| < | 1. Wstęp | 2. printk | 3. klogd i syslogd | 4. strace i ltrace | 6. kdb i kgdb | > |
gdb - GNU Project debugger, pozwala na kontrolę nad tym, co dzieje się "wewnątrz" innych programów podczas ich działania lub w momencie przerwania wykonywania na skutek błędu. Umożliwia przede wszystkim:
W jaki sposób gdb może kontrolować inny proces? Do tego celu służy funcja ptrace. Za jej pomocą gdb informuje system, ze interesują go zdarzenia związane z debugowanym procesem, takie jak otrzymanie sygnału, napotkanie pułapki lub wywołanie funkcji systemowej, oraz że w przypadku zajścia takiego zdarzenia wykonanie tego programu powinno zostać wstrzymane. Kiedy to nastąpi system informuje gdb o tym zdarzeniu za pomocą odpowiedniego sygnału. Wtedy gdb może za pomocą funkcji ptrace uzyskać dostęp do przestrzeni danych debugowanego programu, zmienić pewne dane, a następnie wznowić jego wykonanie. Szczegółowej informacji na temat ptrace można szukać na stronie linuxgazette.net/issue81/sandeep.html oraz na odpowiednich stronach podręcznika systemowego.
Aby praca z gdb była możliwa, program przeznaczony do debugowania musi być wcześniej skompilowany z opcją -g. Powoduje to zapisanie w programie informacji symbolicznej i powiązanie poszczególnych rozkazów w binarnym kodzie z odpowiednimi fragmentami kodu źródłowego.
Chcąc rozpocząć debugowanie programu program należy wywołać:
$ gdb program
Wyświetlona zostanie informacja o gdb oraz wiersz poleceń:
GNU gdb 6.4-debian Copyright 2005 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "i486-linux-gnu"...Using host libthread_db library "/lib/tls/i686/cmov/libthread_db.so.1". (gdb)
W tym momencie debugowany program jeszcze nie został uruchomiony. Można to spowodować wydając odpowiednie polecenie, można też przed uruchomieniem programu wykonać pewne dodatkowe czynności. Podstawowe polecenia gdb (zamiast pełnych nazw można również używać jednoliterowych skrótów pochodzących najczęściej od pierwszej litery polecenia) to:
run argsargs. Jeżeli gdb uruchomiono bez parametrów, nazwę programu można wprowadzić wykonując polecenie run program args . Działanie programu można w każdej chwili przerwać, przesyłając do niego sygnał SIGINT (^C).break place
(gdb) break Traverse Breakpoint 2 at 0x2290: file main.c, line 20
Można również ustawić breakpoint na wybranej linii kodu źródłowego:
(gdb) break 20 Breakpoint 2 at 0x2290: file main.c, line 20
Kiedy program w trakcie wykonywania natrafi na breakpoint, przerwie swoją pracę, a gdb wyświetli stosowny komunikat:
Breakpoint 1, Traverse(head=0x6110, NumNodes=4) at main.c:16 (gdb)
handle signal keywordssignal (podany jako nazwa symboliczna) przychodzący do debugowanego programu. Słowa kluczowe keywords należą do zbioru: stop - gdb zatrzymuje debugowany program po nadejściu sygnału, print - po nadejściu sygnału wyświetlana jest stosowna wiadomość, pass - sygnał jest widoczny dla debugowanego programu, ignore - sygnał jest widoczny dla debugowanego programu. Do każdego z tych słów można dodać przedrostek no-, np: nostop - powodujemy wtedy oczywiście przeciwne zachowanie gdb (pass i noignore są synonimami, podobnie jak nopass i ignore). Przykładowa komenda wygląda następująco:
handle SIGINT pass noprint nostop
continuedelete nn. Użycie bez parametru powoduje usunięcie wszystkich breakpointówstepnextstep z tą różnicą, że jeśli bieżąca linia kodu zawiera wywołanie funkcji, to zostanie ona wykonana, a wykonywanie programu zatrzyma się na następnej liniifinishinfo argarg. Na przykład info breakpoint wyświetla informację o aktualnie założonych breakpointach:
Breakpoint 1, Traverse(head=0x6110, NumNodes=4) at main.c:16 (gdb)Jest to bardzo przydatne polecenie, a pełna lista możliwych parametrów jest długa. Można ją otrzymać wywołując
info bez parametrów.where, backtraceprint exprexpr w aktualnym kontekście programu. expr jest zwykłym wyrażeniem w C, najczęściej po prostu nazwą zmiennej.display exprprint, ale po każdym wywołaniu step lub next wyświetla wartość wyrażenia obliczoną na podstawie aktualnych wartości zmiennychset var v=exprv na wartość wyrażenia exprdetatt pidpidquithelp, help commandDziałanie podstawowych komend można prześledzić na przykładzie prostego programu seg, który można skompilować, ale który generuje błąd po uruchomieniu:
#include <stdio.h>
void przypisz(int *a, int b)
{
*a = b;
}
int main(int argc, char *argv[] )
{
int i, j;
j = 0;
for(i=0;i<5;i++)
{
przypisz((int*) &j, i);
przypisz((int*) j, i);
}
return 0;
}
Uruchamiamy gdb:
$ gdb seg
i wydajemy polecenie run (pisząc skrótowo r):
(gdb) r
Program seg zostanie uruchomiony, po czym wygeneruje błąd "Segmentation fault" i zatrzyma się:
Starting program: /home/vmware/seg Program received signal SIGSEGV, Segmentation fault. 0x08048335 in przypisz (a=0x0, b=0) at seg.c:5 5 *a = b;
Polecenie continue (c) spowoduje dokończenie działania programu, a więc jego zakończenie z powodu powstałego błędu:
(gdb) c Continuing. Program terminated with signal SIGSEGV, Segmentation fault. The program no longer exists.
W momencie powstania błędu otrzymaliśmy informację, że zdarzenie to nastąpiło wewnątrz funkcji przypisz. W naszym programie mamy jednak dwa wywołania tej funkcji, aby więc dowiedzieć się, które z nich zawiniło, uruchamiamy program ponownie, ustawiając uprzednio breakpoint na tej funkcji:
(gdb) b przypisz Breakpoint 1 at 0x804832f: file seg.c, line 5. (gdb) r
Wykonywanie programu zatrzyma się po osiągnięciu tego breakpointa, czyli w momencie wywołania przypisz:
Starting program: /home/vmware/seg Breakpoint 1, przypisz (a=0xbf872830, b=0) at seg.c:5 5 *a = b;
Wywołując w tym momencie trzykrotnie polecenie step (s) uzyskujemy informację, że pierwsze wywołanie podejrzanej funkcji przebiega prawidłowo i "lądujemy" w wywołaniu drugim (z 16-tej linii kodu programu):
(gdb) s 6 } (gdb) s main (argc=1, argv=0xbf8728c4) at seg.c:16 16 przypisz((int*) j, i); (gdb) s Breakpoint 1, przypisz (a=0x0, b=0) at seg.c:5 5 *a = b;
Wywołując jeszcze raz step upewniamy się, że to właśnie to wywołanie jest przyczyną kłopotów:
(gdb) s Program received signal SIGSEGV, Segmentation fault. 0x08048335 in przypisz (a=0x0, b=0) at seg.c:5 5 *a = b;
UML to odpowiednio skompilowane jądro Linuxa, przygotowane do pracy na specjalnej platformie um. Jest ono uruchamiane pod kontrolą "zwykłego" Linuxa jako proces użytkownika, dlatego często jest nazywany "Linuxem w Linuxie". Takie podejście zapewnia bardzo dobrą wydajność "wirtualnego" Linuxa oraz dobrą jego izolację od systemu gospodarza. Możliwe jest uruchamianie nowszej wersji jądra pod kontrolą starszej, a nawet uruchamianie UML-a wewnątrz innego UML-a. Istnieją dwa podstawowe tryby pracy:
Różne techniki wirtualizacji, w szczególności UML, były tematem poprzedniej prezentacji, zatem bardziej szczegółowych informacji można szukac w materiałach do niej lub na stronach user-mode-linux.sourceforge.net.
Do uruchomienia UML, oprócz działającego "normalnego" Linuxa (nazywanego dalej gospodarzem (ang. host)), potrzeba dwóch głównych składników:
Uwaga: Jądra starsze niż 2.6.9 wymagają dodatkowo zainstalowania odpowiednich łatek zarówno na jądro gospodarza, jak i gościa. Począwszy od jądra 2.6.9 UML jest jego integralną częścią i instalowanie łatek nie jest wymagane. W przypadku, kiedy decydujemy się na używanie starszej wersji, odpowiednie łatki możemy ściągnąć ze strony www.user-mode-linux.org/~blaisorblade
Najprostszą i najszybszą (przynajmniej teoretycznie) metodą na rozpoczęcie zabawy z UML jest ściągnięcie obu tych elementów gotowych do pracy. Duży wybór skompilowanych jąder oraz systemów plików znajduje się pod adresem: uml.nagafix.co.uk. Długą listę systemów plików znajdziemy również na stronie user-mode-linux.sourceforge.net/dl-fs-sf.html. Po ściągnięciu odpowiednich plików wydajemy polecenie:
$ ./kernel ubd0=./root_fs
gdzie kernel to nazwa pliku jądra, a root_fs - systemu plików i już możemy się cieszyć działającym UML-em
Z naszego punktu widzenia wskazane jest jednak, abyśmy sami przygotowali jądro. W tym celu należy wykonać następujące czynności:
Najlepszym miejscem na szukanie odpowiedniego źródła jest witryna www.kernel.org. Można na niej znaleźć wszystkie wersje jądra, począwszy od 0.01, a na najnowszych (w chwili obecnej 2.6.18.3) skończywszy. Jądra serii 2.6 znajdują się pod adresem http://www.kernel.org/pub/linux/kernel/v2.6/ (dostępne są również przez FTP: ftp://ftp.kernel.org/pub/linux/kernel/v2.6/). Na maszynie podłączonej do internetu możemy posłużyć się poleceniem wget:
$ wget ftp://ftp.kernel.org/pub/linux/kernel/v2.6/linux-2.6.17.13.tar.bz2
$ tar jfx ../linux-2.6.17.13.tar.bz2 $ cd linux-2.6.17.13
CONFIG_DEBUGSYM - Enable Kernel debugging symbols - powoduje kompilację jądra z opcją -g (wsparcie dla gdb)CONFIG_PT_PROXY - Kernel ptrace proxy - wspomaganie dla gdb, przy śledzeniu wątków systemowych
Odpowiedni dla naszego jądra plik konfiguracyjny można ściągnąć np. ze strony http://uml.nagafix.co.uk, ale lepiej przygotować go samemu. Można to zrobić ręcznie, odpowiednio edytując plik .config Dokładny opis wszystkich parametrów zawartych w tym pliku (nie tylko dwa wymienione wyżej są kluczowe) można znaleźć na stronie tapsa.terae.net/linux/kernel/configure_help.txt. Znacznie jednak łatwiej będzie skorzystać z pomocniczych narzędzi. W tym celu wydajemy polecenia:
$ make defconfig ARCH=um $ make menuconfig ARCH=um
Pierwszy z nich przygotuje plik z ustawieniami domyślnymi. Parametr ARCH=um oznacza, że przygotowujemy kompilację jądra na architekturę um. Nie wolno o nim zapominać!. Drugie z tych poleceń uruchamia wygodny interfejs konfiguracyjny.
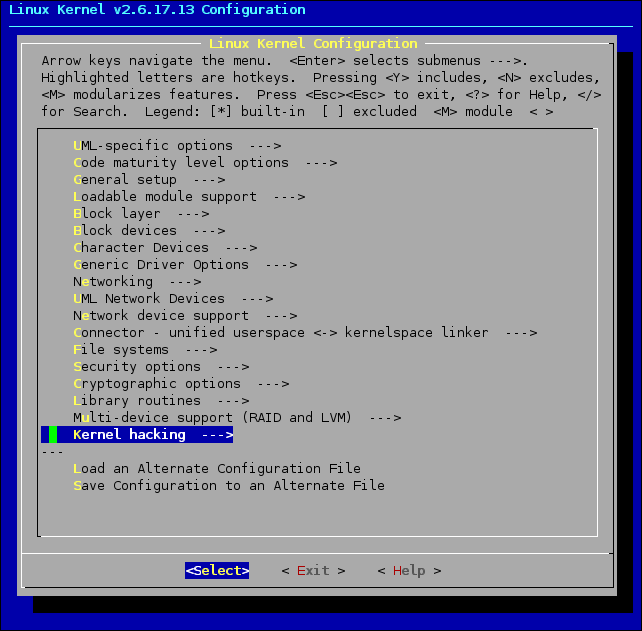
W naszym przypadku najważniejsze są dwie sekcje: UML-specific options oraz Kernel hacking. W pierwszej z nich ustawiamy opcje jak na poniższej ilustracji:
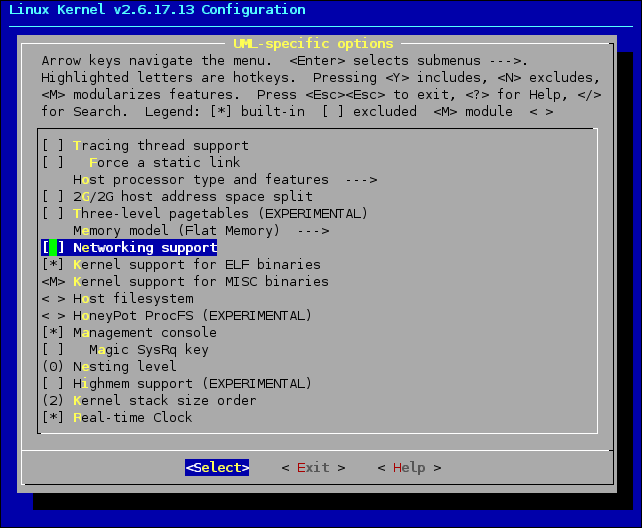
Uwaga: W przypadku jądra 2.6.17.13 nie wybranie wsparcia dla trybu TT (Tracing thread support) może powodować błędy w kompilacji. W takim wypadku należy tę opcję wybrać, nawet jeśli nie zamierzamy korzystać z trybu TT. Opisu alternatywnego rozwiązania tego problemu można szukać tutaj: lkml.org/lkml/2006/9/9/26
Warto również odznaczyć opcje, których użycia nie przewidujemy, np. Networking support
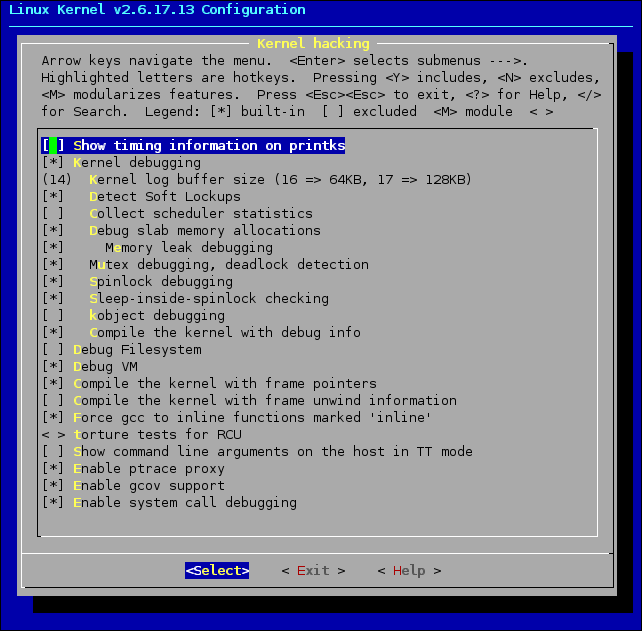
W sekcji Kernel hacking należy dokonać ustawień, jakie pokazano poniżej:
Następnie kończymy konfigurowanie, zapisując jednocześnie zmiany:
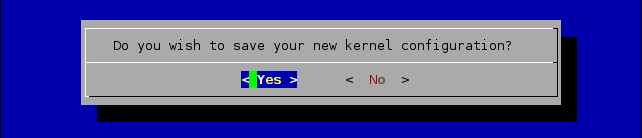
... i otrzymujemy jądro gotowe do kompilacji.
Jądro oraz jego moduły kompilujemy poleceniami:
$ make linux ARCH=um $ make modules ARCH=um
Następnie moduły należy zainstalować, czyli przenieść do odpowiedniego miejsca w systemie plików. Ponieważ systemu plików jeszcze nie mamy, instalujemu moduły w katalogu tymczasowym:
$ make modules_install ARCH=um INSTALL_MOD_PATH=../tmp
System plików można przygotować samemu - szczegółowy opis można znaleźć tutaj: user-mode-linux.sourceforge.net/UserModeLinux-HOWTO-8.html. Ponieważ jednak głównym celem jest praca z konkretnym jądrem, system plików nie jest tak istotny - zatem możemy się posłużyć gotowym rozwiązaniem. Na potrzeby niniejszej prezentacji skorzystano z systemu Slacware 8.1, pobranym z http://prdownloads.sourceforge.net/user-mode-linux/root_fs_slack8.1.bz2. Zakładając, że archiwum to umieściliśmy w katalogu, w którym znajduje sie katalog źródeł jądra, przechodzimy tam i dokonujemy dekompresji:
$ cd .. $ mv root_fs_slack8.1.bz2 root_fs.bz2 $ bzip2 -fd root_fs.bz2
Otrzymany plik root_fs montujemy w katalogu mnt i kopiujemy w odpowiednie miejsce utworzone uprzednio moduły:
$ mkdir mnt $ mount root_fs mnt/ -o loop $ cp -r tmp/lib/modules/2.6.17.13 mnt/lib/modules/2.6.17.13
Należy jeszcze sprawdzić (i ew. poprawić), czy nazwy urządzeń opisanych w naszym sysstemie plików w etc/fstab zgadzają się z nazwami urządzeń w dev/ (na które UML przypisze obraz pliku root_fs):
$ cat etc/fstab #/dev/ubd0 / ext2 defaults 1 1 /dev/ubd/0 / ext2 defaults 1 1 none /dev/pts devpts gid=5,mode=620 0 0 none /proc proc defaults 0 0 $ ls dev/ubd* dev/ubd0 dev/ubd1 dev/ubd2
W tym przypadku musimy usunąć komentarz w pierwszej linii pliku etc/fstab. Usuwamy go dowolnym edytorem i odmontowujemy nasz system plików:
$ umount mnt
Tak przygotowany UML jest gotowy do uruchomienia. W celu jego wystartowania wydajemy wydajemy polecenia:
$ cd linux-2.6.17.13 $ ./linux ubd0=../root_fs
Wyświetlone zostaną komunikaty startowe, po czym ukaże się znak zachęty z pytaniem o login. Jednocześnie zostaną otwarte trzy nowe terminale, w których również można się zalogować do UML-a. Od tej chwili możemy pracować w UML-u jak w normalnym Linuxie. Aby zatrzymać UML wykonujemy polecenie halt
W opisany powyżej sposób uruchomimy UML w domyśnym trybie - najczęściej SKAS. Jeśli chcemy uruchomić go w trybie TT, przy uruchomieniu podajemy odpowiednią opcję:
$ ./linux mode=tt ubd0=../root_fs
Do najczęstszych przyczyn błędów kompilacji i uruchamiania UML należą:
ARCH=um przy konfigurowaniu i kompilacjimenuconfig nie gwarantuje, że wybrany zestaw opcji zapewni poprawną kompilację i działanie UMLetc/fstab z urządzeniami obecnymi w dev. Jeżeli nazwy te zgadzają się, a problemy z systemem plików nadal występują, można spróbować użycia innego systemu plików aby stwierdzić, czy problem leży po jego stronie, czy po stronie jądra.
Jeżeli wykluczyliśmy wszystkie powyższe przyczyny, a problemy z kompilacją lub uruchomieniem UML'a nadal występują, pomocy można szukać na stronach:
user-mode-linux.sourceforge.net/UserModeLinux-HOWTO.html
www.user-mode-linux.org/~blaisorblade/faq.html
user-mode-linux.sourceforge.net/compile.html
www.mail-archive.com/user-mode-linux-devel@lists.sourceforge.net
lkml.org
... www.google.com
W trybie SKAS można debugować jądro UML tak jak każdy inny program działający w trybie użytkownika. Debugowanie rozpoczynamy więc od polecenia:
$ gdb linux
Ponieważ gdb intensywnie korzysta z sygnałów SIGUSR1 i SIGSEGV, może to powodować ciągłe zatrzymywanie wykonywania UML. Dlatego trzeba określić, jak te sygnały mają być traktowane:
(gdb) handle SIGSEGV pass nostop noprint (gdb) handle SIGUSR1 pass nostop noprint
Można już na początku określić jakieś breakpointy, np:
(gdb) b start_kernel
Wykonywanie UML-a rozpoczynamy komendą run z odpowiednim parametrem wywołania:
(gdb) r ubd0=root_fs
Po uruchomieniu UML-a okaże się, że nie można przerwać jego wykonywania i przejść do gdb tak jak dla zwykłego programu - tzn. wysyłając sygnał SIGINT z konsoli, w której mamy uruchomiony UML (Ctrl + C). Dzieje się tak dlatego, że sygnał ten jest odbierany przez proces wykonywany wewnątrz UML-a, a nie przez samego UML-a. Aby obejść ten problem należy otworzyć drugą konsolę i za pomocą polecenia ps odnaleźć proces naszego UML-a o najniższym numerze pid (będzie to zazwyczaj pierwszy proces po gdb) - jest to proces jądra UML. Następnie z tej samej konsoli przesyłamy do niego sygnał SIGINT:
$ kill -INT <pid>
Wtedy gdb sygnał ten przechwyci i w pierwszej konsoli UML zostanie przerwany, a sterowanie powróci do gdb:
Program received signal SIGINT, Interrupt. 0xa00f6c7d in waitpid () at atomic.h:174 174 (gdb)
W tym momencie możemy pracować z UML-em tak, jak z każdym innym programem. W ramach przykładu zobaczmy, jak wygląda funkcja przełączająca aktualnie wykonywany wątek. W tym celu ustawiamy breakpoint na funkcji _switch_to i wydajemy polecenie continue:
(gdb) b _switch_to Breakpoint 1 at 0xa0013837: file arch/um/kernel/process_kern.c, line 118. (gdb) c Continuing.
Ponieważ wykonywany wątek przełączany jest zazwyczaj wiele razy na sekundę, prawie natychmiast zatrzymamy się na ustawionym breakpoincie. Wydając polecenie backtrace (bt) możemy np. uzyskać informację, że funkcja _switch_to została wywołana przez funkcję schedule, a ta z kolei przez default_idle:
Breakpoint 1, _switch_to (prev=0xa027d2c0, next=0xa0ca6660, last=0xa027d2c0)
at arch/um/kernel/process_kern.c:118
(gdb) bt
#0 _switch_to (prev=0xa027d2c0, next=0xa0ca6660, last=0xa027d2c0)
at arch/um/kernel/process_kern.c:118
#1 0xa0228565 in schedule () at kernel/sched.c:1610
#2 0xa0013ca7 in default_idle () at arch/um/kernel/process_kern.c:212
#3 0xa0020aab in init_idle_skas () at arch/um/kernel/skas/process_kern.c:152
#4 0xa0013d1f in cpu_idle () at arch/um/kernel/process_kern.c:220
#5 0xa001012c in rest_init () at init/main.c:402
(...)
Przy użyciu polecenia list (l) możemy natomiast obejrzeć kod _switch_to:
(gdb) l
113 void *_switch_to(void *prev, void *next, void *last)
114 {
115 struct task_struct *from = prev;
116 struct task_struct *to= next;
117
118 to->thread.prev_sched = from;
119 set_current(to);
120
121 do {
122 current->thread.saved_task = NULL ;
(gdb) l
123 CHOOSE_MODE_PROC(switch_to_tt, switch_to_skas, prev, next);
124 if(current->thread.saved_task)
125 show_regs(&(current->thread.regs));
126 next= current->thread.saved_task;
127 prev= current;
128 } while(current->thread.saved_task);
129
130 return(current->thread.prev_sched);
131
132 }
W dalszych działaniach jesteśmy ograniczeni tylko przez swoją wyobraźnię i umiejętności. Dobrze, jeżeli ograniczają nas jednocześnie realne potrzeby...
Ponieważ w trybie TT każdy proces w systemie gościa ma swój odpowiednik w systemie gospodarza, to uruchamiając UML-a tak jak poprzednio:
$ gdb linux
nie możemy kontrolować pracy całego systemu. Dlatego chcąc debugować w tym trybie uruchamiamy UML-a z opcją debug:
$ ./linux ubd0=root_fs mode=tt debug
Parametr mode można pominąć, jeśli dane jądro było skompilowane wyłącznie do pracy w trybie TT. W wyniku takiego wywołania zostanie uruchomiony UML oraz - w osobnym terminalu - gdb, z którego poziomu ten UML kontrolujemy. Praca z gdb wygląda tak samo jak w trybie SKAS z tą różnicą, że mając aktywny debuger w osobnej konsoli nie napotykamy utrudnień w wysyłaniu sygnału SIGINT do procesu UML-a (wystarczy użyć ^C w konsoli z gdb). Ponadto dzięki możliwości odłączania i przyłączania gdb do dowolnego procesu można badać współpracę różnych procesów w UML-u, np. debugowanie zakleszczeń procesów użytkownika (choć znacznie praktyczniej jest badać procesy użytkownika na "zwykłym" Linuxie, bez użycia tak skomplikowanych narzędzi jak UML).
Tak jak wspomniano wcześniej, ten tryb jest mimo swoich zalet nieefektywny, generuje duży narzut na obsługę wielu wątków i być może niedługo przestanie być wspierany.
Ponieważ gdb wspiera debugowanie kodu ładowanego dynamicznie, doskonale nadaje się do odpluskwiania modułów jądra pod UML-em. Nie jest to jednak prosta operacja, ponieważ chcąc debugować dany moduł trzeba poinformować gdb jaki plik obiektowy został załadowany do UML-a i w którym miejscu w pamięci się znajduje. Wtedy gdb może załadować tablicę symboli i odnaleźć te symbole w danym kawałku pamięci.
Najłatwiejszym sposobem poradzenia sobie z tą trudnością jest skorzystanie z gotowego skryptu umlgdb, który automatyzuje cały proces. Skrypt ten stanowi cząść pakietu umltools, którego poszczególne składniki można pobrać ze strony www.user-mode-linux.org/cvs/tools. Po pobraniu skryptu umieszczamy go w tym samym katalogu, co jądro UML. Następnie modyfikujemy go, aby zapisać informację o modułach, które chcemy debugować. W tym celu należy odnaleźć fragment:
set MODULE_PATHS {
"hostfs" "/home/jdike/linux/2.4/um/arch/um/fs/hostfs/hostfs.o"
}
i dla każdego modułu wpisać linię:
"nazwa_modułu" "nazwa_pliku_obiektowego"
a następnie uruchomić skrypt. Po sprawdzeniu modułów wyświetli on informację o tym, jak należy uruchomić UML, aby podłączył się do już działającego gdb:
******** GDB pid is 7784 ********
Start UML as: ./linux <kernel switches> debug gdb-pid=7784
Po uruchomieniu we wskazany sposób UML zachowuje się jak przy normanym działaniu. Kiedy załadujemy moduł, o którym informację zapisaliśmy wcześniej w skrypcie umlgdb, gdb przerwie pracę UML-a i wyświetli odpowiedni komunikat:
*** Module hostfs loaded ***
Breakpoint 1, sys_init_module (name_user=0x805abb0 "hostfs",
mod_user=0x8070e00) at module.c:349
349 char *name, *n_name, *name_tmp = NULL;
(gdb)
W tym momencie możemy rozpocząć pracę z załadowanym modułem.
www.gnu.org/software/gdb
www.cs.princeton.edu/~benjasik/gdb/gdbtut.html
user-mode-linux.sourceforge.net
uml.nagafix.co.uk/
www.user-mode-linux.org/~blaisorblade
| < | 1. Wstęp | 2. printk | 3. klogd i syslogd | 4. strace i ltrace | 6. kdb i kgdb | > |