Narzędzia i metodologie wykorzystywane w procesie testowania
Karol Cwalina, <k.cwalina@zodiac.mimu.edu.pl>
Temat ten podzielimy na dwie części:
- testowanie kodu (także wynikowego) w poszukiwaniu błędów „warsztatowych”;
- testowanie logiki programu.
Narzędzia do weryfikowania jakości kodu i poprawności odwołań do pamięci
Zaprezentujemy narzędzia CodeWizard oraz Insure++ firmy Parasoft, oba działające w środowisku UNIX-owym, ale wymagające X-ów. Zwłaszcza drugie z nich należy do najlepszych tego typu programów dostępnych na rynku, polecanych przez profesjonalnych twórców oprogramowania.
Pierwsze z nich służy do wykonywania tzw. statycznej analizy kodu — analizuje kod pod kątem często popełnianych przez programistów błędów (typowych „literówek”) oraz złych nawyków programistycznych, które nie są błędami, lecz mogą nimi skutkować w przyszłości.
Insure++ z kolei jest narzędziem przeznaczonym do wyszukiwania błędów w zarządzaniu pamięcią (np. wycieków pamięci) w już skompilowanym programie.
Instalacja narzędzi
Instalacja obu narzędzi nie nastręcza trudności, przy czym co ważne, należy jej dokonywać w takim środowisku, w jakim będą wykorzystywane — w szczególności nie jest wymagane instalowanie z wykorzystaniem konta root-a.
Po zainstalowaniu niezbędne jest uzyskanie na stronie WWW producenta klucza aktywującego programy (po jednym dla każdego z nich), a następnie przeprowadzenie aktywacji — polega ona na uruchomieni programu pslic znajdującego się w podkatalogu bin.linux2/ aktywowanego narzędzia i podaniu niezbędnych informacji (program ten jest automatycznie uruchamiany po zakończeniu instalacji, ale wtedy zazwyczaj nie mamy klucza i nie sposób przeprowadzić aktywacji).
Dla wygody użytkowania należy do zmiennej PATH w swoim środowisku dodać ścieżki do podkatalogów bin.linux2/ obu narzędzi — dalej będziemy zakładać, że tak uczyniono.
Omówienie narzędzia CodeWizard
Narzędzie CodeWizard uruchamia się tak, jakby było zwykłym kompilatorem:
codewizard testowany_program.c
albo
codewizard testowany_program.c –o
testowany_program
W wyniku wykonania tego polecenia zostanie stworzony plik wykonywalny oraz otworzone okno programu Insra, służącego do wizualizacji dokonanej analizy i znalezionych przez program błędów — dwukrotne kliknięcie na „tytule” błędu wyświetli jego szczegółowy opis, a kliknięcie znajdującego się obok plusika wyświetli błędny fragment kodu.
|
Rysunek 1. Błędy znalezione w programie cykl.c |

Należy z rezerwą podchodzić do wykrywanych przez program błędów — tylko niektóre z nich są bardzo groźne (jak np. odczyt niezainicjowanej zmiennej, brak operatora przypisania dla klasy zawierającej wskaźnik), niektóre zaś są jedynie złamaniem jednego z przyjętych standardów tworzenia kodu (np. nieotaczanie „następnika” instrukcji if nawiasami klamrowymi).
Aby skoncentrować się na najistotniejszych błędach można je posortować ze względu na typ (klikamy przycisk Sort w oknie programu Insra) — wyróżniono bowiem pięć typów błędów:
|
I |
Informational (informacyjny — najmniejsze prawdopodobieństwo wystąpienia błędu) |
|
PV |
Possible Violation (potencjalne naruszenie reguł) |
|
V |
Violation (naruszenie reguł) |
|
PSV |
Possible Severe Violation (potencjalne wystąpienie groźnego błędu) |
|
SV |
Severe Violation: (wystąpienie groźnego błędu z bardzo dużym prawdopodobieństwem) |
Dlaczego CodeWizard znajduje tyle błędów? I jak on to robi?
Zdecydowana większość błędów znajdowanych przez CodeWizard jest tylko złamaniem pewnego standardu tworzenia kodu. Wspomniane już „błędy” mogą być sygnałem złej architektury programu albo stać się źródłem błędów w przyszłości.
Na przykład:
- brak operatora przypisania dla klasy zawierającej wskaźnik — taka architektura uniemożliwia gospodarkę pamięcią, gdyż poza szczególnymi przypadkami nie wiadomo, kiedy można ją zwolnić (błąd typu V/SV);
- opuszczanie nawiasów klamrowych wokół pojedynczej instrukcji „następnika” instrukcji if — przy próbie szybkiej zmiany „następnika” na bardziej złożony można zapomnieć o dodaniu nawiasów (błąd typu PSV).
O ile powyższe błędy można zaliczyć do błędów stylistycznych, to inne błędy, takie jak odwoływanie się do niezainicjowanych (lub zainicjowanych, ale być może na NULL) zmiennych wskaźnikowych są błędami poważnymi i w dodatku trudnymi do wyśledzenia.
Czasem zdarza się, że zmienna wskaźnikowa jest inicjowana w miejscu deklaracji (istnieje zresztą w CodeWizard wymóg stosowania takich deklaracji), lecz nie ustaloną wartością, a wynikiem wywołania pewnej, nieznanej w fazie kompilacji, funkcji.
Dużym wyzwaniem jest zaproponowanie takiej metodologii analizy kodu, by podnosić alarm tylko wtedy, gdy odwołanie faktycznie grozi wykonaniem niepożądanej operacji (np. próbą dereferencji wskaźnika NULL). Pomysłem teoretycznym radzenia sobie z takimi przypadkami jest wyszukiwanie sprzeczności — zakładamy, że jeśli użytkownik nie sprawdza, czy zwróconą wartość jest NULL, to robi to świadomie; lecz jeśli w innym miejscu kodu dokonuje sprawdzenia, to stwierdzamy, że w którymś z nich mamy do czynienia z błędem.
Omówienie narzędzia Insure++
Narzędzie Insure++ uruchamia się podobnie, jak CodeWizard, czyli tak, jak by było kompilatorem. Ponieważ chcemy, by informacja na temat znalezionych błędów była jak najdokładniejsza, kompilujemy z flagą –g:
insure [gcc] –g
testowany_program.c
albo
insure [gcc] –g
testowany_program.c –o testowany_program
Nawiasy kwadratowe wokół gcc oznaczają, że podanie informacji o kompilatorze jest możliwe, ale niekonieczne.
W wyniku wykonania tego polecenia otrzymamy program wykonywalny. Jego uruchomienie spowoduje otworzenie okna programu Insra, w którym opisane zostaną błędy związane z gospodarką pamięcią, wykryte w czasie jego działania.
|
Rysunek 2. Wykroczenie poza tablicę w programie bubble.c |

Warto zauważyć, że wykryto nie tylko obszar pamięci, którego dotyczy błąd, ale także miejsce w programie, w którym został on spowodowany. Jest to możliwe dzięki kompilacji z flagą –g.
Jeśli nie dysponujemy kodem źródłowym programu, możemy spróbować znaleźć przynajmniej niektóre z błędów, przede wszystkim te, polegające na odwołaniu się do nie przydzielonej pamięci.
W tym celu należy skorzystać z programu Chaperon, będącego częścią instalacji Insure++:
Chaperon wykonywany_program
Na przykład tak:
Chaperon ./writover
|
Rysunek 3. Wykroczenie poza tablicę w programie writover.c |
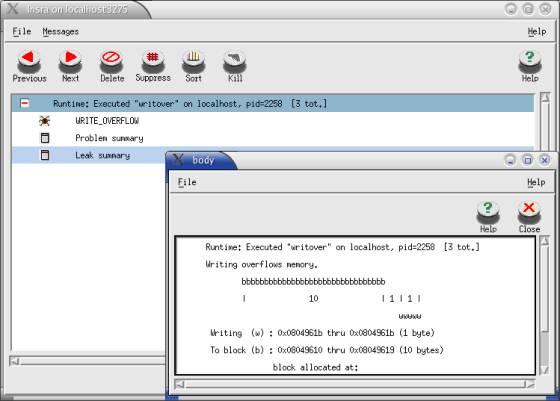
Trzeba zauważyć, że nie da się w ten sposób wychwycić błędu takiego, jak w pierwszym przykładzie, gdy następowało odwołanie do naszej pamięci, ale przydzielonej innej tablicy.
Wycieki pamięci
Czasem źródłem problemu nie jest niepoprawne odwołanie do pamięci, lecz „zgubienie” przydzielonego bloku pamięci — pozostaje on nadal przydzielony, lecz nie ma sposobu, by się do niego odwołać, bo nie istnieje już odpowiedni wskaźnik.
Insure++ pomaga także w tym przypadku — znajduje wyciek oraz podaje informację zarówno o miejscu programu, w którym przydzieliliśmy zgubiony blok, jak i o miejscu kodu, w którym następuje jego zgubienie.
|
Rysunek 4. Wycieki pamięci w programach leakfree.c i leakret.c |
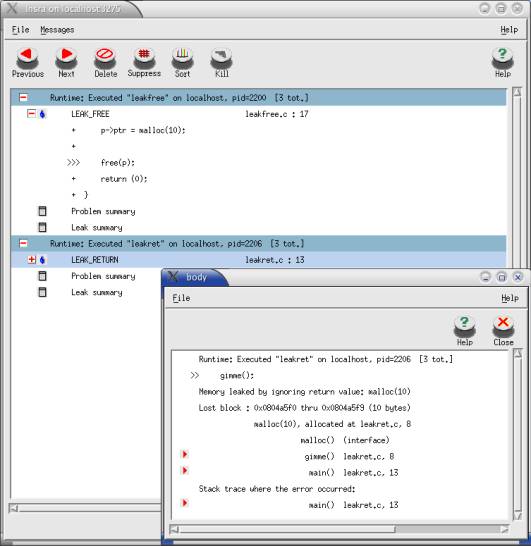
Czasem informacja, jaką otrzymamy w wyniku uruchomienia programu skompilowanego przy użyciu Insure++, może być niewystarczająca, np. gdy pewna funkcja działająca na pamięci jest wywoływana w bardzo wielu różnych miejscach.
W takiej sytuacji pomocny może się okazać program Inuse, obrazujący wykorzystanie pamięci w czasie. Aby go uruchomić, należy w katalogu z kompilowanym plikiem stworzyć plik .psrc o treści
insure++.inuse on
poczym program skompilować przy użyciu polecenia insure.
W wyniku uruchomienia tak skompilowanego programu, obok okna Insr-y pojawi się okno programu Inuse:
|
Rysunek 5. Inuse podłączony do programu slowleak.c |
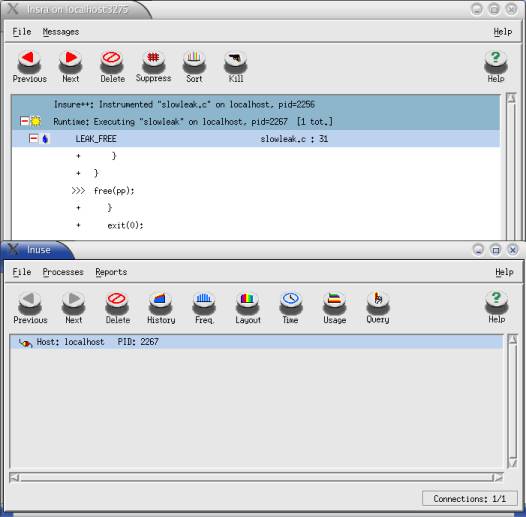
Klikając w odpowiednie ikony możemy otworzyć okna z różnymi informacjami, np. Heap History mówi jaka część z dostępnej pamięci została przydzielona oraz jaka część z niej już wyciekła w danej chwili czasu. Opierając się na tych informacjach można np. określić, w której fazie działania programu następuje wyciek albo kiedy najintensywniej korzystamy z pamięci.
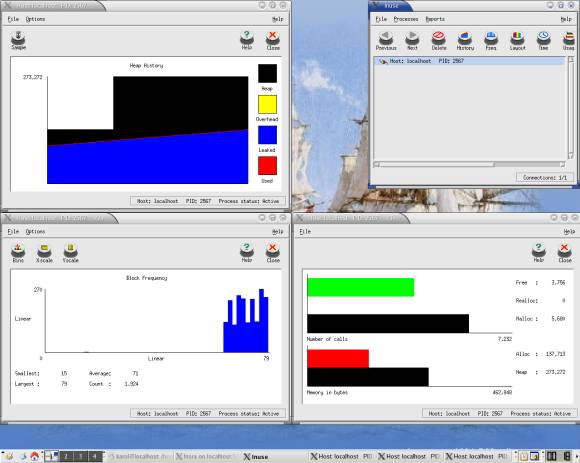
Rysunek 6. Inuse podłączony do programu slowleak.c
Czego nam nie powie Insure++
Z tego co do tej pory powiedzieliśmy można by wnioskować, że Insure++ jest narzędziem doskonałym. Tak jednak nie jest, co zaraz pokażemy.
Oto napisany na potrzeby tego testu program i efekt jego uruchomienia:
|
Rysunek 7. Bezsilność Insure++ wobec programu cykl.c |
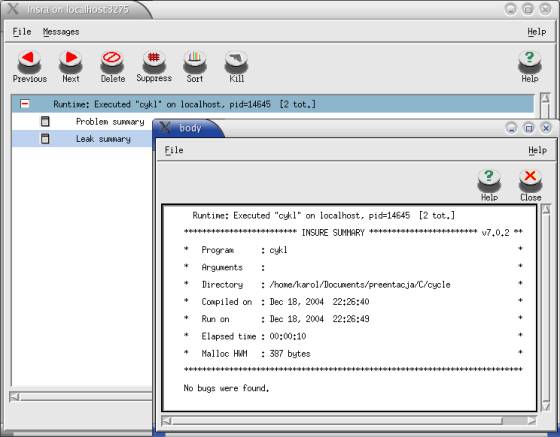
Program ten wywołuje funkcję zapetl(), która tworzy dwie struktury dynamiczne, z których każda wskazuje na drugą. W momencie zakończenia tej funkcji tracimy wskaźniki do każdej z nich, a pomimo to Insure++ nie stwierdza wycieku pamięci — dlaczego tak się stało?
Zagadnienie wykrywania wycieków pamięci mocno wiąże się z problemem odśmiecania (ang. Garbage Collection) w takich językach jak Java — ponieważ nie ma tam sposobu zniszczenia obiektu, system sam musi wykrywać i niszczyć te obiekty, które już nigdy nie zostaną wykorzystane, gdyż w przeciwnym razie bardzo szybko zostanie wykorzystana dostępna programowi pamięć.
Najprostszą techniką znajdowania takich obiektów jest wyszukiwanie tych, do których nie prowadzi żaden „wskaźnik” — jak widać na powyższym przykładzie jest to technika bardzo niedoskonała. Można przypuszczać, że właśnie taka metoda została zastosowana w produkcie Parasoftu.
UWAGA: Ponieważ produkty Parasoftu mają bardzo krótki okres ważności licencji „trial” oraz względnie długi czas oczekiwania na nią, podczas prezentacji wykorzystano bezpłatne narzędzie Valgrind.
Ma ono możliwości zbliżone do narzędzia Chaperon i korzysta się z niego w ten sam sposób, czyli np. pisząc
valgrind --tool=memcheck -—leak-check=yes ./writover
Testowanie logiki programu
W tej części skupimy się na problemie zagwarantowania zgodności naszego programu z naszymi oczekiwaniami wobec niego. Ponieważ jest to ważne przede wszystkim dla bardzo dużych projektów, a w mniejszym stopniu dla nas, przedstawimy jedynie najprostsze rozwiązania.
Jakie testy tworzyć?
W zależności od momentu powstawania testów możemy wyróżnić co najmniej dwie kategorie:
· black-box — testy są tworzone na podstawie specyfikacji programu i sprawdzają, czy program ją spełnia;
· white-box — testy są tworzone na podstawie kodu programu: widząc kod i jego potencjalnie słabe punkty próbuje się skonstruować odpowiednie testy.
Wydaje się, że testy typu black-box są bardziej wiarygodne, gdyż ze swej natury muszą testować bardzo różne aspekty działania programu, nie ograniczając się do samych „trudnych kawałków”.
Niestety, dobre zaprojektowanie zestawu testów nie jest rzeczą prostą — dzieje się tak m.in. ze względu na ogromną liczbę możliwych przebiegów programu w zależności od danych wejściowych.
W takim przypadku trzeba zadowolić się sprawdzeniem tylko części z nich. I to trzeba jednak wykonać „z głową”. Nie wystarczy np. wykonanie wielu testów dla losowych danych — losowe testy pozwalają zazwyczaj sprawdzić zdecydowaną większość z występujących w programie linii kodu, ale zazwyczaj nie udaje się w ten sposób sprawdzić linii obsługujących przypadki brzegowe.
Dlatego też obok testów wygenerowanych losowo, powinny się znaleźć testy badające zachowanie programu dla specjalnych przypadków danych.
Jak testować testy?
Testy również należy testować! Powinniśmy bowiem mieć pewność tego, że jeśli nasz program przeszedł wszystkie testy, to jest poprawny (albo jest tak z bardzo dużym prawdopodobieństwem). Aby nabrać tej pewności możemy zastosować tzw. testowanie mutacyjne.
Polega ono na dodawaniu do przetestowanego programu błędów i uruchomieniu zmodyfikowanego programu na tym samym zestawie testów. Jeśli wykryły one wszystkie błędy, to możemy mieć nadzieję, że testy są faktycznie dobre — jeśli nie, to koniecznie należy je poprawić.
Aby testowanie mutacyjne było wiarygodne, błędy które dodajemy do programu powinny być możliwie subtelne — niestety rzadko kiedy jesteśmy w stanie wymyślić tak subtelne błędy jak te, które się faktycznie w programie ukrywają. To jest właśnie największa bolączka testowania mutacyjnego.
Jak wyręczyć się komputerem?
Proces testowania jest bardzo powtarzalny, a stąd znakomicie nadaje się do zautomatyzowania. Z drugiej strony jest bardzo ważny dla rozwoju każdego programu. Oba te czynniki zaowocowały powstaniem wyspecjalizowanych narzędzi.
Obecnie za wzorcowy jest uważany JUnit. Jest to zbiór klas napisanych w Javie, dziedzicząc z których można dość łatwo zaimplementować proces testowania napisanego w Javie programu.
Jego port dla języka C++ nosi nazwę CppUnit — jest jednak dużo trudniejszy w korzystaniu, ze względu na hybrydowy charakter języka C++, a także, co podkreślają niektórzy użytkownicy, zbyt skomplikowany. To zmotywowało twórcę CppUnit do stworzenia dużo prostszej platformy testowej, którą nazwał CppUnitLite.
Podstawy pracy z CppUnitLite zaprezentujemy na przykładzie testów, zbudowanych dla klasy Complex, implementującej porównywanie liczb zespolonych, której kod został podzielony na dwa pliki: Complex.h oraz Complex.cpp.
Program testujący zapisany jest natomiast w pliku ComplexTest.cpp:

Rysunek 8. Kod programu testującego klasę Complex
Dodawanie kolejnych testów odbywa się poprzez wywołanie makra TEST, po którym następuje blok opisujący test.
Pierwszym argumentem makra jest nazwa grupy testów, drugim zaś nazwa przypadku testowego, która tak, jak w przykładzie, powinna się zmieniać.
Jeśli drzewo katalogowe CppUnitLite-a znajduje się w katalogu z testowaną klasą (tak jak w tym przypadku), to skompilowanie testu może się odbyć np. następującym poleceniem.
g++ ComplexText.cpp
Complex.cpp CppUnitLite/*.cpp –o ComplexTest
,a uruchomienie, to po prostu uruchomienie powstałego programu:
./ComplexTest
Przykładowe wywołanie zostało uwiecznione na screenshocie

Linki
· CodeWizard i Insure++ firmy Parasoft
· Valgrind