Narzędzia do wykrywania wycieków pamięci i profilowania kodu
Autor: Michał Korch
1. Bugi związane z pamięcią
1.1 Charakterystyka
1.2 MEMWATCH
1.3 YAMD
1.4 Electric Fence
1.5 Narzędzia memcheck i adrcheck w Valgrindzie
1.5 Inne narzędzia
2. Profilowanie kodu
2.1 Co to i po co to?
2.2 Metody programistyczne
2.3 Urządzenie prof
2.4 Narzędzie gprof
2.5 gcov
2.6 PAPI
2.7 DynaProf
2.8 Inne narzędzia
Język C daje nam duże możliwość w pracy z pamięcią. Jednak taka wolność powoduje możliwość dość łatwego popełnienia błędów związanych z
pamięcią. Najczęściej są to:
- wycieki pamięci (gdy pamięć zaalokowana malloc nie jest potem zwalniana przez free), wielokrotne lub błędne zwalnianie pamięci,
- używanie niezaalokowanej pamięci.
MEMWATCH jest open-source'owym narzędziem napisanym przez Johan Lindha do wykrywania błędów związanych z alokazją i zwalnianiem pamięcią
dla C. Można go sciągnąć
z tej strony.
Użycie polega po prostu na dodaniu pliku nagłówkowego do kodu testowanego programu i zdefiniowaniu MEMWATCH w poleceniu gcc. Powstanie
wtedy plik z logami wykrytych podwójnych i błędnych zwolnień oraz o niezwolnionej pamięci.
Przykład użycia: chemy przetestować natępujący kod (includujemy więc odpowiedni plik nagłówkowy):
#include < stdlib.h>
#include < stdio.h>
#include "memwatch.h"
int main(void)
{
char *ptr1;
char *ptr2;
ptr1 = malloc(512);
ptr2 = malloc(512);
ptr2 = ptr1;
free(ptr2);
free(ptr1);
}
Kompilujemy:
gcc -DMEMWATCH -DMW_STDIO test1.c memwatch.c -o test1
I uruchamiamy:
./test1
I dostajemy następujący plik memwatch.log:
============= MEMWATCH 2.71 Copyright (C) 1992-1999 Johan Lindh =============
Started at Fri Jan 6 17:01:16 2006
Modes: __STDC__ 32-bit mwDWORD==(unsigned long)
mwROUNDALLOC==4 sizeof(mwData)==32 mwDataSize==32
double-free: <4> test1.c(15), 0x91a56b4 was freed from test1.c(14)
Stopped at Fri Jan 6 17:01:16 2006
unfreed: <2> test1.c(11), 512 bytes at 0x91a58e4 {FE FE FE FE FE FE FE FE FE FE FE FE FE FE FE FE ................}
Memory usage statistics (global):
N)umber of allocations made: 2
L)argest memory usage : 1024
T)otal of all alloc() calls: 1024
U)nfreed bytes totals : 512
Jak widać MEMWATCH wypisuje nawet numer linii, w której problem występuje. Na końcu podaje statystykę.
Jak to działa? Za pomocą preprocesora C podmienia nasze wywołania funkcji związanych z alokowaniem i zwalnianiem pamięci swoimi, w których
zapamiętuje wszystkie alokacje i zwolnienia. I na tej podstawie potem generuje raport.
YAMD (skrót od Yet Another Memory Debugger) to kolejne narzędzie (stworzone przez Nate'a Eldredge'a) do wykrywania błędów związanych z pamięcią. Ze względu na operowanie na dość
niskopoziomowych funkcjach działa zarówno dla C, jak i dla C++ wykrywając wszystkie operacje na pamięci. Można go ściągnąć ze tej strony.
Narzędzie należy najpierw zainsatlować: należy rozpakować, zmake'ować i zainstalować (make install).
Jak skorzystać z tego narzędzia? Powiedzmy, że chcemy przetestować następujący program:
#include < stdlib.h>
#include < stdio.h>
int main(void)
{
char *ptr1;
char *ptr2;
char *chptr;
int i = 1;
ptr1 = malloc(512);
ptr2 = malloc(512);
ptr2 = ptr1;
free(ptr2);
free(ptr1);
chptr = (char *)malloc(512);
for (i; i <= 512; i++) {
chptr[i] = 'S';
}
free(chptr);
}
Wobec tego kopilujemy nasz program z opcją -g:
gcc -g test2.c -o test2
Przed uruchomieniem naszego testu należy ustawić pewne zmienne środowiskowe, ale z przyjemnością zrobi to za nas skrypt yamd-run od razu
opalając nasz program. Wystarczy więc wpisać:
yamd-run ./test2
W odpowiedzi dostaniemy:
YAMD version 0.32
Starting run: ./test2
Executable: /home/michal/yamd-0.32/test2
Virtual program size is 1528 K
Time is Fri Jan 6 18:26:15 2006
default_alignment = 1
min_log_level = 1
repair_corrupted = 0
die_on_corrupted = 1
check_front = 0
INFO: Normal allocation of this block
Address 0xb7ff2e00, size 512
Allocated by malloc at
/lib/tls/libc.so.6(malloc+0x35)[0x410045]
./test2[0x8048b48]
/lib/tls/libc.so.6(__libc_start_main+0xe4)[0x3c4ad4]
./test2[0x8048a79]
INFO: Normal allocation of this block
Address 0xb7fefe00, size 512
Allocated by malloc at
/lib/tls/libc.so.6(malloc+0x35)[0x410045]
./test2[0x8048b5b]
/lib/tls/libc.so.6(__libc_start_main+0xe4)[0x3c4ad4]
./test2[0x8048a79]
INFO: Normal deallocation of this block
Address 0xb7ff2e00, size 512
Allocated by malloc at
/lib/tls/libc.so.6(malloc+0x35)[0x410045]
./test2[0x8048b48]
/lib/tls/libc.so.6(__libc_start_main+0xe4)[0x3c4ad4]
./test2[0x8048a79]
Freed by free at
/lib/tls/libc.so.6(__libc_free+0x35)[0x4126e5]
./test2[0x8048b72]
/lib/tls/libc.so.6(__libc_start_main+0xe4)[0x3c4ad4]
./test2[0x8048a79]
ERROR: Multiple freeing
At
/lib/tls/libc.so.6(__libc_free+0x35)[0x4126e5]
./test2[0x8048b80]
/lib/tls/libc.so.6(__libc_start_main+0xe4)[0x3c4ad4]
./test2[0x8048a79]
free of pointer already freed
Address 0xb7ff2e00, size 512
Allocated by malloc at
/lib/tls/libc.so.6(malloc+0x35)[0x410045]
./test2[0x8048b48]
/lib/tls/libc.so.6(__libc_start_main+0xe4)[0x3c4ad4]
./test2[0x8048a79]
Freed by free at
/lib/tls/libc.so.6(__libc_free+0x35)[0x4126e5]
./test2[0x8048b72]
/lib/tls/libc.so.6(__libc_start_main+0xe4)[0x3c4ad4]
./test2[0x8048a79]
INFO: Normal allocation of this block
Address 0xb7fece00, size 512
Allocated by malloc at
/lib/tls/libc.so.6(malloc+0x35)[0x410045]
./test2[0x8048b90]
/lib/tls/libc.so.6(__libc_start_main+0xe4)[0x3c4ad4]
./test2[0x8048a79]
ERROR: Crash
./test2[0x8048ba5]
/lib/tls/libc.so.6(__libc_start_main+0xe4)[0x3c4ad4]
./test2[0x8048a79]
Tried to write address 0xb7fed000
Seems to be part of this block:
Address 0xb7fece00, size 512
Allocated by malloc at
/lib/tls/libc.so.6(malloc+0x35)[0x410045]
./test2[0x8048b90]
/lib/tls/libc.so.6(__libc_start_main+0xe4)[0x3c4ad4]
./test2[0x8048a79]
Address in question is at offset 512 (out of bounds)
Will dump core after checking heap.
Inny typ komunikatu, który może się pojawić to niezwolnienie pamięci:
WARNING: Memory leak
Address 0x40028e00, size 512
WARNING: Total memory leaks:
1 unfreed allocations totaling 512 bytes
Pełna postać yamd-run, to
yamd-run [opcje] < program> [argumenty]
Opcje można znaleźć w pliku readme. Z przydatniejszych można wymienić -o nazwapliku, która powoduje wypisane spostżerzeń yamda do pliku.
Electric Fence to biblioteka do wykrywania błędów związanych z pamięcią napisana przez Bruce'a Perensa. Wchodzi ona w skład wielu
dystrybucji Linuxa. Ostatnimi czasy (a konkretnie w czasie tworzenia tej prezentacji) strona twórcy projektu i samego
projektu jest
niedostępna.
Electric Fence wykrywa zarówno czytanie, jak i pisanie poza zaalokowanym obszarem pamięci. Można spokojnie używać go razem z gdb, co
pozwala zidentyfikować niedziałającą linię. Ogólna idea polega na tym, że Electric Fence za każdym zaalokowanym obszarem alokuje chroniony obszar
pamięci. To samo robi na obszarach zwolnionych funkcją free.
Jak się z tego korzysta? Wystarczy zlinkować swój program z biblioteką libefence.a. Z reguły wiąże się to po prostu z dodaniem opcji
-lefence. Jeśli to nie zadaziała trzeba linkerowi podać pełną ścieżkę. Powoduje to wykorzystanie funkcji z tej biblioteki zamiast ze
standardowej biblioteki:
#include < stdlib.h>
void * malloc (size_t size);
void free (void *ptr);
void * realloc (void *ptr, size_t size);
void * calloc (size_t nelem, size_t elsize);
void * memalign (size_t alignment, size_t size);
void * valloc (size_t size);
extern int EF_ALIGNMENT;
extern int EF_PROTECT_BELOW;
extern int EF_PROTECT_FREE;
extern int EF_ALLOW_MALLOC_0;
extern int EF_FILL;
Tak zlinkowany program wystarczy uruchomić. W przypadku błędów dostaniemy odpowiedni komunikat, np. taki:
Electric Fence 2.2.0 Copyright (C) 1987-1999 Bruce Perens
ElectricFence Aborting: free(b7ee5e00): address not from malloc().
Ale możemy także uruchomić nasz program pod swoim ulubionym debuggerem i zlokalizować i poprawić błędy.
Całość można konfigurować definiując odpowidnio zmienne środowiskowe:
| EF_ALIGNMENT | Ustala do ilu bajtów dopełnia alokowaną pamięć. Domyślnie do sizeof(int) |
| EF_PROTECT_BELOW | Ustawione na 0 lub 1 odpowiedio wyłącza i włącza zabezpieczenie też pamięć
przed zaalokowaną pamięcią |
| EF_PROTECT_FREE | Ustawione na 0 lub 1 odpowiedio wyłącza i włącza zabezpieczenie pamięci
zwolnionej |
| EF_ALLOW_MALLOC_0 | Ustawione na 0 lub 1 odpowiedio wyłącza i włącza tolerancję dla wywołań
malloca na 0 bajtów. |
| E_FILL | Jeśli jest ustawione na wartość z pomiędzy 0 i 255 każdy bajt alokowanej pamięci
jest ustawiny na tę wartość. |
malloc w Electric Fence działa tak, że alokuje dwie lub więcej strony, z tym, że ostatnią z nich czyni niedostępną, zwracając taki
wskaźnik, żeby pierwszy bajt za żadanym rozmiarem wypadał na początek niedostępnej strony. Wiążą się z tym pewne problemy. Niekiedy zdarza
się, że alokuje się pamięć rozmiaru nie będącego wielokrotnością słowa i oczekuje się, że odpowiednie odwołania wielkości słowa będą działać.
Jeżeli tak ma być to Electric Fence musi zaalokować odpowiednio więcej, czym steruje EF_ALIGNMENT. Aby sprawdzać dokładnie należy więc ustaić
tę zmienną na zero, ale czasem jest to niemożliwe ze względu na biblioteki, z których korzystamy.
Ogólny schemat debuggowania przy użyciu Electric Fence'a jest taki:
- zlinkować program z biblioteką Electric Fence,
- uruchomić program pod debuggerem, poprawić błędy,
- włączyć EF_PROTECT_BELOW,
- uruchomić program pod debuggerem, poprawić błędy,
- ewentualnie ustawić EF_ALIGMENT na 0 i powtórzyć procedurę.
Więcej szczegółów na stronie efence podręcznika man.

Valgrind to kolejne narzędzie zorientowane przede wszystkim na kompleksową kontrolę błędów związanych z pamięcią, ale nie tylko. Można o
nim dokładnie poczytać i ściągnąć ze tej strony. W tej prezentacji jest tylko krótkie wprowadzenie
Valgrind to zbiór kilku narzędzi. Nas chwilowo będą interesowały dwa -- memcheck i adrcheck. Obydwa dokonują kompleksowej kontroli programu
jeżeli chodzi o pamięć, ale memcheck dodatkowo sprawdza, czy nigdzie nie czyta się z niezainicjowanych komórek pamięci, za to adrcheck jest
dużo szybszy.
Po ściągnięciu Valgrinda należy go zainstalować, standardowo, to znaczy kolejno uruchomić:
./configure
make
make install
Aby sprawdzić program wystarczy napisać:
valgrind --tool=nazwa_narzędzia program [argumenty]
Valgrind raportuje błędy w dość przyjazny sposób, np. po uruchomieniu testu użytego wcześniej, dotajemy:
==12926== Memcheck, a memory error detector.
==12926== Copyright (C) 2002-2005, and GNU GPL'd, by Julian Seward et al.
==12926== Using LibVEX rev 1471, a library for dynamic binary translation.
==12926== Copyright (C) 2004-2005, and GNU GPL'd, by OpenWorks LLP.
==12926== Using valgrind-3.1.0, a dynamic binary instrumentation framework.
==12926== Copyright (C) 2000-2005, and GNU GPL'd, by Julian Seward et al.
==12926== For more details, rerun with: -v
==12926==
==12926== My PID = 12926, parent PID = 5295. Prog and args are:
==12926== ./test2
==12926==
==12926== Invalid free() / delete / delete[]
==12926== at 0x4003F62: free (vg_replace_malloc.c:235)
==12926== by 0x8048403: main (in /home/michal/valgrind-3.1.0/test2)
==12926== Address 0x401F028 is 0 bytes inside a block of size 512 free'd
==12926== at 0x4003F62: free (vg_replace_malloc.c:235)
==12926== by 0x80483F5: main (in /home/michal/valgrind-3.1.0/test2)
==12926==
==12926== Invalid write of size 1
==12926== at 0x8048429: main (in /home/michal/valgrind-3.1.0/test2)
==12926== Address 0x401F688 is 0 bytes after a block of size 512 alloc'd
==12926== at 0x400346D: malloc (vg_replace_malloc.c:149)
==12926== by 0x8048413: main (in /home/michal/valgrind-3.1.0/test2)
==12926==
==12926== ERROR SUMMARY: 2 errors from 2 contexts (suppressed: 12 from 1)
==12926== malloc/free: in use at exit: 512 bytes in 1 blocks.
==12926== malloc/free: 3 allocs, 3 frees, 1,536 bytes allocated.
==12926== For counts of detected errors, rerun with: -v
==12926== searching for pointers to 1 not-freed blocks.
==12926== checked 42,548 bytes.
==12926==
==12926== LEAK SUMMARY:
==12926== definitely lost: 512 bytes in 1 blocks.
==12926== possibly lost: 0 bytes in 0 blocks.
==12926== still reachable: 0 bytes in 0 blocks.
==12926== suppressed: 0 bytes in 0 blocks.
==12926== Use --leak-check=full to see details of leaked memory.
Ta prezentacja byłaby starsznie długa, gdyby porządnie opisać wszystkie narzędzia. Kolejne wymieniam, więc tylko z nazwy i linków:
Profilowanie kodu to badanie jak często który kawałek kodu jest wykonywany. Dzięki takiej wiedzy, możemy zdecydować optymalizacji i
udoskonalaniu wydajności której części kodu powinniśmy poświęcić najwięcej czasu. Przy skomplikowanych programach, z wieloma modułami, sprawa
nie jest wcale prosta.
Oczywiście można próbować zrobić to samemu. Jest to dobry pomysł np. do profilowania jądra. Są dwie popularne metody:
Pierwsza metoda jest bajecznie nieskomplikowana. Po prostu, jeśli chcemy policzyć liczbę wykonań danego kawałka kodu dodajemy licznik, np.
tak:
#ifdef PROFILING
counter++;
#endif
i na końcu gdzieś sobie wartość licznika wypisujemy.
druga metoda pozwala na stwierdzenie, nie tylko jak często był wykonywany kawałek kodu, ale też średnio ile czasu. Służy głównie
sprawdzaniu sekcji krytycznych -- pozwala bowiem stwierdzić też, jak często sekcja była dostępna. Można to zrobić np. używając następujących
funkcji:
extern struct timeval time;
boolean_t mymutex_try(mymutex_t *lock) {
int ret;
ret=mutex_try(lock->mutex);
if (ret) {
lock->tryfailcount++;
}
return ret;
}
void mymutex_lock(mymutex_t *lock) {
if (!(mymutex_try(lock))) {
mutex_lock(lock->mutex);
}
lock->starttime = time.tv_sec;
}
void mymutex_unlock(mymutex_t *lock) {
lock->lockheldtime += (time.tv_sec - lock->starttime);
lock->heldcount++;
mutex_unlock(lock->mutex);
}
Oczywiście w przypadku, gdy celowo stawiamy semafor tylko po to, by profilować fragment kodu, może to wpłynąć na działanie całego programu
i wyniki mogą być niewiarygodne. Na szczęście to właśnie sekcje krytyczne są wąskimi gardłami programów.
profile jest urządzeniem, które włącza się dodając napis profile=1 do linii jądra w boot loaderze. Można z niego po prostu czytać
najprostrsze informacje o czasie działania poszczególnych funkcji. Narzędzie readprofile robi to za nas:
$readprofile
2 stext 0.0500
514867 default_idle 12871.6750
1 copy_thread 0.0071
1 restore_sigcontext 0.0030
2 system_call 0.0312
2 handle_IRQ_event 0.0227
13 do_page_fault 0.0111
1 schedule 0.0012
1 wake_up_process 0.0132
1 copy_mm 0.0014
prof jest urządzeniem służącym do profilowania modułów i dostarcza dwupoziomową strukturę katalogową. Jego działanie opisuje
odpowiednia strona man. Jest załączony do niektórych dystrybucji. Na pierwszym poziomie mamy plik kontrolny ctl i zero lub więcej
ponumerowanych katalogów, każdy związany z jakimś modułem, który profilujemy. Do pliku ctl można pisać następujące rzeczy:
| module nazwa | dodaje moduł do profilowania |
| start | rozpoczyna profilowanie dodanych modułów, a gdy ich nie ma, to wszystkich modułów
jądra, poprzez próbkowanie |
| startcp | rozpoczyna profilowanie pokrywające (ang. coverage), to znaczy każda wywoływana
funkcja w załączonych modułach jest liczona |
| startmp | jak wyżej, ale profilowanie pamięci |
| stop | zatrzymuje profilowanie |
| end | zatrzymuje profilowanie, zwalnia pamięć modułów i wyłącza je spod profilowania |
| interval i | zmiena odstępy między próbkowaniem na i ms. Domyślnie 100 ms. |
Katalog dotyczący konkretnego modułu zawiera pliki:
| name | z którego można przeczytać nazwę modułu |
| path | z którego można przeczytać ścieżkę do modułu |
| pctl | nieużywany |
| histogram | z którego można przeczytać wyliczoną statystykę |
gprof jest narzędziem załączanym do większości destrybucji Linuxa. Jego działanie opisuje odpowiednia strona man.
Aby użyć gprofa trzeba skompilować swój program z opcjami -pg i -g i uruchomić go. Powstanie wtedy plik gmon.out z profilami. Aby go
zinterpretować wystarczy uruchomić gprofa:
gprof nazwa_pliku_wykonywalnego
Dotatkowe opcje (np. definiujące co tak na prawdę gprof ma wypisać) są wypisane na odpowiedniej stronie man. Niektóre z nich wymieniam
niżej.
Opcja -p powoduje wypisanie t.zw. flat profile, czyli sum czasów, które program spędził na wykonaniu konkretnych funkcji -- nie zostaną
wypisane funkcje nigdy nie wołane, chyba że dodamy jeszcze opcję -z. Jeżeli, jakaś fukcja nie była skompilowana do profilowania i nie działała
wystarczająco długo, będzie traktowana jak funkja nigdy nie wołana.
Oto przykładowy flat profile:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls ms/call ms/call name
33.34 0.02 0.02 7208 0.00 0.00 open
16.67 0.03 0.01 244 0.04 0.12 offtime
16.67 0.04 0.01 8 1.25 1.25 memccpy
16.67 0.05 0.01 7 1.43 1.43 write
16.67 0.06 0.01 mcount
0.00 0.06 0.00 236 0.00 0.00 tzset
0.00 0.06 0.00 192 0.00 0.00 tolower
0.00 0.06 0.00 47 0.00 0.00 strlen
0.00 0.06 0.00 45 0.00 0.00 strchr
0.00 0.06 0.00 1 0.00 50.00 main
0.00 0.06 0.00 1 0.00 0.00 memcpy
0.00 0.06 0.00 1 0.00 10.11 print
0.00 0.06 0.00 1 0.00 0.00 profil
0.00 0.06 0.00 1 0.00 50.00 report
...
Funkcje mcount i profil to funkcje potrzebne do profilowania, pojawiają się w każdeym flat profilu i pokazują ile czasu zużyto na
profilowanie. Na górze jest wypisany interwał próbkowania, tutaj 0.01 s. Wartości czasów są więc mierzone z taką dokładnością. Cumulative
seconds to czas wykonywania tej funkcji i wszystkich wyżej, a self seconds to czas bez podwywołań. % time mówi ile procent czasu całego
wykonania zajęło wykonywanie danej funkcji (czas self). To, że funkcja ma self seconds równe 0.00 oznacza, że nigdy nie została złapana
próbkowaniem, ale była wołana. Pole calls mówi ile razy wołano daną funkcję. Jeżeli funkcja była profilowana pola self ms/ call i total ms /
call to średnia liczba milisekund spędzona na wywołanie tej funkcji odpowiednio bez czasu podwywołań i z czasem podwywołań. Pole name to
oczywiście nazwa funkcji
Opcja -q powoduje wypisanie t.zw. call graph. Mówi on jak wiele czasu spędziła funkcja na siebie i jak wiele czasu zajęły jej podwywołania.
Przykładowo wygląda to tak:
granularity: each sample hit covers 2 byte(s) for 20.00% of 0.05 seconds
index % time self children called name
< spontaneous>
[1] 100.0 0.00 0.05 start [1]
0.00 0.05 1/1 main [2]
0.00 0.00 1/2 on_exit [28]
0.00 0.00 1/1 exit [59]
-----------------------------------------------
0.00 0.05 1/1 start [1]
[2] 100.0 0.00 0.05 1 main [2]
0.00 0.05 1/1 report [3]
-----------------------------------------------
0.00 0.05 1/1 main [2]
[3] 100.0 0.00 0.05 1 report [3]
0.00 0.03 8/8 timelocal [6]
0.00 0.01 1/1 print [9]
0.00 0.01 9/9 fgets [12]
0.00 0.00 12/34 strncmp < cycle 1> [40]
0.00 0.00 8/8 lookup [20]
0.00 0.00 1/1 fopen [21]
0.00 0.00 8/8 chewtime [24]
0.00 0.00 8/16 skipspace [44]
-----------------------------------------------
[4] 59.8 0.01 0.02 8+472 < cycle 2 as a whole> [4]
0.01 0.02 244+260 offtime < cycle 2> [7]
0.00 0.00 236+1 tzset < cycle 2> [26]
-----------------------------------------------
Główna linia każdego wpisu zaczyna się od numeru (index). Kolejne mówią o podwywołaniach. self to czas jaki został spędzony na wykonanie tej
funkcji bez podwywołań, zaś children to czas podwywołań. Called to liczba wywołań tej funkcji. Jeżeli są dwie liczby oddzielone + to znaczy,
że funkcja wołała się rekurencyjnie i wtedy pierwsza liczba to liczba nierekurencyjnych wywołań, a druga to liczba rekurencyjnych.
Linie powyżej to linie funkcji, z której została wywołana badana funkcja. W called jest zapisane ile razy dana funkcja była wołana z
opisywanej funkcji nadrzędnej i ile w sumie była wołana nierekurencyjnie.
Linie poniżej to linie podwywołań.
Istnieje wiele innych narzędzi bardzo podobnych do gprofa.
gcov pozwala na wypisanie ile razy została użyta każda linia kodu.Aby go użyć kompilujemy program z opcjami -fprofile-arcs -ftest-coverage.
Uruchomienie programu powoduje stworzenie informacji w plikach ".da" dla każdego pliku skompilowanego przy użyciu opisanych opcji. Wtedy
wystarczy zapuścić gcov dla naszego kodu źródłowego:
gcov tescik.c
I dostaniemy następujący plik tescik.c.gcov:
main()
{
1 int i, total;
1 total = 0;
11 for (i = 0; i < 10; i++)
10 total += i;
1 if (total != 45)
###### printf ("Failure\n");
else
1 printf ("Success\n");
1 }
PAPI(Performance Application Programing Interface) to dość duże narzędzie a właściwie duży projekt, którego sedno stanowi dostarczenie
interfejsu (do C i Fortrana) do obsługi różnych liczników. Jest dostępna strona tego projektu
.PAPI dysponuje wersjami na różne platformy i systemy operacyjne. Zajmiemy się tutaj linuxową wersją.
PAPI zapewnie trzy interfejsy:
- low-level, dla wymagających, zaawansowanych użytkowników,
- high-level,
- graficzny do wizualizacji.
PAPI jest zaimplementowany według następującego schematu:
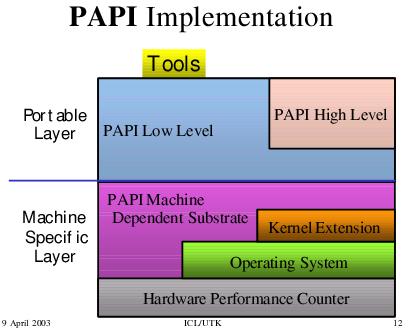
Warstwa portable to rzeczy niezależne od platformy, zaś warstawa specyficzna dla maszyny to elementy projektu zależne od platformy. Ta warstwa
daje niezależny od platformy interfejs dla strukrur danych i właściwości zależnych od platformy, korzystając (w zależności od potrzeby i
dostępności) z własnego rozszerzenia do jądra, samych funkcji systemowych jądra lub za pomocą kodu assemblerowego dostaje się do liczników
wydajności hardware'u.
Instalacja przebiega następująco:
PAPI jest napisany w C, ale udostępnia interfejsy zarówno dla C jak i dla Fortrana.
PAPI w pliku papiStdEventsDefs.h definiuje zbiór najbardziej wpływających na wydajność zdarzeń. To tak zwane zdarzenia predefiniowane
(ang. preset). Zdarzenia te są mapowane na rzeczywiste
zdarzenia (po ang. nazywa się to native) dla danej platformy. Zdarzenia to wystąpienia określonych sygnałów związanych z funkcjami procesora.
Każdy procesor ma pewną liczbę rzeczywistych zdarzeń dla niego.
Rzeczywiste zdarzenia obejmują wszystkie zdarzenia zliczane przez CPU, czyli zależne od platformy. PAPI zapewnia dostęp do tych zadrzeń przez low-level interface
(interfejs jest niezależny od platformy).
Zdarzenia predefiniowane też z reguły są zliczane przez CPU zapewniające liczniki wydajności, więc z reguły mapowanie zdarzeń
predefiniowanych na rzeczywiste jest proste. Zdarzenia te zapewniają informacje o wykorzystaniu hierarchii pamięci, przetwarzania potokowego,
dają dostęp do licznika instrukcji itp. Niekiedy są one jakąś kombinacją zdarzeń rzeczywistych.
Oto tabela z wszystkim predefinowanymi zdarzeniami ze strony projektu:
| PRESET
NAME
| DESCRIPTION
| AMD ATHLON K7
| IBM POWER3
| INTEL/HP ITANIUM
| INTEL PENTIUM III
| MIPS R12K
| ULTRA SPARC I
|
|
PAPI_L1_DCM
| Level 1 data cache misses
| v | v | v | v | v | x |
|
PAPI_L1_ICM
| Level 1 instruction cache
misses
| v | v | v | v | v | v |
|
PAPI_L2_DCM
| Level 2 data cache misses
| v | x | v | v | v | x |
|
PAPI_L2_ICM
| Level 2 instruction cache
misses
| v | x | v | v | v | x |
|
PAPI_L3_DCM
| Level 3 data cache misses
| x | x | v | x | x | x |
|
PAPI_L3_ICM
| Level 3 instruction cache
misses
| x | x | v | x | x | x |
|
PAPI_L1_TCM
| Level 1 total cache misses
| v | v | v | v | v | x |
|
PAPI_L2_TCM
| Level 2 total cache misses
| v | x | v | v | v | x |
|
PAPI_L3_TCM
| Level 3 total cache misses
| x | x | v | x | x | x |
|
PAPI_CA_SNP
| Requests for a Snoop
| x | v | x | x | x | v |
|
PAPI_CA_SHR
| Requests for access to shared
cache line (SMP)
| x | v | x | v | v | x |
|
PAPI_CA_CLN
| Requests for access to clean
cache line (SMP)
| x | x | x | v | x | x |
|
PAPI_CA_INv | Cache Line Invalidation (SMP)
| x | x | x | v | v | v |
|
PAPI_CA_ITv | Cache Line Intervention (SMP)
| x | v | x | v | v | x |
|
PAPI_L3_LDM
| Level 3 load misses
| x | x | v | x | x | x |
|
PAPI_L3_STM
| Level 3 store misses
| x | x | v | x | x | x |
|
PAPI_BRU_IDL
| Cycles branch units are idle
| x | v | x | x | x | x |
|
PAPI_FXU_IDL
| Cycles integer units are idle
| x | v | x | x | x | x |
|
PAPI_FPU_IDL
| Cycles floating point units
are idle
| x | v | x | x | x | x |
|
PAPI_LSU_IDL
| Cycles load/store units are
idle
| x | v | x | x | x | x |
|
PAPI_TLB_DM
| Data translation lookaside
buffer misses
| v | x | v | x | x | x |
|
PAPI_TLB_IM
| Instruction translation
lookaside buffer misses
| v | x | v | v | x | x |
|
PAPI_TLB_TL
| Total translation lookaside
buffer misses
| v | v | x | x | v | x |
|
PAPI_L1_LDM
| Level 1 load misses
| v | v | v | v | x | v |
|
PAPI_L1_STM
| Level 1 store misses
| v | v | x | v | x | v |
|
PAPI_L2_LDM
| Level 2 load misses
| v | v | v | x | x | x |
|
PAPI_L2_STM
| Level 2 store misses
| v | v | v | x | x | x |
|
PAPI_BTAC_M
| Branch target address cache
(BTAC) misses
| x | v | x | v | x | x |
|
PAPI_PRF_DM
| Pre-fetch data instruction
caused a miss
| x | v | x | x | v | x |
|
PAPI_L3_DCH
| Level 3 Data Cache Hit
| x | x | v | x | x | x |
|
PAPI_TLB_SD
| Translation lookaside buffer
shootdowns (SMP)
| x | v | x | x | x | x |
|
PAPI_CSR_FAL
| Failed store conditional
instructions
| x | v | x | x | v | x |
|
PAPI_CSR_SUC
| Successful store conditional
instructions
| x | v | x | x | v | x |
|
PAPI_CSR_TOT
| Total store conditional
instructions
| x | v | x | x | v | x |
|
PAPI_MEM_SCY
| Cycles Stalled Waiting for
Memory Access
| x | v | v | x | v | x |
|
PAPI_MEM_RCY
| Cycles Stalled Waiting for
Memory Read
| x | v | x | x | x | x |
|
PAPI_MEM_WCY
| Cycles Stalled Waiting for
Memory Write
| x | v | x | x | x | x |
|
PAPI_STL_ICY
| Cycles with No Instruction
Issue
| x | v | v | x | x | x |
|
PAPI_FUL_ICY
| Cycles with Maximum
Instruction Issue
| x | x | x | x | x | x |
|
PAPI_STL_CCY
| Cycles with No Instruction
Completion
| x | v | x | x | x | x |
|
PAPI_FUL_CCY
| Cycles with Maximum
Instruction Completion
| x | x | x | x | x | x |
|
PAPI_HW_INT
| Hardware interrupts
| v | x | x | v | x | x |
|
PAPI_BR_UCN
| Unconditional branch
instructions executed
| v | x | x | x | x | x |
|
PAPI_BR_CN
| Conditional branch
instructions executed
| v | v | x | v | x | x |
|
PAPI_BR_TKN
| Conditional branch
instructions taken
| v | x | v | v | x | x |
|
PAPI_BR_NTK
| Conditional branch
instructions not taken
| v | x | v | v | x | x |
|
PAPI_BR_MSP
| Conditional branch
instructions mispredicted
| v | v | v | v | v | v |
|
PAPI_BR_PRC
| Conditional branch
instructions correctly predicted
| v | v | v | v | x | x |
|
PAPI_FMA_INS
| FMA instructions completed
| x | v | x | x | x | x |
|
PAPI_TOT_IIS
| Total instructions issued
| x | v | x | v | v | v |
|
PAPI_TOT_INS
| Total instructions executed
| v | v | v | v | v | v |
|
PAPI_INT_INS
| Integer instructions executed
| x | v | x | x | x | x |
|
PAPI_FP_INS
| Floating point instructions
executed
| x | v | v | v | v | v |
|
PAPI_LD_INS
| Load instructions executed
| x | v | v | x | v | v |
|
PAPI_SR_INS
| Store instructions executed
| x | v | v | x | v | v |
|
PAPI_BR_INS
| Total branch instructions
executed
| v | v | v | v | v | x |
|
PAPI_VEC_INS
| Vector/SIMD instructions
executed
| v | x | x | v | x | x |
|
PAPI_FLOPS
| Floating Point Instructions
executed per second
| x | v | v | v | v | x |
|
PAPI_RES_STL
| Cycles processor is stalled on
resource
| v | x | x | v | x | x |
|
PAPI_FP_STAL
| Cycles any FP units are
stalled
| x | x | x | x | x | x |
|
PAPI_TOT_CYC
| Total cycles
| v | v | v | v | v | v |
|
PAPI_IPS
| Instructions executed per
second
| v | v | x | v | v | v |
|
PAPI_LST_INS
| Total load/store instructions
executed
| x | v | v | x | v | x |
|
PAPI_SYC_INS
| Synchronization instructions
executed
| x | v | x | x | x | x |
|
PAPI_L1_DCH
| L1 data cache hits
| v | x | v | v | x | x |
|
PAPI_L2_DCH
| L2 data cache hits
| v | x | x | x | x | x |
|
PAPI_L1_DCA
| L1 data cache accesses
| v | x | v | v | x | x |
|
PAPI_L2_DCA
| L2 data cache accesses
| v | x | v | v | x | x |
|
PAPI_L3_DCA
| L3 data cache accesses
| x | x | v | x | x | x |
|
PAPI_L1_DCR
| L1 data cache reads
| x | x | x | x | x | v |
|
PAPI_L2_DCR
| L2 data cache reads
| v | x | v | v | x | x |
|
PAPI_L3_DCR
| L3 data cache reads
| x | x | v | x | x | x |
|
PAPI_L1_DCW
| L1 data cache writes
| x | x | x | x | x | v |
|
PAPI_L2_DCW
| L2 data cache writes
| v | x | v | v | x | x |
|
PAPI_L3_DCW
| L3 data cache writes
| x | x | v | x | x | x |
|
PAPI_L1_ICH
| L1 instruction cache hits
| x | x | x | v | x | v |
|
PAPI_L2_ICH
| L2 instruction cache hits
| x | x | x | v | x | v |
|
PAPI_L3_ICH
| L3 instruction cache hits
| x | x | v | x | x | x |
|
PAPI_L1_ICA
| L1 instruction cache accesses
| v | x | x | v | x | v |
|
PAPI_L2_ICA
| L2 instruction cache accesses
| v | x | x | v | x | x |
|
PAPI_L3_ICA
| L3 instruction cache accesses
| x | x | x | x | x | x |
|
PAPI_L1_ICR
| L1 instruction cache reads
| v | x | v | v | x | x |
|
PAPI_L2_ICR
| L2 instruction cache reads
| x | x | v | v | x | x |
|
PAPI_L3_ICR
| L3 instruction cache reads
| x | x | v | x | x | x |
|
PAPI_L1_ICW
| L1 instruction cache writes
| x | x | x | x | x | x |
|
PAPI_L2_ICW
| L2 instruction cache writes
| x | x | x | x | x | x |
|
PAPI_L3_ICW
| L3 instruction cache writes
| x | x | x | x | x | x |
|
PAPI_L1_TCH
| L1 total cache hits
| x | x | x | x | x | x |
|
PAPI_L2_TCH
| L2 total cache hits
| x | x | x | v | x | x |
|
PAPI_L3_TCH
| L3 total cache hits
| x | x | x | x | x | x |
|
PAPI_L1_TCA
| L1 total cache accesses
| v | x | x | v | x | x |
|
PAPI_L2_TCA
| L2 total cache accesses
| x | x | x | v | x | v |
|
PAPI_L3_TCA
| L3 total cache accesses
| x | x | x | x | x | x |
|
PAPI_L1_TCR
| L1 total cache reads
| x | x | x | x | x | x |
|
PAPI_L2_TCR
| L2 total cache reads
| x | x | x | v | x | x |
|
PAPI_L3_TCR
| L3 total cache reads
| x | x | x | x | x | x |
|
PAPI_L1_TCW
| L1 total cache writes
| x | x | x | x | x | x |
|
PAPI_L2_TCW
| L2 total cache writes
| x | x | x | v | x | x |
|
PAPI_L3_TCW
| L3 total cache writes
| x | x | x | x | x | x |
|
PAPI_FML_INS
| Floating Multiply instructions
| x | x | x | v | x | x |
|
PAPI_FAD_INS
| Floating Add instructions
| x | x | x | x | x | x |
|
PAPI_FDV_INS
| Floating Divide instructions
| x | v | x | v | x | x |
|
PAPI_FSQ_INS
| Floating Square Root
instructions
| x | v | x | x | x | x |
|
PAPI_FNV_INS
| Floating Inverse instructions
| x | x | x | x | x | x |
Wysokopoziomowy interfejs dostarcza funkcji pozwalających na uruchomienie, zatrzymanie i czytanie odpowiednich liczników. Napeży załączyć
plik nagłówkowy papi.h.
Oto funkcje:
| PAPI_num_counters() | funkcja inicjalizujuje PAPI (jeśli trzeba), zwraca optymalną długość tablicy wartości dla
funkcji interfejsu high-level, związaną z liczbą liczników. |
| PAPIF_start_counters(*events, array_length) | inincjalizuje PAPI (jeśli trzeba) i startuje
liczenie zdarzeń z tablicy events o długości array_length. |
| PAPI_flops(*real_time, *proc_time, *flpins, *mflops) | po prostu inicjalizuje
PAPI (jeśli trzeba), i ustawia wartości wskazywane przez wskaźniki (od ostatniego wywołania PAPI_flops): real_time -- czas rzeczywisty, proc_time -- czas wirtualny (tyle ile dany
proces był wyonywany), flpins -- liczba wykonanych instrukcji zmiennoprzecinkowych, mflops -- Mflop/s rating. |
| PAPI_read_counters(*values, array_length) | Wstawia do tablicy values bieżące wartości
liczników i je wyzerowuje. |
| PAPI_accum_counters(*values, array_length) | Dodaje do tablicy values bieżące wartości
wskaźników i je wyzerowuje. |
| PAPI_stop_counters(*values, array_length) | Wstawia bieżące wartości licznikow do tablicy
values i kończy ich wyliczanie. |
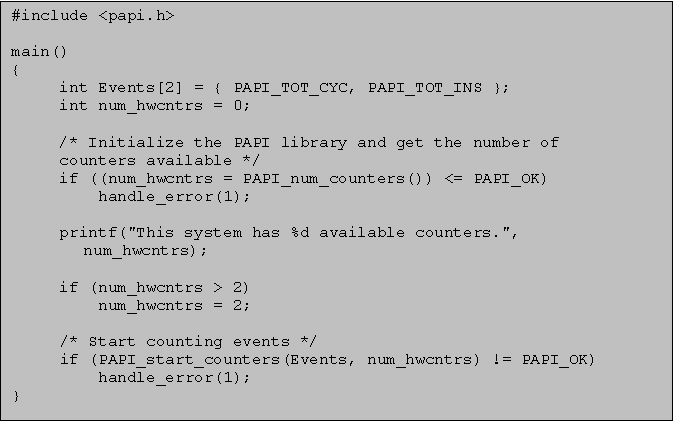
W poniższym przykładze inicjalizujemy bibliotekę poprzez PAPI_num_counters i strtujemy przez PAPI_start_counters.
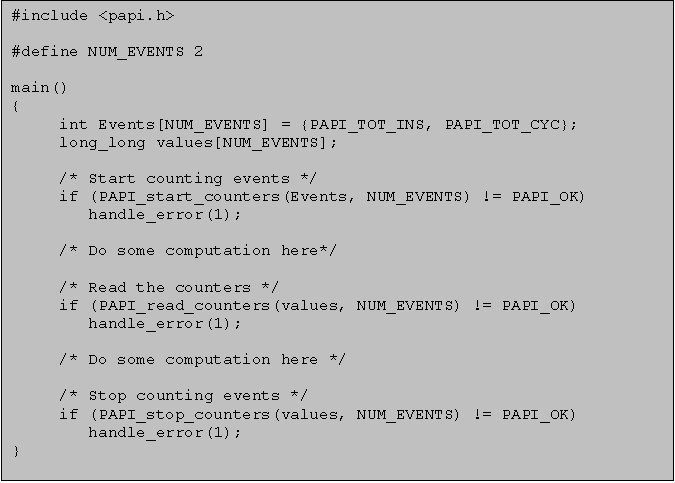
W poniższym przykładzie śledzimy liczbę wykonanych instrukcji i liczbę cyklów:
Interfejs nisko-poziomowy udostępnia dużo więcej, nisko-poziomowych funkcji.
Załączone są też nażędzia, w szczególności interfejs graficzny.
Więcej szczegółów w podręczniku użytkownika.
DynaProf jest open-source'owym, ciągle rozwijanym narzędziem do profilowania aplikacji. Działa poprzez próbkowanie. Dynaprof mierzy zarówno po
prostu czas, jak i dane dające się zmierzyć poprzez PAPI (korzysta z niego). Działa na plikach wykonywalnych, niepotrzebne mu źródło. Narzędzie wraz z dokładnym opisem jest dostępne na tej stronie.
Aby zainstalować DynaProf wystarczy ściągnąć, rozpakować i podążać za instrukcjami w pliku INSTALL.
Aby uruchomić to narzędzie należy napisać (tu ogólna postać):
./dynaprof [options] [[--] executable-file [executable-args]]
Oto dostępne opcje:
-b | --batch Exit after processing options.
-c | --commmand= Execute Dynaprof commands from .
-d | --debug Enable debugging statements in Dynaprof.
-h | --help Print this message.
-q | --quiet Do not print version number on startup.
-t | --tty= Use for input/output by the program being profiled.
-g | --gui Gui mode, only buffering one line.
-v | --version Print version information and then exit.
Po uruchomieniu narzędzia można wydawać komendy, opisane szczegółowo w
podręczniku użytkownika.
Wiele ich jest:
- IBM: prof, gprof, tprof,
- SGI: ssrun, prof, perfex,
- HP/Compaq: prof, pixie, gprof, hiprof, uprofile,
- Giude View,
- Vampir,
- Vprof,
- HPCView,
- po części Valgrind