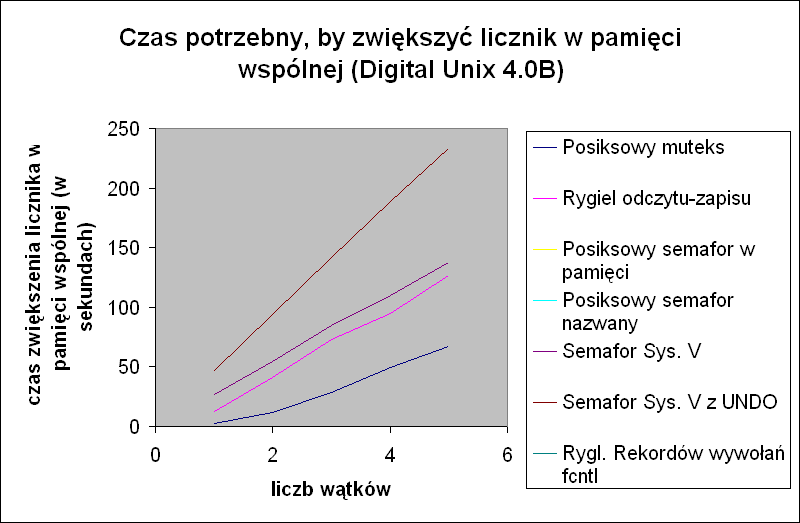
Wyniki przy synchronizacji wątków
W kolejnych tabelach przedstawione są czasy potrzebne do synchronizacji za pomocą różnych metod jednego lub więcej wątków. Każdy wątek zwiększa licznik milion razy, a liczba wątków zwiększających licznik zmienia się od 1 do 5. Ryglowanie rekordów za pomocą wywołaniafcntl możemy zmierzyć tylko dla jednego wątku, ponieważ ta forma synchronizacji działa między procesami, a nie między wieloma wątkami jednego procesu.W systemie Digital Unix dla dwóch typów semaforów posiksowych czas staje się bardzo duży, gdy mamy więcej niż jeden wątek, co wskazuje pojawienie się jakiejś anomalii. Te pomiary nie są przedstawione na wykresie.
Wyniki pomiaru czasu oczekiwania przy przesyłaniu komunikatów
Czas potrzebny by zwiększyć licznik w pamięci wspólnej (Solaris 2.6)Czas potrzebny by zwiększyć licznik w pamięci wspólnej (Digital Unix 4.0B)