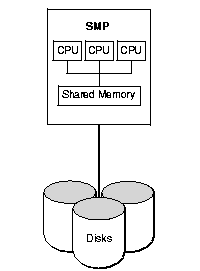
SMP:
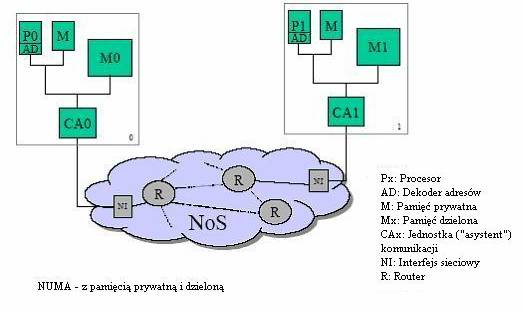
NUMA:
Obsługa NUMA i Hyperthreading
NUMA (Non-Uniform Memory Access) – jedna z architektur komputerowych (ma sens tylko przy wielu procesorach) , gdzie czas dostępu procesora do pamięci zależy od jej fizycznej lokalizacji. Każdy procesor ma dużo szybszy dostęp do swojej lokalnej pamięci (z założenia musi ją mieć), niż do nie-lokalnej (czyli lokalnej jakiegoś innego, tudzież dzielonej przez procesory). Jest to zerwanie z balastem SMP (Symmetric Multiprocessing) gdzie pamięć operacyjna, współdzielona przez wszystkie procesory maszyny, staje się szybko wąskim gardłem całego systemu.
SMP:
NUMA:
Przykłady - NEC Azusa, IBM x440, IBM NUMAQ. Wykorzystanie takich komputerów – np. wielkie serwerownie
Po co jeszcze rozdzielać pamięć w ten sposób? Mogłoby się wydawać, że to niepotrzebna komplikacja, że jedyną zaletą jest to, że każdy procesor ma jakąś pamięć bliżej, ale... wszystkie inne dalej. Niewiele jednak rzeczy tak obniża wydajność pamięci cache jak dostęp do tych samych obszarów danych przez różne procesory. W takich sytuacjach (gdy procesor sięga to tu, to tam) w pamięci cache dużo częściej zapisywane są coraz to nowe rzeczy, natomiast dużo rzadziej korzysta się z tego, co już tam jest. Ograniczanie każdego procesora do ‘jego działki’ eliminuje marnowanie cache’a, czym mocno zwiększa wydajność.
Do optymalnego działania (czyt. - obsługi architektury NUMA) jądro musi znać szczegóły rozmieszczenia pamięci (i procesorów) i zapewniać, żeby była ona używana przez odpowiedni procesor. Służą temu odpowiednie struktury i makra, wykorzystywane przez podsystem VM (wirtualnej pamięci) – on odpowiednio przydziela pamięć. Oczywiście bardzo ważną rolę odgrywa tu również scheduler, omówiony w punkcie Scheduler O(1) .
W architekturze NUMA dla większości procesów optymalnym rozwiązaniem jest przydzielenie im pamięci w jednym węźle i obsłużenie ich przez procesor z tego węzła. Również należy pamiętać, aby proces, przez całe swoje istnienie w systemie był wykonywany w jednym węźle (tzn. zawsze na tym samym procesorze). Dzięki temu ma on częściej szansę skorzystać z danych w pamięci podręcznej tego procesora.
Hyperthreading – hiperwątkowość, technologia opracowana przez firmę Intel (i na razie obecna jedynie w pocesorach Intel IV) umozliwiająca wykonywanie wielu wątków (procesów wynikających z procesu nadrzędnego) równolegle na pojedynczym procesorze. Takie „udawanie” kilku procesorów odbywa się na poziomie sprzętowym i często przyspiesza wykonywanie tych programów, ale jednocześnie komplikuje procedurę schedule() i nie tylko.
Obsługa mechanizmu HT w jądrze 2.6 to kolejny krok Linuxa w kierunku superserwerów, ale również komputerów domowych. Linux 2.6 jest w stanie zoptymalizować rozdział zadań pomiędzy wirtualne procesory w taki sposób, aby optymalnie wykorzystać opisywany mechanizm sprzętowy. Kluczem jest to, że obecnie scheduler wie jak rozpoznać obciążenie zarówno procesora fizycznego, jak i wirtualnego.
Ciekawostka – Microsoft wprowadził pełną obsługę HT w Windows XP
Dokumentacja