 |
 |
 |
 |
Bezpieczeństwo w systemach komputerowych
|
Wstęp
Niniejsza prezentacja
dotyczy
bezpieczeństwa w systemach komputerowych i powstała na potrzeby
przedmiotu Systemy
Operacyjne wykładanego na III roku Informatyki Uniwersytetu
Warszawskiego. Autorami
prezentacji są Łukasz Pejas, Piotr Turski i Rafał Wawrzyńczyk.
Prezentacja problemu
Bezpieczeństwo w systemach komputerowych jest
tematem tak bogatym,
że nie sposób choćby skrótowo przedstawić wszystkich jego aspektów w
ramach jednej
prezentacji. Obejmuje ono bowiem takie dziedziny jak:
- ludzie
(pracownicy, obsługa, użytkownicy)
- sprzęt
- oprogramowanie
- nośniki danych
- infrastruktura
(budynki, kontrola, zasilanie)
- dane (wyniki
obliczeń, książki adresowe, itd.)
- komunikacja (sieć,
poczta elektroniczna, itd.)
W związku z powyższym
autorzy
prezentacji zdecydowali się skoncentrować na kilku wybranych kwestiach.
Plan prezentacji
jest następujący:
- bezpieczeństwo
aplikacji - luki, metody włamań
- wybrane aspekty
bezpieczeństwa w sieciach
- mechanizmy obronne
na granicy sieci
- mechanizmy obronne
zintegrowane z systemem operacyjnym
|
Bezpieczeństwo aplikacji - luki, metody włamań
|
Istnieją setki rodzajów zagrożeń prawidłowego
funkcjonowania
systemów komputerowych. Należą tu m.in.
- przepełnienie bufora (buffer-overflow)
- niebezpieczne konstrukcje SQL (SQL
Injection)
- wirusy
- robaki
- konie trojańskie
- bomby logiczne
- ataki DoS i DDoS
i wiele, wiele
innych. Poniżej
przedstawimy skrótowe omówienie wybranych rodzajów zagrożeń, a ze
szczególną uwaga
potraktowane zostaną przepełnienie bufora i niebezpieczne konstrukcje
SQL.
Wirusy -
programy posiadające
zdolność do samopowielania się bez wiedzy użytkownika, dzięki czemu
mogą szybko
rozprzestrzeniać się w zainfekowanym systemie jak i poza nim (np. za
pośrednictwem
sieci internetowej). Wirus może doczepić się do kodu programu powodując
jego
wydłużenie lub nadpisać istniejący kod. Wirus składa się z głowy (część
przejmująca sterowanie wykonaniem programu i służąca do samoreplikacji)
oraz ogona (mającego charakter opcjonalny
i zawierającego kod
odpowiedzialny np. za wyświetlanie jakiegoś napisu, kasowanie plików,
itp.).
Przykładowymi klasyfikacjami wirusów są następujące podziały:
- wirusy rezydentne
- instalujące się w pamięci i rozpoczynające swoje działanie wówczas,
gdy są spełnione określone warunki (np. nastaje wyznaczony dzień).
- wirusy
nierezydentne - aktywowane wraz z zarażonym programem i usuwane z
pamięci po wykonaniu swoich "zadań"
- wirusy dyskowe
(wirusy sektora ładującego, boot sector viruses) - wirusy
rezydentne, które uaktywniają się przy starcie systemu z zainfekowanego
nośnika
- wirusy plikowe -
wirusy dołączające się do plików wykonywalnych i aktywowane przez
uruchomienie tego programu; mogą być zarówno rezydentne, jak
i nierezydentne
- wirusy hybrydowe -
atakują zarówno rekord ładujący systemu jak i pliki.
Robaki (worms)
-
programy, których celem jest rozprzestrzenianie się za pośrednictwem
sieci internetowej
(niekoniecznie ma na celu modyfikowanie plików w systemie). Robaki
propagują się np.
drogą rozsyłania swoich kopii do osób zapisanych w książce adresowej
danej osoby.
Robak przesyłany jest w załączniku, a plik go zawierający ma często
podwójne
rozszerzenie (np. girl.jpg.vbs).
Rozszerzenie .vbs
jest ukrywane
domyślnie.
Konie trojańskie
- fragmenty
kodu ukryte w programie i mogące wykonywać w sposób utajony zadania
niemile widziane
przez użytkownika (np. usuwanie plików). Konie trojańskie nie posiadają
zdolności do
samopowielania, a zarazić się nimi można jedynie instalując na dysku
program będący
nosicielem.
Bomby logiczne
- fragmenty kodu
zazwyczaj "uśpionego", a uruchamianego w przypadku spełnienia
określonego warunku
(np. uruchomienie określonego programu, nastanie wyznaczonego dnia).
Bomby są często
wykorzystywane do szantażu komputerowego.
Ataki DoS (Denial
of Service)
i DDoS (Distributed Denial of Service) - celem
ataków odmowy
dostępu jest zawieszenie lub ograniczenie funkcjonalności atakowanego
serwera. Istnieje
kilka głównych odmian ataków DoS; jedną z najczęściej stosowanych jest
"zasypanie" ofiary ogromną liczbą pakietów, co powoduje znaczne
spowolnienie
działania wybranej maszyny lub jej całkowite zawieszenie. Wersja
rozproszona stosowana
jest przeciwko dużym serwisom internetowym i w znaczniej mierze
utrudnia identyfikację
napastników.
Przepełnienie bufora (buffer
overflow) - spopularyzowane zostało artykułem "Smashing The Stack
For Fun And
Profit" opublikowanym w czasopiśmie Phrack w listopadzie 1996 r. Jest
jedną z
najczęściej stosowanych metod włamań do systemów komputerowych,
ponieważ
niejednokrotnie umożliwia uruchomienie dowolnego kodu z prawami roota.
Aby osiągnąć swój cel, osoba dokonująca włamania
przy pomocy
przepełnienia stosu musi spełnić dwa cele cząstkowe:
- sprawić, by
spreparowany przez nią kod znalazł się w przestrzeni adresowej
atakowanego programu
- spowodować, by
program przeszedł do tak załadowanego kodu
Pierwszy z
wymienionych celów
osiągnąć można dwoma sposobami: aplikując przygotowany kod jako wejście
programu lub
parametryzując kod już obecny w przestrzeni adresowej (np. ustawiając
parametr "/bin/sh"
i skacząc do kodu
biblioteki libc).
Cel drugi
osiągany jest przez przepełnienie bufora i nadpisanie sąsiednich
adresów żądaną
sekwencją bajtów. Najczęściej nadpisywane są:
- rekordy aktywacji
- odkładane na stosie przy każdym wywołaniu funkcji i zawierające m.in.
adresy powrotu, informujące o miejscu, do którego powinien "skoczyć"
program po zakończeniu wykonywania funkcji (rys. 1)

Rys. 1. Rekord
aktywacji odkładany na stos.
- wskaźniki funkcji,
które mogą być alokowane na stosie, stercie i w obszarze danych
statycznych (static data area)
- bufory longjmp
Najbardziej
powszechnym sposobem
osiągnięcia wymienionych powyżej celów jest zaaplikowanie do programu
spreparowanego
słowa i nadpisanie rekordu aktywacji. Ujmując rzecz od strony
praktycznej, fragment kodu
uruchamiający shella zostaje skompilowany do postaci maszynowej i
włączony do
spreparowanego napisu, który przekracza rozmiar bufora i będzie
argumentem funkcji. Po
przekazaniu napisu do funkcji adres powrotny zostaje nadpisany
wykonywalnym kodem lub
wskaźnikiem do kodu uruchamiającego shell. Tak uruchomiony shell
posiada uprawnienia
programu, spod którego został uruchomiony (w szczególności są to
uprawnienia roota).
Przykładem programu
prowadzącego do
przepełnienia stosu jest
void
function(char *str)
{
char buffer[16];
strcpy(buffer,str);
}
void main()
{
char large_string[256];
int i;
for( i = 0; i < 255; i++)
large_string[i] = 'A';
function(large_string);
}
Ilustrację graficzną
przepełnienia
bufora przedstawia rys. 2.

Rys. 2. Przepełnienie
bufora.
Jak dotychczas brak w
pełni skutecznego
sposobu ochrony systemu przed atakami wykorzystującymi przepełnienie
bufora. Do
najczęściej wymienianych metod obrony należą:
- poprawne kodowanie
- zwrócenie szczególnej uwagi na funkcje strcpy, sprintf, scanf,
itd., które nie sprawdzają długości swoich argumentów. Większość z nich
posiada bardziej bezpieczne odpowiedniki (strncpy, snprintf,
itd.).
Niepoprawnie:
void func(char
*str)
{
char
buffer[256];
strcpy(buffer,
str);
return;
}
Poprawnie:
void func(char
*str)
{
char
buffer[256];
strncpy(buffer,
str, sizeof(buffer) -1);
buffer[sizeof(buffer)
- 1] = 0;
return;
}
Niepoprawnie:
void
func(char *str)
{
char
buffer[256];
buffer[0]
= '\0';
strcat(buffer,
str);
return;
}
Poprawnie:
void
func(char *str1, *str2)
{
char
buffer[256];
buffer[0]
= '\0';
strncpy(buffer,
str1, sizeof(buffer) - 1);
buffer[sizeof(buffer)
- 1] = '\0';
/*
concatenate string, calculate amount of space we have left in buffer */
strncat(buffer,
str2, sizeof(buffer) - strlen(buffer) - 1);
return;
}
(na
podstawie [8])
Wykaz
funkcji
stwarzających bezpośrednią okazję do przepełnienia bufora
obejmuje:
- specjalne
debuggery, dokonujące losowych iniekcji "podejrzanych" miejsc i
sprawdzające, czy może dojść do przepełnienia bufora
- blokada
wykonywania kodu w segmencie stosu (dostępne są patche dla Linuxa i
Solaris)
- kompilatory C z
kontrolą przepełnienia bufora: Compaq C (ograniczona kontrola przy
opcji -check_bounds),
patch gcc autorstwa
Jonesa i Kelly'ego (pełna kontrola kosztem 30-krotnego spowolnienia;
kompilator zawodzi w przypadku dużych programów)
- stosowanie
"bezpiecznych" języków programowania (Java, ML). Należy jednak mieć na
uwadze, że większość kodu systemów operacyjnych została napisana w C;
podobnie rzecz się ma z wirtualną maszyną Javy (jest programem C).
- StackGuard - jedna
z metod tzw. code pointer integrity checking, czyli innego niż
kontrola przepełnienia bufora podejścia do zapobiegania buffer-overflows.
Istotą tej grupy metod jest wykrycie faktu nadpisania wskaźnika (adresu
powrotu) zanim program zdąży się do niego odwołać.
Sam
StackGuard jest
patchem gcc
umieszczającym
specjalne słowo (tzw. canary) na stosie tuż po adresie
powrotnym. Nadpisanie
adresu powrotu (a więc i nadpisanie canary) zostanie wykryta
zanim program odwoła
się do zmienionego adresu (rys. 3).
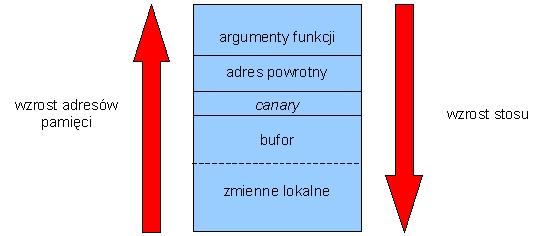
Rys. 3. StackGuard
Canary
może być słowem losowym (wybieranym z każdym uruchomieniem programu)
albo zawierać
terminatory, tj. symbole przerywające działanie funkcji kopiujących C:
0 (null), CR,
LF, -1 (EOF). Daje to gwarancję, że osoba dokonująca próby
przepełnienia bufora nie
będzie w stanie przekazać canary w spreparowanym przez siebie
słowie.
Testy
wykazują,
że najbardziej efektywną kombinacją jest stosowanie StackGuard wraz z
blokadą
wykonywania kodu w segmencie stosu.
Modyfikacją
idei
StackGuard jest PointGuard, umieszczający canary przy wszystkich
wskaźnikach funkcji.
SQL Injection -
metoda ataku baz
danych wykorzystująca luki w aplikacjach SQL i pozwalająca na ominięcie
firewalla
chroniącego bazę. Ogólnie rzecz biorąc, polega na podaniu aplikacji
sieciowej takich
parametrów, które przekażą do bazy "wrogie" zapytania SQL i zwrócą ich
wyniki.
Celem ataku może być kradzież danych lub uzyskanie dostępu do hostów
organizacji za
pośrednictwem serwera bazy danych. Aby atak mógł dojść do skutku, w
aplikacji
będącej jego przedmiotem musi być używany dynamiczny SQL.
Lista najczęściej
wykorzystywanych
metod przeprowadzenia SQL Injection obejmuje:
- dodanie do
zapytania UNION,
po
którym następuje "wrogie" zapytanie
- wykorzystanie
podzapytań
- "skrócenie"
instrukcji SQL w taki sposób, by zwracała
ona dane dotyczące większej liczby rekordów, niż instrukcja pierwotna
- wykorzystanie
składowanych pakietów i procedur (wśród nich znajdują się często takie,
które odpowiadają za odczyt i zapis w plikach)
- wykorzystanie DDL (Data
Definition Language), o ile jest on używany w aplikacji
- wykorzystanie
instrukcji INSERT,
UPDATE
lub DELETE
- wykorzystanie
powiązań między bazami danych - jeżeli zaatakowana baza zawiera
połączenia (links) z inną bazą, to możliwe jest dokonanie ataku
na bazę danych, do której nie ma bezpośredniego dostępu przez Internet
Załóżmy (przykład na podstawie
[2]), że w bazie
danych składowana jest procedura get_cust(surname
in
varchar2) podająca numer
pracownika o nazwisku surname:
create or
replace
procedure
get_cust (lv_surname in varchar2)
is
type cv_typ is ref cursor;
cv cv_typ;
lv_phone
customers.customer_phone%type;
lv_stmt
varchar2(32767):='select
customer_phone '||
'from customers '||
'where
customer_surname='''||
lv_surname||'''';
begin
dbms_output.put_line('debug:'||lv_stmt);
open cv for lv_stmt;
loop
fetch cv into lv_phone;
exit when cv%notfound;
dbms_output.put_line('::'||lv_phone);
end loop;
close cv;
end get_cust;
/
(na podstawie [2])
Możliwymi sposobami dokonania ataku SQL Injection
są w tej sytuacji
np.
- wykorzystanie UNION
(dołączone zapytanie
przekazuje osobie dokonującej ataku nazwy wszystkich użytkowników):
SQL>
exec get_cust('x'' union select username from all_users where
''x''=''x');
debug:select customer_phone
from
customers where customer_surname='x' union
select username from
all_users where
'x'='x'
::AURORA$JIS$UTILITY$
::AURORA$ORB$UNAUTHENTICATED
::CTXSYS
::DBSNMP
::MDSYS
::ORDPLUGINS
::ORDSYS
::OSE$HTTP$ADMIN
::OUTLN
::SYS
::SYSTEM
::TRACESVR
- skrócenie instrukcji pierwotnej drogą
dołączenia tożsamości do klauzuli WHERE:
SQL>
exec get_cust('x'' or ''x''=''x');
debug:select customer_phone
from
customers where customer_surname='x' or 'x'='x'
::999444888
::999555888
::999777888
Obrona przed atakami SQL
Injection obejmuje w
głównej mierze
- kontrolę kodu
aplikacji wykorzystywanych do obsługi bazy danych
- przestrzeganie
zasady najmniejszego uprzywilejowania (principle of least privilege)
na etapie projektowania i wdrażania bazy danych -
nikt, włącznie z potencjalnym napastnikiem, nie może "zobaczyć" w bazie
więcej, niż powinien
|
Wybrane aspekty bezpieczeństwa w sieciach
|
Sniffing
Sniffing jest
jedną z
najbardziej rozpowszechnionych metod przechwytywania danych
przesyłanych przez sieć.
Polega na przejmowaniu pakietów sieciowych, które często są
niezaszyfrowane (telnet,
ftp, poczta elektroniczna), a mogą zawierać interesujące dla napastnika
informacje
(login, hasło, adresy IP, itp.). Sniffery wykorzystywane są nie tylko
przez hackerów,
ale i przez agencje wywiadowcze, instytucje zajmujące się pomiarem
ruchu w sieci,
administratorów sieci, itp. Zainstalowanie sniffera wymaga praw
administratora sieci.
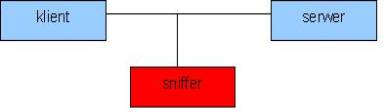
Rys. 4. Sniffer
Idea
sniffingu opiera się na fakcie,
że w sieci nie posiadającej switcha pakiety rozsyłane są do wszystkich
maszyn. W
zwykłych warunkach komputer ignoruje wiadomości nie przeznaczone dla
niego, jednak
zmiana ustawień karty sieciowej (na tzw. promiscuous mode) może
sprawić, że
komputer akceptuje wszystkie pakiety. Zamontowany sniffer może
dodatkowo usuwać z
przechwytywanych danych warstwy właściwe dla użytego protokołu i
dostarczać same
istotne informacje. Poniżej przedstawiono przykład przechwyconego
pakietu sieciowego
(żądanie klienta wysłane do serwera); po prawej stronie treść
informacji zdekodowana
do ASCII.
21:06:30.786814
0:1:3:e5:46:6b 0:4:5a:d1:46:ad 0800 650: 192.168.1.3.32946 >
66.38.151.10.80: P
[tcp sum ok] 1:585(584) ack 336 win 64080 <nop,nop,timestamp 608776
899338>
(DF)
(ttl 64, id 7468, len 636)
0x0000 4500 027c 1d2c 4000
4006 8074 c0a8 0103
E..|.,@.@..t....
0x0010 4226 970a 80b2 0050
54ac b070 78ef d6c3
B&.....PT..px...
0x0020 8018 fa50 c663 0000
0101 080a 0009 4a08
...P.c........J.
0x0030 000d b90a 4745 5420
2f63 6f72 706f 7261
....GET./corpora
0x0040 7465 2f69 6d61 6765
732f 6275 696c 642f
te/images/build/
0x0050 626c 6c74 5f72 645f
312e 6769 6620 4854
bllt_rd_1.gif.HT
0x0060 5450 2f31 2e31 0d0a
486f 7374 3a20 7777
TP/1.1..Host:.ww
0x0070 772e 7365 6375 7269
7479 666f 6375 732e
w.securityfocus.
0x0080 636f 6d0d 0a55 7365
722d 4167 656e 743a
com..User-Agent:
0x0090 204d 6f7a 696c 6c61
2f35 2e30 2028 5831
.Mozilla/5.0.(X1
0x00a0 313b 2055 3b20 4c69
6e75 7820 6936 3836
1;.U;.Linux.i686
(na podstawie [3])
Metody obrony przed sniffingiem to
- oprogramowanie typu antisniff - skanuje sieć i sprawdza, czy
jakieś karty sieciowe pracują w trybie promiscuous. System
sniffujacy jest zwykle obciążony (programowo filtruje ramki) i może
mieć to wpływ na szybkość udzielania przez niego odpowiedzi; tryb promiscuous
można wykryć dzięki niedociągnięciom w TCP/IP
- szyfrowanie pakietów (np. przy użyciu SSL). Pakiet zaszyfrowany,
nawet jeśli został przechwycony, pozostaje "nieczytelny" dla osoby
korzystającej ze snifffera
21:09:04.599289
opensource-01.ee.ethz.ch.https > 192.168.1.3.32933: P [tcp sum ok]
7011:7135(124)
ack 793 win
10052 (DF)
(ttl 237, id
65192, len 164)
0x0000 4500
00a4 fea8 4000
ed06 43e2
8184 0799 E.....@...C.....
0x0010 c0a8
0103 01bb 80a5
be10 d77f
19a2 0520 ................
0x0020 5018
2744 8303 0000
4d3a a587
805e e2bc P.'D....M:...^..
0x0030 9a2a
8ff3 fe95 46d4
930e b2bc
74f0 a484 *....F.....t...
0x0040 fcae
33ad 6d1f 0198
6020 aee5
0c26 908e ..3.m...`....&..
0x0050 a1b5
17b4 84b7 44bc
1b0b 434e
bbae a483 ......D...CN....
0x0060 1e23
38d3 520f 687e
c5e3 b62e
5225 aa2f .#8.R.h~....R%./
0x0070 f747
1a71 669c 8fd1
55bd 511c
4988 b78a .G.qf...U.Q.I...
0x0080 a08d
554e a3fe bb7d
36ca e66b
fb8b 0392 ..UN...}6..k....
0x0090 a3f3
4cef 7b04 af5a
7a94 cb4c
a1e6 e7fa ..L.{..Zz..L....
0x00a0
9610
a5ee
....
(na podstawie [3])
-
stosowanie
sieci ze switchem - inaczej niż w sieciach z hubem, do danego komputera
trafiają tylko pakiety przeznaczone dla niego. Ten sposób obrony jest
jednak łamany przy użyciu techniki zwanej arp-spoofingiem, polegającej
na podszywaniu się pod inny komputer dzięki wysyłaniu pakietów o innym,
niż rzeczywisty, adresie źródłowym.
SSL - secure sockets layer
SSL - uniwersalny standard bezpiecznych połączeń szyfrowanych klient -
serwer (opracowany przez Netscape). SSL jest protokołem ogólnego
przeznaczenia. W założeniu stanowi uzupełnienie protokołów już
istniejących, działających poniżej warstwy aplikacji (czyli HTTP, FTP,
SMTP, POP3, Telnet, etc.), a powyżej warstwy sieci i transportu (czyli
TCP/IP). Zadaniem SSL jest stworzenie wirtualnego, odpornego na próby
podsłuchiwania kanału transmisji dla informacji przesyłanych przez
aplikacje (serwery sieciowe).
zadania:
- autentyfikacja serwera
- autentyfikacja klienta
- szyfrowanie połączenia
- zapewnianie integralności danych
autentyfikacja:
SSL jest protokołem scentralizowanym, wykorzystuje instytucje
certyfikujące (Certyfing Authorities - CA) i technologię kluczy
publicznych i prywatnych. Największe firmy certyfikujące płacą
producentom przeglądarek, takich jak Netscape Navigator czy Internet
Explorer, za umieszczanie ich certyfikatów nadrzędnych w kolejnych
wersjach programów. Dzięki temu użytkownicy tych przeglądarek mogą w
bezpieczny sposób weryfikować certyfikaty serwerów podpisane przez te
firmy.
autentyfikacja serwera:
- Czy przedział czasu dla ważności certyfikatu obejmuje aktualną
datę? Jeśli nie, komunikacja zostaje zerwana.
- Czy CA, które wydało ten certyfikat jest wiarygodnym CA? klient
szuka w swojej wewnętrznej bazie certyfikatu tego urzędu. Jeśli go nie
znajdzie, może szukać go w bazie zewnętrznej, do tego celu wykorzystuje
się powszechnie katalogi LDAP. Jeśli przeglądarka uzyska w ten sposób
poszukiwany certyfikat, nie ma pewności, że certyfikat jest prawdziwy -
katalog mógł paść ofiarą włamania. Dlatego program sprawdza, kto
podpisał certyfikat znaleziony w bazie. Jeśli nikt, to hierarchia
podpisów jest naruszona, a otrzymany od serwera klucz publiczny nie
może być uznany za wiarygodny i program pyta użytkownika o decyzje.
Jeżeli jednak certyfikat CA został podpisany przez urząd znany
przeglądarce (posiada ona jego klucz publiczny wbudowany na stałe),
autentyczność klucza serwera jest potwierdzona.
- Czy klucz publiczny wydawcy certyfikatu serwera zatwierdza podpis
elektroniczny tego CA (zawarty w jego certyfikacie)? Klient za pomocą
klucza publicznego z trzymanej u siebie listy zaufanych CA weryfikuje
podpis elektroniczny dołączony do certyfikatu serwera (lub sprawdzanego
CA). Wszelka rozbieżność powoduje zerwanie połączenia.
- Czy nazwa domeny na certyfikacie serwera zgadza się z domeną
samego serwera? Nie jest to technicznie częścią protokołu SSL ale
zapobiega niebezpieczeństwu Man-in-the-Middle - programowi, który
umiejscawia się pomiędzy serwerem i klientem , generuje odrębny zestaw
kluczy dla każdego z nich i pośredniczy w komunikacji, dając złudzenie
obu stronom, że komunikują się bezpośrednio ze sobą.
autentyfikacja klienta:
- Czy klucz publiczny klienta potwierdza jego podpis elektroniczny?
Serwer sprawdza zgodność podpisu klienta z kluczem publicznym w jego
certyfikacie.
- Dalszy ciąg weryfikacji odbywa się według schematu dla
autentyfikacji serwera.
- Czy certyfikat klienta znajduje się w serwerze LDAP? Jest to
opcjonalny krok pozwalający na dodatkową weryfikację okresu ważności
certyfikatu klienta, ponieważ niektóre serwery mogą samodzielnie
określać te przedziały ważności dla swoich klientów.
- Czy dany klient ma prawo dostępu do żądanych zasobów? Ostatni
krok weryfikacji polega na sprawdzeniu praw dostępu tego klienta w ACL
(access control lists) i ustala połączenie według określonych praw.
Jak to działa?
Najważniejszą częścią protokołu SSL jest SSL Handshake Protocol,
służący ustanowieniu szyfrowanego połączenia klient-serwer. "Handshake"
przebiega według następującego schematu:
- Klient wysyła serwerowi numer swojej wersji SSL, listę
obsługiwanych algorytmów szyfrujących i kompresujących, pewne dane
losowe.
- Serwer przesyła klientowi numer swojej wersji SSL, listę
obsługiwanych algorytmów szyfrujących i kompresujących. Serwer przesyła
również swój certyfikat i - jeśli klient żąda zasobu, który wymaga
uwierzytelnienia odbiorcy - również zapytanie o certyfikat klienta.
- Klient używa informacji przesłanej przez serwer do
uwierzytelnienia serwera. Jeśli serwer nie może zostać uwierzytelniony,
komunikacja zostaje zerwana.
- Klient szyfruje za pomocą klucza publicznego serwera pewne
wstępne dane (premaster secret) i przesyła je do serwera. Jeśli serwer
żądał uwierzytelnienia klienta, klient wysyła swój certyfikat razem z
podpisem elektronicznym (czyli z losowymi danymi unikatowymi dla tej
sesji, znanymi obu stronom komunikacji, zaszyfrowanymi kluczem
prywatnym klienta).
- Jeśli serwer żądał uwierzytelnienia klienta, sprawdza przysłane
przez klienta dane, jeśli klient nie może zostać uwierzytelniony,
komunikacja zostaje zerwana. Jeśli sesja trwa dalej, serwer używa
swojego klucza prywatnego do rozkodowania danych przesłanych przez
klienta (premaster secret), a następnie wykonuje szereg kroków w celu
wygenerowania tzw. master secret. Te same kroki wykonuje równocześnie
klient.
- Master secret jest używany przez serwer i klienta do
wygenerowania kluczy sesji - symetrycznych kluczy do szyfrowania i
rozszyfrowywania danych i do zapewnienia ich integralności (wykrywania
cudzej ingerencji w treść przesyłanych komunikatów).
- Klient przesyła serwerowi komunikat o gotowości swojego klucza i
oddzielny, zaszyfrowany komunikat, że etap "handhake" po stronie
klienta zakończył się.
- Serwer przesyła klientowi komunikat o gotowości swojego klucza i
oddzielny, zaszyfrowany komunikat, że etap "handshake" po stronie
serwera zakończył się.
- Etap "handshake" zakończył się, teraz klient i serwer używają
wygenerowanego klucza do przesyłania zaszyfrowanych informacji między
sobą.
Kryptografia w SSL
SSL jest protokołem otwartym i rozszerzalnym, nie ma w nim nawiązania
do jednego konkretnego algorytmu szyfrującego. Protokół umożliwia
stronom połączenia przedstawienie propozycji obsługiwanych algorytmów
szyfrujących i wybranie wspólnego, najbardziej odpowiedniego dla obu.
Ogólnie mówiąc, SSL wykorzystuje dwa podstawowe rodzaje szyfrów -
szyfry asymetryczne (z kluczem prywatnym i publicznym) oraz symetryczne
(z jednym kluczem szyfrujaco - deszyfrującym). Algorytmy z kluczem
publicznym są znacznie wolniejsze od szyfrów symetrycznych, dlatego nie
nadają się do wydajnego kodowania danych przesyłanych w dużych
strumieniach. Z drugiej strony zastosowanie tylko i wyłącznie szyfru
symetrycznego wymagałoby wcześniejszej wymiany klucza za pomocą
jakiegoś innego kanału. Dzięki połączeniu dwóch rodzin algorytmów oba
problemy są rozwiązywane w sposób efektywny.
SSL 2.0 i SSL 3.0 pozwalają administratorom na wybór algorytmów,
których będzie używał dany serwer. Administrator, chcąc zapewnić
bezpieczeństwo swojego serwisu, może wyłączyć komunikację z użyciem
słabszych algorytmów kodowania. Z drugiej strony, jeśli chce udostępnić
dany serwer do użytku większej liczbie klientów, może pozwolić na
użycie szerszej gamy algorytmów, a podczas komunikacji klient i serwer
ustalą najsilniejszy algorytm jaki obie strony potrafią obsłużyć.
Ze względu na ograniczenia prawne w Stanach, amerykańskie przeglądarki
eksportowane poza USA obsługują jedynie kodowanie z kluczem publiczny
do 512 bitów (1024 bity w USA) i kluczem sesji do 40 bitów (128 bitów w
USA)
|
Mechanizmy obronne na granicy sieci
|
IDS / IPS (intrusion detection / prevention system)
IDS
IDS to system wykrywania prób ataku. Działa on na zasadzie sondy
wpiętej w monitorowany segment sieci. Sonda ta powinna otrzymywać cały
ruch sieciowy (jego "kopię") przeznaczony dla monitorowanego systemu.
IDS umie wykrywać w monitorowanym ruchu objawy charakterystyczne dla
prób ataku. W wielkim uproszczeniu działa on podobnie do systemu
antywirusowego. Porównuje analizowany ruch z bazą sygnatur ataków,
która jest integralną częscią IDS. Aktualność tej bazy decyduje o
skuteczności IDS. Współczesne produkty IDS pozwalają na zdalne
aktualizacje bazy sygantur ataków. Drugim ważnym aspektem wpływającym
na skuteczność IDS jest dostrojenie systemu do charakterystyki
monitorowanego ruchu. Źle dostrojony IDS będzie generował dużą ilość
fałszywych alarmów i informacji o niewielkim stopniu ważności. W
powodzi informacji może zginąć wiadomość o faktycznym ataku. Po
wykryciu potencjalnego ataku, standardowy IDS może zarchiwizować
podejrzany ruch sieciowy i zawiadomić administratora. Jak wynika z
powyższego opisu, IDS jest urządzeniem pasywnym. Umie wykryć atak, ale
podjęcie akcji należy już do administratora. Jeśli administrator nie
będzie w stanie podjąć kroków natychmiastowo, to atakujący może mieć
wystarczająco dużo czasu żeby dokonać ataku i zatrzeć po sobie ślady. W
związku z powyższym współczesne IDS są coraz częściej wyposażane w
możliwości reakcji na atak. Typową opcją jest wyposażanie IDS w moduł
integrujący go z zewnętrznym firewallem. W razie wykrycia próby ataku,
IDS jest w stanie zdalnie zrekonfigurować firewalla tak żeby blokował
on ruch z adresu podejrzanego o atak.
IPS
Obecnie coraz częściej mówi się o IPS. Są to systemy IDS rozbudowane o
możliwości aktywnej reakcji na wykryte zdarzenia. Pierwszym ruchem
zmierzającym do rozszerzenia możliwości reakcji standardowego systemu
IDS było pojawienie się technologii przerywania połączeń. W skrócie,
współczesne IDS-y mogą w przypadku wykrycia podejrzanego połączenia TCP
przerwać to połączenie przez pod-szycie się pod stronę atakującą i
wysłanie pakietu kończącego połączenie. Tak więc atakowany serwer
zakończy połączenie i atak nie będzie mógł dojść do skutku.
IDS-inline
Kolejnym krokiem jest IDS-inline. O ile tradycyjny IDS ma jedną kartę
sieciową, która jest sondą wpinaną w monitorowaną sieć, to IDS-inline
posiada dwie karty - zewnętrzną i wewnętrzną. Cały monitorowany ruch
sieciowy przechodzi przez urządzenie. Przypomina to budowę firewalla,
jednak w środku działa silnik IDS, który wykrywa ataki i umie je
blokować. W sumie urządzenie pełni podobne funkcje jak firewall
jednakże działa w inny sposób. Firewalle to technologia restryktywna.
Blokują one cały ruch z wyjątkiem ruchu dozwolonego. Istotą działania
IDS jest wykrywanie prób ataku, w związku z tym IDS-inline chociaż jest
umieszczony w tym samym miejscu co firewall, to działa w ten sposób, że
przepuszcza cały ruch z wyjątkiem tego co uzna za próbę ataku. W
przypadku IDS-inline klasyfikacja aktywności sieciowej jest o wiele
bardziej za-awansowana niż w przypadku firewalli. IDS stosuje do tego
wiele technologii. Ogólnie mówi się że IDS-y działają na podstawie
dopasowywania sygnatur ataków. W rzeczywistości współczesne IDS-y
stosują wiele różnych technik detekcji prób ataku. Np. normalizatory i
interpretery poszczególnych protokołów, sygnatury opisowe w miejsce
konkretnych wzorców, metody heurystyczne oraz sztuczną inteligencję.
Główne zadania
- analiza aktywności systemu i użytkowników
- wykrywanie zbyt dużych przeciążeń
- analiza plików dziennika
- rozpoznawanie standardowych działań włamywacza
- natychmiastowa reakcja na wykryte zagrożenia
- tworzenie i uruchamianie pułapek systemowych
- ocena integralności poszczególnych części systemu wraz z danymi
Dwa podstawowe typy systemów wykrywania włamań:
- Systemy oparte na zbiorze zasad - wykorzystują one bazy danych
znanych ataków i ich sygnatur. Kiedy pakiety przychodzące spełnią
określone kryterium lub zasadę, oznaczane są jako usiłowanie włamania.
Wadą tych systemów jest fakt, że muszą zawsze korzystać z jak
najbardziej aktualnych baz danych, a także to, że jeśli atak określono
zbyt precyzyjnie - to podobne, ale nie identyczne włamanie nie zostanie
rozpoznane.
- Systemy adaptacyjne - tutaj wykorzystane są bardziej zaawansowane
techniki, w tym nawet sztuczna inteligencja. Rozpoznawane są nie tylko
istniejące ataki na podstawie sygnatur - system taki potrafi także
uczyć się nowych ataków. Ich główną wadą jest cena, skomplikowana
obsługa i konieczność posiadania dużej wiedzy z zakresu matematyki oraz
statystyki.
Stosowane rozwiązania
- Host IDS (HIDS). Rozwiązania te opierają się na modułach agentów
rezydujących na wszystkich monitorowanych hostach. Moduły te analizują
logi zdarzeń, kluczowe pliki systemu i inne sprawdzalne zasoby,
poszukując nieautoryzowanych zmian lub podejrzanej aktywności.
Wszystko, co odbiega od normy, powoduje automatyczne generowanie
alarmów lub uaktywnienie pułapek. Monitorowane są m.in. próby logowania
do systemu i odnotowywane używanie niewłaściwego hasła - jeżeli próby
takie powtarzają się wielokrotnie w krótkich odstępach, można założyć,
że ktoś próbuje dostać się do systemu nielegalnie. Innym sposobem jest
monitorowanie stanu plików systemowych i aplikacyjnych. Wykonuje się to
metodą "fotografii stanów", rejestrując na początku stany istotnych
plików. Jeżeli napastnikowi (lub niektórym postaciom konia
trojańskiego) uda się uzyskać dostęp do systemu i wykonać zmiany,
zostanie to zauważone (na ogół jednak nie w czasie rzeczywistym).
Współczesne systemy potrafią monitorować i przechwytywać odwołania do
jądra systemu operacyjnego lub API.
Serwer www + system Host IDS
/
/
/
Wezeł(router+firewall)--- Serwer SQL + system Host IDS
\
\
\
Serwer poczty + system Host IDS
- Network IDS (NIDS). Rozwiązania te monitorują ruch sieciowy w
czasie rzeczywistym, sprawdzając szczegółowo pakiety zanim osiągną one
miejsce przeznaczenia. W swoim działaniu opierają się na porównywaniu
pakietów z wzorcami (sygnaturami) ataków (attack signatures),
przechowywanymi w bazie danych anomalii w ich wykonywaniu. Bazy danych
sygnatur uaktualnianie są przez dostawców pakietów IDS w miarę
pojawiania się nowych form ataków. Po wykryciu podejrzanej aktywności
monitor sieciowy może zaalarmować obsługę sieci, a także zamknąć
natychmiast podejrzane połączenie. Wiele tego typów rozwiązań jest
integrowanych z zaporami ogniowymi w celu ustalenia dla nich nowych
reguł blokowania ruchu, umożliwiających zatrzymania atakującego już na
zaporze ogniowej przy próbie kolejnego ataku. Rozwiązania oparte na
metodzie sieciowej funkcjonują w tzw. trybie rozrzutnym (promiscous
mode), polegającym na przeglądaniu każdego pakietu w kontrolowanym
segmencie sieci, niezależnie od adresu przeznaczenia pakietu. Z uwagi
na duże obciążenie, jakie niesie ze sobą przeglądanie każdego pakietu,
rozwiązania te wymagają zazwyczaj dedykowanego hosta (specjalnie do
tego przeznaczonego).
Serwer www
/
/
/
Wezeł(router+firewall+network IDS)--- Serwer SQL
\
\
\
Serwer poczty
- Network Node IDS (NNIDS). Jest to stosunkowo nowy typ hybrydowego
agenta IDS, wolny od niektórych ograniczeń sieciowych IDS. Agent taki
pracuje w sposób podobny do sieciowych IDS - pakiety przechwytywane w
sieci są porównywane z sygnaturami ataków z bazy danych - interesuje
się jednak tylko pakietami adresowanymi do węzła (ang. node), na którym
rezyduje (stąd nazwa IDS węzła sieci, czasami też Stack-based IDS).
Systemy takie są niekiedy określone jako "hostowe", jednak termin ten
dotyczy systemów skupiających się na monitorowaniu plików logu i
analizie zachowań, natomiast sieciowe i węzłowe IDS skupiają się na
analizie ruchu TCP - z tą jedynie różnicą, że NIDS pracuje w trybie
"rozrzutnym", podczas gdy NNIDS skupiają się na wybranych pakietach
sieci. Fakt, że systemy NNIDS nie zajmują się analizą wszystkich
pakietów krążących w sieci, powoduje, iż pracują one znacznie szybciej
i wydajniej, co pozwala na instalowanie ich na istniejących serwerach
bez obawy ich przeciążenia. W tym przypadku trzeba zainstalować cały
szereg agentów - jeden na każdym chronionym serwerze - a każdy z nich
musi przekazywać raporty do centralnej konsoli lub serwera logów.
Metody detekcji
- Dopasowywanie wzorców - najprostsza metoda, w której pojedyncze
pakiety porównywane są z listą reguł. Jeśli któryś z warunków zostanie
spełniony, uruchamiany jest alarm. Na tej zasadzie działają listy
dostępu.
- Kontekstowe dopasowywanie wzorców - program bierze pod uwagę
kontekst każdego pakietu. System NIDS stara się śledzić połączenia,
dokonywać łączenia fragmentowanych pakietów, aby móc wychwycić większą
grupę ataków oraz odfiltrować fałszywe.
- Dekodowanie protokołów wyższych warstw - NIDS dekoduje m.in.
protokoły FTP, HTTP w celu analizy ich zawartości i wychwycenia
specyficznych dla nich ataków. Metoda ta używana jest przez urządzenia
Cisco wyposażone w moduł Content Based Access Lists.
- Analiza heurystyczna - sygnatury tego typu wykorzystują algorytmy
do identyfikacji niepożądanego działania. Algorytmy te są zwykle
statystyczną oceną normalnego ruchu sieciowego. Przykładem sygnatury
heurystycznej jest algorytm określający, kiedy następuje skanowanie
portów - będzie to przekroczona liczba połączeń z jednego adresu na
kilka portów w niedługim czasie. Konkretne wartości dobierane są na
podstawie statystyki.
- Analiza anomalii - sygnatury anomalii starają się wykrywać ruch
sieciowy, który odbiega od normy. Największy problem stanowi określenie
stanu uważanego za normalny. Niektóre systemy zawierają moduły uczące
się, inne mają tą wiedzę zakodowaną na stałe. Przeprowadzanie analizy
anomalii jest trudne, więc systemy stosują ją tylko w ograniczonym
zakresie.
Firewall (zapora, ściana ogniowa)
Powszechnie terminem firewall określa się wszystko co filtruje pakiety,
począwszy od dedykowanych komputerów aż po odpowiednie oprogramowanie.
Główną ideą jest uczynienie zapory jedyną bramą łączącą lokalne zasoby
ze światem zewnętrznym.
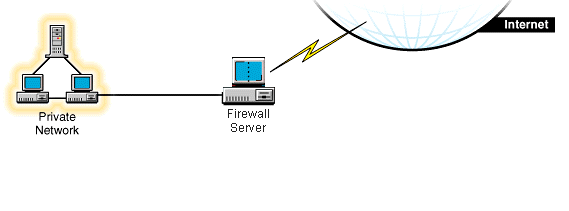
Rys. 5. Firewall
Główne zadania:
1. Badanie i filtracja pakietów
Zapory sieciowe mogą przeprowadzać analizy nadchodzących pakietów
różnych protokołów. W oparciu o taką analizę, zapora sieciowa może
podjąć różne działania, zatem możemy zaprogramować firewall do
przeprowadzania warunkowego przetwarzania pakietów. Reguły akceptacji
lub odrzucenia przechodzącego pakietu możemy tworzyć opierając się
głównie na następujących danych:
- Adres źródłowy
- Protokół
- Numer portu
- Zawartość (rzadziej)
Metody ustalania reguł:
- statyczne filtrowanie pakietów
Zestaw reguł jest niezmienny. Określane są dozwolone adresy źródłowe i
docelowe, porty i ich kombinacje.
Największą wadą tego typu rozwiązań jest to, że (w zależności od
ustawień) albo uniemożliwiają działania pewnym aplikacjom albo nie są
bezpieczne.
- dynamiczne filtrowanie pakietów
Rozwiązuje poprzedni problem. Zestaw reguł zmienia się w trakcie
przepływu pakietów. Pozwala to np. przyjąć odpowiedz do portu/z adresu
który w innych przypadkach jest zabroniony.
Istnieją dwie zasadnicze strategie definiowania sposobu działania
firewalla:
- domyślne przepuszczanie
Polega na takim zdefiniowaniu warunków, aby spowodować blokowanie
danych. Jeśli przychodzący pakiet nie będzie spełniał tych warunków
zostanie on przepuszczony. Zaletą takiego podejścia do konfiguracji
jest łatwość jej utworzenia, wadą natomiast jest to, że sieć pozostaje
otwarta na większość usług i hostów (na ruch sieciowy, którego nie
zablokowano).
- domyślne blokowanie
Każdy przychodzący pakiet będzie blokowany, dopóki nie spełni warunków,
które pozwolą mu przejść przez zaporę. Jest to o wiele trudniejszy
sposób konfiguracji, ponieważ wymaga dokładnej wiedzy o sposobie
działania protokołu TCP/IP.
2. Aplikacja pośrednicząca - proxy
Serwer Proxy to pośrednik pomiędzy programem klienta, a serwerem
znajdującym się w Internecie. Program klienta nawiązuje połączenie z
Proxy zamiast bezpośrednio z serwerem. Serwer Proxy odbiera zapytanie
od klienta i decyduje czy zapytanie ma zostać przepuszczone czy też
należy je odrzucić. Jeżeli zapytanie jest dozwolone to wówczas
komunikuje się z rzeczywistym serwerem i przekazuje otrzymane od
klienta zapytanie, a do klienta przekazuje otrzymaną odpowiedź. Na tym
poziomie oprócz uprawnień maszyn istnieje także możliwość sprawdzania
uprawnień konkretnych protokołów, usług i aplikacji.
Wyróżniamy następujące typy serwerów Proxy:
- Apliction Level - Proxy
Proxy tego typu zna protokół aplikacji dla której świadczy usługę,
rozumie i interpretuje komendy w protokole aplikacji. W momencie kiedy
użytkownik inicjalizuje połączenie z Proxy, wówczas Proxy dokonuje
otwarcia nowego połączenia (innej sesji), czyli każda sesja posiada
drugą automatycznie generowaną.
- Circut Level - Proxy
Tworzy połączenie pomiędzy aplikacją, a serwerem bez znajomości
protokołu aplikacji. Zapytanie wędruje do serwera proxy. Serwer proxy
przekazuje zapytanie do Internetu po tym jak dokona zmiany IP,
zewnętrzni użytkownicy widzą zatem jedynie adres IP serwera proxy.
Odpowiedź jest odbierana przez proxy i przesyłana z powrotem do
klienta. Dzięki temu zewnętrzni użytkownicy nie są w stanie uzyskać
dostępu do wewnętrznego systemu.
3. Diagnostyka antywirusowa przesyłanych plików
Jeżeli firewall "rozumie" dany protokół (np. FTP) jest w stanie go
zdekodować i dokonać pewnej analizy przepływających danych (np.
diagnostyka antywirusowa).
4. Konwersja protokółów
Sieć lokalna nie musi pracować na tym samym protokole co sieć
zewnętrzna. Jeśli firewall zna oba te protokoły może dokonywać
tłumaczenia przepływających pakietów na bieżąco.
5. Ochrona przesyłanych informacji (tworzenie wirtualnych sieci
prywatnych VPN)
Często zachodzi potrzeba bezpiecznego połączenia kilku sieci lokalnych
lecz odległych geograficznie. Jedyną możliwości jest wówczas
wykorzystanie internetu. Firewalle umożliwiają stworzenie bezpiecznego
(szyfrowanego) tunelu między tymi sieciami (tunelowanie), który
następnie będzie wykorzystywany przez wszystkie inne aplikacje (łącznie
z tymi które nie oferują żadnych zabezpieczeń przesyłanych danych).
Jest to przezroczyste dla użytkowników - widzą oni całą sieć jako jedną
sieć lokalną.
6. Translacja adresów (Network Address Translation - NAT)
Ukrywanie wewnętrznych hostów i struktury sieci - cała siec wewnętrzną
jest z zewnątrz widziana jako jeden komputer o adresie zapory.
Poszczególne porty mapowane są na konkretne porty konkretnych hostów.
7. Monitorowanie i rejestrowanie zdarzeń, generowanie
natychmiastowych alarmów
Firewall może monitorować ruch pomiędzy sieciami, prowadzić dzienniki
zdarzeń, zapisywać adresy źródłowe, docelowe, porty oraz inne
informacje zbierane z przepływających pakietów. W razie wykrycia
niedozwolonej działalności możliwe jest powiadomienie administratora
lub automatyczne podjęcie innych natychmiastowych działań.
Typy firewalli
Ze względu na warstwową architekturę stosu protokołów TCP/IP wyróżnia
się trzy główne typy firewalli: aplikacyjne, połączeniowe i filtrujące.
- firewalle aplikacyjne (application gateway)
Umożliwiają kontrolowany dostęp do określonych usług (takich jak ftp,
telnet, www) wewnątrz chronionej podsieci poprzez odpowiedni demon
pośredniczący (proxy serwer). Dla usług nie mających swojego demona
ruch jest zazwyczaj całkowicie blokowany.
- firewalle połączeniowe(circuit gateway)
Zestawiają połączenia TCP pomiędzy komputerami z sieci wewnętrznej a
Internetem, korzystając z określonych zasad. (przyporządkowują pakiety
do istniejących połączeń TCP i dzięki temu mogą kontrolować całą
transmisję) Zaawansowane systemy potrafią także kojarzyć pakiety
protokołu UDP, który w rzeczywistości kontroli połączeń nie posiada. W
żadnym z powyższych przypadków firewalle połączeniowe nie kontrolują
jednak samej zawartości pakietów.
- firewalle filtrujące(packet filtering gateway)
Segreguje pakiety IP, TCP, ICMP, itp. przechodzące przez host według
określonych reguł. Przeważnie reguły te opierają się na testowaniu
adresu źródłowego i docelowego oraz portu pojedynczego pakietu.
Filtry pakietowe są zwykle bardzo szybkie, jednak ich wadą jest to, że
podane kryteria selekcji mogą okazać się niewystarczające dla
niektórych usług internetowych.
Dwie idee projektowania firewalli
- idea ,,czarnej skrzynki''
Są to firewalle projektowane głównie przez komercyjne firmy. To zwykle
urządzenia, których sposób działania nie jest bliżej znany, posiadają
interfejs użytkownika i inne ułatwienia w ich sterowaniu, jednak nigdy
nie możemy być pewni że nie istnieją w nich jakieś luki i
nieudokumentowane obejścia.
- idea ,,kryształowej skrzynki''
Przy koncepcji ,,kryształowej skrzynki'' zasady filtrowania pakietów są
ogólno dostępne, ponieważ udostępniony jest kod źródłowy wraz z
kompletną dokumentacją. Pozwala to na dokładne sprawdzenie całego kodu
i wprowadzenie ewentualnych poprawek. Ma to ogromne znaczenie w
przypadku systemów, gdzie dostępny jest kod źródłowy całego systemu
operacyjnego, a co za tym idzie możemy dostosować konfigurację
firewalla do ewentualnych niedociągnięć w samym kodzie systemu. Ten typ
zdobywa sobie coraz więcej zwolenników.
Wady i niedogodności:
- ograniczają dostęp do sieci z Internetu
- wymagają częstych uaktualnień, gdyż nowe typy klientów sieciowych
i serwerów przybywają prawie codziennie
- uniemożliwiają bądź utrudniają zdalne zarządzanie siecią
- mało wydajne serwery pośredniczące zmniejszają wydajność sieci
|
Mechanizmy obronne zintegrowane z systemem operacyjnym
|
SELinux
SELinux projektem w ramach którego wzbogacono system GNU/Linux o
mechanizmy obowiązkowej kontroli dostępu. W jądrze umieszczono nowe
komponenty, które zostały
tworzone dla polepszenia bezpieczeństwa systemu. W ramach projektu
dostosowano również kod wielu programów systemowych tak, aby były one w
stanie korzystać z dobrodziejstw architektury SELinux. Opracowano
definicje uprawnień poszczególnych programów, tak aby z jednej strony
mogły one wypełniać swoje zadania, a z drugiej - na
wypadek błednego działania -- nie mogły spowodować dużych szkód w
bezpieczeństwie systemu i jego danych.
Każdy proces i obiekt (plik, gniazdo, itd.) w systemie otzrymuje zestaw
atrybutów bezpieczeństwa tworzący tzw. kontekst bezpieczeństwa.
Kontekst ten zawiera pełne dane na temat uprawnień danego obiektu. W
momencie, gdy potrzebna jest kontrola uprawnień (np. gdy proces stara
się otworzyć plik) funkcji kontrolującej uprawnienia przekazywane są
dwa zestawy atrybutów bezpieczeństwa - w tym wypadku procesu i pliku
(sprawdzone będzie czy proces może otwierać pliki oraz czy dany plik
możne być otworzony przez proces). Na tej podstawie podejmowana jest
decyzja o zezwoleniu na wykonanie operacji lub jej odrzucenie.
Oprócz operacji kontorli dostępu drugim istatnym zadaniem jest
inicjowanie praw (kontekstu bezpieczeństwa) nowo tworzonego obiektu. W
tradycyjnym systemie UNIX np. przy tworzeniu pliku brany jest pod uwagę
identyfikator i grupa użytkowników, prawa dostępu do katalogu
nadrzędnego itd. Używając SELinux początkowy zestaw parametrów nowego
obiektu może być znacznie szerszy.
Należy też zwrócić uwagę, że dodatkowa informacja o kontekście
bezpieczeństwa musi być gdzieś przechowywana. W przypadku pewnych
danych dynamicznych, jak proces, gniazda TCP, czy pamięć dzielona -
mogą być one zawsze przechowywane w strukturach jądra systemu. Jednak
np. kontekst bezpieczeństwa plików czy katalogów musi być przechowywany
w sposób trwały - jako rozszerzone atrybuty danego obiektu na dysku.
Wymaga to współpracy ze strony systemu plików.
Faktem jest - i nikt tego nie ukrywa - że projekt SELinux jest
projektem badawczym, który innym pozostawia kwestie końcowych
implementacji. Jednak mimo swojego mocno naukowego charakteru - zdobywa
on sobie coraz większe uznanie i popularność w praktycznych
zastosowaniach. Każdy z nas przy odrobinie starań może już dziś
zabezpieczyć lepiej swój komputer przed niepowołanym dostępem z
zewnątrz z powodu błedów oprogramowania. Jednak na na prawdę szerokie
użycie SELinuksa przyjdzie nam jeszcze chwilę poczekać.
RBAC (Role Based Access Control)
W modelu zwanym TE (ang. Type Enforcement) każdy proces w systemie
otrzymuje atrybut zwany domeną, a każdy obiekt - otrzymuje atrybut
zwany typem. Wszystkie procesy będące w tej samej domenie są traktowane
jednakowo (mają jednakowe uprawnienia), jak również wszystkie obiekty o
danym typie są traktowane na równi. Dla każdej pary domeny i typu
możemy określić, jakie działania mogą być podejmowane. Domena może być
powiązana z kilkoma punktami wejścia - programami,które mogą być
wykonywane przez użytkowników spoza domeny, a także wybranymi
programami pomocniczymi i/lub bibliotekami, które są używane w ramach
domeny. Pozwala to np. oddzielić programy zajmujżce się pocztą od
innych części systemu.
Tradycyjny model RBAC (ang. Role-Based Access Control) spotykany np. w
systemach UNIX pozwala użytkownikom spełniać określoną role i dostarcza
jednego zestawu uprawnień dla tej roli. W systemie SELinux użytkownik
może posiadać nie jedną rolę, ale zestaw ról, a uprawnienia każdej z
nich mogą być definiowane zestawem domen (patrz wcześniejszy akapit).
Można powiedzieć, że w modelu tym użytkownik może się przemieszczać
pomiędzy różnymi domenami uprawnień - zgodnie z nadanymi mu
uprawnieniami przemieszczania.
ACL (Access Control List)
Tradycyjne prawa dostępu (odczyt, zapis, wykonanie) pokazują podstawę
mechanizmu sterowania dostępem do różnych plików w oparciu o dziewięć
bitów plus dwa bity na każdy plik. Zaletą tego rozwiązania jest
absolutna prostota.
Niestety, jeżeli administrator systemu będzie chciał ustawić wszystkie
możliwe uprawnienia dostępu do pliku n użytkownikom, będzie potrzebował
2n różnych grup. Jest to oczywiście strajnie niepraktyczne, zatem
nowsze systemy operacyjne wykorzystują pojęcie grupy rozszerzonej -
listy kontroli dostępu - ACL. ACL umożliwia bardzo szczegółową kontrolę
uprawnień w porównaniu z tradycyjnym modelem uprawnień.
Przy użyciu list kontroli dostępu system operacyjny dołącza do pliku
dodatkową listę uprawnień dla określonych użytkowników i grup.
Umożliwia to przypisanie uprawnień odczytu lub zapisu dla pojedynczego
pliku dwóm lub trzem użytkownikom, a nie tylko całej grupie.
ASLR (Address Space Layout Randomizatoin)
Poprawka sprawiająca, że ładowany dynamicznie kod, pojawia się pod
losowym (a więc nie znanym włąmywaczowi) adresem. Praktycznie
uniemożliwia to ingerencję w taki kod, dodatkową zaletą jest to, że
funkcja ta nie ma wpływu na wydajność systemu.
Ochrona pamięci, PaX.
Podjęto wiele prób mających na celu stworzenie poprawki jądra lepiej
zabezpieczającej pamięć. Projekt PaX należe do najczęściej używanych.
Do momentu wykorzystania PaX w poprawce gr-security, nie był on zbyt
znany i rozpowszechniony. Gr-security jest bardzo popularna i wiele
osób z niej korzysta.
Mówiąc ogólnie, istnieją trzy grupy ataków, pod kątem których tworzone
są poprawki wzmacniające ochronę pamięci:
- wprowadzenie i
wykonanie dowolnego kodu
- wykonanie
isniejącego kodu w innej kolejności niż go opracowano
- wykonanie
istniejącego kodu w prawidłowej kolejności, ale ze zmienionymi danymi
Wprowadzenie i wykonanie dowolnego kodu oznacza, że można:
- zastąpić kod
znajdujący się w pamięci innym kodem
- zastąpić dane
znajdujące się w pamięci i wykonać je tak, jakby były oryginalnym kodem
- załadować nowy kod
do pamięci i wykonać go
Jeżeli zatem można zastąpić kod oryginalny, intruz może wprowadzić swój
kod do działającego procesu. Tak więc, zamiast wykonywać określone
zadania, program będzie robił to, czego oczekuje od niego intruz.
Dwie pierwsze techniki wymadają wyłącznie dostępu zapisu i możliwości
wykonywania w pamięci. PaX radzi sobie z tymi technikami na swój własny
sposób. Trzecia technika różni się w tym względzie, że wymaga także
dostępu do plików. Przy pomocy list kontroli dostępu (ACL) i/lub innych
mechanizmów kontroli dostępu (np. RSBAC), PaX gwarantuje kompleksową
ochronę przed wszelkimi odmianami ataków klasy pierwszej (wprowadzenie
i wykonywanie dowolnego kodu).
SSP (Stack Smashing Protector)
Przełącznik ochrony stosu (SSP) to poprawka dla kompilatora gcc
zabazpieczająca system przed grupą ataków zwanych pod nazwą błędów
przepełnienia stosu.
SSP wykorzystuje dwa mechanizmy:
- w chwili wykrycia
potencjalnie niebezpiecznej funkcji dołącza "minę-pułapkę" do stosu
(ponieważ niestety mechanizm detekcji nie jest jeszcze niezawodny)
- zmienia kolejność
lokalnych zmiennych w taki sposób, aby podejrzane zmienne znalazły się
obok "miny-pułapki", zwiększając w ten sposób prawdopodobieństwo
wykrycia błędu
"Mina-pułapka" często w żargonie określana jest mianem kanarka (w
kopalniach kanarki wykrywały kiedyś obecność śmiercionośnego tlenku
węgla, który zabijał kanarki zanim zabił górników). Kanarkiem jest w
naszym przypadku losowa liczba umieszczana na stosie. Atak
przepełnienia stosu tę liczbę, która jest następnie wykrywana prze SSP
przed wykonaniem kodu wykorzystującego ten błąd. Jeżeli SSP wykryje
zatąpienie losowej liczb inną liczbą, dokonuje zapisu komunikatu w
dzienniku systemu i przerywa pracę programu.
Systemy ze zintegrowanym bezpieczeństwem
- Hardened Gentoo-
projekt realizowany w ramach popularnej ostatnio dystrybucji Linux-a
celem projektu jest stworzenie stabilnego systemu o wysokim poziomie
bezpieczeństwa, w skład projektu wchodzą między innymi: SELinux,
PaX/Gr-security, RSBAC, protokoły kryptograficzne, działające elementy
włączane będą do głównej lini dystrybucji - Gentoo
- Adamantix -
dystrybucja rozwinięta z projektu Trusted Debian mającego na celu
poprawienie bezpieczeństwa zintegrowanego z systemem w dystrybucji
Debian, teraz jako samodzielny projekt; w skład projektu wchodzą: PaX,
SSP, RSBAC; najwyższa dbałość o bezpieczeństwo z wymienionych tu
systemów, część ogólnie dostępnych funkcjonalność Linuxa uważana za
niedostatecznie przetestowane - nie są włączone do tej dystrybucji.
- OpenBSD - system z
ogólnie pojętej rodziny Unix-ów, od początku główny nacisk położony na
integrację bezpieczeństwa z systemem, zaletą jest daleko bardziej
posunięta integracja bezpieczeństwa, wadą zaś nie dostateczne
wspieranie nowych rozwiązań
- Windows - nie
można obejrzeć źródeł systemu, więc mówienie o integracji opierać może
się tylko na zapewnieniach prasowych, ACL, protokoły kryptograficzne
oraz Service Pack polepszają bezpieczeńśtwo
Bibliografia
[1]
http://downloads.securityfocus.com/library/discex00.pdf [buffer-overflow]
[2]
http://www.securityfocus.com/infocus/1644 [SQL Injection]
[3]
http://www.securityfocus.com/infocus/1549 [sniffing]
[4]
http://www.republika.pl/b_s_k/bsk/index2.htm [bezpieczeństwo w
systemach komputerowych]
[5]
http://arch.ipsec.pl/ref/agh-5/ [bezpieczeństwo systemach
komputerowych na przykładzie Linuxa]
[6]
http://arch.ipsec.pl/ref/agh-3/ [administracja systemów
komputerowych - bezpieczeństwo]
[7]
http://www.leon.w-wa.pl/texts/security.php [bezpieczeństwo w
Linuxie]
[8]
http://www.securityfocus.com/popups/forums/secprog/secure-programming.shtml
[bezpieczne programowanie]
[9]
http://marcin.owsiany.pl/sec/buffer_overflow.txt ["Smashing The
Stack For Fun And Profit" - lokalna kopia]
[10]
http://marcin.owsiany.pl/security.pl.html [strona z linkami do
stron poświęconych bezpieczeństwu]
[11] http://www.nsa.gov/selinux/
[SecurityEnchanced Linux]
[12] http://www.adamantix.org/[Adamantix]
[13] http://www.gentoo.org/proj/en/hardened/
[Hardened Gentoo]
[14] http://www.openbsd.org/
[OpenBSD]
[15] http://www.grsecurity.net/
[Grsecurity/PaX]
[16] http://www.rsbac.org/[Rule
Set Based Access Control]
[17] http://www.kernelthread.com/publications/security/index.html
[A Taste of Computer Security]
[18] http://www.hacking.pl