
Zauważmy, że EIP = adres bazowy funkcji + offset instrukcji. Ślad wykonania to łańcuch wywołania funkcji prowadzący do błędu. Aby dokładnie go przeanalizować możemy zdekodować naszego oopsa za pomocą polecenia ksymoops.
Use the Source, Luke, use the Source. Be one with the code.'. Think of Luke Skywalker discarding the automatic firing system when closing on the deathstar, and firing the proton torpedo (or whatever) manually. _Then_ do you have the right mindset for fixing kernel bugs.
Linus
Jak już pewnie wszyscy wiecie, z przygód związanych z labami do tego przedmiotu, jedną z ważniejszych cech różniącą programowanie w jądrze od programowania przestrzeni użytkownika jest stopień trudności w diagnostyce błędów. Problem komplikuje choćby to, że błąd przy programowaniu w jądrze może załamać cały system. Ta część prezentacji została pomyślana po to, żeby choć trochę pomóc w trudnym zadaniu odpluskwiania kodu w jądrze.
W kwestii samych błędów (a raczej tego, co widzi użytkownik systemu, gdy następi błąd), to należy rozróżnić cztery sytuacje:
W testowaniu kodu jądra i debuggowaniu przydatne mogą się okazać dostępne liczne opcje konfiguracyjne kompilacji jądra. Opcje te są zebrane w dziale Kernel hacking. Aktywność wszystkich tych opcji uzależniona jest od włączenia ogólnej opcji CONFIG_DEBUG_KERNEL. Jeżeli zamierzamy modyfikować jądro warto włączyć je wszystkie. W niniejszej prezentacji opisane są niektóre (częściej używane) z tych opcji.
Najmniej skomplikowanym sposobem próby diagnozy tego, co tak na prawdę się złego dzieje i dlaczego jest wyprowadzenie informacji.
Funkcja printk() działa niemal identycznie, jak funkcja printf() z biblioteki dostępnej przy programowaniu przestrzeni użytkownika. Tak więc jest to funkcja wypisująca sformatowany ciąg znakowy. Nie jest jednak do końca taka zwyczajna.
Jej przydatność polega właśnie na tym, że jest niezawodna i wszechstronna. Daje się wywołać niemal z dowolnego miejsca jądra, w dowolnym momencie wykonania, z dowolnego kontekstu. Można ją wywołać współbieżnie na wilu procesorach, bez konieczności pozyskiwania jakiejkolwiek blokady.
Z jednym wyjątkiem: nie da się jej wywołać we wczesnej fazie rozruchu jądra, przed momentem zainicjowania konsoli. Niektórzy programiści wyprowadzają wtedy komunikaty na sprzęt, który działa zawsze, np. na port szeregowy. Istnieje jednak jeszcze słabo przenośna i nie na każdej architekturze zaimplementowana fukcja early_printk(), niczym się nie różniąca od printk(), poza tym, że można ją wywołać wcześniej.
Inna główna różnica między wywołaniami printk() i printf() tkwi w zdolności tej pierwszej do określania poziomu rejestrowania (ang. loglevel). Wygląda to tak:
printk(KERN_WARNING "Minister zdrowia ostrzega: palenie tytoniu powoduje choroby płuc.\n");W poniższej tabeli wypisano dostępne poziomy rejestrowania:
printk(KERN_INFO "To jest prezentacja o odpluskwianiu.\n");
printk("Nie został określony poziom rejestrowania.\n");
| KERN_EMERG | < 0> | Sytuacja awaryjna |
| KERN_ALERT | < 1> | Problem wymagający natychmiastowej interwencji |
| KERN_CRIT | < 2> | Sytuacja krytyczna |
| KERN_ERR | < 3> | Błąd |
| KERN_WARNING | < 4> | Ostrzeżenie |
| KERN_NOTICE | < 5> | Sytuacja normalna, warta odnotowania |
| KERN_INFO | < 6> | Informacja |
| KERN_DEBUG | < 7> | Komunikat diagnostyczny |
Komunikaty jądra umieszczane są w cyklicznym buforze o rozmiarze LOG_BUF_LEN. Można go konfigurować przy kompilacji bodajże za pomocą opcji CONFIG_LOG_BUF_SHIFT. Z reguły jest to 16kB.
Za pobieranie komunikatów jądra z bufora odpowiedzialny jest demon przestrzeni użytkownika klogd. Demon ten zapisuje komunikaty do systemowego pliku dziennika, korzystając przy tym z pomocy demona syslogd. klogd w celu odczytywania komunikatów korzysta z pliku /proc/kmsg (bądź też z systemowego wywołania syslog()). klog budzi się, gdy przychodzi nowy komunikat i przekazuje go do demona syslogd.
syslogd natomiast dostarcza wywołane komunikaty do pliku (domyślnie jest to plik /var/log/messages). Dziłanie demona można konfigurować w pliku /etc/syslog.conf, który wygląda mniej więcej tak:
# Log all kernel messages to the console. # Logging much else clutters up the screen. #kern.* /dev/console # Log anything (except mail) of level info or higher. # Don't log private authentication messages! *.info;mail.none;authpriv.none;cron.none /var/log/messages # The authpriv file has restricted access. authpriv.* /var/log/secure # Log all the mail messages in one place. mail.* /var/log/maillog # Log cron stuff cron.* /var/log/cron # Everybody gets emergency messages *.emerg * # Save news errors of level crit and higher in a special file. uucp,news.crit /var/log/spooler # Save boot messages also to boot.log local7.* /var/log/boot.log
if (zle_sie_dzieje) BUG();co jest równoważne:
BUG_ON(zle_sie_dzieje);
if (straszny_i_okropny_blad) panic("Maksymalna kicha!\n");
Panic jako argumenty bierze formatowany tekst.
if (trzeba_analizowac_slad_stosu) dump_stack();
Blad oops to standardowy sposób informowania użytkownika o nieprawidłowościach w działaniu jądra. Zgłoszenie błędu oops polega na wyświetleniu komunikatu o błędzie wraz z zawartością rejestrów i śladem wykonania (ang. backtrace). Niekiedy po zakończeniu obsługi pojawia się niespójność jądra. Konieczne jest wtedy ostrożne wycofanie się do poprzedniego kontekstu i przywrócenie kontroli nad systemem.
Czasem jest to niemożliwe. Jeśli bład wystąpi w kontekście przerwania, jądro nie może nic zrobić i ,,panikuje'' dając w efeckie bład paniczny (kernel panic). Pojawia się on też przy błedzie podczas wykonywania procesu jałowego lub procesu init. Jedynie wystąpienie oopsa w kontekście jednego ze zwykłych procesów daje możliwość unicestwienia tego procesu i kontynuowania działania reszty systemu.
Oto przykładowy oops:
Zauważmy, że EIP = adres bazowy funkcji + offset instrukcji.
Ślad wykonania to łańcuch wywołania funkcji prowadzący do błędu. Aby dokładnie go przeanalizować możemy zdekodować naszego oopsa za pomocą
polecenia ksymoops.
ksymoops zapis_oops.txtOto przykładowy oops:



Od wersji rozwojowej jądra 2.5 zostła wprowadzona funkcja kallsyms, aktywowana przy użyciu opcji konfiguracyjnej CONFIG_KALLSYMS. Uaktywnienie tej opcji powoduje umieszczenie w obrazie jądra odwzorowań nazw symbolicznych na adresy pamięci, dzięki czemu jądro może wyprowadzać zdekodowane ślady wykonania. I wtedy ksymoops nie jest już potrzebny.
Gdy już wiemy, jaka funkcja spowodowała błąd możemy użyć informcji o offsecie (u nas 298) do odnalezienia konkretnej instrukcji, która błąd spowodowała. W tym celu potrzebujemy kopii problematycznej funkcji w postaci kodu assemlerowego. Możemy ją uzyskać za pomocą narzędzia objdump:
objdump -d plik.oWtedy możemy znaleźć instrukcję związaną ze znanym nam offsetem. Oto fragment pliku:
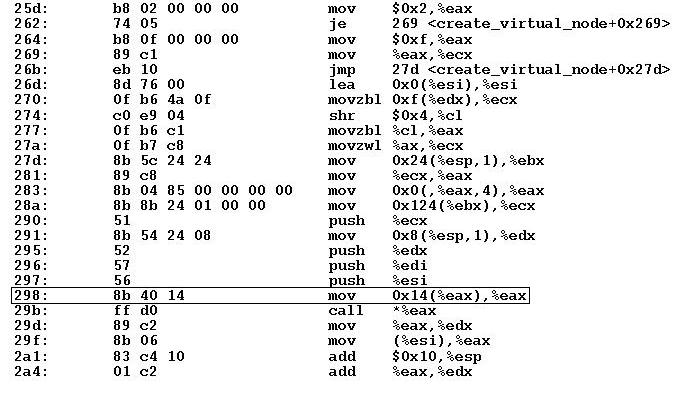
Przydatna może być także zawartość rejestrów. Dysponując kopią problematycznej funkcji w postaci kodu assemlerowego można na podstawie zawartości rejestrów odtworzyć stan jej wykonania w momencie wystąpienia błędu.
Jeśli już wiemy, co w kodzie assemblerowym powoduje błąd warto spróbować odnaleźć to miejsce w kodzie w C. Nie ma jakiejś prostej metody, by to zrobić. Należy zwrócić uwagę, że z reguły:
Mamy z nimi do czynienia, gdy utknęliśmy w nieskończonej pętli lub wisimy na jakimś locku.
Bardzo łatwo sprawdzić, czy przerwania nie są zablokowane. Choćby świadczy o tym reakcja światełek na klawiaturze (np. na klawisz Caps Lock).
Pierwszym mechanizmem, który możemy wtedy wykorzystać, aby zdobyć jakiekolwiek informacje o stanie systemu to klawisze sysinfo. Odpowiednie kombinacje klaswiszy powodują wypisanie informacji. Szczegóły w poniższej tabelce:
| shift + scroll lock | informacje o pamięci |
| ctrl + scroll lock | informacje o stanie procesora |
| prawy alt + scroll lock | informacje o rejestrach i ślad wykonania |
Sporo pracy może zaoszczędzić funkcja Magic SysRq Key, którą można aktywować za pośrednicrtwem opcji konfiguracyjnej CONFIG_MAGIC_SYSRQ. Można ją też włączyć za pomocą odpowiedniego pliku procowego:
echo 1 > /proc/sys/kernel/sysrqMagic SysRq Key umożliwia komunikację z jądrem za pomocą specjalnych klawiszy. Na większości klawiatur znajduje się klawisz SysRq (jest to z reguły alt + print screen). To, co się dzieje po naciśnięciu klawisza SysRq wraz z innym klawiszem obrazuje następująca tabela:
| h | pomoc dla sysrq key |
| s | sync |
| u | przemontowuje wszystkie partycje tylko do odczytu |
| b | rebootuje system |
| o | wyłącza komputer |
| r | zmienia tryb klawiatury na XLATE (wyłącza raw) |
| p | informacje o rejestrach i ślad wykonania |
| t | wypisuje procesy i informacje o nich |
| k | killuje proces na bieżącej konsoli |
| e | wysyła wszystkim oprócz init SIGTERM |
| i | wysyła wszystkim oprócz init SIGKILL |
| l | wysyła wszystkim SIGKILL |
| m | wypisuje informacje o pamięci |
| 0-8 | zmienia console_loglevel |
NMI Watchdog potrafi wykrywać sytuacje, w których mamy do czynienia z takim lockupem (sprawdza czy w przeciągu kilka sekund było jakieś przerwanie) i w razie stwierdzenia takiej sytuacji automatycznie generuje oopsa.
Jedną z opcji konfiguracyjnych (począwszy od wersji rozwojowej jądra 2.5) jest opcja określana w menu konfiguracyjnym sleep-inside-spinlock-checking -- wtedy też dostaniemy automatycznego oopsa w przypadku zawieszenia podczas przetrzymywainia spin_locka.
I'm afraid that I've seen too many people fix bugs by looking at debugger output, and that almost inevitably leads to fixing the symptoms rather than the underlying problems.
Linus
Wielu programistów jądra zawsze chciało mieć debugger działający w jądrze. Niestety Linus nie chciał i blokował i blokuje próby wprowadzenia debuggera do jądra. Twierdził, że obecność debuggera powoduje wprowadzanie błędnych poprawek przeez kiepskich programistów. Jednak wyrodukowano szereg łat uzupełniających jądro o obsługę debuggera (ale są to łaty ,,nieoficjalne'').
Można uruchomić debugger wobec jądra (tak samo, jak wobec zwykłych procesów):
gdb vmlinux /proc/kcoregdzie plik vmlinux to nieskompresowany obraz jkądra. Opcjonalny argument /proc/kcore pełni funkcję pliku obrazu pamięci. Po uruchomieniu debuggera można korzystać z dowolnych implementowanych w nim poleceń podglądu danych, np.:
p zmienna_globalnaDo deasemblacji funkcji należy użyć polecenia dissassemble:
dissassemble moja_funkcjaJeżeli skompilujemy jądro z opcją -g, debugger może wydobyć oczywiście znacznie więcej informacji. Możliwe jest choćby podglądanie zawartości struktur i wyłuskiwanie wskaźników. Oczywiście jednak opcja -g powoduje znaczny rozrost jądra, więc absolutnie nie należy jej stosować przy kompilacji do celów innych niż debuggowanie.
Ale na tym wyczerpuje się lista możliwości gdb jeżeli chodzi o jądro. Nie da się za jego pomocą modyfikować danych działającego jądra. Nie można wykonać pojedyńczej instrukcji kodu, ani też ustawić punktów wstrzymania wykonania. To poważne wady.
Idea jest taka, że na jednej maszynie odpalamy testowane jądro z nałożoną łatą kgdb i odpluskwiamy je za pomocą gdb z drugiej maszyny połączonej z
pierwszą łączem szeregowym (tak zwanym kablem null-modem, choć ostanie wersje wspierają też komunikację przez Ethernet). Potrzebna jest druga maszyna, żeby było gdzie postawić gdb do obsługi kodu
źródłowego i informacji dla debuggera pozostawionych przez gcc.
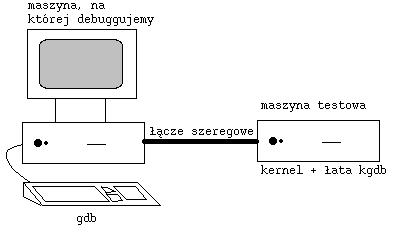
Gdb udostępnia polecenia target, dzięki któremu można debuggować zdalnie różne programy. Aby wszystkie informacje były dostępne dla gdb, na debuggowane jądro trzeba nałożyć łatę kgdb.
Łatę kgdb i inne informacje można znaleźć na tej stronie.
To jak się za to wszystko wziąć? Po kolei:
1
|
6---------------4
2---------------3
3---------------2
4---------------6
|
1
5---------------5
7---------------8
8---------------7
Generalnie takie coś się nazywa: szeregowy kabel 26-152B (Female DB9 - Female DB9) i adapter Null Modem: 26-264B (Female DB9 - Male DB9)kgdbwait kgdb8250=< port number>,< port speed>gdzie port number może być od 0 do 3, a wspierane szybkości to: 9600, 19200, 38400, 57600 i 115200.
stty ispeed < port speed> ospeed < port speed> < /dev/ttyS< port number>
gdbmod vmlinux GNU gdb 20000204 Copyright 2000 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i686-pc-linux-gnu"... (gdb)Może to chwilę potrwać.
Waiting for connection from remote gdb...
(gdb) target remote /dev/ttyS1 Remote debugging using /dev/ttyS1 breakpoint () at gdbstub.c:1153 1153 } (gdb)
(gdb) c Continuing. PCI: PCI BIOS revision 2.10 entry at 0xfb230, last bus=0 PCI: Using configuration type 1 PCI: Probing PCI hardware Limiting direct PCI/PCI transfers. Activating ISA DMA hang workarounds. isapnp: Scanning for PnP cards... isapnp: No Plug & Play device found Linux NET4.0 for Linux 2.4 Based upon Swansea University Computer Society NET3.039 Starting kswapd v1.8
Debuggowanie jest już takie same, jak debuggowanie zwykłych aplikacji, w szczególności można używać: ctrl + C, komend continue, break, step, next, backtrace, delete, info, info threads, thread, ps. Są też instrukcje: hwebrk, hwwbrk, hwabrk, hwrbrk (odpowiednio ustawiające breakpointy związane z pamięcią: wykonania, pisania, dostępu i usuwające te breakpointy).
Problem jest z debuggowaniem modułów. Jak powiedziałem standardowe gdb nie wystarczy. Trzeba ściągnąć specjalne ze strony kgdb. W dodatku nowe wersje kgdb nie są wyposarzone w fubkcjonalność debuggowania modułów. Wręcz jezęli chce się debuggować moduły jądra 2.6 trzeba używać rozwojowej wersji kgdb
Jak w takim razie debuggować moduły? Załóżmy, że mamy kgdb w wersji 1.8 lub wcześniejszej i debuggujemy jądro 2.4. Potrzebujemy jeszcze narzędzia modutils i specjalnego gdb (do ściągnięcia ze strony kgdb). Moduły należy skompilować z opcją -g. Można je załadować do gdb za pomocą polecenia load-symbol-file. Istnieje skrypt loadmodule.sh, który ładuje moduł do jądra i generuje odpowiednie komendy dla gdb. Wygląda to tak dla przykładowego modułu trfs: na maszynie testowej:
$ cd /mnt/work/build/old-pc/trfs/modules/trfs
[amit@askii-pc trfs]$ loadmodule.sh trfs
Copying /mnt/work/build/old-pc/trfs/modules/trfs/trfs to old-pc
Loading module /mnt/work/build/old-pc/trfs/modules/trfs/trfs
Warning: modutils is reading from /etc/conf.modules because
/etc/modules.conf does not exist. The use of /etc/conf.modules is
deprecated, please rename /etc/conf.modules to /etc/modules.conf
as soon as possible. Command
mv /etc/conf.modules /etc/modules.conf
Generating script /mnt/work/gdbscripts/loadtrfs
$
Zostanie wygenerowany następujący skrypt gdb do odpalenia w gdb:
add-symbol-file /mnt/work/build/old-pc/trfs/modules/trfs/trfs 0xc1808060 -s .text.lock 0xc180968c -s .rodata 0xc18097a0 -s __ksymtab 0xc1809a44 -s .data 0xc1809bc0Skrypt wykonujemy na maszynie, z której testujemy:
(gdb) source /mnt/work/gdbscripts/loadtrfs
add symbol table from file "/mnt/work/build/old-pc/trfs/modules/trfs/trfs" at
.text_addr = 0xc1808060
.text.lock_addr = 0xc180968c
.rodata_addr = 0xc18097a0
__ksymtab_addr = 0xc1809a44
.data_addr = 0xc1809bc0
(gdb)
Odładować moduł można normalnie, poprzez rmmod, ale jeżeli chcemy go ponownie załadować musimy coś zrobić z symbolami wczytanymi przez gdb.
Możemy je odświeżyć pisząc:
(gdb) symbol-file vmlinuxi dopiero potem raz jeszcze wykonać skrypt loadtrfs.
W późniejszych wersjach kgdb obsługa modułów jest robiona bardziej automatycznie.
Zmieniamy podejście do problemu. Będziemy debuggować lokalnie a nie zdalnie. Nie potrzebujemy dwóch maszyn, ale za to nasze możliwości będą bardziej ograniczone.
kdb (Build-in Kernel Debugger) to łata na jądro, która pozawala badać pamięć i struktury system podczas gdy system chodzi. Zbiór komend umożliwia mięedzy innymi:
Więcej informacji na tej stronie.

Najkrócej można powiedzieć, że UML to tak zmodyfikowane jądro Linuxa, że można je uruchomiś jako zwykły proces w przestrzeni użytkownika. Powstaje zamknięte środowisko, które "emuluje" Linuksa.
Procesy uruchomione pod kontrolą emulatora nie mogą oczywiście zdawać sobie sprawy, że są "oszukiwane" tzn. z punktu widzenia procesu nie da się rozróżnić że komunikacja przez wywołania systemowe odbywa się z mniejszym systemem. Jądro UML-a nie daje pełnej funkcjonalności zwykłego jądra jeśli chodzi o dostęp do sprzętu. Jest jednak kompatybilne pod względem działania systemu, obsługi procesów, pamięci, plików, wywołań systemowych itp. Daje ten sam interfejs programistyczny. UML może (a nawet powinien) być uruchamiany na systemie plików odwzorowanym w fizycznym pliku na dysku. Zaletą jest, że UML-a może uruchomić każdy, nie są do tego potrzebne uprawnienia root-a.
Podstawowe zastosowanie UML to oczywiście testowanie samego jądra, modułów, aplikacji. Dokonywanie zmian w prawdziwym środowisku zawsze wiąże się z niebezpieczeństwem destabilizacji pracy systemu, zawieszenia go, utraty danych itp. W przypadku UML-a nie ma tego niebezpieczeństwa. Możemy jedynie spowodować zawieszenie procesu emulatora lub zepsuć obraz systemu plików. W każdym wypadku jest to o wiele mniej bolesne, niż spowodowanie paniki jądra, restartowanie systemu, czekanie na naprawienie systemu plików itp.
UML jest dostarczany jako łatka na jądro, lub jako binarny pakiet RPM. Użytkownicy Debiana otrzymują go w dystrybucji. Ponieważ z reguły interesuje nas nie tylko samo uruchomienie UML-a ale także jego modyfikowanie i kompilowanie modułów, chcemy użyć źródeł.
Ściągamy teraz łatkę, której użyjemy do zapatchowania źródeł jądra. Łatki pobieramy ze strony user-mode-linux.sourceforge.net/dl-sf.html. Znajdujemy tam najnowszą łatkę odpowiadającą dokładnie wersji jądra, które będziemy kompilować. Następnie patchujemy nią źródła jądra. Większa część łatki obejmuje utworzenie w drzewie źródeł dodatkowego katalogu arch/um.
W skrócie, zakładając, że spakowane źródła jądra i łatka są bieżącym katalogu wykonujemy:
tar xjf linux-2.4.xx.tar.bz2 cd linux-2.4.xx bzcat ../uml-patch-2.4.xx.bz2 | patch -p1
Kolejny etap przypomina typową kompilację jądra. Robimy to jednak tak, jakbyśmy kompilowali jądro na szczególną architekturę um, tzn. przy każdym uruchomieniu make dodajemy ARCH=um. Nie można zapomnieć o tym przełączniku.
Najpierw konfigurujemy jądro swoim ulubionym narzędziem np.
make menuconfig ARCH=umMamy do wyboru o wiele mniej opcji, niż w standardowym jądrze. Niektóre z nich na które warto zwrócić uwagę, to:
Uruchamiamy teraz
make linux ARCH=umaby skompilować UML-owe jądro. Po jej zakończeniu otrzymamy plik wykonywalny linux. Jego rozmiar może wahać się od kilku do kilkudziesięciu MB w zależności od tego czy wybraliśmy debugowanie w konfiguracji jądra. Jest to plik, którym będziemy uruchamiać UML-a.
Jeżeli postanowiliśmy skompilować część jądra jako moduły, kompilujemy je dalej standardowo, tzn.
make modules ARCH=um make modules_install ARCH=umModuły zostaną zainstalowane w standardowym katalogu /lib/modules/2.4.xx-um. Po utworzeniu systemu plików którego będziemy używać z UML-em będziemy mogli je tam skopiować. Jeżeli nie mamy prawa zapisu do katalogu /lib możemy podać inny katalog w którym mają być zainstalowane moduły pisząc:
make modules_install INSTALL_MOD_PATH=inny_katalog ARCH=um
Możemy skompilować własne moduły tak, aby dało się je załadować w UML-u (moduły skompilowane pod standardowe jądra nie zadziałają). Najważniejsze jest poinformowanie gcc, że chcemy używać plików nagłówkowych z drzewa jądra UML. W tym celu najprościej wydobyć z pliku Makefile z katalogu ze źródłami zmienną CFLAGS:
make script='@echo $(CFLAGS)' ARCH=um > uml_flagsa następnie używać tych flag przy każdym użyciu gcc do kompilowania własnego modułu pod architekturę um, na przykład:
gcc -DMODULE `cat uml_flags` -c nasze_moduly.cOtrzymamy moduł w wersji zgodnej z wersją jądra um.
Przy instalowaniu możemy napotkać kilka problemów. Typowe, to:
| Błąd | Przyczyna | Rozwiązanie |
|---|---|---|
| różnorodne błędy w czasie kompilacji jądra | brak flagi ARCH=um | wyczyścić wszystko (make clean / mrproper) i dodać |
| błąd w ostatniej fazie kompilacji, przy linkowaniu plików vmlinuz.o, main.o | brak statycznej biblioteki glibc | doinstalować np. pakiet glibc-static-devel |
| błąd w jednym ze skryptów Makefile | shell sh ma problem z arytmetyka | zmienić na bash dopisując w arch/um/Makefile zmienną SHELL=/bin/bash |
| moduły kompilują się, ale nie można ich załadować: undefined symbol to_virt | typowy problem UML-a z jądrem 2.4.21 | upgrade jądra, lub dodanie do ksyms.c: EXPORT_SYMBOL(to_virt) |
Następną rzeczą, jaka jest nam potrzebna, gdy mamy już działające jądro UML, jest system plików, na którym będzie mogło ono wystartować (bootable root filesystem).
Ponieważ jądro UML jest uruchamiane jako zwykły program pod kontrolą systemu macierzystego (host system), więc dotyczą go wszystkie ograniczenia nałożone na użytkownika. W szczególności jądro nie posiada swobodnego dostępu do całego dysku, jak i bezpośredniego dostępu do sprzętu. Aby stworzyć iluzję pełnej kontroli nad komputerem, UML symuluje działanie na wirtualnym komputerze, udostępniając wirtualne urządzenia. System plików jest odzwierciedlany jako fizyczny plik na dysku gospodarza, co gwarantuje (o ile tylko użytkownik ma odpowiednie prawa do tego pliku), że UML może wykonywać na nim dowolne operacje, jak na normalnym systemie plików.
Skąd zatem zdobyć odpowiedni uruchamialny system plików?
Najprostszym chyba wyjściem jest ściągnięcie z internetu gotowego obrazu
systemu plików (filesystem image). Na stronie domowej User Mode Linux-a
(http://user-mode-linux.sourceforge.net/dl-sf.html)
jest udostępnionych wiele systemów plików,
zawierających instalacje większości głównych dystrybucji Linuksa.
Ich rozmiary wahają się od 15 do 150 MB (oczywiście w postaci skompresowanej),
a po rozpakowaniu zajmują na dysku zazwyczaj kilkaset MB.
I możemy już normalnie korzystać z UMLa. Uruchamiamy go, wywołując po prostu polecenie
linuxwraz z parametrami służącymi do konfiguracji wirtualnego komputera oraz jego związków z macierzystym systemem. Nie będziemy tu opisywać dokładnie wszystkich możliwych parametrów wywołania, ale tylko te najważniejsze. Pełną ich listę wraz z opisem działania można znaleźć na stronie UML-a (http://user-mode-linux.sourceforge.net/switches.html).
UML może działać w dwóch trybach: trybie tt (od ang. tracing thread) i w trybie skas (od. ang. seperate kernel adress space). Tryb tt jest starszym trybem, ale to on, mimo pewnych wad będzie nas interesował, bo wtedy debuggowanie jest możliwe.
Ogolnie powstaje pytanie w jaki sposób uruchamiać procesy tak, aby działały one pod kontrolą
naszego jądra UML i nie miały kontaktu ze światem zewnętrznym, tj. z jądrem
hosta. W trybie tt podstawową metodą stosowaną w UML jest użycie funkcji systemowej ptrace.
Przypomnijmy najpierw jej działanie (patrz man 2 ptrace). Funkcja ta dostarcza
procesom możliwość kontroli pracy swoich potomków, w szczególności pozwala na
przechwytywanie ich wywołań systemowych i otrzymywanie informacji o sygnałach dostarczanych
do nich. W każdej chwili kiedy proces - dziecko wywołuje funkcję systemową może zostać
wstrzymany a informacja o tym fakcie zostać przekazana śledzącemu procesowi - rodzicowi.
Każdemu procesowi, który "uruchamiamy" pod UML odpowiada rzeczywisty proces uruchomiony pod jądrem hosta, jednak kontrolowany całkowicie przez UML. Aby się o tym przekonać można np. wykonać polecenie ps. W wyniku otrzymamy mnóstwo procesów o nazwie linux. Ponadto przy starcie UML tworzy specjalny proces - wątek śledzący, którego zadaniem jest wirtualizacja wywołań systemowych innych procesów. W tym celu korzysta on oczywiście z funkcji ptrace.
Dokładniej przebiega to następująco:
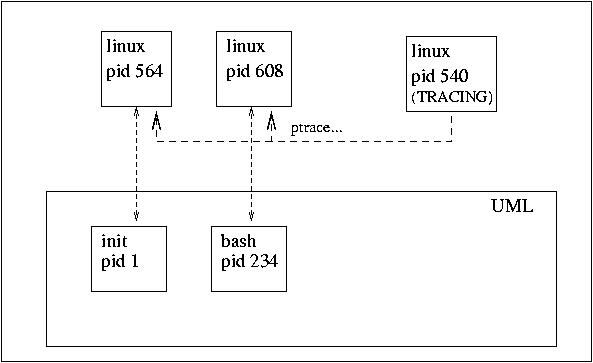
Tryb tt ma swoje wady:
W celu rozwiązanie tych problemów wprowadzono tryb skas, polegający na rozdzieleniu jądra UML od procesów użytkownika UML w kwestii przestrzeni adresowej. W tym trybie UML składa się z punktu widzenia tylko z czterech procesów:
Aby uruchomić UMLa w trybie skas należy ściągnąć odpowiednią łatę. Nie mam ambicji tutaj opisać tego trybu dokładnie, bo to tylko dygresja od tematu tej prezentacji. Po szczegóły odsyłan na stronę temu poświęconą.
Po dłuższej dygresji, jak już wiemy, czym się je UML, to przejdźmy do rzeczy.
Widać, że aż się prosi, aby użyć UMLa do debuggowania jądra. Nie tylko dlatego, że uruchamianie rozwojowych wersji bezpośrednio na naszym komputerze może być niebezpieczne dla naszych danych. Także dla tego, że uruchomiając jądro w UMLu możemy do jego odpluskwiania użyć zwykłego gdb. Przedstawię najpierw przykładową sesję.
Aby odpluswiać jądro UML w gdb należy przede wszystkim pamiętać o włączeniu opcji CONFIG_DEBUGSYM i CONFIG_PT_PROXY podczas konfiguracji. Spowoduje to skompilowanie jąda z opcją -g i włączenie ptrace proxy.
Gdy mamy już takie jądro możdemy je uruchomić pod kontrolą gdb w następujący sposób
linux debug
Jądro njpierw wyśle kilka komend i zatrzyna się na start_kernel, co wygląda mniej więcej tak:
GNU gdb 4.17.0.11 with Linux support Copyright 1998 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i386-redhat-linux"... (gdb) att 1 Attaching to program `/home/dike/linux/2.3.26/um/linux', Pid 1 0x1009f791 in __kill () (gdb) b start_kernel Breakpoint 1 at 0x100ddf83: file init/main.c, line 515. (gdb) c Continuing. Breakpoint 1, start_kernel () at init/main.c:515 515 printk(linux_banner); (gdb)Od tego momentu możemy już sterować gdb, np. tak:
(gdb) n
516 setup_arch(&command_line);
(gdb)
517 printk("Kernel command line: %s\n", saved_command_line);
(gdb)
518 parse_options(command_line);
(gdb)
519 trap_init();
(gdb)
520 init_IRQ();
(gdb)
521 sched_init();
(gdb)
522 time_init();
(gdb)
523 softirq_init();
(gdb)
530 console_init();
(gdb) c
Continuing.
-- jak już się znudziliśmy kazaliśmy kontynuować. Gdy skończy się bootowanie możemy sprawdzić, co się dzieje przerywając poprzez ctr+C
Program received signal SIGINT, Interrupt. 0x100a4bc1 in __libc_nanosleep () (gdb) bt #0 0x100a4bc1 in __libc_nanosleep () #1 0x100a4b7d in __sleep (seconds=10) at ../sysdeps/unix/sysv/linux/sleep.c:78 #2 0x10095fbf in do_idle () at process_kern.c:424 #3 0x10096052 in cpu_idle () at process_kern.c:450 #4 0x100de0a4 in start_kernel () at init/main.c:593 #5 0x10098df2 in start_kernel_proc (unused=0x0) at um_arch.c:72 #6 0x1009858f in signal_tramp (arg=0x10098db8) at trap_user.c:50 (gdb)Jak widać system był zajęty ,,nic nie robieniem''. To może teraz postwimy breakpointa w scheluler i w ten sposób złapiemy sobie najbliższą zmienę kontekstu:
(gdb) b schedule Breakpoint 2 at 0x10004acd: file sched.c, line 496. (gdb) c Continuing. Breakpoint 2, schedule () at sched.c:496 496 if (!current->active_mm) BUG(); (gdb) bt #0 schedule () at sched.c:496 #1 0x10095fb3 in do_idle () at process_kern.c:421 #2 0x10096052 in cpu_idle () at process_kern.c:450 #3 0x100de0a4 in start_kernel () at init/main.c:593 #4 0x10098df2 in start_kernel_proc (unused=0x0) at um_arch.c:72 #5 0x1009858f in signal_tramp (arg=0x10098db8) at trap_user.c:50No i jest.
Możne też deguggować moduły, też za pomocą wsparcia gdb dla debuggowania kodu dynamicznie ładowanego. Ale jest to dość skomplikowane, więc jakiś dobry człowiek napisał skrypt umlgdb do ściągnięcia ze strony umla. W tym skrypcie trzeba wstawić swój moduł do listy ścieżek. Należy go po prostu uruchomić, a on mówi, co zrobić:
******** GDB pid is 21903 ******** Start UML as: ./linuxI od tego momentu debuggujemy normalnie. Gdy zrobimy insmoda, zostanie to dostrzeżone i zobaczymy coś w tym stylu:debug gdb-pid=21903 GNU gdb 5.0rh-5 Red Hat Linux 7.1 Copyright 2001 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i386-redhat-linux"... (gdb) b sys_init_module Breakpoint 1 at 0xa0011923: file module.c, line 349. (gdb) att 1 Attaching to program: /home/jdike/linux/2.4/um/./linux, process 1 0xa00f4221 in __kill () (UML gdb) c Continuing. (UML gdb)
*** Module hostfs loaded ***
Breakpoint 1, sys_init_module (name_user=0x805abb0 "hostfs",
mod_user=0x8070e00) at module.c:349
349 char *name, *n_name, *name_tmp = NULL;
(UML gdb) finish
Run till exit from #0 sys_init_module (name_user=0x805abb0 "hostfs",
mod_user=0x8070e00) at module.c:349
0xa00e2e23 in execute_syscall (r=0xa8140284) at syscall_kern.c:411
411 else res = EXECUTE_SYSCALL(syscall, regs);
Value returned is $1 = 0
(UML gdb)
p/x (int)module_list + module_list->size_of_struct
$2 = 0xa9021054
(UML gdb) symbol-file ./linux
Load new symbol table from "./linux"? (y or n) y
Reading symbols from ./linux...
done.
(UML gdb)
add-symbol-file /home/jdike/linux/2.4/um/arch/um/fs/hostfs/hostfs.o 0xa9021054
add symbol table from file "/home/jdike/linux/2.4/um/arch/um/fs/hostfs/hostfs.o" at
.text_addr = 0xa9021054
(y or n) y
Reading symbols from /home/jdike/linux/2.4/um/arch/um/fs/hostfs/hostfs.o...
done.
(UML gdb) p *module_list
$1 = {size_of_struct = 84, next = 0xa0178720, name = 0xa9022de0 "hostfs",
size = 9016, uc = {usecount = {counter = 0}, pad = 0}, flags = 1,
nsyms = 57, ndeps = 0, syms = 0xa9023170, deps = 0x0, refs = 0x0,
init = 0xa90221f0 , cleanup = 0xa902222c ,
ex_table_start = 0x0, ex_table_end = 0x0, persist_start = 0x0,
persist_end = 0x0, can_unload = 0, runsize = 0, kallsyms_start = 0x0,
kallsyms_end = 0x0,
archdata_start = 0x1b855 ,
archdata_end = 0xe5890000 ,
kernel_data = 0xf689c35d }
>> Finished loading symbols for hostfs ...