|
Informacje Pomocnicze
ptrace() to wywołanie systemowe pozwalające jednemu procesowi monitorować
działanie drugiego procesu. Proces monitorowany, w wypadku otrzymania sygnału w trakcie
wykonywania kodu, informuje o tym proces monitorujący i przechodzi w stan wstrzymania.
Proces śledzony może także zatrzymać się w wyniku wystąpienia zdarzenia określonego przez
proces-monitor.
Każde wywołanie funkcji blokuje dostęp do jądra na czas swojego działania. ptrace() jest
bardzo często używany do zadań związanych z debuggowaniem.
#include <sys/ptrace.h>long int ptrace(enum __ptrace_request
request, pid_t pid,
void * addr, void * data)
gdb (gnu project debugger) to aplikacja pozwalająca analizować proces w trakcie
działania. Służy do wychwytywania pluskiew w kodzie za pomocą kilku podstawowych
technik:
- ustalenie zbioru zdarzeń (breakpointów, watchpointów), których zajście ma wstrzymać działanie
programu
- możliwość odczytu stanu programu w momencie przerwania działania
- stała modyfikacja kodu i analiza zmieniających się wyników debuggera
Najważniejsze instrukcje:
debug plik
- uruchamia gdb na danym pliku
run parametry
- wykonuje bieżacy program z zadanymi parametrami
attach pid
- ładuje debugger dla działającego procesu (o zadanym id)
detach
- zwalnia proces spod kontroli gdb
break nagłówek_funkcji
- ustawia breakpoint (flagę) na danej funkcji
break numer_linii
- ustawia breakpoint na określonej linii pliku źródłowego
info break
- drukuje informację o ustawionych breakpointach
delete numer
- usuwa breakpoint o numerze numer
step
- wykonuje bieżącą linię kodu (po czym zatrzymuje się)
next
- podobnie jak step, lecz jeśli w w następnej linii jest
wywołanie funkcji to zostaje ona wykonana
continue
- wykonuje program w normalnym trybie aż ten się zatrzyma lub natrafi na
breakpoint
finish
- wykonuje kod aż do momentu, gdy funkcja z bieżącej ramki stosu powróci
backtrace
- wyświetla łańcuch wywołań funkcji, który doprowdził program do bieżącego stanu
watch wyrażenie
- wstrzymuje program jeśli wartość wyrażenia ulegnie zmianie (watchpoint)
print wyrażenie
- pokazuje aktualną wartość wyrażenia w programie
condition numer warunek
- wstrzymuje program jeśli warunek = true
quit
- opuszcza gdb
Ctrl^C
- wstrzymuje działanie procesu i czeka na instrukcję użytkownika
ddd (data display debugger) to aplikacja dostarczająca interfejs graficzny dla
debuggerów
tekstowych działających pod Linuksem (np. gdb, dbx, python debugger). Program
wzbogaca zestaw opcji debuggera o szereg narzędzi, m.in. możliwość
wizualizacji stanu struktur danych bieżącego procesu w postaci grafów i diagramów.
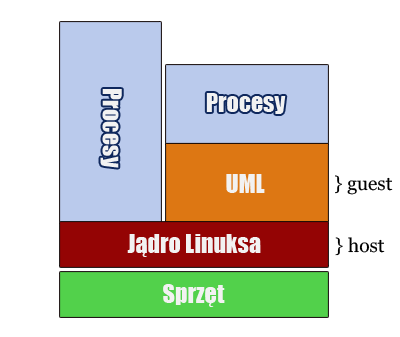
Jądro Sprawy, czyli debuggowanie kernela
Ponieważ jądro UML jest w gruncie rzeczy zwykłym procesem, pozwala się
ono debuggować pod kontrolą gdb jak każdy inny proces utworzony przez
użytkownika w danym systemie.
Proces debuggowania rozpoczynamy od uruchomienia gdb:
gdb
Następnie każemy debuggerowi
ignorować wewnętrzne sygnały UMLa - SIGSEGV i SIGUSR1 - w przeciwynm wypadku będą one cyklicznie
przerywać proces odpluskwiania:
(gdb) handle SIGSEGV pass nostop noprint
(gdb) handle SIGUSR1 pass nostop noprint
ładujemy tablicę symboli jądra UML:
(gdb) file linux
Ustalamy breakpointy, np:
(gdb) b start_kernel()
W końcu, uruchamiamy instancję wirtualnego linuxa z podczepionymi systemami plików:
(gdb) run ubd0=root_fs ubd1=swap_fs(UML gdb) ...
* Możemy też zaaplikować do jądra instancję debuggera o określonym pid:
./linux debug gdb-pid=pid_debuggera
** Aby uruchomić debuggowanie jądra pod ddd:
host% ddd ./linux./linux debug=parent gdb-pid=pid_utworzonego_wyżej_procesu
(gdb) attach 1
(podanie jako parametru attach pid, który nie odnosi się do procesu UML, podłącza gdb do wątku
bieżącego)
*** Aby podłączyć gdb do już działającego jądra UML
Chodzi nam o to by wykonać instrukcję attach na aktywnym
procesie jądra. Robimy to za pośrednictwem sztuczki polegającej na wysłaniu
procesowi guesta sygnału SIGUSR1 (lub SIGINT):
host% kill -USR1 pid_UMLa
W wyniku otrzymamy okno xterm z gdb działającym na kernelu.
|