| 2. NTFS | ||
|---|---|---|
 | Chapter 8. Metody kompresji plików |  |
| 2. NTFS | ||
|---|---|---|
| | Chapter 8. Metody kompresji plików | |
Z kolei - w przeciwieństwie do swoich Windowsowych poprzedników, czyli FAT-ów - NTFS oferuje możliwość kompresji plików za pomocą kilku mechanizmów. Można ustawić żądanie kompresji:
całej zawartości danego woluminu - ustawia się za pomocą funkcji GetVolumeInformation,
danego pliku lub katalogu - ustawia się za pomocą funkcji DeviceIoControl.
UWAGA: Zmiana parametru kompresji danego pliku powoduje natychmiastową zmianę jego stanu, a w przypadku folderów czy woluminów zmiana taka zmienia tylko parametr, jaki będzie przypisywany wszystkim nowym plikom i podkatalogom.
Istnieją dwie główne metody, jakie NTFS stosuje do kompresji plików:
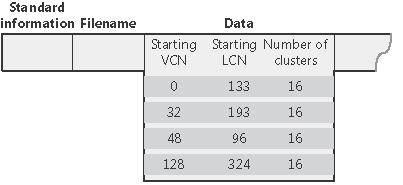
Kompresja rzadkich danych: Rzadkie dane to dane, których znaczną część stanowią zera (dobrym przykładem są rzadkie macierze, które zawierają niewiele niezerowych pól). Kiedy cały dany ekstent wypełniają zera, to NTFS w ogóle nie pamięta zawartości tego ekstentu - patrz rysunek (proszę zwrócić uwagę na brak ekstentów dla VCN-ów 16-31 i 64-127):
W tym przypadku, w MFT nieistniejące ekstenty nie są w ogóle zapisane (o ich istnieniu świadczy tylko nieciągłość w numerach VCN istniejących ekstentów):
Kiedy program próbuje odczytać dane z pliku i w MFT nie ma ekstentu z polami o żądanych numerach, to NTFS zwraca użytkownikowi zera bez jakiegokolwiek odwołania się do dysku, co jest dużym zyskiem czasowym.
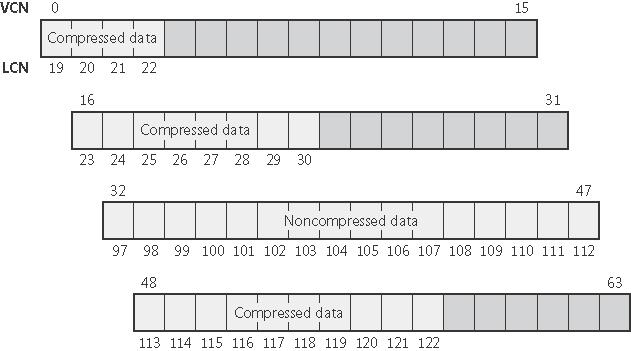
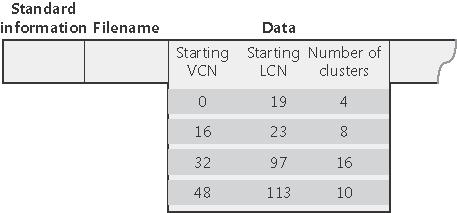
Kompresja gęstych danych: Oczywiście istnieją także metody kompresji, które zmniejszają wielkość gęstych danych (z niewielką liczbą zer). Kompresja takich danych polega na tym, że plik kompresowany jest dzielony na jednostki kompresyjne wielkości 16 klastrów. Dla każdej jednostki system sprawdza, czy jej kompresja zmniejszyłaby jej rozmiar o co najmniej jeden klaster; jeżeli tak, to NTFS alokuje odpowiednio mniejszą liczbę klastrów i zapisuje na dysk dane skompresowane, a jeżeli nie, to dane zostają zapisane na dysku w postaci nieskompresowanej. Przykład tak skompresowanego pliku obrazuje rysunek (pierwszy, drugi i czwarty ekstent zostały skompresowane, trzeci nie - niezaciemnione pola obrazują używane klastry):
Dzięki przyjętej zasadzie kompresji tylko przy pewnym zysku, NTFS wie, które fragmenty pliku zostały skompresowane, a które nie - patrzy na liczbę klastrów danego ekstentu i sprawdza, czy jest równa czy mniejsza niż 16:
Na takim pliku wszystkie operacje odczytu i zapisu są wykonywane tylko na całych jednostkach kompresyjnych. W szczególności przy zapisie danych przez użytkownika dane zostają tylko zapisane w pamięci operacyjnej, kompresja i zapis na dysk odbywają się asynchronicznie (leniwie), co pozwala przyspieszyć działanie. Z kolei w celu przyspieszenia odczytu, NTFS stara się alokować kolejne ekstenty w bezpośrednim fizycznym sąsiedztwie, dzięki czemu mechanizm czytania z dysku z wyprzedzeniem (czyli czytania danych tuż za odczytanymi danymi) w połączeniu z asynchroniczną dekompresją może znacznie ten odczyt usprawnić.
Liczba 16 została wybrana jako "trade-off", czyli jako wartość, która jak najlepiej równoważy zysk przynoszony z kompresji danych (czym większa liczba, tym więcej możemy potencjalnie zyskać) i stratę przynoszoną przez konieczność czytania całych jednostek kompresyjnych danych przy każdym błędzie cache miss (czym mniejsza liczba, tym mniej zbędnych danych trzeba wczytać).
Dodatkowo, NTFS udostępnia także specjalny typ rzadkiego pliku. Tego typu pliki są traktowane jak pliku skompresowane metodą kompresji rzadkich danych, ale nie są dokładnie tym samym. Mianowicie dany proces może wskazać pewne fragmenty pliku, które uznaje za puste i wtedy te fragmenty nie są pamiętane, a próba odczytu daje ciąg zer (jak powyżej). Tego typu pliki przydają się w aplikacjach typu klient-serwer, w których istnieje pewien bufor, do którego serwer pisze, a klient z niego czyta. Kiedy klient przeczyta pewien fragment pliku, to nie będzie on już informacji w nim zawartej potrzebował i może ustawić ten fragment jako pusty. Ten mechanizm pozwala uniknąć nieskończonego wzrostu wielkości plików. Inny przykład rzadkiego pliku stanowi bitmapa błędnych klastrów dyskowych, przechowywana jako omówiony już plik metadanych.
| |  | |
| 1. ext3 |  | Chapter 9. Dowiązania (linki) |