2. Podstawy przetwarzania transakcyjnego
Dzisiejsze systemy transakcyjne cechuje duża różnorodność, zarówno na poziomie
architektury, jak i funkcjonalności. Niemniej jednak pewne elementy i pojęcia
są dla nich wspólne i funkcjonują praktycznie w każdym produkcyjnym systemie
transakcyjnym. Poniżej postaramy się przedstawić zagadnienia, które naszym zdaniem
najlepiej charakteryzują problematykę transakcyjnego stylu przetwarzania danych.
Jedną z podstawowych cech systemów transakcyjnych jest możliwość równoległego
korzystania przez wielu użytkowników ze wspólnych zasobów danych. Powyższe wymaganie
implikuje konieczność wykorzystania odpowiednich mechanizmów kontroli dostępu,
umożliwiających zachowanie spójności danych, pomimo pojawiających się błędów
aplikacji, czy też awarii systemu. Jednym z elementów pozwalających na manipulowanie
dzielonymi zasobami jest posiadanie dobrze zdefiniowanej jednostki przetwarzania
-- transakcji. Transakcję można zdefiniować jako zestaw operacji przekształcających
abstrakcyjne lub fizyczne stany systemu, posiadający własność ACID2.1:
- [Niepodzielność (ang. atomicity)]-- system albo wykonuje w
całości wszystkie elementarne operacje wchodzące w skład transakcji, albo gwarantuje,
że częściowe wykonanie transakcji nie pozostawi żadnych efektów w systemie.
- [Spójność (ang. consistency)]-- transakcja jest poprawną transformacją
stanów tzn. przeprowadza system z jednego stanu spójnego do innego stanu spójnego.
- [Izolacja (ang. isolation)]-- współbieżne wykonanie zestawu
transakcji prowadzi do wyników, które są nierozróżnialne od rezultatów, jakie
można byłoby uzyskać uruchamiając transakcje seryjnie, tj. w izolacji, w pewnym
z góry określonym porządku (często używanym synonimem izolacji jest serializacja).
- [Trwałość (ang. durability)]-- system ma zdolność zachowania
lub odtworzenia efektów pomyślnie zakończonych transakcji w obliczu awarii dowolnego
typu.
Pomimo ścisłej definicji istnieje wiele rodzajów transakcji spełniających własność
ACID, ale jednocześnie w znaczącym stopniu różniących się semantyką przetwarzania2.2. Z naszego punktu widzenia najciekawszym typem transakcji są transakcje
rozproszone2.3, ponieważ duża część systemów transakcyjnych działa w heterogenicznym środowisku
obejmującym wiele maszyn i zasobów danych. W przypadku transakcji rozproszonych
poszczególne operacje mogą być wykonywane na różnych węzłach i dotyczyć różnych
danych. W efekcie trudne staje się osiągnięcie atomowości wykonania takiej transakcji
(z perspektywy użytkownika systemu). Konieczne jest wprowadzenie dodatkowego
narzutu związanego z wprowadzeniem protokołu kontrolnego, który spełniałby następujące
warunki:
- wszyscy uczestnicy transakcji, którzy podjęli decyzję o zatwierdzeniu bądź odrzuceniu
transakcji, podjęli taką samą decyzję,
- uczestnik transakcji nie może zmienić raz podjętej decyzji,
- decyzja o zatwierdzeniu transakcji może zostać podjęta tylko w przypadku, jeśli
wszyscy uczestnicy głosowali za zatwierdzeniem transakcji,
- jeżeli nie wystąpiła awaria i wszyscy uczestnicy transakcji głosowali za zatwierdzeniem
transakcji, to transakcja zostanie zatwierdzona,
- w dowolnym momencie działania, jeśli wszystkie awarie zostały usunięte, to każdy
uczestnik musi podjąć decyzję o zatwierdzeniu bądź odrzuceniu transakcji.
Najczęściej wykorzystywanym protokołem spełniającym powyższe warunki jest opisany
poniżej dwufazowy protokół potwierdzeń (2PC2.4).
- Koordynator (wybrany uczestnik transakcji; zazwyczaj ten, który inicjował transakcję)
rozsyła do wszystkich uczestników informacje o rozpoczęciu głosowania.
- Kiedy uczestnik transakcji odbierze komunikat o rozpoczęciu głosowania, odsyła
komunikat zawierający jego decyzję. Jeżeli zagłosował za odrzuceniem transakcji,
to lokalnie cofa wykonanie transakcji, a następnie kończy swoje działanie.
- Koordynator zbiera głosy od poszczególnych uczestników. Jeżeli wszyscy zagłosowali
za zatwierdzeniem transakcji, to koordynator podejmuje decyzję o jej zatwierdzeniu
i rozsyła informacje o tym do wszystkich uczestników transakcji. W przeciwnym
wypadku (jeśli którykolwiek z uczestników zagłosował za odrzuceniem bądź minął
czas przeznaczony na odpowiedź) koordynator podejmuje decyzję o odrzuceniu transakcji,
a następnie rozsyła informacje o stanie zakończenia transakcji do wszystkich
uczestników, którzy zagłosowali za jej zatwierdzeniem.
- Każdy z uczestników, który zagłosował za zatwierdzeniem transakcji, oczekuje
na komunikat z decyzją od koordynatora.
Kolejną ważną cechą wyróżniającą systemy transakcyjne jest potencjalnie wysoka
liczba użytkowników. Duże systemy obejmują od 1000 do 100 000 klientów. Przy
takiej liczbie użytkowników konieczne staje się zagwarantowanie maksymalnie
wysokiej wydajności i niezawodności systemu.
Z perspektywy użytkownika wydajność systemu mierzy się czasem odpowiedzi
serwera. Jest to czas między wysłaniem zlecenia a uzyskaniem odpowiedzi. Na
czas odpowiedzi mają wpływ dwa czynniki: (1) czas oczekiwania -- czas
spędzony na oczekiwaniu na odbiór zlecenia plus czas konieczny na uzyskanie
dostępu do żądanych zasobów oraz (2) czas wykonania usługi -- czas konieczny
do wykonania zadania bez zbędnego oczekiwania. Jak widać są możliwe dwie drogi
zmniejszenia czasu odpowiedzi serwera: zredukowanie czasu wykonania zlecenia
bądź zmniejszenie czasu oczekiwania.
Inną wspomnianą już wcześniej cechą, wpływającą pośrednio na wydajność systemu,
jest jego niezawodność. Parametrami, które charakteryzują stopień niezawodności
systemu są:
- [Bezawaryjność systemu]-- czas między startem a awarią systemu, przy
czym statystycznie bezawaryjność modułu wyraża się poprzez średni czas
bezawaryjnej pracy (ang. MTTF -- mean-time-to-failure),
- [Przerwa w dostępie do usługi]-- statystycznie wyraża się poprzez
średni czas potrzebny na usunięcie awarii (ang. MTTR -- mean-time-to-repair),
- [Dostępność systemu]-- ułamek wszystkich transakcji, które zostały
przetworzone z akceptowalnym czasem odpowiedzi, co statystycznie wyraża się
wzorem
A = 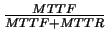
Każdy system można zaklasyfikować do konkretnej klasy niezawodności systemów
na podstawie następującego wzoru:
- [Klasa dostępności systemu]=
 log10
log10
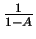
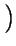
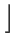 , gdzie A jest dostępnością systemu.
, gdzie A jest dostępnością systemu.
Istnieją dwie podstawowe drogi umożliwiające podniesienie stopnia niezawodności
systemu. Pierwsza opiera się na zwiększeniu dostępności systemu na poziomie
sprzętowym. Polega ona na wprowadzeniu pewnej redundancji sprzętu. Moduły danego
typu (np. dyski, procesory) są zwielokrotniane i traktowane jako jeden, co w
połączeniu z mechanizmami szybkiej naprawy może podnieść parametr MTTF o trzy,
a nawet więcej rzędów wielkości.
Drugim rozwiązaniem jest zwiększenie niezawodności na poziomie oprogramowania.
Osiąga się to poprzez maskowanie błędów w oprogramowaniu oraz replikację udostępnianych
serwisów. Istnieją dwie metody maskowania błędów oprogramowania:
- [N-wersjowe programowanie]-- każdy program jest pisany, a następnie
testowany, w n wersjach, po czym wszystkie wersje uruchamia się równolegle,
a wynik ustala się na podstawie większości odpowiedzi. Zasadniczą wadą takiego
rozwiązania są jego wyjątkowo wysokie koszty.
- [Transakcje]-- program jest pisany jako transakcja, posiada własność
ACID. Jeśli pod koniec wykonania transakcji warunki spójności nie są spełnione,
to transakcja jest wycofywana, a następnie restartowana. Takie rozwiązanie powinno
zamaskować większość nieregularnych błędów oprogramowania (ang. soft software
error).
Z naszego punktu widzenia najciekawsze jest jednak zwiększenie niezawodności
systemu poprzez replikację serwisów, gdyż daje ono możliwość maskowania błędów
nie tylko programowych, ale w dużej mierze również sprzętowych. Niestety takie
podejście powoduje, iż konieczne staje się zreplikowanie nie tylko samego serwisu,
ale w wielu wypadkach również danych, na których on operuje. Ponadto poszczególne
kopie działającego serwisu muszą być ze sobą zsynchronizowane, co może w znaczący
sposób wpłynąć na czas odpowiedzi systemu, a tym samym zmniejszyć jego wydajność.
K. Kowalewski, R. Żmijewski
1999-12-17