Każda strona potrzebuje osobnej ramki. Niestety ramek jest dużo mniej niż stron toteż niektóre ramki muszą być zwalniane. Jeżeli potrzeba przestrzeni i konkretna (dana) strona nie była ostatnio wykorzystywana, jest ona zachowywana na dysku i przestrzeń jest zwalniana dla bardziej aktywnych stron. Strony zachowane na dysku są przywracane do pamięci kiedy znów są potrzebne.
Mapowanie (odwzorowanie) jest funkcją: dana strona wirtualna może mieć tylko jedno fizyczne miejsce.
Informacja o odwzorowaniu jest podzielona na "tablice stron", które są zbiorami "pozycji tablicy strony" (PTEs). Każda PTE zwykle przechowuje informację dla jednej strony w danym czasie.
Mapowanie odwrotne jednakże - od numerów ramki strony do numerów wirtualnych strony - niekoniecznie jest funkcją, jest zatem możliwe zamapowanie kilku wirtualnych stron do tej samej ramki strony.
Rzeczywiste implementacje nie wymagają zarówno numeru strony wirtualnej i numeru ramki strony;
jedno lub drugie wynika często z lokalizacji PTE w tablicy.
Przeszukiwanie tablicy może zostać uproszczone jeśli PTE są złożone kolejno w taki sposób,
że numer strony wirtualnej lub numer ramki strony mogą zostać użyte jako przesunięcie (offset)
do odnalezienia właściwej PTE.
Prowadzi to do dwóch typów organizacji tablic stron:
"odwzorowywane w przód" lub "hierarchiczna tablica stron", indeksowana przez numer strony
wirtualnej;
"odwzorowywana wstecz" lub "odwrócona tablica stron", indeksowane przez numer
ramki strony.
Rysunek pokazuje kroki przy dostępie do hierarchicznej tablicy stron z góry do dołu.
Pierwsze 10 górnych bitów indeksuje 1024-pozycyjną tablicę strony root'a, której adres bazowy jest zwykle
przechowywany w rejestrze sprzętowym.
Oznaczony PTE daje fizyczny adres 4kB strony PTE lub wskazuje czy strona PTE jest na dysku lub niewydzielona.
Zakładając, że strona jest w pamięci, następne 10 bitów adresu wirtualnego indeksuje tą stronę PTE.
Wybrana PTE daje numer ramki strony 4-go kB strony wirtualnej oznaczonej przez brakujący adres wirtualny.
Dolne 12 bitów adresu wirtualnego indeksuje stronę fizycznych danych aby osiągnąć (dostać się do) żądany bajt.
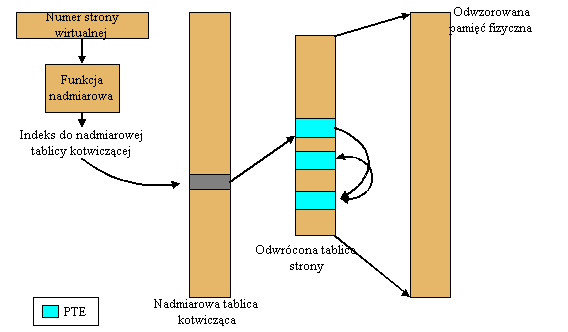
Rysunek powyżej pokazuje klasyczną, odwróconą tablicę strony, która ma kilka zalet w porównaniu z tablicą hierarchiczną.
Zamiast jednej pozycji (wejścia) dla każdej strony wirtualnej należącej do procesu, odwrócona tablica ma jedno
wejście dla każdej ramki strony w pamięci głównej.
Indeks PTE w tablicy odwróconej jest równy numerom ramki strony odwzorowywanej strony.
Zatem zamiast skalowania przestrzeni wirtualnej zajmuje się skalowaniem fizycznej pamięci.
To znaczna przewaga nad tablicą hierarchiczną gdy projektant zajmuje się 64-bitowymi przestrzeniami adresowymi.
Rzadko zdarzają się wejścia niewykorzystane opuszczające miejsce.
Struktura tablicy strony jest zwana "odwróconą", gdyż indeksuje PTE numerami ramek strony a nie numerami stron wirtualnych. Zwykle jednak system przegląda tablicę strony w celu znalezienia numeru ramki strony dla danego numeru strony wirtualnej, więc numer ramki strony nie zawsze jest dostępny. Dlatego odwrócona tablica używa także dodatkowego (nadmiarowego) indeksu opartego na numerze strony wirtualnej. Ponieważ różne numery strony wirtualnej mogą dać w efekcie identyczne wartości nadmiarowe, używa się mechanizmu łańcucha kolizji aby umożliwić jednoczesne istnienie tych odwzorowań w tablicy.
Każda ramka pamięta tablice stron co zajmuje dużo pamięci.
Przy każdym zamapowaniu lub odmapowaniu system musi uaktualniać strukturę.
Mimo wszystko zmiana algorytmu wyszła z korzyścią, przyspiesza administrowanie pamięcią.