Zagrożenia
- Open relay
Open relay czyli otwarty przekaźnik poczty
to taki serwer pocztowy, który poprzez SMTP przyjmuje pocztę nie adresowaną do
lokalnego użytkownika, czy też nie wysyłaną przez lokalnego użytkownika.
Możliwość taką wykorzystują głównie spamerzy, wysyłając za pośrednictwem
takich serwerów ogromne liczby reklam, ogłoszeń, itp.
Obecnie większość MTA ma domyślnie
zablokowaną opcję "open-relay" lub jest konfigurowana w taki sposób,
by przyjmować pocztę tylko z określonych domen, czy też tylko od lokalnych
użytkowników (autoryzacja SMTP), mimo to portale takie jak wp.pl czy o2.pl nadal
działają w trybie "open relay".
- wykorzystanie innych błędów w konfiguracji - np. uzyskanie listy kont
użytkowników na potrzeby spamu.
Zabezpieczanie serwera MTA:
- MAPS i RBL
Zbieranie danych o spamerach indywidualnie
przez użytkowników i administratorów usług pocztowych jest dosyć pracochłonne,
opracowano więc "czarne listy" udostępniające swe zasoby klientom, którymi
zazwyczaj są serwery SMTP. Użyteczność tego typu serwisów stoi na równi z
dużym ryzykiem ich używania - przypadkowe wpisanie na listę serwera
instytucjonalnego lub komercyjnego może przynieść dotkliwe szkody, zaś
monitowanie zarządzających tymi serwisami o zabezpieczenie dostępu do cudzych
MTA bywa uciążliwe.
Pod skrótami MAPS (Mail Abuse Prevention
System) i RBL (Realtime Blackhole List) kryje się globalna,
ogólnodostępna baza danych o hostach podejrzanych o rozsyłanie spamu. Wpisanie
konkretnego adresu IP odbywa się na podstawie skarg użytkowników Internetu.
Odpytanie bazy jest proste i wymaga niewielkich tylko rozszerzeń w stosunku do
istniejących już pakietów (np. sendmail), nawet bez ingerencji w ich teksty
źródłowe. Dane z bazy udostępniane są poprzez DNS, a umieszczenie hosta o
adresie IP x.y.z.v na liście oznacza wpisanie nazwy w DNS w postaci
v.z.y.x.blackholes.mail-abuse.org. Istnienie tak sformułowanego adresu
symbolicznego oznacza wpisanie hosta o odpowiednim adresie IP na listę RBL.
Możliwe jest - obok bezpośredniego zapytywania serwera DNS mail-abuse.org -
ustanowienie serwera zapasowego we własnym środowisku i korzystanie z niego,
gdy np. niedostępny jest ten pierwszy. Korzystanie z RBL nie jest trudne nawet
dla osób początkujących w sztuce programowania.
Współpracę z RBL
zapewniają pakiety: sendmail, smail, qmail, zmailer, exim czy postfix.
Liczne są też programy klienckie, rozszerzenia i łaty do innych pakietów
obsługujące RBL, np. do pakietu kontroli dostępu tcp wrappers czy serwera WWW
Apache. Można też korzystać z innych usług, np. DUL (Dialup Users List) czy
RSS (Relay Spam Stopper), która udostępnia adresy hostów umożliwiających
przekazywanie spamu.
- BlackMail
BlackMail działa jako serwer proxy w
stosunku do konwencjonalnego serwera SMTP. Przyjmując pocztę, dokonuje serii
testów, polegających na sprawdzeniu znanych serwerów rozpowszechniających
spam, słów kluczowych w nagłówkach, poprawności adresu e-mail nadawcy i wpisów
DNS nadsyłającego pocztę hosta oraz sprawdzenia występowania hosta w bazie
RBL. Pakiet został napisany z myślą o systemach Unix, współpracuje z kilkoma
popularnymi serwerami MTA (sendmail, smail, qmail). Dostępny bezpłatnie na
zasadach licencji GPL, niestety, dość sporadycznie uaktualniany.
Źródła:
Raport SANS TOP 20-Lista Top 20 Internetowych Luk Bezpieczeństwa
według SANS
http://www.telenetforum.pl/index_2.php?show=pokaz_art_old&art=19_06_2001
http://www.pckurier.pl/archiwum/art0.asp?ID=4762
Opis
Protokół SNMP (Simple Network Management Protocol) służy do zarządzania i
monitorowania urządzeń sieciowych. Jest to protokół opisywany w terminologii
SNMP jako protokół menedżer/agent. Agent działa na obsługiwanym urządzeniu
nazywanym MNE (Managed Network Entity - obsługiwana jednostka sieciowa) i
monitoruje stan urządzenia. Menedżer działa na jednostce NMS (Network Management
Station - jednostka zarządzania siecią) i odbiera raporty od agenta. Dodatkowo
każdy agent SNMP obsługuje własną niewielką bazę danych (MIB - Management
Information Base), zawierającą informacje o stanie i historii pracy urządzenia,
a także zmienne sterujące jego pracą.

Zalety:
instalowane w węzłach programy zajmują mało miejsca w pamięci,
protokół pozwala kontrolować liczbę generowanych przez stację zarządzania
powtórzeń żądań obsługi oraz czas oczekiwania na odpowiedzi urządzeń,
możliwość wychwytywania konkretnych zdarzeń (informacje typu trap),
powszechna dostępność aplikacji opartych na protokole SNMP,
niskie koszty wdrożenia do eksploatacji.
Wady:
skomplikowana pracę samego agenta,
ograniczanie przepustowości sieci,
brak mechanizmów bezpieczeństwa.
Zagrożenia
SNMP staje się częstym celem ataków, gdyż:
- instaluje się go w kluczowych węzłach sieci, przełącznikach szkieletowych,
serwerach i zaporach - udany atak może więc uniemożliwić działanie całej
sieci,
- z jego pomocą można na przykład wyłączyć filtrowanie pakietów przez zaporę
ogniową, co jest przydatne w pierwszej fazie ataku.
Odnalezione
luki:
- wymiana komunikatów przy użyciu protokołu User Datagram Protocol (UDP); a
UDP jest protokołem bezpołączeniowym, w którym nie jest wymagane potwierdzanie
odbioru komunikatu czy uwierzytelnianie nadawcy,
- praca zgodnie z architekturą zarządzania menedżer/agent, gdzie menedżer
wymienia z agentem informacje w trybie synchronicznym (zgodnie z procedurą
żądanie/odpowiedź); taka architektura nie sprawdza się i powinna być
zamieniona na architekturę opartą na zdarzeniach, w której komunikaty mogą być
wymieniane w trybie asynchronicznym.
Źródła
http://www.eltronik.net.pl/index.pl/informacje_techniczne2#1152
http://hip.ipadmin.info/own/mrtg/mrtg_referat.htm
http://www.okmatura.cad.pl/infa/029.htm
http://www.pckurier.pl/archiwum/art0.asp?ID= 4846
http://www.pckurier.pl/archiwum/art0.asp?ID= 5453
http://www.networld.pl/news/64905.html
Opis
Protokół SSL (Secure Sockets Layer) pozwala na uwierzytelnienie
stron transmisji oraz zachowanie poufności danych. Najogólniej mówiąc, odpowiada
on za wynegocjowanie parametrów bezpiecznego połączenia z serwerem, a jego
działanie opiera się na tzw. certyfikatach cyfrowych. Same algorytmy szyfrujące
nie są częścią SSL, gdyż jest on wykorzystywany jedynie do określenia, które z
nich mają być użyte do transmisji. Technologia SSL koduje hasła i inne tajne
informacje podczas komunikacji serwera z komputerem użytkownika. Adresy URL
stron internetowych chronionych tym protokołem rozpoczynają się od wyrażenia
"https://", a w trakcie ich ładowania i pobytu na nich, w dolnej ramce
przeglądarki widoczna jest ikona kłódki.
Open source'owa biblioteka OpenSSL jest wykorzystywana jako zestaw narzędzi,
których inne aplikacje używają do zapewnienia kryptograficznej ochrony dla
połączeń sieciowych. Zamiast atakowania OpenSSL bezpośrednio, exploity są
skierowane na aplikacje wykorzystujące OpenSSL.
Aplikacje korzystające z OpenSSL:
- serwer WWW Apache
- sendmail
- pakiet openldap
- CUPS
- serwery POP, IMAP, SMTP i LDAP (wykorzystują odpowiedniki OpenSSL)
Zagrożenia
- Man in the middle
Atak polegający na przekierowaniu
ruchu sieciowego do serwera osoby atakującej; następnie ruch ten, po
podsłuchaniu transmisji i zdobyciu np. haseł, jest kierowany z powrotem do
serwera docelowego.

Scenariusz ataku w systemie klucza publicznego:
- X chce połączyć się z Y (np.
stroną banku internetowego). Z jest osobą atakująca
transmisję w celu przechwycenia tajnych haseł X .
- Z w pierwszym etapie musi przekierować ruch z komputera
X do Y na swój komputer, może to zrobić
np. zmieniając dane podawane przez DNS o adresie komputera
Y, lub nasłuchiwać zapytań do DNS i w odpowiednim momencie
wysłać adres swojego komputera. Po połączeniu Z przekazuje
X swój klucz publiczny rzekomo jako klucz publiczny
Y, jednocześnie nawiązuje połączenie z Y,
a otrzymane od niego dane (np. treść strony www) przekazuje
X .
- X widząc stronę logowania Y, wpisuje w
przeglądarce swoje tajne hasło i wysyła je do Z , nie
wiedząc o przechwyceniu transmisji.
- W zależności od celu ataku, Z po odczytaniu hasła albo
przerywa transmisję, albo w dalszym ciągu pośredniczy w transmisji pomiędzy
X i Y , cały czas wykradając tajne dane
(stan konta, dodatkowe hasła itp.).
- W ten sposób Z potrafi odczytać wszystkie przesyłane
pozornie bezpiecznym kanałem dane, nie będąc zmuszonym do czasochonnego
łamania szyfrów zabezpieczających transmisję.
Sytuacja normalna:
X < [Klucz X] --RSA/AES-- [Klucz
Y] > Y
Atak Z:
X < [Klucz X] --RSA/AES-- [Klucz
Z 1] > Z< [Klucz Z 2]--RSA/AES--
[Klucz Y] > Y
- Zbyt krótkie klucze kodowe
Możliwe jest szyfrowanie
danych 128-bitowym kluczem kodowym, niestety nie wszyscy administratorzy
serwisów internetowych korzystają z rozbudowanych możliwości SSL i stosują
"krótsze" klucze. Problem ten dotyczy ok. 18% wszystkich serwisów, które
używają SSL (w Europie 40%). Dzieje się tak dlatego, że klucze o maksymalnej
dostępnej długości w znacznym stopniu obciążają serwery - administratorzy wolą
więc położyć mniejszy nacisk na ochronę przesyłanych danych niż doprowadzić do
przeciążenia serwera.
Źródła:
http://pl.wikipedia.org/
http://www.egospodarka.pl/1095,Dziurawy-SSL,1,12,1.html
http://www.chip.pl/arts/n/sub/article_120062.html
http://www.pckurier.pl/archiwum/art0.asp?ID= 5635
Opis
Kontrola dostępu należy, obok uwierzytelnienia użytkowników, do podstawowych
usług bezpieczeństwa oferowanych przez systemy operacyjne. Warunkiem wstępnym
jest uwierzytelnienie. Uwierzytelniony użytkownik otrzymuje dostęp do tych i
tylko tych obiektów, do których jest upoważniony.
W systemie Unix wszystkie właściwie obiekty są reprezentowane jako "pliki" w
systemie plikowym. Dotyczy to także na przykład aktywnych procesów, gniazd czy
połączeń sieciowych, jak również urządzeń: drukarek, terminali, dysków itp.
Każdy z takich plików posiada nazwę, właściciela, prawa dostępu i inne atrybuty.
Dane te są pamiętane w systemie plików w postaci tzw. i-węzłów (inodes, index
nodes), podstawowej jednostki tworzącej system plików. Jedynie nazwy plików są
zapisane w katalogach i skojarzone z węzłami za pomocą wskaźników.
Przedstawiony sposób obsługi obiektów systemowych powoduje, że zagadnienie
kontroli dostępu do zasobów de facto sprowadza się w Unixie do kontroli dostępu
do plików. Rozróżnia się trzy rodzaje praw dostępu (uprawnień): do odczytu (r,
read), do zapisu (w, write) i do wykonywania (x, execute). Uprawnienia te nadaje
się osobno dla właściciela pliku, członków należących do tej samej grupy, co
plik (nie koniecznie właściciel!), i wreszcie dla wszystkich pozostałych
użytkowników; zapis rwxr-xr-x oznacza pełne prawa właściciela pliku oraz prawo
do odczytu i wykonania (ale nie zapisu) dla wszystkich pozostałych użytkowników.
Superużytkownik - root albo administrator - ma nieograniczone prawa do
wszystkich plików, niezależnie od ustawień praw dostępu.
Niektóre pliki wykonywalne - to jest programy - mogą jednak mieć
inne, zwykle szersze prawa dostępu, niż użytkownik je wywołujący. Jest to
oczywiste - czasami nieuprzywilejowani użytkownicy muszą wykonywać zadania,
które wymagają przywilejów (na przykład polecenie systemowe passwd musi mieć
dostęp do plików systemowych zawierających hasła). Pliki typu SUID (set user id)
oraz SGID (set group id) to pliki wykonywalne, które na czas uruchomienia mogą
przyjąć obcy identyfikator użytkownika lub grupy. Kiedy wykonywany jest program
SUID (lub SGID), jego efektywny identyfikator użytkownika UID (lub grupy GID)
przyjmuje wartość identyfikatora właściciela pliku, a nie uruchamiającego go
użytkownika. Tak więc program SUID, którego właścicielem jest użytkownik root
(czyli tzw. SUID root) może wszystko - ma nieograniczone uprawnienia bez
względu na to, kto go uruchomił.
Zagrożenia
Programy SUID i SGID mogą stanowić poważne zagrożenie bezpieczeństwa systemu.
Nieopatrznie (lub nielegalnie) utworzony program tego typu może dać postronnym
osobom dostęp do chronionych zasobów. Na przykład skopiowanie pliku shella
systemowego (cp /bin/sh super) i nadanie mu uprawnień SUID (np. chmod 4755)
powoduje, że utworzony plik jest wytrychem, pozwalającym na swobodny
dostęp do plików danego użytkownika. W ten sposób na intruz może przejąć
kontrolę na przykład nad plikami superużytkownika root (czyli nad całym systemem
plikowym komputera!).
Zabezpieczenia
Niektóre wersje Unixa obsługują listy kontroli dostępu (ACL - Access
Control Lists). Stanowią one rozszerzenie standardowego systemu uprawnień.
Pozwalają na zdefiniowanie dodatkowych praw dostępu dla poszczególnych
użytkowników lub grup - a nie tylko dla bliżej nieokreślonego ogółu
pozostałych użytkowników. Jeśli na przykład określony użytkownik X ma
współpracownika Y, z którym chciałby dzielić dostęp do określonego pliku, to
przy zastosowaniu ACL może po prostu dołączyć do listy związanej z plikiem
odpowiednie uprawnienia dla Y. Bez list ACL musi się udać do administratora
systemu (superużytkownika), który stworzy grupę użytkowników obejmującą X i Y, a
następnie przepisać plik do tej grupy, jednocześnie ustawiając odpowiednio
atrybuty dostępu do grupy.
Niestety, nie wszystkie systemy Unix zawierają mechanizm ACL; co więcej wśród
tych, które go implementują, nie ma zgody co do tego, jak powinien wyglądać
standard.
Źródła:
http://sun.iinf.polsl.gliwice.pl/~jfrancik/publ/download/bielsko02.pdf
Zalety i wady
Ten rodzaj zabezpieczenia systemu umożliwia ochronę przed
większością exploitów (w szczególności tych opierających swoje działanie na
przepełnieniu bufora). Niestety instalacja łat na jądro powoduje nieznaczny
spadek wydajności działania systemu oraz nieliczne problemy z aplikacjami
takimi jak np. Xfree.
Techniki
-
-
Ochrona stosu metodą stronicowania
-
Ochrona stosu metodą segmentacji
-
Randomizacja adresów (ASLR)
Implementacje
-
OpenWall
http://www.openwall.com/
- ochrona przed większością ataków przepełnienia bufora, ponieważ łata
Openwall czyni stos niewykonywalnym,
- kontrola nad dowiązaniami w katalogach z atrybutem +t (sticky bit),
- kontrola dostępu do /proc, co powoduje, że jedynie uprzywilejowani
użytkownicy mają dostęp do pełnego drzewa procesów,
- restrykcja na kolejki FIFO, co nie pozwala na zapis użytkownikowi, który
nie jest jej właścicielem.
-
GRsecurity
http://www.grsecurity.org/
- zapobiega wykonywaniu kodu w stosie, co komplikuje działanie exploitów i
sprawia że ich stworzenie staje się trudniejsze,
- PaX uniemożliwia wykonywanie niektórych fragmentów pamięci (stos,
sterta), zabezpieczając system skuteczniej niż non-executable stack z
Openwalla,
- ładowany dynamicznie kod, pojawia się pod losowym (a więc nie znanym
włamywaczowi) adresem; praktycznie niemożliwa staje się więc ingerencja w
taki kod,
- uniemożliwia użytkownikom dostęp do plików w /proc które ich nie dotyczą
(informacje o procesach innych użytykoników, sieci, ...),
- zapobiega atakom z użyciem dowiązań poprzez nałożenie pewnych ograniczeń
na system plików,
- deskryptory plików 0 (stdin), 1 (stdout) i 2 (stderr), które mogą zostać
użyte przez włamywacza do odczytu lub zapisu w plikach mu niedostępnych są
zabezpieczane poprzez "wymuszenie" ich otwarcia - jeśli aplikacja ich nie
używa zostaje otwarty /dev/null,
- ogranicza możliwości roota wewnątrz chroot jail; nie będzie on mógł
ładować modułów, korzystać z bespośredniego I/O, zmieniać czasu, rebootować
systemu, itd...,
- umożliwia wybranie dodatkowych zdarzeń, które mają być zapisywane przez
jądro w dzienniku systemowym,
- ograniczenie dostępu do komunikatów wypisywanych przez jądro wyłącznie
do użytkownika root,
- umożliwia wydzielenie (przez dodanie do odpowiedniej grupy),
użytkowników, którzy będą mogli uruchamiać pliki znajdujące się jedynie w
katalogach których właścicielem jest root i tylko on może w nich zapisywać
uniemożliwi to "wybrańcom" uruchomienie nieznanego kodu (np. exploita),
- ograniczanie możliwości tworzenia gniazd sieciowych przez
użytkowników,
-
WOLK (Working Overloaded Linux Kernel) są to stabilne oraz
rozwojowe jądra Linuksa, w których skład wchodzą najważniejsze łaty
niedostępne w standardowej wersji kernela. WOLK ułatwia kompilację jądra -
nie trzeba osobno ściągać i instalować potrzebnych łat. Z drugiej strony,
tak przygotowany kernel jest niestabilny. Ponadto podczas jego konfiguracji
trzeba wybierać spośród wielu niepotrzebnych często opcji. Może się więc
okazać, że najlepszym wyjściem jest, mimo wszystko, samodzielne nałożenie
łat i kompilacja jądra.
Dodatek do GCC
- konieczna rekompilacja ze źródeł
Zabezpieczenie przed nadpisaniem stosu i
sterty
Implementacje
- StackGuard oraz StackShield
Działają na podobnej zasadzie: na stosie umieszczany jest adres
powrotu do procedury i dodatkowe słowo. Jeśli dodatkowe słowo zmieni swą
wartość, oznacza to przepełnienie bufora. Wtedy proces zostaje zatrzymany,
co uniemożliwia dalszą penetrację systemu. Niestety, oba narzędzia są
zdecydowanie przeznaczone dla twórców oprogramowania, a nie użytkowników.
- ProPolice
ProPolice (Stack Smashing Protector) to patch dla popularnego w
linuksie kompilatora "gcc". Uniemożliwia on nadpisania adresu powrotu z
funkcji przez wstawienie wartości kontrolnej, jeżeli zostanie ona zmieniona,
program zostanie zatrzymany. Propolice zmienia również kolejność zmiennych
na stosie w taki sposób, ażeby niemożliwym było nadpisanie wskaźników do
funkcji.
Kontrola dostępu należy, obok uwierzytelnienia użytkowników, do
podstawowych usług bezpieczeństwa oferowanych przez systemy operacyjne.
Warunkiem wstępnym jest uwierzytelnienie. Uwierzytelniony użytkownik otrzymuje
dostęp do tych i tylko tych obiektów, do których jest upoważniony.
Mechanizmy te opierają się na trzech pojęciach:
-
- Podmioty (subject) mają dostęp do obiektów. Np. użytkownik,
terminal, komputer, aplikacja,
- Obiekty (object) są jednostkami, do których kontroluje się
dostęp,
- Prawa dostępu (access rights) określają sposób dostępu podmiotu
do obiektu. Są definiowane dla par (podmiot,
obiekt).
Dostęp uznaniowy DAC (Discretionary Access
Control)
Zestaw procedur i mechanizmów, które realizują kontrolę
dostępu wg uznania użytkownika będącego zwykle właścicielem zasobu. Zapewnia
użytkownikom elastyczność funkcjonowania, zwykle kosztem bezpieczeństwa.
Niektóre zasoby nie są wystarczająco chronione z powodu nieświadomości lub
przeoczenia przez użytkownika. Przykładem rozwiązania typu DAC jest mechanizm
praw dostępu w systemie UNIX. Mechanizm bitów SUID i GUID jest często
wykorzystywany podczas ataku intruza w celu wejścia w prawa użytkownika
root.
Dostęp narzucony MAC (Mandatory Access
Control)
Uprawnienia użytkowników określa administrator systemu.
Umożliwia to zaimplementowanie konsekwentnej polityki ochrony zasobów w całej
sieci. Najczęściej wykorzystywanym mechanizmem są etykiety poziomów zaufania.
Mechanizmy MAC są mniej elastyczne i wręcz przeszkadzają w otwartym
współdzieleniu zasobów przez użytkowników. Mimo to MAC należy do
mechanizmów implementowanych w łatach do systemu UNIX.
-
- ACL (Access Control Lists),
- skanowanie malware,
- jails,
- kontrola zasobów (moduł RES z minimalnymi i maksymalnymi ustawieniami
zasobów dla użytkowników i programów),
- wymuszanie uwierzytelniania,
- Linux Capabilities (np. ukrywanie procesów w module CAP),
- MAC / Bell-LaPadula,
- setuid itp.: powiadomienie jest zawsze wysyłane, nawet jeśli uid został
ustawiony na tę samą wartość; to pozwala osiągnąć właściwą rolę dla
zarezerwowanych ról początkowych po zmianie uid na roota,
- opóźniony init dla ramdysków: opóźnia init RSBAC do chwili, w której
zostanie zamontowane pierwsze urządzenie,
- dodatkowe flagi plików.
NSA Security Enhanced Linux
http://www.nsa.gov/selinux/index.cfm
SELinux został stworzony przez NSA (National Security Agency) w USA i developerów Linuksa. Jest to patch dla kerneli z rodziny 2.4.x i 2.6.x,
ale oprócz tego zawiera także cały zespół łatek dla wielu innych programów (m.in. OpenSSH, coreutils, PAM). Głównym celem twórców SELinux była poprawa
kwestii związanych z dostępem do danych, zabezpieczenie pamięci, w której wykonywane są programy, umożliwienie implementacji biblioteki "libselinux" we
własnym oprogramowaniu i wiele innych zaawansowanych funkcji. Standardowo SELinux zaczyna być dołączany do niektórych dystrybucji Linuksa takich jak Fedora
czy Gentoo, ale wymaga aktywacji i konfiguracji ze strony użytkownika
OpenBSD
http://www.openbsd.org/
Wolnodostępny
system operacyjny typu UNIX z rodziny BSD zgodny z normą POSIX. Projekt
powstał w 1996 roku jako efekt rozłamu w zespole NetBSD, jego inicjatorem był
kanadyjski programista Theo de Raadt.
Chronologia
Pierwsza wersja systemu o numerze 2.0 ukazała się 18 października 1996. 29
października 2004 ukazała się najnowsza aktualnie wersja o numerze 3.6.
Charakterystyka
Nacisk przy tworzeniu systemu został położony przede wszystkim na
bezpieczeństwo. Po rozłamie przyjęty za bazę projektu kod NetBSD został
poddany audytowi w celu wykrycia i usunięcia wszelki dziur i błędów, które
mogłyby zagrozić bezpieczeństwu systemu. Domyślnie wszystkie usługi dostępne w
systemie, a które nie są niezbędne do jego działania, są zdeaktywowane (motto:
Secure by Default). W związku umiejscowieniem siedziby poza USA w początkowej
fazie rozwoju nie dotyczyły go restrykcje eksportowe narzucone na zaawansowane
metody kryptograficzne. Dzięki temu OpenBSD od początku mogło być wyposażone w
takie usługi, jak SSH (wolna wersja OpenSSH) czy SSL (OpenSSL). Dziedzictwo po
NetBSD zaowocowało sporą przenośnością systemu (poszczególne wydania OpenBSD
powstawały na bazie portów NetBSD). Obecnie jest on dostępny dla następujących
platform: i386, SPARC, SPARC64, HP300, Amiga, Mac68k, MacPPC, Mvme68k, Alpha,
VAX. Zarzucone platformy obejmują: Sun3 (do wersji 2.9), ARC, Mvme88k, PMax.
OpenBSD pozwala uruchamiać binaria skompilowane dla następujących systemów:
SVR4, Solaris, FreeBSD, Linux, BSD/OS, SunOS oraz HP-UX.
Zastosowania
Powszechnie stosowany jako system do tworzenia systemów ścian ogniowych
(firewall), serwerów dostępowych czy bramkowych podłączających w bezpieczny
sposób mniejsze sieci do Internetu.

Atak na system komputerowy jest to działanie mające na celu przeniknięcie do chronionego systemu komputerowego
w celu przechwycenia, zniszczenia lub zmodyfikowania przechowywanych tam informacji.
Ataki możemy podzielić ze względu na:
1. Miejsce ich przeprowadzania:
- Zewnętrzne (zdalne) - ataki przeprowadzane są z systemów znajdujących się poza atakowaną siecią
- Wewnętrzne (lokalne) - ataki przeprowadzane są z systemów znajdujących się w atakowanej sieci
2. Zamiar:
- Zamierzony - atakujący zdaje sobie sprawę z tego, co robi i jakie konsekwencje mogą z tego wyniknąć,
na przykład atak w celu uzyskania konkretnie wytyczonych informacji.
- Niezamierzony - atakujący przypadkowo i nieświadomie dokonuje ataku, na przykład jeden z
użytkowników serwera przez błąd programu obchodzi system autoryzacji uzyskując prawa administratora.
3. Aktywność:
- Aktywny - w wyniku ataku system komputerowy traci integralność, na przykład atak włamywacza,
który usuwa pewną ilość ważnych danych oraz powoduje zmianę działania programów. Atakiem aktywnym może
być także modyfikowanie strumienia danych lub tworzenie danych fałszywych.
- Pasywny - atak ten polega na wejściu do systemu bez dokonywania żadnych zmian,
na przykład atak włamywacza, który kopiuje pewną ilość ważnych danych nie powodując zmian w działaniu
programów. Atakiem pasywnym może być także podsłuchiwanie lub monitorowanie przesyłanych danych.
W tym przypadku celem osoby atakującej jest odkrycie zawartości komunikatu.
Ataki pasywne są bardzo trudne do wykrycia, ponieważ nie wiążą się z modyfikacjami jakichkolwiek danych.
4. Przepływ informacji:

- Przerwanie (interruption) - jest atakiem na dyspozycyjność polegającym na częściowym zniszczeniu
systemu lub spowodowaniu jego niedostępności (niezdolności do normalnego użytkowania).
Przykładem tutaj może być fizyczne zniszczenie fragmentu komputera lub sieci, np. uszkodzenie dysku,
przecięcie linii łączności między komputerem a drugim obiektem, lub uniemożliwienie działania systemu
zarządzania plikami.
- Przechwycenie (interception) - jest atakiem opierającym się na poufności i występuje wtedy,
gdy ktoś niepowołany uzyskuje dostęp do zasobów naszego systemu komputerowego. Przykładem tutaj
może być podsłuch pakietów w celu przechwycenia danych w sieci i nielegalne kopiowanie plików lub
programów.
- Modyfikacja (modification) - jest atakiem opierającym się na nienaruszalności polegającym na
zdobyciu dostępu do zasobów przez niepowołaną osobę, która wprowadza do nich jakieś zmiany w celu
uzyskania wyższych praw lub utrzymaniu dostępu do danego systemu. Przykładem tutaj może być zmiana
wartości w pliku z danymi, wprowadzenie zmiany w programie w celu wywołania innego sposobu jego
działania lub modyfikacja komunikatów przesyłanych w sieci.
- Podrobienie (fabrication) - podrobienie jest atakiem opierającym się na autentyczności,
podczas przesyłania danych z jednego do drugiego komputera trzeci komputer blokuje uniemożliwiając
mu dalszy przesył, a sam wprowadza do systemu drugiego komputera fałszywe obiekty.
Przykładem tutaj może być wprowadzenie nieautentycznych komunikatów do sieci lub dodanie danych do pliku.
- Jak UNIX przechowuje hasła?
Każdy system operacyjny przechowuje pewnego rodzaju bazę danych z hasłami, która jest stosowana
do identyfikowania użytkowników podczas logowania. Baza danych systemu UNIX jest zawarta w pliku
/etc/passwd znajdującym się na serwerze. Jednakże ta baza danych nie przechowuje tak naprawdę haseł,
ani nawet haseł zaszyfrowanych, które można potem odszyfrować. Przechowuje jednokierunkową funkcję
haszującą hasła użytkowników.
Jednokierunkowa funkcja haszującą przetwarza dane wejściowe i zapisuje je w postaci unikatowej
wartości. W systemie operacyjnym UNIX hasło podane przez użytkownika jest przedstawiane w postaci
ciągu bajtów, a następnie za pomocą algorytmu jednokierunkowej funkcji haszującej jest przekształcane
w unikatową wartość
Gdy użytkownik próbuje zalogować się do serwera UNIX-owego, wówczas jego terminal przesyła do
serwera żądanie zalogowania w postaci zwykłego tekstu. Serwer z kolei przeprowadza na tym tekście
takie same przekształcenia, jak w wypadku generowania pierwszej wartości funkcji haszującej do bazy
danych z hasłami. Innymi słowy, serwer przeprowadza na podanym haśle operację jednokierunkowego
haszowania. Następnie serwer porównuje wygenerowaną zhaszowaną wartość z wartością znajdującą się
w bazie danych haseł. Jeżeli obie wartości są identyczne, to serwer loguje użytkownika do systemu.
W przeciwieństwie do systemu Windows NT i NetWare, które szyfrują hasło jeszcze przed przesłaniem go do
serwera, system UNIX przesyła nie zaszyfrowane hasło narażając je na wychwycenie przez osoby postronne.
Co gorsza, w przeciwieństwie do systemu Windows NT, który korzysta z Message Digest-4 (MD-4), bardzo silnego
algorytmu szyfrowania, system UNIX korzysta z 8-bitowej funkcji haszującej, dającej w wyniku łatwiejszy do
złamania zestaw haseł. Ze względu na to, że plik haseł jest dostępny domyślnie wszystkim użytkownikom,
a nie ukryty, jak w wypadku systemów Windows NT i NetWare, system UNIX jest znacznie bardziej narażony
na atak brutalny albo atak słownikowy.
- Jak hakerzy łamią hasła?
Aby zdobyć plik z hasłami z sieci UNlX-owej, haker musi mieć dostęp do tej sieci albo przynajmniej
mieć możliwość wykorzystania usług sieciowych do zdobycia dostępu do pliku /etc/passwd.
Po zdobyciu pliku z hasłami haker potrzebuje jeszcze 8-bitowej funkcji szyfrującej używanej w systemie
UNIX. Następnie może on przeprowadzić na pliku z hasłami albo atak brutalny, albo atak słownikowy.
Ponieważ plik /etc/passwd jest dostępny wszystkim użytkownikom na serwerze UNIX, haker może zdobyć
ten plik dysponując minimalnymi prawami dostępu do serwera.
Atak brutalny - metoda ta to najprostszy sposób wyszukiwania tajnych kluczy i haseł.
Polega na wypróbowaniu (podstawianiu) wszystkich możliwych kombinacji znaków w obrębie całej przestrzeni
klucza do momentu jego odnalezienia. Podejście tą metodą może być ogromnie czasochłonne zależnie
od długości hasła i mocy obliczeniowej komputera.
Atak słownikowy - wyszukiwanie słownikowe to szybszy wariant metody brute force. Podstawowym założeniem
tej metody jest przypuszczanie, że do zaszyfrowania tekstu użyto naturalnego słowa (a nie dowolnych
kombinacji liter) pochodzącego z języka, którym włada szyfrujący. Program deszyfrujący podstawia zatem
wyrazy zawarte w dostępnym mu zbiorze (słowniku). Odpowiednie słowniki dla wielu języków można znaleźć w
Internecie. Hackerzy często uzupełniają słowniki o hasła pochodzące z bliskiego otoczenia osoby,
która szyfrowała dany tekst. Do takich wyrazów należą przykładowo imiona członków rodziny czy znajomych,
ksywki, marki samochodów itp.
- Co zrobić?
Utajniać hasła i używać programów zwiększających ich bezpieczeństwo
np. przechowywać hasła w /etc/shadow
Stosować lepsze hasła: minimum 8-znakowe, zawierające cyfry, symbole i litery.
Regularnie zmieniać hasła.
- Więcej o hasłach w linuksie:
http://zgul.ime.uz.zgora.pl/bezpieczenstwo_pdf/network_security.pdf
- Co to jest?
Skaner to program automatycznie wyszukujący luki w systemie. Dobry skaner jest więcej wart niż tysiąc
haseł użytkownika, jest to program, który samodzielnie potrafi wykrywać - nawet na odległość -
słabości sieci oraz serwerów.
Poprzez analizę zainstalowanego oprogramowania i jego konfiguracji, a także przeprowadzanie prób łamania
zabezpieczeń skanery określają, które typy ataków są możliwe do przeprowadzenia, a także podają sposoby
zabezpieczenia się przed nimi.
Skanerów nie należy traktować jako narzędzi, które za nas wszystko załatwią.
One po prostu oszczędzają nam wielu godzin żmudnej pracy. Powinniśmy je wykorzystywać do wstępnego
badania sieci i jej rozpoznania.
- Rodzaje skanerów.
Skanery systemowe.
Skanery systemowe badają host lokalny, poszukują dziur, które wynikły z przeoczeń, problemów przy
konfiguracji i błędów w administracji. Do tego typu luk można zaliczyć błędnie zbudowane identyfikatory
użytkowników, zbyt liberalne prawa dostępu do plików, domyślne konta, słabe hasła i jeszcze parę innych.
Skanery sieciowe.
Skanery sieciowe testują hosty przez łącza sieciowe. Przeszukują dostępne usługi i porty, po prostu
poszukują znanych luk. Rozpoznają więc uruchomione usługi i testują je pod kątem znanych luk w
bezpieczeństwie, które można wykorzystać zdalnie.
- Kto ich używa?
Administrator, aby zwiększyć bezpieczeństwo systemu.
Haker, aby się włamać.
- Co skaner może?
odnaleźć komputer lub sieć
wykryć obsługiwane przez serwer usługi
zdiagnozować je
scharakteryzować system operacyjny
scharakteryzować strukturę sieci komputerowej
- Co więc haker robi?
W pierwszej kolejności wykonuje skanowanie zdalnej maszyny pod kątem
otwartych portów, a następnie próbuje uzyskać informacje o rodzaju i wersji
oprogramowania odpowiedzialnego za obsługę tych portów, a także informacje
o architekturze i systemie operacyjnym.
Większość wykorzystywanych przez hakerów dziur w systemach jest zależna
od oprogramowania zarządającego daną usługą, bądź nawet od wersji całego
systemu. Posiadając już wszelkie informacje, haker może odwiedzając stronę
internetową z listą dostępnych exploitów, ściągnąć z niej odpowiedni program
i przeprowadzić atak.
- Co to jest?
Sniffing jest techniką polegającą na podsłuchiwaniu pakietów przepływających w sieci.
Każdy komputer podłączony do lokalnej sieci komputerowej ma swój własny unikalny adres sprzętowy.
W sieci, w której występuje rozgłaszanie (ang.broadcasting), dane są rozsyłane do wszystkich komputerów,
ale odbierają je tylko te do których są zaadresowane. Wykorzystując fakt, że karty sieciowe w
trybie mieszanym (promiscous mode) pozwalają na odczytywanie pakietów przesyłanych do innych komputerów
w sieci, haker może przechwycić poufne informacje przesyłane poprzez sieć. Programy służące w tym
celu nazywa się snifferami. Zainstalowanie sniffera w jakimś newralgicznym miejscu sieci, np. na
routerze, może doprowadzić do pokonania zabezpieczeń wszystkich innych stacji roboczych z nim połączonych.
Programy tego typu na ogół przechwytują wszystkie pakiety z danymi.
Jeśli haker nie kradnie danych, to z jego punktu widzenia większość pakietów nie ma dla niego większego
znaczenia, dlatego też ogranicza się przechwytywanie do kilkuset bajtów z każdego pakietu.
Zazwyczaj wystarcza to do poznania nazwy użytkownika i jego hasła. Sniffery można zainstalować
praktycznie na każdej maszynie w sieci, ale najbardziej interesujące dla hakera są miejsca,
gdzie dokonuje się procedur autoryzacji.
- Pochodzenie.
Sniffery pierwotnie używane były przez administratorów w celu identyfikacji potencjalnych problemów,
jednakże z czasem zostały zaadaptowane przez hakerów, ponieważ świetnie nadają się do
przechwytywania cennych danych.
- Rodzaje.
Sniffery występują w postaci programów darmowych oraz pakietów komercyjnych.
Te pierwsze są łatwo dostępne, bezpłatne, rozprowadzane głównie w postaci kodu źródłowego.
Drugie są produktami, których cena niejednokrotnie sięga kilku tysięcy dolarów. Dlaczego?
Działający sniffer tak obciąża system, na którym jest zainstalowany, że komercyjne
produkty niejednokrotnie są rozwiązaniami sprzętowoprogramowymi, uwzględniającymi hardware na
którym będą działać oraz funkcję sieciową, jaką będą spełniać.
Oczywiście atutem stosowania komercyjnych rozwiązań jest oferowany przez firmę pełen serwis,
pomoc techniczna, itp. oraz to, że analizują dużą ilość protokołów.
Ze względu na umiejscowienie sniffera w sieci wyróżnić można trzy sytuacje:
1. Sniffer znajduje się na routerze znajdującym się między siecią lokalną a Internetem
(połączenie nie musi być bezpośrednie), bądź też między różnymi sieciami lokalnymi lub rozległymi.
Ten rodzaj sniffingu jest najbardziej niebezpieczny.
2. Sniffer znajduje się na komputerze, z którego inicjowane jest połączenie.
3. Sniffer działa na komputerze, na który następuje próba logowania użytkownika.

- Jak się bronić.
Wykrywanie snifferów w sieci jest zadaniem trudnym, bowiem programy tego typu działają pasywnie
i nie zostawiają żadnych śladów w logach systemowych.
Do znalezienia sniffera na lokalnym komputerze można użyć sum kontrolnych MD5,
oczywiście pod warunkiem, że sam pakiet MD5 został zainstalowany dostatecznie wcześnie,
najlepiej zaraz po instalacji systemu,
a sama baza oryginalnych sum kontrolnych jest fizycznie niedostępna dla hakera.
Jeśli haker podpiął się bezpośrednio do medium transmisyjnego, należy sprawdzić każdy centymetr kabla
sieciowego, bądź też zastosować narzędzia służące do mapowania topologii sieci.
Sniffery przechwytują pakiety wędrujące po medium transmisyjnym, do którego są podpięte.
W związku z tym, podział sieci na mniejsze podsieci zmniejsza ilość informacji,
które mogą być przechwycone. (Sniffery nie potrafią przejść takich
urządzeń jak bridge, switche czy routery). Jest to jednak bardzo kosztowne rozwiązanie.
Idealnym wyjściem jest szyfrowanie danych. Nawet jeśli haker przechwyci pakiety,
to zakodowane informacje w nich zawarte będą dla niego bezużyteczne. Można tu napotkaą problem,
czy metoda szyfrowanej komunikacji jest wspierana przez wszystkie
strony biorące w niej udział, ponieważ szyfrowanie sesji międzyplatformowych jest zjawiskiem dość rzadkim.
Jeśli nie mamy do dyspozycji szyfrowania sesji, należy skorzystać z aplikacji, które oferują
silne dwukierunkowe szyfrowanie danych.
Przykładem może być Secure Shell (SSH), który zastępując standardowego telneta,
przy negocjacji połączenia stosuje algorytm RSA, a po autoryzacji transmisja kodowana jest algorytmem IDEA.
- Co to jest?
Spoofing polega na podszywaniu się pod inny komputer.
Celem jest oszukanie systemów zabezpieczających. Podszywaniem określa się dowolną metodę łamania
zabezpieczeń autoryzacyjnych opartych na adresie lub nazwie hosta. Rodzajami spoofingu jest: ARP spoofing,
DNS spoofing, IP spoofing, Route spoofing, Non-blind i Blind spoofing. Krótko omówię najważniejsze dwa:
IP spoofing (maskarada) - metoda ta polega na podsłuchiwaniu przez sniffer połączenia pomiędzy
klientem a serwerem i wyłapywaniu wysyłanych numerów sekwencji. Po znalezieniu algorytmu jakim są one
tworzone atakujący doprowadza do niestabilności połączenia np. poprzez atak SYN Flood na stacje
klienta, zmienia numer IP na numer klienta i przewidując numery sekwencji korzysta z istniejącego
połączenia jako autoryzowany użytkownik.
DNS spoofing - jest to atak na serwer DNS, który posiada bazę danych przechowującą numery IP
dla poszczególnych adresów mnemonicznych. Atak DNS spoofing polega na ingerencji w tablicę DNS i
modyfikacji poszczególnych wpisów tak, aby klient zamiast do komputera
docelowego kierowany był do komputera atakującego.
Jak to może wyglądać?
- Serwer DNS nie przechowuje wszystkich adresów IP. Zajmowało by to za dużo pamięci. Posiada cache, który pozwala
mu trzymac adres IP przez jakiś czas. Jak można "zatruć" serwer DNS? Załóżmy że atakujący ma własną domenę (attacker.net)
i swój własny zhakowany serwer DNS (ns.attacker.net), gdzie umieścił zapis www.cnn.com = 81.81.81.81.
- Atakujący prosi Twój serwer DNS o połączenie z www.attacker.net

- Twój serwer DNS nie zna tego adresu IP, więc sam o niego pyta.

- Zhakowany serwer odpowiada i jednocześnie "zatruwa" cache
twojego serwera transferując tam swoje zapisy (włączając w to www.cnn.com)

- Twój serwer DNS ma "zatruty" cache.

- Jeśli teraz zechcesz wejść na www.cnn.com twój serwer DNS skieruje cię tam gdzie zażyczył sobie tego atakujący.
- Co to jest?
Jednym z najbardziej niebezpiecznych ataków na system komputerowy jest
atak polegający na przechwyceniu sesji w protokole TCP (ang. hijacking). Technika
polega na tym, że haker powoduje przerwanie połączenia zestawionego pomiędzy
klientem a serwerem, następnie podszywa się pod klienta i podsyła serwerowi
własne numery sekwencji. Aby mieć możliwość wglądu w przesyłane pakiety,
konieczne jest korzystanie ze sniffera. Hijacking jest więc połączeniem dwóch metod: sniffingu i IPspoofingu.
W celu doprowadzenia do przerwania połączenia TCP należy je wcześniej
rozsynchronizować.


- Rodzaje przerwania połączenia
wczesne rozsynchronizowanie
aktywne rozsynchronizowanie
rozsynchronizowanie pustymi danymi
- Dlaczego jest to gorsze niż spoofing?
Przechwycenie sesji umożliwia hakerowi ominięcie weryfikacji hasła, dzięki czemu
może on bezproblemowo wejść do komputera głównego.
Przechwytywanie w protokole TCP jest dużo większym zagrożeniem niż
podszywanie się pod IP, ponieważ przechwytując już odbywające się połączenie ma
zazwyczaj lepszy dostęp do systemu, nią miałby rozpoczynając je od nowa.
- Wirusy i robaki.

- Cechy charakterystyczne:
powielają się (podstawowy wyróżnik)
wirusy rozprzestrzeniają się poprzez pliki wykonywalne (w tym także np. wygaszacze ekranu,
pliki HTML zawierające kod Javascript lub dokumenty Worda z makrami), dawniej także poprzez
boot-sektory dysków
do uaktywnienia wirusa niezbędne jest uruchomienie zawierającego go pliku;
część wirusów wykorzystuje błędy w oprogramowaniu umożliwiające uruchamianie plików automatycznie
(np. REDLOF, różne robaki pocztowe)
robaki potrafią same rozprzestrzeniać się na inne komputery wykorzystując mechanizmy sieciowe
- Możliwe skutki:
utrudnianie (czasami uniemożliwianie) pracy na komputerze -
w przypadku wielu wirusów jedyny cel
mogą niszczyć, zmieniać dane i/lub oprogramowanie zawarte na dysku
mogą wykradać dane
mogą przenosić i instalować inne typy złośliwych programów, np. konie trojańskie
istnieją (bardzo rzadkie) wirusy mogące uszkodzić komputer - np. CIH (Czernobyl) -
kasowanie pamięci Flash
- Konie trojańskie

- Cechy charakterystyczne:
nie powielają się samoczynnie (ale mogą być roznoszone przez wirusy)
udają programy użytkowe, narzędziowe, gry (stąd nazwa)
końmi trojańskimi mogą być także np. strony WWW zawierające odpowiednio
spreparowane kontrolki ActiveX
zazwyczaj ukrywają się w systemie, tak aby ich działania były trudno zauważalne
często umożliwiają dostęp z zewnątrz do komputera bez wiedzy użytkownika
- Możliwe skutki:
mogą umożliwiać innym osobom manipulowanie komputerem i znajdującymi się na
nim danymi bez wiedzy użytkownika
mogą wykradać dane, przechwytywać obraz z ekranu, tekst pisany na klawiaturze
mogą wykorzystywać komputer do rozsyłania spamu lub zdalnych ataków na inne komputery
mogą pobierać z sieci i instalować inne konie trojańskie lub spyware
dialery mogą narazić użytkowników modemów na wysokie koszty
- Spyware

- Cechy charakterystyczne:
zawarte w oficjalnych wersjach instalacyjnych wielu różnych "darmowych" programów !!! (np. KaZaA)
pojawiają się także w postaci kontrolek ActiveX na stronach WWW (np. Gator - "Precision Time")
podstawowy i jedyny cel - szpiegowanie użytkownika
(informacja o odwiedzanych stronach WWW, ściąganych plikach itp. - zazwyczaj anonimowa,
ale niektóre programy mogą przesyłać dane personalne)
obecność w programie okienek reklamowych może świadczyć o obecności spyware
trudne do odinstalowania, nawet po odinstalowaniu programu - "nosiciela" pozostają w systemie
skutkiem ubocznym może być nieprawidłowe działanie innych programów
zazwyczaj niewykrywane przez programy antywirusowe; niezbędne specjalne programy do wykrywania i
usuwania spyware (np. Ad-Aware, Spybot Search & Destroy)
programy użytkowe zawierające spyware często nie działają po jego usunięciu
funkcje szpiegowskie pełnią czasem także reklamy na stronach WWW
- Profilaktyka i zwalczanie
- Co instalować?
aktualne poprawki do systemu operacyjnego
programy antywirusowe
programy anty-spyware
firewall
- Czego nie robić?
NIGDY nie otwierać załączników w listach, jeżeli z TREŚCI listu nie wynika wyraźnie,
co i po co jest w załączniku (niezależnie od adresu nadawcy - wirusy fałszują adresy!) -
w razie jakichkolwiek wątpliwości upewnić się u nadawcy listu!
NIGDY nie zgadzać się na automatyczną instalację żadnych programów (kontrolek) ze stron WWW,
jeżeli na danej stronie nie ma wyraźnej informacji o zastosowaniu i przeznaczeniu danej kontrolki!
nie klikać na żadne odsyłacze w listach pochodzących od nieznanych nadawców i o "dziwnej" treści
ściągać programy z Internetu tylko z "pewnego źródła", najlepiej ze stron producentów
lub z wiarygodnych, znanych serwisów - nie z przypadkowych stron prywatnych
ustawić odpowiednio poziomy zabezpieczeń w przeglądarce (w IE co najmniej "poziom średni")
używać innej przeglądarki i programu pocztowego zamiast IE i OE (wirusy, robaki itp.
wykorzystują błędy w tych programach)
- Co to jest?
W ogólnym znaczeniu metoda ta polega na częściowym lub całkowitym zablokowaniu dostępu do świadczonych usług.
Podatność ośrodków sieciowych na ataki DoS wynika z ograniczenia zasobów każdego serwera/systemu.
W przypadku zastosowań WWW ograniczenie to wynika przede wszystkim z przepustowości łącza.
Ale nie tylko, innymi ograniczeniami są pamięć operacyjna oraz moc obliczeniowa warunkowana rodzajem stosowanego
procesora (procesorów). Celem i konsekwencją ataku DDoS jest uniemożliwienie systemowi świadczenia usług, co osiąga
się przez zajęcie jego zasobów "czymś innym".
- DOS i DDOS
Atak DoS ma dwa zasadnicze ograniczenia.
Po pierwsze przeprowadzany jest z pojedynczego komputera,
którego łącze internetowe może mieć lub ma zbyt małą przepustowość w stosunku do łącza ofiary.
Po drugie prowadząc atak z jednego komputera, atakujący naraża się na szybsze wykrycie.
Dlatego atak DoS przeprowadzany jest najczęściej na mniejsze serwery zawierające strony WWW.
Atak na większy cel, na przykład portal lub serwer DNS, wymaga zastosowania bardziej wyrafinowanej metody -
DDoS, czyli rozproszonego ataku DoS, opracowanego jako remedium na ograniczenia DoS.
Metoda DDoS jest ukierunkowana na wykorzystanie błędów w stosach protokołu TCP/IP,
natomiast ataki DoS wykorzystują charakterystyczne luki znanych pakietów oprogramowania.
Sieci DDoS składają się z trzech elementów:
Attacker (atakujący, zwany też klientem) maszyna, z której rozpoczyna się atak;
Master (zwany również Handler) serwer, na który włamał się haker i umieścił odpowiednie oprogramowanie
pozwalające na kontrolowanie deamonów; każdy master może obsługiwać wiele deamonów;
Deamon (zwany również agentem) serwer, na który włamał się haker i zainstalował oprogramowanie do
generowania potoku pakietów (packet stream); deamon oczekuje na rozkazy od swojego mastera;
Niektóre implementacje dopuszczają zmianę swojego mastera.

- Przykłady ataków:
SYN Flood
- Napastnik wysyła bardzo dużo pakietów SYN do ofiary
- Atakowany komputer dla każdego nadchodzącego pakietu SYN próbuje utworzyć połączenie
- Powstają "pół-otwarte" połączenia (half-open):czekają na odpowiedź od napastnika,
która jednak nigdy nie nadejdzie
- Powoduje to poważne spowolnienie albo całkowite zablokowanie ofiary
Land
- Napastnik wysyła pakiet ACK zawierający sfałszowany adres źródłowy równy adresowi docelowemu
- Atakowany host usiłuje nawiązać połączenie z samym obą
- Powoduje to zawieszenie maszyny
Teardrop
- Błąd w implementacji stosu TCP/IP, występował zarówno w systemach Windows,
jak i Linux/Unix
- System nie radził sobie z pofragmentowanymi pakietami
- Odpowiednio spreparowane i pofragmentowane pakiety, przy łączeniu w całość, powodowały
nadpisanie jądra systemu
- Firewalle bezradne: albo przepuszczały zabójcze pakiety, albo same się wykładały
- Jak się bronić?
Nie ma uniwersalnej i skutecznej metody chroniącej sieć przed opisywanymi tu zagrożeniami. Zasadniczą przyczyną,
dla której ataki DoS i DDoS są tak trudne do opanowania, jest olbrzymia liczba komputerów źle lub w ogóle niezabezpieczonych.
Są to głównie systemy pracujące na uczelniach :) oraz komputery domowe podpięte na stałe do Internetu.
Ataki tego typu należy traktować bardzo poważnie, ponieważ programy
do blokowania usług są ogólnodstępne, a ich użycie niezwykle łatwe.
- Co to jest?
Przepełnienie bufora (ang. buffer overflow) polega na podaniu programowi większej liczby danych,
niż to przewidział twórca programu. Nadmiarowe dane przekraczają obszar pamięci,
który został przeznaczony dla danych, a tym samym wkraczają w obszar pamięci, który był
przeznaczony na instrukcje programu. W idealnej wersji tego ataku nadmiarowe dane są
nowymi instrukcjami, które umożliwiają napastnikowi sterowanie pracą procesora.
- Skąd się wzięło?
Możliwość przepełniania bufora bierze się z wrodzonej słabości języka C++. Problem,
który został odziedziczony z języka C i który dotyczy również innych języków programowania,
takich jak Fortran, polega na tym, że C++ nie kontroluje automatycznie długości
podawanych programowi danych.
- Przykład.
#include
#include
#include
void bigmac(char *p);
int main(int argc, char *argv[]){
bigmac("Could you supersize that please?");
return 0;
}
void bigmac(char *p)
{
char stomach[10];
strcpy(stomach, p);
printf(stomach);
}
Kompilacja przebiegnie bez przeszkód, ale wykonywanie uruchomionego programu
załamie się. Co się stało? Po uruchomieniu programu, funkcji bigmac przekazywany jest długi łańcuch
znaków. Niestety funkcja strcpy() nie sprawdza
długości kopiowanych łańcuchów. Jest to bardzo niebezpieczne, gdyż przekazanie funkcji
łańcucha o długości większej niż dziewięć znaków powoduje przepełnienie bufora.

Funkcja strcpy(), podobnie jak kilka innych funkcji języka C++, ma istotną wadę, która
powoduje, że nadmiarowe znaki są wpisywane do obszaru pamięci leżącego poza
zmienną. Z reguły powoduje to załamanie się programu. W tym konkretnym przypadku
załamanie programu spowodowała próba czytania poza granicą statycznego łańcucha.
W najgorszym przypadku tego rodzaju przepełnienie umożliwia wykonanie w zaatakowanym
systemie dowolnego kodu.
- Jak haker zabiera się za atak?
Najpierw musi znaleźć działający program, który jest podatny na przepełnienie bufora. Nawet
gdy działanie hakera nie zakończy się uruchomieniem szkodliwego kodu, z pewnością
doprowadzi do załamania programu. Haker musi też znać dokładny rozmiar bufora,
który będzie chciał przepełnić.
Drugim etapem ataku przepełnienia bufora jest wykonanie dostarczonego kodu (ładunku).
Ładunkiem jest zwykle polecenie umożliwiające zdalny dostęp do zaatakowanego
komputera lub inne polecenie ułatwiające hakerowi przejęcie komputera.
Przeprowadzenie skutecznego ataku przepełnienia bufora jest trudne. Jednak nawet wtedy,
gdy atak przepełnienia bufora nie powiedzie się do końca, najczęściej i tak spowoduje
problemy w atakowanym komputerze. Zwykle polegają one na załamaniu się działania
zaatakowanego programu lub nawet całego systemu.
- Jak się bronić.
Najlepszym sposobem, by uniemożliwic ataki przepełnienia bufora, jest przestrzeganie
przez programistę właściwych praktyk programowania. Należą do nich:
- sprawdzanie wielkości danych przed umieszczeniem ich w buforze,
- użycie funkcji ograniczających liczbę i (lub) format wprowadzanych znaków,
- unikanie niebezpiecznych funkcji języka C, takich jak scanf( ), strcpy( ),
strcat( ), getwd( ), gets( ), strcmp( ), sprintf( ).
Istnieją narzędzia, których zadaniem jest badanie podatności kodu na przepełnienie bufora.
Jednym z komercyjnych programów służących do tego celu jest PolySpace (http://www.polyspace.com),
zawierający narzędzie do wykrywania w czasie kompilacji możliwości
przepełnienia bufora w programach napisanych w ANSI C.
Dla Linuksa dostępne są dodatki do kompilatora C++ oraz biblioteki, które sprawdzają
w czasie wykonywania się programu wielkość wprowadzanych danych. Przykładem tego
może byc StackGuard (http://immunix.org), który wykrywa ataki uderzenia w stos,
chroniąc przed zmianą adres powrotu funkcji. Podczas wywołania funkcji umieszcza on
obok adresu powrotu bajty przynęty, natomiast podczas kończenia pracy funkcji
sprawdza, czy przynęta została zmieniona. Jeżeli tak się stało, umieszcza zapis w dzienniku
zdarzeń systemu i kończy działanie programu.
Dodatkową linię obrony mogą stanowić narzędzia kontrolujące rozmiar danych.
Do narzędzi tego typu należą BOWall, Boundschecker firmy Compuware czy Purify firmy Rational.
- Co to jest?
SQL injection to typ ataku, który korzysta z dziur w aplikacjach Web'owych.
Wykorzystuje wywołanie zapytania SQL w aplikacji w której nie przetwarza się danych uzyskanych od
użytkownika. Najczęściej polega na takim skonstruowaniu formuły w klauzuli WHERE zapytania,
by sprawdzanie wprowadzonych danych nie miało znaczenia.
- Przykłady:
$login = Request.Form("login")
$password = Request.Form("password")
$query = 'SELECT $field FROM $database WHERE Login=' . $login .'AND Password= '. $password . ';';
logując się do systemu podajmy następujące hasło:
test'or'1=1
w naszym skrypcie php otrzymujemy zapytanie:
SELECT ...
WHERE login='x' AND password='test'or'1=1'
Równie łatwo jest wykorzystać błąd w niecnych celach:
Login: x';DROP TABLE users;--
- Jak unikać?
filtrować dane z wejścia
zwracać uwagę na kluczowe słowa ( SELECT, DROP, TABLE, itd)
zwracać uwagę na kluczowe znaki (cudzysłów, apostrof, itd)
źródła:
- ftp://ftp.helion.pl/online/strada/strada-5.pdf
- http://emkay.spymac.net/publikacje/podrecznik_administratora.pdf
- http://zgul.ime.uz.zgora.pl/pszostak/publikacje.html
- http://inet4u.esol.pl/opatou-dos.pdf
- http://zgul.ime.uz.zgora.pl/bezpieczenstwo_pdf/network_security.pdf
- http://stud.wsi.edu.pl/~dratewka/
- http://www.pckurier.pl/archiwum/art0.asp?ID=6067
- http://www.pckurier.pl/archiwum/art0.asp?ID=3873
W czasach, gdy powstawała sieć Internet, jej twórcy zaprojektowali ją w ten sposób, by była odporna na awarie typu odłączenie
pojedynczych składników sieci, uszkodzenia okablowania, bądź też wahania zasilania. Niestety w tamtych zamierzchłych już
czasach nie przewidziano dodatkowych zabezpieczeń chroniących zasoby prywatne użytkowników Internetu i sieci lokalne
przedsiębiorstw przed atakami z Internetu, bądź też z wnętrza samej sieci lokalnej. Obecnie wraz ze wzrostem popularności Internetu
i liczby jego użytkowników, znacznie wzrosło niebezpieczeństwo utraty prywatności w wewnętrznych sieciach i zagrożenie przeprowadzania ataku na tą sieć
przeprowadzone z Internetu, w celu np. wykradzenia danych lub ich uszkodzenia. Dlatego konieczne stało się zabezpieczanie sieci przed wtargnięciem do niej
osób niepowołanych. Najbardziej skutecznym rozwiązaniem tego problemu byłoby fizyczne odseparowanie wszystkich komputerów realizujących istotne zadania i
przechowujących ważne informacje, lecz oznaczałoby to kompleksową przebudowę całej sieci lokalnej. Rozwiązaniem tego problemu jest zastosowanie
urządzenia zwanego "ścianą ognia" (z ang. firewall, w Polsce często też używa się określenia zapora) chroniącego system lokalny przed ingerencją zewnętrzną.

Firewall jest to zwykle dedykowana maszyna, sprzętowa lub software'owa, która znajduje się między siecią prywatną, a publiczną (z reguły Internetem). Maszyna ta sprawdza każdy
przepływający przez nią pakiet i albo go przepuszcza albo blokuje w zależności od ustalonych przez administratora reguł. Firewalle umożliwiają utworzenie
konfiguracji stanowiącej kompromis pomiędzy siecią prywatną całkowicie izolowaną od publicznej (Internetu), a siecią prywatną swobodnie do publicznej
podłączoną. Umieszczony na styku sieci prywatnej i publicznej, firewall stanowi prosty mechanizm kontroli ilości i rodzaju ruchu sieciowego między obiema
sieciami. Konfiguracja firewalla z reguły może być opisana poprzez następującą politykę bezpieczeństwa: "co nie jest wyraźnie dozwolone, jest zabronione".
Firewalle czasami stosuje się również wewnątrz sieci prywatnych, aby zabezpieczyć istotne elementy przed własnymi użytkownikami (np. dwa działy w jednej
firmie nie powinny mieć dostępu do swoich informacji). Takie rozwiązanie jest korzystne również dlatego, że jeżeli napastnik włamie się do jednej grupy
komputerów to i tak nie będzie miał dostępu do pozostałych komputerów.
Są dwie różne idee projektowania firewalli. Pierwsza to tzw. "czarna skrzynka" - głównie sprzętowe firewalle produkowane przez komercyjne firmy. Ich
sposób działania nie jest bliżej znany. Mamy jedynie dostęp do ich interfejsu użytkownika i ułatwieniach w ich sterowaniu, ale nie mamy pewności czy nie
mają one jakichś luk w bezpieczeństwie, bądź nieudokumentowanych obejść. Druga koncepcja to tzw. "kryształowa skrzynka" - zasady filtrowania pakietów są
ogólno dostępne, ponieważ mamy możliwość obejrzenia kodu źródłowego wraz z jego kompletną dokumentacją. Pozwala to na dokładne sprawdzenie całego kodu
i własnoręczne wprowadzenie ewentualnych poprawek. Firewalle tego typu mają ogromne znaczenie w przypadku, gdy udostępniony jest kod źródłowy całego
systemu operacyjnego, gdyż możemy dostosować konfigurację firewalla do ewentualnych niedociągnięć w samym kodzie systemu.

Żeby dokładniej poznać budowę, sposób działania i typy firewalli, musimy najpierw poznać w jaki sposób komputery komunikują się ze sobą, czyli model OSI (Open System Interconnection) -
standard opisujący strukturę komunikacji sieciowej, zdefiniowany przez organizacje ISO i ITU-T. OSI traktowany jest jako model odniesienia dla większości
rodzin protokołów komunikacji. Podstawowym założeniem tego modelu jest podział na 7 całkowicie niezależnych warstw (ang. layers). OSI definuje jakie zadania
i rodzaje informacji mogą być przesyłane między warstwami w całkowitym oderwaniu od ich fizycznej i algorytmicznej realizacji. Żadna z warstw sama w sobie
nie jest jeszcze funkcjonalna, ale możliwe jest projektowanie warstwy w całkowitym oderwaniu od pozostałych, po uprzednim zdefinowaniu protokołów wymiany
informacji między poszczególnymi warstwami. W modelu OSI wyróżniamy trzy warstwy górne: aplikacji, prezentacji i sesji. Tworzą one interfejs, który pozwala
na współpracę z programistą oraz niższymi warstwami, w zależności od kierunku przepływu informacji. Warstwy dolne to warstwa transportowa, sieciowa, łącza danych i fizyczna.
Odpowiadają one za odnajdywanie odpowiedniej drogi do celu, gdzie ma trafić informacja, weryfikują ich bezbłędność, dzielą informacje na pakiety odpowiednie
dla urządzeń sieciowych. W warstwie dolnej ignorowany jest sens samej informacji. Dla Internetu zdefiniowano uproszczony model DoD (z ang. Department of Defence - Departament
Obrony USA - twórca Arpanet, przodka sieci Internet). Składa się on tylko z 4 warstw. Na poniższym rysunku widzimy porównanie obu modeli: OSI i DoD
A teraz po kolei omówimy kolejne warstwy modelu DoD, gdyż są one dość ważne do zrozumienia działania poszczególnych rodzajów firewalli. Na model DoD składają
się następujące warstwy:
- Warstwa aplikacji - najwyższy poziom, w którym pracują użyteczne aplikacje jak np. serwer WWW, przeglądarka internetowa. Jest to zestaw gotowych protokołów, które te aplikacje
wykorzystują do przesyłania informacji w sieci. Przykładowe protokoły z tej warstwy to: FTP, HTTP, HTTPS, SMTP, Telnet, SSH.
- Warstwa transportowa - zapewnia pewność przesyłania danych i kieruje informacje do odpowiednich dla nich aplikacji. Opiera się to na wykorzystywaniu portów
określonych dla każdego rodzaju połączenia. Każda usługa w Internecie ma przypisany swój własny port, np. dla FTP jest to port 21, dla HTTP port 80. Porty ponumerowane są
liczbami od 1 do 655325. Dzięki takiemu rozwiązaniu w jednym komputerze może istnieć wiele aplikacji wymieniających dane z tym samym komputerem w sieci i nie nastąpi wymieszanie się
przesyłanych przez nie danych. Warstwa transportowa również nawiązuje i zrywa połączenia między komputerami. Protokoły działające w tej warstwie to np.: TCP, UDP, SSL, NetBEUI.
- Warstwa sieciowa - to podstawowa dla działania Internetu warstwa. W niej przetwarzane są pakiety posiadające adres IP. Na jego podstawie ustalana jest odpowiednia
droga do docelowego komputera w sieci. Urządzenia takie jak np. rutery i switche pracują właśnie w tej warstwie, gdyż zajmują się kierowaniem ruchu w Internecie na
podstawie znajomości topologii sieci. Proces znajdowania drogi przez ruter nazywa się routingiem. W tej wartwie działają następujące przykładowe protokoły/urządzenia: IP, ICMP, NAT, NetBEUI.
- Warstwa dostępu do sieci - najniższa warstwa, zajmująca się przekazywaniem danych przez fizyczne połączenia między urządzeniami sieciowymi.
Z reguły są to karty sieciowe lub modemy. Dodatkowo czasem warstwa ta jest wyposażona w dodatkowe protokoły do dynamicznego określania adresów IP. W warstwie tej działają np. następujące protokoły:
802.11 WiFi, ADSL, ISDN, V.90, Token Ring, 10BASE-T, Ethernet.
Istnieją trzy typy firewalli, różniące się między sobą tym, w której warstwie modelu OSI kontrolowana jest komunikacja między sieciami:
- filtrowanie pakietów (packet filtering) - działa w warstwie sieci
- analiza stanu połączeń (circuit level firewall) - działa w warstwie transportu
- firewall poziomu aplikacji (application level firewall) - działa na poziomie aplikacji
|
Filtrowanie pakietów:
Ten rodzaj firewalla to z reguły ruter filtrujący (screening router) lub specjalny komputer.
Na podstawie adresu źródłowego i docelowego oraz portu pojedynczego pakietu decyduje on, czy dana przesyłka może zostać przesłana dalej do sieci lokalnej, czy też powinna zostać zatrzymana.
Firewall na poziomie sieci można na przykład skonfigurować tak, by blokował wszystkie wiadomości pochodzące od oraz wysyłane do określonej konkurencyjnej
firmy. Firewall tego typu blokuje lub zezwala na komunikację z siecią chronioną stosując filtr w formie listy kontroli dostępu ACL (ang. Access Control List).
Jest to lista zawierająca zbiór zasad i odpowiadających im akcji zapisanych w określonym porządku, mających na celu podjęcie decyzji czy dany pakiet jest
dozwolony czy nie.
Firewalle stosujące technikę filtrowania pakietów są zwykle bardzo szybkie, jednak głównym ich ograniczeniem jest to, że pracują one tylko w warstwie
sieciowej i łącza danych. Zapewnia im to dostęp tylko do adresów IP,
numerów portów oraz znaczników TCP, nie mają zaś dostępu do informacji o kontekście konkretnego pakietu, co jest niewystarczające dla niektórych usług
internetowych. Poza tym nie są w stanie filtrować danych
przesyłanych za pomocą protokołu UDP (User Datagram Protocol - protokół przesyłania datagramów). Poza tym że większość firewalli tego typu, przede wszystkim
rutery, nie posiada mechanizmów kontrolnych, ani ostrzegawczych o zatrzymanych pakietach. Firewall może zatem odeprzeć wiele ataków, nie informując nawet o
tym administratora sieci. Ponadto często wystarczy
zmienić adres nadawcy pakietu, aby obejść tego rodzaju zabezpieczenie i filtr pakietowy jest już bezradny. |  |
| Firewall poziomu aplikacji:
Firewalle poziomu aplikacji to hosty, na których
uruchomiono serwery proxy. Nie pozwalają one na bezpośredni ruch pakietów pomiędzy sieciami, a także rejestrują i śledzą cały ruch przechodzący przez
nie. Dla każdej aplikacji (czyli usługi sieciowej, np. HTTP, FTP, telnet, SMTP, POP3, etc.)
istnieje osobny proxy, dla którego definiowane są reguły według których podejmowana jest decyzja o
zaakceptowaniu bądź odrzuceniu połączenia. Proxy serwery potrafią więc niejako odseparować wiarygodną część sieci od podejrzanej. Poza tym mogą
magazynować najczęściej żądane informacje - klient kieruje swoje żądanie do proxy, który jeśli wyszuka obiekt w swoich lokalnych
zasobach to zwraca zamawiającemu bez potrzeby komunikacji z siecią zewnętrzną. Tak więc proxy serwer jest też rodzajem cache'u. Niewątpliwym minusem
tego rozwiązania jest konieczność
stosowania wielu serwerów proxy do obsługi różnych aplikacji (usług sieciowych). Jeżeli dla danej usługi nie jest dostępny odpowiedni
proxy serwer, to dane przesyłane w tym formacie nie będą w ogóle przepuszczane przez bramkę.
Firewalle na poziomie aplikacji umożliwiają kontrolowanie typu i objętości danych napływających do sieci lokalnej. Fizycznie oddzielają one sieć
lokalną od publicznej, dzięki czemu dobrze pełnią funkcje ochronne. Ponieważ jednak program musi kontrolować pakiety i decydować o ich przepuszczaniu,
ten typ zapory ogniowej działa wolniej niż zapora ogniowa na poziomie sieci. Jeśli więc jest planowane użycie tego typu zabezpieczenia, to należy
je umieścić w najszybszym komputerze. |  |
| Analiza stanu połączeń:
Zwane również firewallami typu stateful inspection. Firewalle tego rodzaju są rozwiązaniem kompromisowym między szybkością firewalli
filtrujących pakiety, a bezpieczeństwem firewalli poziomu aplikacji. Firewalle te filtrują poszczególne pakiety, jednak nie tylko na podstawie ich nagłówków, tak
jak w zwykłym filtrowaniu pakietów. Firewalle tego typu potrafią przyporządkowywać pakiety do istniejących
połączeń TCP i dzięki temu kontrolować całą transmisję (zaawansowane systemy potrafią także kojarzyć pakiety protokołu UDP, który w
rzeczywistości kontroli połączeń nie posiada). Technika ta zwana jest TCP tunnelingiem i odbywa się bez kontroli zawartości pakietów. Firewalle te na bieżąco śledzą i analizują przechodzące przez nie połączenia,
co pozwala na znacznie skuteczniejsze kontrolowanie ich zgodności z regułami. Z tych powodów często zapory tego rodzaju są również określane pojęciem dynamicznego
filtrowania pakietów. Firewall cały czas przechowuje w pamięci informacje na temat aktualnego stanu
każdego połączenia, a jednocześnie wie jakie kolejne stany tego połączenia są dozwolone z punktu widzenia protokołu i polityki bezpieczeństwa. Administrator
sieci określa tylko kierunek i politykę względem rozpoczęcia danego połączenia, firewall zaś automatycznie weryfikuje kolejne etapy jego
nawiązywania oraz późniejszy przebieg. Ostatnia cecha pozwala również na odrzucanie pakietów, które do danej sesji nie należą, dzięki czemu firewalle te
skutecznie blokują próby skanowania portów lub wprowadzania sfałszowanych pakietów (ang. spoofing). |  |

Z reguły sieć lokalna zbudowana w architekturze z firewallem składa się z następujących charakterystycznych elementów:

- Ruter ekranujący
Ruter ekranujący z reguły stanowi pierwszą linię obrony sieci. Dzięki temu, że filtruje on pakiety w warstwie sieciowej, niezależnie od warstwy aplikacji,
nie wymaga wprowadzania zmian do żadnej z aplikacji typu klient czy serwer. Rutery są wygodne w obsłudze i stosunkowo niedrogie, jednak nie są wydajnymi
zabezpieczeniami. Dzięki temu, że pracują one wyłącznie w warstwie sieciowej i łącza danych modelu OSI, są to urządzenia nieskomplikowane w
obsłudze, ale z tego powodu ich możliwości są niewystarczające.
- Bastion host
Następnym punktem obrony sieci jest tzw. bastion host, czyli komputer-bastion lub komputer-twierdza. Nazwa ta wywodzi się ze średniowiecznego terminu
określającego ufortyfikowane miejsce służące do odpierania ataków, np. mury obronne. Analogicznie więc, komputer-bastion jest to komputer stojący pomiędzy
siecią lokalną, a publiczną, wyposażony w specjalne zabezpieczenia chroniące go, jak i całą sieć lokalną przed atakami dokonywanymi z sieci zewnętrznej.
Na komputerze-twierdzy uruchomiony jest z reguły firewall poziomu aplikacji (wariant najbezpieczniejszy) wyposażony w serwery proxy używanych w sieci lokalnej usług internetowych.
Jest on więc kolejnym sitem, przepuszczającym pakiety, jednak tym razem już na poziomie aplikacji, czyli analizujący pakiety w kontekście danej usługi internetowej.
Dzięki scentralizowaniu dróg dostępu w jednym komputerze łatwo można zarządzać systemem ochrony sieci oraz konfigurować odpowiednie
aplikacje dla tego pojedynczego komputera.
- Obszary ryzyka i strefa DMZ
Zapora ogniowa powinna zapewniać wysoki poziom bezpieczeństwa sieci jednak bez ograniczania jej funkcjonalności. Musi ona pozwalać autoryzowanym
użytkownikom na korzystanie bez przeszkód z zasobów sieci lokalnej i Internetu, ale jednocześnie musi blokować dostęp nieznanym użytkownikom, umożliwiając
im korzystanie tylko z niewielkiej, wydzielonej części zasobów sieciowych. Ta wydzielona część zwana jest strefą DMZ (z ang. DeMilitared Zone), czyli strefą
zdemilitaryzowaną lub ograniczonego zaufania. Określenie to pochodzi z terminologii wojskowej i oznacza bufor między wrogimi siłami. Strefa DMZ stanowi
podsieć, na której działają serwery dostępne z sieci zewnętrznej (Internetu), oferujące w Interniecie usługi publiczne danej sieci lokalnej, takie jak serwis WWW, serwer FTP, etc.
W wypadku włamania na serwer w strefie DMZ, intruz i tak nie ma możliwości dostać się do wnętrza sieci lokalnej. Strefę DMZ definiuje się na samym firewallu.
Strefa DMZ stanowi tzw. obszar ryzyka czyli obszar, w którym znajdują się informacje i systemy należące do chronionej sieci lokalnej, do których haker
może uzyskać dostęp podczas ataku. Gdyby sieć lokalna była przyłączona do Internetu bez pośrednictwa firewalla i rutera, to cała stanowiłaby obszar ryzyka.
Wszystkie hosty znajdujące się w obszarze ryzyka narażone są na atak hakerów i danych znajdujących się w którymkolwiek pliku lub komputerze tej strefy nie można
uważać za poufne. Poprawnie zaprojektowana architektura sieci z firewallem ogranicza obszar ryzyka (strefę DMZ) do samej siebie lub do niewielkiej
liczby komputerów głównych w sieci.
Jeśli haker pokona firewall, siłą rzeczy obszar ryzyka rozszerza się na całą sieć. Punkt, w którym intruz pokonał zaporę, staje się bazą, z której
będzie on atakował kolejne serwery sieci. Jednak haker przedostając się do systemu przez firewall musi pozostawić ślady swojej obecności, dzięki czemu
administrator systemu wykryje włamanie. Każde wykryte włamanie dostarcza z kolei informacji, o słabych punktach w zabezpieczeniach sieci i pozwala na ich usunięcie.
| Technika konwencjonalna
Klasyczny system firewall złożony jest z:
- zewnętrznego rutera z filtrem pakietowym
- strefy DMZ, w której świadczone będą usługi publiczne w sieci
- bastion hosta/hostów w strefie DMZ przeznaczonego do odparcia najcięższych ataków. Na danym komputerze-bastionie uruchamia się proxy serwery dla
poszczególnych usług sieciowych. Odpowiednia konfiguracja obu routerów gwarantuje, że transmisja wszelkich danych odbywa się poprzez właśnie bastion hosta.
- wewnętrznego rutera, także z filtrem pakietowym
|  |
| Technika perspektywiczna
Nowoczesne firewalle działają według zasady all-in-one. Są to pojedyncze urządzenia, które łączą w sobie funkcje
obu ruterów z filtrami pakietowymi oraz bastion hosta. Czasami dodatkowo dysponują serwisami w rodzaju DNS bądź mail. W tego rodzaju systemie
serwery typu WWW i pozostałe usługi publiczne świadczone w sieci najlepiej umieścić w osobnej sieci-strefie DMZ bezpośrednio podłączonej do
firewalla. Jednak do prawidłowej pracy takiego systemu
niezbędna jest współpraca firewalla z minimum trzema kartami sieciowymi, co w wielu przypadkach jest warunkiem trudnym do spełnienia.
| |
|
Screening Router (ruter ekranujący): Firewall postawiony jest na ruterze ekranującym lub podobnym, którego głównym zadaniem jest ochrona danych w sieci. Jest
on jedynym połaczeniem sieci prywatnej z publiczną. Pracuje w warstwie sieci selekcjonując ruch poprzez filtrowanie pakietów zależny od adresów IP oraz adresu
MAC nadawcy lub odbiorcy (MAC - z ang. Media Access Control address - sprzętowy adres karty sieciowej Ethernet i Token Ring, unikalny w skali światowej,
nadawany przez producenta danej karty podczas produkcji). Ta konfiguracja jest przykładem działania firewalla filtrującego pakiety. Mechanizm ten nie jest bezpieczny,
jeśli jest stosowany bez innych zabezpieczeń. |  |
|
Bastion Host Firewall (firewall na komputerze bastionie): To ogólne określenie konfiguracji, w której komunikacja pomiędzy siecią lokalną, a
publiczną skupia się na jednym punkcie - bastion-hoście, na którym postawiony jest firewall. Rodzaj firewalla determinuje stopień zabezpieczenia sieci. Jeśli jest to firewall poziomu aplikacji to mamy do czynienia
z konfiguracją Application Level Gateway opisaną niżej. Jeśli jest to zwykłe filtrowanie pakietów, rozwiązanie to jest niewiele lepsze, niż ruter ekranujący.
Pośrednim rozwiązaniem jest postawienie firewalla typu stateful inspection (analiza stanu połączeń). Komputer-bastion jest szczególnie narażony na ataki z
zewnątrz sieci, dlatego powinien być jak najlepiej zabezpieczony i szczegółowo monitorowany przez administratora sieci na wypadek ewentualnych prób włamania się do sieci lokalnej.
Rozwiązanie to ma tą wadę, że nie separuje bezpośrednio obu sieci: lokalnej i publicznej, dlatego możliwe jest bezpośrednie połączenie między sieciami oraz
sama struktura sieci lokalnej i jej pojedynccze hosty są widzialne z sieci zewnętrznej.
|  |
|
Dual-Homed Gateway Firewall (firewall na komputerze-bastionie z dwoma kartami sieciowymi): Firewall pracujący na bastion-hoście zawierającym dwa interfejsy sieciowe: jeden dla sieci prywatnej, drugi publicznej. Ruch
na warstwie sieciowej jest zablokowany, nie jest możliwe bezpośrednie przesyłanie pakietów pomiędzy obydwoma interfejsami sieciowym. Jedyny rodzaj ruchu to
ten, który generują wyszczególnione aplikacje po zalogowaniu się na komputerze-bastionie, dlatego też komputer-bastion bywa nazywany bramą (ang. gateway). Struktura sieci i
jej adresacja jest maskowana przez tą bramę. Z reguły na bastion-hoście pracuje firewall poziomu aplikacji dlatego jest to przykład zastosowania czystego mechanizmu
bramy pracującej w warstwie aplikacji.
|  |
|
Application Level Gateway Firewall (firewall poziomu aplikacji na komputerze-bastionie): W tej konfiguracji na komputerze-twierdzy zainstalowany jest
firewall poziomu aplikacji z proxy serwerem. Rola tego komputera polega na odseparowaniu sieci na poziomie aplikacji, w odróżnieniu od Dual-Homed Gateway, gdzie sieci były
odseparowane poprzez zastosowanie dwóch różnych kart sieciowych. Oprogramowanie serwera proxy odbiera pakiety z zewnątrz i przekazuje do sieci chronionej.
Możemy postawić wiele różnych proxy serwerów na różnych maszynach zawierających oprogramowanie obsługujące poszczególne usługi sieciowe. Mechanizm ten spowalnia komunikacje, lecz
jest "przezroczysty" dla użytkownika, i w odróżnieniu od Dual-Homed Gateway nie wymaga logowania się na proxy serwerze.
|  |
|
Screened Host Gateway Firewall (firewall + ruter ekranujący): Konfiguracja ta wymaga dodania WAN rutera (z ang. Wide Area Network - sieć rozległa np. Internet) dostarczającego połączenie z siecią WAN i filtrującego pakiety.
Komputer-bastion to firewall z usługami proxy i np. dodatkowym filtrowaniem pakietów i NAT-em (o NAT dalej). W konfiguracji tej zewnętrzny ruter współpracuje
z komputerem-bastionem w ten sposób, że komputer pracuje w wewnętrznej, chronionej sieci, natomiast ruter tak reguluje dostęp z zewnątrz, by ten komputer był
jedynym widzianym i dostępnym w sieci prywatnej od strony sieci publicznej. Odbywa się to dzięki filtrowaniu pakietów docierających do rutera. Dla użytkowników
zewnętrznych jedyny znany adres IP to adres komputera-twierdzy, nie widzi on struktury sieci lokalnej. Natomiast użytkownicy wewnętrzni mają dostęp do sieci zewnętrznej tylko poprzez komputer-twierdzę.
Konfiguracja ta jest przykładem syntezy dwóch typów firewalli: filtrowania pakietów przez ruter i firewalla poziomu aplikacji na komputerze-twierdzy z serwerem proxy.
|  |
|
Screened Subnet Firewall (firewall + dwa rutery ekranujące): Firewall z dwoma ruterami ekranującymi stanowi dodatkową izolację sieci lokalnej.
Oprócz rutera WAN dodajemy ruter LAN, kontrolujący przepływ danych w sieci lokalnej. Komputer-twierdza z proxy serwerem jest teraz umieszczony w osobnej sieci,
dlatego atak ogranicza się jedynie do uderzenia na niego. Dodatkowy LAN ruter uniemożliwia także nieautoryzowany dostęp do komputera-bastionu z wnętrza sieci
lokalnej. Można także skonfigurować oba rutery tak, by serwer komunikował się tylko z nimi.
W architekturze tej, pomiędzy siecią chronioną, a siecią zewnętrzną znajduje się martwa strefa, strefa DMZ, w której ruch między sieciami jest częściowo blokowany. Dlatego na komputerze bastionie
możemy udostępnić usługi publiczne dla użytkowników Internetu i lokalnych, takie jak serwer WWW, FTP, etc. |  |
Systemy firewall oferują wiele dodatkowych usług, które pomagają zabezpieczyć sieć bądź też przyspieszyć jej pracę. Oto niektóre z nich:
- Serwery proxy-cache (z ang. proxy cache servers)
Usługa ta umożliwia zmniejszenie ruchu na łączu WAN poprzez przechowywanie informacji (z reguły stron WWW), do których
często odwołują się użytkownicy sieci. Zwykle serwer proxy-cache jest zintegrowany z serwerami pośredniczącymi. W przypadku przyspieszania pracy klientów
sieci LAN, Proxy Cache Server umieszczamy pomiędzy nimi, a Internetem. Wówczas jeśli żądanie dotyczy strony umieszczonej w pamięci serwera to obsługiwane jest
z prędkością LAN, a łącze WAN nie jest wcale obciążane.
Serwery proxy-cache możemy także zastosować w przypadku intensywnie eksploatowanych serwerów WWW, umieszczonych w głębi sieci lokalnej. Wówczas, między tymi serwerami WWW, a Internetem znajduje się serwer proxy
i każde żądanie strony przychodzące z Internetu jest obsługiwane przez serwer proxy, i jeśli strona jest na tym serwerze to jest bezpośrednio z niego wysyłana. To rozwiązanie odciąża sieci LAN i lokalne serwery w nich się znajdujące.
W przypadku, gdy w sieci lokalnej jest dużo serwerów WWW i są one intensywnie wykorzystywane, możemy wykorzystać kilka połączonych równolegle serwerów proxy-cache.
Mogą one obsługiwać nawet serwery WWW różnych producentów.
- Wirtualne sieci prywatne (VPN)
Jeżeli sieć jakiejś firmy składa się z wielu rozrzuconych po świecie, (np. nawet na różnych kontynentach) elementów sieci korporacyjnej, potrzebna jest jakaś komunikacja pomiędzy tymi elementami sieci. Wykupienie
łącza dzierżawionego jest bardzo drogie, a czasem wręcz niemożliwe. Dlatego jedynym wyjściem jest połączenie wszystkich filli do sieci globalnej, z reguły Internetu, poprzez usługę VPN, z ang. Virtual Private Network, wirtualne sieci prywatne.
Jest to usługa, która pozwala łączyć kilka sieci prywatnych "tunelami", przez które przenoszone są tylko informacje zaszyfrowane. Proces wymiany informacji w takich sieciach
znacznie wspomagają firewalle, ponieważ oprócz zapewnienia bezpieczeństwa własnym filiom sieci, jednocześnie automatycznie dokonują szyfrowania i odszyfrowywania informacji.
- Serwery typu NAT i IP Gateway
Narzędzia typu IP Gateway umożliwiają sieciom pracującym z innymi protokołami, bądź z adresami IP,
które nie są unikalne, korzystanie z sieci Internet. Dzięki temu cały system może korzystać z jednego
adresu IP, który również może być przydzielany dynamicznie, co zwiększa bezpieczeństwo sieci,a w dodatku ukrywa lokalne adresy systemu.
Usługa Network Address Translation (NAT), podobnie jak IP Gateway, pozwala klientom, którzy nie posiadają
unikalnych adresów, korzystać z Internetu. Ale dodatkowo może pracować jako filtr pozwalający tylko na niektóre
połączenia z zewnątrz i gwarantujący, że wewnętrzne połączenia nie będą inicjowane z sieci publicznej.
- Możliwość kontroli i ogranicznia ruchu w sieci zewnętrznej
W celu precyzyjnego określenia praw rządzących dostępem do sieci programując firewall tworzy się tak zwane listy reguł. Listy takie
opisują prawa poszczególnych uczestników sieci lokalnej do korzystania z określonych usług/protokołów sieciowych, zezwalają na
pewne rodzaje połączeń z zewnątrz i zabraniają innych, mogą ograniczać liczbę połączeń z jakiegoś
adresu albo liczbę jednoczesnych połączeń. Umożliwia to wprowadzenie ograniczeń w ruchu sieciowym w jakimś konkretnym celu. Na przykład kierownictwo firmy
może zabronić swym pracownikom korzystania z usługi http z konkretnych miejsc sieci w określonych godzinach. Ooczywiście taka decyzja jest
decyzją polityczną, mającą na celu zdyscyplinowanie pracowników do bardziej sumiennej pracy.
Integralną częścią systemów firewall jest mechanizm o zbliżonej roli do "czarnej skrzynki" w samolotach. śledzi on i
rejestruje wszelkie wydarzenia w sieci. Dzięki temu uwadze administratora z pewnością nie umkną pewne anomalie w korzystaniu z sieci, jak na
przykład 30-krotna nieudana próba zdalnego logowania się do systemu, co zwiększa czujność administratora. Innym zastosowaniem może być analiza
adresów, z którymi najczęściej nawiązywane są połączenia przez lokalnych użytkowników, gdyż dane takie są
istotne do efektywnego skonfigurowania serwera proxy. Tak więc firewall może pełnić także funkcje dodatkowego urządzenia nadzorującego wszystkich użytkowników w sieci lokalnej.
Ponieważ firewalle swoje działanie opierają na ograniczaniu ruchu sieciowego, z ich stosowania wynikają również pewne wady:
ograniczają dostęp do sieci z Internetu - tylko usługi zezwolone firewallowi są dostępne, co często ogranicza użyteczność sieci zewnętrznej.
Poza tym w przypadku stosowania firewalli poziomu aplikacji ograniczają liczbę usług internetowych świadczonych w sieci. Dostępne są tylko te usługi, dla
których zainstalowano odpowiedni serwer proxy.
wymagają częstych uaktualnień - nowe typy klientów sieciowych i serwerów przybywają prawie codziennie. Dlatego zanim zostaną użyte, trzeba wynaleźć
nowy sposób zezwolenia na kontrolowany ich dostęp do sieci. Zaś w przypadku firewalli sprzętowych wszelkie upgrade'y są kłopotliwe i dość drogie.
nie są przezroczyste dla użytkownika (w przypadku niektórych implementacji firewalli poziomu aplikacji) - często wymagają zalogowania się na serwerze proxy
przez użytkownika i uruchomienia na nim odpowiedniego programu dla dalszej komunikacji. Często trzeba także zainstalować na komputerze klienta odpowiednią
aplikację do pracy z daną usługą poprzez serwer proxy.
firewalle poziomu aplikacji, z powodu pracy w warstwie najwyższego poziomu są dość trudne w implementacji i z tego wynika ich dość wysoka cena. Ponadto trudna
jest ich konfiguracja. Mało wydajne serwery proxy zmniejszają także wydajność całej sieci, ponieważ każdy pakiet musi przejść dwa razy przez wszystkie
warstwy protokołu.
firewalle filtrujące pakiety są wprawdzie szybsze ale ich wadą jest niska skuteczność
uniemożliwiają bądź utrudniają zdalne zarządzanie siecią
Do najważniejszych zalet firewalli należą natomiast:
- ochrona systemu
- umożliwiają całej sieci korzystanie z jednego wspólnego adresu IP
- dają możliwość na podłączenie do Internetu systemom z protokołami innymi niż TCP/IP
- pozwalają monitorować połączenia z siecią zewnętrzną
- przy intensywnej pracy ze serwerami WWW serwer proxy z własnym cache'm pozwala zoptymalizować obciążenia na łączu z Internetem
- możliwość używania sieci VPN i tańszych linii z dostępem do najbliższych węzłów sieci publicznej zamiast łączy dzierżawionych
- zautomatyzowanie procesu szyfrowania i deszyfrowania danych przez firewall
Jeśli już zabezpieczyliśmy sieć komputerową przed włamaniem się (włamanie rozmumiemy tu jako sekwencje zdarzeń zagrażającą bezpieczeństwu sieci) osoby niepowołanej poprzez którąś z konfiguracji firewalla, musimy jeszcze wyposażyć sieć
w system, który jeżeli jednak dojdzie do włamania do sieci, w miarę szybko wykryje włamanie, bądź nawet tylko próbę włamania i poinformuje o tym administratora.
Systemem takim jest tzw. IDS, czyli z ang. Intrusion Detection System. IDS jest więc systemem, który wykrywa ataki na komputer i sieć oraz
niewłaściwe użycie komputera, i wtedy informuje o tym administratora sieci. Działanie IDSu można więc porównać do alarmu zainstalowanego w domu, tak jak
działanie firewalla można przyrównać do ogrodzenia i bramy, szczelnie otaczających dom. Oba systemy, IDS i firewall wzajemnie się bardzo dobrze uzupełniają, i stosowanie ich
razem może w istotny sposób podnieść bezpieczeństwo sieci.
Systemy IDS czyli systemy detekcji intruzów są to programy filtrujące pakiety przepływające w sieci jak i pliki na danym komputerze.
Wiadomo, że same systemy operacyjne rejestrują niektóre ważniejsze zdarzenia zachodzące w systemie, np. Linux
rejestruje zdarzenia od procesu logowania po wychodzenia z systemu, żądania połączeń, awarie sprzętowe, odmowę obsługi i polecenia użytkowników. To bardzo istotna
część systemu, ale specjaliści od bezpieczeństwa wprowadzają rozwiązania jeszcze lepsze, gdyż pliki
dziennika zawierają tylko ślad po czymś, co już zostało dokonane. Skuteczne wykrywanie włamań powinno odbywać się w czasie rzeczywistym, czyli w czasie, w
którym program IDS wykonuje swoje czynności.
Historia systemów IDS sięga już na początku lat 80. Do dziś przeprowadzono ogromną liczbę badań nad zastasowaniem tego rodzaju systemów i powstały setki różnych systemów wykrywania intruzów, ale większość z nich nie jest nawet dostępna
do publicznego użytku.
Do priorytetowych zadań wykonywanych przez systemy IDS należą:
- analiza aktywności systemu i użytkowników
- wykrywanie zbyt dużych przeciążeń
- analiza plików dziennika
- rozpoznawanie standardowych działań włamywacza
- natychmiastowa reakcja na wykryte zagrożenia
- tworzenie i uruchamianie pułapek systemowych
- ocena integralności poszczególnych części systemu wraz z danymi
Zadania wykonywane przez systemy IDS zostały zdefiniowane dzięki wieloletniemu doświadczeniu różnych ludzi zajmujących się bezpieczeństwem. Zwrócili oni uwagę na to, że
większość włamań do systemów komputerowych ma na celu uzyskanie poufnych danych lub w przypadku hakerów osiągnięcie uznania w hakerskim środowisku. Włamując
się do systemu atakujący działa w sposób metodyczny. Typowy atak ma następujący scenariusz:
- penetracja całego systemu, szukanie luki w systemie (np. skanując porty), dzięki której będzie można się włamać
- wtargnięcie do systemu
- próba zamaskowania swojej obecności poprzez zmiany w logach systemowych
- próby modyfikacji narzędzi systemowych tak, by uniemożliwić swoje wykrycie
Systemy IDS analizują przepływ informacji w newralgicznych punktach sieci. Wykrywają ataki na system zarówno podczas prób penetracji systemu poprzez detektory
skanowania portów, jak również po wtargnięciu dzięki
analizatorom logów i analizatorom anomalii).
Obecnie możemy systemy IDS podzielić na dwa typy pod względem mechanizmu identyfikacji włamań:
- Systemy oparte na zbiorze zasad - korzystają one z bazy danych znanych ataków i ich sygnatur. Kiedy pakiety przychodzące spełnią określone
kryterium lub zasadę, zgodnie z sygnaturą w bazie danych, oznaczane są jako usiłowanie włamania. Systemy tego rodzaju muszą jednak zawsze korzystać z jak
najbardziej aktualnych baz danych, gdyż cały czas powstają nowe rodzaje ataków. Inną wadą tego rozwiązania jest to, że jeśli atak określono w bazie danych
zbyt precyzyjnie, to włamanie bardzo podobne, ale nie identyczne nie zostanie rozpoznane.
- Systemy adaptacyjne - w systemach IDS tego rodzaju wykorzystane są dużo bardziej zaawansowane techniki, w tym nawet sztuczna inteligencja.
Rozpoznawane są nie tylko istniejące ataki na podstawie sygnatur, system taki uczy się także nowych ataków, dzięki czemu wyeliminowane są główne wady poprzedniego
rozwiązania. Jednak główną wadą tego rodzaju IDSów jest cena, skomplikowana obsługa oraz dość dobra znajomość zagadnień z zakresu matematyki oraz
statystyki.
Systemy IDS podzielić można także ze względu na sposób w jaki monitorują one sieć. Tutaj znowu istnieją dwa podejścia:
- proaktywne (ang. proactive system) - system, podobnie jak sniffer, nasłuchuje czy w sieci nie dzieje się nic podejrzanego i jeśli coś wykryje to podejmuje
odpowiednie działanie. System proaktywny reaguje już w czasie ataku. W niektórych systemach IDS administrator ma nawet możliwość obserwowania przebiegu
ataku na konsoli zarządzania IDSem. Rozwiązania proaktywne nie są jednak idealne. Przede wszystkim zajmują dość znacząco zasoby komputera. Poza tym, atakujący jeśli wie, że mamy
proaktywny system IDS, może go sparaliżować, ponieważ IDS podejmie zawsze takie samo działanie w przypadku wykrycia takiego samego
ataku. Jeśli więc zaatakuje nasz host takimi samymi atakami z różnych adresów, może doprowadzić do nadmiernego wykorzystania zasobów, gdyż IDS może na
przykład, po wykryciu każdego ataku, uruchamiać proces powłoki. Wystarczy teraz, że intruz zaatakuje tyle razy, bo IDS już nie był w stanie uruchomić
kolejnego procesu i zostanie zablokowany. W ten sposób udało się unieruchomić sam system IDS atakiem typu DDoS (z ang. Distributed Denial of Service -
atak DoS z kilku punktów sieci jednocześnie). Po drugie, w przypadku posiadania wolnego procesora i małej wielkości dostępnej pamięci, możemy być zmuszeni
do wybrania tylko analizy nagłówków pakietów zamiast analizy ich zawartości. Nie chroni to przed wszystkimi atakami, gdyż wiele sygnatur ataków ukrywa się
w zawartości pakietu i prosta analiza ruchu sieciowego nie wystarczy, by się przed nimi uchronić.
- reaktywne (ang. reactive system) - system bada pliki rejestru i jeśli znajdzie podejrzane zapisy, reaguje w odpowiedni sposób. System ten to po
prostu rozbudowany system rejestrowania. Alarmuje on, gdy atak już nastąpił, nawet gdy stało się to tylko pięć sekund temu. Teoretycznie, system reakcyjny
można stworzyć wykorzystując standardowe narzędzia bezpieczeństwa Linuxa: skrypty identyfikujące określone zachowania w plikach dziennika oraz
skrypt, dodający adres atakującego do pliku hosts.deny i tcpd nie pozwoli już na więcej połączeń z tego adresu. Strategia ta nie zawsze jednak jest skuteczna,
gdyż włamywacz mógł się podszyć pod ten zablokowany adres, a w rzeczywistości ma inny adres. Poza tym intruz może dalej przeprowadzać kolejne
próby ataku spod innych adresów.
Widać więc, że oba systemy nie są doskonałe i mają swoje wady i zalety. Obu rodzajów firewalli dotyczy też jeszcze jedna wada: fałszywe alarmy. Z reguły
administratorzy ustawiają opcje alarmowania sygnałem dźwiękowym w IDSie w przypadku włamania. Jeśli alarmy powtarzają się często i z reguły są fałszywe, obniża
to czujność administratora, który na następne dźwięki nie reaguje tak szybko.
Stosowane w systemach IDS rozwiązania z punktu widzenia działania całego systemu w sieci podzielić można na trzy kategorie:
|
Host-based IDS (HIDS)
System Host-based IDS (w skrócie HIDS) polega na zainstalowaniu na wszystkich hostach w sieci, które chcemy objąć monitorowaniem, modułów agentów. Dodatkowo
w sieci istnieje jeden komputer będący konsolą zarządzania systemu HIDS, zbierający informacje od wszystkich agentów i pozwalający na monitorowanie ich pracy
z poziomu jednego hosta. Każdy moduł agenta natomiast
analizuje na danym hoście kluczowe pliki systemu, logi zdarzeń oraz inne sprawdzalne zasoby oraz szuka nieautoryzowanych zmian lub podejrzanej
aktywności i w razie wykrycia jakiegokolwiek zdarzenia odbiegającego od normy generuje alarm lub uaktywnia pułapki SNMP (SNMP, z ang. Simple Network
Monitoring Protocol - standard protokołu używanego do nadzoru i sterowania komputerami w sieci). Agent Host IDS wykorzystuje różne metody w celu wykrycia
próby włamania. Przede wszystkim monitoruje próby zalogowania się do systemu i odnotowywuje każdy przypadek podania niewłaściwego hasła. Jeżeli próby użycia
złego hasłą powtarzają się wielokrotnie w krótkich odstępach czasu, można podejrzewać że ktoś niepowołany próbuje zalogować się do systemu. Inną stosowaną
metodą jest monitorowanie stanu ważnych plików na dysku poprzez metodę "fotografii stanów". Na początku agent rejestruje stany istotnych plików (na tej samej
zasadzie jak program Tripwire). Jeśli intruz dostanie się do systemu i wykona jakieś zmiany na monitorowanych plikach, to agent wykryje to (niestety na ogół
nie zostanie to wykryte w czasie rzeczywistym, czyli podczas samego aktu włamywania się do systemu).
Większość systemów typu HIDS to systemy reaktywne. Monitorują system i w razie pojawienia się jakichś nietypowych zdarzeń podnoszą alarm. Istnieją jednak
także systemy proaktywne, działające w czasie rzeczywistym. W celu zapobiegania atakom analizują one i przechwytują odwołania do jądra systemu operacyjnego
lub API, a następnie rejestrują te fakty w dzienniku zdarzeń. |  |
| Network-based IDS (NIDS)
System Network-based IDS (w skrócie NIDS) monitoruje ruch wewnątrz sieci w czasie rzeczywistym i skupia się on wyłącznie na analizie ruchu TCP. Składa on się z sond NIDS
umieszczonych w kilku newralgicznych miejscach w sieci. Sondy takie muszą być co najmniej między firewallem, a strefą DMZ oraz między chronioną siecią lokalną, a firewallem. Pracę sond koordynuje
konsola zarządzająca systemem NIDS. Zbiera ona informacje od sond i poddaje je analizie, dzięki niej także administrator monitoruje działanie całej sieci
z jednego miejsca. Sondy natomiast szczegółowo sprawdzają każdy pakiet przechodzący w sieci. System NIDS
jest w stanie namierzyć ataki typu Denial of Service lub niebezpieczną zawartość przenoszoną w pakietach (wirusy, konie trojańskie), zanim osiągną one
swoje miejsce przeznaczenia. IDS'y tego rodzaju porównują przechodzące w sieci pakiety z dostępną bazą danych sygnatur ataków.
Bazy te uaktualniane są przez dostawców systemów IDS, możliwie często, w miarę pojawiania się nowych form ataków. W przypadku wykrycia podejrzanej
aktywności w sieci
konsola zarządzająca alarmuje administratora, czasem może także zamknąć natychmiast podejrzane połączenie. Wiele tego typu rozwiązań jest zintegrowanych
bezpośrednio z
firewallami w celu dodawania dla nich nowych reguł blokowania ruchu w czasie rzeczywistym, które wynikają z przeprowadzanych prób ataku na sieć lokalną.
Dzięki takiemu rozwiązaniu atakujący przy kolejnej próbie ataku zostanie zatrzymany już na firewallu. Rozwiązania IDS oparte na metodzie sieciowej
funkcjonują w tzw. trybie rozrzutnym (promiscous mode - tak jak sniffery). Polega to na przeglądaniu przez sondę NIDS
każdego pakietu w kontrolowanym segmencie sieci, bez względu na jego adres przeznaczenia. Z uwagi na dość duże obciążenie, jakie niesie ze sobą przeglądanie
każdego pakietu, sonda NIDS to zazwyczaj dedykowany host, specjalnie do tego przeznaczony.
Sieciowe IDSy, chociaż generalnie skuteczniejsze i oferujące lepszy stopień bezpieczeństwa, niż HIDS, mają jednak dość znaczące wady. Nie są one
kompatybilne z sieciami przesyłającymi zaszyfrowane dane. Nie są także w stanie pracować w sieciach o bardzo szybkim ruchu, już w sieci o prędkości 400Mbit/s
dość znacząco spowalniają jej działanie, dlatego do sieci szybszych nie jest już używany. Systemy NIDS, by nie stać się wąskim gardłem sieci, a jednocześnie
nadążać za ruchem pakietów często tylko powierzchownie analizują ich treść, np. ograniczając się do zwykłego filtrowania pakietów jak ruter ekranujący. |  |
| Network Node IDS (NNIDS)
Network Node IDS (w skrócie NNIDS) jest to typ agenta IDS, stanowiący rozwiązanie będące hybrydą hostowego oraz sieciowego IDS'a. Podobny jest pod
względem architektury do HIDS, gdyż podobnie jak tam NNIDS składa się z agentów - węzłów sieci, umieszczonych na różnych hostach w sieci lokalnej i kontrolowanych
przez jedną centralną konsolę zarządzającą, monitorującą całą sieć. Jednak
agenci ci zamiast skupiać się na monitorowaniu plików
logu, czy analizie zachowań, tak jak to czyniły systemy HIDS działają raczej w sposób podobny do NIDS - analizują przepływ pakietów w sieci. Pakiety te są
następnie porównywane z sygnaturami ataków z bazy danych w identyczny sposób jak sieciowe IDS'y. Różnica tkwi w tym, że o ile NIDS działały w trybie
"rozrzutnym", analizując cały ruch w danym segmencie sieci, tak węzłowe IDS'y skupiają się tylko na wybranych pakietach sieci - tylko tych adresowanych do
danego węzła, na którym agent rezyduje.
Z powyższych powodów NNIDS pozbawiony jest niektórych ograniczeń sieciowych rozwiązań IDS, ponieważ pracują one znacznie
szybciej i wydajniej. Pozwala to na instalowanie ich na istniejących serwerach bez obawy ich przeciążenia. Nie istnieją poza tym tak duże ograniczenia co do
prędkości ruchu w sieci, systemy NNIDS z powodzeniem działają w sieciach szybszych niż 400Mbit/s, a także w sieciach z szyfrowaniem przesyłanych danych.
Rozwiązanie hybrydowe jest obecnie najpopularniejszym rozwiązaniem w zakresie systemów detekcji intruzów.
| 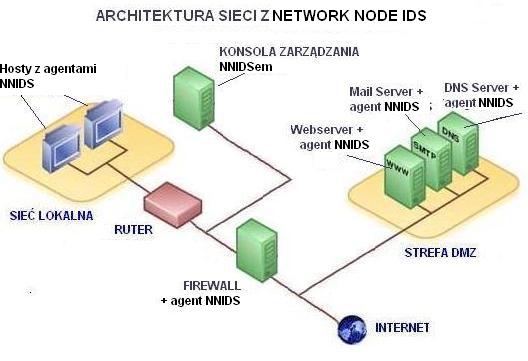 |
Wysokiej klasy systemy IDS wykorzystują wiele rozmaitych metod rozpoznawania ataków i innych
nadużyć w sieci lokalnej. Metody detekcji ataków włączane są w zależności od kontrolowanego ruchu
sieciowego, zaś dane są przetwarzane współbieżnie w czasie rzeczywistym przez poszczególne metody detekcji. Taka polityka zapewnia wysoką wykrywalność
ataków bez
obniżania wydajności. Omówimy teraz współcześnie stosowane technologie wspomagające detekcję ataków stosowane w systemach IDS na przykładzie systemu
zabezpieczeń OneSecure (obecnie nazywa się NetScreen IDP):
- Stateful Signatures - wykrywanie podejmowanych prób ataków w oparciu o bazę danych pełno-stanowych
sygnatur. Pełno-stanowe sygnatury zawierają dane o wzorcu ataku oraz
rodzaju komunikacji, w jakiej to zdarzenie może wystąpić. Pakiety przepływające w sieci poddawane są analizie kontekstowej, co pozwala ograniczyć
ilość fałśzywych alarmów (tzw. false positives). Sygnatury ataków wyszukiwane są tylko w
wybranej komunikacji sieciowej, co zwiększa efektywność kontroli i wydajność zabezpieczeń.
- Protocol Anomalies - wykrywanie niezgodności ruchu sieciowego ze
standardami określonych protokołów (m.in. RFC - zbiór dokumentów informacyjnych dotyczących sieci i protokołów sieciowych). Praktyka pokazuje, że
często włamywacze starają się zmylić zabezpieczenia lub ukryć rzeczywiste ataki generując pakiety TCP odbiegające od przyjętych norm i standardów. Technologia
ta pozwala ostrzec przed tego rodzaju atakiem.
- Backdoor Detection - wykrywanie aktywności koni trojańskich, próbujących włamać się do systemu, oraz wszelkich prób
nieautoryzowanego dostępu do chronionej sieci poprzez tzw. "włazy"
(backdoor). Detekcja odbywa się poprzez porównywanie ruchu sieciowego ze
znanymi wzorcami działań intruzów oraz analizę heurystyczną transmitowanych
pakietów.
- Traffic Anomalies - monitorowanie działań w sieci, uznawanych za
niedozwolone lub podejrzane. Działania takie realizowane są w formie wielu różnych
połączeń (jak np. skanowanie portów). System w określonym przedziale czasowym poddaje połączenia analizie.
- Spoofing Detection - wykrywanie ataków poprzez spoofing czyli wysyłanie pakietów ze sfałszowanymi adresami
IP nadawcy pakietu. Hakerzy poprzez spoofing chcą ukryć rzeczywiste źródło ataku. System wykrywa go
porównując adresy IP w pakietach z adresami wykorzystywanymi w sieciach
wewnętrznych.
- Layer 2 Detection - wykrywanie podejrzanych działań i ataków na poziomie
warstwy sieciowej modelu OSI i adresacji MAC. Zwłaszcza ataki z wykorzystaniem ARP (ARP to mechanizm
przekształcania 32-bitowych adresów IP w 48-bitowe adresy MAC) takie jak ARP cache poisoning. Jest to
szczególnie ważne w przypadku kontroli przez IDS sieci wewnętrznych, a nie pojedynczego hosta.
- Denial of Service Detection - wykrywanie ataków typu Denial of Service. Ataki DoS realizowane są zwykle
poprzez wysyłanie do serwera usługi dużej liczby odpowiednio spreparowanych
zapytań, które wyczerpują jego zasoby (np. SYN-Flood). System odpowiednio reaguje na tego rodzaju zwiększony ruch sieciowy.
Kolejną własnością współczesnych systemów IDS są graficzne konsole do zarządzania całym układem zabezpieczeń. Mimo, że wyglądają z pozoru na efektowny
gadżet, ich rola jest niebagatelna. Przedstawiają one bowiem w syntetycznej formie
spójne informacje zebrane z różnych, często dość odległych miejsc, przez agentów lub sondy IDS. W praktyce liczba zdarzeń rejestrowanych
przez poszczególnych agentów/sondy jest na tyle duża, że możliwości pojedynczego człowieka nie pozwalają na
sprawną ich analizę bez specjalistycznych narzędzi i wcześniejszej obróbki. Odpowiednie
narzędzia administracyjne dostępne z poziomu konsoli, przedstawiające te informacje w syntetycznej formie, pozwalają zapanować nad tym natłokiem
informacji i ułatwiają
podejmowanie decyzji szczególnie w sytuacji awaryjnej. W najnowszych systemach konsole takie potrafią zbierać i interpretować informacje z różnego typu
systemów zabezpieczających: IDS,
skanerów zabezpieczeń, firewalli oraz wykonywać korelacje pomiędzy rejestrowanymi przez
nie zdarzeniami.
Zabezpieczenie sieci lokalnej poprzez firewall połączony z systemem IDS może w obecnych czasach okazać się niezbyt skutecznym rozwiązaniem. Wraz z rozwojem
technologii sieciowych, a zwłaszcza zwiększeniem dostępności aplikacji w
rozległym środowisku sieciowym, powstało mnóstwo nowych zagrożeń, dla których
tradycyjne systemy zabezpieczeń okazały się
niewystarczające. W obecnych czasach włamania do systemu komputerowego wykonują nie tylko ludzie, ale także specjalnie do tego celu zaprogramowane aplikacje - exploity
czyli tzw. robaki internetowe. Są to programy wykorzystujące dziury w istniejącym oprogramowaniu. Najczęściej atakują poprzez techniki w rodzaju przepełnienia
bufora, czy ataków SQL. Exploit wykorzystuje występującą w danej aplikacji dziurę, wykonując odpowiednio spreparowany kod
(ang. shellcode) i następnie przejmuje nad nią kontrolę. Robaki internetowe takie jak Blaster, Slapper, Slammer, czy Sasser wykorzystując proste błędy
systemów operacyjnych i aplikacji były w stanie w ciągu kilku godzin zainfekować miliony komputerów. Powstały także robaki bez problemów przełamujące obronę
nie przygotowanych na to systemów IDS, jak np. Witty.
Projektanci systemów zabezpieczeń, dostrzegając nowe zagrożenia starali się dostosować istniejące urządzenia do większych wymogów bezpieczeństwa.
Można było zauważyć dwie tendencje: projektowanie firewalli wyposażonych w dodatkowe funkcje wykrywania prób ataków oraz IDS'y stosowane w roli tradycyjnie
zarezerwowanej dla firewalli. Oba podejścia zaczęły się przenikać, co świetnie widać na przykładzie liderów technologii IDS i firewall.
W ten sposób zaczęto mówić o nowym typie zabezpieczenia - systemie IPS (z ang. Intrusion Prevention System). W dużym uproszczeniu można powiedzieć, że
są to systemy IDS, ale wyposażone w możliwości aktywnej reakcji na wykryte niepokojące zdarzenia. Pierwszym krokiem ku systemom IPS, umożliwiającym aktywną reakcję systemowi
IDS była technologia przerywania połączeń (TCP Reset), co pozwala w przypadku wykrycia podejrzanego połączenia TCP przerwać je poprzez podszycie się pod
stronę atakującą i wysłanie pakietu TCP z flagą RST (Reset), co oznacza zakończenie połączenia. Tak więc atakowany serwer zakończy połączenie i atak
nie będzie mógł dojść do skutku. Technika ta działa przy atakach angażujących całą sesję TCP, ale nie zadziała np. dla ataków składających się z jednego
pakietu, czy ataków poprzez inne protokoły niż TCP, zwłaszcza protokoły bezstanowe, jak np. UDP. Inną metodą stosowaną w IDS'ach był mechanizm rekonfiguracji
firewalla (Firewall Signaling) w czasie rzeczywistym w przypadku zaistnienia ataku, w celu zablokowania niepożądanego adresu IP, z którego był dokonany atak.
Wymienione wcześniej metody przerywania połączeń oraz rekonfiguracji firewalla są już zupełnie nieskuteczne, a współczesne systemy IPS
stosują znacznie bardziej zaawansowane metody prewencji, takie jak:
- wykrywanie i blokowanie penetracji i ataków wykonywanych przez intruzów i robaki internetowe
- monitorowanie stanu bezpieczeństwa czyli np. wykrywanie robaków działających na hostach pracowników firmy
- wspomaganie administratorów w znajdywaniu źródeł naruszeń bezpieczeństwa
- oszukiwanie intruzów poprzez techniki Network Honeypot
- detekcja nieupoważnionych komputerów przyłączonych do sieci lokalnej
- monitorowanie przestrzegania przez pracowników przyjętej polityki bezpieczeństwa czyli np. wykorzystywania niedozwolonych aplikacji
- wykrywanie systemów i aplikacji podatnych na błędy bezpieczeństwa
- wykrywanie sytuacji przełamania zabezpieczeń czyli np. identyfikowanie połączeń z backdoor za pomocą technik analizy heurystycznej oraz nowo otwartych
portów na serwerach specyficznych dla backdoor (backdoor oznacza pozostawione przez włamywacza po włamaniu "tylne furtki", czyli programy (z reguły kopia
shell'a), które pozwolą mu na ponowne wejście do systemu nawet, gdy administrator zmieni hasło i wprowadzi dodatkowe zabezpieczenia)
- zabezpieczenie przed exploitami poprzez blokadę pakietów, w których wykryty został złośliwy kod (np. exploit,
atak Denial of Service, czy shellcode) i nie dopuszczenie ich do chronionych zasobów systemu informatycznego
- konsola zarządzająca systemem IPS, zbierająca informacje ze wszystkich sensorów IPS, i przedstawiająca je w syntetycznej postaci, z reguły jako graficzna
konsola GUI lub konsola WWW.
Powyższe cechy charaktyrystyczne są dla sieciowej wersji IPS'ów (Network IPS). Oprócz sieciowych rozwiązań dostępne są także Host IPS. Różnica między nimi
jest analogiczna do sieciowych i hostowych IDS'ów. Jednak hostowe IPS'y nie przyjęły się w powszechnym zastosowaniu, ponieważ stwarzają problemy ze stabilnością
pracy chronionych serwerów. Wynika to z tego, że oprogramowanie Host IPS jest instalowane bezpośrednio na serwerach i przez to dodatkowo je obciąża i może
powodować zakłócenia w ich pracy. Poza tym hostowe IPS nie blokują wielu ataków.
Pod pojęciem IPS możemy rozumieć każde urządzenie będące w stanie wykryć próbę przeprowadzenia ataku i udaremnić ten atak. W tym ujęciu niektóre rodzaje
firewalli też możemy uznać za systemy IPS. Przyjrzymy się teraz pięciu rodzajom urządzeń, działających wg. powyższej zasady, dlatego stanowiącymi rodzaj IDS'ów,
jednak pracujących w sposób dla obecnych firewalli niedostępny. Rozwiązania te są relatywnie nowe, każde z nich pracuje w inny sposób, ale cel jest ten sam -
wykryć i udaremnić próbę przeprowadzenia ataku.
Inline IDS

Inline IDS podobny jest do sieciowego IDS'a, o ile jednak tradycyjny IDS wykorzystuje jedną
kartę sieciową, która pełni rolę sondy wpinanej w monitorowaną sieć lokalna, tak inline IDS skłaa się z dwóch kart: zewnętrznej i wewnętrznej. Pierwsza służy
do zwykłych zastosowań, czyli normalnego przesyłu pakietów w sieci, tak druga wykorzystywana jest wyłącznie do wykrywania zagrożeń w systemie informatycznym.
Karta monitorująca nie posiada przypisanego adresu IP i jest przezroczysta dla reszty systemu. Oznacza to, że nie można skierować do niej żadnego pakietu,
ani poprosić ją o odpowiedź. Cały ruch sieciowy przechodzi przez inline IDS, który monitoruje pakiety szukając w nich podobieństw do wzorców sygnatur.
Są nawet rozwiązania idące o krok dalej, takie jak HogWash, które potrafią zmienić treść złośliwych pakietów, tak aby nie mogły działać na niekorzyść
systemu (tzw. packet scrubbing). Sposób ten zapewnia, że atakujący nie będzie nawet wiedział, że jego próby są nieudane, zaś w tym samym czasie broniący się
będzie mógł zebrać więcej dowodów i odpowiednio zabezpieczyć się przed ponownym atakiem.
Inline IDS w budowie przypomina firewalla, jednakże w działaniu bardziej IDS. W środku urządzenia działa silnik IDS, wykrywający i blokujący ataki.
Urządzenie pełni również funkcje charakterystyczne dla firewalli jednakże jednakże w trochę inny sposób. Firewalle bowiem to technologia restryktywna,
działająca wg. polityki:" "wszystko co nie jest dozwolone, jest zabronione". Blokują one wszystkie pakiety prócz tych dozwolonych poprzez reguły danego firewalla.
Natomiast istotą działania IDS'ów jest wykrywanie prób ataku, dlatego inline IDS chociaż umieszczony w tym samym miejscu co firewall, przepuszcza cały ruch
z wyjątkiem tego co uzna za próbę ataku.
W przypadku inline IDS klasyfikacja ruchu sieciowego jest dużo bardziej zaawansowana, niż w firewallach. Inline IDS stosują do tego celu mnóstwo zaawansowanych
technologii, zamiast opierać się na zwykłym zestawie reguł, czy serwerach pośredniczących. Ogólnie IDS analizuje ruch TCP i dopasowywuje przesyłane pakiety
do sygnatur ataków. Nie opiera się jednak wyłącznie na bazie sygnatur, lecz na jej podstawie potrafi także wykryć ataki do nich podobne. Inaczej bowiem
IDS'y byłyby łatwe do obejścia, przykładowo jeśli IDS analizowałby zapytania SQL, to wstawienie jednej lub więcej spacji spowodowałoby brak dopasowania reguły i udałoby
się obejść całe zabezpieczenie. Nowoczesne inline IDS stosują całe mnóstwo zaawansowanych technik detekcji prób ataku, takich jak np. normalizatory i
interpretery poszczególnych protokołów, sygnatury opisowe w miejsce konkretnych wzorców (wyżej opisane), oraz metody heurystyczne.
Podobnie do sieciowego IDS'a inline IDS może monitorować działanie wielu serwerów i całego segmentu sieci z jednej maszyny. Pociąga to za sobą pewne wady.
Po pierwsze w przypadku awarii systemu z IDS'em rych sieciowy nie musi już przepływać przez to urządzenie i przestaje być kontrolowany. Systemy IDS najlepiej
przystosowane są do pracy z popularnymi, powszechnymi w użyciu aplikacjami takimi jak np. Apache, Microsoft Internet Information Service. Wówczas zabezpieczają
luki w tych programach, oraz ich złe skonfigurowanie. Z pozostałymi, mniej popularnymi aplikacjami także współpracują oferując jednak podstawową ochronę, nie dostosowaną specjalnie
do tej aplikacji. Nadal jednak stanowią jedno z lepszych rozwiązań w zakresie bezpieczeństwa, zwłaszcza dla urządzeń i aplikacji, dla których nie istnieje
dedykowane zabezpieczenie i które zabezpieczyć trudno czyli np. IBM AS400, Tandem, mainframe'y i duże serwery.
Mimo wyżej wymienionych zalet technologia inline IDS nie zastępuje firewalla, lecz tylko go uzupełnia.
Wynika to ze wspomnianej wcześniej restryktywności firewalli, która jest potrzebna w dobrze zabezpieczonej sieci, lecz która nie jest możliwa do zrealizowania
w inline IPS'ach. Z tych powodów rynek systemów IPS (w tym inline IDS) będzie prawdopodobnie rozwijał się w kierunku rozwiązań hybrydowych,
w których funkcjonalność inline IDS będzie uzupełniana tradycyjnym firewallem typu stateful inspection (analiza stanu połączeń). Ponadto wykorzystywane
metody obrony uzależnione będą od miejsca, w którym dane urządzenie jest zainstalowane. Na przykład na zewnętrznym styku sieci z Internetem będzie działał
IPS wykorzystujący inline IDS i zintegrowany firewall, zaś wewnątrz sieci IPS zintegrowany w switchu (o switchach dalej) bazujący
na technologii wieloportowego inline IDS.
Switche warstwy siódmej (z ang. layer seven switches)
Tradycyjne switche (przełączniki) są urządzeniami operującymi na drugiej warstwie modelu OSI, czyli warstwie łącza danych.
Layer seven switches, zwane również content switches, jak sama nazwa wskazuje operują na wartwie siódmej OSI czyli warstwie aplikacji.
Powstały one wskutek znacznego wzrostu wymagań przepustowości łączy i szybkości operacji przesyłu danych.
Najczęstszym zastosowaniem tego rodzaju switchy jest więc równoważenie obciążenia powodowanego przez daną usługę sieciową, np. serwis WWW, sklep internetowy,
serwer FTP, DNS, etc. Do tego typu usług chce mieć dostęp mnóśtwo ludzi z całego świata jednocześnie. Dlatego firmy udostępniające daną usługę instalują kilka
serwerów ją oferujących i następnie starają się je w miarę równomiernie obciązać, by prędkość przesyłu była jak najszybsza. Procesem wysyłania żądania danej
usługi mogą zajmować się właśnie przełączniki siódmej warstwy. Ich zadaniem jest skierowanie żądania klienta do właściwego serwera lub urządzenia typu
cache. Decyzja o tym, do którego serwera skierować żądanie podejmowana jest w oparciu o szereg konfigurowalnych parametrów:
- dostępność serwera
- obciążenie serwera
- czas odpowiedzi z serwera
- dostępność żądanego pliku na serwerze
- parametry sieciowe warstwy 3 i 4 żądania (adres IP, port TCP, itp.)
- parametry sieciowe warstwy 5, 6 i 7 żądania takie jak adres URL, identyfikator sesji SSL czy obecne w żądaniu Cookie.
Co więcej, w sytuacji, gdy wszystkie dostępne serwery są przeciążone przełącznik jest w stanie uruchomić dodatkowe serwery lub urządzenia typu cache, o ile
takowe są dostępne, i skopiować na nie szczególnie często żądane pliki, a następnie dodać je do farmy serwerów do czasu zmniejszenia obciążenia głównych
serwerów.
Stosowanie content switcha pozwala zatem zminimalizować czas odpowiedzi od serwera w sposób zauważalny przez klienta oraz wyeliminować okresy
niedostępności usług. Wiadomo jak ważne są to korzyści w przypadku firm prowadzących w Internecie działalność komercyjną.
Jednakże przełączniki siódmej warstwy stanowią także dodatkowe zabezpieczenie sieci. Umieszczony przed firewallem switch tego rodzaju pracuje jak wieloportowy
inline IDS, który tak jak wyżej tego typu IDS'y monitoruje przesyłane pakiety danych i porównuje je z bazą danych sygnatur ataków. Switch ten został
stworzony do pracy w sieciach z dużymi
prędkościami przesyłu danych, rzędu nawet kilku Gbps. Co więcej, potrafi także zablokować ataki typu Denial of Service i Distributed Denial of Service, nie wpływając
na działanie reszty sieci, co jest cechą wyjątkową nawet w przypadku systemów IPS. Niestety podobnie jak inline IDS switch warstwy aplikacji nie potrafi
powstrzymać ataków, których sygnatur nie ma w swojej bazie, ale urządzenie jest w pełni konfigurowywalne i bazę danych z atakami można aktualizować software'owo.
Software'owe systemy firewall/IDS
Software'owe systemy spełniające funkcje firewalla i IDS'a, są z reguły traktowane jako systemy IPS, niż tradycyjne IDS'y. Aplikacja tego typu
powinna być zainstalowana na każdym hoście, który ma być chroniony. Rozwiązanie takie jest co prawda bardzo pracochłonne przy konfiguracji i konserwacji, gdyż
na każdym hoście z osobna trzeba skonfigurować aplikację, co jak się zaraz przekonamy jest czynnością dość żmudną. Jednak z drugiej strony po zastosowaniu tego rodzaju
aplikacji bezpieczeństwo systemu znacznie podniesie się.
IPS tego rodzaju nie zajmuje się analizowaniem pakietów przepływających w sieci. Jako jedyny z tutaj wymienionych rodzajów podejść do systemu IPS,
dostosowywuje ochronę do każdej poszczególnej aplikacji
na hoście, poprzez sprawdzanie wywołań API, monitorowanie pamięci (w celu wykrycia próby ataku poprzez przepełnienie bufora) oraz badanie interakcji aplikacji
z systemem operacyjnym.
Na początku aplikacja typu firewall/IDS tworzy profil systemu. Określa jak wygląda zwyczajna aktywność użytkownika w systemie, podgląda interakcje
użytkownika z oprogramowaniem oraz oprogramowania z systemem operacyjnym i zapisuje je w formie reguł, po to by móc potem stwierdzić zdarzenia odbiegające
od normy. Z tego też powodu
samo konfigurowanie jest czynnością ciężką. Trzeba bowiem wykonać wszystkie dozwolone aspekty użycia danej aplikacji, dla każdej aplikacji znajdującej się
w systemie, tak aby potem IPS nie zrozumiał prawidłowego, lecz nie zdefiniowanego w czasie konfiguracji użycia aplikacji jako anomalii i próby ataku.
Co więcej przy zainstalowaniu nowej aplikacji, bądź nowej wersji starej należy od nowa stworzyć jej profil w systemie IPS.
O systemach tego typu mówi się, że są typu "file close", co oznacza, że jeśli w jakiejś aplikacji została podjęta akcja, dla której nie istnieje reguła w systemie
IPS, to IPS ją anuluje. Systemy takie zabezpieczają także przed błędami w aplikacji, gdyż sytuacja błędu nie została raczej wcześniej zdefiniowana i zostanie potraktowana
jako anomalia i anulowana. No i oczywiście IPS ten zabezpiecza przed nieznanymi atakami, obojętnie czy z Internetu, czy z sieci lokalnej. Dlatego software'owe
firewalle/IDS'y są jednymi z najsilniejszych systemów typu IPS, oferujących największe bezpieczeństwo. IPS zajmuje się ochroną każdej aplikacji z osobna, dzięki
czemu działa dużo dokładniej, kosztem jednak znacznego nakładu pracy podczas i późniejszych każdorazowych rekonfiguracji aplikacji na każdym hoście z osobna.
Switche hybrydowe
Switche hybrydowe, jak mówi sama nazwa, są hybrydą switchy warstwy aplikacji oraz software'owych systemów typu firewall/IDS.
Są to rozwiązania sprzętowe, podobnie jak przełączniki siódmej warstwy umieszczone przed firewallem. Jednak zamiast badać każdy pakiet i przyrównywać do sygnatur
z bazy, działają podobnie do aplikacyjnych firewalli/IDS'ów. Na początku poszczególne aplikacje na hostach, przed którymi stoi switch, są skanowane w poszukiwaniu
słabych punktów bezpieczeństwa i metod jego zachowywania. Następnie informacje z takiego skanu są importowane bezpośrednio do switcha, który na tej podstawie
opracowywuje odpowiednią politykę
bezpieczeństwa i metody postępowania z danymi aplikacjami. Takie postępowanie oszczędza czas pracy administratora systemu, zużyty na konfigurację polityki switcha ochrony poszczególnych aplikacji.
Następnie, podczas normalnego użycia, switch monitoruje przesyłane pakiety w poszukiwaniu podejrzanej, potencjalnie złośliwej zawartości w kontekście reguł zdefiniowanych
przy skonfigurowaniu switcha. Przykładem takiej złośliwej zawartości pakietu może być żądanie pobrania pliku z hasłami danej aplikacji. Switch przy konfigurowaniu wykrył, że plik ten
jest słabym punktem tej aplikacji i nie zezwolił na wysyłanie tego pliku.
Przełaczniki hybrydowe mogą np. posłużyć do ochrony serwera WWW. Wówczas switch przechowuje dokładną wiedzę o serwerze i aplikacjach, na nim działających.
Jest to też system typu "fail close", gdyż jeśli żadne żądanie klienta nie jest dozwolone, żadna akcja się nie wykona. Jeżeli sam switch jest podłączony do
sieci o dużym przepływie danych i staje się jej wąskim gardłem, można go połączyć z przełącznikiem warstwy aplikacji. Wówczas najpier jest switch siódmego poziomu,
analizujący pakiety, i jeśli jakiś pakiet jest podejrzany, to przesyła go dalej do switcha hybrydowego, by ten zdecydował co z nim zrobić, natomiast jeśli nie jest podejrzany
to idzie dalej omijając switch hybrydowy. Takie rozwiązanie znacznie redukuje ilość pakietów analizowanych przez przełącznik hybrydowy i odciąża go.
Aplikacje oszukujące
Ten rodzaj IPS, zwany po ang. deceptive applications, reprezentuje trochę inne podejście do zagadnienia, niż pozostałe systemy IPS. Idea tej technologii
powstała w 1998, więc nie jest ona nowa. Jest to rozwiązanie software'owe, opierające się na zwodzeniu intruza. Na początku, w fazie konfiguracji, analogicznie
do konfiguracji systemów aplikacyjnych typu firewall/IDS, aplikacja monitoruje ruch TCP w sieci i wprowadza reguły dla występujących rodzajów połączeń (adresy IP i numery portów TCP używanych połączeń).
Adresy z portami nie znajdujące się na liście będą traktowane podejrzliwie. W przypadku próby połączenia przez taki adres (np. przez intruza skanującego porty) i port, zostanie mu odesłany specjalny, zamarkowany
nieistotnymi danymi pakiet, w ten sposób, że jeśli atakujący wróci i będzie chciał zaatakować serwer, IPS zauważy zamarkowane dane i zablokuje połączenie z intruzem.
Intruz widząc fałszywy serwer, nie będzie już atakował.
Podsumowanie
Przedstawione wyżej pięć zupełnie różnych realizacji systemu prewencji IPS pokazuje, w jak różnych kierunkach systemy tego typu się rozwijają. Są to idee dość nowe i stale rozwiją się oraz powstają nowe.
Mimo, że celem każdego
systemu IPS jest rozpoznanie i zareagowanie na atak, każda z koncepcji realizuje ten cel zupełnie innymi metodami. Co więcej niektóre z nich można łączyć
w celu jeszcze osiągnięcia jeszcze większego stopnia bezpieczeństwa. Zastosowanie konkretnej realizacji idei IPS, zależy od własnych potrzeb, nie ma rozwiązań uniwersalnych.
I tak możemy przed firewallem zainstalować przełącznik siódmej warstwy, chroniący przed atakami DoS i atakami o znanych sygnaturach, następnie przełącznik hybrydowy, bądź
aplikacyjny system typu firewall/IPS do ochrony serwerów WWW wewnątrz sieci, oraz inline IDS do ochrony stacji roboczych AS400.
Kerberos jest to system uwiarygodniania i autoryzacji. Powstał w 1980 roku w laboratorium komputerowym instytutu MIT. Sama nazwa pochodzi
od imienia Cerber - trzygłowego psa strzegącego bram Hadesu. Reprezentuje on trochę inne
podejście do zagadnienia ochrony danych w sieci lokalnej, niż wcześniej omówione rodzaje zabezpieczeń. Idea opiera się na dość prostej zasadzie.
W systemie Kerberos zakłada się, że cała sieć jest jednym wielkim obszarem ryzyka, poza jednym serwerem (czasem nawet dwoma serwerami lub całą grupą).
Serwer ten zwany jest dalej bezpiecznym serwerem (np. w instytucie MIT komputer
ten nosi nazwę kerberos.mit.edu). Wyposażony jest w niezwykle sprawne zabezpieczenia przed włamaniami zarówno z sieci lokalnej, jak i publicznej.
Powinien być umieszczony w pokoju chronionym przez 24 godziny na dobę, by nikt niepowołany nie uzyskał do niego fizaycznego dostępu. Na komputerze tym
znajduje się baza danych zawierająca informacje o hasłach i prawach dostępu każdego użytkownika w danym systemie informatycznym. Wszystkie komputery i
użytkownicy sieci działają tylko na podstawie danych dostarczanych przez ten serwer. W systemie Kerberos serwer ten, jest jedynym serwerem w sieci, który
może dostarczać programom sieciowym informacje związane z
dostępem. Dla serwerów działających w systemie Kerberos oraz pracujących w nim użytkowników wszystkie pozostałe elementy sieci są niepewne.
Sama idea systemu opiera się na zasadzie upraszczania. Nie zabezpieczamy całej sieci lokalnej i wszystkich jej elementów z osobna, lecz ochrona całej sieci
skupiona jest na jednym komputerze. Opiera się to na obserwacji, że łatwiej i taniej jest utrzymać jeden całkowicie bezpieczny serwer, niż zabezpieczać
całą sieć.

Sposób działania systemu Kerberos zależy od zastosowanej jego implementacji. Przedstawię wersję z dwoma bezpiecznymi
serwerami.
Kerberos umożliwia przeprowadzenie uwierzytelnienia zarówno przesyłanych komunikatów, jak i stron nawiązujących komunikację.
Sam proces uwierzytelniania odbywa się za pośrednictwem tzw. centrum dystrybucji klucza czyli KDC (z ang. Key
Distribution Center). Centrum to stanowią dwa bezpieczne, niezależne od siebie serwery: serwer uwierzytelniania
AS (z ang. Authentification Server) oraz serwer
przyznający bilety TGS (Ticket Granting Server). Serwer AS przechowuje hasła wszystkich użytkowników sieci, zaś serwer TGS zajmuje się weryfikacją i
organizacją dostępu użytkowników do zasobów sieci.
Typowy proces uwierzytelnienia w systemie Kerberos wygląda następująco:
- Klient chcący się uwierzytelnić u określonego dostawcy usług lub na danym serwerze z zasobami, zwraca się do serwera autentyfikacji AS z prośbą o
dostęp. Wysyła zatem wiadomość zaszyfrowaną kluczem opartym na haśle użytkownika.
- Serwer AS sprawdza w swojej bazie uprawnienia klienta do żądanego serwera, po czym w przypadku posiadania przez klienta takowych praw
przyznaje tzw. bilet na przyznanie biletu czyli TGT
(z ang. ticket granting ticket). Następnie wynik całej operacji czyli bilet TGT wraz z kluczem sesji jest szyfrowany kluczem opartym na haśle użytkownika i
odsyłany z powrotem do klienta.
- Klient, korzystając ponownie ze swojego hasła użytkownika, rozszyfrowywuje otrzymane dane. Dzięki takiemu podejściu hasło w żadnym momencie nie jest przesyłane
przez sieć.
- Klient, po wcześniejszym zaszyfrowaniu przesyłki kluczem sesji, przesyła do serwera TGS otrzymany bilet TGT wraz z tzw. wartością uwierzytelniającą,
zawierającą nazwę użytkownika, (a dokładniej identyfikator klucza sesji), adres sieciowy i stempel czasowy.
- Serwer TGT rozszyfrowywuje przesyłkę i weryfikuje żądanie.
- W przypadku pozytywnej weryfikacji tworzy bilet do żądanego serwera i odsyła go do
klienta.
- Klient, po odebraniu biletu, może się już zwrócić do żądanego serwera. Musi mu wówczas wysłać bilet wraz z wartością uwierzytelniającą. Serwer również
zwraca wartość uwierzytelniającą, jeśli wymagane jest obustronne uwierzytelnienie.
Klient może otrzymany bilet TGT ponownie użyć, w celu otrzymania biletów do innych serwerów systemu. Ważne jest to, że klient uwierzytelnia się na
kolejnych serwerach bez konieczności podawania swojego hasła, do uwierzytelnienia wystarczy przesłanie biletu. Zaletą tego rozwiązania jest to, ze
użytkownik nie musi zdradzać hasła w nieznanym bliżej serwerze, który jest w końcu w obszarze ryzyka danej sieci. Serwer zaś może wpuścić użytkownika, bez podania
hasłą, tylko na podstawie biletu, gdyż obie strony: użytkownik i serwer ufają centrum dystrybucji kluczy KDC. Zatem obie strony mogą się wzajemnie
uwierzytelnić. Dla użytkownika istotne jest to, że musi on tylko raz podać swoje hasło, przy autentyfikacji na serwerze AS. Potem otrzymuje on bilet TGT
i od tej chwili ma dostęp do zdalnych serwerów bez konieczności podawania hasła, gdyż nie jest ono wymagane do otrzymania biletu na konkretny serwer.
System Kerberos stanowi metodę weryfikowania tożsamości użytkowników w sieciach otwartych (nie zabezpieczonych). Weryfikacja tożsamości użytkowników
w systemie odbywa się bez użycia mechanizmów uwiarygodniania systemu operacyjnego odległego komputera głównego oraz nie wymaga, aby
wszystkie komputery główne w sieci były fizycznie wyposażone w systemy
ochrony. Co więcej, system Kerberos zakłada, że każdy użytkownik może odczytywać i modyfikować pakiety przesyłane w sieci oraz dodawać nowe. Innymi słowy,
w systemie tym cała sieć, oprócz serwera Kerberos, jest traktowana jako jeden wielki obszar zwiększonego ryzyka. System dopuszcza możliwość podglądania
wszystkich transakcji przez hakerów i ich ciągłe próby włamania się do sieci.
Tak więc Kerberos dokonuje uwiarygodniania transakcji działając zgodnie z tymi niedoskonałymi założeniami. System ten jest po prostu dodatkową bezpieczną
usługą uwiarygodniania. Samo uwiarygodnianie transakcji odbywa się przy zastosowaniu tradycyjnych metod kryptograficznych, czyli z użyciem wspólnego klucza
tajnego. Ważnym założeniem systemu jest to , że klucz ten jest wymieniany między dwiema stronami połączenia jeszcze przed rozpoczęciem
przesyłania danych za pośrednictwem bezpiecznego kanału. Klucze te określa się jako wspólne klucze tajne, ponieważ podczas ich używania poufne
informacje są wspólne dla dwóch (lub więcej) stron. Nie należy jednak mylić klucza tajnego z kluczem prywatnym używanym w systemach kryptograficznych, gdyż
oba pojęcia oznaczają co innego. Klucz prywatny powinien znać tylko użytkownik, do którego ten klucz należy i nikt więcej.
Wspólny klucz tajny zaś znają co najmniej dwie strony (użytkownik, chcący się uwierzytelnić i serwer).
System Kerberos korzysta z jednego lub kilku serwerów uwiarygodniania (bezpiecznych serwerów) działających na zabezpieczonych fizycznie komputerach
głównych. Serwery uwiarygodniania zawierają bazę danych z informacjami o użytkownikach. Baza taka zawiera spis wszystkich użytkowników i serwerów, a także
wspólny klucz tajny i klucz publiczny każdego użytkownika.
Biblioteki źródłowe systemu dostarczają gotowe mechanizmy szyfrowania i implementują protokół
Kerberos. W każdej aplikacji, która musi się uwierzytelnić przez system Kerberos musimy wprowadzić odwołania do biblioteki Kerberos. Biblioteka ta udostępnia
aplikacjom
funkcje uwiarygodniania przesyłanych danych. Typowa aplikacja sieciowa, aby się uwiarygodnić musi wysyłać jedno lub dwa zapytania do biblioteki Kerberos.
Wprowadzanie w aplikacjach odwołań do biblioteki Kerberos nosi nazwę kerberyzowania aplikacji.
System Kerberos opiera swoje działanie na tym, że pracuje w sieci stanowiącej jeden duży obszar zwiększonego ryzyka. Aby jednak Kerberos spełniał
właściwie swoje zadania trzeba spełnić kilka dodatkowych założeń. Założenia te precyzują jak powinno wyglądać środowisko, w którym może on właściwie
funkcjonować. Ich niespełnienie może osłabić bezpieczeństwo i odsłonić przed włamywaczami potencjalne czułe punkty systemu.
- System Kerberos nie oferuje możliwości obrony przed atakami ze strony usług. W systemie tym bowiem intruz może z łatwością uniemożliwić aplikacji
wzięcie udziału we właściwym przeprowadzeniu operacji uwiarygodniania. Wykrywanie ataków tego typu, z których niektóre wyglądają na normalne sytuacje awaryjne w
systemie) i zapobieganie im spoczywa na administratorach systemu i jego użytkownikach.
- System Kerberos zakłada, że wspólny klucz tajny jest rzeczywiście tajny, dlatego użytkownicy muszą go bezwzględnie chronić, ponieważ w wypadku
skradzenia klucza użytkownika intruz może posłużyć się nim do podszycia się pod użytkownika lub dowolny serwer.
- System Kerberos nie chroni przed atakami polegającymi na odgadywaniu hasła. Dlatego użytkownicy nie mogą wybierać sobie łatwych haseł, gdyż w innym wypadku
włamywacz może z łatwością zastosować metodę pozasieciowego ataku przy użyciu słownika i w końcu odkryć hasło. Wystarczy, że haker zacznie poddawać
skopiowane przez siebie wiadomości orzesyłane między serwerem AS, a użytkownikiem kolejnym próbom odszyfrowania. Ponieważ użytkownik szyfruje te wiadomości
przy użyciu klucza generowanego na podstawie
hasła użytkownika, teoretycznie więc, po dostatecznie długim czasie i przy odrobinie szczęścia, haker może odgadnąć hasło użytkownika.
Jak wiadomo, system Kerberos wydaje uwiarygodnienie na podstawie identyfikatora logowania użytkownika i wspólnego klucza tajnego. Z takim rozwiązaniem
wiąże się niebezpieczeństwo oszukania serwera przez hakera. Włamywacz może bowiem sprawić, że bezpieczny serwer będzie go traktował jak uprawnionego
użytkownika i wówczas uzyska wszelkie prawa dostępu. Na przykład przy wysyłaniu do bezpiecznego serwera wiadomości z prośbą o przyznanie prawa dostępu
do serwera plików, haker może ją przechwycić i przesłać ją następnie do bezpiecznego serwera. Wówczas serwer uzna, że to uprawniony użytkownik zażądał
uwiarygodnienia, i haker uzyska dostęp. Jedną z prób wyeliminowania możliwości takiego ataku, było wprowadzenie przez twórców Kerberosa mechanizmu znaczników
(stempli) czasowych. Mechanizm ten zapewnia, że wszystkie wiadomości otrzymywane przez bezpieczny serwer zawierają datę i czas. Bezpieczny serwer odrzuca
wówczas wszystkie te wiadomości, które są przestarzałe o co najmniej 5 minut. Mechanizm znaczników czasu pomaga zapobiec wielu działaniom osób
nieuprawnionych.
Nadal jednak system Kerberos pozostaje niezwykle wrażliwy na atak poprzez rozszyfrowywanie poza siecią. Włamywacz może przechwycić wiadomość z
odpowiedzią serwera przesłaną do użytkownika. Wiadomość taka zawiera bilet i zaszyfrowana jest przy użyciu publicznego klucza użytkownika). Dlatego może on
próbować odszyfrować wiadomość poprzez odgadnięcie klucza prywatnego. Włamywacz może także wzmocnić atak poprzez obserwację przesyłanych wiadomości od
dłuższego czasu i w celu zdobycia klucza prywatnego zastosować metodę ataku czasowego. Jeśli mu się powiedzie i odczyta wiadomość (znacznik czasu lub adres sieciowy), to może
złamać klucz prywatny.



