--->[prezentacja]
Debugowanie jest obrzydliwe.Debugowanie programów jest jedną z ważniejszych potrzeb programisty. Kiedy coś nie działa, nie zawsze możemy wykryć i naprawić błąd tylko i wyłącznie czytając kod. Kiedy po którejś desperackiej próbie zauważamy, że zamiana kolejności dwu procedur w programie powoduje wystąpienie błędu lub nie, po chwili ogłupienia dochodzimy do wniosku, że musiało dojść do wycieku pamięci. Objawy takiego błędu mogą być bardzo różne i nie mają większego związku z przyczyną (możemy tylko podejrzewać, w którym miejscu piszemy poza tablicą). W takich przypadkach czytanie kodu lub druga najważniejsza metoda: wypisywanie komunikatów diagnostycznych ("nadziewanie" programu printfami) nie zdają egzaminu. Potrzebujemy mocniejszego mechanizmu diagnostyki błędu. Takim narzędziem jest debugger, program uruchamiający nasz program w "podporządkowanym" trybie, pozwalający drobiazgowo śledzić (i modyfikować) jego działanie w czasie wykonania.
W przypadku języków "niekompilowanych", np. skryptowych, a także dla Javy, debugger może być po prostu programem wykonującym za nas nasz program krok po kroku, mającym pełną kontrolę z racji swej funkcji. W przypadku zwykłych programów, jeżeli program ma być uruchomiony w naturalnym środowisku, wykonaniem zawiaduje system operacyjny, i to on (wraz z maszyną) musi udostępnić odpowiednie mechanizmy umożliwiające śledzenie. W przypadku Linuksa na maszynie intelowskiej są to syscall ptrace (opisana dalej) oraz instrukcja INT3, pozwalająca na wstawianie breakpointów.
Jeszcze inaczej sprawa się ma w przypadku debugowania samego jądra systemu. Zwyczajny debugger sie spełnia swej roli, gdyż system, poprzez PSW (processor status word) zabrania debuggerowi pewnych operacji (debugger, jako normalny program, działa w trybie użytkownika). Jest to trudne i złożone zagadnienie, któremu poświęcamy całą tę prezentację.
Mechanizmy odpluskwiania jądra stają się potrzebne, gdy:
Poniżej przeanalizujemy metody przydatne w tych przypadkach.
Skoro to jądro sprawuję władzę w systemie, jak można je odpluskwiać "zwykłymi" programami? Taki np. debugger wymaga przecież pełnej kontroli nad śledzonym procesem. Otóż, jądro musi nam zezwolić na pewne operacje i samo udostępniać opcje debugowania. Tak że debuggerem jądra jest w dużej mierze samo jądro!
Poniżej opiszę, w jaki sposób jądro pomaga nam w jego odpluskwianiu.
Kiedy jądro chce coś zakomunikować, nie może oczywiście ot tak sobie wypisać komunikatu diagnostycznego na ekran. Dlatego komunikaty jądra są przechowywane, a w dostępie do nich pośredniczą elementy jądra: system plików proc oraz wywołanie systemowe sys_syslog(int type, char *buf, int len) oraz programy dmesg, klogd i syslogd.
Od strony kodu jądra wygląda to tak, że jeśli chcemy wypisać komunikat, używamy funkcji printk. Jej składnia jest podobna do składni funkcji printf, z kilkoma różnicami:
Jej działanie polega na dodaniu do bufora komunikatów (log_buf) sformatowanego uprzednio komunikatu.
Komunikaty rożnią się stopniem istotności, od komunikatów diagnostycznych dodawanych w celu debugowania do komunikatów krytycznych, dotyczących np. załamania pracy systemu. W tym celu, komunikat systemowy może być opatrzony informacją o istotności (loglevel), która może przyjmować następujące wartości:
| loglevel | nazwa stałej | opis |
|---|---|---|
| 0 | KERN_EMERG | Awaria (np. kernel panic) |
| 1 | KERN_ALERT | Alarm |
| 2 | KERN_CRIT | Błąd krytyczny |
| 3 | KERN_ERR | Błąd |
| 4 | KERN_WARNING | Ostrzeżenie |
| 5 | KERN_NOTICE | Uwaga |
| 6 | KERN_INFO | Informacja |
| 7 | KERN_DEBUG | Komunikat diagnostyczny |
To daje nam możliwość filtrowania logów systemowych; w normalnych sytuacjach, chcemy widzieć tylko ważniejsze komunikaty, a liczne komunikaty informacyjne niewiele nas obchodzą; w sytuacji awaryjnej, kiedy liczy się zdiagnozowanie problemu, chcielibyśmy widzieć wszystkie komunikaty jądra. Możemy określić, które komunikaty chcemy widzieć (tzn. maksymalny loglevel dla komunikatów), za pomocą pliku /proc/sys/kernel/printk, który zawiera cztery liczby:
Dotyczy to tylko trafiania komunikatów na konsolę.
Jak programy trybu użytkownika mogą się dostać do listy komunikatów? Jądro udostępnia dwie możliwości:
BHP. Nigdy nie używajcie printk (ani innych operacji blokujących, np. kmalloc) mając spinlocka!
Z tego, co napisałem powyżej wynika, że dowolny program może czytać komunikaty jądra. W systemach Linuksowych obsługą komunikatów zajmują się demony systemowe klogd i syslogd, ten pierwszy przechwytuje komunikaty jądra, przetwarza je (np. zamieniając niektóre adresy w pamięci na symbole korzystając z pliku System.map) i podaje temu drugiemu, czyli syslogd. Syslogd zajmuje się obsługą różnych komunikatów w systemie, nie tylko pochodzących z jądra. Umieszcza on różnorakie logi w katalogu /var/log, np. zwykłe logi systemowe trafiają do /var/log/messages.
Oprócz klogd i syslogd, jest też program dmesg, który po prostu wypisuje komunikaty jądra.
Wszystko powyżej o obiegu komunikatów w Linuksie streszcza poniższy rysunek:
A oto przykład praktyczny w postaci modułu:
#include <linux/module.h>
MODULE_LICENSE("GPL");
static int init() {
printk(KERN_DEBUG "komunikat diagnostyczny\n");
printk(KERN_INFO "informacja\n");
printk(KERN_NOTICE "uwaga\n");
printk(KERN_WARNING "ostrzezenie\n");
printk(KERN_ERR "blad\n");
printk(KERN_ALERT "alarm\n");
printk(KERN_EMERG "awaria\n");
return 0;
}
static void exit() {}
module_init(init);
module_exit(exit);
Przenosimy się do konsoli (w zwykłym terminalu komunikaty się nie pojawią):
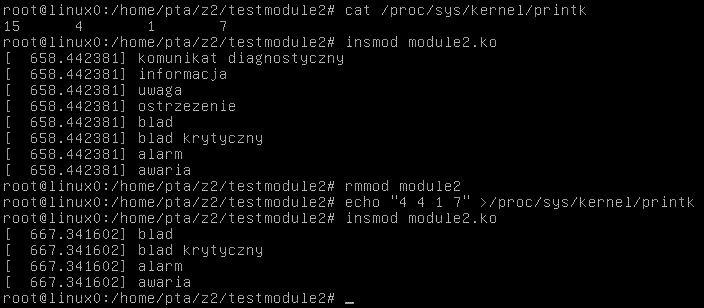
Widzimy, jak wpływa zawartość /proc/sys/kernel/printk na wypisywanie komunikatów. A oto, co wypisuje dmesg, a co trafia do /var/log/messages:
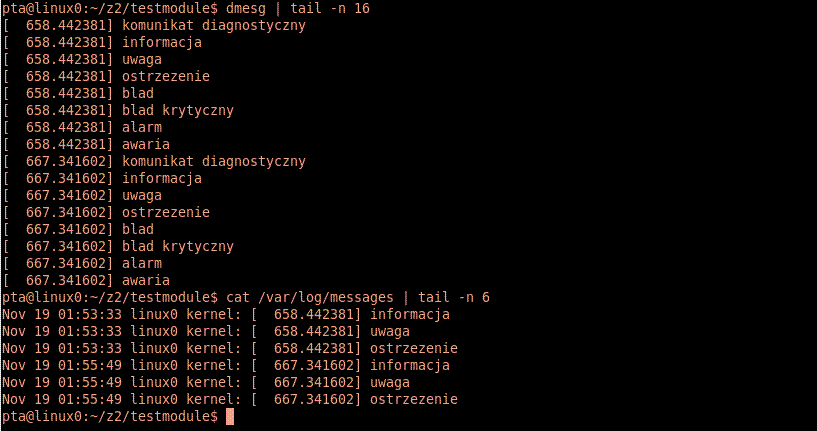
Zaobserwowaliśmy brak wpływu stałej console_loglevel na zachowanie obu.
Trzeba się liczyć z tym, że w przypadku błędu często nie dostajemy od jądra informacji, które są "human-readable", np. zawartość rejestru EIP czy stosu wywołań (adresów funkcji) nie mówią nam zbyt wiele. Sytuację pogarsza różnorodność jąder - różnią się nie tylko wersją, ale też opcjami kompilacji itp. Dlatego w Linuksie istnieje szereg sposobów na wydobycie potrzebnych informacji, np. przetworzenia adresów na symbole:
Część informacji przetwarza za nas klogd. Można się też posłużyć programem ksymoops, który do wersji 2.6 wchodził w skład źródeł jądra.
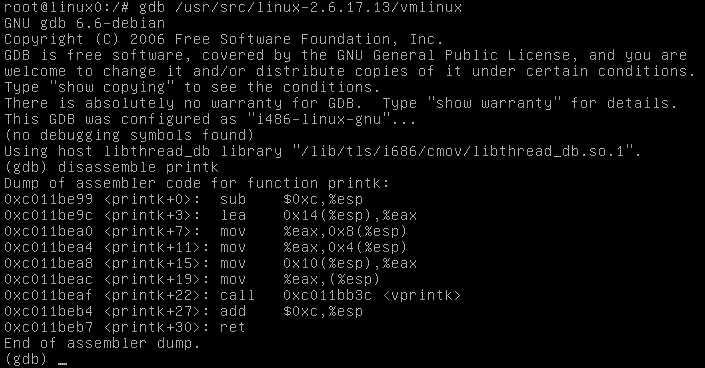
Mając zdekompresowane jądro vmlinux oraz dostęp do pamięci, możemy debugować jądro zwykłym debuggerem gdb, jednak jego działanie będzie ograniczone do dezasemblowania oraz podglądania zmiennych.
Oto przykład użycia debuggera gdb do zdezasemblowania funkcji printk:
Komunikat Oops jest złożonym komunikatem wypisywanym w momencie poważnego błędu. Taki błąd nie musi spowodować załamania się systemu. Komunikat zawiera rozliczne dane, takie jak:
Informacje o skażeniu: w momencie kiedy bład wystąpi wewnątrz kodu własnosciowego (np. firmowego sterownika), komunikat Oops staje się w pewnym stopniu bezużyteczny -- nikt poza firmą która wyprodukowała ten sterownik nie odczyta z niego, co tak naprawdę się stało. Informacja o skażeniu mówi własnie, czy takie zdarzenie miało miejsce.
Jak już pisałem, klogd samoczynnie zamienia magiczne adresy funkcji na symbole i numery instrukcji.
Dla przykładu, testowy moduł o treści:
#include <linux/module.h>
MODULE_LICENSE("GPL");
static int init() {
printk(KERN_INFO "Jestem\n");
return 0;
}
static void exit() {
char * ptr = NULL;
printk(KERN_INFO "Pa pa\n");
ptr[0] = 'a'; // null pointer
}
module_init(init);
module_exit(exit);
w przypadku próby jego usunięcia poleceniem rmmod może spowodować wyrzucenie takiego oto komunikatu:
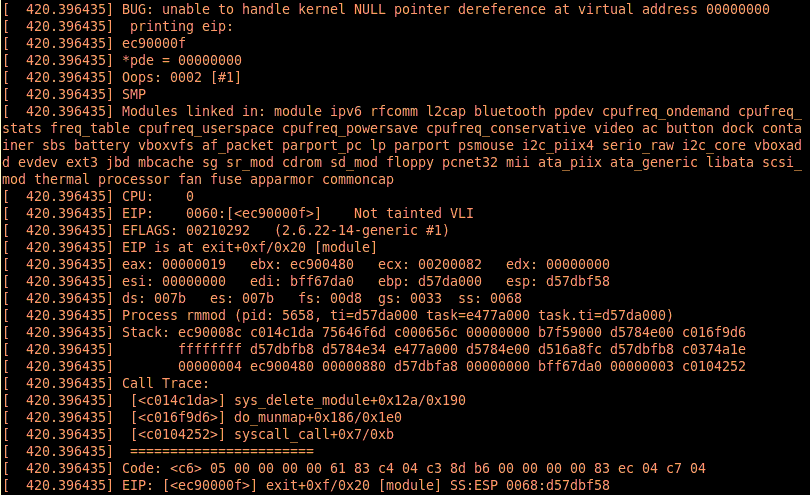
Wspomniane makra działają jak asercje, tzn. dają przezornemu programiście możliwość zapewnienia, że jeżeli zajdzie coś, co nie powinno nigdy zajść, zgłoszony zostanie błąd. Składnia jest prosta: BUG() oraz BUG_ON(warunek). Dodanie opcji kompilacji CONFIG_DEBUG_BUGVERBOSE spowoduje, że będą one wypisywać jeszcze więcej informacji niż zwykle.
Dla przykładu, moduł jak wyżej z BUG() zamiast null pointera:
#include <linux/module.h>
MODULE_LICENSE("GPL");
static int init() {
printk(KERN_INFO "Jestem\n");
return 0;
}
static void exit() {
printk(KERN_INFO "Pa pa\n");
BUG();
}
module_init(init);
module_exit(exit);
w przypadku próby jego usunięcia poleceniem rmmod może spowodować wyrzucenie komunikatu:
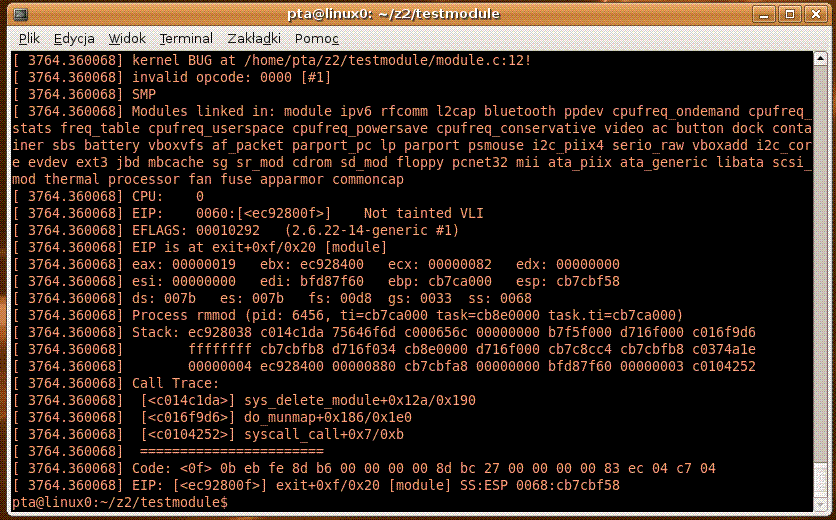
Kiedy jądro napotyka na naprawdę poważny błąd, podejmuje taktyczną decyzję o odwrocie, tj. panikuje. Kernel panic polega na:
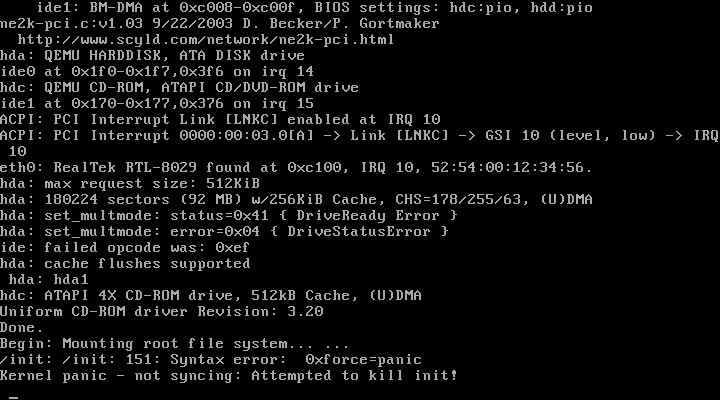
Jak widzimy, nawet w takiej sytuacji jądro wspiera chcących je debugować, zrzucając pamięć, aby można było dojść przyczyn błędu.
A oto przykładowy kernel panic:
W konfiguracji jądra, w części "Kernel Hacking" można znaleźć następujące opcje:
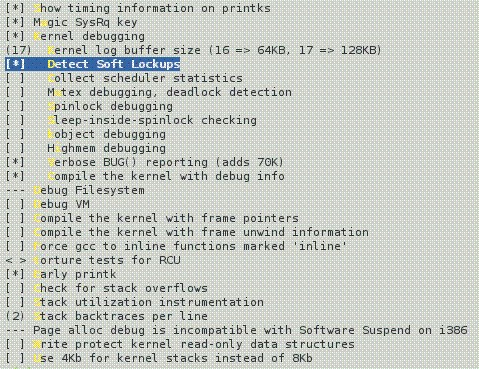
| CONFIG_PRINTK_TIME | Powoduje, że funkcja printk oprócz komunikatu wypisuje czas systemowy w momencie jego nadania; przydatne do oceny różnicy czasowej pomiędzy komunikatami jądra. |
| CONFIG_MAGIC_SYSRQ | Włącza obsługę kombinacji Magic SysRq, której działanie opiszę poniżej. |
| CONFIG_LOG_BUF_SHIFT | Logarytm dwójkowy z rozmiaru bufora komunikatów. Domyślna wartość to 16 odpowiadająca 64K, wartość 17 odpowiada 128K etc. |
| CONFIG_DETECT_SOFT_LOCKUPS | Włącza wykrywanie "miękkich lockupów", reagując na przestoje dłuższe niż 10 sekund wypisaniem stack trace. |
| CONFIG_SCHEDSTATS | Powoduje generowanie statystyk nt działania schedulera i udostępnia je w /proc/schedstat |
| CONFIG_DEBUG_MUTEXES | Wykrywa deadlocki sekcji krytycznych |
| CONFIG_DEBUG_SPINLOCK | Wykrywa deadlocki na spinlockach i inne błędy związane ze spinlockami |
| CONFIG_DEBUG_SPINLOCK_SLEEP | System buntuje się, kiedy coś usiłuje zasnąć mając włączony spinlock. |
| CONFIG_DEBUG_KOBJECT | Dodatkowe informacje o kobjectach. |
| CONFIG_DEBUG_BUGVERBOSE | Powoduje wypisywanie większej ilości informacji przez makra BUG i BUG_ON |
| CONFIG_DEBUG_INFO | Kompilacja z dodaniem informacji potzrbnej do odpluskwiania przez kompilator (opcja -g gcc) |
| CONFIG_DEBUG_FS | Włącza debug_fs, pomocniczy system plików, podobny do proc-a |
| CONFIG_DEBUG_VM | Włącza debugowanie obsługi pamięci wirtualnej |
| CONFIG_EARLY_PRINTK | Włącza funkcję early_printk, działająca jak printk, kiedy printk nie może zostać jeszcze użyta (np. przed zainicjalizowaniem konsoli). Powoduje ona wypisywanie komunikatów do bufora VGA lub portu szeregowego. |
| CONFIG_DEBUG_STACKOVERFLOW | Powoduje wykrywanie błędu przepełnienia stosu. |
| CONFIG_STACK_BACKTRACE_COLS | Określa liczbę pozycji stosu wywołań w jednej linijce komunikatów takich jak oops |
| CONFIG_DEBUG_RODATA | Chroni struktury jądra "tylko do odczytu" przed zapisem. Spowalnia pracę systemu, gdyż uniemożliwia użycie TLB dla stron na których są te dane. |
| CONFIG_MODULE_FORCE_UNLOAD | Powoduje "siłowe" usuwanie modułów w przypadku błędu. |
Magic SysRq jest kombinacją klawiszy pozwalającą na zareagowanie na destabilizację pracy systemu (np. lockupy z reagowaniem na przerwania). Zwykle przywołujemy go, wciskając kombinację prawy alt + print screen + X, gdzie X może być jedną z poniższych opcji:
| Action | X |
|---|---|
| Set the console log level, which controls the types of kernel messages that are output to the console | 0 - 9 |
| Immediately reboot the system, without unmounting partitions or syncing | b |
| Reboot kexec and output a crashdump | c |
| Send the SIGTERM signal to all processes except init (PID 1) | e |
| Call oom_kill, which will kill a process that is consuming all available memory. | f |
| Output a terse help document to the console Any key which is not bound to a command should also do the trick |
h |
| Send the SIGKILL signal to all processes except init | i |
| Kill all processes on the current virtual console (Can be used to kill X and svgalib programs, see below) This was originally designed to imitate a Secure Access Key |
k |
| Send the SIGKILL signal to all processes, including init | l |
| Output current memory information to the console | m |
| Shut off the system | o |
| Output the current registers and flags to the console | p |
| Switch the keyboard from raw mode, the mode used by programs such as X11 andsvgalib, to XLATE mode | r |
| Sync all mounted filesystems | s |
| Output a list of current tasks and their information to the console | t |
| Remount all mounted filesystems in read-only mode | u |
| Output Voyager SMP processor information | v |
Aby pamiętać sekwencję opcji prowadzących do stabilnego rebootu, wymyślono następujący mnemonik:
"Raising Skinny Elephants Is Utterly Boring" is often useful. It stands for Raw (take control of keyboard back from X), Sync (flush data to disk), tErminate (kill -15 programs, allowing them to terminate gracefully), kIll (kill -9 unterminated programs), Unmount (remount everything read-only), reBoot.
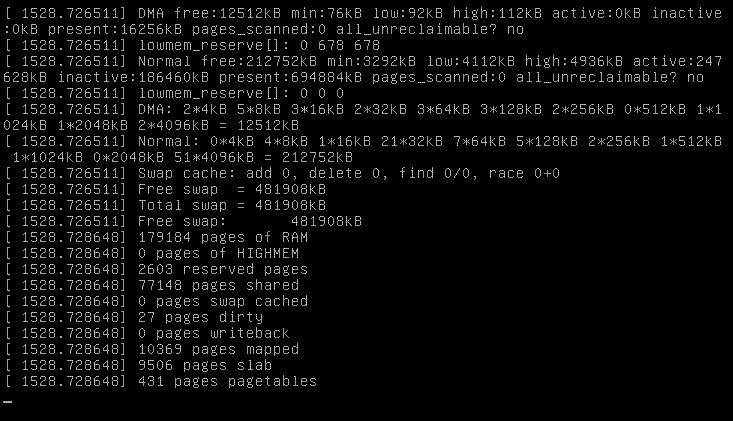
A oto obrazek z Magic SysRq + m:
Chyba najważniejszą funkcją związaną z tematem debuggowania w Linuksie jest ptrace.
#include <sys/ptrace.h> long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data);
Wywołanie to udostępnia procesowi-rodzicowi możliwość śledzenia jego dziecka, a także pozwala na obserwowanie i kontrolowanie go. Jest to podstawowy mechanizm służący do implementacji pułapek (breakpoint) i śledzenia wywołań systemowych.
Ojciec może wywołać śledzenie poprzez użycie wywołania systemowego fork, ptrace(PTRACE_TRACEME, ...) oraz exec w tej właśnie kolejności.
pid_t child = fork();
if (child == 0) {
ptrace(PTRACE_TRACEME, 0, NULL, NULL);
exec(...);
}
Śledzenie można wywołać również na zewnętrznym, już uruchomionym procesie używając wywołania z PTRACE_ATTACH i podając pid celu jako drugi paramet funkcji. Po takim wywołaniu program śledzony staje się dzieckiem śledzącego, ale getpid() w dziecku nadal zwraca pid starego ojca.
Tak wywołany program zostaje wstrzymany przy pierwszym sygnale, a jego rodzic zostaje powiadomiony o tym przy najbliższym wywołaniu systemowym wait. Tak wstrzymany proces można wznowić poprzez wywołanie ptrace z flagą PTRACE_CONT.
Innmi flagami, które warto omówić są PTRACE_SYSCALL i PTRACE_SINGLESTEP, które działają podobnie do PTRACE_CONT, ale wstawiają pułapki odpowiednio na następne wywołanie systemowe, lub kolejną wykonywaną instrukcję.
Czasami jednak nie chcemy więcej śledzić programu, wtedy przydatne będą flagi PTRACE_DETACH, która zaprzestaje śledzenia procesu bez przerywania jego działania, oraz PTRACE_KILL, która poprostu zabija proces-dziecko.
Przykładowe użycie ptrace:
#include <unistd.h>
#include <sys/types.h>
#include <sys/ptrace.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <stdio.h>
int main() {
int status;
pid_t child = fork();
if (child == 0) {
ptrace(PTRACE_TRACEME, 0, NULL, NULL);
// tu zwykle umieszcza sie exec(...);
system("echo bleh");
printf("A\n");
system("echo blah");
printf("B\n");
system("echo blooh");
printf("C\n");
exit(0);
}
else {
wait(&status);
printf("mamy wait 1\n");
ptrace(PTRACE_CONT, child, NULL, NULL);
wait(&status);
printf("mamy wait 2\n");
ptrace(PTRACE_CONT, child, NULL, NULL);
wait(&status);
printf("mamy wait 3\n");
ptrace(PTRACE_KILL, child, NULL, NULL);
wait(&status);
printf("koniec\n");
}
return 0;
}
A oto jego wynik:
bleh mamy wait 1 A blah mamy wait 2 B blooh mamy wait 3 koniec
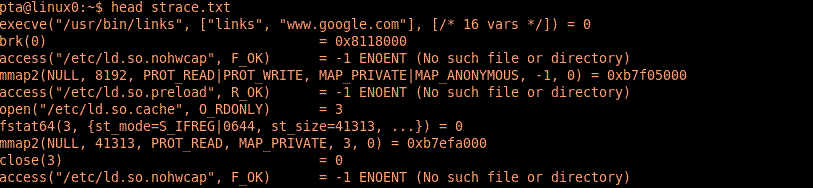
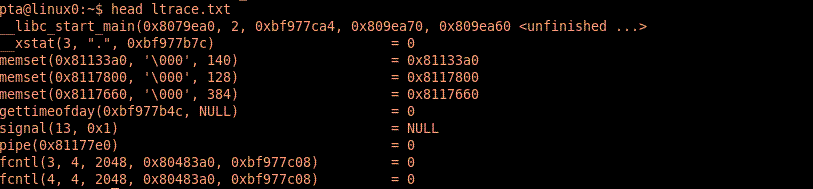
Programy strace i ltrace służą do śledzenia wywołań odpowiednio funkcji systemowych oraz bibliotecznych. Wypisują one na stderr informację o kolejnych wywołaniach.
Przykład: poniżej fragmenty wyników wywołania strace i ltrace dla links www.google.com:
KDB jest debuggerem działającym w trybie jądra. Jest dystrybuowany jako patch na jądro, zatem aby go używać musimy go w nie wkompilować. Projekt KDB jest zarządzany przez Silicon Graphics i można go sciągnąć ze strony http://oss.sgi.com/projects/kdb/.
Opiszę, jak u mnie przebiegała instalacja. Po sciągnięciu patchy kdb-v4.4-2.6.17-i386-1.bz2 oraz kdb-v4.4-2.6.17-common-1.bz2 i odbzip2owaniu ich, zainstalowałem je poleceniem:
patch -p1 < kdb-v4.4-2.6.17-common-1 patch -p1 < kdb-v4.4-2.6.17-common-1
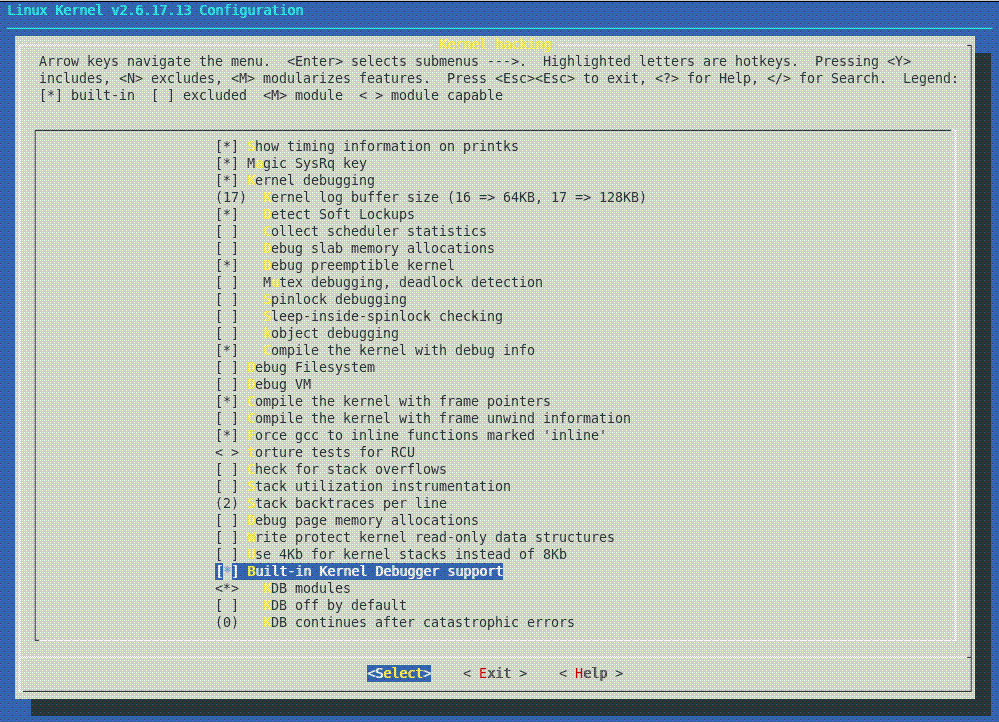
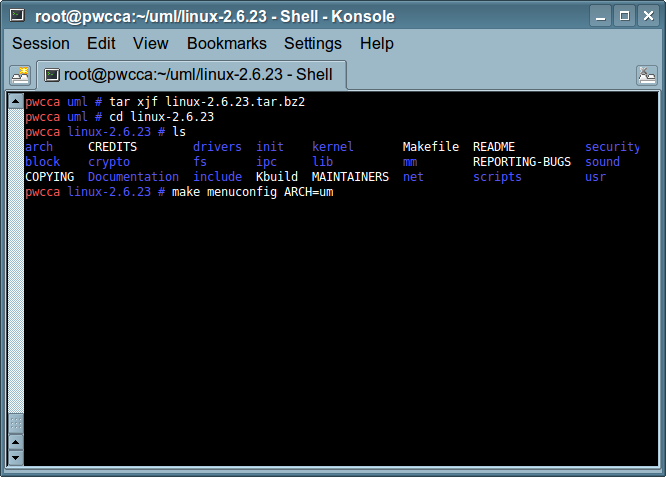
Potem jeszcze konfiguracja (make menuconfig), w której należy włączyć "Built-in kernel debugger support" (opcja dodana przez patch) oraz "Debug info" (przydają się także inne flagi np. debug frame pointer):
Następnie kompilujemy jądro poleceniem make bzImage i utworzony obraz jądra kopiujemy do /boot:
cp arch/i386/boot/bzImage /boot/bzImageKDB
Aby odpalić teraz jądro z KDB, podczas startu systemu wchodzimy do gruba, wybieramy 'c' (command line) i wpisujemy:
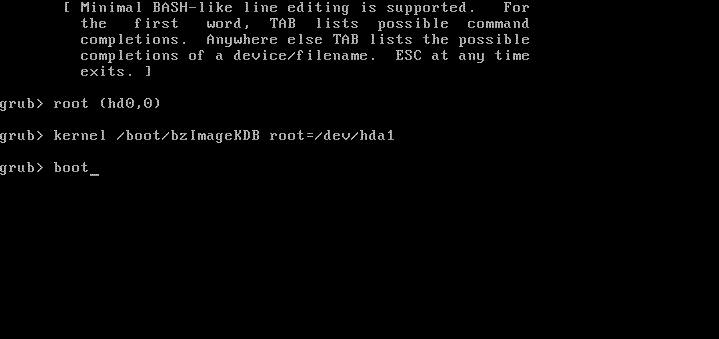
Po odpaleniu Linuksa z włączonym kdb, możemy wejść do debuggera wciskając klawisz Pause. Praca z debuggerem przypomina pracę z gdb. Poniżej opiszę podstawowe komendy.
| id [symbol|addr] | dezasembluje funkcję o podanej nazwie / adresie |
| md addr l | wypisuje l linii pamięci, poczynając od adresu addr |
| mm addr val | Umieszcza wartość val pod adresem addr |
| rd | Wypisanie zawartości rejestrów procesora |
| rm %reg val | Umieszcza wartość val w rejetrze reg |
| bp [symbol|addr] | Ustawia breakpoint na funkcji o podanym symbolu / adresie |
| bl | Wypisuje wszystkie breakpointy |
| [be/bd] nr | Włącza/wyłącza breakpoint o podanym numerze |
| bc nr | Usuwa breakpoint o podanym numerze |
| btp pid | Wypisuje ślad stosu procesu o numerze pid |
| ss | "Single step" - wykonuje pojedynczą instrukcję |
Na koniec -- przykład użycia KDB. Będąc w konsoli, naciskamy Pause, aby znaleźć się w KDB. Mogą wystąpić problemy z klawiaturą!
Na początek wypiszemy stan rejestrów komendą rd:
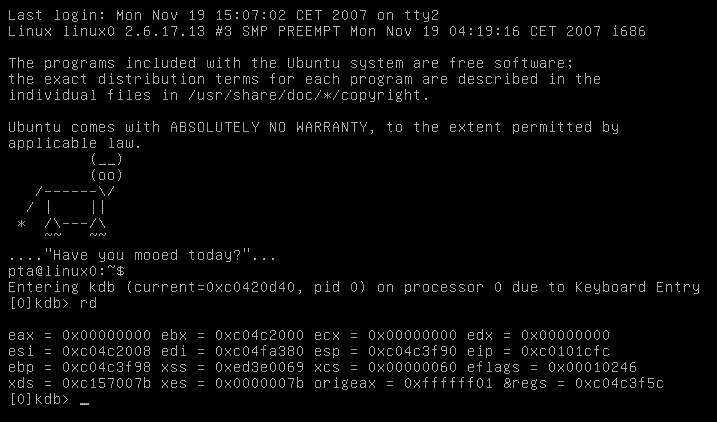
Następnie obejrzymy fragment kodu funkcji scheduler_tick:
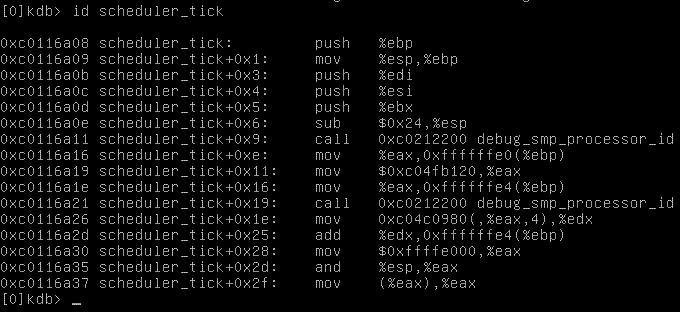
Na koniec, obejrzymy sobie stos wywołań wybranego procesu o pidzie 6, po czym ustawimy breakpoint na scheduler_tick. Wracamy do systemu poleceniem go. Oczywiście breakpoint od razu zadziała i znajdziemy się znowu w debuggerze.
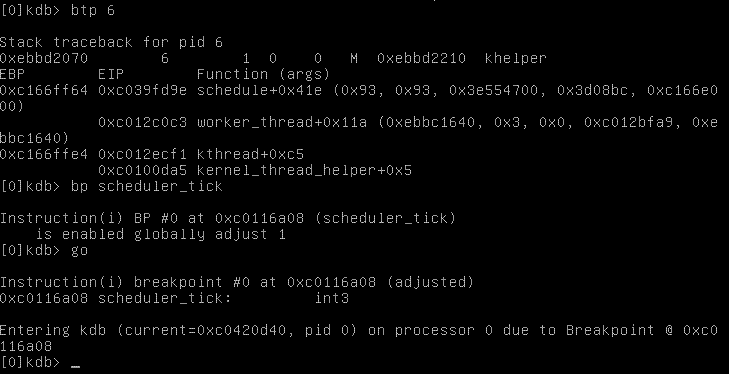
Jak wcześniej wspomniano, jest wiele problemów związanych z debugowaniem jądra, takich jak zależnością działania debbugera od działania jądra, brak możliwości skorzystania z interfejsów graficznych czy choćby nawet braku oficjalnego wsparcia dla debbugerów od strony jądra. Jednym z rozwiązań, które rozwiązuje przynajmniej część z nich jest KGDB.
| Strona domowa: | http://kgdb.linsyssoft.com/index.html |
| Wikipedia: | http://en.wikipedia.org/wiki/Kgdb |
| FreeBSD Developers' Handbook: | http://www.freebsd.org/doc/en_US.ISO8859-1/books/developers-handbook/kerneldebug.html |
Zastosowana technika jest znana od względnie wielu lat i polega na debbugowaniu maszyny z innego komputera, stosowana głównie do pracy na bardzo niskim poziomie, który uniemożliwia normalną pracę na komputerze. Jest to pomocne np. przy pisaniu sterowników, ale znajduje również inne rozmaite zastosowania, jak np. crackowanie gier (SoftICE).
Zależnie od debbugera, komputery mogą połączone w różny sposób, w przypadku KGDB jest to łącze szeregowe. Nie jest to jednak kłopot, ze względu na to, że emulacja (na wirtualnej maszynie) portu szeregowego nie jest trudna (na linuxie nie, a na windowsie tak), a w dodatku w nowszych wersjach KGDB istnieje również (podobno) możliwość komunikacji przez Ethernet.
Zacznijmy od tego, czym jest KGDB.
Właściwie KGDB nie jest tak naprawdę debuggerem, a niezależnym zestawem łat na jądro, które umożliwiają
zdalne połączenie się z komputerem na niskim, zależnym od bardzo niewielu rzeczy poziomie.
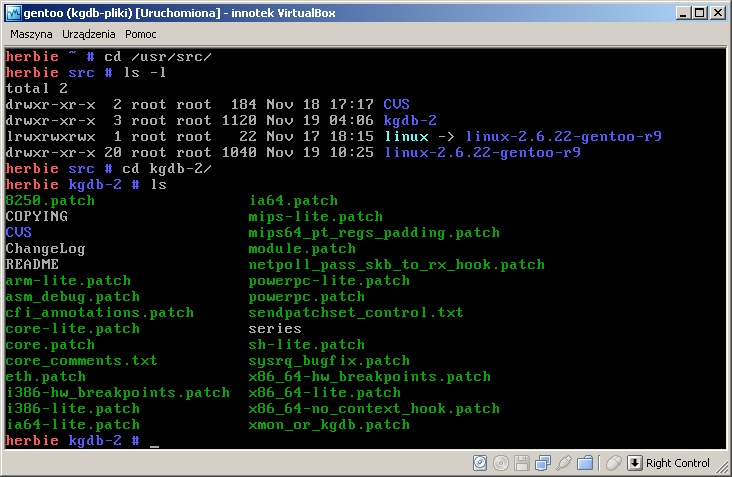
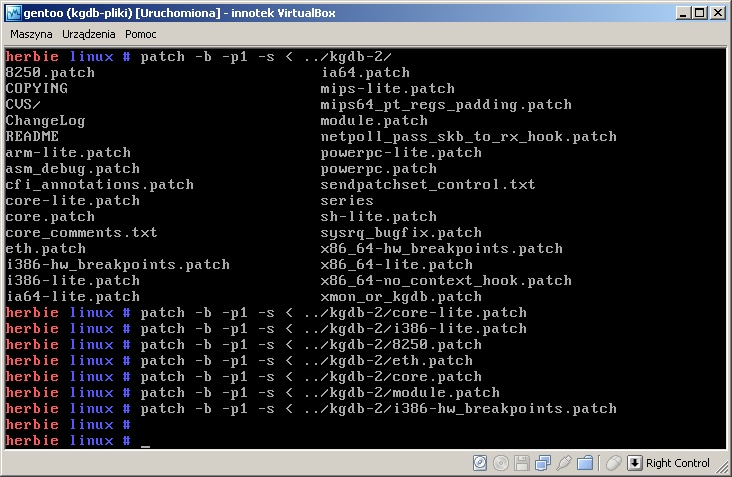
Po dodaniu poprawek do jądra (w prawdzie tutaj używałem jądra 2.6.22, ale dla 2.6.17.13 patche też są dostępne)
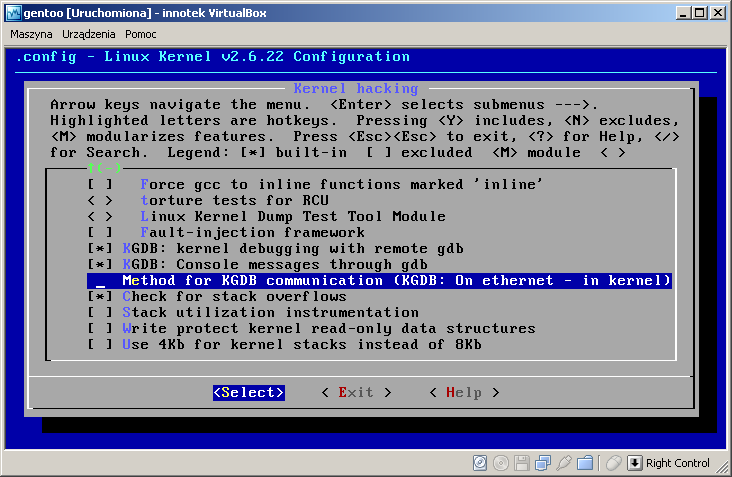
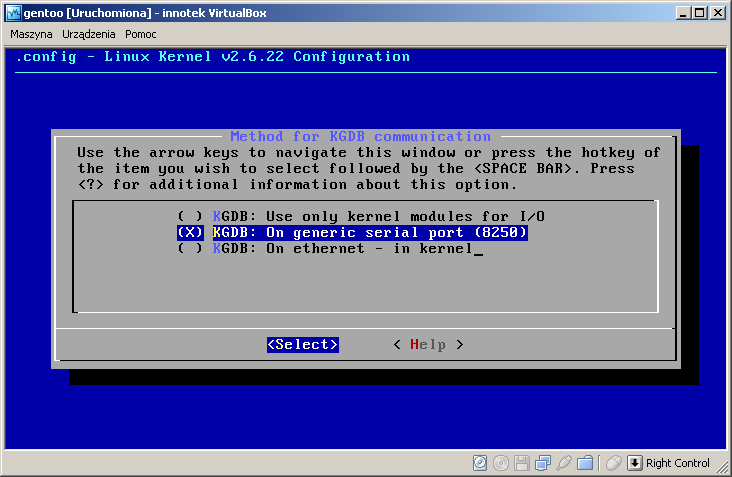
Włączamy odpowiednie opcje w jądrze
I rekompilujemy jądro
# make && make install_modules . . . # cp arch/i386/boot/bzImage /boot/vmlinuz_kgdb
Teraz trzeba przekazać do jądra przy uruchomieniu odpowiednie parametry:
kgdbwait kgdb8250=numer_portu,predkosc_portEdytujemy Gruba
title=Gentoo Linux 2.6.22-r9 KGDB root (hd0,1) kernel /boot/vmlinuz_kgdb root=/dev/hda2 kgdbwait kgdb8250=0,112500lub LILO
image=/boot/vmlinuz_kgdb label=gentoo_kgdb root=/dev/hda2 append="kgdbwait kgdb8250=0,112500"
Uruchamiamy maszynę, ktora będzie debugowana.
Potrzebujemy podobne jądro dla maszyny, z której będziemy debugować, a później tylko odpalamy gdb i mamy standardowe środowisko:
stty ispeed 115200 ospeed 115200 < /dev/ttyS0 gdb vmlinux (gdb) target remote /dev/ttyS1 . . . (gdb) c . .
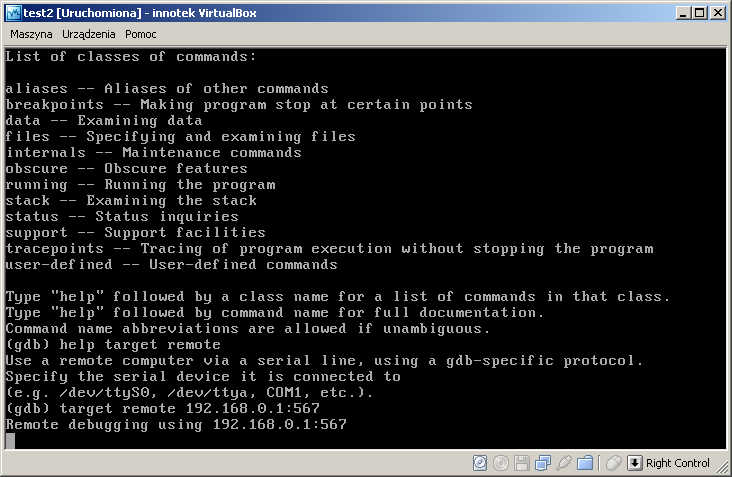
(używamy narzędzia vmwaregateway, które przekierowuje COM1 na port TCP:567)
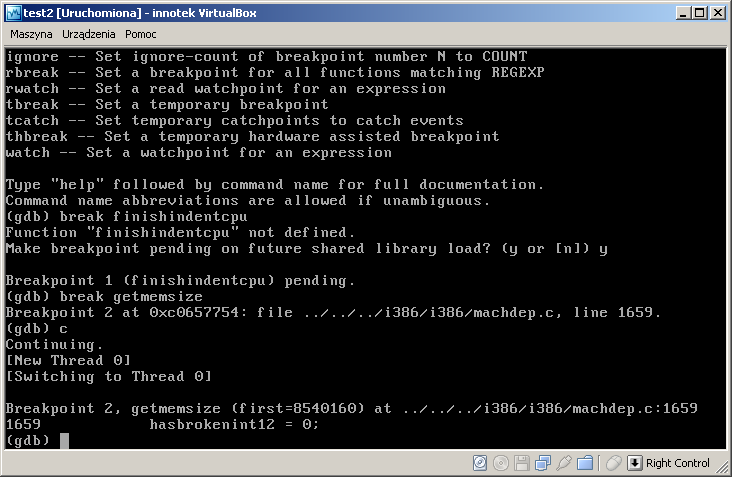
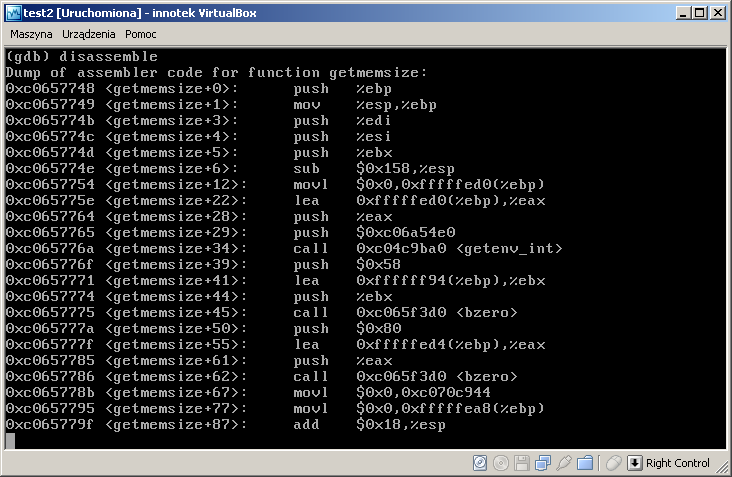
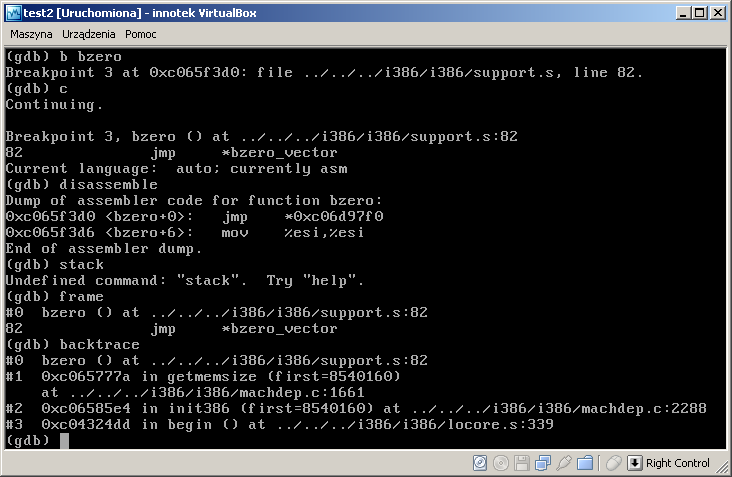
GDB na komputerze, z którego debugujemy działa tak jak się spodziewamy
i można do niego podłączyć bez problemów podłączyć środowisko graficzne,
np. ddd (http://www.gnu.org/software/ddd/):
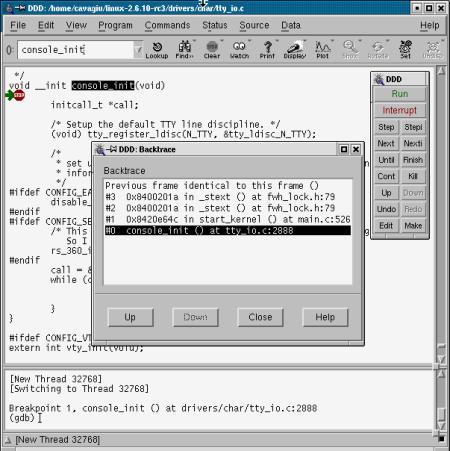
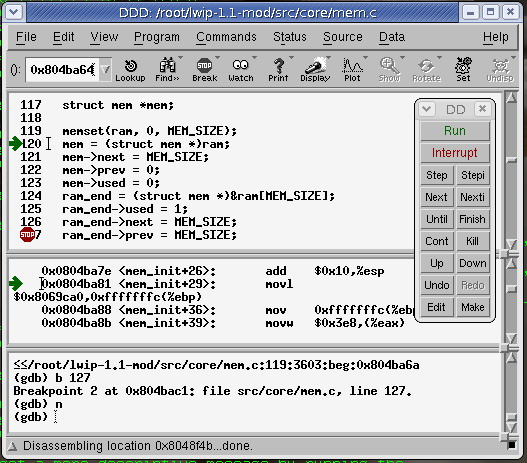
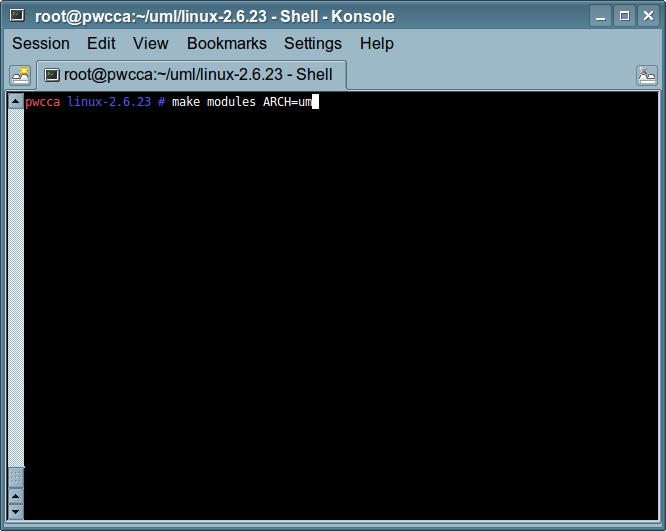
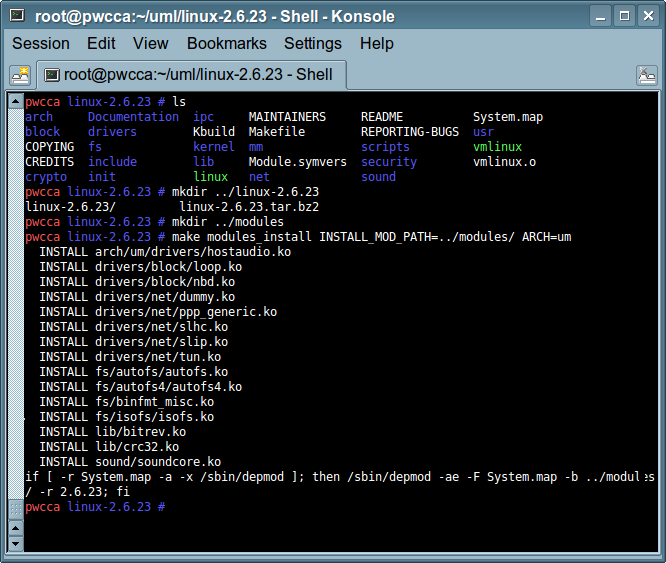
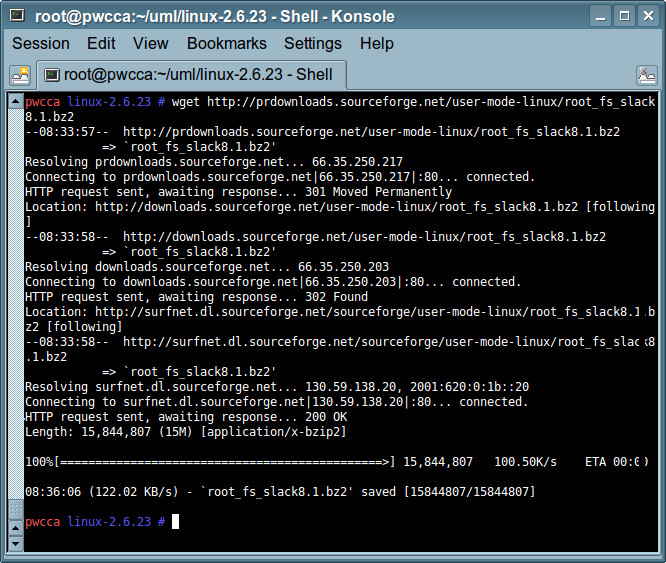
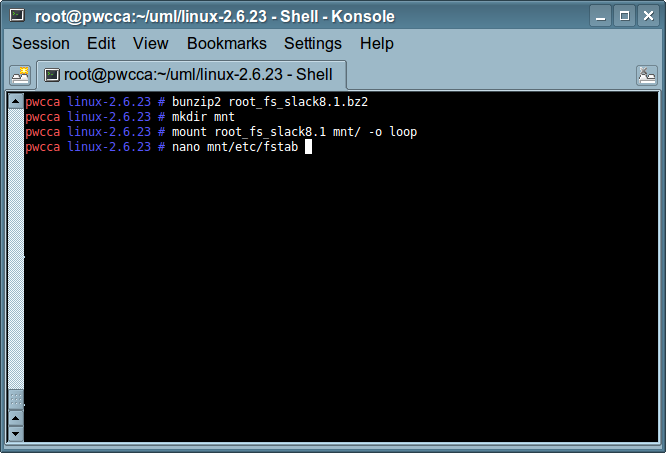
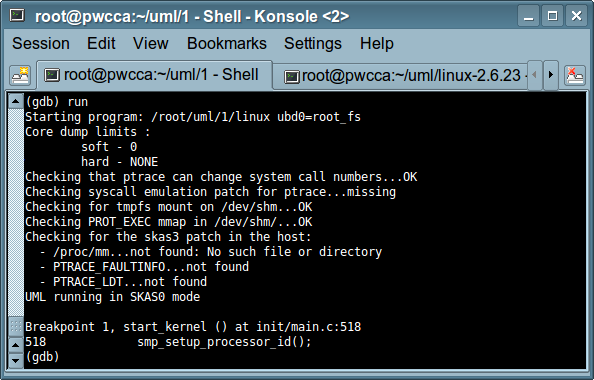
(gdb) break kernel/module.c:1775 (gdb) continue (gdb) print ((struct module *) _mod)->module_core (gdb) add-symbol-file HOST_PATH_TO_KO [wynik_poprzedniej_linijki] (gdb) break debugowana_funkcja (gdb) continue
Teraz, gdy już wiemy jak odpluskwiać kod systemowy, warto na koniec zacytować osobę, która jest odpowiedzialna, za to całe zamieszanie.
I'm afraid that I've seen too many people fix bugs by looking at debugger output, and that almost inevitably leads to fixing the symptoms rather than the underlying problems.
Jak widać nie wszyscy chwalą wsparcie debbugerów w jądrze. Czy to dobrze? Nie będziemy tu spekulować nad znaczeniem tych słów, kwestie, którymi kierował się cytowany podczas swojej wypowiedzi pozostawimy słuchaczom jako zadanie do rozważenia.
RR0D RASTA DEBUGGER
Cytaty z FAQ:
Q: Hey man, is rr0d at least has a rasta mode? A: yea man, Of course it has. Q: Hey man, why rr0d and not KGDB? A: man, KGDB is *not* a rasta debugger Q: Hey man, how many functionalities rr0d has? A: man, it has plenty rasta functionalities