Nowa obsługa wieloprocesorowości
Wprowadzenie oddzielnych kolejek dla każdego procesora (oraz dla każdego procesora wirtualnego w SMT) sprawia, że procesy są mocno związane z procesorami, na których ostatnio się wykonywały (to dobrze - z powodów dotyczących aktualności cache procesora i przydzielonych banków pamięci). Pozwala to uprościć metody przenoszenia procesów między procesorami.
Każda kolejka runqueue przechowuje informację o aktualnym obciązeniu procesora - cpu_load. Wartość ta zależy od ilości procesów w kolejce. Gdy obciążenia procesorów w grupie są zbyt różne (warunek ten jest sprawdzany przy okazji wywołania funkcji scheduler_tick(), zawiadującej wywoływaniem schedulera), uruchamiany jest (na tymże procesorze) specjalny proces migracji, który zajmuje się odebraniem procesów najbardziej obciążonemu procesorowi w grupie. (Czynność migracji procesów nazywa się balansowaniem.)
struct runqueue {
...
unsigned int nr_active; /* liczba aktywnych procesów na prio_array */
unsigned long cpu_load; /* uśredniona ilość aktywnych procesów */
task_t *migration_thread; /* proces migracji */
...
};
Balansowanie w NUMA
W strukturze Non-Uniform Memory Access pożądane jest, aby proces wykonywał się w miarę możliwości na tym samym procesorze. Ponieważ w NUMA grupy procesorów mają rozłączną pamięć, ważne jest też, aby niepotrzebnie nie przenosić procesów pomiędzy grupami. Scheduler efektywnie wspiera NUMA dzięki organizowaniu procesów w grupy.
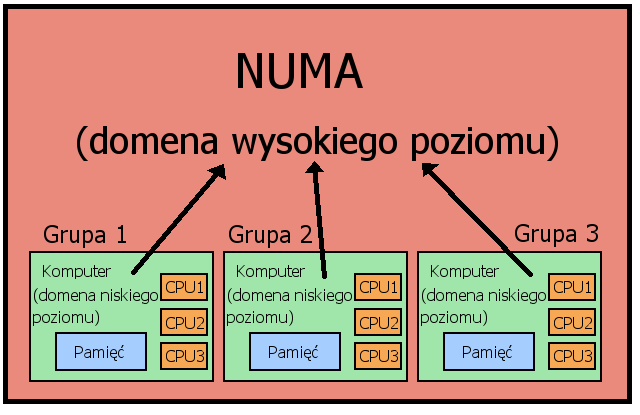
- Domena niskiego poziomu - scheduler ma przyporządkowaną domenę, w której znajdują się pojedyncze procesory. Balansowanie jest wywoływane między procesorami w domenie, tylko wtedy, gdy jest duża różnica w obciążeniach procesorów
- Domena wysokiego poziomu - w tej domenie podstawowymi jednostkami są nie procesory, lecz grupy procesorów. Balansowanie jest wywoływane między grupami, i to tylko wtedy, gdy jest duża różnica w obciążeniach grup (nie procesorów). Balansowanie na tym poziomie jest wywoływane rzadziej niż w domenach niskiego poziomu.
Zaletą tego rozwiązania jest pierwszeństwo balansowania wewnątrz grupy przed balansowaniem między grupami. Procesor mniej obciążony przyjmie procesy z innej grupy tylko wtedy, gdy jest różnica w obciążeniu całych grup - w przypadku, gdy różnice między grupami są małe, procesor najpierw przyjmie procesy od innego procesora znajdującego się w tej samej grupie.