(Źródło: Wikipedia)
Szczegóły implementacji 64-bitowej przestrzeni adresowej są bardzo związane ze szczegółami technicznymi budowy i działania procesorów, dlatego w tym opracowaniu może być więcej informacji o działaniu i wsparciu procesora dla pamięci niż o jej implementacji w jądrze Linuksa.
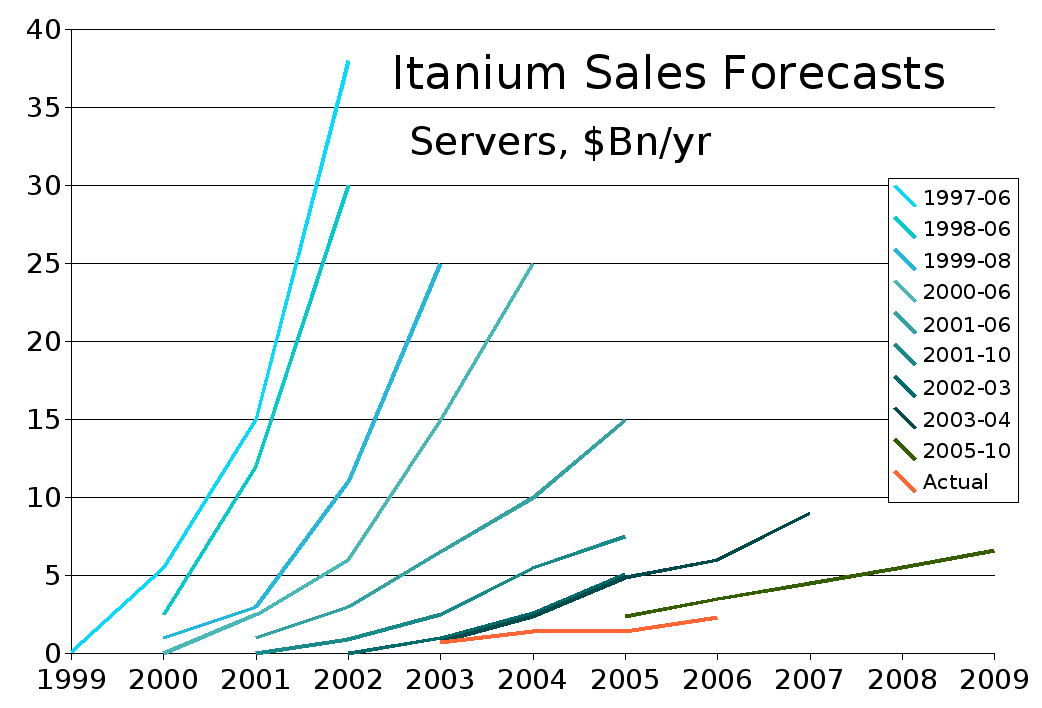
Historia wprowadzania 64-bitowych procesorów na rynek jest dosyć skompilkowana. W 2001 roku Intel zaprezentował architekturę IA-64 wraz z rodziną procesorów Itanium. Z powodu niedociągnięć związanych z wydajnością procesorów oraz wsteczną kompatybilnością projekt ten okazał się porażką. Najlepiej obrazuje to poniższy wykres:
Następnie AMD zaprezentowało architekturę x86-64 później znaną jako AMD64, z której wywodzą się EM64T lub Intel 64 - niecałkiem kompatybilne implementacje Intela tej architektury. Jest ona w pełni kompatybilna z 32-bitowym kodem.
W jądrze Linuksa zaimplementowana została osobno obsługa architektury Itanium oraz x86-64. W dalszym toku skupimy się na implementacji tej ostatniej, jako bardziej popularnej.

Procesory w architekturze AMD64 oferują dwa podstawowe tryby pracy:
Dzisiejsze procesory implementujące architekturę AMD64 mogą zaadresować do 256 TiB (2^48) wirtualnej przestrzeni adresowej. W przyszłości istnieje możliwość rozszerzenia do 16 EiB (2^64). Oznacza to, że można mapować bardzo duże pliki bezpośrednio do pamięci wirtualnej procesu (co z reguły jest dużo szybsze niż wielokrotne odczyty i zapisy), a nie stosować obejścia polegające na mapowaniu tylko fragmentów plików do przestrzeni adresowej procesu.
Współczesne implementacje mogą zaadresować do 256 TiB pamięci fizycznej (identycznie jak w przypadku pamięci wirtualnej), co może być w przyszłości rozszerzone do 4 PiB (2^52). Ograniczeniem tutaj jest wielkość wpisu w tablicy stron Podczas pracy w legancy mode, gdy uruchomione jest rozszerzenie PAE, można zaadresować do 64 GiB pamięci fizycznej.
Większość systemów operacyjnych oraz aplikacji nie będzie potrzebowała całej przestrzeni adresowej oferowanej przez architekturę 64-bitową w dającej się przewidzieć przyszłości (Linux wykorzystuje do 46 bitów przestrzeni adresowej, gdy była implementowana w 2004 roku procesory obsługiwały jedynie 40 bitów), więc implementowanie tak szerokiego zakresu pamięci wirtualnej zwiększyłoby jedynie złożoność i koszt translacji adresów bez żadnych wymiernych korzyści.
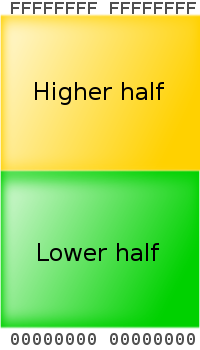
Z tego powodu AMD zdecydowało pierwszy raz implementując tę architekturę obłsugiwać jedynie 48 mniej znaczących bitów w adresach wirtualnych do translacji adresów. Bity od 48 do 63 muszą być kopiami bitu 47, w przeciwnym wypadku procesor wyrzuci wyjątek. Adresy w tym formacie nazywane są adresami w postaci kanonicznej. Przestrzeń adresowa w postaci kanonicznej rozciąga się od 0 do 00007FFF`FFFFFFFF oraz od FFFF8000`00000000 do FFFFFFFF`FFFFFFFF, adresując 256 TiB wirtualnej przestrzeni adresowej.
Te dziwactwa pozwalają na ważną funkcjonalność z punktu widzenia skalowania do przyszłego pełnego 64-bitowego adresowania: Linux wykorzystuje na przykład górną połowę adresów na pamięć jądra oraz bezpośrednie mapowania pamięci fizycznej, natomiast dolną do mapowania przestrzeni adresowej procesów. Adres kanoniczny zapewnia, że wszystkie zgodne z architekturą AMD64 implementacje dzielą pamięć na dwie połowy: dolną, zaczynającą się od 00000000`00000000 i rosnącą do góry, w miarę jak kolejne bity wirtualnej pamięci będą sprzętowo obsługiwane oraz górną, rosnącą w dół. Zafiksowanie nieużywanych przez procesor bitów w adresacji zabezpiecza poza tym twórców systemów operacyjnych przed wykorzystaniem nieużywanych bitów na flagi, co mogłoby skutkować niekompatybilnością kodu z kolejnymi wersjami procesorów.
Poniżej zamieszczam schematy kanonicznych postaci adresów o różnej wielkości:


Adresowanie w 64-bitowym trybie (long mode) jest nadzbiorem PAE, z tego powodu legalne rozmiary stron to 4 KiB, 2 MiB lub 1 GiB. Jednakże system działający w long mode używa czteropoziomowej tablicy stron: PAE's Page-Directory Pointer Table jest rozszerzony z 4 pozycji do 512, oraz dodano Page-Map Level 4 (PML4) Table, zawierającą 512 pozycji w 48-bitowych implementacjach. W implementacjach zapewniających większą wirtualną przestrzeń adresową ta ostatnia tabela będzie rosła, żeby pomieścić odpowiednią liczbę wpisów, aż do teoretycznego maksimum 33,554,432 wpisów przy pełnej 64-bitowej implementacji, lub zostanie dodany nowy poziom mapowania PML5. Pełne mapowanie 4 KiB stron z całej 48 bitowej przestrzeni adresowej powinno zająć trochę więcej niż 512 GiB pamięci RAM (około 0.196% spośród całej 256 TiB wirtualnej przestrzeni adresowej).
Linux był pierwszym systemem operacyjnym, który działał z architekturą x86-64 w long mode, czyli ze wsparciem dla 64-bitowych instrukcji procesora (wersja 2.4, wcześniej niż wsparcie sprzętowe). Poza tym posiadał wsteczną kompatybilność z plikami wykonywalnymi dla architektury 32-bitowej. Od tego czasu kilka dystrybucji Linuksa dostarcza dla x86-64 natywne jądra oraz środowiska użytkownika skompilowane pod te architektury (Debian GNU/Linux, SUSE, Madriva).
Osobą odpowiedzialną za wprowadzenie do jądra obsługi pamięci dla architektury AMD64 był Andi Kleen, co można zauważyć śledząc zmiany w kodzie. Obecnie pracuje dla Intela.

Przyjrzyjmy się teraz co w dokumentacji jądra jest napisane na ten temat.
// Wyjęte z : linux-2.6.29.6/Documentation/x86/x86_64/mm.txt
previous description obsolete, deleted>
Virtual memory map with 4 level page tables:
0000000000000000 - 00007fffffffffff (=47 bits) user space, different per mm
hole caused by [48:63] sign extension
ffff800000000000 - ffff80ffffffffff (=40 bits) guard hole
ffff880000000000 - ffffc0ffffffffff (=57 TB) direct mapping of all phys. memory
ffffc10000000000 - ffffc1ffffffffff (=40 bits) hole
ffffc20000000000 - ffffe1ffffffffff (=45 bits) vmalloc/ioremap space
ffffe20000000000 - ffffe2ffffffffff (=40 bits) virtual memory map (1TB)
... unused hole ...
ffffffff80000000 - ffffffffa0000000 (=512 MB) kernel text mapping, from phys 0
ffffffffa0000000 - fffffffffff00000 (=1536 MB) module mapping space
The direct mapping covers all memory in the system up to the highest
memory address (this means in some cases it can also include PCI memory
holes).
vmalloc space is lazily synchronized into the different PML4 pages of
the processes using the page fault handler, with init_level4_pgt as
reference.
Current X86-64 implementations only support 40 bits of address space,
but we support up to 46 bits. This expands into MBZ space in the page tables.
-Andi Kleen, Jul 2004
// Wyjęte z : linux-2.6.29.6/Documentation/x86/x86_64/kernel-stacks
Most of the text from Keith Owens, hacked by AK
x86_64 page size (PAGE_SIZE) is 4K.
Like all other architectures, x86_64 has a kernel stack for every
active thread. These thread stacks are THREAD_SIZE (2*PAGE_SIZE) big.
These stacks contain useful data as long as a thread is alive or a
zombie. While the thread is in user space the kernel stack is empty
except for the thread_info structure at the bottom.
In addition to the per thread stacks, there are specialized stacks
associated with each CPU. These stacks are only used while the kernel
is in control on that CPU; when a CPU returns to user space the
specialized stacks contain no useful data. The main CPU stacks are:
* Interrupt stack. IRQSTACKSIZE
Used for external hardware interrupts. If this is the first external
hardware interrupt (i.e. not a nested hardware interrupt) then the
kernel switches from the current task to the interrupt stack. Like
the split thread and interrupt stacks on i386 (with CONFIG_4KSTACKS),
this gives more room for kernel interrupt processing without having
to increase the size of every per thread stack.
The interrupt stack is also used when processing a softirq.
Switching to the kernel interrupt stack is done by software based on a
per CPU interrupt nest counter. This is needed because x86-64 "IST"
hardware stacks cannot nest without races.
x86_64 also has a feature which is not available on i386, the ability
to automatically switch to a new stack for designated events such as
double fault or NMI, which makes it easier to handle these unusual
events on x86_64. This feature is called the Interrupt Stack Table
(IST). There can be up to 7 IST entries per CPU. The IST code is an
index into the Task State Segment (TSS). The IST entries in the TSS
point to dedicated stacks; each stack can be a different size.
An IST is selected by a non-zero value in the IST field of an
interrupt-gate descriptor. When an interrupt occurs and the hardware
loads such a descriptor, the hardware automatically sets the new stack
pointer based on the IST value, then invokes the interrupt handler. If
software wants to allow nested IST interrupts then the handler must
adjust the IST values on entry to and exit from the interrupt handler.
(This is occasionally done, e.g. for debug exceptions.)
Events with different IST codes (i.e. with different stacks) can be
nested. For example, a debug interrupt can safely be interrupted by an
NMI. arch/x86_64/kernel/entry.S::paranoidentry adjusts the stack
pointers on entry to and exit from all IST events, in theory allowing
IST events with the same code to be nested. However in most cases, the
stack size allocated to an IST assumes no nesting for the same code.
If that assumption is ever broken then the stacks will become corrupt.
The currently assigned IST stacks are :-
* STACKFAULT_STACK. EXCEPTION_STKSZ (PAGE_SIZE).
Used for interrupt 12 - Stack Fault Exception (#SS).
This allows the CPU to recover from invalid stack segments. Rarely
happens.
* DOUBLEFAULT_STACK. EXCEPTION_STKSZ (PAGE_SIZE).
Used for interrupt 8 - Double Fault Exception (#DF).
Invoked when handling one exception causes another exception. Happens
when the kernel is very confused (e.g. kernel stack pointer corrupt).
Using a separate stack allows the kernel to recover from it well enough
in many cases to still output an oops.
* NMI_STACK. EXCEPTION_STKSZ (PAGE_SIZE).
Used for non-maskable interrupts (NMI).
NMI can be delivered at any time, including when the kernel is in the
middle of switching stacks. Using IST for NMI events avoids making
assumptions about the previous state of the kernel stack.
* DEBUG_STACK. DEBUG_STKSZ
Used for hardware debug interrupts (interrupt 1) and for software
debug interrupts (INT3).
When debugging a kernel, debug interrupts (both hardware and
software) can occur at any time. Using IST for these interrupts
avoids making assumptions about the previous state of the kernel
stack.
* MCE_STACK. EXCEPTION_STKSZ (PAGE_SIZE).
Used for interrupt 18 - Machine Check Exception (#MC).
MCE can be delivered at any time, including when the kernel is in the
middle of switching stacks. Using IST for MCE events avoids making
assumptions about the previous state of the kernel stack.
For more details see the Intel IA32 or AMD AMD64 architecture manuals.
| Janina Mincer-Daszkiewicz |